1. Introduction
In stochastic programming, the involved random variables usually satisfy certain distribution. However, in the real world, the certain distribution may be unknown or only the part of it is known. Distributionally robust optimization (DRO) method happens to be an effective way to solve such uncertain problems.
The study of the DRO method can be traced back to Scarf’s early work [
1], which is intended to address potential uncertainties in supply chain and inventory control. In the DRO method, historical data may not be sufficient to estimate future distribution, therefore, a larger distribution set containing the true distribution can adequately address the risk of fuzzy uncertainty sets. The DRO model has been widely used in operations research, finance and management science, see [
2,
3,
4,
5,
6] for recent development and further research. However, most of the ambiguity set of DRO are independent of decision variable.
Recently, Zhang, Xu and Zhang [
7] have proposed a parameter-dependent DRO model, where the probability of the underlying random variables depends on the decision variables and the ambiguity set is defined through parametric moment conditions with generic cone constraints. Under Slater-type conditions, the quantitative stability results are established for the parameter-dependent DRO. By recent developments from the variational theory, Royset and Wets [
8] have established convergence results for approximations of a class of DRO problems with decision-dependent ambiguity sets. Their discussion covers a variety of ambiguity sets, including moment-based and stochastic-dominance-based ones. Luo and Mehrotra [
9] have obtained formulations for problems that feature distributional ambiguity sets defined by decision-dependent bounds on moments. Until recently, DRO with decision-dependent ambiguity sets has been an almost untouched research field. The few studies [
7,
8,
9] on DRO with decision-dependent ambiguity sets are mostly theoretical achievements and the algorithms for solving such DRO are not related.
In this paper, for the parameter-dependent DRO model in [
7], we propose an alternating iteration algorithm for solving it and propose a less-conservative solution strategy for its special case.
As far as we are concerned, the main contributions of this paper can be summarized as follows. Firstly, we carry out convergence analysis for alternating iteration algorithm. Under the Slater constraint qualification, we show that any cluster point of the sequence generated by the alternating iteration algorithm is an optimal solution of the parameter-dependent DRO. Notice that the proof of the convergence of successive convex programming method in [
10] cannot cover our convergence analysis, since the uncertain set in Equation (
1) depends on
x, therefore our convergence analysis can be seen an extension of the proposition in [
10]. Secondly, when the corresponding objective function is convex, a less-conservative DRO is constructed and a modified algorithm is proposed for it. At last, numerical experiments are carried out to show the efficiency of the algorithm.
The paper is organized as follows.
Section 2 demonstrates the structure of the algorithm for the parameter-dependent DRO and establishes the convergence of the algorithm. In
Section 3, the modified algorithm is proposed for a special case of DRO and the less-conservative solution is obtained. In
Section 4, some numerical test results are illustrated to show the less conservative property of solutions obtained by the modified algorithm.
Throughout the paper, we use the following notations. By convention, we use and to denote the space of all matrices and symmetric matrices respectively. For matrix , means that A is a negative semidefinite symmetric matrix, denotes the Euclidean norm of a vector x in . For a real-valued function , denotes the gradient of at x.
2. DRO Model and Its Algorithm
Consider the following distributionally robust optimization (DRO) problem:
where
X is a compact set of
,
is a continuously differentiability function,
is a vector of random variables defined on probability space
with support set
, for fixed
,
is a set of distributions which contains the true probability distribution of random variable
, and
denotes the expected value with respect to probability measure
.
In this paper, we consider the case when
is constructed through moment condition
where
is a random map which consists of vectors and/or matrices with measurable random components, and
denotes the set of all probability distributions/measures in the space
and
is a closed convex cone in a finite dimensional vector and/or matrix spaces. If we consider
as a measurable space equipped with Borel sigma algebra
, then
may be viewed as a set of probability measures defined on
induced by the random variate
. To ease notation, we will use
to denote either the random vector
or an element of
depending on the context.
When
is a finite discrete set, that is,
, for some
N, (
2) can be written as
In this section, we consider the DRO model (
1) with
defined by (
3). In this case,
In [
10], a successive convex programming (SCP) method for a max–min problem with fixed compact set is proposed. However, the SCP method in [
10] cannot be used to solve (
1) directly, since
in (
1) depends on
x.
Based on the SCP algorithm, we propose an alternating iteration algorithm for solving (
1). In the algorithm proposed, the optimal solution is obtained by alternative iteration of solutions of inner maximum problems and outer minimum problems in (
1). For convenience, let
We know from the algorithm that if the algorithm stops in finite steps with
or
, then
is an optimal solution of (
1). In practice, problem (
6) can be solved by its dual problem. In the case when an infinite sequence is produced, we use the following theorem to ensure the validity of the algorithm.
We introduce a notation, which is used in the proof of the convergence of the Algorithm in
Table 1. Let
, the
total variation metric between
P and
Q is defined as (see, e.g., page 270 in [
11]),
where,
Using the total variation norm, we can define the distance from a metric
to a metric set
, that is,
We next provide the convergence of the Algorithm in
Table 1.
Theorem 1. Let be a sequence generated by Algorithm in Table 1 and be a cluster point. If (a) and are both continuous on , (b) for and are finite valued and continuous on Ξ, (b) , then is an optimal solution of problem (1). Proof. Since
is an increasing sequence of sets and
is a compact set, we have
Since
is a cluster point of
, there exists an subsequence of
converging to
. Without loss of generality, for simplicity, we assume that
is the limit point of
. We know from step 2 in the algorithm that
is an optimal solution of
Let
and
denote the optimal solution set and optimal value of
respectively,
and
denote the optimal solution set and optimal value of
respectively. Then, we have from (
8) that:
We proceed the rest of the proof in three steps.
Let
, by compactness of
,
has cluster points. We assume
is a cluster point of
, then there exists a subsequence
such that
converges to
weakly as
and
. Under conditions (a) and (b), we have
as
. Hence, we have
Since
, we have form condition (a) that
, which means that
. Let
, we next show that there exists a sequence
with
such that
converges to
weakly as
. Under conditions (b) and (c), we know from [Theorem 2.1] in [
7] that there exist positive constants
and
such that:
for all
and
n large enough, which means that for
,
for
n large enough. Let
, then by (
12), we have
converges to
weakly as
n converges to infinity. Consequently, under condition (b),
as
and hence,
Combining (
11) and (
13), we have
converges to
as
.
Step 2. We next show for any fixed
,
Since , we have .
Then under conditions (a) and (b), similarly to the proof of step 1, we have converges to as
Step 3. Combining (
9), (
10) and (
14), we have
which means that,
is an optimal solution of
By step 3 in algorithm, we have
which means that
Then by the proof in step 1, letting
, we have
Consequently, by (
15), we have
for all
. Therefore,
is an optimal solution of (
1). □
Remark 1. In [10], without any constraint qualifications, the proof of the convergence of SCP method is obtained. However, in our proof, since the uncertain set in (1) depends on x, the Slater condition ensures the proof. We know from the above proof that if the uncertain set in (1) independent on x, the Slater condition can be omitted. Therefore our convergence analysis can be seen an extension of the proposition in [10]. 3. Less Conservative Model and a Modified Algorithm
In this section, we consider a special case of (
1) and provide a less-conservative model.
In the case when
and the ambiguity set is
where
and
are nonnegative constants,
and
is positive semidefinite, the model (
1) is the following problem:
where
and
The model has been investigated in [
2]. As shown in [
2], the constraints in (
18) imply that the mean of
lies in an ellipsoid of size
centered at the estimate
and the centered second moment matrix of
lies in a positive semidefinite cone defined with a matrix inequality.
However, in the constraints of (
18), not all
lies in the ellipsoid of size
centered at the estimate
. In practice, we may be only interested in the
which lies in the ellipsoid and omit the ones outside the ellipsoid. Consequently, we propose a less-conservative DRO model, that is
In the above model, if the
does not lie in an ellipsoid of size
centered at the estimate
or does not satisfy the matrix inequality
, the corresponding constraints are vanished. Moreover, we can choose
and
such the feasible set of the inner problem is not empty, for example, for the first constraint, let
. Compare with model (
18), the model (
19) is less conservative since the feasible set of the inner maximum problem is smaller.
Let
be a set of probability distributions defined as
Next we give a modified alternative solution algorithm for (
19):
The above algorithm is based on the algorithm in Pflug and Wozabal [
10] for solving a distributed robust investment problem and a cutting plane algorithm in Kelley [
12] for solving convex optimization problems. A similar algorithm has been used in Xu et al. [
5] to solve a different DRO model and the proof of the convergence is omitted. In the following, we provide convergence analysis of the modified alternative solution algorithm based on Theorem 1.
Theorem 2. Let be a sequence generated by Algorithm in Table 2 and be a limit point. If for each , is continuously differentiable and convex on X, then is an optimal solution of problem (19). Proof. The proof is similar as the proof of Theorem 1. Since is an increasing sequence of sets and is a compact set, we have
Let
and
denote the optimal solution set and optimal value of
respectively,
and
denote the optimal solution set and optimal value of
respectively. Then we have
Let
, by compactness of
,
has cluster points. We assume
is a cluster point of
, then there exists a subsequence
such that
converges to
weakly as
and
. Then we have
as
. Hence, we have
On the other hand, for
, which means that
such that
as
. Therefore, we have
as
. Combining (
24) and (
25), we obtain
The else of proof follows from the proof of Theorem 1. □
Remark 2. Notice that the Slater condition is not used in the proof, since the uncertain set in (1) is independent on x, the Slater condition can be omitted. 4. Numerical Tests
In this section, we discuss the numerical performance of proposed alternating iteration algorithm for solving (
18) and (
19). We do so by applying the alternating iteration algorithm to a news vender problem [
4] and provide comparative analysis of the numerical results.
Suppose the company has to decide the order quantity
of a product to meet the demand
and the news provider trades in
products. Before knowing the uncertain demand
, the news vender orders
units of product
j at the wholesale price
. Once the demand
is known, it can be quantified
at the retail price of
. Any stock that have not been sold
are cleared by the remedy price
. Any unsatisfied demand
is lost. The total loss of the news vendors can be described as a function of the order decision
:
where non-negativity and minimum operators are applied to the component method. We study the risk aversion of the news vendor problem on two models:
and
where
is an exponential distribution function,
and
is defined as in (
20). Notice that for the news vender problem, problems (
18) and (
19) are just (
) and (
) respectively.
The data are generated as follows: for
i-th product, wholesale, retail and remedy prices are
,
and
respectively; the product demands vector
is characterized by a multivariate log-normal distribution with the mean
,
In the execution of the algorithm, we use an ambiguity set
in (
20) with
and
. The mean and convariance matrix
and
are calculated to be generated through a computer. The experiments are carried out through Matlab 2016 installed on a Dell notebook computer with Windows 7 operating system and Intel Core i5 processor. The SDP subproblems in Algorithms are solved by Matlab solver “SDPT3-4.0” [
13].
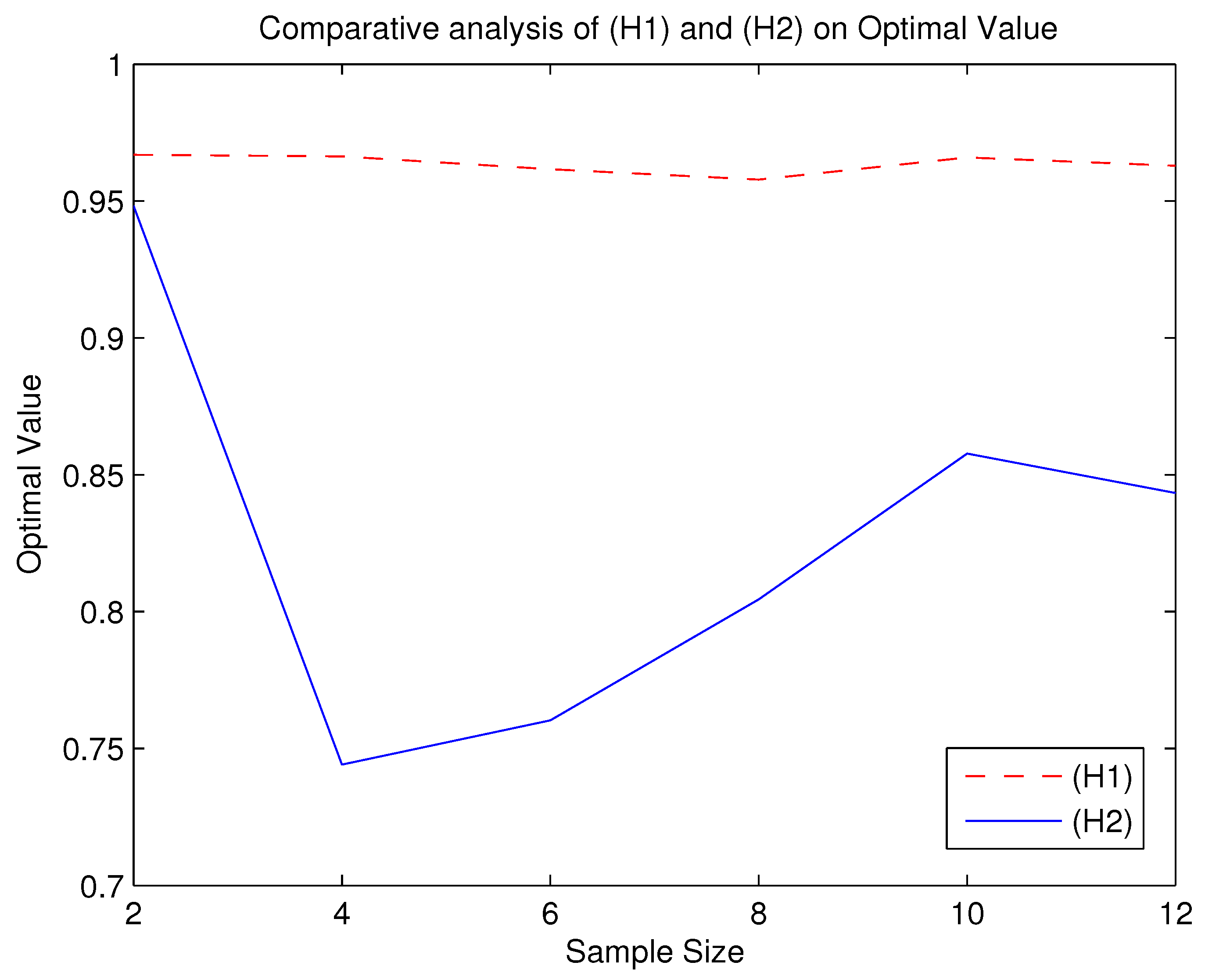
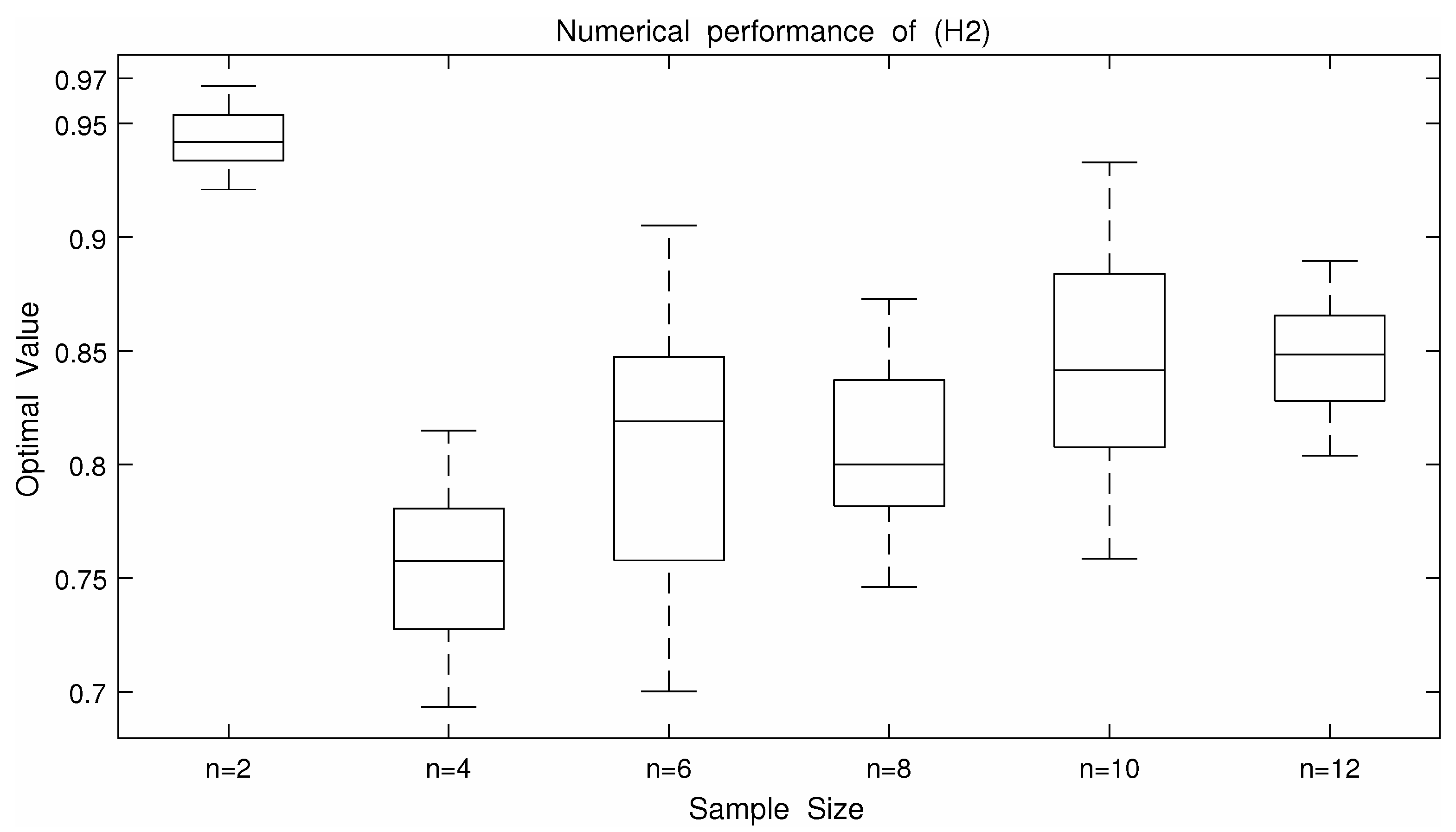
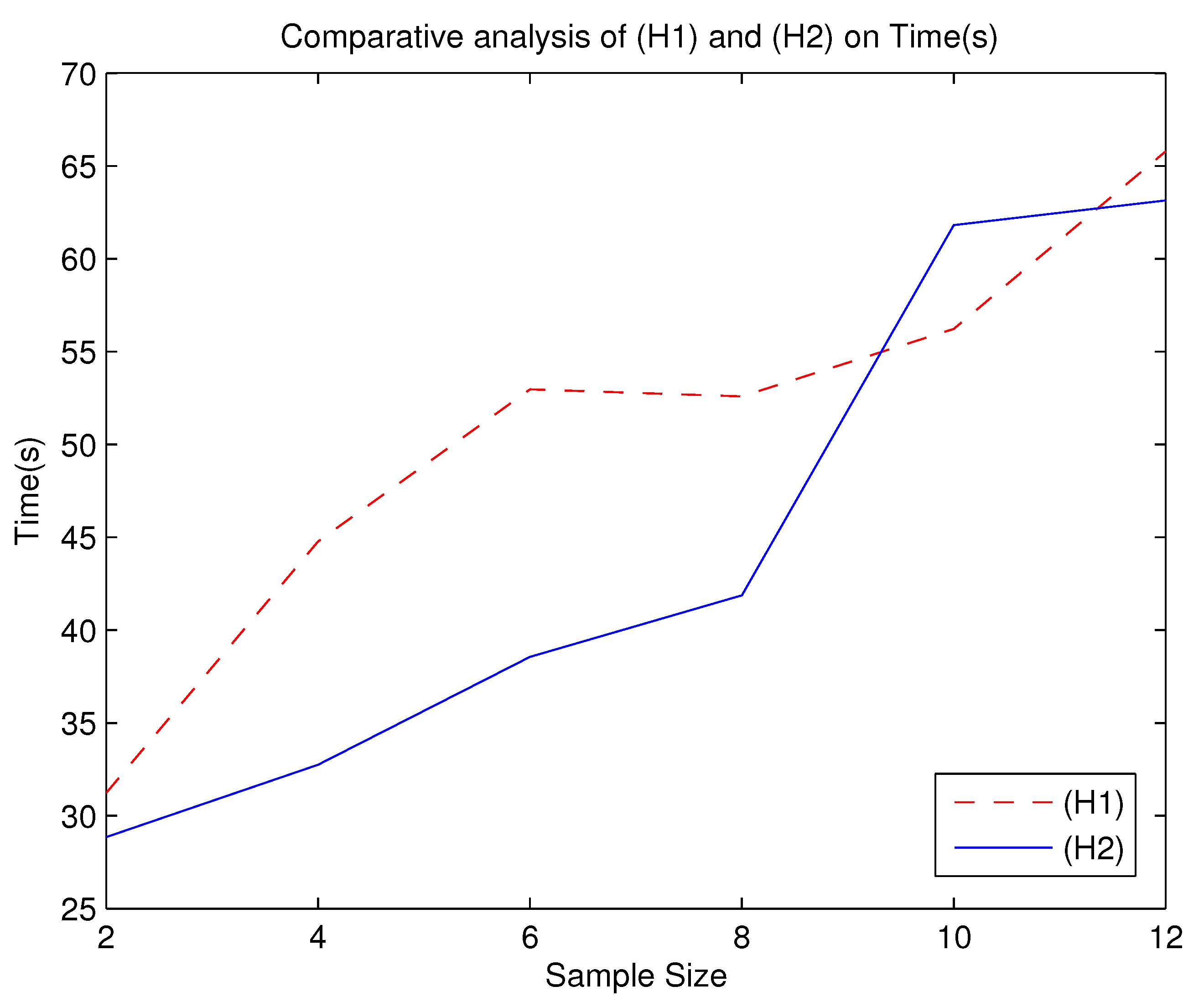
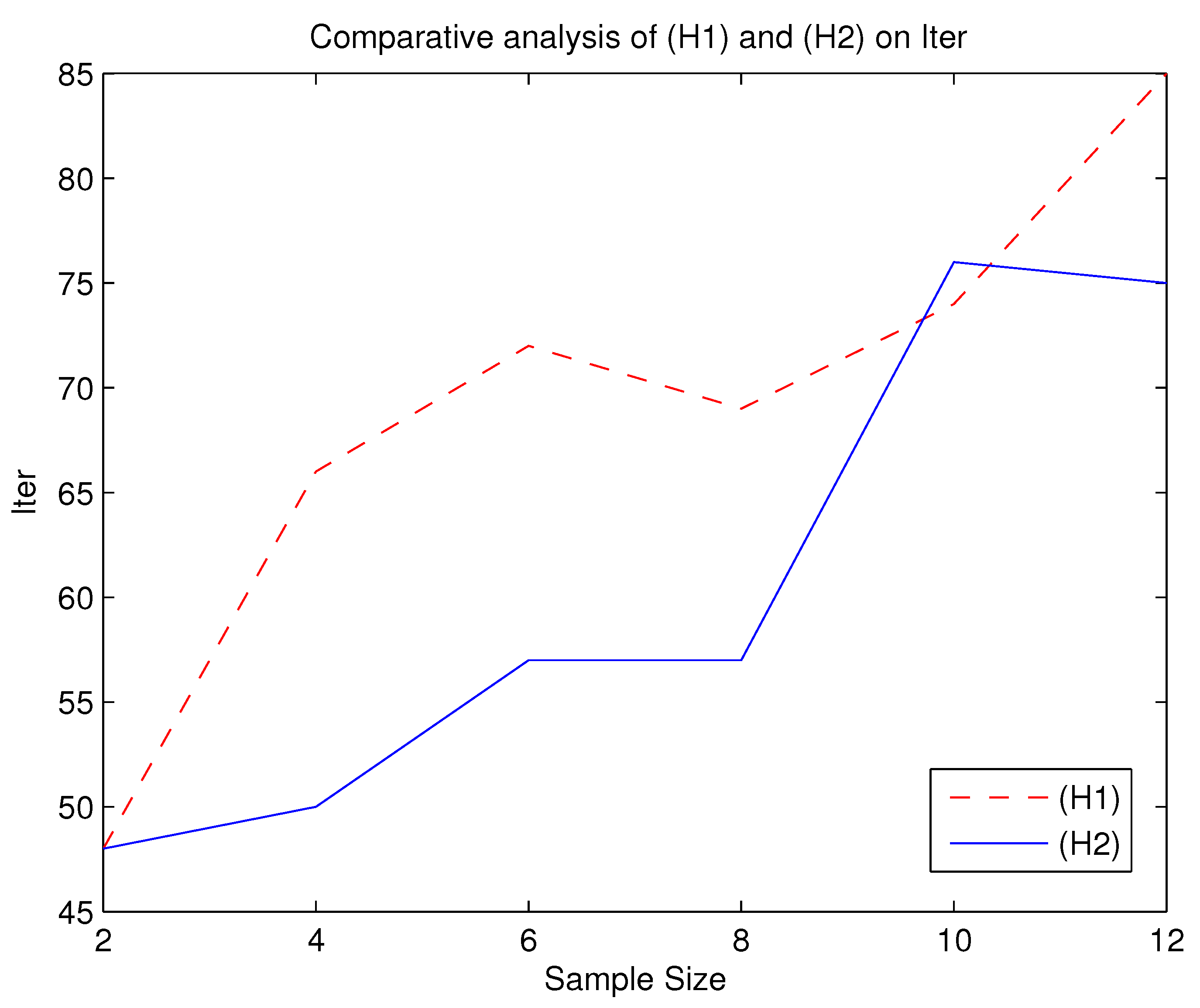
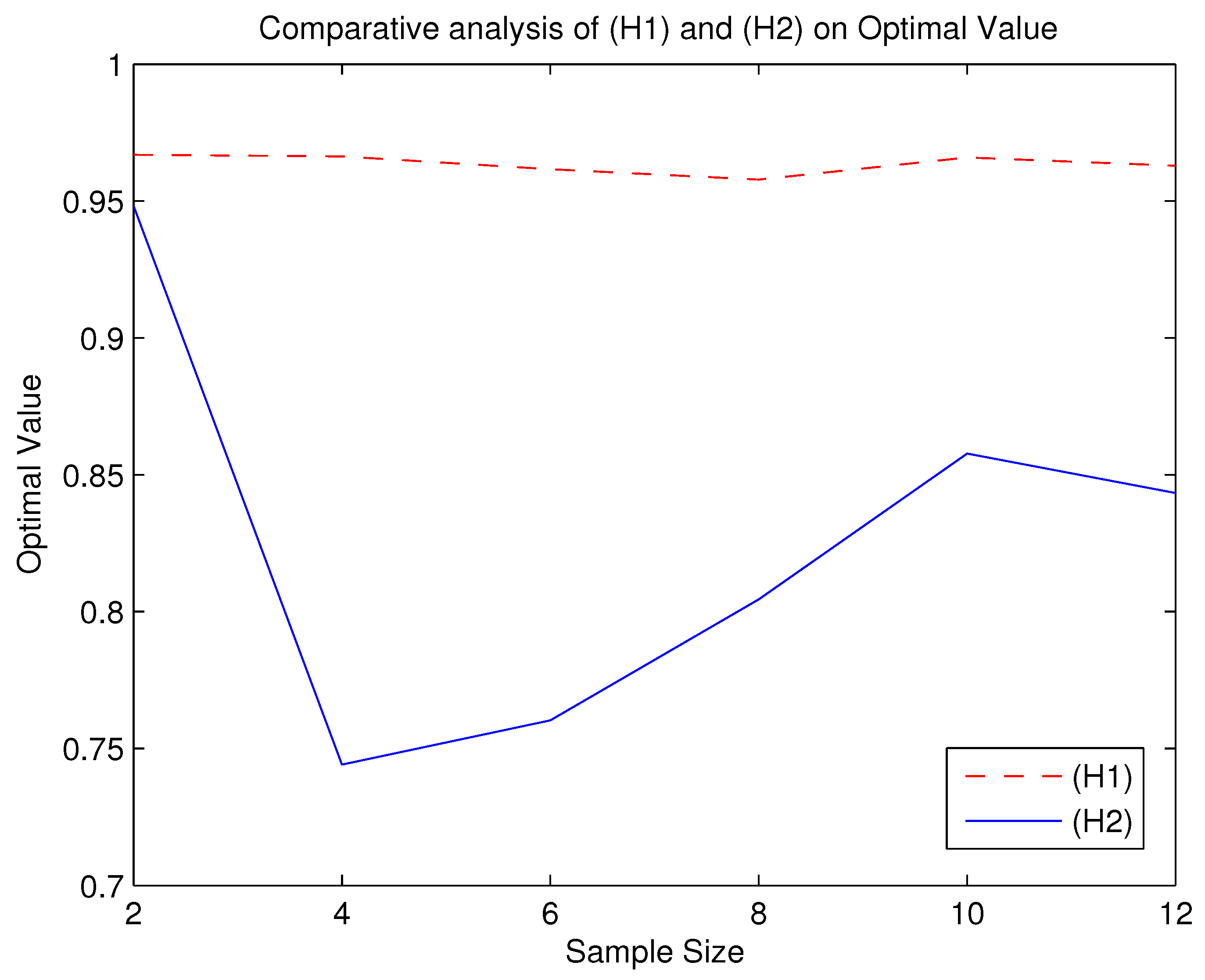
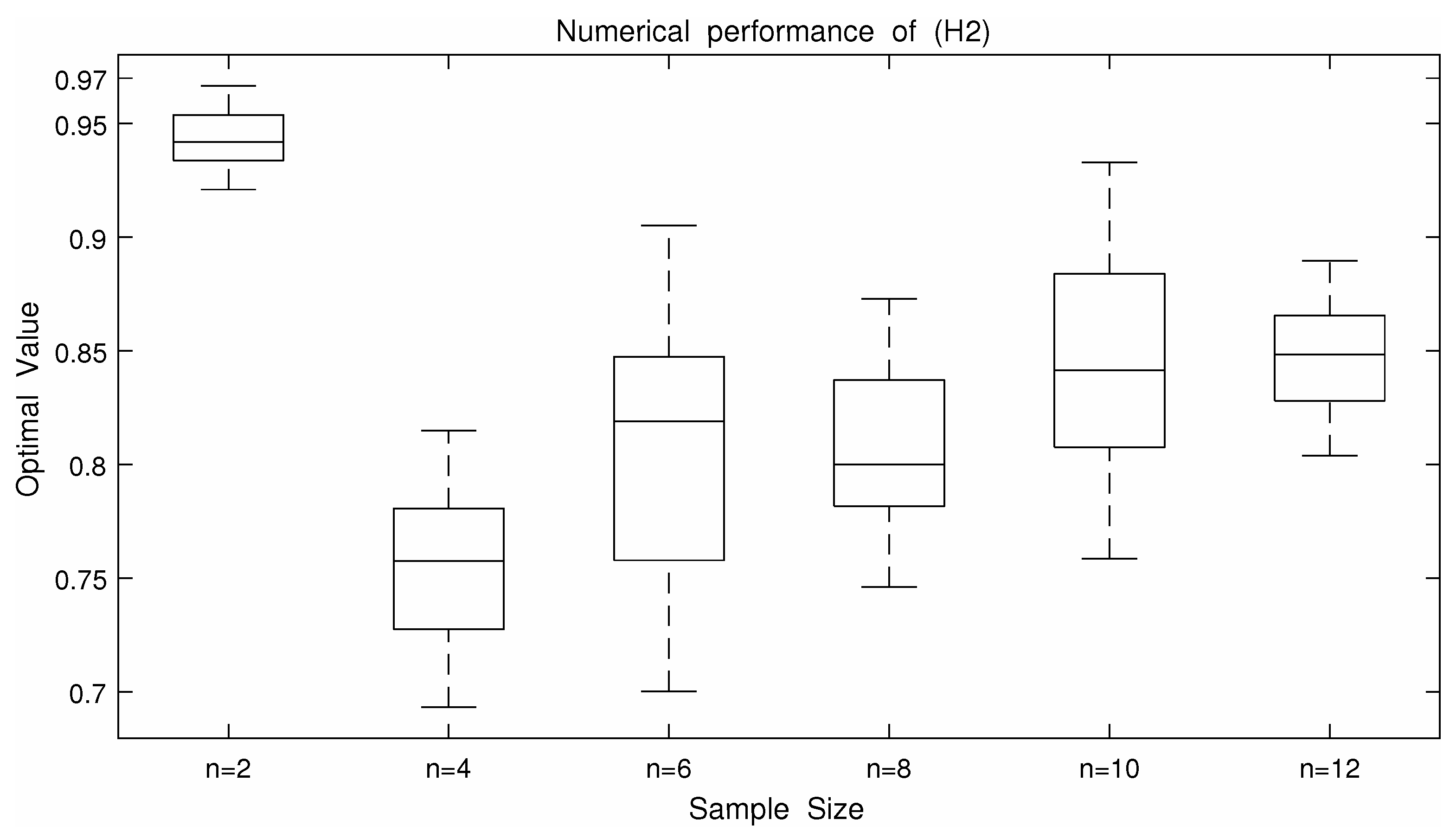
From the
Table 3 and
Table 4 and
Figure 1,
Figure 2,
Figure 3,
Figure 4 and
Figure 5, we can roughly see that problems (
) and (
) can be solved by the alternating iteration algorithm. We know from
Figure 1,
Figure 2,
Figure 3,
Figure 4 and
Figure 5 that when using the algorithm to solve (
) and
, the number of iterations and time of solving
are basically more than that of solving (
). Moreover, the optimal values of
is smaller than the ones of (
). Since the DRO model is usually used to describe an upper bound of uncertain optimization problems, the smaller the optimal value of the DRO model, the less conservative the DRO model is. Therefore,
is a less conservative DRO model. However, according to
Figure 3, (
) is more robust than
because the curve shown by (
) is more stable.
The numerical results show that, in order to obtain a conservative total loss in the news vender problem, solving DRO model
by the alternating iteration algorithm usually performs better than solving DRO model
. However, in our observations, when we only focus on the robustness, DRO model (
) may be the better choice. We provide the links to the source codes as follows:
https://pan.baidu.com/s/1dSmMUynZqi5LzWgn6aUUoQ?pwd=xn44 (accessed on 25 January 2022).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}