

Identification of Review Helpfulness Using Novel Textual and Language-Context Features

 ,
,  ,
,  , ,
, ,  and
and 
Abstract
:1. Introduction
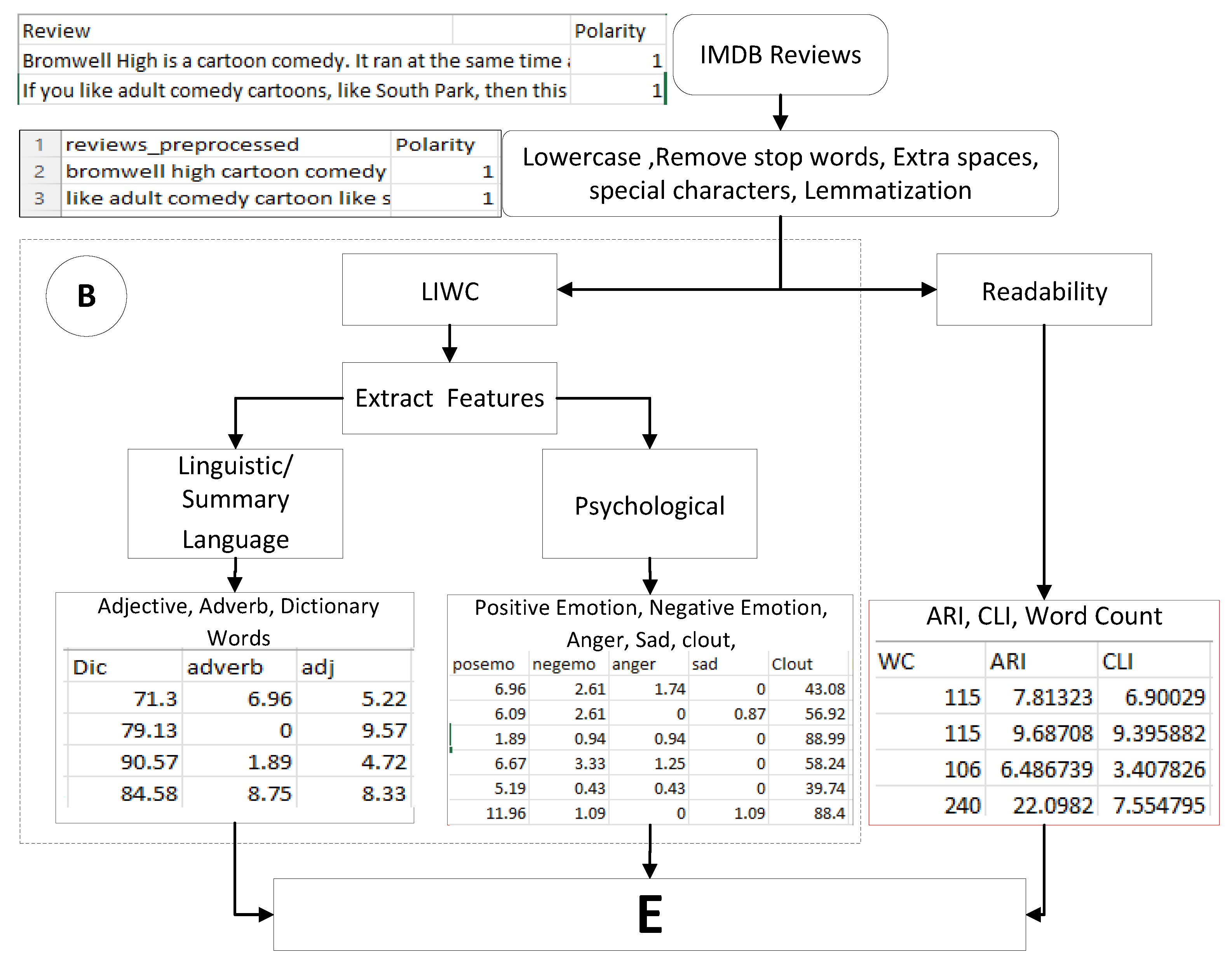
- The proposed psychological features are positive emotion, negative emotion, anger, sadness, clout (confidence level) and dictionary words.
- The readability features extracted according to Automated Readability Index (ARI), Coleman Liau Index (CLI) and Word Count (WC) are calculated to measure the review’s understandability score.
- The linguistic features extracted are adjectives and adverbs.
- The psychological, readability and linguistic features are concatenated with Word2Vec features to train the machine-learning models.
2. Related Work
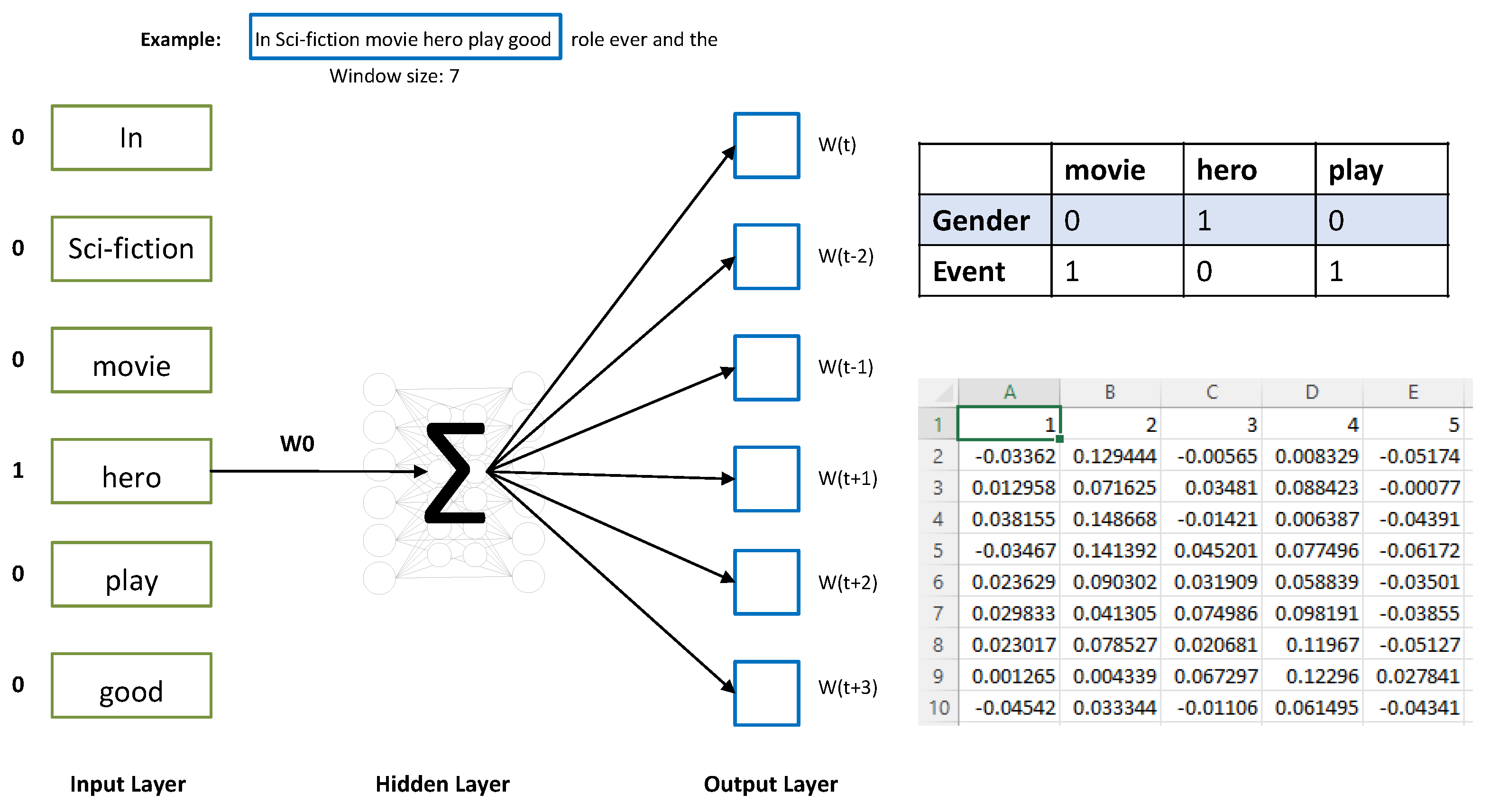
Word Embedding Using the Word2Vec Approach
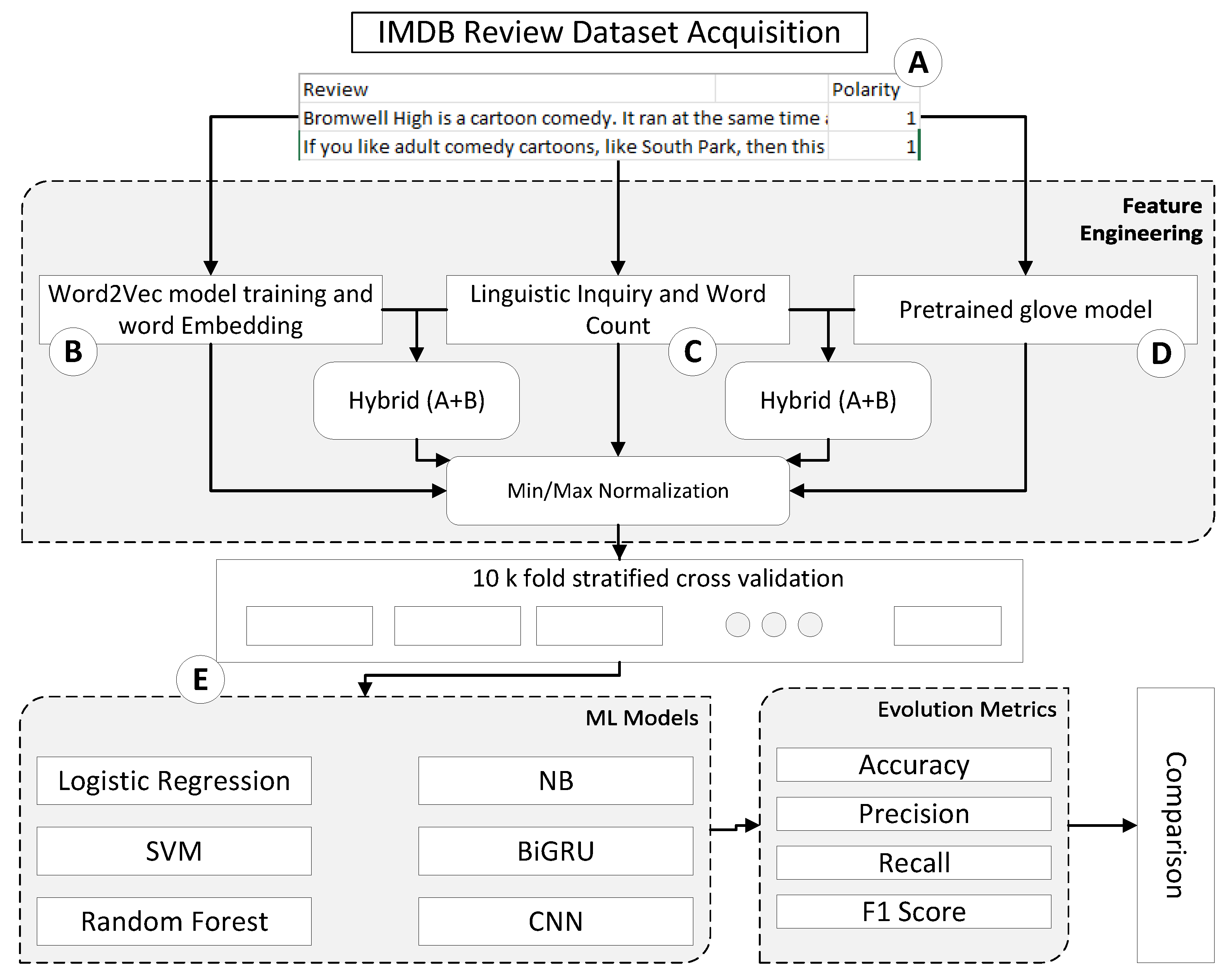
3. Proposed Methodology
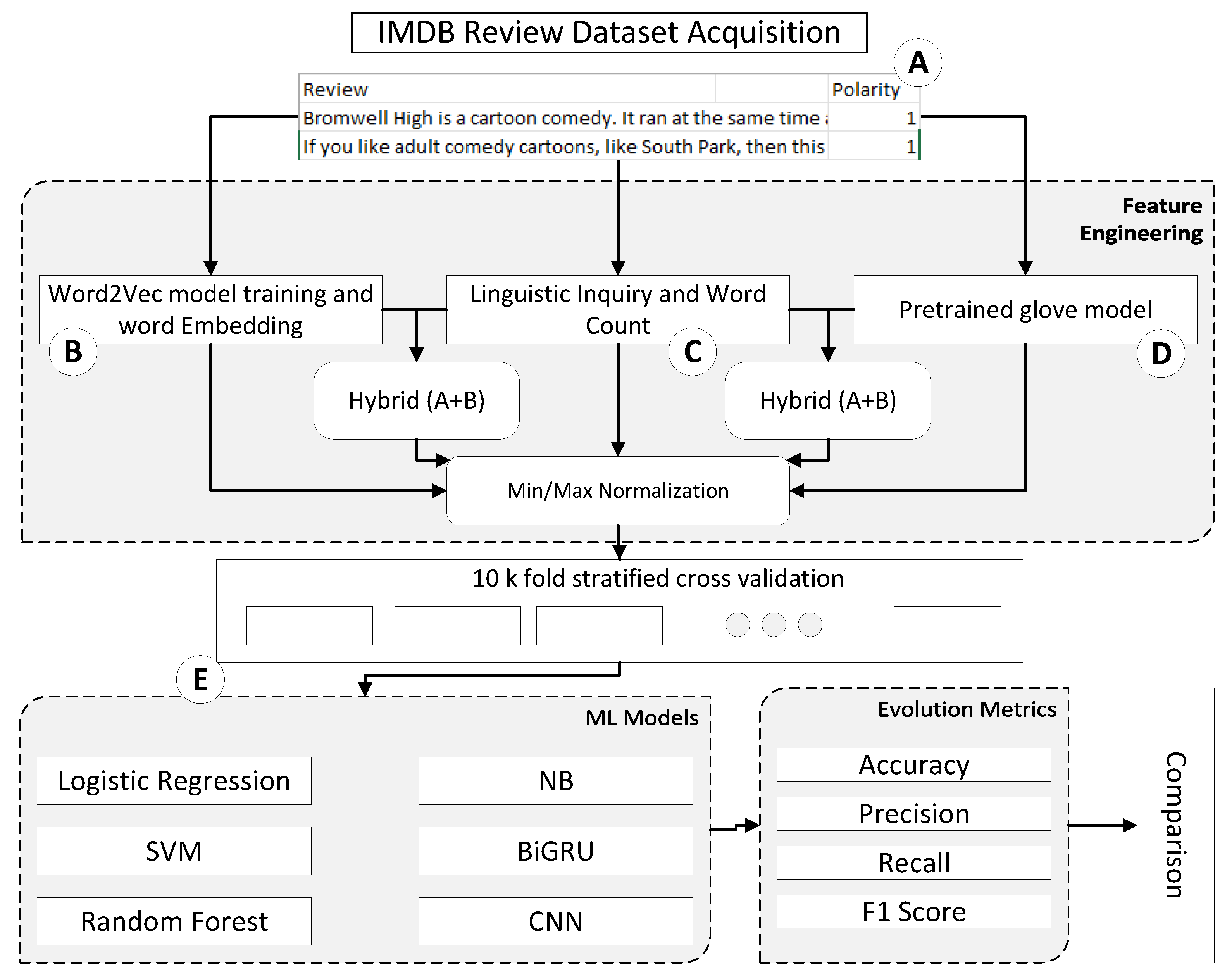
3.1. Dataset Acquisition
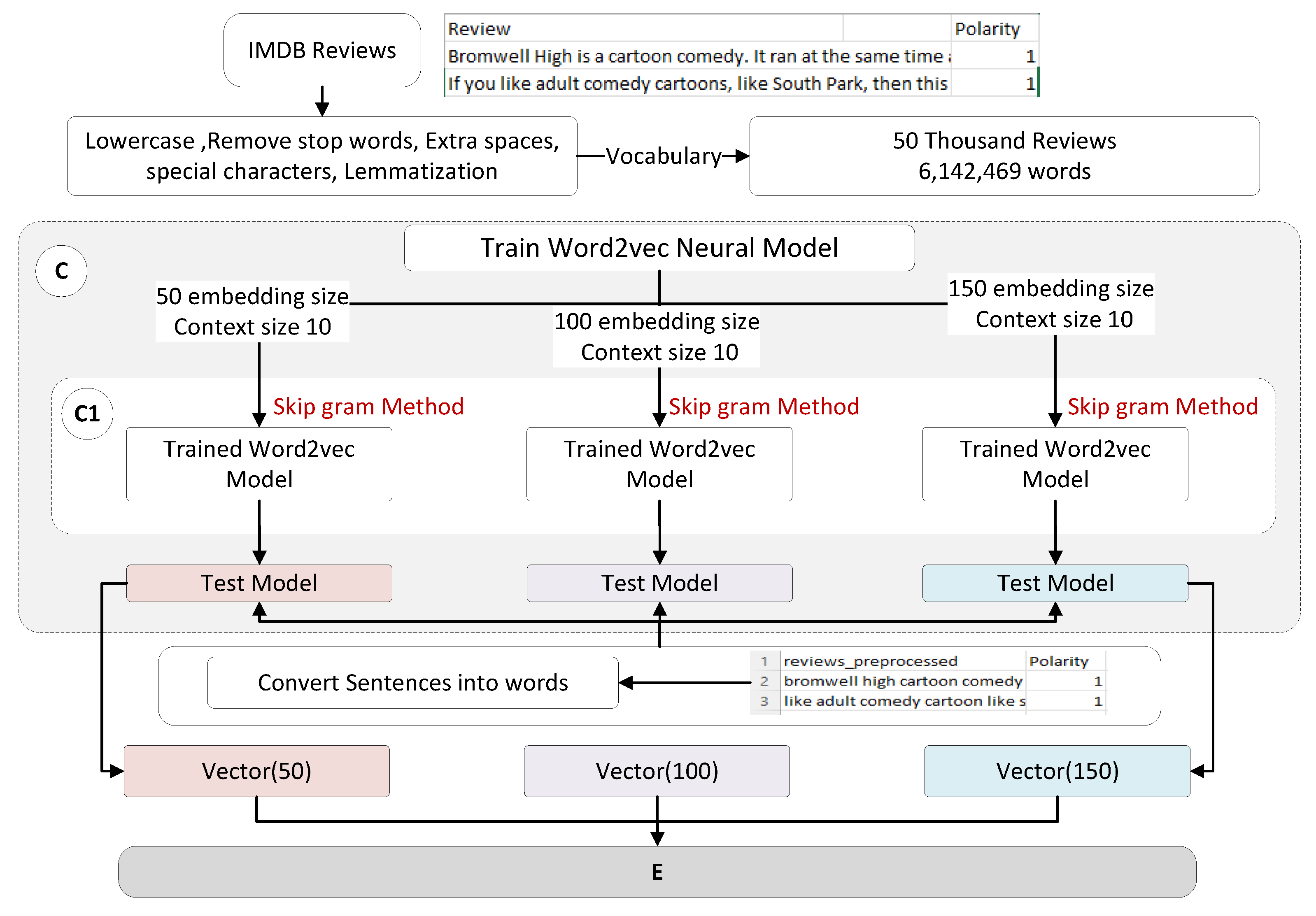
3.1.1. Preprocessing for Feature Extraction
3.1.2. Data Preprocessing Tool
3.2. Feature Engineering
3.2.1. Feature Extraction Using LIWC
3.2.2. Readability Feature Extraction
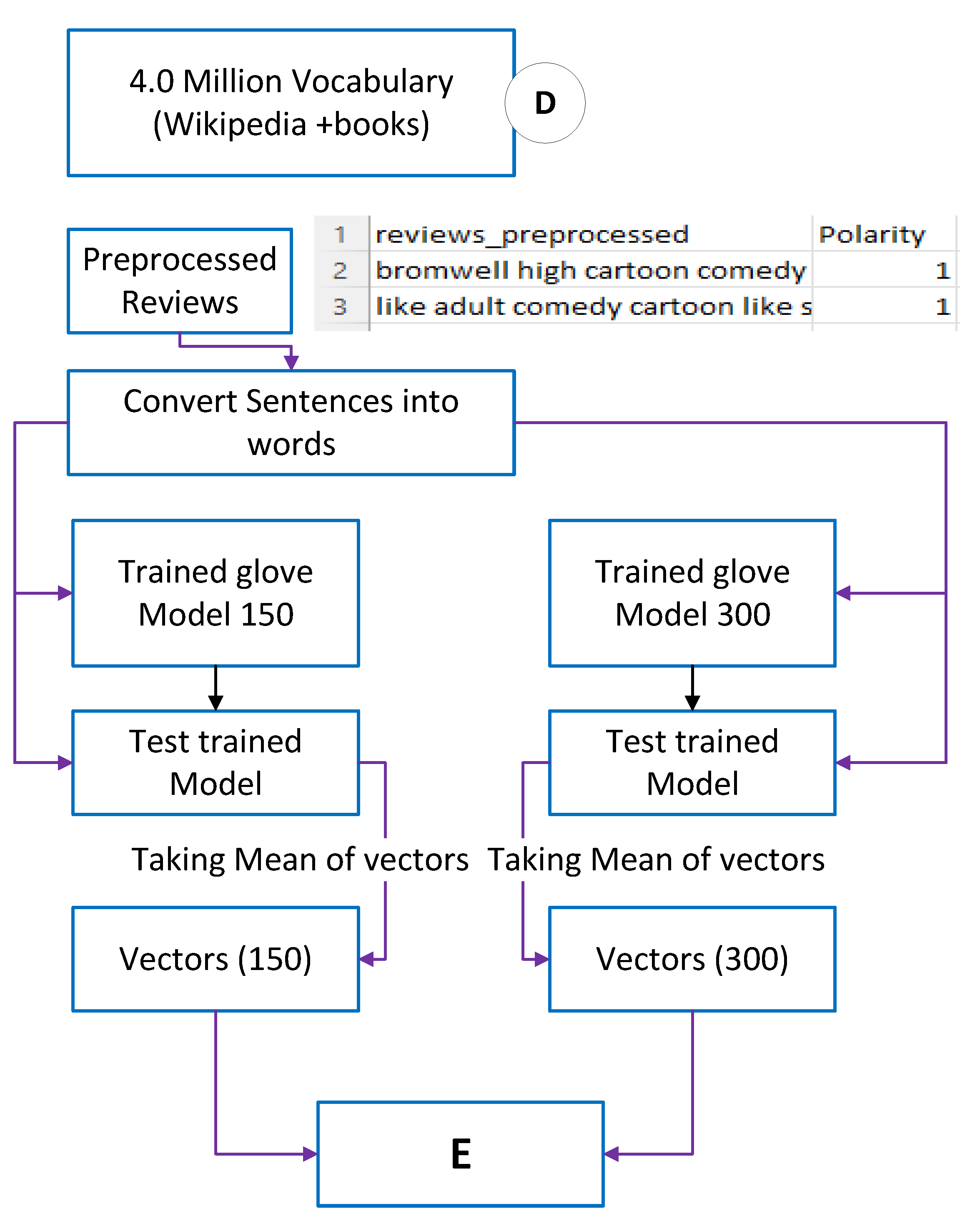
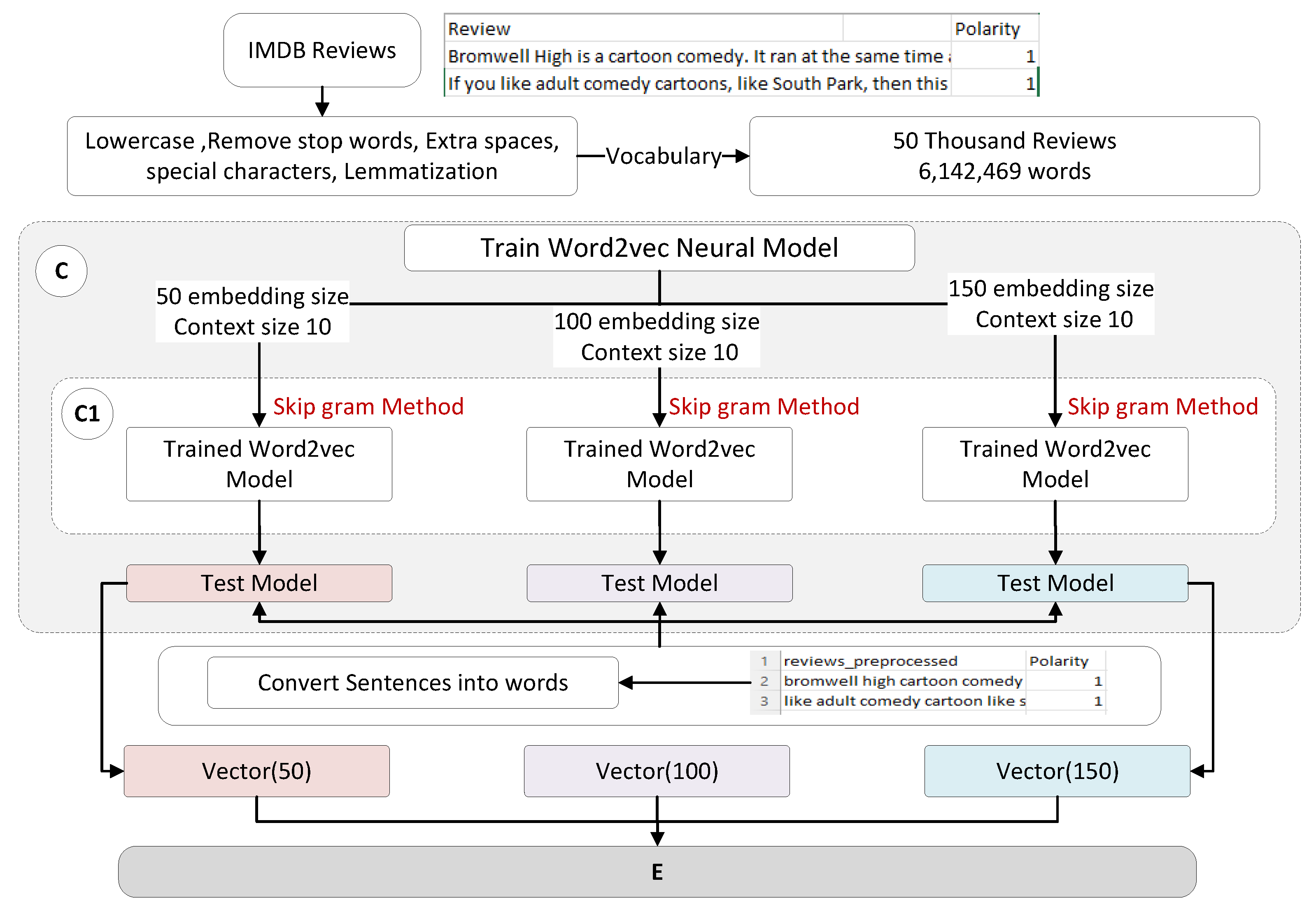
3.3. Word Embedding by Review-Based Training of Word2Vec Model
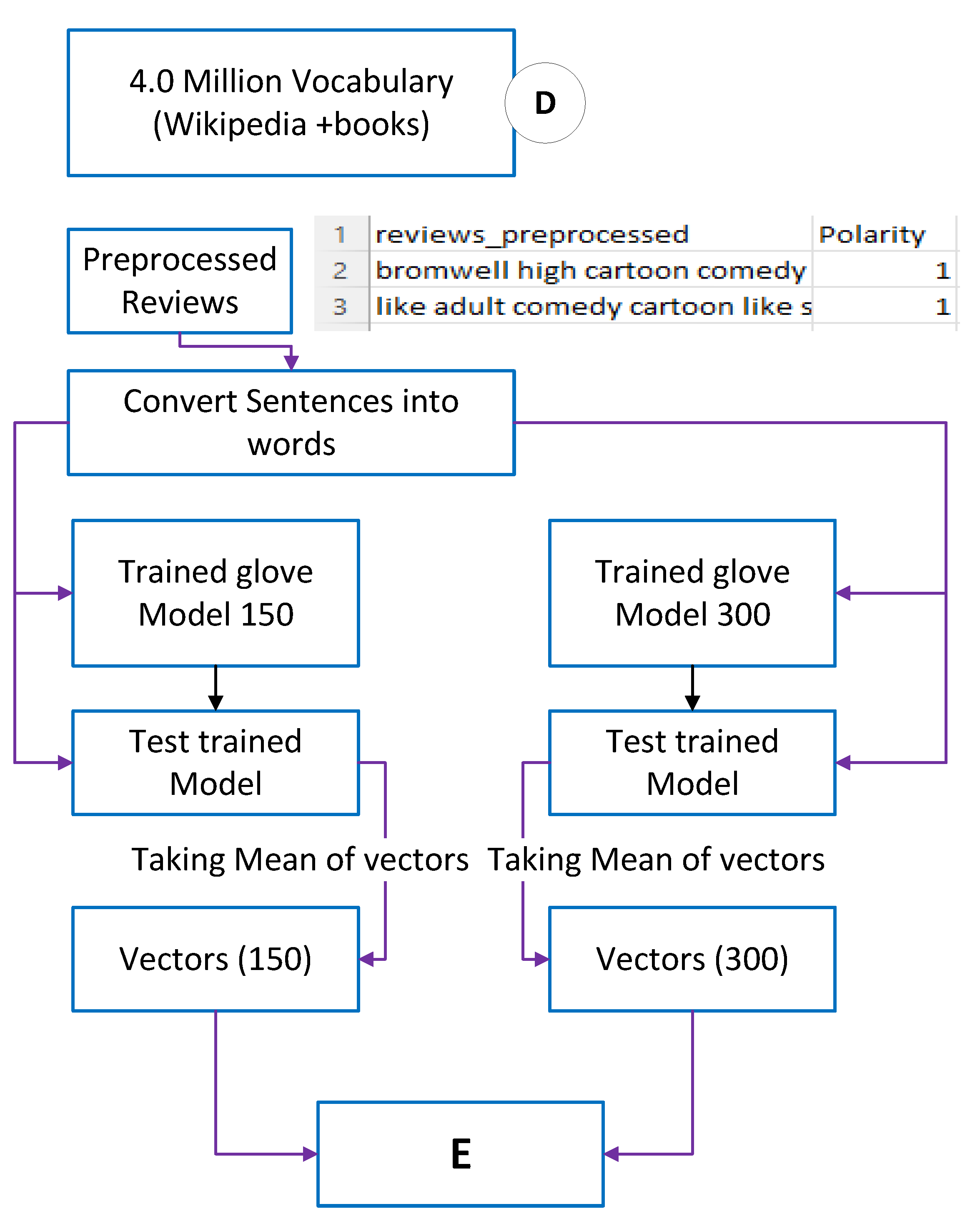
3.4. Word Embedding by Pretrained Word2Vec Model
4. Evaluation and Results
4.1. Dataset
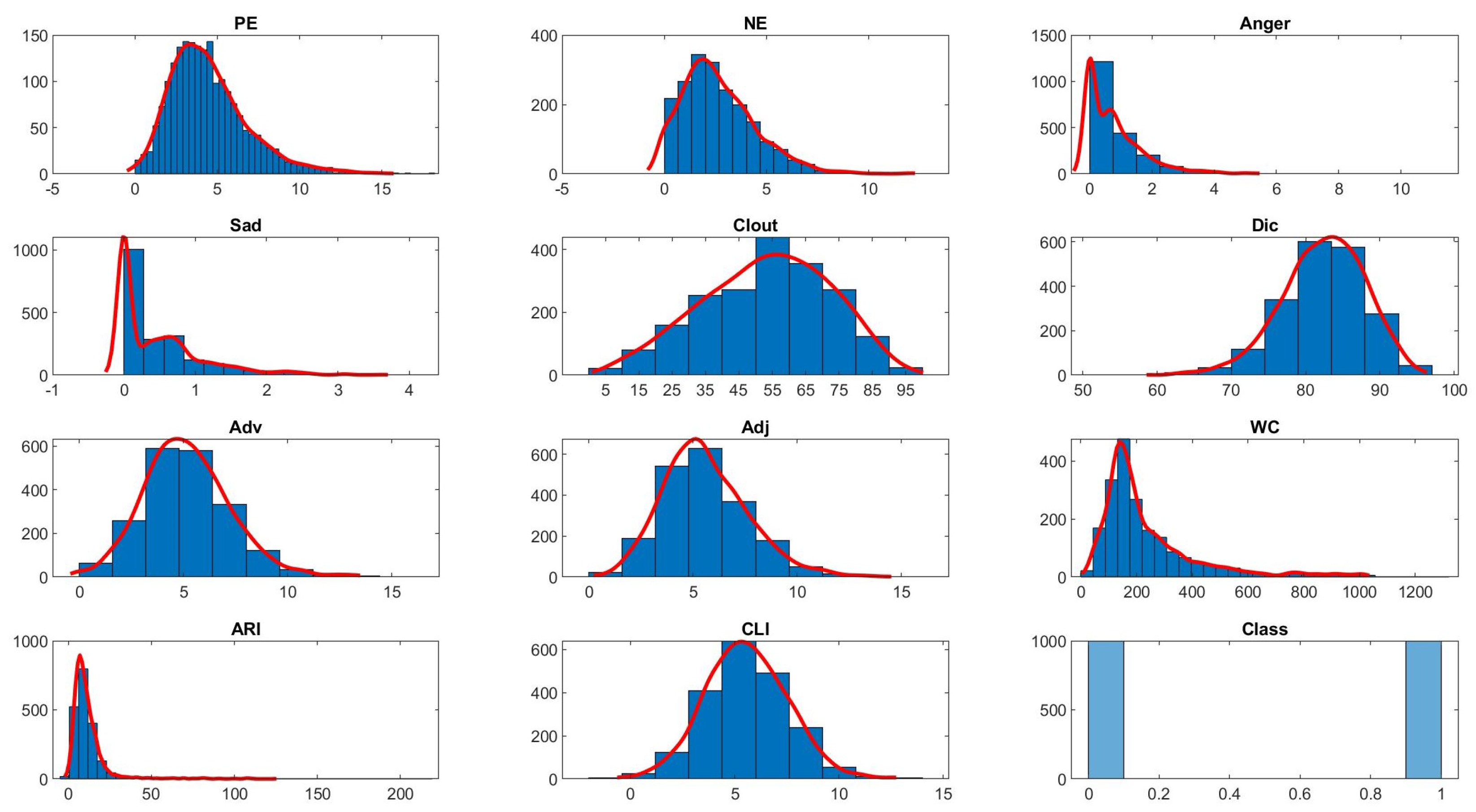
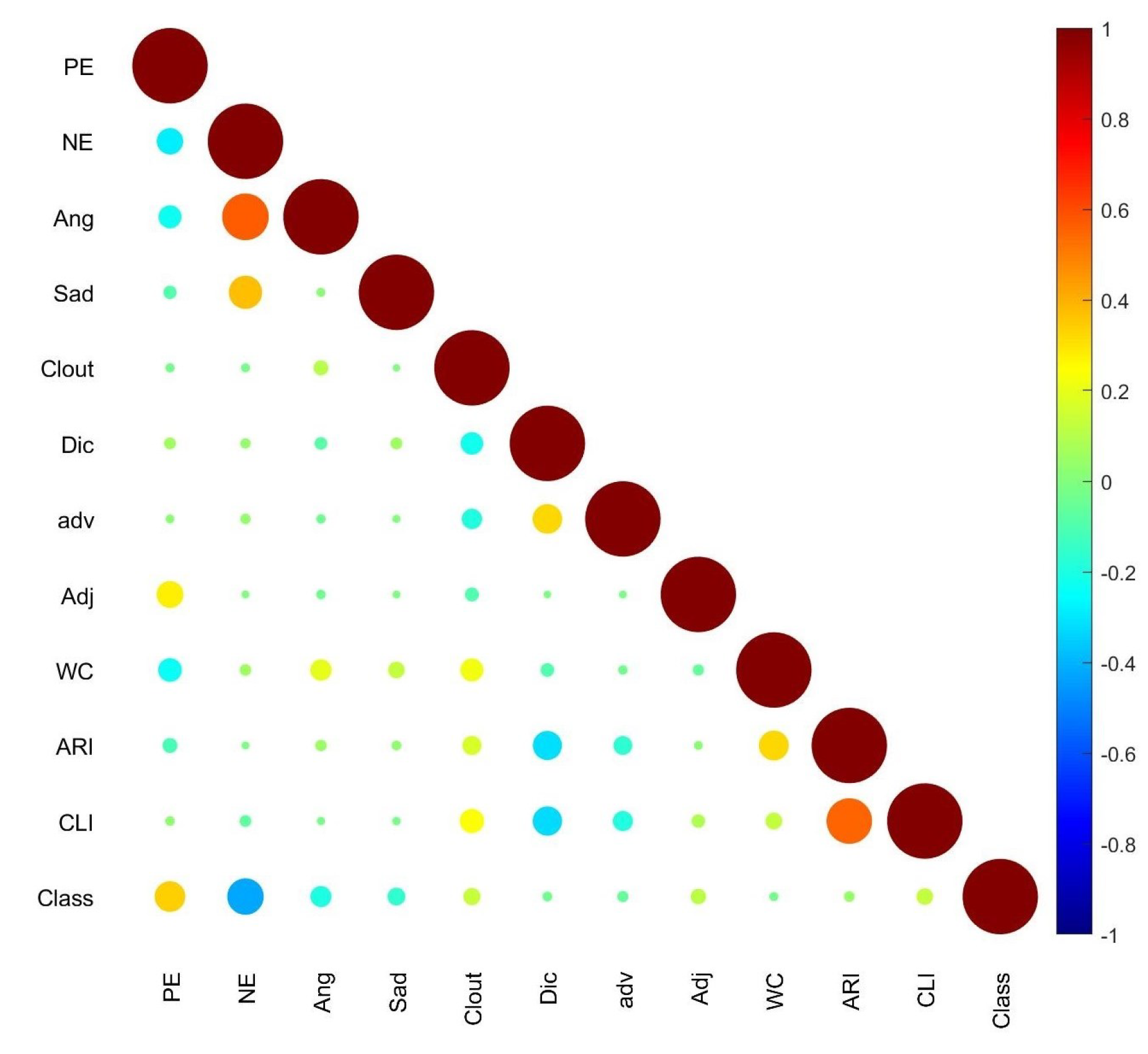
4.2. Feature Exploration and Hypothesis Testing
4.3. Evaluation Measure and Performance Comparison
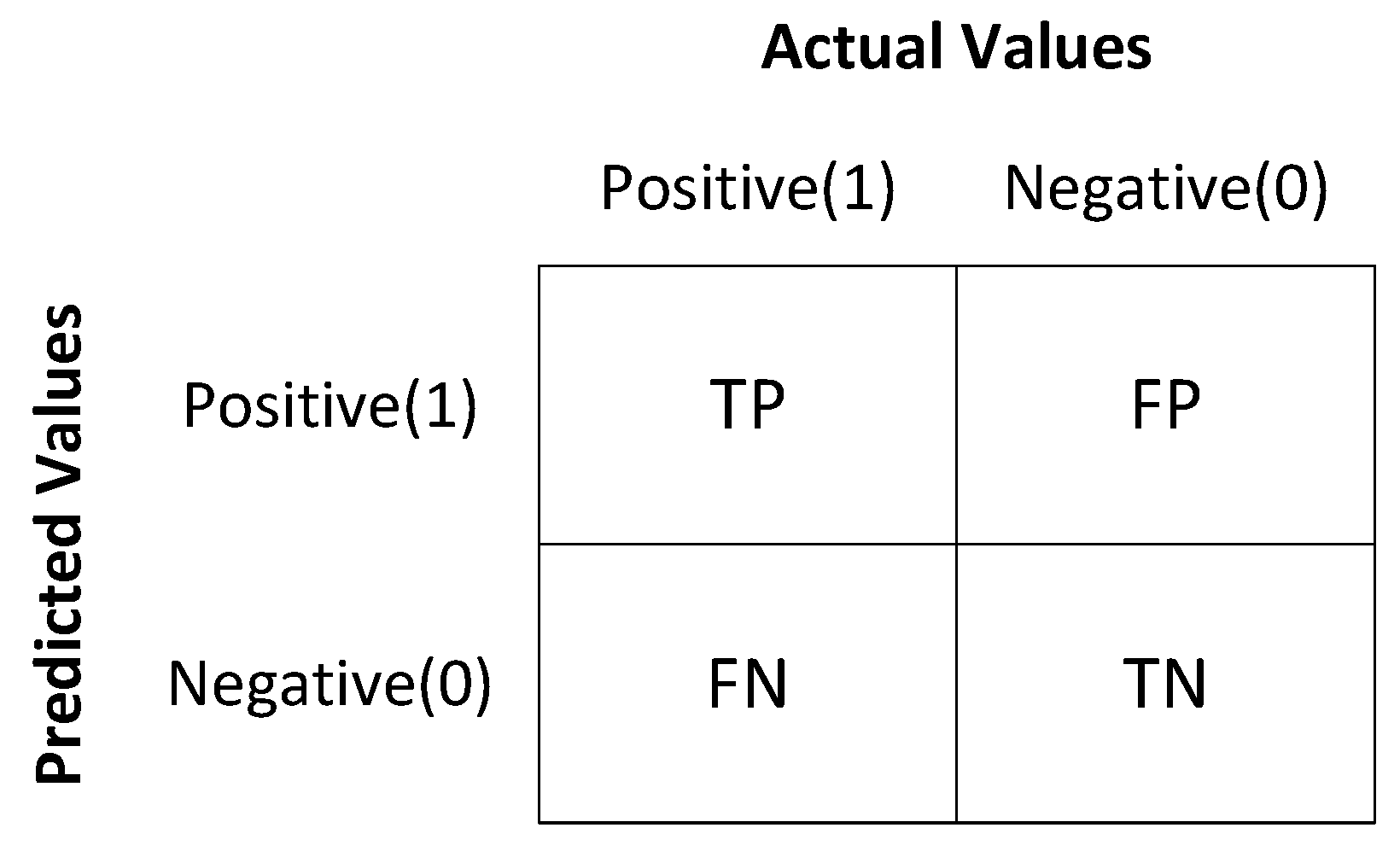
4.3.1. Confusion Matrix
4.3.2. Pretrained Word Embedding
4.3.3. Review-Based Trained Word2Vec Model Word Embedding
- The self-trained Word2Vec model on movie reviews with 150 dimension parameter has a higher impact on performance than the pretrained Glove Model.
- The CLI readability achieved the highest score compared to ARI and WC.
- The SVM algorithm performs better than the applied algorithms: NB, LR, RF, CNN, KNN and MLP.
- The use of the psychological and readability feature CLI to classify reviews with self-trained embedding improves the performance from 86% to 87.93%.
- The smaller number of words embedding dimension 150 performs better concerning the traditional ML algorithm and for the DL algorithm 300 dimensions gives a better result.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, S.; Fang, H.; Khabsa, M.; Mao, H.; Ma, H. Entailment as Few-Shot Learner. arXiv 2021, arXiv:2104.14690. [Google Scholar]
- Tran, D.D.; Nguyen, T.T.S.; Dao, T.H.C. Sentiment Analysis of Movie Reviews Using Machine Learning Techniques. In Proceedings of the Sixth International Congress on Information and Communication Technology, London, UK, 25–26 February 2021; Springer: Berlin, Germany, 2022; pp. 361–369. [Google Scholar]
- Khan, U.; Khan, S.; Rizwan, A.; Atteia, G.; Jamjoom, M.M.; Samee, N.A. Aggression Detection in Social Media from Textual Data Using Deep Learning Models. Appl. Sci. 2022, 12, 5083. [Google Scholar] [CrossRef]
- Ahmad, T.; Faisal, M.S.; Rizwan, A.; Alkanhel, R.; Khan, P.W.; Muthanna, A. Efficient Fake News Detection Mechanism Using Enhanced Deep Learning Model. Appl. Sci. 2022, 12, 1743. [Google Scholar] [CrossRef]
- Faisal, M.S.; Rizwan, A.; Iqbal, K.; Fasihuddin, H.; Banjar, A.; Daud, A. Prediction of Movie Quality via Adaptive Voting Classifier. IEEE Access 2022, 10, 81581–81596. [Google Scholar] [CrossRef]
- Nawaz, A.; Abbas, Y.; Ahmad, T.; Mahmoud, N.F.; Rizwan, A.; Samee, N.A. A Healthcare Paradigm for Deriving Knowledge Using Online Consumers’ Feedback. Healthcare 2022, 10, 1592. [Google Scholar] [CrossRef]
- Tripathy, A.; Agrawal, A.; Rath, S.K. Classification of sentiment reviews using n-gram machine learning approach. Expert Syst. Appl. 2016, 57, 117–126. [Google Scholar] [CrossRef]
- Moussa, M.E.; Mohamed, E.H.; Haggag, M.H. A survey on opinion summarization techniques for social media. Future Comput. Inform. J. 2018, 3, 82–109. [Google Scholar] [CrossRef]
- Hemalatha, I.; Varma, G.S.; Govardhan, A. Preprocessing the informal text for efficient sentiment analysis. Int. J. Emerg. Trends Technol. Comput. Sci. (IJETTCS) 2012, 1, 58–61. [Google Scholar]
- Manek, A.S.; Shenoy, P.D.; Mohan, M.C. Aspect term extraction for sentiment analysis in large movie reviews using Gini Index feature selection method and SVM classifier. World Wide Web 2017, 20, 135–154. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment classification using machine learning techniques. arXiv 2002, arXiv:cs/0205070. [Google Scholar]
- Ahmad, S.R.; Bakar, A.A.; Yaakub, M.R. A review of feature selection techniques in sentiment analysis. Intell. Data Anal. 2019, 23, 159–189. [Google Scholar] [CrossRef]
- Revanasiddappa, M.; Harish, B. A New Feature Selection Method based on Intuitionistic Fuzzy Entropy to Categorize Text Documents. Int. J. Interact. Multimed. Artif. Intell. 2018, 5, 106. [Google Scholar] [CrossRef]
- Taboada, M.; Brooke, J.; Tofiloski, M.; Voll, K.; Stede, M. Lexicon-based methods for sentiment analysis. Comput. Linguist. 2011, 37, 267–307. [Google Scholar] [CrossRef]
- Mudinas, A.; Zhang, D.; Levene, M. Combining lexicon and learning based approaches for concept-level sentiment analysis. In Proceedings of the First International Workshop on Issues of Sentiment Discovery and Opinion Mining, Beijing, China, 12 August 2012; pp. 1–8. [Google Scholar]
- Zheng, L.; Wang, H.; Gao, S. Sentiment feature selection for sentiment analysis of Chinese online reviews. Int. J. Mach. Learn. Cybern. 2018, 9, 75–84. [Google Scholar] [CrossRef]
- Gupta, S.; Kar, A.K.; Baabdullah, A.; Al-Khowaiter, W.A. Big data with cognitive computing: A review for the future. Int. J. Inf. Manag. 2018, 42, 78–89. [Google Scholar] [CrossRef]
- Fink, L.; Rosenfeld, L.; Ravid, G. Longer online reviews are not necessarily better. Int. J. Inf. Manag. 2018, 39, 30–37. [Google Scholar] [CrossRef]
- Li, L.; Goh, T.T.; Jin, D. How textual quality of online reviews affect classification performance: A case of deep learning sentiment analysis. Neural Comput. Appl. 2020, 32, 4387–4415. [Google Scholar] [CrossRef]
- Yang, Z. Sentiment Analysis of Movie Reviews based on Machine Learning. In Proceedings of the 2020 2nd International Workshop on Artificial Intelligence and Education, Montreal, QC, Canada, 6–8 November 2020; pp. 1–4. [Google Scholar]
- Karim, M.; Das, S. Sentiment analysis on textual reviews. IOP Conf. Ser. Mater. Sci. Eng. 2018, 396, 012020. [Google Scholar] [CrossRef]
- Kumar, H.; Harish, B.; Darshan, H. Sentiment Analysis on IMDb Movie Reviews Using Hybrid Feature Extraction Method. Int. J. Interact. Multimed. Artif. Intell. 2019, 5, 109–114. [Google Scholar] [CrossRef]
- Bandana, R. Sentiment analysis of movie reviews using heterogeneous features. In Proceedings of the 2018 2nd International Conference on Electronics, Materials Engineering & Nano-Technology (IEMENTech), Kolkata, India, 4–5 May 2018; pp. 1–4. [Google Scholar]
- Sharma, A.K.; Chaurasia, S.; Srivastava, D.K. Sentiment short sentences classification by using CNN deep learning model with fine tuned Word2Vec. Procedia Comput. Sci. 2020, 167, 1139–1147. [Google Scholar] [CrossRef]
- Wang, J.H.; Liu, T.W.; Luo, X.; Wang, L. An LSTM approach to short text sentiment classification with word embeddings. In Proceedings of the 30th conference on computational linguistics and speech processing (ROCLING 2018), Hsinchu, Taiwan, 4–5 October 2018; pp. 214–223. [Google Scholar]
- Shaukat, Z.; Zulfiqar, A.A.; Xiao, C.; Azeem, M.; Mahmood, T. Sentiment analysis on IMDB using lexicon and neural networks. SN Appl. Sci. 2020, 2, 1–10. [Google Scholar] [CrossRef]
- Mukherjee, A.; Mukhopadhyay, S.; Panigrahi, P.K.; Goswami, S. Utilization of oversampling for multiclass sentiment analysis on Amazon review dataset. In Proceedings of the 2019 IEEE 10th International Conference on Awareness Science and Technology (iCAST), Morioka, Japan, 23–25 October 2019; pp. 1–6. [Google Scholar]
- Krishna, A.; Akhilesh, V.; Aich, A.; Hegde, C. Sentiment analysis of restaurant reviews using machine learning techniques. In Emerging Research in Electronics, Computer Science and Technology; Springer: Berlin, Germany, 2019; pp. 687–696. [Google Scholar]
- Dey, A.U.; Ghosh, S.K.; Valveny, E.; Harit, G. Beyond visual semantics: Exploring the role of scene text in image understanding. Pattern Recognit. Lett. 2021, 149, 164–171. [Google Scholar] [CrossRef]
- Xiao, L.; Wang, G.; Zuo, Y. Research on patent text classification based on Word2Vec and LSTM. In Proceedings of the 2018 11th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 8–9 December 2018; Volume 1, pp. 71–74. [Google Scholar]
- Pan, Q.; Dong, H.; Wang, Y.; Cai, Z.; Zhang, L. Recommendation of crowdsourcing tasks based on Word2Vec semantic tags. Wirel. Commun. Mob. Comput. 2019, 2019, 2121850. [Google Scholar] [CrossRef]
- Soriano, I.M.; Peña, J.L.C.; Breis, J.T.F.; San Román, I.; Barriuso, A.A.; Baraza, D.G. Snomed2Vec: Representation of SNOMED CT terms with Word2Vec. In Proceedings of the 2019 IEEE 32nd International Symposium on Computer-Based Medical Systems (CBMS), Cordoba, Spain, 5–7 June 2019; pp. 678–683. [Google Scholar]
- Khatua, A.; Khatua, A.; Cambria, E. A tale of two epidemics: Contextual Word2Vec for classifying twitter streams during outbreaks. Inf. Process. Manag. 2019, 56, 247–257. [Google Scholar] [CrossRef]
- Chen, T.; Mao, Q.; Lv, M.; Cheng, H.; Li, Y. Droidvecdeep: Android malware detection based on Word2Vec and deep belief network. KSII Trans. Internet Inf. Syst. (TIIS) 2019, 13, 2180–2197. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Croux, C.; Dehon, C. Influence functions of the Spearman and Kendall correlation measures. Stat. Methods Appl. 2010, 19, 497–515. [Google Scholar] [CrossRef] [Green Version]
- Collett, D. Modelling Binary Data; CRC Press: Boca Raton, FL, USA, 2002. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Serial Number | Models/Approach | Features | Dataset | Accuracy |
|---|---|---|---|---|
| 1 | CNN BLSTM CNN-BLSTM Hybrid [20] | Word embedding into vectors | IMDb reviews | 84.5% Pre train model 82% without the Pre train model |
| 2 | LDA on Naive Bayes [21] | Sentiword Net | IMDb reviews | 75.2% |
| 3 | Maximum Entropy [22] | Sentiment words with TF IDF | IMDb reviews | 83.9% |
| 4 | Naive Bayes [23] | Heterogeneous Features | Movie review | 89% |
| 5 | Naive Bayes, KNN [2] | Word vector (sentiword) | Movie reviews | 81.4% |
| 6 | Entailment as Few | |||
| Shot Learner [1] | Word embedding into vectors | IMDb reviews | 87.4% pretrain model | |
| 7 | Deep Convolution | |||
| Neural Network [24] | Vector Features | IMDb Movie Reviews | 82.19% | |
| 8 | LSTM [25] | Vector Features | IMDb Movie Reviews | 84.7% |
| 9 | Neural Network [26] | Lexicon Features | IMDb reviews | 86% |
| Fields | Results |
|---|---|
| Image Processing [29] | 90% accuracy |
| Natural Language Processing Tasks [30] | More than 90% accuracy |
| Recommendation Tasks [31] | Up to 95% accuracy |
| Biosciences [32] | More than 90% accuracy |
| Semantics Task [33] | More than 90% accuracy |
| Malware Detection Tasks [34] | Up to 99% accuracy |
| Input | Output |
|---|---|
| In | sci-fiction |
| In | movie |
| In | hero |
| In | play |
| In | good |
| In | role |
| In | ever |
| PE | NE | Ang | Sad | Clout | Dic | Adv | Adj | WC | ARI | CLI | Polarity | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | 4.480845 | 2.661335 | 0.766645 | 0.472065 | 53.13244 | 82.39125 | 5.163 | 5.582745 | 238.085 | 11.73598 | 5.562898 | 0.5 |
| Median | 4.11 | 2.35 | 0.555 | 0.27 | 54.415 | 82.75 | 5.035 | 5.36 | 175 | 9.085006 | 5.496083 | 0.5 |
| SD | 2.391582 | 1.83451 | 0.942292 | 0.625222 | 19.12675 | 5.64622 | 2.0876 | 2.07515 | 181.0702 | 12.71127 | 1.988948 | 0.500125 |
| Min | 0 | 0 | 0 | 0 | 2.66 | 53.95 | 0 | 0 | 12 | −3.15818 | −1.66788 | 0 |
| Max | 18.18 | 13.4 | 11.2 | 4.17 | 99 | 96.6 | 15.5 | 15.56 | 1304 | 215.7948 | 13.0732 | 1 |
| N | 2000 | 2000 | 2000 | 2000 | 2000 | 2000 | 2000 | 2000 | 2000 | 2000 | 2000 | 2000 |
| Estimate | S-Error | t-Statistics | p-Value | Quality | |
|---|---|---|---|---|---|
| PE | −2.7014 | 0.95065 | −2.8417 | 0.000449 | ** |
| NE | 0.29091 | 0.028457 | 10.223 | 1.57E-24 | *** |
| Ang | 0.42588 | 0.083814 | 5.0812 | 3.75E-07 | *** |
| Sad | 0.23262 | 0.101 | 2.3031 | 0.021273 | * |
| Clout | 0.015815 | 0.003053 | 5.1809 | 2.21E-07 | *** |
| Dic | 0.010314 | 0.010277 | 1.0035 | 3.16E-01 | |
| Adv | 0.002505 | 0.027959 | 0.089602 | 9.29E-01 | |
| Adj | 0.08203 | 0.028151 | 2.9139 | 3.57E-03 | ** |
| WC | 0.000306 | 0.000294 | 1.0428 | 2.97E-01 | |
| ARI | −0.00196 | 0.004221 | −0.46527 | 6.42E-01 | |
| CLI | 0.11089 | 0.030421 | 3.6452 | 2.67E-04 | *** |
| Model | Accuracy | Precision | Recall | F Score |
|---|---|---|---|---|
| Multi-Layer Perceptron | 0.8346 | 0.8424 | 0.8242 | 0.8326 |
| “Logistic Regression” | 0.8316 | 0.8293 | 0.8350 | 0.832 |
| “K Nearest Neighbor” | 0.792 | 0.829 | 0.7360 | 0.779 |
| Random Forest | 0.788 | 0.791 | 0.7839 | 0.7879 |
| Naive Bayes | 0.7552 | 0.7525 | 0.7605 | 0.7565 |
| Support Vector Machine | 0.8454 | 0.8419 | 0.8506 | 0.8462 |
| Model | Training Accuracy Average | Testing Accuracy Average |
|---|---|---|
| CNN | 0.828 | 0.813 |
| Bi-GRU | 0.869 | 0.843 |
| Model | Accuracy | Precision | Recall | F Score |
|---|---|---|---|---|
| Naive Bayes | 0.690 | 0.690 | 0.692 | 0.691 |
| Logistic Regression | 0.79214 | 0.791 | 0.793 | 0.792 |
| KNN | 0.756 | 0.810 | 0.670 | 0.733 |
| Random Forest | 0.766 | 0.761 | 0.775 | 0.768 |
| Multi-Layer Perceptron | 0.801 | 0.797 | 0.810 | 0.802 |
| Support Vector Machine | 0.816 | 0.813 | 0.822 | 0.817 |
| Model | Accuracy | Precision | Recall | F Score |
|---|---|---|---|---|
| Naive Bayes | 0.736 | 0.735 | 0.740 | 0.737 |
| Logistic Regression | 0.836 | 0.832 | 0.841 | 0.837 |
| K Nearest Neighbor | 0.795 | 0.839 | 0.730 | 0.781 |
| Random Forest | 0.802 | 0.798 | 0.807 | 0.803 |
| Multi-Layer Perceptron | 0.839 | 0.829 | 0.856 | 0.842 |
| Support Vector Machine | 0.856 | 0.850 | 0.865 | 0.850 |
| Model | Accuracy | Precision | Recall | F Score |
|---|---|---|---|---|
| Naive Bayes | 0.7727 | 0.7655 | 0.786 | 0.775 |
| Logistic Regression | 0.844 | 0.841 | 0.848 | 0.844 |
| K Nearest Neighbor | 0.8164 | 0.847 | 0.772 | 0.805 |
| Random Forest | 0.818 | 0.815 | 0.822 | 0.818 |
| Multi-Layer Perceptron | 0.849 | 0.847 | 0.853 | 0.859 |
| Support Vector Machine | 0.860 | 0.855 | 0.866 | 0.861 |
| Model | Accuracy | Precision | Recall | F Score |
|---|---|---|---|---|
| Naive Bayes | 0.7810 | 0.775 | 0.791 | 0.783 |
| Logistic Regression | 0.8632 | 0.859 | 0.868 | 0.863 |
| K Nearest Neighbor | 0.8323 | 0.8701 | 0.7812 | 0.823 |
| Random Forest | 0.8308 | 0.8211 | 0.845 | 0.833 |
| Multi-Layer Perceptron | 0.864 | 0.854 | 0.8804 | 0.8669 |
| Support Vector Machine | 0.8787 | 0.8743 | 0.8845 | 0.8793 |
| Model | Training Average Accuracy | Testing Accuracy |
|---|---|---|
| CNN (2 Layers) | 0.853 | 0.840 |
| Bi-GRU | 0.861 | 0.845 |
| Model | Training Accuracy Average | Testing Accuracy Average |
|---|---|---|
| CNN | 0.861 | 0.845 |
| Bi-GRU | 0.901 | 0.871 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, M.S.; Rizwan, A.; Faisal, M.S.; Ahmad, T.; Khan, M.S.; Atteia, G. Identification of Review Helpfulness Using Novel Textual and Language-Context Features. Mathematics 2022, 10, 3260. https://doi.org/10.3390/math10183260
Khan MS, Rizwan A, Faisal MS, Ahmad T, Khan MS, Atteia G. Identification of Review Helpfulness Using Novel Textual and Language-Context Features. Mathematics. 2022; 10(18):3260. https://doi.org/10.3390/math10183260
Chicago/Turabian StyleKhan, Muhammad Shehrayar, Atif Rizwan, Muhammad Shahzad Faisal, Tahir Ahmad, Muhammad Saleem Khan, and Ghada Atteia. 2022. "Identification of Review Helpfulness Using Novel Textual and Language-Context Features" Mathematics 10, no. 18: 3260. https://doi.org/10.3390/math10183260
APA StyleKhan, M. S., Rizwan, A., Faisal, M. S., Ahmad, T., Khan, M. S., & Atteia, G. (2022). Identification of Review Helpfulness Using Novel Textual and Language-Context Features. Mathematics, 10(18), 3260. https://doi.org/10.3390/math10183260