
Identification of Homogeneous Groups of Actors in a Local AHP-Multiactor Context with a High Number of Decision-Makers: A Bayesian Stochastic Search


Abstract
:1. Introduction
2. Background
2.1. The Analytic Hierarchy Process
2.2. Multi-Actor Decision Making
3. Methodology
3.1. Problem Formulation
- (a)
- D[k] ∈ Gg(k) with g(k) ∈ {1, …, m} being the index of the group of which contains D[k]
- (b)
- ; i = 1, …, n being the priority (without normalising) given to the alternative Ai by the members of the group Gg(k)
- (c)
- (that is to say, ) to avoid identifiability problems
- (d)
- ; k = 1, …, K; 1 ≤ i < j ≤ n independent.
3.2. Analysis of the Priorities and the Homogeneity of the Groups of
3.2.1. Posterior Distribution
- -
- xij = 1 if the i-th judgement is yjk with k ≠ j;
- -
- xij = −1 if the i-th judgement is ykj with k ≠ j;
- -
- xij = 0 in any other case.
3.2.2. Analysis of the Representativeness of a Partition
3.2.3. Selection of the Best Partitions . Stochastic Search Algorithm
Stochastic Search Algorithm
Algorithm
3.2.4. Solution Post-Processing
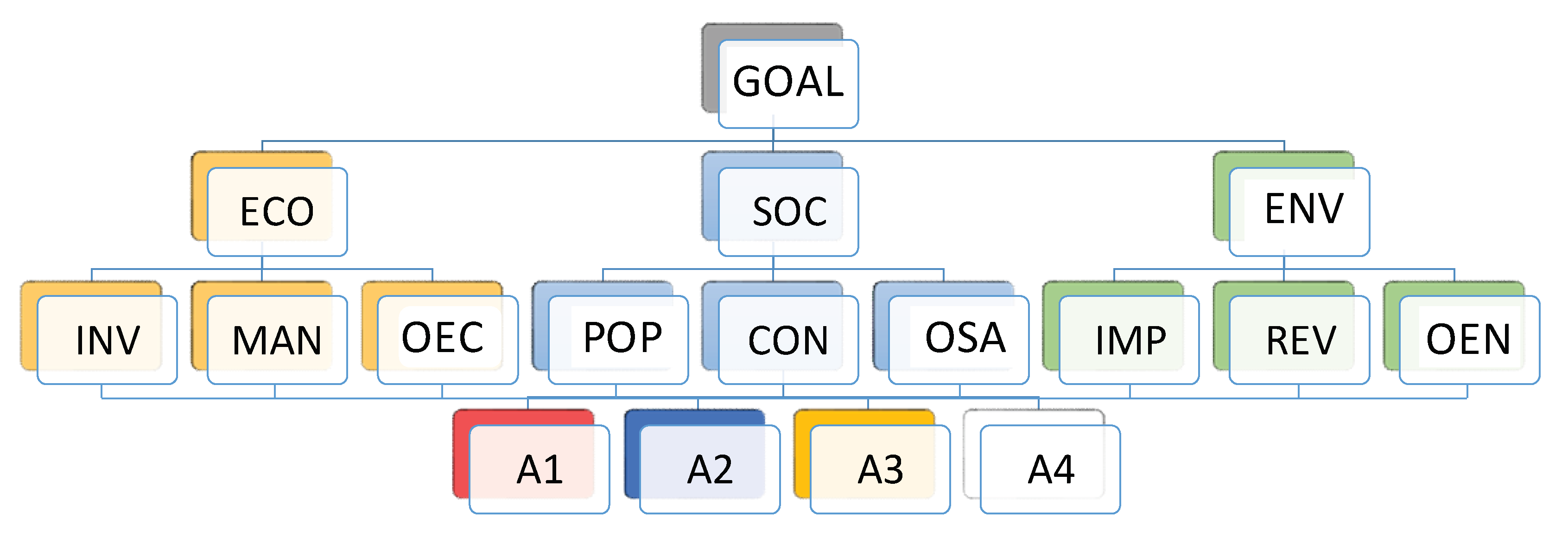
4. Case Study
- A1:
- Build a new tramline
- A2:
- Use a tram and bus combination called Tran bus
- A3:
- Use a tram combination with commuter lines
- A4:
- Do nothing
4.1. Simulation Study
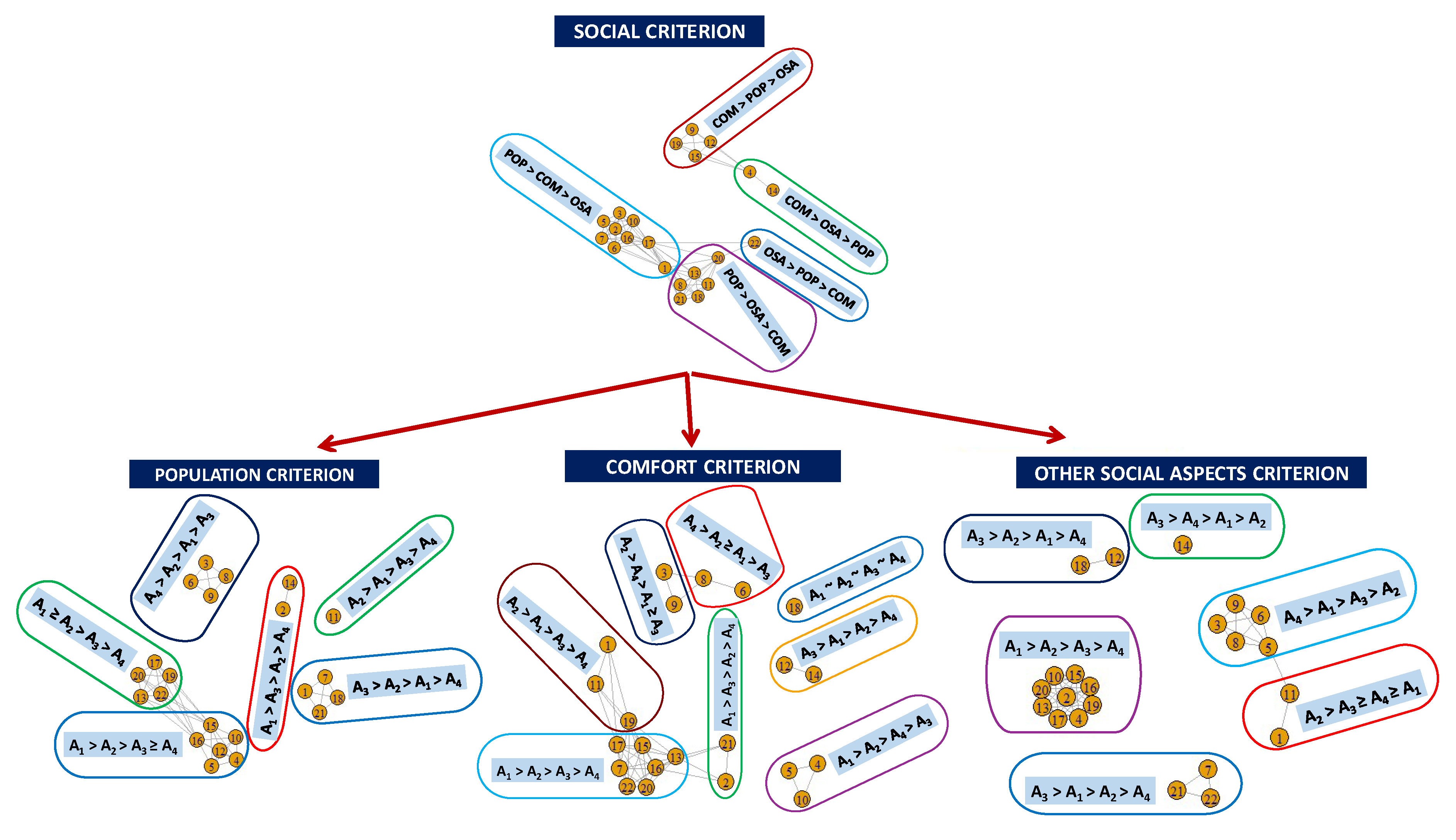
4.2. Empirical Study
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Stochastic Search Algorithm
- a)
- Let = be the partition drawn from = .
- b)
- Draw one of the four movements described below with the same probabilityb1) Movement 1
- i)
- Draw G from with a probability proportional to . Put C1 = ∅ and C2 = G the clusters into which G is to be subdivided.
- ii)
- Determining D ∈ C2 such that + is maximum.
- iii)
- Checking if ≤ +If this condition is verified, put = and and go to ii). Otherwise, put = ∪ and go to Step 3).
b2) Movement 2Draw G from such that |G| > 1. Draw, for each D ∈ G, a preference ranking γD using his/her individual P.γ distribution . Determine the groups Gγ,i = {D ∈ G: γD = γi}; i = 1, …, n! where γi is the i-th permutation of ordered according to the lexicographic order. Notice that Gγ,i contains the decision-makers of G who have the same preference ranking γi. Let C1, …, Cm the non-empty groups of {Gγ,i; 1 ≤ i ≤ n!}.Put = ∪ and go to Step 3.b3) Movement 3Draw C1 ≠ C2 from with probability proportional to . Calculate G = and put = ∪ . Go to Step 3.b4) Movement 4Draw C1 ≠ C2 from without replacement. Put G = and applying to G the Movement 2.
- a)
- If ∉ put = ∪ {} and go to Step 3 b).If ∈ put counter = counter + 1. If counter = go to Step 4; otherwise go to Step 2.
- b)
- Calculate Lmax = = L(Y|). If there are ties in the maximum, the partitions with minimum number of groups are selected.
- c)
- Calculate = { ∈ ∪ {}: L(Y|) ≥ Lmax + log(α) and || ≤ ||}
- d)
- If ≠ put s = s + 1 and counter = 0 and go to Step 2.If = put counter = counter + 1. If counter = go to Step 4; otherwise, go to Step 2.
- a)
- Put =
- b)
- Determine Dmin ∈ D such that:= Min D∈D {L(Y{D}|{GD})}where ∈ is the group of such that D ∈ . Therefore, is the worst decision-maker classified according to .
- c)
- Determine ∈ such that:
- d)
- Calculate = ∪If L(Y|) > L(Y|) or L(Y|) ≥ L(Y|) + log(β) with || < || put = and go to Step 4 b). Otherwise, go to Step 4 e).
- e)
- If ≠ go to Step 3. Otherwise, proceed to examine another partition of by repeating Steps 4 a)–4 d) until all its elements have been examined without any change in the partitions. In this last case go to Step 5.
References
- Saaty, T.L. The Analytic Hierarchy Process; Mc Graw-Hill: New York, NY, USA, 1980. [Google Scholar]
- Escobar, M.; Moreno-Jiménez, J.M. Aggregation of Individual Preference Structures in AHP-Group Decision Making. Group Decis. Negotiat. 2007, 16, 287–301. [Google Scholar] [CrossRef]
- Altuzarra, A.; Gargallo, P.; Moreno-Jiménez, J.M.; Salvador, M. Homogeneous Groups of Actors in an AHP-Local Decision Making Context: A Bayesian Analysis. Mathematics 2019, 7, 294. [Google Scholar] [CrossRef] [Green Version]
- Altuzarra, A.; Moreno-Jiménez, J.M.; Salvador, M. Consensus Building in AHP-Group Decision Making: A Bayesian Approach. Oper. Res. 2010, 58, 1755–1773. [Google Scholar] [CrossRef]
- Moreno-Jiménez, J.M.; Salvador, M.; Gargallo, P.; Altuzarra, A. Systemic decision making in AHP: A Bayesian approach. Ann. Oper. Res. 2016, 245, 261–284. [Google Scholar] [CrossRef]
- Zhou, M.; Hu, M.; Chen, Y.-W.; Cheng, B.-Y.; Wu, J.; Herrera-Viedma, E. Towards achieving consistent opinion fusion in group decision making with complete distributed preference relations. Knowledge-Based Systems. 2021, 236, 107740. [Google Scholar] [CrossRef]
- Madigan, D.; Raftery, A.E. Model Selection and Accounting for Model Uncertainty in Graphical Models Using Occam’s Window. J. Am. Stat. Assoc. 1994, 89, 1535–1546. [Google Scholar] [CrossRef]
- Clyde, M.; Gosh, J. Finite Population Estimators in Stochastic Search Variable Selection. Biometrika 2012, 99, 981–988. [Google Scholar] [CrossRef] [Green Version]
- Lamnisos, D.; Griffin, J.E.; Steel, M.F.J. Adaptive Monte Carlo for Bayesian Variable Selection in Regression Models. J. Comput. Graph. Stat. 2013, 22, 729–748. [Google Scholar] [CrossRef]
- Lyiang, F.; Paulo, R.; Molina, G.; Clyde, M.A.; Berger, J.O. Mixtures of g Priors for Bayesian Variable Selection. J. Am. Stat. Assoc. 2008, 103, 410–423. [Google Scholar] [CrossRef]
- Nott, D.J.; Kohn, R. Adaptive sampling for Bayesian variable selection. Biometrika 2005, 92, 747–763. [Google Scholar] [CrossRef]
- Steel, M.F.J. Model Averaging and Its Use in Economics. J. Econ. Lit. 2020, 58, 644–719. [Google Scholar] [CrossRef]
- Kass, R.E.; Raftery, A.E. Bayes factors. J. Am. Stat. Assoc. 1995, 90, 773–795. [Google Scholar] [CrossRef]
- Crawford, G.; Williams, C. A Note on the Analysis of Subjective Judgment Matrices. J. Math. Psychol. 1985, 29, 387–405. [Google Scholar] [CrossRef]
- Aguarón, J.; Moreno-Jiménez, J.M. The geometric consistency index: Approximate thresholds. Eur. J. Oper. Res. 2003, 147, 137–145. [Google Scholar] [CrossRef]
- Altuzarra, A.; Moreno-Jiménez, J.M.; Salvador, M. A Bayesian priorization procedure for AHP-group decision making. Eur. J. Oper. Res. 2007, 182, 367–382. [Google Scholar] [CrossRef]
- Moreno-Jiménez, J.M.; Aguarón, J.; Escobar, M.T. The core of consistency in AHP-group decision making. Group Decis. Negotiat. 2008, 17, 249–265. [Google Scholar] [CrossRef]
- Escobar, M.T.; Aguarón, J.; Moreno-Jiménez, J.M. Some extensions of the precise consistency consensus matrix. Decis. Support Syst. 2015, 74, 67–77. [Google Scholar] [CrossRef]
- Ramanathan, R.; Ganesh, L.S. Group preference aggregation methods employed in AHP: An evaluation and intrinsic process for deriving members’ weightages. Eur. J. Oper. Res. 1994, 79, 249–265. [Google Scholar] [CrossRef]
- Forman, E.; Peniwati, K. Aggregating individual judgements and priorities with the analytic hierarchy process. Eur. J. Oper. Res. 1998, 108, 165–169. [Google Scholar] [CrossRef]
- Aguarón, J.; Escobar, M.T.; Moreno-Jiménez, J.M.; Turón, A. Geometric Compatibility Indexes in a Local AHP-Group Decision Making Context: A Framework for Reducing Incompatibility. Mathematics 2022, 10, 278. [Google Scholar] [CrossRef]
- Akogul, S.; Erisoglu, M. An Approach for Determining the Number of Clusters in a Model-Based Cluster Analysis. Entropy 2017, 19, 452. [Google Scholar] [CrossRef] [Green Version]
- Benítez, J.; Carpitella, S.; Certa, A.; Ilaya-Ayza, A.E.; Izquierdo, J. Consistent clustering of entries in large pairwise comparison matrices. J. Comput. Appl. Math. 2018, 343, 98–112. [Google Scholar] [CrossRef]
- Meixner, O.; Haas, R.; Pöchtrager, S. AHP Group Decision Making and Clustering. In Proceedings of the International Symposium on the Analytic Hierarchy Process (ISAHP) Multi-Criteria Decision Making, London, UK, 4–8 August 2016; Available online: https://www.researchgate.net/publication/327733984_AHP_GROUP_DECISION_MAKING_AND_CLUSTERING (accessed on 21 January 2022). [CrossRef]
- Song, Y.; Hu, Y. Group Decision-Making Method in the Field of Coal Mine Safety Management Based on AHP with Clustering. In Proceedings of the 6th International ISCRAM Conference, Gothenburg, Sweden, 10–13 May 2009. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criterion | Exhaustive Average CPU Time (Standard Deviation) (K = 11) | Stochastic Search Average CPU Time (Standard Deviation) (K = 11) | % of Simulations Where opt = max (K = 11) | Average Factor Bayes (Standard Deviation) (K = 11) | Stochastic Search Average CPU Time (Standard Deviation) (K = 22) |
|---|---|---|---|---|---|
| Environmental | 98.68 (0.55) | 7.19 (0.20) | 93.00% | 0.9735 (0.1267) | 17.93 (1.50) |
| Comfort | 112.68 (2.10) | 9.20 (1.18) | 73.00% | 0.8762 (0.2583) | 80.38 (18.27) |
| Economic | 101.85 (6.81) | 7.21 (0.54) | 97.00% | 1.0000 (0.0000) | 15.58 (0.19) |
| Impact | 116.53 (5.73) | 8.59 (0.96) | 68.00% | 0.8271 (0.2826) | 51.65 (1.97) |
| Investment | 112.23 (1.17) | 7.92 (0.60) | 81.00% | 0.9162 (0.2033) | 29.83 (1.47) |
| Maintenance | 115.58 (6.11) | 9.33 (1.59) | 61.00% | 0.7716 (0.3288) | 68.16 (1.25) |
| Goal | 99.59 (1.72) | 7.24 (0.25) | 100.00% | 1.0000 (0.0000) | 16.43 (0.28) |
| Other Environmental Aspects | 125.25 (7.29) | 9.25 (1.53) | 52.00% | 0.6996 (0.3576) | 74.60 (3.11) |
| Other Economic Aspects | 120.29 (2.00) | 8.19 (0.93) | 52.00% | 0.6772 (0.3782) | 50.54 (4.17) |
| Other Social Aspects | 121.41 (4.70) | 8.71 (1.06) | 69.00% | 0.8734 (0.2428) | 70.29 (4.20) |
| Population | 131.03 (11.65) | 9.01 (1.13) | 58.00% | 0.7771 (0.3130) | 56.67 (10.01) |
| Reversibility | 130.84 (11.03) | 10.80 (1.94) | 73.00% | 0.8649 (0.2693) | 88.74 (4.51) |
| Social | 105.16 (2.21) | 7.25 (0.37) | 93.00% | 0.9581 (0.1742) | 17.57 (1.86) |
| GOAL | |||||||||||
| Groups | Priorities | ||||||||||
| ECO | SOC | ENV | |||||||||
| 1, 6, 7, 9, 10, 11, 15, 19, 20 | 0.6420 | 0.2481 | 0.1094 | ||||||||
| 2, 8, 13 | 0.4212 | 0.1145 | 0.4623 | ||||||||
| 3 | 0.0826 | 0.3497 | 0.5650 | ||||||||
| 4, 5, 12, 14, 18, 21, 22 | 0.2515 | 0.6673 | 0.0806 | ||||||||
| 16, 17 | 0.1171 | 0.5791 | 0.3031 | ||||||||
| ECONOMIC | SOCIAL | ENVIRONMENTAL | |||||||||
| Groups | Priorities | Groups | Priorities | Groups | Priorities | ||||||
| INV | MAN | OEC | POP | COM | OSA | IMP | REV | OEN | |||
| 1, 8, 11, 22 | 0.5652 | 0.1150 | 0.3182 | 1, 2, 3, 5, 6, 7, 10, 16, 17 | 0.6503 | 0.2274 | 0.1217 | 1,11 | 0.5423 | 0.2278 | 0.2292 |
| 2,7, 10, 13, 15, 19, 20, 21 | 0.6296 | 0.2435 | 0.1267 | 4, 14 | 0.0858 | 0.6437 | 0.2666 | 2, 3, 6, 13, 15, 16, 18, 20, 22 | 0.6568 | 0.2266 | 0.1160 |
| 3, 4, 5, 6, 9, 12, 14, 16, 17 | 0.2626 | 0.6441 | 0.0929 | 8, 11, 13, 18, 20, 21 | 0.6344 | 0.1239 | 0.2410 | 4, 5 | 0.1347 | 0.3111 | 0.5533 |
| 18 | 0.1164 | 0.2764 | 0.6039 | 9, 12, 15, 19 | 0.2237 | 0.6460 | 0.1290 | 7, 12, 19, 21 | 0.2578 | 0.6333 | 0.1078 |
| 22 | 0.2419 | 0.1095 | 0.6438 | 8, 9, 10, 14, 17 | 0.4649 | 0.1137 | 0.4186 | ||||
| INVESTMENT | MAINTENANCE | OTHER ECONOMIC ASPECTS | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Groups | Priorities | Groups | Priorities | Groups | Priorities | |||||||||
| A1 | A2 | A3 | A4 | A1 | A2 | A3 | A4 | A1 | A2 | A3 | A4 | |||
| 1, 2, 3, 7, 12, 15, 16, 17, 19, 20, 21, 22 | 0.0626 | 0.2573 | 0.1197 | 0.5597 | 1, 16, 19 | 0.1898 | 0.054 | 0.1615 | 0.5891 | 1, 11 | 0.1562 | 0.5718 | 0.1398 | 0.127 |
| 4, 10 | 0.6129 | 0.1602 | 0.0925 | 0.1318 | 2, 6, 7, 12, 17, 20 | 0.2295 | 0.1238 | 0.0788 | 0.5657 | 2, 7, 16 | 0.2280 | 0.1829 | 0.1607 | 0.4255 |
| 5, 6 | 0.2979 | 0.1300 | 0.0639 | 0.5032 | 3 | 0.1247 | 0.5702 | 0.0655 | 0.2339 | 3 | 0.1163 | 0.5631 | 0.0658 | 0.2479 |
| 8, 18 | 0.1132 | 0.2716 | 0.0512 | 0.5609 | 4, 10 | 0.5738 | 0.2082 | 0.1151 | 0.0985 | 4, 10, 20 | 0.5589 | 0.1828 | 0.1517 | 0.1042 |
| 9, 14 | 0.1427 | 0.1128 | 0.6566 | 0.078 | 5, 8, 15, 18, 22 | 0.0878 | 0.2337 | 0.0753 | 0.6014 | 5, 6, 8, 17, 19 | 0.1366 | 0.1800 | 0.0532 | 0.6287 |
| 11 | 0.1225 | 0.4685 | 0.2744 | 0.1289 | 9, 14 | 0.2169 | 0.1261 | 0.5848 | 0.0701 | 9, 14, 18, 22 | 0.1560 | 0.1212 | 0.6302 | 0.0882 |
| 13 | 0.1014 | 0.1672 | 0.2855 | 0.4422 | 11 | 0.2613 | 0.446 | 0.1424 | 0.1483 | 12, 13, 15, 21 | 0.0663 | 0.1773 | 0.1811 | 0.5734 |
| 13, 21 | 0.1145 | 0.1233 | 0.2621 | 0.4969 | ||||||||||
| POPULATION | COMFORT | OTHER SOCIAL ASPECTS | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Groups | Priorities | Groups | Priorities | Groups | Priorities | |||||||||
| A1 | A2 | A3 | A4 | A1 | A2 | A3 | A4 | A1 | A2 | A3 | A4 | |||
| 1, 7, 18, 21 | 0.1432 | 0.3243 | 0.466 | 0.0615 | 1, 11, 19 | 0.2409 | 0.4903 | 0.1865 | 0.0758 | 1, 11 | 0.1139 | 0.6195 | 0.1401 | 0.1182 |
| 2, 14 | 0.4726 | 0.1551 | 0.2581 | 0.1094 | 2, 21 | 0.4476 | 0.1967 | 0.2676 | 0.0858 | 2, 4, 10, 13, 15, 16, 17, 19, 20 | 0.4938 | 0.2627 | 0.1703 | 0.0715 |
| 3, 6, 8, 9 | 0.1269 | 0.3035 | 0.0716 | 0.4931 | 3, 9 | 0.0938 | 0.4797 | 0.0864 | 0.3337 | 3, 5, 6, 8, 9 | 0.1428 | 0.3025 | 0.0820 | 0.4691 |
| 4, 5, 10, 12, 15, 16 | 0.5502 | 0.2368 | 0.1074 | 0.1041 | 4, 5, 10 | 0.5373 | 0.2482 | 0.0884 | 0.1247 | 7, 21, 22 | 0.2144 | 0.2916 | 0.4194 | 0.0722 |
| 11 | 0.2248 | 0.4525 | 0.1446 | 0.1754 | 6, 8 | 0.1856 | 0.1924 | 0.0669 | 0.5498 | 12, 18 | 0.2998 | 0.0972 | 0.5464 | 0.0531 |
| 13, 17, 19, 20, 22 | 0.4269 | 0.3742 | 0.1479 | 0.0486 | 7, 13, 15, 16, 17, 20, 22 | 0.5012 | 0.2781 | 0.1607 | 0.0594 | 14 | 0.1141 | 0.0867 | 0.5519 | 0.2400 |
| 12, 14 | 0.2418 | 0.116 | 0.5813 | 0.0582 | ||||||||||
| 18 | 0.2500 | 0.2500 | 0.2500 | 0.2500 | ||||||||||
| IMPACT | REVERSIBILITY | OTHER ENVIRONMENTAL ASPECTS | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Groups | Priorities | Groups | Priorities | Groups | Priorities | |||||||||
| A1 | A2 | A3 | A4 | A1 | A2 | A3 | A4 | A1 | A2 | A3 | A4 | |||
| 1 | 0.0773 | 0.5945 | 0.1991 | 0.1274 | 1 | 0.0579 | 0.6617 | 0.2061 | 0.0679 | 1 | 0.0680 | 0.6584 | 0.1869 | 0.0807 |
| 2, 7 | 0.1802 | 0.0951 | 0.2849 | 0.4369 | 2, 3, 7, 9, 12, 17, 21, 22 | 0.0722 | 0.3139 | 0.1298 | 0.4831 | 2, 6, 16, 17 | 0.2396 | 0.1144 | 0.0735 | 0.5705 |
| 3, 5, 8, 18, 20 | 0.1137 | 0.3355 | 0.0772 | 0.4728 | 4, 11 | 0.2668 | 0.4765 | 0.1374 | 0.1173 | 3, 13, 15, 19, 21, 22 | 0.0764 | 0.1791 | 0.1584 | 0.584 |
| 4, 9 | 0.3354 | 0.0967 | 0.4601 | 0.1027 | 5 | 0.3090 | 0.2674 | 0.1559 | 0.2656 | 4, 11 | 0.2549 | 0.4865 | 0.1370 | 0.1195 |
| 6, 17 | 0.2783 | 0.1141 | 0.0799 | 0.5253 | 6, 8, 16, 18 | 0.1275 | 0.2291 | 0.0632 | 0.5767 | 5, 8 | 0.1192 | 0.2793 | 0.0711 | 0.5278 |
| 10, 16 | 0.5395 | 0.2163 | 0.1176 | 0.1221 | 10, 20 | 0.5753 | 0.2007 | 0.1253 | 0.0948 | 7, 12, 18 | 0.2329 | 0.0666 | 0.1686 | 0.5282 |
| 11 | 0.2387 | 0.5230 | 0.1150 | 0.1208 | 13, 14, 15, 19 | 0.0854 | 0.1145 | 0.2095 | 0.5874 | 9, 10, 20 | 0.4846 | 0.2108 | 0.1770 | 0.1180 |
| 12, 13, 15, 19, 21, 22 | 0.0572 | 0.2056 | 0.1167 | 0.6190 | 14 | 0.1006 | 0.1461 | 0.5129 | 0.2358 | |||||
| 14 | 0.0945 | 0.1985 | 0.5457 | 0.1565 | ||||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Altuzarra, A.; Gargallo, P.; Moreno-Jiménez, J.M.; Salvador, M. Identification of Homogeneous Groups of Actors in a Local AHP-Multiactor Context with a High Number of Decision-Makers: A Bayesian Stochastic Search. Mathematics 2022, 10, 519. https://doi.org/10.3390/math10030519
Altuzarra A, Gargallo P, Moreno-Jiménez JM, Salvador M. Identification of Homogeneous Groups of Actors in a Local AHP-Multiactor Context with a High Number of Decision-Makers: A Bayesian Stochastic Search. Mathematics. 2022; 10(3):519. https://doi.org/10.3390/math10030519
Chicago/Turabian StyleAltuzarra, Alfredo, Pilar Gargallo, José María Moreno-Jiménez, and Manuel Salvador. 2022. "Identification of Homogeneous Groups of Actors in a Local AHP-Multiactor Context with a High Number of Decision-Makers: A Bayesian Stochastic Search" Mathematics 10, no. 3: 519. https://doi.org/10.3390/math10030519
APA StyleAltuzarra, A., Gargallo, P., Moreno-Jiménez, J. M., & Salvador, M. (2022). Identification of Homogeneous Groups of Actors in a Local AHP-Multiactor Context with a High Number of Decision-Makers: A Bayesian Stochastic Search. Mathematics, 10(3), 519. https://doi.org/10.3390/math10030519