
Estimating the Conditional Density in Scalar-On-Function Regression Structure: k-N-N Local Linear Approach



Abstract
:1. Introduction
1.1. Related Works
1.2. Contribution
1.3. Organization
2. Methodology: Notations and Necessary Background Knowledge
2.1. Model and Its Estimator
2.2. Functional Statistics Framework: General Assumptions
3. Main Result and Proof
4. Discussion on the Impact of the Main Result and Its Usefulness
- UNN consistency vs. fixed number neighborhood consistency. As discussed in the introduction, kNN smoothing is an important estimation algorithm in nonparametric statistics. Concerning the functional L-L-E of the conditional density, the literature is limited; only the authors of [34] have proposed an estimator based on the Hilbertian version of the local linear approach introduced by [33]. They derived the almost -consistency for the fixed number neighborhood of the proposed estimator. Alternatively, we use here the fast version, which can be adapted for semi-metric space and applied even if the functional variables are discontinuous, unlike the Hilbertian version that requires oversmoothing curves to use the Fourier decomposition. Moreover, we state here the uniform consistency with respect to the number of the neighborhood, which allows us to derive the asymptotic property of the estimator even if this number is random. This last statement has a significant impact in practice. In particular, it covers the realistic situation where the best estimator (that corresponds to the best smoothing parameters, according to the criterion (5)), has a random number neighborhood. Indeed, usually, the best estimator of the conditional density is obtained by using the following cross-validation criterion,wherewith is the leave-out-one estimator of the conditional density. We point out that this criterion is inspired by the local constant estimation method (see [39] for the vectorial case or [40] for the functional case). Moreover, this rule was also used for the local linear estimator, in the nonfunctional case, by [41]. However, still now there is no mathematical support to justify the optimality of selected parameters by this rule. In fact, all the previous studies fail to guarantee the convergence of the best estimator which is associated with the values of and because they only treat the simple case when k and l are deterministic, unlike the optimal case and , which are random variables. Then, the determined uniform consistency result offers the opportunity to derive asymptotic properties of the built estimator even if the smoothing parameter is a random variable. Precisely, we obtain the following corollary.
- Local linear estimator vs. classical kernel estimator. The second advantage of our proposed estimator is the fact that the estimator for the conditional density is constructed by combining two excellent algorithms: the k-N-N smoothing technique and the L-L approach. Such consideration permits accumulation of the advantages of the two approaches. In particular, the k-N-N method allows obtaining flexibility in the bandwidth selection, which is adapted to the local structure of the functional data. Precisely, the smoothing parameter is locally selected with respect to the vicinity at the conditioning point, which allows to take into account the local behavior of the data. Despite the practical interest of this approach in functional statistics, it is not fully explored in this field. The first result on the functional conditional mode estimation was determined by [42]. They study the asymptotic properties of the kNN version of the functional Nadraya–Watson estimator. As an alternative, we use in this paper the L-L estimation method. Note that the bias that produced by the L-L method is smaller that that for the standard kernel method. This merit is also produced in the UNN consistency. Indeed, if we replace the regularity Assumption (2), for all , by and then use , to reformulate the estimator bias term as follows:
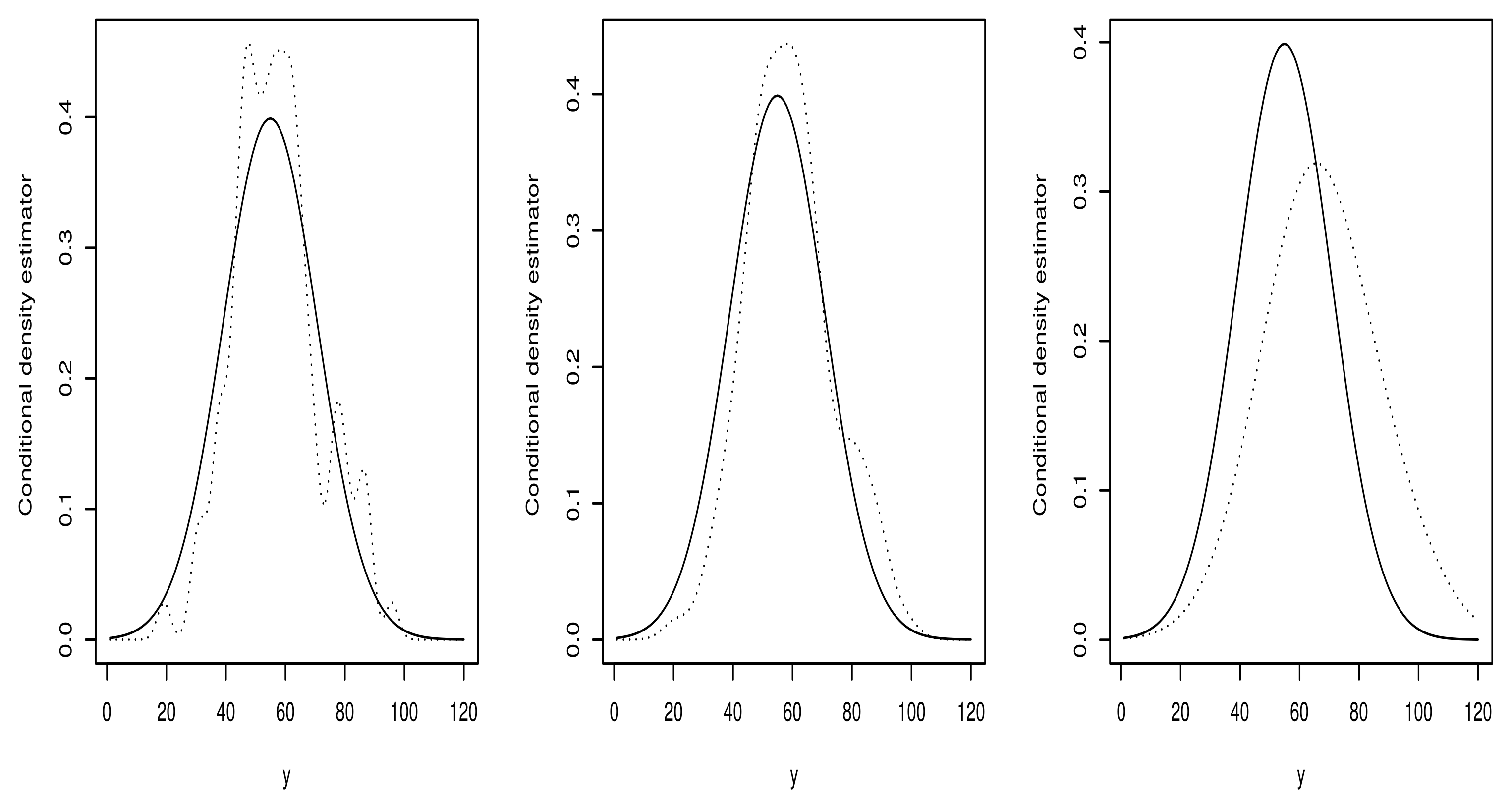
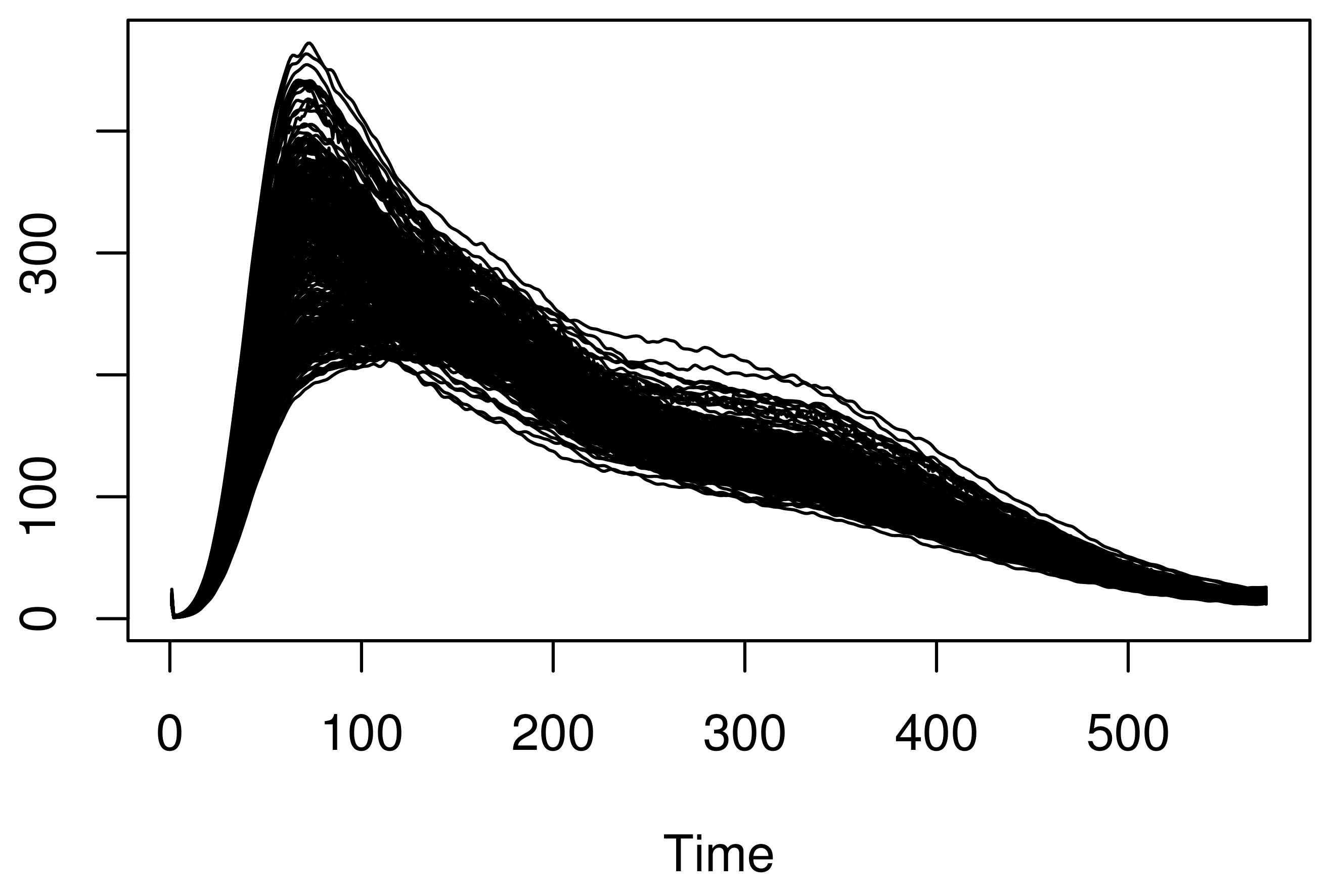
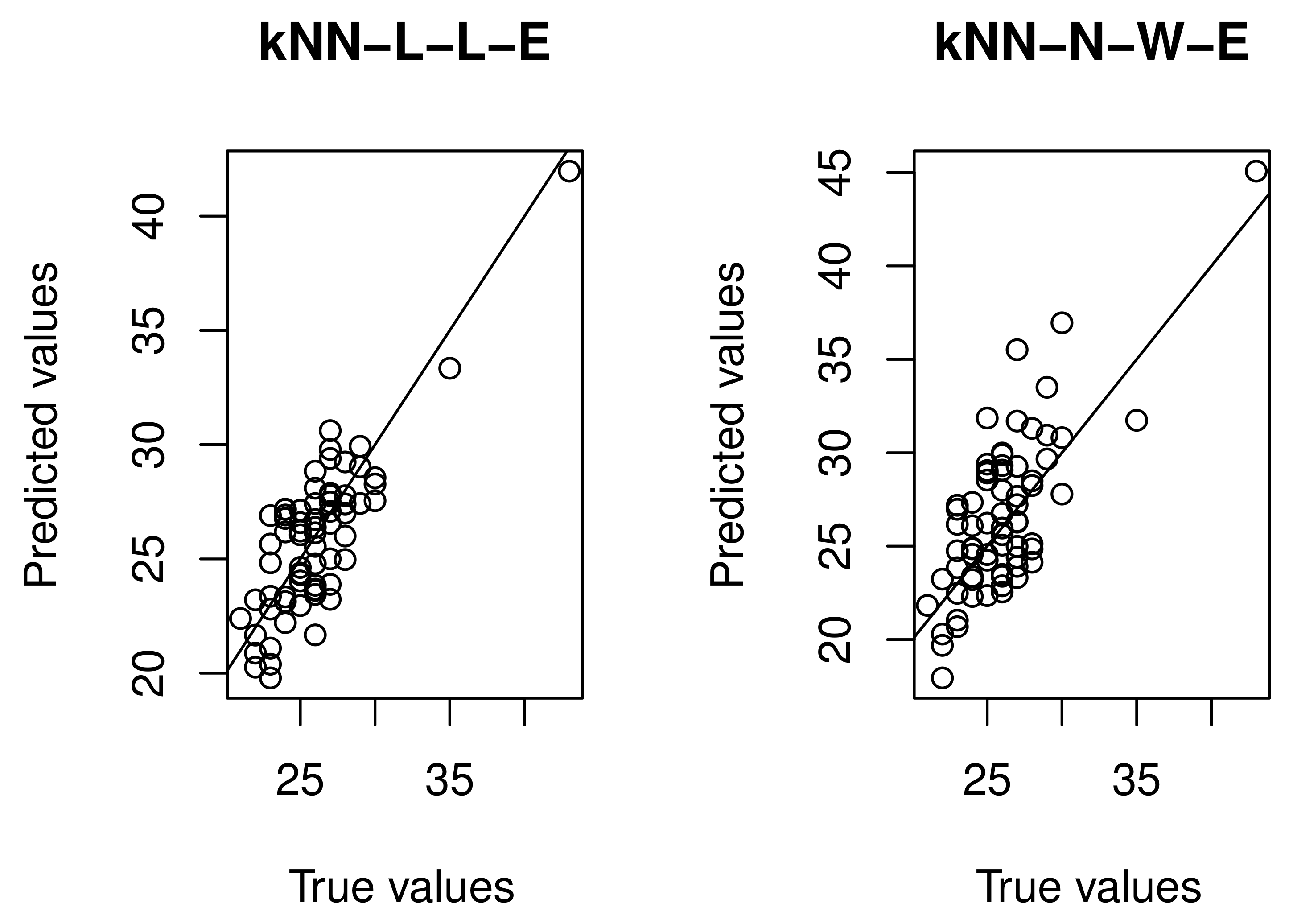
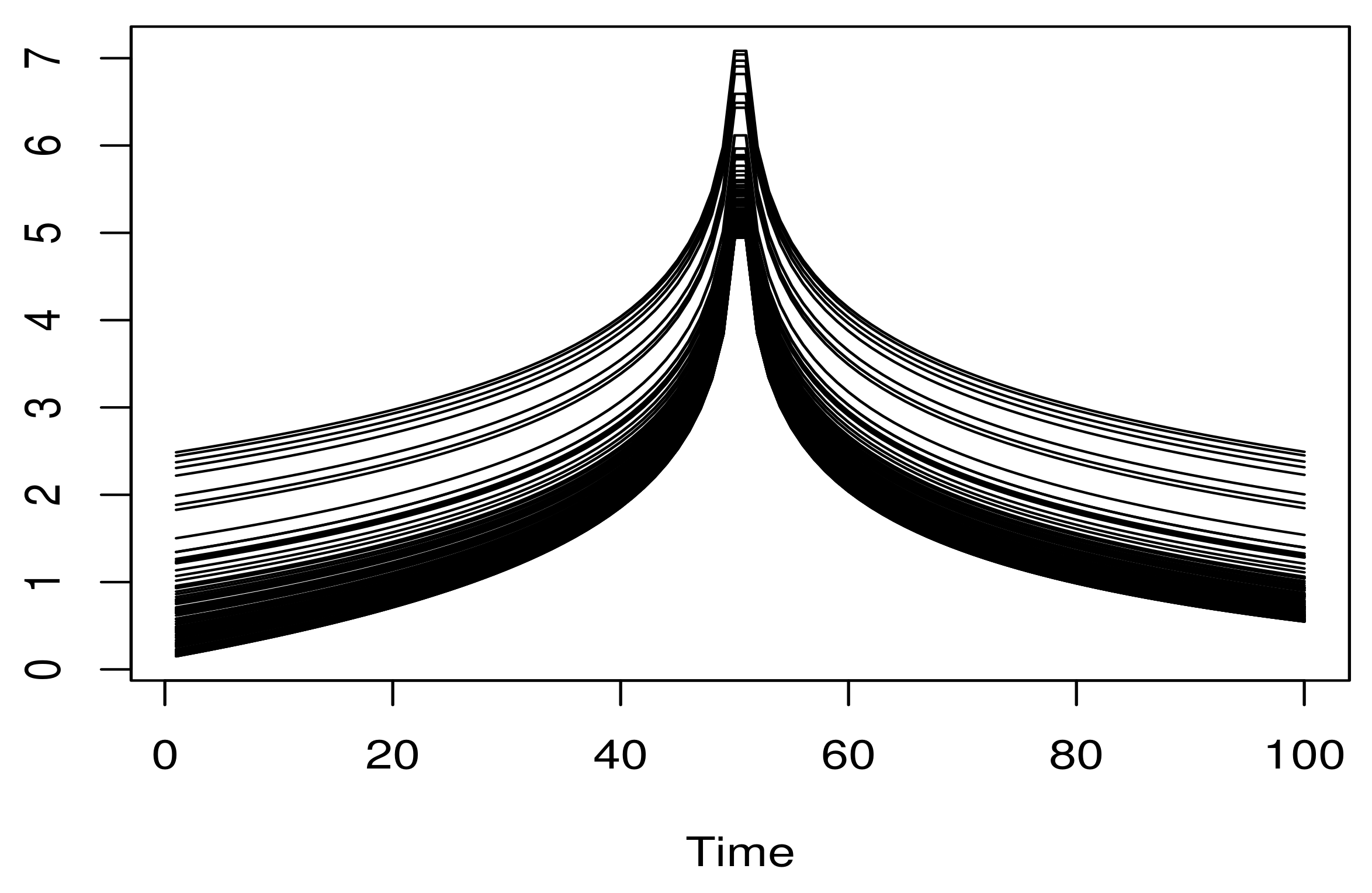
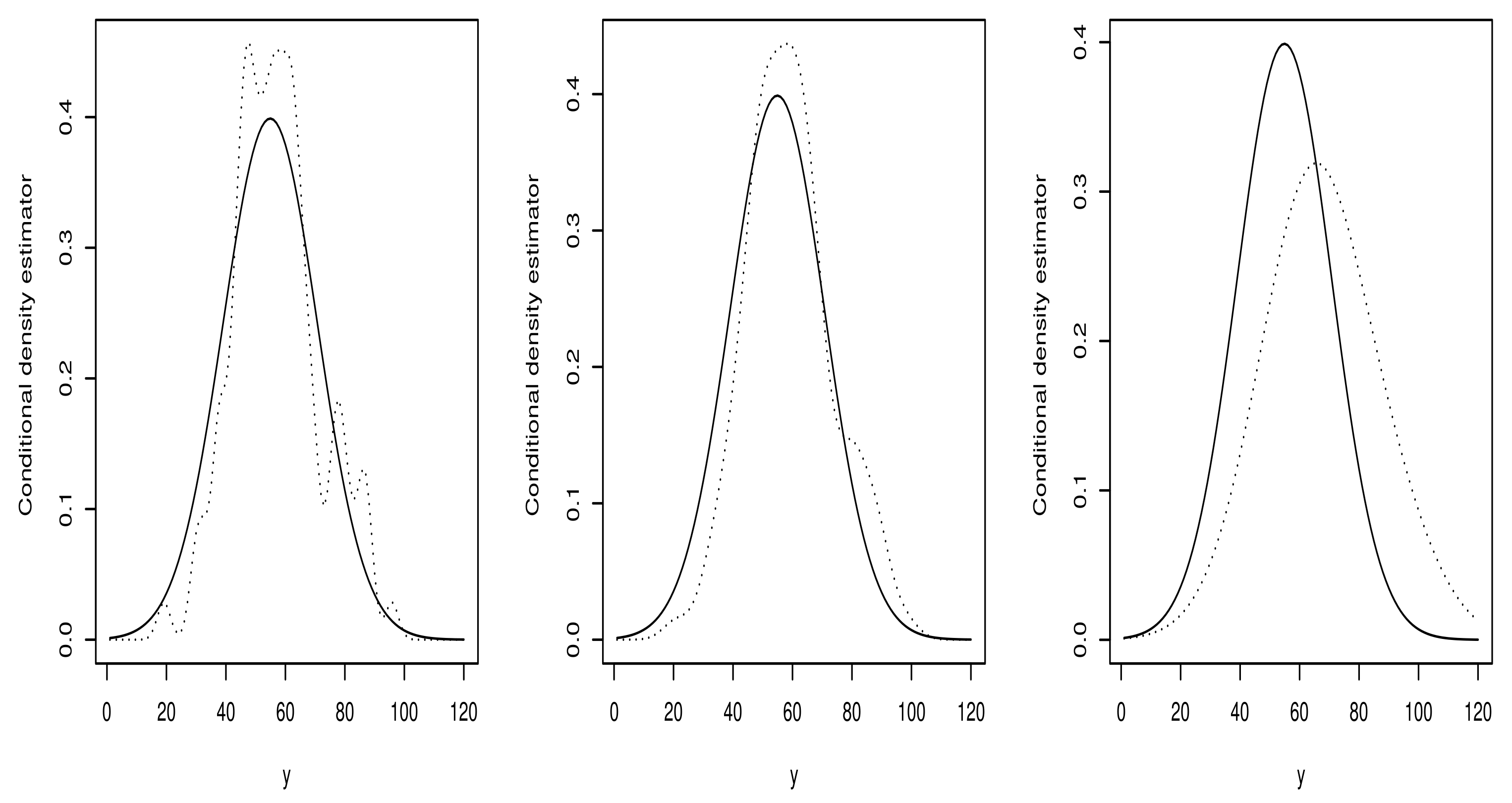
4.1. Empirical Analysis and Simulation Study
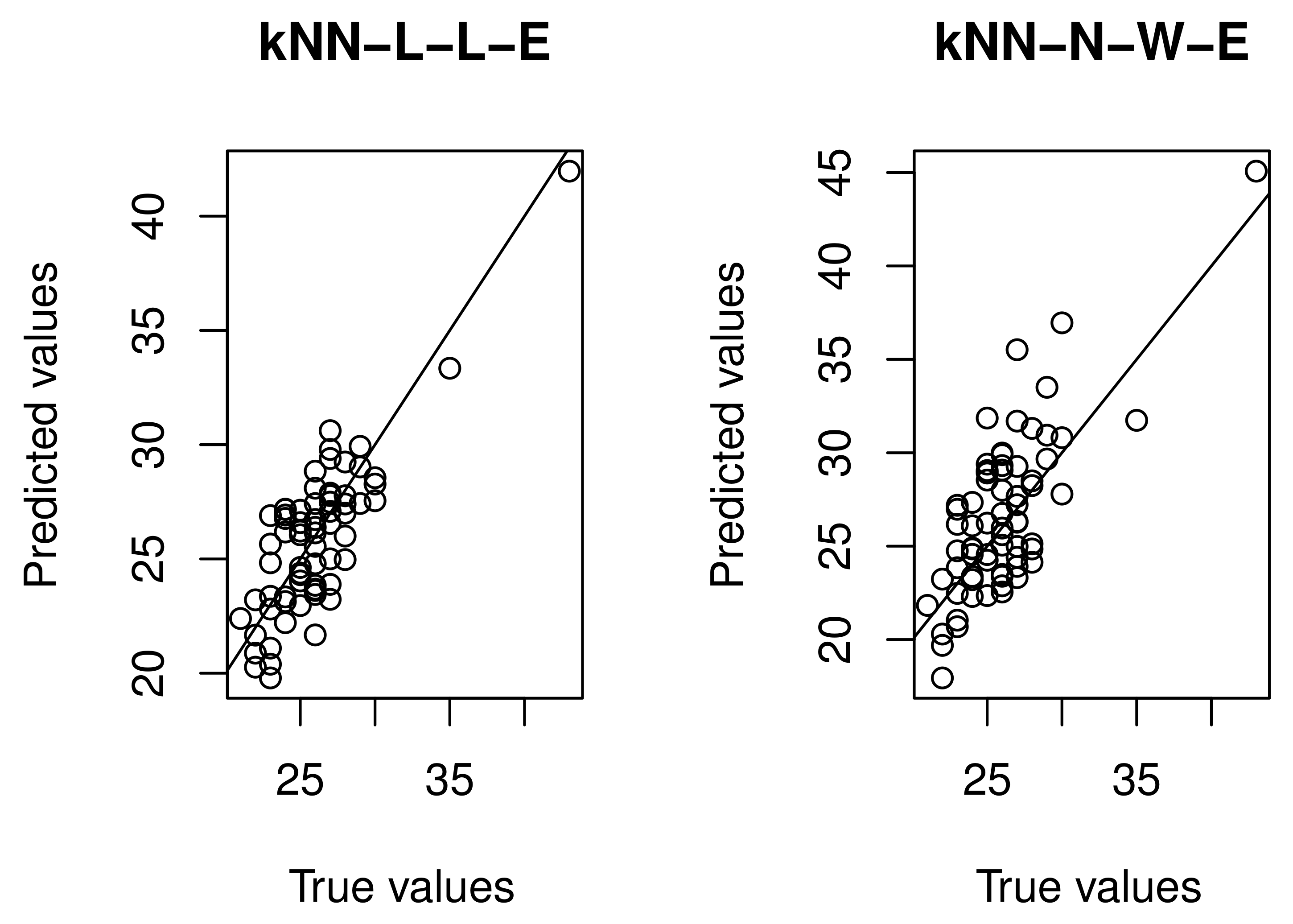
4.2. Real Data Application
5. Conclusions and Perspectives
6. Proofs of the Intermediate Results
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bosq, D. Linear Processes in Function Spaces Theory and Applications; Lecture Notes in Statistics; Springer: Berlin, Germany, 2000; Volume 149. [Google Scholar]
- Ferraty, F.; Vieu, P. Nonparametric Functional Data Analysis. Theory and Practice; Springer Series in Statistics; Springer: New York, NY, USA, 2006. [Google Scholar]
- Ramsay, J.O.; Silverman, B.W. Functional Data Analysis, 2nd ed.; Springer: New York, NY, USA, 2005. [Google Scholar]
- Aneiros, G.; Cao, R.; Fraiman, R.; Genest, C.; Vieu, P. Recent advances in functional data analysis and high-dimensional statistics. J. Multivar. Anal. 2019, 170, 3–9. [Google Scholar] [CrossRef]
- Aneiros Pérez, G.; Cao, R.; Vieu, P. Editorial on the special issue on functional data analysis and related topics. Comput. Statist. 2019, 34, 447–450. [Google Scholar] [CrossRef] [Green Version]
- Geenens, G. Curse of dimensionality and related issues in nonparametric functional regression. Stat. Surv. 2001, 5, 30–43. [Google Scholar] [CrossRef]
- Ling, N.; Vieu, P. Nonparametric modelling for functional data: Selected survey and tracks for future. Statistics 2018, 52, 934–949. [Google Scholar] [CrossRef]
- Tengteng, X.; Zhang, R. Estimation of the nonparametric mean and covariance functions for multivariate longitudinal and sparse functional data. Comm. Stat. Theory Methods 2022, 1–24. [Google Scholar] [CrossRef]
- Gattone, S.A.; Fortuna, F.; Evangelista, A.; Battista, D. Simultaneous confidence bands for the functional mean of convex curves. Econom. Stat. 2022. [Google Scholar] [CrossRef]
- Agarwal, G.; Tu, W.; Sun, Y.; Kong, L. Flexible quantile contour estimation for multivariate functional data: Beyond convexity. Comput. Stat. Data Anal. 2022, 168, 107400. [Google Scholar] [CrossRef]
- Jiang, J.; Lin, H.; Peng, H.; Fan, G.; Li, Y. Cluster analysis with regression of non-Gaussian functional data on covariates. Can. J. Stat. 2021, 50, 221–240. [Google Scholar] [CrossRef]
- To, D.; Adimari, G.; Chiogna, M. Estimation of the volume under a ROC surface in presence of covariates. Comput. Statist. Data Anal. 2022, 107–434. [Google Scholar] [CrossRef]
- Zhou, X.; Gao, X.; Zhang, Y.; Yin, X.; Shen, Y. Efficient Estimation for the Derivative of Nonparametric Function by Optimally Combining Quantile Information. Symmetry 2021, 13, 2387. [Google Scholar] [CrossRef]
- Zhao, Y.Y.; Lin, J.; Zhao, J.; Miao, Z. Estimation of semi-varying coefficient models for longitudinal data with irregular error structure. Comput. Stat. Data Anal. 2022, 169, 107389. [Google Scholar] [CrossRef]
- Zhou, Z.; Si, G.; Sun, H.; Qu, K.; Hou, W. A robust clustering algorithm based on the identification of core points and KNN kernel density estimation. Expert Syst. Appl. 2022, 195, 116573. [Google Scholar] [CrossRef]
- Shi, H.; Chen, L.; Wang, X.; Wang, G.; Wang, Q. A Nonintrusive and Real-Time Classification Method for Driver’s Gaze Region Using an RGB Camera. Sustainability 2022, 14, 508. [Google Scholar] [CrossRef]
- Cengiz, E.; Babagiray, M.; Aysal, E.F.; Aksoy, F. Kinematic viscosity estimation of fuel oil with comparison of machine learning methods. Fuel 2022, 316, 123422. [Google Scholar] [CrossRef]
- Chesneau, C.; Maillot, B. Superoptimal Rate of Convergence in Nonparametric Estimation for Functional Valued Processes. Int. Sch. Res. Not. 2014, 2014, 1–9. [Google Scholar] [CrossRef]
- Amiri, A.; Dabo-Niang, S.; Yahaya, M. Nonparametric recursive density estimation for spatial data. Comptes Rendus Math. 2016, 354, 205–210. [Google Scholar] [CrossRef]
- Giraldo, R.; Dabo-Niang, S.; Martínez, S. Statistical modeling of spatial big data: An approach from a functional data analysis perspective. Stat. Probab. Lett. 2018, 136, 126–129. [Google Scholar] [CrossRef] [Green Version]
- Chaouch, M.; Laïb, N.; Louani, D. Rate of uniform consistency for a class of mode regression on functional stationary ergodic data. Stat. Meth. Appl. 2017, 26, 19–47. [Google Scholar]
- Maillot, B.; Chesneau, C. On the conditional density estimation for continuous time processes with values in functional spaces. Stat. Probab. Lett. 2021, 178, 109179. [Google Scholar] [CrossRef]
- Kirkby, J.L.; Leitao, A.; Nguyen, D. Nonparametric density estimation and bandwidth selection with B-spline bases: A novel Galerkin method. Comput. Stat. Data Anal. 2021, 159, 107202. [Google Scholar] [CrossRef]
- Megheib, M. A Bayesian approach for nonparametric regression in the presence of correlated errors. Comm. Stat. Theory Methods 2021, 1–10. [Google Scholar] [CrossRef]
- Slaoui, Y. Two-time-scale nonparametric recursive regression estimator for independent functional data. Comm. Stat. Theory Methods 2021, 1–33. [Google Scholar] [CrossRef]
- Oshinubi, K.; Ibrahim, F.; Rachdi, M.; Demongeot, J. Functional Data Analysis: Transition from Daily Observation of COVID-19 Prevalence in France to Functional Curves. AIMS Math. 2022, 7, 5347–5385. [Google Scholar] [CrossRef]
- Aneiros, G.; Horová, I.; Hušková, M. Special Issue on Functional Data Analysis and related fields. J. Multivar. Anal. 2022, 104908. [Google Scholar] [CrossRef]
- Yang, Y.; Yao, F. Online Estimation for Functional Data. J. Amer. Stat. Ass. 2021, 1–35. [Google Scholar] [CrossRef]
- Burba, F.; Ferraty, F.; Vieu, P. k-nearest neighbor method in functional non-parametric regression. J. Nonparametr. Stat. 2009, 21, 453–469. [Google Scholar] [CrossRef]
- Barrientos-Marin, J.; Ferraty, F.; Vieu, P. Locally Modelled Regression and Functional Data. J. Nonparametr. Stat. 2010, 22, 617–632. [Google Scholar] [CrossRef]
- Demongeot, J.; Laksaci, A.; Madani, F.; Rachdi, M. Functional data: Local linear estimation of the conditional density and its application. Statistics 2013, 4, 26–44. [Google Scholar] [CrossRef]
- Demongeot, J.; Laksaci, A.; Rachdi, M.; Rahmani, S. On the local linear modelization of the conditional distribution for functional data. Sankhya A 2014, 76, 328–355. [Google Scholar] [CrossRef]
- Baìllo, A.; Grané, A. Local linear regression for functional predictor and scalar response. J. Multivar. Anal. 2009, 100, 102–111. [Google Scholar] [CrossRef] [Green Version]
- Chikr-Elmezouar, Z.; Almanjahie, I.M.; Laksaci, A.; Rachdi, M. FDA: Strong consistency of the kNN local linear estimation of the functional conditional density and mode. J. Nonparametr. Stat. 2019, 31, 175–195. [Google Scholar] [CrossRef]
- Kara-Zaitri, L.; Laksaci, A.; Rachdi, M.; Vieu, P. Data-driven k-N-N estimation in nonparametric functional data analysis. J. Multiv. Anal. 2017, 153, 176–188. [Google Scholar] [CrossRef]
- Attouch, M.; Laksaci, A.; Ould Saïd, E. Asymptotic normality of a robust estimator of the regression function for functional time series data. J. Korean Stat. Soc. 2010, 39, 489–500. [Google Scholar] [CrossRef]
- Van der Vaart, A.W.; Wellner, J.A. A local maximal inequality under uniform entropy. Electron. J. Stat. 2011, 5, 192–203. [Google Scholar] [CrossRef] [PubMed]
- Einmahl, U.; Mason, D. Uniform in bandwidth consistency of kernel-type function estimators. Ann. Stat. 2005, 33, 1380–1403. [Google Scholar] [CrossRef] [Green Version]
- Youndjé, E. Propriétés de convergence de l’estimateur à noyau de la densité conditionnelle. Rev. Roum. Math. Pures Appl. 1996, 41, 535–566. [Google Scholar]
- Laksaci, A.; Madani, F.; Rachdi, M. Kernel conditional density estimation when the regressor is valued in a semi-metric space. Comm. Stat. Theory Methods 2013, 42, 3544–3570. [Google Scholar] [CrossRef]
- Yao, Q.; Tong, H. Cross-validatory bandwidth selections for regression estimation based on dependent data. J. Stat. Plann. Inference 1998, 68, 387–415. [Google Scholar] [CrossRef] [Green Version]
- Attouch, M.; Bouabca, W. The k-nearest neighbors estimation of the conditional mode for functional data. Rev. Roum. Math. Pures Appl. 2013, 58, 393–415. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Size | The Optimal Case | (ı, j) = (−3, −4) | (ı, j) = (−3, 4) | (ı, j) = (3, 4) |
|---|---|---|---|---|
| n = 50 | 0.18 | 0.54 | 0.34 | 0.29 |
| n = 100 | 0.11 | 0.42 | 0.38 | 0.24 |
| n = 150 | 0.08 | 0.33 | 0.22 | 0.20 |
| n = 200 | 0.06 | 0.19 | 0.15 | 0.17 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almanjahie, I.M.; Kaid, Z.; Laksaci, A.; Rachdi, M. Estimating the Conditional Density in Scalar-On-Function Regression Structure: k-N-N Local Linear Approach. Mathematics 2022, 10, 902. https://doi.org/10.3390/math10060902
Almanjahie IM, Kaid Z, Laksaci A, Rachdi M. Estimating the Conditional Density in Scalar-On-Function Regression Structure: k-N-N Local Linear Approach. Mathematics. 2022; 10(6):902. https://doi.org/10.3390/math10060902
Chicago/Turabian StyleAlmanjahie, Ibrahim M., Zoulikha Kaid, Ali Laksaci, and Mustapha Rachdi. 2022. "Estimating the Conditional Density in Scalar-On-Function Regression Structure: k-N-N Local Linear Approach" Mathematics 10, no. 6: 902. https://doi.org/10.3390/math10060902
APA StyleAlmanjahie, I. M., Kaid, Z., Laksaci, A., & Rachdi, M. (2022). Estimating the Conditional Density in Scalar-On-Function Regression Structure: k-N-N Local Linear Approach. Mathematics, 10(6), 902. https://doi.org/10.3390/math10060902