1. Introduction
The rapid development of big data technology and Internet technology has greatly improved the efficiency of data transmission, management, and storage, but has also brought serious data security problems, including unintentional data leakage and malicious data theft [
1]. In all kinds of massive data, image data play important or dominant roles in our daily lives. However, some image data may contain personal private information, confidential business information, or even military information. Protection of these secret image data and prevention of information leakage has aroused increasing concern in various fields. An interesting security technology known as steganography has attracted wide attention and undergone tremendous development in recent years [
2], this technology aims to embed secret messages into digital media carriers in an imperceptible fashion, thus guaranteeing information security. Compared with widely used encryption technology [
3] that generally encodes the secret message into an incomprehensible cipher text, steganography technology encodes the secret message into an imperceptible form, which can conceal the existence of secret content, thus avoiding arousing the attention and suspicion of third-party attackers. Currently, various digital carriers such as audio [
4], images [
5], and video [
6] have been adapted to implement steganography. Among these, digital imagery serves as the most prevalent carrier, relying on its properties of large capacity and rich texture. Many image steganography algorithms have been proposed to date, and we can roughly divide these algorithms into two categories: traditional image steganography algorithms and deep learning-based algorithms.
Among traditional image-steganography algorithms, the least significant bit (LSB) [
7] algorithm is the most representative, embedding secret data into the lowest bits of each pixel to keep unchanged the carrier’s visual appearance. Owing to its widespread applicability, the LSB algorithm has been widely applied to conceal various kinds of secret data, including plain text data and image data. However, when the embedding payload is large, this algorithm leaves visible tampering artifacts in the carrier’s smooth regions. Subsequently, Ge et al. [
8] proposed a multi-level embedding framework based on the single-level embedding approach, to achieve a much higher embedding capacity. Combined with encryption technology, Qian et al. [
9] proposed a novel framework for hiding reversible data in an encrypted JPEG bitstream, thus achieving high content security. Recently, Su et al. [
10] further proposed a fast algorithm to accelerate distortion calculations and the embedding process.
Although the abovementioned traditional steganography algorithms have greatly improved steganography performance in terms of embedding capacity and efficiency, they continue to encounter certain problems. (1) They are always designed for concealing small quantities of bit-level messages, and the limited payload capacity greatly impedes their practical application and popularization. (2) They are usually heuristically proposed based on professional domain knowledge and manually extracted features, which is expensive, time-consuming, and laborious.
The past few years have witnessed the rapid development of deep learning in various intelligent tasks, such as machine translation [
11] and computer vision [
12]. Deep learning has been proven capable of automatically extracting high-level potential features. To enable a breakthrough in steganography performance and eliminate dependence on hand-crafted features, scholars have attempted to leverage deep learning to achieve image steganography.
Tang et al. [
13] pioneered the combination of deep learning and steganography, and designed an automatic distortion learning framework. However, their method relied heavily on traditional embedding algorithms. To this end, Zhang et al. [
14] utilized generative adversarial networks (GAN) to construct an end-to-end image steganography framework called SteganoGAN. To further improve steganography security, Zhou et al. [
15] leveraged GAN to generate adversarial images for embedding secret information. However, such deep learning-based algorithms were designed for carrying small amounts of bit-level information. Recently, scholars have identified a potential route to conceal image data using convolution neural networks (CNN). Specifically, Kumar et al. [
16] applied CNN to design a steganography framework for concealing image data with minimal changes in the hidden image. Sharma et al. [
14] combined neural networks with cryptography techniques to improve content security. However, due to premature model design [
16,
17], secret images recovered via these methods contained severe content distortions. Rehman et al. [
18] designed an encoder–decoder framework to embed an image into another cover image, although the recovered secret image still exhibited some color distortion. Duan et al. [
19] proposed a steganography network with a deep structure and achieved perceptually pleasing performance in secret image restoration. Subsequently, Baluja [
20] considered the issue of visual security and indicated a direction for steganography performance improvement, but the quality of the synthetic hidden image was not fundamentally improved. Chen et al. [
21] tried to widen the network using various strategies, and fundamentally improved the concealment performance by boosting the quality of the hidden image.
Although these various deep learning-based algorithms have obtained more competitive results than traditional algorithms in terms of security and payload capacity, they remain in a developmental stage and the study of image-to-image steganography has not identified suitable unified evaluation criteria. The computation complexity and running speed have been consistently neglected in the model designs. Steganography performance still has much room for improvement, especially in terms of security.
Motivated by the above issues, this paper presents a design for a low-complexity fast steganography network based on deep learning to automatically conceal and protect image data. Compared with traditional algorithms, our approach eliminates dependence on handcrafted features and requires no human labor. Compared with recent deep learning-based algorithms, our approach achieves higher security with lower computation complexity and faster running speed.
The major contributions of this paper are summarized as follows:
Inspired by the attention mechanism, we designed a residual dense attention (RDA) module to extract the significant information from the cover image, thus assisting in reconstructing the salient target of the hidden image and improving the concealment performance.
We explore and propose an activation removal strategy (ARS) to avoid undermining the fidelity of the low-level features and to preserve more of the raw information from the input cover image and secret image, significantly boosting the concealing and revealing performance.
Study of image-to-image steganography is still in an embryonic stage, and we introduce visual security as a unified evaluation criterion. We designed a mixed steganography loss function to further enhance steganography security.
2. Methods
In this section, we first describe briefly the overall architecture of our approach, then we give a detailed introduction and analysis of specific designs, including the RDA module, the ARS strategy, and the mixed steganography loss function.
2.1. Overall Architecture
To reduce memory consumption, we adopted a down–up structure to construct the backbone network, thus reducing the resolution of intermediate feature maps.
Figure 1 displays the overall architecture of our approach.
As shown in
Figure 1, the steganography framework consists of a concealing network and a revealing network. The sender conceals the secret image within a common cover image using the concealing network, and synthesizes a hidden image that appears the same as the cover image. The receiver is able to extract the secret image from the hidden image using the revealing network, without any prior secret information. For the concealing network, a sequence of down-sampling operations is employed to compress the input cover image and the secret image, thus reducing the resolution of intermediate feature maps and obtaining small-scale feature maps that contain rich semantic information. Then, symmetrical up-sampling operations are applied to expand the size of feature maps to the original resolution. Finally, cover information and secret information extracted by the two branches are fused through channel concatenation to produce the hidden image. The whole process of the revealing network is similar to that of the concealing network. Generally, a sequence of down-sampling operations would inevitably discard some detailed information contained in the input cover image and the secret image, thus severely deteriorating the steganography performance. To alleviate this deterioration, we have applied residual connections [
22] to connect the symmetrical convolution and deconvolution layers, passing more detailed information to the upper layers.
Note that the down-sampling and up-sampling operations are separately achieved by convolution and deconvolution layers with kernel size of 4 × 4 and a stride of 2. Numbers 3, 64, and 128 represent the channel numbers of feature maps.
To guarantee imperceptibility, it is expected that the synthetic hidden image is as similar to the cover image as possible. For this purpose, the attention mechanism was introduced and an RDA module was designed to extract the cover image’s salient information and obtain an attention mask, thus assisting in reconstructing the hidden image’s salient target and boosting the image quality.
2.2. RDA Module
The attention mechanism plays a key role in the human visual perception system (HVPS), guiding the HVPS to focus on the salient target and to ignore useless background information [
23]. In recent years, the attention mechanism has been widely applied in various fields, including person identification [
24], image classification [
25], and video captioning [
26]. Inspired by these works, this study sought to introduce the attention mechanism into the image steganography task, aiming to improve the similarity between the hidden image and the cover image.
Recently, a novel parameter-free attention mechanism (PFAM) was proposed [
27], designed based on neuroscience theories to calculate attention weights by deriving an energy function. In visual neuroscience, the informative or active neuron usually displays a distinctive firing pattern within its surrounding neurons. Thus, the informative neuron that displays spatial suppression effects is of high importance and should be given more attention in visual processing. Based on this neuroscientific finding, an energy function was defined to weigh the importance of each neuron. The energy function for each neuron is defined as:
where
and
indicate the linear transform;
,
are the transform weight and bias;
represents the target neuron;
represents other neurons on one channel of feature maps
;
and
are two different values;
is the regularization term and
indicates the number of neurons on that channel. For simplicity, binary labels (i.e., 1 and −1) are adopted for
and
, and the final energy function can be obtained as:
We can derive the minimal energy from the above equation as:
where
,
. It can be found that the lower the energy
, the larger the target neuron
, meaning that the target neuron’s performance is distinct from that of its surrounding neurons. Thus, the importance of a neuron can be evaluated by
. To obtain the weighted value of importance in the range (0, 1), the Sigmoid function is performed on
.
Based on PFAM, we designed an RDA module as an auxiliary branch to densely extract the prominent feature information from the cover image, thus reconstructing the hidden image’s salient target. The specific framework of the RDA module is presented in
Figure 2.
As shown in
Figure 2, to enhance the nonlinear representation ability while avoiding dramatically increasing parameters, we adopted Conv 1 × 1 (the small-scale convolution with kernel size of 1 × 1) followed by the ReLU function and PFAM to construct the RDA module. To fully integrate multi-level feature information, we also applied numerous residual connections [
22] to densely connect multi-level features without increasing any parameters. In addition, the skip channel concatenation was adopted for sending the original input information directly to the output, thus preserving the integrity of raw information. Numbers 32 and 29 represent the channel numbers of feature maps.
2.3. Activation Removal Strategy (ARS)
The activation operation plays a key role in most high-level computer vision tasks, such as target recognition, object detection, and semantic segmentation. The activation operation can enhance the nonlinear representation ability, in order to extract high-level features and attributes conductive to the abovementioned high-level tasks. However, the particular image steganography task belongs to a mixed regime of high- and low-level tasks. Although the activation operation is conductive to the extraction of high-level features, it may modify the detailed information and undermine the fidelity of some of the original information passing through the residual connection and the skip channel concatenation. For this reason, we propose an ARS to remove the activation operation in the last layers of the concealing network and the revealing network, respectively, to preserve more detailed information including the raw information sent through the residual connection and the skip channel concatenation, thus further improving concealing performance and revealing performance.
2.4. Mixed Loss Function
Most previous studies on image steganography have adopted mean squared error (MSE) as the loss function to conduct the network training, while structural similarity (SSIM) has been used as a metric to evaluate image quality. However, it has been proven that MSE usually generates images of poor perceptual quality, which is particularly disadvantageous to the imperceptibility and security of steganography. To address this issue, we introduced SSIM into the steganography loss function, allowing the network to focus on the structural quality of the generated hidden image and the recovered secret image, thus improving the visual quality and the issue of imperceptibility. In addition, we also introduced Kullback–Leibler (KL) divergence to construct a mixed loss function, thus comprehensively improving the quality of the generated hidden image and the recovered secret image. Given two images
and
with size of
, we can obtain:
where
,
represent the image pixels;
,
represent the pixel means;
,
, and
represent the variances and covariance;
,
;
denotes the max pixel value;
and
by default [
28];
and
represent the probability distributions of the images
and
, respectively.
Combining the abovementioned MSE, SSIM and KL, we designed the mixed steganography loss function as:
where
and
represent the generated hidden image and the original cover image;
and
indicate the recovered image and the original secret image;
,
,
, and
are hyperparameters to balance various losses.
3. Experimental Results and Analysis
In this section, we first briefly introduce our experimental setup, then we describe an ablation study that was conducted to evaluate the effectiveness of our designs, followed by a comparison experiment carried out to demonstrate the performance of the proposed approach.
3.1. Experimental Setup
In this study, we selected 30,000 and 1000 images from ImageNet [
29] as the respective training and testing sets of cover images, and then selected 30,000 and 1000 images from NWPU-RESISC45 [
30] as the respective training and testing sets of secret images.
The experiments were conducted on a workstation equipped with an Intel Xeon(R) Bronze 3104 CPU and Nvidia Titan RTX 2080 Ti GPU. This workstation used an Ubuntu 18.04 operating system with Python 3.6 programming languages and Pytorch 1.3.0 frameworks. The batch size was set as four (i.e., four pairs of cover images and secret images). We applied the Adam optimizer with an initial learning rate of 0.001 to optimize the proposed model, and used the ReduceLROnPlateau tool to adjust the learning rate automatically and achieve effective optimization. The additional regularization term should necessarily be small, thus we set . Compared with the recovered secret image, more attention should be paid to the quality of the hidden image, because this largely determines steganography security. Thus, we set to ensure that the concealing loss accounted for a larger proportion of the total loss. In addition, the generated image’s visual appearance is mainly determined by its pixel values, thus we set , so that MSE loss represented larger proportions of the concealing loss and the revealing loss.
3.2. Ablation Study on RDA and ARS
To evaluate the effectiveness of our proposed RDA module and ARS strategy, we conducted an ablation study to analyze their influence on network performance. For simplicity, here we assessed only MSE loss. The following abbreviations denote the corresponding frameworks: (1) BL: The baseline of our approach; (2) BL-RDA: The baseline with the RDA module; (3) BL-RDA-ARS: The baseline with the RDA module and ARS strategy.
Figure 3 shows the network performances of different frameworks.
By observing
Figure 3, we can obtain the following conclusions.
- (1)
BL and BL-RDA demonstrated that the proposed RDA module significantly reduced the concealing loss, meaning that it greatly boosted the hidden image’s quality.
- (2)
BL-RDA and BL-RDA-ARS demonstrated that the proposed ARS strategy effectively reduced the concealing loss as well as the reveling loss, thus improving the quality of the generated hidden image and also the recovered secret image.
- (3)
Due to the elaborate design, the proposed RDA module and ARS strategy significantly improved concealing and revealing performances, with almost no increase of parameters.
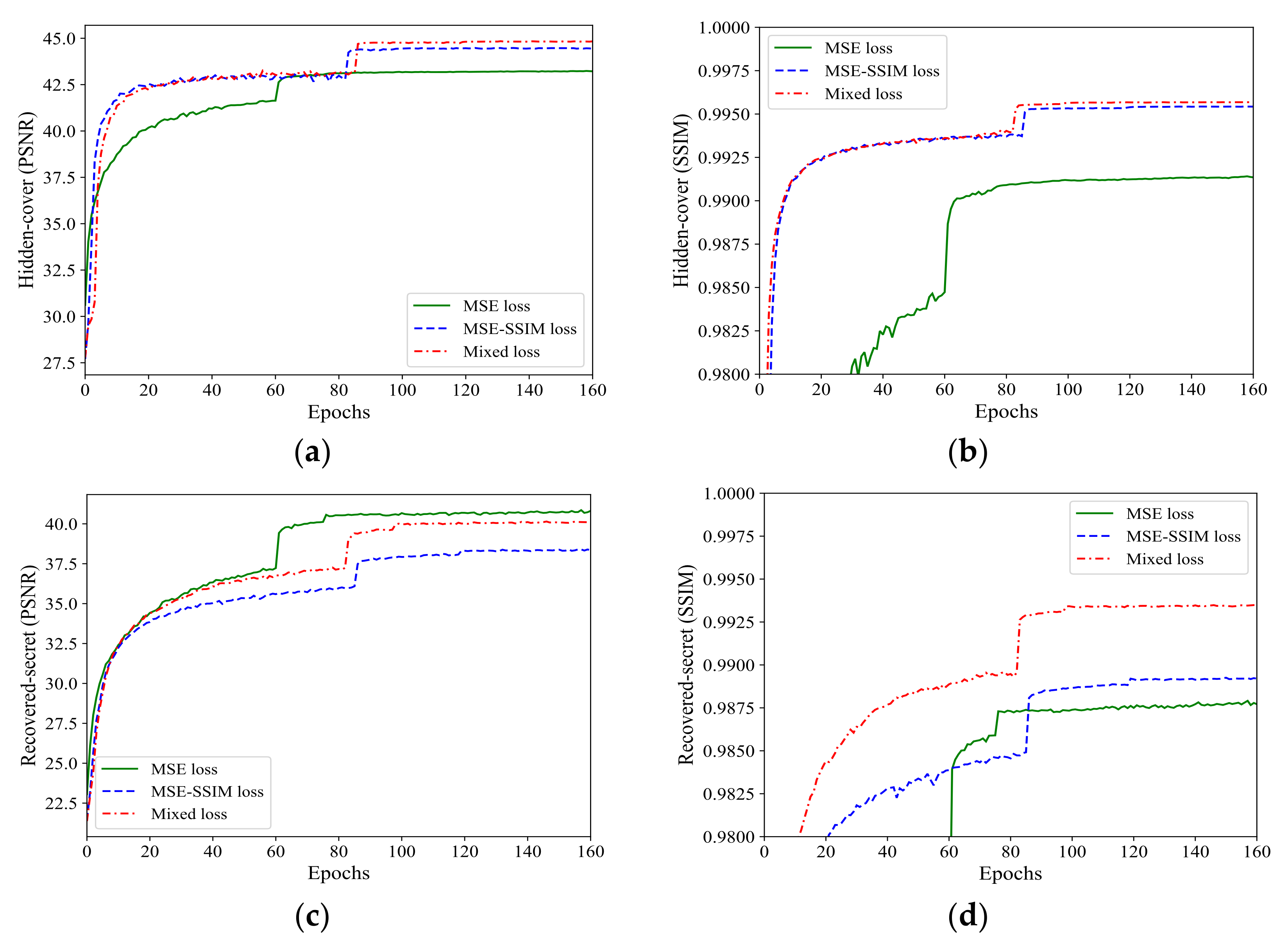
3.3. Ablation Study on the Mixed Loss Function
To further evaluate the effectiveness of our mixed steganography loss function design (composed of MSE, SSIM, and KL), we conducted an ablation study on the mixed loss function to analyze its influence on the concealing and revealing performances. The results are shown in
Figure 4.
Observing
Figure 4, we can obtain the following conclusions:
(1) MSE loss and MSE-SSIM loss demonstrate that introducing SSIM into the steganography loss function effectively improved the SSIM values of the hidden image and the recovered secret image, meaning that the structural quality of the hidden image and the recovered image were greatly improved. Introducing SSIM also improved the hidden image’s PSNR value, but slightly reduced the recovered image’s PSNR value. However, it is worth sacrificing the recovered image’s PSNR value for the abovementioned improvements. Here we give our descriptions and considerations.
Different from previous single-object tasks, our image steganography research represented a kind of double-object task, aiming to pursue two goals; one of these was to improve the hidden image’s quality as much as possible, and the other to improve the recovered image’s quality as much as possible. However, it proved difficult to achieve both goals simultaneously. In practical application, greater attention should be paid to the hidden image’s quality because this largely determines steganography security. More attention should also be paid to SSIM values, because the image’s information is mainly expressed through its visual appearance, and a higher SSIM value means higher visual quality.
(2) MSE-SSIM loss and mixed loss demonstrated that the proposed mixed loss function further improved the quality of the hidden image and the recovered secret image. Particularly, it significantly boosted the SSIM value of the recovered secret image.
3.4. Comparison Results
To further demonstrate the superiority of our approach, we compared it with a typical representative of traditional steganography algorithms, namely LSB, and deep learning-based image-to-image steganography algorithms [
18,
19,
20,
21]. Note that other algorithms [
16,
17] were not included because their recovered secret images had severe content distortions. To guarantee fairness of comparison, we used the same training set and batch size described in this paper to pre-train the abovementioned methods, and then we verified the well-trained models with the same testing set used previously in this study. The average results are shown in
Table 1.
From
Table 1, we can see that the traditional LSB method performed poorly when applied to large image data; its generated hidden images and recovered secret images were of poor quality. Relying on powerful feature-extraction and self-learning abilities, the deep learning-based methods [
18,
19,
20,
21] not only overcome dependence on human labor and hand-crafted features, but can also greatly boost concealing and revealing performance as well as the synthesis quality of the hidden image and the restoration quality of the secret image. However, as shown by the last row in
Table 1, our proposed approach achieved the best concealing and revealing performance, and our generated hidden images and recovered secret images achieved the highest PSNR and SSIM values. More importantly, compared with the advanced method [
21], the computation complexity of our proposed approach was significantly reduced by 75%, demonstrating that our approach consumed less memory resource during practical application. In the last column, we present the computation time (per batch) of different methods; it can be seen that our approach was 10× faster than the advanced method [
21].
To demonstrate intuitively the performance difference between the abovementioned methods, we further conducted a visualization comparison between different methods, as shown in
Figure 5. To guarantee fairness of comparison, we selected the same cover image and secret image for visual comparison. Due to limited article space, only two visualization examples are displayed in
Figure 5.
The four columns to the left of
Figure 5 display the original cover image, the original secret image, the generated hidden image, and the recovered secret image, respectively. The three columns to the right display the residual image obtained by pixel errors between the hidden image and the cover image, as well as its 10× and 30× enhanced versions. From
Figure 5, we can see that the traditional LSB algorithm attained poor imperceptibility when applied to conceal image data. It produced obvious modification traces in the hidden image (highlighted by the red box), which failed to meet the imperceptibility requirement. In addition, its recovered secret image also displayed obvious content distortion (highlighted by the red box). Although the deep learning-based algorithm [
18] further improved the concealing performance, its recovered secret image still had color distortions. It can be seen that the recent algorithms [
19,
20,
21] achieved high steganography performance, their generated hidden images and recovered secret images were of high visual quality, and it was difficult to distinguish their performance differences by only observing their generated hidden images and recovered secret images, or even their residual images. However, after the residual image was magnified 10 or 30 times, an interesting phenomenon occurred; algorithms [
19,
20] obviously exposed the secret content in their 10× enhanced residual images, and algorithm [
21] obviously exposed the secret content in its 30× enhanced residual image. However, as shown by the final two rows in
Figure 5, our proposed approach greatly reduced the secret content exposure in the enhanced residual images and achieved higher visual security than the algorithms, even when trained with the general MSE loss function. As shown by the last row, due to the mixed loss design, our approach completely eliminated the secret content and displayed only the cover image’s contour in the enhanced residual images. This indicates that our proposed approach can well meet security requirements for practical application. Even if attackers can obtain the original cover image from the public Internet, they would remain unable to discover the secret content. If attackers have access to the original cover images, they could use residual information from between the hidden image and the cover image to decipher the embedded secret content.
5. Conclusions
This paper proposes a novel RDA-based network to protect important or secret image data. The method can automatically embed a secret image into another common cover image to prevent secret information leakage. The designed RDA module can effectively extract significant information from the cover image for reconstructing the hidden image’s salient target, and can make the hidden image appear similar to the cover image, thus improving the concealing performance. The ARS strategy is proposed to avoid undermining the fidelity of low-level features and to preserve more raw input information, which significantly boosts concealing and revealing performance. Furthermore, the designed mixed loss function can further boost the hidden image’s quality and completely eliminate the exposure of secret content in the residual image, thus effectively preventing information leakage and guaranteeing the security of secret content.
According to the above results, it can be concluded that an appropriate network structure and loss function can greatly improve the performance of the method. In future, we will improve the network structure and loss function to enable further performance improvement, and we will extend the algorithm for use with video or other carriers, thus extending its range of application.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}