
Improving Machine Reading Comprehension with Multi-Task Learning and Self-Training


Abstract
:1. Introduction
2. Materials and Methods
2.1. Materials
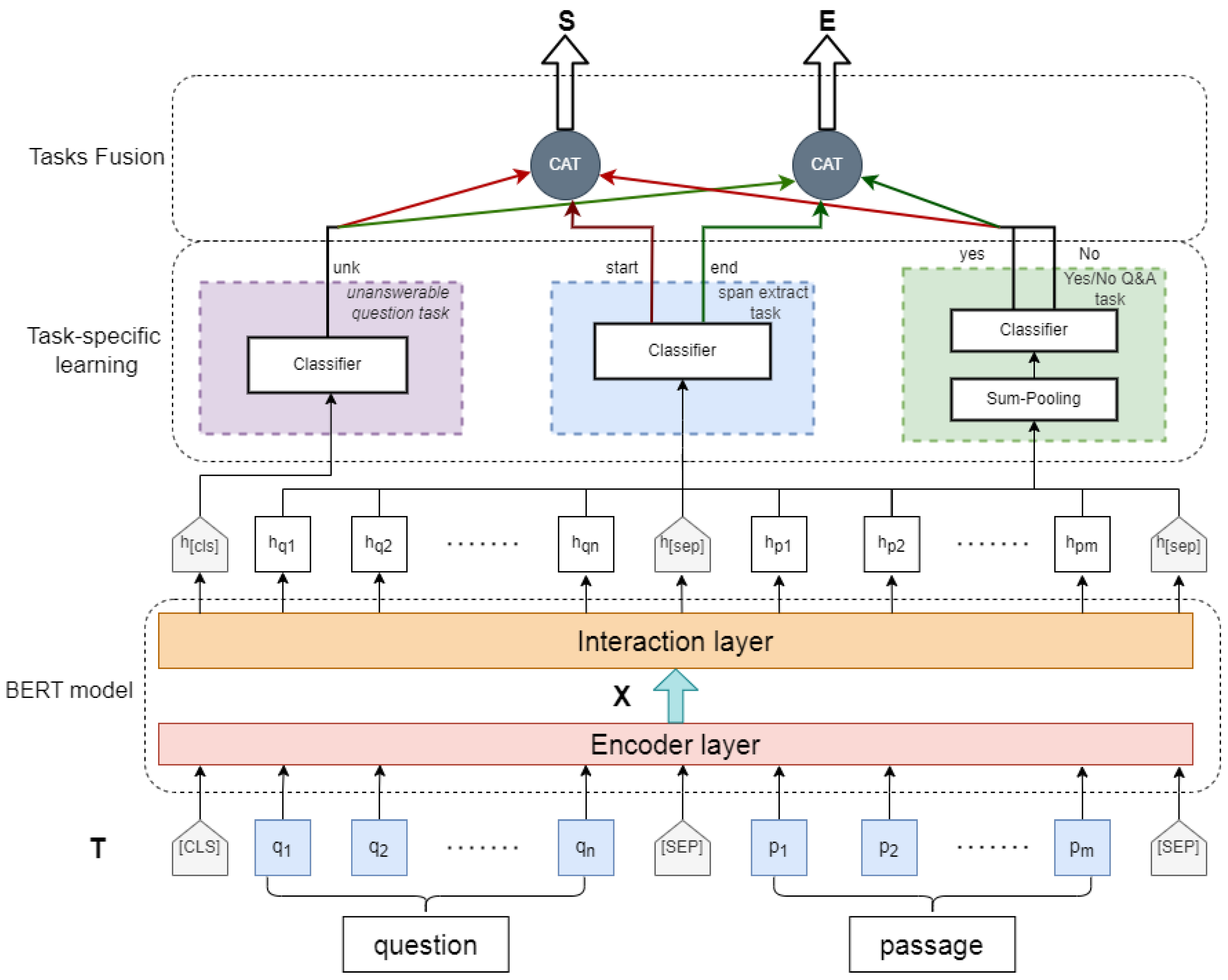
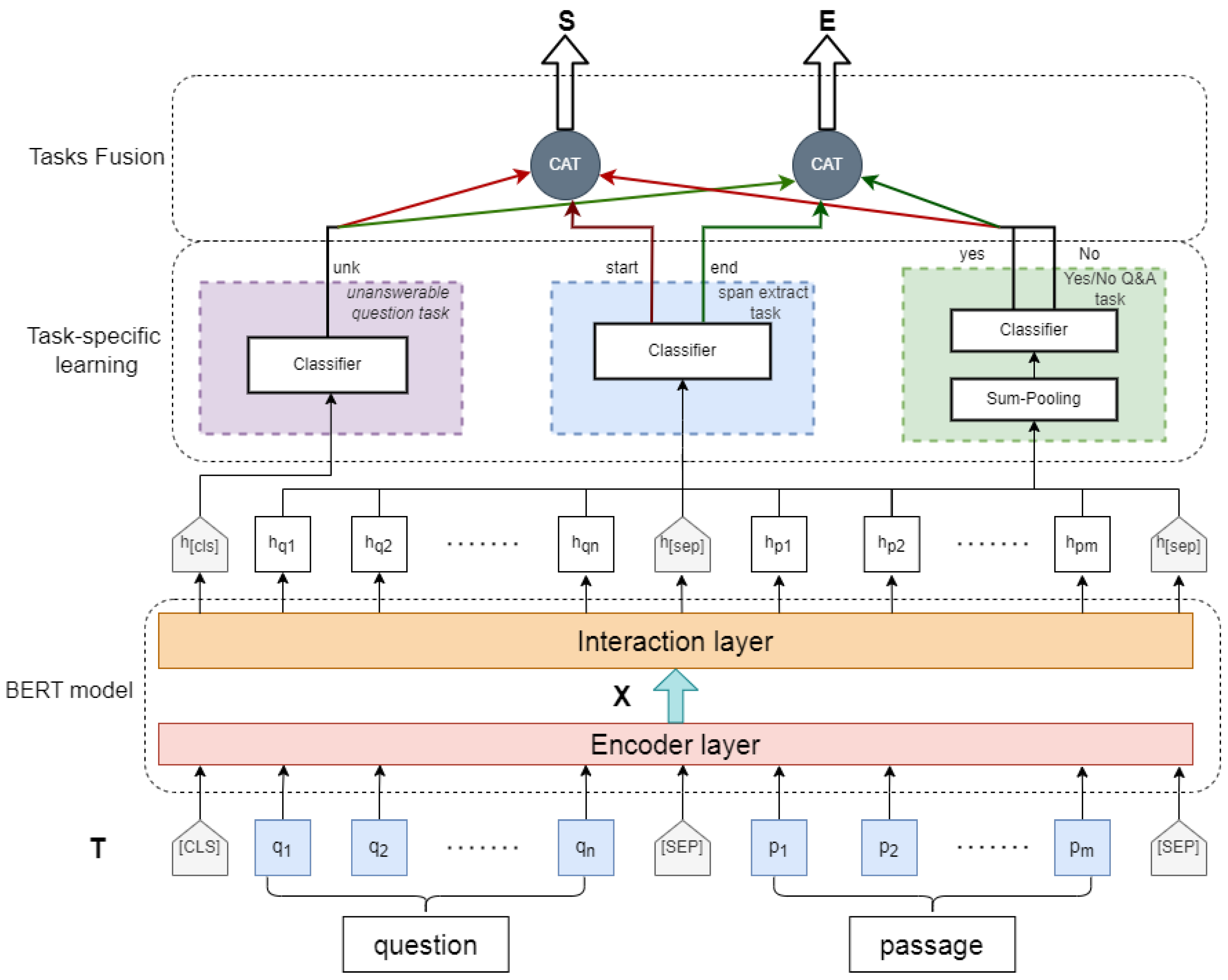
2.2. Method
2.2.1. Embedding
2.2.2. Interaction
2.2.3. Multi-Tasking Fusion Training
2.2.4. Self Training
| Algorithm 1 MRC self-training process |
Require: Pre-trained MRC model, ; Labeled dataset, ; Unlabeled dataset, ; Number of self-training iterations, N; Threshold for filtering pseudo-labels,
|
| Algorithm 2 Pseudo-label generation |
Require: Model used in self-training process, M; Passages in unlabeled dataset, ; Questions in unlabeled dataset, ; Unlabeled dataset, ; Threshold for filtering pseudo-labels,
|
3. Experiments and Results
3.1. Experiments
3.1.1. Evaluation
3.1.2. Setup
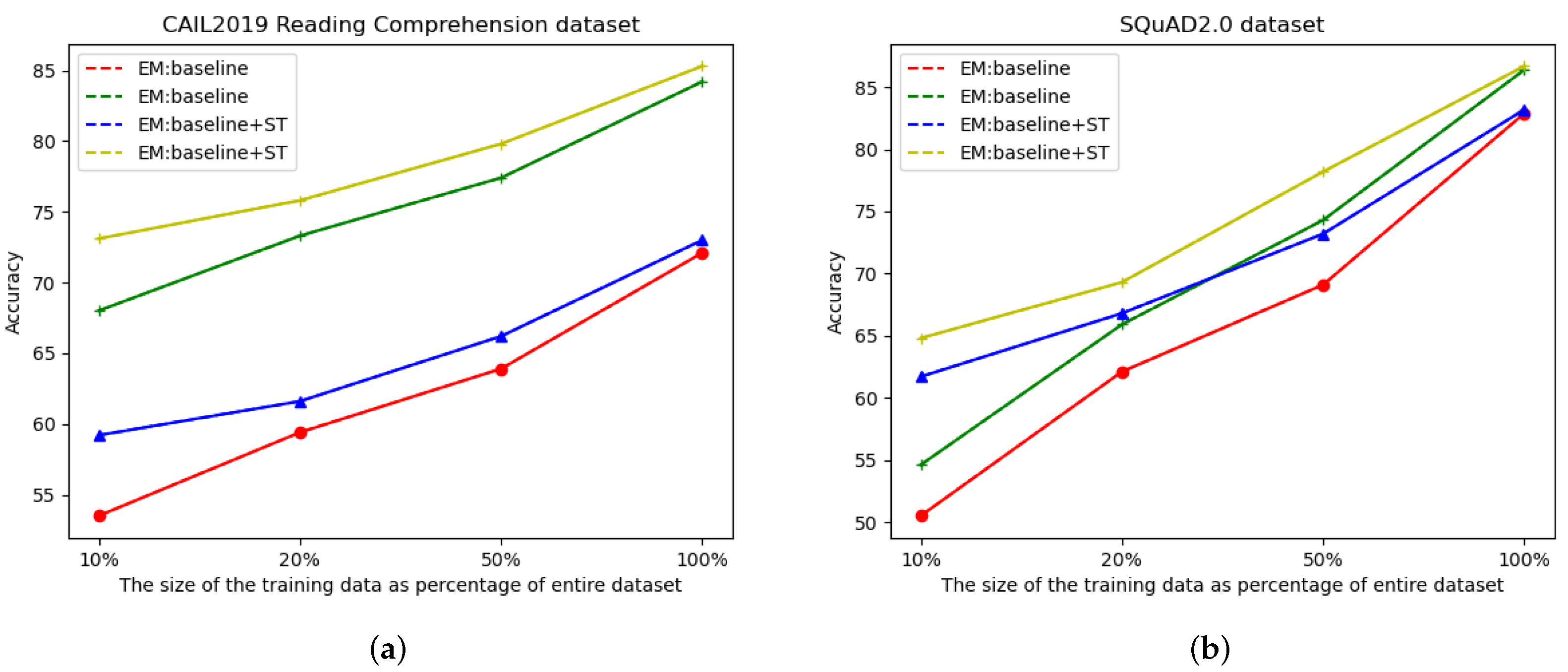
3.2. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hermann, K.M.; Kocisky, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; Blunsom, P. Teaching machines to read and comprehend. Adv. Neural Inf. Process. Syst. 2015, 28, 1693–1701. [Google Scholar]
- Zhang, Z.; Yang, J.; Zhao, H. Retrospective Reader for Machine Reading Comprehension. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; AAAI Press: Palo Alto, CA, USA, 2021; Volume 35, pp. 14506–14514. [Google Scholar]
- Xie, Q.; Lai, G.; Dai, Z.; Hovy, E. Large-scale Cloze Test Dataset Created by Teachers. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2344–2356. [Google Scholar]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. SQuAD: 100,000+ Questions for Machine Comprehension of Text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, Texas, USA, 1–5 November 2016; pp. 2383–2392. [Google Scholar]
- Inoue, N.; Stenetorp, P.; Inui, K. R4C: A Benchmark for Evaluating RC Systems to Get the Right Answer for the Right Reason. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Stroudsburg, PA, USA, 6–8 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 6740–6750. [Google Scholar]
- Rajpurkar, P.; Jia, R.; Liang, P. Know what you don’t know: Unanswerable questions for SQuAD. arXiv 2018, arXiv:1806.03822. [Google Scholar]
- Reddy, S.; Chen, D.; Manning, C.D. Coqa: A conversational question answering challenge. Trans. Assoc. Comput. Linguist. 2019, 7, 249–266. [Google Scholar] [CrossRef]
- Xiao, C.; Zhong, H.; Guo, Z.; Tu, C.; Liu, Z.; Sun, M.; Xu, J. Cail2019-scm: A dataset of similar case matching in legal domain. arXiv 2019, arXiv:1911.08962. [Google Scholar]
- Jacob, I.J. Performance evaluation of caps-net based multitask learning architecture for text classification. J. Artif. Intell. 2020, 2, 1–10. [Google Scholar]
- Peng, Y.; Chen, Q.; Lu, Z. An empirical study of multi-task learning on BERT for biomedical text mining. arXiv 2020, arXiv:2005.02799,. [Google Scholar]
- Ruder, S.; Bingel, J.; Augenstein, I.; Søgaard, A. Latent multi-task architecture learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January 2019; AAAI: Honolulu, HI, USA, 2019; Volume 33, pp. 4822–4829. [Google Scholar]
- Zhang, Y.; Yang, Q. A survey on multi-task learning. IEEE Trans. Knowl. Data Eng. 2021, 2, 1–10. [Google Scholar] [CrossRef]
- Liu, X.; Li, W.; Fang, Y.; Kim, A.; Duh, K.; Gao, J. Stochastic answer networks for squad 2.0. arXiv 2018, arXiv:1809.09194,. [Google Scholar]
- Hu, M.; Wei, F.; Peng, Y.; Huang, Z.; Yang, N.; Li, D. Read+ verify: Machine reading comprehension with unanswerable questions. In Proceedings of the AAAI Conference on Artificial Intelligence, Palo Alto, CA, USA, 2–9 February 2019; Volume 33, pp. 6529–6537. [Google Scholar]
- Back, S.; Chinthakindi, S.C.; Kedia, A.; Lee, H.; Choo, J. NeurQuRI: Neural question requirement inspector for answerability prediction in machine reading comprehension. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Zhang, Z.; Wu, Y.; Zhou, J.; Duan, S.; Zhao, H.; Wang, R. SG-Net: Syntax-guided machine reading comprehension. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 9636–9643. [Google Scholar]
- Kadlec, R.; Schmid, M.; Bajgar, O.; Kleindienst, J. Text Understanding with the Attention Sum Reader Network. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 908–918. [Google Scholar]
- Dhingra, B.; Liu, H.; Yang, Z.; Cohen, W.W.; Salakhutdinov, R. Gated-Attention Readers for Text Comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1832–1846. [Google Scholar]
- Park, C.; Song, H.; Lee, C. S3-NET: SRU-based sentence and self-matching networks for machine reading comprehension. ACM Trans. Asian -Low-Resour. Lang. Inf. Process. (TALLIP) 2020, 19, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Cui, Y.; Chen, Z.; Wei, S.; Wang, S.; Liu, T.; Hu, G. Attention-over-Attention Neural Networks for Reading Comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 593–602. [Google Scholar]
- Kim, J.H.; Jun, J.; Zhang, B.T. Bilinear attention networks. arXiv 2018, arXiv:1805.07932,. [Google Scholar]
- Sarzynska-Wawer, J.; Wawer, A.; Pawlak, A.; Szymanowska, J.; Stefaniak, I.; Jarkiewicz, M.; Okruszek, L. Detecting formal thought disorder by deep contextualized word representations. Psychiatry Res. 2021, 304, 114135. [Google Scholar] [CrossRef] [PubMed]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Amodei, D. Language models are few-shot learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32, 5753–5763. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. Electra: Pre-training text encoders as discriminators rather than generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Lee, D.H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Workshop on Challenges in Representation Learning; ICML: Atlanta, GA, USA, 2013; Volume 3, p. 896. [Google Scholar]
- Yarowsky, D. Unsupervised word sense disambiguation rivaling supervised methods. In Proceedings of the 33rd Annual Meeting of the Association for Computational Linguistics, Cambridge, MA, USA, 26–30 June 1995; pp. 189–196. [Google Scholar]
- Zhu, X.; Goldberg, A.B. Introduction to semi-supervised learning. Synth. Lect. Artif. Intell. Mach. Learn. 2009, 3, 1–130. [Google Scholar] [CrossRef] [Green Version]
- Zoph, B.; Ghiasi, G.; Lin, T.Y.; Cui, Y.; Liu, H.; Cubuk, E.D.; Le, Q.V. Rethinking pre-training and self-training. arXiv 2020, arXiv:2006.06882. [Google Scholar]
- Zhao, R.; Liu, T.; Xiao, J.; Lun, D.P.; Lam, K.M. Deep multi-task learning for facial expression recognition and synthesis based on selective feature sharing. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 4412–4419. [Google Scholar]
- Wang, Y.; Mukherjee, S.; Chu, H.; Tu, Y.; Wu, M.; Gao, J.; Awadallah, A.H. Adaptive self-training for few-shot neural sequence labeling. arXiv 2020, arXiv:2010.03680. [Google Scholar]
- Li, C.; Li, X.; Ouyang, J. Semi-Supervised Text Classification with Balanced Deep Representation Distributions. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Bangkok, Thailand, 1–6 August 2021; pp. 5044–5053. [Google Scholar]
- He, J.; Gu, J.; Shen, J.; Ranzato, M.A. Revisiting self-training for neural sequence generation. arXiv 2019, arXiv:1909.13788. [Google Scholar]
- Jiao, W.; Wang, X.; Tu, Z.; Shi, S.; Lyu, M.R.; King, I. Self-Training Sampling with Monolingual Data Uncertainty for Neural Machine Translation. arXiv 2021, arXiv:2106.00941. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; NeurIPS Proceedings: Long Beach, CA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Dean, J. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | EM (%) | F1 (%) | Time (h) |
|---|---|---|---|
| NeurQuRI | 81.3 | 84.3 | 7 |
| BERT | 82.1 | 84.8 | 8.5 |
| ALBERT | 86.9 | 89.8 | 22.5 |
| ELECTRA | 87.0 | 89.9 | 20 |
| Our model | 82.9 | 86.4 | 8.5 |
| Our model + | 83.2 (+0.3) | 86.7 (+0.3) | 42.5 (5 iters) |
| Model | EM (%) | F1 (%) | Time (h) |
|---|---|---|---|
| NeurQuRI | 67.2 | 79.8 | 5 |
| BERT | 69.5 | 81.7 | 6 |
| ELECTRA | 71.2 | 83.6 | 11 |
| Our model | 72.1 | 84.2 | 6 |
| Our model + | 73.0 (+0.9) | 85.3 (+1.1) | 30 (5 iters) |
| Training Method | EM | F1 |
|---|---|---|
| MLT with Fusion training | 72.1 | 84.2 |
| MLT with Three Auxiliary losses | 72.6 | 83.4 |
| Pipeline method | 70.6 | 81.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ouyang, J.; Fu, M. Improving Machine Reading Comprehension with Multi-Task Learning and Self-Training. Mathematics 2022, 10, 310. https://doi.org/10.3390/math10030310
Ouyang J, Fu M. Improving Machine Reading Comprehension with Multi-Task Learning and Self-Training. Mathematics. 2022; 10(3):310. https://doi.org/10.3390/math10030310
Chicago/Turabian StyleOuyang, Jianquan, and Mengen Fu. 2022. "Improving Machine Reading Comprehension with Multi-Task Learning and Self-Training" Mathematics 10, no. 3: 310. https://doi.org/10.3390/math10030310
APA StyleOuyang, J., & Fu, M. (2022). Improving Machine Reading Comprehension with Multi-Task Learning and Self-Training. Mathematics, 10(3), 310. https://doi.org/10.3390/math10030310