
Multi-Level Cross-Modal Semantic Alignment Network for Video–Text Retrieval


Abstract
:1. Introduction
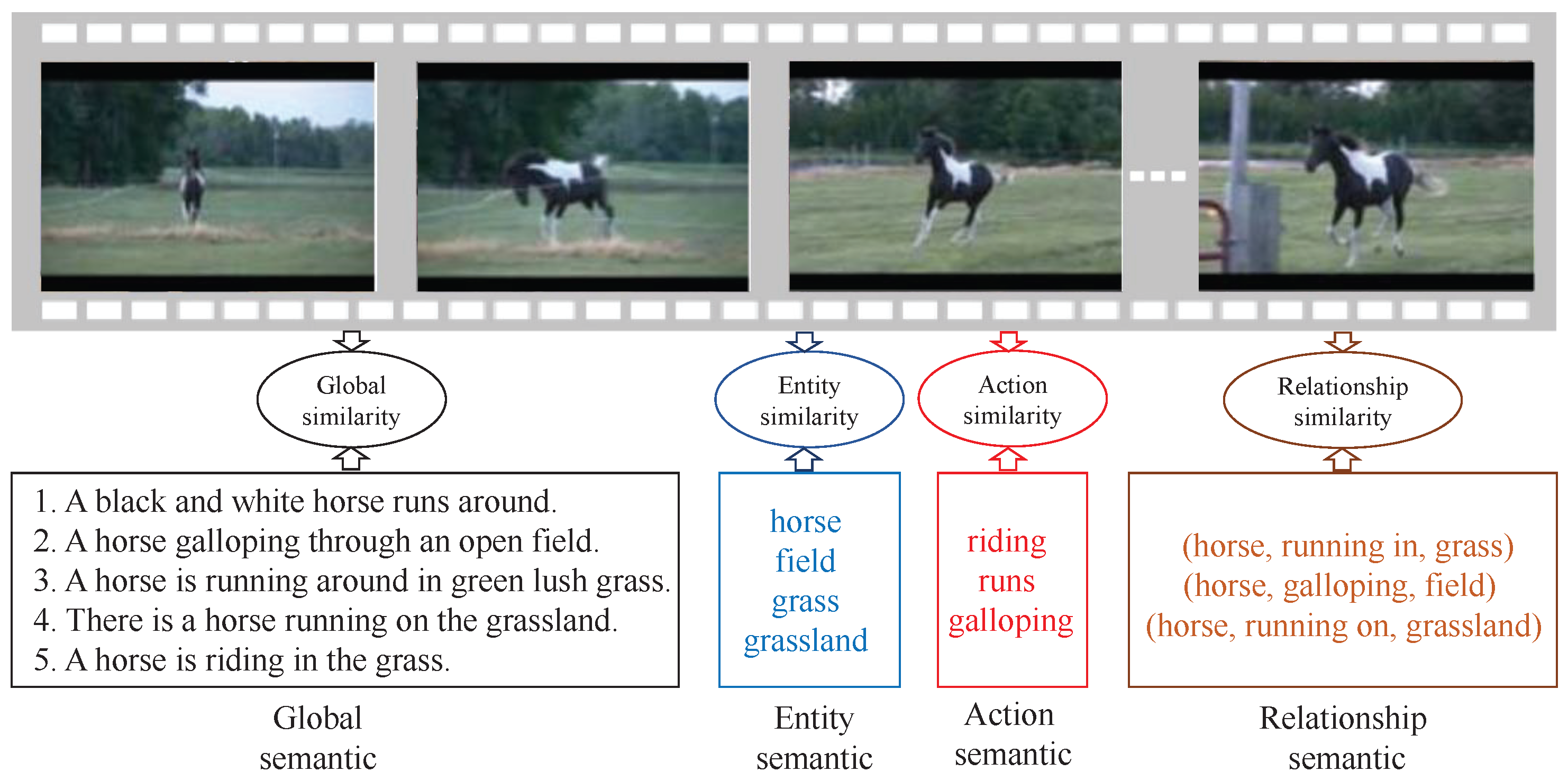
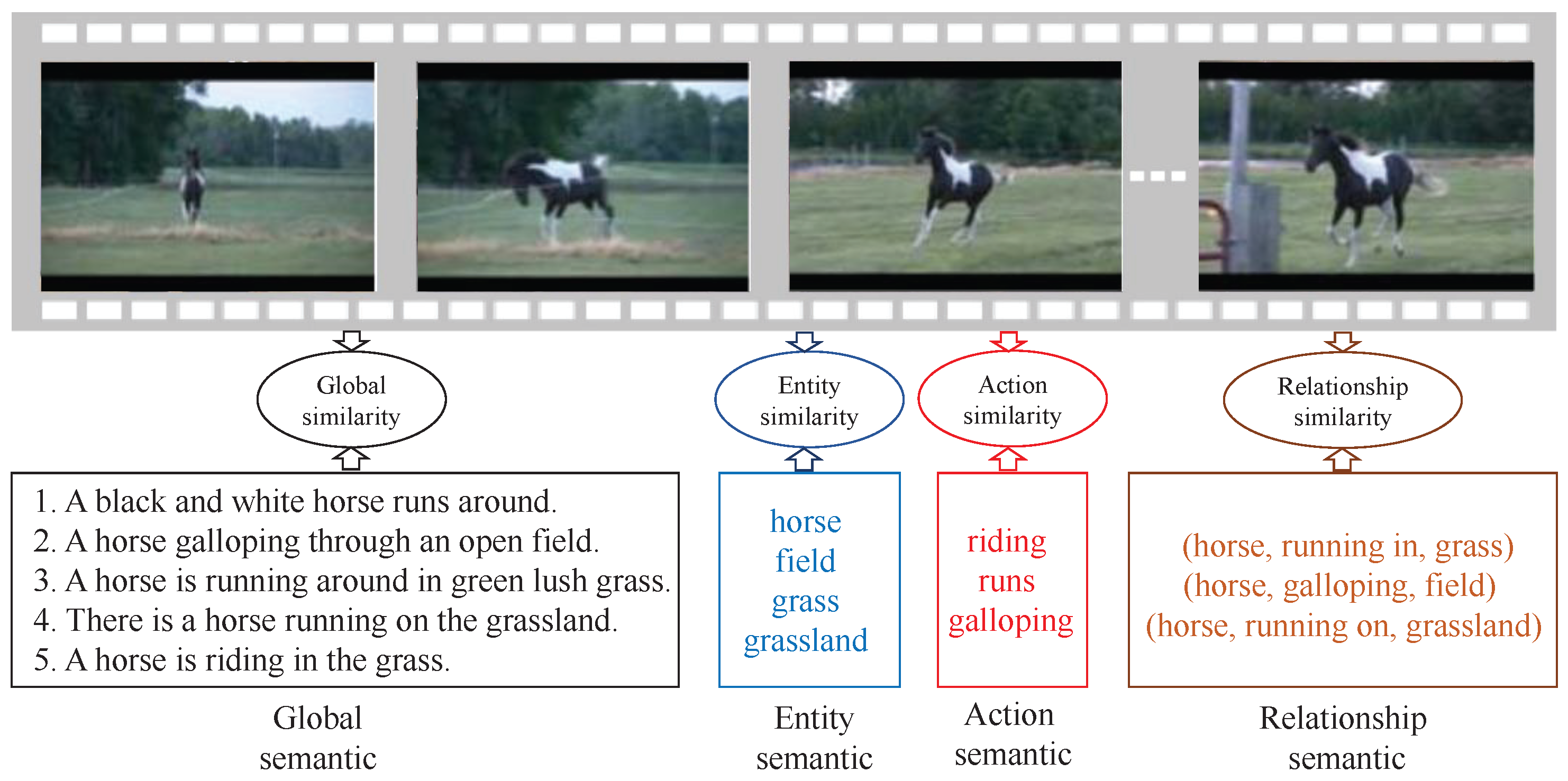
- A novel Multi-Level Cross-Modal Semantic Alignment Network (MCSAN) is developed for video–text retrieval tasks. The semantic similarity between video and text is fully considered at four semantic levels (global, action, entity and relationship) by carefully designing spatial–temporal semantic learning structures and cross-modal representation distribution constraints in an end-to-end framework, which offers an alternative orientation for video–text retrieval.
- Compared with existing works, we are the first to measure the similarity of video–text pairs using relationship semantic level. We demonstrate that relationship, which is also a complementary and crucial clue for video–text retrieval.
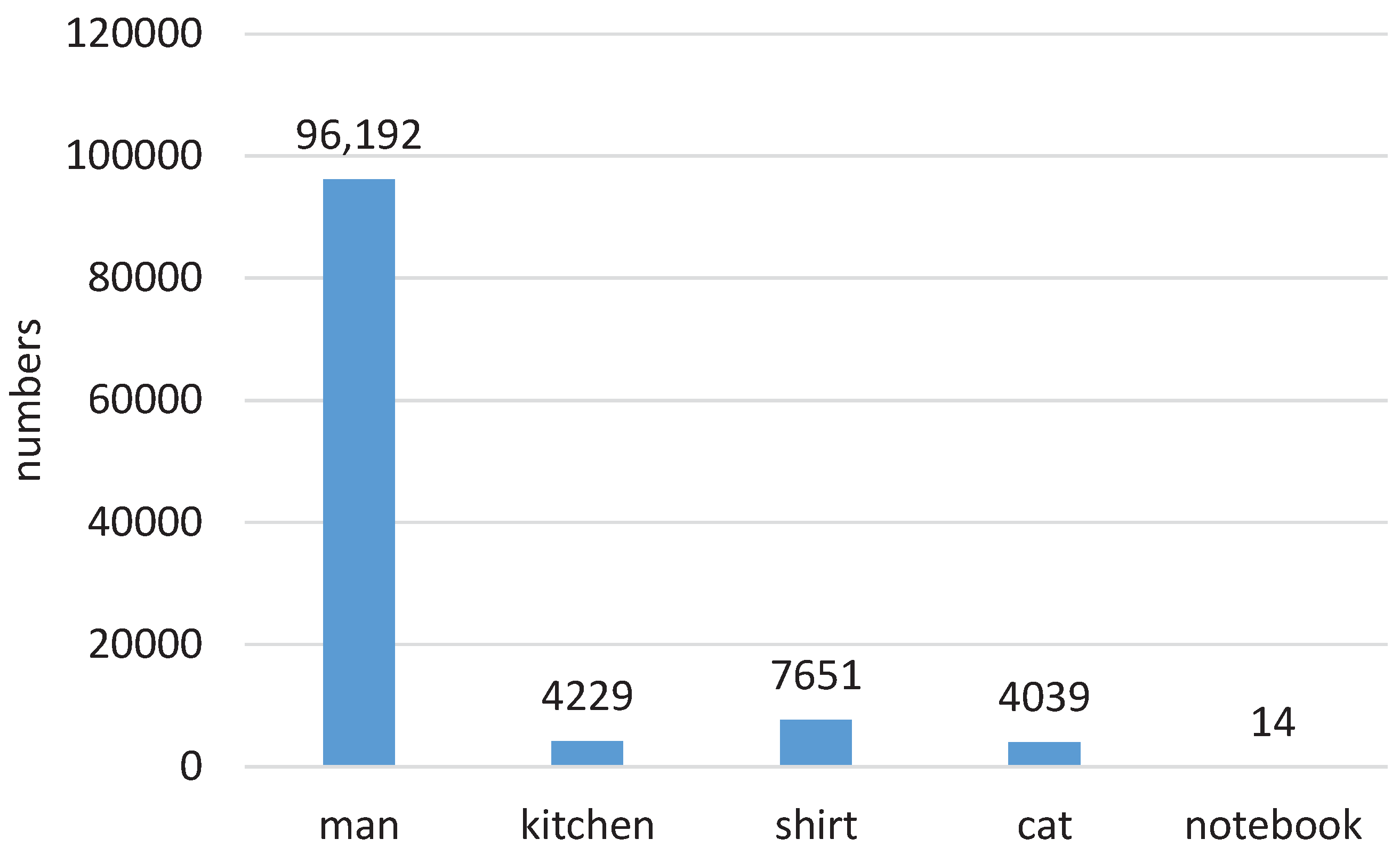
- We introduce a novel focal binary cross-entropy (FBCE) loss function for multi-label attributes regression. Though several papers adopt attributes to improve the performance of video–text retrieval, to the best of our knowledge, this is the first effort to consider and handle the unbalanced attributes distribution problem in video–text retrieval scenarios.
- By carefully incorporating spatial–temporal semantic learning structures, cross-modal representation distribution constraints, novel multi-label classification loss function, adaptive graph learning, and cross-modal contextual attention module, our proposed method can jointly enjoy the merits of alleviate semantic gap and long-tailed multi-level multi-modal attributes learning for video–text retrieval. Moreover, we conduct extensive experiments on two popular benchmarks, i.e., MSR-VTT [27] and VATEX [30], demonstrating the rationality and effectiveness of the proposed multi-level cross-modal semantic alignment network.
2. Related Work
2.1. Modality Encoding
2.2. Similarity Calculation
3. Methodology
3.1. Problem Statement
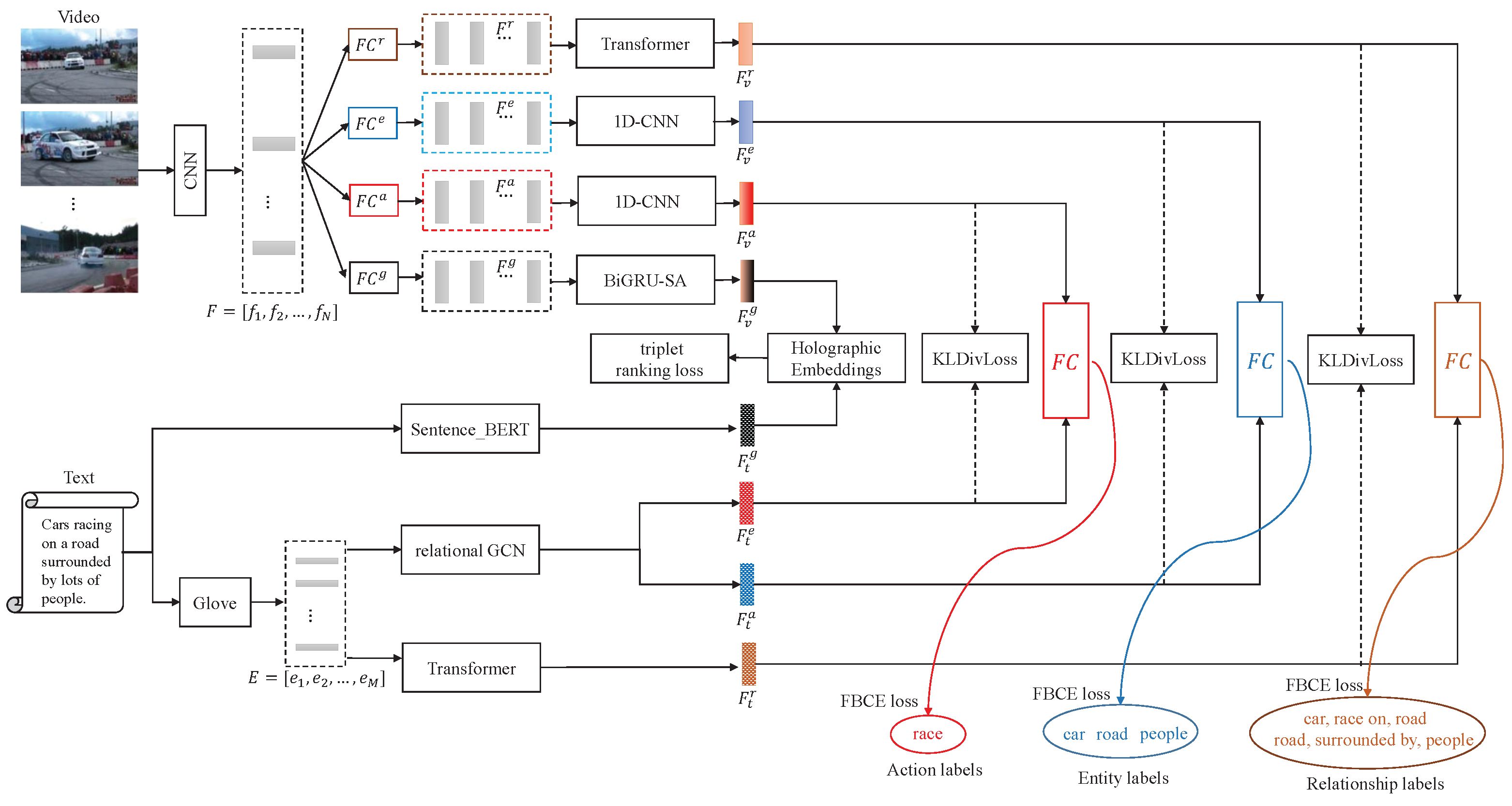
3.2. Overall Framework
3.3. Multi-Level Attributes Vocabulary Construction
3.4. Multi-Level Text and Video Semantics Encoding
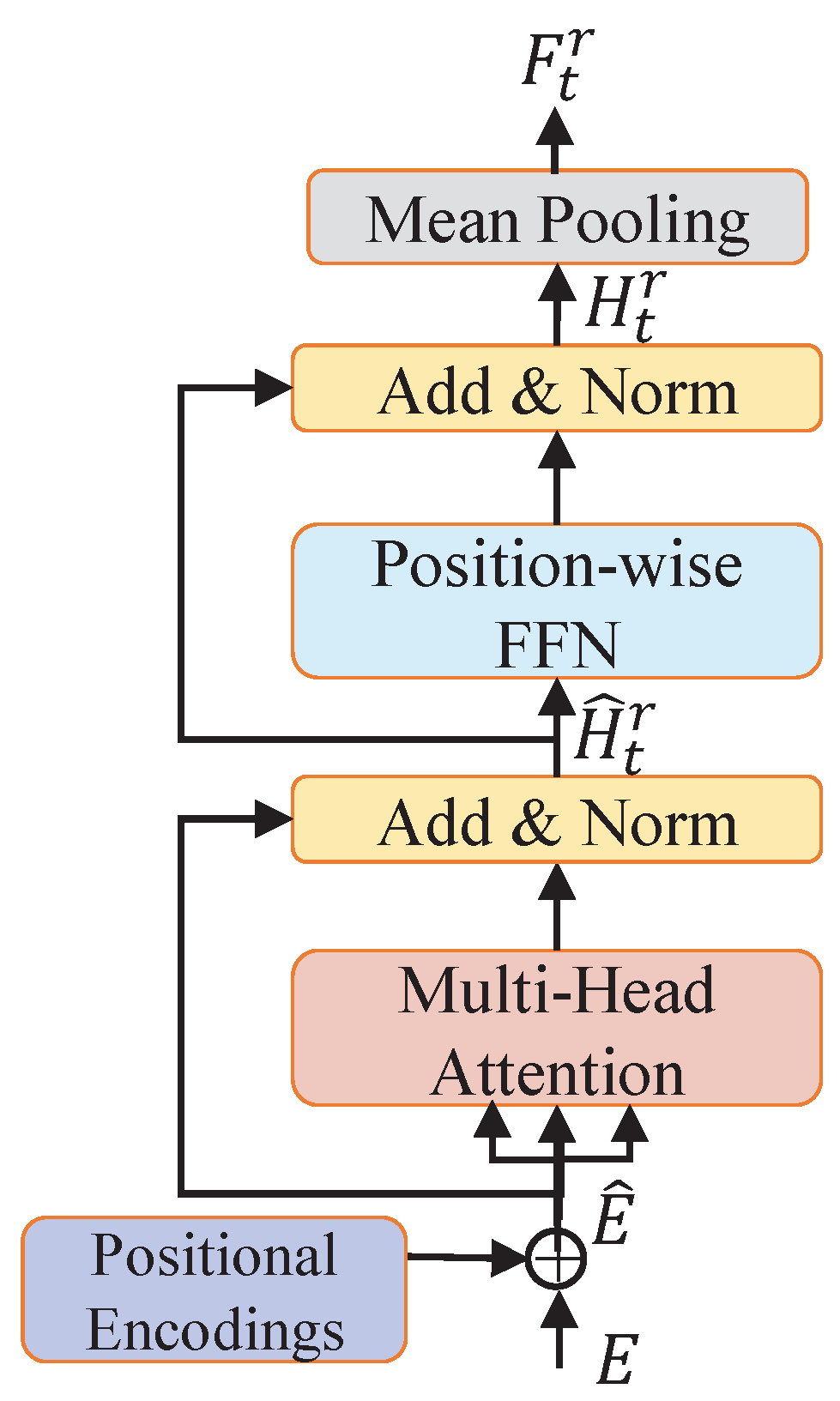
3.4.1. Multi-Level Text Semantics Encoding
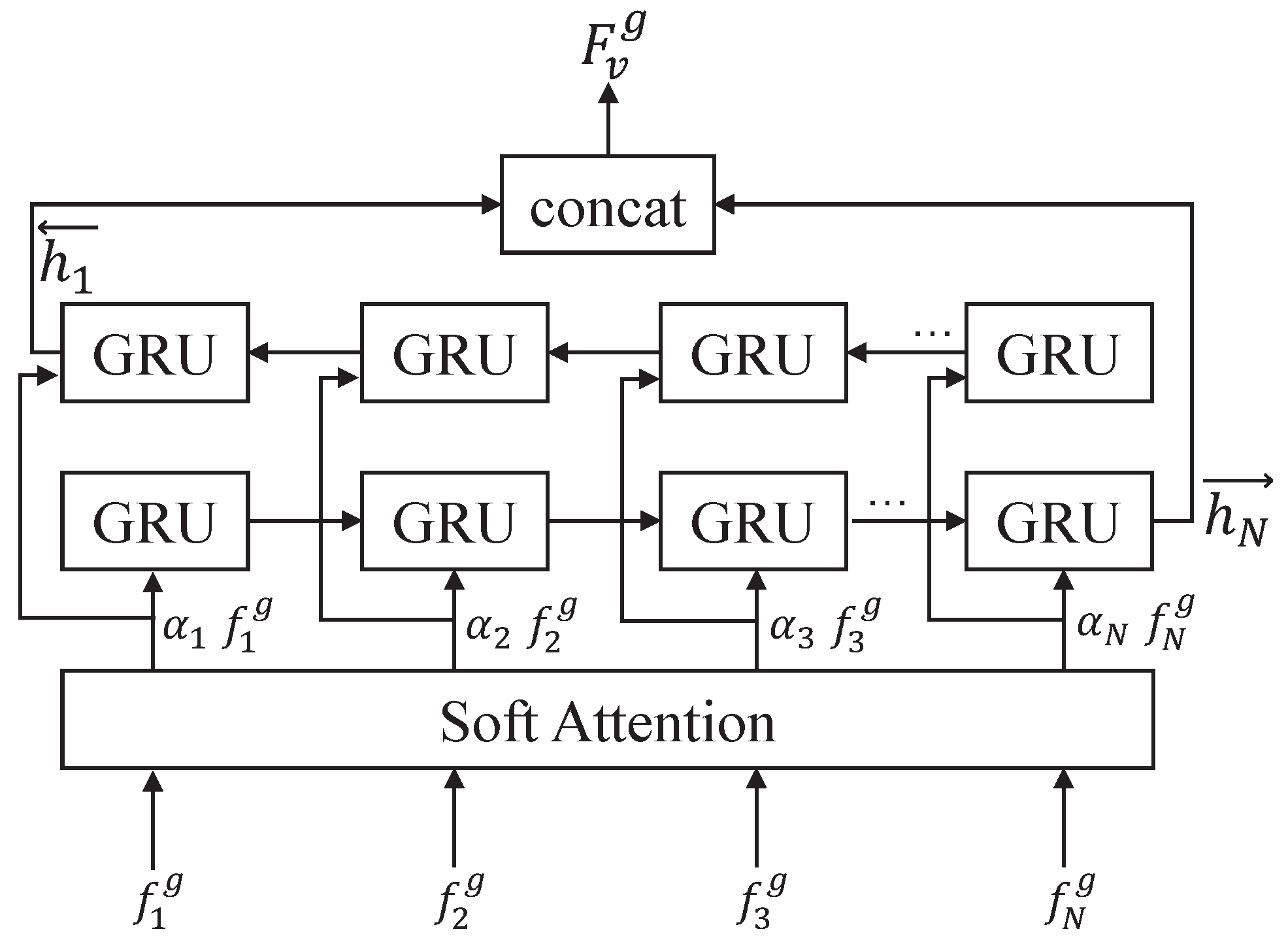
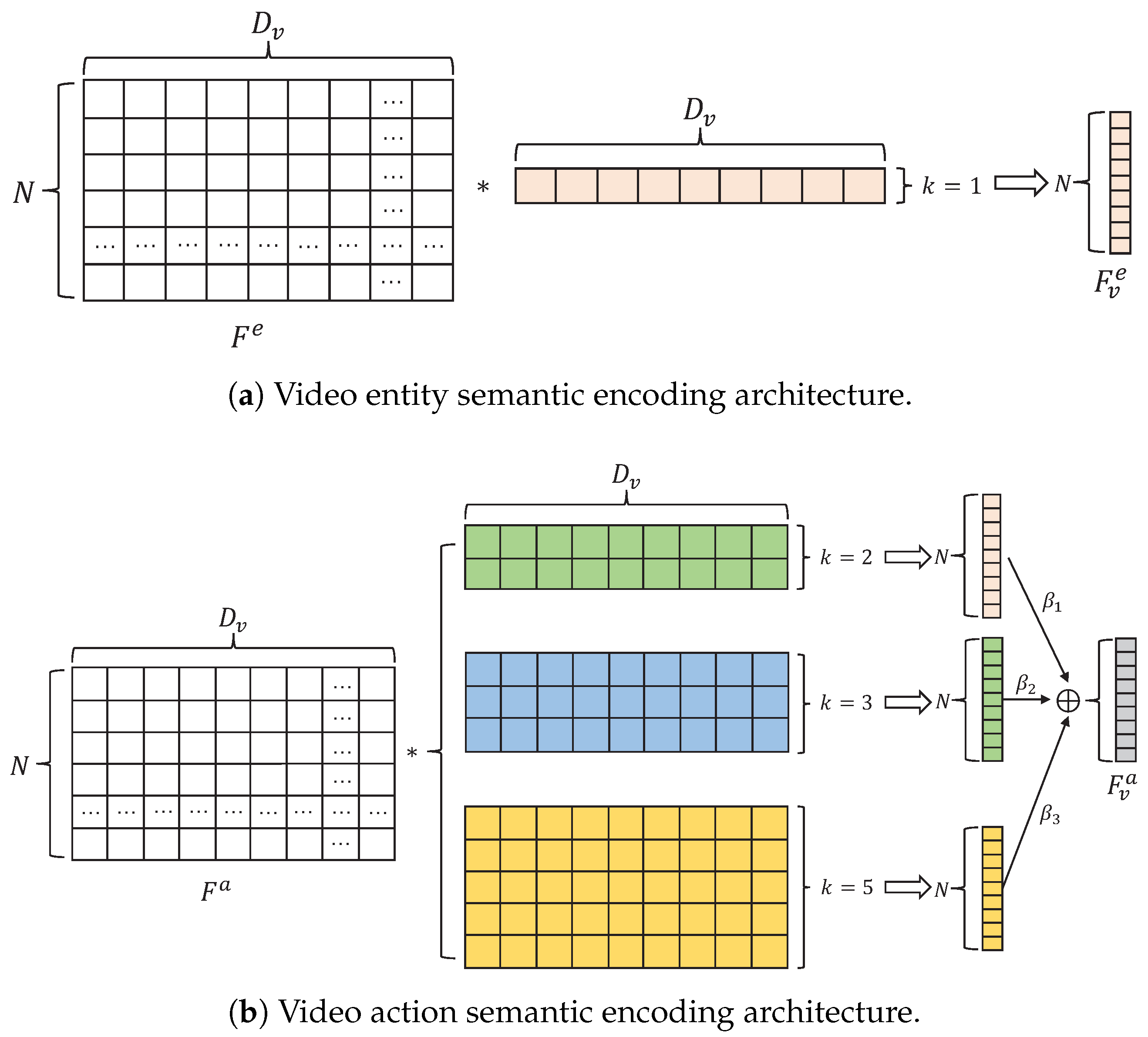
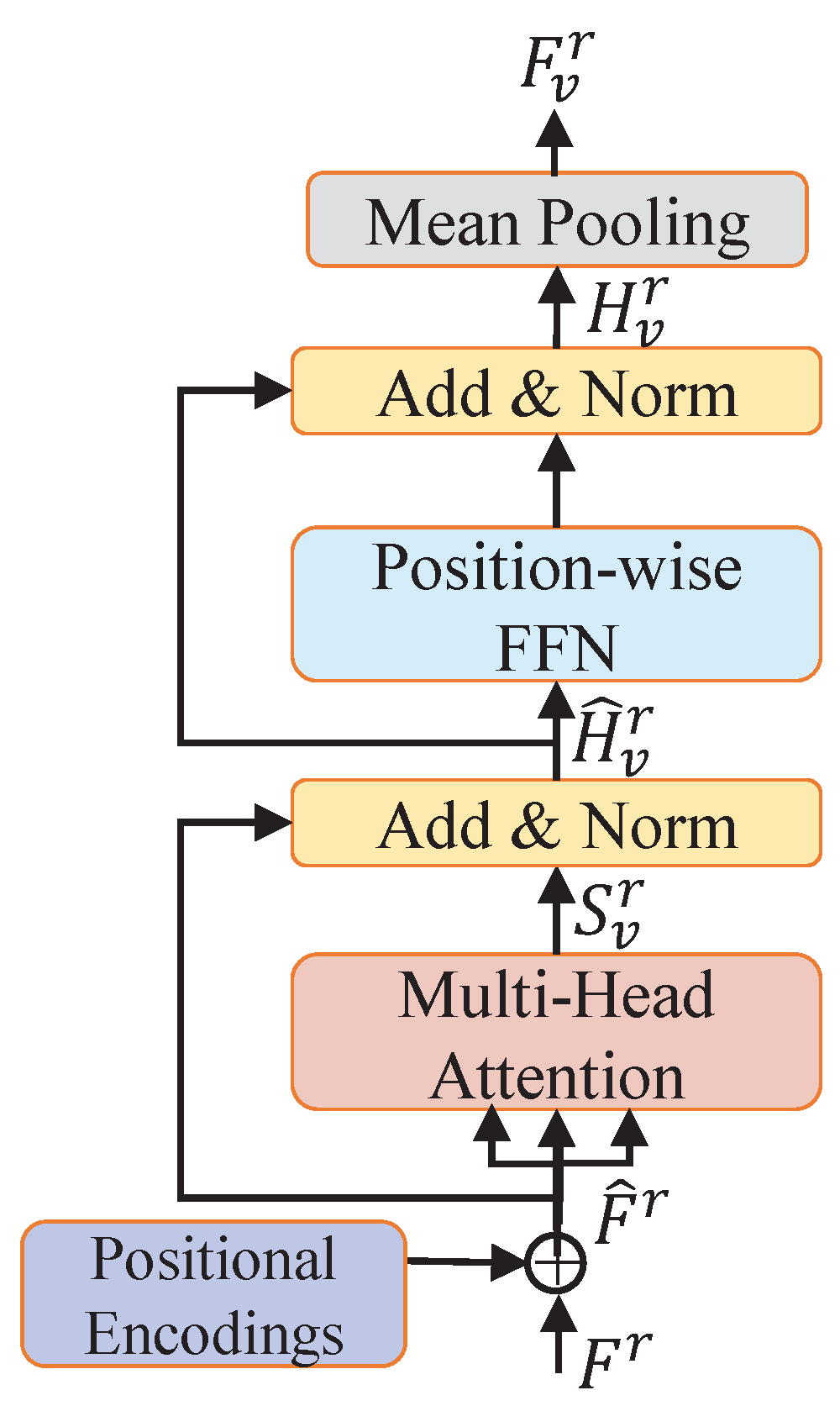
3.4.2. Multi-Level Video Semantics Encoding
3.5. Multi-Level Text and Video Semantics Alignment
3.5.1. Global Alignment
3.5.2. Entity, Action and Relationship Alignment
3.6. Training and Inference
3.6.1. Training
3.6.2. Inference
4. Experiments and Results
4.1. Experimental Settings
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.1.3. Implementation Details
4.2. Comparison with State-of-the-Art Methods

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Text-to-Video | Video-to-Text | SumR | ||||
|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | ||
| VSE [57] | 5.0 | 16.4 | 24.6 | 7.7 | 20.3 | 31.2 | 105.2 |
| VSE++ [58] | 5.7 | 17.1 | 24.8 | 10.2 | 25.4 | 35.1 | 118.3 |
| Mithum et al. [2] | 5.8 | 17.6 | 25.2 | 10.5 | 26.7 | 35.9 | 121.7 |
| W2VV [41] | 6.1 | 18.7 | 27.5 | 11.8 | 28.9 | 39.1 | 132.1 |
| Dual Encoding [3] | 7.7 | 22.0 | 31.8 | 13.0 | 30.8 | 43.3 | 148.6 |
| TCE [33] | 7.7 | 22.5 | 32.1 | - | - | - | - |
| Zhao et al. [59] | 8.8 | 25.5 | 36.5 | 14.0 | 33.1 | 44.9 | 162.8 |
| HGR [9] | 9.2 | 26.2 | 36.5 | 15.0 | 36.7 | 48.8 | 172.4 |
| HANet [11] | 9.3 | 27.0 | 38.1 | 16.1 | 39.2 | 52.1 | 181.8 |
| HSL [60] | 10.8 | 29.2 | 38.5 | 20.3 | 45.1 | 55.9 | 201.7 |
| MCSAN | 10.9 | 29.6 | 40.1 | 21.1 | 46.8 | 57.4 | 205.3 |
| Method | Text-to-Video | Video-to-Text | SumR | ||||
|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | ||
| W2VV [41] | 14.6 | 36.3 | 46.1 | 39.6 | 69.5 | 79.4 | 285.5 |
| VSE++ [58] | 31.3 | 65.8 | 76.4 | 42.9 | 73.9 | 83.6 | 373.9 |
| CE [36] | 31.1 | 68.7 | 80.2 | 41.3 | 71.0 | 82.3 | 374.6 |
| W2VV++ [8] | 32.0 | 68.2 | 78.8 | 41.8 | 75.1 | 84.3 | 380.2 |
| Dual Encoding [3] | 31.1 | 67.4 | 78.9 | - | - | - | - |
| HGR [9] | 35.1 | 73.5 | 83.5 | - | - | - | - |
| HSL [60] | 36.8 | 73.6 | 83.7 | 46.8 | 75.7 | 85.1 | 401.7 |
| HANet [11] | 36.4 | 74.1 | 84.1 | 49.1 | 79.5 | 86.2 | 409.4 |
| MCSAN | 36.6 | 74.2 | 84.1 | 51.4 | 81.3 | 86.8 | 411.8 |
4.3. Ablation Studies
4.4. Qualitative Analyses
4.5. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kaur, P.; Pannu, H.S.; Malhi, A.K. Comparative analysis on cross-modal information retrieval: A review. Comput. Sci. Rev. 2021, 39, 100336. [Google Scholar] [CrossRef]
- Mithun, N.C.; Li, J.; Metze, F.; Roy-Chowdhury, A.K. Learning joint embedding with multimodal cues for cross-modal video–text retrieval. In Proceedings of the 2018 ACM on International Conference on Multimedia Retrieval, Yokohama, Japan, 11–14 June 2018; pp. 19–27. [Google Scholar]
- Dong, J.; Li, X.; Xu, C.; Ji, S.; He, Y.; Yang, G.; Wang, X. Dual encoding for zero-example video retrieval. In Proceedings of the IEEE/CVF Conference On Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9346–9355. [Google Scholar]
- Wang, W.; Gao, J.; Yang, X.; Xu, C. Learning coarse-to-fine graph neural networks for video–text retrieval. IEEE Trans. Multimed. 2020, 23, 2386–2397. [Google Scholar] [CrossRef]
- Jin, W.; Zhao, Z.; Zhang, P.; Zhu, J.; He, X.; Zhuang, Y. Hierarchical cross-modal graph consistency learning for video–text retrieval. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 11–15 July 2021; pp. 1114–1124. [Google Scholar]
- Gorti, S.K.; Vouitsis, N.; Ma, J.; Golestan, K.; Volkovs, M.; Garg, A.; Yu, G. X-Pool: Cross-Modal Language-Video Attention for Text-Video Retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 5006–5015. [Google Scholar]
- Feng, Z.; Zeng, Z.; Guo, C.; Li, Z. Exploiting visual semantic reasoning for video–text retrieval. arXiv 2020, arXiv:2006.08889. [Google Scholar]
- Li, X.; Xu, C.; Yang, G.; Chen, Z.; Dong, J. W2vv++ fully deep learning for ad-hoc video search. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1786–1794. [Google Scholar]
- Chen, S.; Zhao, Y.; Jin, Q.; Wu, Q. Fine-grained video–text retrieval with hierarchical graph reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10638–10647. [Google Scholar]
- Wray, M.; Larlus, D.; Csurka, G.; Damen, D. Fine-grained action retrieval through multiple parts-of-speech embeddings. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 450–459. [Google Scholar]
- Wu, P.; He, X.; Tang, M.; Lv, Y.; Liu, J. HANet: Hierarchical Alignment Networks for Video–text Retrieval. In Proceedings of the 29th ACM international conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 3518–3527. [Google Scholar]
- Reddy, M.D.M.; Basha, M.S.M.; Hari, M.M.C.; Penchalaiah, M.N. Dall-e: Creating images from text. UGC Care Group I J. 2021, 8, 71–75. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning (PMLR), Virtual Event, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Wei, L.; Xie, L.; Zhou, W.; Li, H.; Tian, Q. MVP: Multimodality-guided Visual Pre-training. arXiv 2022, arXiv:2203.05175. [Google Scholar]
- Yang, Z.; Garcia, N.; Chu, C.; Otani, M.; Nakashima, Y.; Takemura, H. Bert representations for video question answering. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1556–1565. [Google Scholar]
- Tang, M.; Wang, Z.; Liu, Z.; Rao, F.; Li, D.; Li, X. Clip4caption: Clip for video caption. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 4858–4862. [Google Scholar]
- Wang, Z.; Codella, N.; Chen, Y.C.; Zhou, L.; Yang, J.; Dai, X.; Xiao, B.; You, H.; Chang, S.F.; Yuan, L. CLIP-TD: CLIP Targeted Distillation for Vision-Language Tasks. arXiv 2022, arXiv:2201.05729. [Google Scholar]
- Luo, J.; Li, Y.; Pan, Y.; Yao, T.; Chao, H.; Mei, T. CoCo-BERT: Improving video-language pre-training with contrastive cross-modal matching and denoising. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 5600–5608. [Google Scholar]
- Fang, H.; Xiong, P.; Xu, L.; Chen, Y. Clip2video: Mastering video–text retrieval via image clip. arXiv 2021, arXiv:2106.11097. [Google Scholar]
- Luo, H.; Ji, L.; Zhong, M.; Chen, Y.; Lei, W.; Duan, N.; Li, T. Clip4clip: An empirical study of clip for end to end video clip retrieval. arXiv 2021, arXiv:2104.08860. [Google Scholar] [CrossRef]
- Gao, Z.; Liu, J.; Chen, S.; Chang, D.; Zhang, H.; Yuan, J. Clip2tv: An empirical study on transformer-based methods for video–text retrieval. arXiv 2021, arXiv:2111.05610. [Google Scholar]
- Nian, F.; Bao, B.K.; Li, T.; Xu, C. Multi-modal knowledge representation learning via webly-supervised relationships mining. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 411–419. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Mei, T. Exploring visual relationship for image captioning. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 684–699. [Google Scholar]
- Wang, S.; Wang, R.; Yao, Z.; Shan, S.; Chen, X. Cross-modal scene graph matching for relationship-aware image-text retrieval. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1508–1517. [Google Scholar]
- Shvetsova, N.; Chen, B.; Rouditchenko, A.; Thomas, S.; Kingsbury, B.; Feris, R.S.; Harwath, D.; Glass, J.; Kuehne, H. Everything at Once-Multi-Modal Fusion Transformer for Video Retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 20020–20029. [Google Scholar]
- Wray, M.; Doughty, H.; Damen, D. On semantic similarity in video retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 3650–3660. [Google Scholar]
- Xu, J.; Mei, T.; Yao, T.; Rui, Y. Msr-vtt: A large video description dataset for bridging video and language. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5288–5296. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S.Y. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Wang, X.; Wu, J.; Chen, J.; Li, L.; Wang, Y.F.; Wang, W.Y. Vatex: A large-scale, high-quality multilingual dataset for video-and-language research. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 4581–4591. [Google Scholar]
- Li, T.; Ni, B.; Xu, M.; Wang, M.; Gao, Q.; Yan, S. Data-driven affective filtering for images and videos. IEEE Trans. Cybern. 2015, 45, 2336–2349. [Google Scholar] [CrossRef]
- Nian, F.; Li, T.; Wu, X.; Gao, Q.; Li, F. Efficient near-duplicate image detection with a local-based binary representation. Multimed. Tools Appl. 2016, 75, 2435–2452. [Google Scholar] [CrossRef]
- Yang, X.; Dong, J.; Cao, Y.; Wang, X.; Wang, M.; Chua, T.S. Tree-augmented cross-modal encoding for complex-query video retrieval. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; pp. 1339–1348. [Google Scholar]
- Dong, J.; Wang, Y.; Chen, X.; Qu, X.; Li, X.; He, Y.; Wang, X. Reading-strategy inspired visual representation learning for text-to-video retrieval. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5680–5694. [Google Scholar] [CrossRef]
- Gabeur, V.; Sun, C.; Alahari, K.; Schmid, C. Multi-modal transformer for video retrieval. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 214–229. [Google Scholar]
- Liu, Y.; Albanie, S.; Nagrani, A.; Zisserman, A. Use what you have: Video retrieval using representations from collaborative experts. arXiv 2019, arXiv:1907.13487. [Google Scholar]
- Miech, A.; Laptev, I.; Sivic, J. Learning a text-video embedding from incomplete and heterogeneous data. arXiv 2018, arXiv:1804.02516. [Google Scholar]
- Gabeur, V.; Nagrani, A.; Sun, C.; Alahari, K.; Schmid, C. Masking modalities for cross-modal video retrieval. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 1766–1775. [Google Scholar]
- Song, X.; Chen, J.; Wu, Z.; Jiang, Y.G. Spatial–temporal graphs for cross-modal text2video retrieval. IEEE Trans. Multimed. 2021, 14, 2914–2923. [Google Scholar] [CrossRef]
- Miech, A.; Zhukov, D.; Alayrac, J.B.; Tapaswi, M.; Laptev, I.; Sivic, J. Howto100m: Learning a text-video embedding by watching hundred million narrated video clips. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 2630–2640. [Google Scholar]
- Dong, J.; Li, X.; Snoek, C.G. Predicting visual features from text for image and video caption retrieval. IEEE Trans. Multimed. 2018, 20, 3377–3388. [Google Scholar] [CrossRef]
- Dong, J.; Long, Z.; Mao, X.; Lin, C.; He, Y.; Ji, S. Multi-level alignment network for domain adaptive cross-modal retrieval. Neurocomputing 2021, 440, 207–219. [Google Scholar] [CrossRef]
- Yu, Z.; Yu, J.; Cui, Y.; Tao, D.; Tian, Q. Deep modular co-attention networks for visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6281–6290. [Google Scholar]
- Yu, J.; Li, J.; Yu, Z.; Huang, Q. Multimodal transformer with multi-view visual representation for image captioning. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 4467–4480. [Google Scholar] [CrossRef]
- Rao, J.; Wang, F.; Ding, L.; Qi, S.; Zhan, Y.; Liu, W.; Tao, D. Where Does the Performance Improvement Come From?—A Reproducibility Concern about Image-Text Retrieval. arXiv 2022, arXiv:2203.03853. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.R.; Bethard, S.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 23–24 June 2014; pp. 55–60. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv 2019, arXiv:1908.10084. [Google Scholar]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; Berg, R.v.d.; Titov, I.; Welling, M. Modeling relational data with graph convolutional networks. In Proceedings of the European Semantic Web Conference, Heraklion, Greece, 3–7 June 2018; pp. 593–607. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Nickel, M.; Rosasco, L.; Poggio, T. Holographic embeddings of knowledge graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 1955–1961. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Qu, L.; Liu, M.; Wu, J.; Gao, Z.; Nie, L. Dynamic modality interaction modeling for image-text retrieval. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 11–15 July 2021; pp. 1104–1113. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Kiros, R.; Salakhutdinov, R.; Zemel, R.S. Unifying visual-semantic embeddings with multimodal neural language models. arXiv 2014, arXiv:1411.2539. [Google Scholar]
- Faghri, F.; Fleet, D.J.; Kiros, J.R.; Fidler, S. Vse++: Improving visual-semantic embeddings with hard negatives. arXiv 2017, arXiv:1707.05612. [Google Scholar]
- Zhao, R.; Zheng, K.; Zha, Z.J. Stacked convolutional deep encoding network for video–text retrieval. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), Virtual, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Dong, J.; Li, X.; Xu, C.; Yang, X.; Yang, G.; Wang, X.; Wang, M. Dual encoding for video retrieval by text. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4065–4080. [Google Scholar] [CrossRef]


| Method | Text-to-Video | Video-to-Text | SumR | ||||
|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | ||
| MCSAN¬R | 9.4 | 27.1 | 37.9 | 17.2 | 42.3 | 54.7 | 195.8 |
| MCSAN¬S | 10.1 | 27.8 | 39.8 | 19.9 | 45.9 | 57.0 | 202.6 |
| MCSAN¬L | 10.6 | 28.8 | 39.2 | 20.8 | 46.4 | 56.6 | 203.7 |
| MCSAN | 10.9 | 29.6 | 40.1 | 21.1 | 46.8 | 57.4 | 205.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nian, F.; Ding, L.; Hu, Y.; Gu, Y. Multi-Level Cross-Modal Semantic Alignment Network for Video–Text Retrieval. Mathematics 2022, 10, 3346. https://doi.org/10.3390/math10183346
Nian F, Ding L, Hu Y, Gu Y. Multi-Level Cross-Modal Semantic Alignment Network for Video–Text Retrieval. Mathematics. 2022; 10(18):3346. https://doi.org/10.3390/math10183346
Chicago/Turabian StyleNian, Fudong, Ling Ding, Yuxia Hu, and Yanhong Gu. 2022. "Multi-Level Cross-Modal Semantic Alignment Network for Video–Text Retrieval" Mathematics 10, no. 18: 3346. https://doi.org/10.3390/math10183346
APA StyleNian, F., Ding, L., Hu, Y., & Gu, Y. (2022). Multi-Level Cross-Modal Semantic Alignment Network for Video–Text Retrieval. Mathematics, 10(18), 3346. https://doi.org/10.3390/math10183346