
Privacy-Preserving Data Aggregation Scheme Based on Federated Learning for IIoT
Abstract
:1. Introduction
- (1)
- A privacy-preserving, multidimensional data aggregation scheme based on federated learning is proposed. This scheme enables multidimensional data aggregation for the IIoT. For federated learning, data aggregation is adopted to protect local model changes and resist reverse analysis attacks.
- (2)
- Through the PBFT algorithm, initialization and aggregation nodes are selected to achieve independence from any trusted entity. Secret sharing is used to achieve fault tolerance. Even if IIoT devices collude with each other or fail, the aggregation information from the IIoT can be obtained.
- (3)
- Compared with existing schemes, PPDAFL has lower communication and computational overheads, faster execution, and higher efficiency. It is well suited for data aggregation in the IIoT.
2. Related Work
3. Preliminary Concepts
3.1. Federated Learning
3.2. Secret Sharing
3.3. Paillier Cryptosystem
- (1)
- Key generation. Randomly select two primes and , and calculate . Define , where . Choose a generator , and calculate . The public and private keys are and , respectively.
- (2)
- Encryption. Choose , , given a message . The ciphertext is calculated as .
- (3)
- Decryption. Decrypt with the private key using .
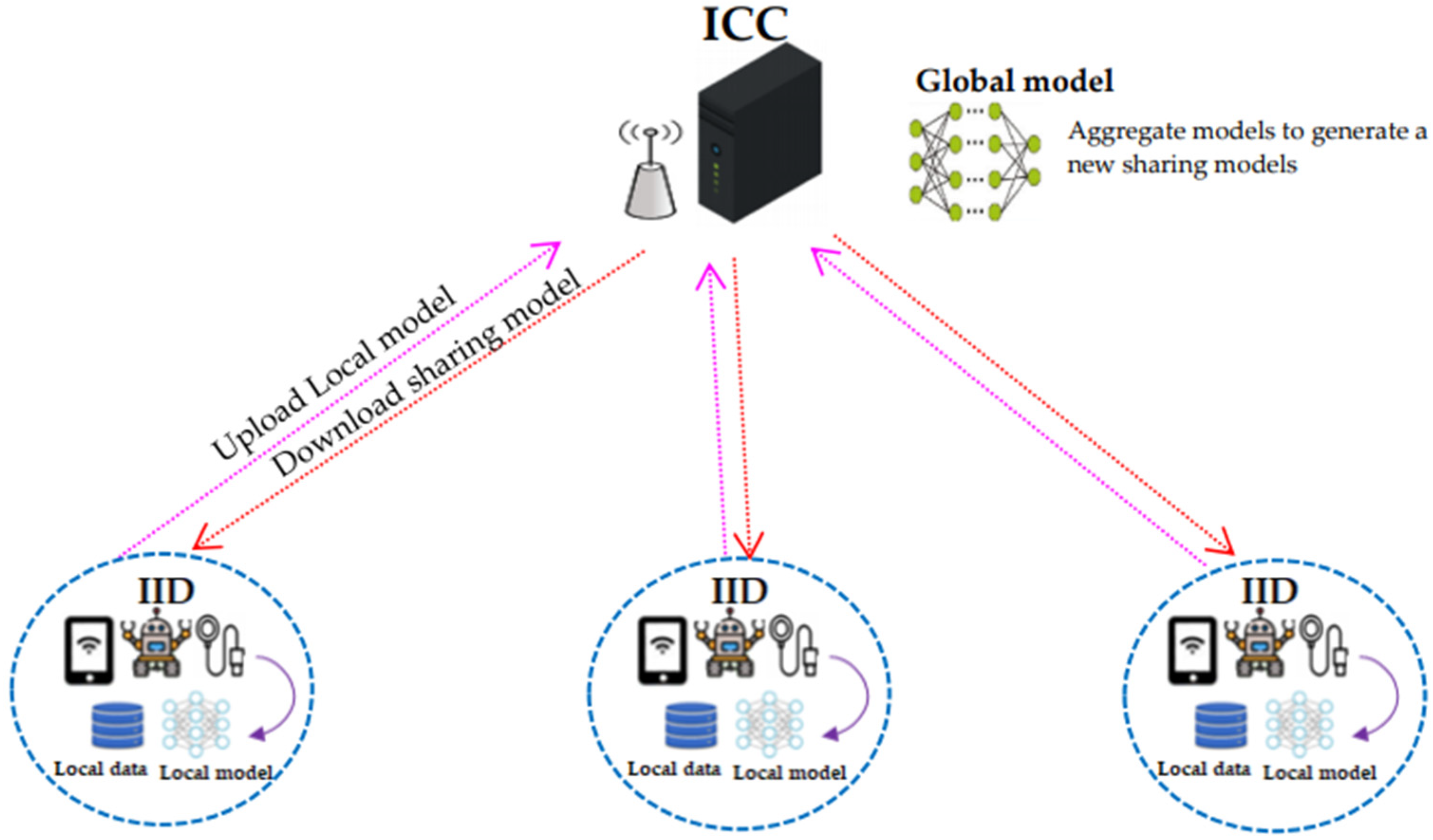
4. System Model
4.1. Communication Model
- (1)
- IID: IIDs collect IIoT data using P2P communication. An IID is selected from the aggregation area as the data aggregation and initialization node (DN) by using the PBFT algorithm. IIDs may stop reporting data from attacks or failures. They are assumed to be honest but curious.
- (2)
- ICC: The ICC reads the aggregated IIoT data. Assume the ICC is not trusted. The ICC is assumed to be honest but curious. The HMC is considered to be untrusted, and the SD is semitrusted.
4.2. Adversary Model
- (1)
- The ICC wants to infer the information of a single user from the collected data.
- (2)
- The IID does not tamper with its industrial data. Still, it is curious about the private information of others, and tries to collude with other IIDs in the aggregated area to infer the information of others.
4.3. Design Goals
- (1)
- Privacy protection. The scheme protects against internal and external attacks. No entity can access industrial data from a single IID.
- (2)
- Data security. Industrial data can be securely aggregated. Even if the ciphertext of the IIoT data aggregation collected by IIDs is intercepted, the IIoT data of a single IID cannot be recovered.
- (3)
- Fault tolerance. If an IID is maliciously attacked or fails to collect IIoT data, the utility of the system is significantly compromised. Even if some IIDs do not work properly, the system can still aggregate IIoT data from other IIDs.
5. The Proposed Scheme
5.1. Initialization
5.2. Advertise Keys (Round 0)
- (1)
- Request the ICC to update data.
- (2)
- selects to compute the public key ; then, it sends to the ICC.
- (1)
- collects at least L messages from of the i-th aggregation area.
- (2)
- Set the number of IIDs to and the threshold to L when dividing each aggregation area.
- (3)
- Broadcast the list of received public keys to the IIDs in .
5.3. Share Generation (Round 1)
- (1)
- Receive global parameters from the ICC. Verify that .
- (2)
- generates its polynomial , , then sends to .
- (1)
- Forward the received shares to the IIDs in .
5.4. Generate Ciphertext and Signature Verification (Round 2)
- (1)
- generates at , and computes ; next, it selects to generate the ciphertext:
- (2)
- generates the signature .
- (3)
- sends to and .
- (1)
- The ICC verifies signatures after receiving . If , then the validation is successful; otherwise, it fails. If it holds, the signature is valid. Next, send the signature verification results to , and will accept ’s ciphertext. Otherwise, the DN will not accept the ciphertext of
- (2)
- To make the verification more efficient, after receiving , obtain batch verification signature.
- (3)
- Forward the batch signature verification results to .
5.5. Aggregate Ciphertext and Reconstruct Secret (Round 3)
- (1)
- aggregates the ciphertext of IIDs.
- (2)
- sends to .
- (1)
- After the signatures are verified, chooses L shares of from the received shares of to reconstruct the secret.
5.6. Ciphertext Decryption (Round 4)
| Algorithm 1. Recover aggregated reports for each aggregation area. |
| 1. procedure Input: and Input: |
| 2. Set |
| 3. for |
| 4. |
| 5. |
| 6. end for |
| 7. |
| 8. return |
| 9. end procedure |
6. Security Analysis
6.1. Privacy Preservation
6.2. Data Integrity
6.3. Fault Tolerance
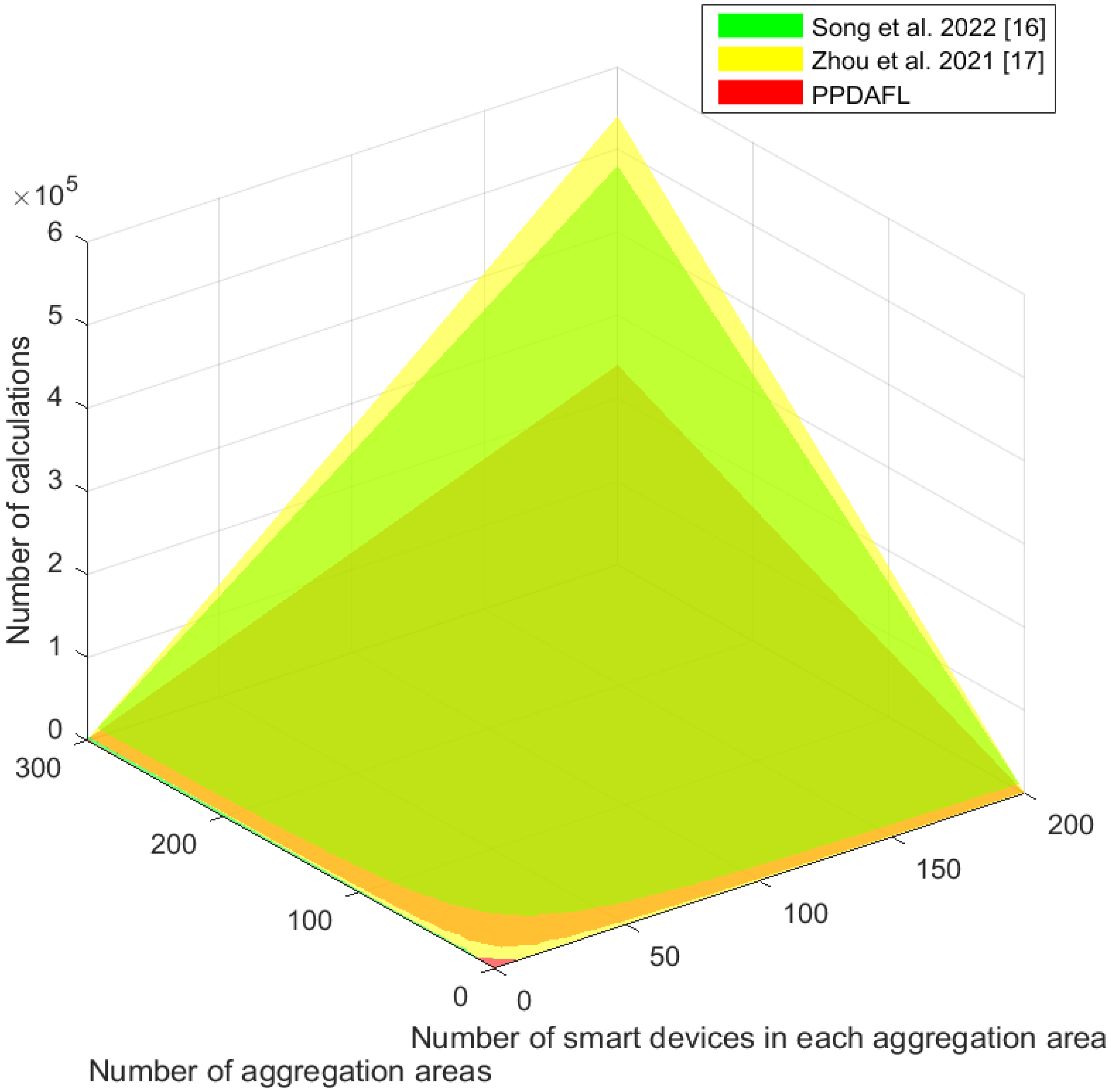
7. Performance Evaluation
7.1. Computation Complexity
7.2. Communication Overhead
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sisinni, E.; Saifullah, A.; Han, S.; Jennehag, U.; Gidlund, M. Industrial Internet of Things: Challenges, Opportunities, and Directions. IEEE Trans. Ind. Inform. 2018, 14, 4724–4734. [Google Scholar] [CrossRef]
- Zhao, Q.; Qi, X.; Hua, M.; Liu, J.; Tian, H. Review of the Recent Blackouts and the Enlightenment; IET: London, UK, 2020; Volume 2020, pp. 312–314. [Google Scholar]
- Tange, K.; De Donno, M.; Fafoutis, X.; Dragoni, N. A systematic survey of industrial Internet of things security: Requirements and fog computing opportunities. IEEE Commun. Surv. Tutor. 2020, 22, 2489–2520. [Google Scholar] [CrossRef]
- Raymond, K.K.; Stefanos, G.; Park, J.H. Cryptographic solutions for industrial Internet-of-things: Research challenges and opportunities. IEEE Trans. Ind. Inform. 2018, 14, 3567–3569. [Google Scholar]
- Xu, L.D.; He, W.; Li, S. Internet of things in industries: A survey. IEEE Trans. Ind. Inform. 2014, 10, 2233–2243. [Google Scholar] [CrossRef]
- Zhang, X.; Fang, F.; Wang, J. Probabilistic solar irradiation forecasting based on variational Bayesian inference with secure federated learning. IEEE Trans. Ind. Inform. 2020, 17, 7849–7859. [Google Scholar] [CrossRef]
- Bahrami, S.; Chen, Y.C.; Wong, V.W.S. Deep reinforcement learning for demand response in distribution networks. IEEE Trans. Smart Grid 2021, 12, 1496–1506. [Google Scholar] [CrossRef]
- Zhao, B.; Liu, X.; Chen, W.N.; Liang, W.; Zhang, X.; Deng, R.H. PRICE: Privacy and reliability-aware real-time incentive system for crowdsensing. IEEE Internet Things J. 2021, 8, 17584–17595. [Google Scholar] [CrossRef]
- Ur Rehman, M.H.; Dirir, A.M.; Salah, K.; Damiani, E.; Svetinovic, D. TrustFed: A framework for fair and trustworthy cross-device federated learning in IIoT. IEEE Trans. Ind. Inform. 2021, 17, 8485–8494. [Google Scholar] [CrossRef]
- Yin, X.; Zhu, Y.; Hu, J. A comprehensive survey of privacy-preserving federated learning: A taxonomy, review, and future directions. ACM Comput. Surv. (CSUR) 2021, 54, 1–36. [Google Scholar] [CrossRef]
- Sun, W.; Lei, S.; Wang, L.; Liu, Z.; Zhang, Y. Adaptive federated learning and digital twin for industrial internet of things. IEEE Trans. Ind. Inform. 2020, 17, 5605–5614. [Google Scholar] [CrossRef]
- Hao, M.; Li, H.; Luo, X.; Xu, G.; Yang, H.; Liu, S. Efficient and privacy-enhanced federated learning for industrial artificial intelligence. IEEE Trans. Ind. Inform. 2019, 16, 6532–6542. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Agueray, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Zhang, L.; Luo, Y.; Bai, Y.; Du, B.; Duan, L.Y. Federated learning for non-iid data via unified feature learning and optimization objective alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4420–4428. [Google Scholar]
- Kadhe, S.; Rajaraman, N.; Koyluoglu, O.O.; Ramchandran, K. Fastsecagg: Scalable secure aggregation for privacy-preserving federated learning. arXiv 2020, arXiv:2009.11248. [Google Scholar]
- Song, J.; Wang, W.; Gadekallu, T.R.; Cao, J.; Liu, Y. Eppda: An efficient privacy-preserving data aggregation federated learning scheme. IEEE Trans. Netw. Sci. Eng. 2022, in press. [Google Scholar] [CrossRef]
- Zhou, Z.; Tian, Y.; Peng, C. Privacy-preserving federated learning framework with general aggregation and multiparty entity matching. Wirel. Commun. Mob. Comput. 2021, 2021, 6692061. [Google Scholar] [CrossRef]
- Liu, Y.; Garg, S.; Nie, J.; Zhang, Y.; Xiong, Z.; Kang, J.; Hossain, M.S. Deep anomaly detection for time-series data in industrial IoT: A communication-efficient on-device federated learning approach. IEEE Internet Things J. 2020, 8, 6348–6358. [Google Scholar] [CrossRef]
- Zhang, P.; Wang, C.; Jiang, C.; Han, Z. Deep reinforcement learning assisted federated learning algorithm for data management of IIoT. IEEE Trans. Ind. Inform. 2021, 17, 8475–8484. [Google Scholar] [CrossRef]
- Jia, B.; Zhang, X.; Liu, J.; Zhang, Y.; Huang, K.; Liang, Y. Blockchain-enabled federated learning data protection aggregation scheme with differential privacy and homomorphic encryption in IIoT. IEEE Trans. Ind. Inform. 2021, 18, 4049–4058. [Google Scholar] [CrossRef]
- Qu, Y.; Pokhrel, S.R.; Garg, S.; Gao, L.; Xiang, Y. A blockchained federated learning framework for cognitive computing in industry 4.0 networks. IEEE Trans. Ind. Inform. 2020, 17, 2964–2973. [Google Scholar] [CrossRef]
- Fu, A.; Zhang, X.; Xiong, N.; Gao, Y.; Wang, H.; Zhang, J. VFL: A verifiable federated learning with privacy-preserving for big data in industrial IoT. IEEE Trans. Ind. Inform. 2022, 18, 3316–3326. [Google Scholar] [CrossRef]
- Qu, Y.; Gao, L.; Luan, T.H.; Xiang, Y.; Yu, S.; Li, B.; Zheng, G. Decentralized privacy using blockchain-enabled federated learning in fog computing. IEEE Internet Things J. 2020, 7, 5171–5183. [Google Scholar] [CrossRef]
- Islam, T.U.; Ghasemi, R.; Mohammed, N. Privacy-Preserving Federated Learning Model for Healthcare Data. In Proceedings of the 2022 IEEE 12th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 26–29 January 2022; IEEE: New York, NY, USA, 2022; pp. 281–287. [Google Scholar]
- Zhao, L.; Jiang, J.; Feng, B.; Wang, Q.; Shen, C.; Li, Q. Sear: Secure and efficient aggregation for byzantine-robust federated learning. IEEE Trans. Dependable Secur. Comput. 2021, 19, 3329–3342. [Google Scholar] [CrossRef]
- Pillutla, K.; Kakade, S.M.; Harchaoui, Z. Robust aggregation for federated learning. IEEE Trans. Signal Process. 2022, 70, 1142–1154. [Google Scholar] [CrossRef]
- Zhao, B.; Fan, K.; Yang, K.; Wang, Z.; Li, H.; Yang, Y. Anonymous and privacy-preserving federated learning with industrial big data. IEEE Trans. Ind. Inform. 2021, 17, 6314–6323. [Google Scholar] [CrossRef]
- Yu, K.; Tan, L.; Yang, C.; Choo, K.K.R.; Bashir, A.K.; Rodrigues, J.J.; Sato, T. A blockchain-based shamir’s threshold cryptography scheme for data protection in industrial internet of things settings. IEEE Internet Things J. 2022, 9, 8154–8167. [Google Scholar] [CrossRef]
- Boneh, D.; Gentry, C.; Lynn, B.; Shacham, H. Aggregate and verifiably encrypted signatures from bilinear maps. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Warsaw, Poland, 4–8 May 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 416–432. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Quantity |
|---|---|
| A generator of G | |
| Industrial control center | |
| The j-th IIoT device in the i-th aggregation area | |
| Data aggregation and system initialization node | |
| Industrial data of | |
| Aggregated industrial data | |
| The i-th aggregated industrial data | |
| Hash functions: | |
| Hash functions: : → | |
| Number of smart devices in each aggregation area | |
| Number of aggregation areas | |
| Data length | |
| ‖ | Concatenation operation |
| Features | [14] | [15] | [16] | [17] | PPDAFL |
|---|---|---|---|---|---|
| Privacy preservation | √ | √ | √ | √ | √ |
| Fault tolerance | × | √ | √ | √ | √ |
| Dropout | √ | √ | √ | √ | √ |
| Round efficiency | √ | × | √ | √ | √ |
| No expensive operations | × | √ | √ | √ | √ |
| No trusted entity | × | × | √ | × | √ |
| Resist reverse attacks | × | × | √ | √ | √ |
| Resilience against reply attacks | × | × | × | × | √ |
| Defense against collusion attacks | × | × | √ | √ | √ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hongbin, F.; Zhi, Z. Privacy-Preserving Data Aggregation Scheme Based on Federated Learning for IIoT. Mathematics 2023, 11, 214. https://doi.org/10.3390/math11010214
Hongbin F, Zhi Z. Privacy-Preserving Data Aggregation Scheme Based on Federated Learning for IIoT. Mathematics. 2023; 11(1):214. https://doi.org/10.3390/math11010214
Chicago/Turabian StyleHongbin, Fan, and Zhou Zhi. 2023. "Privacy-Preserving Data Aggregation Scheme Based on Federated Learning for IIoT" Mathematics 11, no. 1: 214. https://doi.org/10.3390/math11010214
APA StyleHongbin, F., & Zhi, Z. (2023). Privacy-Preserving Data Aggregation Scheme Based on Federated Learning for IIoT. Mathematics, 11(1), 214. https://doi.org/10.3390/math11010214