Abstract
Kinship verification aims to determine whether two given persons are blood relatives. This technique can be leveraged in many real-world scenarios, such as finding missing people, identification of kinship in forensic medicine, and certain types of interdisciplinary research. Most existing methods extract facial features directly from given images and examine the full set of features to verify kinship. However, most approaches are easily affected by the age gap among faces, with few methods taking age into account. This paper accordingly proposes an Age-Invariant Adversarial Feature learning module (AIAF), which is capable of factoring in full facial features to create two uncorrelated components, i.e., identity-related features and age-related features. More specifically, we harness a type of adversarial mechanism to make the correlation between these two components as small as possible. Moreover, to pay different attention to identity-related features, we present an Identity Feature Weighted module (IFW). Only purified identity features are fed into the IFW module, which can assign different weights to the features according to their importance in the kinship verification task. Experimental results on three public popular datasets demonstrate that our approach is able to capture useful age-invariant features, i.e., identity features, and achieve significant improvements compared with other state-of-the-art methods on both small-scale and large-scale datasets.
1. Introduction
Kinship verification, which aims to determine whether a pair of input images are those of blood relatives, is a challenging but exciting task. Since the face is a pivotal biological feature of the human body, irrational use will cause serious consequences. Nevertheless, it is beneficial to many real-world scenarios if it can be used wisely, including finding missing people, human trafficking, paternity tests and identification of kinship in forensic medicine, and even interdisciplinary research such as the relationship analysis of historical figures. Many approaches, such as those based on traditional machine learning [1,2,3,4,5,6] or emerging deep learning [7,8,9,10,11,12,13,14], have been proposed for kinship verification and have achieved great performance.
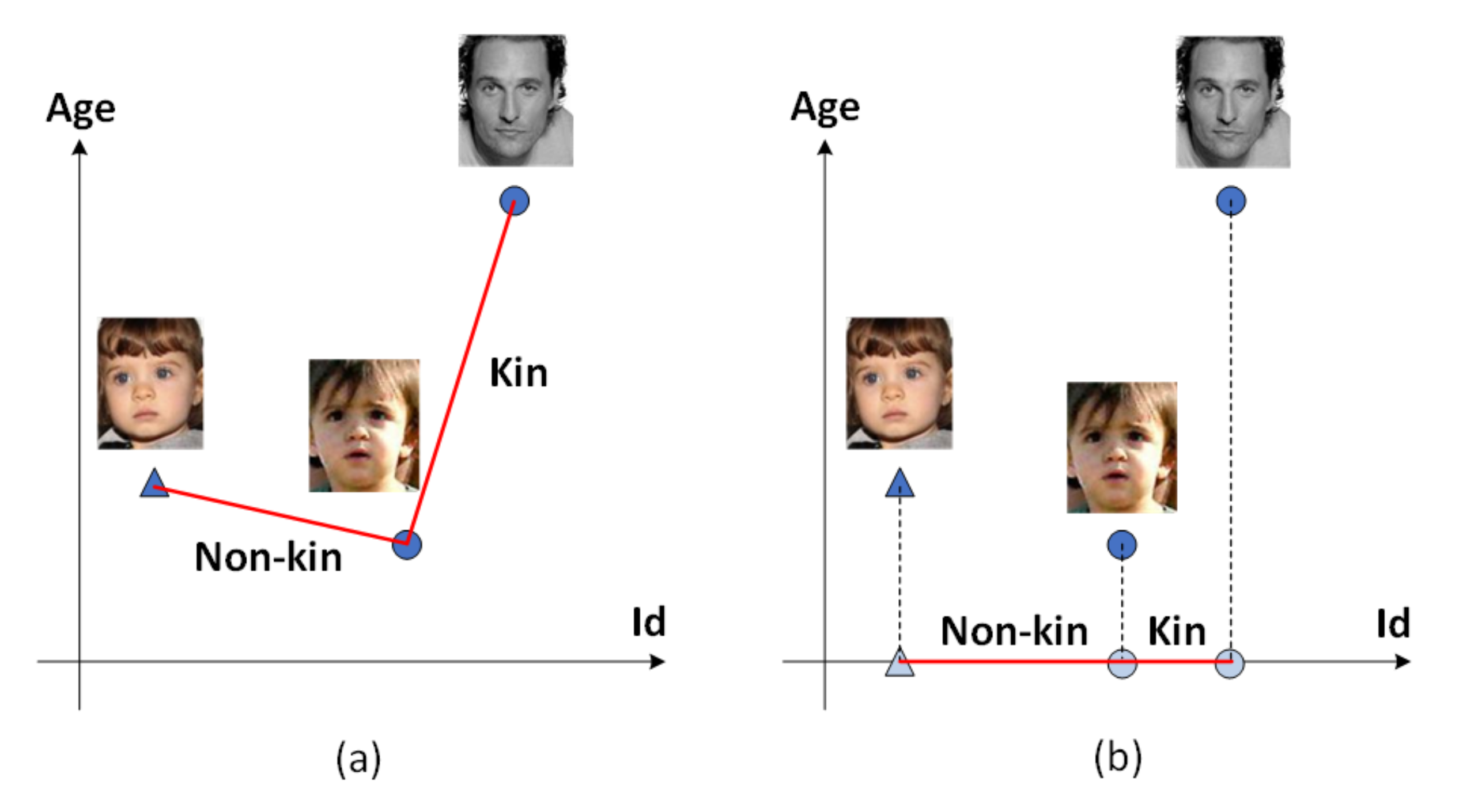
Despite their success, several recent kinship verification approaches [7,15] focus on learning separable features rather than discriminative ones, making them difficult to generalize to other datasets; hence, they cannot be directly applied to open-set problems in numerous real-world situations. In recent years, some researchers [16,17] have attempted to exploit discriminative features for these purposes. Liu et al. [18] proposed SphereFace, applying the strategy of ensuring that the maximal intra-class distance is smaller than the minimal inter-class distance. Robinson et al. [11] then applied this approach to the kinship verification task, achieving state-of-the-art results. Although SphereFace employs an effective strategy to learn discriminative features, it still includes age information, which poses a threat to the result. Figure 1a demonstrates that the distance between two persons with kinship is larger than those without kinship because of the considerable age gaps. As we know, kinship does not change as age increases; hence, our hope is that algorithms can correctly verify kinship regardless of the size of the age gap. Indeed, Wang et al. [10] take age information into account in an indirect manner. They introduce an intermediate domain to generate fake face images that look real and have an identifiable age, then use them to perform the kinship verification task. More specifically, they cut the problem into two steps: (1) generating intermediate face images to mitigate age gaps and then (2) verifying them. However, this approach requires learning a generative model to generate young face images; accordingly, it is prone to introducing unexpected errors and bringing about training instability. Furthermore, it is a two-stage approach, which increases computational costs.
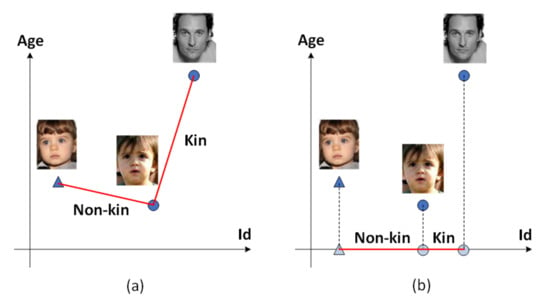
Figure 1.
The influence of age on kinship verification. (a) The distance between two kinship (dubbed) faces may be greater than that between non-kinship faces if the age factor is not eliminated. (b) Our approach can refine age-invariant features to improve the performance of the kinship verification.
To address these problems, we propose an efficient approach comprising two modules, i.e., an Age-Invariant Adversarial Feature Learning module (AIAF) and Identity Feature Weighted module (IFW). As shown in Figure 1b, AIAF is able to strip out age-related facial features, retaining only identity-related features for subsequent kinship verification. To further enhance performance, IFW is introduced to automatically assign different weights to identity features according to their importance in kinship verification. Our approach is entirely end-to-end, therefore introducing fewer errors and accordingly yielding higher accuracy without too much instability. Experimental results demonstrate that our approach achieves state-of-the-art results compared to other baseline methods.
In summary, the major contributions of this paper are three-fold:
- We design an Age-Invariant Adversarial Feature Learning module (AIAF) that can effectively extract age-invariant features. Within the proposed AIAF, the Feature Splitter (FS) is designed to split original features into two parts. An Identity classifier and Age classifier are trained to ensure that these two parts represent identity and age information, respectively;
- An Adversarial Canonical Correlation Regularizer (ACCR) is further introduced to reduce the correlation between the age features and identity features using a form of adversarial mechanism;
- Unlike face recognition, the kinship verification task is more dependent on key features. Some features may be critical than other features; e.g., the contribution of shape and surface reflectance information to kinship detection may be different [19]. To this end, we design an Identity Feature Weighted module (IFW) that assigns different weights to different facial features according to their importance. Finally, the weighted features are leveraged to make the final decision.
The rest of this paper is organized as follows. Section 2 discusses related works to the kinship verification task and some recent methods. Section 3 explains the motivation and introduces the details of our proposed approach. Section 4 conducts some experiments and experimental results demonstrate that our approach achieves state-of-the-art results compared to other methods. Section 5 concludes this paper and proposes some points for future work.
2. Related Work
2.1. Kinship Verification
Over the past decade, several approaches based on visual images have been proposed to handle the kinship verification problem. The existing approaches can be roughly divided into two categories: feature-based approaches [4,20,21,22,23,24,25], and similarity learning-based approaches [2,3,6,26,27,28,29,30].
Feature-based approaches typically learn a model capable of extracting discriminatory features from images, then verifying whether they are blood relatives. For instance, Fang et al. [20] first dealt with kinship verification via low-level feature extraction on parent-child pairs. These authors proposed manually selecting the most discriminatory features. Zhou et al. [21] developed a spatial pyramid learning-based feature descriptor for face representation and applied support vector machines for kinship verification. Guo et al. [22] leveraged the DAISY descriptor [31] to extract salient features for kinship recognition. Bottinok et al. [24] harnessed the LPQ, WLD, TPLBP, and FPLBP textural features to perform kinship verification. Bottinok et al. [23] took geometric, textural, and holistic features into account and achieved great performance on the KinFaceW-II dataset.
Moreover, similarity learning-based approaches present another way of dealing with the kinship verification problem that involves learning a semantic feature space via metric learning or subspace learning. Xia et al. [19] recognized that the faces of young children are more similar to their parents’ in previous models, consequently proposing a transfer subspace-learning-based algorithm to reduce the difference. Moreover, Lu et al. [2] proposed a neighborhood repulsed metric learning method that works by pulling intra-class images as close together as possible and pushing inter-class images as far apart as possible. Zhao et al. [32] developed a multiple kernel similarity metric method, which operates by weighting several basic metrics that measure face resemblance from various local aspects. In order to handle ambiguous pairs, Wei et al. [33] devised an adversarial similarity metric learning method to iteratively learn a robust and discriminative similarity metric.
2.2. Deep Learning-Based Face Feature Learning
Since 2012, an increasing number of researchers harnessed deep learning-based approaches to tackle kinship verification. This is because artificial neural networks, particularly Convolutional Neural Networks (CNNs) [34], are powerful tools that enable the comprehensive and automatic extraction of facial features. We accordingly highlight these methods for discussion. For example, Dehghan et al. [35] proposed a method that fuses the features and metrics by means of gated autoencoders to learn genetic features. Zhang et al. [36] leverage CNNs to extract high-level features and facial key points for kinship verification. Ding et al. [37] proposed a Discriminative Low-rank Metric Learning method (DLML) to discover the global data structure by searching for a low-rank representation. In 2016, Robinson et al. [7] released the largest kinship recognition dataset so far to promote the development of kinship verification tasks. Their fine-tuned CNN model was also found to outperform the other traditional methods. Wang et al. [9] proposed a denoising auto-encoder based on Denoising Metric Learning (DML), along with its marginalized version (mDML), to preserve the intrinsic structure of data while simultaneously endowing the learned features with discriminative information. Furthermore, Robinson et al. [11] leveraged SphereFace for handling kinship verification problems. While Wang et al. [10] did take age gaps into account, they also needed to introduce GAN as an intermediate domain. There are also many other related methods [12,14,30,38,39] that have been proposed. Overall, compared with traditional methods, deep models are better able to extract representative and comprehensive features that are difficult to select by hand. Although these approaches have made great progress in the field of kinship verification, few of them take age gaps into account.
3. Methodology
3.1. Motivation
Most existing kinship verification methods harness either traditional or deep models to extract different features. However, regardless of which approach they use, age can be easily overlooked. In fact, age is not relevant to kinship; hence, age-related information within face embeddings is minimally beneficial to this task, and may even bring about adverse effects. Even though some researchers take age into account, there exist several shortcomings of these approaches, as outlined in Section 1. Therefore, this paper will first aim to design an architecture capable of preserving only identity-related features, abandoning age-related features from the mathematical perspective. Second, in the kinship verification task, the cosine similarity of two face embeddings is often used to determine whether the pair are blood relatives; the bigger the cosine value, the higher the probability of kinship. There is however a default assumption being made here, specifically that every feature in face embeddings has the same weight; in real-world scenarios, this assumption is not always valid. For example, when people are asked to verify kin relations, we are likely, but not sure, to pay attention to the eyes, nose, mouth, or some significant organs rather than the cheeks, forehead, or other some trivial things. Furthermore, even though many people are well aware that the eyes, nose, or mouth are pivotal to this task, it remains unclear which of these is more important, or rather, what respective contribution is made by each feature. To this end, we devise a module that learns to assign different weights to features according to their importance in kinship verification.
Based on the ideas discussed above, we devise a novel approach to learn age-invariant features in an adversarial manner. Our proposed approach consists of two major modules: an Age-Invariant Adversarial Feature Learning module (AIAF) and an Identity Feature Weighted module (IFW). In the following subsections, we will describe their structures in detail and explain how they are trained.
3.2. Age-Invariant Adversarial Feature Learning Module
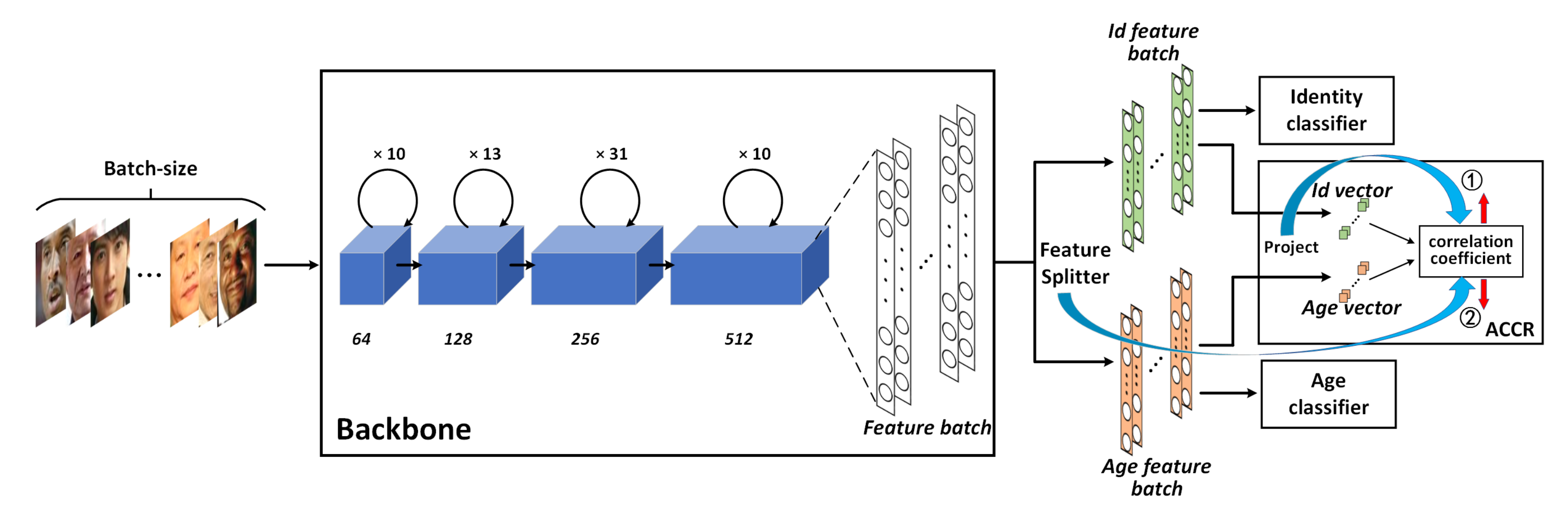
As illustrated in Figure 2, this module has five components, each of which is responsible for a specific function. (1) Backbone: is used to extract facial features from input images. (2) Feature Splitter: can divide a full facial feature vector into two feature vectors with equal dimensions. (3) Identity classifier and (4) Age classifier: these two classifiers can ensure that the two vectors split by Feature Splitter contain identity information and age information, respectively, meaning that they can subsequently be regarded as identity-related and age-related features. (5) Adversarial Canonical Correlation Regularizer: responsible for minimizing the correlation between the two feature vectors via a type of adversarial mechanism. Finally, identity-related features and age-related features are uncorrelated.
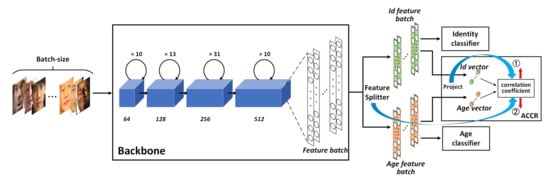
Figure 2.
The architecture of the Age-Invariant Adversarial Feature Learning module (AIAF). First, Backbone is leveraged to extract facial features. Next, Feature splitter (FS) splits the facial features into two parts with the same size. Finally, the two parts are fed into the identity classifier, age classifier, and ACCR to jointly optimize the networks.
3.2.1. Feature Splitter
As discussed above, general facial features contain both identity information and age information, although only identity information is useful in the kinship verification task. Motivated by this, we propose the Feature Splitter (FS), which is capable of directly splitting full facial features into two groups. Formally, given a CNN-based backbone B and an input image , a full facial feature vector can be expressed as . Through FS, x can be factorized as follows:
Here, S denotes the FS operation, while and denote two types of features, i.e., identity features and age features. Note that FS simply separates a feature vector from the middle into two small vectors.
3.2.2. Identity Loss
After the feature splitter has been applied, two vectors are acquired. As discussed in Section 3.1, we need one of the two vectors—let this be denoted as to represent identity features. We thus train to perform the identity classification task. When different identities in a vast dataset can be classified correctly, we deem that the vector is able to extract discriminative features. While the traditional Softmax loss used in classifiers is usually able to classify faces correctly, it is not robust enough for our purposes and does not generalize well. For open-set problems, we hope the classifier can learn a rule to increase the inter-class distance and decrease the intra-class distance as much as possible. Fortunately, many promising approaches of this kind have been proposed [40,41,42,43]. Here, we adopt Additive Angular Margin Loss (ArcFace) [43] for implementation due to its popularity and excellent face recognition performance. We note that other loss functions (e.g., [40,41,42]) can be applied in our framework as well.
where N is the number of identities, is the label of the i-th identity, is the angle between the j-th trainable weight and the i-th identity feature , and . Moreover, s is a scaling factor, while m is an additive angular margin penalty between and introduced to boost intra-class compactness and inter-class distance. In fact, is fixed to 1 through normalization, and is also fixed through normalization and rescale it via s. When approaches zero, the feature vector can be viewed as the identity-related features , i.e., . Please refer to [43] for a more detailed description of the behavior of this loss function.
3.2.3. Age Loss
In the previous section, we harnessed a feature vector to express identity-related features . The remaining feature vector is leveraged to represent the age-related features . Theoretically, we could use age labels to train the vector. However, age values are difficult to label precisely due to the presence of noise. If age labels are classified according to all accessible integers, this can easily lead to misclassification; after all, even humans find it very difficult to determine whether a person is 20 or 21 years old. Thus, our strategy is to divide ages into eight age groups, such that every age label belongs to one of the groups. Subsequently, Softmax loss is adopted to optimize the age classification task:
where refers to the age feature of the i-th sample, is the output of through , and is the ground truth of the i-th sample. and are the corresponding weight matrix and bias. When approaches zero, the feature vector can be viewed as the age-related features , i.e., .
3.2.4. Adversarial Canonical Correlation Regularizer Loss
When a full facial feature vector is split by the Feature Splitter, two small feature vectors and can be obtained, but these might be correlated due to the presence of latent relationships. Following the optimization of identity classification and age classification, and represent the identity-related features and age-related features , respectively. Nevertheless, the correlation between and is not eliminated. Accordingly, inspired by Wang et al. [44], we design the Adversarial Canonical Correlation Regularizer (ACCR) to minimize the correlation between and . Unlike their work, we do not assume two groups of features have linear relationship. In the context of the kinship verification problem, we cannot directly calculate the correlation coefficient because identity-related features and age-related features are high-dimensional. The correlation coefficient considers only the correlation between two groups of features without considering the correlation between the variables within the two groups. Thus, in order to analyze the overall correlation between the identity and age features, the canonical correlation analysis [45] is leveraged to extract two representative variables (dimensionality reduction) in order to reflect the overall correlation between the two groups of features. In more detail, we input a batch of images rather than individual images. Through the backbone and FS module, their identity feature batch and age feature batch are obtained; these are then projected by ACCR into the identity vector and age vector, respectively. The final step is to output the correlation coefficient between the two vectors.
Formally, given two groups of features and extracted by FS, where n and L refer to the mini-batch size and feature length, respectively. The canonical correlation between and can be formulated as follows:
where and indicate trainable vectors, while and denote the projection vectors. and project the matrices and into vectors and , respectively. To optimize and , we define the correlation coefficient as follows:
Based on this formula, the correlation coefficient between and can be calculated. In other words, ( for short) reflects the correlation between and . Importantly, our goal is to train the backbone B and feature splitter S to make identity features and age features as irrelevant as possible. One way is to minimize . However, due to the introduction of and , they can also be optimized resulting in the decrease of the , which is unexpected because we will not know exactly which variable caused the decrease. For addressing this issue, in practice, we first freeze the backbone B and feature splitter S, then train and by maximizing . When reaches the maximum value, we unfreeze B and S, and freeze and , updating B and S to minimize , which ensures that the decrease of is credited to B and S instead of and . These two operations are iterated repeatedly until converges to a minimum. At this point, the projection vectors and are optimal, which means they can maximize . As a result, the minimum totally depends on B and S.
This training process can be viewed as a sort of adversarial game: one side ( and ) wants to maximize , while the other (B and S) wants to minimize it. In other words, the process involves repeatedly minimizing the maximum , which is formulated as follows:
where refers to a mini-batch of n images. The overall intention of this module is to minimize the canonical correlation between and . Note that min operation is outside of max operation so that the final result is minimum. Through canonical correlation analysis, we convert the problem to one of minimizing the maximal correlation coefficient between and . Finally, after adequate training, the and generated by Feature Splitter will be uncorrelated.
3.2.5. Multi-Task Learning
Overall, in order to train different components simultaneously to perform their own jobs, the three aforementioned losses are assembled into a multi-task learning loss, which is formulated as follows:
where , , and are loss terms for optimizing identity classification, age classification, and ACCR, respectively, while are hyperparameters used to balance weights among the three losses.
For clarity, the procedure of training the Age-Invariant Adversarial Feature Learning module is outlined in Algorithm 1.
| Algorithm 1: Age-Invariant Adversarial Feature Learning algorithm. |
 |
3.3. Identity Feature Weighted Module
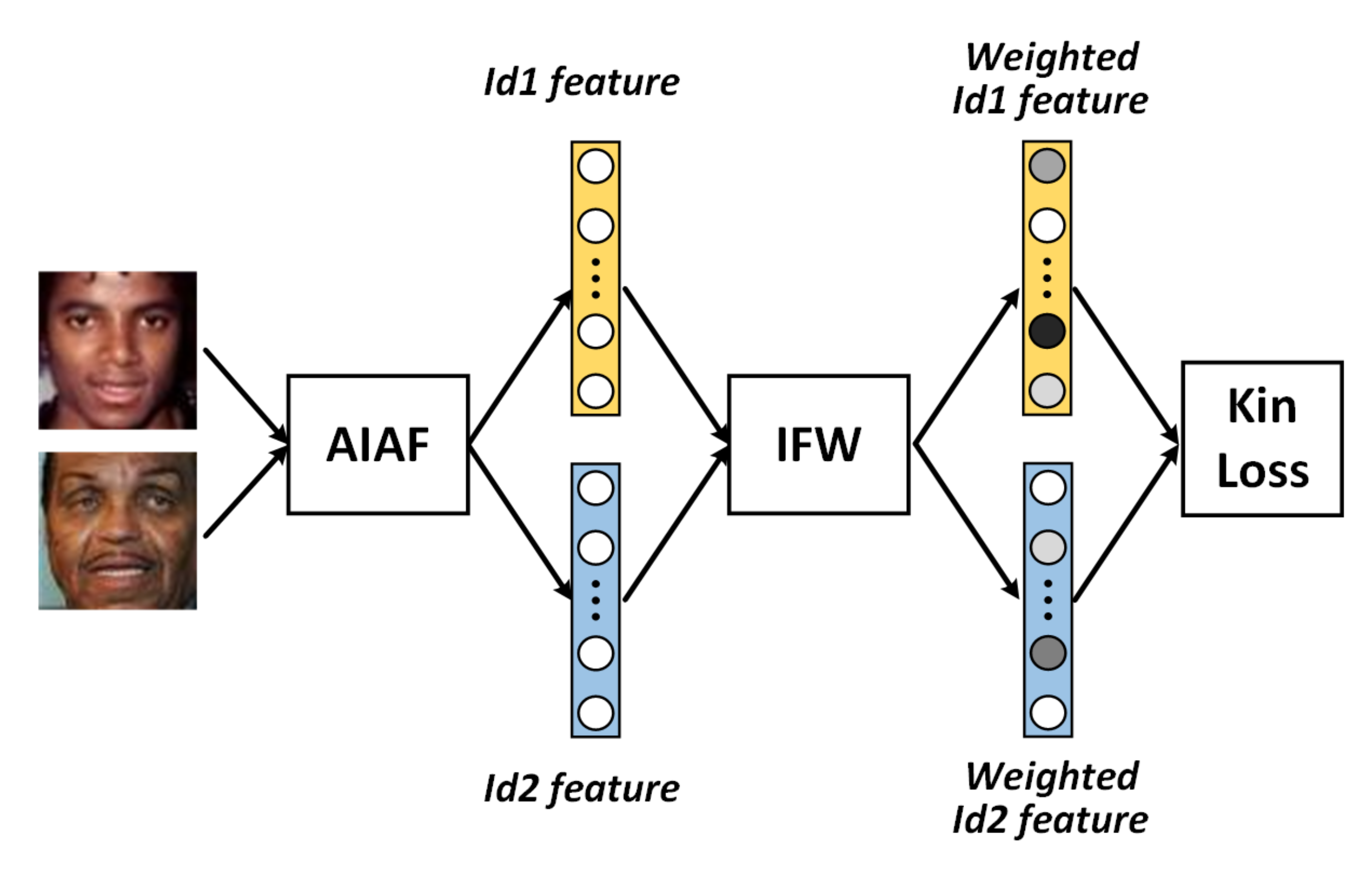
After the Age-Invariant Adversarial Feature Learning module has been trained, the purified facial identity features can be extracted. From a face recognition perspective, this is enough to go on to the next step. However, more details have to be considered when conducting kinship verification. As mentioned in Section 3.1, most existing algorithms use the cosine similarity of two facial features to determine whether they are blood relatives. These algorithms tend to assume that every feature possesses the same weight. In fact, when humans decide kinship, we typically pay more attention to key features (such as the eyes, nose, and mouth) rather than the cheeks or forehead. Moreover, although some facial features are more important, the degree of importance of each feature remains unclear. Furthermore, facial features extracted via deep learning-based methods are usually high-dimensional, making it difficult to determine which point represents the nose or eyes. Motivated by this, we design an Identity Feature Weighted module (IFW) capable of automatically assigning different weights to the extracted identity features based on importance.
As shown in Figure 3, the input of IFW is two identity features extracted by AIAF. Our goal is to find a weight matrix that represents the weights of different features. Formally, given two original features , and weight matrix the weighted features and are formulated as follows:
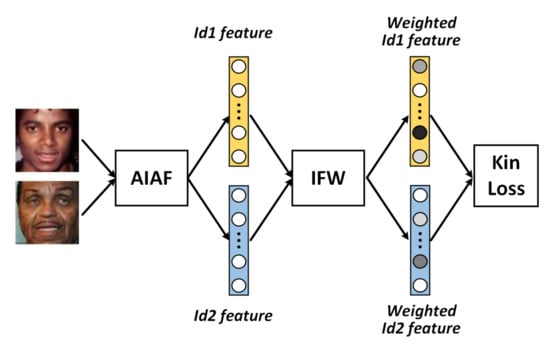
Figure 3.
The workflow of Identity Feature Weighted module. Identity features extracted by AIAF are transmitted to IFW, which assigns different weights to the features according to their importance in kinship verification.
Please note that we initialize M with a diagonal matrix. On one hand, it assigns the same weights to all features; on the other hand, it can accelerate training, since the features extracted by AIAF are reliable in most cases.
The cosine similarity between and is then calculated as follows:
where is a very small number included to avoid division by zero. ranges from −1 to 1. We use the following linear transformation to change its range:
where , which can be interpreted as the probability of kinship. Therefore, it can work properly with the binary cross-entropy. Given the ground truth y, the loss is formulated as follows:
During the training process, M can be learned by minimizing the loss . The finally obtained optimal matrix can pay more attention to important features than trivial ones.
4. Experiments
4.1. Implementation Details
4.1.1. Network Configuration
- Backbone. We used a CNN backbone similar to Wang et al. [44] and OE-CNN [46]. As shown in Figure 2, each convolutional layer comprises batch normalization, convolution with kernel size 3, and Leaky ReLU. The final layer is one fully connected layer with 1024 neurons.
- Feature Splitter. In our implementation, FS is an operation that directly splits a 1024-dimensional input feature vector at the middle into two 512-dimensional feature vectors. We set the angular margin penalty m to 0.3 and the scaling factor s to 64.
- Age Classifier. Following common practice, the age classifier comprises three fully connected layers with 512, 512, and 8 (corresponding to 8 age groups) neurons, respectively. The first two layers are followed by Leaky ReLU.
- Adversarial Canonical Correlation Regularizer. The dimension of the identity projection vector is and that of the age projection vector is the same.
- Multi-task Learning. We performed hyper-parameter search and empirically chose which works best in our experiments. We use Adam optimizer to train the model with a initial learning rate of 1 × 10 . The batchsize is set to 512.
- Identity Feature Weighted module. The weight matrix M is initialized with a diagonal matrix. is set to 1 × 10 .
4.1.2. Data Preprocessing
In our approach, we leverage multi-task learning to train our AIAF. It is vital that the facial images possess both identity-related labels and age-related labels, and that these images should have large age gaps. However, there are no appropriate existing datasets that meet these criteria; accordingly, our strategy is to train an age estimation model to label datasets containing only identity labels. First, following the procedures outlined in [47,48], we train an age estimation model on the IMDB-WIKI dataset with data augmentation [49,50]. Second, the age estimation model is applied to the VGGFace2 dataset [51], which contains only identity labels. Third, the CACD2000 dataset [52], containing both labels, is mixed with the processed VGGFace2 dataset to create an entirely new dataset. Fourth, with the help of MTCNN [53], the five facial key points (left eye, right eye, nose, mouth left, mouth right) are detected. We harness these to align the faces and crop the images to a size of 64 × 64 pixels in order to form the final dataset for the AIAF module.
4.2. Experiments on KinFaceW-I and KinFaceW-II Datasets
KinFaceW-I and KinFaceW-II [2] are two popular kinship datasets consisting of four kinds of relations (Father-Son, Father-Daughter, Mother-Son, and Mother-Daughter). Part of the datasets are shown in Figure 4 and Figure 5. The only difference between KinFaceW-I and KinFaceW-II is that face images with a kin relation in the former are from different photos, while they are from the same photos in the latter. There exist 156, 134, 116, and 127 pairs of kinship images for these four relations in KinFaceW-I, with each relation containing 250 pairs of kinship images in KinFaceW-II.

Figure 4.
Part of the kinship pairs (up and down) in KinFaceW-I.

Figure 5.
Part of the kinship pairs (up and down) in KinFaceW-II.
In this experiment, following the image-restricted setting protocol [4], we use the pre-specified training and testing sets that are generated randomly and independently for five-fold cross-validation. We compare our AIAF + IFW against current state-of-the-art methods. The results of the experiments on KinFaceW-I and KinFaceW-II are drawn from their respective papers [4,13,54]. Note that, as an important baseline, Human A in the Table 1 and Table 2 is shown cropped face regions without color, which means the experimental subject relies on the face alone; by contrast, Human B is shown the original color images, which means the person can harness many clues other than the face (such as skin color and hairstyle).

Table 1.
Kinship verification accuracies (%) under the image-restricted setting on KinFaceW-I.
Table 2.
Kinship verification accuracies (%) under the image-restricted setting on KinFaceW-II.
As shown in Table 1 and Table 2, both traditional machine learning-based approaches and deep learning-based approaches achieve good performance, and many of them outperform a human’s level. Our proposed approach achieves the best results in almost all relationships compared with other state-of-the-art methods except for F-S kinship on KinFaceW-II. Even though the F-S kinship performance of our AIAF + IFW on KinFaceW-II is not the best, it (87.20) is very close to the best (87.51). Furthermore, we deem the reason for this is that KinFaceW-II is a relatively simple dataset so that traditional methods are good enough to reach a high level. In this case, due to the desire for big datasets and fitting complex data distributions, deep learning-based models lose their edge. Generally speaking, our approach performs pretty well on individual kinship and average compared with other excellent approaches, indicating that our approach is promising on small-scale datasets.
4.3. Experiments on FIW Dataset
To demonstrate the advantages of our approach on large-scale datasets, Families in the Wild (FIW) [11], the largest and most comprehensive kinship dataset compiled to date, is leveraged. FIW is made up of 11,932 natural family photos of 1000 families. There are a total of 656,954 image pairs split between 11 relationships: Father-Daughter (F-D), Father-Son (F-S), Mother-Daughter (M-D), Mother-Son (M-S), Brother-Brother (B-B), Sister-Sister (S-S), Sister-Brother (SIBS), GrandFather-GrandDaughter (GF-GD), GrandFather-GrandSon (GF-GS), GrandMother-GrandDaughter (GM-GD), and GrandMother-GrandSon (GM-GS).
To facilitate fair comparison, we follow the protocol outlined in [11] to perform the five-fold cross-validation. We compare our approach with both deep learning-based and traditional methods. Average accuracy, Area Under Curve (AUC), and Receiver Operating Characteristic (ROC) are used as our evaluation criteria. The results [10,11] are presented in Table 3 and Figure 6. Note that some methods have two lines of results in Table 3: the upper line indicates the results produced from the original parent-child or grandparent-grandchild pairs, while the lower line contains the results derived by introducing a young parent intermediate domain, proposed by this work [10], to mitigate the impact of age gaps.
Table 3.
Kinship verification accuracies (%) for five-fold experiment on FIW with no family overlap between folds.
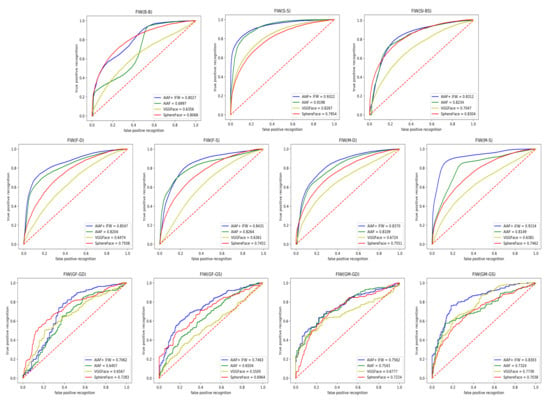
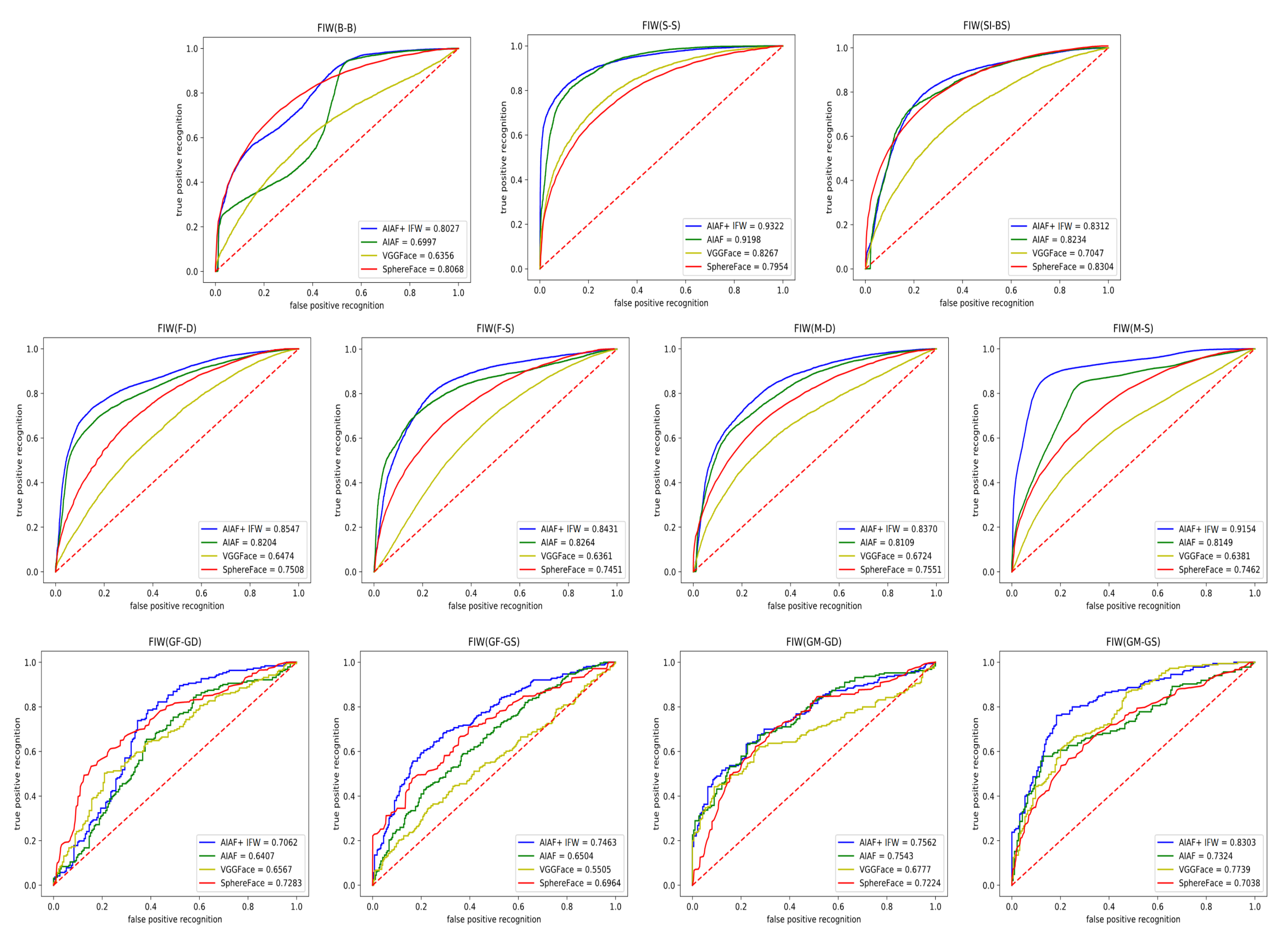
Figure 6.
Comparisons of ROC curves of 11 relationships between our AIAF + IFW and other state-of-the-art methods on FIW dataset.
In Table 3 we can see that the performance of deep learning-based approaches, such as a series of VGG and ResNet, is far beyond traditional algorithms. We believe the reason for this is that deep learning is more adept at handling large-scale data than traditional methods. This point is also widely demonstrated in a large number of recent literatures [34]. Unsurprisingly, experimental results reveal that our AIAF + IFW achieves the best results out of all compared approaches on FIW, demonstrating the superiority of our approach on large-scale datasets.
4.4. Ablation Study
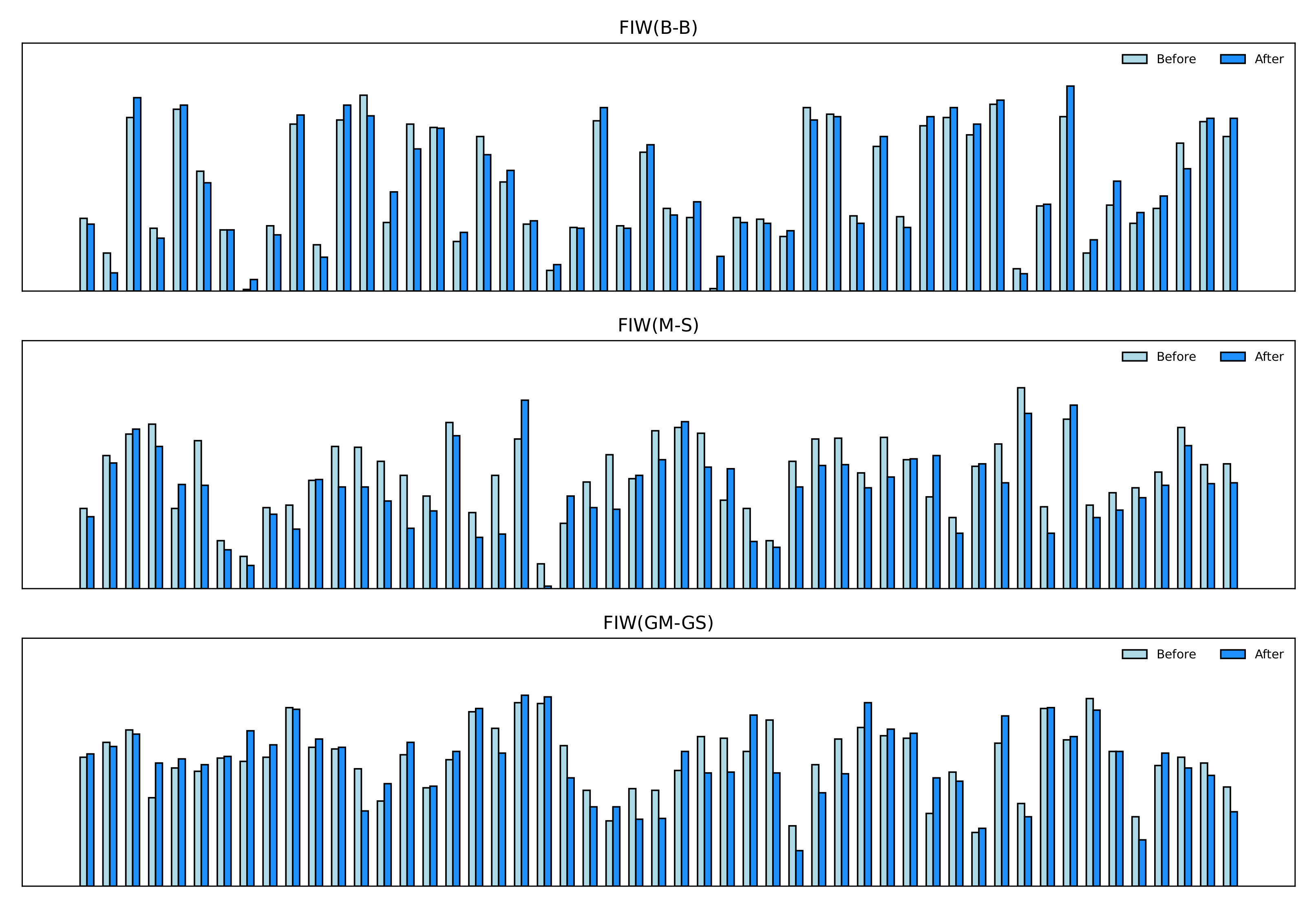
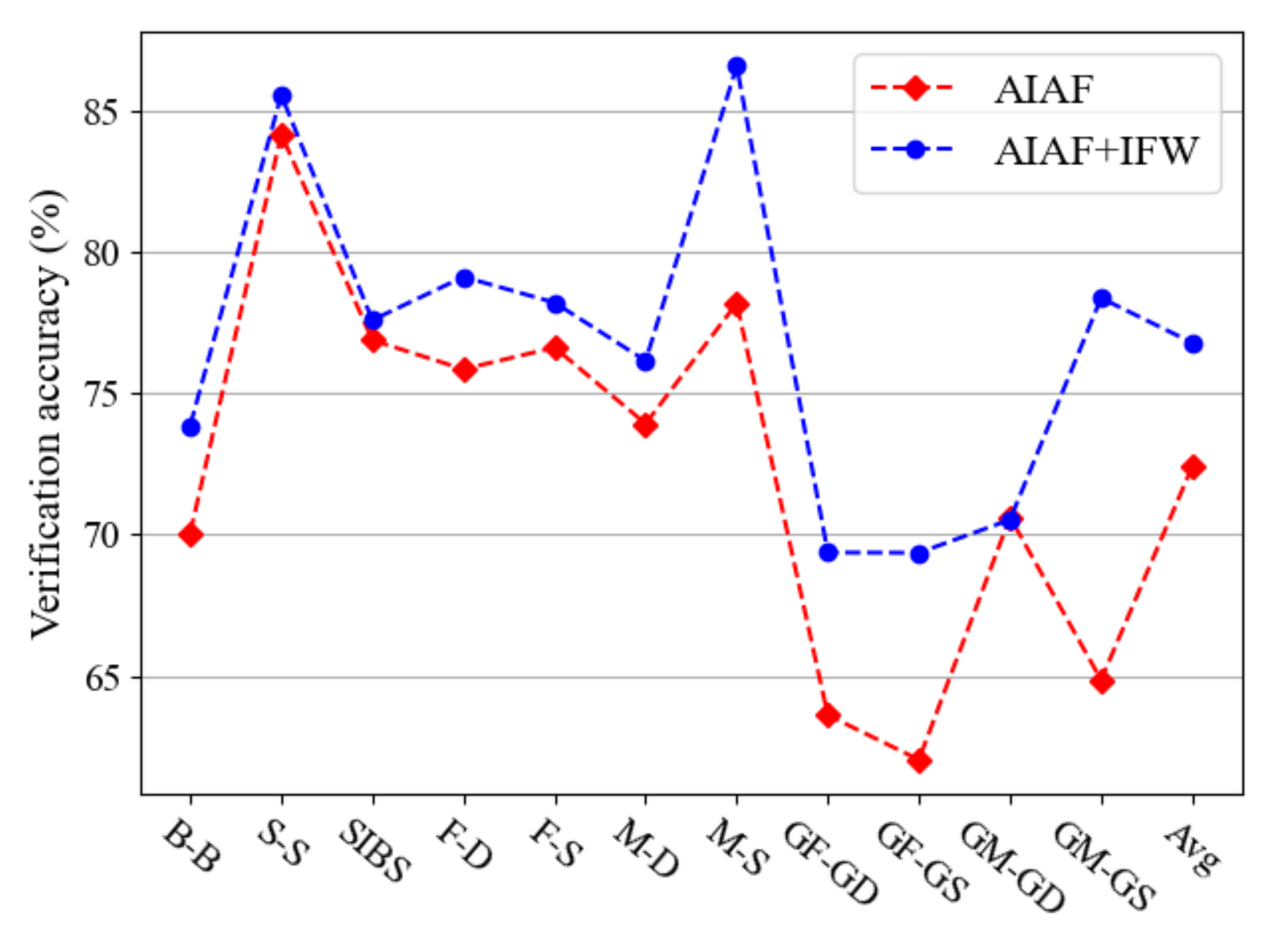
As discussed in Section 3.3, the IFW module is able to assign different weights to features depending on their importance. Here, the effectiveness of IFW is demonstrated. Figure 7 presents part of the weights of identity features both before and after the transformation. The height represents the importance of features. We notice that the original features have large numbers of vague pieces. After the IFW module is applied, some features are strengthened while others are weakened. Overall, after calculation, more features are suppressed, which confirms the point we proposed in Section 3.3, i.e., that some facial features are significant in face recognition but not in kinship verification, resulting in only those features making sense in kinship verification task can be retained. As shown in Figure 8, the experiment demonstrates that IFW makes sense in every type of kinship, which further strengthens our conclusion that AIAF + IFW is superior than single AIAF. However, we found that the improvement of verification accuracy is not consistent across different kinship relations. For example, the accuracy improvement on GM-GD verification is very small. We suspect that this is because there are other influencing factors besides age in facial features. Therefore, further refining the face features to remove other influencing factors may further improve performance. We will investigate this point in our future work.
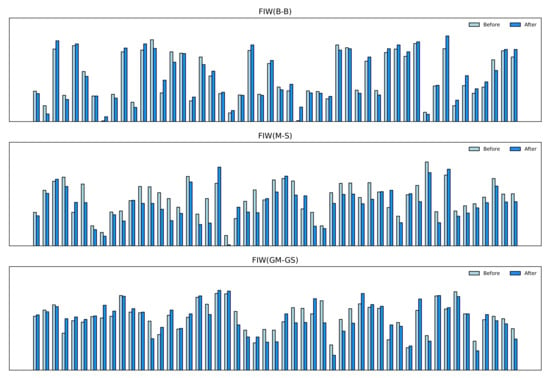
Figure 7.
Examples of the importance of facial age-invariant features before and after IFW. The height represents the importance of features.
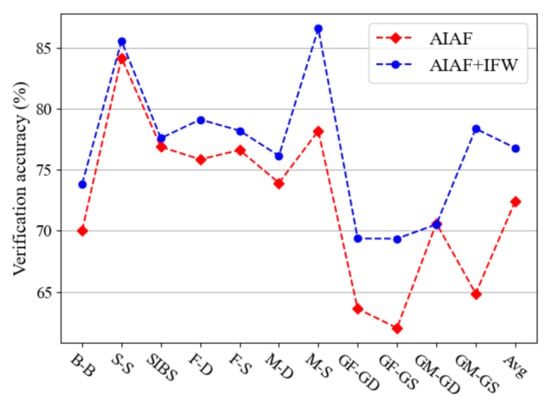
Figure 8.
Comparison of kinship verification accuracies (%) of AIAF and AIAF + IFW on FIW dataset.
For clarity, we select several challenging kinship pairs, shown in Figure 9, from KinFaceW-I, KinFaceW-II, and FIW datasets where the age has a huge impact on kinship verification as there exists a large age gap between each pair. Traditional methods fail to deal with them, whereas our proposed approach is capable of handling it.

Figure 9.
Examples of kinship pairs with large age gap from KinFaceW-I, KinFaceW-II, and FIW.
5. Conclusions
In this paper, we proposed an Age-Invariant Adversarial Feature Learning approach for kinship verification, which comprises two modules: AIAF and IFW. More specifically, identity classification, age classification, and Adversarial Canonical Correlation Regularizer modules are jointly optimized, which ensures that identity features are not correlated with age features. IFW is then leveraged to assign different weights to features according to their importance. Extensive experiments were conducted on both small-scale and large-scale datasets to demonstrate that our approach outperforms other state-of-the-art methods. Theoretically, our AIAF is capable of serving as a fundamental feature descriptor for other methods to eliminate the error introduced by age gaps. Furthermore, our approach is not limited to the kinship verification task, as it can also be generalized to kinship recognition and other tasks. More research will be explored in the future to promote the development of kinship-related tasks.
Author Contributions
Conceptualization and methodology, F.L. and Z.L.; validation, Z.L. and W.Y.; formal analysis and investigation, F.L., Z.L. and F.X.; software, W.Y.; writing—original draft preparation, Z.L.; writing—review and editing, F.L., Z.L. and W.Y.; visualization, Z.L. and W.Y.; writing—review & editing, F.L.; supervision, F.L. and F.X.; project administration, F.L.; funding acquisition, F.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partially funded by Natural Science Foundation of Jiangsu Province under Grant No. BK20191298, and Water Science and Technology Project of Jiangsu Province under Grant No. 2021072.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Xia, S.; Shao, M.; Fu, Y. Kinship verification through transfer learning. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Catalonia, Spain, 16–22 July 2011. [Google Scholar]
- Lu, J.; Zhou, X.; Tan, Y.P.; Shang, Y.; Zhou, J. Neighborhood repulsed metric learning for kinship verification. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 331–345. [Google Scholar]
- Hu, J.; Lu, J.; Yuan, J.; Tan, Y.P. Large Margin Multi-metric Learning for Face and Kinship Verification in the Wild. In Proceedings of the 12th Asian Conference on Computer Vision (ACCV 2014), Singapore, 1–5 November 2014. [Google Scholar]
- Lu, J.; Hu, J.; Liong, V.E.; Zhou, X.; Bottino, A.; Islam, I.U.; Vieira, T.F.; Qin, X.; Tan, X.; Chen, S.; et al. The fg 2015 kinship verification in the wild evaluation. In Proceedings of the 2015 11th IEEE international Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; Volume 1, pp. 1–7. [Google Scholar]
- Kou, L.; Zhou, X.; Xu, M.; Shang, Y. Learning a Genetic Measure for Kinship Verification Using Facial Images. Math. Probl. Eng. 2015, 2015, 472473. [Google Scholar] [CrossRef]
- Zhou, X.; Shang, Y.; Yan, H.; Guo, G. Ensemble similarity learning for kinship verification from facial images in the wild. Inf. Fusion 2016, 32, 40–48. [Google Scholar] [CrossRef]
- Robinson, J.P.; Shao, M.; Wu, Y.; Fu, Y. Families in the Wild (FIW): Large-Scale Kinship Image Da. Kinship verification from facial images by scalable similarity fusion.tabase and Benchmarks. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016. [Google Scholar]
- Zhou, X.; Yan, H.; Shang, Y. Kinship verification from facial images by scalable similarity fusion. Neurocomputing 2016, 197, 136–142. [Google Scholar] [CrossRef]
- Wang, S.; Robinson, J.P.; Fu, Y. Kinship verification on families in the wild with marginalized denoising metric learning. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 216–221. [Google Scholar]
- Wang, S.; Ding, Z.; Yun, F. Cross-Generation Kinship Verification with Sparse Discriminative Metric. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2783–2790. [Google Scholar] [CrossRef] [PubMed]
- Robinson, J.P.; Shao, M.; Wu, Y.; Liu, H.; Gillis, T.; Fu, Y. Visual kinship recognition of families in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2624–2637. [Google Scholar] [CrossRef]
- Nandy, A.; Mondal, S.S. Kinship verification using deep siamese convolutional neural network. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–5. [Google Scholar]
- Yan, H.; Wang, S. Learning part-aware attention networks for kinship verification. Pattern Recognit. Lett. 2019, 128, 169–175. [Google Scholar] [CrossRef]
- Jain, A.; Bhagat, N.; Srivastava, V.; Tyagi, P.; Jain, P. A Feature-Based kinship verification technique using convolutional neural network. In Advances in Data Sciences, Security and Applications; Springer: Berlin/Heidelberg, Germany, 2020; pp. 353–362. [Google Scholar]
- Chergui, A.; Ouchtati, S.; Mavromatis, S.; Bekhouche, S.E.; Sequeira, J. Investigating Deep CNNs Models Applied in Kinship Verification through Facial Images. In Proceedings of the 2019 5th International Conference on Frontiers of Signal Processing (ICFSP), Marseille, France, 18–20 September 2019. [Google Scholar]
- Lu, J.; Wang, G.; Deng, W.; Jia, K. Reconstruction-based metric learning for unconstrained face verification. IEEE Trans. Inf. Forensics Secur. 2014, 10, 79–89. [Google Scholar] [CrossRef]
- Wang, Q.; Guo, G. Ls-cnn: Characterizing local patches at multiple scales for face recognition. IEEE Trans. Inf. Forensics Secur. 2019, 15, 1640–1653. [Google Scholar] [CrossRef]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. SphereFace: Deep Hypersphere Embedding for Face Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Xia, S.; Shao, M.; Luo, J.; Fu, Y. Understanding kin relationships in a photo. IEEE Trans. Multimed. 2012, 14, 1046–1056. [Google Scholar] [CrossRef]
- Fang, R.; Tang, K.D.; Snavely, N.; Chen, T. Towards computational models of kinship verification. In Proceedings of the International Conference on Image Processing, ICIP 2010, Hong Kong, China, 26–29 September 2010. [Google Scholar]
- Zhou, X.; Hu, J.; Lu, J.; Shang, Y.; Guan, Y. Kinship verification from facial images under uncontrolled condition. In Proceedings of the 19th ACM International Conference on Multimedia, Scottsdale, AZ, USA, 28 November–2 December 2011; pp. 953–956. [Google Scholar]
- Guo, G.; Wang, X. Kinship Measurement on Salient Facial Features. IEEE Trans. Instrum. Meas. 2012, 61, 2322–2325. [Google Scholar] [CrossRef]
- Bottino, A.; Vieira, T.F.; Ul Islam, I. Geometric and Textural Cues for Automatic Kinship Verification. Int. J. Pattern Recognit. Artif. Intell. 2015, 29, 1556001. [Google Scholar] [CrossRef]
- Bottinok, A.; Islam, I.U.; Vieira, T.F. A multi-perspective holistic approach to Kinship Verification in the Wild. In Proceedings of the IEEE International Conference & Workshops on Automatic Face & Gesture Recognition, Ljubljana, Slovenia, 4–8 May 2015; pp. 1–6. [Google Scholar]
- Yan, H.; Lu, J.; Zhou, X. Prototype-based discriminative feature learning for kinship verification. IEEE Trans. Cybern. 2014, 45, 2535–2545. [Google Scholar] [CrossRef]
- Somanath, G.; Kambhamettu, C. Can faces verify blood-relations? In Proceedings of the 2012 IEEE Fifth International Conference on Biometrics: Theory, Applications and Systems (BTAS), Arlington, VA, USA, 23–27 September 2012; pp. 105–112. [Google Scholar]
- Yan, H.; Lu, J.; Deng, W.; Zhou, X. Discriminative multimetric learning for kinship verification. IEEE Trans. Inf. Forensics Secur. 2014, 9, 1169–1178. [Google Scholar] [CrossRef]
- Xu, M.; Shang, Y. Kinship measurement on face images by structured similarity fusion. IEEE Access 2016, 4, 10280–10287. [Google Scholar] [CrossRef]
- Qin, X.; Tan, X.; Chen, S. Tri-subject kinship verification: Understanding the core of a family. IEEE Trans. Multimed. 2015, 17, 1855–1867. [Google Scholar] [CrossRef] [Green Version]
- Zhou, X.; Jin, K.; Xu, M.; Guo, G. Learning Deep Compact Similarity Metric for Kinship Verification from Face Images. Inf. Fusion 2018, 48, 84–94. [Google Scholar] [CrossRef]
- Tola, E.; Lepetit, V.; Fua, P. Daisy: An efficient dense descriptor applied to wide-baseline stereo. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 815–830. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.G.; Song, Z.; Zheng, F.; Shao, L. Learning a Multiple Kernel Similarity Metric for Kinship Verification. Inf. Sci. 2017, 430, 247–260. [Google Scholar] [CrossRef]
- Wei, Z.; Xu, M.; Geng, L.; Liu, H.; Yin, H. Adversarial Similarity Metric Learning for Kinship Verification. IEEE Access 2019, 7, 100029–100035. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Dehghan, A.; Ortiz, E.G.; Villegas, R.; Shah, M. Who do i look like? Determining parent-offspring resemblance via gated autoencoders. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1757–1764. [Google Scholar]
- Zhang, K.; Huang, Y.; Song, C.; Wu, H.; Wang, L.; Intelligence, S.M. Kinship Verification with Deep Convolutional Neural Networks. 2015. Available online: www.bmva.org/bmvc/2015/papers/paper148/paper148.pdf (accessed on 14 December 2021).
- Ding, Z.; Suh, S.; Han, J.J.; Choi, C.; Fu, Y. Discriminative low-rank metric learning for face recognition. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; Volume 1, pp. 1–6. [Google Scholar]
- Van, T.N.; Hoang, V.T. Early and late features fusion for kinship verification based on constraint selection. In Proceedings of the 2019 25th Asia-Pacific Conference on Communications (APCC), Ho Chi Minh City, Vietnam, 6–8 November 2019; pp. 116–121. [Google Scholar]
- Dehshibi, M.M.; Shanbehzadeh, J. Cubic norm and kernel-based bi-directional PCA: Toward age-aware facial kinship verification. Vis. Comput. 2017, 35, 23–40. [Google Scholar] [CrossRef]
- Liu, Y.; Li, H.; Wang, X. Rethinking feature discrimination and polymerization for large-scale recognition. arXiv 2017, arXiv:1710.00870. [Google Scholar]
- Wang, F.; Cheng, J.; Liu, W.; Liu, H. Additive margin softmax for face verification. IEEE Signal Process. Lett. 2018, 25, 926–930. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Wang, Y.; Zhou, Z.; Ji, X.; Gong, D.; Zhou, J.; Li, Z.; Liu, W. CosFace: Large Margin Cosine Loss for Deep Face Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4690–4699. [Google Scholar]
- Wang, H.; Gong, D.; Li, Z.; Liu, W. Decorrelated adversarial learning for age-invariant face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3527–3536. [Google Scholar]
- Hotelling, H. Relations between two sets of variates. In Breakthroughs in Statistics; Springer: Berlin/Heidelberg, Germany, 1992; pp. 162–190. [Google Scholar]
- Wang, Y.; Gong, D.; Zhou, Z.; Ji, X.; Wang, H.; Li, Z.; Liu, W.; Zhang, T. Orthogonal deep features decomposition for age-invariant face recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 738–753. [Google Scholar]
- Rothe, R.; Timofte, R.; Gool, L.V. DEX: Deep EXpectation of Apparent Age from a Single Image. In Proceedings of the IEEE International Conference on Computer Vision Workshop, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Rothe, R.; Timofte, R.; Van Gool, L. Deep expectation of real and apparent age from a single image without facial landmarks. Int. J. Comput. Vis. 2018, 126, 144–157. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random erasing data augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York City, NY, USA, 7 February 2020; Volume 34, pp. 13001–13008. [Google Scholar]
- Cao, Q.; Shen, L.; Xie, W.; Parkhi, O.M.; Zisserman, A. Vggface2: A dataset for recognising faces across pose and age. In Proceedings of the 2018 13th IEEE international Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 67–74. [Google Scholar]
- Chen, B.C.; Chen, C.S.; Hsu, W.H. Cross-age reference coding for age-invariant face recognition and retrieval. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 768–783. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Lu, J.; Hu, J.; Tan, Y.P. Discriminative deep metric learning for face and kinship verification. IEEE Trans. Image Process. 2017, 26, 4269–4282. [Google Scholar] [CrossRef]
- Ahonen, T.; Hadid, A.; Pietikainen, M. Face description with local binary patterns: Application to face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 2037–2041. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Zhang, L.; Duan, Q.; Zhang, D.; Jia, W.; Wang, X. AdvKin: Adversarial convolutional network for kinship verification. IEEE Trans. Cybern. 2020, 51, 5883–5896. [Google Scholar] [CrossRef]
- Laiadi, O.; Ouamane, A.; Benakcha, A.; Taleb-Ahmed, A.; Hadid, A. Tensor cross-view quadratic discriminant analysis for kinship verification in the wild. Neurocomputing 2020, 377, 286–300. [Google Scholar] [CrossRef]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition. 2015. Available online: http://cis.csuohio.edu/~sschung/CIS660/DeepFaceRecognition_parkhi15.pdf (accessed on 14 December 2021).
- Davis, J.V.; Kulis, B.; Jain, P.; Sra, S.; Dhillon, I.S. Information-theoretic metric learning. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; pp. 209–216. [Google Scholar]
- He, X.; Niyogi, P. Locality preserving projections. Adv. Neural Inf. Process. Syst. 2004, 16, 153–160. [Google Scholar]
- Weinberger, K.Q.; Saul, L.K. Distance metric learning for large margin nearest neighbor classification. J. Mach. Learn. Res. 2009, 10, 207–244. [Google Scholar]
- Peng, Y.; Wang, S.; Lu, B.L. Marginalized denoising autoencoder via graph regularization for domain adaptation. In International Conference on Neural Information Processing; Springer: Berlin/Heidelberg, Germany, 2013; pp. 156–163. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A discriminative feature learning approach for deep face recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 499–515. [Google Scholar]
- He, X.; Cai, D.; Yan, S.; Zhang, H.J. Neighborhood preserving embedding. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05) Volume 1, Beijing, China, 17–21 October 2005; Volume 2, pp. 1208–1213. [Google Scholar]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).