1. Introduction
Dynamic modeling of industrial robotic manipulators is one of the key steps in industrial robotic manipulator design. In addition, it is key in various other applications such as path planning and optimization [
1]. Precise dynamics models are commonly needed for any research concerning the realistic movement of industrial robotic manipulators. Still, the process of determining the dynamics model of a robot manipulator can be complex, and error-prone, exacerbated by the issue of dynamic models of individual robotic manipulators rarely being readily available to researchers. Plancher et al. (2021) [
2] discussed the application of various optimizations for different hardware architectures, including CPU, GPU, and FPGA, in order to accelerate the calculation of dynamic gradients. Some authors have used artificial intelligence (AI) techniques to assist in determining the dynamic properties of a robot. For example, Yovchev and Miteva (2021) [
3] presented the application of a genetic algorithm for determination of the dynamic parameter estimation, while Mitsioni et al. (2021) [
4] demonstrated the application of LSTM networks to determine the dynamics of a single-action robot, namely, in the task of food cutting. There seems to be a lack of papers in recent years focusing on dynamic model generation using the machine learning approach.
Machine learning (ML) is a field within AI that allows for the creation of data-driven models. The models achieved with ML tend to be very precise, but their main pitfall is the need for large amounts of data to achieve not only precise models but models that generalize well. For this reason, a number of researchers have lately focused on synthetic dataset generation [
5,
6,
7]. Synthetic dataset generation refers to the process of in silico dataset generation, where computer models are used for the generation of data points. This approach has a few benefits. Synthetic data generation can be used in instances where there is a limited number of data points that can be collected, which is extremely common when ML is applied in healthcare [
8], where the patients exhibiting data belonging to a certain class may be rare [
9]. Another instance where synthetic data generation may be utilized is for those cases where data collection may be extremely time-intensive [
10]; this is a common application in engineering [
11] and physics [
12,
13], as simulations in those fields may take a long time, but can be significantly sped up using simulations in high-performance computing environments. The final application of synthetic dataset generation is when measurements may be hard or expensive to perform, and the virtual generation of data points can serve to alleviate those concerns [
14]. Robotics are mainly affected by the last two points, as more complex simulations may be time-intensive and require fairly expensive equipment, in the shape of the robotic manipulators themselves, as well as sensors to be locked-up in the experiment for a long time [
15].
In this paper, the authors aim to apply ML with a synthetic dataset on the problem of dynamic modeling. The goal of the paper is to serve as a proof-of-concept in two areas: the first is the utilization of the synthetically generated data in machine learning within robotics; the second is the use of ML models for determination of the dynamic models of robotic manipulators. The novelty presented by this paper is also two-fold, as there is a lack of similar research in both the modeling of dynamic models using regressive ML methods, and the creation and application of synthetic datasets for the given purpose. These contributions may allow researchers to simplify the process of dynamic modeling, or modeling in general, provided they have means to collect or synthetize the data. The paper first discusses the usual process of dynamic modeling, followed by how those results have been applied to generate the dataset, with ML methodology finally being discussed-with the achieved results presented.
2. Materials and Methods
In this section, the methods used to generate the dataset are described along with the ML methodology used by researchers, including the algorithm itself as well as the evaluation process.
2.1. Dynamics Modeling
The dynamic model of the robot can be determined in various ways. In this paper, two methods were applied—the Newton–Euler (NE) algorithm and Lagrange–Euler (LE) algorithm. Two separate algorithms were used to cross-reference the obtained values and assure that the obtained model is correct. The following subsections will first present the kinematic model, which is necessary in both of the methods discussed, followed by the description of both algorithms.
The calculations and modeling were performed using the industrial robotic manipulator ABB IRB 120 manufactured by ABB Inc. (Zurich, Switzerland) for the basis of the calculations, with the measurements used (distance between joints, centers of mass, tensors of inertia) being determined using a manufacturer-provided CAD model [
16]. The visualization of the used manipulator is provided in
Figure 1.
2.1.1. Kinematic Model
The Dennavit–Hartenberg (DH) method was applied by setting an orthonormal coordinate system in each of the robotic manipulator joints, where axis
z matches the axis of the joint. With the coordinate systems positioned, the parameters
,
,
, and
can be determined based on the distances between the centers of the coordinate systems and the relations between the axis [
17]. The values can then be placed into a transformation matrix. The transformation matrix between joints
and
k is given as [
18]
The transformation matrix of the entire manipulator is calculated using a product of all the individual joint transformation matrices [
19]:
resulting in a matrix given as [
20]:
where the tool orientation matrix
consists of the perpendicular vector
, movement vector
, and approach vector
and
represents the tool end position. Values
and
represent the perspective vector and the scaling coefficient, commonly set to
and 1, respectively [
21]. The calculated transformation matrices can then be used within the NE and LE algorithms.
2.1.2. Lagrange–Euler
The basis of the LE algorithm is the definition of the differential equations that serve to calculate the torque of joint
i as
using [
22]
where
defines the moments and the inertial forces, Coriolis forces are presented by the term
, gravity’s effect is given by
, and
defines the internal friction of the manipulator’s joint.
In the beginning of the LE algorithm, three values are defined. First is the iterator
i set to 1, followed with
, a
identity matrix, and
, a
zeroes matrix. The LE algorithm then starts by calculating the tensor of inertia
with [
23]
Following this, the vector
z for the joint
is calculated as per [
24]
followed by the calculation of the homogeneous transformation between the base and the current joint [
25]:
To transpose the position of the center of mass in relation to the coordinate system of the base, the following equation is used [
26]:
with
being the homogeneous coordinates of the robotic link
i. The tensor of inertia in relation to the base coordinate system can then be calculated:
To correlate the infinitesimal movements of the manipulator joints and the infinitesimal movements of the tool, the Jacobian matrix is defined [
27]:
The total torsion of inertia can be calculated with [
28]:
with
being the mass of the current joint. If the tensors of inertia have not been calculated for all the individual joints, the procedure is repeated for the next joint. If the calculation has been performed,
i is reset to 1, and the calculations are performed for each of the joints for the speed connectivity matrix [
29]:
gravity influence vector, as per
and finally, the friction is approximated using Tustin’s friction model [
30]:
Once the second iteration of calculations is complete, each of the joints has an equation calculated, relating to the joints torque defined using [
31]:
2.1.3. Newton–Euler
NE differentiates from LE in the fact that it has a forward (in the direction from the base of the manipulator to the tool) and backward (from the tool to the base of the robotic manipulator) calculation. In the forward calculation, the speeds and accelerations (linear and angular) are calculated for each joint. In the backward calculation, the forces and momenta on each of the links are calculated. At the start of the NE algorithm, initial values need to be set [
22]:
,
,
,
,
,
,
, and
.
The initial calculation step is the same as in LE—determining the vector
z,
followed by the calculation of the angular speed
[
32]:
with
being set to 1 for the revolutional joint and to 0 for the linear joint. The angular speed is calculated with [
33]
The complex homogeneous transformation matrix is again determined as
which allows for calculation of the vector [
34]
The final value that needs to be calculated is the linear acceleration [
35]:
This process is repeated for each of the joints, until the final joint of the robotic manipulator is reached. At that point, the backward calculation begins, from the final joint to the base. The first value to be calculated is the vector
[
36]:
The force acting on the joint
i is calculated using [
37]:
The momentum of the joint can consequently be calculated according to [
38]
with
defined as per Equation (
5). With the force and the momentum calculated, we can determine the joint actuator momentum using the following equation [
39]:
The value of the iterator i is then lowered, and the calculation is repeated for the next joint. Once the base of the robot manipulator is reached, the NE algorithm is completed.
2.2. Dataset Generation
The dataset was generated by taking the equations obtained using the methods described in the previous section. As can be seen by observing Equations (
15) and (
25), the inputs necessary to calculate the joint torsion are the joint position
, the angular speed of the joint
, and the angular acceleration of the joint
. Only the angular speeds and accelerations are considered since all the joints in the modeled robotic manipulator are rotational.
To generate the dataset, the values
are uniformly randomly generated. The value of the
are then calculated using the equations obtained from the NE algorithm and verified using the LE model. The ranges of variables for random generation are set as given in
Table 1. The values for the individual joints have been selected according to the ranges provided by the manufacturer [
40]. Values for the minimal and maximal joint speeds and accelerations have been set uniformly for all joints, with the values selected as being realistic speeds and accelerations that could be encountered during the operation of the industrial robotic manipulator, to the ranges of
rad/s and
rad/s
[
40].
The total torque of all the joints is calculated as the sum of all the joint torques
[
41].
Q defines all the joint position values,
defines all the angular speeds of joints,
defines the angular accelerations of the joints, and
T are the values of the joint torques; then, the values are written in a Comma-Separated Values (CSV) file in the following shape:
where the input vector consists of
A total of 20,000 data points were generated in this manner. While the inputs are generated uniformly and randomly, meaning their distribution is known, the outputs may have a different distribution. For this reason, the histograms of the outputs are plotted and shown in
Figure 2. The analysis of the histograms was performed through distribution fitting [
42,
43]; this analysis shows that the datasets generated for individual joints follow a generalized normal distribution [
44] centered around 0, while the data generated for the total joint torque follows a reciprocal inverse Gaussian distribution [
45].
In a realistic application, the dataset would have instead been collected using a sensor array that measures the aforementioned values on a robotic manipulator. Still, in this instance, a synthetic approach was selected to test the validity of synthetic dataset generation.
2.3. Machine Learning Approach
The ML algorithm selected for use in the presented research is the multilayer perceptron (MLP). MLP is a feed-forward type of artificial neural network, which is trained using the processes of forward propagation and backpropagation.
Forward propagation refers to the process used by the MLP model to obtain the output values. The model consists of neurons placed in layers, using a fully connected architecture in which every neuron in one layer is connected to all the neurons in the subsequent layer, using weighted connections. The value of each individual neuron—barring the ”input“ neurons in the first layer, which are set to the values of the inputs being modeled—is calculated as the activated weighted sum of the values of neurons in the previous layer as per [
46,
47]
where
is the value of a given neuron,
is the value of the neuron in the previous layer,
is the weight of the connection between the
i-th neuron in the layer
and the
k-th neuron in the layer
j, with
F being the activation function—a predefined function that serves to transform the output of the neuron by either eliminating the unwanted values (ReLU) or limiting the output (sigmoid) [
48].
To obtain a well-performing model, the weights connecting the neurons need to be adjusted. This is performed in the backpropagation process. When the input neurons are set to the value of desired inputs
, forward propagation is performed using Equation (
28) to generate the values for each of the layers. This process is repeated until the last layer, consisting of a single neuron, is reached. The value of that neuron
is used as the output of the MLP model. Comparing that value with the expected output
will yield a difference that is the error of the model for the given weight
W, commonly referred to as the cost function, defined as [
49]
This error is then used to adjust the weights of the model using gradient-based adjustment. If we define
as the learning rate—the value that specifies how fast the model learns—then the weight adjustment between the new weight values in layer
j-
and old values
can be defined using [
50,
51]
The introduced
is one of the so-called hyperparameters of the model. These are values that define the model architecture, and obtaining correct values of those hyperparameters is the key to obtaining a quality model. A number of hyperparameters can be tuned, and the ones that were adjusted in the presented research are as follows [
52]:
Hidden layer size—the number of neurons and layers, given as a tuple in which each value presents a number of neurons in a given layer;
Activation function—activation function to be used within all of the model’s neurons;
Initial learning rate—the learning rate of the model;
Learning rate type—the manner in which the learning rate is adjusted through the training process, inversely to the elapsed training iterations, kept constant, or adapted to the model error;
Solver—the algorithm used for weight adjustment during training. The possible solvers are Adam, Stochastic Gradient Descent (SGD), and Limited-Memory Broyden–Fletcher–Goldfarb–Shanno (LBFGS);
L2 regularization parameter—the value that controls the influence of the individual inputs, preventing a single input from having too much influence on the output, to provide models that have better generalization.
As previously mentioned, the hyperparameter tuning process is key in achieving a well-performing model. The issue is that there are no set rules as to which hyperparameters will perform well for a given problem [
53]. For this reason, a randomized search (RS) is defined [
52]. Possible values of the hyperparameters are either set as a list, if discrete, or given as a range if continuous, as shown in
Table 2. The random search procedure then randomly constructs a vector of hyperparameter values and uses that value to construct a model that is then trained using the forward- and backpropagation process previously described. The trained model is evaluated, and the process is repeated until satisfactory scores are achieved, or the process is manually interrupted—in which case the best-achieved model is presented. The evaluation procedure used is given in the subsection below.
It should be noted that the tuned hyperparameters, for the number of neurons per layer, only affect the so-called hidden layers between the input and output neuron layers, which are defined by the problem being modeled. While the output layer always consists of one neuron, the number of input neurons depends on the problem that is being regressed. In the presented case, the inputs consist of 18 values, these being the position of each joint, angular speed of each joint, and angular acceleration of each joint. As there are six joints present in the robot manipulator that is being modeled, with three values per joint, this means that each model will have eighteen inputs. Since each of the models can only have one input, only one value can be regressed at one time. For this reason, seven different models are developed—one for the torque of each joint and one for the total torque.
Model Evaluation
The trained models were evaluated using two metrics: coefficient of determination (
) and mean absolute percentage error (MAPE).
compares two sets of data, the predicted values
and
y, in terms of variance.
is calculated using [
54]
and its value will be
in the case when there is no unexplained variance between two sets (the desired outcome) and
when there is no explained variance between the datasets [
55]. While being an effective and popular measure,
can be hard to directly interpret. For this reason, MAPE is introduced as a secondary performance measure.
MAPE is expressed as the percentage of the value range that the average achieved absolute error is and can be calculated using [
56,
57]
Splitting the dataset into training and testing set in order to determine the performance is an industry-standard practice in ML. In this approach, the dataset is split into two parts, where the first part (training) is utilized in the training process described in the previous subsection, while the evaluation is performed on the testing dataset, which is data previously unseen by the model. This approach has certain issues. The main issue is that the random training–testing split can be particularly positive for the model being evaluated. This can lead to deceptively high-performance metrics for a model that happened to obtained the right data but would perform poorly in a generalized environment with new data provided to it [
58]. For this reason, cross-validation was performed. Instead of splitting the dataset into training and testing sets, the dataset was split into 10 equal parts, so-called folds [
59]. Then, the training–testing procedure was repeated ten times, each time with a different data fold being used as the testing dataset, with the remaining folds being used for training. The scores are then expressed as the average score across all folds, with a standard error. This allows determining the performance of the model on the entirety of the collected dataset [
60].
3. Results and Discussion
The best-achieved results per each of the targets are given below in
Table 3. The models trained using RS were set to test new hyperparameters until the
value of 0.99 was reached, or for 10,000 iterations. None of the models achieved the
score necessary to preemptively stop the execution and were trained for the full number of RS iterations. Observing
Table 3, it can be seen that all the individual joint torque models achieved
scores higher than 0.90 and MAPE below 2%. These scores indicate a successful regression, especially considering the relatively high number of data points and the relatively complex problem being modeled. Observing the individual joints, it can be seen that the first four joints (in the direction from the base to the tool of the robotic manipulator) achieved
scores higher than 0.95, indicating high-quality models. All of the models exhibit very low standard deviations, indicating that they are stable across various data folds.
For the first joint model , the average achieved across the folds is 0.96, with a standard deviation of 0.01. The model in question also achieved the lowest MAPE, with 1.18% average error across folds and a standard error of 0.03%. A relatively large neural network was used, with three hidden layers of 288 neurons activated using the logistic activation function. The learning rate was set on the lower side of the range but was adapted during the execution. The L2 regularization parameter was set high in comparison with the other models and the selected solver algorithm was Adam. Similar values were used for , , and . Exceptions are that utilized a significantly smaller network architecture consisting of three layers of 144 neurons, achieving an score of 0.98 with a standard error of 0.04 and MAPE of 1.16% with a standard error of 0.02, which are the best scores achieved by any of the models on any of the joints. Observing , it differs by using a neural network with an additional layer of 288 neurons, a ReLU activation function, and a constant learning rate. managed to achieve somewhat poorer, but still very good scores of 0.95 ± 0.04 for and 1.59 ± 0.03% for MAPE. Finally, achieved an of 0.96 ± 0.03 and MAPE of 1.81 ± 0.08, differing from its predecessors by using the inverse scaling adjustment for the learning rate.
Models for and show somewhat weaker results, with scores of 0.92 ± 0.05 and 0.93 ± 0.03, and MAPE scores of 1.91 ± 0.02 and 1.93 ± 0.03, respectively. The model uses an ANN architecture with four hidden layers of 144 neurons and a hyperbolic tangent activation function. The learning rate of the model is near the upper side of the range at 0.4375 and is not adjusted during the execution. The regularization parameter value was set at 0.00184—significantly lower than other models’ regularization values. utilizes the smallest of all the neural networks, with two layers of 144 neurons. The same activation function was used as in . This model uses a relatively high learning value but allows for its adaptation. Both and models used the LBFGS solver algorithm.
Finally, we can observe the model for the total joint torque . This model is similar to the first four joints, with three hidden layers of 288 neurons, activated with logistic function. The inverse scaling learning rate is applied to the initial learning rate of 0.00951. Adam regularization function is used, as in the best-performing models, for the first four joints. A relatively high regularization value is used for the model.
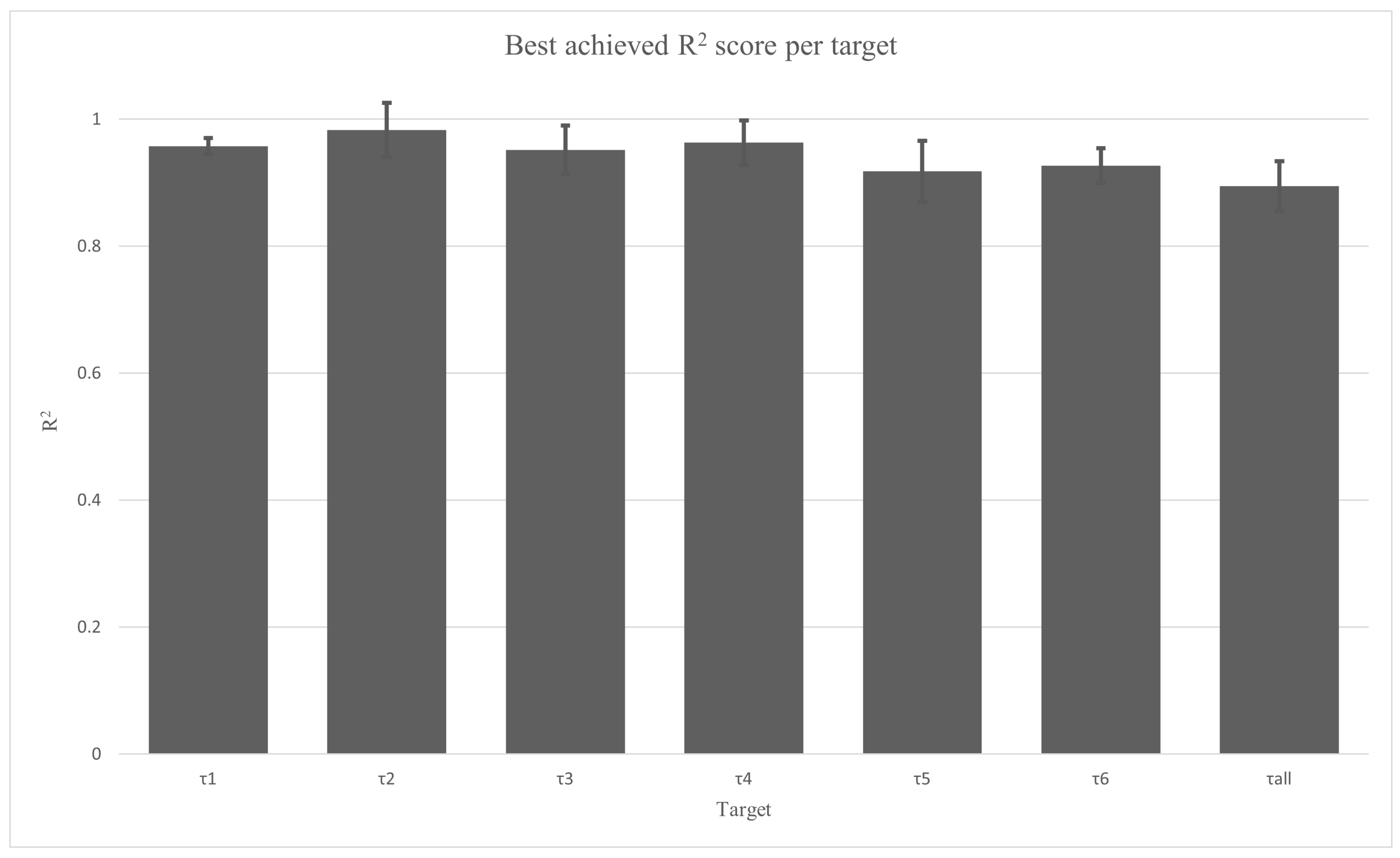
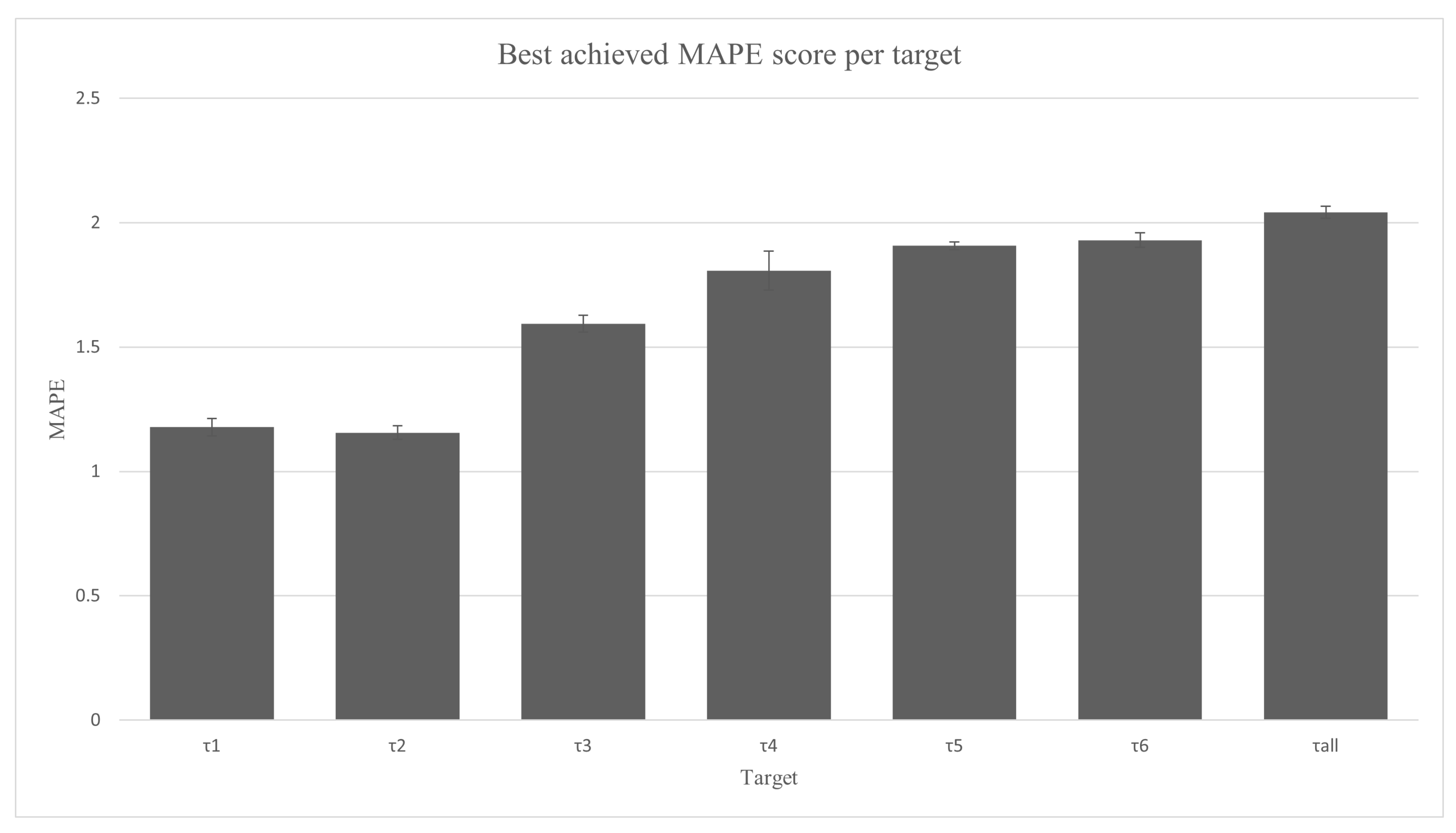
For the ease of result comparison, the achieved scores per each goal are also given in
Figure 3 and
Figure 4.
Figure 3 shows the comparison between the achieved
scores. The drop in performance between the first four joints, the fifth and sixth joint, and the total torque has already been noted. This is also noticeable in
Figure 4, where the same trend can be noticed with the increase in the error value.
The values that determine a high-quality solution vary depending on the problem at hand. For example, models trained on larger datasets have a tendency to exhibit lower scores due to a larger amount of variance in the dataset [
58]. In the presented research, due to the high number of data points and a complex problem that is attempting to be regressed (robot dynamics are described by very large mathematical models), we can consider the values of
and
as indicative of a high-quality model.
Observing all the values, it can be seen that the RS process led to the selection of larger network architectures. This indicates that the modeled problem is relatively complex regarding its ease-of-modeling using the MLP algorithm. Still, all the models achieved results that can be regarded as satisfactory. It is interesting to note that the poorest performing model is the only one that has a non-normal distribution, supporting a potential link to modeling complexity.
4. Conclusions
The paper presents the utilization of NE and LE algorithms for the modeling of the industrial robot manipulator dynamics. The obtained mathematical models are then used to generate a synthetic dataset used for the training of ML-based models using the MLP algorithm. The achieved results are promising and point towards two possibilities. The first is the use of ML algorithms, namely, ANNs, for the dynamic modeling of industrial robotic manipulators. It should be noted that in a realistic application scenario, the data used would be collected from sensors. This leads to the second possibility investigated in the paper—the use of the synthetically designed dataset in the area of robotics modeling, which can assist in saving time and funds during research operations.
Future work in the field could include the application of different ML algorithms with the goal of model quality improvement, and further testing on synthetic datasets in robotics, such as investigating whether an improvement can be seen when real-world data are mixed with synthetically generated data.
The paper presents the utilization of NE and LE algorithms for the dynamics modeling process of an industrial robotic manipulator. The paper also showcases the use of the generated models in the creation of a synthetic dataset, which is used to train an ML-based MLP algorithm. The torsion values were regressed for each of the six joints, as well as the total torque. For the first joint, the MLP managed to achieve a model with scores of . Scores for the second joint were , , and for the third, . The scores for the fourth and fifth joint were , and , respectively. The best-achieved scores for the sixth joint were . Finally, the scores for the total torque of the industrial robotic manipulator were , . All of the scores, except the score for the total torque, are above the set expected threshold of , indicating that they are high-quality models. The total torque achieves somewhat poorer results, but could still be usable in practice. This means that the goal of developing an ML system for predicting the torque values of a robotic manipulator was successful. Additionally, the fact that the models were possible to regress with a low standard error across folds, and that the generated dataset outputs have smooth distributions, indicates that a synthetic dataset can be used to regress this kind of problem.
The advantages of the used approach for modeling the torque are that the modeling process is less error-prone and user time-intensive in comparison with the classical methods. Still, it is not as precise as deterministically determining the torque model and requires a relatively powerful machine to be developed as the used neural networks are relatively large. Of course, it has to be noted again that, in a realistic application, data used would not be fully synthetic, but consist of either a mix of collected and synthetic data or only collected data. Limitations of the approach are clear, as the models developed are only valid for the used industrial manipulator and the modeling process would have to be repeated for different robots. Still, the approach could be implemented in cases of geometrically complex manipulators, especially ones with a higher number of degrees of freedom, in such applications where a precise torque value is not necessary.
As for the synthetic dataset generation, a number of applications are possible, which can be seen from the current research. It has to be noted that such data could have differences compared with real data, either due to modeling errors or outside influences. Still, if the process is verified, synthetic data generation can be used to generate new or additional data points and expand the collected datasets, especially in cases where the data collection is expensive or extremely time-consuming.
Future work in the field of dynamics modeling can rely on the process of generalizing the models to multiple manipulators, especially similar ones, through the introduction of additional input variables that pertain to the models in question, such as the mass and geometry of the manipulator links. Additional network architectures, such as LSTM networks, should also be tested, as they may be capable of fitting the data provided better. In the case of synthetic dataset generation, future work relating to the dynamics data being generated could focus on stricter comparisons of the synthetic data to the collected data in order to determine the possible statistical differences between the generated sets.
Author Contributions
Conceptualization, S.B.Š. and N.A.; methodology, S.B.Š., N.A., M.Š. and H.M.; software, S.B.Š.; validation, N.A., M.Š. and H.M.; formal analysis, M.Š. and H.M.; investigation, S.B.Š. and N.A.; resources, S.B.Š.; data curation, N.A.; writing—original draft preparation, S.B.Š. and N.A.; writing—review and editing, M.Š. and H.M.; visualization, S.B.Š.; supervision, M.Š. and H.M.; project administration, M.Š. and H.M.; funding acquisition, N.A., M.Š. and H.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The equations obtained from the described procedure, as well as the generated dataset, may be obtained through contact with the first author.
Acknowledgments
This research has been (partly) supported by the CEEPUS network CIII-HR-0108, European Regional Development Fund under the grant KK.01.1.1.01.0009 (DATACROSS), project CEKOM under the grant KK.01.2.2.03.0004, Erasmus+ project WICT under the grant 2021-1-HR01-KA220-HED-000031177, University of Rijeka scientific grant uniri-tehnic-18-275-1447, and project Metalska jezgra Čakovec (KK.01.1.1.02.0023).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial Intelligence |
| ANN | Artificial Neural Network |
| DH | Dennavit–Hartenberg |
| LBFGS | Limited-Memory Broyden–Fletcher–Goldfarb–Shanno |
| LE | Lagrange–Euler |
| LSTM | Long short-term memory |
| MAPE | Mean Absolute Percentage Error |
| ML | Machine Learning |
| LSTM | Long short-term memory |
| MAPE | Mean Absolute Percentage Error |
| ML | Machine Learning |
| MLP | Multilayer Perceptron |
| NE | Newton–Euler |
| RS | Random Search |
| Coefficient of determination |
| SGD | Stochastic Gradient Descent |
References
- Baressi Šegota, S.N.; Lorencin, I.; Saga, M.; Car, Z. Path planning optimization of six-degree-of-freedom robotic manipulators using evolutionary algorithms. Int. J. Adv. Robot. Syst. 2020, 17, 1729881420908076. [Google Scholar] [CrossRef] [Green Version]
- Plancher, B.; Neuman, S.M.; Bourgeat, T.; Kuindersma, S.; Devadas, S.; Reddi, V.J. Accelerating robot dynamics gradients on a CPU, GPU, and FPGA. IEEE Robot. Autom. Lett. 2021, 6, 2335–2342. [Google Scholar] [CrossRef]
- Yovchev, K.; Miteva, L. Genetic Algorithm with Iterative Learning Control for Estimation of the Parameters of Robot Dynamics. In IFToMM Symposium on Mechanism Design for Robotics; Springer: Berlin/Heidelberg, Germany, 2021; pp. 226–235. [Google Scholar]
- Mitsioni, I.; Karayiannidis, Y.; Kragic, D. Modelling and learning dynamics for robotic food-cutting. In Proceedings of the 2021 IEEE 17th International Conference on Automation Science and Engineering (CASE), Lyon, France, 23–27 August 2021; pp. 1194–1200. [Google Scholar]
- Jordon, J.; Jarrett, D.; Saveliev, E.; Yoon, J.; Elbers, P.; Thoral, P.; Ercole, A.; Zhang, C.; Belgrave, D.; van der Schaar, M. Hide-and-Seek Privacy Challenge: Synthetic Data Generation vs. Patient Re-identification. In NeurIPS 2020 Competition and Demonstration Track; PMLR: New York, NY, USA, 2021; pp. 206–215. [Google Scholar]
- Soltana, G.; Sabetzadeh, M.; Briand, L.C. Synthetic data generation for statistical testing. In Proceedings of the 2017 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE), Champaign, IL, USA, 30 October–3 November 2017; pp. 872–882. [Google Scholar]
- Dahmen, J.; Cook, D. SynSys: A synthetic data generation system for healthcare applications. Sensors 2019, 19, 1181. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tucker, A.; Wang, Z.; Rotalinti, Y.; Myles, P. Generating high-fidelity synthetic patient data for assessing machine learning healthcare software. NPJ Digit. Med. 2020, 3, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Chen, R.J.; Lu, M.Y.; Chen, T.Y.; Williamson, D.F.; Mahmood, F. Synthetic data in machine learning for medicine and healthcare. Nat. Biomed. Eng. 2021, 5, 493–497. [Google Scholar] [CrossRef] [PubMed]
- Raghunathan, T.E. Synthetic data. Annu. Rev. Stat. Its Appl. 2021, 8, 129–140. [Google Scholar] [CrossRef]
- Eno, J.; Thompson, C.W. Generating synthetic data to match data mining patterns. IEEE Internet Comput. 2008, 12, 78–82. [Google Scholar] [CrossRef]
- You, H.; Yu, Y.; Trask, N.; Gulian, M.; D’Elia, M. Data-driven learning of nonlocal physics from high-fidelity synthetic data. Comput. Methods Appl. Mech. Eng. 2021, 374, 113553. [Google Scholar] [CrossRef]
- Hernandez, M.; Epelde, G.; Beristain, A.; Álvarez, R.; Molina, C.; Larrea, X.; Alberdi, A.; Timoleon, M.; Bamidis, P.; Konstantinidis, E. Incorporation of Synthetic Data Generation Techniques within a Controlled Data Processing Workflow in the Health and Wellbeing Domain. Electronics 2022, 11, 812. [Google Scholar] [CrossRef]
- Tremblay, J.; Prakash, A.; Acuna, D.; Brophy, M.; Jampani, V.; Anil, C.; To, T.; Cameracci, E.; Boochoon, S.; Birchfield, S. Training deep networks with synthetic data: Bridging the reality gap by domain randomization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 969–977. [Google Scholar]
- Martinez-Gonzalez, P.; Oprea, S.; Garcia-Garcia, A.; Jover-Alvarez, A.; Orts-Escolano, S.; Garcia-Rodriguez, J. Unrealrox: An extremely photorealistic virtual reality environment for robotics simulations and synthetic data generation. Virtual Real. 2020, 24, 271–288. [Google Scholar] [CrossRef] [Green Version]
- ABB Group. IRB 120 CAD Models-Industrial Robots (Robotics). Available online: Https://new.abb.com/products/robotics/industrial-robots/irb-120/irb-120-cad (accessed on 13 March 2022).
- Lipkin, H. A note on Denavit-Hartenberg notation in robotics. In Proceedings of the International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Long Beach, CA, USA, 24–28 September 2005; Volume 47446, pp. 921–926. [Google Scholar]
- Corke, P.I. A simple and systematic approach to assigning Denavit–Hartenberg parameters. IEEE Trans. Robot. 2007, 23, 590–594. [Google Scholar] [CrossRef] [Green Version]
- Rocha, C.; Tonetto, C.; Dias, A. A comparison between the Denavit–Hartenberg and the screw-based methods used in kinematic modeling of robot manipulators. Robot.-Comput.-Integr. Manuf. 2011, 27, 723–728. [Google Scholar] [CrossRef]
- Hayat, A.A.; Chittawadigi, R.G.; Udai, A.D.; Saha, S.K. Identification of Denavit-Hartenberg parameters of an industrial robot. In Proceedings of the Conference on Advances in Robotics, Pune, India, 4–6 July 2013; ACM: New York, NY, USA, 2013; pp. 1–6. [Google Scholar]
- Gaidhani, A.; Moon, K.S.; Ozturk, Y.; Lee, S.Q.; Youm, W. Extraction and analysis of respiratory motion using wearable inertial sensor system during trunk motion. Sensors 2017, 17, 2932. [Google Scholar] [CrossRef] [Green Version]
- Yoshikawa, T. Foundations of Robotics: Analysis and Control; MIT Press: Cambridge, MA, USA, 1990. [Google Scholar]
- Urrea, C.; Saa, D. Design and implementation of a graphic simulator for calculating the inverse kinematics of a redundant planar manipulator robot. Appl. Sci. 2020, 10, 6770. [Google Scholar] [CrossRef]
- Wang, N.; Xiang, X. A New Numerical Scheme with B-Spine Wavelet on the Interval for Transverse Vibration Problem of the Tethered Deep-Sea Robot. J. Mar. Sci. Eng. 2022, 10, 317. [Google Scholar] [CrossRef]
- Krakhmalev, O.; Krakhmalev, N.; Gataullin, S.; Makarenko, I.; Nikitin, P.; Serdechnyy, D.; Liang, K.; Korchagin, S. Mathematics model for 6-DOF joints manipulation robots. Mathematics 2021, 9, 2828. [Google Scholar] [CrossRef]
- Martínez, O.; Campa, R. Comparing methods using homogeneous transformation matrices for kinematics modeling of robot manipulators. In International Symposium on Multibody Systems and Mechatronics; Springer: Berlin/Heidelberg, Germany, 2021; pp. 110–118. [Google Scholar]
- Waldron, K.; Wang, S.L.; Bolin, S. A study of the Jacobian matrix of serial manipulators. J. Mech. Des. 1985, 107, 230–237. [Google Scholar] [CrossRef]
- Falkenhahn, V.; Mahl, T.; Hildebrandt, A.; Neumann, R.; Sawodny, O. Dynamic modeling of constant curvature continuum robots using the Euler-Lagrange formalism. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 2428–2433. [Google Scholar]
- Falkenhahn, V.; Mahl, T.; Hildebrandt, A.; Neumann, R.; Sawodny, O. Dynamic modeling of bellows-actuated continuum robots using the Euler–Lagrange formalism. IEEE Trans. Robot. 2015, 31, 1483–1496. [Google Scholar] [CrossRef]
- Lu, J.; Wu, Z.; Yang, C. High-Fidelity Fin–Actuator System Modeling and Aeroelastic Analysis Considering Friction Effect. Appl. Sci. 2021, 11, 3057. [Google Scholar] [CrossRef]
- Roy, S.; Baldi, S.; Li, P.; Sankaranarayanan, V.N. Artificial-delay adaptive control for underactuated Euler–Lagrange robotics. IEEE/ASME Trans. Mechatron. 2021, 26, 3064–3075. [Google Scholar] [CrossRef]
- Kou, B.; Guo, S.; Ren, D. A New Method for Identifying Kinetic Parameters of Industrial Robots. Actuators 2021, 11, 2. [Google Scholar] [CrossRef]
- Khosla, P.K.; Kanade, T. Parameter identification of robot dynamics. In Proceedings of the 24th IEEE Conference on Decision and Control, Ft. Lauderdale, FL, USA, 11–13 December 1985; pp. 1754–1760. [Google Scholar]
- Zhu, A.; Ai, H.; Chen, L. A Fuzzy Logic Reinforcement Learning Control with Spring-Damper Device for Space Robot Capturing Satellite. Appl. Sci. 2022, 12, 2662. [Google Scholar] [CrossRef]
- Featherstone, R. Robot dynamics algorithms. In Annexe Thesis Digitisation Project 2016 Block 5; ERA: Parsippany-Troy Hills, NJ, USA, 1984. [Google Scholar]
- Sutanto, G.; Wang, A.; Lin, Y.; Mukadam, M.; Sukhatme, G.; Rai, A.; Meier, F. Encoding physical constraints in differentiable newton-euler algorithm. In Learning for Dynamics and Control; PMLR: New York, NY, USA, 2020; pp. 804–813. [Google Scholar]
- Chen, Y.; Sun, Q.; Guo, Q.; Gong, Y. Dynamic Modeling and Experimental Validation of a Water Hydraulic Soft Manipulator Based on an Improved Newton—Euler Iterative Method. Micromachines 2022, 13, 130. [Google Scholar] [CrossRef]
- Featherstone, R.; Orin, D. Robot dynamics: Equations and algorithms. In Proceedings of the 2000 ICRA, Millennium Conference, IEEE International Conference on Robotics and Automation, Symposia Proceedings (Cat. No. 00CH37065), San Francisco, CA, USA, 24–28 April 2000; Volume 1, pp. 826–834. [Google Scholar]
- Liang, P.; Gao, X.; Zhang, Q.; Gao, R.; Li, M.; Xu, Y.; Zhu, W. Design and stability analysis of a wall-climbing robot using propulsive force of propeller. Symmetry 2020, 13, 37. [Google Scholar] [CrossRef]
- Product Specification IRB-120. 2019.
- Garg, D.P.; Kumar, M. Optimization techniques applied to multiple manipulators for path planning and torque minimization. Eng. Appl. Artif. Intell. 2002, 15, 241–252. [Google Scholar] [CrossRef] [Green Version]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental algorithms for scientific computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [Green Version]
- Haeussling Loewgren, B.; Weigert, J.; Esche, E.; Repke, J.U. Uncertainty analysis for data-driven chance-constrained optimization. Sustainability 2020, 12, 2450. [Google Scholar] [CrossRef] [Green Version]
- Nadarajah, S. A generalized normal distribution. J. Appl. Stat. 2005, 32, 685–694. [Google Scholar] [CrossRef]
- Tweedie, M.C. Statistical properties of inverse Gaussian distributions. I. Ann. Math. Stat. 1957, 28, 362–377. [Google Scholar] [CrossRef]
- Çolak, A.B. A novel comparative analysis between the experimental and numeric methods on viscosity of zirconium oxide nanofluid: Developing optimal artificial neural network and new mathematical model. Powder Technol. 2021, 381, 338–351. [Google Scholar] [CrossRef]
- Šegota, S.B.; Anđelić, N.; Mrzljak, V.; Lorencin, I.; Kuric, I.; Car, Z. Utilization of multilayer perceptron for determining the inverse kinematics of an industrial robotic manipulator. Int. J. Adv. Robot. Syst. 2021, 18, 1729881420925283. [Google Scholar] [CrossRef]
- Wang, Y.; Li, Y.; Song, Y.; Rong, X. The influence of the activation function in a convolution neural network model of facial expression recognition. Appl. Sci. 2020, 10, 1897. [Google Scholar] [CrossRef] [Green Version]
- Shafiq, A.; Çolak, A.B.; Sindhu, T.N.; Al-Mdallal, Q.M.; Abdeljawad, T. Estimation of unsteady hydromagnetic Williamson fluid flow in a radiative surface through numerical and artificial neural network modeling. Sci. Rep. 2021, 11, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Zhao, F.; Hu, G.; Zhan, C.; Zhang, Y. DOA Estimation Method Based on Improved Deep Convolutional Neural Network. Sensors 2022, 22, 1305. [Google Scholar] [CrossRef] [PubMed]
- Baressi Šegota, S.; Lorencin, I.; Anđelić, N.; Mrzljak, V.; Car, Z. Improvement of marine steam turbine conventional exergy analysis by neural network application. J. Mar. Sci. Eng. 2020, 8, 884. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Nagelkerke, N.J. A note on a general definition of the coefficient of determination. Biometrika 1991, 78, 691–692. [Google Scholar] [CrossRef]
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef]
- Pavlicko, M.; Vojteková, M.; Blažeková, O. Forecasting of Electrical Energy Consumption in Slovakia. Mathematics 2022, 10, 577. [Google Scholar] [CrossRef]
- Lubis, A.R.; Prayudani, S.; Fatmi, Y.; Lubis, M. MAPE accuracy of CPO Forecasting by Applying Fuzzy Time Series. In Proceedings of the 8th International Conference on Electrical Engineering, Computer Science and Informatics (EECSI), Semarang, Indonesia, 20–21 October 2021; pp. 370–373. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009; Volume 2. [Google Scholar]
- Cherradi, B.; Terrada, O.; Ouhmida, A.; Hamida, S.; Raihani, A.; Bouattane, O. Computer-aided diagnosis system for early prediction of atherosclerosis using machine learning and K-fold cross-validation. In Proceedings of the 2021 International Congress of Advanced Technology and Engineering (ICOTEN), Virtual, 4–5 July 2021; pp. 1–9. [Google Scholar]
- Lorencin, I.; Anđelić, N.; Mrzljak, V.; Car, Z. Genetic algorithm approach to design of multi-layer perceptron for combined cycle power plant electrical power output estimation. Energies 2019, 12, 4352. [Google Scholar] [CrossRef] [Green Version]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).







{kind=link}
{kind=link}
{kind=link}
{kind=link}