
Statistical Depth for Text Data: An Application to the Classification of Healthcare Data


Abstract
1. Introduction
- The first depth function aimed for text data, in particular for text data vectorized through the tf-idf statistic.
- The usefulness of this depth function in depth-based supervised classification of text data.
2. Theoretical Framework
2.1. Statistical Data Depth: Formal Definition
- P1.
- Affine invariance: For any nonsingular real matrix any vector , any and any
- P2.
- Maximality at center: For any distribution with a unique center of symmetry θ, with respect to some notion of symmetry,
- P3.
- Monotonicity relative to deepest point: For any distribution having deepest point θ,for all and .
- P4.
- Vanishing at infinity: For each distribution , as .
2.2. Statistical Data Depths for Functional Data
2.2.1. Fraiman and Muniz Depth
2.2.2. Random Projection Depth
2.2.3. Random Tukey Depth
2.3. Depth-Based Classification: The -Classifier
3. Materials and Methodology
3.1. Dataset
- It allows the dataset to be divided into 184 text fragments of participant intervention, each of which is assigned a category labeled with 1 or 0 depending on whether it has at least one CFIR construct assigned to it or not, respectively. In particular, 85 of the 184 fragments are labeled as 1, while the remaining 99 are labeled as 0. The moderator statements were removed.
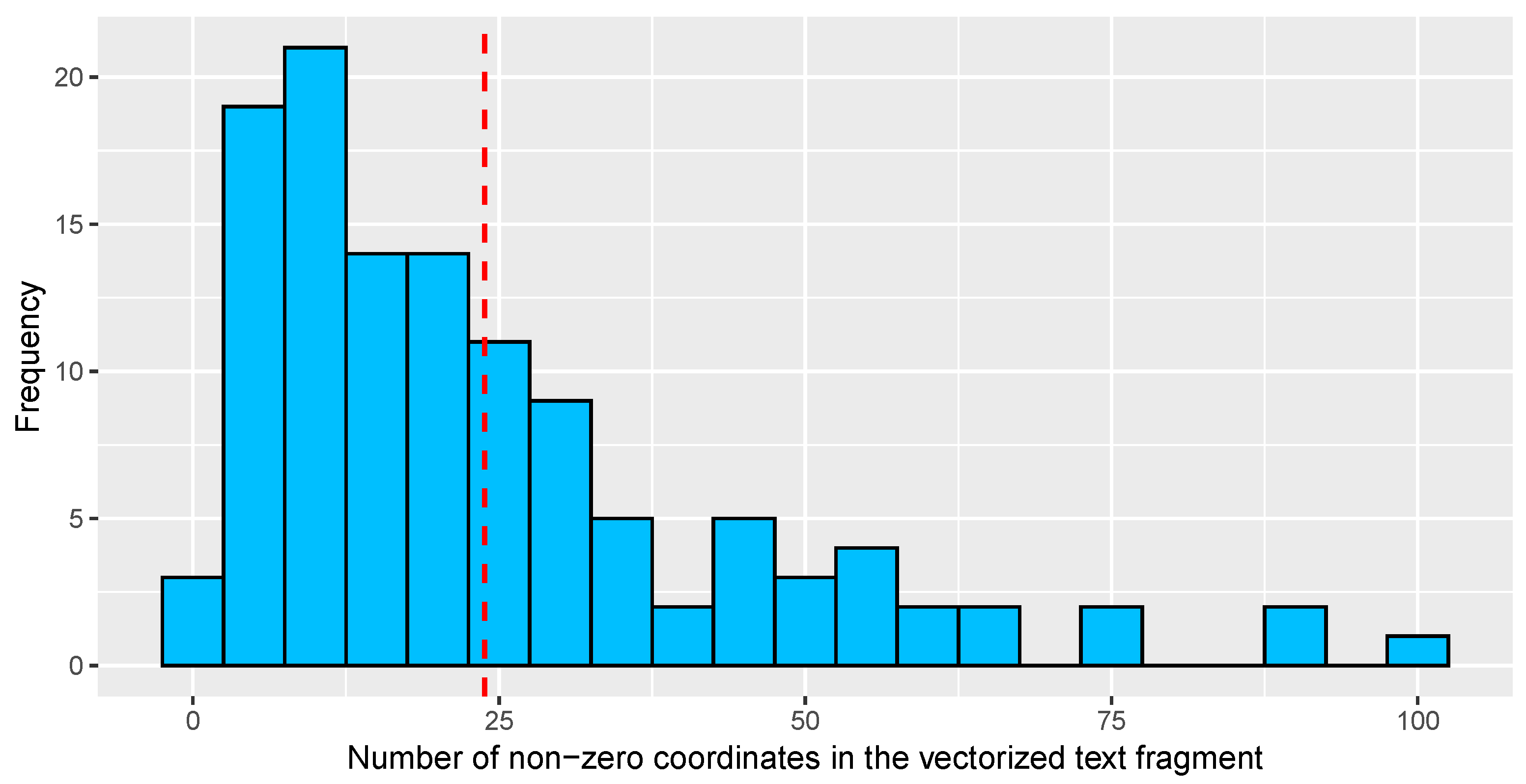
- It allows transforming variable length text fragments into fixed length numerical vectors through a vectorization process based on the tf-idf statistic [52]. The length of these numerical vectors is exactly the number of unique words in the corpus or set of text fragments considered in each case (see [25] for further details). For instance, if the training set is composed of 848 unique words, as is the case in Section 4, each text fragment is transformed into a vector in whose coordinates are the values of the tf-idf statistic of each unique word (which depends both on the text fragment and the corpus under consideration) sorted alphabetically.
3.2. Data Depths for Text Data
3.2.1. Compositional Depth: The Inverse Fourier Transform
4. Results
- The training set, , consists of the first 65% of the text fragments in the entire dataset and the test set, , is its complement. In particular, the training set consists of 119 observations. It is worth noting that the distribution of observations in this training dataset is relatively balanced, with 66 observations labeled as “1” (indicating the presence of at least one associated CFIR construct) and 53 labeled as “0” (indicating the absence of an associated CFIR construct). This results in a proportion of 55.5% of the training sample being labeled as “1” and 44.5% being labeled as “0”. The balanced nature of the data suggests that the model’s performance may not be significantly impacted by imbalanced class distribution, which can often be a concern when working with classification tasks. For further details, see Section 3.1.
- A text fragment belongs to class 1 if it has at least one CFIR construct assigned to it. Conversely, an observation belongs to class 0 if a CFIR construct is not allocated to it.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ANNs | Artificial Neural Networks |
| AUC | Area under the ROC curve |
| CFIR | Consolidated Framework for Implementation Research |
| ChordDist | Chord Distance |
| DTs | Decision Trees |
| FM | Fraiman–Muniz |
| FT | Fourier Transform |
| HS | halfspace |
| IFT | Inverse Fourier Transform |
| kNN | k-Nearest Neighbors |
| LASSO | Least Absolute Shrinkage and Selection Operator |
| ML | Machine Learning |
| NLP | Natural Language Processing |
| PVS | Prescribing Health Life |
| RF | Random Forests |
| RP | Random Projection |
| RT | Random Tukey |
| SVMs | Support Vector machine |
| tf-idf | Term frequency–inverse document frequency |
| TM | Text Mining |
References
- Kowsari, K.; Jafari Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text Classification Algorithms: A Survey. Information 2019, 10, 150. [Google Scholar] [CrossRef]
- Indurkhya, N. Emerging Directions in Predictive Text Mining. WIREs Data Min. Knowl. Discov. 2015, 5, 155–164. [Google Scholar] [CrossRef]
- Chowdhary, K.R. Natural Language Processing. In Fundamentals of Artificial Intelligence; Chowdhary, K.R., Ed.; Springer: New Delhi, India, 2020; pp. 603–649. ISBN 978-81-322-3972-7. [Google Scholar]
- Vijayakumar, B.; Fuad, M.M.M. A New Method to Identify Short-Text Authors Using Combinations of Machine Learning and Natural Language Processing Techniques. Procedia Comput. Sci. 2019, 159, 428–436. [Google Scholar] [CrossRef]
- Osorio, J.; Beltran, A. Enhancing the Detection of Criminal Organizations in Mexico Using ML and NLP. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Gupta, S.; Nishu, K. Mapping Local News Coverage: Precise Location Extraction in Textual News Content Using Fine-Tuned BERT Based Language Model. In Proceedings of the Fourth Workshop on Natural Language Processing and Computational Social Science, Online, 20 November 2020; pp. 155–162. [Google Scholar]
- Kastrati, Z.; Dalipi, F.; Imran, A.S.; Pireva Nuci, K.; Wani, M.A. Sentiment Analysis of Students’ Feedback with NLP and Deep Learning: A Systematic Mapping Study. Appl. Sci. 2021, 11, 3986. [Google Scholar] [CrossRef]
- Hossain, A.; Karimuzzaman, M.; Hossain, M.M.; Rahman, A. Text Mining and Sentiment Analysis of Newspaper Headlines. Information 2021, 12, 414. [Google Scholar] [CrossRef]
- Rajput, A. Chapter 3 - Natural Language Processing, Sentiment Analysis, and Clinical Analytics. In Innovation in Health Informatics; Lytras, M.D., Sarirete, A., Eds.; Next Gen Tech Driven Personalized Med&Smart Healthcare; Academic Press: Cambridge, MA, USA, 2020; pp. 79–97. ISBN 978-0-12-819043-2. [Google Scholar]
- Alnazzawi, N.; Alsaedi, N.; Alharbi, F.; Alaswad, N. Using Social Media to Detect Fake News Information Related to Product Marketing: The FakeAds Corpus. Data 2022, 7, 44. [Google Scholar] [CrossRef]
- Hvitfeldt, E.; Silge, J. Supervised Machine Learning for Text Analysis in R, 1st ed.; CRC Press: New York, NY, USA, 2021. [Google Scholar]
- Haynes, C.; Palomino, M.A.; Stuart, L.; Viira, D.; Hannon, F.; Crossingham, G.; Tantam, K. Automatic Classification of National Health Service Feedback. Mathematics 2022, 10, 983. [Google Scholar] [CrossRef]
- Fan, H.; Du, W.; Dahou, A.; Ewees, A.A.; Yousri, D.; Elaziz, M.A.; Elsheikh, A.H.; Abualigah, L.; Al-qaness, M.A.A. Social Media Toxicity Classification Using Deep Learning: Real-World Application UK Brexit. Electronics 2021, 10, 1332. [Google Scholar] [CrossRef]
- Rish, I. An Empirical Study of the Naïve Bayes Classifier. In Proceedings of the International Joint Conference on Artificial Intelligence: Workshop on Empirical Methods in Artificial Intelligence, Seattle, WA, USA, 4–10 August 2001; pp. 41–46. [Google Scholar]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling, 1st ed.; Springer: New York, NY, USA, 2013. [Google Scholar]
- Hastie, T.; Tibshirani, R. Statistical Learning with Sparsity, 1st ed.; CRC Press: New York, NY, USA, 2015. [Google Scholar]
- Boser, B.; Guyon, I.; Vapnik, V. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992. [Google Scholar]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000; Available online: www.support-vector.net (accessed on 20 May 2022).
- Kim, S.M.; Han, H.; Park, J.M.; Choi, Y.J.; Yoon, H.S.; Sohn, J.H.; Baek, M.H.; Kim, Y.N.; Chae, Y.M.; June, J.J.; et al. A Comparison of Logistic Regression Analysis and an Artificial Neural Network Using the BI-RADS Lexicon for Ultrasonography in Conjunction with Introbserver Variability. J. Digit. Imaging 2012, 25, 599–606. [Google Scholar] [CrossRef]
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Kalchbrenner, N.; Blunsom, P. Recurrent convolutional neural networks for discourse compositionality. In Proceedings of the Workshop on Continuous Vector Space Models and their Compositionality, Sofia, Bulgaria, 9 August 2013; pp. 119–126. [Google Scholar]
- Aldjanabi, W.; Dahou, A.; Al-qaness, M.A.A.; Elaziz, M.A.; Helmi, A.M.; Damaševičius, R. Arabic Offensive and Hate Speech Detection Using a Cross-Corpora Multi-Task Learning Model. Informatics 2021, 8, 69. [Google Scholar] [CrossRef]
- Lee, E.; Lee, C.; Ahn, S. Comparative Study of Multiclass Text Classification in Research Proposals Using Pretrained Language Models. Appl. Sci. 2022, 12, 4522. [Google Scholar] [CrossRef]
- Bolívar, S.; Nieto-Reyes, A.; Rogers, H.L. Supervised Classification of Healthcare Text Data Based on Context-Defined Categories. Mathematics 2022, 10, 2005. [Google Scholar] [CrossRef]
- Najafabadi, M.M.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep Learning Applications and Challenges in Big Data Analytics. J. Big Data 2015, 2, 1. [Google Scholar] [CrossRef]
- Akhtar, M.S.; Sawant, P.; Sen, S.; Ekbal, A.; Bhattacharyya, P. Solving Data Sparsity for Aspect Based Sentiment Analysis Using Cross-Linguality and Multi-Linguality. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 572–582. [Google Scholar]
- Pervaiz, A.; Hussain, F.; Israr, H.; Tahir, M.A.; Raja, F.R.; Baloch, N.K.; Ishmanov, F.; Zikria, Y.B. Incorporating Noise Robustness in Speech Command Recognition by Noise Augmentation of Training Data. Sensors 2020, 20, 2326. [Google Scholar] [CrossRef]
- Zhang, Y.; Jin, R.; Zhou, Z.-H. Understanding Bag-of-Words Model: A Statistical Framework. Int. J. Mach. Learn. Cyber. 2010, 1, 43–52. [Google Scholar] [CrossRef]
- Landauer, T.K.; Foltz, P.W.; Laham, D. An Introduction to Latent Semantic Analysis. Discourse Process. 1998, 25, 259–284. [Google Scholar] [CrossRef]
- Chatterjee, N.; Sahoo, P.K. Random Indexing and Modified Random Indexing Based Approach for Extractive Text Summarization. Comput. Speech Lang. 2015, 29, 32–44. [Google Scholar] [CrossRef]
- Weinberger, K.; Dasgupta, A.; Attenberg, J.; Langford, J.; Smola, A. Feature Hashing for Large Scale Multitask Learning. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009. [Google Scholar]
- Drikvandi, R.; Lawal, O. Sparse Principal Component Analysis for Natural Language Processing. Ann. Data Sci. 2020. [Google Scholar] [CrossRef]
- Serfling, R.; Zuo, Y. General Notions of Statistical Depth Function. Ann. Stat. 2000, 28, 461–482. [Google Scholar] [CrossRef]
- Nieto-Reyes, A.; Battey, H. A Topologically Valid Definition of Depth for Functional Data. Stat. Sci. 2016, 31, 61–79. [Google Scholar] [CrossRef]
- González-De La Fuente, L.; Nieto-Reyes, A.; Terán, P. Statistical Depth for Fuzzy Sets. Fuzzy Sets Syst. 2022, 443, 58–86. [Google Scholar] [CrossRef]
- Cuesta-Albertos, J.A.; Febrero-Bande, M.; Oviedo, M. The DDG-Classifier in the Functional Setting. Test 2017, 26, 119–142. [Google Scholar] [CrossRef]
- Rogers, H.L.; Pablo-Hernando, S.; Núñez-Fernández, S. Barriers and facilitators in the implementation of an evidence-based health promotion intervention in a primary care setting: A qualitative study. J. Health Organ. Manag. 2021, 35, 349–367. [Google Scholar] [CrossRef]
- Fraiman, R.; Muniz, G. Trimmed Means for Functional Data. Test 2001, 10, 419–440. [Google Scholar] [CrossRef]
- Cuevas, A.; Febrero, M.; Fraiman, R. Robust Estimation and Classification for Functional Data via Projection-Based Depth Notions. Comput. Stat. 2007, 22, 481–496. [Google Scholar] [CrossRef]
- Hlubinka, D.; Gijbels, I.; Omelka, M.; Nagy, S. Integrated Data Depth for Smooth Functions and Its Application in Supervised Classification. Comput. Stat. 2015, 30, 1011–1031. [Google Scholar] [CrossRef]
- Tukey, J.W. Mathematics and picturing of data. Proc. ICM Vanc. 1975, 2, 523–531. [Google Scholar]
- Cuesta-Albertos, J.A.; Nieto-Reyes, A. The Random Tukey Depth. Comput. Stat. Data Anal. 2008, 52, 4979–4988. [Google Scholar] [CrossRef]
- Cuesta-Albertos, J.; Nieto-Reyes, A. Albertos, J.; Nieto-Reyes, A. A Random Functional Depth. In Functional and Operatorial Statistics; Dabo-Niang, S., Ferraty, F., Eds.; Physica-Verlag HD: Heidelberg, Germany, 2008; pp. 121–126. [Google Scholar]
- Mosler, K.; Hoberg, R. Data analysis and classification with the zonoid depth. Amer. Math. Soc. DIMACS Ser. 2006, 72, 49–59. [Google Scholar]
- Liu, R.Y. On a Notion of Data Depth Based on Random Simplices. Ann. Stat. 1990, 18, 405–414. [Google Scholar] [CrossRef]
- Liu, R.Y.; Parelius, J.M.; Singh, K. Multivariate Analysis by Data Depth: Descriptive Statistics, Graphics and Inference, (with Discussion and a Rejoinder by Liu and Singh). Ann. Stat. 1999, 27, 783–858. [Google Scholar] [CrossRef]
- Li, J.; Cuesta-Albertos, J.A.; Liu, R.Y. DD-Classifier: Nonparametric Classification Procedure Based on DD-Plot. J. Am. Stat. Assoc. 2012, 107, 737–753. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 1st ed.; Springer: New York, NY, USA, 2001. [Google Scholar]
- Cover, T.; Hart, P. Nearest Neighbor Pattern Classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Damschroder, L.J.; Aron, D.C. Fostering implementation of health services research findings into practice: A consolidated framework for advancing implementation science. Implement. Sci. 2009, 4, 50. [Google Scholar] [CrossRef]
- Manning, C.D.; Raghavan, P. Introduction to Information Retrieval, 1st ed.; Cambridge University Press: New York, NY, USA, 2008. [Google Scholar]
- Inselberg, A.; Dimsdale, B. Parallel Coordinates: A Tool for Visualizing Multi-Dimensional Geometry. In Proceedings of the Proceedings of the First IEEE Conference on Visualization: Visualization ‘90, San Francisco, CA, USA, 23–26 October 1990; pp. 361–378. [Google Scholar]
- Pandolfo, G.; Paindaveine, D.; Porzio, G.C. Distance-Based Depths for Directional Data. Can. J. Stat. 2018, 46, 593–609. [Google Scholar] [CrossRef]
- Hornik, K.; Feinerer, I.; Kober, M.; Buchta, C. Spherical K-Means Clustering. J. Stat. Softw. 2012, 50, 1–22. [Google Scholar] [CrossRef]
- Mahalanobis, P.C. On the Generalized Distance in Statistics; National Institute of Science of India: Calcutta, India, 1936. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | Misclassification Rate (Training Sample) | Misclassification Rate (Test Sample) |
|---|---|---|
| LASSO | – | 0.11 |
| SVMs | – | 0.14 |
| ANNs | – | 0.17 |
| DTs | – | 0.22 |
| DD-classifier(HS, maxD) | 0.27 | 0.68 |
| DD-classifier(HS, lda) | 0.29 | 0.31 |
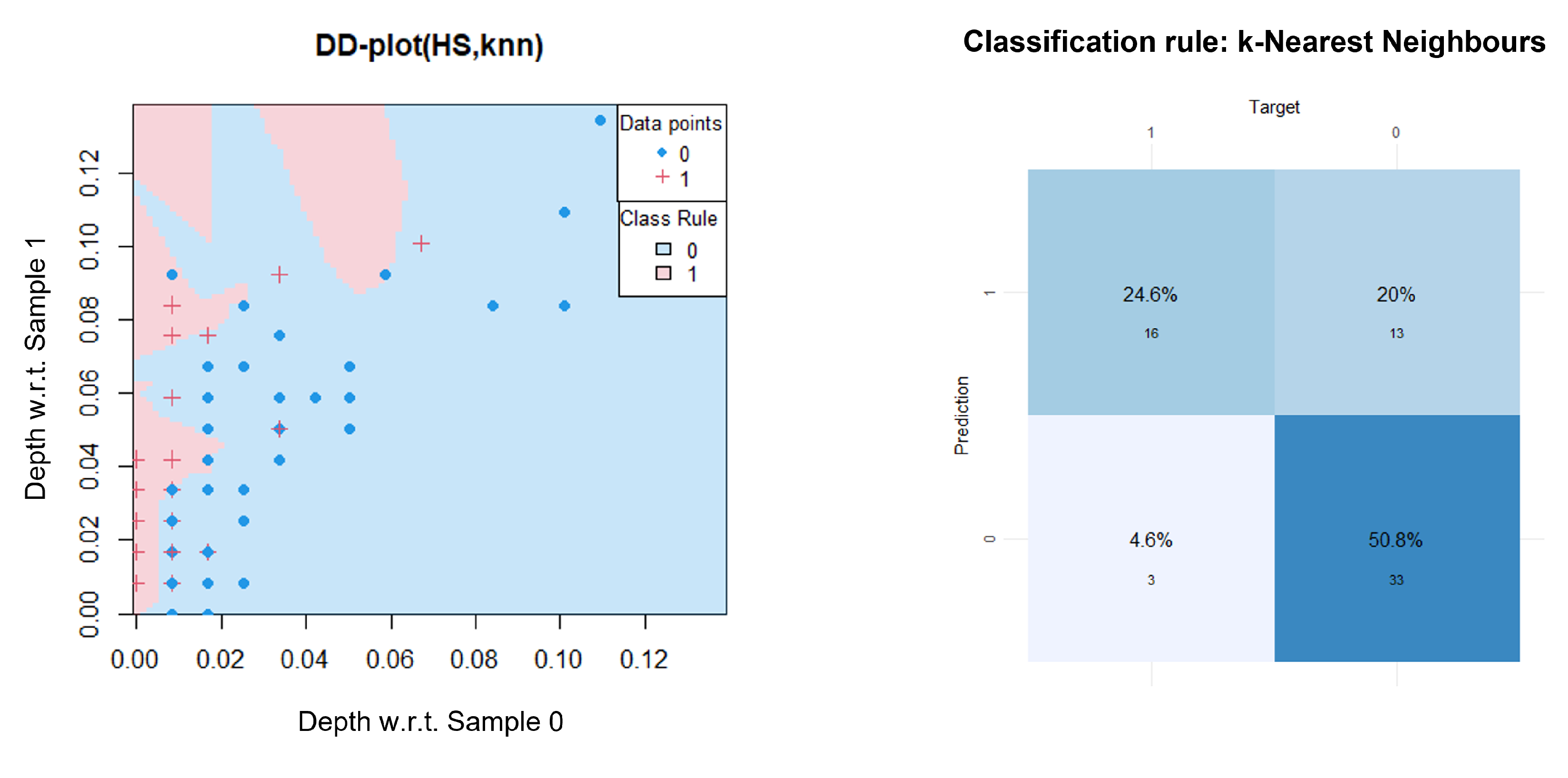
| DD-classifier(HS, knn) | 0.17 | 0.25 |
| DD-classifier(MhD, maxD) | 0.29 | 0.49 |
| DD-classifier(MhD, lda) | 0.23 | 0.71 |
| DD-classifier(MhD, knn) | 0.25 | 0.69 |
| DD-classifier(ChordDist, RF) | 0.16 | 0.38 |
| DD-classifier(ChordDist, knn) | 0.21 | 0.46 |
| DD-classifier(compFM, maxD) | 0.35 | 0.17 |
| DD-classifier(compFM, lda) | 0.29 | 0.15 |
| DD-classifier(compFM, knn) | 0.34 | 0.25 |
| DD-classifier(compRP, maxD) | 0.35 | 0.18 |
| DD-classifier(compRP, lda) | 0.32 | 0.09 |
| DD-classifier(compRP, knn) | 0.38 | 0.31 |
| DD-classifier(compHS, maxD) | 0.34 | 0.17 |
| DD-classifier(compHS, lda) | 0.36 | 0.37 |
| DD-classifier(compHS, knn) | 0.38 | 0.32 |
| DD-Classifier (compFM, lda) | DD-Classifier (compRP, lda) | |||
|---|---|---|---|---|
| Metric | Training Sample | Test Sample | Training Sample | Test Sample |
| Misclassification rate | 0.29 | 0.15 | 0.32 | 0.09 |
| Precision | 0.71 | 0.71 | 0.71 | 0.88 |
| Recall | 0.80 | 0.79 | 0.76 | 0.79 |
| F1-score | 0.75 | 0.75 | 0.74 | 0.83 |
| AUC | 0.69 | 0.83 | 0.69 | 0.85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bolívar, S.; Nieto-Reyes, A.; Rogers, H.L. Statistical Depth for Text Data: An Application to the Classification of Healthcare Data. Mathematics 2023, 11, 228. https://doi.org/10.3390/math11010228
Bolívar S, Nieto-Reyes A, Rogers HL. Statistical Depth for Text Data: An Application to the Classification of Healthcare Data. Mathematics. 2023; 11(1):228. https://doi.org/10.3390/math11010228
Chicago/Turabian StyleBolívar, Sergio, Alicia Nieto-Reyes, and Heather L. Rogers. 2023. "Statistical Depth for Text Data: An Application to the Classification of Healthcare Data" Mathematics 11, no. 1: 228. https://doi.org/10.3390/math11010228
APA StyleBolívar, S., Nieto-Reyes, A., & Rogers, H. L. (2023). Statistical Depth for Text Data: An Application to the Classification of Healthcare Data. Mathematics, 11(1), 228. https://doi.org/10.3390/math11010228