1. Introduction
Heavy-tailed distributions have been used to model data in various applied sciences, such as environmental sciences, earth sciences, and economic and actuarial sciences. Insurance datasets tend to be positive and asymmetric to the right, with heavy tails (see Ibragimov and Prokhorov [
1]); distributions with these characteristics are therefore used to model insurance data. Some authors have extended certain asymmetric distributions using the slash methodology, for instance, to increase the weight of the right tail, e.g., Olmos et al. [
2], Olmos et al. [
3] in the half-normal (HN) and generalized half-normal (GHN) models, Astorga et al. [
4] in the generalized exponential model (see Gupta and Kundu [
5]; Mudholkar et al. [
6]), and Gómez et al. [
7] in the Gumbel model. Two other recent works are, for example, Bhati and Ravi [
8] in the generalized log-Moyal model and Afify et al. [
9] in the heavy-tailed exponential model. It is known that the Pareto distribution and its corresponding generalizations are heavy-tailed distributions; they have been used in several areas of knowledge, e.g., by Choulakian and Stephens [
10], Zhang [
11], Akinsete et al. [
12], Nassar and Nada [
13], Mahmoudi [
14] and Boumaraf et al. [
15]. It is important to study distributions with these characteristics in order to model, for example, insurance datasets and financial yields. In the present paper, we study a distribution with a heavy right tail that provides a good fit to family income data. A very necessary function in this paper is the beta function, denoted by B(
), which can be expressed as:
where
,
and
is the gamma function. The beta function is the normalisation constant of the beta distribution, i.e., we say that the random variable Y has a beta distribution with parameters
a and
b if its probability density function (pdf) is given by
where
and
.
The incomplete beta function is denoted by B(
) and can be expressed as:
where
and
. Another related function is the regularised incomplete beta function, denoted by
, and expressed as
.
Gleser [
16] introduced a representation of the gamma distribution, the product of a mixed scale between an unknown distribution and the exponential distribution. The object of the present paper is to study this unknown distribution, which we call the Gleser (G) distribution. A random variable
X has a G distribution with parameter
if its pdf is given by
with
shape parameter and
. The G distribution is a particular case of the beta prime distribution (see Keeping [
17]), also called the inverted beta distribution (see Tiao and Cuttman [
18]), but as it is a distribution with only one parameter, we were interested in studying it and applying some of its properties.Taking the density given in (
4), and considering a new scale parameter, we obtain a more flexible distribution for modelling positive data with heavy right tail.
The article is organised as follows. In
Section 2 we give some properties of the G distribution. In
Section 3 we study the behaviour of the tail of the G distribution. In
Section 4 we carry out parameter estimation using the maximum likelihood (ML) method and do a simulation study and asymptotic convergence of the ML estimators.
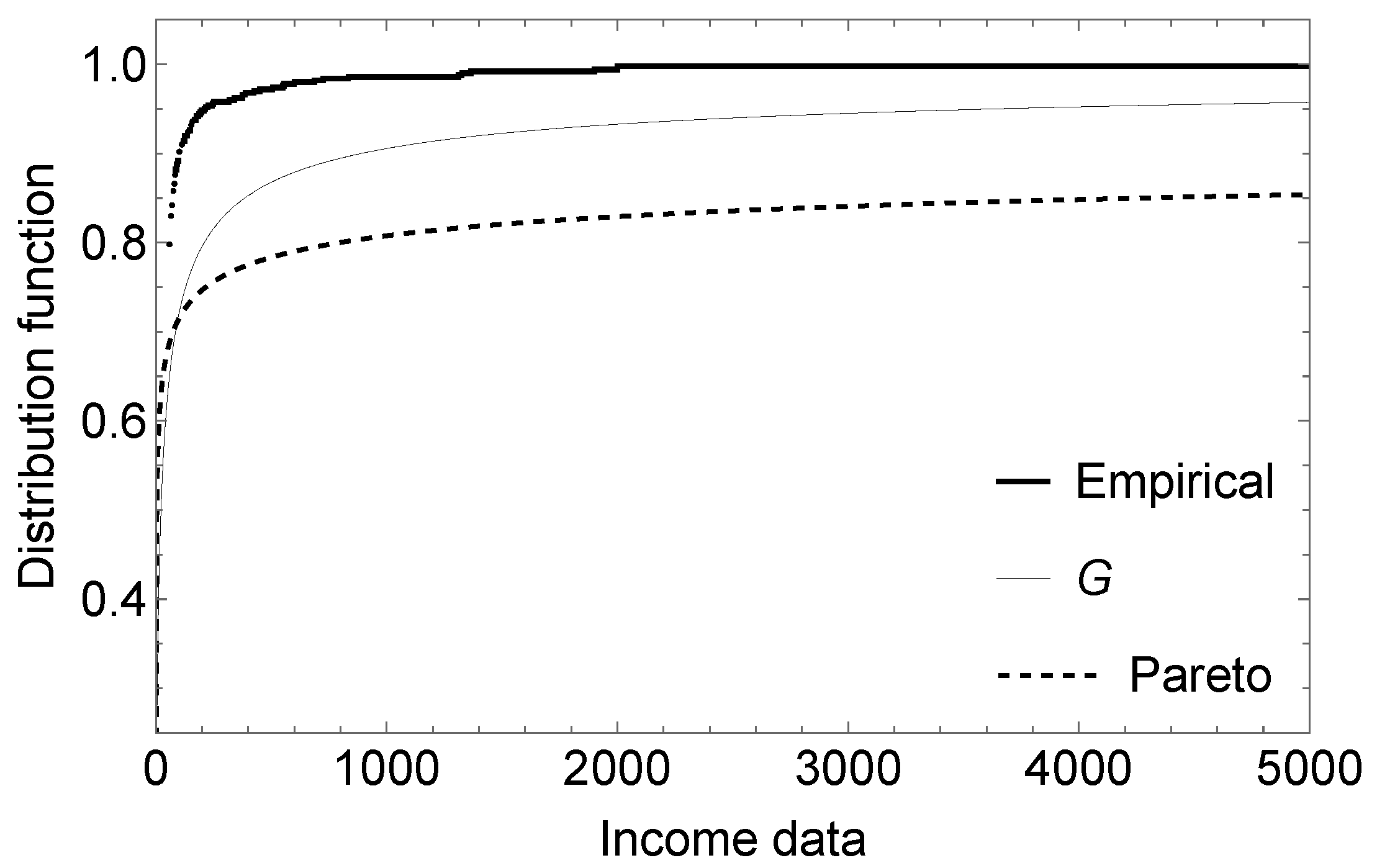
Section 5 shows an application with data from the economic field. In
Section 6 we offer some conclusions.
2. The G Distribution
In this section, we study the basic properties of the G distribution given in (
4) incorporating a scale parameter. A random variable
X has a G distribution with positive support and parameters
and
if its pdf is:
where
scale parameter and
shape parameter; we denote this by
. The G distribution is an alternative model to distributions with two parameters, to be used for modelling actuarial statistics data such as the Pareto and GHN distributions, among others.
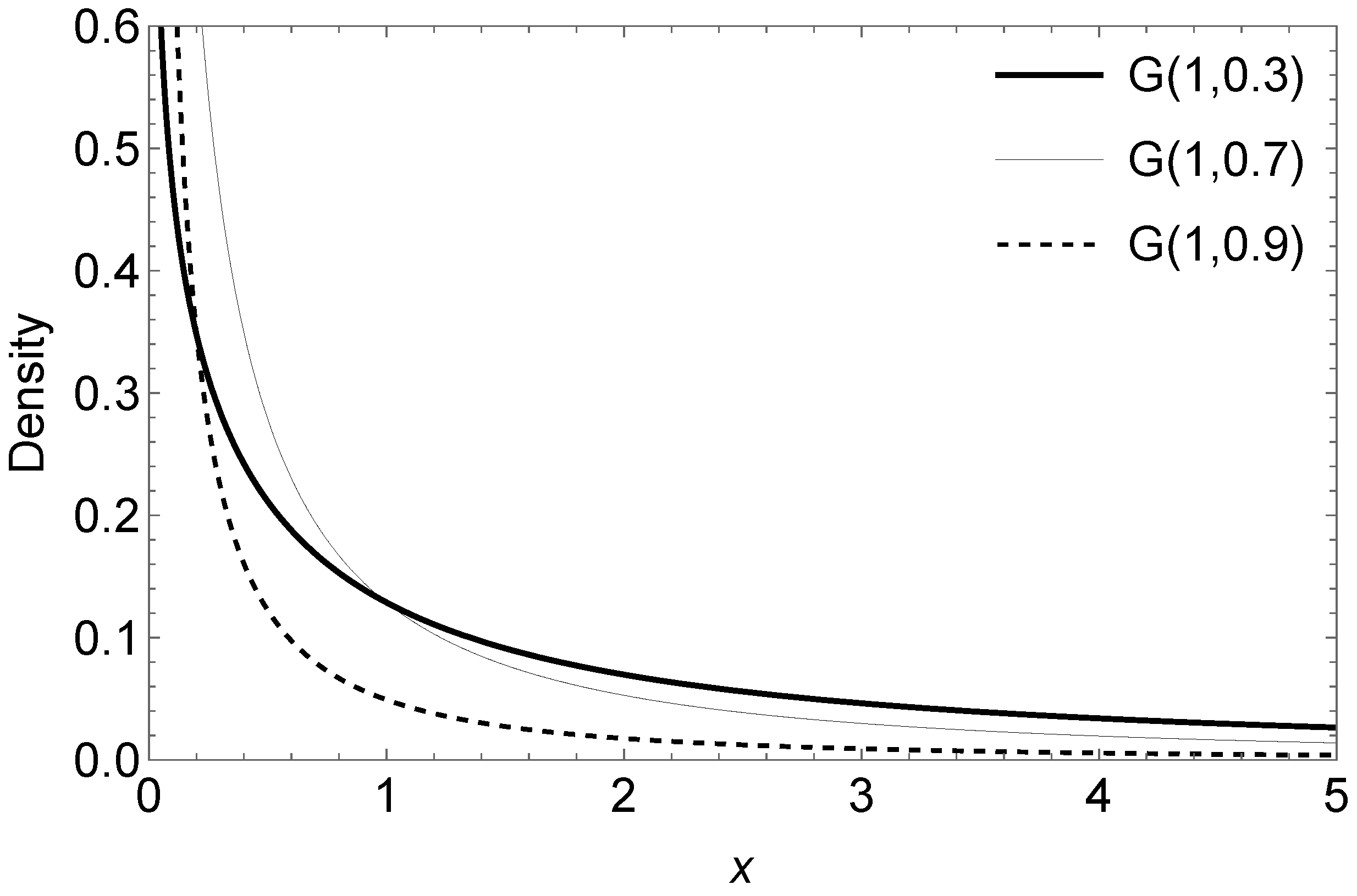
Figure 1 shows the graph of the G density for different values of parameter
, fixing
.
We perform a brief comparison illustrating that the tails of the G distribution are heavier when the
parameter decreases.
Table 1 shows
for different values of
x in this distribution.
2.1. Properties
The following proposition shows some properties of the G distribution.
Proposition 1. Let and . Then,
- (a)
the G distribution has unimodality (at 0).
- (b)
.
- (c)
the cumulative distribution function (cdf) of X is given bywhere and is the regularised incomplete beta function. - (d)
the hazard function of X is decreasing for all .
- (e)
the r-th moment of the random variable X does not exist for .
- (f)
- (g)
the quantile function (Q) of the G distribution is given bywhere is the inverse function of the regularised incomplete beta function.
Proof. (
d) Using the theorem, item (
b), given in Glaser [
19] we have that
where
is the pdf given in (
5), then the derivative of
with respect to
x
gives the result.
- (e)
Considering , we claim that the integral is divergent.
In fact, taking
and
, we have that
and as the integral
is divergent for
this proves the claim.
On the other hand, since
, by using comparison
and the above claim, the result is reached.
□
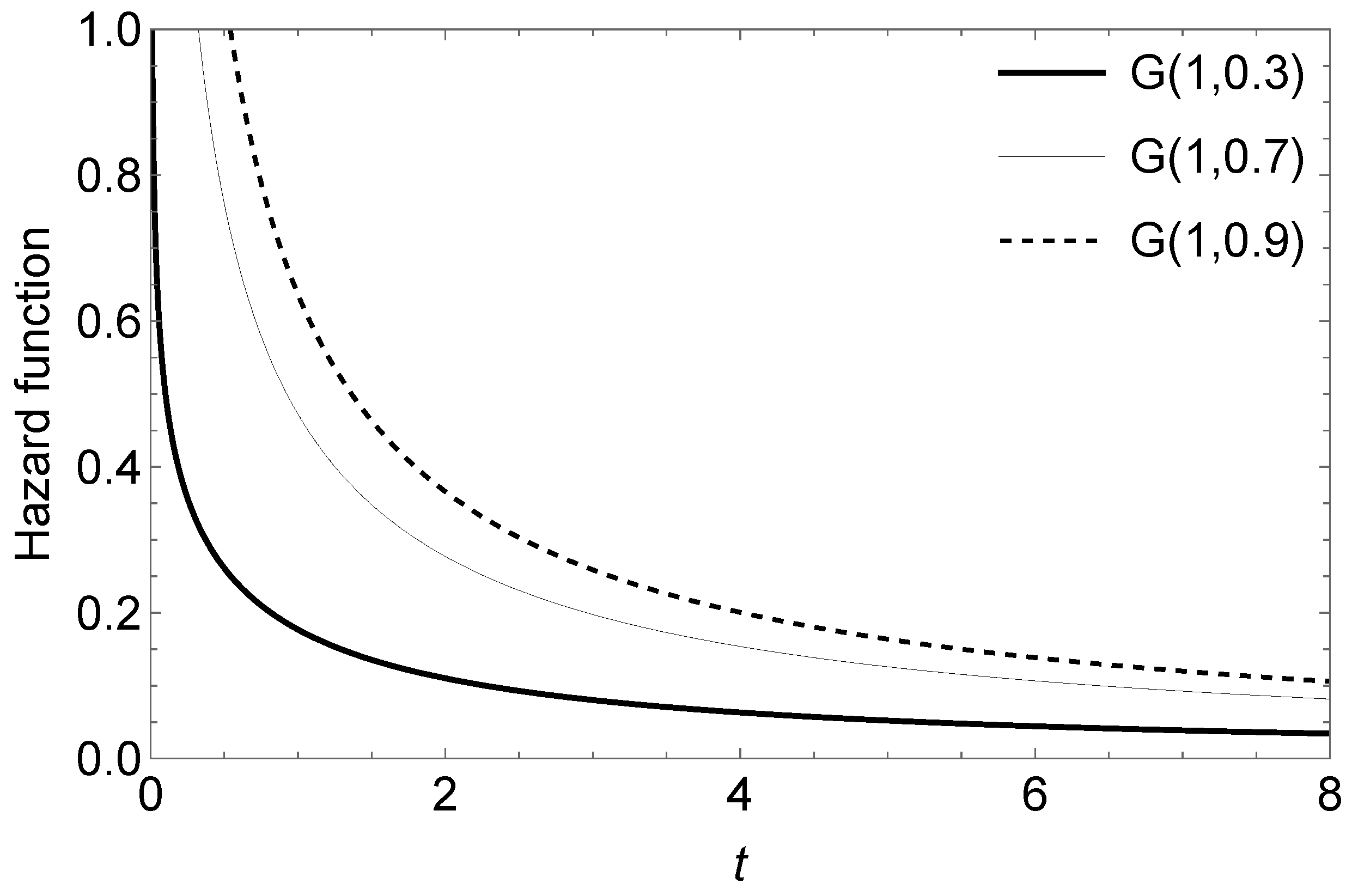
The survival function , which is the probability that an item will not fail before time t, is defined by . The survival function for a G random variable is given by .
The hazard function
, defined by
, for a G random variable is given by
Figure 2 shows the form of the hazard function for different values of
, considering
. As we show in Proposition 1, part
, the hazard function is always a decreasing function. In the context of reliability, it indicates that failures are more likely to occur earlier in a product’s useful life.
Using the
function given in Proposition 1
, we can compute the coefficient of skewness (
) and the coefficient of kurtosis (
) for the random variable
Figure 3 depicts plots for the skewness and kurtosis coefficients in the G distribution.
2.2. Actuarial Measure
The value at risk (VaR) is used to assess the risk exposure, i.e., it can be used to determine the amount of capital necessary to liquidate adverse results. The VaR of the random variable
is defined as (see Artzner [
20] and Artzner et al. [
21])
where
is the inverse function of the regularised incomplete beta function.
Figure 4 shows graphs of the VaR
measurement of distribution G(
) for different values of parameter
. We may observe that the smaller the value of parameter
, the larger the value of the VaR
measurement.
2.3. Order Statistics
Let be a random sample of the random variable , let us denote by the —order statistics, .
Proposition 2. where . In particular, the pdf of the minimum, , is and the pdf of the maximum, , is Proof. Since we are dealing with an absolutely continuous model, the pdf of the
—order statistics is obtained by applying
where
F and
f denote the cdf and pdf of the parent distribution,
in this case. □
2.4. Entropy
In this subsection we will discuss the Shannon and Rényi entropies of the G model.
2.4.1. Shannon Entropy
The following lemma will be very useful for calculating the Shannon entropy.
Lemma 1. Let , then we have the following results.
- 1.
- 2.
where is the digamma function and is Euler’s constant.
Proof. Both results are obtained directly using the pdf given in (
5). □
The Shannon (S) entropy (see Shannon [
22]) for a random variable
X is defined as
Therefore, it can be verified that the S entropy for the G model is
Proposition 3. Let . Then the Shannon entropy of X is Figure 5 shows the Shannon entropy for the G model fixing
.
2.4.2. Rényi Entropy
A generalization of the Shannon entropy is the Rényi (
) entropy, which is defined as
Therefore, it can be verified that the entropy for the G model is
Proposition 4. Let . Then the Rényi entropy of X iswhere Corollary 1. Let with and the Shannon and Rényi entropies. Then we have 3. Tail of the Distribution
A random variable with a non-negative support, like the classic Pareto distribution, is commonly used in insurance contexts to model the amount of losses. The size of the distribution tail is fundamental if we want the chosen model to capture quantities sufficiently removed from the start of the distribution support, i.e., atypical (extreme) values. The concept of heavy tail is fundamental for this and other financial scenarios.
The use of heavy right-tailed distributions is of vital importance in general insurance. Pareto, Log-normal and Weibull distributions, among others, have been used to model third party liability insurance losses for motor vehicles, re-insurance and catastrophe insurance.
Let
be the class of subexponential distributions. That is,
defined in
satisfies that:
where
is the
j-fold convolution of
F.
The following Lemma, appearing, among others, in Chapet 2, p. 55 in Rolski et al. [
23], is required in the next Theorem.
Lemma 2. Let and be two distributions on and assume that there exists a constant such that Then, if and only if .
Theorem 1. Let the cdf of given in (6). Then, . Proof. Let
the survival function of the Pareto Type II distribution (Lomax distribution). By using this together with the complementary of the cdf (
6) and by computing (
14) we get, after applying L’Hopital’s rule, that
Now, taking into account that the Pareto type II distribution belongs to the class of subexponential distributions, we have the result. □
As a consequence of the previous Theorem (see Rolski et al. [
23] p. 50), we have the following Corollary.
Corollary 2. If and are independent and identically distributed random variables with distributions given in (
6),
then as Proof. The result is a consequence of the fact that . □
Proposition 5. It is verified that is heavy right-tailed distribution.
Proof. Since
, the result is a consequence of applying Theorem 2.5.2 in Rolski et al. [
23]. □
Another way to see that is a heavy right-tailed distribution is by computing the limit , which results 0. Observe that is the hazard function of X.
As a consequence of the last result, we have the following Corollary:
Corollary 3. It is verified that , .
In this case the distribution fails to possess any positive exponential moment, i.e.,
for all
see Chapter 1, p. 2 [
24]. Distributions of this type have moment generating function
, for all
. This occurs, for example, with the log-normal distribution.
An important issue in extreme value theory is regular variation (see Bingham [
25] and Konstantinides [
26]). This is a flexible description of the variation of some functions according to the polynomial form of the type
,
. This concept is formalized in the following definition.
Definition 1. A CDF (measurable function) is called regular varying at infinity with index if it holds:where and the parameter is called the tail index. The following proposition establishes that the survival function of the G distribution is a distribution with regular variation.
Proposition 6. The survival function of is regularly varying with tail index α.
Proof. Applying the above definition and using L’Hopital’s Rule, we have that
Calculating the limit to the right, we obtain the result. □
In actuarial settings and individual and collective risk models, the practitioner is usually interested in the random variable
for
. Although its pdf is difficult or impossible to calculate in practice, we can approximate its probabilities using the following Corollary (see Jessen and Mikosch [
27]).
Corollary 4. If are iid random variables and , then Therefore, if
, we have that
This means that for large x the event is due to the event . Therefore, high thresholds being exceeded by the sum are due to this threshold being exceeded by the largest value in the sample.
As Jessen and Mikosch [
27] point out, expression (
15) can be taken as the definition of a subexponential distribution. The class of those distributions is larger than the class of regularly varying distributions. The result, given in Corollary 4, remains valid for subexponential distributions because the subexponentiality of
implies subexponentiality of
. Usually, this property is referred to as convolution root closure of subexponential distributions. More details can be viewed in [
28,
29].
On the other hand, let the random variable
X, whose support is
, represents either a policy limit or reinsurance deductible (from an insurer’s perspective); then the limited expected value function
L of
X with cdf
, is defined by (see Boland [
30] and Hogg and Klugman [
31]):
which is the expectation of the cdf
truncated at this point. In other words, it represents the expected amount per claim retained by the insured on a policy with a fixed amount deductible of
x. Observe that we integrate according to the interval
.
Proposition 7. Let X be a random variable following the pdf (
5).
Then the limited expected value of X is given by where represents the hypergeometric function. Proof. By making the change of variable
in the integral
gives the result. □












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}