1. Introduction
Game development is a complicated professional domain in which three limited resources, i.e., money, manpower, and time, have to be carefully managed. First, we should note that the cost of developing a multimedia game, e.g., an online game, is rising. The budget for developing a commercial multi-player game is at least
$1,000,000. For some large-scale games, e.g.,
Grand Theft Auto V, developing a single version may even cost a company around
$10,000,000 [
1,
2,
3,
4]. But once a successful game is released, it might earn a billion dollars in profit, e.g., [
5,
6]. In light of the above observations, game development involves considerable expertise, such as product planning, graphic design, sound design, programming, and testing. To avoid endless budget amendments, it is essential to carefully schedule all the jobs at the beginning.
Such a large game cannot be implemented by a single developer, making good teamwork another essential factor. A small-sized game may be implemented by a single designer. However, for some large-scale multimedia games, the team size may range from 3 to 100 professionals [
7,
8]. Each game draws upon various areas of expertise. For instance, a single piece of music requires various professional skills, e.g., composing, songwriting, dubbing, and sound effects. The professionals with these skills are sourced from different kinds of personnel pools. Some may be official company employees, while others may be temporarily recruited freelancers. Clearly, semi-finished products made by the former must be passed to the latter on schedule. If a critical job is delayed, it may leave dozens of professionals idle. Since their wages, hotel expenses, and dining fees need to be paid even during such an idle period, such costly human resources need to be carefully scheduled in advance.
The third major resource is time. These multimedia games must eventually be released onto the market, so game developers have to race against time to finish them as early as possible. Since these developers have various areas of expertise, their time costs are different. Consider two developers, Mary and Tom. Mary may be highly proficient at figure design, while Tom may excel in scene design. There are 100 figure design jobs, and both developers are qualified for these jobs. Any daily delay of a job will result in a $100 penalty. Consider further that Mary requires 30 person-days and charges $50,000; Tom takes 50 person-days and charges $30,000. To whom should we assign these jobs? How does a delayed job affect the following jobs? These jobs must be carefully scheduled in the beginning. Any delay in a critical job may cause serious damage. For scheduling such a project, the cost, time, and expertise should be considered as a whole. Clearly, it is not easy to solve such a scheduling problem by labor-intensive means. That is, such a scheduling problem in the game industry is no less challenging than those in the aviation, semiconductor, and construction industries.
In light of the above observations, it is clear that tardiness minimization is important in the game industry. In general, the jobs in a large multimedia game have various properties and different tolerance degrees to delay. For example, the job of leading figure design should be completed as early as possible—such an urgent job had better not be delayed. Conversely, late poster design or user manual translation may not cause a huge loss. If possible, all the jobs would best be completed on time. However, as in other industries, it is difficult to schedule more than 20 jobs manually. Therefore, tailored scheduling algorithms for reducing tardiness in the game industry are called for.
Assigning similar jobs to a developer with corresponding expertise helps to reduce tardiness. With the continued refinement of the game industry, developers specialize in different areas of expertise. Let us consider the above example again. Mary should be assigned figure design jobs, and Tom, scene design jobs. However, there are still some other constraints. Suppose that Mary is overloaded with a lot of figure design jobs. Although Mary is highly proficient at figure design, we had better assign some figure design jobs to Tom. Clearly, the computation of such trade-offs is very complicated. This is because multi-specialty developers are not taken into account in traditional scheduling models. Again, some new algorithms for scheduling such jobs and developers in the game industry are needed.
The following three properties distinguish the presented problem from traditional ones. First, for traditional
heterogeneous machine scheduling problems, e.g., [
9,
10], a capable machine always outperforms others in terms of speed. However, for the presented problem, a developer may excel in figure design and programming but be mediocre in script design. That is, a single developer (or machine) simultaneously has both merits and shortcomings. It depends on what jobs are assigned to him/her. The considerations of the presented problem are more complicated than those of traditional heterogeneous machine scheduling problems.
Second, compared with
identical machine scheduling problems, e.g., [
11,
12], the amount of computation of the presented problem is large. For
m identical machines, we do not need to consider their permutations. Therefore, the solution space of the presented problem is about
m! times larger than that of an identical machine scheduling problem. To our best knowledge, few researchers have focused their efforts on this emerging industry. However, the limited resources (i.e., money, time, and manpower) in this industry are seldom discussed.
Third, it is difficult to develop efficient lower bounds in a traditional
unrelated machine scheduling problem, e.g., [
13,
14]. For
n jobs, the processing speeds of
m machines are all different; there are
m ×
n various combinations, i.e., a large solution space. However, in most situations, a game developer usually processes his/her own desired jobs, i.e., one or two types. Such unrelated machine models are too complicated to schedule these developers in the game industry.
In this study, an optimization problem is presented. It is obvious that traditional scheduling algorithms cannot be directly applied to the problem. First, in unifunctional machine scheduling problems, a machine usually processes jobs at a fixed speed, e.g., a welding robot. In the presented problem, the processing speed is determined by the fitness between developers and job types. That is, the combinations that are needed to be considered become greater in number. Second, jobs with agreeable processing times and due dates, e.g., [
15], are commonly employed to develop lower bounds and minimize tardiness. However, this technique will lead to an anomaly. Consequently, we propose an exact algorithm to schedule these various jobs and versatile developers in the game industry. Two main contributions are made in this study. First, a branch-and-bound algorithm is proposed for ensuring the optimality for
n ≤ 18. Second, a lower bound based on a harmonic mean is developed to improve the execution efficiency.
The rest of this study is organized as follows. In the
Section 2, past research is introduced. In the
Section 3, the scheduling problem considering versatile developers is formulated. In the
Section 4, a lower bound and a branch-and-bound algorithm are developed. In the
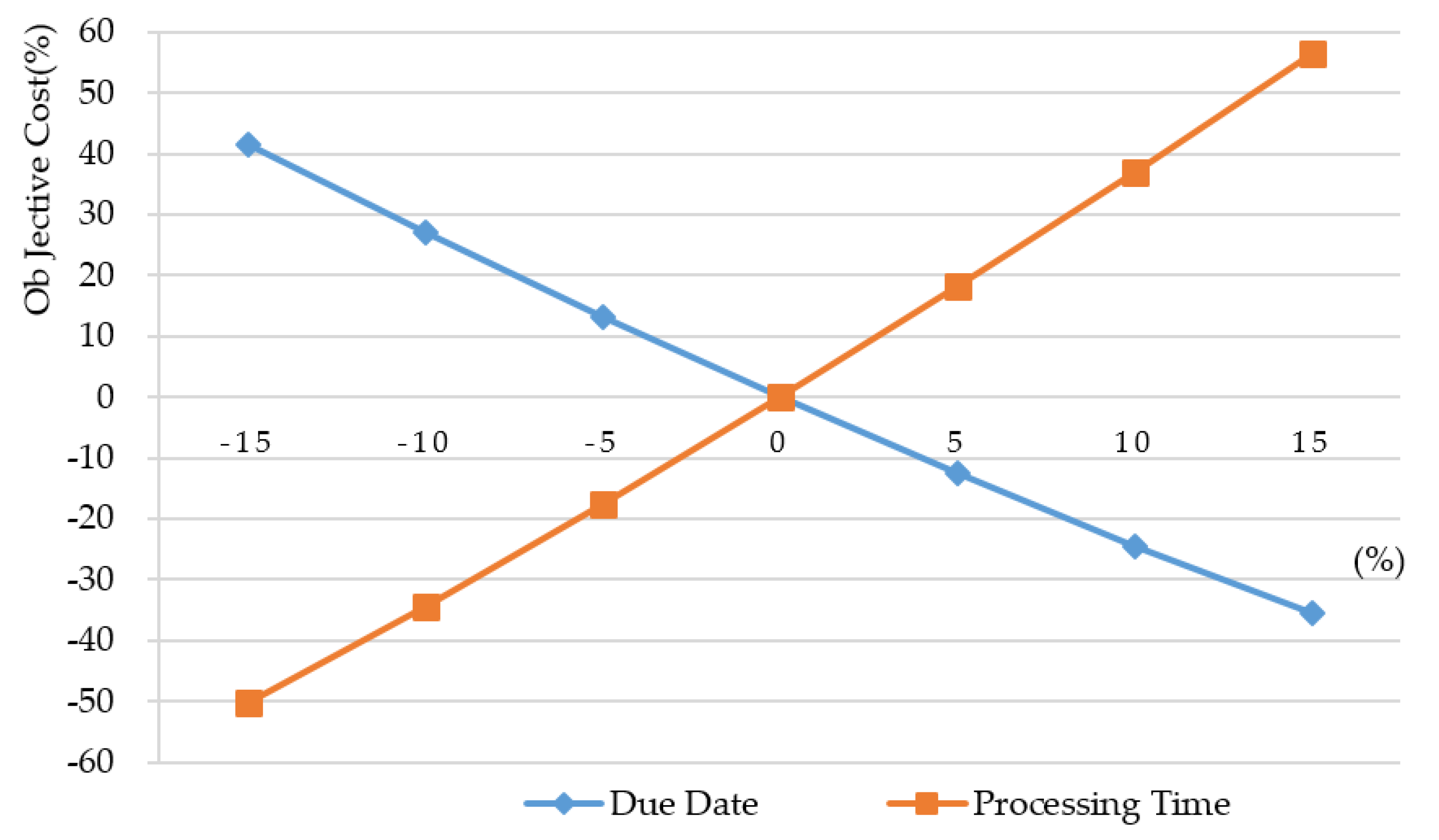
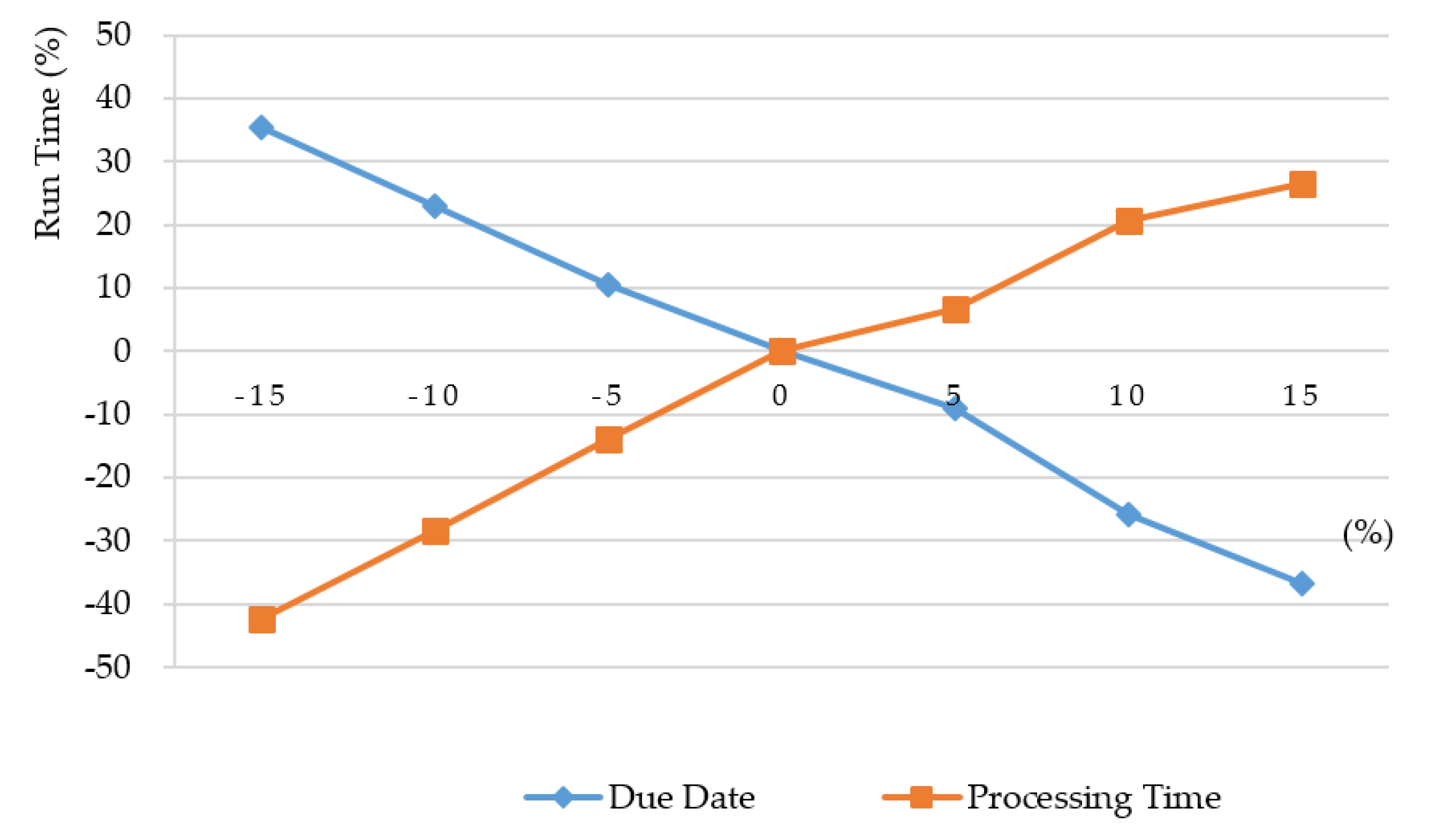
Section 5, experiments are conducted to show the execution efficiency of the proposed algorithms. Conclusions are drawn in the
Section 6.
3. Problem Formulation
The optimization problem is formulated as follows. There are
n non-preemptive jobs and
m developers. Each job
j has a default processing time
, a due date
, and a job type
for
. For each job type
x, developer
a has a processing difficulty ratio
for
and
. That is, if job
j of type
x (i.e.,
) is assigned to developer
a, the actual processing time is
. Each job needs to be assigned to one and only one developer, and each developer can process only one job at a time. On the other hand, if job
j is assigned to developer
a according to a schedule
, the actual completion time is denoted by
and the tardiness is defined by
. Under the above assumptions and constraints, we aim to determine an optimal schedule
which minimizes the total tardiness; i.e., the minimization problem is defined by
where
means the objective function.
A problem instance is shown in
Figure 1a. Let
n = 5,
m = 2,
= 20, 10, 30, 6, 10,
= 20, 20, 50, 70, 10, and
= 1, 1, 2, 3, 3, for
= 1, 2, 3, 4, 5. The processing difficulty ratios are listed in
Figure 1b. Let
be a schedule, where number 0 means a separator used to divide jobs between developers. Since developer 1 is highly proficient at dealing with jobs of type 1, job 1 and job 2 are assigned to developer 1, and their processing times are 20 and 10, respectively. Similarly, since developer 2 excels at processing jobs of type 2, job 3 is processed by developer 2, and its actual processing time is 30. Note that neither developer is skilled in processing jobs of type 3 (i.e., jobs 4 and 5). Since job 5 has an early due date, let developer 2 process it first, and its actual processing time is 30 (= 10 ×
= 10 × 3). Similarly, developer 1 requires a processing time of 30 (= 6 ×
= 6 × 5) to process job 5. Eventually, the total tardiness is
= 40 (i.e., 0 + 10 + 10 + 0 + 20).
It is clear that the above scheduling problem is different from traditional ones. The following features differentiate the presented problem from traditional ones:
Compared with traditional
unrelated machine scheduling problems, the concept of job type can reduce the amount of computation. For example, all the relationships between machines and jobs must be taken into account, e.g., the probability of machine
i processing job
j (
pij) in [
13] and the processing time of machine
i processing job
j (
pij) in [
14]. All the
m ×
n combinations must be considered. If a job set is not given, blindly estimating each machine’s average processing speed cannot determine a good lower bound. However, in the presented problem, jobs can be categorized into three types and only
m × 3 processing speeds are considered and their average processing speeds can be employed to develop a lower bound.
In past
heterogeneous machine scheduling models [
41,
69,
71], a capable developer (or machine) always outperforms others in terms of processing speed. That is, each heterogeneous machine has its own fixed speed. However, in this presented problem, a developer might be mediocre in processing jobs of type 1 but excel in dealing with jobs of other types. Clearly, these developers cannot be modeled by such unifunctional machines.
Compared with traditional
identical machine scheduling problems, e.g., [
11,
12], the presented problem is more difficult. An example is given in
Table 2. Consider that we allocate the three jobs to three identical machines. It is obvious that there is only one schedule, and it is just the optimal schedule; i.e., each machine takes one job. However, in the presented problem, a capable developer might take all three jobs to achieve optimality. Consequently, we need to check all the possible situations listed in
Table 2 to determine the optimal schedule.
Traditional tardiness minimization techniques cannot be directly applied to this problem. Jobs with larger processing difficulty ratios may take precedence over jobs with earlier due dates. In the presented problem, the processing difficulty ratio, processing time, and due date should be considered as a whole.
In light of the above observations, traditional scheduling algorithms cannot be directly applied to this problem, and a new optimization algorithm is thus required. That is, if a project meets the following two criteria, manpower can be arranged by such algorithms. First, a project is interdisciplinary and it recruits cross-domain workers, no matter what kinds of workers it needs, e.g., employee or freelancer. A developer may acquire several competencies and can perform several kinds of jobs in the project. Second, the performance pattern of each developer is known. That is, we have the big data of all developers and can estimate each one’s processing time for processing a given kind of job [
32,
33,
34].
4. Branch-and-Bound Algorithm
In this section, we develop a branch-and-bound algorithm (named BB). To obtain the optimal schedules, BB will explore each search tree in the depth-first-search (DFS) order. Moreover, to deter us from exploring useless partial schedules, we also propose some dominance rules and develop a lower bound.
4.1. Dominance Rules
For convenience, we introduce some notations at the beginning of developing dominance rules. Let be an undetermined schedule, where is a determined partial sequence and is the undetermined part. We wonder if there exists any better schedule that outperforms . Consequently, some dominance rules are developed to prove our doubts. Since these rules are similar, we provide only the first proof.
Case I: Consider that jobs i and j are the last two jobs of and both jobs are assigned to the same developer a. Let be the schedule obtained by only interchanging the last two jobs i and j in . For simplicity, let , , and . In the following rules, both jobs i and j in are tardy. However, if we interchange both of them, their tardiness can be alleviated a little. In Rule 1, though both jobs are still tardy in , their resulting tardiness is lower than . In Rule 2, the interchange makes job j not tardy, i.e., the resulting tardiness is reduced.
Rule 1. If , , , , and , then dominates .
Proof. We prove this property by showing
>
. That is,
The proof is complete. □
Rule 2. If , , , and , then dominates .
In the following four rules, job j is tardy and job i is not in . Rules 3 and 4 show that job j can be done in time in and the resulting tardiness can be improved. In Rules 5 and 6, job j is still tardy in , but the accumulated tardiness can be alleviated.
Rule 3. If , , , and , then dominates .
Rule 4. If , , , , and , then dominates .
Rule 5. If , , , , and , then dominates .
Rule 6. If , , , , and , then dominates .
Rule 7 lets the job with an earlier due date be processed first if both jobs, i.e., i and j, are not tardy in . That is, both objective costs of and are the same, and we can stop searching for one of them.
Rule 7. If , , and , let dominate .
Case II: Consider that job i is the last job of , which is assigned to developer a, and job j can be any undetermined job in . Moreover, job i is also the last job assigned to developer a. For simplicity, let and . In Rule 8, it would be wasteful to assign very few jobs to developer a. That is, he/she can accept some extra job in if no tardiness occurs.
Rule 8. If , then dominates .
Case III: Consider that job i is the last job of , which is assigned to developer a, and job j can be any undetermined job in . Let , , and be the schedule obtained by interchanging job i in and job j in . For simplicity, let and . In Rule 9, we interchange job i in and job j in if job j is more urgent and the total tardiness will not deteriorate. In Rule 10, developer a is mediocre at processing jobs of type x but highly proficient at processing jobs of type y. On the other hand, all the remaining developers excel at dealing with jobs of type x and are mediocre at processing jobs of type y. Therefore, we interchange jobs i in and j in . Note that the total tardiness will not be worse in the case.
Rule 9. If , , , and , then dominates .
Rule 10. If , , , , and , then dominates .
The following lemma shows that each developer’s workload has a squeeze effect. That is, if there exists a developer whose workload is unreasonably heavy, then there must be another developer who has a relatively light workload. Due to space limitations, the following proofs can be found in
Appendix A.
Lemma 1. For a schedule , if there exists a developer a whose maximum completion time is larger than , there exists another developer b whose maximum completion time is less than .
The following rule can help us to avoid some unnecessary searches if any developer is overloaded. If there exists a developer whose maximum completion time is unreasonably long, then we can remove a job from the overloaded developer and assign it to a half-loaded developer. That is, the previous schedule is dominated.
Rule 11. For an optimal schedule , each developer’s maximum completion time is less than or equal to .
4.2. Lower Bound
A lower bound is needed to avoid unnecessary searching if we are in the middle of a schedule that is dominated or outperformed by others. That is, after adding up the determined cost and the estimated cost of the remaining part, if the sum is still larger than the current minimal objective cost, we can abandon further searches for the remaining part. Consequently, the earlier we can stop useless searches, the more execution time we can save.
Arranging jobs with
agreeable processing times and due dates is a useful way to obtain a lower bound for traditional tardiness minimization problems [
15]. Here agreeableness is a kind of job correlation. As with precedence between two jobs in which a successor (e.g., testing) cannot start until a predecessor (e.g., programming) has finished, agreeableness between any two jobs implies that the smaller job (i.e., less processing time) always has an earlier due date, i.e., another kind of job correlation. However, it may lead to some anomalies in our problem. Consider that two identical developers (or machines) deal with the two jobs shown in
Figure 2a. To obtain a lower bound, in
Figure 2b, traditional algorithms may adjust the processing times and due dates and make them
agreeable, i.e.,
if and only if
. Hence, the lower bound for these jobs is 0; i.e., max{0, 4 − 6} + max{0, 6 − 8}. However, in our problem, an
anomaly occurs. Let
,
, and the processing difficulty ratios are shown in
Figure 2c. For the original jobs shown in
Figure 2a, the optimal objective cost is 4; i.e., max{0, 3 × 4 − 8} + max{0, 1 × 6 − 6}. For these virtual jobs shown in
Figure 2b, the lower bound is 6; i.e., max{0, 3 × 4 − 6} + max{0, 1 × 6 − 8}. However, a lower bound is never larger than the minimal cost. Consequently, we cannot directly apply this technique here. In our problem, a job with a larger processing difficulty ratio may be more urgent than another with an earlier due date. That is, the processing times, due dates, and processing difficulty ratios should be considered as a whole in this problem.
Since these developers differ in their abilities (i.e., various processing difficulty ratios), we aim to fabricate an equivalent substitute to replace these heterogeneous developers in the real world. Consider that there are k different developers in the real world and assume that there are k virtually identical developers whose integrated ability is just equal to the sum of all the real ones’ abilities. The following definition gives the correct magnitude of processing difficulty ratio for each virtual developer. It is interesting that the magnitude is the harmonic mean of all the real developers’ processing difficulty ratios.
Definition 1. There are k available developers numbered from m − k + 1 to m in the real world. Let there be k virtually identical developers. For each job type x, the equivalent processing difficulty ratio of each virtual developer is and denoted by .
The following lemma shows that the throughput (i.e., the amount of work per unit time) of these virtual developers is the same as the sum of all the real ones’ throughputs. For more information about harmonic mean, readers can refer to [
72,
73].
Lemma 2. For a given job type x, the sum of the last k real developers’ throughputs (i.e., ) is equivalent to that of the k virtual ones’ throughputs (i.e., ).
Now we can merge these virtual developers into a virtual substitute. The following definition gives the correct magnitude of the processing difficulty ratio of the single substitute. Moreover, the following lemma shows that the throughput of the k virtual developers is exactly equal to that of the virtual single substitute.
Definition 2. There are k available developers numbered from m − k + 1 to m in the real world. Let there be only one virtually equivalent developer, called the substitute. For each job type x, the processing difficulty ratio of the substitute is and denoted by , i.e., .
Lemma 3. For a given job type x, the sum of the last k real developers’ throughputs (i.e., ) is equivalent to that of the substitute’s throughput (i.e., ).
For each different job type, the virtual substitute still has different processing difficulty ratios. The following definition provides the upper and lower limits of the processing difficulty ratios for the substitute. The following lemma shows the boundary of the k real developers’ throughputs. This lemma guarantees that the throughput of the virtual substitute is larger than or at least equal to that of the k real developers.
Definition 3. For each virtual developer transformed by k available real developers, letand denote his/her minimal processing difficulty ratio and maximal processing difficulty ratio, respectively.
Lemma 4. The throughput of the last k real developers is less than or equal to.
Algorithm 1 shows the algorithm of the proposed lower bound (named LB). Note that BB explores a schedule
in the DFS order. Since the jobs in
are determined, we let some job
k be the last job of
, i.e.,
=
k, and some developer
a process it, i.e.,
=
a. Hence, there are
available developers before
. By Lemma 4, we can regard the
developers as a virtual developer with processing speed
. Similarly, the
developers before
can be viewed as another virtual developer with processing speed
. In Step 1, we determine which job is the last job in
and which developer completes the job. In Steps 2–3, the jobs in
are transformed into
new jobs whose processing times and due dates are agreeable, i.e.,
if and only if
. This modification ensures that such a lower bound will not be larger than the actual optimal cost [
74,
75]. Then we allocate these jobs to the two virtual developers at the pace of a unit job in Steps 5–14. We preemptively allocate the transformed jobs and start from time 0. If
LB proceeds before time
, we allocate the workload to the first virtual developer (Steps 9–10); otherwise, we let the second virtual developer process the remaining part (Steps 12–13). In Step 15, the estimated tardiness is accumulated, if any. Finally, the estimated lower bound is returned.
| Algorithm 1. The proposed lower bound (LB(,)). |
| INPUT |
| , where is a determined partial sequence and is the undetermined part |
| is the number of jobs in |
| OUTPUT |
| is the lower bound for the current schedule |
| (1) Set a = and k = ; |
| (2) Sort the processing times of the jobs in in ascending order, i.e., for j = 1 to n − l; |
| (3) Sort the due dates of the jobs in in ascending order, i.e., for j = 1 to ; |
| (4) Set and currentTime=0; //start to allocate the workload of |
| (5) For to do Steps 6–15; |
| (6) Set currentAmount=; //the amount of work of job (j) |
| (7) Repeat Steps 8–14 until currentAmount=0; |
| (8) If then do Steps 9–10; |
| (9) Set ; |
| (10) Set ; |
| (11) Else do Steps 12–13; |
| (12) Set ; |
| (13) Set
; |
| (14) Set ; |
| (15) Set ; |
| (16) Output . |
Theorem 1 shows the correctness of the proposed lower bound. By Theorem 1, the object cost of the substitute (i.e., the lower bound) will not be larger than the actual optimal cost in the real world.
Theorem 1. Let be the optimal objective cost and be the lower bound. Then , where denotes the optimal schedule and denotes a schedule.
4.3. Branch-and-Bound Algorithm
Given the above dominance rules and lower bound, a branch-and-bound algorithm (named BB) is therefore developed and shown in Algorithm 2. The exact algorithm recursively explores the solution space in a DFS manner. Every time we enter the recursive algorithm, we check if the current partial sequence of length l is dominated or the current lower bound is larger than the up-to-the-minute lowest cost (Step 1). If not, BB recursively calls itself (Steps 5–8). Since there are still undetermined jobs in , we make new subsequences, and each starts with a different leading job. Then, we repeatedly replace the original and obtain new schedules (Steps 5–7). At the end, BB is recursively called by itself for times (Step 8). Note that both and are global variables. When the recursive algorithm ends, the globally optimal schedule and the minimal cost are stored in both of them.
| Algorithm 2. The proposed branch-and-bound algorithm (BB(,)). |
| INPUT |
| , where is a determined partial sequence and is the undetermined part |
| is the number of jobs in |
| OUTPUT |
| is the minimal cost //a global variable |
| is the optimal schedule //a global variable |
| (1) If ( is not dominated and LB(,)) then do Steps 2–8; |
| (2) If then do Step 3; |
| (3) If then set and ; |
| (4) Else do Steps 5–8; |
| (5) For j = l + 1 to do Steps 6–8; |
| (6) Set ; |
| (7) Swap the (+1)st and th jobs of ; |
| (8) Call BB(,+1) recursively. |
So far, we have proposed an exact algorithm named BB for locating the optimal solutions. With the aid of the dominance rules and lower bound, BB does not need to search for the entire solution space. Some dominated branches can be omitted, and the execution time is thereby reduced.









{kind=link}
{kind=link}
{kind=link}
{kind=link}