
Some Technical Remarks on Negations of Discrete Probability Distributions and Their Information Loss

Abstract
1. Introduction
- It will be proven that independent negations have to be affine-linear.
- It will be proven that the uniform distribution maximizes all -entropies with strictly concave generating function .
- It will be proven that the Yager negation minimizes any -entropy in the class of affine-linear negations, with the consequence that the information loss has to be discussed only for Yager negation.
- It will be proven that the information loss, measured by the difference of -entropies, increases separately for odd and even sequences of repetition numbers of Yager negation.
- It will be proven that the uniform distribution yields a local minimum of the information loss produced by the Yager negation for each -entropy.
- It will be proven that the uniform distribution yields the global minimum of the information loss produced by the Yager negation for Gini, paired Shannon, Shannon and Havrda–Charvát entropy.
- An explicit formula for Yager negation’s information loss in the case of the Gini entropy will be given.
- It will be shown that results concerning the information loss of Havrda–Charvát entropy can be transferred to Rényi and Sharma–Mittal entropies by using the concept of -entropies with h strictly increasing.
- An impression of how the information loss behaves for dependent negations when analytical results do not seem to be available will be given.
2. Definitions
- A probability transformation maps into such thatwith , and for all .
- The probability transformation is independent, if there exists a function such thatfor all .
- In Wu et al. [7] an exponential probability transformation withwas considered.
- Another example could be the cosinus transformation
- Affine-linear probability transformations are given byfor a and b such that , .
- The probability transformation withis called a negation, iffor all and .
- For independent negations there exists a function withN will be called a negator [3].
3. Independence and Linearity
- .
- for , for . This means that, depending on n, an independent negator takes on values in a very small interval.
- can be equivalently represented as the convex combination of the constant (or uniform) negator and the Yager negator for . This means, there exists an such that
4. Information Loss for Independent Negations and General -Entropies
4.1. -Entropies
4.2. Yager Negation Minimizes -Entropies
4.3. -Entropy and Yager Negation
4.4. Lagrangian Approach
- The first criterion is that the function (32) is strictly monotone on . In this case, one can conclude from that , . In Section 5.1, it will be shown that this criterion can be applied to paired Shannon entropy.
- The second criterion allows (32) to be non-monotone. In principle, there could be other candidates satisfying (33). If we can show that these candidates violate the restriction that the probabilities add to 1, we are left with the uniform distribution as the only point where (31) has a local minimum. This criterion can be applied for Shannon and Havrda–Charvát entropy (see Section 5.2 and Section 5.3).
5. Information Loss for Special Entropies
5.1. Paired Shannon Entropy and Yager Negation
5.2. Shannon Entropy and Yager Negation
5.3. Havrda–Charvát Entropy and Yager Negation
5.4. Gini Entropy and Independent Negations
5.5. Information Loss If Is Not Strictly Concave
6. Strictly Increasing Relationship between Entropies
6.1. -Entropies
6.2. Rényi Entropy, Havrda–Charvát Entropy and Yager Negation
6.3. Sharma–Mittal Entropy, Harvda–Charvát Entropy and Yager Negation
7. -Entropy in the Dependent Case
- Yager negator [1] with
- exponential negator [7] with
- cosinus negator with
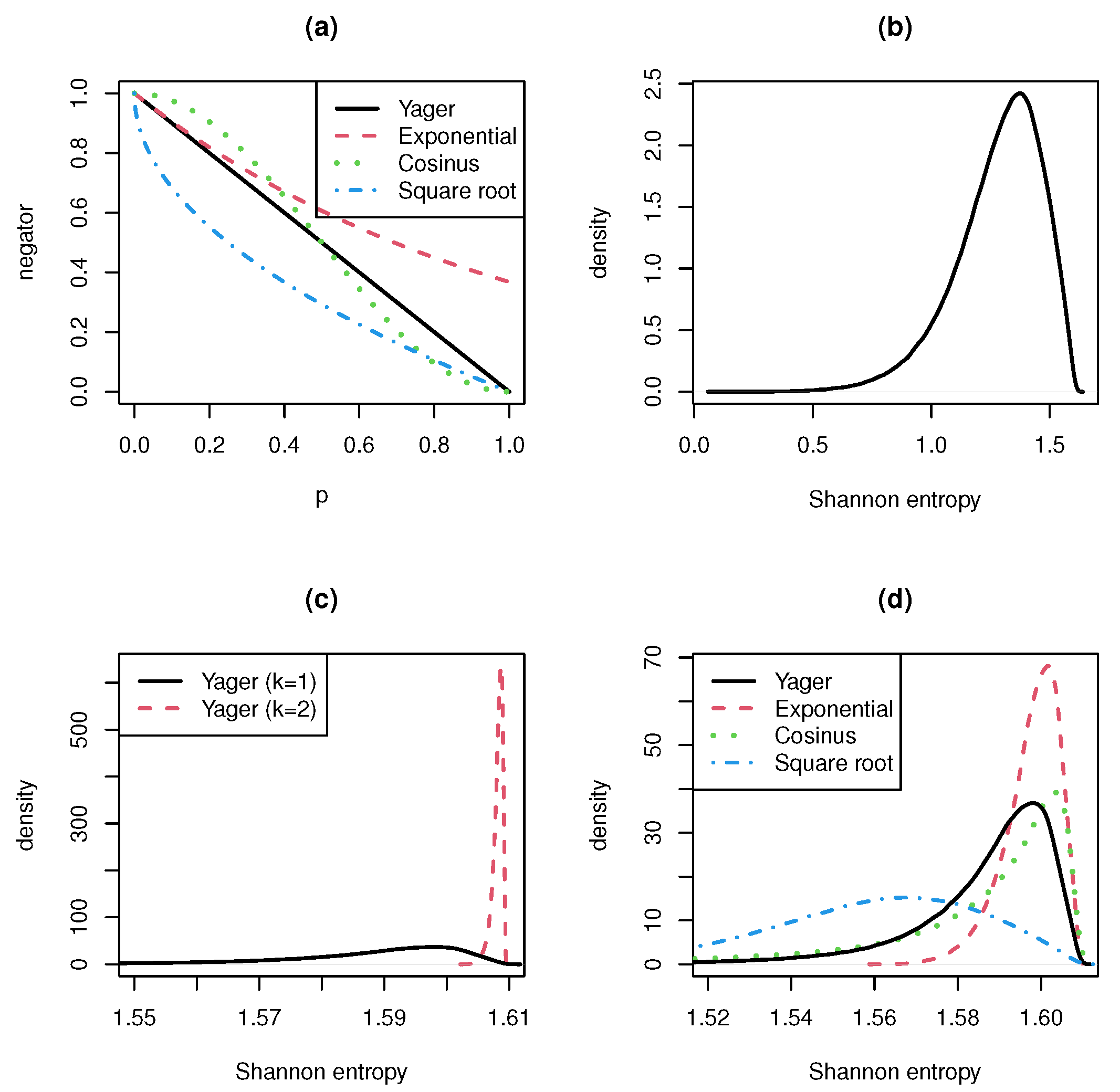
- and square root negator (special case of the Tsallis negator discussed by Zhang et al. [6]):, and are generating functions for dependent negations. For dependent negations, it is not easy to prove properties of their entropies. Wu et al. [7] discussed the exponential negation. They considered the Shannon entropy for this negator. In their numerical examples, they compared Yager und exponential negators for different concrete probability vectors and a different number of categories n. Their general result is that exponential negator converges faster to the uniform distribution than Yager negator.
- A single application of the negation already results in a very concentrated and strongly peaked entropy distribution. This confirms the fact stated in Remark 1 that the range of negations is very narrow.
- The double or multiple use of a negation leads to a distribution that resembles a singular distribution concentrated at the entropy’s maximum value. Therefore, the convergence rate to the uniform distribution is very high.
- The convergence rate is even higher when we consider negations with generating function f with for . The reverse is also true. Negations with generating function , give lower convergence rates.
- In the interval , the generating function of the cosinus negation is greater and in smaller than the generating function of the Yager negation. Nevertheless, the cosinus negation produces entropy distributions looking similar to the entropy distribution of the Yager negation. The entropy formula seems to eliminate the difference between the cosinus and the Yager negator.
8. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix B
- Case 1: . We haveIt is
- -
- Subcase 1.1: . For it holdsConsider such that and with .We have such that and .
- -
- Subcase 1.2: : First, reformulate asThis gives for andThe rest follows the arguments from subcase 1.1.
- Case 2: means that holds. Then, since for . Now, we haveFrom this and it followsConsider such that and with . Because g is strictly decreasing in we have such that and . This contradicts the fact that and are probabilities.
References
- Yager, R. On the maximum entropy negation of a probability distribution. IEEE Trans. Fuzzy Syst. 2014, 23, 1899–1902. [Google Scholar] [CrossRef]
- Batyrshin, I.; Villa-Vargas, L.A.; Ramirez-Salinas, M.A.; Salinas-Rosales, M.; Kubysheva, N. Generating negations of probability distributions. Soft Comput. 2021, 25, 7929–7935. [Google Scholar] [CrossRef]
- Batyrshin, I. Contracting and involutive negations of probability distributions. Mathematics 2021, 9, 2389. [Google Scholar] [CrossRef]
- Gao, X.; Deng, Y. The generalization negation of probability distribution and its application in target recognition based on sensor fusion. Int. J. Distrib. Sens. Netw. 2019, 15, 1–8. [Google Scholar] [CrossRef]
- Gao, X.; Deng, Y. The negation of basic probability assignment. IEEE Access 2019, 7, 107006–107014. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, R.; Zhang, J.; Kang, B. Extension of Yager’s negation of a probability distribution based on Tsallis entropy. Int. J. Intell. Syst. 2020, 35, 72–84. [Google Scholar] [CrossRef]
- Wu, Q.; Deng, Y.; Xiong, N. Exponential negation of a probability distribution. Soft Comput. 2022, 26, 2147–2156. [Google Scholar] [CrossRef]
- Srivastava, A.; Maheshwari, S. Some new properties of negation of a probability distribution. Int. J. Intell. Syst. 2018, 33, 1133–1145. [Google Scholar] [CrossRef]
- Aczél, J. Vorlesungen über Funktionalgleichungen und ihre Anwendungen; Birkhauser: Basel, Switzerland, 1961. [Google Scholar]
- Ilić, V.; Korbel, J.; Gupta, S.; Scarfone, A. An overview of generalized entropic forms. Europhys. Lett. 2021, 133, 50005. [Google Scholar] [CrossRef]
- Burbea, J.; Rao, C. On the convexity of some divergence measures based on entropy functions. IEEE Trans. Inf. Theory 1982, 28, 489–495. [Google Scholar] [CrossRef]
- Salicrú, M.; Menéndez, M.; Morales, D.; Pardo, L. Asymptotic distribution of (h,Φ)-entropies. Commun. Stat. Theory Methods 1993, 22, 2015–2031. [Google Scholar] [CrossRef]
- Gini, C. Variabilità e Mutabilità: Contributo alla Distribuzioni e delle Relazioni Statistiche; Tipografia di Paolo Cuppin: Bologna, Italy, 1912. [Google Scholar]
- Onicescu, O. Théorie de l’information énergie informationelle. Comptes Rendus l’Academie Sci. Ser. AB 1966, 263, 841–842. [Google Scholar]
- Vajda, I. Bounds on the minimal error probability and checking a finite or countable number of hypotheses. Inf. Transm. Probl. 1968, 4, 9–17. [Google Scholar]
- Rao, C. Diversity and dissimilarity coefficients: A unified approach. Theor. Popul. Biol. 1982, 21, 24–43. [Google Scholar] [CrossRef]
- Shannon, C. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Havrda, J.; Charvát, F. Quantification method of classification processes. Concept of structural α-entropy. Kybernetika 1967, 3, 30–35. [Google Scholar]
- Daróczy, Z. Generalized information functions. Inf. Control. 1970, 16, 36–51. [Google Scholar] [CrossRef]
- Tsallis, C. Possible generalization of Boltzmann-Gibbs statistics. J. Stat. Phys. 1988, 52, 479–487. [Google Scholar] [CrossRef]
- Leik, R. A measure of ordinal consensus. Pac. Sociol. Rev. 1966, 9, 85–90. [Google Scholar] [CrossRef]
- Klein, I.; Mangold, B.; Doll, M. Cumulative paired ϕ-entropy. Entropy 2016, 18, 248. [Google Scholar] [CrossRef]
- Shafee, F. Lambert function and a new non-extensive form of entropy. IMA J. Appl. Math. 2007, 72, 785–800. [Google Scholar] [CrossRef]
- Mosler, K.; Dyckerhoff, R.; Scheicher, C. Mathematische Methoden für Ökonomen; Springer: Berlin, Germany, 2009. [Google Scholar]
- Rényi, A. On measures of entropy and information. In Proceedings 4th Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Berkeley, CA, USA, 1961; pp. 547–561. [Google Scholar]
- Sharma, B.; Mittal, D. New nonadditive measures of entropy for discrete probability distributions. J. Math. Sci. 1975, 10, 28–40. [Google Scholar]
- Uffink, J. Can the maximum entropy principle be explained as a consistency requirement? Stud. Hist. Philos. Sci. Part B Stud. Hist. Philos. Mod. Phys. 1995, 26, 223–261. [Google Scholar] [CrossRef]
- Jizba, P.; Korbel, J. When Shannon and Khinchin meet Shore and Johnson: Equivalence of information theory and statistical inference axiomatics. Phys. Rev. E 2020, 101, 042126. [Google Scholar] [CrossRef] [PubMed]
- Martin, A.; Quinn, K.; Park, J. MCMCpack: Markov Chain Monte Carlo in R. J. Stat. Softw. 2011, 42, 22. [Google Scholar] [CrossRef]
- Walley, P. Inferences From multinomal data: Learning sbout a bag of marbles (with discussion). J. R. Stat. Soc. Ser. B 1996, 58, 3–57. [Google Scholar]



{kind=link}
{kind=link}
| Entropy | Source | Result | Method |
|---|---|---|---|
| Theorem 4 | strict concavity | ||
| Theorem 5 | Lagrange | ||
| for | |||
| paired Shannon | Theorem 6 | Lagrange | |
| Shannon | Theorem 7 | Lagrange | |
| Havrda-Charvát | Theorem 8 | Lagrange | |
| Gini | Theorem 10 | updating formula | |
| Leik | Example 6 | ||
| Rényi | Theorem 11 | transformation | |
| Sharma-Mittal | Theorem 12 | transformation | |
| Uffink | Remark 2 | transformation |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Klein, I. Some Technical Remarks on Negations of Discrete Probability Distributions and Their Information Loss. Mathematics 2022, 10, 3893. https://doi.org/10.3390/math10203893
Klein I. Some Technical Remarks on Negations of Discrete Probability Distributions and Their Information Loss. Mathematics. 2022; 10(20):3893. https://doi.org/10.3390/math10203893
Chicago/Turabian StyleKlein, Ingo. 2022. "Some Technical Remarks on Negations of Discrete Probability Distributions and Their Information Loss" Mathematics 10, no. 20: 3893. https://doi.org/10.3390/math10203893
APA StyleKlein, I. (2022). Some Technical Remarks on Negations of Discrete Probability Distributions and Their Information Loss. Mathematics, 10(20), 3893. https://doi.org/10.3390/math10203893