


Denoising in Representation Space via Data-Dependent Regularization for Better Representation

Abstract
1. Introduction
- (1)
- Using a data model based on a feature dictionary, we propose the notion of OoFS noise and argue that OoFS noise is a factor that leads to poor representation and hurts generalization. To our knowledge, we are the first to propose this notion. Additionally, we theoretically study OoFS noise in the feature extractor of a single-hidden-layer neural network and prove two theorems to (probabilistically) bound the output of a random OoD test point. Moreover, we identify two sources of OoFS noise and prove that OoFS noise due to random initialization can be filtered out via L2 regularization (Section 3).
- (2)
- Because both the noises in the data and the model are embedded in the representations, we propose a novel approach to regularizing the weights of the fully connected layer in a data-dependent way, which aims to reduce noise in the representation space and implicitly force the feature extractor to focus more on informative features instead of relying on noise (Section 4).
- (3)
- We propose a new method to examine the behavior and to evaluate the performance of a learning algorithm via a simple task. Specifically, we disentangle the model’s performance into two distinct aspects and, thus, inspect each aspect individually (Section 5.1).
2. Related Work
3. Theoretical Analysis of the Noise in Hidden Neurons
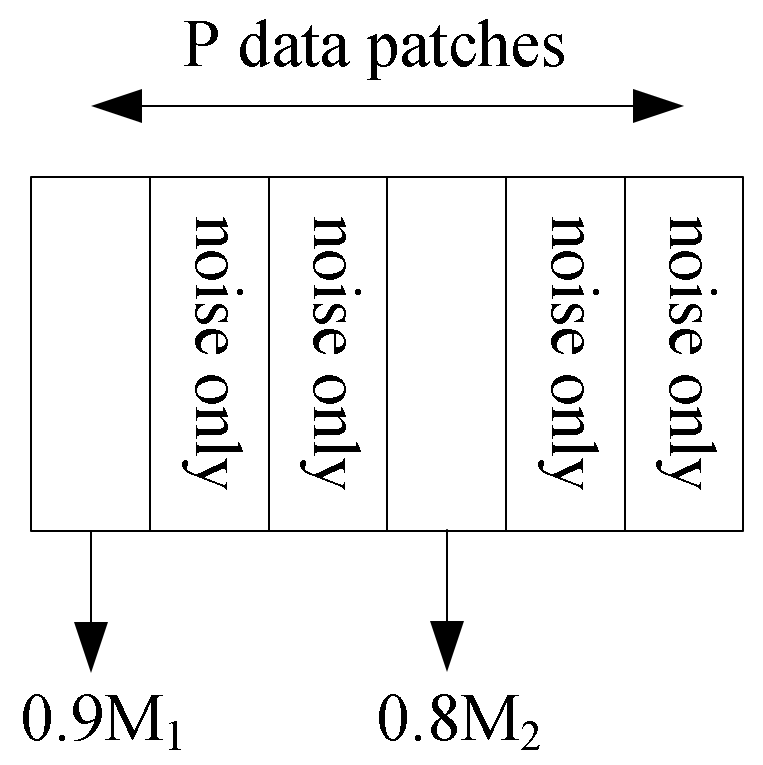
3.1. Data Distribution, Model, and Definitions
- (1)
- Uniformly sample the label from {−1, 1}.
- (2)
- Let , where each patch .
- (3)
- Signal patch: choose one signal patch such that , where , , and .
- (4)
- is distributed as with probability , and otherwise, where corresponds to the majority of the samples that have a large margin and corresponds to the minority of samples that have a small margin.
- (5)
- Noisy patches: , for .
3.2. The Impact of OoFS Noise in the Model
- (1)
- For GD, and for all .
- (2)
- For GD+M, at least one of , and for all .
- (1)
- For GD and arbitrary , . Specifically, setting , we have: .
- (2)
- For GD and GD+M, we have: . Specifically, for GD, we have: , and for GD+M, we have: .
- (1)
- For GD, since holds for all , then, according to Lemma K.12 in [19], for , we have:
- (2)
- We know that ; then, by Lemma K.13 in [19], we have: is -subGaussian.>
- (1)
- For GD, ;
- (2)
- For GD+M, ;
- (3)
- For GD, ;
- (4)
- For GD+M, .
3.3. The OoFS Noise in the Model Induced by Random Initialization
- (1)
- The performance in the feature subspace, which further depends on two factors: (i) Does the model learn all the informative features, i.e., does the model learn the basis of and the relative strength of the learned features, i.e., the signal strength , in the hidden neurons? (ii) How does the model explain the data in ? Different algorithms have different biases and provide different explanations;
- (2)
- The performance in the OoF subspace, which is determined by the OoFS noise in the model.
4. From Neurons to Representations—Data-Dependent Regularization for the Fully Connected Layer
4.1. Data-Dependent Regularization on the Weights of the Fully Connected Layer for Binary Classification
4.2. Extension to Multi-Class Classification
| Algorithm 1 The training process of the proposed method |
| Input: the training set, ; the model, ; max number of steps, ; the size of a mini-batch, ; the number of mini-batches, ; the weighting of the regularizer, ; the parameter of the regularizer, ; |
| Output: the model, |
| for to do |
| for to do |
| Sample a mini-batch of training inputs, , and the ground-truth labels, ; |
| Compute the outputs and representations with current , ; |
| Compute the cross-entropy loss, ; |
| Compute the SVD decomposition of the representations, ; |
| Compute with formula (43), i.e., ; |
| Compute the regularization item with formula (49), ; |
| Compute the mini-batch loss, ; |
| Update by taking an SGD step on the mini-batch loss, ; end for |
| end for |
5. Experiments
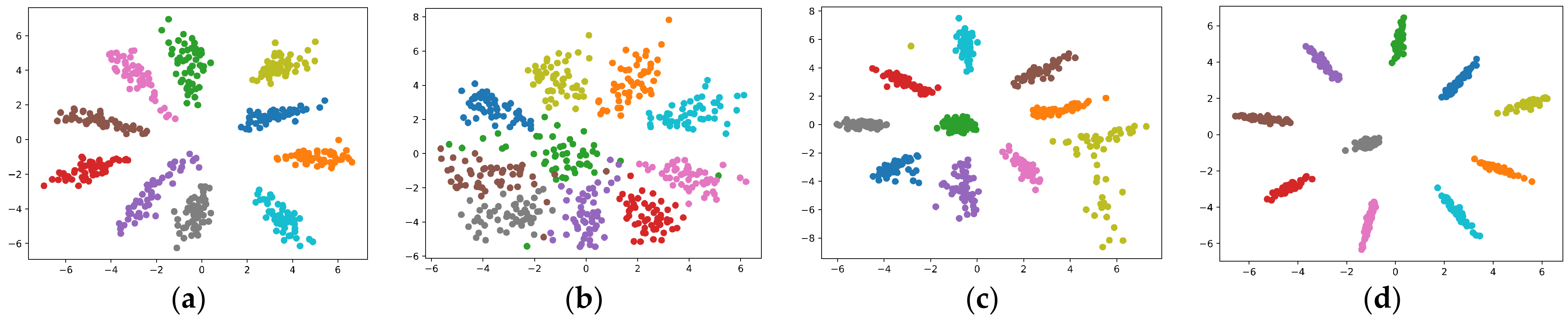
5.1. Binary Classification Task with a Synthetic Dataset
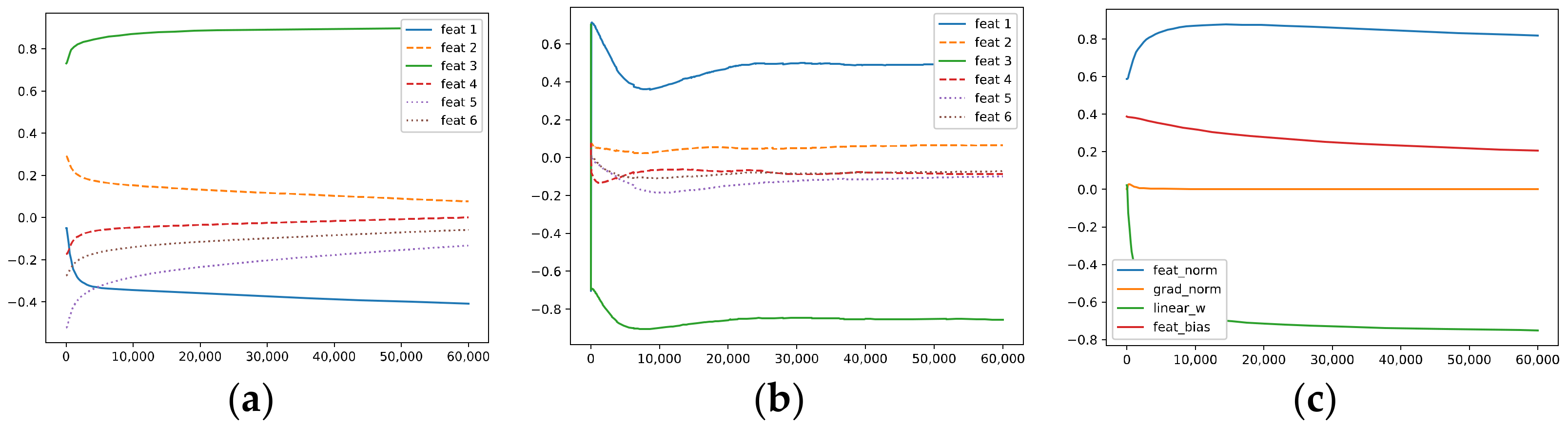
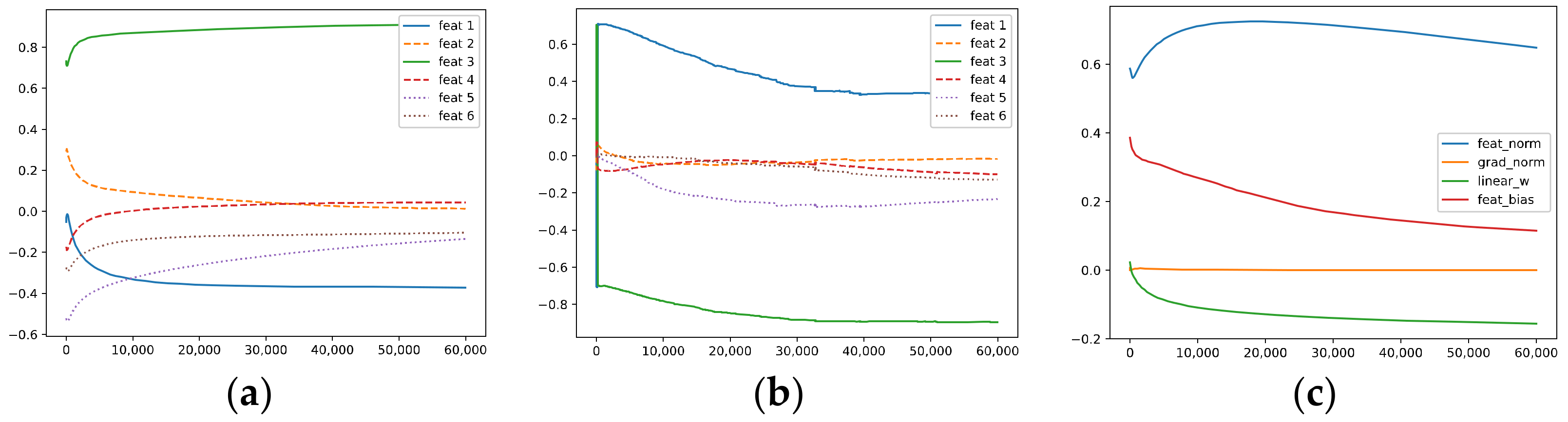
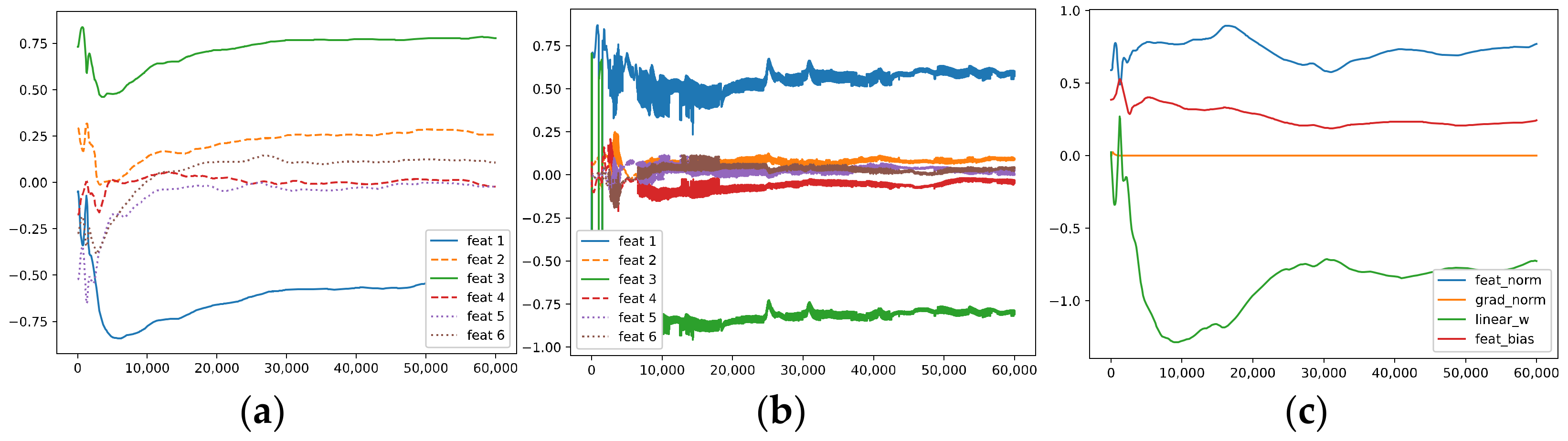
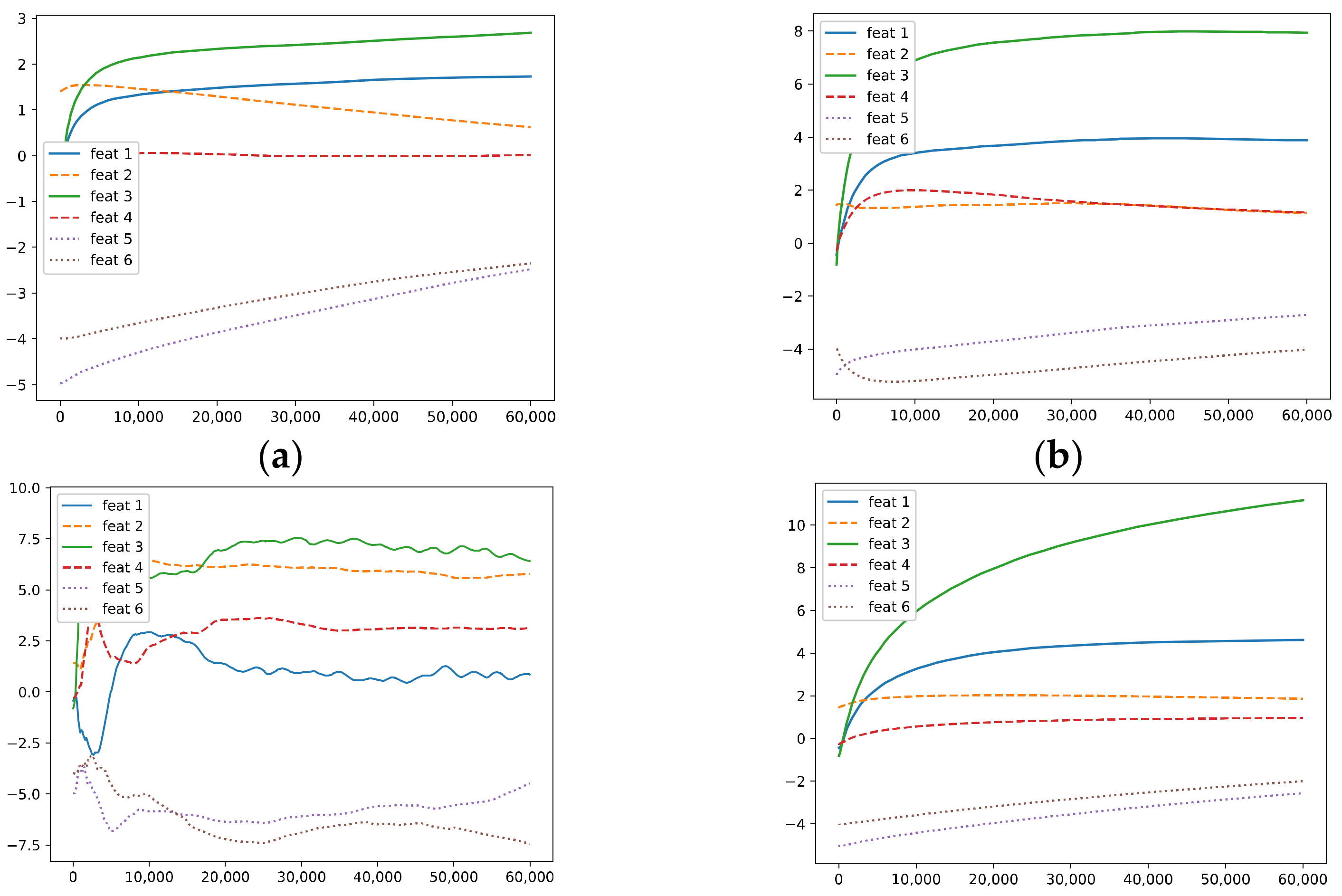
5.1.1. The Signal and Noise in a Hidden Neuron
- The correlation between the hidden weight of the r-th neuron and the k-th ground-truth feature (i.e., the k-th feature in the feature dictionary) : ;
- The correlation between the gradient of the loss with respect to the weight of the r-th neuron and the k-th ground-truth feature: ;
- The norm of the weight vector of the r-th neuron: ;
- The norm of the gradient: ;
- The weight of the fully connected layer corresponding to the r-th neuron: ;
- The bias of the r-th neuron: .
- (1)
- Optimization via GD
- (2)
- Optimization via AdaGrad
- (3)
- Optimization via KFAC
- (4)
- Optimization via GD with the proposed regularizer
- (i)
- Due to the existence of underlying noise in the data (i.e., the gradients have non-zero correlation with the two OoFS features and .
- (ii)
- The correlations between the gradients and the ground-truth features tend to converge, and the norm of the gradients converges to zero fast.
- (iii)
- The correlations between the hidden weights and the ground-truth features tend to converge but with different rates.
- (iv)
- Due to both the OoFS noise in the data and the influence of the random initialization, the learned features (i.e., the hidden weights) have non-zero correlations with and , which may induce noise in the output for the OoFS test samples.
- (v)
- Although the six ground-truth features in the feature dictionary are orthogonal, the neurons in the models do not learn these pure ground-truth features; instead, they learn a mixture of the ground-truth features ~ and contain OoFS noise (i.e., and ) as well.
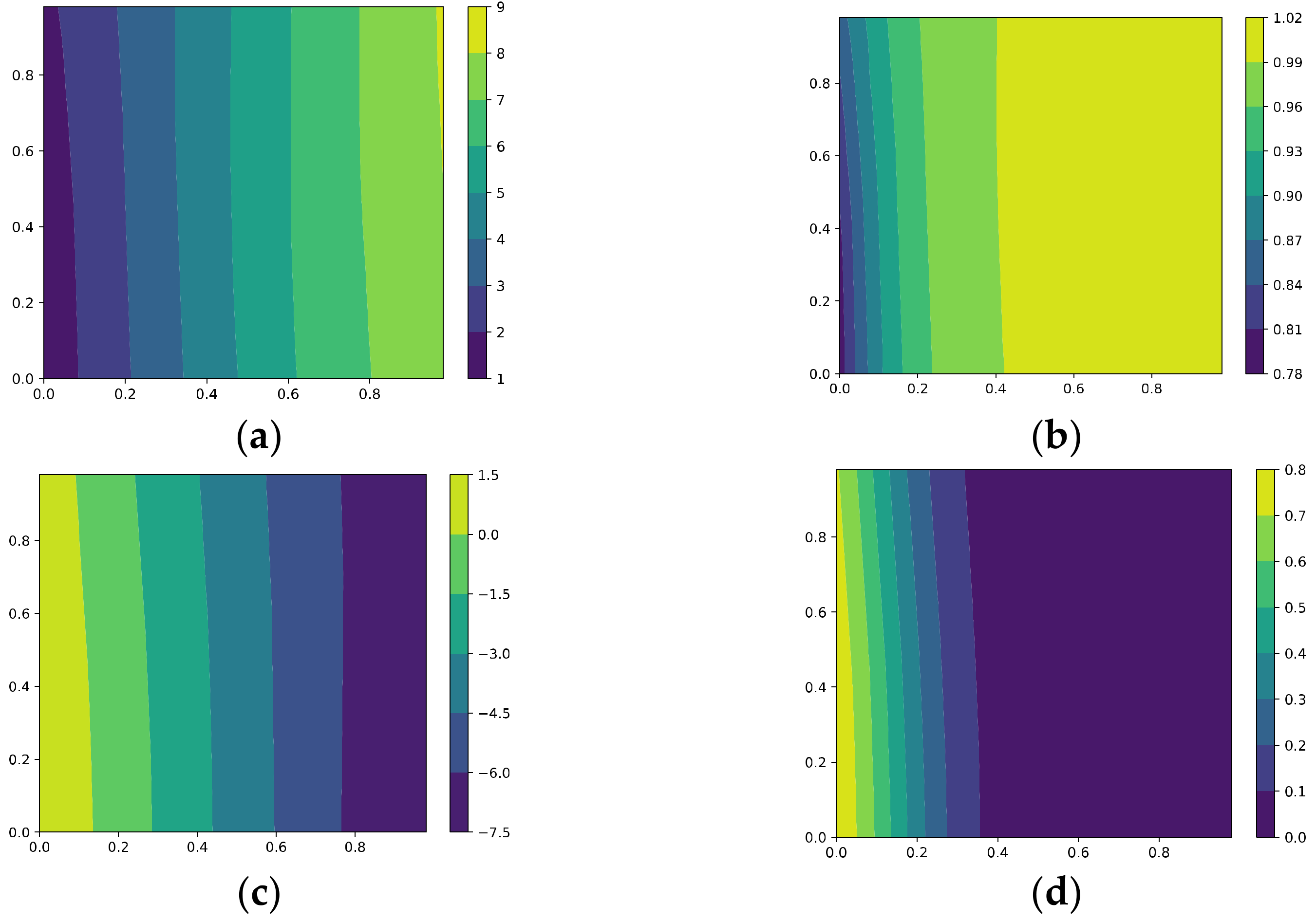
5.1.2. Test with Samples within the Feature Subspace
- (1)
- Optimization via GD
- (2)
- Optimization via AdaGrad
- (3)
- KFAC
- (4)
- Optimization via GD with the proposed regularizer
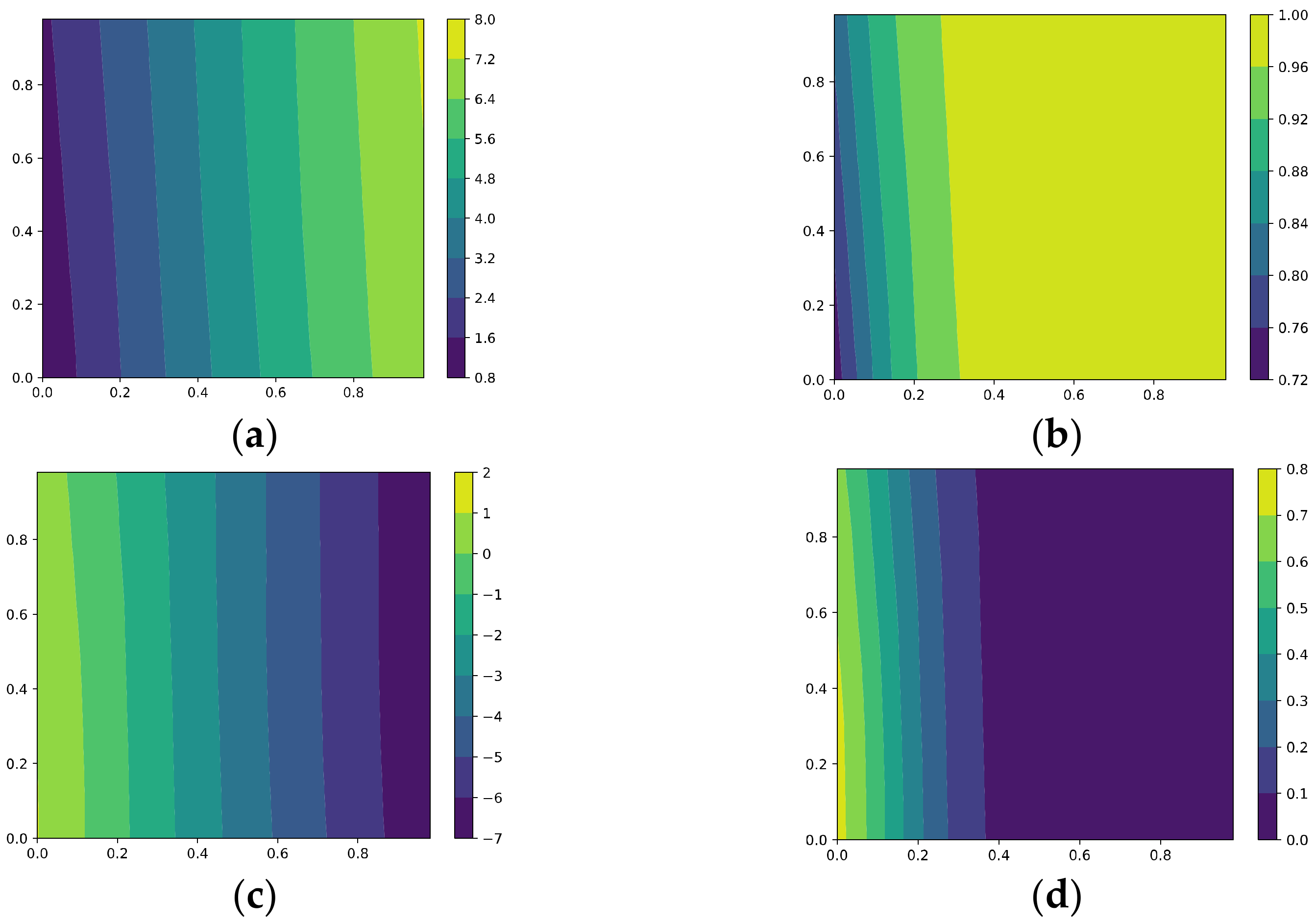
5.1.3. Test with Samples within the OoFS
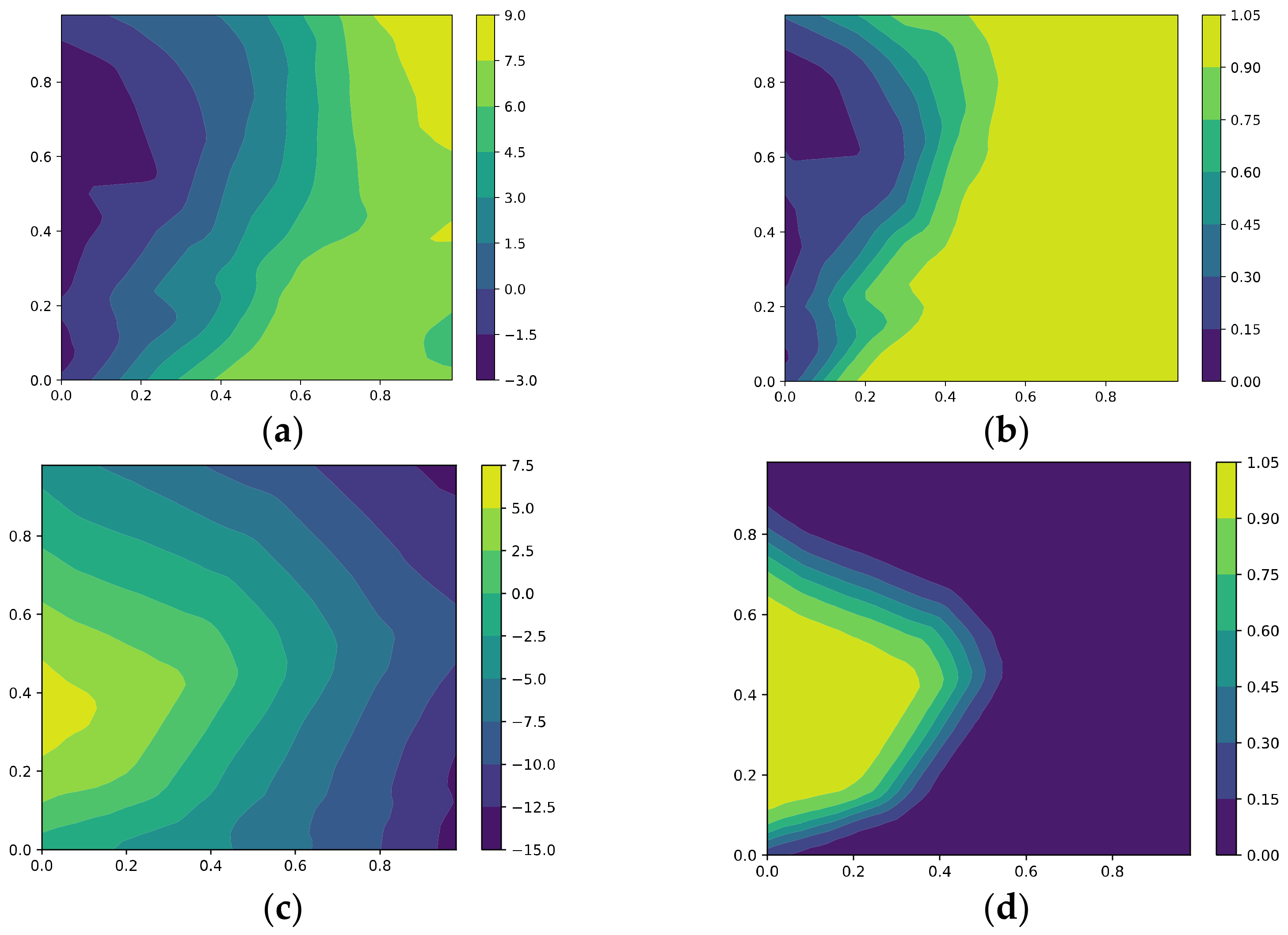
5.1.4. The Signal and Noise in the Hidden Layer
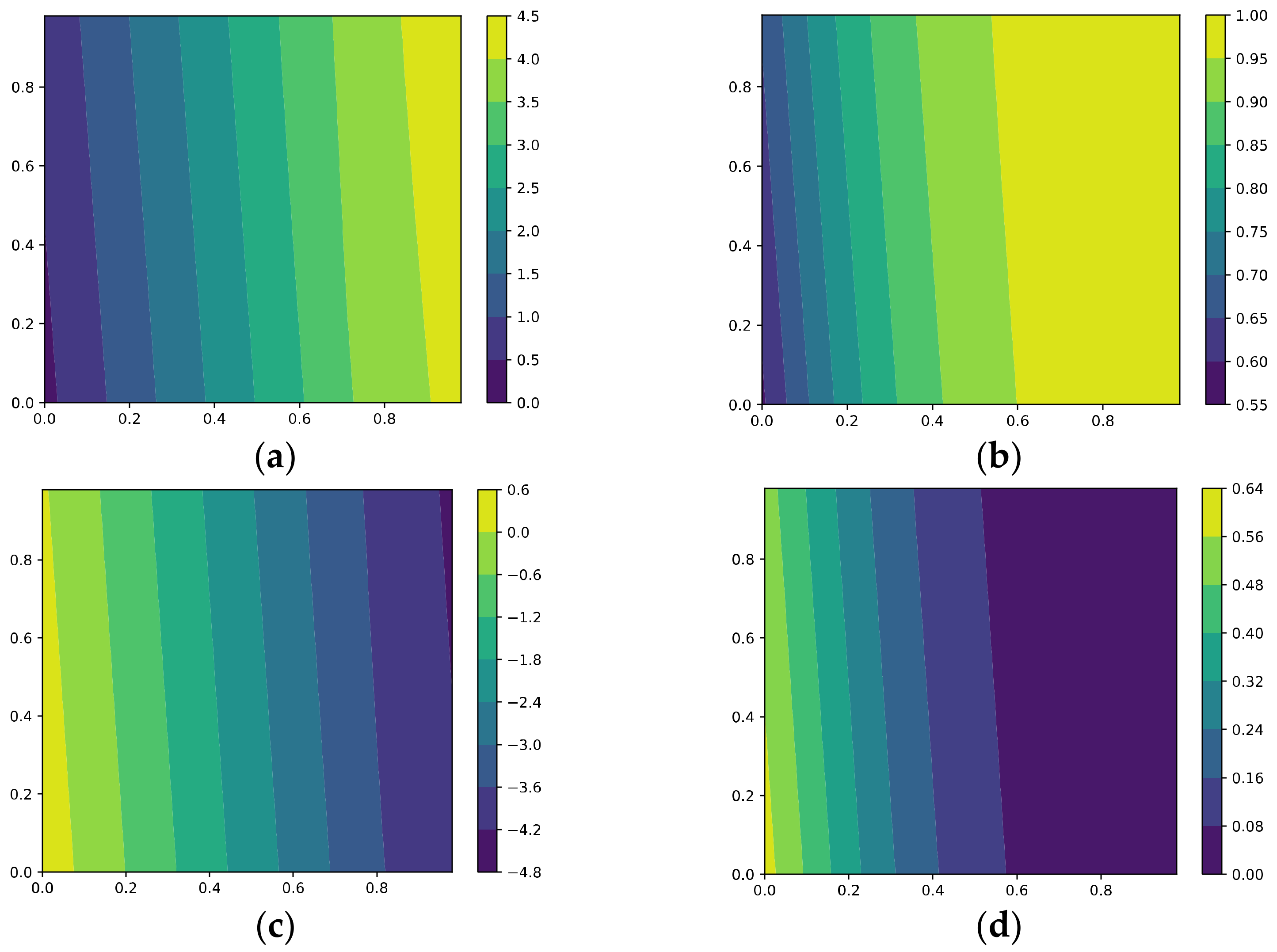
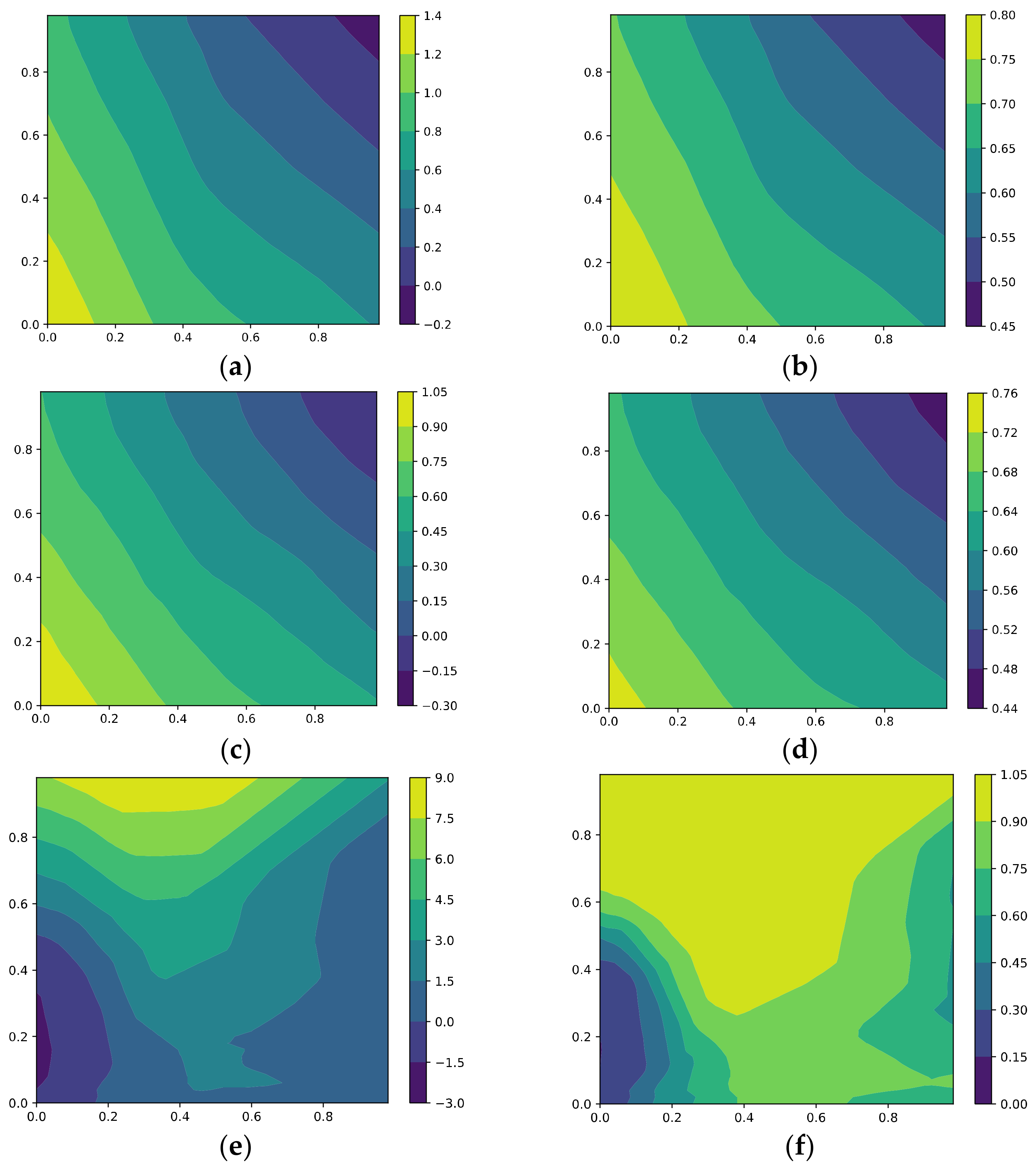
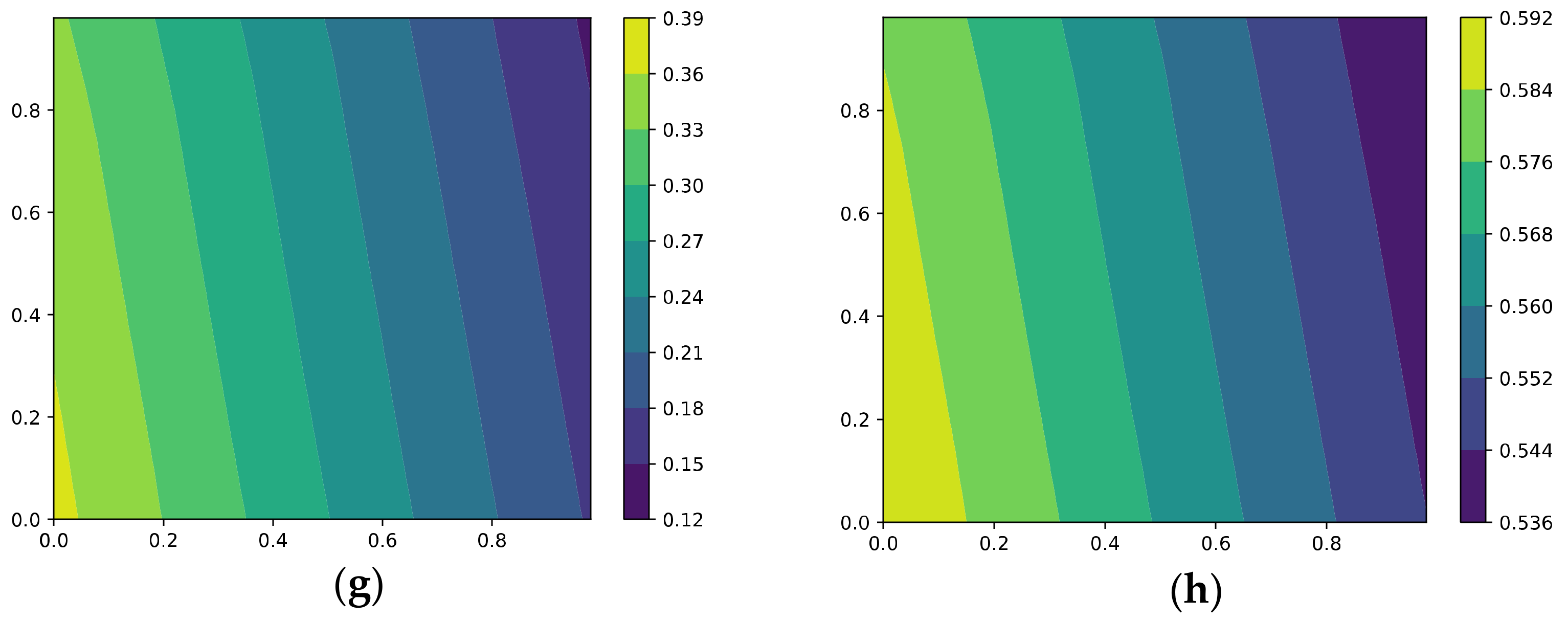
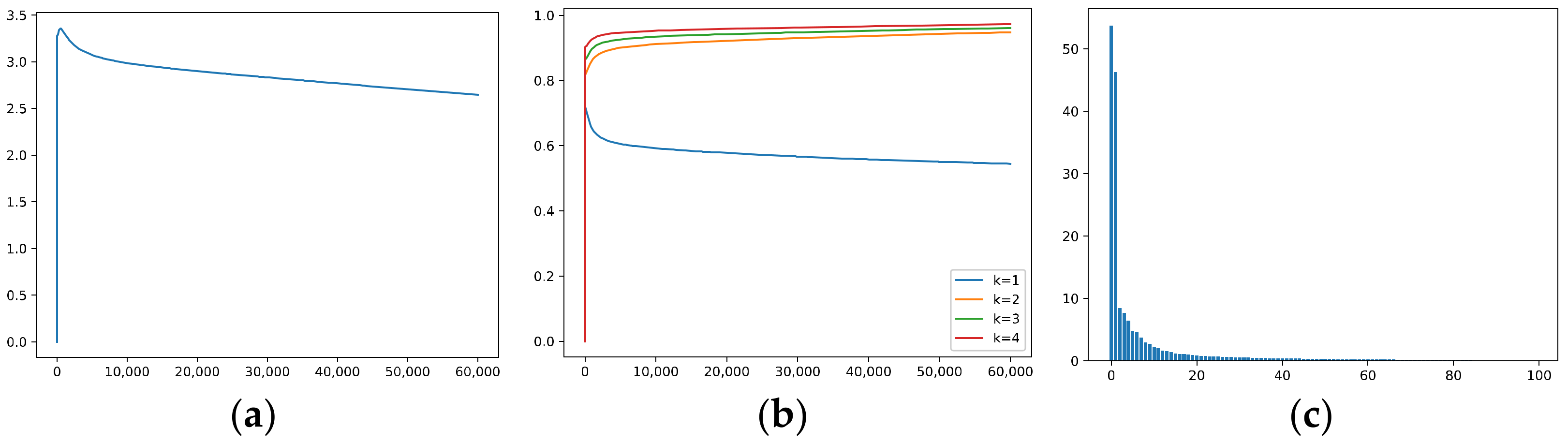
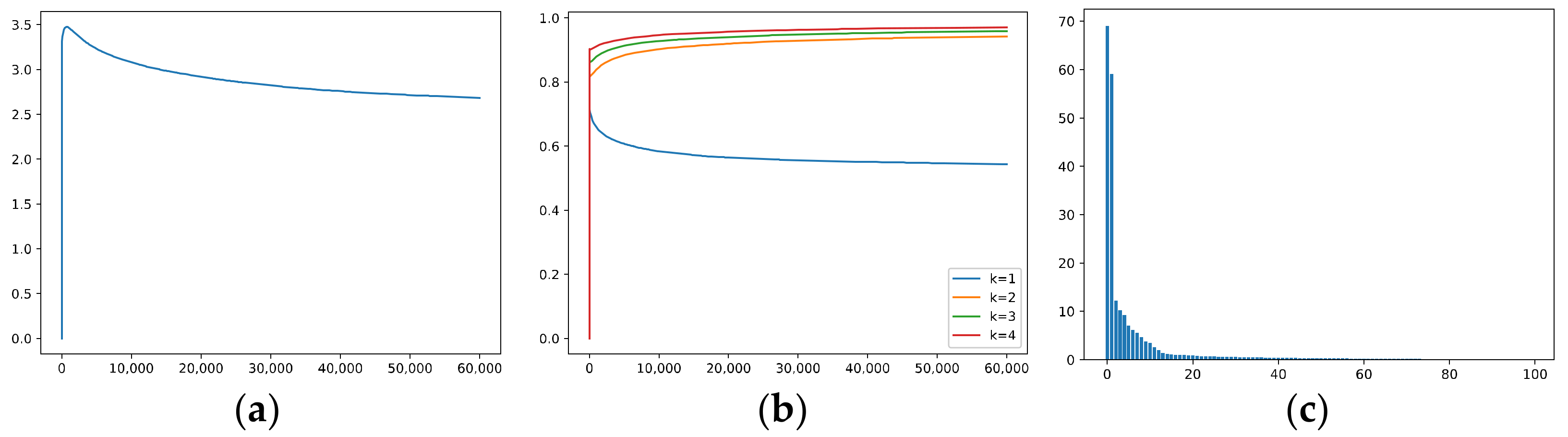
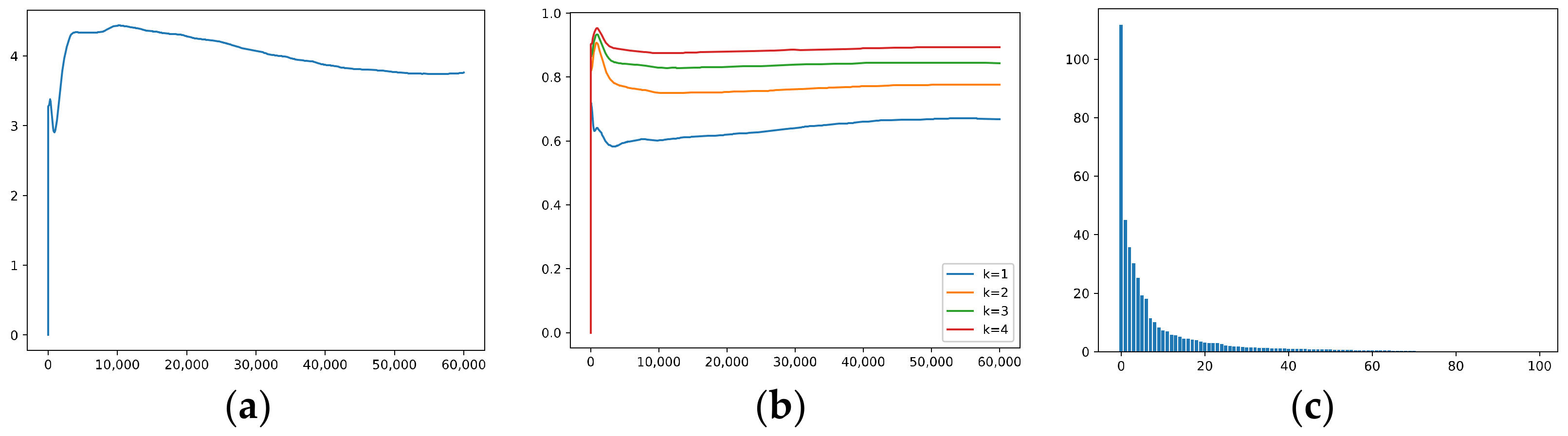
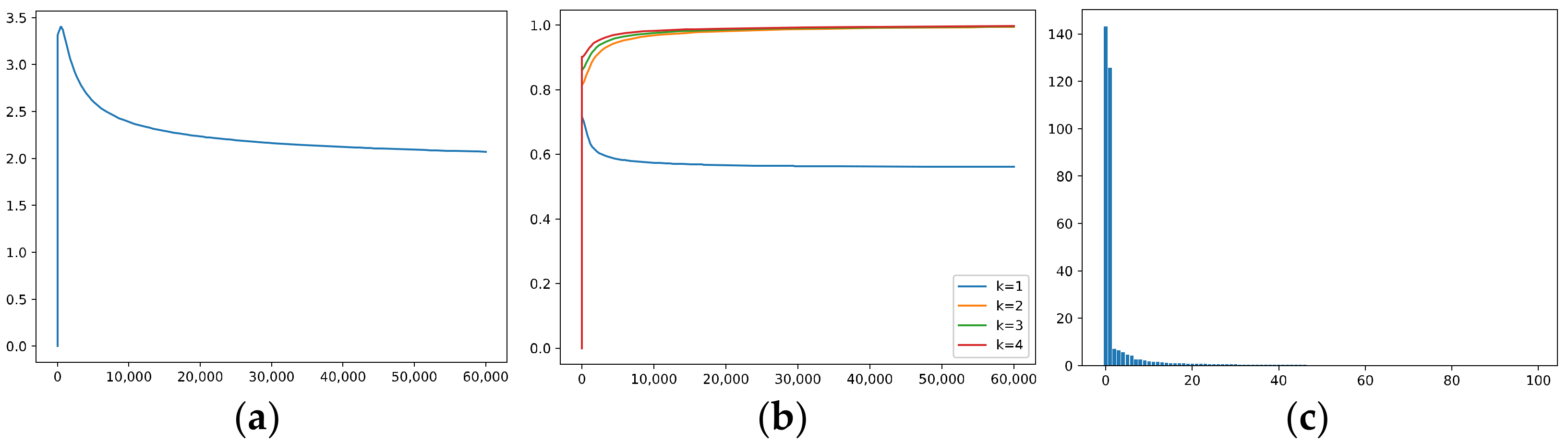
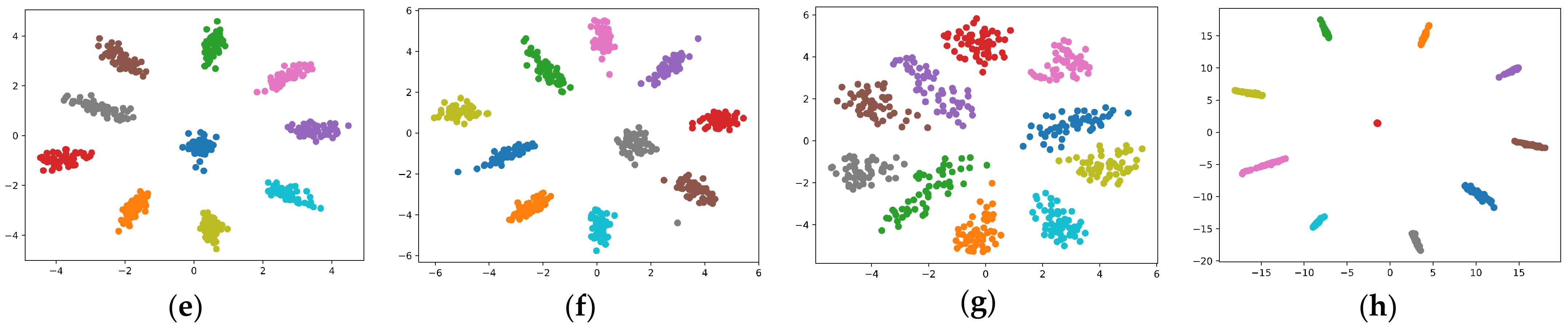
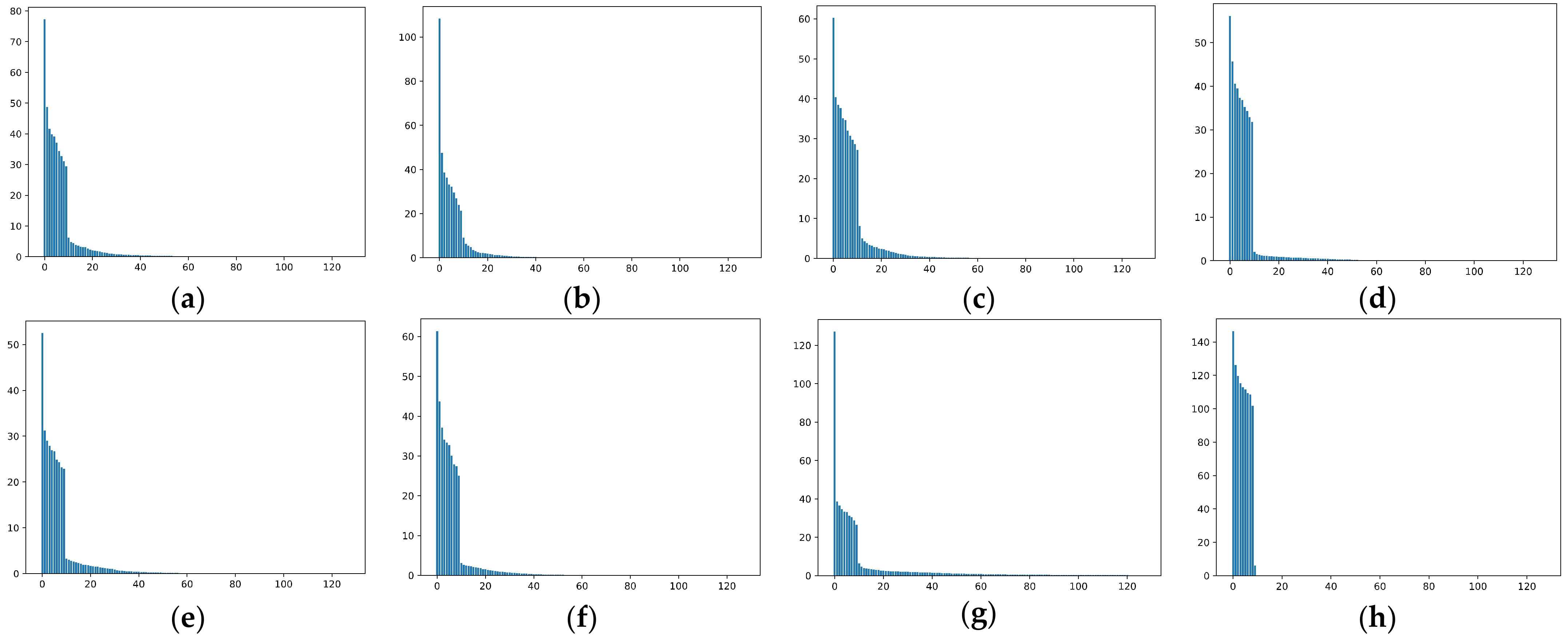
5.1.5. The Effective Rank, Trace Ratios, and Spectrum
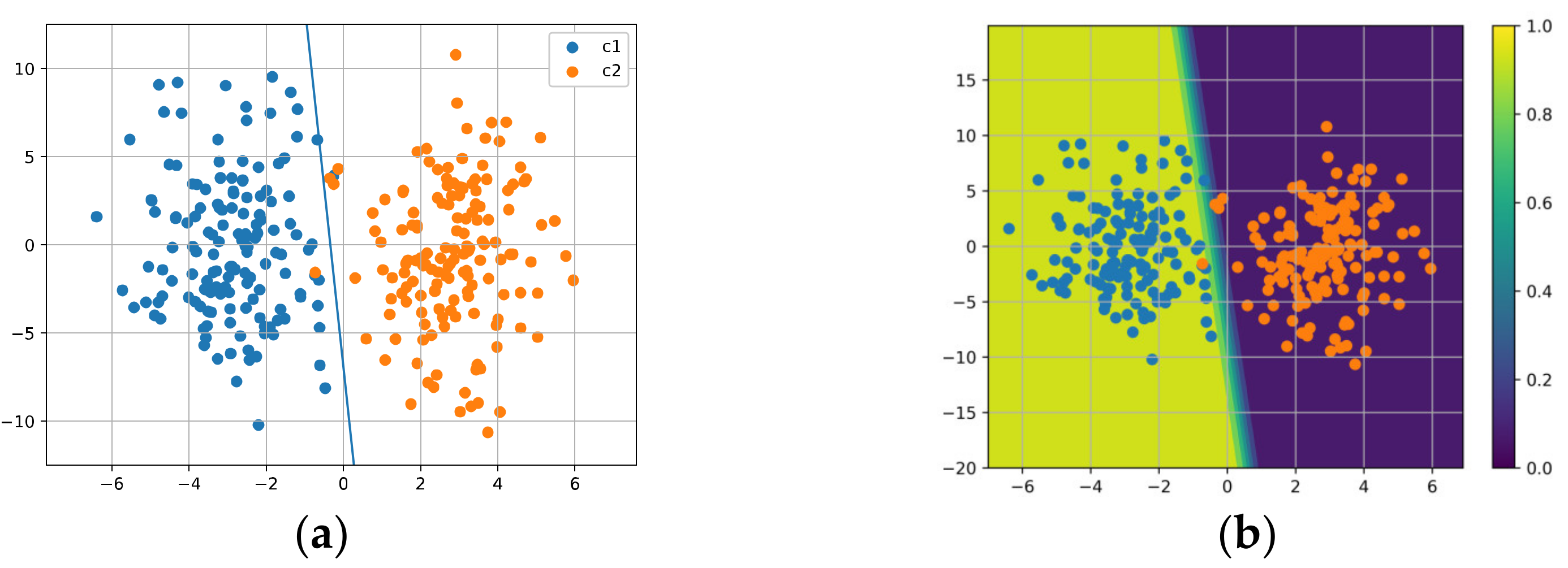
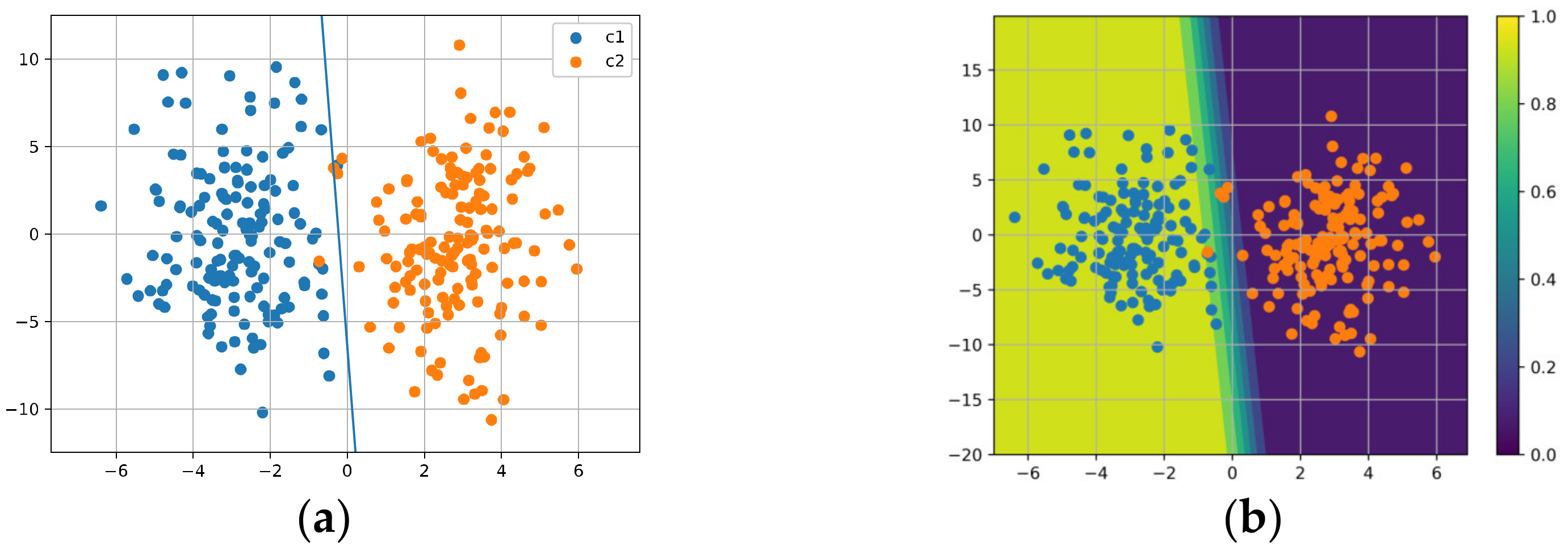
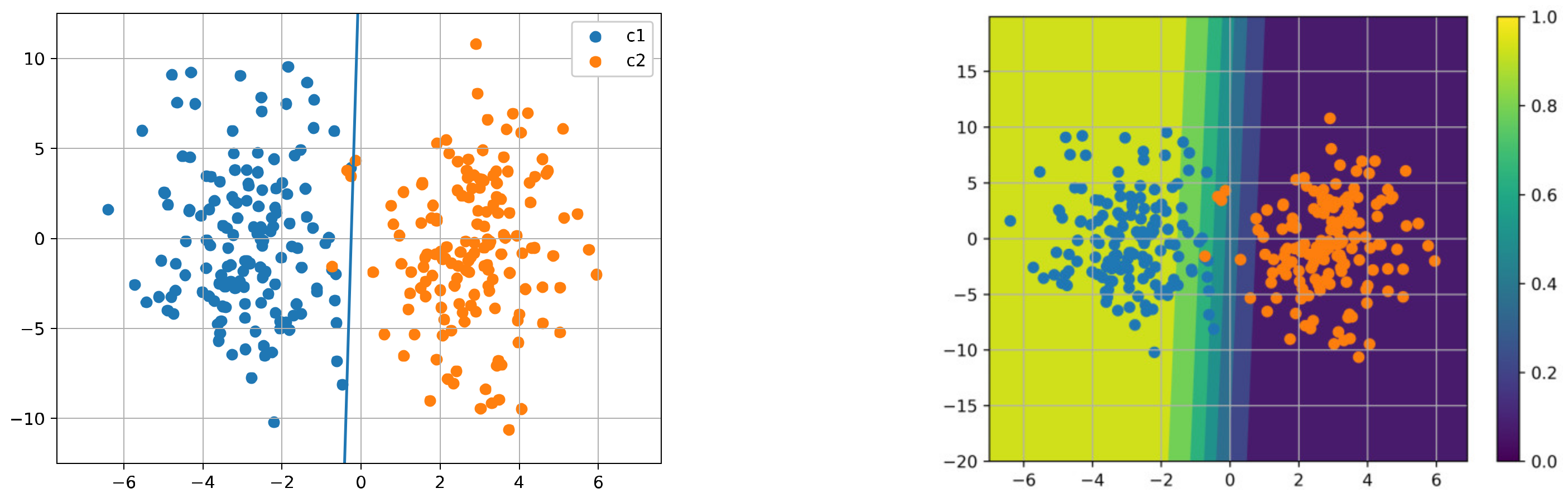
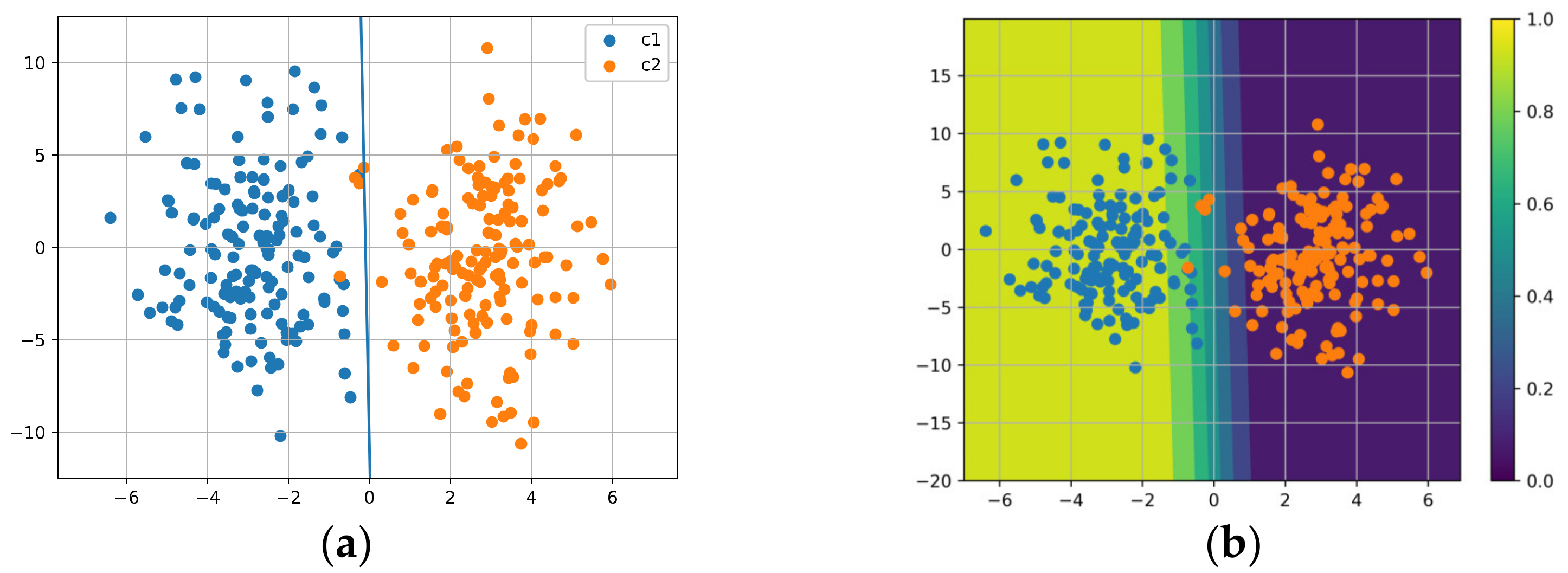
5.2. Linear Binary Classification Task
5.3. Image Classification Task on Benchmark Datasets
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding Deep Learning Requires Rethinking Generalization. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Buckner, C. Understanding Adversarial Examples Requires a Theory of Artefacts for Deep Learning. Nat. Mach. Intell. 2020, 2, 731–736. [Google Scholar] [CrossRef]
- Wang, M.; Deng, W. Deep Visual Domain Adaptation: A Survey. Neurocomputing 2018, 312, 135–153. [Google Scholar] [CrossRef]
- Salehi, M.; Mirzaei, H.; Hendrycks, D.; Li, Y.; Rohban, M.H.; Sabokrou, M. A Unified Survey on Anomaly, Novelty, Open-Set, and Out-of-Distribution Detection: Solutions and Future Challenges. arXiv 2021, arXiv:2110.14051. [Google Scholar]
- Allen-Zhu, Z.; Li, Y.; Liang, Y. Learning and Generalization in Overparameterized Neural Networks, Going Beyond Two Layers. In Proceedings of the Advances in Neural Information Processing Systems 32, Montreal, QC, Canada, 2–8 December 2018. [Google Scholar]
- Jiang, Y.; Krishnan, D.; Mobahi, H.; Bengio, S. Predicting the Generalization Gap in Deep Networks with Margin Distributions. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhang, R.; Zhai, S.; Littwin, E.; Susskind, J. Learning Representation from Neural Fisher Kernel with Low-Rank Approxima-tion. In Proceedings of the International Conference on Learning Representations, Online, 25–29 April 2022. [Google Scholar]
- Yu, Y.; Chan, K.H.R.; You, C.; Song, C.; Ma, Y. Learning Diverse and Discriminative Representations via the Principle of Maximal Coding Rate Reduction. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020. [Google Scholar]
- Soudry, D.; Hoffer, E.; Nacson, M.S.; Gunasekar, S.; Srebro, N. The Implicit Bias of Gradient Descent on Separable Data. J. Mach. Learn. Res. 2018, 19, 2822–2878. [Google Scholar]
- Zhou, K.; Liu, Z.; Qiao, Y.; Xiang, T.; Loy, C.C. Domain Generalization: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 4396–4415. [Google Scholar] [CrossRef]
- Zhou, K.; Liu, Z.; Qiao, Y.; Xiang, T.; Loy, C.C. Domain Generalization in Vision: A Survey. arXiv 2021, arXiv:2103.02503. [Google Scholar]
- Sun, J.; Wang, H.; Dong, Q. MoEP-AE: Autoencoding Mixtures of Exponential Power Distributions for Open-Set Recognition. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 312–325. [Google Scholar] [CrossRef]
- Shen, Z.; Liu, J.; He, Y.; Zhang, X.; Xu, R.; Yu, H.; Cui, P. Towards Out-Of-Distribution Generalization: A Survey. arXiv 2021, arXiv:2108.13624. [Google Scholar]
- Ye, N.; Li, K.; Hong, L.; Bai, H.; Chen, Y.; Zhou, F.; Li, Z. OoD-Bench: Benchmarking and Understanding Out-of-Distribution Generalization Datasets and Algorithms. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Hofer, C.D.; Graf, F.; Niethammer, M.; Kwitt, R. Topologically Densified Distributions. In Proceedings of the 37th International Conference on Machine Learning, Online, 13–18 July 2020. [Google Scholar]
- Wager, S.; Fithian, W.; Wang, S.; Liang, P. Altitude Training: Strong Bounds for Single-Layer Dropout. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Allen-Zhu, Z.; Li, Y. Feature Purification: How Adversarial Training Performs Robust Deep Learning. In Proceedings of the IEEE 62nd Annual Symposium on Foundations of Computer Science (FOCS), Denver, CO, USA, 7–10 February 2020. [Google Scholar]
- Allen-Zhu, Z.; Li, Y. Towards Understanding Ensemble, Knowledge Distillation and Self-Distillation in Deep Learning. arXiv 2021, arXiv:2012.09816. [Google Scholar]
- Jelassi, S.; Li, Y. Towards Understanding How Momentum Improves Generalization in Deep Learning. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022. [Google Scholar]
- Saxe, A.M.; McClelland, J.L.; Ganguli, S. A Mathematical Theory of Semantic Development in Deep Neural Networks. Proc. Natl. Acad. Sci. 2019, 116, 11537–11546. [Google Scholar] [CrossRef]
- Tachet, R.; Pezeshki, M.; Shabanian, S.; Courville, A.; Bengio, Y. On the Learning Dynamics of Deep Neural Networks. arXiv 2020, arXiv:1809.06848. [Google Scholar]
- Pezeshki, M.; Kaba, S.-O.; Bengio, Y.; Courville, A.; Precup, D.; Lajoie, G. Gradient Starvation: A Learning Proclivity in Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020. [Google Scholar]
- Geirhos, R.; Jacobsen, J.-H.; Michaelis, C.; Zemel, R.; Brendel, W.; Bethge, M.; Wichmann, F.A. Shortcut Learning in Deep Neural Networks. Nat. Mach. Intell. 2020, 2, 665–673. [Google Scholar] [CrossRef]
- Huh, M.; Mobahi, H.; Zhang, R.; Cheung, B.; Agrawal, P.; Isola, P. The Low-Rank Simplicity Bias in Deep Networks. arXiv 2022, arXiv:2103.10427. [Google Scholar]
- Teney, D.; Abbasnejad, E.; Lucey, S.; Van den Hengel, A. Evading the Simplicity Bias: Training a Diverse Set of Models Discovers Solutions with Superior OOD Generalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 21–23 June 2022. [Google Scholar]
- Shah, H.; Tamuly, K.; Raghunathan, A. The Pitfalls of Simplicity Bias in Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020. [Google Scholar]
- Oymak, S.; Fabian, Z.; Li, M.; Soltanolkotabi, M. Generalization Guarantees for Neural Networks via Harnessing the Low-Rank Structure of the Jacobian. arXiv 2019, arXiv:1906.05392. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Amari, S.; Ba, J.; Grosse, R.; Li, X.; Nitanda, A.; Suzuki, T.; Wu, D.; Xu, J. When Does Preconditioning Help or Hurt General-ization? In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26 April 2020. [Google Scholar]
- Martens, J. New Insights and Perspectives on the Natural Gradient Method. J. Mach. Learn. Res. 2020, 21, 5776–5851. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Nagarajan, V.; Andreassen, A. Understanding the Failure Modes of Out-of-distribution Generalization. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26 April 2020. [Google Scholar]
- Vardi, G.; Yehudai, G.; Shamir, O. Gradient Methods Provably Converge to Non-Robust Networks. arXiv 2022, arXiv:2202.04347. [Google Scholar]
- Belkin, M.; Ma, S.; Mandal, S. To Understand Deep Learning We Need to Understand Kernel Learning. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Muthukumar, V. Classification vs. Regression in Overparameterized Regimes: Does the Loss Function Matter? J. Mach. Learn. Res. 2021, 22, 1–69. [Google Scholar]
- Hastie, T.; Montanari, A.; Rosset, S.; Tibshirani, R.J. Surprises in High-Dimensional Ridgeless Least Squares Interpolation. Ann. Stat. 2022, 50, 949–986. [Google Scholar] [CrossRef]
- Baratin, A.; George, T.; Laurent, C.; Hjelm, R.D.; Lajoie, G.; Vincent, P.; Lacoste-Julien, S. Implicit Regularization via Neural Feature Alignment. In Proceedings of the 24th International Conference on Artificial Intelligence and Statistics, San Diego, CA, USA, 13–15 April 2021. [Google Scholar]
- Arora, R.; Bartlett, P.; Mianjy, P.; Srebro, N. Dropout: Explicit Forms and Capacity Control. In Proceedings of the 37th International Conference on Machine Learning, Online, 13–18 July 2020. [Google Scholar]
- Cavazza, J.; Morerio, P.; Haeffele, B.; Lane, C.; Murino, V.; Vidal, R. Dropout as a Low-Rank Regularizer for Matrix Factorization. In Proceedings of the 21st International Conference on Artificial Intelligence and Statistics, Playa Blanca, Lanzarote, Canary Islands, 9–11 April 2018. [Google Scholar]
- Mianjy, P.; Arora, R.; Vidal, R. On the Implicit Bias of Dropout. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Wager, S.; Wang, S.; Liang, P. Dropout Training as Adaptive Regularization. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013. [Google Scholar]
- Huang, Z.; Wang, H.; Xing, E.P.; Huang, D. Self-Challenging Improves Cross-Domain Generalization. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; Volume 12347, pp. 124–140. [Google Scholar] [CrossRef]
- Hoffman, J.; Roberts, D.A.; Yaida, S. Robust Learning with Jacobian Regularization. arXiv 2019, arXiv:1908.02729. [Google Scholar]
- Cogswell, M.; Ahmed, F.; Girshick, R.; Zitnick, L.; Batra, D. Reducing Overfitting in Deep Networks by Decorrelating Representations. In Proceedings of the International Conference on Learning Representations, San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Choi, D.; Rhee, W. Utilizing Class Information for Deep Network Representation Shaping. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January 2019. [Google Scholar]
- Gunasekar, S.; Lee, J.; Soudry, D.; Srebro, N. Characterizing Implicit Bias in Terms of Optimization Geometry. In Proceedings of the 35th International Conference on Machine Learning, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Shlens, J. A Tutorial on Principal Component Analysis. arXiv 2014, arXiv:1404.1100. [Google Scholar]
- Martens, J.; Grosse, R. Optimizing Neural Networks with Kronecker-Factored Approximate Curvature. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Chatterjee, S. Coherent Gradients: An Approach to understanding generalization in gradient descent-based optimization. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26 April 2020. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading Digits in Natural Images with Unsupervised Feature Learning. In Proceedings of the Conference on Neural Information Processing Systems, Granada, Spain, 12–17 December 2011. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Laine, S.; Aila, T. Temporal ensembling for semisupervised learning. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving Neural Networks by Preventing Co-Adaptation of Feature Detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Ma, P.; Ren, J.; Sun, G.; Zhao, H.; Jia, X.; Yan, Y.; Zabalza, J. Multiscale Superpixelwise Prophet Model for Noise-Robust Feature Extraction in Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–12. [Google Scholar] [CrossRef]
- Fu, H.; Sun, G.; Zhang, A.; Shao, B.; Ren, J.; Jia, X. Tensor Singular Spectral Analysis for 3D feature extraction in hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2023. [Google Scholar] [CrossRef]
- Li, Y.; Ren, J.; Yan, Y.; Petrovski, A. CBANet: An End-to-end Cross Band 2-D Attention Network for Hyperspectral Change Detection in Remote Sensing. IEEE Trans. Geosci. Remote Sens. 2023; in press. [Google Scholar]
- Xie, G.; Ren, J.; Marshall, S.; Zhao, H.; Li, R.; Chen, R. Self-attention Enhanced Deep Residual Network for Spatial Image Steganalysis. Digit. Signal Process. 2023, 104063. [Google Scholar] [CrossRef]
- Chen, R.; Huang, H.; Yu, Y.; Ren, J.; Wang, P.; Zhao, H.; Lu, X. Rapid Detection of Multi-QR Codes Based on Multistage Stepwise Discrimination and a Compressed MobileNet. IEEE Internet Things J. 2023. [Google Scholar] [CrossRef]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Regularization | MNIST-250 | SVHN-250 | CIFAR10-500 | CIFAR10-1k |
|---|---|---|---|---|
| Vanilla | 7.1 ± 1.0 | 30.1 ± 2.9 | 39.4 ± 1.5 | 29.5 ± 0.8 |
| +Jac.-Reg [43] | 6.2 ± 0.8 | 33.1 ± 2.8 | 39.7 ± 2.0 | 29.8 ± 1.2 |
| +DeCov [44] | 6.5 ± 1.1 | 28.9 ± 2.2 | 38.2 ± 1.5 | 29.0 ± 0.6 |
| +VR [45] | 6.1 ± 0.5 | 28.2 ± 2.4 | 38.6 ± 1.4 | 29.3 ± 0.7 |
| +cw-CR [45] | 7.0 ± 0.6 | 28.8 ± 2.9 | 39.0 ± 1.9 | 29.1 ± 0.7 |
| +cw-VR [45] | 6.2 ± 0.8 | 28.4 ± 2.5 | 38.5 ± 1.6 | 29.0 ± 0.7 |
| +Sub-batches [15] | 7.1 ± 0.5 | 27.5 ± 2.6 | 38.3 ± 3.0 | 28.9 ± 0.4 |
| +Sub-batches + Top.-Reg [15] | 5.6 ± 0.7 | 22.5 ± 2.0 | 36.5 ± 1.2 | 28.5 ± 0.6 |
| +Sub-batches + Top.-Reg [15] | 5.9 ± 0.3 | 23.3 ± 1.1 | 36.8 ± 0.3 | 28.8 ± 0.3 |
| +FC_Reg (ours) | 5.3 ± 0.3 | 27.8 ± 1.3 | 36.2 ± 0.7 | 28.4 ± 0.3 |
| Regularization | Trace Ratios of the Representations |
|---|---|
| Vanilla | [0.3169, 0.4428, 0.5347, 0.6189, 0.7002, 0.7735, 0.8363, 0.8934, 0.9445, 0.9903] |
| +Jac.-Reg [43] | [0.5379, 0.6417, 0.7099, 0.7706, 0.8209, 0.8686, 0.9089, 0.9422, 0.9684, 0.9891] |
| +DeCov [44] | [0.2386, 0.3460, 0.4434, 0.5366, 0.6175, 0.6964, 0.7638, 0.8259, 0.8841, 0.9380] |
| +VR [45] | [0.3013, 0.4078, 0.4997, 0.5849, 0.6643, 0.7422, 0.8100, 0.8746, 0.9335, 0.9909] |
| +cw-CR [45] | [0.2001, 0.3326, 0.4374, 0.5364, 0.6252, 0.7113, 0.7902, 0.8650, 0.9338, 0.9983] |
| +cw-VR [45] | [0.3013, 0.4078, 0.4997, 0.5849, 0.6643, 0.7422, 0.8100, 0.8746, 0.9335, 0.9909] |
| +Top.-Reg [15] | [0.6253, 0.6835, 0.7317, 0.7781, 0.8220, 0.8608, 0.8971, 0.9313, 0.9637, 0.9883] |
| +FC_Reg (ours) | [0.1727, 0.3008, 0.4158, 0.5226, 0.6253, 0.7254, 0.8217, 0.9165, 0.9997, 1.0000] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, M.; Wang, D.; Feng, S.; Zhang, Y. Denoising in Representation Space via Data-Dependent Regularization for Better Representation. Mathematics 2023, 11, 2327. https://doi.org/10.3390/math11102327
Chen M, Wang D, Feng S, Zhang Y. Denoising in Representation Space via Data-Dependent Regularization for Better Representation. Mathematics. 2023; 11(10):2327. https://doi.org/10.3390/math11102327
Chicago/Turabian StyleChen, Muyi, Daling Wang, Shi Feng, and Yifei Zhang. 2023. "Denoising in Representation Space via Data-Dependent Regularization for Better Representation" Mathematics 11, no. 10: 2327. https://doi.org/10.3390/math11102327
APA StyleChen, M., Wang, D., Feng, S., & Zhang, Y. (2023). Denoising in Representation Space via Data-Dependent Regularization for Better Representation. Mathematics, 11(10), 2327. https://doi.org/10.3390/math11102327