
Stochastic Triad Topology Based Particle Swarm Optimization for Global Numerical Optimization

 ,
, 
Abstract
1. Introduction
- (1)
- A stochastic triad topology is employed to connect the personal best position of each particle and two different personal best positions randomly selected from those of the rest particles to select guiding exemplars for particles to update. Different from existing studies [22,37], which only utilize the topologies to determine the best position to replace the social exemplar, namely gbest, in the classical PSO (with another guiding exemplar as the personal best position of the particle), the proposed STTPSO utilizes the stochastic triad topology to select the best one and computes the mean position of the triad best positions as the two guiding exemplars to direct the update of each particle. Since the topology is stochastic, it is likely that different particles preserve different guiding exemplars. As a result, the learning diversity of particles can be largely promoted, and thus the probability of the swarm escaping from local areas can be promoted.
- (2)
- An archive is maintained to store the obsolete personal best positions and then is combined with the personal best positions of all particles in the current generation to form the triad topologies for particles. In this way, valuable historical information can be utilized to direct the update of particles, which is helpful for improving swarm diversity.
- (3)
- A random restart strategy is designed by randomly initializing a solution with a small probability. However, instead of employing this restart strategy on the swarm, we utilize it on the archive. That is to say, a randomly initialized solution is inserted into the archive with a small probability. In this way, the swarm diversity can be promoted without significant sacrifice of convergence speed.
- (4)
- A dynamic strategy for the acceleration coefficients is devised to alleviate the sensitivity of STTPSO. Instead of utilizing fixed values for the two acceleration coefficients, this paper randomly samples the two acceleration coefficients based on the Gaussian distribution with the mean value set as the classical setting of the two coefficients and a small deviation. With this dynamic strategy, different particles can have different settings, and thus the learning diversity can be further promoted.
2. Related Works
2.1. Basic PSO
2.2. Advanced Learning Strategies for PSO

{kind=link}
| Category | Methods | Characteristics | ||
|---|---|---|---|---|
| Topology-based Methods | Static Topology | Full Topology | PSO [6,7] | Each particle can only communicate with fixed peers. The learning diversity of particles is limited. |
| Ring Topology | MRTPSO [26], GGL-PSOD [56] | |||
| Pyramid Topology | PMKPSO [27] | |||
| Star Topology | PSO-Star [29,55] | |||
| Von Neumann Topology | PSO-Von-Neumann [29] | |||
| Hybrid Topology | XPSO [23] | |||
| Dynamic Topology | Dynamic Topology | DNSPSO [28], DMSPSO [15], SPSO [22] | Each particle communicates with dynamic peers. The learning diversity of particles is high. | |
| Dynamic Size Topology | RPSO [16] | |||
| Exemplar construction-based Methods | Random Construction | CLPSO_LS [14], CLPSO [17], HCLPSO [25], TCSPSO [19] | Randomly recombine dimensions of personal best positions. The exemplar construction efficiency is low, but it consumes no fitness evaluations in exemplar construction. | |
| Operator-based Construction | MPSOEG [24], GLPSO [18] | Recombine dimensions of personal best positions based evolutionary operators in other EAs. The exemplar construction efficiency is high, but it consumes many fitness evaluations in exemplar construction | ||
| Orthogonal Recombination | OLPSO [37] | Recombine dimensions of personal best positions based on orthogonal experimental design. The exemplar construction efficiency is high, but it consumes a lot of fitness evaluation in exemplar construction | ||
3. Stochastic Triad Topology-Based Particle Swarm Optimization
3.1. Stochastic Triad Topology
Remark
- (1)
- Unlike existing studies that use the random topologies to determine only one guiding exemplar to replace the social exemplar (gbest) in the classical PSO [6,7], the proposed STTPSO utilizes the stochastic triad topology for each particle to select the best one among the triad personal best positions and computes the mean position of these pbests as the two guiding exemplars to direct the update of this particle. In this way, due to the randomness of the triad topology, not only the diversity of the first exemplar is promoted largely, but also the diversity of the second exemplar is promoted to a large extent. Therefore, the learning diversity of particles is improved, which is beneficial for enhancing the chance of escaping from local areas for the swarm.
- (2)
- Unlike existing studies that change the random topology structure every generation, this paper adaptively changes the triad topology structure based on the evolution state of each particle. In particular, we record stagnation times of each particle (xi), which is actually the number of continuous generations where the personal best position (pbesti) of the particle remains unchanged. When such a number exceeds a predefined threshold stopmax, the triad topology structure is reconstructed by randomly reselecting two different personal best positions from those of other particles. In this way, the triad topology structure of each particle is changed asynchronously, which guarantees the learning effectiveness of particles.
3.2. Dynamic Acceleration Coefficients
3.3. Historical Information Utilization
3.4. Random Restart Strategy
3.5. Overall Procedure
| Algorithm 1: The pseudocode of STTPSO |
| Input: swarm size PS, maximum fitness evaluations FEmax, maximum stagnation times stopmax, restart probability pm; |
| 1: Initialize PS particles randomly and calculate their fitness; |
| 2: Set fes = PS, and set the archive empty; |
| 3: Randomly select two different personal best positions (pbestr1 and pbestr2) from the personal best positions of |
| other particles and the archive for each particle to form the associated triad topology; |
| 4: Set the stagnation time stopi = 0 (1 ≤ i ≤ PS) for each particle; |
| 5: While (fes ≤ FEmax) do |
| 6: For i = 1:PS do |
| 7: Compute w according to Equation (3); |
| 8: Randomly sample c1 and c2 from Gaussian(1.49618,0.1); |
| 9: If c1 < c2 then |
| 10: Swap c1 and c2; |
| 11: End If |
| 12: Update xi and vi according to Equations (2) and (4); |
| 13: Calculate the fitness of the updated xi: f(xi) and fes + = 1; |
| 14: If f(xi) < f(pbesti) then |
| 15: Put pbesti in the archive and set stopi = 0; |
| 16: pbesti = xi; |
| 17: Else |
| 18: stopi += 1; |
| 19: End If |
| 20: If stopi >= stopmax then |
| Reselect two different personal best positions (pbestr1 and pbestr2) from those of other particles and |
| 21: the archive for xi to form the associated triad topology; |
| 22: End If |
| 23: End For |
| 24: If rand(0, 1) < pm then |
| 25: Randomly initialize a solution and store it into the archive; |
| 26: End If |
| 27: End While |
| 28: Obtain the global best solution gbest and its fitness f(gbest); |
| Output: f(gbest) and gbest |
4. Experiments
4.1. Experimental Setup
4.2. Comparison with State-of-the-Art PSO Variants
- (1)
- According to the Friedman test results as shown in the last row, STTPSO achieves the lowest rank among all eight algorithms and its rank value (1.86) is much smaller than those (at least 2.55) of the seven compared algorithms. This demonstrates that STTPSO achieves the best overall performance on the 30-D CEC 2017 benchmark functions, and presents significant superiority over the seven compared algorithms.
- (2)
- The second last row of Table 2 shows that STTPSO is significantly superior to the compared algorithms on at least 21 problems except for XPSO, and only presents inferior performance on, at most, five problems. Compared with XPSO, STTPSO obtains significantly better performance on 18 problems, while only performing worse than XPSO on three problems.
- (3)
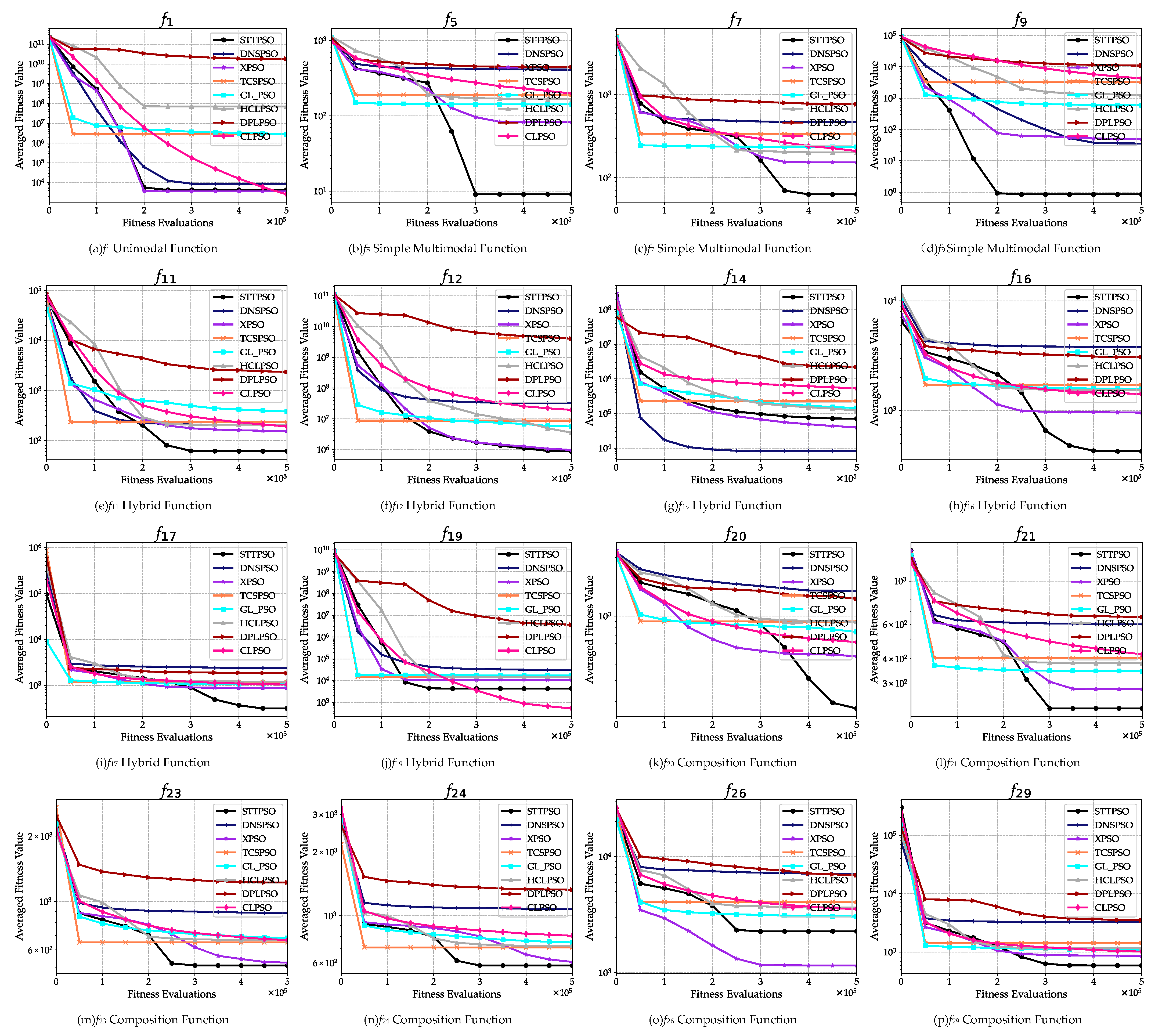
- In terms of the comparison results on different types of optimization problems, STTPSO achieves highly competitive performance with all the compared algorithms on the two unimodal problems. In particular, it shows significant dominance to DNSPSO and DPLPSO both on the two problems. In terms of the six simple multimodal problems, except for DNSPSO, STTPSO shows significantly better performance than the other six compared algorithms on all these problems. Compared with DNSPSO, STTPSO presents significant superiority on five problems and shows inferiority on only one problem. Regarding the 10 hybrid problems, STTPSO shows much better performance than DPLPSO on all 10 problems. Compared with DNSPSO, TCSPSO, and HCLPSO, STTPSO obtains significantly better performance on seven, six, and seven problems, respectively, and only shows inferiority to them on, at most, two problems. In comparison with XPSO, GLPSO, and CLPSO, STTPSO achieves no worse performance on at least seven problems and displays inferiority to them on, at most, three problems. Concerning the 11 composition problems, STTPSO outperforms the seven compared algorithms on at least nine problems, and only shows inferiority on, at most, two problems. In particular, STTPSO significantly outperforms both TCSPSO and GLPSO on all these problems and obtains much better performance than both HCLPSO and DPLPSO on 10 problems with no inferiority to them on all the 11 problems. Overall, it is demonstrated that STTPSO shows promise in solving various kinds of problems and particularly obtains good performance on complicated problems, such as multimodal problems, hybrid problems, and composition problems.
- (1)
- According to the Friedman test results shown in the last row, STTPSO achieves the lowest rank. This indicates that STTPSO still achieves the best overall performance on the whole 50-D CEC 2017 benchmark set. In particular, except for XPSO, its rank value (2.17) is much smaller than those (at least 4.14) of the other six compared algorithms. This demonstrates that STTPSO displays significantly better overall performance than the six compared algorithms.
- (2)
- From the perspective of the Wilcoxon rank sum test, as shown in the second to last row, STTPSO achieves significantly better performance than the seven compared algorithms on at least 19 problems and shows inferiority to them on, at most, five problems. In particular, compared with DNSPSO, TCSPSO, GLPSO, and CLPSO, STTPSO significantly dominates them all on 23 problems. In comparison with DPLPSO, STTPSO presents significant superiority on all the 29 problems.
- (3)
- In terms of different types of optimization problems, STTPSO achieves highly competitive performance with the seven compared state-of-the-art PSO variants regarding the two unimodal problems. Particularly, STTPSO defeats DPLPSO concerning these two problems. On the six simple multimodal problems, STTPSO performs much better than the seven compared algorithms on at least five problems. In particular, STTPSO presents significant dominance to XPSO, TCSPSO, GLPSO, DPLPSO, and CLPSO on all the six problems. Regarding the 10 hybrid problems, except for XPSO, STTPSO is significantly superior to the seven compared algorithms on at least seven problems, and shows inferiority on, at most, three problems. In particular, STTPSO significantly outperforms DPLPSO on all the 10 problems and obtains significantly better performance than DNSPSO on nine problems. Concerning the 11 composition problems, STTPSO displays significantly better performance than the seven state-of-the-art PSO variants on at least eight problems, and performs worse than them on, at most, two problems. Particularly, STTPSO shows significant dominance to DPLPSO on all the 11 problems and obtains much better performance than both TCSPSO and GLPSO on 10 problems. Overall, it is still demonstrated that STTPSO is a promising approach for problem optimization and displays its sound optimization ability in solving complicated optimization problems, such as multimodal problems, hybrid problems, and composition problems.
- (1)
- According to the Friedman test results, STTPSO achieves the lowest rank among all algorithms. This verifies that STTPSO still obtains the best overall performance on the 100-D CEC 2017 benchmark set. In particular, its rank value (1.52) is much smaller than those (at least 2.72) of the seven compared algorithms. This further demonstrates that STTPSO displays significant dominance to the seven compared algorithms. Together with the observations on the 30-D and 50-D CEC 2017 benchmark set, we can see that STTPSO consistently performs the best on the CEC 2017 benchmark set with different dimension sizes among all eight algorithms, and consistently presents its significant superiority to the seven compared algorithms on the benchmark set with the three dimension sizes. Therefore, it is demonstrated that STTPSO preserves a good scalability to solve optimization problems.
- (2)
- Regarding the Wilcoxon rank sum test, from the second to last row, it is observed that STTPSO achieves significantly better performance than the seven compared algorithms on at least 20 problems and shows inferiority to them on, at most, four problems. In particular, STTPSO outperforms DPLPSO significantly on all the 29 problems, and obtains much better performance than TCSPSO, GLPSO, HCLPSO, and CLPSO on 24, 24, 26, and 27 problems, respectively.
- (3)
- With respect to the optimization performance on different types of optimization problems, STTPSO obtains highly competitive or even much better performance than the seven compared algorithms on the two unimodal problems. Particularly, STTPSO shows significant dominance to DPLPSO and CLPSO on the two problems. As for the six simple multimodal problems, except for DNSPSO, STTPSO exhibits significant superiority to the other six compared algorithms on all these six problems. Competed with DNSPSO, STTPSO also shows much better performance on five problems. In terms of the 10 hybrid problems, except for XPSO, STTPSO is significantly superior to the other six compared algorithms on at least seven problems. Compared with XPSO, STTPSO illustrates significantly better performance on five problems and does not show inferiority on any of the problems. In particular, it is discovered that STTPSO is significantly better than HCLPSO and DPLPSO on all the 10 problems. Regarding the 11 composition problems, except for DNSPSO, STTPSO achieves much better performance than the other six compared algorithms on at least nine problems. Compared with DNSPSO, it still performs much better on seven problems. Particularly, STTPSO shows significant superiority to DPLPSO on all the 11 problems, and obtains much better performance than TCSPSO, GLPSO, and CLPSO on 10 problems and shows no inferiority to the three compared methods on these kinds of problems. Overall, it is demonstrated that STTPSO is still effective at solving optimization problems, especially complicated problems, such as multimodal problems, hybrid problems, and composition problems.
4.3. Deep Investigation on STTPSO
4.3.1. Effectiveness of the Reformulation of the Stochastic Triad Topology
4.3.2. Effectiveness of the Additional Archive and the Proposed Random Restart Strategy
4.3.3. Effectiveness of the Dynamic Acceleration Coefficients
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Li, L.; Chang, L.; Gu, T.; Sheng, W.; Wang, W. On the Norm of Dominant Difference for Many-Objective Particle Swarm Optimization. IEEE Trans. Cybern. 2021, 51, 2055–2067. [Google Scholar] [CrossRef] [PubMed]
- Xia, X.; Gui, L.; Yu, F.; Wu, H.; Wei, B.; Zhang, Y.L.; Zhan, Z.H. Triple Archives Particle Swarm Optimization. IEEE Trans. Cybern. 2020, 50, 4862–4875. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Wang, Z.; Yuan, Y.; Zeng, N.; Hone, K.; Liu, X. A Novel Sigmoid-Function-Based Adaptive Weighted Particle Swarm Optimizer. IEEE Trans. Cybern. 2021, 51, 1085–1093. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.; Hua, L.; Gao, X.; Xu, D.; Lu, Z.; Jeon, S.-W.; Zhang, J. Stochastic Cognitive Dominance Leading Particle Swarm Optimization for Multimodal Problems. Mathematics 2022, 10, 761. [Google Scholar] [CrossRef]
- Yang, Q.; Chen, W.-N.; Zhang, J. Probabilistic Multimodal Optimization. In Metaheuristics for Finding Multiple Solutions; Springer: Berlin/Heidelberg, Germany, 2021; pp. 191–228. [Google Scholar]
- Eberhart, R.; Kennedy, J. A New Optimizer Using Particle Swarm Theory. In Proceedings of the International Symposium on Micro Machine and Human Science, Nagoya, Japan, 4–6 October 1995; pp. 39–43. [Google Scholar]
- Shi, Y.; Eberhart, R.C. Empirical Study of Particle Swarm Optimization. In Proceedings of the Congress on Evolutionary Computation, Washington, DC, USA, 6–9 July 1999; pp. 1945–1950. [Google Scholar]
- Tsekouras, G.E.; Tsimikas, J.; Kalloniatis, C.; Gritzalis, S. Interpretability Constraints for Fuzzy Modeling Implemented by Constrained Particle Swarm Optimization. IEEE Trans. Fuzzy Syst. 2018, 26, 2348–2361. [Google Scholar] [CrossRef]
- Lin, C.; Chen, C.; Lin, C. Efficient Self-Evolving Evolutionary Learning for Neurofuzzy Inference Systems. IEEE Trans. Fuzzy Syst. 2008, 16, 1476–1490. [Google Scholar]
- Yang, Q.; Chen, W.N.; Gu, T.; Jin, H.; Mao, W.; Zhang, J. An Adaptive Stochastic Dominant Learning Swarm Optimizer for High-Dimensional Optimization. IEEE Trans. Cybern. 2022, 52, 1960–1976. [Google Scholar] [CrossRef]
- Zhang, X.; Du, K.J.; Zhan, Z.H.; Kwong, S.; Gu, T.L.; Zhang, J. Cooperative Coevolutionary Bare-Bones Particle Swarm Optimization with Function Independent Decomposition for Large-Scale Supply Chain Network Design with Uncertainties. IEEE Trans. Cybern. 2020, 50, 4454–4468. [Google Scholar] [CrossRef]
- Chen, W.N.; Tan, D.Z.; Yang, Q.; Gu, T.; Zhang, J. Ant Colony Optimization for the Control of Pollutant Spreading on Social Networks. IEEE Trans. Cybern. 2020, 50, 4053–4065. [Google Scholar] [CrossRef]
- Ge, Q.; Guo, C.; Jiang, H.; Lu, Z.; Yao, G.; Zhang, J.; Hua, Q. Industrial Power Load Forecasting Method Based on Reinforcement Learning and PSO-LSSVM. IEEE Trans. Cybern. 2022, 52, 1112–1124. [Google Scholar] [CrossRef]
- Cao, Y.; Zhang, H.; Li, W.; Zhou, M.; Zhang, Y.; Chaovalitwongse, W.A. Comprehensive Learning Particle Swarm Optimization Algorithm With Local Search for Multimodal Functions. IEEE Trans. Evol. Comput. 2019, 23, 718–731. [Google Scholar] [CrossRef]
- Liang, J.J.; Suganthan, P.N. Dynamic Multi-swarm Particle Swarm Optimizer. In Proceedings of the IEEE Swarm Intelligence Symposium, Pasadena, CA, USA, 8–10 June 2005; pp. 124–129. [Google Scholar]
- Mirjalili, S.; Lewis, A. Obstacles and Difficulties for Robust Benchmark Problems: A Novel Penalty-based Robust Optimisation Method. Inf. Sci. 2016, 328, 485–509. [Google Scholar] [CrossRef]
- Liang, J.J.; Qin, A.K.; Suganthan, P.N.; Baskar, S. Comprehensive Learning Particle Swarm Optimizer for Global Optimization of Multimodal Functions. IEEE Trans. Evol. Comput. 2006, 10, 281–295. [Google Scholar] [CrossRef]
- Gong, Y.-J.; Li, J.-J.; Zhou, Y.; Li, Y.; Chung, H.S.-H.; Shi, Y.-H.; Zhang, J. Genetic Learning Particle Swarm Optimization. IEEE Trans. Cybern. 2015, 46, 2277–2290. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Liu, H.; Zhang, T.; Wang, Q.; Wang, Y.; Tu, L. Terminal Crossover and Steering-based Particle Swarm Optimization Algorithm with Disturbance. Appl. Soft Comput. 2019, 85, 105841. [Google Scholar] [CrossRef]
- Liu, Z.; Nishi, T. Strategy Dynamics Particle Swarm Optimizer. Inf. Sci. 2022, 582, 665–703. [Google Scholar] [CrossRef]
- Kennedy, J.; Mendes, R. Population Structure and Particle Swarm Performance. In Proceedings of the Congress on Evolutionary Computation, Honolulu, HI, USA, 12–17 May 2002; pp. 1671–1676. [Google Scholar]
- Clerc, M. Beyond Standard Particle Swarm Optimisation. Int. J. Swarm Intell. Res. 2010, 1. [Google Scholar] [CrossRef]
- Xia, X.; Gui, L.; He, G.; Wei, B.; Zhang, Y.; Yu, F.; Wu, H.; Zhan, Z.-H. An Expanded Particle Swarm Optimization Based on Multi-exemplar and Forgetting Ability. Inf. Sci. 2020, 508, 105–120. [Google Scholar] [CrossRef]
- Karim, A.A.; Isa, N.A.M.; Lim, W.H. Modified Particle Swarm Optimization with Effective Guides. IEEE Access 2020, 8, 188699–188725. [Google Scholar] [CrossRef]
- Lynn, N.; Suganthan, P.N. Heterogeneous Comprehensive Learning Particle Swarm Optimization with Enhanced Exploration and Exploitation. Swarm Evol. Comput. 2015, 24, 11–24. [Google Scholar] [CrossRef]
- Yue, C.; Qu, B.; Liang, J. A Multiobjective Particle Swarm Optimizer Using Ring Topology for Solving Multimodal Multiobjective Problems. IEEE Trans. Evol. Comput. 2018, 22, 805–817. [Google Scholar] [CrossRef]
- Chakraborty, A.; Ray, K.S.; Dutta, S.; Bhattacharyya, S.; Kolya, A. Species Inspired PSO based Pyramid Match Kernel Model (PMK) for Moving Object Motion Tracking. In Proceedings of the Fourth International Conference on Research in Computational Intelligence and Communication Networks, Kolkata, India, 22–23 November 2018; pp. 152–157. [Google Scholar]
- Nianyin, Z.; Zidong, W.; Weibo, L.; Hong, Z.; Kate, H.; Xiaohui, L. A Dynamic Neighborhood-based Switching Particle Swarm Optimization Algorithm. IEEE Trans. Cybern. 2020, 8, 701–717. [Google Scholar]
- Vazquez, J.C.; Valdez, F. Fuzzy Logic for Dynamic Adaptation in PSO with Multiple Topologies. In Proceedings of the 2013 Joint IFSA World Congress and NAFIPS Annual Meeting, Edmonton, AB, Canada, 24–28 June 2013; pp. 1197–1202. [Google Scholar]
- Liu, Q.; Wei, W.; Yuan, H.; Zhan, Z.-H.; Li, Y. Topology Selection for Particle Swarm Optimization. Inf. Sci. 2016, 363, 154–173. [Google Scholar] [CrossRef]
- Lin, W.; Bo, Y.; Jeff, O. Particle Swarm Optimization Using Dynamic Tournament Yopology. Appl. Soft Comput. 2016, 48, 584–596. [Google Scholar]
- Xia, X.; Gui, L.; Zhan, Z.-H. A Multi-swarm Particle Swarm Optimization Algorithm based on Dynamical Topology and Purposeful Detecting. Appl. Soft Comput. 2018, 67, 126–140. [Google Scholar] [CrossRef]
- Zou, J.; Deng, Q.; Zheng, J.; Yang, S. A Close Neighbor Mobility Method Using Particle Swarm Optimizer for Solving Multimodal Optimization Problems. Inf. Sci. 2020, 519, 332–347. [Google Scholar] [CrossRef]
- Parrott, D.; Xiaodong, L. Locating and Tracking Multiple Dynamic Optima by a Particle Swarm Model Using Speciation. IEEE Trans. Evol. Comput. 2006, 10, 440–458. [Google Scholar] [CrossRef]
- Cervantes, A.; Galvan, I.M.; Isasi, P. AMPSO: A New Particle Swarm Method for Nearest Neighborhood Classification. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2009, 39, 1082–1091. [Google Scholar] [CrossRef]
- Janson, S.; Middendorf, M. A Hierarchical Particle Swarm Optimizer and Its Adaptive Variant. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2005, 35, 1272–1282. [Google Scholar] [CrossRef]
- Zhan, Z.; Zhang, J.; Li, Y.; Shi, Y. Orthogonal Learning Particle Swarm Optimization. IEEE Trans. Evol. Comput. 2011, 15, 832–847. [Google Scholar] [CrossRef]
- Chen, S.; Hong, X.; Harris, C.J. Particle Swarm Optimization Aided Orthogonal Forward Regression for Unified Data Modeling. IEEE Trans. Evol. Comput. 2010, 14, 477–499. [Google Scholar] [CrossRef]
- Yang, Q.; Chen, W.N.; Yu, Z.; Gu, T.; Li, Y.; Zhang, H.; Zhang, J. Adaptive Multimodal Continuous Ant Colony Optimization. IEEE Trans. Evol. Comput. 2017, 21, 191–205. [Google Scholar] [CrossRef]
- Yang, Q.; Chen, W.N.; Li, Y.; Chen, C.L.P.; Xu, X.M.; Zhang, J. Multimodal Estimation of Distribution Algorithms. IEEE Trans. Cybern. 2017, 47, 636–650. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.; Li, Y.; Gao, X.-D.; Ma, Y.-Y.; Lu, Z.-Y.; Jeon, S.-W.; Zhang, J. An Adaptive Covariance Scaling Estimation of Distribution Algorithm. Mathematics 2021, 9, 3207. [Google Scholar] [CrossRef]
- Wei, F.F.; Chen, W.N.; Yang, Q.; Deng, J.; Zhang, J. A Classifier-Assisted Level-Based Learning Swarm Optimizer for Expensive Optimization. IEEE Trans. Evol. Comput. 2020, 25, 219–233. [Google Scholar] [CrossRef]
- Yang, Q.; Chen, W.N.; Gu, T.; Zhang, H.; Yuan, H.; Kwong, S.; Zhang, J. A Distributed Swarm Optimizer with Adaptive Communication for Large-Scale Optimization. IEEE Trans. Cybern. 2020, 50, 3393–3408. [Google Scholar] [CrossRef]
- Wu, G.; Mallipeddi, R.; Suganthan, P.N. Problem Definitions and Evaluation Criteria for The CEC 2017 Competition on Constrained Real-Parameter Optimization; Technical Report; National University of Defense Technology: Changsha, China; Kyungpook National University: Daegu, Korea; Nanyang Technological University: Singapore, 2017; pp. 1–16. [Google Scholar]
- Shen, Y.; Wei, L.; Zeng, C.; Chen, J. Particle Swarm Optimization with Double Learning Patterns. Comput. Intell. Neurosci. 2016, 2016, 6510303. [Google Scholar] [CrossRef]
- Xie, H.-Y.; Yang, Q.; Hu, X.-M.; Chen, W.N. Cross-generation Elites Guided Particle Swarm Optimization for large scale optimization. In Proceedings of the IEEE Symposium Series on Computational Intelligence, Athens, Greece, 6–9 December 2016; pp. 1–8. [Google Scholar]
- Yang, Q.; Chen, W.N.; Gu, T.; Zhang, H.; Deng, J.D.; Li, Y.; Zhang, J. Segment-Based Predominant Learning Swarm Optimizer for Large-Scale Optimization. IEEE Trans. Cybern. 2017, 47, 2896–2910. [Google Scholar] [CrossRef]
- Hesam, V.; Naser, S.H.; Mahsa, S. A Hybrid Generalized Reduced Gradient-based Particle Swarm Optimizer for Constrained Engineering Optimization Problems. J. Comput. Civ. Eng. 2021, 5, 86–119. [Google Scholar]
- Riaan, B.; Engelbrecht, A.P.; van den Bergh, F. A Niching Particle Swarm Optimizer. In Proceedings of the Asia-Pacific Conference on Simulated Evolution and Learning, Orchid Country Club, Singapore, 18–22 November 2002; pp. 692–696. [Google Scholar]
- Yousri, D.; Thanikanti, S.B.; Allam, D.; Ramachandaramurthy, V.K.; Eteiba, M.B. Fractional Chaotic Ensemble Particle Swarm Optimizer for Identifying the Single, Double, and Three Diode Photovoltaic Models’ Parameters. Energy 2020, 195, 116979. [Google Scholar] [CrossRef]
- Chen, X.; Tianfield, H.; Du, W. Bee-foraging Learning Particle SwarmOptimization. Appl. Soft Comput. 2021, 102, 107134. [Google Scholar] [CrossRef]
- Zhan, Z.-H.; Shi, L.; Tan, K.C.; Zhang, J. A Survey on Evolutionary Computation for Complex Continuous optimization. Artif. Intell. Rev. 2021, 55, 59–110. [Google Scholar] [CrossRef]
- Tao, X.; Li, X.; Chen, W.; Liang, T.; Qi, L. Self-Adaptive Two Roles Hybrid Learning Strategies-based Particle Swarm Optimization. Inf. Sci. 2021, 578. [Google Scholar] [CrossRef]
- Xu, G.; Zhao, X.; Wu, T.; Li, R.; Li, X. An Elitist Learning Particle Swarm Optimization with Scaling Mutation and Ring Topology. IEEE Access 2018, 6, 78453–78470. [Google Scholar] [CrossRef]
- Kennedy, J. Small Worlds and Mega-minds: Effects of Neighborhood Topology on Particle Swarm Performance. In Proceedings of the Congress on Evolutionary Computation, Washington, DC, USA, 6–9 July 1999; Volume 1933, pp. 1931–1938. [Google Scholar]
- Lin, A.; Sun, W.; Yu, H.; Wu, G.; Tang, H. Global Genetic Learning Particle Swarm Optimization with Diversity Enhancement by Ring Topology. Swarm Evol. Comput. 2019, 44, 571–583. [Google Scholar] [CrossRef]
- Turkey, M.; Poli, R. A Model for Analysing the Collective Dynamic Behaviour and Characterising the Exploitation of Population-Based Algorithms. Evol. Comput. 2014, 22, 159–188. [Google Scholar] [CrossRef]
- Zhang, J.; Sanderson, A.C. JADE: Adaptive Differential Evolution with Optional External Archive. IEEE Trans. Evol. Comput. 2009, 13, 945–958. [Google Scholar] [CrossRef]
- Djellali, H.; Ghoualmi, N. Improved Chaotic Initialization of Particle Swarm applied to Feature Selection. In Proceedings of the International Conference on Networking and Advanced Systems, Annaba, Algeria, 26–27 June 2019; pp. 1–5. [Google Scholar]
- Watanabe, M.; Ihara, K.; Kato, S.; Sakuma, T. Initialization Effects for PSO Based Storage Assignment Optimization. In Proceedings of the Global Conference on Consumer Electronics, Kyoto, Japan, 12–15 October 2021; pp. 494–495. [Google Scholar]
- Wang, C.J.; Fang, H.; Wang, C.; Daneshmand, M.; Wang, H. A Novel Initialization Method for Particle Swarm Optimization-based FCM in Big Biomedical Data. In Proceedings of the IEEE International Conference on Big Data, Santa Clara, CA, USA, 29 October–1 November 2015; pp. 2942–2944. [Google Scholar]
- Farooq, M.U.; Ahmad, A.; Hameed, A. Opposition-based Initialization and A Modified Pattern for Lnertia Weight (IW) in PSO. In Proceedings of the IEEE International Conference on INnovations in Intelligent SysTems and Applications, Gdynia, Poland, 3–5 July 2017; pp. 96–101. [Google Scholar]
- Guo, J.; Tang, S. An Improved Particle Swarm Optimization with Re-initialization Mechanism. In Proceedings of the International Conference on Intelligent Human-Machine Systems and Cybernetics, Hangzhou, China, 26–27 August 2009; pp. 437–441. [Google Scholar]

| Algorithm | D | Parameter Settings | |
|---|---|---|---|
| STTPSO | 30 | PS = 300 | AS = PS/2; w = 0.9~0.4; c~N(1.49618,0.1); pm = 0.01; stopmax = 30 |
| 50 | PS = 300 | ||
| 100 | PS = 300 | ||
| DNSPSO | 30 | PS = 50 | w = 0.4~0.9; k = 5; F = 0.5; CR = 0.9; |
| 50 | PS = 50 | ||
| 100 | PS = 60 | ||
| XPSO | 30 | PS = 100 | η = 0.2; Stagmax = 5; p = 0.5; σ = 0.1 |
| 50 | PS = 150 | ||
| 100 | PS = 150 | ||
| TCSPSO | 30 | PS = 50 | w = 0.9~0.4; c1 = c2 = 2 |
| 50 | PS = 50 | ||
| 100 | PS = 50 | ||
| GLPSO | 30 | PS = 40 | w = 0.7298; c = 1.49618; pm = 0.1; sg = 7 |
| 50 | PS = 40 | ||
| 100 | PS = 50 | ||
| HCLPSO | 30 | PS = 160 | w = 0.99~0.2; c1 = 2.5~0.5; c2 = 0.5~2.5; c = 3~1.5 |
| 50 | PS = 180 | ||
| 100 | PS = 180 | ||
| DPLPSO | 30 | PS = 40 | c1 = c2 = 2; L = 50 |
| 50 | PS = 40 | ||
| 100 | PS = 40 | ||
| CLPSO | 30 | PS = 40 | Pc = 0.05~0.5 |
| 50 | PS = 40 | ||
| 100 | PS = 40 | ||
| f | Category | Quality | STTPSO | DNSPSO | XPSO | TCSPSO | GLPSO | HCLPSO | DPLPSO | CLPSO |
|---|---|---|---|---|---|---|---|---|---|---|
| f1 | Unimodal Functions | Median | 1.19 × 103 | 1.95 × 105 | 2.26 × 103 | 3.20 × 103 | 2.30 × 103 | 5.49 × 103 | 2.64 × 109 | 1.52 × 102 |
| Mean | 2.10 × 103 | 2.11 × 105 | 4.05 × 103 | 3.66 × 103 | 3.06 × 103 | 8.65 × 103 | 2.87 × 109 | 3.88 × 102 | ||
| Std | 2.28 × 103 | 1.30 × 105 | 4.72 × 103 | 4.08 × 103 | 2.42 × 103 | 7.34 × 103 | 1.11 × 109 | 7.31 × 102 | ||
| p-value | - | 1.83 × 10−6+ | 2.17 × 10−1= | 1.95 × 10−1= | 5.85 × 10−2= | 8.55 × 10−5+ | 1.83 × 10−6+ | 7.84 × 10−5− | ||
| f3 | Median | 1.52 × 104 | 1.51 × 105 | 6.26 × 10−2 | 9.94 × 103 | 1.14 × 10−13 | 4.54 × 101 | 3.91 × 104 | 4.30 × 104 | |
| Mean | 1.53 × 104 | 1.54 × 105 | 7.91 × 10−1 | 1.15 × 104 | 1.33 × 10−13 | 6.87 × 101 | 3.87 × 104 | 4.41 × 104 | ||
| Std | 4.39 × 103 | 3.37 × 104 | 2.00 × 100 | 3.68 × 103 | 5.36 × 10−14 | 8.17 × 101 | 8.36 × 103 | 1.00 × 104 | ||
| p-value | - | 1.83 × 10−6+ | 1.83 × 10−6− | 2.51 × 10−4− | 1.83 × 10−6− | 1.83 × 10−6− | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f1–3 | w/t/l | - | 2/0/0 | 0/1/1 | 0/1/1 | 0/1/1 | 1/0/1 | 2/0/0 | 1/0/1 | |
| f4 | Simple Multimodal Functions | Median | 8.47 × 101 | 2.54 × 101 | 1.24 × 102 | 1.30 × 102 | 1.47 × 102 | 8.56 × 101 | 7.62 × 102 | 9.09 × 101 |
| Mean | 8.48 × 101 | 2.56 × 101 | 1.20 × 102 | 1.32 × 102 | 1.48 × 102 | 8.73 × 101 | 7.99 × 102 | 9.12 × 101 | ||
| Std | 3.74 × 10−1 | 1.07 × 100 | 2.71 × 101 | 4.84 × 101 | 4.27 × 101 | 7.92 × 100 | 1.86 × 102 | 1.57 × 100 | ||
| p-value | - | 1.83 × 10−6− | 3.56 × 10−5+ | 3.89 × 10−5+ | 4.97 × 10−6+ | 7.84 × 10−5+ | 1.83 × 10−6+ | 1.82 × 10−6+ | ||
| f5 | Median | 4.98 × 100 | 2.04 × 102 | 4.18 × 101 | 8.56 × 101 | 6.77 × 101 | 6.45 × 101 | 2.00 × 102 | 7.66 × 101 | |
| Mean | 4.71 × 100 | 2.03 × 102 | 4.38 × 101 | 8.92 × 101 | 6.68 × 101 | 6.77 × 101 | 1.93 × 102 | 7.52 × 101 | ||
| Std | 1.96 × 100 | 1.25 × 101 | 1.58 × 101 | 2.54 × 101 | 1.96 × 101 | 1.67 × 101 | 3.28 × 101 | 6.69 × 100 | ||
| p-value | - | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.82 × 10−6+ | 1.82 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f6 | Median | 1.14 × 10−13 | 1.87 × 10−1 | 3.82 × 10−3 | 8.01 × 10−1 | 6.34 × 10−3 | 1.62 × 10−4 | 2.97 × 101 | 2.66 × 10−6 | |
| Mean | 1.12 × 10−7 | 1.91 × 10−1 | 1.50 × 10−2 | 1.04 × 100 | 9.69 × 10−3 | 2.41 × 10−3 | 2.98 × 101 | 2.86 × 10−6 | ||
| Std | 2.91 × 10−7 | 5.92 × 10−2 | 3.82 × 10−2 | 1.15 × 100 | 8.77 × 10−3 | 5.85 × 10−3 | 5.82 × 100 | 1.90 × 10−6 | ||
| p-value | - | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.82 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.82 × 10−6+ | 1.83 × 10−6+ | ||
| f7 | Median | 3.44 × 101 | 2.36 × 102 | 7.94 × 101 | 1.45 × 102 | 9.75 × 101 | 1.06 × 102 | 2.90 × 102 | 9.23 × 101 | |
| Mean | 3.46 × 101 | 2.33 × 102 | 8.17 × 101 | 1.42 × 102 | 9.86 × 101 | 1.01 × 102 | 2.88 × 102 | 9.05 × 101 | ||
| Std | 1.12 × 100 | 1.69 × 101 | 1.81 × 101 | 2.87 × 101 | 1.53 × 101 | 1.86 × 101 | 2.45 × 101 | 7.88 × 100 | ||
| p-value | - | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f8 | Median | 3.98 × 100 | 2.01 × 102 | 3.83 × 101 | 9.55 × 101 | 5.97 × 101 | 5.66 × 101 | 1.94 × 102 | 8.09 × 101 | |
| Mean | 4.15 × 100 | 2.02 × 102 | 3.98 × 101 | 9.33 × 101 | 6.08 × 101 | 6.35 × 101 | 1.90 × 102 | 8.18 × 101 | ||
| Std | 1.67 × 100 | 1.03 × 101 | 1.37 × 101 | 2.22 × 101 | 1.65 × 101 | 2.08 × 101 | 3.20 × 101 | 9.86 × 100 | ||
| p-value | - | 1.82 × 10−6+ | 1.82 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.82 × 10−6+ | 1.83 × 10−6+ | ||
| f9 | Median | 5.69 × 10−14 | 1.50 × 100 | 1.45 × 100 | 3.01 × 102 | 5.98 × 101 | 4.90 × 101 | 1.27 × 103 | 6.58 × 102 | |
| Mean | 5.69 × 10−14 | 2.09 × 100 | 2.73 × 100 | 3.85 × 102 | 7.13 × 101 | 8.90 × 101 | 1.50 × 103 | 6.76 × 102 | ||
| Std | 5.69 × 10−14 | 1.39 × 100 | 3.44 × 100 | 3.36 × 102 | 4.83 × 101 | 1.49 × 102 | 6.80 × 102 | 2.80 × 102 | ||
| p-value | - | 1.83 × 10−6+ | 1.82 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.82 × 10−6+ | 1.83 × 10−6+ | ||
| f4–9 | w/t/l | - | 5/0/1 | 6/0/0 | 6/0/0 | 6/0/0 | 6/0/0 | 6/0/0 | 6/0/0 | |
| f10 | Hybrid Functions | Median | 1.81 × 103 | 6.21 × 103 | 2.80 × 103 | 2.98 × 103 | 3.26 × 103 | 2.87 × 103 | 6.39 × 103 | 3.00 × 103 |
| Mean | 2.82 × 103 | 5.90 × 103 | 2.62 × 103 | 2.97 × 103 | 3.23 × 103 | 2.90 × 103 | 6.33 × 103 | 2.94 × 103 | ||
| Std | 1.82 × 103 | 1.01 × 103 | 6.13 × 102 | 4.22 × 102 | 8.64 × 102 | 5.17 × 102 | 4.47 × 102 | 2.77 × 102 | ||
| p-value | - | 4.50 × 10−6+ | 5.37 × 10−1= | 7.89 × 10−1= | 2.41 × 10−1= | 8.69 × 10−1= | 1.83 × 10−6+ | 8.53 × 10−1= | ||
| f11 | Median | 1.79 × 101 | 9.12 × 101 | 8.01 × 101 | 1.16 × 102 | 7.24 × 101 | 1.09 × 102 | 4.10 × 102 | 1.21 × 102 | |
| Mean | 2.79 × 101 | 9.19 × 101 | 8.63 × 101 | 1.18 × 102 | 7.82 × 101 | 1.08 × 102 | 4.23 × 102 | 1.16 × 102 | ||
| Std | 2.33 × 101 | 8.54 × 100 | 4.60 × 101 | 4.27 × 101 | 3.83 × 101 | 4.49 × 101 | 1.19 × 102 | 1.72 × 101 | ||
| p-value | - | 1.83 × 10−6+ | 9.77 × 10−6+ | 4.50 × 10−6+ | 1.68 × 10−5+ | 3.03 × 10−6+ | 1.83 × 10−6+ | 2.02 × 10−6+ | ||
| f12 | Median | 5.38 × 104 | 5.52 × 107 | 2.64 × 104 | 1.86 × 105 | 1.13 × 106 | 2.39 × 105 | 1.55 × 108 | 1.74 × 106 | |
| Mean | 6.09 × 104 | 6.25 × 107 | 1.93 × 105 | 5.12 × 105 | 3.35 × 106 | 2.55 × 105 | 1.77 × 108 | 2.01 × 106 | ||
| Std | 3.97 × 104 | 2.90 × 107 | 5.57 × 105 | 6.68 × 105 | 4.39 × 106 | 1.70 × 105 | 9.46 × 107 | 1.11 × 106 | ||
| p-value | - | 1.83 × 10−6+ | 2.17 × 10−1= | 1.36 × 10−5+ | 1.72 × 10−5+ | 8.88 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f13 | Median | 5.18 × 103 | 1.32 × 106 | 7.54 × 103 | 8.24 × 103 | 7.23 × 103 | 6.10 × 104 | 6.71 × 106 | 3.39 × 103 | |
| Mean | 1.10 × 104 | 1.52 × 106 | 9.83 × 103 | 3.28 × 105 | 1.19 × 104 | 3.80 × 104 | 2.47 × 107 | 3.40 × 103 | ||
| Std | 1.11 × 104 | 7.16 × 105 | 1.02 × 104 | 1.14 × 106 | 1.45 × 104 | 2.64 × 104 | 7.42 × 107 | 1.42 × 103 | ||
| p-value | - | 1.83 × 10−6+ | 9.34 × 10−1= | 4.59 × 10−1= | 1.00 × 100= | 2.26 × 10−5+ | 1.83 × 10−6+ | 1.14 × 10−2− | ||
| f14 | Median | 3.89 × 103 | 1.90 × 102 | 3.75 × 103 | 3.49 × 104 | 1.66 × 103 | 1.43 × 104 | 1.20 × 105 | 4.42 × 104 | |
| Mean | 6.63 × 103 | 1.93 × 102 | 5.36 × 103 | 5.20 × 104 | 3.38 × 104 | 1.55 × 104 | 1.66 × 105 | 4.93 × 104 | ||
| Std | 6.41 × 103 | 2.22 × 101 | 4.38 × 103 | 7.90 × 104 | 7.81 × 104 | 9.99 × 103 | 2.35 × 105 | 3.41 × 104 | ||
| p-value | - | 1.83 × 10−6− | 2.49 × 10−1= | 5.93 × 10−4+ | 9.51 × 10−1= | 2.51 × 10−4+ | 4.08 × 10−6+ | 4.50 × 10−6+ | ||
| f15 | Median | 3.91 × 103 | 4.24 × 104 | 1.61 × 103 | 1.08 × 104 | 5.46 × 103 | 8.96 × 103 | 1.28 × 104 | 4.08 × 102 | |
| Mean | 7.84 × 103 | 4.70 × 104 | 3.59 × 103 | 1.33 × 104 | 8.80 × 103 | 1.35 × 104 | 2.61 × 104 | 4.59 × 102 | ||
| Std | 8.32 × 103 | 2.04 × 104 | 4.74 × 103 | 1.04 × 104 | 8.48 × 103 | 1.22 × 104 | 3.16 × 104 | 2.45 × 102 | ||
| p-value | - | 1.83 × 10−6+ | 8.04 × 10−2= | 3.41 × 10−2+ | 7.89 × 10−1= | 4.38 × 10−2+ | 2.33 × 10−3+ | 3.34 × 10−6− | ||
| f16 | Median | 2.22 × 101 | 1.88 × 103 | 5.70 × 102 | 8.65 × 102 | 8.49 × 102 | 7.46 × 102 | 1.57 × 103 | 6.61 × 102 | |
| Mean | 5.93 × 101 | 1.87 × 103 | 5.33 × 102 | 8.54 × 102 | 8.21 × 102 | 7.11 × 102 | 1.52 × 103 | 6.24 × 102 | ||
| Std | 6.79 × 101 | 1.61 × 102 | 1.96 × 102 | 2.56 × 102 | 2.22 × 102 | 2.08 × 102 | 2.55 × 102 | 1.64 × 102 | ||
| p-value | - | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f17 | Median | 4.48 × 101 | 8.55 × 102 | 1.64 × 102 | 3.18 × 102 | 2.02 × 102 | 3.12 × 102 | 4.36 × 102 | 1.96 × 102 | |
| Mean | 4.69 × 101 | 8.68 × 102 | 1.45 × 102 | 2.96 × 102 | 2.28 × 102 | 3.22 × 102 | 4.31 × 102 | 1.88 × 102 | ||
| Std | 1.01 × 101 | 1.21 × 102 | 8.08 × 101 | 1.44 × 102 | 1.38 × 102 | 1.54 × 102 | 1.50 × 102 | 6.59 × 101 | ||
| p-value | - | 1.83 × 10−6+ | 4.97 × 10−6+ | 1.83 × 10−6+ | 3.34 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f18 | Median | 1.87 × 105 | 1.88 × 105 | 9.24 × 104 | 1.41 × 105 | 1.68 × 104 | 1.90 × 105 | 8.67 × 105 | 1.87 × 105 | |
| Mean | 2.64 × 105 | 2.16 × 105 | 1.46 × 105 | 2.78 × 105 | 1.23 × 105 | 2.05 × 105 | 1.03 × 106 | 2.46 × 105 | ||
| Std | 2.51 × 105 | 8.08 × 104 | 1.27 × 105 | 2.93 × 105 | 4.87 × 105 | 1.47 × 105 | 8.56 × 105 | 1.55 × 105 | ||
| p-value | - | 1.00 × 100= | 5.58 × 10−2= | 9.18 × 10−1= | 1.20 × 10−4− | 9.34 × 10−1= | 6.60 × 10−5+ | 9.18 × 10−1= | ||
| f19 | Median | 5.77 × 103 | 1.95 × 103 | 3.65 × 103 | 7.66 × 103 | 2.99 × 103 | 1.31 × 104 | 1.52 × 104 | 1.05 × 102 | |
| Mean | 1.10 × 104 | 2.25 × 103 | 4.56 × 103 | 1.49 × 104 | 7.89 × 103 | 1.63 × 104 | 3.47 × 104 | 1.35 × 102 | ||
| Std | 1.32 × 104 | 1.04 × 103 | 4.83 × 103 | 1.58 × 104 | 1.05 × 104 | 1.76 × 104 | 7.74 × 104 | 8.36 × 101 | ||
| p-value | - | 2.86 × 10−3− | 3.78 × 10−2− | 3.24 × 10−1= | 3.34 × 10−1= | 2.94 × 10−1= | 1.80 × 10−2+ | 1.83 × 10−6− | ||
| f10–19 | w/t/l | - | 7/1/2 | 3/6/1 | 6/4/0 | 4/5/1 | 7/3/0 | 10/0/0 | 5/2/3 | |
| f | Category | Quality | STTPSO | DNSPSO | XPSO | TCSPSO | GLPSO | HCLPSO | DPLPSO | CLPSO |
| f20 | Composition Functions | Median | 3.72 × 101 | 3.50 × 102 | 1.74 × 102 | 3.84 × 102 | 1.96 × 102 | 2.13 × 102 | 3.66 × 102 | 1.94 × 102 |
| Mean | 4.65 × 101 | 3.87 × 102 | 1.84 × 102 | 3.70 × 102 | 2.16 × 102 | 2.09 × 102 | 4.00 × 102 | 1.89 × 102 | ||
| Std | 3.35 × 101 | 1.20 × 102 | 6.75 × 101 | 1.39 × 102 | 1.01 × 102 | 1.04 × 102 | 1.28 × 102 | 6.57 × 101 | ||
| p-value | - | 1.83 × 10−6+ | 2.48 × 10−6+ | 1.83 × 10−6+ | 3.69 × 10−6+ | 5.48 × 10−6+ | 1.83 × 10−6+ | 3.69 × 10−6+ | ||
| f21 | Median | 2.12 × 102 | 4.04 × 102 | 2.35 × 102 | 2.81 × 102 | 2.66 × 102 | 2.75 × 102 | 4.02 × 102 | 2.88 × 102 | |
| Mean | 2.13 × 102 | 4.04 × 102 | 2.38 × 102 | 2.84 × 102 | 2.67 × 102 | 2.76 × 102 | 4.00 × 102 | 2.83 × 102 | ||
| Std | 3.76 × 100 | 9.54 × 100 | 1.05 × 101 | 2.25 × 101 | 2.07 × 101 | 1.25 × 101 | 2.25 × 101 | 2.53 × 101 | ||
| p-value | - | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.82 × 10−6+ | 1.82 × 10−6+ | 1.82 × 10−6+ | 2.47 × 10−6+ | ||
| f22 | Median | 1.00 × 102 | 6.38 × 103 | 1.00 × 102 | 1.05 × 102 | 1.00 × 102 | 1.02 × 102 | 5.79 × 102 | 2.06 × 102 | |
| Mean | 1.00 × 102 | 6.29 × 103 | 4.30 × 102 | 1.70 × 103 | 1.02 × 102 | 8.37 × 102 | 5.92 × 102 | 8.25 × 102 | ||
| Std | 0.00 × 100 | 7.48 × 102 | 9.91 × 102 | 1.75 × 103 | 3.08 × 100 | 1.49 × 103 | 1.44 × 102 | 1.18 × 103 | ||
| p-value | - | 1.82 × 10−6+ | 3.82 × 10−3+ | 1.43 × 10−4+ | 1.63 × 10−3+ | 4.67 × 10−4+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f23 | Median | 3.85 × 102 | 5.83 × 102 | 3.99 × 102 | 4.44 × 102 | 4.26 × 102 | 4.53 × 102 | 6.77 × 102 | 4.46 × 102 | |
| Mean | 3.86 × 102 | 5.87 × 102 | 3.98 × 102 | 4.47 × 102 | 4.33 × 102 | 4.51 × 102 | 6.84 × 102 | 4.45 × 102 | ||
| Std | 7.70 × 100 | 3.62 × 101 | 1.15 × 101 | 2.85 × 101 | 3.02 × 101 | 2.02 × 101 | 4.57 × 101 | 1.09 × 101 | ||
| p-value | - | 1.83 × 10−6+ | 6.89 × 10−4+ | 1.82 × 10−6+ | 2.24 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f24 | Median | 4.60 × 102 | 6.68 × 102 | 4.70 × 102 | 5.37 × 102 | 4.88 × 102 | 5.35 × 102 | 7.32 × 102 | 5.60 × 102 | |
| Mean | 4.61 × 102 | 6.82 × 102 | 4.73 × 102 | 5.38 × 102 | 4.99 × 102 | 5.39 × 102 | 7.37 × 102 | 5.60 × 102 | ||
| Std | 8.66 × 100 | 4.48 × 101 | 2.40 × 101 | 5.08 × 101 | 3.90 × 101 | 2.34 × 101 | 3.79 × 101 | 1.66 × 101 | ||
| p-value | - | 1.83 × 10−6+ | 1.28 × 10−2+ | 2.24 × 10−6+ | 2.06 × 10−5+ | 1.83 × 10−6+ | 1.82 × 10−6+ | 1.83 × 10−6+ | ||
| f25 | Median | 3.87 × 102 | 3.79 × 102 | 3.91 × 102 | 4.14 × 102 | 4.09 × 102 | 3.89 × 102 | 6.00 × 102 | 3.89 × 102 | |
| Mean | 3.87 × 102 | 3.78 × 102 | 3.92 × 102 | 4.12 × 102 | 4.04 × 102 | 3.89 × 102 | 6.18 × 102 | 3.89 × 102 | ||
| Std | 2.06 × 10−1 | 1.04 × 100 | 4.86 × 100 | 1.56 × 101 | 1.24 × 101 | 8.23 × 100 | 8.24 × 101 | 5.62 × 10−1 | ||
| p-value | - | 1.77 × 10−6− | 6.65 × 10−6+ | 1.83 × 10−6+ | 1.82 × 10−6+ | 1.74 × 10−2+ | 1.83 × 10−6+ | 1.78 × 10−6+ | ||
| f26 | Median | 1.47 × 103 | 3.28 × 103 | 3.00 × 102 | 2.32 × 103 | 1.94 × 103 | 2.04 × 103 | 1.61 × 103 | 1.85 × 103 | |
| Mean | 1.49 × 103 | 3.45 × 103 | 6.97 × 102 | 2.23 × 103 | 1.92 × 103 | 1.82 × 103 | 1.95 × 103 | 1.58 × 103 | ||
| Std | 1.09 × 102 | 4.89 × 102 | 6.06 × 102 | 6.97 × 102 | 4.77 × 102 | 6.36 × 102 | 1.02 × 103 | 4.70 × 102 | ||
| p-value | - | 1.83 × 10−6+ | 3.56 × 10−5− | 1.97 × 10−4+ | 1.67 × 10−4+ | 1.52 × 10−2+ | 1.92 × 10−1= | 1.88 × 10−1= | ||
| f27 | Median | 5.13 × 102 | 5.00 × 102 | 5.36 × 102 | 5.61 × 102 | 5.48 × 102 | 5.14 × 102 | 8.09 × 102 | 5.11 × 102 | |
| Mean | 5.18 × 102 | 5.00 × 102 | 5.35 × 102 | 5.61 × 102 | 5.50 × 102 | 5.16 × 102 | 8.19 × 102 | 5.10 × 102 | ||
| Std | 1.40 × 101 | 0.00 × 100 | 1.10 × 101 | 1.95 × 101 | 1.28 × 101 | 1.59 × 101 | 5.73 × 101 | 4.56 × 100 | ||
| p-value | - | 2.24 × 10−6− | 9.31 × 10−5+ | 2.87 × 10−6+ | 2.48 × 10−6+ | 8.05 × 10−1= | 1.82 × 10−6+ | 1.70 × 10−2− | ||
| f28 | Median | 4.08 × 102 | 5.00 × 102 | 4.03 × 102 | 4.40 × 102 | 4.72 × 102 | 4.55 × 102 | 8.24 × 102 | 4.74 × 102 | |
| Mean | 3.79 × 102 | 5.00 × 102 | 3.86 × 102 | 4.51 × 102 | 4.51 × 102 | 4.48 × 102 | 8.80 × 102 | 4.83 × 102 | ||
| Std | 5.79 × 101 | 0.00 × 100 | 6.85 × 101 | 5.21 × 101 | 7.00 × 101 | 3.48 × 101 | 1.61 × 102 | 2.88 × 101 | ||
| p-value | - | 1.81 × 10−6+ | 7.76 × 10−1= | 3.73 × 10−4+ | 1.72 × 10−3+ | 1.54 × 10−4+ | 1.83 × 10−6+ | 2.02 × 10−6+ | ||
| f29 | Median | 4.84 × 102 | 1.66 × 103 | 5.66 × 102 | 8.62 × 102 | 7.74 × 102 | 6.92 × 102 | 1.34 × 103 | 6.58 × 102 | |
| Mean | 5.11 × 102 | 1.56 × 103 | 5.88 × 102 | 9.05 × 102 | 8.17 × 102 | 6.98 × 102 | 1.34 × 103 | 6.46 × 102 | ||
| Std | 7.29 × 101 | 2.89 × 102 | 9.03 × 101 | 1.86 × 102 | 2.37 × 102 | 1.56 × 102 | 2.29 × 102 | 7.20 × 101 | ||
| p-value | - | 1.83 × 10−6+ | 2.95 × 10−4+ | 1.83 × 10−6+ | 1.72 × 10−5+ | 1.30 × 10−5+ | 1.83 × 10−6+ | 7.33 × 10−6+ | ||
| f30 | Median | 4.19 × 103 | 4.00 × 104 | 8.04 × 103 | 1.20 × 104 | 9.45 × 103 | 7.39 × 103 | 1.96 × 106 | 1.27 × 104 | |
| Mean | 5.03 × 103 | 6.20 × 104 | 9.78 × 103 | 1.80 × 104 | 2.08 × 104 | 8.59 × 103 | 2.55 × 106 | 1.37 × 104 | ||
| Std | 2.02 × 103 | 5.12 × 104 | 6.72 × 103 | 1.77 × 104 | 2.96 × 104 | 4.52 × 103 | 1.97 × 106 | 3.99 × 103 | ||
| p-value | - | 1.83 × 10−6+ | 4.36 × 10−4+ | 4.08 × 10−6+ | 1.88 × 10−5+ | 1.54 × 10−3+ | 1.83 × 10−6+ | 2.02 × 10−6+ | ||
| f20–30 | w/t/l | - | 9/0/2 | 9/1/1 | 11/0/0 | 11/0/0 | 10/1/0 | 10/1/0 | 9/1/1 | |
| w/t/l | - | 23/1/5 | 18/8/3 | 23/5/1 | 21/6/2 | 24/4/1 | 28/1/0 | 21/3/5 | ||
| rank | 1.86 | 6.00 | 2.55 | 5.48 | 4.00 | 4.41 | 7.45 | 4.24 | ||
| f | Category | Quality | STTPSO | DNSPSO | XPSO | TCSPSO | GLPSO | HCLPSO | DPLPSO | CLPSO | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| f1 | Unimodal Functions | Median | 2.89 × 103 | 5.13 × 103 | 8.51 × 102 | 5.47 × 103 | 3.11 × 103 | 9.83 × 103 | 1.92 × 1010 | 2.06 × 103 | |
| Mean | 4.33 × 103 | 8.53 × 103 | 3.66 × 103 | 2.84 × 106 | 2.76 × 106 | 7.15 × 107 | 1.84 × 1010 | 2.59 × 103 | |||
| Std | 4.38 × 103 | 1.13 × 104 | 5.11 × 103 | 1.52 × 107 | 1.37 × 107 | 2.72 × 108 | 4.36 × 109 | 1.88 × 103 | |||
| p-value | - | 2.02 × 10−1= | 4.97 × 10−1= | 2.02 × 10−1= | 7.69 × 10−2= | 2.51 × 10−4+ | 1.83 × 10−6+ | 2.67 × 10−1= | |||
| f3 | Median | 5.80 × 104 | 3.84 × 105 | 4.35 × 103 | 5.55 × 104 | 4.55E−13 | 4.71 × 103 | 1.23 × 105 | 1.31 × 105 | ||
| Mean | 5.85 × 104 | 3.82 × 105 | 4.72 × 103 | 5.83 × 104 | 3.92E−12 | 5.11 × 103 | 1.22 × 105 | 1.31 × 105 | |||
| Std | 8.60 × 103 | 6.15 × 104 | 1.64 × 103 | 9.39 × 103 | 1.49E−11 | 2.41 × 103 | 1.62 × 104 | 2.22 × 104 | |||
| p-value | - | 1.83 × 10−6+ | 1.83 × 10−6− | 5.51 × 10−1= | 1.83 × 10−6− | 1.83 × 10−6− | 1.83 × 10−6+ | 1.83 × 10−6+ | |||
| f1–3 | w/t/l | - | 1/1/0 | 0/1/1 | 0/2/0 | 0/1/1 | 1/0/1 | 2/0/0 | 1/1/0 | ||
| f4 | Simple Multimodal Functions | Median | 1.75 × 102 | 4.57 × 101 | 2.46 × 102 | 2.88 × 102 | 3.22 × 102 | 1.61 × 102 | 3.81 × 103 | 1.90 × 102 | |
| Mean | 1.69 × 102 | 5.24 × 101 | 2.33 × 102 | 2.93 × 102 | 3.29 × 102 | 1.48 × 102 | 4.02 × 103 | 1.87 × 102 | |||
| Std | 3.35 × 101 | 2.36 × 101 | 5.15 × 101 | 9.09 × 101 | 8.97 × 101 | 5.23 × 101 | 1.06 × 103 | 2.00 × 101 | |||
| p-value | - | 2.24 × 10−6− | 5.08 × 10−5+ | 6.65 × 10−6+ | 2.02 × 10−6+ | 9.99 × 10−2= | 1.83 × 10−6+ | 1.90 × 10−2+ | |||
| f5 | Median | 8.96 × 100 | 4.11 × 102 | 8.21 × 101 | 1.87 × 102 | 1.47 × 102 | 1.65 × 102 | 4.58 × 102 | 2.02 × 102 | ||
| Mean | 9.09 × 100 | 4.12 × 102 | 8.33 × 101 | 1.91 × 102 | 1.42 × 102 | 1.66 × 102 | 4.46 × 102 | 1.98 × 102 | |||
| Std | 2.70 × 100 | 1.88 × 101 | 1.50 × 101 | 3.82 × 101 | 3.83 × 101 | 3.23 × 101 | 4.64 × 101 | 1.55 × 101 | |||
| p-value | - | 1.82 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.82 × 10−6+ | 1.82 × 10−6+ | 1.83 × 10−6+ | |||
| f6 | Median | 1.22 × 10−6 | 1.02 × 10−1 | 5.59 × 10−2 | 3.01 × 100 | 1.19 × 10−2 | 1.85 × 10−3 | 5.28 × 101 | 1.23 × 10−8 | ||
| Mean | 4.48 × 10−6 | 1.16 × 10−1 | 1.53 × 10−1 | 3.93 × 100 | 2.00 × 10−2 | 2.65 × 10−3 | 5.18 × 101 | 2.45 × 10−3 | |||
| Std | 8.10 × 10−6 | 4.66 × 10−2 | 2.59 × 10−1 | 3.68 × 100 | 2.08 × 10−2 | 2.37 × 10−3 | 4.60 × 100 | 1.32 × 10−2 | |||
| p-value | - | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 3.56 × 10−5+ | |||
| f7 | Median | 6.27 × 101 | 4.70 × 102 | 1.51 × 102 | 3.18 × 102 | 2.27 × 102 | 1.94 × 102 | 7.71 × 102 | 2.11 × 102 | ||
| Mean | 6.33 × 101 | 4.70 × 102 | 1.53 × 102 | 3.35 × 102 | 2.36 × 102 | 2.02 × 102 | 7.70 × 102 | 2.10 × 102 | |||
| Std | 3.22 × 100 | 1.85 × 101 | 2.57 × 101 | 6.19 × 101 | 3.89 × 101 | 3.06 × 101 | 6.79 × 101 | 1.44 × 101 | |||
| p-value | - | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | |||
| f8 | Median | 8.96 × 100 | 3.99 × 102 | 8.81 × 101 | 1.97 × 102 | 1.36 × 102 | 1.56 × 102 | 4.60 × 102 | 1.96 × 102 | ||
| Mean | 9.35 × 100 | 4.00 × 102 | 9.29 × 101 | 2.09 × 102 | 1.41 × 102 | 1.56 × 102 | 4.45 × 102 | 1.97 × 102 | |||
| Std | 3.22 × 100 | 1.86 × 101 | 2.34 × 101 | 6.12 × 101 | 3.13 × 101 | 2.68 × 101 | 4.48 × 101 | 1.61 × 101 | |||
| p-value | - | 1.82 × 10−6+ | 1.83 × 10−6+ | 1.82 × 10−6+ | 1.82 × 10−6+ | 1.83 × 10−6+ | 1.82 × 10−6+ | 1.82 × 10−6+ | |||
| f9 | Median | 4.99 × 10−1 | 1.72 × 101 | 1.55 × 101 | 2.85 × 103 | 4.51 × 102 | 1.25 × 103 | 1.08 × 104 | 3.95 × 103 | ||
| Mean | 8.56 × 10−1 | 3.56 × 101 | 4.97 × 101 | 3.34 × 103 | 5.98 × 102 | 1.26 × 103 | 1.10 × 104 | 4.22 × 103 | |||
| Std | 1.05 × 100 | 5.56 × 101 | 8.96 × 101 | 1.87 × 103 | 5.23 × 102 | 5.35 × 102 | 1.90 × 103 | 1.20 × 103 | |||
| p-value | - | 3.34 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | |||
| f4−9 | w/t/l | - | 5/0/1 | 6/0/0 | 6/0/0 | 6/0/0 | 5/1/0 | 6/0/0 | 6/0/0 | ||
| f10 | Hybrid Functions | Median | 3.60 × 103 | 1.16 × 104 | 5.17 × 103 | 5.57 × 103 | 5.59 × 103 | 5.58 × 103 | 1.23 × 104 | 6.66 × 103 | |
| Mean | 3.49 × 103 | 1.15 × 104 | 5.00 × 103 | 5.56 × 103 | 6.27 × 103 | 5.57 × 103 | 1.23 × 104 | 6.59 × 103 | |||
| Std | 5.89 × 102 | 1.43 × 103 | 8.85 × 102 | 6.71 × 102 | 1.85 × 103 | 6.10 × 102 | 5.33 × 102 | 4.43 × 102 | |||
| p-value | - | 1.83 × 10−6+ | 6.04 × 10−6+ | 1.83 × 10−6+ | 2.02 × 10−6+ | 1.82 × 10−6+ | 1.82 × 10−6+ | 1.82 × 10−6+ | |||
| f11 | Median | 6.11 × 101 | 2.04 × 102 | 1.58 × 102 | 2.15 × 102 | 2.90 × 102 | 2.08 × 102 | 2.34 × 103 | 1.93 × 102 | ||
| Mean | 6.12 × 101 | 2.02 × 102 | 1.56 × 102 | 2.36 × 102 | 3.81 × 102 | 2.07 × 102 | 2.38 × 103 | 1.92 × 102 | |||
| Std | 1.18 × 101 | 2.05 × 101 | 3.37 × 101 | 9.86 × 101 | 3.27 × 102 | 6.30 × 101 | 5.66 × 102 | 4.10 × 101 | |||
| p-value | - | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | |||
| f12 | Median | 8.59 × 105 | 2.78 × 107 | 5.18 × 105 | 1.83 × 106 | 1.19 × 106 | 2.94 × 106 | 3.95 × 109 | 1.86 × 107 | ||
| Mean | 8.89 × 105 | 3.23 × 107 | 9.85 × 105 | 8.82 × 106 | 5.72 × 106 | 3.61 × 106 | 4.04 × 109 | 1.96 × 107 | |||
| Std | 5.26 × 105 | 1.68 × 107 | 1.13 × 106 | 2.40 × 107 | 1.24 × 107 | 2.48 × 106 | 1.72 × 109 | 9.49 × 106 | |||
| p-value | - | 1.83 × 10−6+ | 7.11 × 10−1= | 2.97 × 10−5+ | 1.52 × 10−2+ | 2.24 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | |||
| f13 | Median | 1.88 × 104 | 2.62 × 106 | 2.30 × 103 | 3.81 × 103 | 3.32 × 103 | 2.15 × 104 | 3.11 × 108 | 1.11 × 104 | ||
| Mean | 1.63 × 104 | 2.73 × 106 | 4.40 × 103 | 7.76 × 103 | 5.58 × 103 | 2.29 × 104 | 5.22 × 108 | 1.13 × 104 | |||
| Std | 1.12 × 104 | 1.72 × 106 | 4.74 × 103 | 9.15 × 103 | 6.22 × 103 | 1.32 × 104 | 7.74 × 108 | 3.04 × 103 | |||
| p-value | - | 1.83 × 10−6+ | 1.30 × 10−4− | 1.44 × 10−2− | 1.54 × 10−4− | 9.99 × 10−2= | 1.83 × 10−6+ | 4.60 × 10−2− | |||
| f14 | Median | 5.52 × 104 | 7.90 × 103 | 3.86 × 104 | 4.09 × 104 | 4.01 × 104 | 8.86 × 104 | 1.56 × 106 | 4.64 × 105 | ||
| Mean | 7.09 × 104 | 8.09 × 103 | 3.97 × 104 | 2.30 × 105 | 1.43 × 105 | 1.22 × 105 | 2.21 × 106 | 5.29 × 105 | |||
| Std | 5.64 × 104 | 3.51 × 103 | 2.64 × 104 | 5.29 × 105 | 2.20 × 105 | 1.15 × 105 | 2.01 × 106 | 2.65 × 105 | |||
| p-value | - | 8.07 × 10−6− | 1.36 × 10−2− | 3.65 × 10−1= | 7.42 × 10−1= | 4.38 × 10−2+ | 2.02 × 10−6+ | 1.83 × 10−6+ | |||
| f15 | Median | 1.18 × 104 | 4.55 × 105 | 2.69 × 103 | 7.12 × 103 | 3.89 × 103 | 1.81 × 104 | 2.93 × 106 | 8.15 × 102 | ||
| Mean | 1.32 × 104 | 4.80 × 105 | 4.24 × 103 | 1.46 × 104 | 5.84 × 103 | 1.92 × 104 | 1.79 × 107 | 9.31 × 102 | |||
| Std | 9.68 × 103 | 1.58 × 105 | 4.08 × 103 | 2.54 × 104 | 6.28 × 103 | 1.01 × 104 | 2.92 × 107 | 4.49 × 102 | |||
| p-value | - | 1.83 × 10−6+ | 4.71 × 10−4− | 2.76 × 10−1= | 1.07 × 10−3− | 6.41 × 10−2= | 1.83 × 10−6+ | 6.65 × 10−6− | |||
| f16 | Median | 4.55 × 102 | 3.79 × 103 | 9.27 × 102 | 1.63 × 103 | 1.60 × 103 | 1.52 × 103 | 3.13 × 103 | 1.45 × 103 | ||
| Mean | 4.23 × 102 | 3.78 × 103 | 9.56 × 102 | 1.70 × 103 | 1.57 × 103 | 1.53 × 103 | 3.06 × 103 | 1.41 × 103 | |||
| Std | 1.90 × 102 | 2.33 × 102 | 3.27 × 102 | 4.35 × 102 | 4.06 × 102 | 3.57 × 102 | 5.41 × 102 | 2.00 × 102 | |||
| p-value | - | 1.83 × 10−6+ | 6.04 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | |||
| f17 | Median | 2.45 × 102 | 2.41 × 103 | 8.83 × 102 | 1.15 × 103 | 1.03 × 103 | 1.30 × 103 | 1.85 × 103 | 1.06 × 103 | ||
| Mean | 3.11 × 102 | 2.40 × 103 | 8.56 × 102 | 1.17 × 103 | 1.05 × 103 | 1.20 × 103 | 1.83 × 103 | 1.04 × 103 | |||
| Std | 1.43 × 102 | 2.00 × 102 | 2.56 × 102 | 2.97 × 102 | 2.23 × 102 | 3.24 × 102 | 2.86 × 102 | 1.94 × 102 | |||
| p-value | - | 1.82 × 10−6+ | 3.69 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 2.02 × 10−6+ | |||
| f18 | Median | 3.71 × 105 | 3.27 × 106 | 1.71 × 105 | 3.12 × 106 | 1.09 × 106 | 3.18 × 105 | 7.61 × 106 | 1.14 × 106 | ||
| Mean | 4.28 × 105 | 3.47 × 106 | 3.94 × 105 | 5.58 × 106 | 3.42 × 106 | 4.33 × 105 | 1.04 × 107 | 1.31 × 106 | |||
| Std | 2.34 × 105 | 1.61 × 106 | 4.88 × 105 | 5.71 × 106 | 5.02 × 106 | 3.40 × 105 | 9.88 × 106 | 7.63 × 105 | |||
| p-value | - | 1.83 × 10−6+ | 2.58 × 10−1= | 4.50 × 10−6+ | 1.90 × 10−3+ | 6.81 × 10−1= | 1.83 × 10−6+ | 2.24 × 10−6+ | |||
| f19 | Median | 1.60 × 103 | 2.67 × 104 | 9.19 × 103 | 1.30 × 104 | 1.42 × 104 | 1.03 × 104 | 1.44 × 106 | 3.36 × 102 | ||
| Mean | 4.33 × 103 | 3.18 × 104 | 1.12 × 104 | 1.51 × 104 | 1.74 × 104 | 1.48 × 104 | 3.65 × 106 | 5.26 × 102 | |||
| Std | 6.31 × 103 | 1.73 × 104 | 8.07 × 103 | 1.38 × 104 | 1.07 × 104 | 1.36 × 104 | 8.78 × 106 | 5.03 × 102 | |||
| p-value | - | 1.83 × 10−6+ | 1.42 × 10−4+ | 1.54 × 10−3+ | 3.26 × 10−5+ | 1.90 × 10−3+ | 1.83 × 10−6+ | 1.10 × 10−4− | |||
| f10–19 | w/t/l | - | 9/0/1 | 5/2/3 | 7/2/1 | 7/1/2 | 7/3/0 | 10/0/0 | 7/0/3 | ||
| f | Category | Quality | STTPSO | DNSPSO | XPSO | TCSPSO | GLPSO | HCLPSO | DPLPSO | CLPSO | |
| f20 | Composition Functions | Median | 9.66 × 101 | 1.66 × 103 | 4.66 × 102 | 9.58 × 102 | 7.45 × 102 | 9.48 × 102 | 1.44 × 103 | 5.92 × 102 | |
| Mean | 1.76 × 102 | 1.59 × 103 | 4.70 × 102 | 9.01 × 102 | 7.43 × 102 | 8.97 × 102 | 1.38 × 103 | 6.14 × 102 | |||
| Std | 1.38 × 102 | 3.96 × 102 | 2.19 × 102 | 2.96 × 102 | 2.66 × 102 | 2.33 × 102 | 2.58 × 102 | 1.30 × 102 | |||
| p-value | - | 1.83 × 10−6+ | 2.97 × 10−5+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | |||
| f21 | Median | 2.22 × 102 | 6.01 × 102 | 2.79 × 102 | 3.77 × 102 | 3.37 × 102 | 3.86 × 102 | 6.59 × 102 | 4.21 × 102 | ||
| Mean | 2.22 × 102 | 6.00 × 102 | 2.80 × 102 | 4.02 × 102 | 3.46 × 102 | 3.80 × 102 | 6.53 × 102 | 4.21 × 102 | |||
| Std | 3.65 × 100 | 2.02 × 101 | 1.96 × 101 | 6.26 × 101 | 4.16 × 101 | 2.91 × 101 | 3.35 × 101 | 1.52 × 101 | |||
| p-value | - | 1.82 × 10−6+ | 1.83 × 10−6+ | 1.82 × 10−6+ | 1.82 × 10−6+ | 1.82 × 10−6+ | 1.83 × 10−6+ | 1.82 × 10−6+ | |||
| f22 | Median | 3.04 × 103 | 1.28 × 104 | 5.63 × 103 | 6.39 × 103 | 6.49 × 103 | 6.24 × 103 | 1.26 × 104 | 7.13 × 103 | ||
| Mean | 3.10 × 103 | 1.27 × 104 | 4.80 × 103 | 6.14 × 103 | 5.88 × 103 | 5.76 × 103 | 1.13 × 104 | 7.14 × 103 | |||
| Std | 1.34 × 103 | 9.78 × 102 | 2.20 × 103 | 1.52 × 103 | 3.61 × 103 | 1.63 × 103 | 3.48 × 103 | 2.75 × 102 | |||
| p-value | - | 1.83 × 10−6+ | 1.01 × 10−2+ | 1.18 × 10−5+ | 1.33 × 10−3+ | 8.55 × 10−5+ | 2.48 × 10−6+ | 2.02 × 10−6+ | |||
| f23 | Median | 5.06 × 102 | 8.64 × 102 | 5.27 × 102 | 6.43 × 102 | 6.65 × 102 | 6.66 × 102 | 1.22 × 103 | 6.66 × 102 | ||
| Mean | 5.09 × 102 | 8.88 × 102 | 5.24 × 102 | 6.50 × 102 | 6.81 × 102 | 6.65 × 102 | 1.22 × 103 | 6.66 × 102 | |||
| Std | 1.71 × 101 | 6.87 × 101 | 3.11 × 101 | 5.85 × 101 | 8.50 × 101 | 3.99 × 101 | 6.75 × 101 | 1.90 × 101 | |||
| p-value | - | 1.83 × 10−6+ | 4.38 × 10−2+ | 1.82 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | |||
| f24 | Median | 5.81 × 102 | 1.06 × 103 | 5.90 × 102 | 7.06 × 102 | 7.38 × 102 | 7.27 × 102 | 1.31 × 103 | 8.04 × 102 | ||
| Mean | 5.83 × 102 | 1.08 × 103 | 6.06 × 102 | 7.09 × 102 | 7.49 × 102 | 7.23 × 102 | 1.33 × 103 | 8.05 × 102 | |||
| Std | 1.63 × 101 | 1.26 × 102 | 5.78 × 101 | 7.38 × 101 | 9.38 × 101 | 3.46 × 101 | 9.27 × 101 | 2.65 × 101 | |||
| p-value | - | 1.82 × 10−6+ | 3.41 × 10−2+ | 1.83 × 10−6+ | 2.02 × 10−6+ | 1.83 × 10−6+ | 1.82 × 10−6+ | 1.82 × 10−6+ | |||
| f25 | Median | 4.80 × 102 | 4.31 × 102 | 5.98 × 102 | 6.75 × 102 | 6.61 × 102 | 4.80 × 102 | 2.60 × 103 | 5.31 × 102 | ||
| Mean | 5.06 × 102 | 4.41 × 102 | 5.97 × 102 | 6.76 × 102 | 6.66 × 102 | 5.01 × 102 | 2.77 × 103 | 5.30 × 102 | |||
| Std | 3.55 × 101 | 2.14 × 101 | 2.43 × 101 | 6.58 × 101 | 7.00 × 101 | 3.54 × 101 | 6.68 × 102 | 6.29 × 100 | |||
| p-value | - | 3.14 × 10−6− | 1.83 × 10−6+ | 1.82 × 10−6+ | 2.02 × 10−6+ | 2.33 × 10−1= | 1.82 × 10−6+ | 5.91 × 10−4+ | |||
| f26 | Median | 2.23 × 103 | 6.70 × 103 | 9.43 × 102 | 3.98 × 103 | 2.96 × 103 | 3.70 × 103 | 7.22 × 103 | 3.60 × 103 | ||
| Mean | 2.27 × 103 | 7.10 × 103 | 1.15 × 103 | 4.07 × 103 | 3.04 × 103 | 3.64 × 103 | 6.89 × 103 | 3.52 × 103 | |||
| Std | 1.23 × 102 | 1.63 × 103 | 8.75 × 102 | 1.02 × 103 | 6.50 × 102 | 3.13 × 102 | 2.09 × 103 | 3.37 × 102 | |||
| p-value | - | 1.83 × 10−6+ | 1.42 × 10−5− | 1.18 × 10−5+ | 6.87 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 2.02 × 10−6+ | |||
| f27 | Median | 7.00 × 102 | 5.00 × 102 | 7.19 × 102 | 9.01 × 102 | 8.35 × 102 | 6.54 × 102 | 1.98 × 103 | 6.35 × 102 | ||
| Mean | 6.94 × 102 | 5.00 × 102 | 7.35 × 102 | 9.06 × 102 | 8.39 × 102 | 6.89 × 102 | 1.99 × 103 | 6.33 × 102 | |||
| Std | 5.44 × 101 | 0.00 × 100 | 8.89 × 101 | 9.24 × 101 | 8.57 × 101 | 1.06 × 102 | 1.76 × 102 | 2.76 × 101 | |||
| p-value | - | 1.82 × 10−6− | 7.03 × 10−2= | 1.83 × 10−6+ | 7.69 × 10−6+ | 7.50 × 10−1= | 1.83 × 10−6+ | 7.84 × 10−5− | |||
| f28 | Median | 5.08 × 102 | 5.00 × 102 | 5.38 × 102 | 6.68 × 102 | 7.00 × 102 | 4.92 × 102 | 2.91 × 103 | 1.71 × 103 | ||
| Mean | 9.06 × 102 | 5.00 × 102 | 5.47 × 102 | 6.77 × 102 | 6.97 × 102 | 4.92 × 102 | 3.04 × 103 | 1.79 × 103 | |||
| Std | 1.14 × 103 | 0.00 × 100 | 3.99 × 101 | 6.99 × 101 | 5.82 × 101 | 3.40 × 101 | 5.38 × 102 | 4.45 × 102 | |||
| p-value | - | 6.21 × 10−2= | 7.35 × 10−2= | 1.52 × 10−2− | 1.52 × 10−2− | 9.56 × 10−2= | 3.69 × 10−6+ | 4.71 × 10−4+ | |||
| f29 | Median | 5.58 × 102 | 3.32 × 103 | 8.90 × 102 | 1.43 × 103 | 1.03 × 103 | 1.19 × 103 | 3.44 × 103 | 1.01 × 103 | ||
| Mean | 5.90 × 102 | 3.27 × 103 | 8.66 × 102 | 1.43 × 103 | 1.08 × 103 | 1.16 × 103 | 3.52 × 103 | 1.02 × 103 | |||
| Std | 1.75 × 102 | 2.69 × 102 | 1.87 × 102 | 2.49 × 102 | 2.75 × 102 | 3.49 × 102 | 5.07 × 102 | 1.49 × 102 | |||
| p-value | - | 1.83 × 10−6+ | 2.07 × 10−5+ | 1.83 × 10−6+ | 7.33 × 10−6+ | 2.02 × 10−6+ | 1.83 × 10−6+ | 2.48 × 10−6+ | |||
| f30 | Median | 8.17 × 105 | 1.79 × 106 | 1.93 × 106 | 2.00 × 106 | 2.00 × 106 | 1.16 × 106 | 1.38 × 108 | 7.30 × 105 | ||
| Mean | 8.55 × 105 | 2.22 × 106 | 1.92 × 106 | 2.36 × 106 | 2.40 × 106 | 1.23 × 106 | 1.38 × 108 | 7.40 × 105 | |||
| Std | 1.54 × 105 | 1.12 × 106 | 3.32 × 105 | 8.05 × 105 | 1.44 × 106 | 4.15 × 105 | 5.12 × 107 | 7.50 × 104 | |||
| p-value | - | 4.50 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 4.36 × 10−4+ | 1.83 × 10−6+ | 1.15 × 10−3− | |||
| f20–30 | w/t/l | - | 8/1/2 | 8/2/1 | 10/0/1 | 10/0/1 | 8/3/0 | 11/0/0 | 9/0/2 | ||
| w/t/l | - | 23/2/4 | 19/5/5 | 23/4/2 | 23/2/4 | 21/7/1 | 29/0/0 | 23/1/5 | |||
| rank | 2.17 | 5.72 | 2.45 | 5.14 | 4.31 | 4.14 | 7.79 | 4.28 | |||
| f | Category | Quality | STTPSO | DNSPSO | XPSO | TCSPSO | GLPSO | HCLPSO | DPLPSO | CLPSO |
|---|---|---|---|---|---|---|---|---|---|---|
| f1 | Unimodal Functions | Median | 2.53 × 103 | 3.31 × 103 | 3.50 × 103 | 2.62 × 103 | 6.15 × 103 | 1.37 × 104 | 1.10 × 1011 | 1.63 × 109 |
| Mean | 4.29 × 103 | 7.08 × 103 | 8.27 × 103 | 6.22 × 103 | 1.21 × 104 | 1.93 × 107 | 1.10 × 1011 | 1.78 × 109 | ||
| Std | 4.43 × 103 | 1.04 × 104 | 9.67 × 103 | 7.24 × 103 | 1.60 × 104 | 1.04 × 108 | 1.17 × 1010 | 1.48 × 109 | ||
| p-value | - | 7.89 × 10−1= | 2.41 × 10−1= | 4.34 × 10−1= | 5.15 × 10−3+ | 7.20 × 10−5+ | 1.83 × 10−6+ | 4.08 × 10−6+ | ||
| f3 | Median | 2.22 × 105 | 1.07 × 106 | 7.04 × 104 | 2.55 × 105 | 7.98 × 101 | 8.06 × 104 | 3.82 × 105 | 5.10 × 105 | |
| Mean | 2.23 × 105 | 1.04 × 106 | 6.94 × 104 | 2.53 × 105 | 3.93 × 103 | 8.23 × 104 | 3.73 × 105 | 5.12 × 105 | ||
| Std | 2.17 × 104 | 1.25 × 105 | 9.80 × 103 | 3.05 × 104 | 9.85 × 103 | 2.40 × 104 | 4.19 × 104 | 3.83 × 104 | ||
| p-value | - | 1.83 × 10−6+ | 1.83 × 10−6− | 1.74 × 10−4+ | 1.83 × 10−6− | 1.82 × 10−6− | 1.83 × 10−6+ | 1.82 × 10−6+ | ||
| f1–3 | w/t/l | - | 1/1/0 | 0/1/1 | 1/1/0 | 1/0/1 | 1/0/1 | 2/0/0 | 2/0/0 | |
| f4 | Simple Multimodal Functions | Median | 2.16 × 102 | 1.99 × 102 | 4.80 × 102 | 6.28 × 102 | 8.16 × 102 | 2.45 × 102 | 2.20 × 104 | 3.17 × 102 |
| Mean | 2.18 × 102 | 2.07 × 102 | 4.77 × 102 | 7.03 × 102 | 8.54 × 102 | 2.46 × 102 | 2.25 × 104 | 3.26 × 102 | ||
| Std | 1.89 × 101 | 5.44 × 101 | 5.85 × 101 | 1.82 × 102 | 1.91 × 102 | 2.61 × 101 | 3.31 × 103 | 4.30 × 101 | ||
| p-value | - | 2.41 × 10−1= | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 4.36 × 10−4+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f5 | Median | 3.08 × 101 | 1.02 × 103 | 2.29 × 102 | 5.36 × 102 | 3.76 × 102 | 4.78 × 102 | 1.20 × 103 | 7.46 × 102 | |
| Mean | 2.96 × 101 | 1.03 × 103 | 2.28 × 102 | 5.55 × 102 | 3.85 × 102 | 4.96 × 102 | 1.20 × 103 | 7.46 × 102 | ||
| Std | 4.78 × 100 | 4.29 × 101 | 4.81 × 101 | 1.09 × 102 | 5.70 × 101 | 7.09 × 101 | 4.04 × 101 | 4.13 × 101 | ||
| p-value | - | 1.82 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.82 × 10−6+ | 1.83 × 10−6+ | ||
| f6 | Median | 1.13 × 10−3 | 2.42 × 10−1 | 3.95 × 100 | 1.85 × 101 | 4.94 × 10−2 | 9.66 × 10−3 | 7.63 × 101 | 1.07 × 10−2 | |
| Mean | 1.90 × 10−3 | 2.82 × 10−1 | 4.43 × 100 | 1.78 × 101 | 5.62 × 10−2 | 1.54 × 10−2 | 7.59 × 101 | 2.65 × 10−2 | ||
| Std | 2.09 × 10−3 | 1.54 × 10−1 | 3.28 × 100 | 6.21 × 100 | 2.65 × 10−2 | 1.99 × 10−2 | 4.73 × 100 | 3.21 × 10−2 | ||
| p-value | - | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.07 × 10−5+ | 1.83 × 10−6+ | 5.09 × 10−4+ | ||
| f7 | Median | 1.80 × 102 | 1.14 × 103 | 4.41 × 102 | 1.22 × 103 | 7.93 × 102 | 6.74 × 102 | 2.78 × 103 | 7.07 × 102 | |
| Mean | 1.80 × 102 | 1.13 × 103 | 4.48 × 102 | 1.23 × 103 | 7.99 × 102 | 6.80 × 102 | 2.77 × 103 | 7.02 × 102 | ||
| Std | 1.07 × 101 | 4.09 × 101 | 8.25 × 101 | 1.99 × 102 | 1.16 × 102 | 1.08 × 102 | 2.21 × 102 | 6.34 × 101 | ||
| p-value | - | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.82 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f8 | Median | 2.89 × 101 | 1.02 × 103 | 2.14 × 102 | 5.29 × 102 | 4.02 × 102 | 5.48 × 102 | 1.26 × 103 | 7.41 × 102 | |
| Mean | 2.98 × 101 | 1.02 × 103 | 2.15 × 102 | 5.54 × 102 | 4.08 × 102 | 5.46 × 102 | 1.26 × 103 | 7.48 × 102 | ||
| Std | 5.21 × 100 | 3.27 × 101 | 4.03 × 101 | 8.00 × 101 | 6.80 × 101 | 8.92 × 101 | 4.77 × 101 | 3.22 × 101 | ||
| p-value | - | 1.82 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f9 | Median | 2.53 × 101 | 8.78 × 102 | 4.97 × 102 | 1.38 × 104 | 8.82 × 103 | 7.70 × 103 | 5.07 × 104 | 2.24 × 104 | |
| Mean | 2.81 × 101 | 2.10 × 103 | 5.37 × 102 | 1.40 × 104 | 8.58 × 103 | 8.23 × 103 | 5.10 × 104 | 2.32 × 104 | ||
| Std | 1.44 × 101 | 2.82 × 103 | 3.40 × 102 | 4.05 × 103 | 2.37 × 103 | 2.91 × 103 | 5.93 × 103 | 4.46 × 103 | ||
| p-value | - | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f4–9 | w/t/l | - | 5/1/0 | 6/0/0 | 6/0/0 | 6/0/0 | 6/0/0 | 6/0/0 | 6/0/0 | |
| f10 | Hybrid Functions | Median | 8.46 × 103 | 3.03 × 104 | 1.23 × 104 | 1.37 × 104 | 3.05 × 104 | 1.35 × 104 | 2.90 × 104 | 2.17 × 104 |
| Mean | 8.52 × 103 | 3.00 × 104 | 1.24 × 104 | 1.34 × 104 | 3.04 × 104 | 1.32 × 104 | 2.91 × 104 | 2.18 × 104 | ||
| Std | 8.64 × 102 | 7.81 × 102 | 1.41 × 103 | 1.08 × 103 | 3.27 × 102 | 1.10 × 103 | 8.24 × 102 | 4.97 × 102 | ||
| p-value | - | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f11 | Median | 5.25 × 102 | 2.87 × 104 | 1.16 × 103 | 2.74 × 103 | 1.41 × 104 | 8.15 × 102 | 7.75 × 104 | 1.34 × 103 | |
| Mean | 5.22 × 102 | 2.90 × 104 | 1.20 × 103 | 3.42 × 103 | 1.61 × 104 | 7.93 × 102 | 7.82 × 104 | 1.34 × 103 | ||
| Std | 1.17 × 102 | 7.16 × 103 | 2.46 × 102 | 1.92 × 103 | 7.38 × 103 | 2.03 × 102 | 9.38 × 103 | 1.60 × 102 | ||
| p-value | - | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 3.89 × 10−5+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f12 | Median | 7.69 × 105 | 1.49 × 107 | 1.15 × 107 | 5.19 × 107 | 5.53 × 107 | 1.55 × 107 | 3.01 × 1010 | 7.81 × 107 | |
| Mean | 7.68 × 105 | 1.63 × 107 | 1.94 × 107 | 8.56 × 107 | 1.07 × 108 | 2.18 × 107 | 3.03 × 1010 | 8.97 × 107 | ||
| Std | 2.66 × 105 | 8.03 × 106 | 2.04 × 107 | 9.57 × 107 | 1.58 × 108 | 2.60 × 107 | 6.25 × 109 | 4.08 × 107 | ||
| p-value | - | 1.83 × 10−6+ | 1.43 × 10−5+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f13 | Median | 1.40 × 103 | 4.13 × 103 | 3.05 × 103 | 4.13 × 103 | 3.44 × 103 | 1.18 × 104 | 2.58 × 109 | 3.82 × 104 | |
| Mean | 4.47 × 103 | 9.58 × 103 | 4.62 × 103 | 6.81 × 103 | 1.87 × 104 | 1.86 × 104 | 2.78 × 109 | 4.13 × 104 | ||
| Std | 5.03 × 103 | 1.16 × 104 | 4.04 × 103 | 5.71 × 103 | 7.41 × 104 | 1.27 × 104 | 1.14 × 109 | 1.59 × 104 | ||
| p-value | - | 8.78 × 10−2= | 4.72 × 10−1= | 1.50 × 10−1= | 3.55 × 10−1= | 2.26 × 10−5+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f14 | Median | 1.92 × 105 | 2.02 × 106 | 2.23 × 105 | 9.21 × 105 | 8.66 × 105 | 4.17 × 105 | 1.20 × 107 | 4.85 × 106 | |
| Mean | 2.04 × 105 | 2.19 × 106 | 4.45 × 105 | 1.48 × 106 | 1.30 × 106 | 8.45 × 105 | 1.39 × 107 | 5.01 × 106 | ||
| Std | 7.61 × 104 | 8.82 × 105 | 6.26 × 105 | 1.37 × 106 | 1.34 × 106 | 1.08 × 106 | 7.91 × 106 | 1.20 × 106 | ||
| p-value | - | 1.83 × 10−6+ | 8.78 × 10−2= | 7.33 × 10−6+ | 1.67 × 10−4+ | 1.30 × 10−5+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f15 | Median | 1.10 × 103 | 4.68 × 104 | 1.43 × 103 | 2.33 × 103 | 2.57 × 103 | 2.77 × 104 | 3.46 × 108 | 4.82 × 103 | |
| Mean | 3.87 × 103 | 1.16 × 105 | 2.18 × 103 | 4.88 × 103 | 3.92 × 103 | 1.85 × 104 | 3.92 × 108 | 5.32 × 103 | ||
| Std | 5.76 × 103 | 1.61 × 105 | 1.96 × 103 | 5.47 × 103 | 4.10 × 103 | 1.10 × 104 | 2.20 × 108 | 2.70 × 103 | ||
| p-value | - | 1.83 × 10−6+ | 5.65 × 10−1= | 3.76 × 10−1= | 6.51 × 10−1= | 7.20 × 10−5+ | 1.83 × 10−6+ | 2.77 × 10−2+ | ||
| f16 | Median | 1.57 × 103 | 8.87 × 103 | 2.91 × 103 | 3.71 × 103 | 3.98 × 103 | 4.01 × 103 | 9.81 × 103 | 4.02 × 103 | |
| Mean | 1.58 × 103 | 8.88 × 103 | 2.84 × 103 | 3.82 × 103 | 4.06 × 103 | 4.16 × 103 | 9.62 × 103 | 4.07 × 103 | ||
| Std | 4.82 × 102 | 3.59 × 102 | 4.77 × 102 | 6.74 × 102 | 8.46 × 102 | 6.93 × 102 | 5.78 × 102 | 3.37 × 102 | ||
| p-value | - | 1.83 × 10−6+ | 4.08 × 10−6+ | 1.83 × 10−6+ | 2.02 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f17 | Median | 1.16 × 103 | 5.97 × 103 | 2.52 × 103 | 3.23 × 103 | 2.77 × 103 | 3.72 × 103 | 6.77 × 103 | 3.23 × 103 | |
| Mean | 1.22 × 103 | 5.95 × 103 | 2.43 × 103 | 3.07 × 103 | 2.80 × 103 | 3.81 × 103 | 7.04 × 103 | 3.21 × 103 | ||
| Std | 3.81 × 102 | 3.03 × 102 | 4.78 × 102 | 5.17 × 102 | 5.82 × 102 | 6.74 × 102 | 1.41 × 103 | 2.81 × 102 | ||
| p-value | - | 1.83 × 10−6+ | 2.48 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f18 | Median | 3.35 × 105 | 3.02 × 107 | 3.87 × 105 | 2.76 × 106 | 3.39 × 105 | 1.17 × 106 | 2.20 × 107 | 7.77 × 106 | |
| Mean | 3.70 × 105 | 3.11 × 107 | 4.91 × 105 | 3.38 × 106 | 5.25 × 105 | 1.63 × 106 | 2.45 × 107 | 7.50 × 106 | ||
| Std | 1.72 × 105 | 1.18 × 107 | 3.58 × 105 | 2.09 × 106 | 4.73 × 105 | 1.25 × 106 | 1.25 × 107 | 2.41 × 106 | ||
| p-value | - | 1.83 × 10−6+ | 1.62 × 10−1= | 1.83 × 10−6+ | 4.97 × 10−1= | 2.74 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f19 | Median | 5.57 × 103 | 4.75 × 103 | 3.13 × 103 | 2.30 × 103 | 4.20 × 109 | 1.28 × 104 | 6.56 × 108 | 1.79 × 103 | |
| Mean | 7.46 × 103 | 7.38 × 103 | 4.46 × 103 | 4.86 × 103 | 4.12 × 109 | 1.93 × 104 | 6.13 × 108 | 1.97 × 103 | ||
| Std | 7.38 × 103 | 6.43 × 103 | 5.99 × 103 | 6.41 × 103 | 7.32 × 108 | 1.52 × 104 | 2.78 × 108 | 7.13 × 102 | ||
| p-value | - | 9.67 × 10−1= | 1.33 × 10−1= | 8.04 × 10−2= | 1.83 × 10−6+ | 3.06 × 10−3+ | 1.83 × 10−6+ | 2.18 × 10−3− | ||
| f10–19 | w/t/l | - | 8/2/0 | 5/5/0 | 7/3/0 | 7/3/0 | 10/0/0 | 10/0/0 | 9/0/1 | |
| f | Category | Quality | STTPSO | DNSPSO | XPSO | TCSPSO | GLPSO | HCLPSO | DPLPSO | CLPSO |
| f20 | Composition Functions | Median | 7.56 × 102 | 5.57 × 103 | 2.10 × 103 | 2.88 × 103 | 5.26 × 103 | 2.86 × 103 | 4.69 × 103 | 2.29 × 103 |
| Mean | 7.88 × 102 | 5.20 × 103 | 2.16 × 103 | 2.83 × 103 | 5.23 × 103 | 2.76 × 103 | 4.69 × 103 | 2.34 × 103 | ||
| Std | 2.72 × 102 | 9.09 × 102 | 3.96 × 102 | 4.93 × 102 | 1.93 × 102 | 3.59 × 102 | 4.05 × 102 | 2.09 × 102 | ||
| p-value | - | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f21 | Median | 2.98 × 102 | 1.22 × 103 | 4.64 × 102 | 7.91 × 102 | 6.06 × 102 | 8.46 × 102 | 1.60 × 103 | 9.66 × 102 | |
| Mean | 2.96 × 102 | 1.22 × 103 | 4.66 × 102 | 7.87 × 102 | 6.26 × 102 | 8.42 × 102 | 1.60 × 103 | 9.62 × 102 | ||
| Std | 9.91 × 100 | 3.32 × 101 | 5.19 × 101 | 8.43 × 101 | 7.42 × 101 | 6.64 × 101 | 8.73 × 101 | 3.02 × 101 | ||
| p-value | - | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.82 × 10−6+ | 1.83 × 10−6+ | 1.82 × 10−6+ | 1.83 × 10−6+ | ||
| f22 | Median | 8.16 × 103 | 3.08 × 104 | 1.36 × 104 | 1.46 × 104 | 1.80 × 104 | 1.41 × 104 | 3.08 × 104 | 2.25 × 104 | |
| Mean | 8.11 × 103 | 3.02 × 104 | 1.22 × 104 | 1.46 × 104 | 1.81 × 104 | 1.42 × 104 | 3.07 × 104 | 2.23 × 104 | ||
| Std | 1.17 × 103 | 1.39 × 103 | 4.91 × 103 | 1.35 × 103 | 3.93 × 103 | 1.27 × 103 | 1.24 × 103 | 6.52 × 102 | ||
| p-value | - | 1.83 × 10−6+ | 7.05 × 10−3+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f23 | Median | 7.10 × 102 | 1.84 × 103 | 8.13 × 102 | 1.04 × 103 | 1.11 × 103 | 8.83 × 102 | 2.82 × 103 | 9.01 × 102 | |
| Mean | 7.18 × 102 | 1.89 × 103 | 8.09 × 102 | 1.07 × 103 | 1.12 × 103 | 8.89 × 102 | 2.85 × 103 | 9.01 × 102 | ||
| Std | 2.95 × 101 | 2.76 × 102 | 4.95 × 101 | 1.09 × 102 | 1.66 × 102 | 4.44 × 101 | 2.15 × 102 | 2.66 × 101 | ||
| p-value | - | 1.83 × 10−6+ | 2.48 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f24 | Median | 1.14 × 103 | 3.00 × 103 | 1.20 × 103 | 1.52 × 103 | 1.68 × 103 | 1.50 × 103 | 4.68 × 103 | 1.50 × 103 | |
| Mean | 1.14 × 103 | 3.14 × 103 | 1.25 × 103 | 1.55 × 103 | 1.64 × 103 | 1.51 × 103 | 4.69 × 103 | 1.49 × 103 | ||
| Std | 5.71 × 101 | 6.83 × 102 | 1.17 × 102 | 1.46 × 102 | 2.19 × 102 | 6.83 × 101 | 4.23 × 102 | 2.50 × 101 | ||
| p-value | - | 1.83 × 10−6+ | 1.67 × 10−4+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.82 × 10−6+ | 1.83 × 10−6+ | 1.82 × 10−6+ | ||
| f25 | Median | 8.21 × 102 | 7.62 × 102 | 1.09 × 103 | 1.29 × 103 | 1.38 × 103 | 7.63 × 102 | 1.10 × 104 | 9.02 × 102 | |
| Mean | 7.97 × 102 | 7.67 × 102 | 1.10 × 103 | 1.35 × 103 | 1.37 × 103 | 7.80 × 102 | 1.10 × 104 | 9.08 × 102 | ||
| Std | 5.15 × 101 | 5.19 × 101 | 7.56 × 101 | 2.93 × 102 | 2.10 × 102 | 6.35 × 101 | 1.35 × 103 | 4.80 × 101 | ||
| p-value | - | 3.00 × 10−2− | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.68 × 10−1= | 1.82 × 10−6+ | 1.83 × 10−6+ | ||
| f26 | Median | 6.53 × 103 | 2.88 × 104 | 5.34 × 103 | 1.06 × 104 | 8.54 × 103 | 1.13 × 104 | 2.89 × 104 | 1.09 × 104 | |
| Mean | 6.55 × 103 | 2.92 × 104 | 3.90 × 103 | 1.14 × 104 | 8.61 × 103 | 1.12 × 104 | 2.85 × 104 | 1.10 × 104 | ||
| Std | 4.55 × 102 | 5.67 × 103 | 2.58 × 103 | 2.40 × 103 | 1.57 × 103 | 5.79 × 102 | 2.39 × 103 | 3.16 × 102 | ||
| p-value | - | 1.83 × 10−6+ | 4.97 × 10−6− | 1.83 × 10−6+ | 4.08 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f27 | Median | 7.39 × 102 | 5.00 × 102 | 8.54 × 102 | 1.12 × 103 | 1.02 × 103 | 8.05 × 102 | 4.00 × 103 | 7.58 × 102 | |
| Mean | 7.53 × 102 | 5.00 × 102 | 8.75 × 102 | 1.12 × 103 | 1.01 × 103 | 8.17 × 102 | 4.05 × 103 | 7.59 × 102 | ||
| Std | 4.28 × 101 | 0.00 × 100 | 7.68 × 101 | 1.75 × 102 | 8.73 × 101 | 8.19 × 101 | 4.27 × 102 | 2.21 × 101 | ||
| p-value | - | 1.83 × 10−6− | 3.34 × 10−6+ | 1.83 × 10−6+ | 1.82 × 10−6+ | 1.15 × 10−3+ | 1.83 × 10−6+ | 3.99 × 10−1= | ||
| f28 | Median | 5.85 × 102 | 5.00 × 102 | 8.26 × 102 | 1.33 × 103 | 1.27 × 103 | 5.85 × 102 | 1.43 × 104 | 1.28 × 104 | |
| Mean | 4.99 × 103 | 5.00 × 102 | 8.26 × 102 | 1.37 × 103 | 1.32 × 103 | 1.12 × 103 | 1.41 × 104 | 1.28 × 104 | ||
| Std | 5.82 × 103 | 0.00 × 100 | 4.81 × 101 | 3.31 × 102 | 1.61 × 102 | 2.21 × 103 | 1.54 × 103 | 5.96 × 101 | ||
| p-value | - | 1.82 × 10−6− | 3.88 × 10−1= | 3.88 × 10−1= | 3.88 × 10−1= | 2.33 × 10−1= | 3.34 × 10−6+ | 1.13 × 10−5+ | ||
| f29 | Median | 1.76 × 103 | 6.76 × 103 | 3.08 × 103 | 3.91 × 103 | 3.53 × 103 | 3.95 × 103 | 1.03 × 104 | 3.30 × 103 | |
| Mean | 1.82 × 103 | 6.79 × 103 | 3.10 × 103 | 3.91 × 103 | 3.71 × 103 | 3.94 × 103 | 1.05 × 104 | 3.30 × 103 | ||
| Std | 3.67 × 102 | 3.36 × 102 | 5.11 × 102 | 5.41 × 102 | 7.04 × 102 | 6.27 × 102 | 1.15 × 103 | 2.71 × 102 | ||
| p-value | - | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.82 × 10−6+ | 1.83 × 10−6+ | 1.82 × 10−6+ | ||
| f30 | Median | 4.41 × 103 | 7.97 × 102 | 2.59 × 104 | 1.04 × 105 | 2.24 × 105 | 1.13 × 104 | 2.38 × 109 | 5.76 × 104 | |
| Mean | 4.74 × 103 | 8.61 × 102 | 3.28 × 104 | 1.46 × 105 | 6.40 × 105 | 1.50 × 104 | 2.49 × 109 | 7.32 × 104 | ||
| Std | 1.39 × 103 | 2.29 × 102 | 2.36 × 104 | 1.34 × 105 | 1.01 × 106 | 1.62 × 104 | 7.38 × 108 | 5.20 × 104 | ||
| p-value | - | 1.83 × 10−6− | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.83 × 10−6+ | 1.07 × 10−5+ | 1.83 × 10−6+ | 1.83 × 10−6+ | ||
| f20–30 | w/t/l | - | 7/0/4 | 9/1/1 | 10/1/0 | 10/1/0 | 9/2/0 | 11/0/0 | 10/1/0 | |
| w/t/l | - | 21/4/4 | 20/7/2 | 24/5/0 | 24/4/1 | 26/2/1 | 29/0/0 | 27/1/1 | ||
| rank | 1.52 | 5.31 | 2.72 | 4.83 | 4.83 | 4.00 | 7.72 | 5.07 | ||
| Category | D | DNSPSO | XPSO | TCSPSO | GLPSO | HCLPSO | DPLPSO | CLPSO |
|---|---|---|---|---|---|---|---|---|
| Unimodal Functions | 30 | 2/0/0 | 0/1/1 | 0/1/1 | 0/1/1 | 1/0/1 | 2/0/0 | 1/0/1 |
| 50 | 1/1/0 | 0/1/1 | 0/2/0 | 0/1/1 | 1/0/1 | 2/0/0 | 1/1/0 | |
| 100 | 1/1/0 | 0/1/1 | 1/1/0 | 1/0/1 | 1/0/1 | 2/0/0 | 2/0/0 | |
| Simple Multimodal Functions | 30 | 5/0/1 | 6/0/0 | 6/0/0 | 6/0/0 | 6/0/0 | 6/0/0 | 6/0/0 |
| 50 | 5/0/1 | 6/0/0 | 6/0/0 | 6/0/0 | 5/1/0 | 6/0/0 | 6/0/0 | |
| 100 | 5/1/0 | 6/0/0 | 6/0/0 | 6/0/0 | 6/0/0 | 6/0/0 | 6/0/0 | |
| Hybrid Functions | 30 | 7/1/2 | 3/6/1 | 6/4/0 | 4/5/1 | 7/3/0 | 10/0/0 | 5/2/3 |
| 50 | 9/0/1 | 5/2/3 | 7/2/1 | 7/1/2 | 7/3/0 | 10/0/0 | 7/0/3 | |
| 100 | 8/2/0 | 5/5/0 | 7/3/0 | 7/3/0 | 10/0/0 | 10/0/0 | 9/0/1 | |
| Composition Functions | 30 | 9/0/2 | 9/1/1 | 11/0/0 | 11/0/0 | 10/1/0 | 10/1/0 | 9/1/1 |
| 50 | 8/1/2 | 8/2/1 | 10/0/1 | 10/0/1 | 8/3/0 | 11/0/0 | 9/0/2 | |
| 100 | 7/0/4 | 9/1/1 | 10/1/0 | 10/1/0 | 9/2/0 | 11/0/0 | 10/1/0 | |
| Whole Set | 30 | 23/1/5 | 18/8/3 | 23/5/1 | 21/6/2 | 24/4/1 | 28/1/0 | 21/3/5 |
| 50 | 23/2/4 | 19/5/5 | 23/4/2 | 23/2/4 | 21/7/1 | 29/0/0 | 23/1/5 | |
| 100 | 21/4/4 | 20/7/2 | 24/5/0 | 24/4/1 | 26/2/1 | 29/0/0 | 27/1/1 |
| f | stopmax = 0 | stopmax = 5 | stopmax = 10 | stopmax = 15 | stopmax = 20 | stopmax = 25 | stopmax = 30 | stopmax = 35 | stopmax = 40 |
|---|---|---|---|---|---|---|---|---|---|
| f1 | 9.66 × 106 | 1.07 × 104 | 7.82 × 103 | 6.64 × 103 | 6.20 × 103 | 9.07 × 103 | 4.33 × 103 | 7.55 × 103 | 8.64 × 103 |
| f3 | 1.75 × 105 | 7.17 × 104 | 6.60 × 104 | 6.66 × 104 | 6.17 × 104 | 6.53 × 104 | 5.85 × 104 | 6.16 × 104 | 6.14 × 104 |
| f4 | 2.32 × 102 | 1.97 × 102 | 1.88 × 102 | 1.91 × 102 | 1.95 × 102 | 1.83 × 102 | 1.69 × 102 | 1.74 × 102 | 1.87 × 102 |
| f5 | 3.99 × 102 | 9.49 × 101 | 1.50 × 101 | 1.47 × 101 | 1.77 × 101 | 1.67 × 101 | 9.09 × 100 | 1.84 × 101 | 1.69 × 101 |
| f6 | 6.74 × 100 | 8.56 × 10−7 | 1.51 × 10−6 | 1.26 × 10−6 | 1.78 × 10−6 | 1.50 × 10−6 | 4.48 × 10−6 | 1.83 × 10−6 | 2.53 × 10−6 |
| f7 | 4.76 × 102 | 3.35 × 102 | 1.16 × 102 | 6.12 × 101 | 6.52 × 101 | 6.75 × 101 | 6.33 × 101 | 6.90 × 101 | 6.32 × 101 |
| f8 | 3.97 × 102 | 4.72 × 101 | 1.68 × 101 | 1.74 × 101 | 1.63 × 101 | 1.73 × 101 | 9.35 × 100 | 1.80 × 101 | 1.81 × 101 |
| f9 | 1.46 × 102 | 6.68 × 10−1 | 1.62 × 100 | 1.39 × 100 | 1.92 × 100 | 1.93 × 100 | 8.56 × 10−1 | 1.19 × 100 | 1.17 × 100 |
| f10 | 1.32 × 104 | 1.25 × 104 | 1.22 × 104 | 1.13 × 104 | 1.15 × 104 | 1.14 × 104 | 3.49 × 103 | 1.09 × 104 | 1.09 × 104 |
| f11 | 5.40 × 102 | 4.67 × 101 | 5.27 × 101 | 5.62 × 101 | 5.81 × 101 | 6.07 × 101 | 6.12 × 101 | 5.77 × 101 | 6.07 × 101 |
| f12 | 7.61 × 107 | 2.82 × 106 | 1.83 × 106 | 2.12 × 106 | 2.16 × 106 | 1.64 × 106 | 8.89 × 105 | 1.64 × 106 | 1.69 × 106 |
| f13 | 3.65 × 104 | 3.01 × 104 | 2.19 × 104 | 3.04 × 104 | 2.92 × 104 | 2.72 × 104 | 1.63 × 104 | 2.70 × 104 | 2.64 × 104 |
| f14 | 4.53 × 105 | 2.17 × 105 | 2.34 × 105 | 1.77 × 105 | 1.74 × 105 | 2.21 × 105 | 7.09 × 104 | 2.19 × 105 | 1.83 × 105 |
| f15 | 3.11 × 104 | 3.13 × 104 | 3.13 × 104 | 2.98 × 104 | 3.12 × 104 | 3.11 × 104 | 1.32 × 104 | 3.00 × 104 | 3.00 × 104 |
| f16 | 3.04 × 103 | 1.71 × 103 | 6.33 × 102 | 4.70 × 102 | 4.38 × 102 | 5.28 × 102 | 4.23 × 102 | 5.27 × 102 | 5.81 × 102 |
| f17 | 1.95 × 103 | 1.04 × 103 | 7.59 × 102 | 5.10 × 102 | 4.22 × 102 | 3.80 × 102 | 3.11 × 102 | 5.28 × 102 | 6.00 × 102 |
| f18 | 5.94 × 106 | 2.78 × 106 | 2.51 × 106 | 2.00 × 106 | 1.82 × 106 | 1.82 × 106 | 4.28 × 105 | 1.51 × 106 | 1.64 × 106 |
| f19 | 2.46 × 103 | 2.29 × 103 | 2.11 × 103 | 2.02 × 103 | 1.91 × 103 | 1.90 × 103 | 4.33 × 103 | 1.69 × 103 | 1.81 × 103 |
| f20 | 1.63 × 103 | 1.29 × 103 | 1.17 × 103 | 1.01 × 103 | 8.36 × 102 | 8.01 × 102 | 1.76 × 102 | 6.15 × 102 | 6.60 × 102 |
| f21 | 6.00 × 102 | 2.79 × 102 | 2.28 × 102 | 2.28 × 102 | 2.30 × 102 | 2.29 × 102 | 2.22 × 102 | 2.32 × 102 | 2.32 × 102 |
| f22 | 1.33 × 104 | 1.21 × 104 | 1.19 × 104 | 1.05 × 104 | 9.73 × 103 | 1.02 × 104 | 3.10 × 103 | 9.29 × 103 | 9.76 × 103 |
| f23 | 8.36 × 102 | 5.13 × 102 | 5.11 × 102 | 5.14 × 102 | 5.18 × 102 | 5.18 × 102 | 5.09 × 102 | 5.21 × 102 | 5.20 × 102 |
| f24 | 8.85 × 102 | 5.98 × 102 | 5.89 × 102 | 5.90 × 102 | 5.94 × 102 | 5.91 × 102 | 5.83 × 102 | 5.96 × 102 | 5.95 × 102 |
| f25 | 5.48 × 102 | 4.81 × 102 | 4.82 × 102 | 4.83 × 102 | 4.81 × 102 | 4.82 × 102 | 5.06 × 102 | 4.84 × 102 | 4.83 × 102 |
| f26 | 5.49 × 103 | 2.37 × 103 | 2.40 × 103 | 2.45 × 103 | 2.51 × 103 | 2.51 × 103 | 2.27 × 103 | 2.54 × 103 | 2.57 × 103 |
| f27 | 6.92 × 102 | 7.72 × 102 | 7.66 × 102 | 7.52 × 102 | 7.59 × 102 | 7.56 × 102 | 6.94 × 102 | 7.59 × 102 | 7.63 × 102 |
| f28 | 5.01 × 103 | 4.99 × 103 | 4.30 × 103 | 5.00 × 103 | 4.92 × 103 | 4.96 × 103 | 9.06 × 102 | 4.77 × 103 | 4.78 × 103 |
| f29 | 2.07 × 103 | 1.32 × 103 | 1.16 × 103 | 1.00 × 103 | 1.03 × 103 | 9.13 × 102 | 5.90 × 102 | 9.35 × 102 | 1.01 × 103 |
| f30 | 1.57 × 106 | 1.52 × 106 | 1.45 × 106 | 1.36 × 106 | 1.37 × 106 | 1.34 × 106 | 8.55 × 105 | 1.15 × 106 | 1.24 × 106 |
| rank | 8.55 | 6.52 | 5.14 | 4.31 | 4.69 | 4.62 | 2.14 | 4.31 | 4.72 |
| f | STTPSO | STTPSO_WR | STTPSO_WA |
|---|---|---|---|
| f1 | 4.33 × 103 | 8.59 × 103 | 5.75 × 103 |
| f3 | 5.85 × 104 | 6.82 × 104 | 6.08 × 104 |
| f4 | 1.69 × 102 | 1.96 × 102 | 1.96 × 102 |
| f5 | 9.09 × 100 | 1.64 × 101 | 1.46 × 101 |
| f6 | 4.48 × 10−6 | 2.38 × 10−6 | 3.85 × 10−6 |
| f7 | 6.33 × 101 | 9.71 × 101 | 5.95 × 101 |
| f8 | 9.35 × 100 | 1.56 × 101 | 1.45 × 101 |
| f9 | 8.56 × 10−1 | 1.59 × 100 | 1.57 × 100 |
| f10 | 3.49 × 103 | 1.21 × 104 | 1.18 × 104 |
| f11 | 6.12 × 101 | 5.07 × 101 | 5.07 × 101 |
| f12 | 8.89 × 105 | 2.46 × 106 | 1.85 × 106 |
| f13 | 1.63 × 104 | 2.52 × 104 | 2.46 × 104 |
| f14 | 7.09 × 104 | 2.17 × 105 | 1.88 × 105 |
| f15 | 1.32 × 104 | 3.13 × 104 | 2.70 × 104 |
| f16 | 4.23 × 102 | 6.87 × 102 | 6.41 × 102 |
| f17 | 3.11 × 102 | 5.46 × 102 | 3.78 × 102 |
| f18 | 4.28 × 105 | 1.99 × 106 | 1.63 × 106 |
| f19 | 4.33 × 103 | 2.16 × 103 | 2.03 × 103 |
| f20 | 1.76 × 102 | 1.12 × 103 | 8.45 × 102 |
| f21 | 2.22 × 102 | 2.29 × 102 | 2.27 × 102 |
| f22 | 3.10 × 103 | 1.15 × 104 | 1.01 × 104 |
| f23 | 5.09 × 102 | 5.12 × 102 | 5.16 × 102 |
| f24 | 5.83 × 102 | 5.94 × 102 | 5.98 × 102 |
| f25 | 5.06 × 102 | 4.81 × 102 | 4.82 × 102 |
| f26 | 2.27 × 103 | 2.40 × 103 | 2.47 × 103 |
| f27 | 6.94 × 102 | 7.56 × 102 | 7.47 × 102 |
| f28 | 9.06 × 102 | 4.96 × 103 | 4.34 × 103 |
| f29 | 5.90 × 102 | 1.01 × 103 | 8.27 × 102 |
| f30 | 8.55 × 105 | 1.30 × 106 | 1.12 × 106 |
| rank | 1.31 | 2.62 | 2.07 |
| f | Dynamic | Dynamic1 | Dynamic2 | c1 = 1.0 | c1 = 1.5 | c1 = 2.0 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| c2 = 1.0 | c2 = 1.5 | c2 = 2.0 | c2 = 1.0 | c2 = 1.5 | c2 = 2.0 | c2 = 1.0 | c2 = 1.5 | c2 = 2.0 | ||||
| f1 | 4.33 × 103 | 7.70 × 103 | 8.72 × 103 | 2.44 × 103 | 4.08 × 103 | 7.78 × 103 | 6.41 × 103 | 7.75 × 103 | 1.74 × 104 | 1.37 × 104 | 1.93 × 104 | 5.31 × 107 |
| f3 | 5.85 × 104 | 6.84 × 104 | 6.43 × 104 | 6.42 × 104 | 7.20 × 104 | 7.39 × 104 | 5.43 × 104 | 6.76 × 104 | 9.44 × 104 | 6.18 × 104 | 9.54 × 104 | 1.46 × 105 |
| f4 | 1.69 × 102 | 1.91 × 102 | 1.90 × 102 | 1.18 × 102 | 1.75 × 102 | 1.94 × 102 | 1.91 × 102 | 1.84 × 102 | 1.93 × 102 | 1.80 × 102 | 1.93 × 102 | 2.33 × 102 |
| f5 | 9.09 × 100 | 1.68 × 101 | 1.82 × 101 | 9.78 × 100 | 8.50 × 100 | 1.08 × 101 | 1.72 × 101 | 1.71 × 101 | 2.90 × 102 | 2.89 × 101 | 2.94 × 102 | 3.90 × 102 |
| f6 | 4.48 × 10−6 | 2.37 × 10−4 | 2.39 × 10−6 | 7.32 × 10−5 | 5.44 × 10−6 | 1.27 × 10−6 | 8.07 × 10−4 | 1.50 × 10−6 | 3.54 × 10−4 | 3.90 × 10−5 | 3.99 × 10−3 | 3.02 × 100 |
| f7 | 6.33 × 101 | 9.75 × 101 | 7.80 × 101 | 6.67 × 101 | 6.24 × 101 | 1.80 × 102 | 6.07 × 101 | 9.58 × 101 | 3.61 × 102 | 1.03 × 102 | 3.65 × 102 | 4.44 × 102 |
| f8 | 9.35 × 100 | 1.70 × 101 | 1.76 × 101 | 8.57 × 100 | 8.18 × 100 | 1.13 × 101 | 1.68 × 101 | 1.77 × 101 | 2.85 × 102 | 2.87 × 101 | 2.74 × 102 | 3.88 × 102 |
| f9 | 8.56 × 10−1 | 1.74 × 100 | 1.60 × 100 | 6.85 × 10−1 | 3.14 × 10−1 | 8.52 × 10−1 | 1.22 × 100 | 1.49 × 100 | 2.31 × 100 | 4.38 × 100 | 3.46 × 100 | 2.95 × 102 |
| f10 | 3.49 × 103 | 1.22 × 104 | 1.21 × 104 | 3.52 × 103 | 7.09 × 103 | 1.22 × 104 | 7.77 × 103 | 1.23 × 104 | 1.27 × 104 | 1.14 × 104 | 1.29 × 104 | 1.28 × 104 |
| f11 | 6.12 × 101 | 5.16 × 101 | 5.39 × 101 | 7.72 × 101 | 5.91 × 101 | 4.65 × 101 | 5.81 × 101 | 5.04 × 101 | 1.72 × 102 | 8.09 × 101 | 1.91 × 102 | 4.75 × 102 |
| f12 | 8.89 × 105 | 2.18 × 106 | 2.40 × 106 | 7.14 × 105 | 1.23 × 106 | 1.87 × 106 | 1.46 × 106 | 2.16 × 106 | 5.52 × 106 | 3.38 × 106 | 6.65 × 106 | 1.08 × 108 |
| f13 | 1.63 × 104 | 3.26 × 104 | 3.00 × 104 | 9.33 × 103 | 1.82 × 104 | 2.72 × 104 | 2.11 × 104 | 3.14 × 104 | 3.61 × 104 | 3.65 × 104 | 3.63 × 104 | 3.77 × 104 |
| f14 | 7.09 × 104 | 2.77 × 105 | 2.14 × 105 | 7.15 × 104 | 1.02 × 105 | 1.81 × 105 | 1.93 × 105 | 2.41 × 105 | 2.84 × 105 | 2.43 × 105 | 2.40 × 105 | 4.09 × 105 |
| f15 | 1.32 × 104 | 3.12 × 104 | 3.14 × 104 | 3.71 × 103 | 2.15 × 104 | 2.97 × 104 | 3.07 × 104 | 3.12 × 104 | 3.15 × 104 | 3.15 × 104 | 3.15 × 104 | 3.19 × 104 |
| f16 | 4.23 × 102 | 6.14 × 102 | 5.99 × 102 | 4.96 × 102 | 4.02 × 102 | 6.90 × 102 | 3.92 × 102 | 5.46 × 102 | 2.26 × 103 | 6.08 × 102 | 2.16 × 103 | 2.80 × 103 |
| f17 | 3.11 × 102 | 7.20 × 102 | 6.73 × 102 | 3.01 × 102 | 3.85 × 102 | 7.63 × 102 | 2.39 × 102 | 5.93 × 102 | 1.38 × 103 | 4.69 × 102 | 1.26 × 103 | 1.78 × 103 |
| f18 | 4.28 × 105 | 2.45 × 106 | 2.39 × 106 | 3.80 × 105 | 6.79 × 105 | 1.55 × 106 | 1.64 × 106 | 2.45 × 106 | 3.21 × 106 | 2.25 × 106 | 3.06 × 106 | 4.03 × 106 |
| f19 | 4.33 × 103 | 2.09 × 103 | 2.20 × 103 | 5.91 × 103 | 1.75 × 103 | 1.86 × 103 | 1.70 × 103 | 2.14 × 103 | 2.32 × 103 | 2.37 × 103 | 2.40 × 103 | 2.48 × 103 |
| f20 | 1.76 × 102 | 1.13 × 103 | 1.12 × 103 | 1.73 × 102 | 4.35 × 102 | 1.11 × 103 | 4.18 × 102 | 1.17 × 103 | 1.32 × 103 | 1.11 × 103 | 1.36 × 103 | 1.47 × 103 |
| f21 | 2.22 × 102 | 2.27 × 102 | 2.30 × 102 | 2.32 × 102 | 2.33 × 102 | 2.22 × 102 | 2.30 × 102 | 2.30 × 102 | 4.92 × 102 | 2.43 × 102 | 4.82 × 102 | 5.92 × 102 |
| f22 | 3.10 × 103 | 1.17 × 104 | 1.18 × 104 | 3.24 × 103 | 4.42 × 103 | 1.18 × 104 | 4.83 × 103 | 1.18 × 104 | 1.25 × 104 | 1.23 × 104 | 1.28 × 104 | 1.29 × 104 |
| f23 | 5.09 × 102 | 5.18 × 102 | 5.16 × 102 | 5.36 × 102 | 5.40 × 102 | 5.04 × 102 | 5.22 × 102 | 5.15 × 102 | 6.38 × 102 | 5.27 × 102 | 6.32 × 102 | 8.21 × 102 |
| f24 | 5.83 × 102 | 5.89 × 102 | 5.87 × 102 | 6.04 × 102 | 6.06 × 102 | 5.73 × 102 | 5.90 × 102 | 5.90 × 102 | 7.90 × 102 | 5.88 × 102 | 7.45 × 102 | 8.85 × 102 |
| f25 | 5.06 × 102 | 4.83 × 102 | 4.84 × 102 | 5.51 × 102 | 5.16 × 102 | 4.80 × 102 | 4.84 × 102 | 4.82 × 102 | 5.24 × 102 | 5.16 × 102 | 5.31 × 102 | 5.69 × 102 |
| f26 | 2.27 × 103 | 2.44 × 103 | 2.49 × 103 | 2.15 × 103 | 2.34 × 103 | 2.28 × 103 | 2.40 × 103 | 2.42 × 103 | 2.65 × 103 | 2.56 × 103 | 2.67 × 103 | 5.09 × 103 |
| f27 | 6.94 × 102 | 7.43 × 102 | 7.67 × 102 | 7.46 × 102 | 7.31 × 102 | 7.07 × 102 | 7.75 × 102 | 7.53 × 102 | 7.42 × 102 | 8.28 × 102 | 8.04 × 102 | 7.80 × 102 |
| f28 | 9.06 × 102 | 5.13 × 103 | 5.10 × 103 | 5.29 × 102 | 5.27 × 102 | 2.37 × 103 | 4.60 × 103 | 5.14 × 103 | 5.30 × 103 | 5.67 × 103 | 5.66 × 103 | 5.74 × 103 |
| f29 | 5.90 × 102 | 1.14 × 103 | 1.33 × 103 | 5.62 × 102 | 5.92 × 102 | 8.11 × 102 | 1.13 × 103 | 1.13 × 103 | 1.43 × 103 | 1.80 × 103 | 1.62 × 103 | 1.80 × 103 |
| f30 | 8.55 × 105 | 1.48 × 106 | 1.38 × 106 | 8.27 × 105 | 9.18 × 105 | 1.33 × 106 | 1.29 × 106 | 1.41 × 106 | 1.53 × 106 | 1.59 × 106 | 1.54 × 106 | 1.51 × 106 |
| rank | 2.83 | 6.45 | 6.21 | 3.66 | 3.79 | 4.66 | 4.55 | 5.97 | 9.72 | 8.10 | 10.38 | 11.69 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Q.; Bian, Y.-W.; Gao, X.-D.; Xu, D.-D.; Lu, Z.-Y.; Jeon, S.-W.; Zhang, J. Stochastic Triad Topology Based Particle Swarm Optimization for Global Numerical Optimization. Mathematics 2022, 10, 1032. https://doi.org/10.3390/math10071032
Yang Q, Bian Y-W, Gao X-D, Xu D-D, Lu Z-Y, Jeon S-W, Zhang J. Stochastic Triad Topology Based Particle Swarm Optimization for Global Numerical Optimization. Mathematics. 2022; 10(7):1032. https://doi.org/10.3390/math10071032
Chicago/Turabian StyleYang, Qiang, Yu-Wei Bian, Xu-Dong Gao, Dong-Dong Xu, Zhen-Yu Lu, Sang-Woon Jeon, and Jun Zhang. 2022. "Stochastic Triad Topology Based Particle Swarm Optimization for Global Numerical Optimization" Mathematics 10, no. 7: 1032. https://doi.org/10.3390/math10071032
APA StyleYang, Q., Bian, Y.-W., Gao, X.-D., Xu, D.-D., Lu, Z.-Y., Jeon, S.-W., & Zhang, J. (2022). Stochastic Triad Topology Based Particle Swarm Optimization for Global Numerical Optimization. Mathematics, 10(7), 1032. https://doi.org/10.3390/math10071032