1. Introduction
Regression models are one of the main statistical techniques frequently used in data analysis in any area of knowledge, especially when there is interest in studying the relationship between a dependent variable (response) and two or more independent (explanatory) variables. In this sense, a regression model with a response variable following a normal distribution is perhaps best known in the literature, and could be considered one of the most widely used; however, the assumption of normality may not be adequate in the dataset under analysis, since these may present degrees of skewness or kurtosis that are not within the range covered by the normal model. Consequently, inferences made from the fitted model may not have statistical validity, and erroneous conclusions may be reached. A solution to the problem of the assumption of normality of the variable of interest is the use of transformations, although it is well known that this solution makes it difficult to interpret results since data are not in the original measurement scale. As an alternative to this issue, many authors have introduced new family distributions that are capable of capturing degrees of skewness and kurtosis greater than those that the normal distribution can capture.
One of the most important works in the context of data with a high degree of asymmetry is Azzalini [
1], which is known in the statistical literature as the skew-normal (SN) model. The main characteristic of the SN model is its ability to fit degrees of asymmetry (on the left and right) greater than those of the normal model; however, it is not the best model in terms of capturing high degrees of kurtosis. Relating to the latter, the power-normal (PN) model introduced by Durrans [
2] has the particularity of fitting data with a higher degree of kurtosis than the normal and SN model but with less range of asymmetry. The SN and PN models have been studied extensively by many authors, and different extensions of this model have been considered. In Gupta and Gupta [
3] for example, the authors showed the existing practical problems when the asymmetry parameter of the SN model is estimated, and they proposed an alternative model named the PN model. The authors also investigated the closeness between the proposed model and the SN model. In Pewsey et al. [
4], the authors presented the general results of the likelihood-based inference for the family of power distributions, with particular emphasis on the case of the PN model, complementing the work of Gupta and Gupta [
3]. In Martínez-Flórez et al. [
5], the authors introduced a new model that generalized both the SN model by Azzalini [
1] and the PN model by Durrans [
2]. The new model, which is called power-skew-normal (PSN), has the particularity of fitting data with degrees of asymmetry greater than those of the SN model, and is also capable of capturing degrees of kurtosis greater than those of the PN model. Furthermore, the authors showed that the information matrix of the new model is non-singular, which permits carrying out hypothesis tests on the asymmetry parameters based on likelihood-ratio statistics. On the other hand, Martínez-Flórez et al. [
6] generalized the log-normal (LN) model from the SN and PN models. In addition, these new proposals contain the LN model as a particular case, and they are more flexible regarding skewness and kurtosis to fit positive data.
Alternatives for fitting asymmetric data with a high degree of kurtosis were reported by other authors such as Tovar-Falón et al. [
7], who introduced a new model that generalizes the skew-
t model of Azzalini and Capitanio [
8] and power-
t of Zhao and Kim [
9]. Here, the inference was carried out from a classical perspective using the maximum likelihood method. This new model also has, as particular cases, the PSN, SN, PN, Student-
t and normal models. In Tung et al. [
10], the authors considered a mixture class of log-F distributions to characterize asymmetric distributions by integrating it into a pH acceleration model. The authors studied the impact of the new model in the presence of misspecification of particle size distribution.
Models for asymmetric data with high degrees of skewness and kurtosis, and presenting more than one mode and censored data, were also considered. More details about these topics can be found in Martínez-Flórez et al. [
11] and Martínez-Flórez et al. [
12], respectively. In addition, all the aforementioned models are easily extensible to the situations of regression models, including cases in which the data show censoring in some value; see Sahu et al. [
13], Martínez-Flórez et al. [
14].
In Amini et al. [
15], the authors introduced a new family of distributions useful for modelling asymmetric data. This new family of continuous distributions is generated by a distribution
F and two positive real parameters
and
, which control the skewness and tail weight of the distribution. The probability density function (PDF) of this family is given by
where
and
is the complete gamma function,
is the cumulative distribution function (CDF) of
X, and
is the associated PDF. In this work, the authors studied the main properties of the distribution and addressed the estimation process of the unknown parameters of the model using the likelihood approach.
From the
generator, the authors studied some particular properties of the family, among which are the exponential, Weibull, power, Pareto, extreme value and Gumbel distributions. If
and
and
in model (
1), i.e., the CDF and PDF of the standard normal distribution, respectively, the model in (
1) is reduced to the PN model by Durrans [
2]. Hence, the model in (
1) is an extension of the PN model. In Cordeiro et al. [
16], the authors studied in detail the properties of the log-gamma-generated family of distributions introduced by Amini et al. [
15] and presented some applications of this family. Other particular cases of the model introduced by Amini et al. [
15] correspond to the generalized gamma and log-gamma distributions, which have been extensively studied by many authors; see Prentice [
17], Lawless [
18], Young and Bakir [
19], Ortega et al. [
20,
21] among others.
The main goal of this article is to focus on the study of the regression model under the assumption that the errors follow a log-gamma-normal (LGN) distribution, which is obtained by taking
and
in model (
1). We also consider the case of the regression model for censored data, and we conduce the parameter estimation using the maximum likelihood approach and its large sample properties.
Although there are many works in the literature related to the generalized log-gamma distribution, our proposal is based on the family of distributions presented by Amini et al. [
15], which is known in the literature as log-gamma-generated. For the case of this family, we focus on the case in which the generating function is the normal distribution and the distribution called log-gamma-normal is obtained, and this distribution does not correspond to the distributions previously mentioned. In our proposal, we change the assumption that the errors in the multiple linear regression model follow a normal distribution to that of errors with a log-gamma-normal distribution. It is also important to note that the generalized log-gamma and log-gamma distributions are also particular cases of the family introduced by Amini et al. [
15] (assuming a gamma distribution instead of the standard normal distribution), but in our proposal we do not consider these cases.
In addition to carrying out the estimation process of the parameters in the model, we present two applications using real datasets. The first dataset was previously analyzed by Zhang and Davidian [
22], and the second dataset is related to a study on the abundance of beryllium scaled to the Sun’s abundance. For the particular case of these datasets, the model fits well, and therefore we can conclude that, apart from the existence of statistical literature for the analysis of asymmetric data, our proposal is a viable alternative that competes with existing models. The main contribution of this model is that the trend of the dataset under examination is better explained using a model with log-gamma type errors instead of one with asymmetric errors using another distribution.
The article is organized as follows. In
Section 2, we define the family of LGN distributions and discuss some of its properties. In
Section 3, the LGN regression model is defined, and its properties studied. The inference is implemented using the maximum likelihood approach. The censored LGN model for dealing with censored data by maximum likelihood estimation is discussed in
Section 4. The results of a small-scale simulation study reveal the good performance of the estimation approach in
Section 5. In
Section 6, two real data applications are considered, revealing that the datasets in question are better fitted by LGN model than PN and models.
2. Log-Gamma-Normal Distribution
In this section, we define the LGN model, which is obtained from the family given in (
1) by taking the CDF of the standard normal distribution, and we study some basic properties.
Definition 1. The random variable X is said to have a LGN distribution, if X has PDF given bywhere , is the gamma function, and the functions and are the PDF and CDF of the standard normal distribution, respectively. A random variable with LGN distribution is shortly denoted by
. One can note that the function (
2) is a proper PDF since
for all
and
. Thus, letting
, it follows that
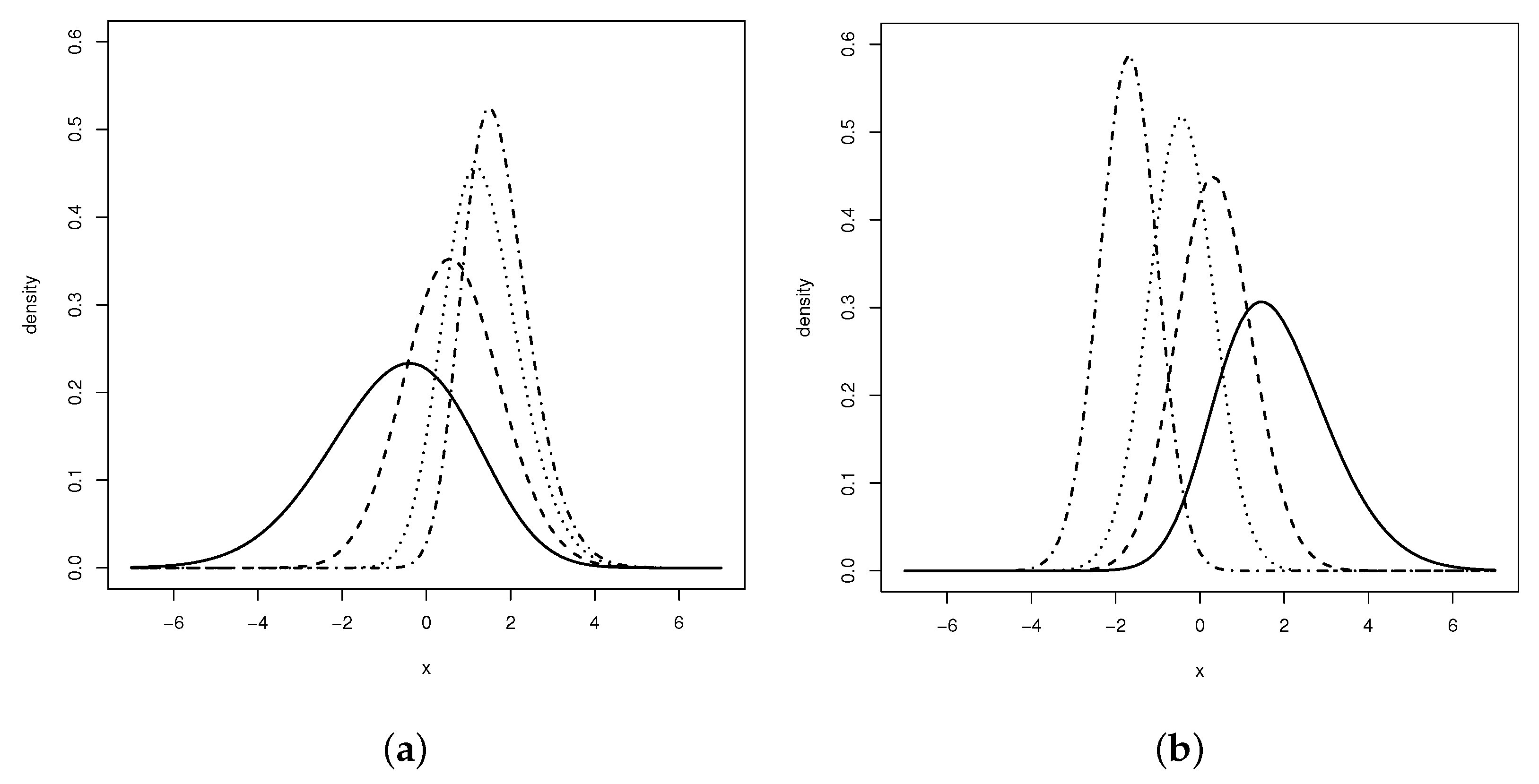
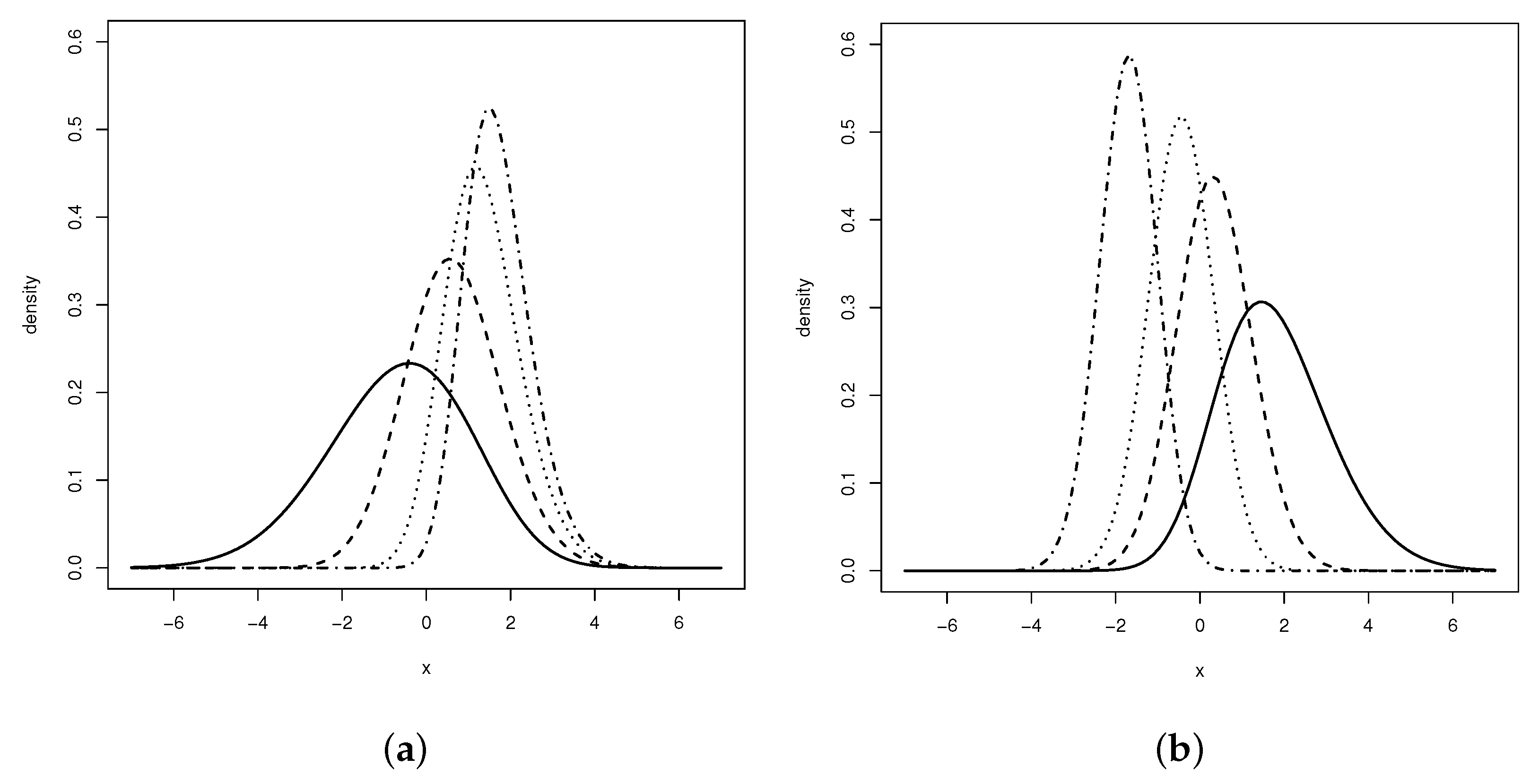
Figure 1 depicts some shapes of LGN distribution for some selected values of the parameters
and
. It can be seen that the parameters
and
affect both the skewness and kurtosis of the model, and hence, the LGN distribution is more flexible for fitting data that may be skewed as well as having thinner or thicker tails than the normal, SN and PN distributions.
The LGN distribution reduces to some specific distributions as special cases for specified values of the parameters and ; some of them are available in the literature and have been widely studied.
Proposition 1. Let
- (i)
if, then,
- (ii)
if, then,
- (iii)
ifand, then.
Proof. Demonstration of (i)–(iii) is immediate from the definition of LGN distribution. □
2.1. Moments
Measures of skewness and kurtosis can be given from the moments of the LGN distribution. The following proposition gives an expression of the rth moment of the random variable which does not have a closed form.
Proposition 2. Letthenwhereis the inverse of the CDFand the random variable W follows a gamma distribution with parameters δ and γ. Proof. We have by definition that
Letting
, then
, it follows that
which is the expected value of the function
, where
W follows a
distribution. □
Based on moments (
3), one can obtain the skewness
and the kurtosis
coefficients of the LGN model using the following expressions
and
respectively, where
for
. The skewness and kurtosis coefficients for values of
and
ranging between 0.1 and 200 were calculated using numerical integration with an integrate function of R Development Core Team [
23] for LGN model. It was found that
and
. The given intervals contain the corresponding intervals of skewness and kurtosis coefficients of the SN model, which are
and
, respectively, and the PN model, which are
and
, respectively. More details can be found in Pewsey et al. [
4]. The previous results illustrate the fact that the LGN model contains models with greater (and smaller) asymmetry degree than both the SN and PN models.
2.2. Distribution Function
In this section, we present the explicit formula for the CDF of LGN distribution.
Proposition 3. Let,
thenwhereis the gamma function andis the upper incomplete gamma function.
Proof. The CDF of the LGN distribution is obtained as follows:
□
It can be shown that (see Cordeiro et al. [
16]) for the density function given in (
2), the quantile function is given by:
where
is the inverse function of
.
The inversion method can be used to generate a random variable with LGN distribution. Thus, let
and
U be a random variable with uniform distribution, namely
. Then, the random variable
X with distribution
can be obtained by letting
where
and
are the inverses of the CDF of the normal and gamma distributions, respectively. The survival and hazard functions for the LGN distribution can be obtained from (
2) and (
4), and they are given by
and
respectively.
2.3. Location-Scale Extension
Let
. The location-scale extension of the random variable
X is defined using the transformation
, where
and
. The corresponding PDF of
Y is given by
where
is a location parameter and
is a scale parameter. The random variable
Y that has a distribution with density function given in Equation (
5) is denoted as
.
The previous representation of location scale can be extended to the case where response variable depends on regressor variables, say , through the relationship ; where is an unknown vector of regression coefficients and is a vector of known regressors correlated with the response vector.
The
rth moment of a variable
can be obtained using the formula
where
.
Proof. Let
, then, for
and
it has
In the second line, the binomial theorem is used. □
3. Log-Gamma-Normal Regression Model
Regression models have been a statistical technique widely used in many areas of knowledge to explain the behavior of a response variable, say
Y, as a function of other variables called regressors, say
, and a vector of unknown parameters called regression coefficients denoted by
. Specifically, for a random sample of
n individuals indexed by
, we have
where
is a random variable (random error) with certain PDF, the most common being the normal distribution assumption, i.e.,
. Given the multiple departures from the normality assumption and the actual behavior of the random variable
, this assumption has been replaced in numerous instances by other more realistic ones, usually looking for distributions to fit data with higher or lower skewness and/or kurtosis than that allowed by the normal distribution. Notable inferential mistakes are made (invalid results) when we work under the normal assumption and this assumption is not true. In some cases, a simple transformation helps to solve this problem, but this strategy typically has problems of interpretability of the results or the coefficients of the model.
Now, we change the normal assumption using the LGN assumption in the random error term , so we suppose that and this leads to for . The case follows the ordinary normal regression model. Using the least squares method, we obtain the estimators , which are not unbiased for the parameters of the regression coefficients but the correction , where the last term represents the estimated expected value of the random variable , such that we can obtain unbiased estimators of the parameters.
Estimation Using Maximum Likelihood Method
We initially define some quantities:
is a matrix
where rows
correspond to observations for the
ith individual for
p independent variables;
is a vector
corresponding to responses for the
ith individual; and
is an unknown vector of regression coefficients. Thus, given a random sample of size
n, say
, where
for
; the log-likelihood function for the vector
can be written as follows:
After taking the first partial derivatives of the log-likelihood function (
7) regarding the parameters of interest and setting them equal to zero, we obtain the following score equations:
where
, and
with
and
; and
for
;
is the identity matrix of order
n, and
is the digamma function.
The elements of the observed information matrix for the parameter
are easily computed by taking second partial derivatives, obtaining:
where
and
with
;
,
, and
with
,
,
for
,
is the trigamma function and
with
for
.
The Fisher information matrix can be obtained numerically, calculating times the expected value of the observed information matrix. When , we obtain the case of the normal distribution for the random variable . Using numerical approximation, the determinant of the Fisher information matrix is , where denotes the determinant function of a matrix and denotes the mean in the sample of the variable . Thus, the determinant of the information matrix is different to zero, and the information matrix is non-singular, ensuring the conditions to apply asymptotic approximation to the normal distribution of the maximum likelihood estimator vector of . Here, the covariances matrix of is the inverse of the Fisher information matrix, i.e., .
Approximation can be used to construct confidence intervals for , which are given by , where corresponds to the rth diagonal element of the matrix and denotes quantile of the standard normal distribution.
5. Simulation Study
To study the performance of the MLE of parameter vector , we conducted a Monte Carlo simulation study with small and moderate samples. In the study, we generated 5000 samples of sizes 50, 100, 200 and 500, and we considered the LGN model. The following parameter values were taken: , 1.50; and we took .
We considered a linear model with a single covariate
Z whose values were generated according to a uniform distribution
. We also took errors
. To evaluate estimators performance for point estimates we considered the bias
, the relative bias (RB) defined as (absolute value of bias / true parameter value) and the square root of the mean squared error
, which is the mean over all samples of the squared bias plus the variance. Maximum likelihood parameter estimates were computed using the optim function in statistical package R Development Core Team [
23].
Table 1 and
Table 2 present the results of the simulation study. It can be seen from the table that the RMSEs of MLEs for
,
,
,
and
decreases as sample sizes increase, which is expected since estimators are consistent. The relative bias of the MLEs also decrease as sample sizes increase. The MLEs of
are unstable because this parameter is affected by the asymmetry parameter; however, its MLE becomes more stable as the sample size becomes larger. It can also be seen that when the parameter
increases, the bias of the MLEs of the
,
and
is larger. The main conclusion is that we are quite safe working with the MLEs if sample sizes are greater than 100.





{kind=link}
{kind=link}
{kind=link}
{kind=link}