

OADE-Net: Original and Attention-Guided DenseNet-Based Ensemble Network for Person Re-Identification Using Infrared Light Images

Abstract
1. Introduction
- -
- This study proposes the OADE-Net for IR image-based person ReID for solving person ReID performance affected considerably by illuminance and environmental changes of visible images;
- -
- In the OADE-Net, DenseNet was combined with the attention-guided DenseNet, including the convolutional block attention module (CBAM), in the form of an ensemble network. A shallow convolutional neural network (CNN) for ensemble network (SCE-Net) was newly proposed for combining the DenseNet and attention-guided DenseNet;
- -
- SCE-Net uses a multiple channel input consisting of feature and score maps obtained from DenseNet and attention-guided DenseNet, achieving higher person ReID accuracies compared to those obtained using conventional score-level fusion methods;
- -
- The proposed models are disclosed on the GitHub site [8] for a fair performance evaluation by other researchers.
2. Related Works
2.1. Person ReID Using Visible Camera
2.2. Person ReID Using Visible and IR Cameras
2.3. Person ReID Using IR Camera
2.3.1. Method Using Night IR Image
2.3.2. Method Using Daytime and Night IR Images
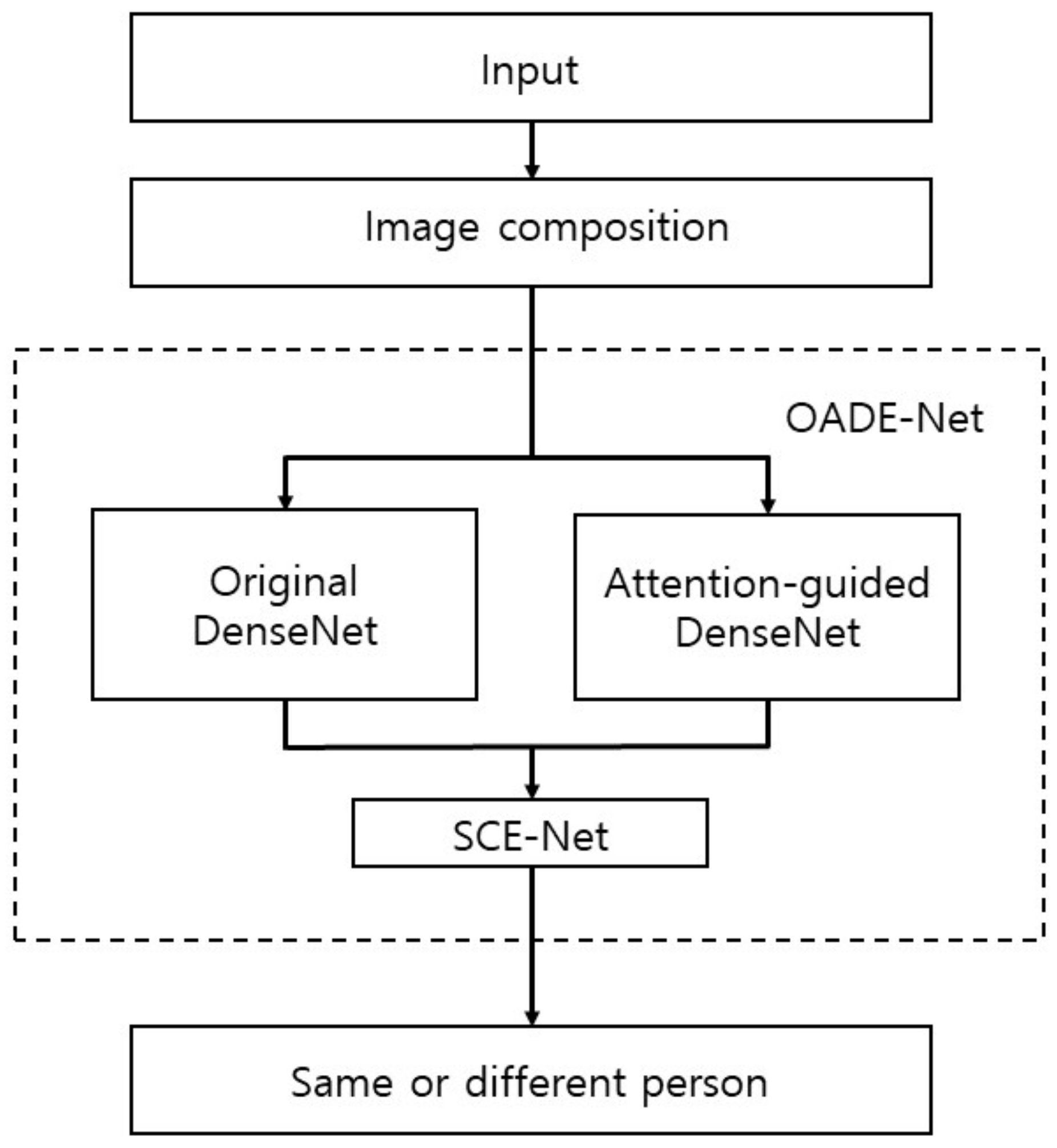
3. Proposed Method
3.1. Image Composition
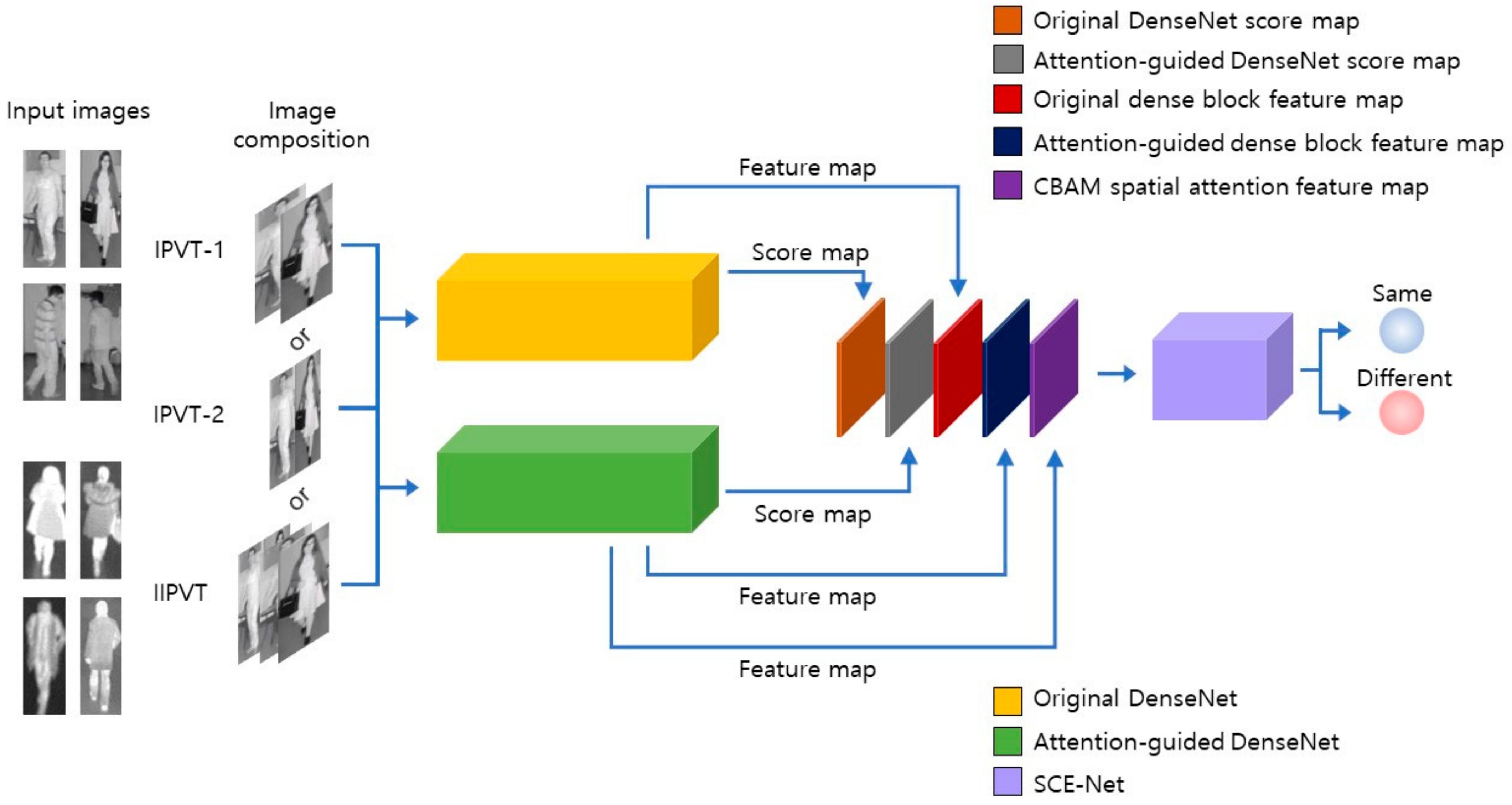
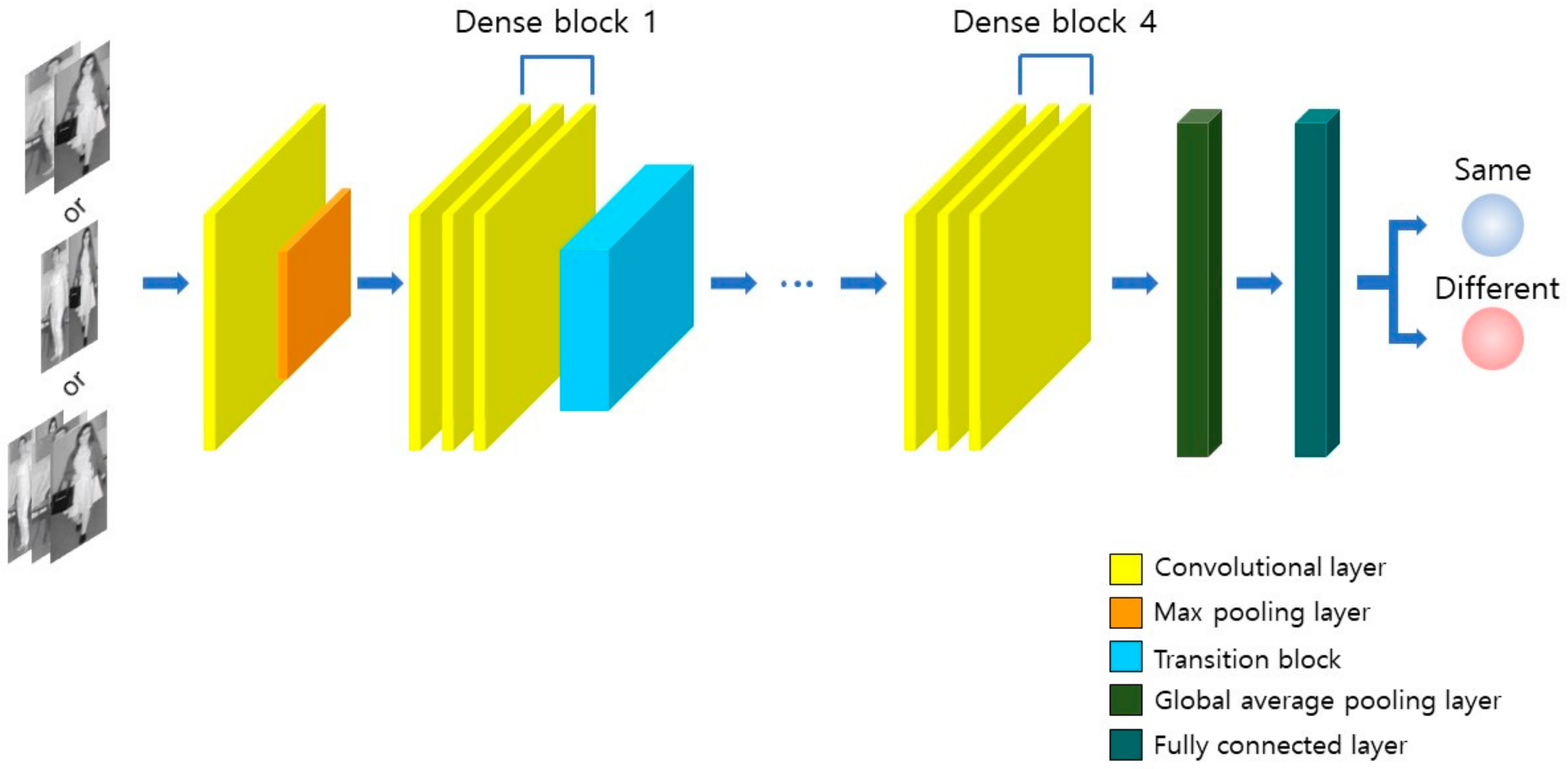
3.2. OADE-Net
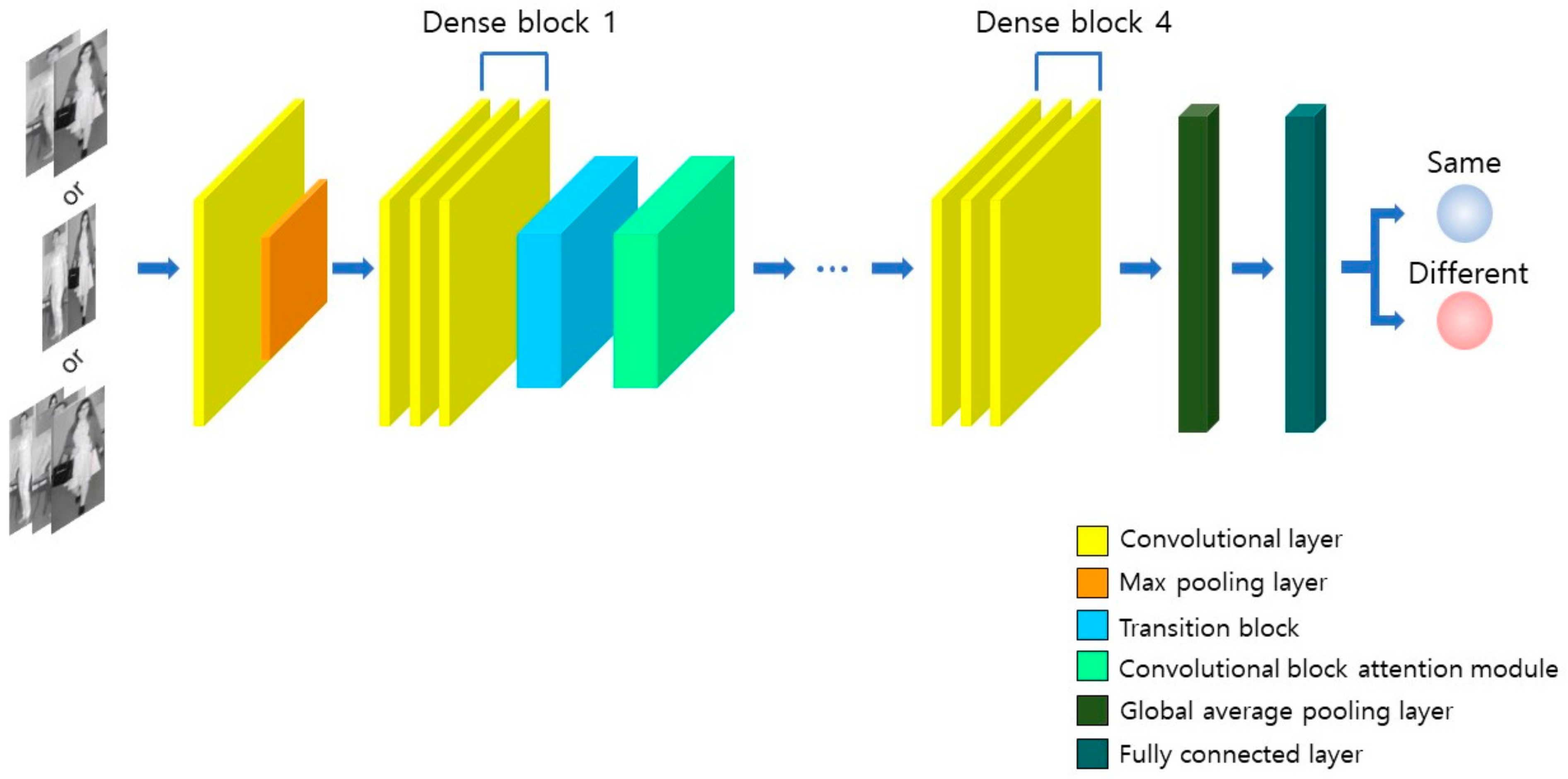
3.3. Attention-Guided DenseNet
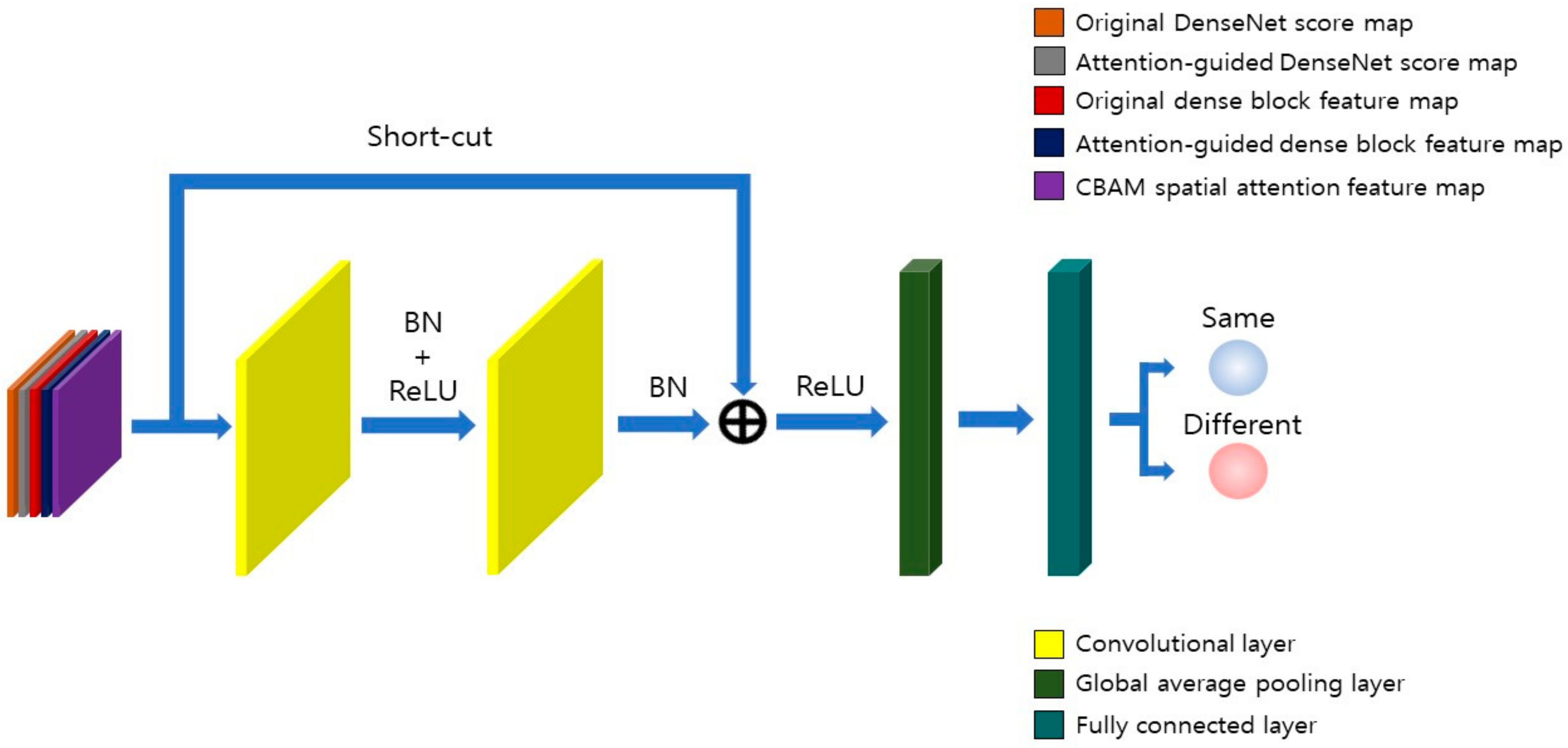
3.4. SCE-Net
4. Experimental Results
4.1. Experimental Data and Setup
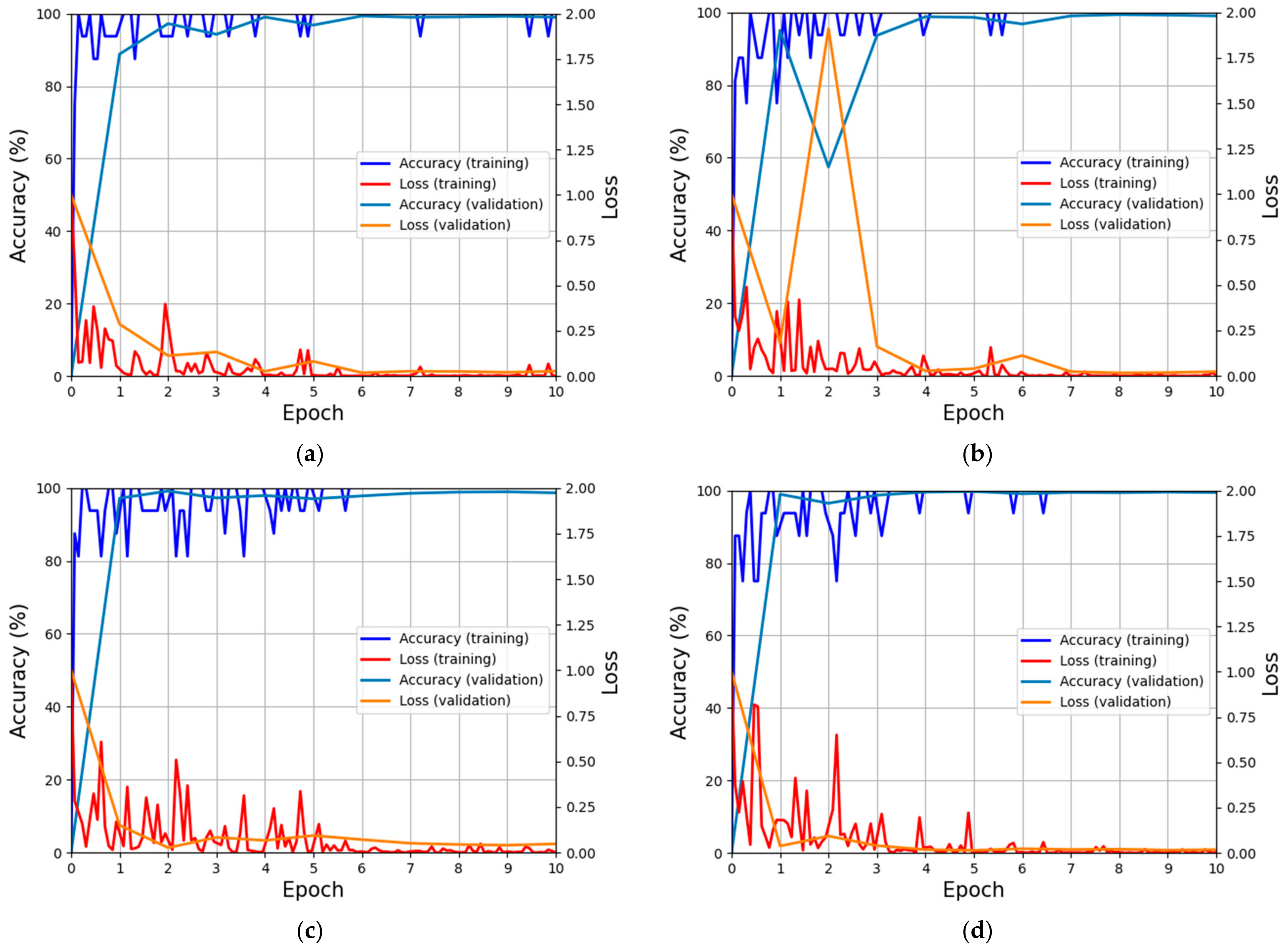
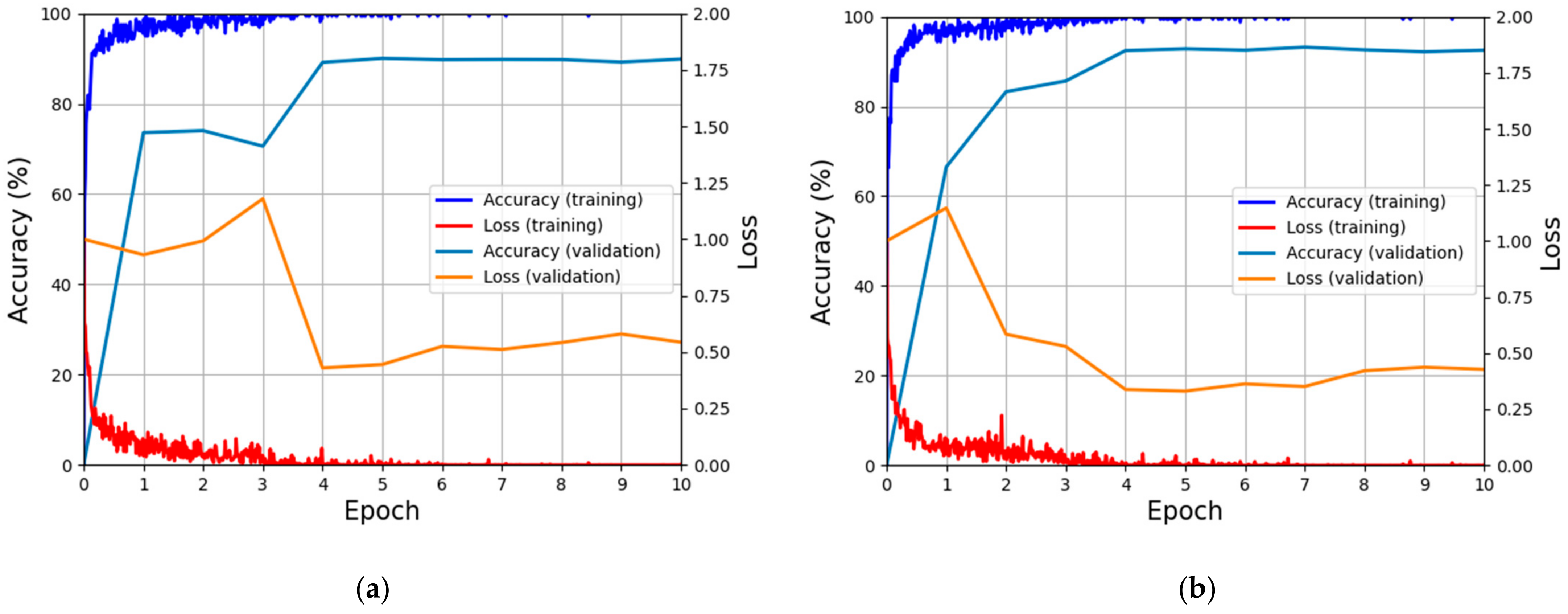
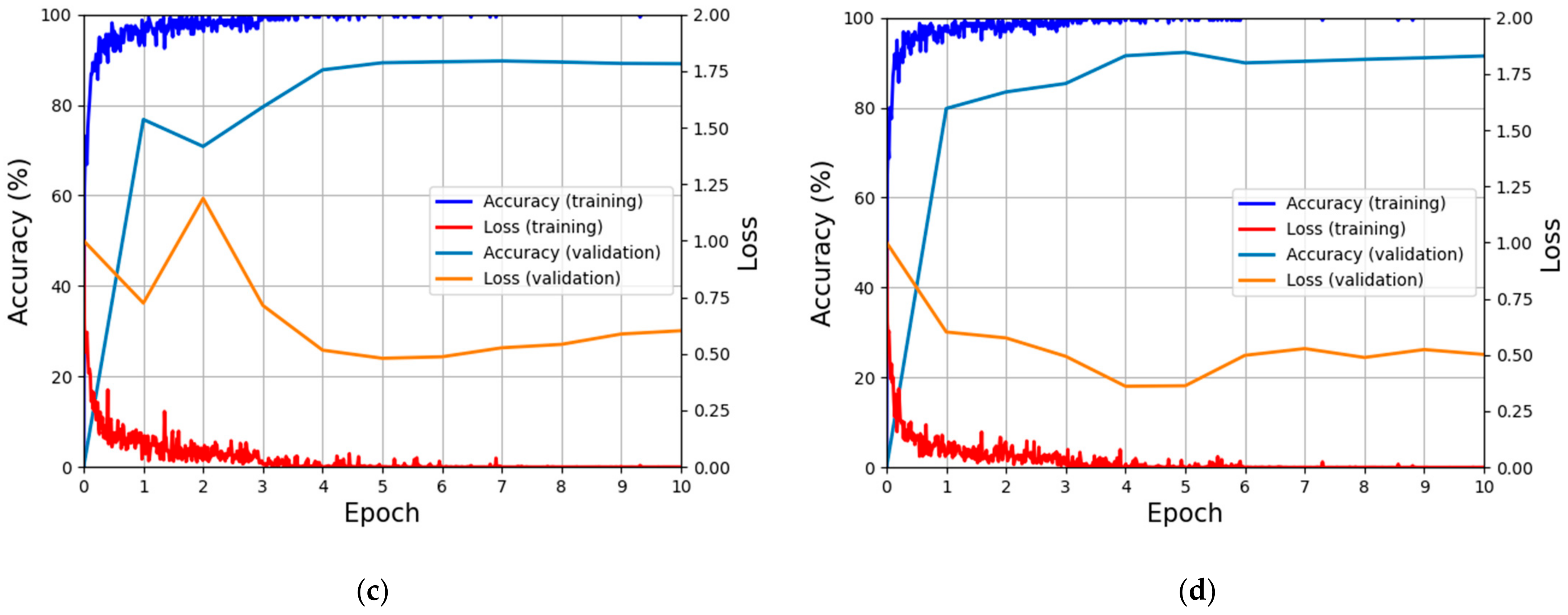
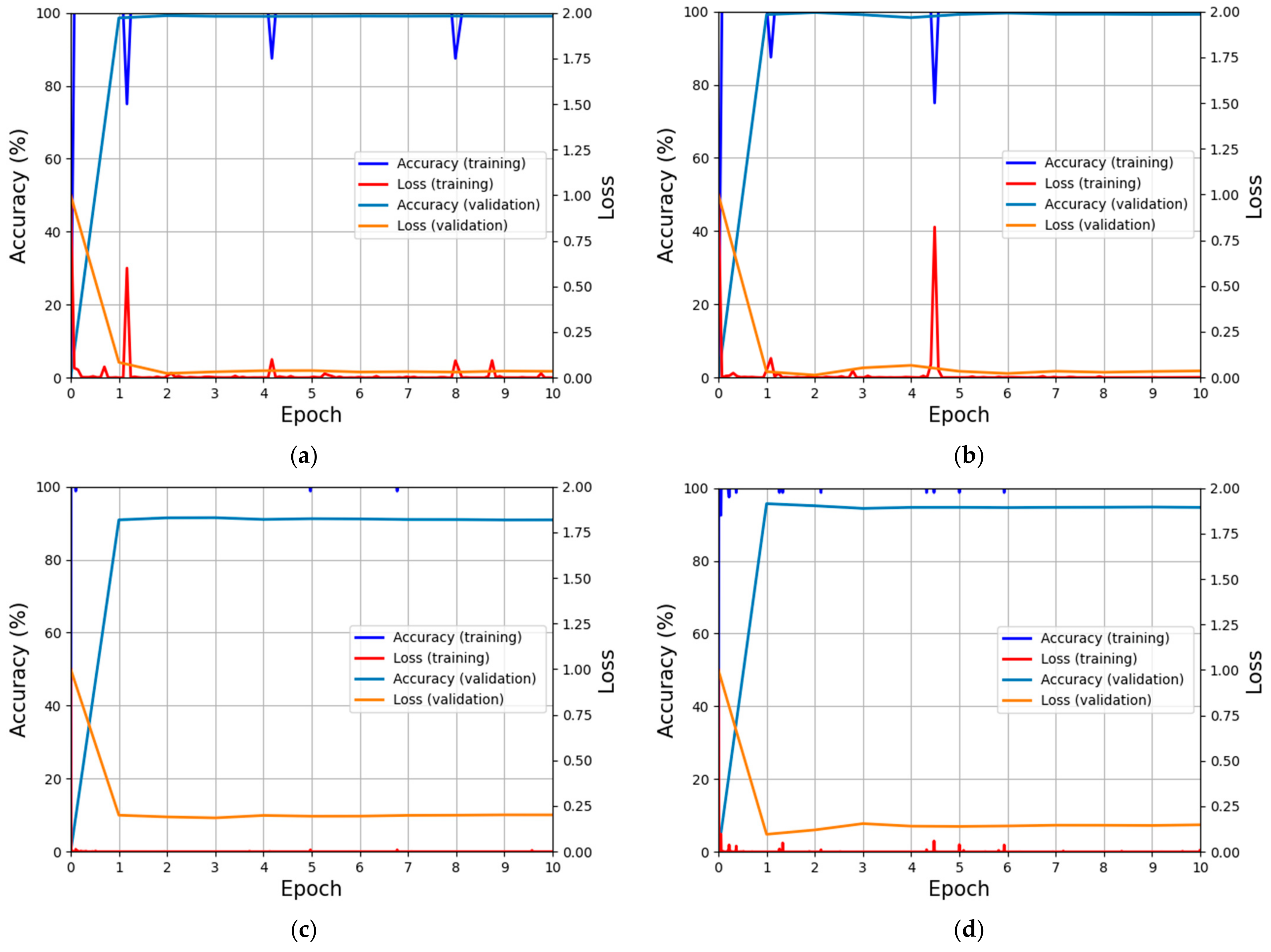
4.2. Training and Validation
4.3. Testing of Proposed Method with DBPerson-Recog-DB1
4.3.1. Performance Metrics
4.3.2. Ablation Studies
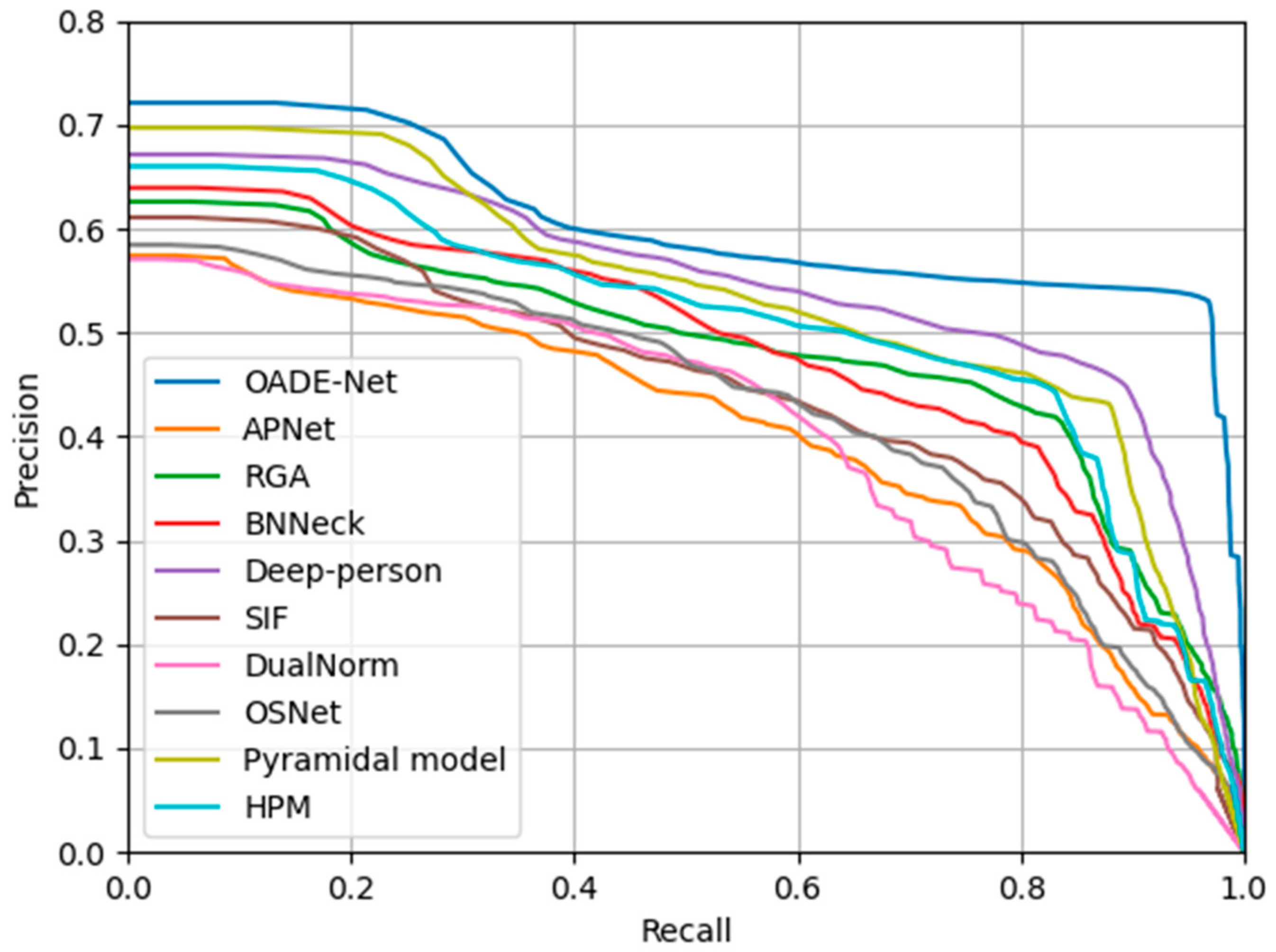
4.3.3. Comparisons of Proposed Method with State-of-the-Art Methods
4.4. Testing of Proposed Method with SYSU-MM01
4.4.1. Ablation Studies
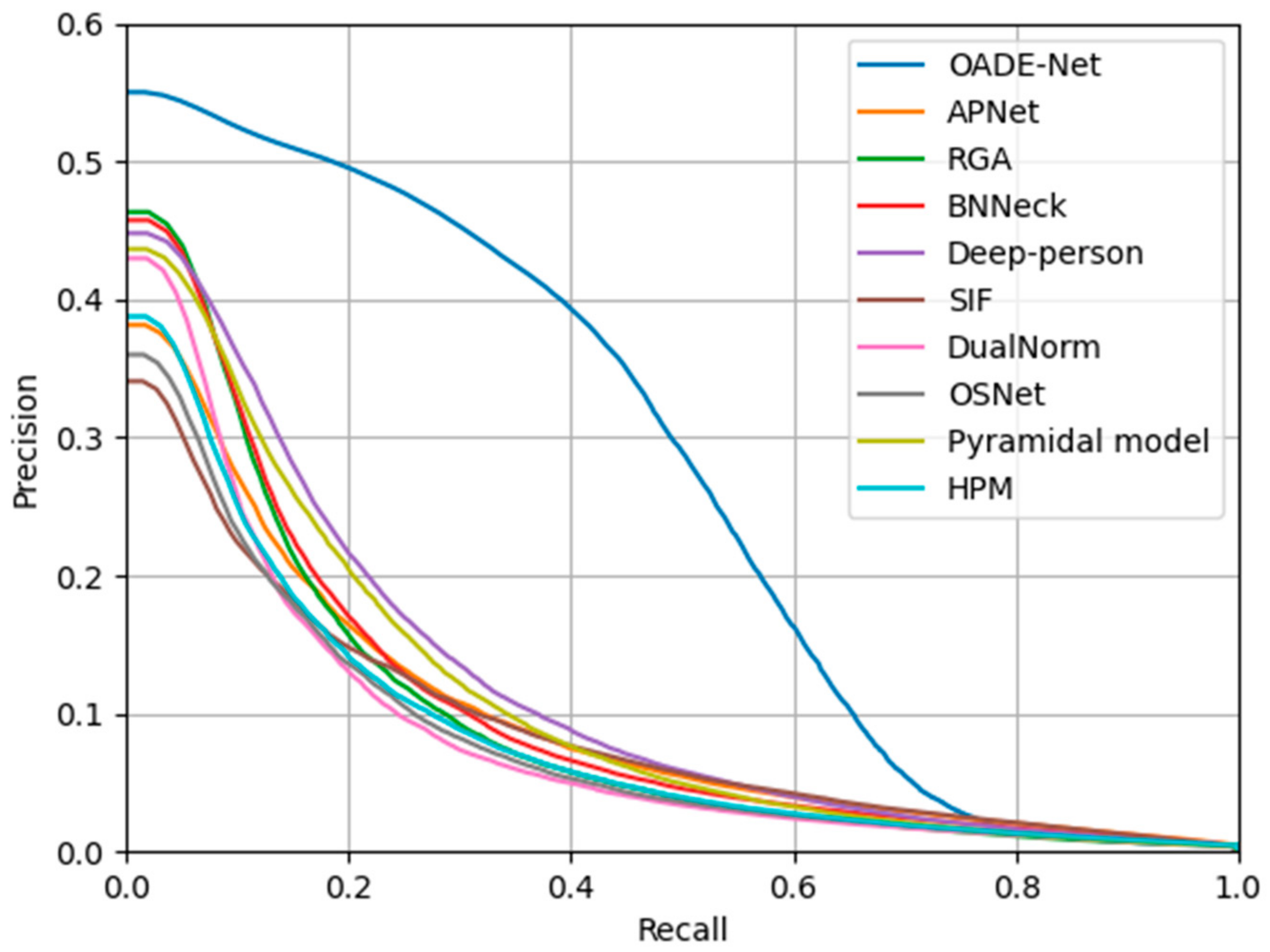
4.4.2. Comparisons of Proposed Method with State-of-the-Art Methods
4.5. Analysis of Proposed Method
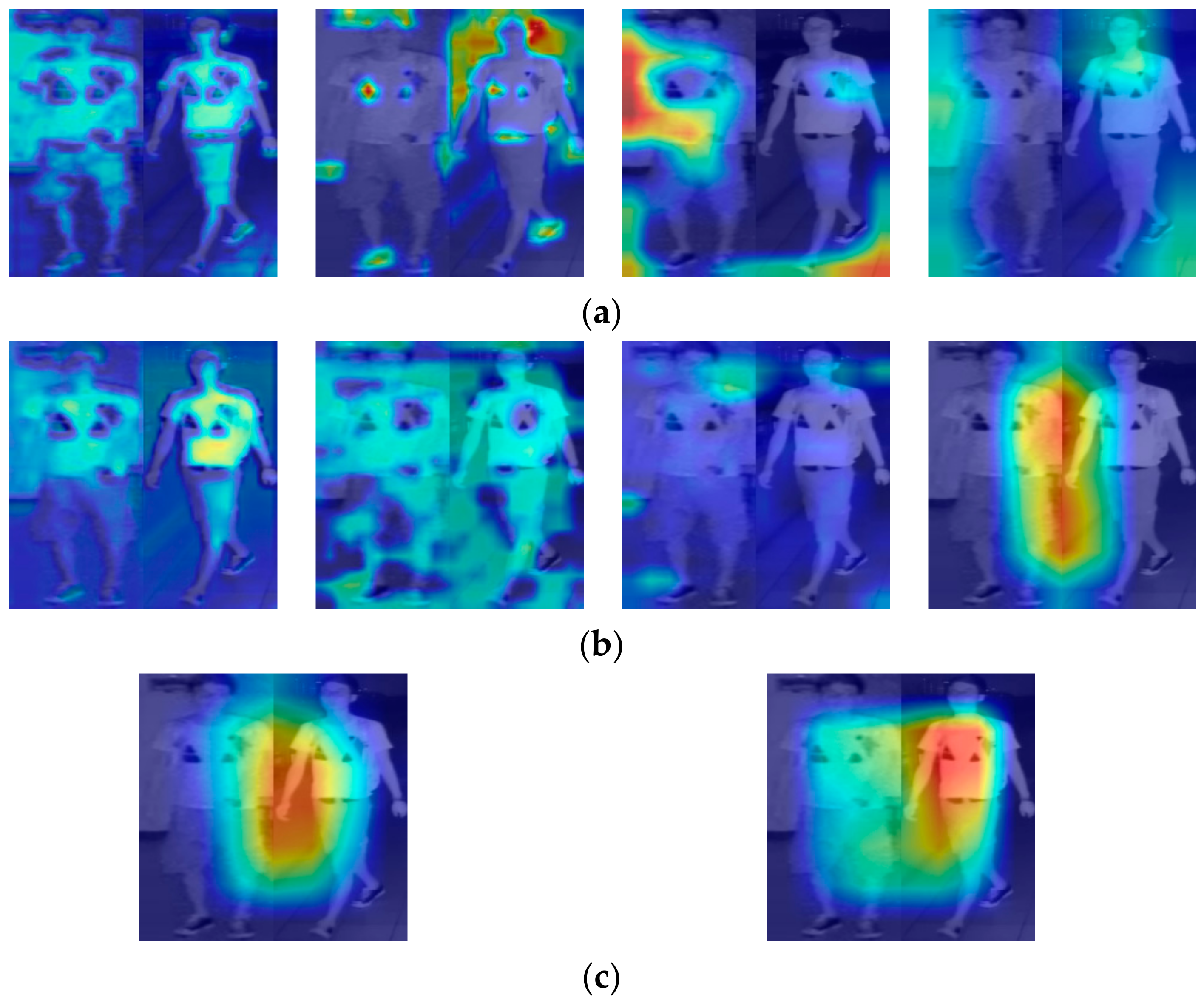
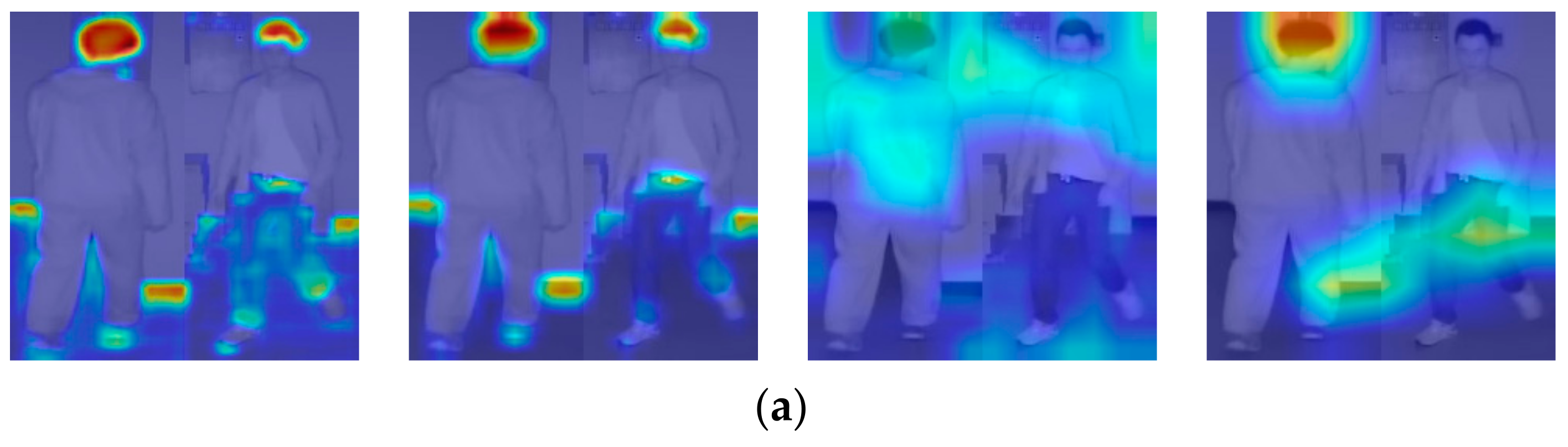
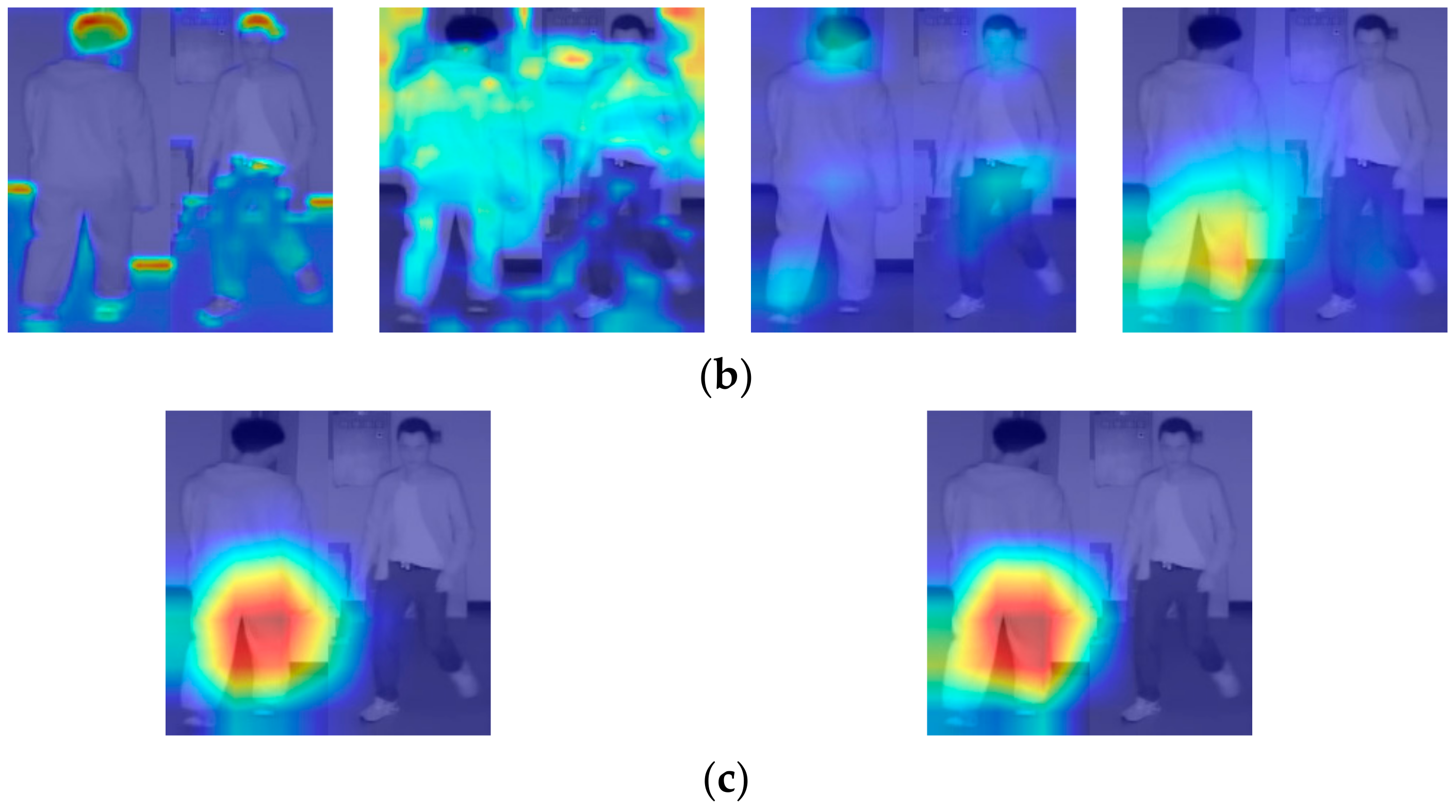
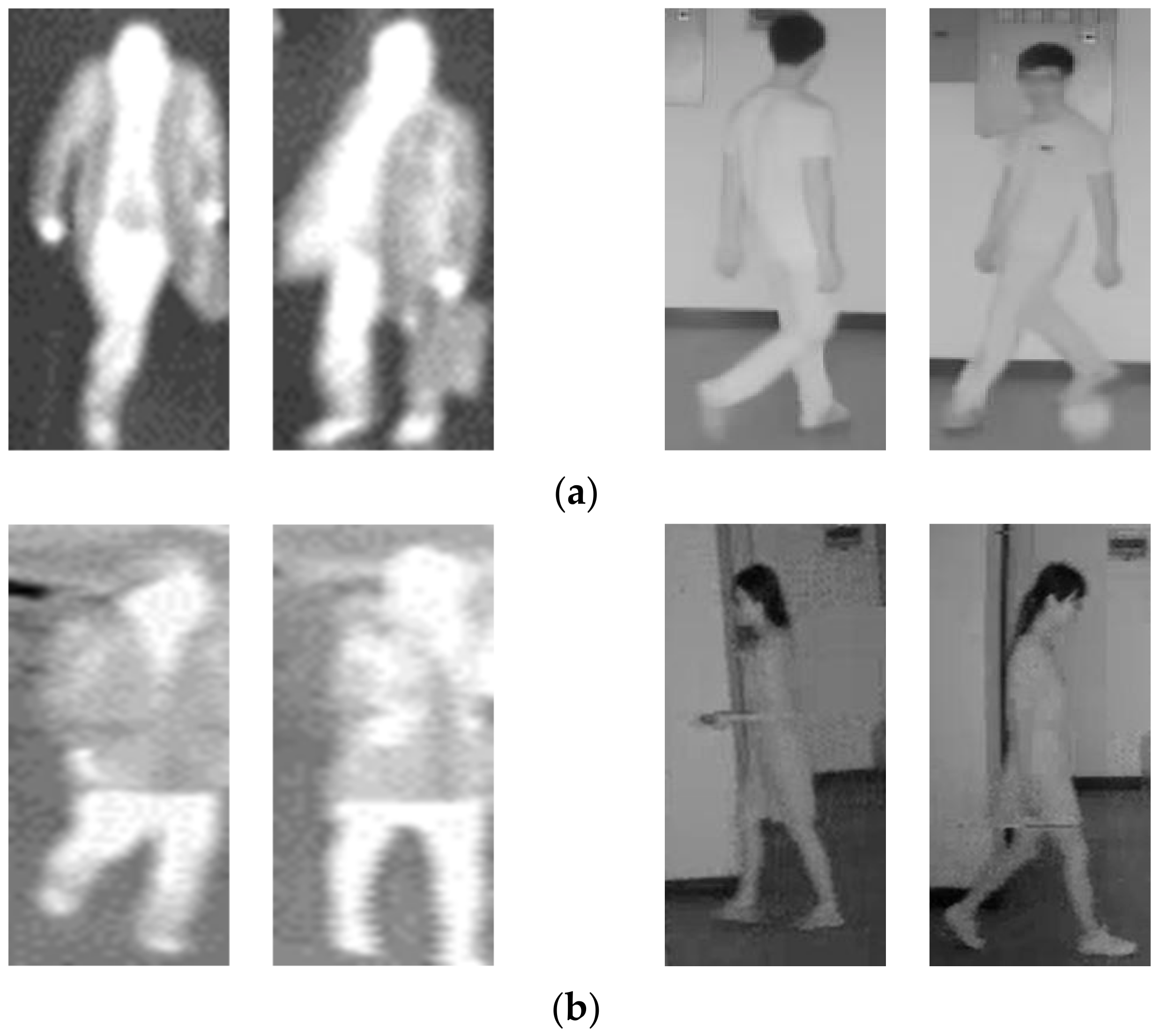
4.5.1. Visual Inspection of Extracted Features by Gradient-Weighted Class Activation Mapping (Grad-Cam) and Analyses of Correct and Incorrect Matching Cases
4.5.2. Computational Cost and Processing Time
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Filter (Number of Filters, Size, Stride) | Padding | Input | Output |
|---|---|---|---|---|
| Input layer | 224 × 224 × 3 | 224 × 224 × 3 | ||
| Convolution (Conv) block | 96, 7 × 7 × 3, 2 | 3 × 3 | 224 × 224 × 3 | 112 × 112 × 96 |
| Maximum (Max) pooling | 96, 3 × 3 × 96, 2 | 1 × 1 | 112 × 112 × 96 | 56 × 56 × 96 |
| Dense block 1 | 6 × 192, 1 × 1 × 96, 1 6 × 48, 3 × 3 × 192, 1 | 1 × 1 | 56 × 56 × 96 | 56 × 56 × 384 |
| Transition block 1 | 192, 1 × 1 × 384, 1 192, 2 × 2 × 192, 2 | 56 × 56 × 384 | 28 × 28 × 192 | |
| Dense block 2 | 12 × 192, 1 × 1 × 192, 1 12 × 48, 3 × 3 × 48, 1 | 1 × 1 | 28 × 28 × 192 | 28 × 28 × 768 |
| Transition block 2 | 384, 1 × 1 × 768, 1 384, 2 × 2 × 384, 2 | 28 × 28 × 768 | 14 × 14 × 384 | |
| Dense block 3 | 36 × 192, 1 × 1 × 384, 1 36 × 48, 3 × 3 × 192, 1 | 1 × 1 | 14 × 14 × 384 | 14 × 14 × 2112 |
| Transition block 3 | 1056, 1 × 1 × 2112, 1 1056, 2 × 2 × 1056, 2 | 14 × 14 × 2112 | 7 × 7 × 1056 | |
| Dense block 4 | 24 × 192, 1 × 1 × 1056, 1 24 × 48, 3 × 3 × 192, 1 | 1 × 1 | 7 × 7 × 1056 | 7 × 7 × 2208 |
| Global average pooling | 2208, 7 × 7 × 2208, 1 | 7 × 7 × 2208 | 1 × 1 × 2208 | |
| Fully connected layer | 1 × 1 × 2208 | 1 × 1 × 2 | ||
| Softmax | 1 × 1 × 2 | 1 × 1 × 2 |
| Layer | Filter (Number of Filters, Size, Stride) | Padding | Input | Output |
|---|---|---|---|---|
| Input layer | 224 × 224 × 3 | 224 × 224 × 3 | ||
| Conv block | 96, 7 × 7 × 3, 2 | 3 × 3 | 224 × 224 × 3 | 112 × 112 × 96 |
| Max pooling | 96, 3 × 3 × 96, 2 | 1 × 1 | 112 × 112 × 96 | 56 × 56 × 96 |
| Dense block 1 | 6 × 192, 1 × 1 × 96, 1 6 × 48, 3 × 3 × 192, 1 | 1 × 1 | 56 × 56 × 96 | 56 × 56 × 384 |
| Transition block 1 | 192, 1 × 1 × 384, 1 192, 2 × 2 × 192, 2 | 56 × 56 × 384 | 28 × 28 × 192 | |
| Convolutional block attention module (CBAM) 1 | 2, 28 × 28 × 192, 28 1, 7 × 7 × 2, 1 | 3 × 3 | 28 × 28 × 192 | 28 × 28 × 192 |
| Dense block 2 | 12 × 192, 1 × 1 × 192, 1 12 × 48, 3 × 3 × 48, 1 | 1 × 1 | 28 × 28 × 192 | 28 × 28 × 768 |
| Transition block 2 | 384, 1 × 1 × 768, 1 384, 2 × 2 × 384, 2 | 28 × 28 × 768 | 14 × 14 × 384 | |
| CBAM 2 | 2, 14 × 14 × 384, 14 1, 7 × 7 × 2, 1 | 3 × 3 | 14 × 14 × 384 | 14 × 14 × 384 |
| Dense block 3 | 36 × 192, 1 × 1 × 384, 1 36 × 48, 3 × 3 × 192, 1 | 1 × 1 | 14 × 14 × 384 | 14 × 14 × 2112 |
| Transition block 3 | 1056, 1 × 1 × 2112, 1 1056, 2 × 2 × 1056, 2 | 14 × 14 × 2112 | 7 × 7 × 1056 | |
| CBAM 3 | 2, 7 × 7 × 1056, 7 1, 7 × 7 × 2, 1 | 3 × 3 | 7 × 7 × 1056 | 7 × 7 × 1056 |
| Dense block 4 | 24 × 192, 1 × 1 × 1056, 1 24 × 48, 3 × 3 × 192, 1 | 1 × 1 | 7 × 7 × 1056 | 7 × 7 × 2208 |
| Global average pooling | 2208, 7 × 7× 2208, 1 | 7 × 7 × 2208 | 1 × 1 × 2208 | |
| Fully connected layer | 1 × 1 × 2208 | 1 × 1 × 2 | ||
| Softmax | 1 × 1 × 2 | 1 × 1 × 2 |
| Layer | Filter (Number of Filters, Size, Stride) | Padding | Input | Output |
|---|---|---|---|---|
| Input layer | 7 × 7 × 4419 | 7 × 7 × 4419 | ||
| Conv layer 1 | 2210, 3 × 3 × 4419, 1 | 1 × 1 | 7 × 7 × 4419 | 7 × 7 × 2210 |
| Conv layer 2 | 4419, 3 × 3 × 2210, 1 | 1 × 1 | 7 × 7 × 2210 | 7 × 7 × 4419 |
| Global average pooling | 4419, 7 × 7 × 4419, 1 | 7×7 × 4419 | 1 × 1 × 4419 | |
| Fully connected layer | 1 × 1 × 4419 | 1 × 1 × 2 | ||
| Softmax | 1 × 1 × 2 | 1 × 1 × 2 |
References
- Huang, T.; Russell, S. Object identification in a Bayesian context. In Proceedings of the International Joint Conference on Artificial Intelligence, Nagoyam, Japan, 23–29 August 1997; pp. 1276–1282. [Google Scholar]
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. Deepreid: Deep filter pairing neural network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 152–159. [Google Scholar]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep learning for person re-identification: A survey and outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2872–2893. [Google Scholar] [CrossRef] [PubMed]
- Yaghoubi, E.; Kumar, A.; Proença, H. SSS-PR: A short survey of surveys in person re-identification. Pattern Recognit. Lett. 2021, 143, 50–57. [Google Scholar] [CrossRef]
- Zheng, H.; Zhong, X.; Huang, W.; Jiang, K.; Liu, W.; Wang, Z. Visible-infrared person re-identification: A comprehensive survey and a new setting. Electronics 2022, 11, 454. [Google Scholar] [CrossRef]
- Zhang, J.A.; Yuan, Y.; Wang, Q. Night person re-identification and a benchmark. IEEE Access 2019, 7, 95496–95504. [Google Scholar] [CrossRef]
- Wu, A.; Zheng, W.-S.; Yu, H.-X.; Gong, S.; Lai, J. RGB-infrared cross-modality person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5380–5389. [Google Scholar]
- OADE-Net for Person Re-Identification Using Infrared Light Images with Algorithm. Available online: https://github.com/MinsuJeong95/OADE (accessed on 19 July 2022).
- Bai, X.; Yang, M.; Huang, T.; Dou, Z.; Yu, R.; Xu, Y. Deep-person: Learning discriminative deep features for person re-identification. Pattern Recognit. 2020, 98, 107036. [Google Scholar] [CrossRef]
- Lin, Y.; Zheng, L.; Zheng, Z.; Wu, Y.; Hu, Z.; Yan, C.; Yang, Y. Improving person re-identification by attribute and identity learning. Pattern Recognit. 2019, 95, 151–161. [Google Scholar] [CrossRef]
- Zheng, Z.; Zheng, L.; Yang, Y. Pedestrian alignment network for large-scale person re-identification. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 3037–3045. [Google Scholar] [CrossRef]
- Zheng, L.; Huang, Y.; Lu, H.; Yang, Y. Pose-invariant embedding for deep person re-identification. IEEE Trans. Image Process. 2019, 28, 4500–4509. [Google Scholar] [CrossRef] [PubMed]
- Song, L.; Wang, C.; Zhang, L.; Du, B.; Zhang, Q.; Huang, C.; Wang, X. Unsupervised domain adaptive re-identification: Theory and practice. Pattern Recognit. 2020, 102, 107173. [Google Scholar] [CrossRef]
- Wu, L.; Wang, Y.; Gao, J.; Li, X. Where-and-when to look: Deep Siamese attention networks for video-based person re-identification. IEEE Trans. Multimed. 2018, 21, 1412–1424. [Google Scholar] [CrossRef]
- Zheng, Z.; Zheng, L.; Yang, Y. A discriminatively learned CNN embedding for person reidentification. ACM Trans. Multimed. Comput. Commun. Appl. 2017, 14, 1–20. [Google Scholar] [CrossRef]
- Wu, A.; Zheng, W.-S.; Gong, S.; Lai, J. RGB-IR person re-identification by cross-modality similarity preservation. Int. J. Comput. Vis. 2020, 128, 1765–1785. [Google Scholar] [CrossRef]
- Kang, J.K.; Hoang, T.M.; Park, K.R. Person re-identification between visible and thermal camera images based on deep residual CNN using single input. IEEE Access 2019, 7, 57972–57984. [Google Scholar] [CrossRef]
- Kang, J.K.; Lee, M.B.; Yoon, H.S.; Park, K.R. AS-RIG: Adaptive selection of reconstructed input by generator or interpolation for person re-identification in cross-modality visible and thermal images. IEEE Access 2021, 9, 12055–12066. [Google Scholar] [CrossRef]
- Liu, H.; Cheng, J.; Wang, W.; Su, Y.; Bai, H. Enhancing the discriminative feature learning for visible-thermal cross-modality person re-identification. Neurocomputing 2020, 398, 11–19. [Google Scholar] [CrossRef]
- Wang, G.A.; Zhang, T.; Cheng, J.; Liu, S.; Yang, Y.; Hou, Z. RGB-infrared cross-modality person re-identification via joint pixel and feature alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3623–3632. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person re-identification: A benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance measures and a data set for multi-target, multi-camera tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 17–35. [Google Scholar]
- Wei, L.; Zhang, S.; Gao, W.; Tian, Q. Person transfer GAN to bridge domain gap for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 79–88. [Google Scholar]
- Nguyen, D.T.; Hong, H.G.; Kim, K.W.; Park, K.R. Person recognition system based on a combination of body images from visible light and thermal cameras. Sensors 2017, 17, 605. [Google Scholar] [CrossRef] [PubMed]
- C600 Webcam Camera. Available online: https://support.logitech.com/en_us/product/5869 (accessed on 10 June 2022).
- Tau2 Thermal Imaging Camera. Available online: http://www.flir.com/cores/display/?id=54717 (accessed on 10 June 2022).
- NVIDIA GeForce GTX 1070 Card. Available online: https://www.nvidia.com/en-in/geforce/products/10series/geforce-gtx-1070/ (accessed on 10 June 2022).
- Pytorch. Available online: https://pytorch.org/get-started/previous-versions (accessed on 19 June 2022).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Softmax Function. Available online: https://en.wikipedia.org/wiki/Softmax_function (accessed on 9 August 2022).
- Cross Entropy. Available online: https://en.wikipedia.org/wiki/Cross_entropy (accessed on 9 August 2022).
- mAP. Available online: https://en.wikipedia.org/wiki/Evaluation_measures_(information_retrieval)#Mean_average_precision (accessed on 10 June 2022).
- Sensitivity and Specificity. Available online: https://en.wikipedia.org/wiki/Sensitivity_and_specificity (accessed on 10 June 2022).
- Mateo, J.R.S.C. Weighted sum method and weighted product method. In Multi Criteria Analysis in the Renewable Energy Industry; Springer: London, UK, 2012; pp. 19–22. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: New York, NY, USA, 1999. [Google Scholar]
- Zhou, K.; Yang, Y.; Cavallaro, A.; Xiang, T. Omni-scale feature learning for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3702–3712. [Google Scholar]
- Jia, J.; Ruan, Q.; Hospedales, T.M. Frustratingly easy person re-identification: Generalizing person re-id in practice. In Proceedings of the British Machine Vision Conference, Cardiff, UK, 9–12 September 2019. [Google Scholar]
- Chen, G.; Gu, T.; Lu, J.; Bao, J.-A.; Zhou, J. Person re-identification via attention pyramid. IEEE Trans. Image Process. 2021, 30, 7663–7676. [Google Scholar] [CrossRef] [PubMed]
- Wei, L.; Wei, Z.; Jin, Z.; Yu, Z.; Huang, J.; Cai, D.; He, X.; Hua, X.-S. SIF: Self-inspirited feature learning for person re-identification. IEEE Trans. Image Process. 2020, 29, 4942–4951. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Lan, C.; Zeng, W.; Jin, X.; Chen, Z. Relation-aware global attention for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3186–3195. [Google Scholar]
- Luo, H.; Jiang, W.; Gu, Y.; Liu, F.; Liao, X.; Lai, S.; Gu, J. A strong baseline and batch normalization neck for deep person re-identification. IEEE Trans. Multimed. 2019, 22, 2597–2609. [Google Scholar] [CrossRef]
- Fu, Y.; Wei, Y.; Zhou, Y.; Shi, H.; Huang, G.; Wang, X.; Yao, Z.; Huang, T. Horizontal pyramid matching for person re-identification. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8295–8302. [Google Scholar]
- Zheng, F.; Deng, C.; Sun, X.; Jiang, X.; Guo, X.; Yu, Z.; Huang, F.; Ji, R. Pyramidal person re-identification via multi-loss dynamic training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8514–8522. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Ptflops. Available online: https://github.com/sovrasov/flops-counter.pytorch (accessed on 19 June 2022).
- Jetson TX2 Module. Available online: https://developer.nvidia.com/embedded/jetson-tx2 (accessed on 29 April 2022).
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. Shufflenet v2: Practical guidelines for efficient CNN architecture design. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]



















| Category | Method | Advantages | Disadvantages | |
|---|---|---|---|---|
| Use of visible cameras | Deep-person [9] | Used partial information of a person’s body parts to outperform the method that used the entire area of a person | When only visible images are used, ReID performance is degraded due to weather, changes in lighting, and night environment | |
| APR [10] | Improved person ReID by using identity labels and attribute annotation | |||
| PAN [11] | Used a network that aligned detected images that is advantageous for training | |||
| PIE [12] | Solved the misalignment problem of pedestrian images in the dataset and reduced pose estimation errors | |||
| Unsupervised domain adaptive re-identification [13] | Applied unsupervised domain adaptive classification theories to ReID tasks and performed self-training | |||
| Siamese attention architecture [14] | Proposed a Siamese attention architecture that sufficiently utilized temporal and spatial information to improve performance | |||
| Siamese network using identification and verification losses [15] | Improved person ReID performance based on a Siamese network capable of simultaneously computing identification and verification losses | |||
| Use of visible and infrared (IR) cameras | Inter-channel pair between the visible light and thermal images (IPVT-1) and multi-scale Retinex (MSR) [17] | Lowered computational complexity of ReID by combining various input images | Computational complexity increases due to processing images input by two cameras, and the cost also increases from the use of two cameras | |
| Zero padding [7] | Proved that performance can be improved through zero-padding | |||
| AS-RIG [18] | Improved ReID performance through adaptive selection of reconstructed inputs by generator or interpolation methods | |||
| EDFL [19] | Performed skip-connection for mid-level features of two convolutional neural networks (CNNs) and improved performance by using dual-modality triplet loss | |||
| AlignGAN [20] | Enhanced performance by simultaneously performing pixel and feature alignment | |||
| Use of IR cameras | Uses night IR images | Peak signal-to-noise ratio (PSNR) loss-based method [6] | Pointed out the problem in the resolution of IR images and proposed a pre-processing method for restoring the resolution during model training | Did not consider various problems that occur in IR images captured daytime (difficult to distinguish an object owing to similar background temperatures and the object) |
| Uses daytime and night IR images | OADE-Net (Proposed method) | Proposed the person ReID method for both daytime and night IR images based on the OADE-Net | Long training time due to the use of three CNNs | |
| Type | Original DenseNet | Attention-Guided DenseNet | SCE-Net | |
|---|---|---|---|---|
| Learning rate | ||||
| Decay learning rate | 0.1 every three epochs | 0.1 every three epochs | 0.1 every three epochs | |
| Weight decay | ||||
| Batch size | 16 | 16 | 16 | |
| Epoch | 10 | 10 | 10 | |
| Input image type | DBPerson-Recog-DB1 | IIPVT | IPVT1 | - |
| SYSU-MM01 | IPVT2 | IPVT2 | - | |
| Method | Image Composition | Rank 1 | Rank 10 | Rank 20 | mAP |
|---|---|---|---|---|---|
| Original DenseNet | IPVT1 | 73.36 | 87.27 | 92.33 | 76.13 |
| IPVT2 | 73.36 | 89.80 | 94.87 | 75.40 | |
| IIPVT | 73.39 | 88.55 | 92.37 | 76.91 | |
| Attention-guided DenseNet | IPVT1 | 72.14 | 91.12 | 96.18 | 75.73 |
| IPVT2 | 72.11 | 87.33 | 94.90 | 67.63 | |
| IIPVT | 67.05 | 87.30 | 96.15 | 70.15 |
| Method | Rank 1 | Rank 10 | Rank 20 | mAP |
|---|---|---|---|---|
| Original DenseNet | 73.39 | 88.55 | 92.37 | 76.91 |
| Attention-guided DenseNet | 72.14 | 91.12 | 96.18 | 75.73 |
| Original DenseNet + Attention-guided DenseNet + SCE-Net (proposed method) | 79.71 | 92.37 | 94.90 | 78.17 |
| Method | Rank 1 | Rank 10 | Rank 20 | mAP |
|---|---|---|---|---|
| Weighted sum (WS) | 73.42 | 92.37 | 97.46 | 77.33 |
| Weighted product (WP) | 73.42 | 92.37 | 97.46 | 77.39 |
| Support vector machine (SVM) | 75.96 | 94.93 | 97.46 | 77.79 |
| SCE-Net (proposed method) | 79.71 | 92.37 | 94.90 | 78.17 |
| Method | Rank 1 | Rank 10 | Rank 20 | mAP |
|---|---|---|---|---|
| DualNorm [42] | 58.20 | 63.26 | 67.05 | 48.20 |
| APNet [43] | 59.48 | 69.64 | 77.27 | 46.89 |
| OSNet [41] | 59.51 | 70.89 | 78.52 | 48.50 |
| SIF [44] | 62.01 | 79.64 | 86.05 | 54.89 |
| RGA [45] | 63.26 | 74.64 | 81.02 | 58.77 |
| BNNeck [46] | 65.83 | 78.46 | 84.80 | 58.99 |
| Deep-person [9] | 68.30 | 84.74 | 91.05 | 67.74 |
| HPM [47] | 68.36 | 78.49 | 83.55 | 65.37 |
| Pyramidal model [48] | 73.46 | 83.58 | 87.40 | 69.39 |
| OADE-Net (proposed method) | 79.71 | 92.37 | 94.90 | 78.17 |
| Method | Image Composition | Rank 1 | Rank 10 | Rank 20 | mAP |
|---|---|---|---|---|---|
| Original DenseNet | IPVT1 | 37.98 | 56.65 | 60.51 | 22.64 |
| IPVT2 | 50.01 | 63.97 | 66.33 | 33.76 | |
| IIPVT | 36.05 | 53.86 | 55.58 | 20.23 | |
| Attention-guided DenseNet | IPVT1 | 36.04 | 55.57 | 58.78 | 21.26 |
| IPVT2 | 48.92 | 61.36 | 64.59 | 33.39 | |
| IIPVT | 39.05 | 54.07 | 58.15 | 19.75 |
| Method | Rank 1 | Rank 10 | Rank 20 | mAP |
|---|---|---|---|---|
| Original DenseNet | 50.01 | 63.97 | 66.33 | 33.76 |
| Attention-guided DenseNet | 48.92 | 61.36 | 64.59 | 33.39 |
| Original DenseNet + Attention-guided DenseNet + SCE-Net (proposed method) | 57.30 | 67.41 | 71.07 | 41.50 |
| Method | Rank 1 | Rank 10 | Rank 20 | mAP |
|---|---|---|---|---|
| WS | 53.86 | 65.23 | 67.40 | 38.30 |
| WP | 54.29 | 65.25 | 67.83 | 38.22 |
| SVM | 54.29 | 64.61 | 67.19 | 38.81 |
| SCE-Net (proposed method) | 57.30 | 67.41 | 71.07 | 41.50 |
| Method | Rank 1 | Rank 10 | Rank 20 | mAP |
|---|---|---|---|---|
| SIF [44] | 40.11 | 80.88 | 91.18 | 13.60 |
| OSNet [41] | 42.70 | 84.77 | 92.92 | 12.20 |
| APNet [43] | 44.40 | 85.17 | 92.90 | 14.89 |
| HPM [47] | 46.57 | 80.92 | 88.42 | 13.78 |
| Pyramidal model [48] | 49.38 | 87.14 | 92.71 | 16.29 |
| Deep-person [9] | 50.00 | 88.62 | 93.77 | 17.47 |
| DualNorm [42] | 51.93 | 83.27 | 90.55 | 13.03 |
| BNNeck [46] | 53.86 | 88.61 | 94.62 | 15.03 |
| RGA [45] | 54.68 | 90.33 | 95.27 | 14.34 |
| OADE-Net (proposed method) | 57.30 | 67.41 | 71.07 | 41.50 |
| Model | FLOPs | Number of Parameters |
|---|---|---|
| Original DenseNet | 26.48 M | |
| Attention-guided DenseNet | 26.64 M | |
| SCE-Net | 175.82 M |
| Model | Desktop Computer | Jetson TX2 Embedded System |
|---|---|---|
| Original DenseNet | 40.35 | 158.42 |
| Attention-guided DenseNet | 43.17 | 160.06 |
| SCE-Net | 18.09 | 155.07 |
| Total | 101.61 | 473.55 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeong, M.S.; Jeong, S.I.; Kang, S.J.; Ryu, K.B.; Park, K.R. OADE-Net: Original and Attention-Guided DenseNet-Based Ensemble Network for Person Re-Identification Using Infrared Light Images. Mathematics 2022, 10, 3503. https://doi.org/10.3390/math10193503
Jeong MS, Jeong SI, Kang SJ, Ryu KB, Park KR. OADE-Net: Original and Attention-Guided DenseNet-Based Ensemble Network for Person Re-Identification Using Infrared Light Images. Mathematics. 2022; 10(19):3503. https://doi.org/10.3390/math10193503
Chicago/Turabian StyleJeong, Min Su, Seong In Jeong, Seon Jong Kang, Kyung Bong Ryu, and Kang Ryoung Park. 2022. "OADE-Net: Original and Attention-Guided DenseNet-Based Ensemble Network for Person Re-Identification Using Infrared Light Images" Mathematics 10, no. 19: 3503. https://doi.org/10.3390/math10193503
APA StyleJeong, M. S., Jeong, S. I., Kang, S. J., Ryu, K. B., & Park, K. R. (2022). OADE-Net: Original and Attention-Guided DenseNet-Based Ensemble Network for Person Re-Identification Using Infrared Light Images. Mathematics, 10(19), 3503. https://doi.org/10.3390/math10193503