1. Introduction
In this paper, we study a class of distributed multi-agent problems on networks. Each agent in the network system has the following private objective function to be solved
where
is the decision variable,
is a Lipschitz-differentiable convex function, and
is a non-smooth convex function. Examples of
include quadratic functions and logistic functions [
1], and applications of function
include the elastic-net norm, L1-norm, and indicator functions [
2].
For the network system, we consider that each agent in the system is only allowed to interact with neighbor agents, and there is no central agent to process data; then we can obtain
where
is the local estimation for
and
represents a collection of edges in the network. This distributed computing architecture captures various areas containing distributed information processing and decision making, networked multi-vehicle coordination, distributed estimation, etc. Typical applications include power systems control [
3], model predictive control [
4], statistical inference and learning [
5], and distributed average consensus [
6].
In recent years, most of the literature has mainly focused on the case that the optimization objective function contains only one smooth convex function. At the same time, many centralized algorithms with excellent performance, such as proximal gradient descent, sub-gradient algorithm, Newton method, and so on, solve these problems by extending to a distributed form. The sub-gradient algorithm is the most commonly used method. In [
7], Nedić and Ozdaglar apply this method to the distributed optimization problem on time-varying networks and creatively propose the distributed sub-gradient method (DGD). Shi et al. [
8] propose an exact first-order algorithm (EXTRA) and prove the linear convergence of the algorithm. The algorithm makes use of the error between adjacent iterations of the DGD algorithm. Then, [
9] designs a distributed first-order algorithm by combining DGD and the gradient tracking method. In order to further accelerate the convergence of the algorithm, researchers successively propose the distributed ADMM algorithm in [
10,
11,
12,
13]. However, these algorithms can only solve the optimization problem of a single function.
For (
2) this composite distributed optimization problem with a non-smooth term, many research results have emerged. The authors of [
14] design a proximal gradient method by combining Nesterov acceleration mechanisms. However, each iteration will lead to the consumption of more computing resources because more internal iteration steps are required. In undirected networks, Shi et al. design a proximal gradient exact first-order algorithm (PG-EXTRA) for composite optimization problems based on the classical first-order distributed optimization algorithm (EXTRA) [
8] in [
15]. The algorithm can accurately converge to the optimal solution of the problem by using a fixed step-size, so it is different from most algorithms that must use attenuation step-size. The authors of [
16] propose a communication-efficient random walk named Walkman by using a Markov chain. By analyzing the relationship between optimization accuracy and network connectivity, this method obtains the explicit expression of communication complexity and the communication efficiency of the system. Further, considering that the complex situation of the real scene causes most agents in the network to transmit data in a directed way, ref. [
17] uses the push sum mechanism to eliminate the information imbalance caused by the directed network and proposes the PG-ExtraPush algorithm on the basis of [
8] and maintains the same convergence property.
Recently developed, the operator splitting technology has become the mainstream method to deal with this kind of complex optimization problem. Operator splitting technology is applied for the first time to composite optimization since Combettes and Pesquet designed a fully splitting algorithm, refs. [
18,
19,
20,
21] and others successively propose various algorithms for composite optimization. However, operator splitting technology is rarely applied to distributed composite optimization. Based on this, this paper aims to design a distributed algorithm with excellent performance by using the operator splitting method and based on the theory of operator monotonicity.
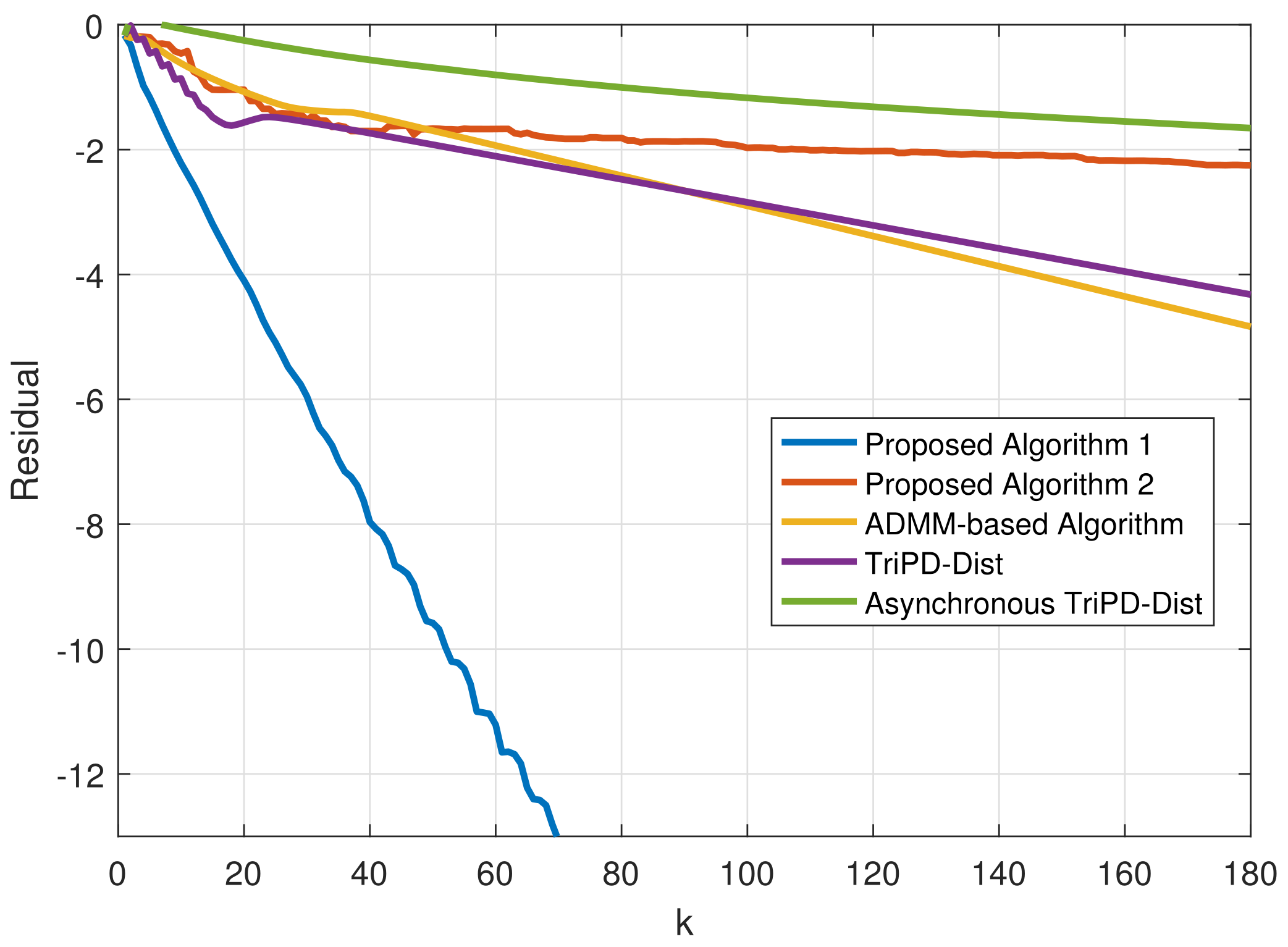
Contributions: Compared with most existing distributed optimization algorithms, the main contributions of this paper are summarized as follows:
- 1.
To solve problem (
2), this paper develops a novel, fully distributed algorithm based on the operator splitting method, which has superiorities in flexibility and efficiency compared with relatively centralized counterparts [
18,
19,
20,
21].
- 2.
Based on a class of randomized block-coordinate methods, an asynchronous iterative version of the proposed algorithm is also derived, wherein only a subset of agents that are independently activated participate in the updates. Note that such an activation scheme is more flexible compared with the single coordinate activation [
22].
- 3.
Both proposed algorithms allow not only local information interaction among neighboring agents but also the use of uncoordinated step-sizes, without any requirement of coordinated or dynamic ones considered in [
7,
8,
9,
14,
23]. Additionally, the convergence of both algorithms is ensured under the same mild assumptions. In particular, the consideration of the local Lipschitz assumption avoids the conservative selections of step-sizes, unlike the global one assumed in [
8,
14,
15,
17].
Organization: The contents of the remaining sections of the paper are as follows.
Section 2 provides the symbols, lemmas, definitions, and assumptions that will be used in the paper. We give the specific process of algorithm derivation in
Section 3. In
Section 4, we show the convergence analysis of the proposed algorithms.
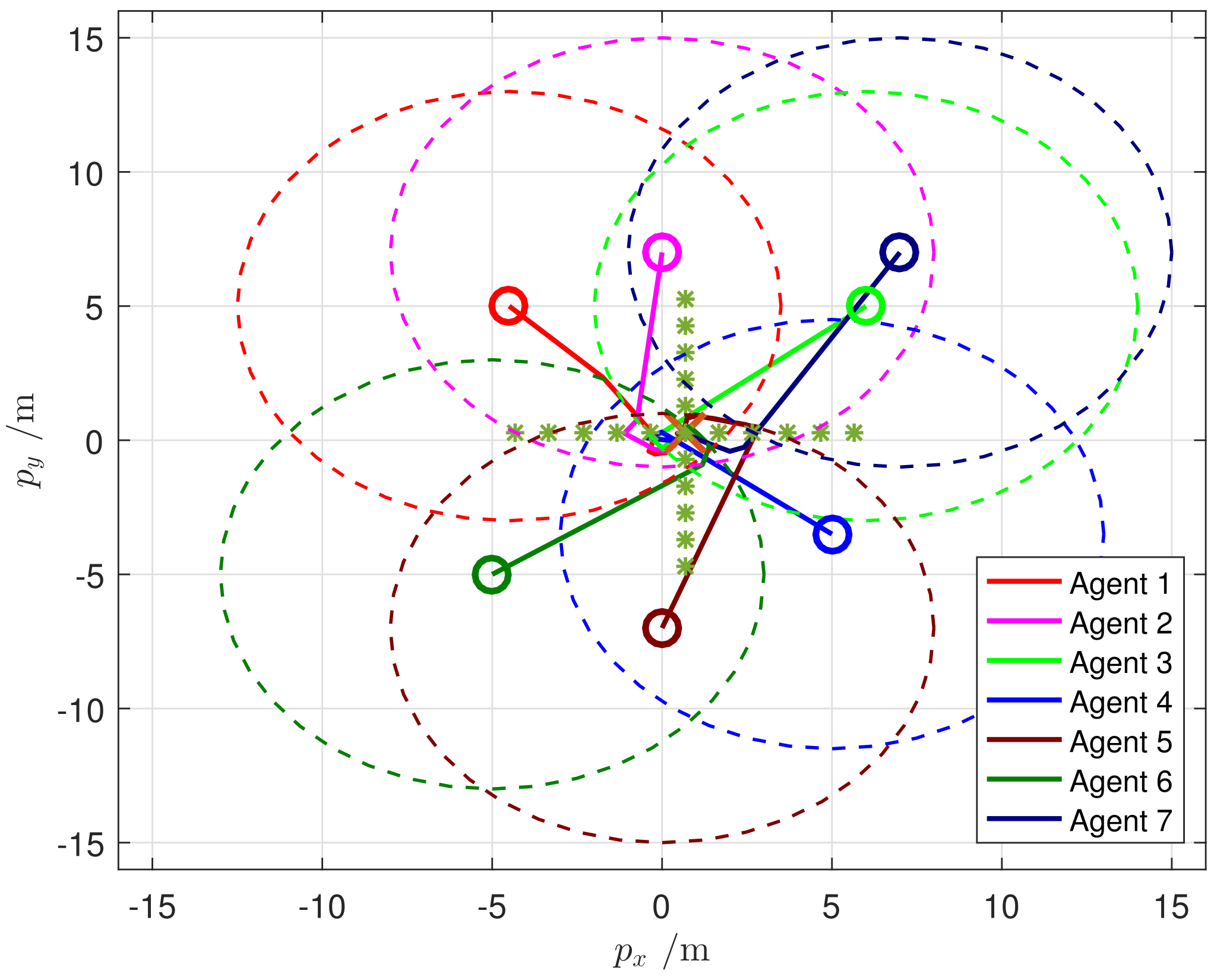
Section 5 presents the simulation experiment to verify the algorithms. Finally,
Section 6 gives the conclusion of the paper.
2. Preliminaries
In this section, we give the notations and display the definitions and lemmas that will be used in the paper. Then, we give two important assumptions.
Above all, we introduce some knowledge about graph theory. Let represent an undirected network composed of n agents, where denotes the set of agents and denotes the set of edges. The neighborhood of the i-th agent is recorded as . Specifically, when there is at least one path in any two agents in an undirected network , the network is connected.
Let denote the n-dimensional Euclidean space and denote the Euclidean norm of a vector . The notation is the spectral radius of a matrix, and represents the set of positive integers. Then let denote the collection of all proper lower semi-continuous convex functions from to . When denotes a positive definite matrix, using as the diagonal element can form a positive definite diagonal matrix . Let denote the interior of a convex subset and denote the effective domain of f. The subdifferential of function is expressed as The proximity operator of a function related to is defined by The convex conjugate function of f is written as .
At the same time, we give the following lemmas and assumptions.
Lemma 1 ([
24]).
Let , then for vectors , the following relation holds: Lemma 2 ([
25]).
Let , then both and satisfy a firmly nonexpansive relationship. Lemma 3 ([
19]).
For a fixed point iteration , will converge to the fixed point of T when it satisfies the following conditions:- 1.
T is continuous,
- 2.
is non-increasing,
- 3.
Definition 1. For all , if an operator T satisfies , then T is a nonexpansive operator. Further, if T satisfies , then T is firmly a nonexpansive operator.
Definition 2. When exist for a constant and operator T, then operator T satisfies -strongly monotone.
The following assumptions will also be used.
Assumption 1. Graph satisfies undirected and connected operators.
Assumption 2. The following three points are satisfied:
- 1.
is a smooth convex function, let be Lipschitz constant, then satisfies - 2.
is a convex non-smooth function,
- 3.
Problem (
2)
has at least one solution.
3. Algorithm Development
In this section, we design and derive the synchronous algorithm and asynchronous algorithm.
We next carry on the equivalent transformation to problem (
2) to facilitate the subsequent algorithm design. The constraint,
in (
2) can be written as the edge-based form
where
for
, and
otherwise. Then, define the following linear operator:
with the compact variable
. We stack all
to get the following operator:
with the dimension
, where
is the number of edges of the network
. Considering the set
Then, constraint (
4) can be further reformulated in the following form:
Based on the above analysis, problem (
2) can be transformed into
where
represents the indicator function, i.e.,
Then, let
and
(
denotes the Cartesian product). Hence, the compact form of problem (
8) can be expressed by
3.1. Synchronous Algorithm 1
According to the fixed point theory, we design the distributed optimization algorithm of problem (
2) from (
9). We define the step-size matrices
,
, and
, where we let
, and then introduce the following operators:
where
and
with
are the fixed points of
T. In particular,
and
are maintained by
i and
j, respectively. Considering the update variables
,
, and
with the edge-based variable
, we give the Picard sequence of
T and obtain the following update rules:
Let
. Using Lemma 2, (
14) can be rewritten as
Next, we split (
15a)–(
15c) in a distributed manner. It follows from (
5) and (
6) that the
i-th component of
is
. Note that (
15a) can be decomposed into
For (
15b), multiply both sides of the equality by
. As done in (
16), we also split (
15b) and (
15c) and use the result
to get the semi-distributed form:
Note that (
17b) is not fully distributed due to the structure
. By using (
4) and (
5), we can derive that the projection of vectors
to
is expressed as
which contributes to the local update of (
17b), i.e.,
Therefore, according to (
17a), (
17c), and the update of
, we can summarize the synchronous distributed algorithm as follows:
Remark 1. Notice that Algorithm 1 is completely distributed without involving any global parameters. For example, each agent individually maintains the private primal variable , auxiliary variable , and edge-based variables . For each edge in the network, as an auxiliary profile contains two components, i.e., and , which are respectively kept by i and j. Meanwhile, the information exchange is locally conducted; that is, agent i shares its updated data and with its all neighbors . On the other hand, the proposed algorithm takes uncoordinated constant positive step-sizes, , essentially distinguished from the global and dynamic ones in [7,8,9,14,23]. It is also worth noting that the edge-based step-size , held by agents i and j linked by the edge , can be seen as inherent parameters of the communication network, revealing the quality of the communication. | Algorithm 1 Distributed algorithm based on proximal operators |
Input: For all agents , , and , where . And select proper positive step-sizes or parameters, and .
For :
1.
2.
3.
4. Send , to j for ,
5. Until the approaches zero.
End
Output: The primal variable as the optimal solution .
|
3.2. Asynchronous Algorithm 2
Here, we extend the synchronous Algorithm 1 to the asynchronous iterative version based on the random-block coordinate mechanism in [
2]. Combining with the principle of this mechanism, we define the diagonal matrix
(where
denotes the number of edges of the graph
) diagonal elements of 0 or 1 to represent the coordinate matrix, and then divide the vector
into
m blocks. At the same time, we define the activation vector
of
-valued, where
is a binary string with length
m. When
, it means that the agent
i is activated at the
k-th iteration; otherwise it is not activated.
In order to describe the activation state of different coordinate blocks and ensure random activation, we give the following assumption.
Assumption 3. The following two points are satisfied:
- 1.
The sum of satisfies ,
- 2.
is a ϕ-valued vector satisfying identical independent distributionsand its probability is
Then, based on the given assumption, we can develop the asynchronous algorithm as follows:
It can be seen that Algorithm 2 allows each agent to awaken with an independent probability, which means that a subset of randomly activated agents will participate in the updates while inactivated ones stay in previous states. Such a scheme is more flexible than the single waking-up scheme [
22] or other activated block coordinates that are uniformly selected [
26]. In addition, the probability is completely independent of the others, which does not meet some strict conditions, such as
.
| Algorithm 2 Asynchronous distributed version |
Input: For all agents , , and , where . And select proper positive step-sizes or parameters, and .
For For , each agent i is activated independently with probability , and further performs the update steps 1–5 in Algorithm 1. While agents that are not activated, the last values keep unchanged.
End
Output: The primal variable as the optimal solution .
|
In order to facilitate the subsequent derivation of convergence, we need to give a compact form of Algorithm 2. By making
, we get
where
and operator
T can be seen in Equation (
11).
4. Convergence Analysis
The convergence proof of the algorithms is provided in this section. The following assumption is the condition to be met for the convergence of the algorithms.
Assumption 4. Recall the local Lipschitz constant in Assumption 2. It is assumed that the step-sizes satisfy the following conditions: Lemma 4. Let be a solution to (9), then there arewhich means is a fixed point of T. On the contrary, is the solution to (9) when is the fixed point of T. Proof. Use the first-order optimal condition of (
9) to obtain
, where
is the optimal solution. According to the definition of matrix step-sizes, we further obtain
Use Lemma 1 and let
to get
Then according to (
19) and (
20), we can get
Therefore, we have
and
. Meanwhile,
, where
. Accordingly, if there is
, it can also be deduced that
satisfies the first-order optimality condition of problem (
9). Thus
is an optimal solution of problem (
9). □
Lemma 5. Let Assumptions 1 and 2 hold, then there are Proof. Combining (
14), (
19), and Lemma 2, we get
It is further concluded that
Here we introduce an equality. For a positive definite matrix
and
, we have
Combining the above two results, we derive
In order to prove the validity of (
22), (
3) is used for (
14)
Using subdifferential properties to obtain
and equivalent
A derivation similar to (
25) is obtained for (
14)
Combining the above two equalities and (
26), we can get (
22). □
Lemma 6. Let Assumptions 1 and 2 hold. Set . For matrix and , there is Proof. Adding (
21) and (
22), then rearranging to get
Then we deal with some terms in the above inequality. For (
20) combined with Lemma 1 can deduce
Further using subdifferential properties, we have
Meanwhile, because
is
-strongly monotone, there is
Bring the above results back to (
28) and get (
27). □
Lemma 7. Under Assumptions 1–4, is non-increasing and .
Proof. If Assumption 4 holds, we can deduce that satisfies non-increasing operators.
Sum (
27) over
k from 0 to
N to obtain
When
N tends to infinity, we can get
Next, according to (
32) and (
33), we obtain
Meanwhile, if Assumption 4 holds,
is a symmetric positive definite. Therefore, we can get
According to (
31) and (
35) we obtain
Combining with (
34), we get
Then according to (
35) and (
36), we get
□
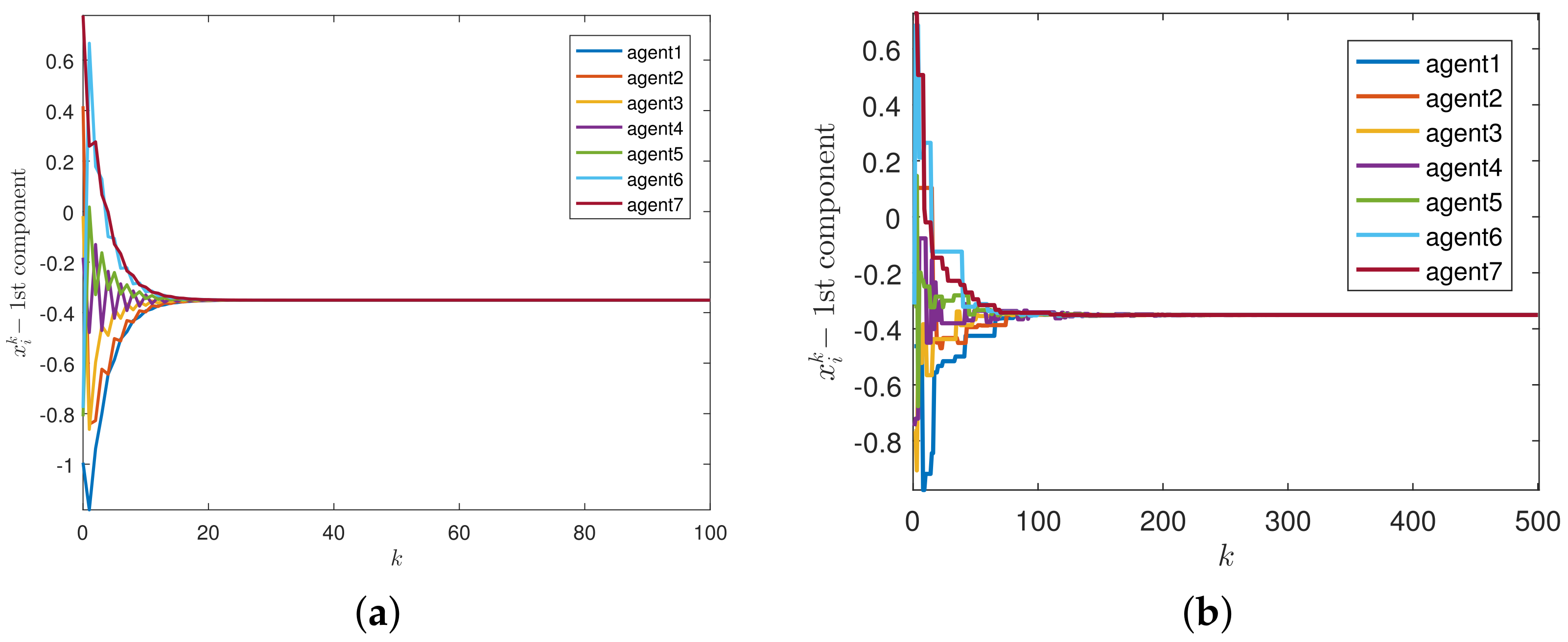
Next, we give the following theorem to prove the convergence of Algorithm 1.
Theorem 1. Under Assumptions 1–4, and converge to the optimal solution of (2) and the fixed points of T, respectively. Proof. Because
and
are firmly nonexpansive,
T is continuous. Then,
and the sequence
satisfies non-increasing are obtained from Lemma 7. Based on Lemma 3, the sequence
converges to a fixed point of
T. According to Lemma 4, it can be concluded that
converges to a solution to (
2). □
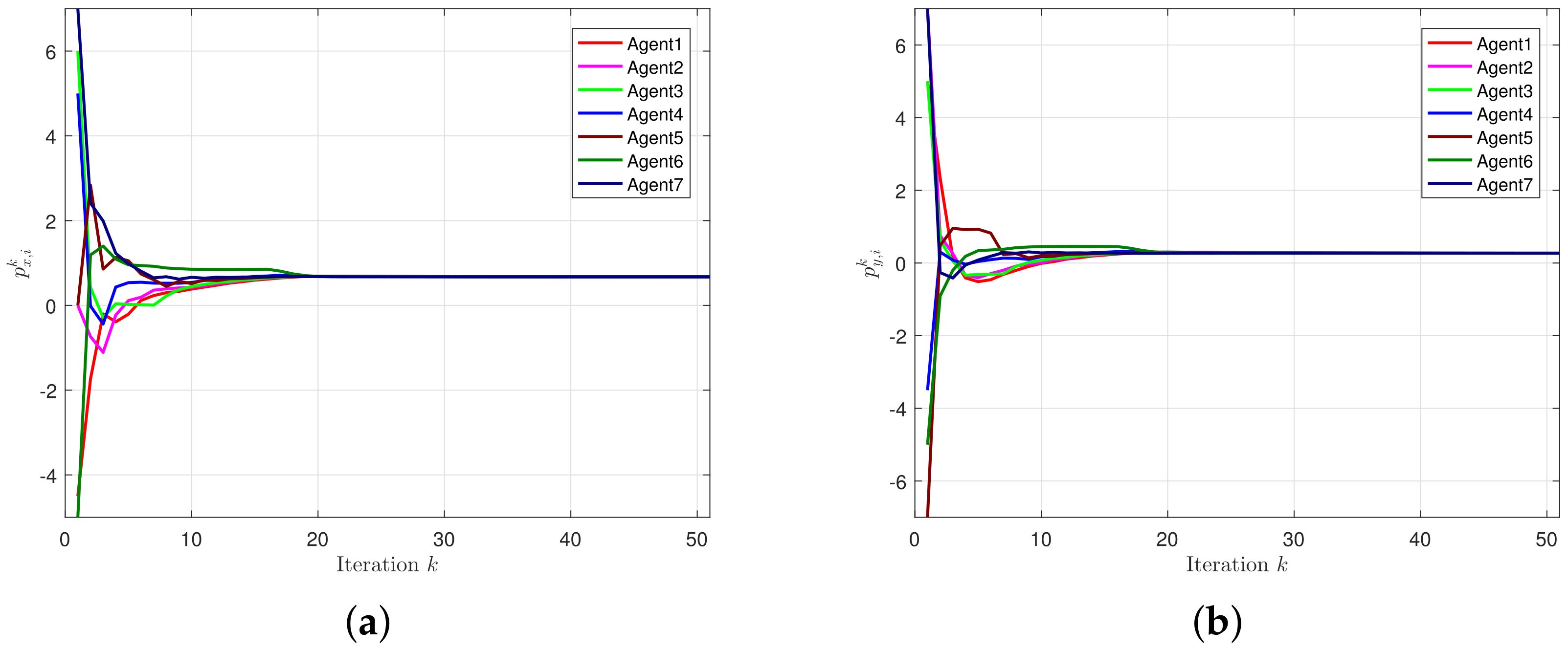
At the same time, we also give the following theorem to prove the convergence of Algorithm 2.
Theorem 2. Under Assumptions 1–4, relative to the solution set , the sequence satisfies stochastic Fejér monotonicity [27]: Further, the sequence converges almost surely to some .
Proof. Before proving, we give some definitions. Here denotes the probability matrix, and is ca onditional expectation, and its abbreviation is , where represents the filtration generated by . We use to map the components of to .
Based on the definition of , we have
Using the idempotent property of
, we have
Then according to Lemma 6 and (
23), we get
Therefore, if Assumption 4 holds, we can obtain the convergence of (
37) according to [
28] Th. 3, [
27] Prop. 2.3, and the Robbins–Siegmund lemma in [
29]. □


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}