
Robust Data Augmentation for Neural Machine Translation through EVALNET


Abstract
1. Introduction
Contributions of This Study
- We propose a new simple data evaluator—EvalNet—to score parallel data for NMT;
- We show that the cross attention between an encoder and a decoder of an NMT system can be an effective factor to recognize a word-order corruption;
- We show that the cross-attention map and the semantic similarity can be an effective combination to evaluate parallel data;
- We show that EvalNet can outperform other data evaluation models and help NMT systems to learn effectively and reliably from augmented data.
2. Related Studies
2.1. Data Weighting
2.2. Data Filtering for Back Translation
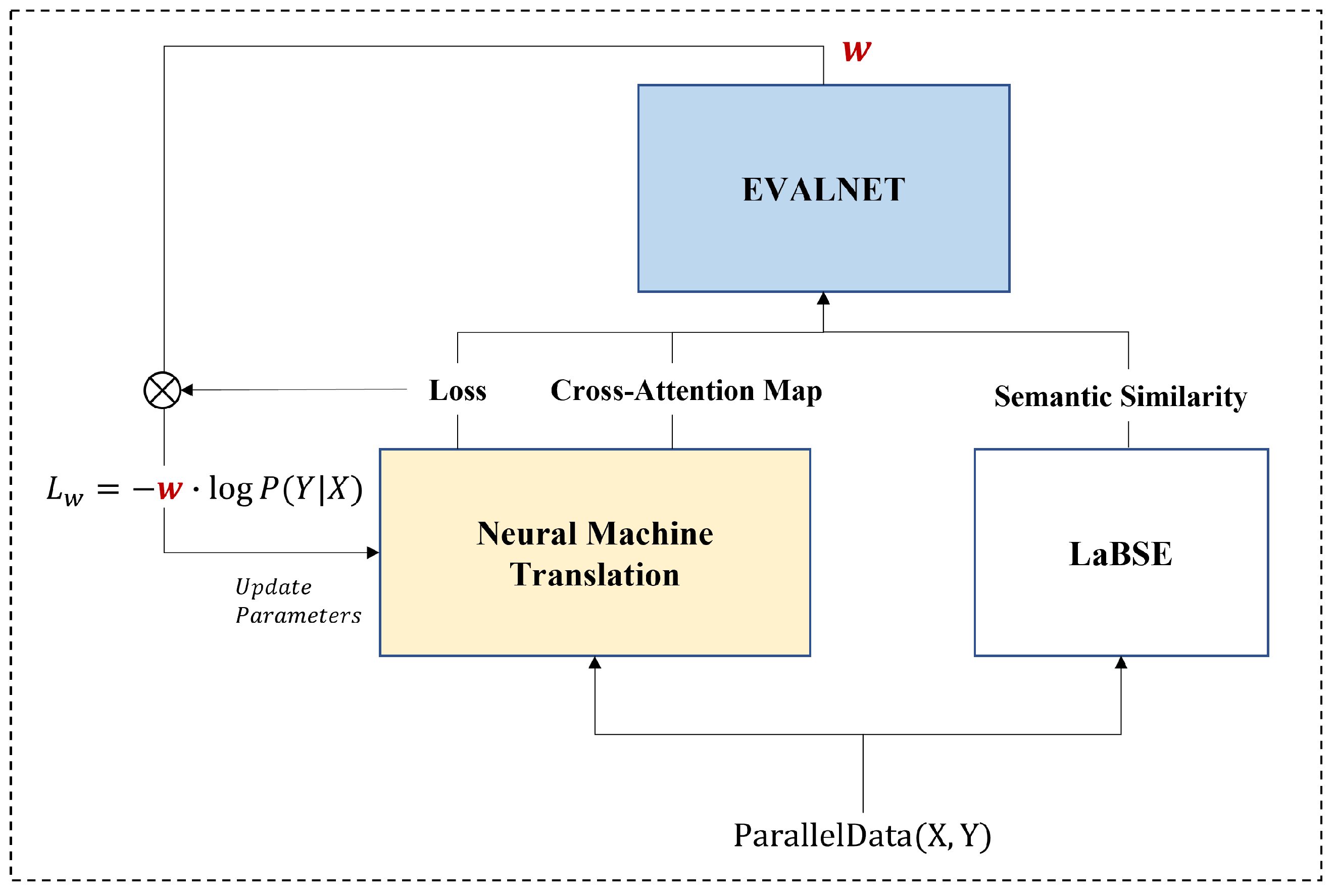
3. EVALNET
3.1. Architecture of EVALNET
3.1.1. Loss
3.1.2. Semantic Similarity
3.1.3. Cross-Attention Map
3.2. Training EVALNET
4. Experimental Results
4.1. Training Datasets
4.2. Experimental Environments
4.3. Experimental Results
4.3.1. Performance of the NMT Systems According to the Features of EvalNet
4.3.2. Comparisons of Weight Values of EvalNet According to the Feature Sets
4.3.3. Performance Comparison with Previous Approaches
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Attn | Cross Attention Map |
| BLEU | Bilingual Evaluation Understudy |
| CIFAR | Canadian Institute for Advanced Research |
| CNN | Convolutional Neural Network |
| EDA | Easy Data Augmentation |
| EvalNet | Evaluation Network |
| IWSLT | The International Conference on Spoken Language Translation |
| LSTM | Long Short-Term Memory |
| LaBSE | Language-agnostic BERT Sentence Embedding |
| NMT | Neural Machine Translation |
| RNN | Recurrent Neural Network |
| Sim | Semantic Similarity |
| WAT | The Workshop on Asian Translation |
References
- Wei, J.; Zou, K. EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 6382–6388. [Google Scholar] [CrossRef]
- Sennrich, R.; Haddow, B.; Birch, A. Improving Neural Machine Translation Models with Monolingual Data. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 86–96. [Google Scholar] [CrossRef]
- Shu, J.; Xie, Q.; Yi, L.; Zhao, Q.; Zhou, S.; Xu, Z.; Meng, D. Meta-weight-net: Learning an explicit mapping for sample weighting. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Jiang, L.; Zhou, Z.; Leung, T.; Li, L.J.; Fei-Fei, L. MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks on Corrupted Labels. In Proceedings of the 35th International Conference on Machine Learning (PMLR), Stockholm, Sweden, 10–15 July 2018; Dy, J., Krause, A., Eds.; Volume 80, pp. 2304–2313. [Google Scholar]
- Ren, M.; Zeng, W.; Yang, B.; Urtasun, R. Learning to Reweight Examples for Robust Deep Learning. In Proceedings of the 35th International Conference on Machine Learning (PMLR), Stockholm, Sweden, 10–15 July 2018; Dy, J., Krause, A., Eds.; Volume 80, pp. 4334–4343. [Google Scholar]
- Ghader, H.; Monz, C. What does Attention in Neural Machine Translation Pay Attention to? In Proceedings of the Eighth International Joint Conference on Natural Language Processing, Taipei, Taiwan, 27 November–1 December 2017; pp. 30–39. [Google Scholar]
- Hu, Z.; Tan, B.; Salakhutdinov, R.; Mitchell, T.; Xing, E.P. Learning Data Manipulation for Augmentation and Weighting. arXiv 2019, arXiv:cs.LG/1910.12795. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K.N. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Khatri, J.; Bhattacharyya, P. Filtering back-translated data in unsupervised neural machine translation. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 4334–4339. [Google Scholar]
- Ramnath, S.; Johnson, M.; Gupta, A.; Raghuveer, A. HintedBT: Augmenting Back-Translation with Quality and Transliteration Hints. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online, 7–11 November 2021; pp. 1717–1733. [Google Scholar]
- Kumar, M.; Packer, B.; Koller, D. Self-paced learning for latent variable models. Adv. Neural Inf. Process. Syst. 2010, 23, 1189–1197. [Google Scholar]
- Feng, F.; Yang, Y.; Cer, D.; Arivazhagan, N.; Wang, W. Language-agnostic BERT Sentence Embedding. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; pp. 878–891. [Google Scholar] [CrossRef]
- Caswell, I.; Chelba, C.; Grangier, D. Tagged Back-Translation. arXiv 2019, arXiv:1906.06442. [Google Scholar]
- Chen, P.J.; Shen, J.; Le, M.; Chaudhary, V.; El-Kishky, A.; Wenzek, G.; Ott, M.; Ranzato, M. Facebook AI’s WAT19 Myanmar-English Translation Task Submission. In Proceedings of the 6th Workshop on Asian Translation, Hong Kong, China, 3–4 November 2019; pp. 112–122. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, É.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-lingual Representation Learning at Scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 8440–8451. [Google Scholar]
- Liu, Y.; Gu, J.; Goyal, N.; Li, X.; Edunov, S.; Ghazvininejad, M.; Lewis, M.; Zettlemoyer, L. Multilingual Denoising Pre-training for Neural Machine Translation. Trans. Assoc. Comput. Linguist. 2020, 8, 726–742. [Google Scholar] [CrossRef]
- Cui, Y.; Jia, M.; Lin, T.; Song, Y.; Belongie, S.J. Class-Balanced Loss Based on Effective Number of Samples. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9268–9277. [Google Scholar]
- Xiao, T.; Xia, T.; Yang, Y.; Huang, C.; Wang, X. Learning from massive noisy labeled data for image classification. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2691–2699. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Model | Type | Train | Valid | Test |
|---|---|---|---|---|---|
| AIHUB | NMT | Parallel | 234,080 | 9393 | 2572 |
| Back-translation | 2,340,800 | - | - | ||
| EVALNET | Real | 23,408 | 2000 | 2000 | |
| Augment | 23,408 | 2000 | 2000 | ||
| Noise | 23,408 | 2000 | 2000 | ||
| IWSLT | NMT | Parallel | 234,080 | 9393 | 2572 |
| Back-translation | 2,340,800 | - | - | ||
| EVALNET | Real | 23,408 | 2000 | 2000 | |
| Augment | 23,408 | 2000 | 2000 | ||
| Noise | 23,408 | 2000 | 2000 | ||
| WAT | NMT | Parallel | 256,100 | 1000 | 1018 |
| Back-translation | 531,697 | 1000 | 1018 | ||
| EVALNET | Real | 800 | 100 | 100 | |
| Augment | 800 | 100 | 100 | ||
| Noise | 800 | 100 | 100 |
| Hyper-Parameters | Values | |
|---|---|---|
| Transformer-base | Embedding dimension | 768 |
| Feed-forward dimension | 3027 | |
| Encoder / Decoder layers | 6 | |
| Attention heads | 8 | |
| Activation Function | Relu | |
| Criterion | Label smoothed cross entropy | 0.2 |
| Learning parameters | Optimizer | Adam |
| eps | ||
| Betas | (0.9, 0.98) | |
| Learning rate scheduler | polynomial decay | |
| Learning rate | 0.001 | |
| Warmup updates | 40,000 (only parallel data) 100,000 (+augmented data) | |
| Total updates | 120,000 (only parallel data) 300,000 (+augmented data) | |
| Max tokens | 1024 | |
| Dropout | 0.3 | |
| Attention dropout | 0.1 |
| Hyper-Parameters | Values | |
|---|---|---|
| EvalNet parameters | Loss vector dimension | 16 |
| Similarity vector dimension | 16 | |
| Attention RNN | Bi-LSTM | |
| Attention RNN layers | 2 | |
| Attention RNN dimension | 16 | |
| Attention dimension | 16 | |
| MLP dimension | 16 | |
| Learning parameters | margin | 0.35 |
| batch size | 128 | |
| Optimizer | Adam | |
| learning rate | 0.001 | |
| dropout | 0.3 |
| Language Pair | En-Ko | En-My | ||||||
|---|---|---|---|---|---|---|---|---|
| Dataset | AIHUB | IWSLT | WAT | |||||
| MODEL | En→Ko | Ko→En | En→Ko | Ko→En | En→My | My→En | ||
| (a) | BASELINE | 23.3 | 25.4 | 17.3 | 16.3 | 30.8 | 19.8 | |
| (b) | (a) + Back-translation | 27.0 | 28.8 | 18.6 | 17.4 | 32.7 | 23.0 | |
| (c) | (b) + EvalNet | Loss | 27.5 | 28.9 | 18.6 | 17.1 | 32.3 | 23.0 |
| (d) | Sim | 27.3 | 29.0 | 18.8 | 17.4 | 33.3 | 22.9 | |
| (e) | Attn | 27.9 | 29.3 | 18.8 | 17.1 | 33.1 | 22.4 | |
| (f) | Loss + Sim | 27.7 | 29.0 | 18.7 | 17.3 | 33.2 | 23.5 | |
| (g) | Loss + Attn | 27.7 | 29.4 | 18.5 | 17.2 | 32.8 | 23.3 | |
| (h) | Sim + Attn | 27.4 | 29.4 | 18.7 | 17.6 | 33.5 | 23.1 | |
| (i) | Loss + Sim + Attn | 27.9 | 28.9 | 18.8 | 17.3 | 32.2 | 23.6 | |
| Sentences | Weights According to | ||||
|---|---|---|---|---|---|
| Features of EvalNet | |||||
| Loss | Sim | Attn | |||
| (a) | Ori | What limits should be set for agencies to use funds for people and facilities? | 0.975 | 0.959 | 0.899 |
| RD | What limits should be set for agencies to use funds for people and facilities? | 0.836 | 0.954 | 0.571 | |
| RS | What limits should be set agencies for to use funds for people and facilities? | 0.926 | 0.96 | 0.808 | |
| RI | What limits should be set for agencies to use determine funds for people and facilities? | 0.937 | 0.958 | 0.888 | |
| RR | What limits should be set for agencies to use funds for people and facilities? | 0.717 | 0.919 | 0.58 | |
| (b) | Ori | I want to stay at a nearby hotel for a day on the 2nd when I arrive in Paris and stay in your apartment from the 3rd when I can be made. | 0.996 | 0.96 | 0.65 |
| RD | I want to stay at a nearby hotel for a day on the 2nd when I arrive in Paris and stay in your apartment from the 3rd when I can be made. | 0.714 | 0.843 | 0.48 | |
| RS | I want to stay at a nearby hotel for a day on the made. when I arrive in Paris and stay in your apartment from the 3rd when I can be 2nd | 0.983 | 0.948 | 0.479 | |
| RI | I want to stay at a nearby hotel for a day on the 2nd when I arrive in Paris and stay in your apartment from the 3rd nd when I can be made. | 0.996 | 0.959 | 0.604 | |
| RR | made. be can I when 3rd the from apartment your in stay and Paris in arrive I when 2nd the on day a for hotel nearby a at stay to want I | 0.715 | 0.933 | 0 | |
| (c) | Ori | The dryer has a washer and a low capacity and takes a long time, so I usually use a manual dryer as shown in the picture. | 0.935 | 0.961 | 0.974 |
| RD | The dryer has a washer and a low capacity and takes a long time, so I usually use a manual dryer as shown in the picture. | 0.711 | 0.915 | 0.687 | |
| RS | The dryer low a washer and a has capacity and takes a long time, so I usually use a manual dryer as shown in the picture. | 0.924 | 0.963 | 0.992 | |
| RI | The dryer has a washer and a low capacity and takes a present long time, so I usually use a manual dryer as shown in the picture. | 0.908 | 0.961 | 0.938 | |
| RR | picture. the in shown as dryer manual a use usually I so time, long a takes and capacity low a and washer a has dryer The | 0.534 | 0.952 | 0.565 | |
| Model | Input Feature | Loss Function | Original Dataset | Dataset for NMT |
|---|---|---|---|---|
| Meta-Weight-Net | loss | cross entropy | CIFAR [17], Clothing1M [18] | validation data |
| MentorNet | loss | binary cross entropy | CIFAR [17] | validation data, noisy data |
| EvalNet | loss, semantic similarity, cross-attention map | margin ranking loss | AIHUB, IWSLT, WAT | validation data, back-translation data, noisy data |
| Weighting Model | En → Ko | Ko → En |
|---|---|---|
| Meta-Weight-Net | 26.6 | 28.0 |
| MentorNet | 27.3 | 29.3 |
| EvalNet (loss) | 27.5 | 28.9 |
| EvalNet (cross-attention map) | 27.9 | 29.3 |
| EvalNet (cross-attention map + semantic similarity) | 27.4 | 29.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, Y.-H.; Choi, Y.-S.; Yun, S.; Kim, S.-H.; Lee, K.-J. Robust Data Augmentation for Neural Machine Translation through EVALNET. Mathematics 2023, 11, 123. https://doi.org/10.3390/math11010123
Park Y-H, Choi Y-S, Yun S, Kim S-H, Lee K-J. Robust Data Augmentation for Neural Machine Translation through EVALNET. Mathematics. 2023; 11(1):123. https://doi.org/10.3390/math11010123
Chicago/Turabian StylePark, Yo-Han, Yong-Seok Choi, Seung Yun, Sang-Hun Kim, and Kong-Joo Lee. 2023. "Robust Data Augmentation for Neural Machine Translation through EVALNET" Mathematics 11, no. 1: 123. https://doi.org/10.3390/math11010123
APA StylePark, Y.-H., Choi, Y.-S., Yun, S., Kim, S.-H., & Lee, K.-J. (2023). Robust Data Augmentation for Neural Machine Translation through EVALNET. Mathematics, 11(1), 123. https://doi.org/10.3390/math11010123