3.1. Description
The area on which the studied process
changes is divided into equal sectors that are
points in percentage (pipses) long. Suppose that the process has moved from level
to the level
above it. We can loosely consider this to be an appearance of a positive trend. Such a transition will be denoted as
. Conversely, we can understand
as negative dynamics [
15].
The main problem that we focus on consists in proving the persistence of process defined as it arriving at the next level of the detected trend.
We assess positive outcome probability, i.e., going from after it has gone from . We define a negative outcome as a opposite transition to the level below directly after an upwards transition . Due to symmetry, similar measurements work for downwards transitions as well. Therefore, the set of exhaustive events consists of two positive outcomes , and two negative outcomes .
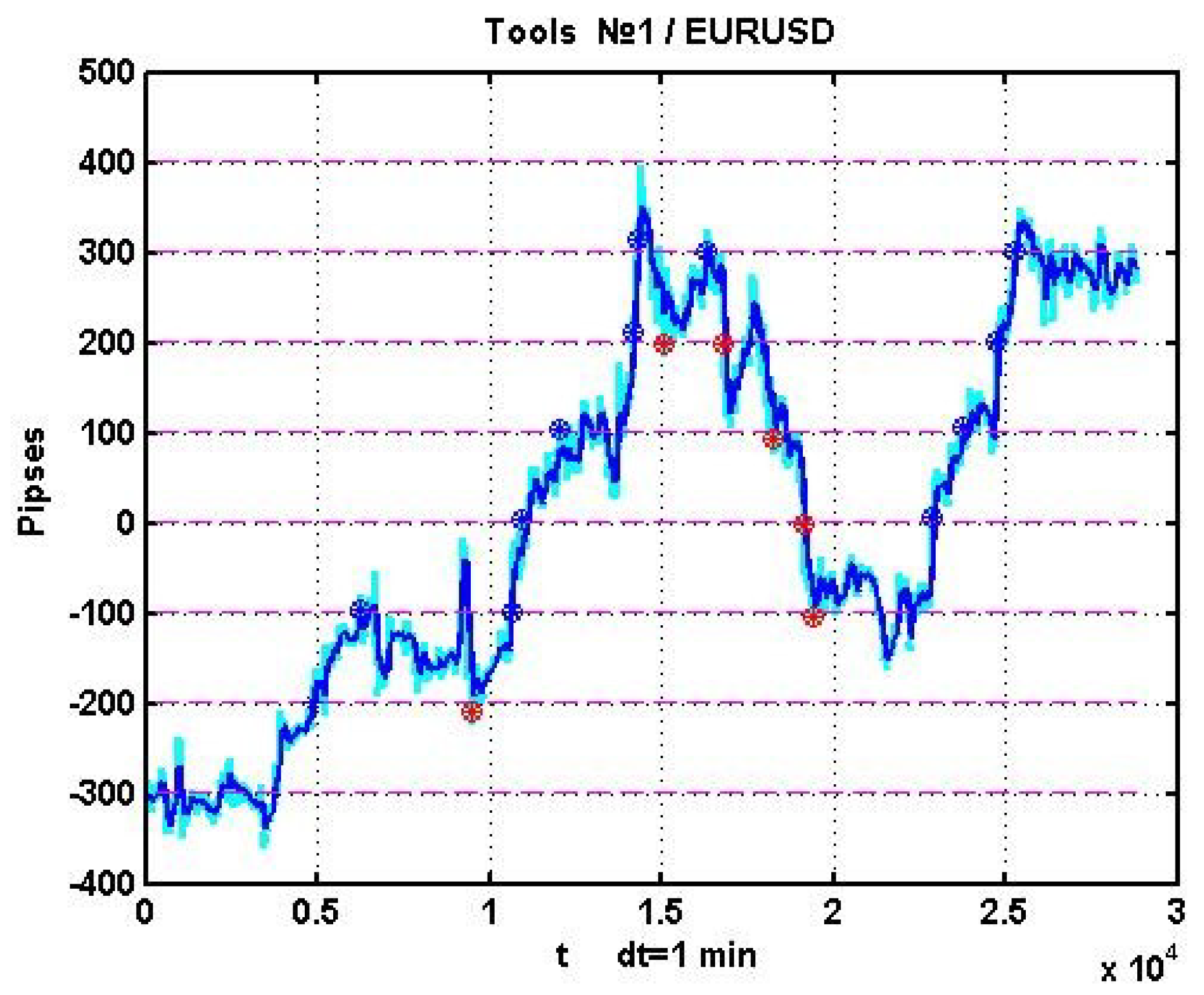
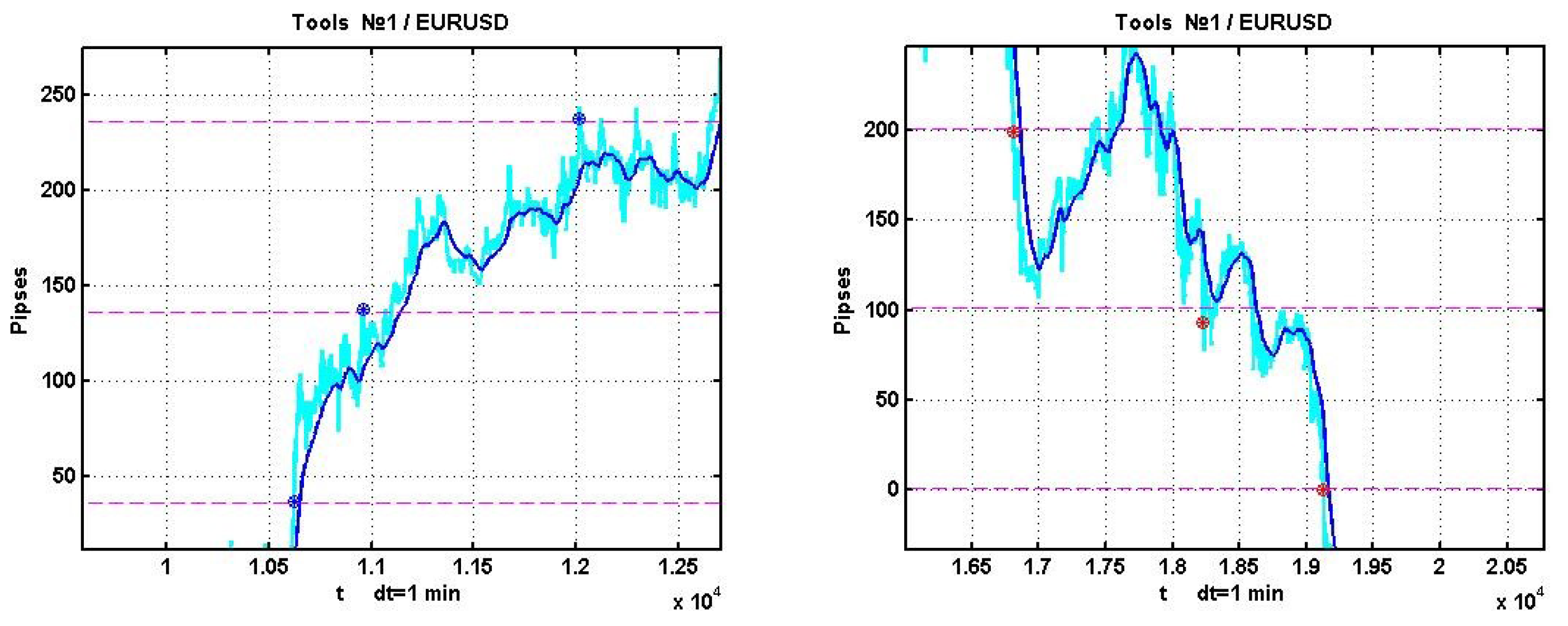
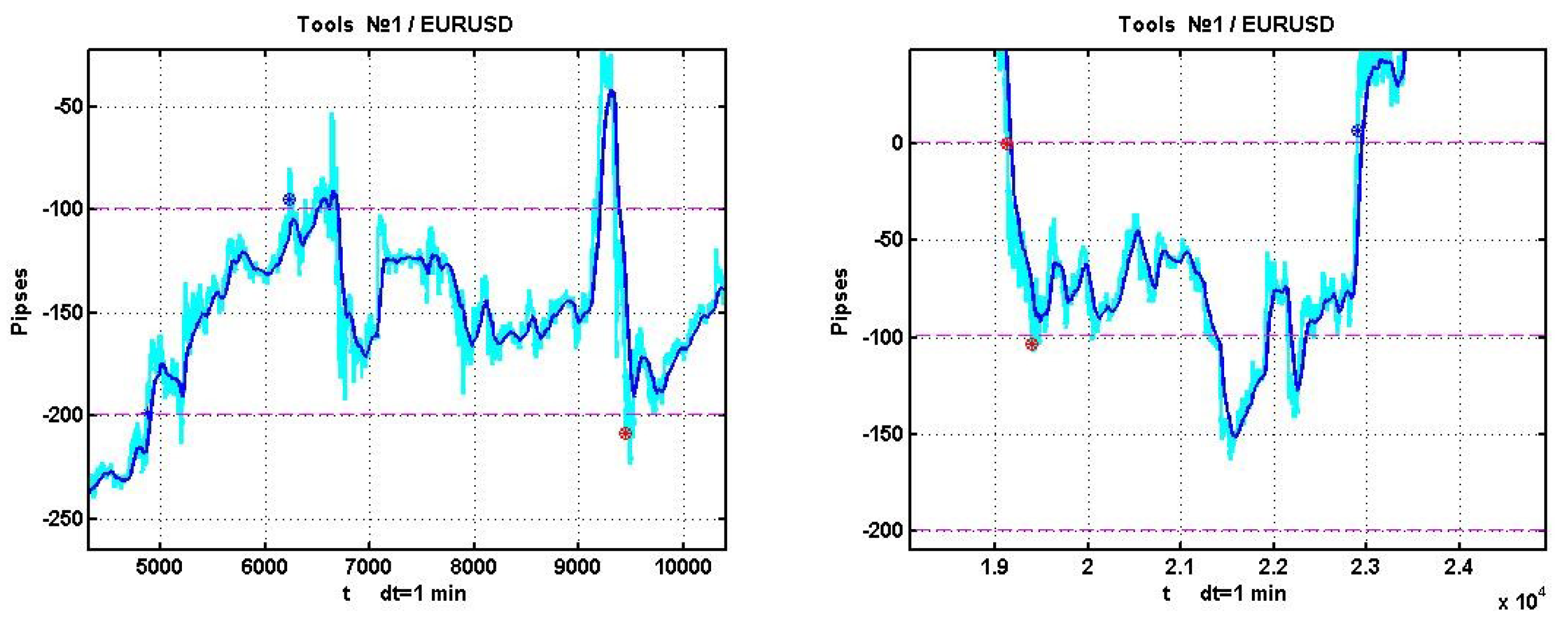
As in illustration,
Figure 2 presents an example of EURUSD quotation dynamics on a 10-day observation interval with segmentation boundaries and marks denoting boundary intersections.
The figure presents both the process and its smoothed version . It was smoothed via a simple exponential filter , in which .
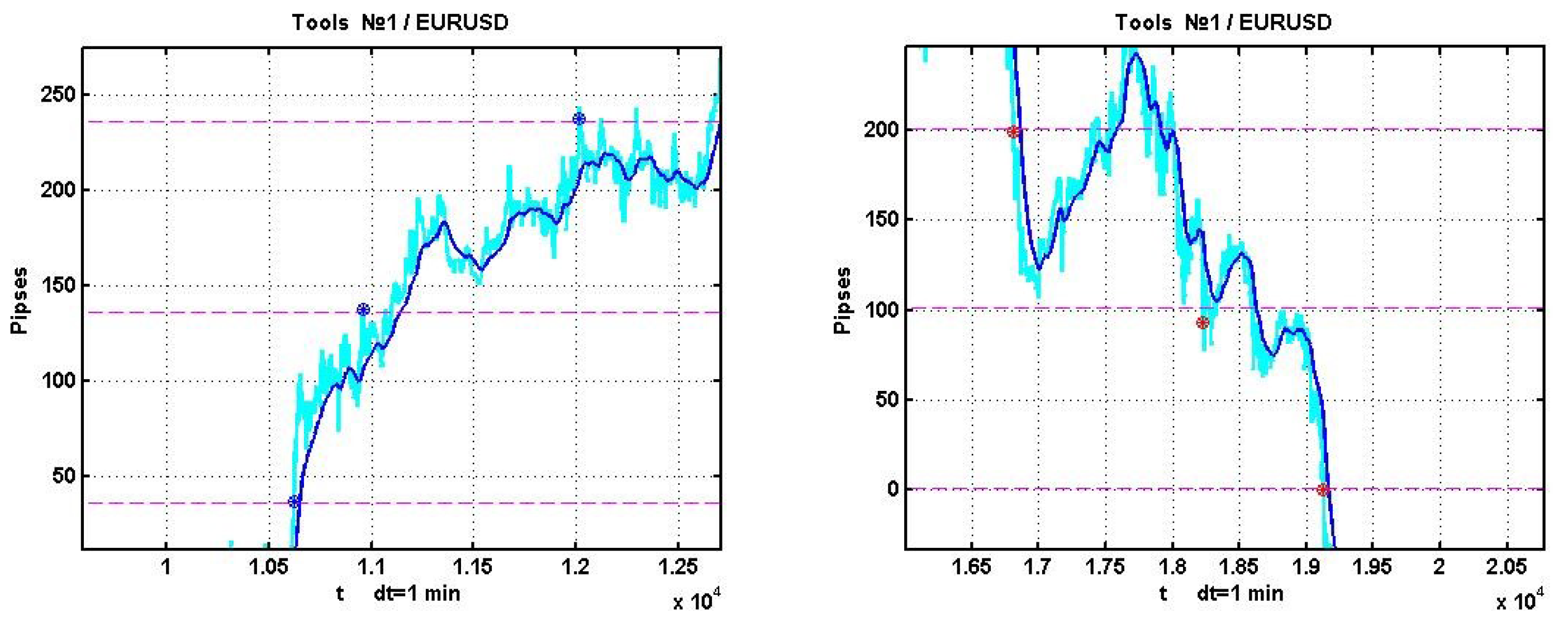
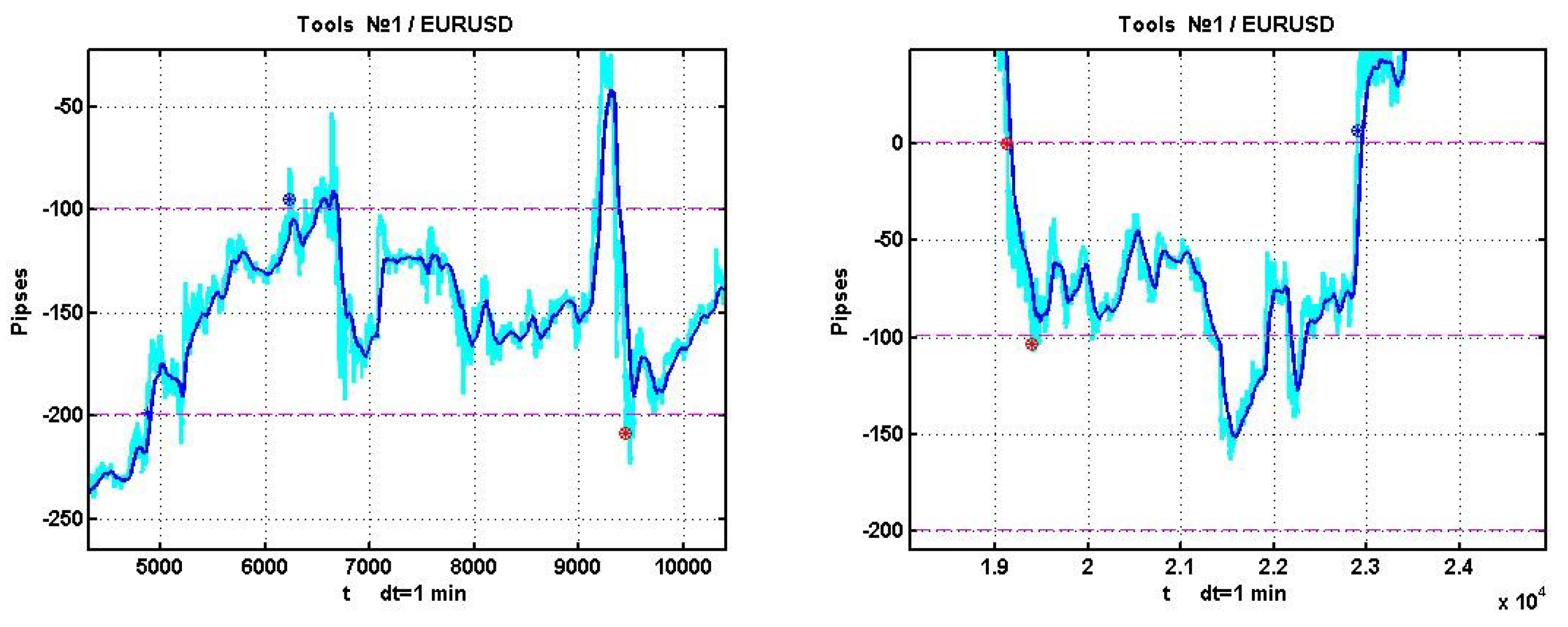
Examples of positive outcomes are shown in
Figure 3, and negative ones in
Figure 4.
Assume that N experiments were run, each of which has identified a transition from level to level, interpreted as a trend. If this direction persists until the process intersects the next level, this outcome will confirm the trend. Conversely, if the process reverses and reaches the previous level, it will point to trend absence. Suppose that as the result of N consecutive experiments m outcomes prove trend presence, and outcomes disprove it.
Thus, this can be considered as an alternative
to the null hypothesis
of trend absence, in which
is the frequency of experiments that confirm trend presence. If an experiment is repeated a sufficient number of times, the frequency of observed event is considered to be an estimate of the probability of the corresponding assumption. To test the
hypothesis, it is possible to use a well-known rule
, where
[
8,
9,
10]. The critical value
for the right-tailed criterion is found using the Laplace function
table of values, considering that
. Here,
is the significance level of the null hypothesis.
3.2. Results
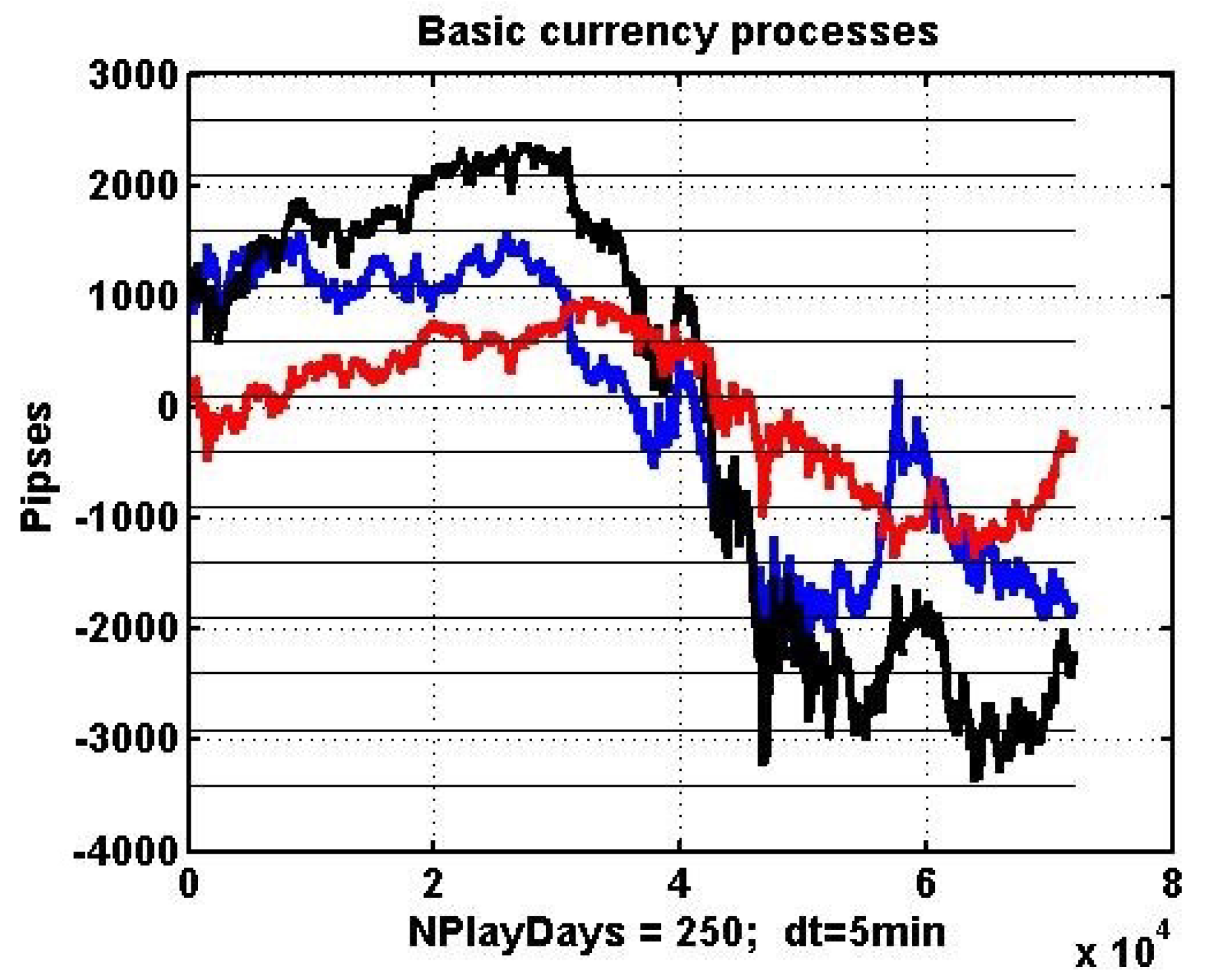
In order to cover as many variations of chaotic dynamics in electronic trading as possible, we have considered five 100-day segments for three most widespread financial instruments: EURUSD, EURJPY, and USDJPY. We have used the (pipses) as the size of the inter-level interval.
Probability is estimated using the frequency of positive outcomes, that is, the ratio of positive outcomes to the total number of experiments. The corresponding results of the computational experiment are presented in
Table 1.
The presented data clearly indicates complete absence of any inertia in quotation dynamics. This statement can be verified with statistical hypothesis testing. As mentioned above, the null hypothesis is tested against the alternative .
As an example, consider an experiment for the 100-day interval of EURUSD observation. It resulted in
closes, out of which
corresponded to the inertia condition at
. The relative frequency
corresponds to the value of the decision statistic
Here, , i.e., it is subject to the standard Gaussian distribution with the parameters. The assumption about the normal distribution of the criterion follows from Laplace’s theorem (for a sufficiently large n, the relative frequency can be approximately considered normally distributed with the mathematical expectation p and standard deviation ). In the general case, this assumption needs additional verification.
The critical area for the symmetrical competing hypothesis is determined based on the selected significance level . For a two-sided critical area, is determined via the Laplace function value table according to . Using the distribution tables of the Laplace function, we determine . Therefore, the calculated value of statistic belongs to the area of hypothesis acceptance , which means that statistical solutions are unsuitable for the considered processes.
The conclusion that inertia is absent in the previous experiment may be caused by an excessively large confirmation interval p. Let us check whether we can confirm the presence of inertia on smaller segmentation levels. Note that the considered process contains a significant completely random component. Considering the random value spread relatively to the smoothed process from then its SD on 100-day observation segments oscillates within 11–14 pipses for various currency instruments. Decreasing to , the corresponding SD changes within 15–20 pipses, which is due to a lower degree of smoothness and therefore a smaller difference between the initial and smoothed processes.
The width of the spread is responsible for random decisions that do not correspond to systemic processes of quotation dynamics and therefore skews the conclusions on inertia presence. Thus, in order to obtain a correct conclusion on inertia, the size of the segmentation step (system dynamics) must be significantly larger than the random component.
As an example that illustrates the minimum feasible segmentation step for the presented
SD values, consider the same task with
. The frequencies of positive outcomes that confirm process inertia can be found in
Table 2.
The results, similarly to the previous case, confirm the stability of the hypothesis , which refutes the use of statistical management techniques in a chaotic environment. The positive asymmetry is too small to accept the null hypothesis on the significance of the difference between the frequency of positive outcomes and 50%. The difference between the following series of experiments is that the beginning of each stage of the management process is fixed when the segmentation level is crossed not by the process itself, but by its smoothed version. Positions are closed (i.e., establishing the fact of recognizing or not recognizing inertia in each experiment) by the process itself.
Obviously, the higher the degree of smoothness, the less the result will depend on the fluctuating component of the process randomly crossing the levels. On the other hand, a higher degree of smoothness inevitably leads to a lag in the smoothed process relative to the original one, which skews the resulting estimates. As a compromise, we will use values
. The segmentation step, as in the first experiment, is equal to 100 p. The results of estimating the probability of a positive outcome confirming the alternative
for five 100-day observation intervals and different values of the exponential filter transfer coefficient
are presented in
Table 3.
It can be seen from the above data that the smoothed version of the process has more inertia, which in general is suitable for making useful trading recommendations. However, one should keep in mind that negative decisions are more drastic in terms of loss, since in this case the dynamics of the quote reverse, and the departure of the process during the time when the smoothed curve crosses the opening level can be very large.
The final computational experiment is similar to the previous one, but both were carried out by a smoothed process
at the intersection of the corresponding level. The results of the experiment are shown in
Table 4.
It is easy to see that the presented results are quite close to the corresponding estimates given in
Table 3. In other words, using a smoothed curve did not change the final result. This is due to the fact that the probability of process
reaching the decision level will be higher both with a positive and negative outcome.
The disadvantage of the analysis method proposed above is that it does not take into account the quality of the transitions on which the local trend is detected. For example, transition
can go on for a long time, with fluctuations and with a large negative “sagging” (it is only necessary that it does not turn around and does not reach level
). Such a process is quite difficult to perceive as a trend. However, in accordance with the above formalization, such a transition will also be interpreted as a positive trend. In this regard, it makes sense to move on to a more complex trend detection criterion, based, for example, on the average rate of change in the state of the process on a sliding time window of size
l:
Trend detection in this case is exceeding the value of the linear approximation coefficient
calculated at the observation site
of a certain critical value
. This approach can be generalized to more complex trend detection rules. In particular, we can consider a version of trend detection based on linear approximation coefficients calculated on two observation windows of different lengths
and
,
, or a version that uses a sliding approximation by a second-order polynomial. The second half of the proposed effectiveness analysis approach, namely, confirming the existence of a trend, remains unchanged. The
hypothesis of trend absence in the prolongation of the detected trend means that the process, after its detection at
, reaches threshold values
and
with the same probability, i.e.,
,
p being the value of the observed process at the time of trend detection. An alternative hypothesis indicating the possibility of using such strategies in conditions of market chaos will have the form
. As in previous experiments, in addition to the main chaotic process
, we will use its smoothed version
(4) with a transmission coefficient. The process
, which simulates the system component of chaotic dynamics makes it possible to isolate the purely random component of the initial noise chaotic process
, which is a centered random process with a distribution that is close to Gaussian. The variance of the residual process
, in turn, allows us to estimate the lower bound of the parameter
that determines the level of confirmation or denial of the trend presence hypothesis. The method of conducting computational experiments is close to its prototype described above. An observation series of a trading asset’s state at various non-intersecting 100-day observation intervals is considered as the polygon of chaotic data. Next, we form a sliding observation window
of size
l, on which we calculate approximating polynomials
,
q being their degree. A decision about the presence of a trend is made based on the comparison of estimated coefficients of
a with critical values
. The number of outcomes corresponding to the process reaching a predetermined level
is calculated to statistically verify the effectiveness of management decisions made following trend-based strategies. Due to the symmetry of the task, the negative result consists in a trend reversal and reaching the
level. If the ratio of reaching
to the total number of position openings
(the frequency of the event) is close to 0.5, then this confirms the hypothesis
that it is impossible to successfully implement trend-based management strategies. The parameters of the computational experiment are observation window
l, degree of smoothing polynomial
q, threshold values of trends
, and trend confirmation level
. The simplest linear approximation scheme
is used on a sliding observation window
. A trend is confirmed when the linear approximation coefficient
exceeds a pre-set value
. Trend presence is either denied or confirmed when the condition
is met, in which
is the value of the process at the time of trend detection
, and
are the trend confirmation levels. The size of the observation window
l varies in the (0.1–0.5) day range. A trend is detected if
is satisfied, and confirmed when
levels are reached. Estimates of the probability (frequency) of reaching the trend confirmation level for its various values
, for the
-day observation window and for threshold values
on a 100-day observation interval are shown in
Table 5.
The presented data clearly confirms that it is impossible to successfully prolongate
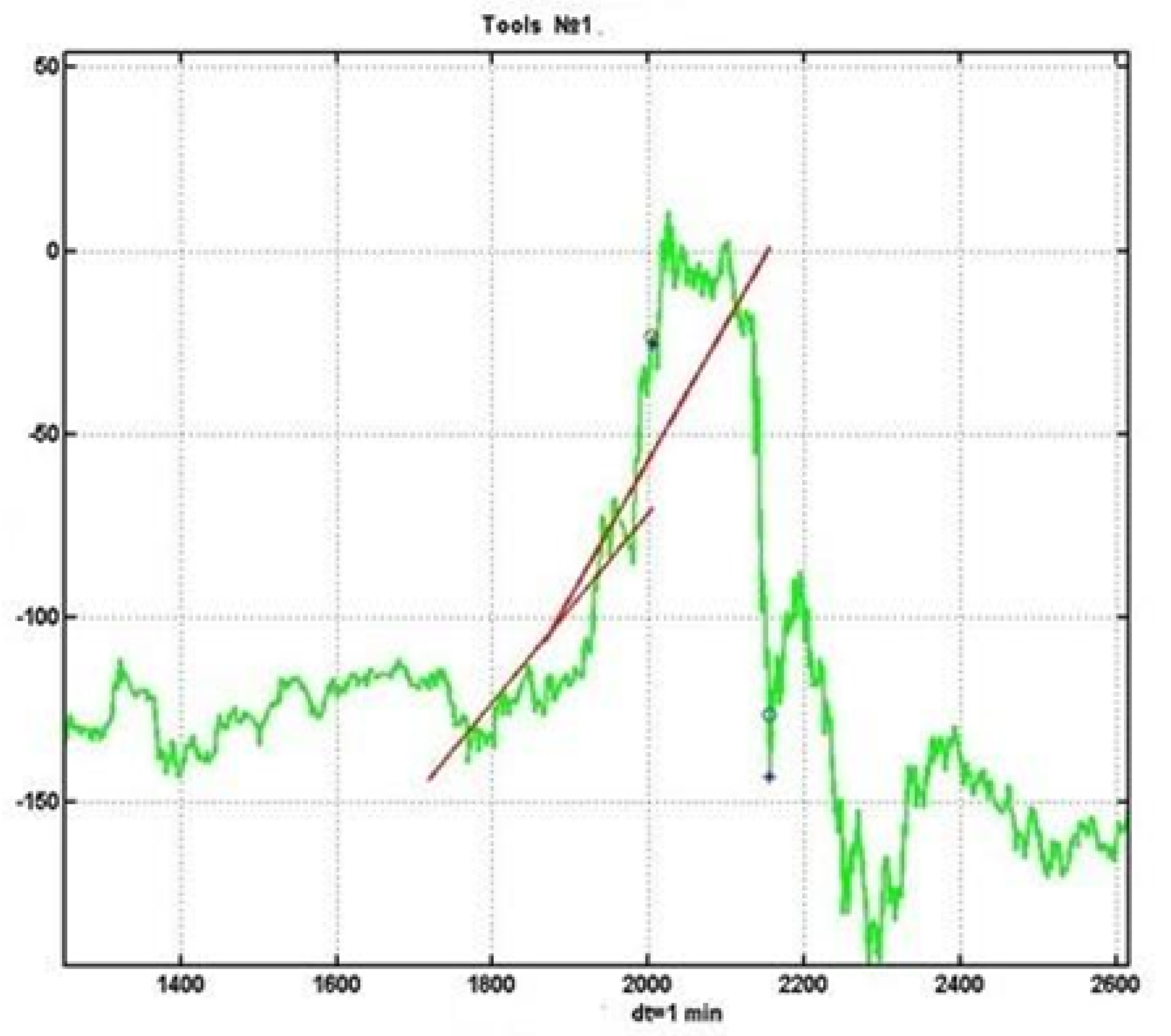
in a wide range of changes in intensity values, fixation levels and trend confirmation levels. The disadvantage of this experiment is the fixed length of the sliding observation window
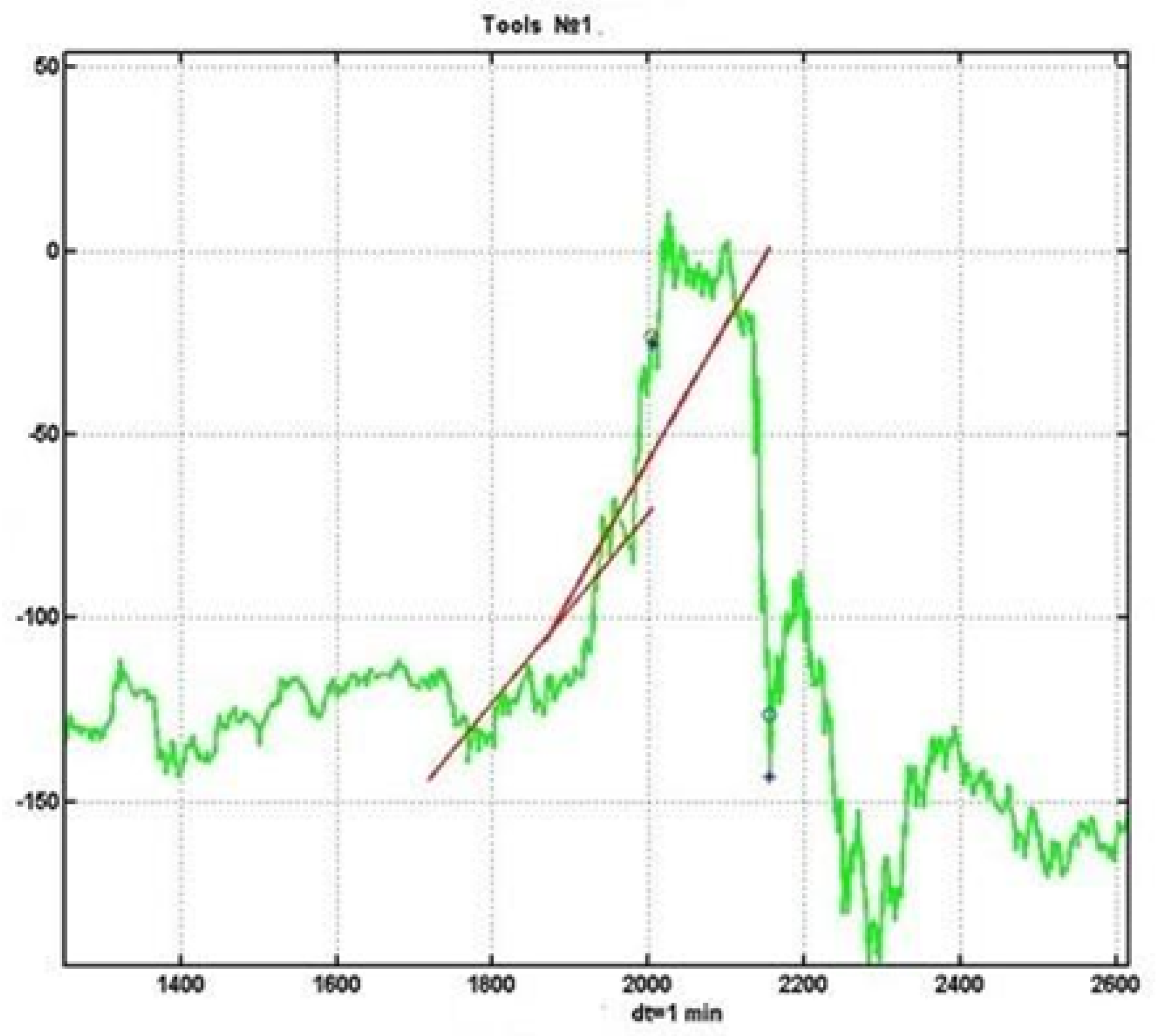
l. A large window causes a significant delay in trend detection, which leads to a delayed decision and, as a result, to an incorrect assessment of the probability of trend confirmation. An example is shown in
Figure 5.
A small window leads to an increased sensitivity of the trend detection procedure to the random component, which, in turn, leads to statistical errors of Type II (false alarms), that is, to the detection of a non-existent trend. In this regard, it makes sense to consider the problem of trend detection based on a complex criterion that uses two sliding observation windows of different sizes.
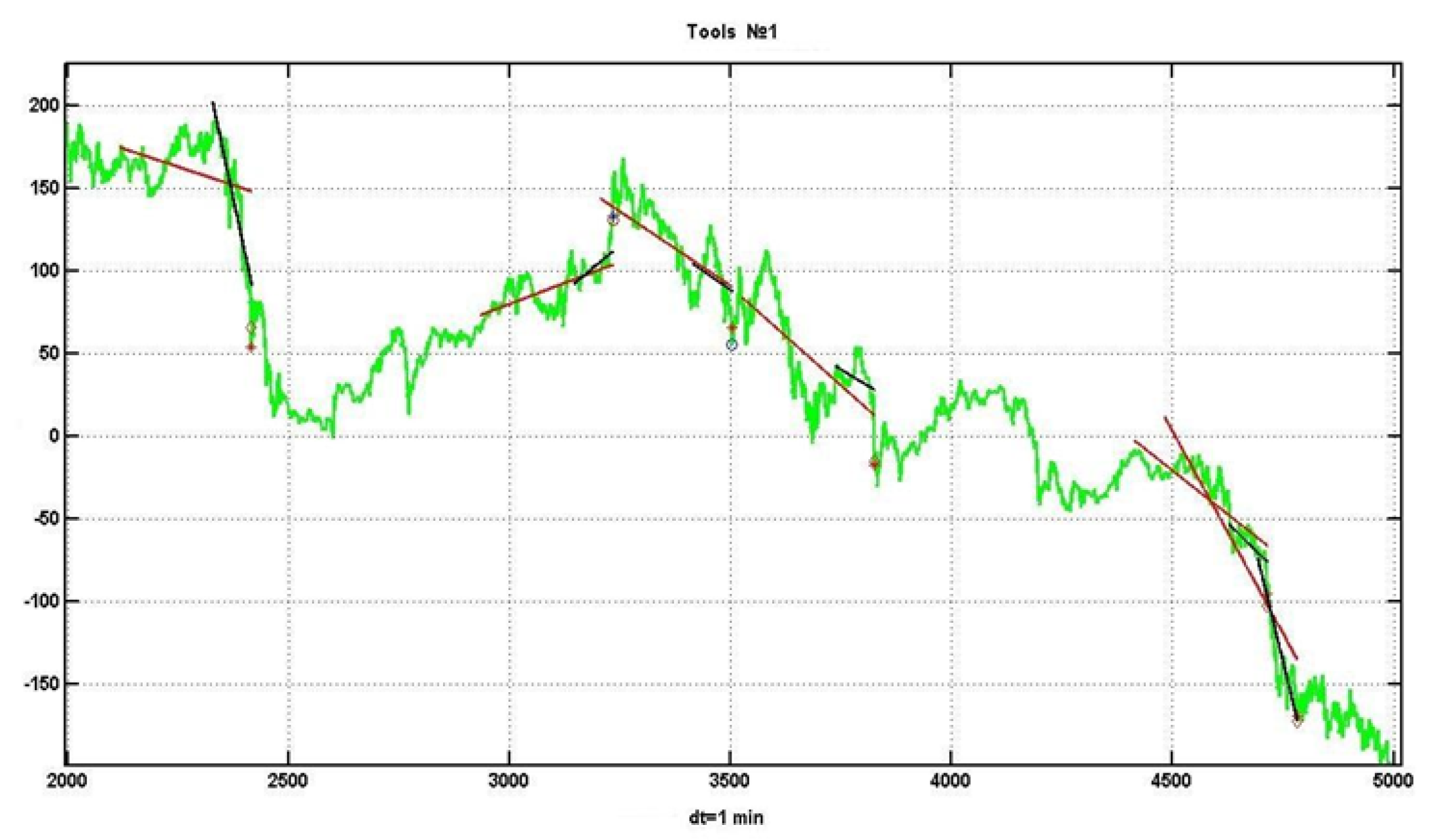
Unlike the previous experiment, in this one we consider two trends. In this case, linear approximations
are used for two sliding observation windows of size
and
,
. It is obvious that the first trend has stronger smoothing characteristics, and the second is more sensitive to both systemic process changes and “false alarms”. Let
,
minute counts, critical values of the linear regression coefficient
, the level of trend confirmation
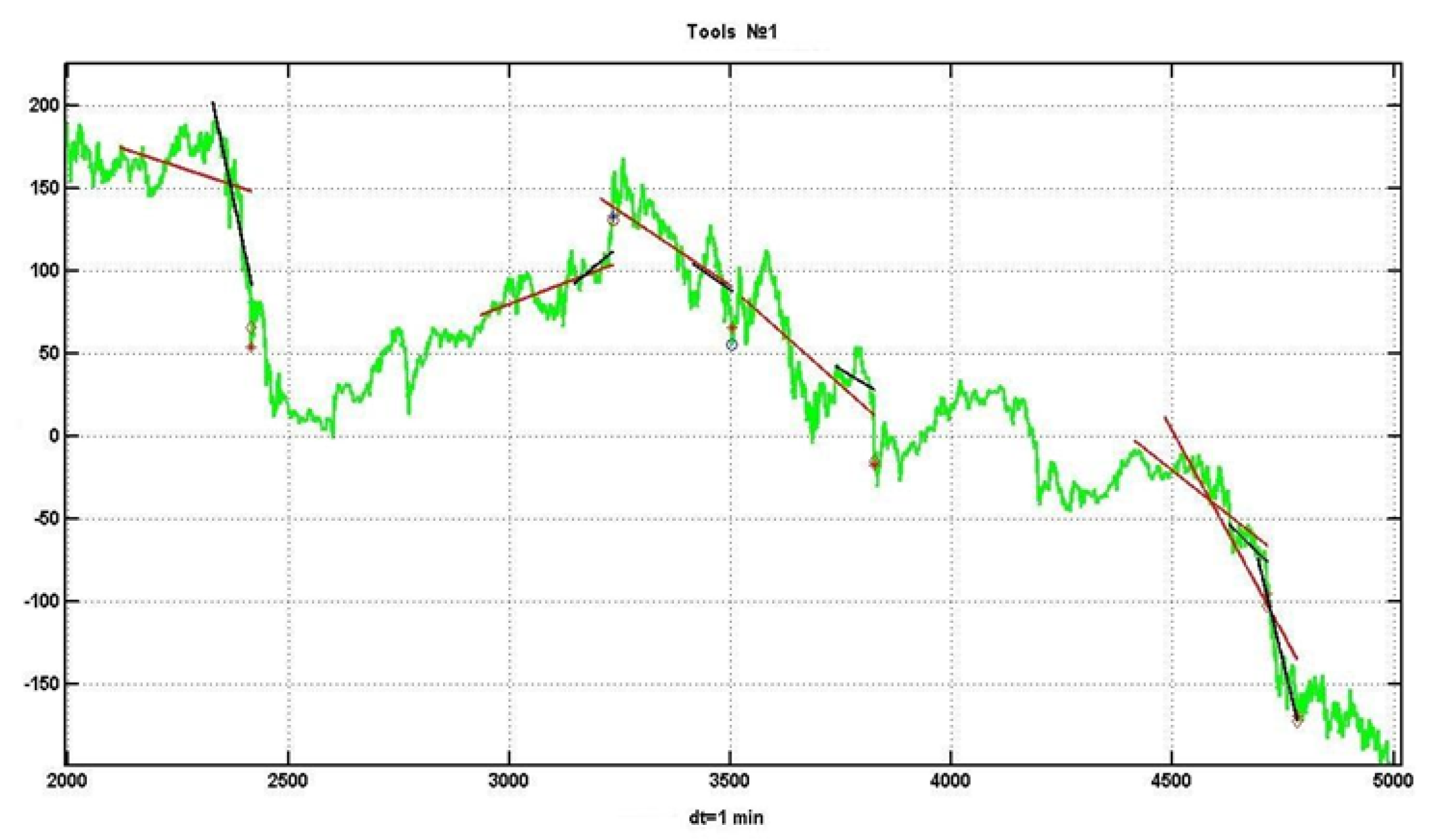
. The decision on the presence of a trend is made if both linear regression coefficients exceed their critical values by the absolute value. An example of the implementation of such a scheme is shown in
Figure 6.
Longer trends correspond to larger observation windows. Let us consider the result of using this method for four 100-day intervals with different levels of trend confirmation
. The corresponding data is presented in
Table 6. It is easy to see that the modification did not have a positive effect.
Obviously, the issues of the previous version of this approach have not been resolved. Additionally, the method, as a rule, detects a trend at the time of confirmation (or denial) of the previous trend. At the same time, there is no new trend detection during the confirmation time: this would require a method that simultaneously analyzes several trends. The provided data clearly illustrates the extremely insignificant fluctuations in the frequency of trend confirmation relative to the 0.5 value. This conclusion is easily confirmed by testing the statistical hypothesis about the absence of a trend using U-statistics and confidence level .



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}