2. Related Work
Existing methods of intelligent smoke detection have been collected and summarized by us. After comparison, the methods can be divided into two categories: smoke detection based on traditional machine learning and smoke detection based on deep learning convolutional neural network feature extraction. Based on traditional machine learning, there are usually three steps: (1) using foreground extraction or subregional interception of images; (2) followed by the design of digital image processing according to distinctive features; (3) input the numerical features to the machine learning classifier. In [
4], the types of feature extraction algorithms commonly used in machine learning are detailed. Most of the existing algorithms are based on color [
5,
6,
7], texture [
8,
9,
10], motion features [
11,
12], and shape [
13]. In [
6], a color segmentation method was used to classify the smoke moving pixel points successfully. In [
7], the authors combined LBP, KPCA, and GPR to propose a new smoke detection channel. Therefore, the smoke was classified according to its texture. Although the smoke constantly moves, this feature was also captured in [
9]. Firstly, the area where the smoke was located was known through the color distribution rules, and then the motion energy was used to estimate the saliency map of the pre-segmentation, and the accurate smoke segmentation result is obtained. An innovative method for segmenting the smoke region was proposed to classify smoke pixels based on smoke’s color and motion features [
11]. In [
13], although only pedestrians were detected, it was quite close to the method for detecting smoke. This paper mentioned that the optimal hyperplane is obtained through the distribution in the multi-channel image space. Then, the pedestrian was segmented by shape statistics. This method could also be used in smoke detection. Although traditional detection methods detect smoke more accurately, they can be much slower in terms of efficiency than deep learning methods. Traditional machine learning methods require subjective judgments on the features to be extracted, and they often tend to lack large data to support the diversity of smoke features caused by different environments at different times. Moreover, when detecting small smoke, the accuracy needs to be improved. Therefore, people now prefer to use deep learning convolutional neural networks for smoke detection.
Many approaches have also emerged in smoke detection using deep learning convolutional neural networks since the introduction of AlexNet [
14], one of the convolutional neural networks. In [
1,
15], the VGG16 convolutional neural network [
16] was used as the backbone network of model detection and improved accordingly. In order to address the identification of smoke in haze and improve the robustness of the network model, an artificial smoke dataset was also used in [
1]. Moreover, the authors use ImageNet to pretrain the weights before training their dataset, thus solving the problem of interference caused by the natural environment, as expected. Furthermore, in [
15], the authors also used VGG16 as the backbone network [
16] and added spatial and channel attention mechanisms. Finally, feature-level and decision-level fusion models were added to reduce the model parameters. Therefore, it reduced the size of the model and improved the accuracy.
Moreover, ref. [
17] also studied smoke detection in haze weather. A dark channel-assisted, hybrid attention, and feature fusion algorithm was proposed. An unbalanced data set was trained first, improving smoke detection accuracy in a haze environment. In addition, to solve the large deformation of smoke shape in the case of large outdoor wind speed, ref. [
18] proposed a cascade classification of smoke and a deep convolutional neural network based on AlexNet to improve smoke detection in some extreme environments. In both [
19,
20], the authors included a BN (batch normalize) [
21] layer, which aimed to unify the scattered data and normalize the data in each layer, thus achieving a training model acceleration as well as overfitting mitigation. Dual deep convolutional neural networks, DCNN and SBNN, were used in [
19]. The authors added BN layers to both networks to detect smoke accurately. The role of the SBNN network was to extract detailed information about smoke, and the role of the SCNN was to capture the basic information about the smoke. Finally, the ninth max-pooling layer of the SBNN network was removed and connected to the feature fusion to achieve the dual network connection. In [
20], the data set was first preprocessed by detecting the dynamic track of smoke, and the suspicious smoke area was obtained. Next, the SqueeezeNet lightweight convolutional network [
22] was used for feature extraction. It is worth noting that the authors used a three-network progressively improved SqueezeNet network, a network with BN layers, and a depth-wise separable convolution instead of the traditional convolutional network. In [
23], to reduce the detection difficulty and real-time detection monitoring, the existing convolutional neural was modified and a new convolutional neural network SCCNN was proposed to get good results for real-time smoke detection. In [
24], the authors adopted the lightweight object detection network Efficientdet-D2 [
25]. The problem of false-negative detection results caused by insufficient consideration of scene information in actual smoke scenes was solved by adding a self-attention mechanism to the network. Furthermore, the problem of false detection caused by class smoke was solved by successfully obtaining multi-level nodes for a multi-feature fusion of smoke.
In general, the deep learning smoke detection methods proposed above all have achieved excellent smoke detection results. However, there are two main problems with smoke detection. (1) In [
1,
15,
18], the authors mainly solve the problem of smoke in the haze environment. Nevertheless, there is less corresponding work for detecting small and thin smoke in the early stage of the fire. This is one of the most effective and rapid ways to prevent fire occurrence. (2) The detection algorithm can be more lightweight because Edge computing based on lightweight algorithms is the trend in deep learning. Using a more lightweight detection model smoke was detected faster without internet interference. Therefore, there are the following challenges: (1) Deep learning relies heavily on an effective dataset and finding an effective small and thin smoke dataset in the early stage of fire from the internet are difficult. (2) Detections for small and thin are more difficult than normal smoke detection because they are located in small areas and carry less information. (3) The accuracy of smoke detection using a lightweight model is usually lower than that of a large network model.
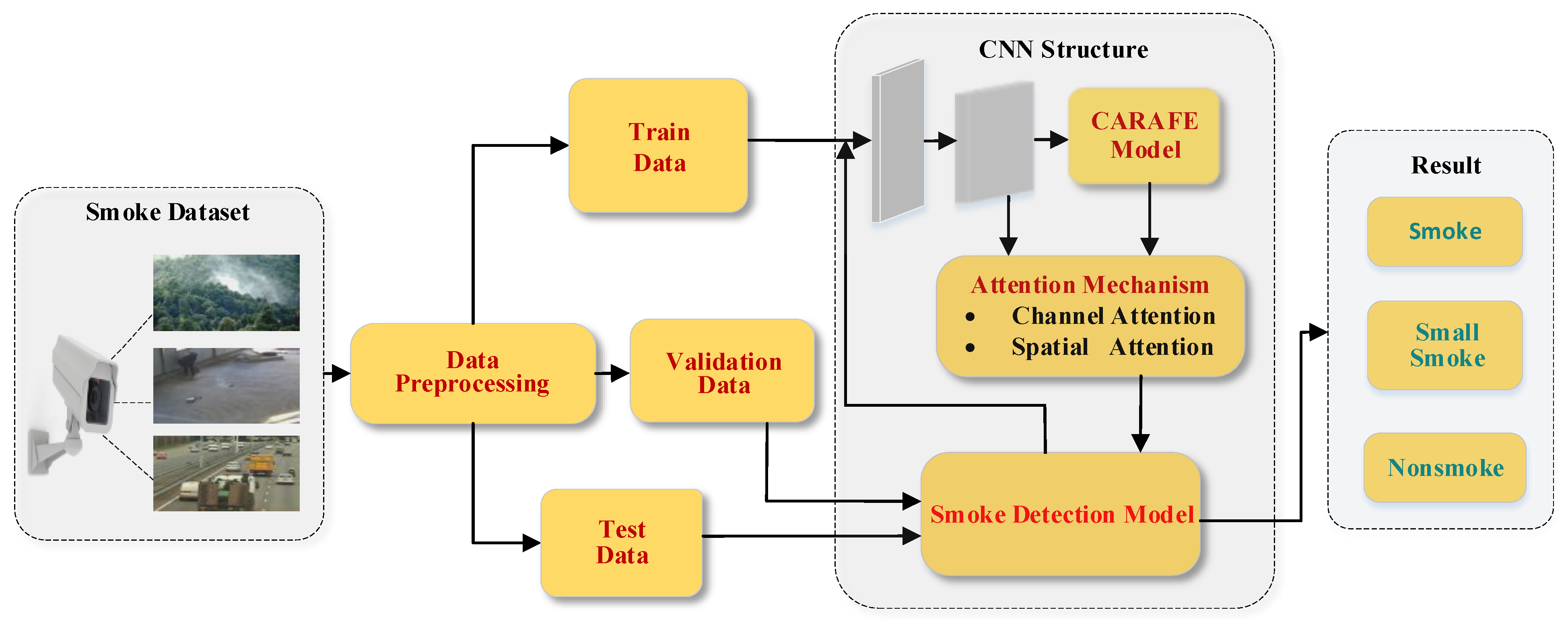
In order to solve the problems raised above, an improved YOLO v5s CNN network based on the spatial and the channel attention mechanisms and replacing the original upsampling content-aware reassembly of features (CARAFE) is proposed by us. Firstly, smoke video was shoot from an empty warehouse through cameras. Frame-by-frame screenshots have been taken to get the initial dataset and use public datasets to enhance the scene robustness of data. Secondly, a channel and spatial attention mechanism is added after the first two C3 convolutions in the feature fusion network [
26]. A novel upsampling CARAFE [
27] instead of the first one in the feature fusion network upsampling was used. The proposed smoke detection framework is shown in
Figure 1. Specifically,
In order to solve the problem of being less small and thin smoke in the early stage of fire, practical shooting was carried out to collect real-time dataset. Smoke generators, sheets, and cotton ropes were used during the shooting as different small and thin smoke sources.
A combination of spatial attention mechanism and channel attention mechanism network has been added to the feature fusion network of YOLO v5s to solve the problem of small and thin smoke detection at the beginning of a fire. Instead of a single spatial attention module, a combination of spatial and channel modules has been used. When extracting smoke, this will assign a higher weight to the area where the smoke is located and the channel. Therefore, the model can pay more attention to the smoke itself to reduce the interference of the scene and solve the problem of such small and thin smoke detection.
In order to further improve the detection effect of smoke, the improved upsampling CARAFE has been taken in the feature fusion network of YOLO v5s instead of the original nearest neighbor interpolation upsampling. Compared with the nearest neighbor interpolation upsampling, the CARAFE algorithm can obtain a larger receptive field in the smoke photo to aggregate information. The contents of the smoke pictures are perceptually processed by generating adaptive kernels in real-time. Moreover, the algorithm has fewer parameters and a faster calculation speed, which is suitable for purpose of detecting smoke.
3. Methods
An efficient smoke detection method that combines an attention mechanism with a novel upsampling algorithm has been proposed to address small and thin smoke detection in the early stage of fire. As seen from
Figure 1, firstly, offline videos of common combustibles were taken just as they were starting to burn. Then, the original video data were preprocessed to obtain data in the form of images. The normal smoke dataset in different scenarios and the smoke-free dataset in different scenarios were combined to form a complete smoke dataset, divided into training, validation, and test datasets. Next, based on the YOLO v5s network, the structure of the convolutional neural network was redesigned, and an attention mechanism combined with spatial and channel has been added. The attention mechanism is used after the C3 module in feature fusion. Next, the first upsampling of the feature fusion network has been replaced with a novel upsampling CARAFE. Then, the training set was used to train the new convolutional neural network to obtain the smoke detection model. Finally, the smoke detection model types are normal smoke, small smoke, and non-smoke.
3.1. YOLO v5 Object Detection Network
Since Joseph Redmon proposed the YOLO [
28] object detection algorithm in 2016, there has been increasing acceptance of this single-stage object detection algorithm. Compared with Fast RCNN [
29], Faster RCNN [
30] and other two-stage object detections, the YOLO series may be inferior to them in terms of detection accuracy. However, the significant reduction in the size of network parameters and the significant increase in detection speed will make it more suitable for real-time target detection. So far, the original author has continued to propose YOLO v2 [
31], YOLOv3 [
32] versions whereas Alexey Bochkovskiy proposed YOLO v4 [
33] and YOLO v5 series that have been updated and maintained on GitHub. These YOLO series object detection algorithms continue improving target detection accuracy. It would be a suitable choice for us to use for smoke detection in real-time. Therefore, the more lightweight version s in YOLO v5s was chosen to conduct experiments and improve its performance to obtain higher object detection evaluation indicators.
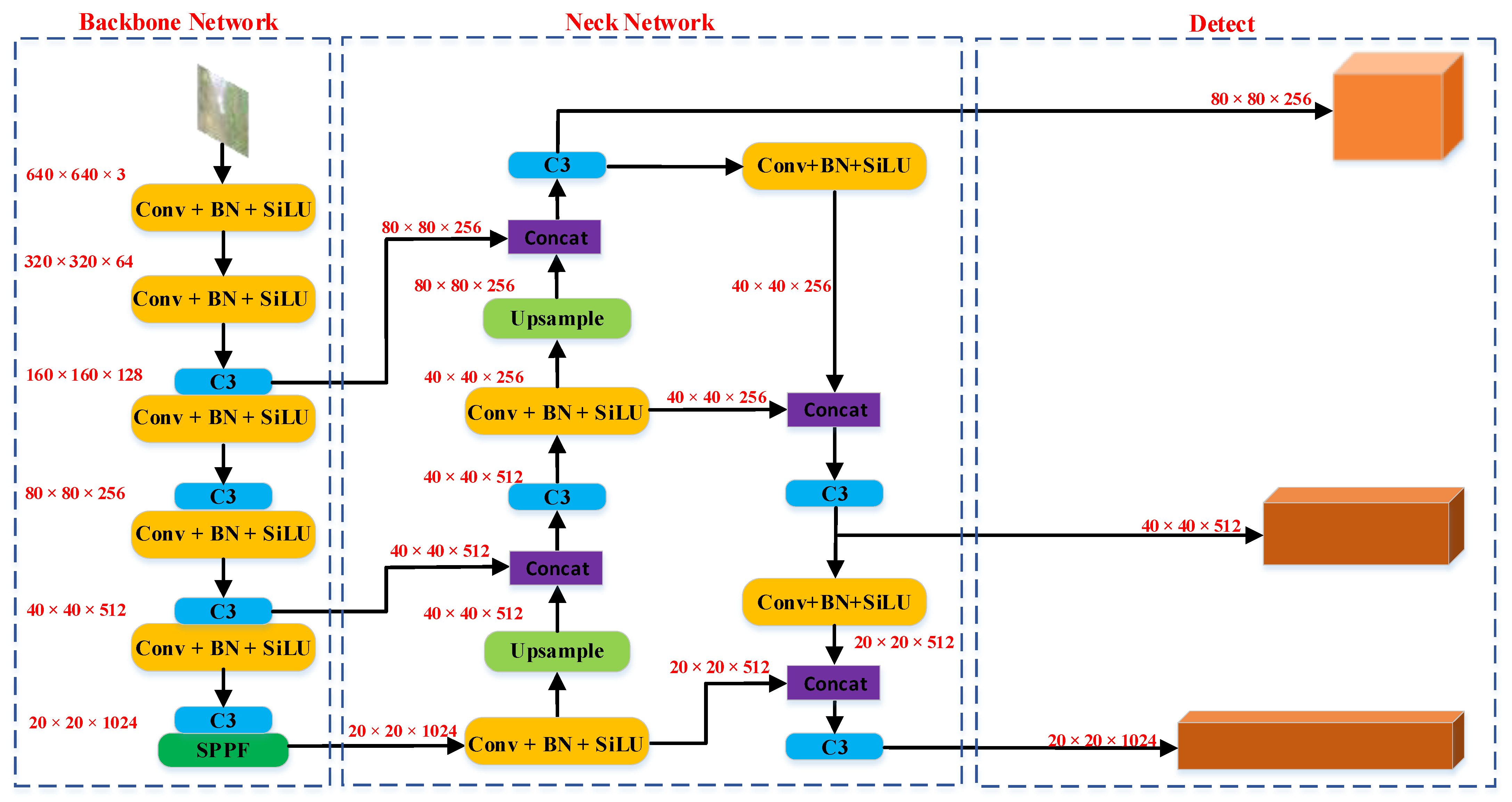
As can be seen in
Figure 2 and
Figure 3, the model of YOLO v5s removes the region proposal network and significantly improves the detection speed compared with the two-stage algorithm mentioned above. The model of YOLO V5 consists of three parts, namely Backbone Network, Neck Network, and Detect. Backbone Network is the most important part of the overall network. Because it takes a critical role in feature extraction of smoke pictures, which is an initial part of the network. The role of the Neck Network is to fuse features from the Backbone Network. The part of Detect can create a bounding box (location box) to detect smoke. YOLO V5 is configured with four performance models of different sizes. The parameters are arranged from low to high as YOLO v5s, YOLO V5m, YOLO V5l, and YOLO V5x. YOLO V5 uses CSPDarknet53 as a feature extraction network [
34]. The feature fusion neck network is composed of an integrated spatial pyramid pooling fast (SPPF) network, feature pyramid networks (FPN) [
35], and pixel aggregation network (PAN) [
36].
The loss function of YOLO v5s consists of three parts, classification loss, localization loss, and confidence loss. Using binary cross entropy (BCE) loss, classification loss is used to indicate whether the anchor box matches the previously calibrated classification. Localization loss indicates the difference between the prediction and calibration frames using Complete-IOU (C-IOU). Moreover, confidence loss also represents the confidence error of the network with BCE loss.
3.2. Small and Thin Smoke Detection Using Spatial and Channel Attention Mechanisms
The timely detection of small and thin smoke in the early stages of fire is a key factor affecting the ability to detect fires early and protect lives and property accurately. Since small objects are always located in small areas and carry little information, the features finally extracted by the multi-layer convolutional neural network are few compared with the background, resulting in weak feature expression ability and reduced detection ability for small objects. A combined channel and spatial attention mechanism module has been added to address this issue.
As shown in
Figure 4, channel attention emphasizes the channel features of smoke, which give higher weights to object regions in the image. After the channel attention, the color of the photos input channel is more obvious. The weight of model becomes higher. Spatial attention emphasizes the location features representing the smoke and gives them higher weight. After the spatial attention algorithm, the location’s color representing the smoke becomes darker. Therefore, in extracting smoke features, this attention mechanism can pay more attention to the location of smoke to reduce background interference and improve the accuracy of small and thin smoke detection.
Taking the output of C3 of the basic convolutional neural network YOLO v5s feature fusion network as the input feature
Xi, the channel attention layer is composed of convolutional layers with
W1 and
B1 parameters, which represent the weight and bias of the convolutional layer, respectively. In the channel attention layer, average pooling and max pooling operations have been used to aggregate feature information. Then, feature extraction is performed through multiple fully connected layers. Finally, sigmoid activation has been used to generate the weights
W1 for each channel. When the feature
Xi passes through the channel attention, the output feature
Xo1 is obtained, as
Two pooling operations have been used consecutively in the spatial attention layer to aggregate the channel information from the
Xo1 feature maps. Next, feature extraction is performed through multi-layer convolution. Finally, the sigmoid activation generates the weighted spatial attention
W2. The final output feature
Xo2 obtained from the output feature
Xo1 after channel attention as input and
B2 is biased, as
3.3. CARAFE Upsampling
In the original YOLO V5s, the feature fusion network upsampling is achieved by nearest-neighbor interpolation. However, nearest-neighbor interpolation only considers sub-pixel neighborhoods. It cannot capture the rich semantic information required for dense prediction tasks. In addition, deconvolution [
37] is also one of the upsampling approaches. However, it also has two drawbacks: a deconvolution operator covers the same kernel throughout the image, regardless of the underlying content. This limits its ability to respond to local changes, and it comes with a large number of parameters. However, CARAFE has the attributes of a larger field of view, content-aware handing, lightweight, and fast to compute. Large field of view can receive more information of smoke pictures to complete the detection task. The attribute of content-aware handing uses adaptive kernels instead of the fixed kernel to better process different features of smoke. Lightweight and fast to compute, can detect smoke in real-time without increasing parameters much, which is the expectation of using a lightweight CNN.
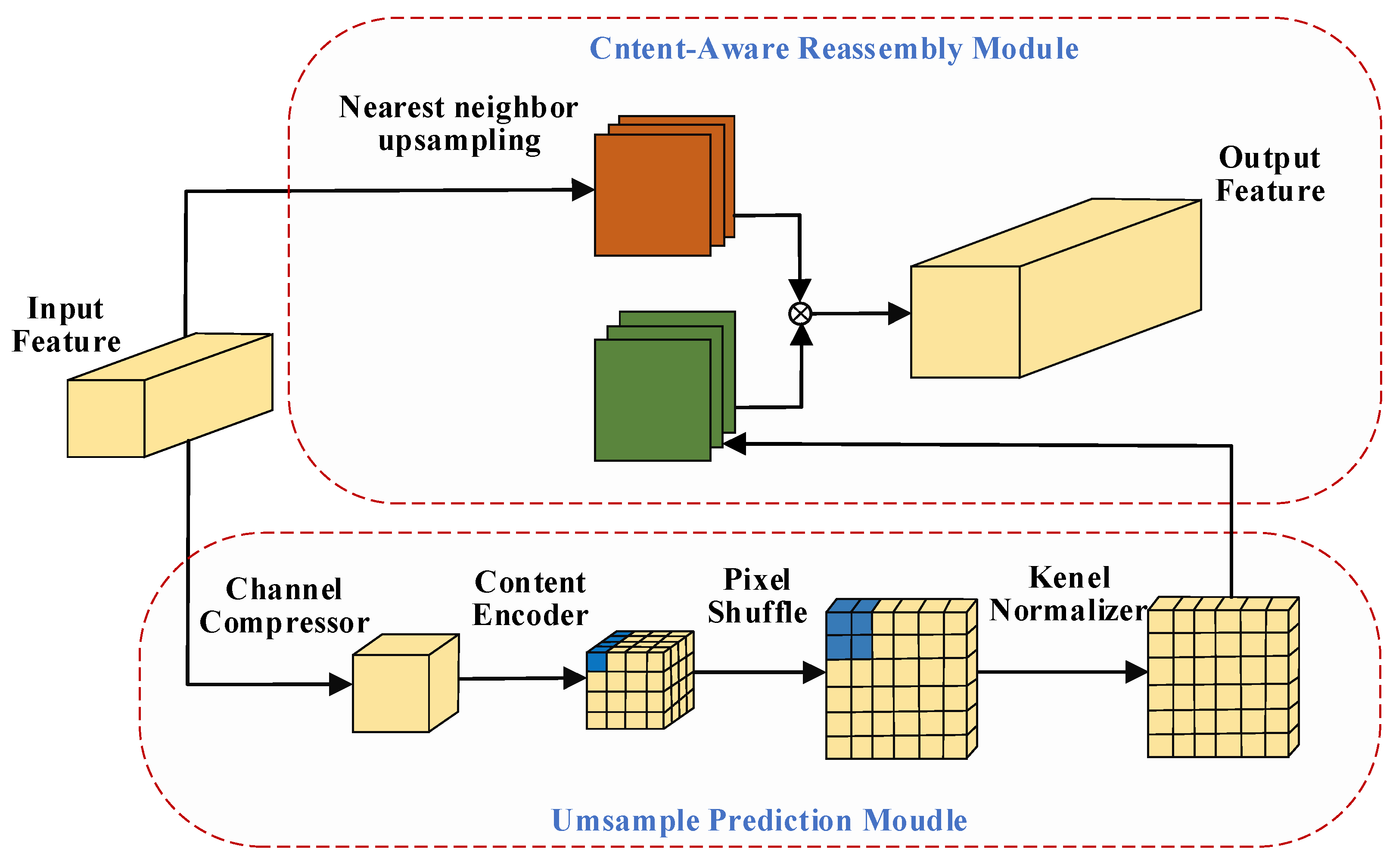
The original upsampling has been changed to CARAFE up-sampling. As shown in
Figure 5, CARAFE consists of two steps: the kernel prediction module and the content-aware reorganization module. In the kernel prediction module, the feature map of a given smoke image is C × H × W, and a convolution kernel with a 1 × 1 channel compression convolution C2 was performed. Then, to encode convolution, the number of channels were redistributed, where σ is the upsampling factor (assuming as an integer). Then, pixel shuffling is performed to expand the receptive field of upsampling for the smoke feature map. Next, the feature map is normalized to reduce the number of parameters in operation. Then, in the content-aware recombination module, the feature map obtained using the prediction kernel and the feature map obtained by ordinary upsampling are used for the dot product to reorganize the feature with the prediction kernel. Therefore, the formula of the kernel prediction module and the content-aware reorganization module are as follows:
Among them, every target location requires a kup × kup reassembly kernel, where kup is the reassembly kernel size. ψ represents the kernel prediction module, Kencoder is the convolution kernel of the coding convolution, N (Xl, k) is the X sub-region of X centered on this position, and Wo is the output of the prediction module. ϕ is the content-aware reorganization module, and Zo is the total output of the upsampling model.
3.4. Innovative Datasets
A unique dataset was sought to address the lack of small and thin smoke in the early stages of fire in public datasets. These data include the smoke data of the smoke generator after the smoking sheet and the cotton rope is burned. The normal smoke and non-smoke pictures of the public dataset were combined to create a new dataset.
As shown in
Figure 6, the smoke in the first photo of a column of small smoke of
Figure 6 is from the smoke generator, the second photo from a smoke sheet, third photo from cotton rope. A total of 120 videos were collected, and the videos are divided into three types of smoke, namely the smoke from the smoke generator, the smoking sheet, and the cotton rope. The small and thin smoke dataset is unique. Because the small and light smoke images within 100 × 100 pixels from the high-definition video screenshots of 1080 × 1920 pixels were screened out, the smoke of the smoke generator is relatively uniform. Its smoking principle is to use the manual button to smoke, and the difficulty of smoke detection is relatively simple compared with the other two types of smoke. The smoke emitted by the cotton rope and the smoking sheet after burning will not be so obvious. Its initial smoke and smoke are relatively small, equivalent to the smoke of indoor objects that do note easily cause fires. Moreover, the smoke of cotton rope is particularly small, which is in line with the requirements of small and thin smoke in the early stage of fire.
In addition, in
Figure 6, photos are added of normal smoke and non-smoke from the internet for training to enhance the robustness of model, which will lead to an imbalance between smoke and non-smoke data. Moreover, as shown in
Figure 7, a dataset was added for the small and thin, such as horizontal flip (a), rotating 45 degrees (b), and rotating 315 degrees (c).
As shown in
Table 1, 10,800 pictures have been used. After data enhancement, there will be 4000 pictures, and then add 3400 pictures to the public data set, so there are 7400 pictures of smoke data. Moreover, 3400 pieces of non-smoke photos are also prepared. So the total dataset contains a total of 10,800 images. The dataset has been divided into a training set, validation set, and test set, accounting for 81%, 9%, and 10%, respectively.
4. Results
Open-source deep learning framework PyTorch has been used to train a smoke detection model based on the basic convolutional neural YOLO V5s, combining an attention mechanism and an improved upsampling network CARAFE3.1. To evaluate the algorithm’s performance, firstly, the algorithm is tested on public smoke datasets and a smoke dataset. Secondly, the algorithm is compared with the existing excellent algorithms based on different evaluation metrics. The model’s detection speed and parameters are tested to verify the algorithm’s real-time detection performance. In order to verify the effect of CARAFE, a comparative experiment is applied. Ablation experiments with the attention mechanism are also conducted.
4.1. Evaluation Criteria
After the experiment, precision, recall, F1-Score, and AP
0.5 (mAP
0.5) are used to evaluate the model detection and compare it with the classic model. Precision is the ratio of the number of samples accurately predicted to be positive to the sum of the number of samples that are predicted to be true. A recall is the ratio of the number of samples accurately predicted to be positive to the sum of the positive samples. F1 score is the harmonic mean of precision and recall. AP
0.5 is the average precision when the confidence level is 0.5, and the area enclosed by the PR curve mAP
0.5 is the average value of AP value under all categories. For example, Formulas (6)–(10), which refer to class
i, belong to normal smoke, little smoke, and non-smoke.
TPi means that the model predicts the
i-th sample as the
i-th sample.
FPi means that the model predicts samples that do not belong to class
i as class
i.
TNi means that the model predicts samples that do not belong to class
i as not belonging to class
i.
FNi shows that the
i-th sample predicted by the model does not belong to the
i-th sample. The code of
r is the abbreviation for recall and the code of
P is the abbreviation for precision. The definition of
P(
r) is function with recall as abscissa and Precision as ordinate. The formulas are as follows:
The algorithm was compared with some representative single-stage networks based on convolutional neural networks and excellent object detection networks, namely YOLO V4 [
33], SSD [
38], Efficient-d2, Retinanet [
39], and YOLO V5s, to evaluate the performance of proposed smoke detection method. The most of the traditional smoke detection methods extract features subjectively, which is easily affected by the external environment. Their performance is lower than the use of depth features.
Therefore, the comparison between method and traditional methods is not fair.
The proposed model is compared with SSD, RetinaNet, Efficientdet-d2, YOLO v4, and YOLO v5s original models in the self-created dataset through four evaluation metrics, namely Precision, Recall, F1-Score, AP0.5(mAP0.5). To fully and objectively demonstrate proposed method’s effectiveness on the smoke object detection task, the following four experiments are conducted: (1) Overall experimental results from the data set were compared. (2) The experimental results of detecting small smoke in the early stage of the fire were compared. (3) The detection experiments performed on the smoke-free pictures are compared. (4) The model detection speed and parameters of the models are compared. (5) The effects of CARAFE module are compared.
4.2. Training Environment and Hyperparameters
The experimental environment is based on the Ubuntu 18.04 operating system and GeForce RTX 3090 GPU. In the training parameter, the dataset is trained for 100 epochs with batch size 16. Moreover, SGD is an optimizer with a learning rate of 0.001.
4.3. Results Compared to Dataset
Table 2 shows the overall evaluation metric of different object detection models in the dataset. The evaluation indicators of different target detection models are above 88% and close to 90%. Different target detection models have nice results for large-scale smoke image detection in this case. Among them, the SSD [
38] and RetinaNet [
39] object detection models perform weakly in the dataset compared to the other three models. Based on the result, the original YOLO V5s model has certain advantages over other models in dataset, which is why YOLO V5s was chosen for further improvement. Moreover, a channel attention and spatial attention mechanism were used and improved upsampling CARAFE to improve YOLO V5s and get better results on our dataset.
4.4. Results Compared on the Small and Thin Smoke Dataset
As shown in
Table 3, the evaluation indicators were used to obtain by different models to detect objects only on the small smoke dataset in the early fire stage. As shown in
Table 3, yolov4 performs poorly overall on unique dataset. Although the original model of YOLO V5s also has a good detection effect on the detection of small smoke in dataset, better results were obtained on the small smoke data set in the early stage of the fire, and the four evaluation indicators all reached more than 83%. Therefore, the proposed model to detect small and thin smoke has achieved an ideal result.
4.5. The Result of the Detection Experiment on the Non-Smoke Dataset
Table 4 shows that different models have been used to detect non-smoke pictures in the test dataset. The table shows that different object detection models, whether the proposed model or other models, detect non-smoke pictures well.
4.6. Detection Speed and Parameter Results
In order to evaluate whether the detection speed of the algorithm reaches real-time detection, the average detection speed of different methods on the test set was tested, and the test results are shown in
Table 5. From the table, SSD [
38] has the fastest detection speed on test set, reaching 75.38 detections per second. The proposed model is not the fastest among the comparison models due to network changes, and its detection speed is slightly slower than the original model. However, it also detected 69 pictures per second, which is far beyond the frame rate of everyday HD cameras. Furthermore, the parameter of original YOLO v5s is the smallest of them all. However, there is a conclusion that though the improved model’s parameter is not the smallest, the parameter of the attention mechanism and CARAFE upsampling algorithm is small.
4.7. Image Example of a Model Detection Result
Figure 8 shows the effect of the proposed model and different contrasting models in smoke detection. In order to ensure fairness, the detection effects of the same image in each category in the dataset for comparison were selected. From the result, the proposed model has better detection performance.
4.8. Comparative Experiment of CARAFE
In this subsection, the improved upsampling CARAFE method is only used to compare it with existing object detection models, such as SSD, Retinanet, Efficientdet-2, YOLO v4, and YOLO 5s, based on created smoke dataset.
The experimental results of the improved upsampling are shown in
Table 6. CARAFE, with a detection effect of 92.52% for precision, 90.74% for recall, 91.60 for F1-Score, and 91.83% for AP
0.5, achieved the best results among all comparison models. Moreover, all the upsampling in the feature fusion network with the CARAFE module was replaced. After replacing the original upsampling in the YOLO v5s feature fusion network with the improved upsampling CARAFE, the detection effect was more than 0.5% lower than the effect of replacing only one upsampling. The improved upsampling CARAFE can increase the receptive field of the smoke feature fusion network and adapt to the content information of specific smoke in real-time. There is a conclusion that if CARAFE modules replace both upsampling, the weights of the front and rear feature fusion networks will be disordered, which is not better for smoke detection.
4.9. Comparison of Attention Mechanism Ablation Experiments
In this subsection, the proposed method using only the attention mechanism models is compared with existing object detection, such as SSD, RetinaNet, Efficientdet-D2, YOLO v4, and YOLO 5s, based on the self-created smoke dataset. The quantitative results of the Note module are shown in
Table 7. From the table, when only using the channel attention module that removes the spatial attention model, the detection effect is not optimal or lower than the index of Recall and AP
0.5 of the original model. However, when the spatial attention mechanism was added, the model’s precision was 93.20%, the recall was 89.1%, F1-Score was 92.10, and AP
0.5 was 91.83%, achieving the best results among all comparison models. The proposed channel attention emphasizes the feature channel representing the smoke and gives it a higher weight. After channel attention, the color of the channel representing the smoke becomes red, while the color of the background channel becomes smoke area. The model can thus focus on the smoke in the detection task, thereby improving the detection efficiency of small smoke.
In
Figure 9, heatmaps of different small smoke in self-created dataset are compared. The column in (a) represents the original image, the column in (b) represents the heatmap without attention mechanism added, and the column in (c) represents the heatmap with attention added. Considering the situation, after adding attention, the focus on small smoke will be closer to the source of the smoke. This effect is consistent with the expectation that more attention will lead to the accelerated discovery of the source of the smoke in the early stage of the fire to prevent the fire from spreading.
5. Conclusions and Future Work
This paper proposes a new method with an attention mechanism and an improved upsampling algorithm to solve the small and thin smoke detection problem. Firstly, an innovative smoke dataset was created, consisting of self-created small and thin smoke images and public smoke images. Secondly, an attention mechanism module combining spatial and channel attention is used to solve the problem of small and thin smoke detection. Thirdly, a light-weighted upsampling module is used to improve further the ability to identify small smoke and ensure the model’s real-time detection characteristics. Extensive experiments on the results show that the proposed method has higher precision, recall, F1-score and mAP0.5(AP0.5) than existing methods under the premise of guaranteeing real-time performance.
In the future, the proposed algorithm will be deployed on embedded systems and development boards, such as Jetson Nano, Beagle Bone, and Raspberry Pi 3B+. In addition, the algorithm will be improved to obtain detailed information about the smoke, such as the burning substances that cause it and the speed of the smoke spreading.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}