
Computational Analysis of XLindley Parameters Using Adaptive Type-II Progressive Hybrid Censoring with Applications in Chemical Engineering




Abstract
:1. Introduction
2. Classical Inference
3. Bayes MCMC Paradigm
- Step 1.
- Set the start value for the parameter , say .
- Step 2.
- Put .
- Step 3.
- Generate from the full conditional distribution in (18) from the normal distribution .
- Step 4.
- Calculate the ratio:
- Step 5.
- Generate w, where .
- Step 6.
- If , set , otherwise, set .
- Step 7.
- Based on a distinct value t, obtain and asand
- Step 8.
- Put .
- Step 9.
- Redo Steps 3–8 H times to bring
- Step 10.
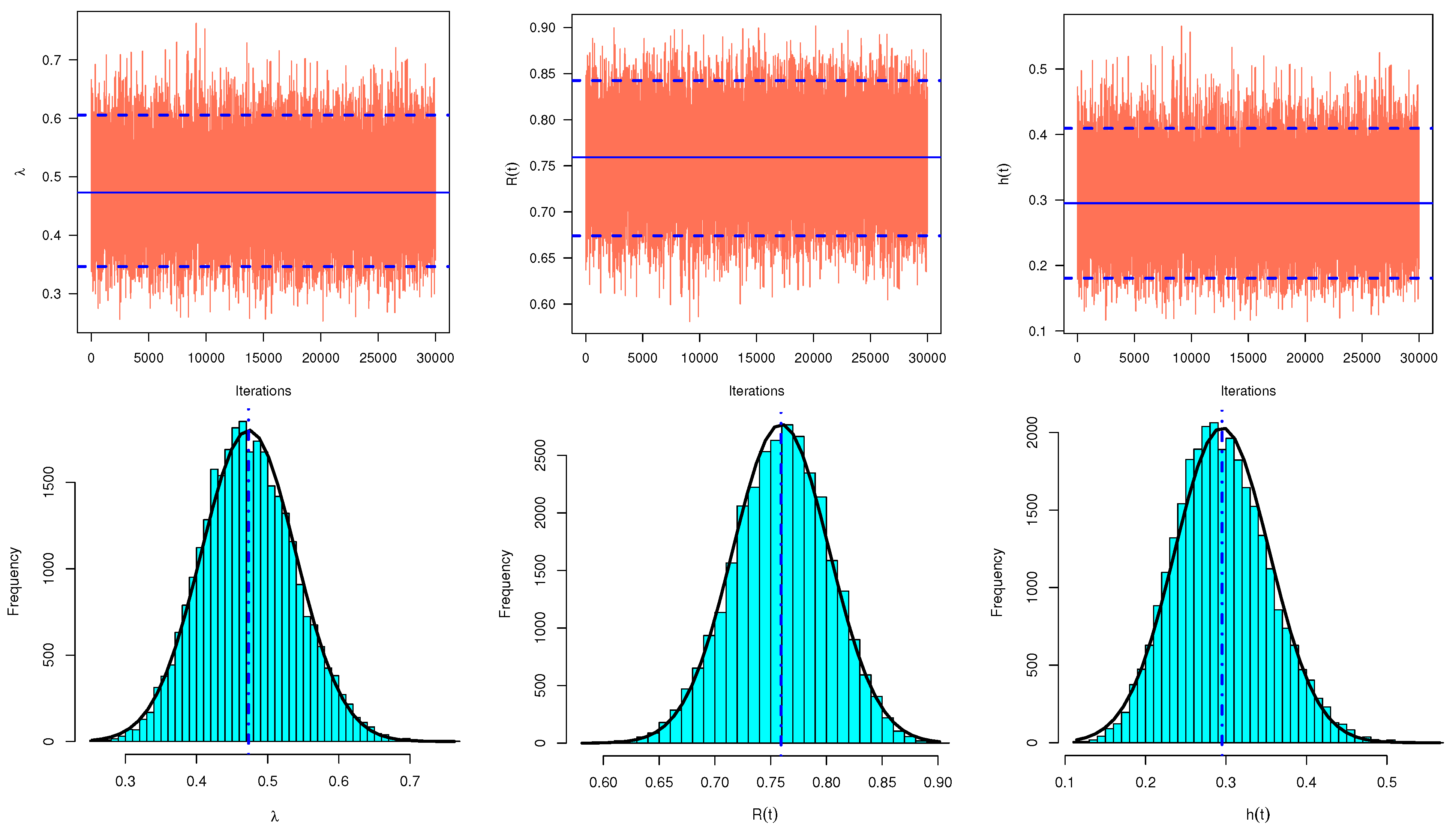
- Calculate the Bayesian estimates of , and employing the SEL function, after a burn-in period M, as
- Step 11.
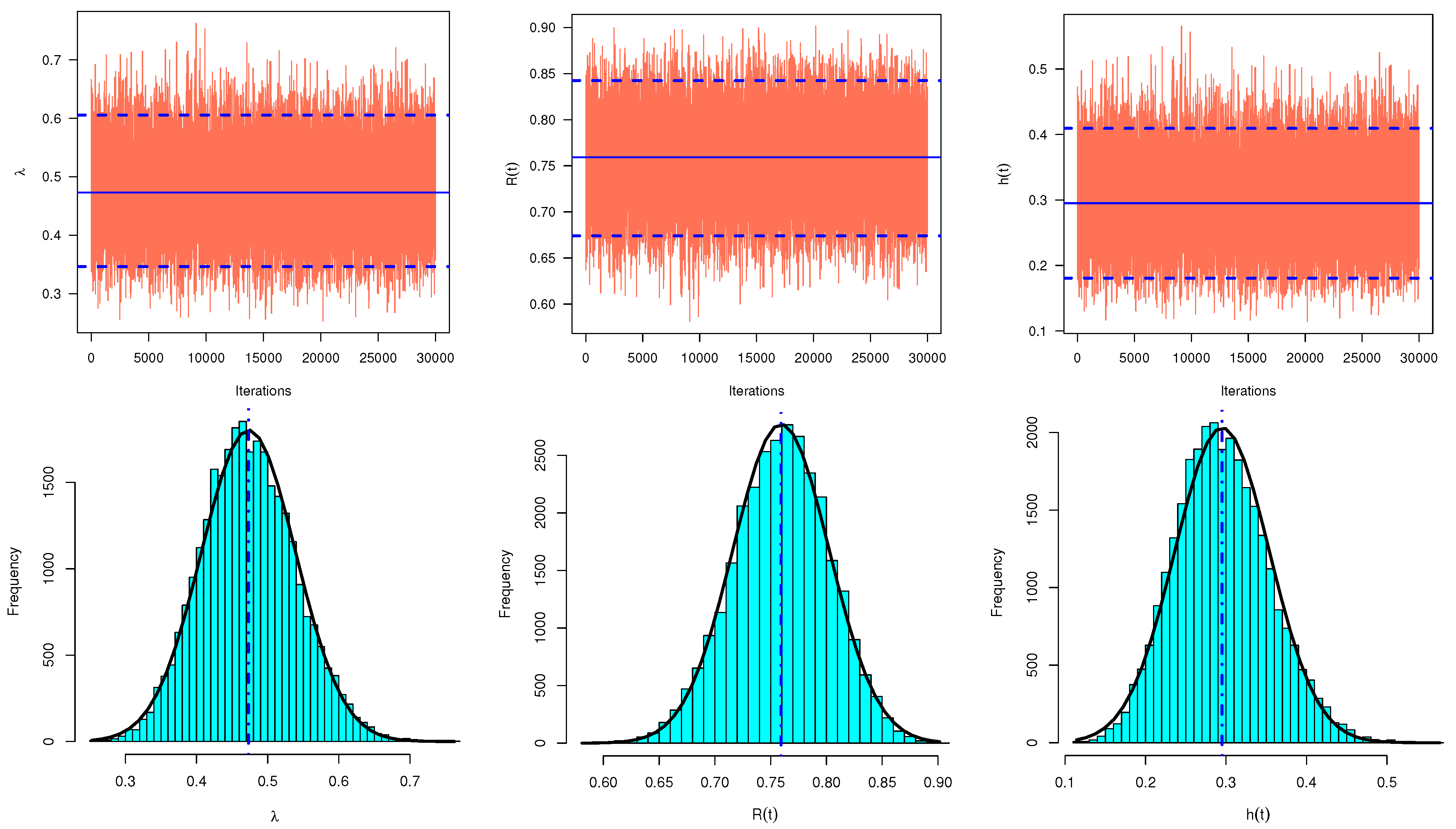
- To acquire the HPD credible intervals of , RF, and HRF: First, sort the generated samples of , and after burn-in period as , , , and , respectively. Employing the procedure suggested by Chen and Shao [19], the two-sided HPD credible interval for the unknown parameter is given bywhere is selected such thatThe largest integer less than or equal to x is denoted by . Then, the HPD credible interval of x with the smallest length is that interval. The HPD credible intervals of RF and HRF can be easily computed using the same approach.
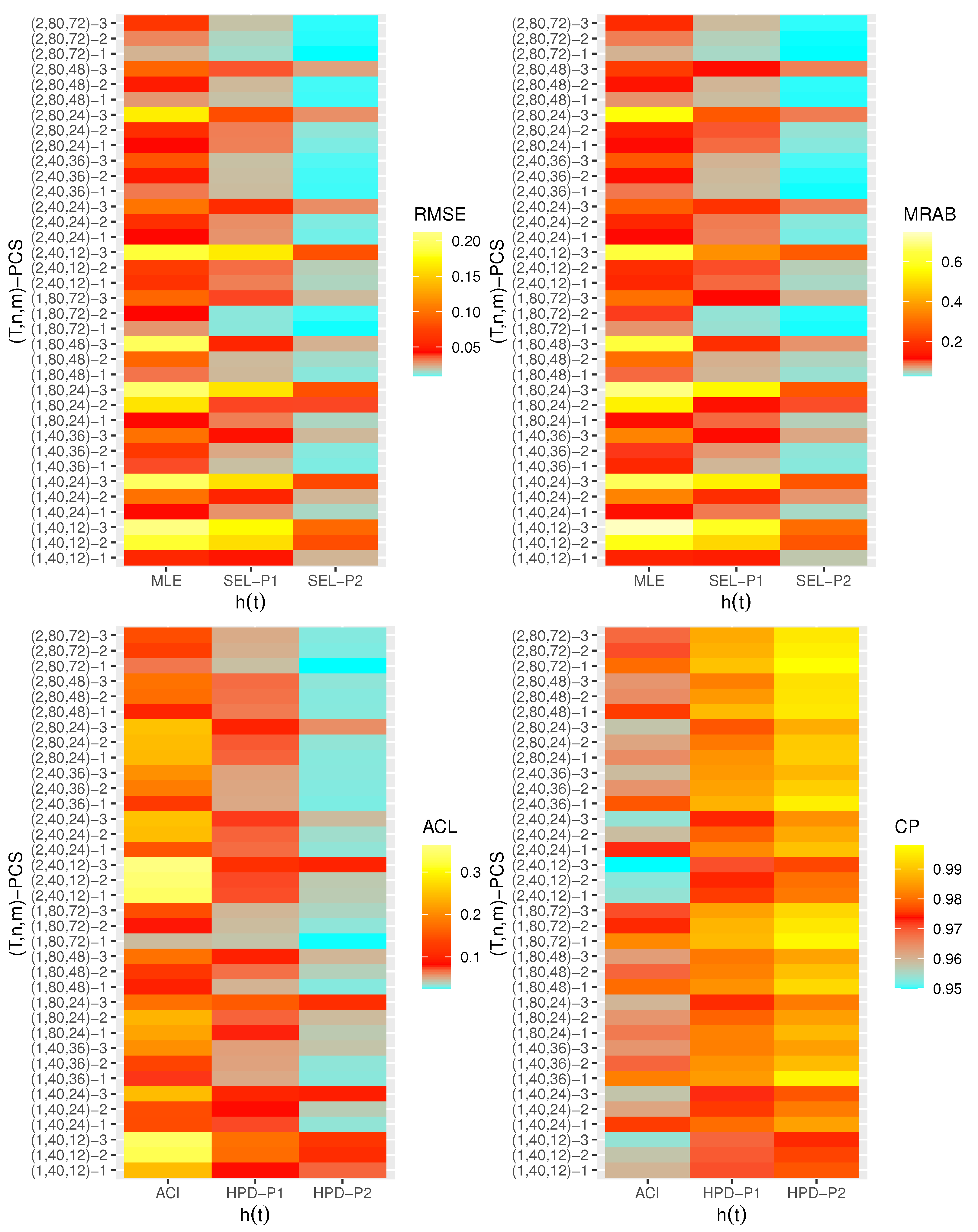
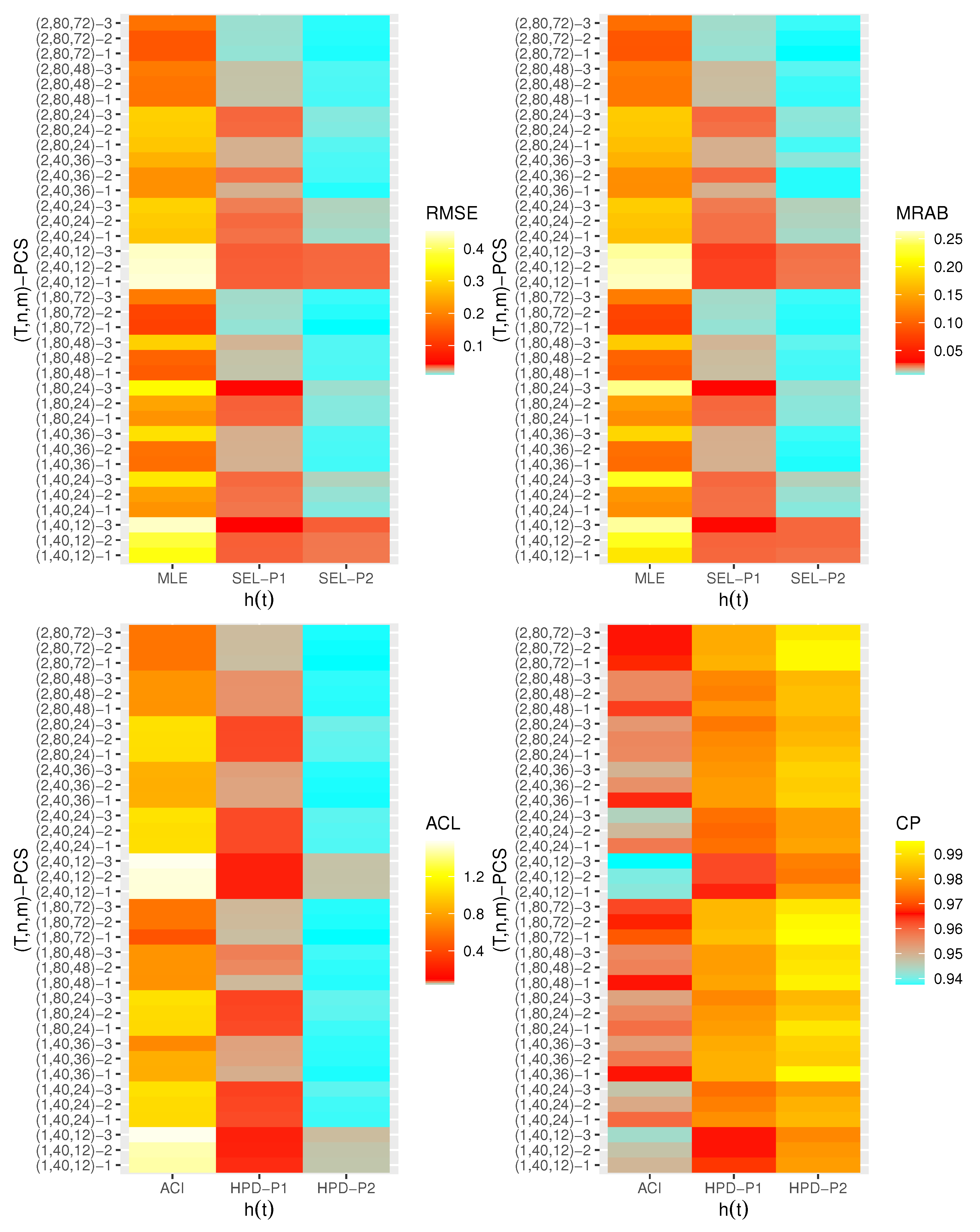
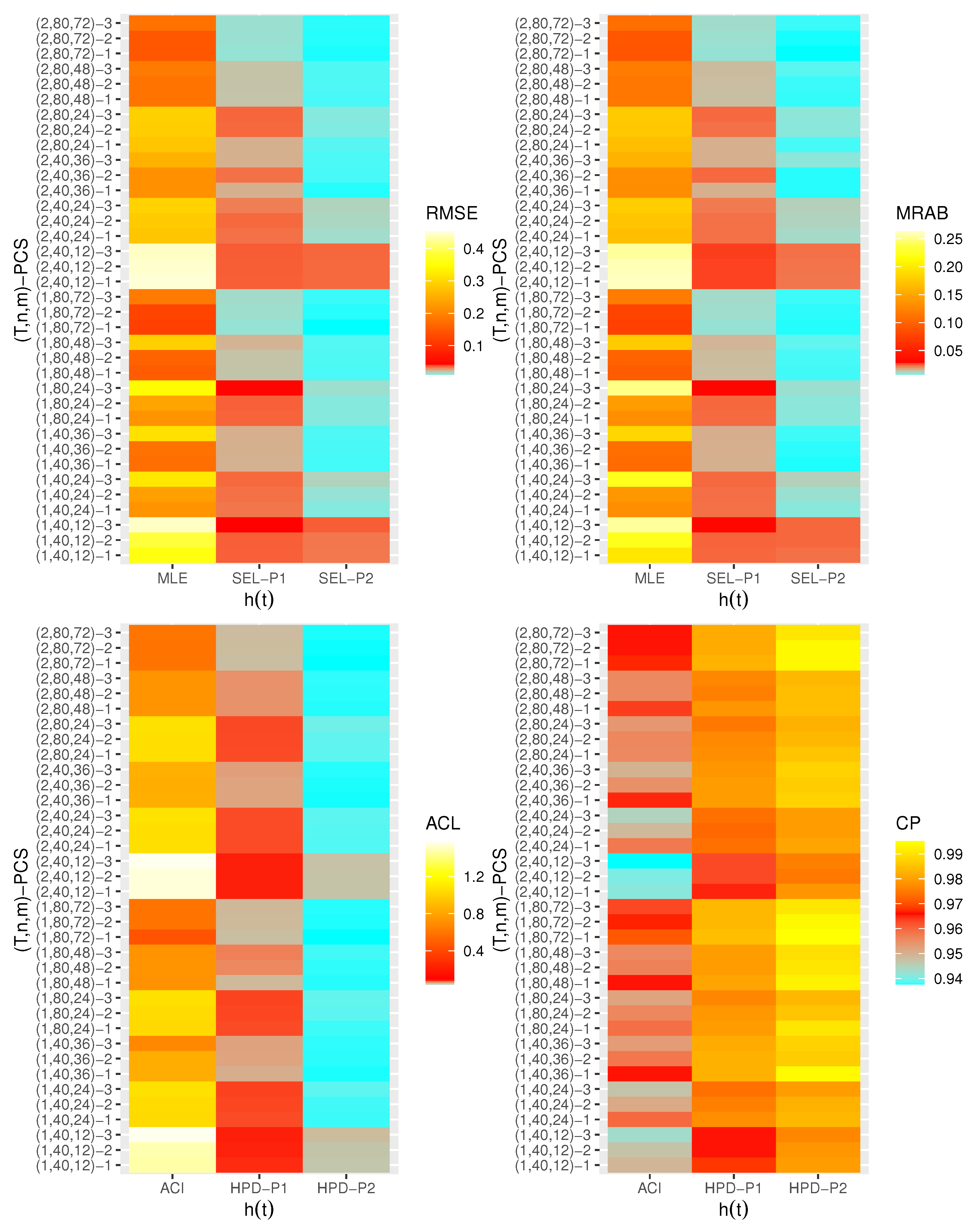
4. Monte Carlo Simulation
- Step 1.
- Generate an ordinary Type-II progressive censored sample as discussed in Balakrishnan and Cramer [20] as
- (i)
- Generate m independent observations as .
- (ii)
- Set for
- (iii)
- Set for . Hence, is a simulated sample of size m from the uniform distribution.
- (iv)
- Set the Type-II progressive censored sample from is generated.
- Step 2.
- Obtain d-th failure and discard for .
- Step 3.
- Obtain order statistics from a truncated distribution with sample size .
- Prior-I (say P1):(1.5, 3) and Prior-II (say P2):(2.5, 5) when .
- Prior-I (say P1):(4.5, 3) and Prior-II (say P2):(7.5, 5) when .
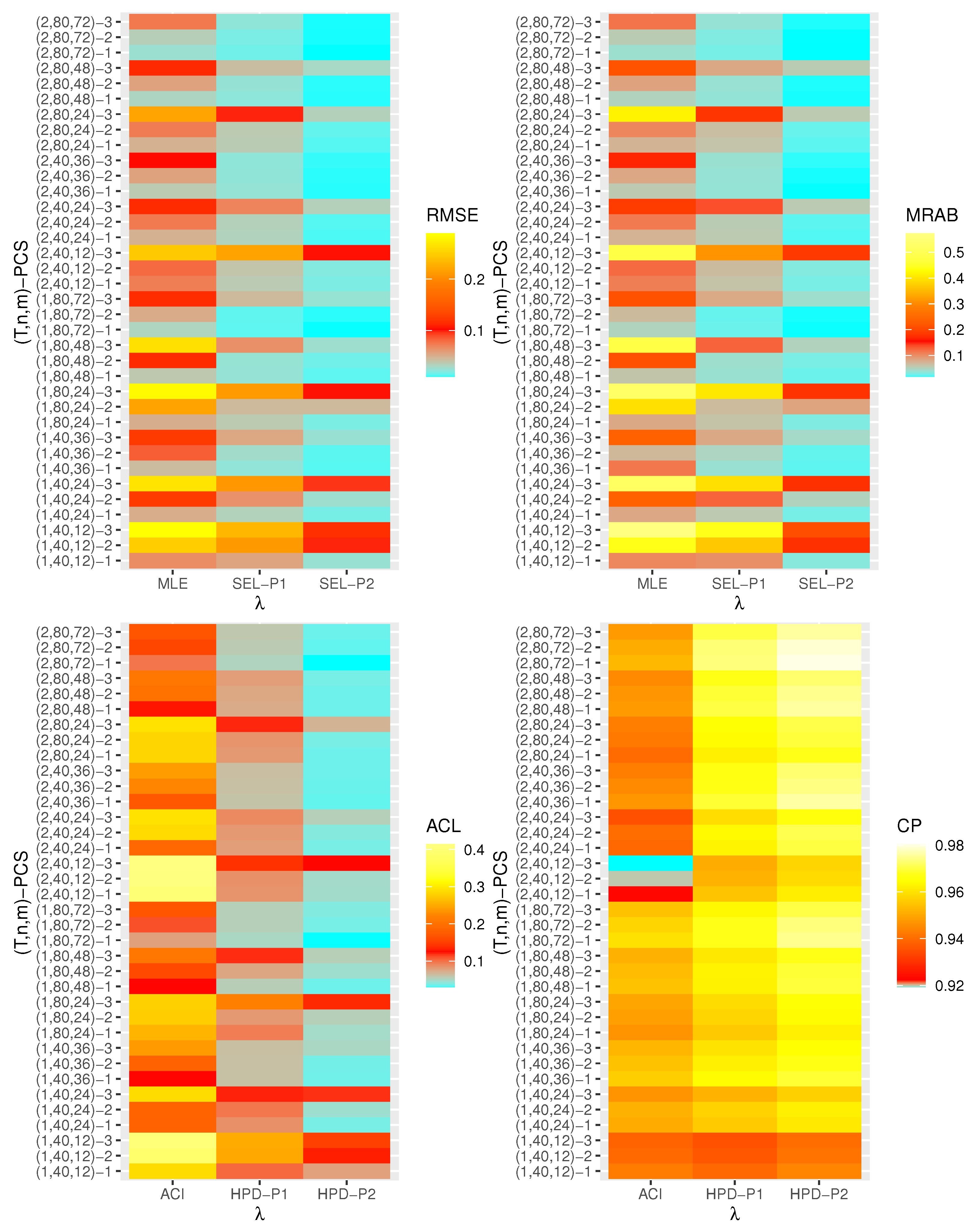
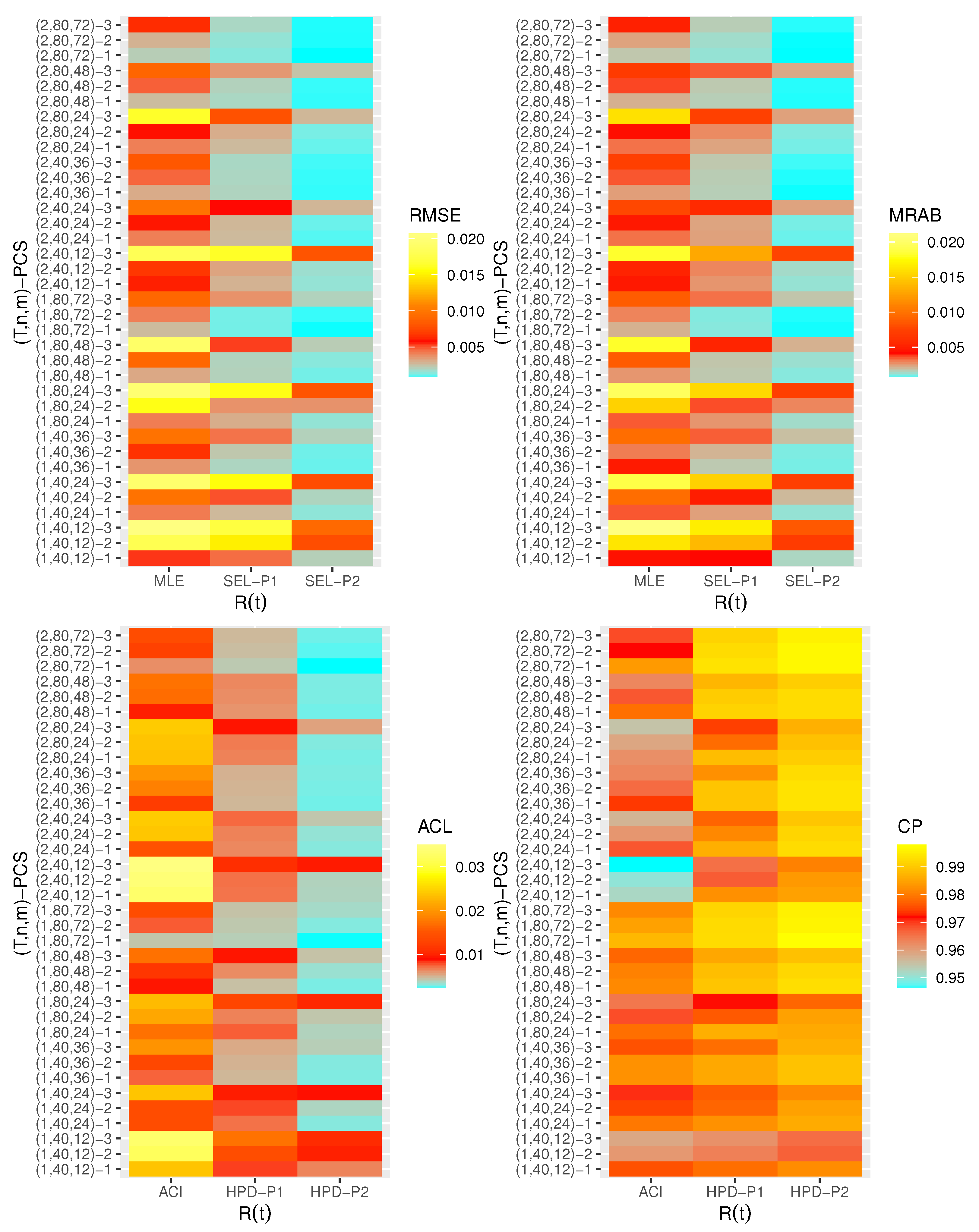
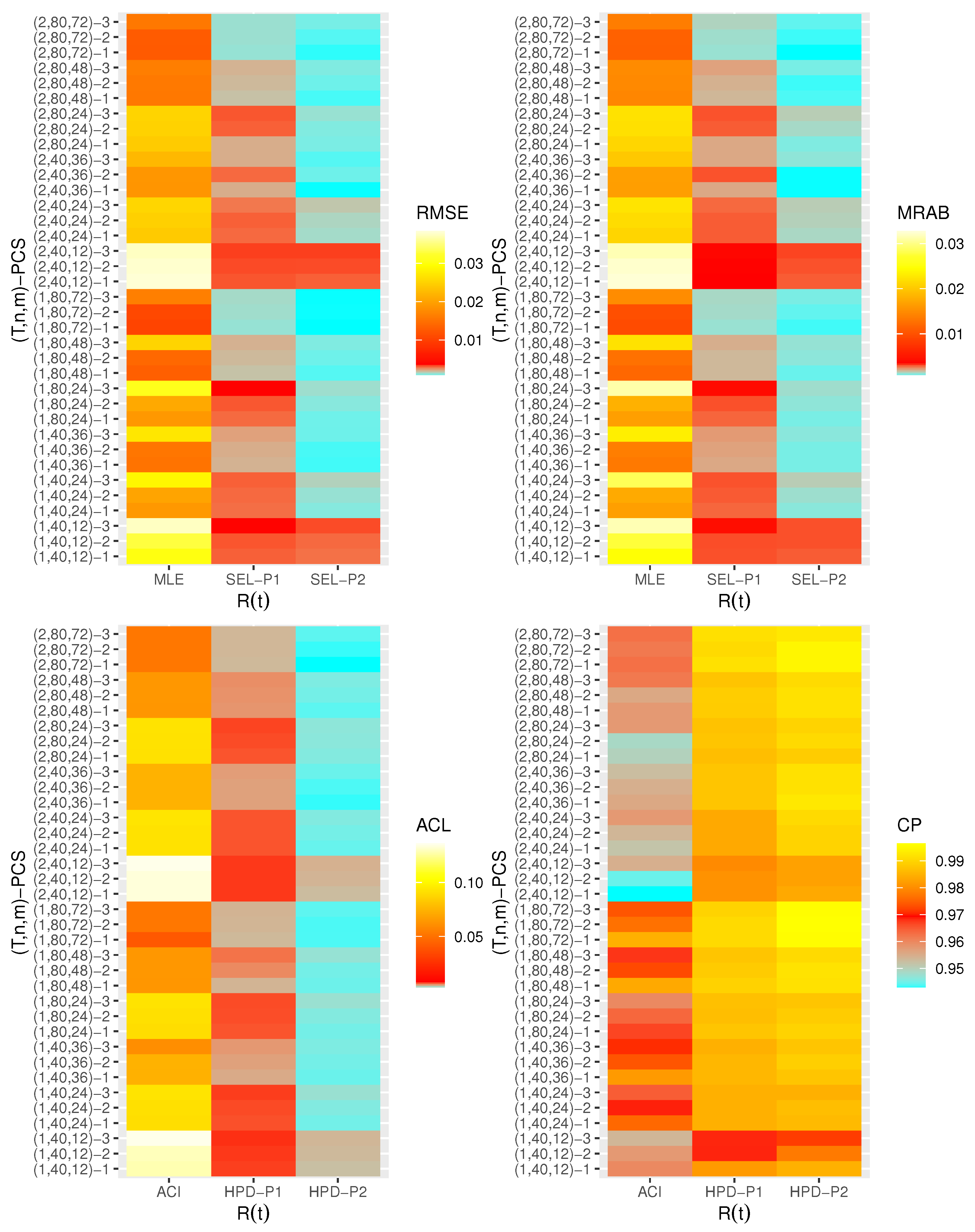
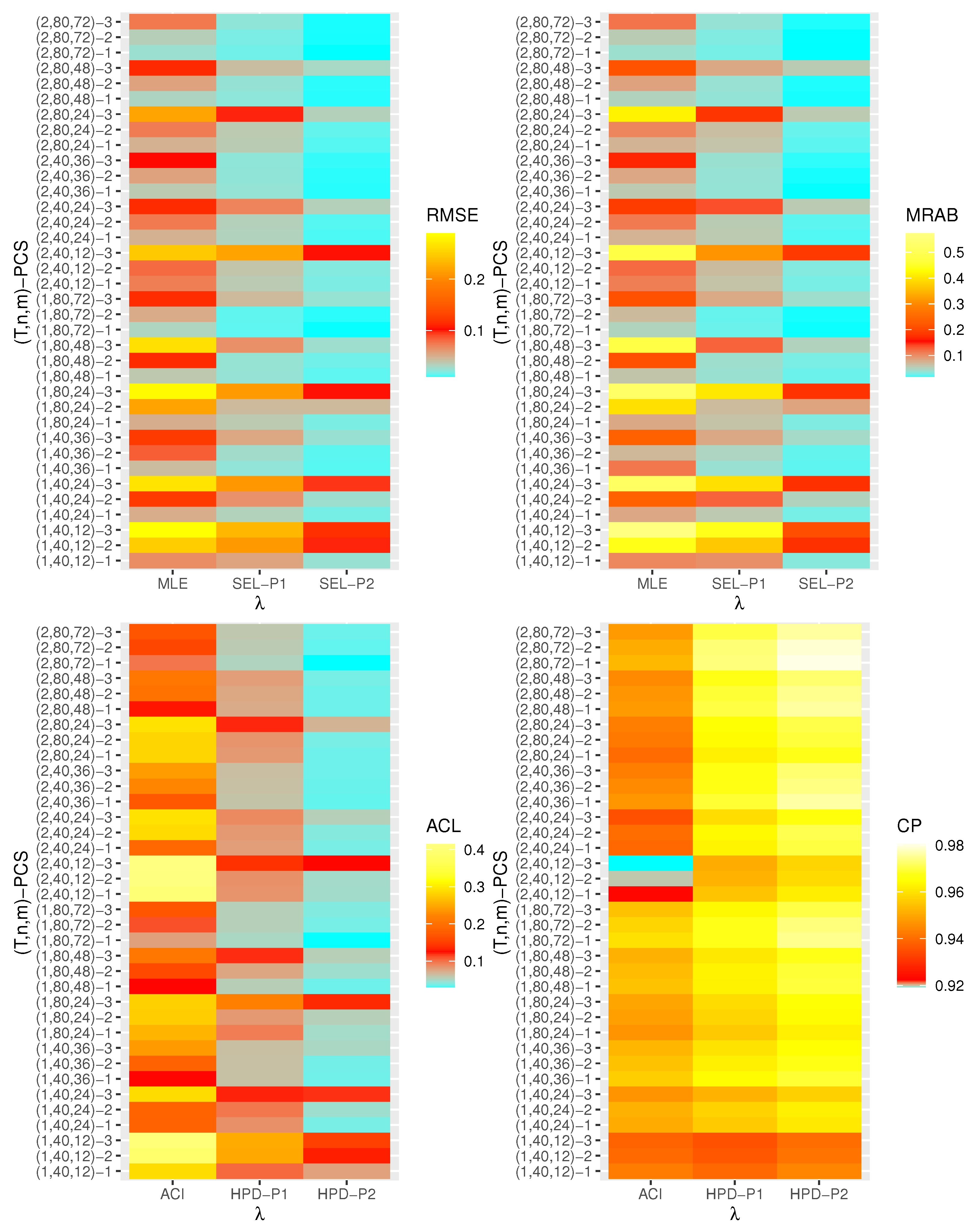
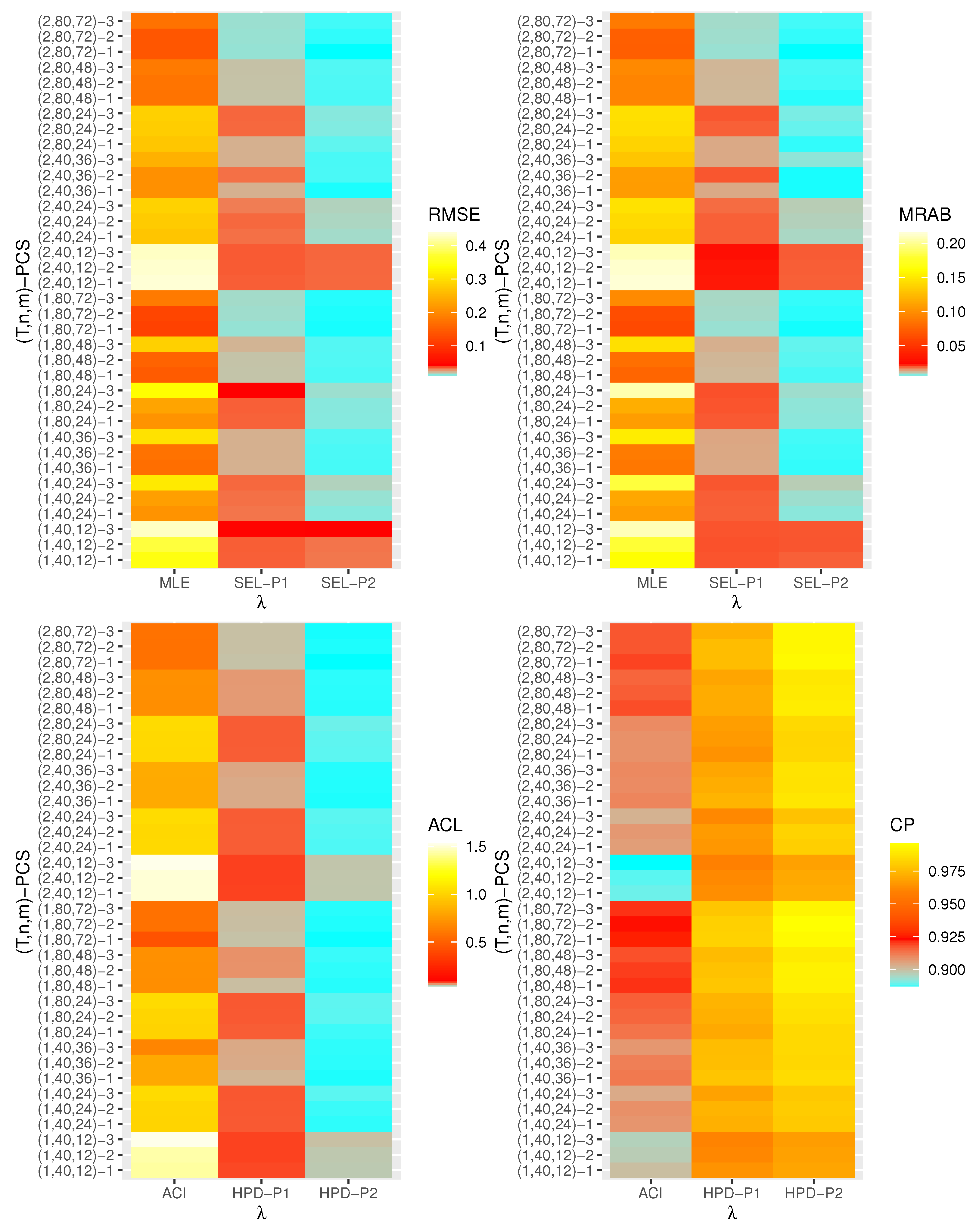
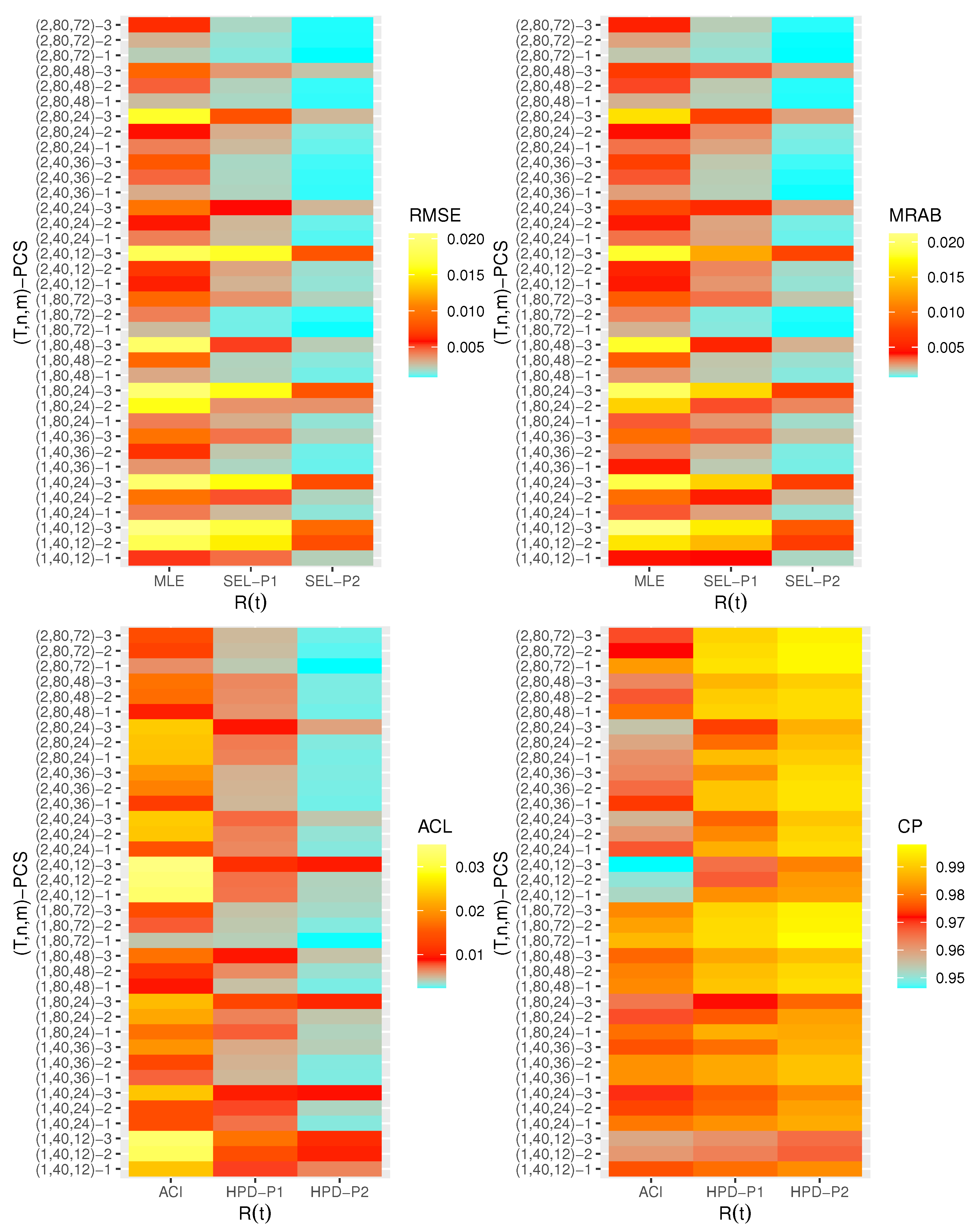
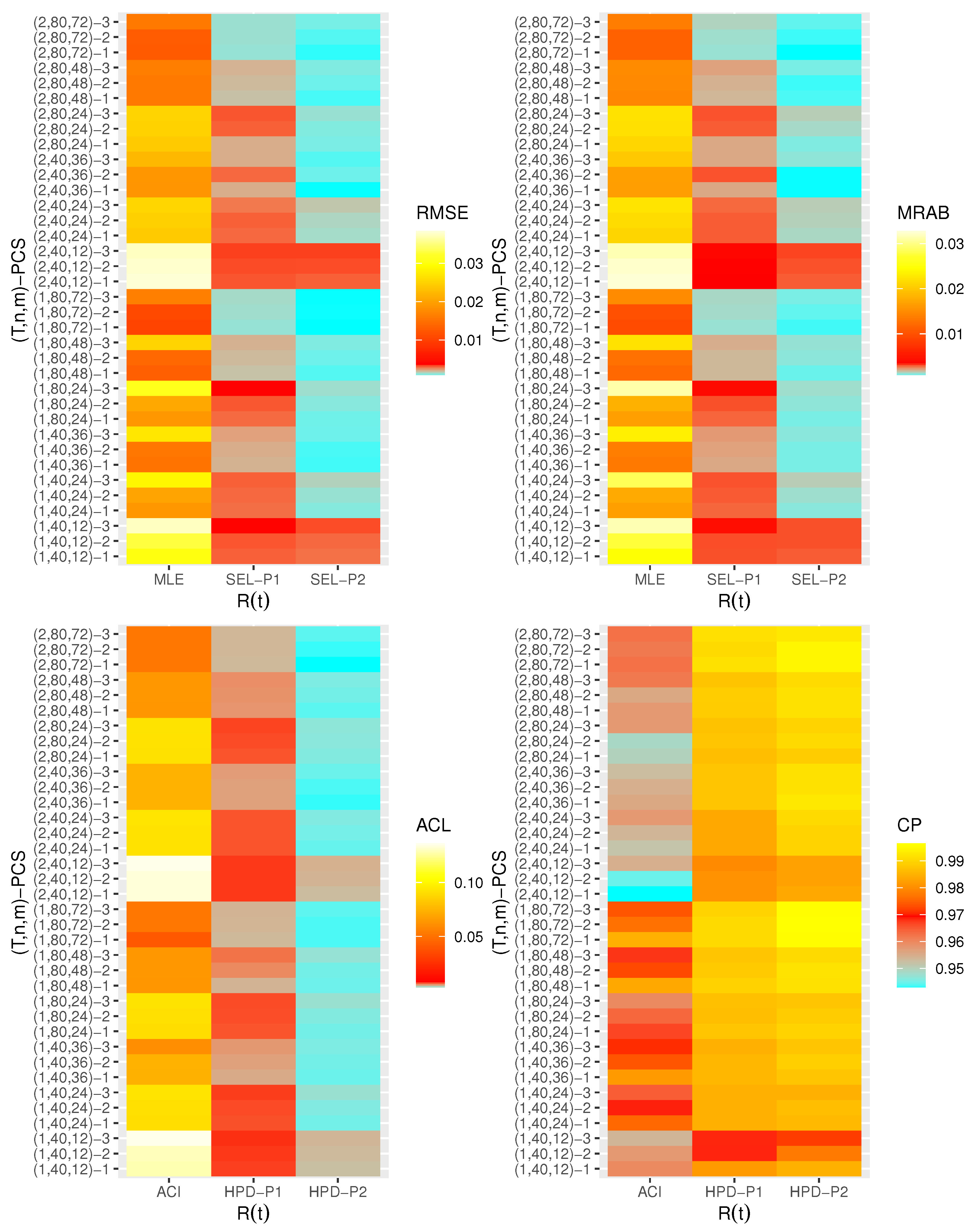
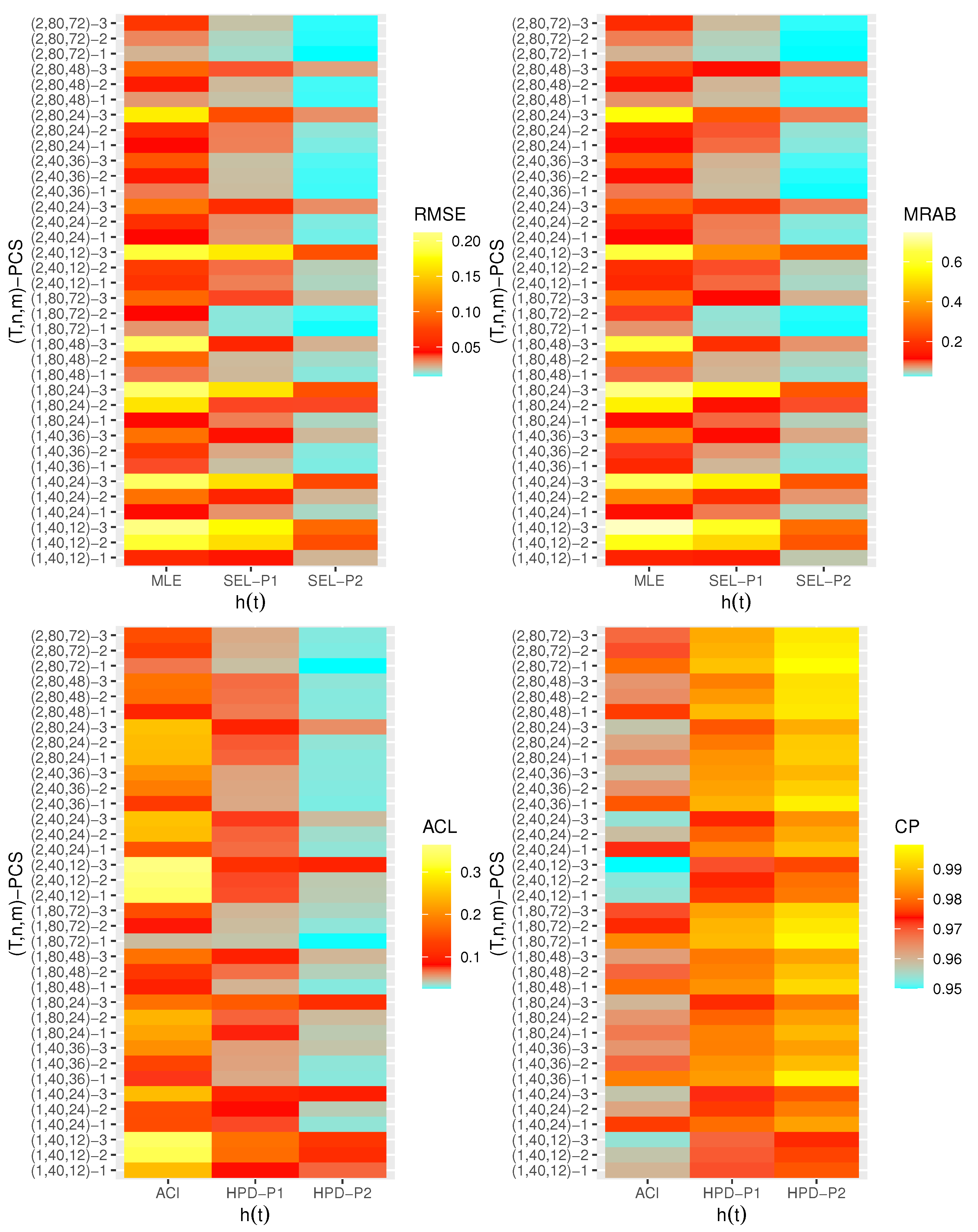
- Generally, the proposed estimates of the unknown parameters , , and behave well in terms of lowest RMSE, MRAB, and ACL values, as well as the highest CP values;
- As n(or m) increases, all estimates of , , and perform better. A similar result is found in the case of the total number of removal patterns, as , decreases;
- Comparing PCSs 1, 2 and 3, we can observe that the RMSEs, MRABs, ACLs, and CPs of all unknown parameters are critically good based on PCS-1 (when the live items are removed at the first stage) compared to others. Since the expected duration of the life test experiment based on the first stage is greater than any other, the data collected under PCS-1 provided more information about the unknown parameters , , and than those obtained based on any others;
- Comparing the gamma priors P1 and P2 on the Bayesian analysis, since the variance of P2 is less than the variance of P1, it can be seen that the Bayesian point/interval estimators of all unknown parameters from P2 perform more satisfactorily than those obtained from P1 in terms of the lowest RMSE, MRAB, and ACL values and largest CP values;
- As T increases, the RMSEs and MRABs of all estimates of all unknown parameters for decrease, while there is an increase for ;
- As T increases, the ACLs of all ACIs of all unknown parameters increase for both and , whereas the associated CPs decrease.
- As T increases, the ACLs of all HPD credible interval estimates of all unknown parameters decrease for and increase for . The opposite behavior is also observed in case of the CPs for all HPD credible interval estimates of , , and ;
- As increases, the RMSEs and MRABs of the MLEs of , , and increase, while those based on the MCMC of decrease and increase for and in most cases;
- As increases, the associated ACLs of the ACIs of , , and become wider, while those based on the HPD credible interval estimates of decrease and increase for and in most cases. Additionally, as increases, the opposite behavior is noted in the case of CPs for ACI/HPD credible interval estimates of , , and ;
- To sum up, the Bayesian paradigm utilizing the M–H algorithm is advised to estimate the scale parameter and the reliability indices RF and HRF of the XL distribution in the presence of the adaptive Type-II progressively hybrid censored scheme.
5. Real-Life Applications
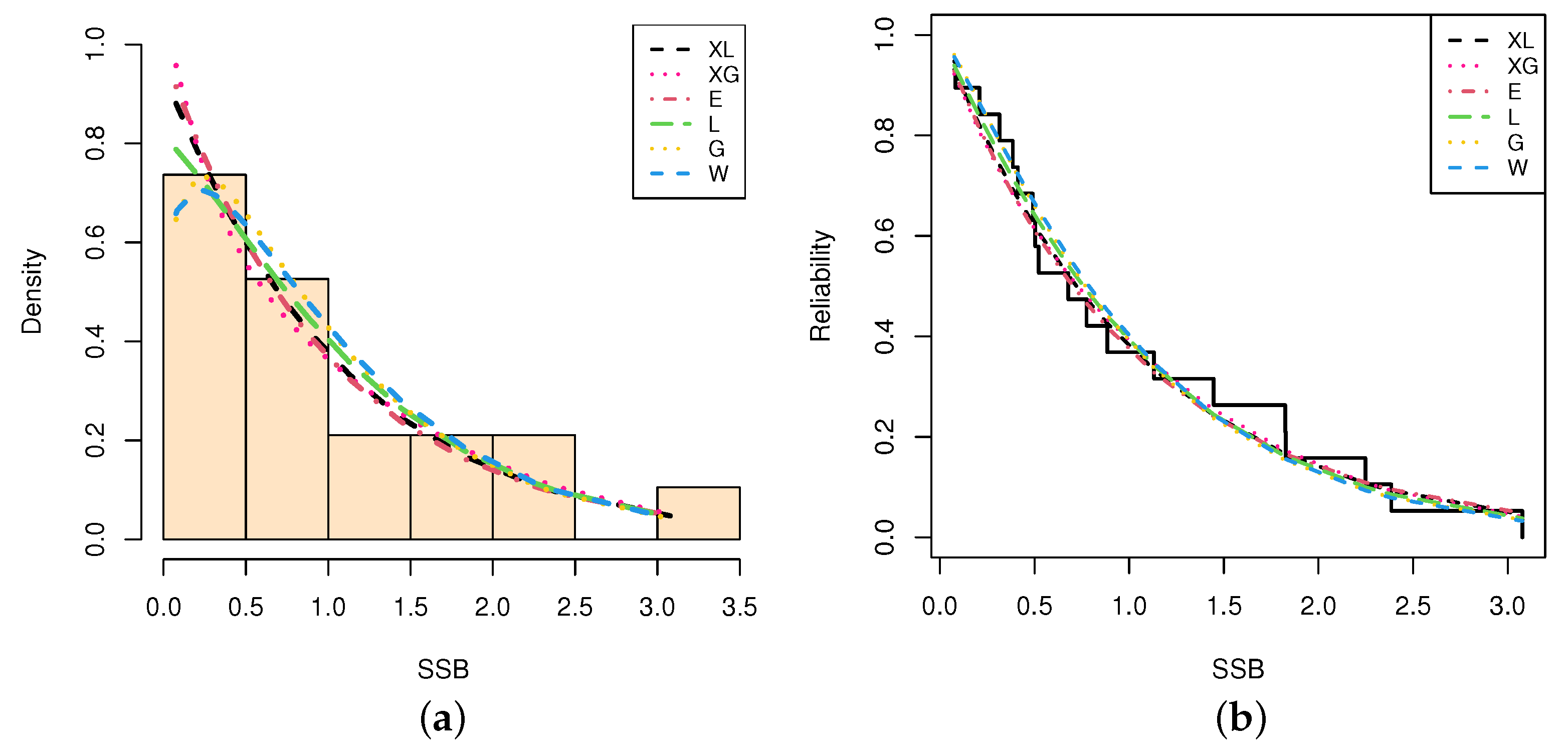
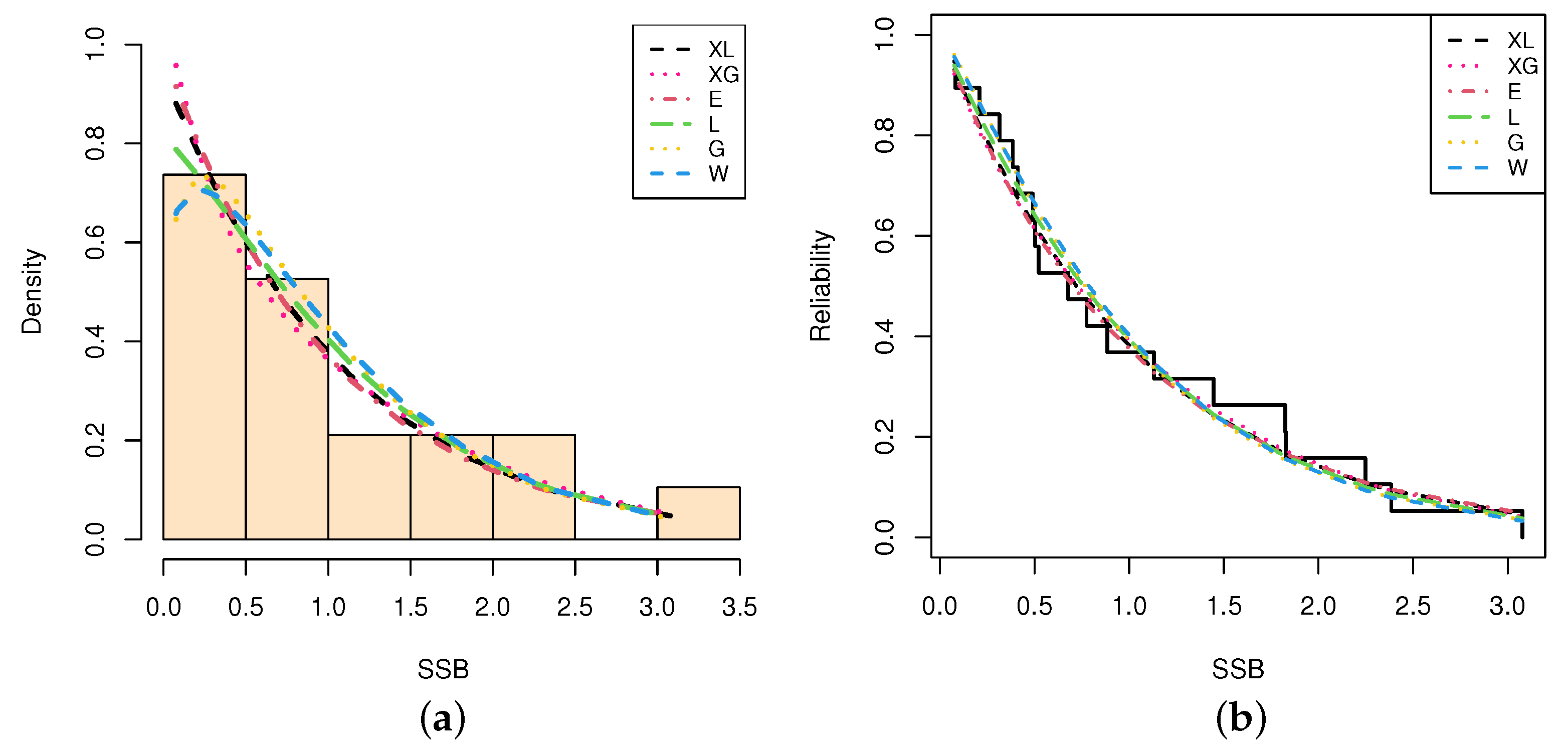
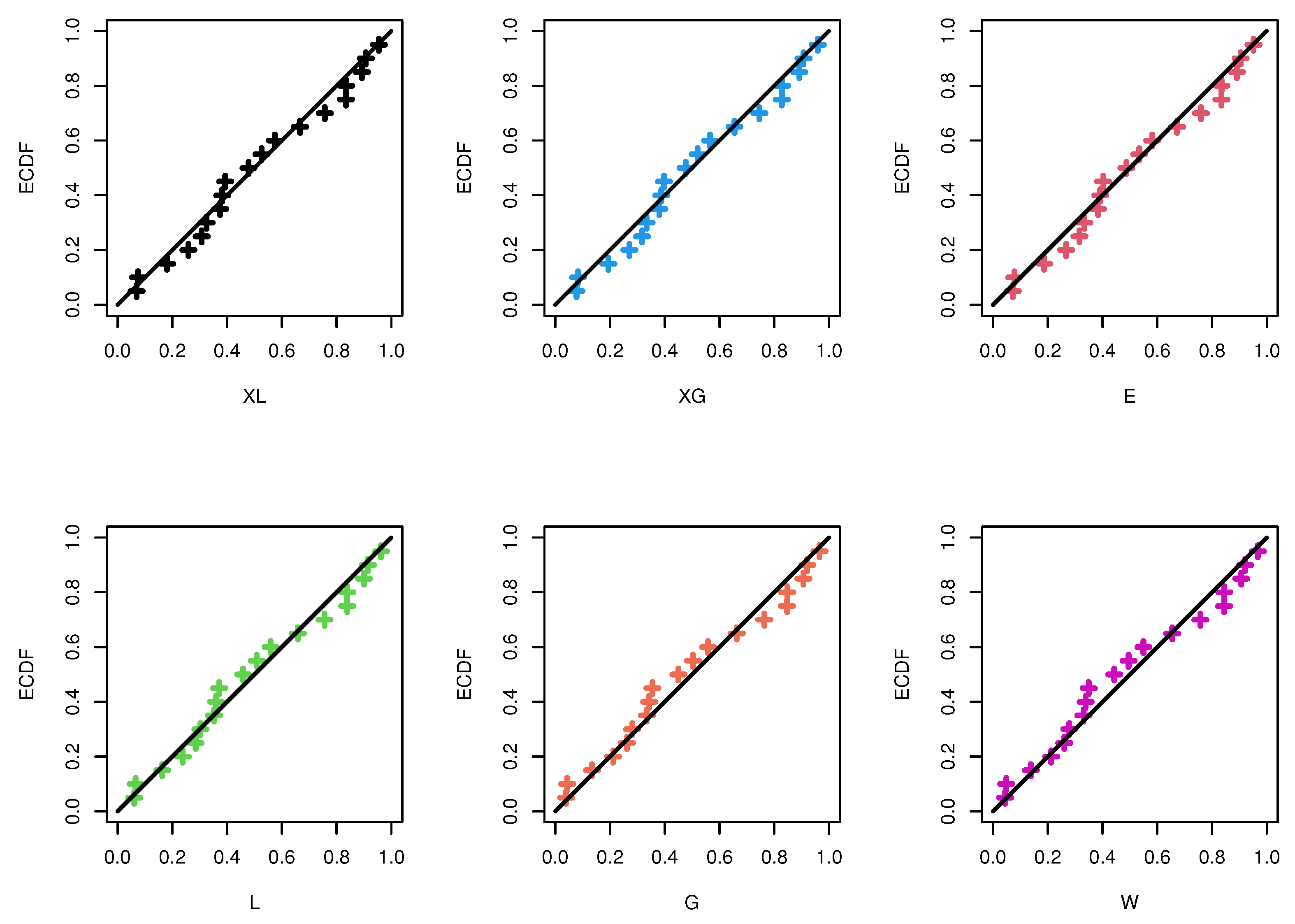
5.1. Sodium Sulfur
5.2. Vinyl Chloride
6. Concluding Remarks
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kundu, D.; Joarder, A. Analysis of Type-II progressively hybrid censored data. Comput. Stat. Data Anal. 2006, 50, 2509–2528. [Google Scholar] [CrossRef]
- Ng, H.K.T.; Kundu, D.; Chan, P.S. Statistical analysis of exponential lifetimes under an adaptive Type-II progressive censoring scheme. Nav. Res. Logist. 2009, 56, 687–698. [Google Scholar] [CrossRef]
- Hemmati, F.; Khorram, E. On adaptive progressively Type-II censored competing risks data. Commun. Stat.-Simul. Comput. 2017, 46, 4671–4693. [Google Scholar] [CrossRef]
- Nassar, M.; Abo-Kasem, O.E. Estimation of the inverse Weibull parameters under adaptive type-II progressive hybrid censoring scheme. J. Comput. Appl. Math. 2017, 315, 228–239. [Google Scholar] [CrossRef]
- Ateya, S.F.; Mohammed, H.S. Statistical inferences based on an adaptive progressive type-II censoring from exponentiated exponential distribution. J. Egypt. Math. Soc. 2017, 25, 393–399. [Google Scholar] [CrossRef]
- Nassar, M.; Abo-Kasem, O.; Zhang, C.; Dey, S. Analysis of Weibull distribution under adaptive type-II progressive hybrid censoring scheme. J. Indian Soc. Probab. Stat. 2018, 19, 25–65. [Google Scholar] [CrossRef]
- Nassar, M.; Alotaibi, R.; Dey, S. Estimation Based on Adaptive Progressively Censored under Competing Risks Model with Engineering Applications. Math. Probl. Eng. 2022, 2022, 6731230. [Google Scholar] [CrossRef]
- Sobhi, M.M.A.; Soliman, A.A. Estimation for the exponentiated Weibull model with adaptive Type-II progressive censored schemes. Appl. Math. Model. 2016, 40, 1180–1192. [Google Scholar] [CrossRef]
- Panahi, H.; Moradi, N. Estimation of the inverted exponentiated Rayleigh distribution based on adaptive Type II progressive hybrid censored sample. J. Comput. Appl. Math. 2020, 364, 112345. [Google Scholar] [CrossRef]
- Chen, S.; Gui, W. Statistical analysis of a lifetime distribution with a bathtub-shaped failure rate function under adaptive progressive type-II censoring. Mathematics 2020, 8, 670. [Google Scholar] [CrossRef]
- Panahi, H.; Asadi, S. On adaptive progressive hybrid censored Burr type III distribution: Application to the nano droplet dispersion data. Qual. Technol. Quant. Manag. 2021, 18, 179–201. [Google Scholar] [CrossRef]
- Okasha, H.; Nassar, M.; Dobbah, S.A. E-Bayesian estimation of Burr Type XII model based on adaptive Type-II progressive hybrid censored data. AIMS Math. 2021, 6, 4173–4196. [Google Scholar] [CrossRef]
- Alotaibi, R.; Elshahhat, A.; Rezk, H.; Nassar, M. Inferences for Alpha Power Exponential Distribution Using Adaptive Progressively Type-II Hybrid Censored Data with Applications. Symmetry 2022, 14, 651. [Google Scholar] [CrossRef]
- Lindley, D.V. Fiducial distributions and Bayes’ theorem. J. R. Stat. Soc. Ser. B 1958, 20, 102–107. [Google Scholar] [CrossRef]
- Chouia, S.; Zeghdoudi, H. The XLindley Distribution: Properties and Application. J. Stat. Theory Appl. 2021, 20, 318–327. [Google Scholar] [CrossRef]
- Greene, W.H. Econometric Analysis, 4th ed.; Prentice-Hall: New York, NY, USA, 2000. [Google Scholar]
- Ahmed, E.A. Bayesian estimation based on progressive Type-II censoring from two-parameter bathtub-shaped lifetime model: An Markov chain Monte Carlo approach. J. Appl. Stat. 2014, 41, 752–768. [Google Scholar] [CrossRef]
- Dey, S.; Wang, L.; Nassar, M. Inference on Nadarajah–Haghighi distribution with constant stress partially accelerated life tests under progressive type-II censoring. J. Appl. Stat. 2021, 49, 2891–2912. [Google Scholar] [CrossRef]
- Chen, M.H.; Shao, Q.M. Monte Carlo estimation of Bayesian credible and HPD intervals. J. Comput. Graph. Stat. 1999, 8, 69–92. [Google Scholar]
- Balakrishnan, N.; Cramer, E. The Art of Progressive Censoring; Springer, Birkhäuser: New York, NY, USA, 2014. [Google Scholar]
- Plummer, M.; Best, N.; Cowles, K.; Vines, K. CODA: Convergence diagnosis and output analysis for MCMC. R News 2006, 6, 7–11. [Google Scholar]
- Henningsen, A.; Toomet, O. maxLik: A package for maximum likelihood estimation in R. Comput. Stat. 2011, 26, 443–458. [Google Scholar] [CrossRef]
- Pavia, J.M. Testing goodness-of-fit with the kernel density estimator: GoFKernel. J. Stat. Softw. 2015, 66, 1–27. [Google Scholar] [CrossRef]
- Elshahhat, A.; Nassar, M. Bayesian survival analysis for adaptive Type-II progressive hybrid censored Hjorth data. Comput. Stat. 2021, 36, 1965–1990. [Google Scholar] [CrossRef]
- Elshahhat, A.; Elemary, B.R. Analysis for Xgamma Parameters of Life under Type-II Adaptive Progressively Hybrid Censoring with Applications in Engineering and Chemistry. Symmetry 2021, 13, 2112. [Google Scholar] [CrossRef]
- Ansell, R.O.; Ansell, J.I. Modelling the reliability of sodium sulphur cells. Reliab. Eng. 1987, 17, 127–137. [Google Scholar] [CrossRef]
- Phillips, M.J. Statistical Methods for Reliability Data Analysis. In Handbook of Reliability Engineering; Springer: London, UK, 2003. [Google Scholar]
- Sen, S.; Maiti, S.S.; Chandra, N. The xgamma distribution: Statistical properties and application. J. Mod. Appl. Stat. Methods. 2016, 15, 774–788. [Google Scholar] [CrossRef]
- Bhaumik, D.K.; Kapur, K.; Gibbons, R.D. Testing parameters of a gamma distribution for small samples. Technometrics 2009, 51, 326–334. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
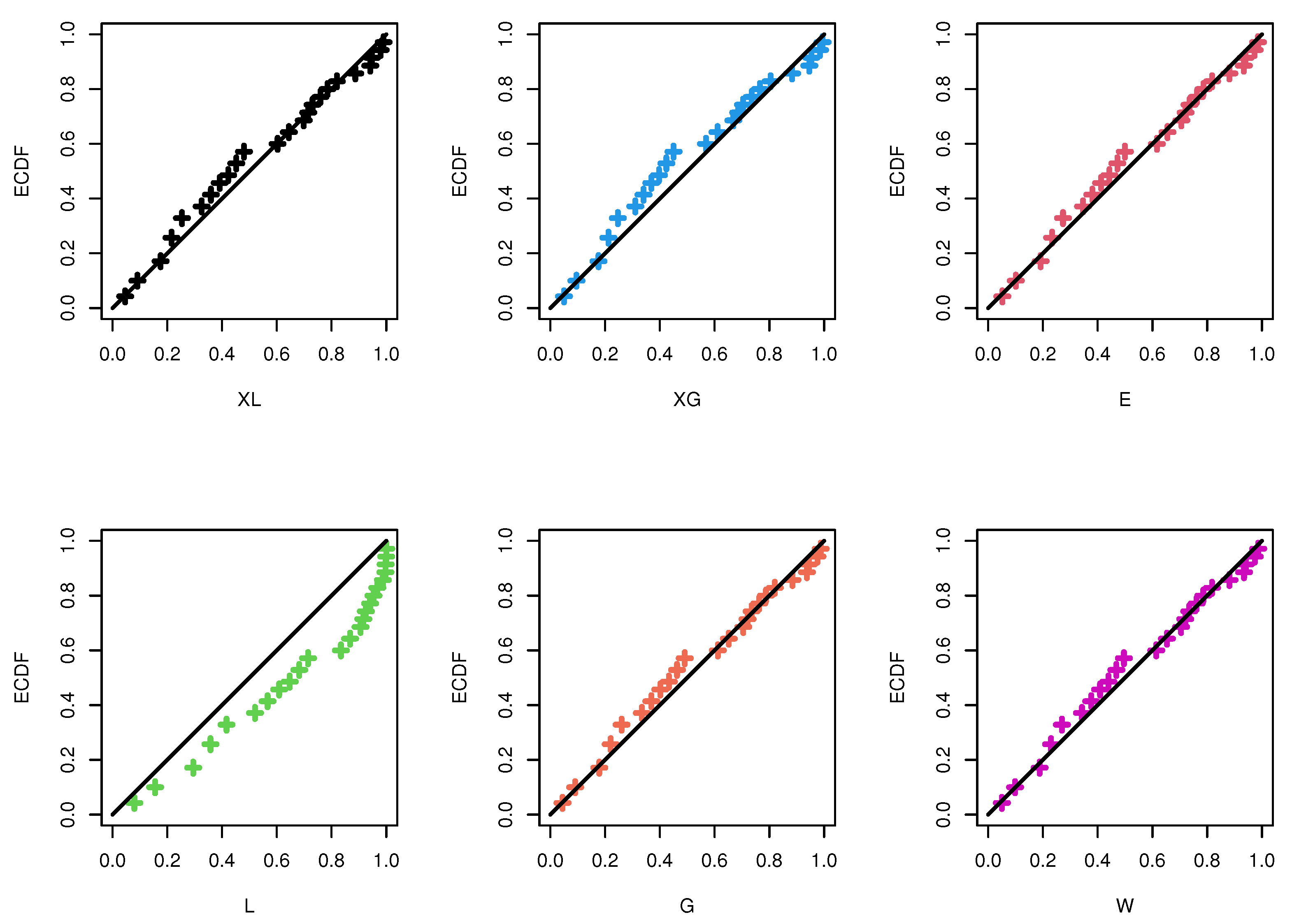
| Model | MLE(SE) | A | CA | B | HQ | KS | ||
|---|---|---|---|---|---|---|---|---|
| Distance | p-Value | |||||||
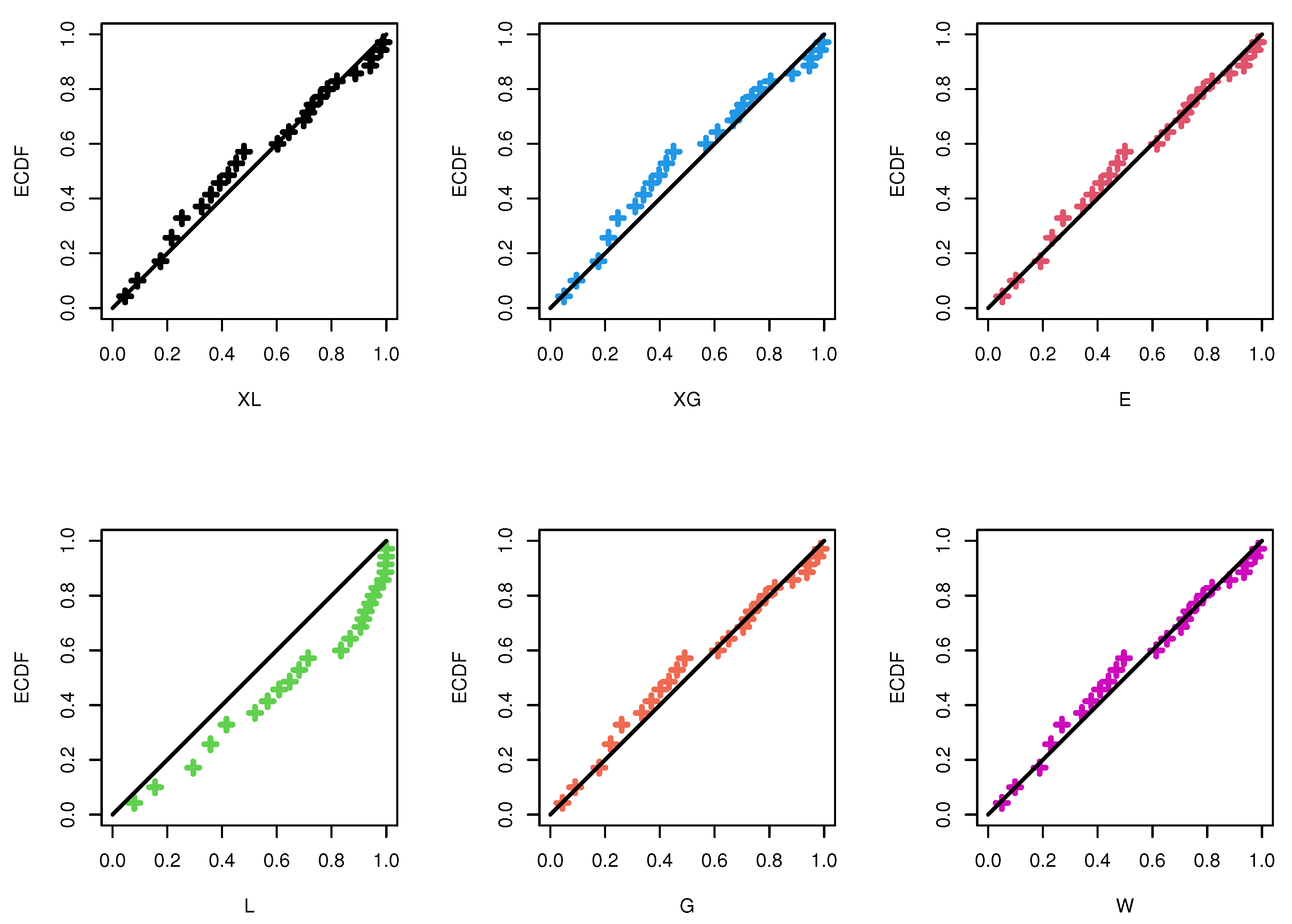
| XL | - | 1.1897(0.2230) | 40.3272 | 40.5655 | 41.2676 | 40.4870 | 0.1009 | 0.979 |
| XG | - | 1.7176(0.2910) | 40.3342 | 40.5695 | 41.2786 | 40.4940 | 0.1127 | 0.947 |
| E | - | 0.9859(0.2262) | 40.5401 | 40.7754 | 41.4846 | 40.7000 | 0.1091 | 0.959 |
| L | - | 1.4191(0.2466) | 41.3270 | 41.5492 | 42.3227 | 41.5213 | 0.1015 | 0.976 |
| G | 1.1697(0.2119) | 1.0749(0.2228) | 41.8206 | 42.5706 | 43.7095 | 42.1403 | 0.1245 | 0.896 |
| W | 1.2970(0.3788) | 1.2787(0.4537) | 41.8005 | 42.5505 | 43.6894 | 42.1202 | 0.1191 | 0.921 |
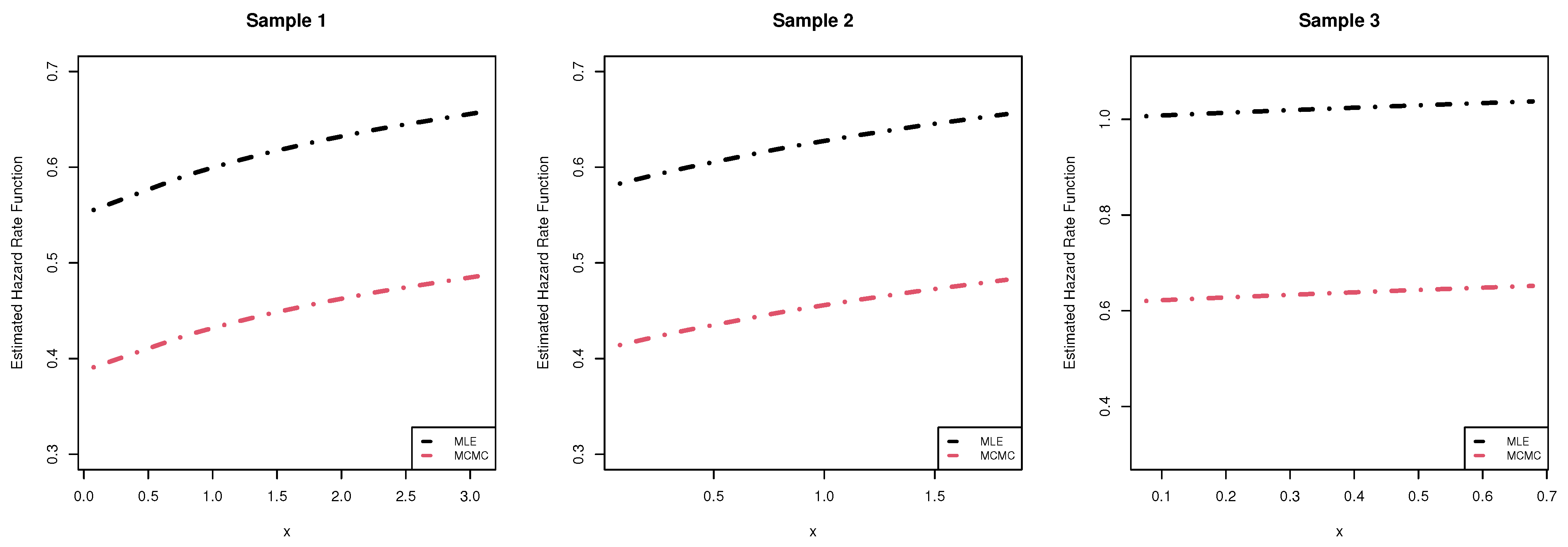
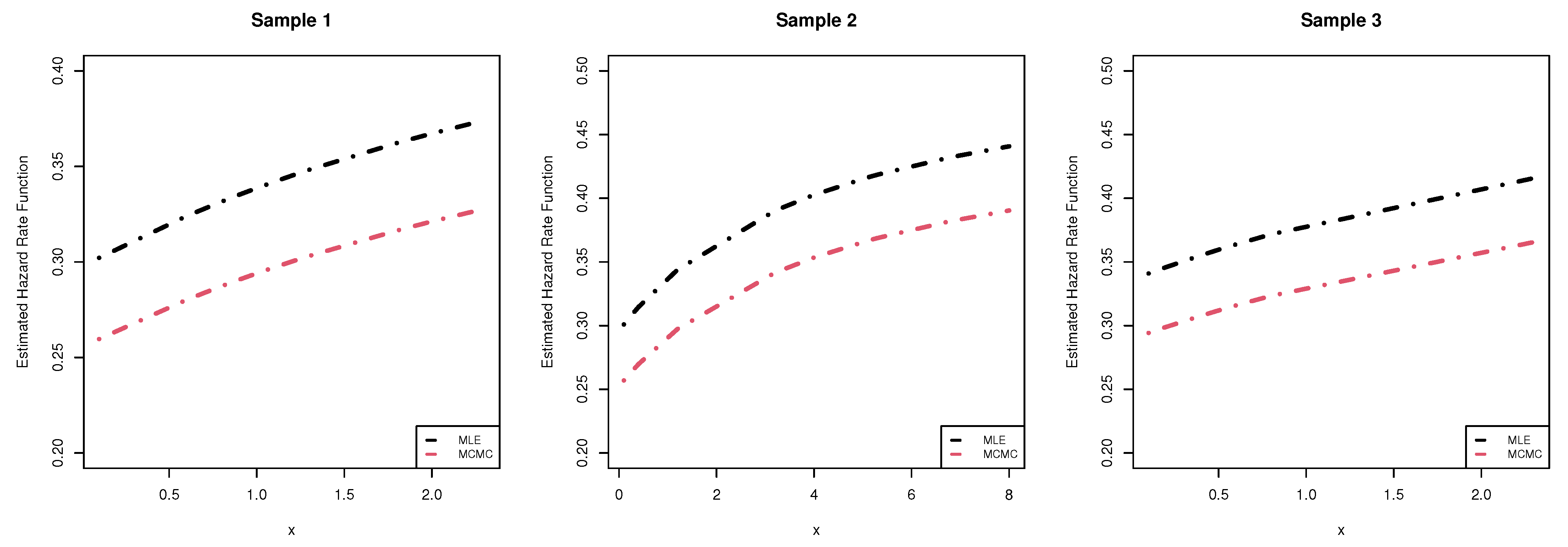
| Sample | R | Censored Data | ||
|---|---|---|---|---|
| 1 | 4(10) | 0 | 0.076, 0.775, 0.884, 1.131, 1.446, 1.824, 1.827, 2.248, 2.385, 3.077 | |
| 2 | 0.7(5) | 4 | 0.076, 0.082, 0.210, 0.315, 0.385, 0.775, 0.884, 1.131, 1.446, 1.824 | |
| 3 | 0.4(5) | 9 | 0.076, 0.082, 0.210, 0.315, 0.385, 0.412, 0.491, 0.504, 0.522, 0.678 |
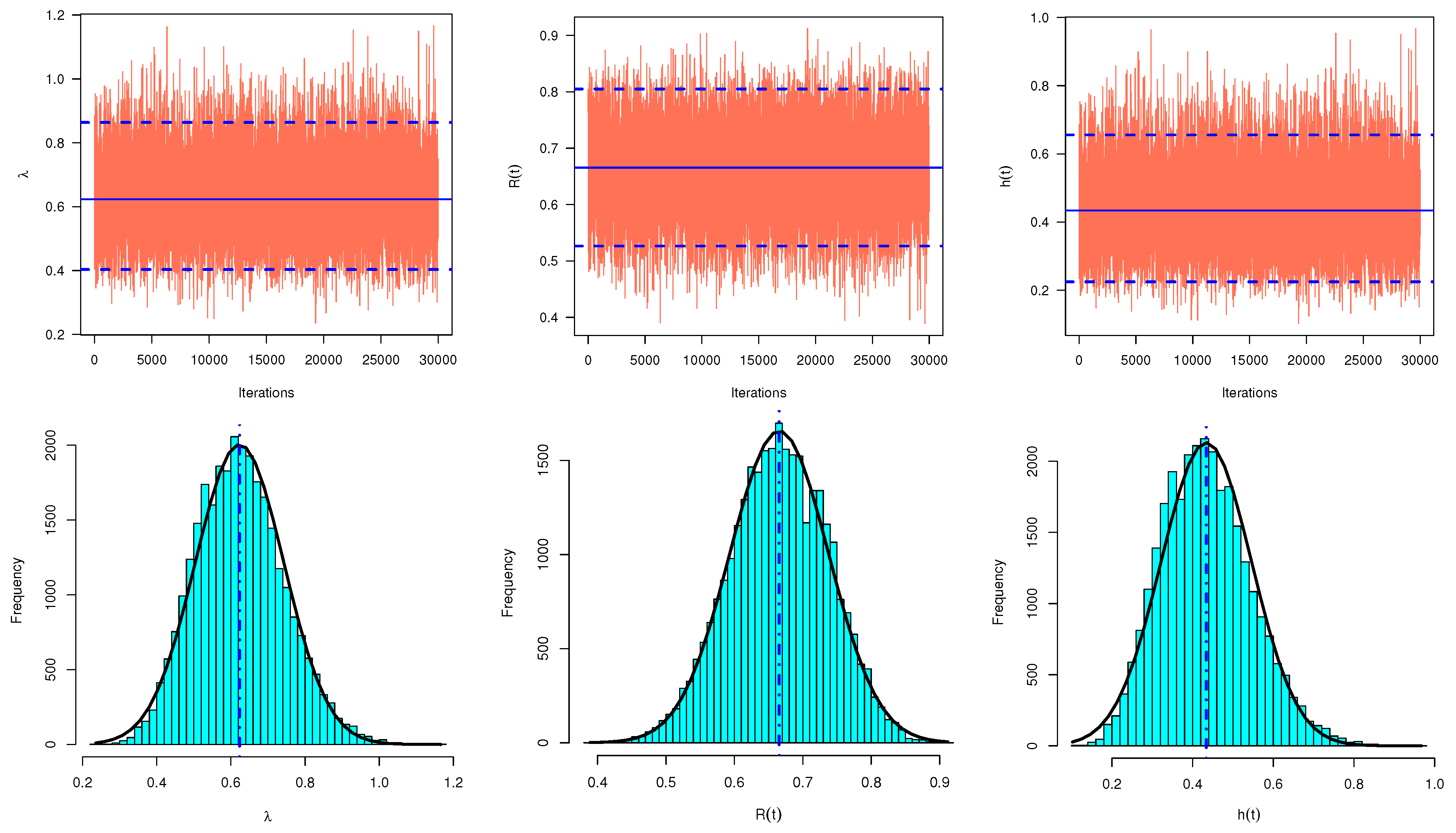
| Sample | Parameter | MLE | MCMC | ACI | HPD |
|---|---|---|---|---|---|
| 1 | 0.7976 | 0.6233 | (0.4132,1.1820) | (0.4033,0.8636) | |
| 0.1961 | 0.0007 | 0.7688 | 0.4603 | ||
| 0.5616 | 0.6654 | (0.3457,0.7775) | (0.5265,0.8049) | ||
| 0.1101 | 0.0005 | 0.4318 | 0.2785 | ||
| 0.5996 | 0.4340 | (0.3691,0.8301) | (0.2246,0.6556) | ||
| 0.1176 | 0.0006 | 0.4610 | 0.4310 | ||
| 2 | 0.8261 | 0.6486 | (0.4388,1.2133) | (0.4190,0.8862) | |
| 0.1976 | 0.0007 | 0.7746 | 0.4672 | ||
| 0.5462 | 0.6502 | (0.3347,0.7578) | (0.5085,0.7878) | ||
| 0.1079 | 0.0004 | 0.4231 | 0.2793 | ||
| 0.6275 | 0.4577 | (0.3845,0.8706) | (0.2467,0.6868) | ||
| 0.1240 | 0.0007 | 0.4861 | 0.4401 | ||
| 3 | 1.2491 | 0.8647 | (0.6276,1.8706) | (0.5382,1.1899) | |
| 0.3171 | 0.0010 | 1.2430 | 0.6517 | ||
| 0.3576 | 0.5318 | (0.1353,0.5798) | (0.3710,0.7054) | ||
| 0.1134 | 0.0005 | 0.4444 | 0.3344 | ||
| 1.0511 | 0.6673 | (0.3979,1.7043) | (0.3529,0.9911) | ||
| 0.3333 | 0.0010 | 1.3065 | 0.6382 |
| Model | MLE(SE) | A | CA | B | HQ | KS | ||
|---|---|---|---|---|---|---|---|---|
| Distance | p-Value | |||||||
| XL | - | 0.5321(0.0913) | 112.9052 | 113.0302 | 114.4316 | 113.4257 | 0.0890 | 0.9507 |
| XG | - | 1.0313(0.1235) | 114.9701 | 115.0951 | 116.4965 | 115.4906 | 0.1384 | 0.5330 |
| E | - | 0.7145(0.0944) | 113.4008 | 113.5258 | 114.9271 | 113.9213 | 0.1081 | 0.8221 |
| L | - | 0.8238(0.1054) | 114.6073 | 114.7323 | 116.1336 | 115.1278 | 0.1327 | 0.5878 |
| G | 1.0627(0.2281) | 0.5654(0.1536) | 114.8263 | 115.2134 | 117.8790 | 115.8674 | 0.0973 | 0.9042 |
| W | 1.0121(0.1328) | 1.8855(0.3377) | 114.8996 | 115.2867 | 117.9523 | 115.9407 | 0.0916 | 0.9376 |
| Sample | R | Censored Data | ||
|---|---|---|---|---|
| 1 | 0.50(1) | 10 | 0.1, 0.6, 0.8, 0.9, 0.9, 1.0, 1.1, 1.2, 1.2, 1.3, 1.8, 2.0, 2.0, 2.3 | |
| 2 | 1.15(7) | 0 | 0.1, 0.1, 0.2, 0.2, 0.4, 0.4, 0.4, 1.2, 3.2, 4.0, 5.1, 5.3, 6.8, 8.0 | |
| 3 | 2.2(13) | 10 | 0.1, 0.1, 0.2, 0.2, 0.4, 0.4, 0.4, 0.5, 0.5, 0.5, 0.6, 0.6, 0.8, 2.3 |
| Sample | Parameter | MLE | MCMC | ACI | HPD |
|---|---|---|---|---|---|
| 1 | 0.5226 | 0.4730 | (0.3274,0.7178) | (0.3464,0.6055) | |
| 0.0996 | 0.0004 | 0.3904 | 0.2591 | ||
| 0.7267 | 0.7593 | (0.5848,0.8685) | (0.6740,0.8424) | ||
| 0.0724 | 0.0002 | 0.2837 | 0.1684 | ||
| 0.3386 | 0.2951 | (0.2725,0.4047) | (0.1807,0.4094) | ||
| 0.0337 | 0.0003 | 0.1322 | 0.2287 | ||
| 2 | 0.5212 | 0.4698 | (0.3192,0.7232) | (0.3399,0.6063) | |
| 0.1301 | 0.0004 | 0.4040 | 0.2664 | ||
| 0.7275 | 0.7614 | (0.5806,0.8745) | (0.6735,0.8466) | ||
| 0.0750 | 0.0003 | 0.2939 | 0.1731 | ||
| 0.3374 | 0.2923 | (0.2692,0.4055) | (0.1746,0.4093) | ||
| 0.0348 | 0.0003 | 0.1363 | 0.2347 | ||
| 3 | 0.5666 | 0.5135 | (0.3577,0.7754) | (0.3764,0.6473) | |
| 0.1066 | 0.0004 | 0.4177 | 0.2709 | ||
| 0.6985 | 0.7331 | (0.5526,0.8444) | (0.6456,0.8197) | ||
| 0.0744 | 0.0003 | 0.2917 | 0.1741 | ||
| 0.3790 | 0.3313 | (0.2998,0.4581) | (0.2106,0.4546) | ||
| 0.0404 | 0.0004 | 0.1583 | 0.2440 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alotaibi, R.; Nassar, M.; Elshahhat, A. Computational Analysis of XLindley Parameters Using Adaptive Type-II Progressive Hybrid Censoring with Applications in Chemical Engineering. Mathematics 2022, 10, 3355. https://doi.org/10.3390/math10183355
Alotaibi R, Nassar M, Elshahhat A. Computational Analysis of XLindley Parameters Using Adaptive Type-II Progressive Hybrid Censoring with Applications in Chemical Engineering. Mathematics. 2022; 10(18):3355. https://doi.org/10.3390/math10183355
Chicago/Turabian StyleAlotaibi, Refah, Mazen Nassar, and Ahmed Elshahhat. 2022. "Computational Analysis of XLindley Parameters Using Adaptive Type-II Progressive Hybrid Censoring with Applications in Chemical Engineering" Mathematics 10, no. 18: 3355. https://doi.org/10.3390/math10183355
APA StyleAlotaibi, R., Nassar, M., & Elshahhat, A. (2022). Computational Analysis of XLindley Parameters Using Adaptive Type-II Progressive Hybrid Censoring with Applications in Chemical Engineering. Mathematics, 10(18), 3355. https://doi.org/10.3390/math10183355