
Evaluating Research Trends from Journal Paper Metadata, Considering the Research Publication Latency


Abstract
:1. Introduction
- A novel methodology that includes the new nsaMK method to identify term trends from metadata from journal paper, when considering the inherent time lag between the research completion and paper publication date;
- A definition of the research publication latency and an empirical formula to derive the number of prediction steps considered by the proposed method to countermeasure the effect of the journal review and publication process upon the research trend evaluation;
- An evaluation of the new nsaMK method in an electronic design automation case study by comparing it with the classical MK trend test. The superiority of nsaMK is confirmed by a 45% reduction of the mean square error of Sen’s slope evaluations and by an increase of correct term trend indications with 66%.
2. Preliminaries
2.1. Time-Series ARIMA Model Prediction. Auto-ARIMA Method
2.2. Mann–Kendall Trend Test with Sen’s Slope Estimator
3. Proposed Research Term Trend Evaluation
3.1. Proposed Methodology
- Phase I: identify the number of steps N to be predicted. This number depends on the research publication latency and on the moment in time for which the research trends are computed and can be obtained using the following formula:where is the rounding (nearest integer) function, and is the time deviation from the moment in time the last value in the annual time series was recorded to the date for which the research trends are computed. Since the published papers within a year are grouped in journal issues that are generally uniformly distributed during that year, we may consider that the recording day for each year is the middle of that year. Thus, if we want to calculate the research trends on 1 January, 2021, when having the last time series observation recorded for 2020, years, while if we calculate the research trends for 2 July, 2021, year.
- Phase II: form the annual time series for a specified key term by computing the number of its occurrences in paper metadata (i.e., title, keywords and abstract) during each year. For this, the following procedure can be used: each paper’s metadata are automatically or manually collected; the titles, keywords, and abstracts are concatenated into a text document, which is fed into an entity-linking procedure (e.g., TagMe [28], AIDA [29], Wikipedia Miner [30]), to obtain the list of terms that characterizes the paper; and, count the number of papers per each year where the key term occurs.
- Phase III: apply the proposed n-steps-ahead Mann–Kendall procedure for the annual time series containing the occurrences of the specified key term.
3.2. N-Steps-Ahead Mann–Kendall Method
4. Experimental Results
4.1. Data Acquisition and Preprocessing
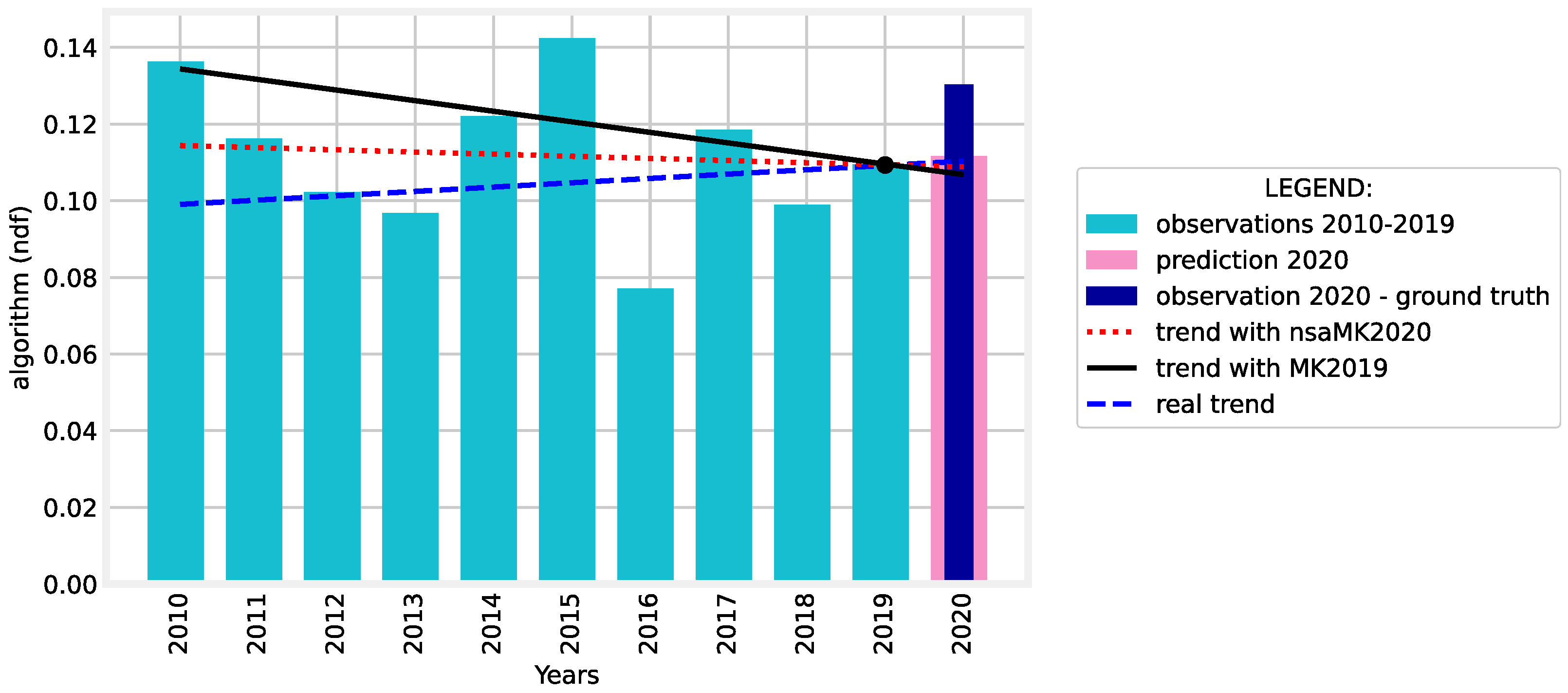
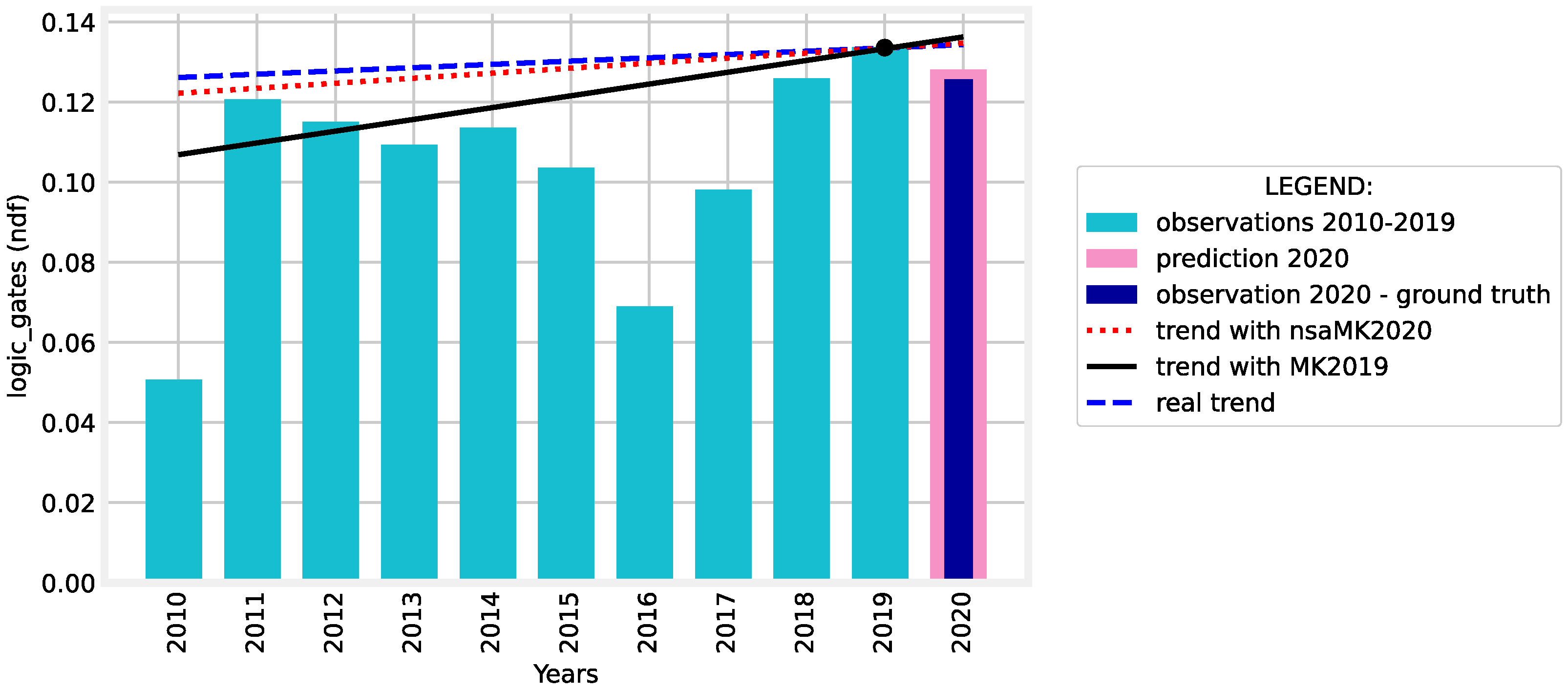
4.2. nsaMK Method Evaluation
- Using the Yue and Wang variant of MK test for journal papers published between 2011 and 2020 (MK2020). The results of the MK2020 are considered as ground-truth.
- Using our nsaMK method when considering journal papers published between 2010 and 2019 and the predicted values for 2020 (nsaMK2020).
- Using the Yue and Wang variant of MK test for journal papers published between 2010 and 2019 (MK2019).
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Marrone, M. Application of entity linking to identify research fronts and trends. Scientometrics 2020, 122, 357–379. [Google Scholar] [CrossRef] [Green Version]
- Hamed, K.H. Trend detection in hydrologic data: The Mann–Kendall trend test under the scaling hypothesis. J. Hydrol. 2008, 349, 350–363. [Google Scholar] [CrossRef]
- Önöz, B.; Bayazit, M. The power of statistical tests for trend detection. Turk. J. Eng. Environ. Sci. 2003, 27, 247–251. [Google Scholar]
- Wang, F.; Shao, W.; Yu, H.; Kan, G.; He, X.; Zhang, D.; Ren, M.; Wang, G. Re-evaluation of the power of the mann-kendall test for detecting monotonic trends in hydrometeorological time series. Front. Earth Sci. 2020, 8, 14. [Google Scholar] [CrossRef]
- Hirsch, R.M.; Slack, J.R. A nonparametric trend test for seasonal data with serial dependence. Water Resour. Res. 1984, 20, 727–732. [Google Scholar] [CrossRef] [Green Version]
- Marchini, G.S.; Faria, K.V.; Neto, F.L.; Torricelli, F.C.M.; Danilovic, A.; Vicentini, F.C.; Batagello, C.A.; Srougi, M.; Nahas, W.C.; Mazzucchi, E. Understanding urologic scientific publication patterns and general public interests on stone disease: Lessons learned from big data platforms. World J. Urol. 2021, 39, 2767–2773. [Google Scholar] [CrossRef]
- Sharma, D.; Kumar, B.; Chand, S. A trend analysis of machine learning research with topic models and mann-kendall test. Int. J. Intell. Syst. Appl. 2019, 11, 70–82. [Google Scholar] [CrossRef] [Green Version]
- Zou, C. Analyzing research trends on drug safety using topic modeling. Expert Opin. Drug Saf. 2018, 17, 629–636. [Google Scholar] [CrossRef]
- Merz, A.A.; Gutiérrez-Sacristán, A.; Bartz, D.; Williams, N.E.; Ojo, A.; Schaefer, K.M.; Huang, M.; Li, C.Y.; Sandoval, R.S.; Ye, S.; et al. Population attitudes toward contraceptive methods over time on a social media platform. Am. J. Obstet. Gynecol. 2021, 224, 597.e1–597.e4. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Xie, H. A structural topic modeling-based bibliometric study of sentiment analysis literature. Cogn. Comput. 2020, 12, 1097–1129. [Google Scholar] [CrossRef]
- Chen, X.; Xie, H.; Cheng, G.; Li, Z. A Decade of Sentic Computing: Topic Modeling and Bibliometric Analysis. Cogn. Comput. 2021, 1–24. [Google Scholar] [CrossRef]
- Zhang, T.; Huang, X. Viral marketing: Influencer marketing pivots in tourism–a case study of meme influencer instigated travel interest surge. Curr. Issues Tour. 2021, 1–8. [Google Scholar] [CrossRef]
- Chakravorti, D.; Law, K.; Gemmell, J.; Raicu, D. Detecting and characterizing trends in online mental health discussions. In Proceedings of the 2018 IEEE International Conference on Data Mining Workshops (ICDMW), Singapore, 17–20 November 2018; pp. 697–706. [Google Scholar]
- Modave, F.; Zhao, Y.; Krieger, J.; He, Z.; Guo, Y.; Huo, J.; Prosperi, M.; Bian, J. Understanding perceptions and attitudes in breast cancer discussions on twitter. Stud. Health Technol. Inform. 2019, 264, 1293. [Google Scholar] [PubMed]
- Neresini, F.; Crabu, S.; Di Buccio, E. Tracking biomedicalization in the media: Public discourses on health and medicine in the UK and Italy, 1984–2017. Soc. Sci. Med. 2019, 243, 112621. [Google Scholar] [CrossRef] [Green Version]
- King, A.L.O.; Mirza, F.N.; Mirza, H.N.; Yumeen, N.; Lee, V.; Yumeen, S. Factors associated with the American Academy of Dermatology abstract publication: A multivariate analysis. J. Am. Acad. Dermatol. 2021. [Google Scholar] [CrossRef] [PubMed]
- Andrew, R.M. Towards near real-time, monthly fossil CO2 emissions estimates for the European Union with current-year projections. Atmos. Pollut. Res. 2021, 12, 101229. [Google Scholar] [CrossRef]
- Box, G.; Jenkins, G.; Reinsel, G. Time-Series Analysis: Forecasting and Control; Holden-Day Inc.: San Francisco, CA, USA, 1970; pp. 575–577. [Google Scholar]
- Chatfield, C. Time-Series Forecasting; CRC Press: Boca Raton, FL, USA, 2000. [Google Scholar]
- Whittle, P. Hypothesis Testing in Time-Series Analysis; Almquist and Wiksell: Uppsalla, Sweden, 1951. [Google Scholar]
- Cryer, J.; Chan, K. Time-Series Analysis with Applications in R; Springer Science & Business Media: New York, NY, USA, 2008. [Google Scholar]
- Hyndman, R.; Athanasopoulos, G. Forecasting: Principles and Practice; OTexts: Melbourne, Australia, 2018. [Google Scholar]
- Şen, Z. Innovative Trend Methodologies in Science and Engineering; Springer: New York, NY, USA, 2017. [Google Scholar]
- Yue, S.; Wang, C. The Mann–Kendall test modified by effective sample size to detect trend in serially correlated hydrological series. Springer Water Resour. Manag. 2004, 18, 201–218. [Google Scholar] [CrossRef]
- Best, D.; Gipps, P. Algorithm AS 71: The upper tail probabilities of Kendall’s Tau. J. R. Stat. Society. Ser. C (Appl. Stat.) 1974, 23, 98–100. [Google Scholar] [CrossRef]
- Helsel, D.; Hirsch, R.; Ryberg, K.; Archfield, S.; Gilroy, E. Statistical Methods in Water Resources; Technical Report; US Geological Survey Techniques and Methods, Book 4, Chapter A3; Elsevier: Amsterdam, The Netherlands, 2020; 458p. [Google Scholar]
- Sen, P.K. Estimates of the regression coefficient based on Kendall’s tau. J. Am. Stat. Assoc. 1968, 63, 1379–1389. [Google Scholar] [CrossRef]
- Ferragina, P.; Scaiella, U. TagMe: On-the-fly annotation of short text fragments (by Wikipedia entities). In International Conference on Information and Knowledge Management; ACM: Toronto, ON, Canada, 2010; pp. 1625–1628. [Google Scholar]
- Yosef, M.A.; Hoffart, J.; Bordino, I.; Spaniol, M.; Weikum, G. Aida: An online tool for accurate disambiguation of named entities in text and tables. Proc. VLDB Endow. 2011, 4, 1450–1453. [Google Scholar] [CrossRef]
- Milne, D.; Witten, I.H. Learning to link with wikipedia. In Proceedings of the 17th ACM conference on Information and knowledge management, Napa Valley, CA, USA, 26–30 October 2008; pp. 509–518. [Google Scholar]
- Happel, H.J.; Stojanovic, L. Analyzing organizational information gaps. In Proceedings of the 8th Int. Conference on Knowledge Management, Graz, Austria, 3–5 September 2008; pp. 28–36. [Google Scholar]
- Hussain, M.; Mahmud, I. PyMannKendall: A python package for non parametric Mann–Kendall family of trend tests. J. Open Source Softw. 2019, 4, 1556. [Google Scholar] [CrossRef]
- Seabold, S.; Perktold, J. Statsmodels: Econometric and statistical modeling with python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; pp. 92–96. [Google Scholar]

{kind=link}
{kind=link}
| Rank | Term | ndf | Rank | Term | ndf |
|---|---|---|---|---|---|
| 1. | integrated circuit | 13. | neural network | ||
| 2. | optimization | 14. | low power | ||
| 3. | computer architecture | 15. | hybrid | ||
| 4. | algorithm | 16. | system on chip | ||
| 5. | logic gates | 17. | mathematical model | ||
| 6. | computational modeling | 18. | power | ||
| 7. | latency | 19. | convolutional neural network | ||
| 8. | fpga | 20. | logic | ||
| 9. | task analysis | 21. | memory management | ||
| 10. | energy efficiency | 22. | real time systems | ||
| 11. | machine learning | 23. | cmos | ||
| 12. | ram | 24. | nonvolatile memory |
| Term | nsaMK2020 | MK2019 | MK2020—Ground Truth | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| z | p-Value | Slope | z | p-Value | Slope | z | p-Value | Slope | |||
| 1 | integrated circuit | −5.057 | −0.008 | −2.715 | 0.00662 | −0.005 | −4.809 | −0.008 | ✓ | ||
| 2 | optimization | 8.494 | 0 | 0.005 | 5.964 | 0.005 | 10.738 | 0 | 0.006 | ✓ | |
| 3 | computer architecture | 4.856 | 0.009 | 4.059 | 0.009 | 6.828 | 0.012 | ✓ | |||
| 4 | algorithm | 0 | 1 | −0.000 | −2.047 | 0.04060 | −0.002 | 1.061 | 0.28868 | 0.001 | ✓ |
| 5 | logic gates | 0.597 | 0.54995 | 0.001 | 1.257 | 0.20871 | 0.002 | 0.300 | 0.76357 | 0.000 | ✓ |
| 6 | computational modeling | 0.590 | 0.55509 | 0.001 | −0.522 | 0.60141 | −0.000 | 1.714 | 0.08649 | 0.001 | ✓ |
| 7 | latency | 1.459 | 0.14438 | 0.001 | 2.027 | 0.04261 | 0.001 | 4.459 | 0.004 | ✓ | |
| 8 | fpga | 3.910 | 0.006 | 1.842 | 0.06533 | 0.003 | 3.571 | 0.00035 | 0.008 | ✓ | |
| 9 | task analysis | 1.862 | 0.06250 | 0 | 1.816 | 0.06932 | 0 | 2.031 | 0.04216 | 0.001 | ✓ |
| 10 | energy efficiency | 5.235 | 0.007 | 4.005 | 0.004 | 4.894 | 0.007 | ✓ | |||
| 11 | machine learning | 5.856 | 0.003 | 4.512 | 0.003 | 5.025 | 0.005 | ✓ | |||
| 12 | ram | 4.346 | 0.002 | 4.232 | 0.003 | 5.118 | 0.004 | ||||
| 13 | neural network | 1.938 | 0.05250 | 0.002 | 0.907 | 0.36428 | 0 | 2.892 | 0.00382 | 0.004 | ✓ |
| 14 | low power | 0 | 1 | 0.000 | 1.712 | 0.08684 | 0.001 | 1.910 | 0.05607 | 0.001 | |
| 15 | hybrid | 3.298 | 0.00097 | 0.003 | 2.580 | 0.00987 | 0.002 | 4.213 | 0.004 | ✓ | |
| 16 | system on chip | 3.637 | 0.00027 | 0.003 | 6.111 | 0.004 | 3.694 | 0.00022 | 0.003 | ✓ | |
| 17 | mathematical model | −5.016 | −0.005 | −0.924 | 0.35519 | −0.004 | −3.686 | 0.00022 | −0.004 | ||
| 18 | power | −4.734 | −0.002 | −3.678 | 0.00023 | −0.001 | −2.532 | 0.01133 | −0.001 | ||
| 19 | convolutional neural network | 3.842 | 0.00012 | 0.001 | 3.275 | 0.00105 | 0.001 | 3.361 | 0.00077 | 0.002 | ✓ |
| 20 | logic | 0.497 | 0.61901 | 0.000 | −0.685 | 0.49291 | −0.001 | 2.419 | 0.01553 | 0.001 | ✓ |
| 21 | memory management | 5.262 | 0.003 | 5.672 | 0.003 | 9.513 | 0 | 0.004 | ✓ | ||
| 22 | real time systems | 0 | 1 | 0 | 2.307 | 0.02102 | 0.002 | 1.859 | 0.06289 | 0.003 | |
| 23 | cmos | 7.518 | 0.003 | 7.646 | 0.004 | 6.133 | 0.002 | ✓ | |||
| 24 | nonvolatile memory | 2.058 | 0.03958 | 0.001 | 2.701 | 0.00690 | 0.002 | 5.340 | 0.003 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Curiac, C.-D.; Banias, O.; Micea, M. Evaluating Research Trends from Journal Paper Metadata, Considering the Research Publication Latency. Mathematics 2022, 10, 233. https://doi.org/10.3390/math10020233
Curiac C-D, Banias O, Micea M. Evaluating Research Trends from Journal Paper Metadata, Considering the Research Publication Latency. Mathematics. 2022; 10(2):233. https://doi.org/10.3390/math10020233
Chicago/Turabian StyleCuriac, Christian-Daniel, Ovidiu Banias, and Mihai Micea. 2022. "Evaluating Research Trends from Journal Paper Metadata, Considering the Research Publication Latency" Mathematics 10, no. 2: 233. https://doi.org/10.3390/math10020233
APA StyleCuriac, C.-D., Banias, O., & Micea, M. (2022). Evaluating Research Trends from Journal Paper Metadata, Considering the Research Publication Latency. Mathematics, 10(2), 233. https://doi.org/10.3390/math10020233