1. Introduction
The multi-object tracking algorithm is inseparable from the accurate positioning information of the target, so that accurate detection results can bring better tracking results. At present, the target detection algorithm shows great progress [
1,
2,
3,
4,
5], but the detection effect is not always ideal due to the complex tracking environment. Therefore, the rational use of detection information is also the focus of this task [
6]. Although current association algorithms can combine different types of information and use multiple methods for tracking [
7], it is still difficult to make full use of detection information. These algorithms can only track the detected targets and cannot supplement the undetected targets. Moreover, offline tracking can supplement the missing information in the current trajectory based on subsequent trajectory information or overall trajectory information, but online tracking cannot predict the image content of the next frame. In order to enhance the robustness of tracking and prevent the detection performance from determining the upper limit of the tracking performance, some researchers have begun to study how to use the existing trajectory to compensate for the lack of detection.
One approach is to model historical trajectories to directly predict the trajectory of the current image in an end-to-end fashion [
8,
9]. Another approach is to use historical trajectory information to aid detection. For example, MOTDT [
10] supplements the detection candidate box by predicting the position of the trajectory in the current image as a generation candidate box, and then completes the supplementation of detection information through a series of screening steps. TraDes [
11] fuses the tracked information into the current frame to address detection occlusion issues. However, the end-to-end trajectory modeling method lacks scalability, and supplementing the detection information alone cannot solve the information loss caused by trajectory mismatch.
In this paper, we analyze the reasons for the abnormal termination of the trajectory from the perspective of the trajectory itself. Since the movement of the target is an existing process, the normal trajectory termination occurs mainly because the target gradually disappears from the field of view, such as being obscured or moving out of the field of view until it disappears completely. In this process, the detection confidence should have a gradually decaying trend. When the trajectory with high confidence of the target matched last time is suddenly lost, it is most likely due to missing target information. Therefore, we propose a multi-object tracking algorithm of fusing trajectory compensation, named FTC.
FTC uses different thresholds to filter candidate targets for two matches during data association. Using different confidence thresholds in different matching processes can not only provide high-quality appearance features for similarity matching, but also can provide more candidate bounding boxes for IoU matching, making detection information allocation more reasonable. After completing two matches, FTC starts from the trajectory of the missing target, analyzes the trajectory of the unmatched target, and selects the missing trajectory from the active trajectory. Then, the missing trajectory is extended for several frames according to the predefined extension threshold and confidence decay coefficient to realize the compensation for the missing information.
Furthermore, we use YOLOX-s [
5] to build a one-shot tracking model for experimental validation. The experimental results show that our method can effectively solve the problem of missing information and bring about a significant improvement in tracking performance. The effect of applying FTC on different association and tracking algorithms also demonstrates the scalability of our method.
The article proceeds as follows.
Section 2 introduces the FTC algorithm.
Section 3 describes the process of building an efficient one-shot multi-object tracking model for experimental validation. The experimental results and analysis are given in
Section 4, including ablation experiments and comparisons with other algorithms.
Section 5 concludes this paper.
2. FTC
As shown in
Figure 1, FTC contains two improvements (marked by dotted lines). First, FTC sets different thresholds to filter the targets to be matched so as to fully exploit the detection information. Then, FTC uses the predicted trajectory position to expand the trajectory that is judged to be missing, so as to compensate for the missing information.
Considering the excellent prediction effect and wide application of the Kalman filter (KF) algorithm [
12], we employ a Kalman filter to predict trajectory positions, and assume that the target is in gentle motion (i.e., no sudden movements and stops). The pseudocode of FTC is shown in Algorithm 1.
We take a video sequence as input, along with a detector with embeddings and . There are five thresholds, including and . and are tracking thresholds. is a trajectory expansion threshold and is a confidence decay factor. The output of FTC is the track of the video. Each track contains the bounding box and the identity. The confidence of the latest matching target is recorded as the current score of the trajectory, and the trajectory that does not lose the target in the last match is recorded as the active state.
For each frame of the input video, the predicted detection boxes, detection confidence and corresponding embedding features are simultaneously obtained through . Then, the target is divided into and according to different thresholds, and the trajectory state is predicted by using the Kalman filter, as shown in lines 4 to 8 of Algorithm 1. When associating, we first perform feature similarity matching based on the embeddings of and the current trajectory . Then, we update the matched target to , and record the unmatched target to and trajectory to , as shown in lines 9 to 11 of Algorithm 1. Unmatched targets need to be merged into before the second match. The second match uses the IoU distance to match the unmatched trajectory with the target , and updates the matched target to . The unmatched target records to and the unmatched trajectory records to . contains targets with low confidence. In order to prevent low-quality embeddings affecting subsequent trajectory matching, for matches with confidence less than , their embedding features are not updated to the trajectory. Considering the length of the algorithm, we do not describe it in detail in Algorithm 1.
Afterwards, the unmatched trajectories and targets are processed separately. First, we determine whether each unmatched trajectory is a missing trajectory. The judgment condition is in the 17th line of Algorithm 1. Three conditions must be satisfied at the same time—that is, the trajectory score is greater than the trajectory expansion threshold, the trajectory length is greater than 2, and the trajectory is active.
| Algorithm 1: Pseudo-code of FCT. |
Input: A video sequence
; object detector with embeddings
; Kalman Filter
; tracking thresholds
; trajectory expansion threshold
; confidence decay factor
Output: Tracks
of the video
|
(Initialization) for in do / * predict detection boxes, confidences and embeddings * / Targets in with greater confidence than Targets in with confidence between and for in do / * predict new locations of tracks * / end
- 9
Associate and using embedding feature similarity - 10
remaining object boxes from - 11
remaining tracks from
- 12
- 13
Associate and using IoU distance and update - 14
remaining object boxes from - 15
remaining tracks from - 16
for in do - 17
if then / * trajectory expansion * / - 18
- 19
update with - 20
else - 21
/ * delete unmatched tracks * / - 22
end - 23
end - 24
for in do - 25
if then - 26
/ * initialize new tracks * / - 27
end - 28
end - 29
end - 30
return
|
These three conditions are described in detail as follows. (1) Only if the trajectory score, i.e., the confidence of the latest matching target, is greater than a certain threshold will the possibility that the trajectory belongs to a sudden interruption be higher. (2) The trajectory with a length equal to 1 is the initial trajectory, and many initial trajectories are initialized from single-frame high-confidence targets generated by detection or association problems, and usually will not match new targets to become long trajectories. At this time, it is impossible to determine whether the trajectory is a real trajectory, so the initial trajectory is also called an undetermined trajectory. To prevent the expansion of undetermined trajectories, trajectories with a trajectory length less than 2 are excluded. (3) The activation state of the trajectory means that the trajectory has recently completed the matching of the new target in the previous frame. Trajectory expansion is not performed on trajectories that have not been updated twice or more.
When the track is judged to be a missing track, we update the predicted position of the track to the current track. Note that the update here is different from the previous two matching process updates. In the first two matches, the trajectory position predicted by the is the predicted value, and the matched target position is the detection result. When the trajectory is updated, the Kalman filter will use the detection result to update, and calculate the target position estimate with the minimum mean square error as the final position to update the trajectory. This not only completes the update of the trajectory state, but also corrects the target position. However, there are no detections when the trajectory extension is updated, so only the predicted position is updated to the trajectory.
If the track is not judged to be a missing track, we will mark it as a lost track. Tracks marked as lost are still retained in and participate in subsequent matching (but not output as tracks in the current frame), and they will not be deleted until the loss time reaches a certain range. For the unmatched target , if the target confidence is greater than the trajectory initialization threshold , the target will be initialized as a new trajectory; otherwise, it will be discarded. Finally, the tracking trajectory of the video is returned.
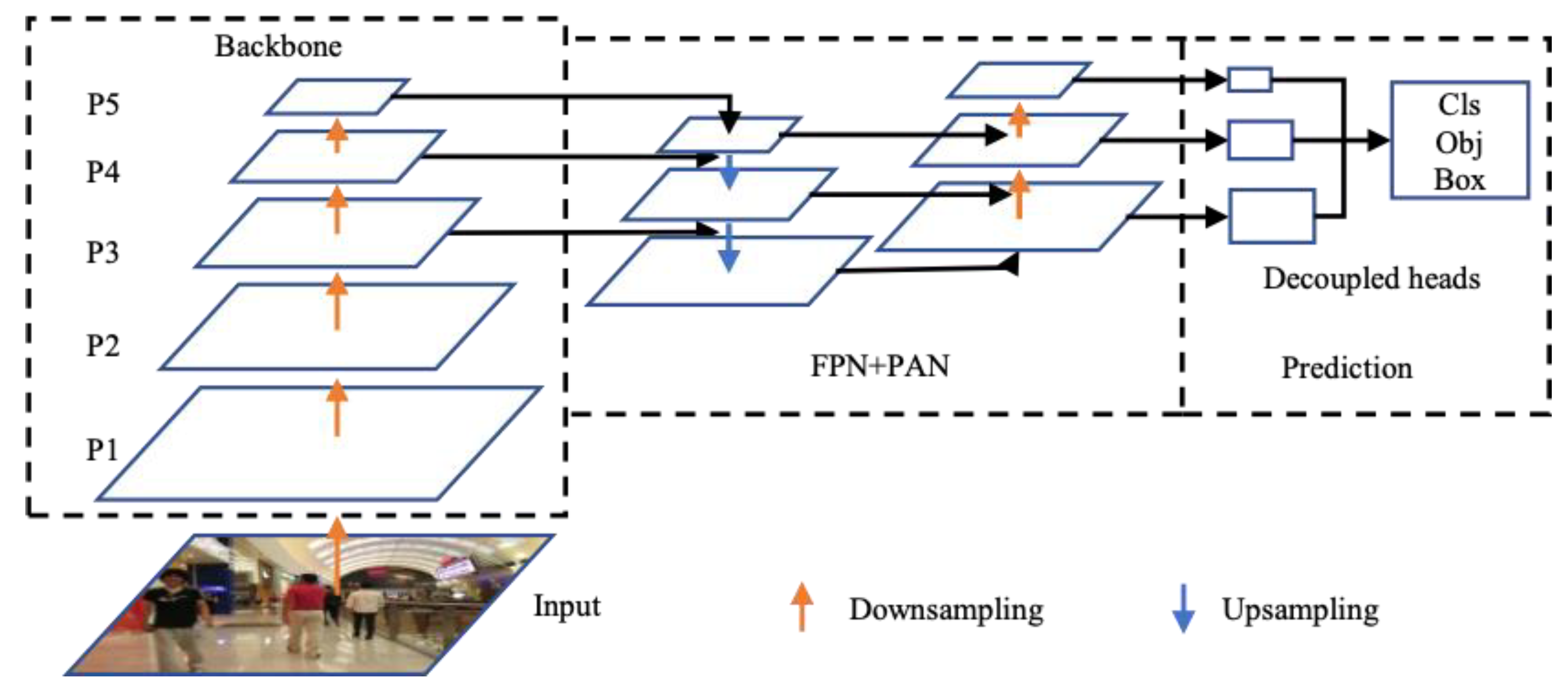
3. FTC Tracker
We use YOLOX-s to build a one-shot multi-target tracker for various experiments. The model structure of YOLOX-s is shown in
Figure 2.
The input part uses Mosaic [
4] and Mixup [
13] for data enhancement. The Mosaic method randomly stitches four images in random scaling, random cropping and random arrangement, which not only enriches the data but also adds many small objects to the dataset, improving the robustness of the model to small objects. Mixup was originally derived from the image classification task. It realizes data expansion by filling and scaling different images to the same size and then performing weighted fusion. This can steadily improve the classification accuracy with almost no computational overhead. The backbone network uses a cross-stage partial network, and the neck part uses feature pyramid networks and path aggregation networks for feature fusion to enhance the detection ability.
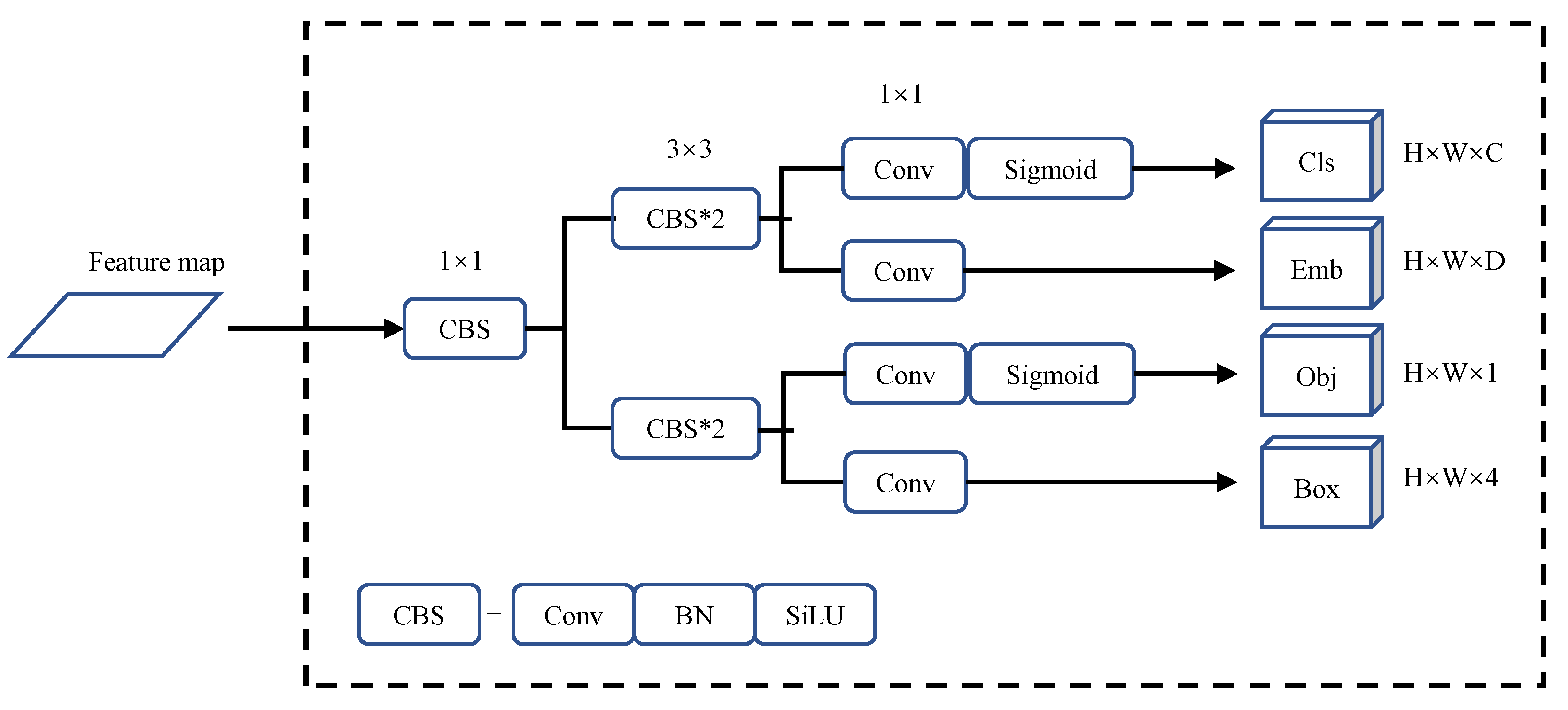
YOLOX improves the prediction module of YOLO into an anchor-free-based decoupling head and uses effective label assignment strategy SimOTA [
14]. One of the embedded decoupled heads is shown in
Figure 3. We embed the appearance model (Emb) into the classification decoupling head with minimal computational cost.
The Emb branch needs to output a D-dimensional vector for each prediction target. Therefore, the output feature map size is . The choice of D value is very important. If the dimension is too low, the target features cannot be accurately expressed, and if the dimension is too high, it will not only affect the training and tracking speed, but also will bring about an imbalance between the dimensions of detection and re-identification (Re-ID) features. Therefore, we compared different dimension values, such as 64, 128, 256 and 512, and finally selected the feature dimension as 128.
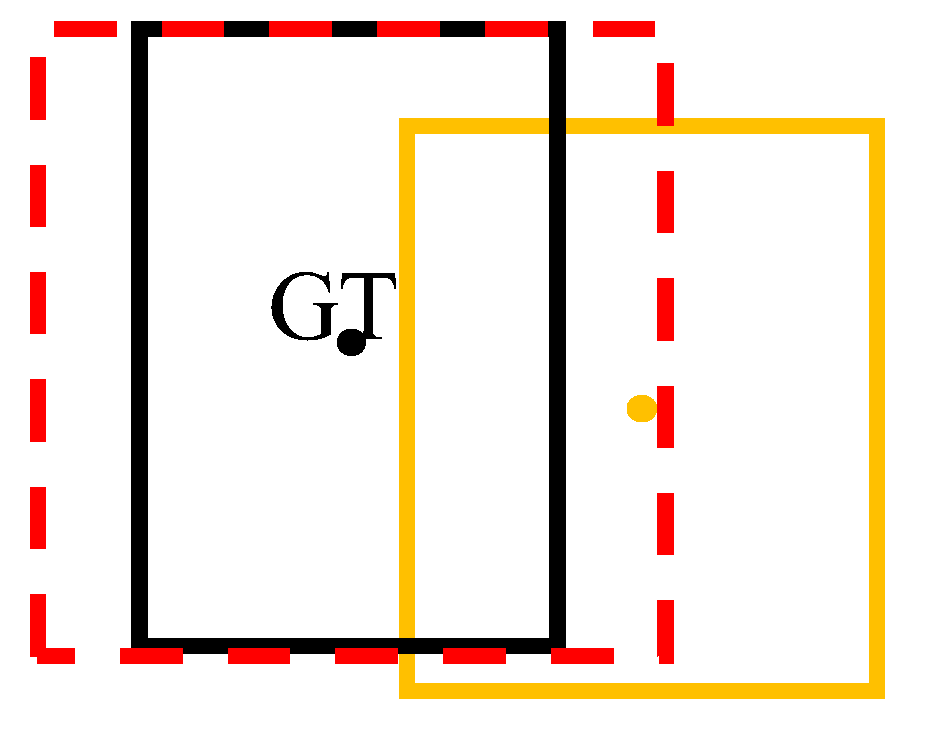
For the selection of positive samples of the prediction frame, YOLOX adopts preliminary screening and the SimOTA algorithm. There are two types of preliminary screening: one is to judge according to the range of the label box and the other is to judge according to the center point of the label box. However, the positive samples are not completely suitable for Re-ID training, because, although some sample prediction boxes are within the range of the screening conditions, their center points are far away from the ground truth (GT) center. This makes the background part in the prediction frame excessive, exceeding the foreground part, which easily leads to blurred Re-ID features. This is not conducive to the re-identification task. In
Figure 4, the dotted boxes represent squares of different scales, the black box is the target GT position, and the yellow box is the predicted position. Points of different colors are the center points of the corresponding target. The background part in the yellow prediction box is redundant with the foreground part.
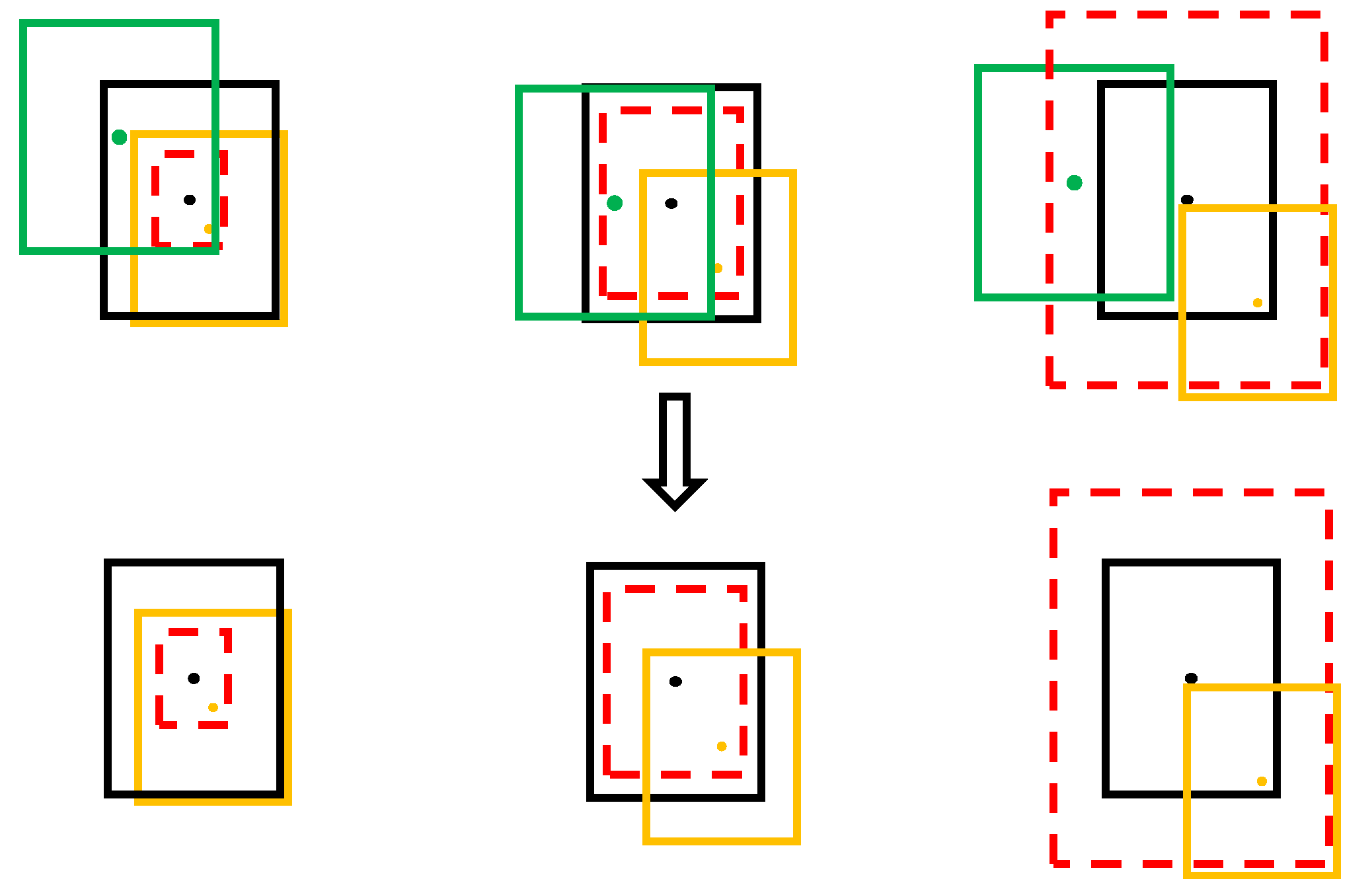
To reduce the feature blur problem, we propose a secondary screening strategy for embedding positive samples. By comparing the distance between the center of the predicted positive sample and the center of the GT, the predicted positive samples are screened for a second time. More specifically, first, the offset range is calculated according to the GT detection frame. A rectangle with a long side of 5 is set on the three feature maps according to the height–width ratio of the labeling frame, and multiplied by the corresponding downsampling multiple to obtain its rectangular range on the input image. In order to ensure that the center point of the predicted positive sample is within the range of the label, the minimum edge length of the above rectangle and the label box is taken as the final offset range. Then, the offset of the current predicted location in the x-axis and y-axis directions for screening is obtained, and the embedding positive sample is achieved after secondary screening.
Figure 5 shows the process of the secondary screening, where the dotted box is the offset range, the black box is the target position, the green box is the predicted position beyond the range, and the yellow box is the predicted position within the range. Points of different colors are the center points of the corresponding target. It can be seen from the rightmost group that when the offset range exceeds the callout frame, the callout frame range shall prevail.
We treat embedding appearance re-identification training as a classification task [
15]. Objects with the same ID in the dataset are regarded as the same category. During the training process, the embedding feature vector of the target is sent to a linear classification layer to obtain the probability value of each category. We use cross-entropy loss for ID classification training. The classifier does not need to be used during testing; only the embedding features are subjected to the association process to calculate the similarity. When testing, the classifier does not need to be used; we only need to submit the embedding features to the association process to calculate the similarity. The category loss (Cls branch) and object confidence loss (Obj branch) use binary cross-entropy to calculate the loss. Box loss uses IoU loss calculation only when Mosaic enhancement is used, and it increases
loss when Mosaic and Mixup enhancement is turned off.
4. Experiments
4.1. Experimental Settings
In this section, we use the MOT17 [
16] and MOT20 [
17] datasets for experimental validation. Specifically, for the ablation experiments, we split the MOT17 training set into train_half and val_half for training and validation, respectively. When comparing with different algorithms, we employed the complete training dataset, and submitted the test data to the MOT Challenge official website to obtain the evaluation results. When using the MOT17 dataset, we set the input image size to be
. Since the MOT20 dataset is denser, for the purpose of obtaining a better tracking effect, the input image was increased to
.
As for the evaluation metrics, we adopted the MOT Challenge Benchmark, including Multiple Object Tracking Accuracy (MOTA), Identification F1-Score (IDF1), False Positive (FP), False Negative (FN), ID switch (IDs), Mostly Tracked trajectories (MT) and Mostly Lost trajectories (ML). MOTA is the tracking accuracy rate, which is calculated based on FPs, FNs, and IDs. IDF1 is the ratio of correctly identified detections over the average number of ground-truth and computed detections. MT is the ratio of ground-truth trajectories that are covered by a track hypothesis for at least 80% of their respective life span. ML is the ratio of ground-truth trajectories that are covered by a track hypothesis for at most 20% of their respective life span. Meanwhile, we also used Frames Per Second (FPS) to evaluate the running speed. In all experimental results, means that the larger the better, and means that the lower the better.
The experimental hardware environment was a deep learning server with an Intel Xeon CPU E5-2650 v4, 2.2 GHz processor and Tesla K80 graphics card (4 photos). The algorithm model was initialized by using the model parameters of YOLOX-s during training. The initial learning rate was set to
, and we used 1 epoch warm-up and cosine annealing schedule [
18] for training. The optimizer was stochastic gradient descent (SGD) with weight decay of
and momentum of 0.9. We trained the model for 50 epochs with batch size 12, and turned off Mixup and Mosaic at the 40th epoch. The threshold settings involved in Algorithm 1 are shown in
Table 1.
4.2. Ablation Studies
First, the selection of the embedding feature dimension was experimentally analyzed. In order to choose the appropriate dimension, we chose the dimension values of 64, 128, 256 and 512 for comparison, as shown in
Table 2. Although increasing the feature dimension can reduce FN, it can also increase FP, and the tracking effect does not improve with the increase in the feature dimension. On the contrary, according to the results in
Table 2, when the lowest dimension is 64, there is a higher IDF1, which shows that the lower feature dimension is more suitable for the model in this work. When the dimension value is 128, it has the highest MOTA and the highest IDF1 value, and the overall tracking effect is more balanced.
Table 3 shows the comparison of model parameters and calculations in different dimensions. We can see that the embedding of the appearance model only increases the parameters and calculations by a very small amount. Therefore, in order to achieve a better tracking effect, we set the Re-ID embedding features in these experiments to be all 128-dimensional.
Next, ablation experiments were performed on the different improved strategies, as shown in
Table 4. It was predicted that the secondary screening of positive samples could significantly reduce the number of missed follow-ups. The MOTA was increased by 1.1%, but the false follow-up and ID switching of the target were increased, and the IDF1 was decreased by 0.6%. On this basis, adding the tracking threshold separation strategy can effectively improve the model tracking effect. Although adding low-confidence targets in the secondary matching produces more misjudgments and leads to an increase in FP, it can reduce the loss of targets, the FN value is greatly reduced, and the MOTA is increased by 0.8%. IDF1 was improved by 0.3%. After restricting the update of low-confidence target embedding features (H-conf), IDF1 increased by 0.3%, and IDs also decreased, indicating that reducing low-quality features in the trajectory is indeed conducive to strengthening the feature matching effect of the algorithm, and the target trajectory is more stable. However, the lack of the latest features of the target can also bring certain tracking of errors and tracking of omissions, which have a certain impact on the tracking accuracy, and the MOTA is reduced by 0.1%.
Track compensation uses the predicted track position to expand the missing track, which can reduce the information loss and fragmentation of trajectories. It can be seen from
Table 4 that the experimental results are consistent with the analysis. Due to the supplementation of the track compensation to the missing track, the FN decreases by 137, and the reduction in the track fragmentation increases the IDF1 by 0.9%. This increases the number of traces that can hold the target ID for a long time and reduces the IDs by 26. At the same time, due to the misjudgment of the normal termination trajectory and the inaccuracy of the predicted position, the number of false calls increased, and the FP increased by 31, but the number of missed calls that were successfully supplemented was greater than the number of false calls added, so the tracking accuracy was also improved to a certain extent. MOTA increased by 0.3%. These improvements only add some judgment and processing procedures in the association stage, and the increase in the amount of calculation is very small, so it will not affect the real-time tracking.
4.3. Robustness Experiment
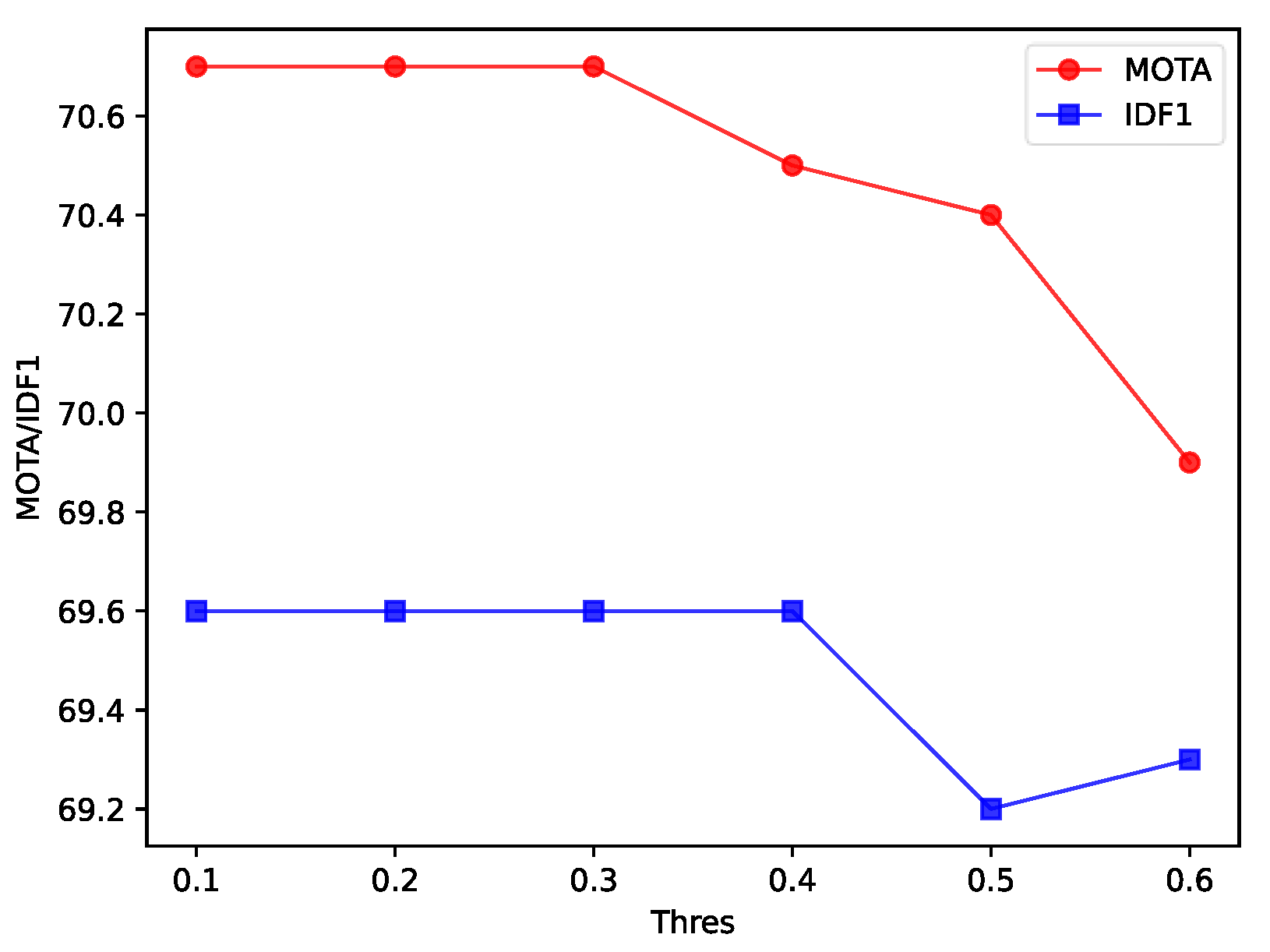
In the tracking threshold separation strategy, the selection of the tracking threshold for secondary matching is also very important. To explore the impact of different thresholds on tracking performance, we took the IoU tracking threshold at intervals of 0.1 between 0.1 and 0.6, and checked the tracking effect of different thresholds, as shown in
Figure 6. The threshold value of 0.6 is the baseline effect of the strategy.
Figure 6 shows that as the IoU tracking threshold decreases, the tracking accuracy gradually increases, but when the threshold is reduced to 0.4 and 0.3, IDF1 and MOTA no longer change. This is because, when performing IoU matching, the calculation of the matching cost needs to be combined with the target confidence. The lower the confidence, the higher the matching cost. Therefore, when the target confidence is lower than a certain range, it no longer affects the tracking effect. Although setting the IoU tracking threshold to a minimum value of 0.1 can ensure that the model has better tracking performance, targets with a confidence level between 0.1 and 0.3 still participate in the association process, resulting in unnecessary calculations. Therefore, the IoU tracking threshold can be taken as the maximum value of 0.3 to stabilize the model tracking performance.
In order to fully demonstrate the improvement of the tracking effect by the tracking threshold separation strategy, a visual analysis was performed on different video sequences of the MOT17 val_half data, and the same adjacent frames before and after the improvement were compared. To ensure the comparison effect, we only printed the information of the comparison target, as shown in
Figure 7. ID is the target ID number, and S is the detection confidence.
Figure 7a shows two sets of comparison targets. The two images on the left are the comparison effects of the 16th frame before and after the improvement. The target with ID number 19 is severely occluded by the target in front of it. Before the improvement, the target was missed. After the improvement, the predicted box with a confidence value of 0.56 was associated to the trajectory. The two images on the right show the comparison effect of the 26th frame. Although the target with ID number 5 is not missed, the detection frame with a confidence level of 0.71 on the left is obviously not as close to the target as the detection frame with a confidence level of 0.51 on the right. In
Figure 7b, the two images on the left are the 57th and 58th frame tracking images before the improvement, and the two groups on the right are the tracking effect images of the two frames after the improvement. After the improvement, The low-confidence detection is successful linked to trajectory. The remaining images from
Figure 7c–f are the same as in
Figure 7b, showing the comparison of the tracking effects of two adjacent frames. Due to the different tracking results before and after the improvement, some targets have different IDs in different results, as shown in
Figure 7c, but they all refer to the same target in the same frame.
From the results of the ablation experiments, we can see that trajectory compensation is a judgment and supplementation to the tracking of the trajectory. Although reducing the leakage of tracking can improve the stability of the trajectory, misjudgment can also increase the false tracking of the trajectory and reduce the tracking accuracy. To verify the effectiveness of the missing trajectory compensation in the trajectory compensation algorithm and explore its advantages and disadvantages under different video conditions, the changes in FP and TP in different video sequences of the dataset were analyzed, and the results are shown in
Figure 8. The abscissa represents different video sequences, and the ordinate represents the numerical variation. For fairness, uniform thresholds were employed for different video sequences.
Figure 8 shows that the number of newly added TPs in 02, 04, 09 and 10 is higher than the number of newly added FPs. Among them, the 02 and 04 sequences have the best effect, and the FP in the 02 sequence greatly decreases. From the overall data, the newly added TP is much higher than the newly added FP, but the effect of the 05, 11 and 13 sequences is poor. Although it can be improved by adjusting the parameters individually, uniform parameters are used considering the overall nature of the dataset. In order to investigate the reasons for the difference in the effects of different video sequences, we analyzed the video data and found that there was camera motion in the video sequences 05, 10, 11 and 13, while the rest were captured by fixed cameras. At the same time, the range of the 05 and 11 sequences of the video crowd is small, and there are many large-scale occlusions. The camera motion and occlusion can affect the prediction effect of the trajectory, so the 05 and 11 sequences are less effective. The 13 sequences were taken by in-vehicle equipment. Although the field of view is very wide, the target scale is small and there is a wide range of camera motion due to vehicle driving and steering. This renders the Kalman filter unable to accurately estimate the trajectory position. Therefore, trajectory compensation is more suitable for trajectories with more accurate motion information estimation.
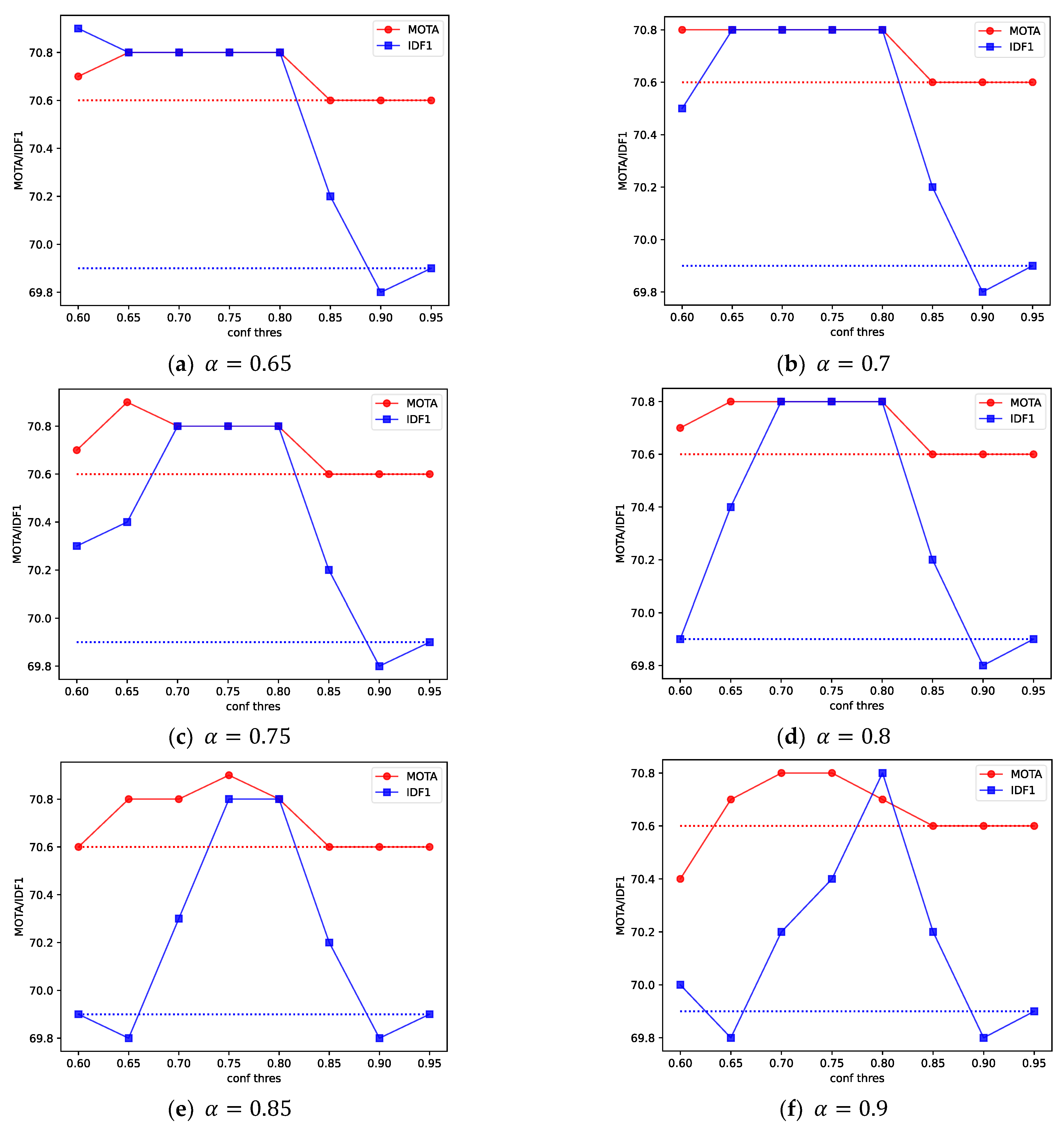
When setting the judgment conditions for missing trajectories, the selection of the trajectory expansion threshold and the confidence attenuation coefficient is also very important, where uses the last matching target confidence of the trajectory to filter the missing trajectories, and controls the expansion times of the missing trajectories. According to experimental experience, should be greater than or equal to the tracking threshold, and it should be selected between the tracking threshold and 1. should be selected between and 1.
In order to explore the change in tracking effect when different parameter values are set, the tracking effect with different
and
was experimentally analyzed. The tracking threshold
is 0.6, so the value range of
and
is 0.6 to 1, and the interval is set to 0.05, as shown in
Figure 9.
Since it is meaningless when and are set to 1, and the result changes significantly when is set to 0.9, only six ranges of experimental results are presented. The two dotted lines represent their baselines, respectively. We can see that when different parameters are taken, the two indicators of MOTA and IDF1 are basically higher than the baseline, and the tracking effect tends to improve gradually as the two parameters decrease, indicating that the reduction relaxes the judgment conditions for missing tracks, and the supplementation for missing tracks increases.
However, it is not true that the more the trajectory is expanded, the better the tracking effect will be. As shown in
Figure 9e,f, after
drops to a certain extent, the two indicators both decrease, and as
decreases, the two indicators gradually increase. This means that the expansion times of some low-scoring trajectories are too high, which can cause many false follow-ups and affect the tracking effect. It can be improved by appropriately reducing the number of expansions through
. Therefore, the selection of the two parameters should be moderate, and it is not easy to take too large or too small values.
4.4. Applications on Other Algorithms
Although the threshold separation strategy has certain limitations, the FTC algorithm has good scalability. In order to fully verify the scalability of FTC, we applied FTC to several different correlation algorithms under the same detection model and different correlation algorithms. The FTC was also extended to several mainstream multi-target tracking algorithms to verify its scalability under different types of algorithms.
Firstly, the expansion experiments of different correlation algorithms were carried out. With YOLOX-s as the detector, four different correlation algorithms, Sort [
19], DeepSort [
20], MOTDT [
10] and JDE [
21], were selected. The detector was trained on MOT17 train_half, and the tracking effect was tested on val_half. The results are shown in
Table 5. After using FTC for trajectory compensation, both MOTA and IDF1 have a certain improvement, and the amount of ID switching is also reduced. This shows that the problem of missing information is common in different association algorithms.
It shows that FTC can judge and compensate for the missing trajectories in different tracking paradigms. Meanwhile, the increase in FP and decrease in FN in the experimental results of the different correlation algorithms are consistent with the analysis of the compensation principle of FTC in this paper, and its accuracy is verified again. Observing the changes in MOTA and IDF1 for different algorithms, we found that the improvement in IDF1 of the other algorithms except Sort is higher than that of MOTA. This is because the addition of missing heels can reduce the problem of trajectory fragmentation. Therefore, although FTC supplements fewer leaks, it can better solve the problem of trajectory fragmentation. However, the Sort algorithm does not use feature similarity matching, and the lost track retrieval ability is poor, so the improvement in IDF1 is lower compared to other algorithms. MOTDT uses the trajectory prediction position to supplement the detection candidate frame before performing matching and association, but after applying FTC, MOTA increases by 0.4%, and IDF1 increases by 0.8%, indicating that supplementing detection information cannot fully solve the problem of missing trajectories.
In addition, extended experiments were also carried out on different mainstream multi-target tracking algorithms, and four different algorithms, JDE [
21], FairMOT [
15], CenterTrack [
22] and CTracker [
23], were selected. In
Table 6, the letter K indicates that the algorithm uses the Kalman filter to predict the trajectory. Among them, JDE and FairMOT are both one-shot algorithms based on the JDE correlation algorithm. The difference is that JDE uses YOLOv3 [
3] as the detector and FairMOT uses CenterNet [
1] as the detector.
Table 6 shows that FTC still achieves a good improvement effect under different detection models.
Since the algorithms in the current experiments all used the Kalman filter to predict the trajectory position, CenterTrack and CTracker were chosen to verify the scalability of FTC without the Kalman filter. Both algorithms use adjacent image pairs as input. The difference is that CenterTrack estimates the target position by outputting the center point offset of the previous frame of the target in the current frame through the deep network, while CTracker calculates the target offset distance through a simple velocity model. However, the center point offset output by CenterTrack is bound to the predicted candidate frame, and CTracker outputs the predicted candidate frame in the form of detection pairs, so it can only predict the trajectory position of adjacent frames, and cannot perform long-term expansion of missing trajectories. Therefore, only the trajectory expansion threshold is set when applying FTC to CenterTrack and CTracker, and only one trajectory expansion is performed for missing trajectories.
The experimental results show that although there is no Kalman filter for the long-term prediction of missing trajectories, it still achieves a good improvement effect. The IDF1 of CenterTrack has an improvement of 0.8%, and the IDF1 of CTracker has an improvement of 1.5%, once again verifying the FTC scalability advantage. However, MOTA has not been improved, indicating that the trajectory position prediction is not as accurate as the Kalman filter.
4.5. MOT Challenge Result
In this section, the MOT Challenge test set is compared with different algorithms, and all the test results were obtained from the MOT Challenge official website. Since the test set annotation is not public, and the datasets used for each algorithm test are different, we used the MOT17 and MOT20 test sets to compare different algorithms.
Table 7 shows the results on the MOT17 test set. Our algorithm achieves higher tracking accuracy and has a much faster online tracking speed than other algorithms.
Table 8 shows the comparison results of different algorithms on the MOT20 test set. Due to the denser pedestrians, there are more crowded scenes and occlusions in the MOT20 dataset. Therefore, we set the input image size to
to achieve a better tracking effect. However, the FPS drops by approximately 2.5 at the expense of some tracking speed. The increase in the number of targets in the data also increases the amount of tracking computation, so the tracking speed in the MOT20 dataset decreases.
Through the sufficient training of a large amount of MOT20 data and large-scale image input, our algorithm has 65.0% MOTA and 65.3% IDF1, while still maintaining the fastest tracking speed of 8.5 FPS. Compared with the test results of MOT17, although the number of targets in the MOT20 dataset is larger, each algorithm can obtain a higher trajectory hit rate ML and a lower trajectory loss rate ML. This should be related to the fact that the MOT20 data are captured at high places. This means that the occlusion range between targets is small and there is no large-scale crowd occlusion. Thus, our algorithm also has higher MT and lower ML, but there is more ID switching.
5. Conclusions
We proposed a simple and effective data association algorithm. The algorithm realized the reasonable distribution of detection results through the tracking threshold separation strategy, and then used the trajectory prediction information to compensate for the missing target information, so as to fully utilize the detection and tracking information. After comparing it with mainstream correlation algorithms such as Sort, DeepSort and JDE, as well as MOTDT supplementing detection, the effectiveness of our method is verified. Furthermore, the process adds only a small amount of computation to data association and has little impact on real-time performance. We also proposed an efficient one-shot tracker, namely FTC Tracker, which achieved high tracking accuracy and high online tracking speed. Compared with mainstream algorithms such as FairMOT and TransCenter, FTC Tracker has great advantages in tracking accuracy and speed. In addition, FTC not only has a stable improvement effect, but also has strong scalability, and can be widely used in various association algorithms or multi-target tracking algorithms. FTC is simple and easy to use, but, due to the dependence on parameter settings, the improvement effect on different methods is not stable enough. In the future, we will consider how to implement FTC in an adaptive way, eliminating the need for parameter adjustment work and improving its stability.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}