Abstract
Dynamic mode decomposition (DMD) is a popular data-driven framework to extract linear dynamics from complex high-dimensional systems. In this work, we study the system identification properties of DMD. We first show that DMD is invariant under linear transformations in the image of the data matrix. If, in addition, the data are constructed from a linear time-invariant system, then we prove that DMD can recover the original dynamics under mild conditions. If the linear dynamics are discretized with the Runge–Kutta method, then we further classify the error of the DMD approximation and detail that for one-stage Runge–Kutta methods; even the continuous dynamics can be recovered with DMD. A numerical example illustrates the theoretical findings.
1. Introduction
Dynamical systems play a fundamental role in many modern modeling approaches of physical and chemical phenomena. The need for high fidelity models often results in large-scale dynamical systems, which are computationally demanding to solve, analyze, and optimize. Thus the last three decades have seen significant efforts to replace the so-called full-order model, which is considered the truth model, with a computationally cheaper surrogate model. In the context of model order reduction, we refer the interested reader to the monographs [1,2,3,4,5]. Often, the surrogate model is constructed by projecting the dynamical system onto a low-dimensional manifold, thus requiring a state-space description of the differential equation.
If a mathematical model is not available or not suited for modification, data-driven methods, such as the Loewner framework [6,7], vector fitting [8,9,10], operator inference [11], or dynamic mode decomposition (DMD) [12] may be used to create a low-dimensional realization directly from the measurement or simulation data of the system. Suppose the dynamical system that creates the data is linear. In that case, the Loewner framework and vector fitting are—under some technical assumptions—able to recover the original dynamical system and hence serve as system identification tools. Despite the popularity of DMD, a similar analysis seems to be missing, and this paper aims to close this gap.
Since DMD creates a discrete, linear time-invariant dynamical system from data, we are interested in answering the following questions:
- What is the impact of transformations of the data on the resulting DMD approximation?
- Assume that the data used to generate the DMD approximation are obtained from a linear differential equation. Can we estimate the error between the continuous dynamics and the DMD approximation?
- Are there situations in which we are even able to recover the original dynamical system from its DMD approximation?
It is essential to know how the data for the construction of the DMD model are generated to answer these questions. Assuming exact measurements of the solution may be valid from a theoretical perspective only. Instead, we take the view of a numerical analyst and assume that the data are obtained via time integration of the dynamics with a general Runge–Kutta method (RKM) with known order of convergence. We emphasize that for linear time-invariant systems, a RKM may not be the method of choice; see, for instance, [13]. Nevertheless, RKMs are a common numerical technique to solve general differential equations, which is our main reason to consider RKMs in the following.
We can summarize the questions graphically as in Figure 1. Thus, the dashed lines represent the questions that we aim to answer in this paper.
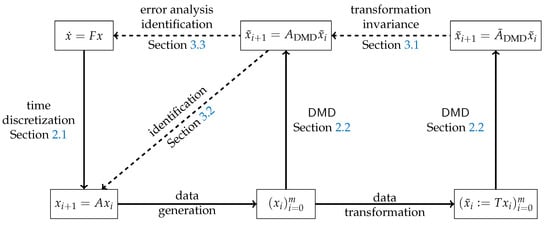
Figure 1.
Problem setup.
Our main results are the following:
- We show in Theorem 1 that DMD is invariant in the image of the data under linear transformations of the data.
- Theorem 2 details that DMD is able to identify discrete-time dynamics, i.e., for every initial value in the image of the data, the DMD approximation exactly recovers the discrete-time dynamics.
- In Theorem 3, we show that if the DMD approximation is constructed from data that are obtained via a RKM, then the approximation error of DMD with respect to the ordinary differential equation is in the order of the error of the RKM. If a one-stage RKM is used and the data are sufficiently rich, then the continuous-time dynamics, i.e., the matrix F in Figure 1, can be recovered cf. Lemma 1.
To render the manuscript self-contained, we recall important definitions and results for RKM and DMD in the upcoming Section 2.1 and Section 2.2, respectively, before we present our analysis in Section 3. We conclude with a numerical example to confirm the theoretical findings.
Notation
As is standard, , , and denote the positive integers, the real numbers, and the polynomials with real coefficients, respectively. For any , we denote with the set of matrices with real entries. The set of nonsingular matrices of size is denoted with . Let , , and (). The transpose and the Moore–Penrose pseudoinverse of A are denoted with and , respectively. The Kronecker product ⊗ is defined as
We use to denote the linear span of the vectors and also casually write for the column space of the matrix X with as its columns. For and a vector , we denote the reachable space as . The Stiefel manifold of dimensional matrices with real entries is denoted by
where denotes the identity matrix. For a continuously differentiable function from the interval to the vector space , we use the notation to denote the derivative with respect to the independent variable t, which we refer to as the time.
2. Preliminaries
As outlined in the introduction, DMD creates a finite-dimensional linear model to approximate the original dynamics. Thus, in view of possibly exact system identification, we need to assume that the data that are fed to the DMD algorithm are obtained from a linear ODE, which in the sequel is denoted by
with given matrix . To fix a solution of (2a), we prescribe the initial condition
and denote the solution of the initial value problem (IVP) as . For the analysis of DMD, we assume that the matrix F is not available. Instead, the question is to what extent DMD is able to recover the matrix F solely from measurements of the state variable x.
Remark 1.
While a DMD approximation, despite its linearity, may well reproduce trajectories of nonlinear systems (see, for example, [14]), the question of DMD being able to recover the full dynamics has to focus on linear systems. Here, the key observation is that a DMD approximation is a finite-dimensional linear map. In contrast, the encoding of nonlinear systems via a linear operator necessarily needs an infinite-dimensional mapping.
2.1. Runge–Kutta Methods
To solve the IVP (2) numerically, we employ a RKM, which is a common one-step method to approximate ordinary and differential-algebraic equations [15,16]. More precisely, given a step size , the solution of the IVP (2) is approximated via the sequence given by
with the so-called internal stages (implicitly) defined via
where denotes the number of stages in the RKM. Using the matrix notation and , the s-stage RKM defined via (3) is conveniently summarized with the pair . Note that we restrict our presentation to linear time-invariant dynamics, and hence, do not require the full Butcher tableau.
Since the ODE (2a) is linear, we can rewrite the internal stages as
Setting and , the linear system in (4) can be written as
where ⊗ denotes the Kronecker product. If h is small enough, the matrix is invertible, and thus, we obtain the discrete linear system
with (using the identity )
Example 1.
The explicit (or forward) Euler method is given as and according to (6) we obtain the well-known formula . For the implicit (or backward) Euler method the discrete system matrix is given by
To guarantee that the representation (6) is valid, we make the following assumption throughout the manuscript.
Assumption A1.
For any s-stage RKM and any dynamical system matrix , we assume that the step size h is chosen such that the matrix is nonsingular.
Remark 2.
Using Assumption 1, the matrix is nonsingular, and thus, there exists a polynomial of degree at most depending on the step size h such that
where the last equality follows from the binomial theorem. Consequently, we have
Rearranging the terms together with the Cayley–Hamilton theorem implies the existence of a polynomial of degree at most n such that . As a direct consequence, we see that any eigenvector of F is an eigenvector of and thus, is diagonalizable if F is diagonalizable.
Having computed the matrix , the question that remains to be answered is the quality of the approximation , which yields the following well-known definition (cf. [15]).
Definition 1.
A RKM has order p if there exists a constant (independent of h) such that
holds, where with defined as in (6).
For one-step methods, it is well known that the local errors—as estimated in (8) for the initial time step—basically sum in the global error such that the following estimate holds:
see, e.g., ([15], Thm. II.3.6).
2.2. Dynamic Mode Decomposition
For , assume data points are available. If not explicitly stated, we do not make any assumption on m. The idea of DMD is to determine a linear time-invariant relation between the data, i.e., finding a matrix such that the data approximately satisfy
Following [17], we introduce
Then, the DMD approximation matrix is defined as the minimum-norm solution of
where denotes the Frobenius norm. It is easy to show that the minimum-norm solution is given by [12], where denotes the Moore–Penrose pseudoinverse of X. This motivates the following definition.
Definition 2.
Consider the data for and associated data matrices X and Z defined in (9). Then the matrix is called the DMD matrix for . If the eigendecomposition of exists, then the eigenvalues and eigenvectors of are called DMD eigenvalues and DMD modes of , respectively.
The Moore–Penrose pseudoinverse and, thus, also the DMD matrix can be computed via the singular value decomposition (SVD); see, for example, ([18], Ch. 5.5.4). Let
denote the SVD of X, with , , and , and , where we use the Stiefel manifold as defined in (1). Then
and, thus,
For later reference, we call the trimmed SVD of X.
3. System Identification and Error Analysis
In this section, we present our main results. Before discussing system identification for discrete-time (cf. Section 3.2) and continuous-time (cf. Section 3.3) dynamical systems via DMD, we study the impact of transformations of the data on DMD in Section 3.1.
3.1. Data Scaling and Invariance of the DMD Approximation
Scaling and more general transformations of data are often used to improve the performance of the methods that work on the data. Since DMD is inherently related to the Moore–Penrose inverse, we first study the impact of a nonsingular matrix on the generalized inverse. To this purpose, consider a matrix with . Let denote the trimmed SVD of X with , and . Let denote the QR-decomposition of with and . We immediately obtain . Let denote the trimmed SVD of with , , and . We immediately infer
It is easy to see that the matrices , and satisfy , i.e., and . The trimmed SVD of is thus given by
We conclude
where we used the identity (13). We have thus shown the following result.
Proposition 1.
Let and . Then .
With these preparations, we can now show that the DMD approximation is partially invariant to general regular transformations applied to the training data. More precisely, a data transformation only affects the part of the DMD approximation that is not in the image of the data.
Theorem 1.
For given data consider the matrices X and Z as defined in (9) and the corresponding DMD matrix . Consider and let
be the matrices of the transformed data. Let denote the DMD matrix for the transformed data. Then the DMD matrix is invariant under the transformation in the image of X, i.e.,
Moreover, if T is unitary or , then
Proof.
Using Proposition 1, we obtain
If T is unitary or , then we immediately obtain , and thus
which concludes the proof. □
While Theorem 1 states that DMD is invariant under transformations in the image of the data matrix, the invariance in the orthogonal complement of the image of the data matrix, i.e., equality (14), is, in general, not satisfied. We illustrate this observation in the numerical simulations in Section 4 and in the following analytical example.
Example 2.
Consider the data vectors for and . Then,
We thus obtain
confirming that DMD is invariant under transformations in the image of the data, but not in the orthogonal complement.
Remark 3.
One can show that in the setting of Theorem 1, the matrix is a minimizer (not necessarily the minimum-norm solution) of
3.2. Discrete-Time Dynamics
In this subsection, we focus on the identification of discrete-time dynamics, which are exemplified by the discrete-time system
with initial value and system matrix . The question that we want to answer is to what extent DMD is able to recover the matrix A solely from data.
Proposition 2.
Proof.
By assumption, we have and . We conclude
Remark 4.
We immediately conclude that DMD recovers the true dynamics, i.e., , whenever . This is the case if and only if is controllable, i.e., has dimension n, and the data set is sufficiently rich, i.e., .
Our next theorem identifies the part of the dynamics that is exactly recovered in the case that that occurs for is not controllable or .
Theorem 2.
Consider the setting of Proposition 2. If is invariant, then the DMD approximation is exact in the image of U, i.e.,
If, in addition, , then also the converse direction holds.
Proof.
Let . Since is invariant, we conclude for , i.e., there exists such that . Using Proposition 2 we conclude
The proof of (17) follows via induction over i. For the converse direction, let with and . Proposition 2 and (17) imply
which completes the proof. □
Remark 5.
The proof of Theorem 2 details that is -invariant if and only if is A invariant. Moreover, implies that this condition can be checked easily during the data-generation process. If we further assume that the data are generated via (15), then this is the case whenever
for some .
3.3. Continuous-Time Dynamics and RK Approximation
Suppose now that the data are generated by a continuous process, i.e., via the dynamical system (2). In this case, we are interested in recovering the continuous dynamics from the DMD approximation. As a consequence of Theorem 2, we immediately obtain the following results for exact sampling.
Corollary 1.
Let be the DMD matrix for the sequence for with . Then
if and only if , where denotes the solution of the IVP (2) with initial value .
Proof.
The assertion follows immediately from Proposition 2 with the observation that is nonsingular. □
We conclude that we can recover the continuous dynamics with the matrix logarithm (see [19] for further details), whenever . In practical applications, an exact evaluation of the flow map is typically not possible. Instead, a numerical time-integration method is used to approximate the continuous dynamics.
Suppose we use a RKM with constant step size to obtain a numerical approximation of the IVP (2) and use these data to construct the DMD matrix as in Definition 2. If we now want to use the DMD matrix to obtain an approximation for a different initial condition, say , we are interested in quantifying the error
Theorem 3.
Suppose that the sequence , with for , is generated from the linear IVP (2) via a RKM of order p and step size and satisfies
Let denote the associated DMD matrix. Then there exists a constant such that
holds for any .
Proof.
Since the data are generated from a RKM, there exists a matrix such that for . Let . Then, Theorem 2 implies for any . Thus, the result follows from the classical error estimates for RKM (see, for example, [15], Thm. II.3.6) and from the equality
for some since the RKM is of order p. □
The proof details that due to Proposition 2, we are essentially able to recover the discrete dynamics obtained from the RKM via DMD, provided that . As laid out in Remark 4, this condition is equivalent to being controllable for which the controllability of is a necessary condition.
The question that remains to be answered is whether it is possible to recover the continuous dynamic matrix F from the discrete dynamics (respectively ) provided that the Runge–Kutta scheme used to discretize the continuous dynamics is known. For any 1-stage Runge–Kutta method , i.e., in (3), this is indeed the case since then (6) simplifies to
which yields
Combining (19) with Proposition 2 yields the following result.
Lemma 1.
Suppose that the sequence is generated from the linear IVP (2) via the 1-stage Runge-Kutta method with step size . Let denote the associated DMD matrix. If , then
provided that the inverse exists.
If the assumption of Lemma 1 holds, then we can recover the continuous dynamic matrix from the DMD approximation. The corresponding formula for popular 1-stage methods is presented in Table 1.

Table 1.
Identification of continuous-time systems via DMD with 1-stage Runge–Kutta methods.
In this scenario, let us emphasize that we can compute the discrete dynamics with the DMD approximation for any time step.
The situation is different for , as we illustrate with the following example.
Example 3.
For given , consider and . Then, for Heun’s method, i.e., and , we obtain with , and thus . In particular, we cannot distinguish the continuous-time dynamics in this specific scenario.
4. Numerical Examples
To illustrate our analytical findings, we constructed a dynamical system that exhibits some fast dynamics that is stable but not exponentially stable and has a nontrivial but exactly computable flow map. In this way, we can check the approximation both qualitatively and quantitatively. In addition, the system can be scaled to arbitrary state-space dimensions. Most importantly, for our purposes, the system is designed such that for any initial value, the space not reached by the system is at least as large as the reachable space. The complete code of our numerical examples can be found in the supplementary material.
With , we consider the continuous-time dynamics (2) with
Starting with an initial value we can thus generate exact snapshots of the solution via , as well as the controllability space
One can confirm that with equality if, for example, the initial state
has no zero entries in its lower part . Due to (7), we immediately infer
for any obtained by a Runge–Kutta method. We conclude that DMD is at most capable of reproducing solutions that evolve in . Indeed, as outlined in Proposition 2, all components of any other initial value that are in the orthogonal complement of are set to zero in the first DMD iteration.
For our numerical experiments, we set , , and consider the time-grid for with uniform step size . A SVD of exactly sampled data
of the matrix of snapshots of the solution reveals that the solution space is indeed of dimension and defines the bases of and its orthogonal complement, respectively.
For our numerical experiment, whose results are depicted in Figure 2, we choose the initial values
with . The exact solution for both initial values is presented in Figure 2a,b, respectively. Our simulations confirm the following:
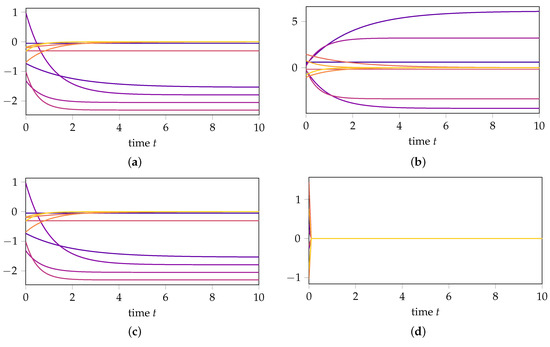
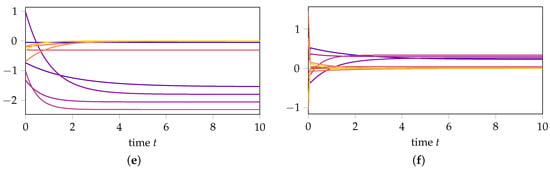
Figure 2.
Comparison of the exact solution, DMD approximation, and DMD approximation based on transformed data for initial values inside the reachable subspace, i.e., and outside the reachable subspace, i.e., . (a) Exact solution with initial value . (b) Exact solution with initial value . (c) DMD approximation with initial value . (d) DMD approximation with initial value . (e) DMD with transformed data with initial value . (f) DMD with transformed data with initial value .
- If we first transform the data with the matrixthen compute the DMD approximation, and then transform the results back, the DMD approximation for remains unchanged (see Figure 2e), confirming (14) from Theorem 1. In contrast, the prediction of the dynamics for changes (see Figure 2f), highlighting that DMD is not invariant under state-space transformations in the orthogonal complement of the data.
The presented numerical example is chosen to illustrate the importance of the reachable space. Computing a subspace numerically is a delicate task in particular if, as in our example, the ratio of the largest and the smallest entry in the controllability matrix is of size , which leads to huge rounding errors already for moderate N. This mainly concerns the separation of the reachable and the unreachable subspace, which, however, can be monitored in a general implementation for a general setup. Since in standard SVD implementations, the dominant directions (and, thus, the Moore–Penrose inverse) are computed with high accuracy, for quantitative approximations using DMD, these numerical issues are less severe.
5. Conclusions
This work highlighted fundamental properties of the DMD approach if applied to linear problems both in continuous and discrete times. Depending on how the initial data relate to the reachable space, the DMD can recover the exact discrete-time dynamics. If, in addition, the discrete-time data are generated from a continuous-time system via time discretization with a Runge–Kutta scheme, then the error of the DMD approximation is in the same order as the time-integration method. As a by-product of our analysis, we made a relation of the Moore–Penrose inverse and regular transformations explicit, which has not been stated so far. Although the findings mainly confirm what should be expected, the basic principles, such as controllability, will well generalize to nonlinear problems.
Supplementary Materials
The following are available at https://www.mdpi.com/article/10.3390/math10030418/s1. Python script to reproduce the numerical results.
Author Contributions
All authors have contributed equally to this work. All authors have read and agreed to the published version of the manuscript.
Funding
B. Unger acknowledges funding from the DFG under Germany’s Excellence Strategy–EXC 2075–390740016 and is thankful for support by the Stuttgart Center for Simulation Science (SimTech).
Data Availability Statement
The code to produce the numerical example is attached to this manuscript as Supplementary Material.
Acknowledgments
We thank Robert Altmann for inviting us to the Sion workshop, where we started this work.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| DMD | dynamic mode decomposition |
| IVP | initial value problem |
| ODE | ordinary differential equation |
| RKM | Runge–Kutta method |
| SVD | singular value decomposition |
References
- Benner, P.; Cohen, A.; Ohlberger, M.; Willcox, K. Model Reduction and Approximation; SIAM: Philadelphia, PA, USA, 2017. [Google Scholar] [CrossRef] [Green Version]
- Quarteroni, A.; Manzoni, A.; Negri, F. Reduced Basis Methods for Partial Differential Equations: An Introduction; UNITEXT, Springer: Berlin, Germany, 2016. [Google Scholar] [CrossRef]
- Antoulas, A.C. Approximation of Large-Scale Dynamical Systems; Advances in Design and Control; SIAM: Philadelphia, PA, USA, 2005; p. 489. [Google Scholar]
- Hesthaven, J.S.; Rozza, G.; Stamm, B. Certified Reduced Basis Methods for Parametrized Partial Differential Equations; Springer: Berlin, Germany, 2016. [Google Scholar]
- Antoulas, A.C.; Beattie, C.A.; Güğercin, S. Interpolatory Methods for Model Reduction; SIAM: Philadelphia, PA, USA, 2020. [Google Scholar] [CrossRef]
- Mayo, A.J.; Antoulas, A.C. A framework for the solution of the generalized realization problem. Linear Algebra Appl. 2007, 425, 634–662. [Google Scholar] [CrossRef] [Green Version]
- Beattie, C.; Gugercin, S. Realization-independent H2-approximation. In Proceedings of the 2012 IEEE 51st IEEE Conference on Decision and Control (CDC), Maui, HI, USA, 10–13 December 2012; pp. 4953–4958. [Google Scholar] [CrossRef]
- Gustavsen, B.; Semlyen, A. Rational approximation of frequency domain responses by vector fitting. IEEE Trans. Power Deliv. 1999, 14, 1052–1061. [Google Scholar] [CrossRef] [Green Version]
- Drmač, Z.; Gugercin, S.; Beattie, C. Quadrature-Based Vector Fitting for Discretized H2 Approximation. SIAM J. Sci. Comput. 2015, 37, A625–A652. [Google Scholar] [CrossRef] [Green Version]
- Drmač, Z.; Gugercin, S.; Beattie, C. Vector Fitting for Matrix-valued Rational Approximation. SIAM J. Sci. Comput. 2015, 37, A2345–A2379. [Google Scholar] [CrossRef]
- Peherstorfer, B.; Willcox, K. Data-driven operator inference for nonintrusive projection-based model reduction. Comput. Methods Appl. Mech. Engrg. 2016, 306, 196–215. [Google Scholar] [CrossRef] [Green Version]
- Kutz, J.; Brunton, S.; Brunton, B.; Proctor, J. Dynamic Mode Decomposition; SIAM: Philadelphia, PA, USA, 2016. [Google Scholar]
- Moler, C.; Van Loan, C. Nineteen Dubious Ways to Compute the Exponential of a Matrix, Twenty-Five Years Later. SIAM Rev. 2003, 45, 3–49. [Google Scholar] [CrossRef]
- Mezić, I. Spectral Properties of Dynamical Systems, Model Reduction and Decompositions. Nonlinear Dyn. 2005, 41, 309–325. [Google Scholar] [CrossRef]
- Hairer, E.; Nørsett, S.; Wanner, G. Solving Ordinary Differential Equations I: Nonstiff Problems; Springer Series in Computational Mathematics; Springer: Berlin, Germany, 2008. [Google Scholar]
- Kunkel, P.; Mehrmann, V. Differential-Algebraic Equations. Analysis and Numerical Solution; European Mathematical Society: Zürich, Switzerland, 2006. [Google Scholar]
- Tu, J.H.; Rowley, C.W.; Luchtenburg, D.M.; Brunton, S.L.; Kutz, J.N. On dynamic mode decomposition: Theory and applications. J. Comput. Dyn. 2014, 1, 391–421. [Google Scholar] [CrossRef] [Green Version]
- Golub, G.H.; Van Loan, C.F. Matrix Computations, 3rd ed.; Johns Hopkins University Press: Baltimore, MD, USA, 1996. [Google Scholar]
- Higham, N. Functions of Matrices: Theory and Computation; Other Titles in Applied Mathematics; SIAM: Philadelphia, PA, USA, 2008. [Google Scholar]
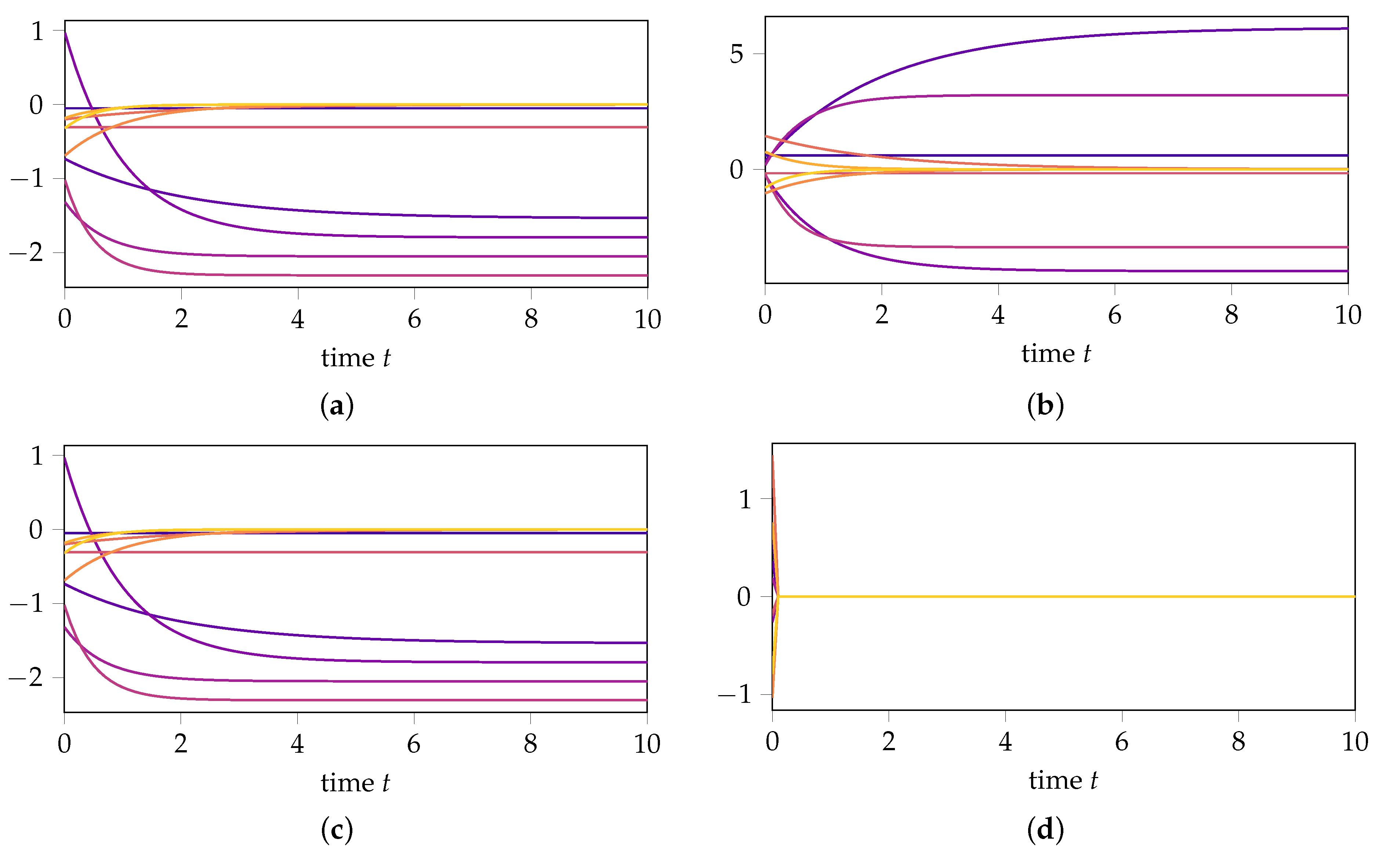
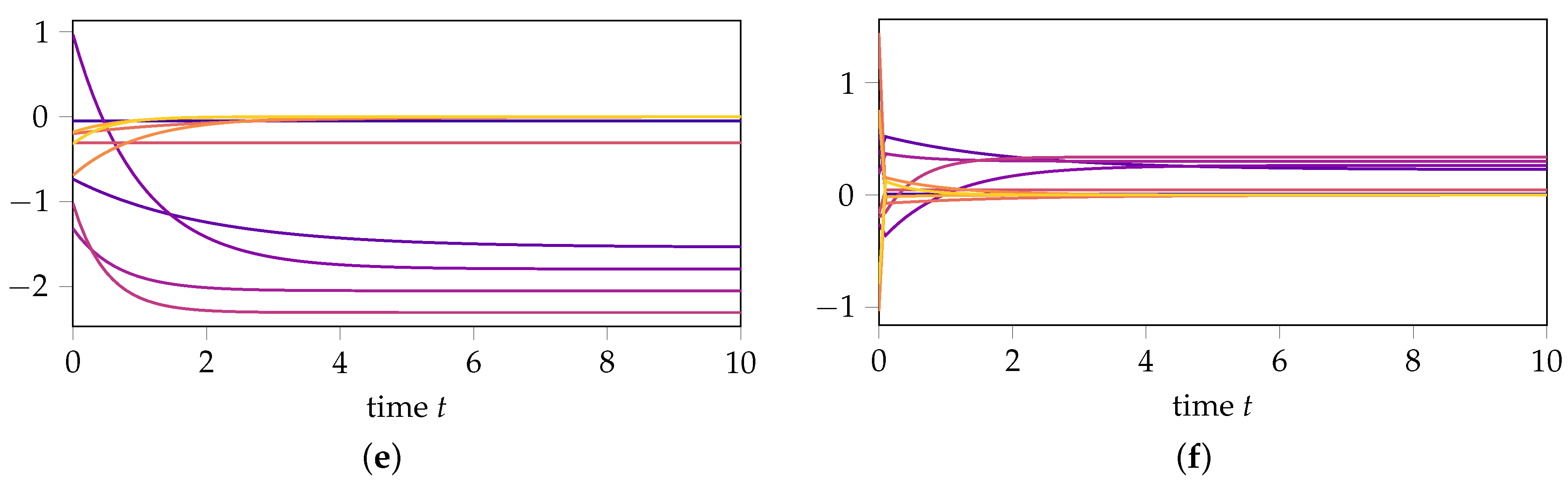
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).