1. Introduction
The rapid evolution in the telecommunications industry has increased competition among service providers in the market, which has resulted in severe revenue losses because of churning [
1]. Churner customers refer to those who leave a service provider and develop a new relationship with another provider in the market. It was confirmed that attracting new customer costs about five to six times the cost of retaining an existing one [
2]. For this reason, telecommunications companies employ customer relationship management (CRM) as an integrated approach in their strategic plan to understand their customers’ needs, and ultimately reduce customer churn [
3]. The customers’ historical data stored in such CRM systems can be transformed into valuable information with the help of ML. The results from these techniques can assist these companies in formulating new policies, detecting customers who have a high tendency to end their relationship with the company, and developing retention strategies for existing customers [
4].
In ML techniques, data preprocessing is vitally essential, and feature selection (FS) is generally considered as a foremost preprocessing step. FS techniques aim to determine the optimum feature subsets (OFS) by removing redundant and irrelevant features from high dimensional data without changing the original data representation. It has been proven that the use of FS in the ML learning process has several benefits [
5,
6], such as that it reduces the amount of required data to achieve a good learning process and that it improves prediction performance and minimizes CT.
FS techniques have been successfully applied in different applications and delivered promising results. Among these techniques, metaheuristic algorithms (MAs) have shown significant success in several applications, such as vehicle routing [
7], energy consumption [
8], fuzzy control design [
9], e-commerce [
10], medical diagnosis [
11] and others, mainly because of their capability to provide high-quality OFS [
12]. MAs utilize two search principles: exploration, where the algorithm investigates different candidate regions in the search space, and exploitation, the algorithm searches around the obtained promising solutions to improve the existing ones.
According to [
13], MAs can be grouped into (i) single solution-based algorithms and (ii) population-based algorithms based on their behaviors. The first group exploits prior search knowledge to expand the search space in some promising environments. Tabu search [
14], greedy randomized adaptive search [
15], and vector neighborhood search [
16] are examples belonging to this group of algorithms. Population-based algorithms generate optimal solutions by exploring a new region in the search space via an iterative process for generating a new population through nature-inspired selection. GWO [
17], cuckoo search algorithm [
18], PSO [
19], firefly algorithm (FFA) [
20], crow search algorithm [
21], dragonfly optimization algorithm [
22], ACO [
23], MVO [
24], and RSA [
25] are examples of the well-known MAs in this group.
In recent years, various researchers explored MAs for customer churn prediction. In [
26], the customer churn prediction business intelligence using text analytics with metaheuristic optimization (CCPBI-TAMO) model is reported. The authors used pigeon inspired optimization (PIO) to select OFS from a customer churn dataset collected from a business sector and used that OFS as inputs to long short-term memory (LSTM) with a stacked autoencoder (LSTM-SAE) model. Their proposed model outperformed other existing models used in their work. In [
27], FFA was applied on both classification and FS using a huge publicly available dataset of churn prediction and the authors reported that FFA performed well for this application. The potential of ACO to predict customer churn was investigated and discussed in [
28]. The results reported that the ACO attained an effective performance compared to other MAs. In [
29], combined multiobjective cost-sensitive ACO (MOCS-ACO) with genetic algorithm (GA) to improve classification results. The GA is employed to select OFS while the MOCS-ACO is used as a classification model. Experimental results reported that the combined model performed well when validated on a customer churn prediction dataset obtained from a company in Turkey. In [
30], the authors employed ACO to identify OFS and the identified features are then fed to the gradient boosting tree (GBT) model. The results showed that the proposed ACO-GBT model produced good results in predicting customer churn.
In [
31], the authors employed PSO to choose OFS and then the selected features were used by an extreme learning machine (ElM) classifier for churn prediction using a public dataset. In [
32], the authors employed information gain and fuzzy PSO to determine OFS from two publicly available churn prediction datasets and then the selected features were used by divergence kernel-based support vector machine (DKSVM) to predict churners and nonchurners. In [
33], a hybrid model based on PSO and feed-forward neural networks for churn prediction was reported to select OFS from one public dataset and another private dataset. In [
34], three variants of PSO were reported for churn prediction using a public dataset. These variants comprise PSO incorporated with FS as a preprocessing step, PSO embedded with simulated annealing (SA), and PSO combined with FS and SA.
All these studies have reported promising results for using MAs to select the most informative features in churn prediction. Although most of these efforts have used MAs to select OFS, a quantitative analysis of methods’ capabilities in terms of accuracy, number of features in OFS, fitness values, and CT in this application is not reported. Thus, there is an imminent need for further works to propose new MAs for FS in this application. Most of these works are limited to using an individual MA. Therefore, combining Mas to produce a hybrid FS method for this application is worth being investigated, while selecting OFS in this application is very important for reliable and safe predictions to the customers who are going to end the relationship and develop a new one with another competitor. Motivated by these limitations, we propose a new metaheuristic-based approach called ACO-RSA that combines standard ACO and RSA in a serial collaborative manner to find the most appropriate features for churn prediction. The comparison with five popular Mas, including PSO, MVO, GWO, standard ACO, and standard RSA, validates the effectiveness of the ACO-RSA approach. The contributions of this paper can be summarized as follows:
A new metaheuristic-based approach, namely ACO-RSA, is proposed for churn prediction, the standard ACO and RSA are combined in a serial collaborative mechanism to achieve exploration-exploitation balance in the proposed ACO-RSA and avoid getting stuck in local optima.
Seven publicly available benchmark customer churn datasets with different records and features and ten CEC 2019 test functions are utilized to check the stability of ACO-RSA performance.
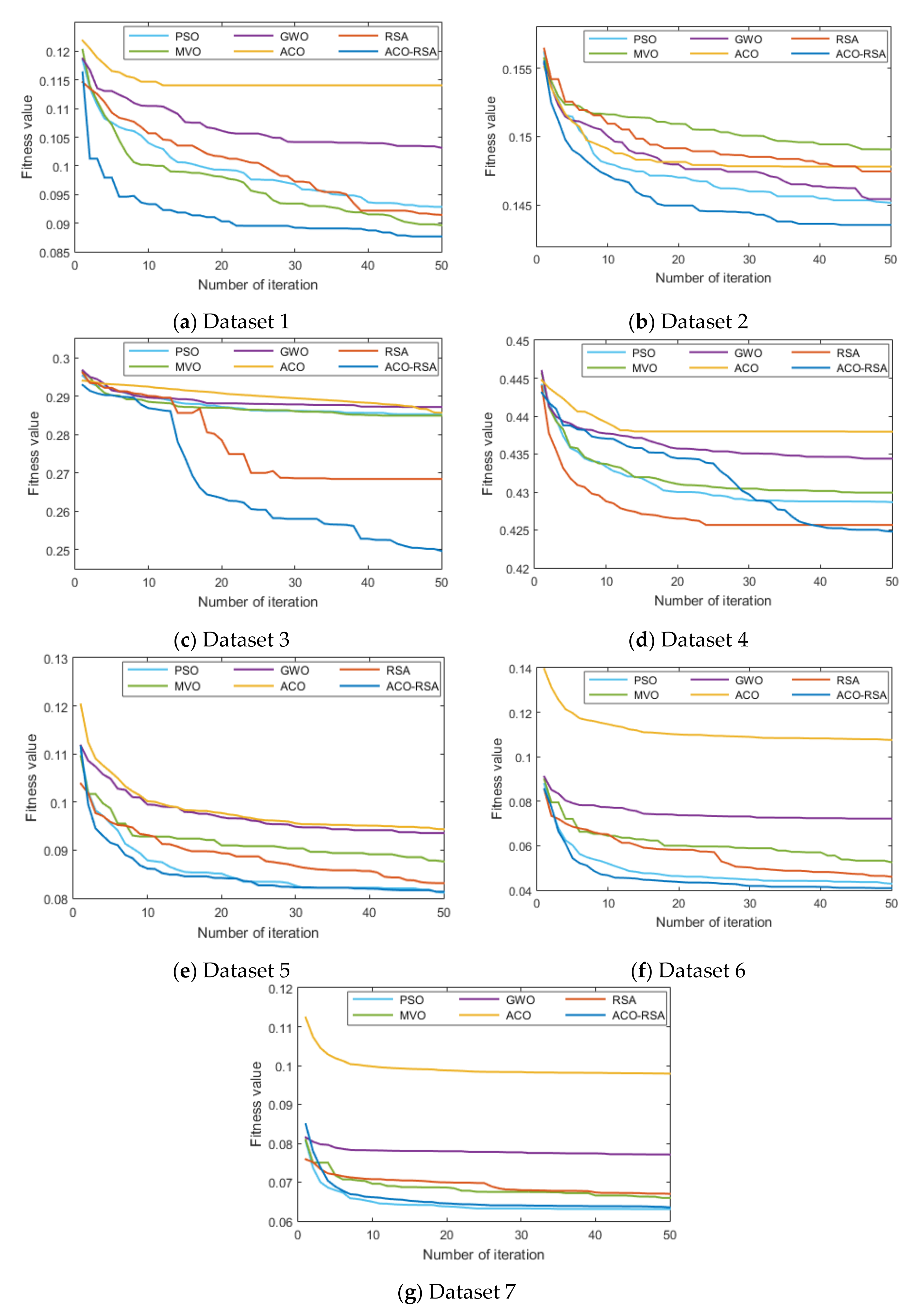
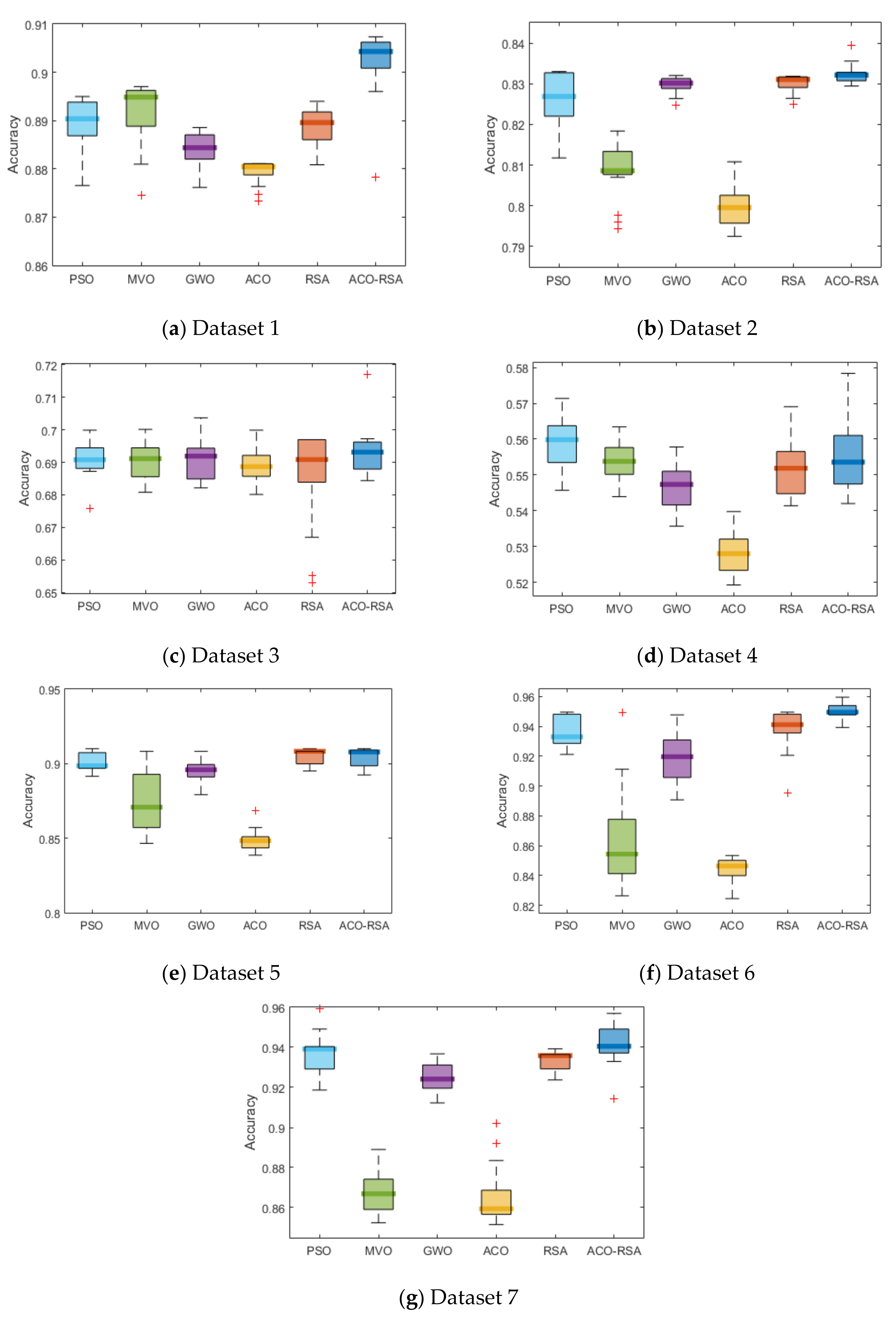
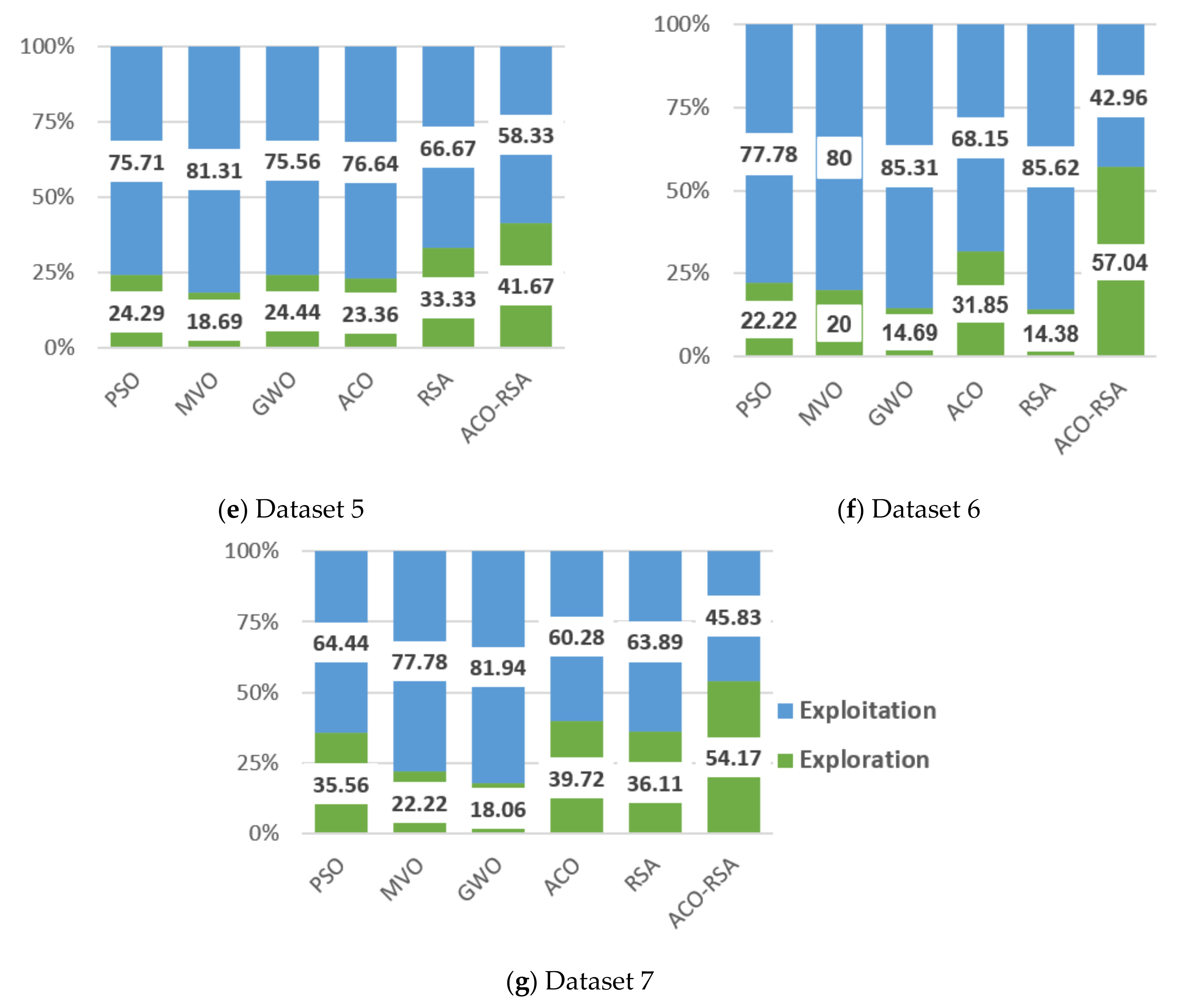
We also investigate the convergence behavior, statistical significance, and exploration-exploitation balance of the proposed ACO-RSA against the competitor MAs.
A brief overview of ACO and RSA is provided in the next section, followed by detailed explanations of the suggested ACO-RSA approach. The experimental results are discussed in
Section 4. Finally, conclusions are noted in
Section 5.
3. Proposed ACO-RSA Based FS Method
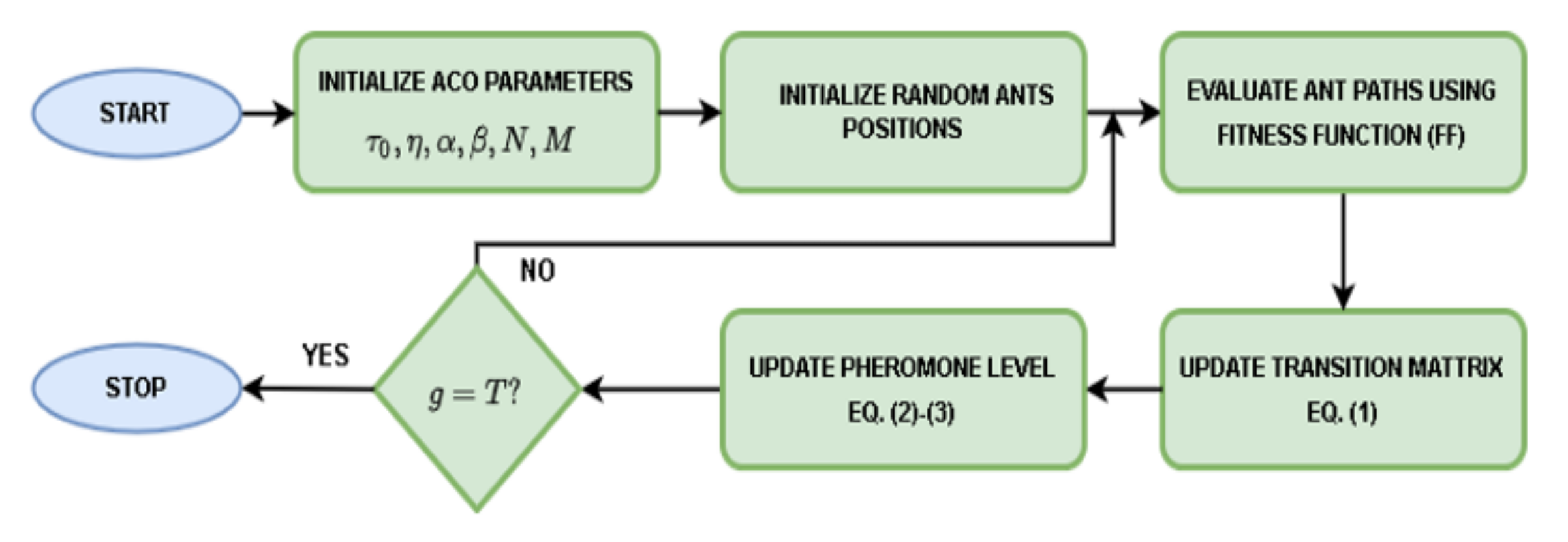
In ACO, a path with the highest pheromone level is the shortest path to transport the food from the source to the nest. Most ants will follow this path unless there is some obstruction and might limit ACO from exploring the quality of existing solutions by searching only within the current search space [
38]. High exploration in MA reduces the quality of the optimum solutions, and fast exploitation prevents the algorithm from finding global optimum solutions [
39]. RSA is the most recent MA, which shows superiority to solve several engineering problems and has an excellent exploration capability. It has an inbuilt exploration-exploitation balance that significantly enhances its performance [
25]. Different MAs can be combined effectively to use the algorithm’s merits while maintaining exploration-exploitation balance and avoiding premature convergence in local optima.
According to [
40], there are several ways to hybrid Mas. High-level relay hybrid (HRH) strategy is one of these methods. In this strategy, two MAs can be executed in homogenous (i.e., same algorithms) or heterogeneous (i.e., different algorithms) sequences. The proposed ACO-RSA method uses the heterogeneous HRH strategy to achieve exploitation-exploration balance as in RSA with high exploitation as in ACO.
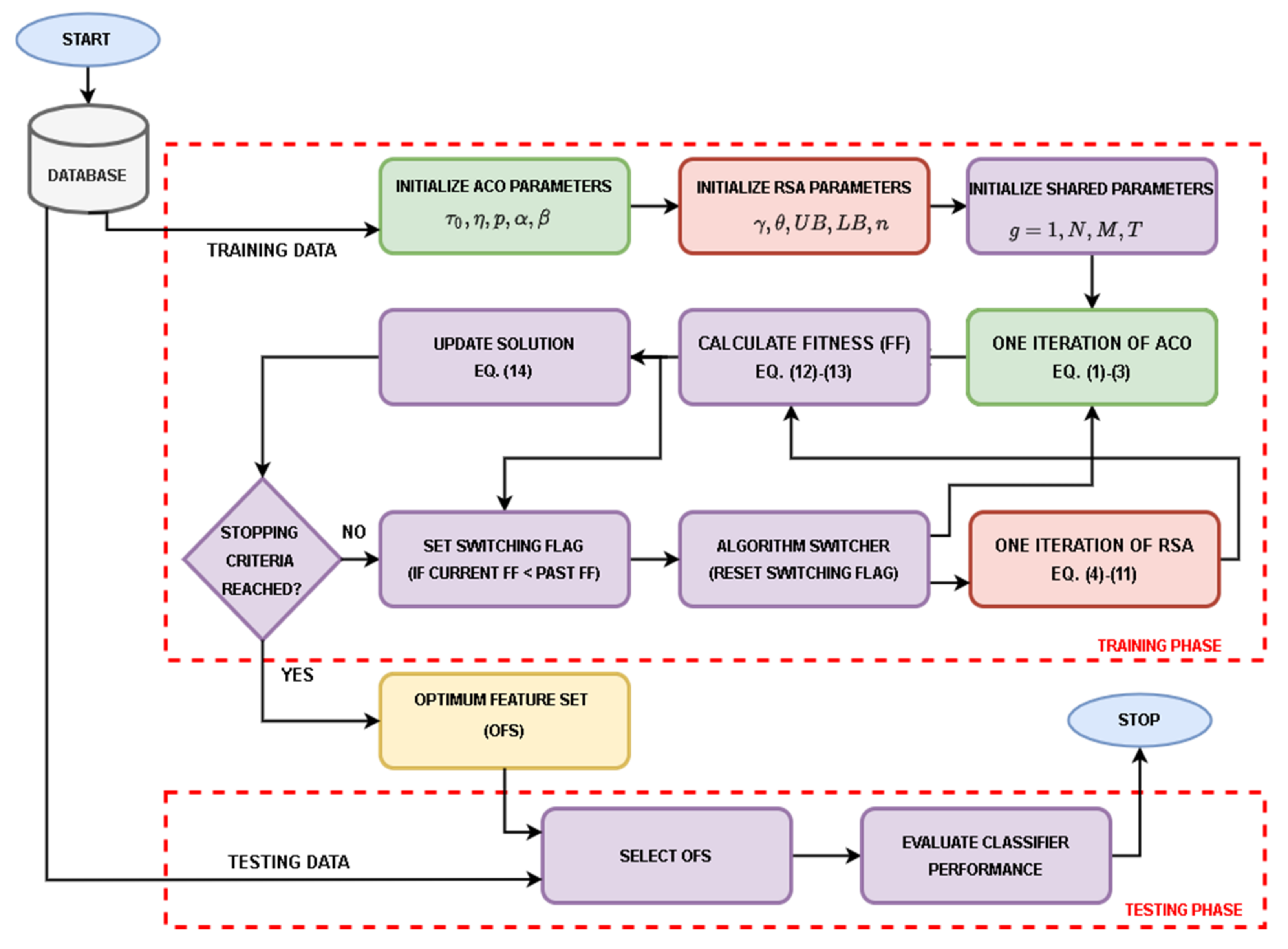
Figure 3 illustrates the overall process of the ACO-RSA approach. At first, ACO, RSA, and shared parameters are initialized. A random number uniformly distributed in the range (−1, 1) initializes N candidate solutions
each for M-dimensional feature vectors. Then FF evaluates candidate solutions to judge the enhancement by comparing current solutions with the obtained solutions in the previous iteration. If the current solution is better than the previous solution, it will be accepted; otherwise, it will be rejected.
The threshold used to convert candidate solutions during the searching process for the informative features into binary vectors is set to 0.5, as recommended by [
39,
41], to produce a small number of features. K-nearest neighbor (KNN) is a widely used classifier due to its simplicity, fast, and flexibility to deal with noisy data [
42]. KNN with a Euclidean distance measure (k = 5) is employed as the classifier. Hence, the FF is considered to achieve dimensionality reduction (by minimizing the number of the selected OFS) and maximum accuracy (by reducing classification error). Therefore, it is defined using the following equation:
where,
and
are weighted factors that vary in the range of (0, 1) (subject to
) to balance the number of features in OFS
out of
features in the original dataset. The parameters
and
are set to 0.99 and 0.01 respectively [
41]. and the is the number of correctly classified instances
out of total N instances in the original dataset by the KNN classifier. Each feature in the OFS follows:
Then the best solution is determined and the current solution
are assigned to the candidate solutions of the ACO. In addition, the ACO starts with assigning each candidate solution
as an initial path for an ant in the colony. An ith ant initially traverses a subset of features initialized with a pheromone value
greater than 0.5 and updates candidate solutions
according to Equations (1)–(3). The
FF evaluates the enhancement in the candidate solution, and it is updated only if its fitness value is decreased after the update. A candidate solution is updated according to the following equation:
In the next iteration, the set of candidate solutions
are given as initial candidate solutions (after thresholding) to either ACO or RSA to extend the searching process into other promising regions in the feature space. If the least FF value in the current iteration is smaller than the smallest FF value in the previous iteration (
), the same algorithm continues in the next iteration; otherwise, an algorithm switching flag is set to switch between the two algorithms. The main goal behind the switching between the two algorithms is that if the ACO could not improve the candidate solutions, it might get stuck in local optima. At this point, the RSA will be employed in the next iteration and will move the candidate solutions into another search region using Equations (4)–(11) to find some better solutions. This process is repeated until the maximum iterations T is reached. A candidate solution with the smallest
FF value
is used to extract OFS. During the testing phase, a reduced feature set is obtained by filtering only the selected features (i.e., OFS). This OFS is used to evaluate classifier performance metrics, as will be discussed later in
Section 4.3. The steps of the ACO-RSA are shown in Algorithm 1.
| Algorithm 1: Proposed ACO-RSA approach |
- 1:
Form mutually exclusive and exhaustive training and testing subsets. Training Phase - 2:
Load training dataset - 3:
Initialize ACO parameters - 4:
Initialize RSA parameters - 5:
Initialize shared parameters - 6:
for g = 1 to T do - 7:
if first iteration - 8:
Perform one iteration of ACO using Equations (1)–(3) - 9:
else - 10:
if switch flag = 1 - 11:
Perform one iteration of an alternate algorithm that was not executed in the previous iteration ACO: Equations (1)–(3) or RSA: Equations (4)–(11) - 12:
switch flag = 0 - 13:
else - 14:
Continue the same algorithm as in the previous iteration ACO: Equations (1)–(3) or RSA: Equations (4)–(11) - 15:
end if - 16:
end if - 17:
Evaluate fitness function (FF) using Equation (13) for updated candidate solutions - 18:
Update candidate solutions using Equation (12) and a threshold of 0.5 - 19:
if < - 20:
switch flag = 1 - 21:
end if - 22:
end for - 23:
Extract OFS by applying a threshold of 0.5 to a candidate solution with the smallest FF. Testing Phase - 24:
Load testing dataset - 25:
Select only optimum features as described in OFS - 26:
Evaluate performance using KNN classifier
|


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}