

A KGE Based Knowledge Enhancing Method for Aspect-Level Sentiment Classification

Abstract
1. Introduction
- The external knowledge is effectively applied to enhance the aspect information, which is also supplementary to the sentence information.
- An information fusion approach is dedicatedly designed to integrate different types of information for ALSC.
- Comparing with the state-of-the-art methods, experimental results on three benchmark datasets corroborate the competitiveness of the proposed methods.
2. Related Work
2.1. Aspect-Level Sentiment Classification
2.2. Semantics and Syntax
2.3. Knowledge Graph
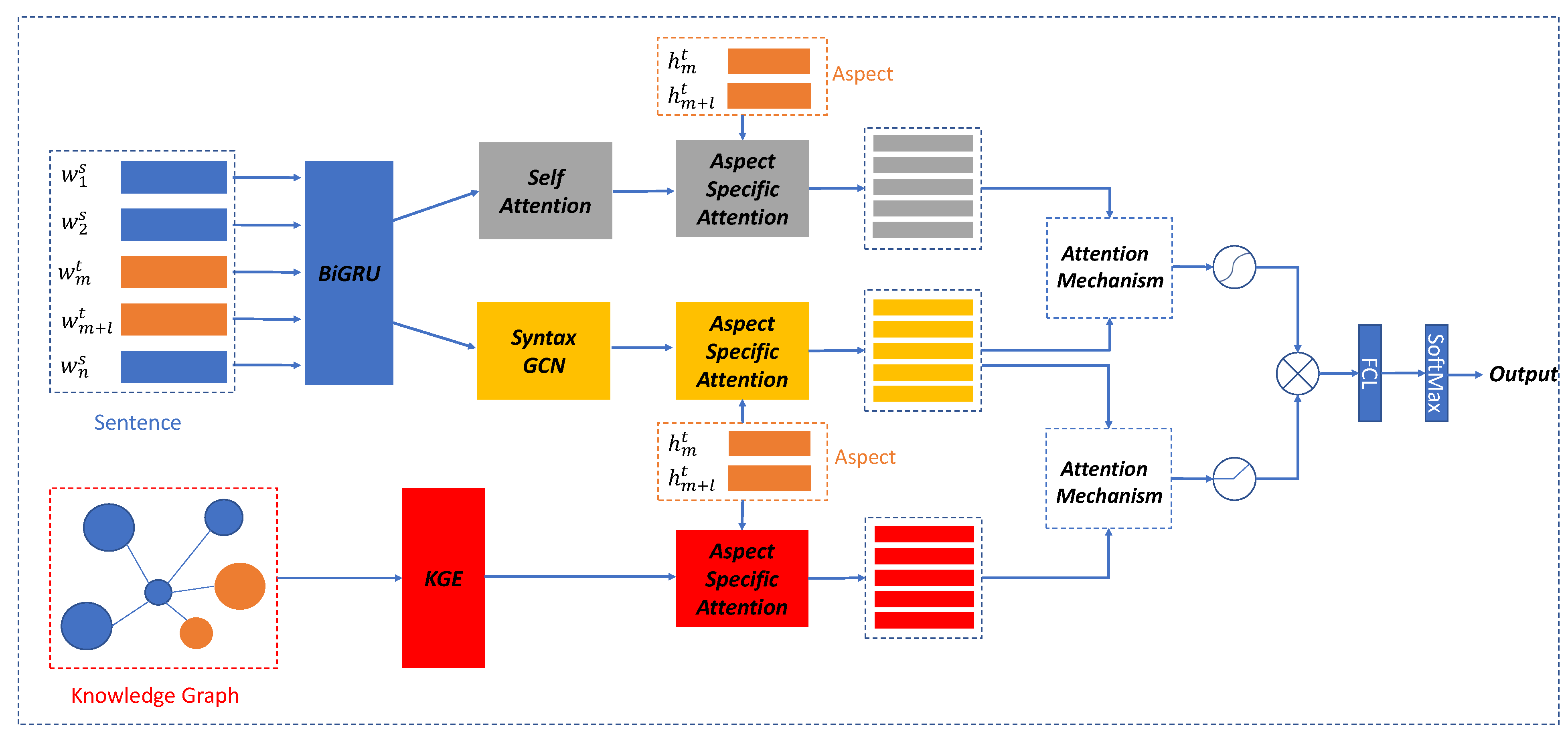
3. Methodology
3.1. Sentence Encoder
3.2. Semantic Learning Module
3.3. Syntax Learning Module
3.4. Knowledge Enhancement Module
3.5. Information Fusion Module
3.6. Sentiment Classifier
4. Experiment
4.1. Dataset
4.2. Implementation Details
4.3. Baseline Methods
- BiGCN [40]: Two graphs, i.e., a global lexical graph and a concept hierarchy graph, are constructed. A bi-level interactive GCN is established to deal with these graphs.
- R-GAT: An aspect-oriented dependency tree is constructed, which is encoded by a relational graph attention network.
- AFGCN [41]: An aspect fusion graph is constructed based on the syntax dependency tree, which captures the aspect-related context words.
- InterGCN [42]: To capture the relation between multiple aspect words, an inter-aspect GCN is devised on the foundation of the AFGCN.
- SK-GCN: A two-GCN-based model that deals with the syntax dependency tree and knowledge graph, respectively.
- Sentic GCN: The external knowledge from SenticNet is introduced to the GCN, which enhances the sentiment dependency between aspects and their contexts.
4.4. Experiment Results
4.5. Impact of GCN Layer Number
4.6. Impact of KGE
4.7. Run Time and Parametric Amount
4.8. Case Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, J.; Huang, J.X.; Chen, Q.; Hu, Q.V.; Wang, T.; He, L. Deep learning for aspect-level sentiment classification: Survey, vision, and challenges. IEEE Access 2019, 7, 78454–78483. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Wang, Y.; Huang, M.; Zhu, X.; Zhao, L. Attention-based LSTM for aspect-level sentiment classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016. [Google Scholar]
- Yang, M.; Tu, W.; Wang, J.; Xu, F.; Chen, X. Attention based LSTM for target dependent sentiment classification. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Zhou, X.; Wan, X.; Xiao, J. Attention-based LSTM network for cross-lingual sentiment classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016. [Google Scholar]
- Nakagawa, T.; Inui, K.; Kurohashi, S. Dependency tree-based sentiment classification using CRFs with hidden variables. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Los Angeles, CA, USA, 2–4 June 2010. [Google Scholar]
- Wu, S.; Xu, Y.; Wu, F.; Yuan, Z.; Huang, Y.; Li, X. Aspect-based sentiment analysis via fusing multiple sources of textual knowledge. Knowl.-Based Syst. 2019, 183, 104868. [Google Scholar] [CrossRef]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge Graph Embedding: A Survey of Approaches and Applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C. A comprehensive survey on graph neural networks. IEEE Trans. Neural Networks Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef] [PubMed]
- Zhao, P.; Hou, L.; Wu, O. Modeling sentiment dependencies with graph convolutional networks for aspect-level sentiment classification. Knowl.-Based Syst. 2020, 193, 105443. [Google Scholar] [CrossRef]
- Zhang, C.; Li, Q.; Song, D. Aspect-based Sentiment Classification with Aspect-specific Graph Convolutional Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Tian, Y.; Chen, G.; Song, Y. Aspect-based sentiment analysis with type-aware graph convolutional networks and layer ensemble. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021. [Google Scholar]
- Wang, K.; Shen, W.; Yang, Y.; Quan, X.; Wang, R. Relational Graph Attention Network for Aspect-based Sentiment Analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar]
- Zhang, Z.; Zhou, Z.; Wang, Y. SSEGCN: Syntactic and Semantic Enhanced Graph Convolutional Network for Aspect-based Sentiment Analysis. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, WA, USA, 10–15 July 2022; pp. 4916–4925. [Google Scholar]
- Bie, Y.; Yang, Y.; Zhang, Y. Fusing Syntactic Structure Information and Lexical Semantic Information for End-to-End Aspect-Based Sentiment Analysis. Tsinghua Sci. Technol. 2022, 28, 230–243. [Google Scholar] [CrossRef]
- Zhang, D.; Zhu, Z.; Kang, S.; Zhang, G.; Liu, P. Syntactic and semantic analysis network for aspect-level sentiment classification. Appl. Intell. 2021, 51, 6136–6147. [Google Scholar] [CrossRef]
- Wu, H.; Zhang, Z.; Shi, S.; Wu, Q.; Song, H. Phrase dependency relational graph attention network for Aspect-based Sentiment Analysis. Knowl.-Based Syst. 2022, 236, 107736. [Google Scholar] [CrossRef]
- Phan, H.T.; Nguyen, N.T.; Hwang, D. Convolutional attention neural network over graph structures for improving the performance of aspect-level sentiment analysis. Inf. Sci. 2022, 589, 416–439. [Google Scholar] [CrossRef]
- He, J.; Wumaier, A.; Kadeer, Z.; Sun, W.; Xin, X.; Zheng, L. A Local and Global Context Focus Multilingual Learning Model for Aspect-Based Sentiment Analysis. IEEE Access 2022, 10, 84135–84146. [Google Scholar] [CrossRef]
- Chen, P.; Lu, Y.; Zheng, V.W.; Chen, X.; Yang, B. KnowEdu: A System to Construct Knowledge Graph for Education. IEEE Access 2018, 6, 31553–31563. [Google Scholar] [CrossRef]
- Rotmensch, M.; Halpern, Y.; Tlimat, A.; Horng, S.; Sontag, D. Learning a Health Knowledge Graph from Electronic Medical Records. Sci. Rep. 2017, 7, 5994. [Google Scholar] [CrossRef] [PubMed]
- Jia, Y.; Qi, Y.; Shang, H.; Jiang, R.; Li, A. A Practical Approach to Constructing a Knowledge Graph for Cybersecurity. Engineering 2018, 4, 53–60. [Google Scholar] [CrossRef]
- Chen, X.; Jia, S.; Xiang, Y. A review: Knowledge reasoning over knowledge graph. Expert Syst. Appl. 2020, 141, 112948. [Google Scholar] [CrossRef]
- Zhou, J.; Huang, J.X.; Hu, Q.V.; He, L. SK-GCN: Modeling Syntax and Knowledge via Graph Convolutional Network for aspect-level sentiment classification. Knowl.-Based Syst. 2020, 205, 106292. [Google Scholar] [CrossRef]
- Liang, B.; Su, H.; Gui, L.; Cambria, E.; Xu, R. Aspect-based sentiment analysis via affective knowledge enhanced graph convolutional networks. Knowl.-Based Syst. 2022, 235, 107643. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, J.; Li, D.; Li, P. Knowledge graph embedding based question answering. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, VIC, Australia, 11–15 February 2019. [Google Scholar]
- Gerritse, E.J.; Hasibi, F.; Vries, A.P. Graph-embedding empowered entity retrieval. In European Conference on Information Retrieval; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Sun, Z.; Yang, J.; Zhang, J.; Bozzon, A.; Huang, L.K. Recurrent knowledge graph embedding for effective recommendation. In Proceedings of the 12th ACM Conference on Recommender Systems, New York, NY, USA, 2 October 2018. [Google Scholar]
- Bordes, A.; Weston, J.; Collobert, R.; Bengio, Y. Learning structured embeddings of knowledge bases. In Proceedings of the Twenty-Fifth AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 7–8 August 2011. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; Volume 28. [Google Scholar]
- Dettmers, T.; Minervini, P.; Stenetorp, P. Convolutional 2d knowledge graph embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Vu, T.; Nguyen, T.D.; Nguyen, D.Q. A capsule network-based embedding model for knowledge graph completion and search personalization. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1. [Google Scholar]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 10–12 June 2008. [Google Scholar]
- Yang, B.; Yih, W.; He, X.; Gao, J.; Deng, L. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. In Proceedings of the International Conference on Learning Representations (ICLR) 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Pontiki, M.; Galanis, D.; Papageorgiou, H. SemEval-2014 Task 4: Aspect Based Sentiment Analysis. SemEval 2014, 2014, 27. [Google Scholar]
- Dong, L.; Wei, F.; Tan, C.; Tang, D.; Zhou, M. Adaptive recursive neural network for target-dependent twitter sentiment classification. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Baltimore, MD, USA, 22–27 June 2014. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Kenton, J.; Chang, D.M.-W.; Toutanova, L.K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Chen, Z.; Ma, T.; Jin, Z.; Song, Y.; Wang, Y. BiGCN: A bi-directional low-pass filtering graph neural network. arXiv 2021, arXiv:2101.05519. [Google Scholar] [CrossRef]
- Zhang, F.; Zhang, Y.; Hou, S.; Chen, F.; Lu, M. Aspect Fusion Graph Convolutional Networks for Aspect-Based Sentiment Analysis. In China Conference on Information Retrieval; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Liang, B.; Yin, R.; Gui, L.; Du, J.; Xu, R. Jointly learning aspect-focused and inter-aspect relations with graph convolutional networks for aspect sentiment analysis. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020. [Google Scholar]
- Cambria, E.; Speer, R.; Havasi, C.; Hussain, A. Senticnet: A publicly available semantic resource for opinion mining. In Proceedings of the 2010 AAAI Fall Symposium Series, Arlington, VA, USA, 11–13 November 2010. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Dataset | Positive | Negative | Neutral | |||
|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | |
| Restaurant | 2164 | 728 | 805 | 196 | 633 | 196 |
| Laptop | 987 | 341 | 866 | 128 | 466 | 169 |
| 1560 | 173 | 1560 | 173 | 3127 | 346 | |
| Models | Restaurant | Laptop | ||||
|---|---|---|---|---|---|---|
| Acc | F1 | Acc | F1 | Acc | F1 | |
| BiGCN | 81.96 | 73.53 | 74.61 | 71.19 | 74.13 | 72.64 |
| AFGCN | 81.70 | 73.43 | 76.80 | 72.88 | - | - |
| InterGCN | 82.23 | 72.81 | 77.12 | 72.87 | - | - |
| RGAT | 83.30 | 76.08 | 77.74 | 73.91 | 73.12 | 72.40 |
| SK-GCN | 81.53 | 72.90 | 77.62 | 73.84 | 71.97 | 70.22 |
| Sentic-GCN | 84.03 | 75.38 | 77.90 | 74.71 | - | - |
| Ours | 84.23 | 76.12 | 77.81 | 73.47 | 77.70 | 76.27 |
| BERT only | 84.11 | 76.66 | 77.90 | 73.30 | 73.27 | 71.52 |
| AFGCN+BERT | 86.16 | 79.34 | 80.88 | 77.24 | - | - |
| RGAT+BERT | 86.61 | 80.99 | 78.53 | 74.06 | 75.72 | 74.60 |
| InterGCN+BERT | 86.43 | 80.75 | 82.29 | 78.9 | - | - |
| Ours+BERT | 86.93 | 81.05 | 82.41 | 79.32 | 78.87 | 77.97 |
| Num of GCN Layers | Restaurant | Laptop | |
|---|---|---|---|
| 1 | 83.68 | 76.94 | 77.13 |
| 2 | 84.23 | 77.81 | 77.70 |
| 3 | 83.12 | 76.55 | 76.81 |
| 4 | 82.83 | 75.98 | 76.44 |
| 5 | 82.35 | 75.50 | 75.93 |
| KGE Methods | Restaurant | Laptop | |
|---|---|---|---|
| TransE | 82.37 | 77.13 | 75.89 |
| TransR | 82.65 | 77.44 | 75.80 |
| TransH | 82.80 | 77.63 | 76.12 |
| DistMult | 84.23 | 77.81 | 77.70 |
| Method | Training Speed (secs.) | Params (M) |
|---|---|---|
| BiGCN | 6.88 | 1.9 |
| RGAT | 4.22 | 3.9 |
| SK-GCN | 8.92 | 8.5 |
| Ours | 7.43 | 7.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, H.; Lu, G.; Cai, Q.; Xue, Y. A KGE Based Knowledge Enhancing Method for Aspect-Level Sentiment Classification. Mathematics 2022, 10, 3908. https://doi.org/10.3390/math10203908
Yu H, Lu G, Cai Q, Xue Y. A KGE Based Knowledge Enhancing Method for Aspect-Level Sentiment Classification. Mathematics. 2022; 10(20):3908. https://doi.org/10.3390/math10203908
Chicago/Turabian StyleYu, Haibo, Guojun Lu, Qianhua Cai, and Yun Xue. 2022. "A KGE Based Knowledge Enhancing Method for Aspect-Level Sentiment Classification" Mathematics 10, no. 20: 3908. https://doi.org/10.3390/math10203908
APA StyleYu, H., Lu, G., Cai, Q., & Xue, Y. (2022). A KGE Based Knowledge Enhancing Method for Aspect-Level Sentiment Classification. Mathematics, 10(20), 3908. https://doi.org/10.3390/math10203908