This section introduces the mathematical notations and the assumptions made in this paper. Then, we describe the penalization model that allows the approach both to incorporate differences among classes and to handle the presence of hubs. After that, we propose the jewel 2.0 algorithm for the joint estimation of Gaussian graphical models. Finally, the section also describes the choice of the regularization parameters and the stability selection procedure and highlights the differences from our previous method, jewel 1.0.
2.1. Problem Set-Up
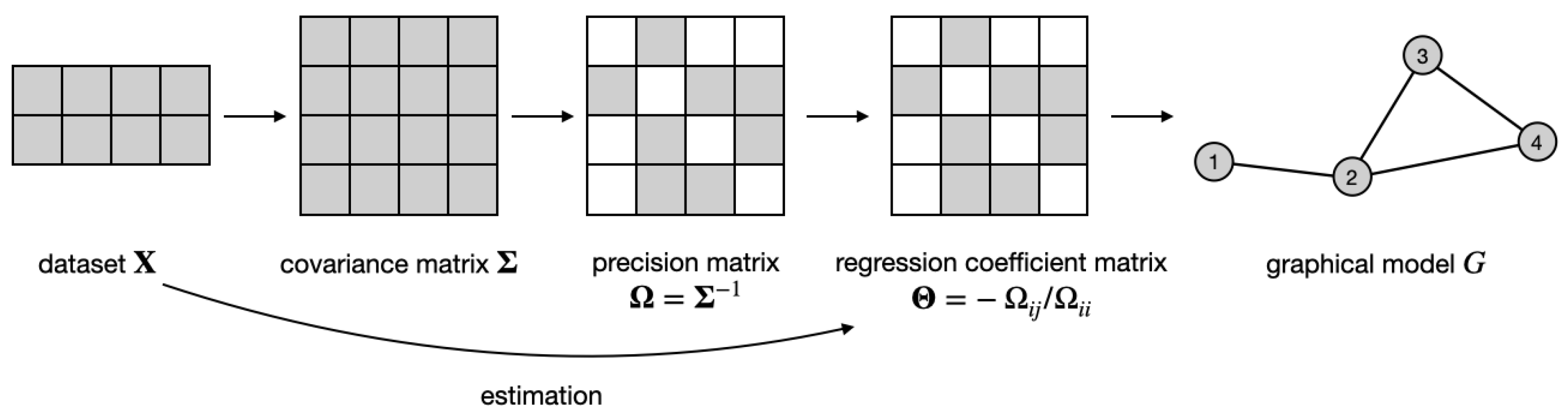
Let be datasets containing measurements of (almost) the same variables under K different but similar conditions (e.g., sub-types of disease) or collected in distinct classes (e.g., different equipment or laboratories). Each dataset is an data matrix with observations of variables. We assume that observations are independent and identically distributed samples from a -variate Gaussian distribution with zero mean and covariance matrix .
Every distribution
is associated with a graphical model
, where vertices correspond to random variables, i.e.,
, and the absence of edges (where
) implies the conditional independence of the corresponding variables, i.e.,
. It is well known that the support of the precision matrix encodes the graph structure, i.e.,
, where
is the true precision matrix for the
k-th class. Therefore, for each dataset, the problem of graph estimation becomes equivalent to estimating the support of the precision matrix, as illustrated in
Figure 1. However, when the
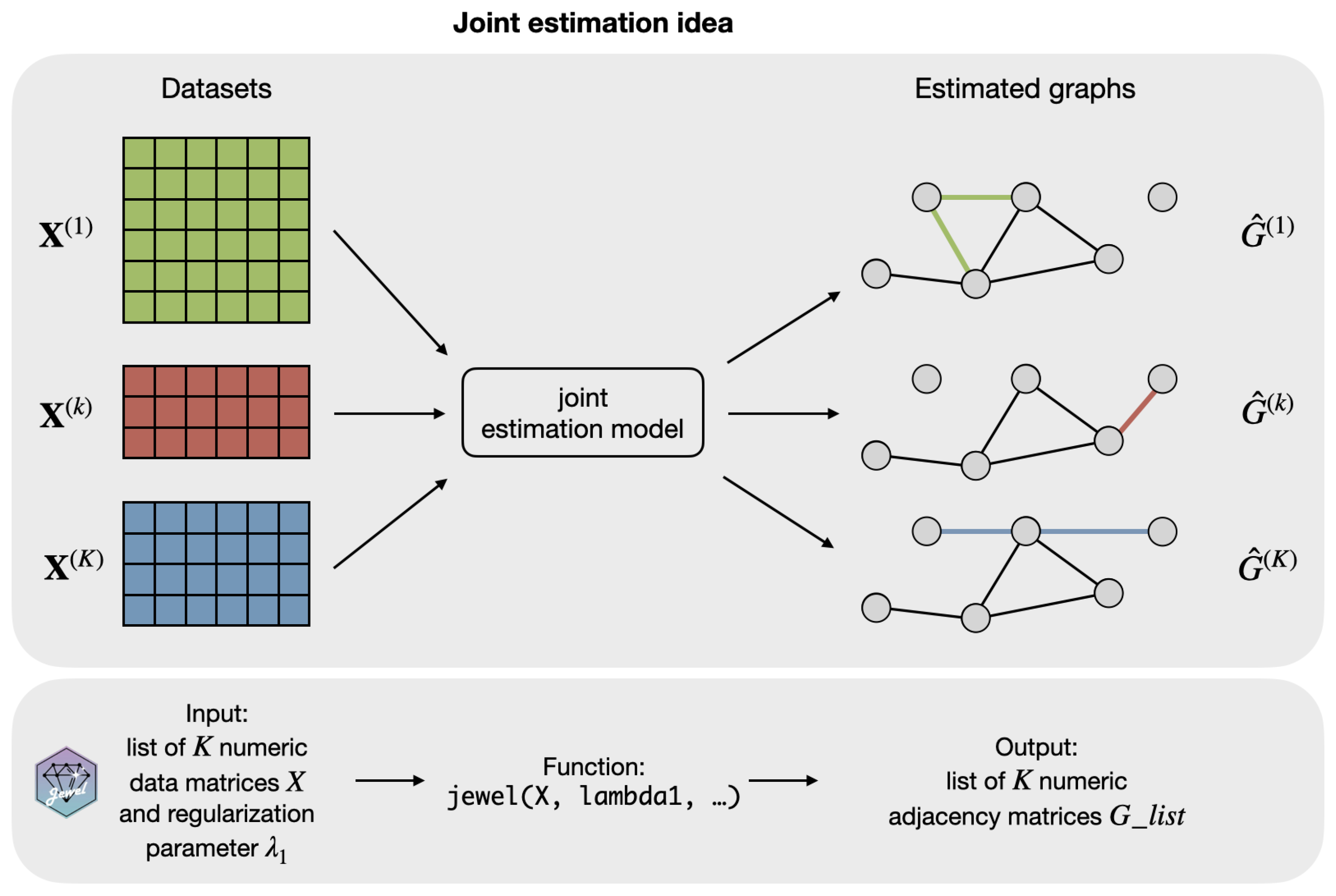
K datasets share some dependency structure (as occurs when we consider similar datasets), a joint inference can be more powerful and accurate, as already shown in [
1] and referenced therein. The joint inference requires modeling how the information about the graphs
is shared across different datasets.
In [
1], we proposed the following joint estimation approach. We started with an assumption that although the covariance matrices
,
, might be different, the structures of
K graphs coincide, i.e., the graph
G is the same across all datasets. Therefore, we needed to estimate the same support from
K precision matrices. However, instead of doing that directly, we estimated the support of
K regression coefficient matrices. We defined them as
with entries
and
. By construction, the support of the extra-diagonal entries of
also encodes the graph structure, i.e.,
. Hence, in
jewel 1.0, we simultaneously estimated
by solving the following minimization problem:
where
denotes the cardinality of the group of symmetric variables
across all the datasets that contain the couple of variables
. As a result, we obtained
K matrices
with the same symmetric support, which represents the adjacency matrix of the common estimated graph
.
However, while the symmetry of the solution of Equation (
1) is one of the main advantages of our original formulation, forcing the datasets to have exactly the same underlying graph might be a limitation in some cases. For example, the assumption that the datasets
,
, share the same graph
G might be reasonable when they represent the gene expression of the same type of cells, measured in different laboratories or with different instruments. In such cases, we expect the actual underlying regulatory mechanisms to remain the same despite the technology. However, the assumption becomes limited when the datasets represent the gene expression in cells isolated from different sub-types or stages of some disease. In such a context, we expect a common underlying mechanism that can be associated with that disease, but there could be sub-type-specific differences that are not shared across all the datasets but characterize only one (or some, but not all) condition. To overcome this limitation, in this paper, we modify the formulation of the minimization problem in Equation (
1) to allow the modeling of both commonalities and differences between the graphs
,
. Therefore, by relaxing the assumptions, we increase the range of applications of our approach.
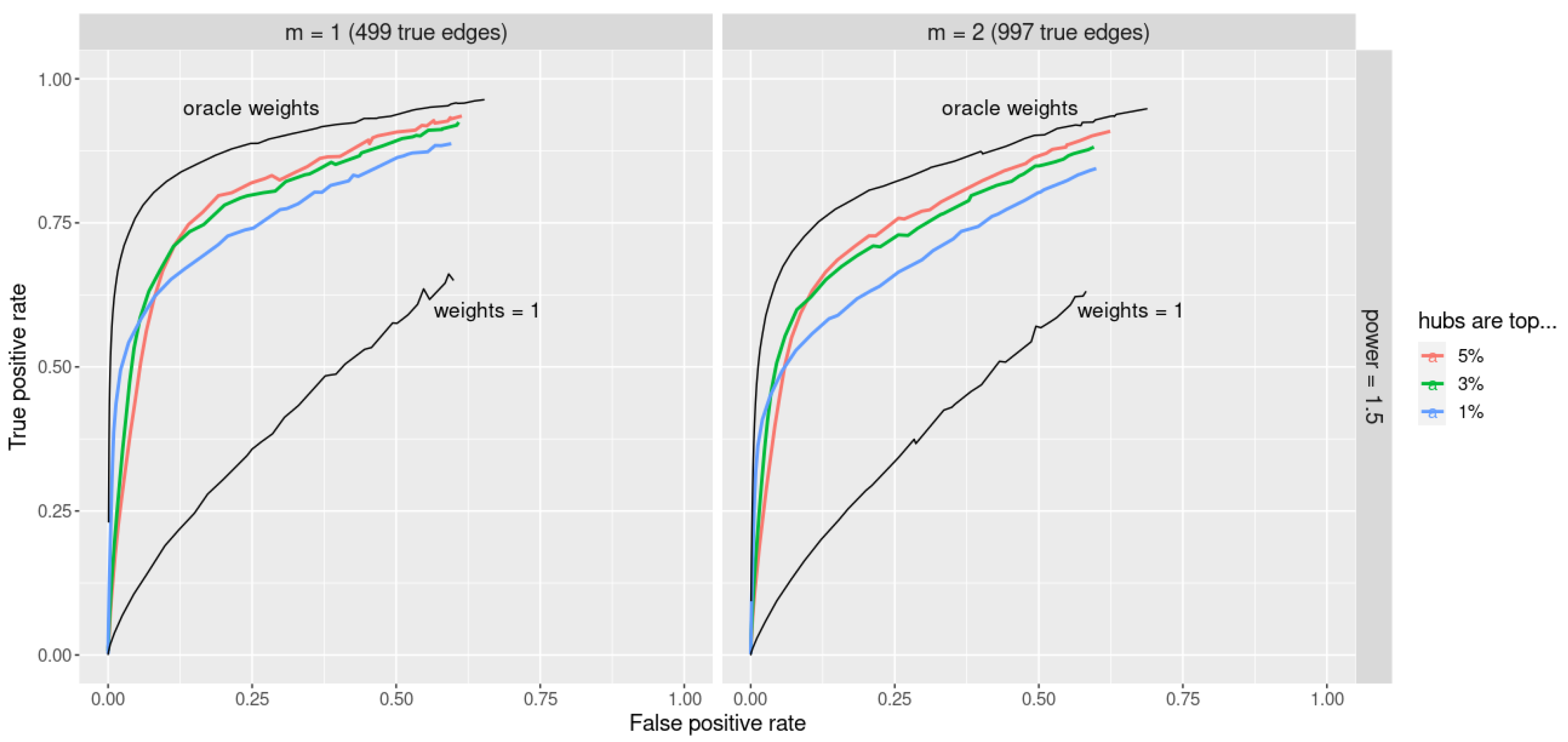
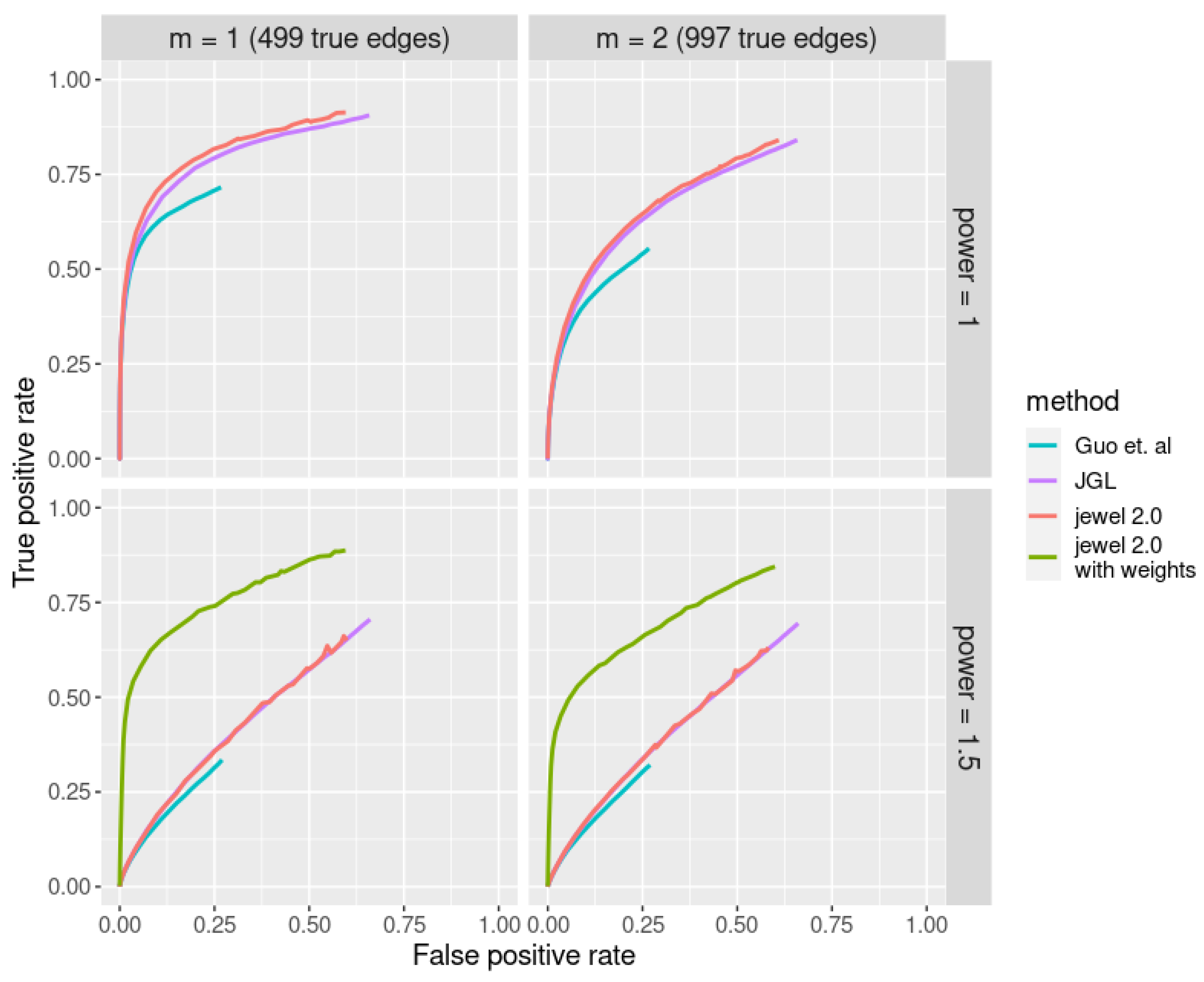
Additionally, in [
1] we demonstrated that
jewel 1.0 performs comparably well or even better than other joint approaches for GGM (i.e., JGL [
4] and the proposal of Guo et al. [
5]). However, we also showed that all methods’ performances significantly decreased when the true graph contained hubs. Scale-free graphs with a power of preferential attachment bigger than 1 constitute typical examples of graphs with hubs. In general, many real-life graphs such as gene regulatory networks or protein–protein interaction networks are estimated to have a power law between 2 and 3. Therefore, we introduced some weights into the penalization problem to allow for a better estimation of hubs. The key idea is that small weights must be assigned to the edges linked to potential hubs so that hubs can emerge (in other words, we allow the preferential attachment of an edge to a hub). We will show that this modification leads to a considerable improvement in performance when some preliminary information on the hubs is available. We note that although other graph estimation methods with weighted penalties exist for one dataset, e.g., DW-lasso [
6],
jewel 2.0 is the first joint method for several datasets with a weighted penalty.
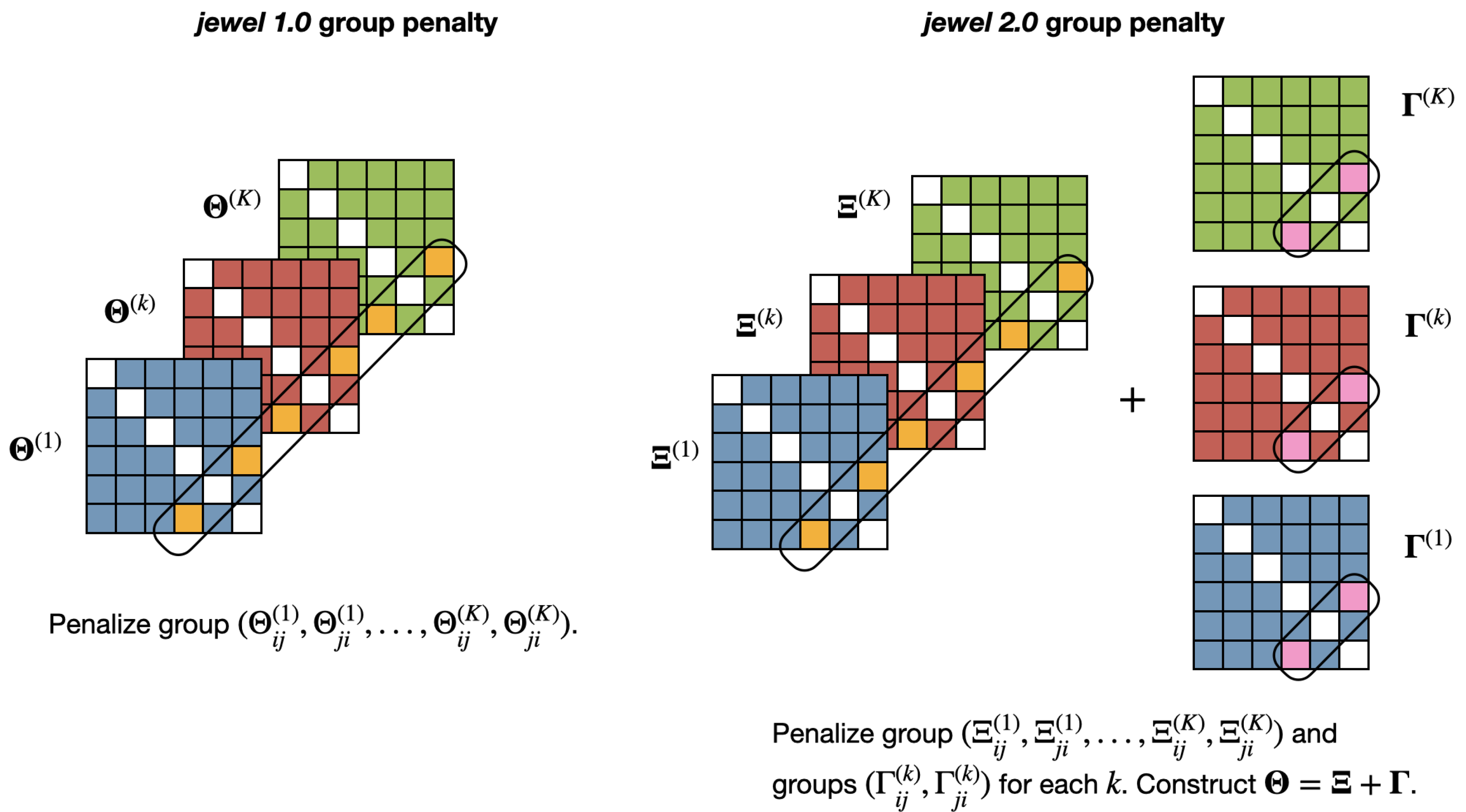
To incorporate both changes, we reformulate the minimization problem as follows. We define the set
with
p being its cardinality. We define matrices of weights for each graph,
, with entries
. These matrices incorporate information about hubs when available (smaller weights should be assigned to edges incident to hubs, larger weights to the others); otherwise, we set
. For each class
we set
, where matrices
share the same support structure among the
K classes (i.e., they represent the common information shared across different graphs) while
are class-specific (hence they allow to model differences among the classes). We emphasize that
and
,
, act as auxiliary (or dummy) variables and do not exactly represent common and specific parts of the graphs
. For example, non-zero elements in position
of all
are an indication of the common edge, despite the fact of being present in class-specific
s. In our procedure, we estimate
through the support of
. Once we have estimated
, we can later identify their common part as the intersection of the estimated graphs and the specific parts as the difference between the common part and the individual estimates. With this notation, we estimate
by solving the following problem:
where
and
,
are two regularization parameters.
Note that the minimization problem in Equation (
2) has two penalty terms. The first penalty is applied to the entire group
and enforces the presence/absence of an edge across all classes containing that edge (to capture common dependencies). The second penalty is applied independently to each group
,
. This enforces the symmetry of the relation between two nodes in each class, allowing class-specific differences to emerge.
Figure 2 provides an illustration of the idea.
Moreover, the weights
in the penalties allow hubs to emerge. By assigning lower weights to edges linked to potential hubs, we reduce the penalty on those edges and allow hubs to emerge. Instead, by choosing
, we have a more democratic approach that is equivalent to an unweighted formulation. Weights could be estimated from the data or provided by the user from prior knowledge, literature, and databases. Currently, using information already available in the literature (from previous experiments) or knowledge stored in databases is becoming widespread, particularly in omics science, where international projects and consortiums have released an enormous amount of data in open form. For example, in [
7], the authors suggested using gene networks retrieved from databases to improve survival prediction. Here, we propose the use of information concerning potential highly influential genes to estimate networks with hubs better.
Section 3.2.2 discusses weight choice in detail.
Finally, we note that the minimization problem in Equation (
2) is not identifiable in terms of
and
but is identifiable in terms of the support of
, provided that we estimate it using
. Furthermore, as a result of the minimization problem in Equation (
2), we obtain
K graphs
with largely the same structure
G but also allow some class-specific edges. See
Figure 3 for an illustration of the idea.
2.2. Jewel 2.0 Algorithm
To solve the minimization problem in Equation (
2), we apply the group descent algorithm presented in [
8]. To better describe this algorithm, we rewrite the problem in Equation (
2) using an equivalent formulation. To this end, we define the following matrices and vectors (note that for the ease of notation without loss of generality, we suppose
):
- -
the i-th column of matrix and the submatrix of without the i-th column;
- -
denotes the vector concatenating the columns of all data matrices, , ;
- -
, , and
, ,
are obtained by concatenating the vectorized matrices over the K classes;
- -
denotes the block-diagonal matrix made up of the block-diagonal matrices
,
,
,
;
- -
augmented matrix ;
- -
diagonal matrix , .
With these notations, the problem in Equation (
2) is equivalent to the following linear regression model with non-overlapping weighted group lasso penalties:
Function
in Equation (
3) is jointly convex in
and
, and the two penalties involve
or
independently. Hence, we can apply an alternating optimization algorithm as follows:
The two steps are alternated and repeated until convergence.
Since the groups are non-overlapping and orthogonal by construction, each minimization step can be solved using the group descent algorithm of [
8]. Algorithm 1 illustrates the steps of the proposed
jewel 2.0 algorithm in details.
Note that Algorithm 1 generalizes the one presented in [
1] to the double penalties (which are alternately updated) in the minimization problem in Equation (
2). However, it still uses the idea of the
Active matrices discussed in [
1], where only non-zero entries are updated. The algorithm provided here also has a minor difference compared to the
jewel 1.0 version: now, the order of variables is randomized instead of being
. Although the algorithm converges regardless of the order [
8], we decided to use the random order of updates because we have empirically seen that it provides an advantage in the running time without loss in performance. Finally, we note that the matrices and vectors defined in this subsection to describe the algorithm do not need to be explicitly constructed to implement the algorithm, as discussed in [
1].
| Algorithm 1 The jewel 2.0 algorithm. |
| INPUT: data , weights |
parameters , , and
|
| INITIALIZE:
|
|
Common part: |
|
Specific part: |
|
Residuals (common and specific): |
Matrices of active pairs
|
|
REPEAT UNTIL CONVERGENCE
|
|
Fix the specific part , update the COMMON part. |
|
Generate by resampling from 1 to p.
|
| for do |
|
for do |
|
if then |
| evaluate by
|
|
compute |
|
evaluate |
|
if then |
|
and |
|
else |
|
|
|
end if |
|
update residuals
|
|
update coefficients |
|
end if |
|
end for |
end for
|
|
Update residuals .
|
|
Fix the common part , update the SPECIFIC part. |
|
Generate by resampling from 1 to p.
|
|
fordo |
|
for do |
|
for do |
|
if then |
|
evaluate by
|
|
evaluate |
|
if then |
|
and |
|
else |
|
|
|
end if |
|
update residuals
|
|
update coefficients |
|
end if |
|
end for |
|
end for |
|
end for |
Update residuals .
|
|
Combine common and specific parts .
|
Check convergence: stop if or .
|
|
OUTPUT:
|
|
, where is the last iteration to achieve the convergence.
|
|
2.3. Selection of Regularization Parameter
The minimization problem of Equation (
2) contains two regularization parameters:
which penalizes the common part of the graphs,
,
, and
which penalizes the class-specific part of the graphs,
,
. In general, larger values of the parameters provide a more sparse estimator, which can lead to many false negatives. In contrast, small values of regularization parameters result in dense graphs with more false positives and less interpretability. Therefore, the choice of such parameters is crucial for the success of any regularization method. In this context, the two parameters are not independent since edges set to zero in the common part might be included in the class-specific part and vice-versa.
To better explain the interplay relation between
and
, we first consider the reparametrization proposed in JGL [
4], which connects the regularization parameters to two physical parameters
and
representing the sparsity of the graphs and the similarity across graphs in different classes
With this reparametrization, we have and . The motivation behind this reparameterization is that it is easier to elicit prior information on and than on and .
In a more data-driven spirit, Chapter 9.7 of [
9] suggests the use of a proportional relation between the two regularization parameters, namely
. In the specific setting of matrix decomposition in the multivariate regression, the author proposes the following estimate (see Equation (9.7) of [
9]):
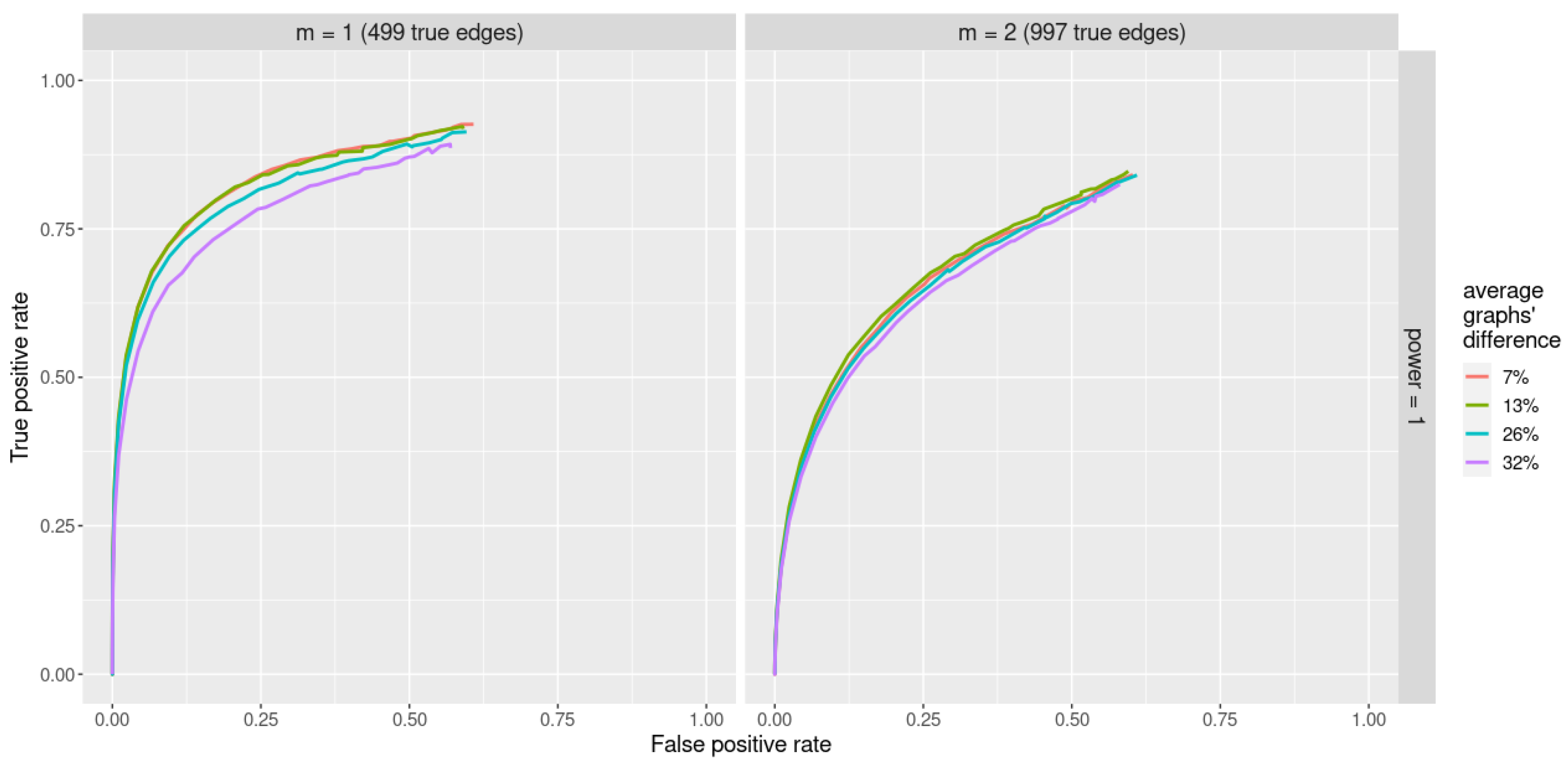
In our case, we still use the relation . However, to avoid a computationally intensive data-driven search over , we chose the value empirically after extensive numerical experimentation under different settings, where we evaluated ROC curves and edges for a range of values . We set (the value that provided the best performance on average among the tested values) and used it in all the subsequent analyses on synthetic and real datasets.
With the established relation
and having fixed the value of
, the complexity of the parameter space reduces to a choice of only the regularization parameter
. In principle, one can extend the Bayesian information criterion (BIC) as done in [
1]. However, there is a long ongoing debate on using BIC in high-dimensional settings. For example, [
10] reported poor performance. In general, BIC might be too liberal in the high-dimensional regime. Therefore, the BIC estimate might represent only an empirical rough estimate of the optimal regularization parameter. Its usage beyond empirical evidence would require studying the conditions to guarantee the recovery of the true structure. Since this paper introduces the stability selection procedure (described in the next section), we suggest that the user chooses a value for
within a plausible range and then applies the stability selection to mitigate the impact on the final estimate of non-optimal choices. We used this suggestion in
Section 4. We further discuss the choice of the regularization parameter in
Section 5.
2.4. Stability Selection
Graph estimation can be regarded as a binary classification problem: for each pair of vertices , we decide whether an edge exists or not. As with any binary classification method, it is essential to estimate as many true edges as possible and avoid false positives for better interpretability, which becomes especially valuable in high dimensions.
In this respect, another important novelty of
jewel 2.0 compared to
jewel 1.0 is the implementation of a stable variable selection procedure that decreases the number of false positives. The idea is that actual positive edges should be more stable than false positive edges because the former result from true numerical significance while the latter are merely the result of a chance. With this in mind, one expects that by repeating the calculation several times (on different realizations with a fixed regularization parameter), the true positive edges are more frequent (i.e., appear more stable) than the false positive edges. Motivated by this argument, we extended the idea presented in [
3] for the first time to the multiple graphs estimation problem.
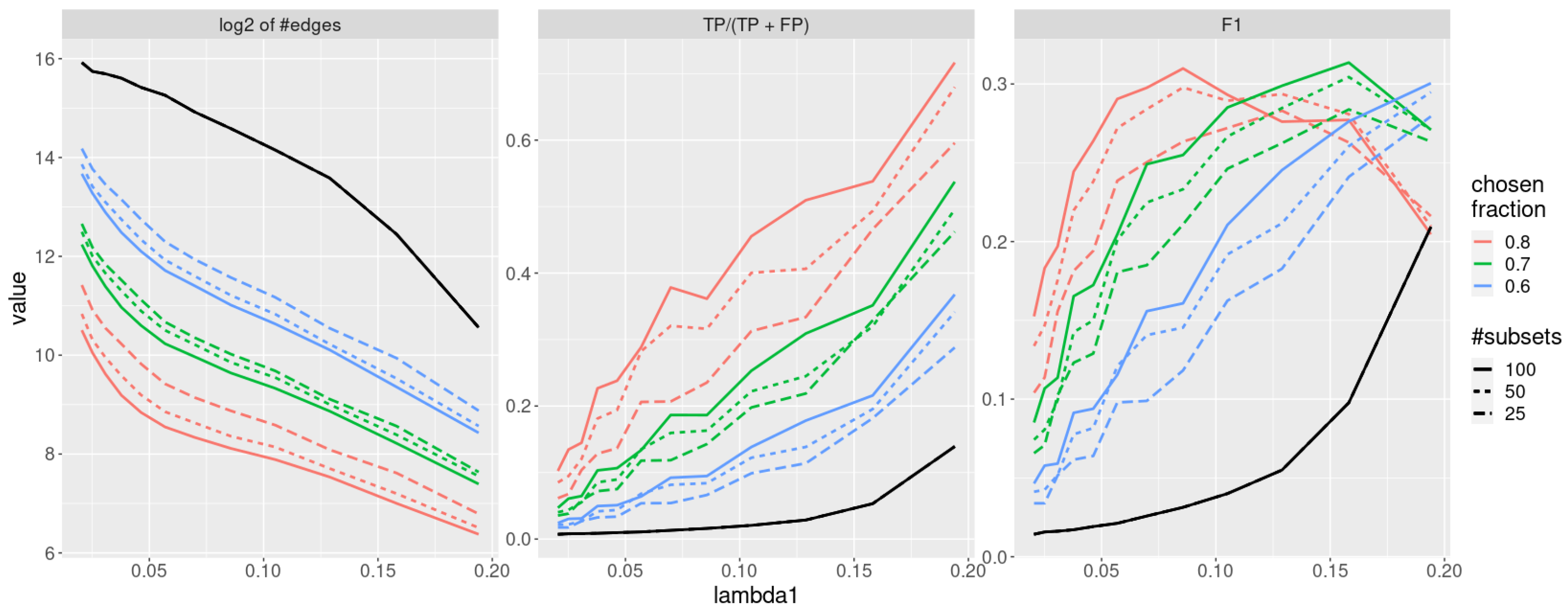
The variable stability selection procedure implemented in jewel 2.0 works as follows. Fix #subsets, representing the number of times we re-run the method on random subsets of the data, and fix chosen fraction, representing the fraction of times that an edge must appear in the results produced on random subsets to be considered stable. Then,
- -
Repeat for #subsets
- -
randomly subsample the data matrices of the size from ;
- -
obtain , , by applying jewel 2.0 to the subsampled data.
- -
Select an edge in the graph k if .
In our approach, the regularization parameter
is the same throughout the entire stability selection procedure. One might choose, for example,
obtained with a model selection estimator such as BIC or select a user-defined value (as performed in
Section 4) within a reasonable range. The main advantage of the stability selection procedure is that the final estimate of the graphs
is not only sparser but also does not critically depend on the specific choice of the regularization parameter. As we show in the numerical experiment, the stability selection procedure effectively refines the graphs (providing sparser solutions) and reduces the number of false positive edges.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








