
A Fuzzy Grammar for Evaluating Universality and Complexity in Natural Language

Abstract
:1. Introduction
- Structural complexity, if we calculate complexity in terms of a formal property of texts related to the number of rules or patterns.
- Cognitive complexity is the type of complexity that calculates the cost of processing.
- Complexity of development. In this case, we are talking about the order in which linguistic structures emerge and are mastered in second (and possibly first) language acquisition.
- What do we mean by complex? More difficult, more costly, more problematic, more challenging?
- Different ways of using language (speaking, hearing, language acquisition, second language learning) may differ in classifying something as difficult or easy.
- When we determine that a phenomenon is complex, we must indicate for whom it is complex, since some phenomena can be very complex for one group and instead facilitate the linguistic task for other groups.
- An approach to the concept of complexity based on use requires focusing on a specific user of the language and determining the “ideal” user. How do we decide which is the main use and user of the language?
- From the point of view of second language learning, is it more difficult for an adult to learn some languages than to learn others?
- If we consider the processing of a language, is it more difficult to speak some languages than others?
- Focusing on the language acquisition process, does it take longer to acquire some languages than others?
- Absolute universals. These universals are those that do not present exception and that, therefore, are fulfilled in all members of the universe. Absolute universals defend the hypothesis that a grammatical property be present in a language.
- Probabilistic or statistical universals. These types of universals are valid for most languages, but not for all. Probabilistic universals defend the hypothesis that a grammatical property can be present in languages with a certain degree of probability.
- Unrestricted universals. These type of universals may be stated for the whole universe of languages. These universals are applicable to any human language.
- Restricted, implicational or typogical universals. These universals affect only a part of the world’s languages: those that share a given characteristic previously (if x, then y).
- Unrestricted and absolute: In all languages, Y.
- Unrestricted and probabilistic: In most languages, Y.
- Restricted and absolute: In all languages, if there is X, there is also Y.
- Restricted and probabilistic: In most languages, if there is X, there is also Y.
2. Related Work
2.1. Fuzzy Property Grammars for Linguistic Universality
2.1.1. Linguistic Constraint
- (determiner);
- (adjectve);
- (noun);
- (proper noun);
- (verb);
- (adverb);
- (conjunction);
- (subordinate conjunction);
- (preposition).
- General or universal constraints that are valid for a universal grammar. They are built from all the possible combinations between linguistic objects and constraints.
- Specific constraints that are applicable to a specific grammar.
- Prototypical constraints that definitely belong to a specific grammar, i.e., their degree of membership is 1.
- Borderline constraints that belong to a specific language with some degree only (we usually measure it by a number from (0, 1)).
- −
- Linearity of precedence order between two elements: A precedes B, in symbols . For example, in “The girl”.
- −
- Co-occurrence between two elements: A requires B, in symbols . For example, in “the red car”.
- −
- Exclusion between two elements: A and B never appear in co-occurrence in the specified construction, in symbols . That is, only A or only B occurs. For example, in “He runs”.
- −
- Uniqueness means that neither a category nor a group of categories (constituents) can appear more than once in a given construction. For example, there is only one in “She eats pizza”.
- −
- Dependency. An element A has a dependency on an element B in symbols . Typical dependencies (but not exclusively) for are (subject), (modifier), (object), (specifier), (verb), and (conjunction).
2.1.2. Definition of a Fuzzy Property Grammar
- is the set of constraints that can be determined in phonology.
- is the set of constraints that can be determined in morphology.
- is the set of constraints that characterize syntax.
- is the set of constraints that characterize semantic phenomena.
- is the set of constraints that occur on a lexical level.
- is the set of constraints that characterize pragmatics.
- is the set of constraints that can be determined in prosody.
2.2. Fuzzy Property Grammars for Linguistic Universality
- is the set of linguistic categories that can be determined in all languages.
- is the set of dependencies that can be determined in all languages.
- is the set of constraints that characterize syntax.
- If a rule in L coincided with a rule in the then add +1;
- The more weight a rule has, the more universal it is in a representative set;
- The less weight a rule has, the less universal it is in a representative set.
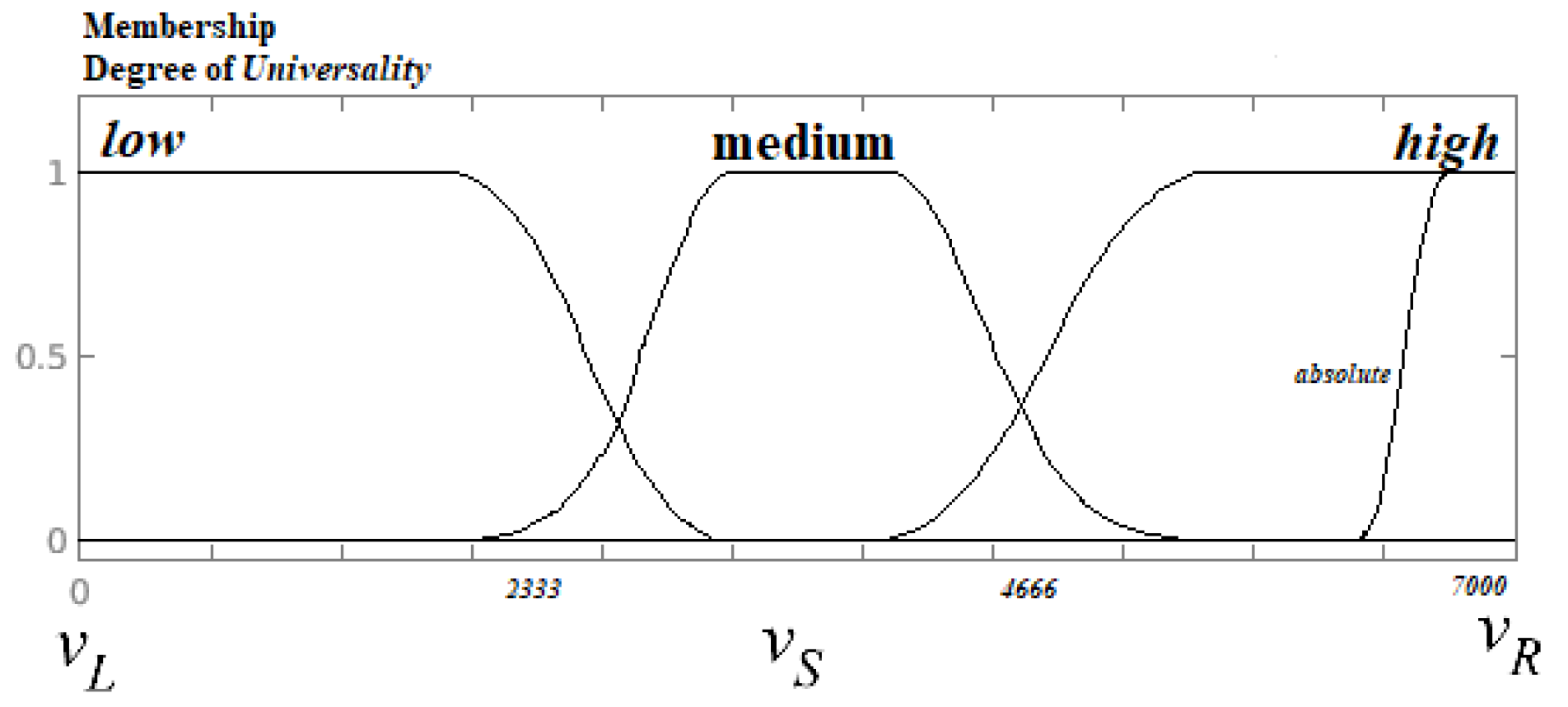
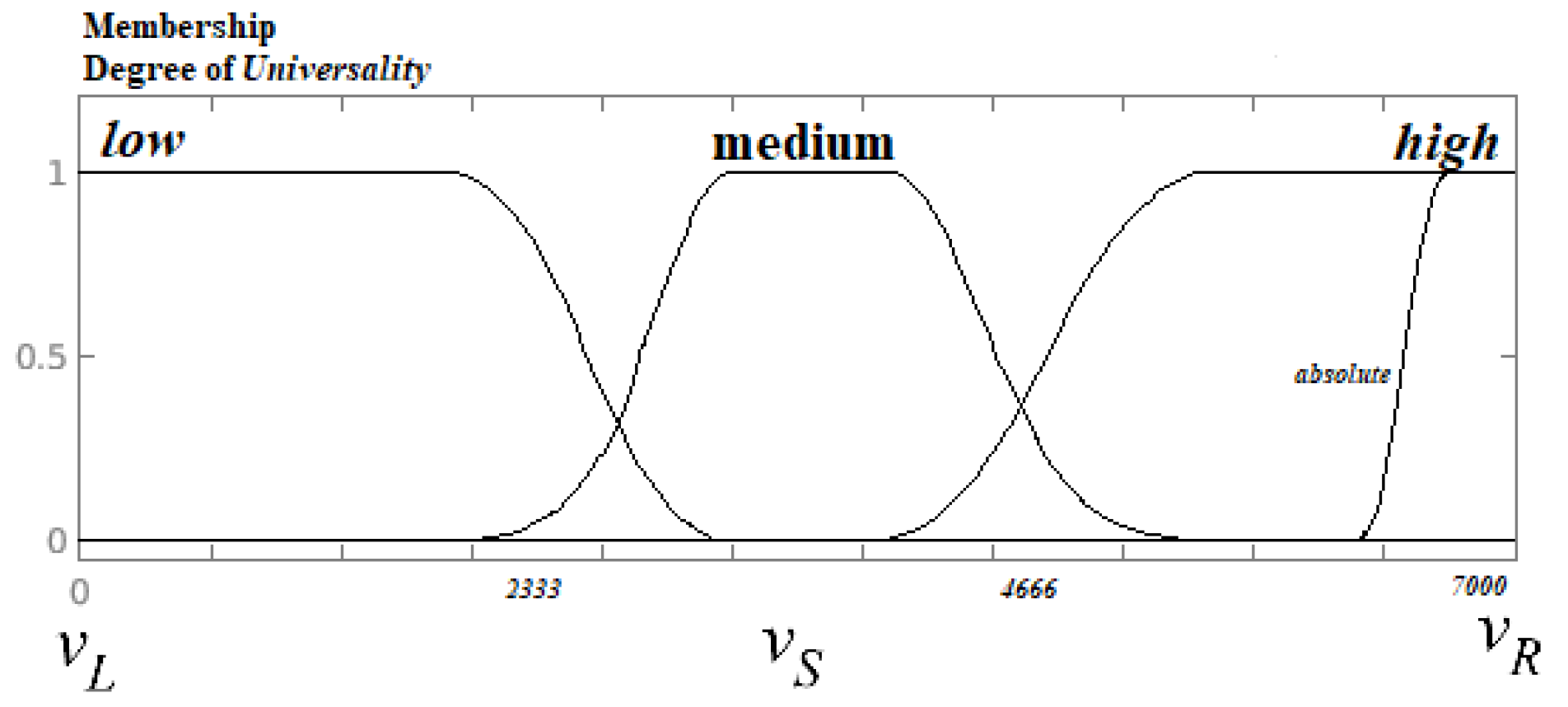
2.3. Fuzzy Natural Logic Computing Universals and Linguistic Complexity with Words
- High Satisfied Universal. Linguistic rules that trigger a high truth value of satisfaction in , therefore, they are found satisfied in quasi-all languages. This fuzzy set includes those rules known as Full Universals, absolute rules, which are located in (almost) all languages.
- Medium Satisfied Universal. Linguistic rules that trigger a medium truth value of satisfaction in therefore, they are found satisfied in the overall average of languages.
- Low Satisfied Universal. Linguistic rules that trigger a low truth value of satisfaction in therefore, they are found satisfied in almost none of the languages.
- IF a rule is a High Universal, THEN the value of complexity is low.
- IF a rule is a Medium Universal, THEN the value of complexity is medium.
- IF a rule is a Low Universal, THEN the value of complexity is high.
- IF the value of complexity is high, THEN the rule is a low universal.
- IF the value of complexity is medium, THEN the rule is medium universal.
- IF the value of complexity is low, THEN the rule is high universal.
- Low Complexity. Linguistic rules that have a high truth value in terms of weight in They are found satisfied in quasi-all languages. This fuzzy set includes rules known as full universals, absolute rules, which are located in (almost) all languages.
- Medium Complexity. Linguistic rules that have a medium truth value in terms of weight in rules found in the overall average of languages.
- High Complexity. Lnguistic rules that have a low truth value in terms of weight in rules satisfied in almost none of the languages.
- The model presents a consistent classification without contradictions in terms of degree for the concepts of universality and complexity.
3. Materials and Methods
3.1. A Fuzzy Universal Grammar with a Representative Set
- (1)
- Difference in the order of the subject–verb relation.
- (2)
- Difference in the order of the object–verb relation.
- (3)
- Difference in the order of the noun–adjective relation.
- Languages from different genus, representatives of the main families.
- Languages from different macro-areas.
- Languages with non-dominant order in different features.
- Isolated languages.
- Agglutinating languages.
- Languages with a greater and lesser degree of ascription to other characteristics such as, for example, the use of cases.
- Corpora with enough tokens and whose source of origin does not have any type of bias, as can be the case of FAQs corpus, for example.
- (1)
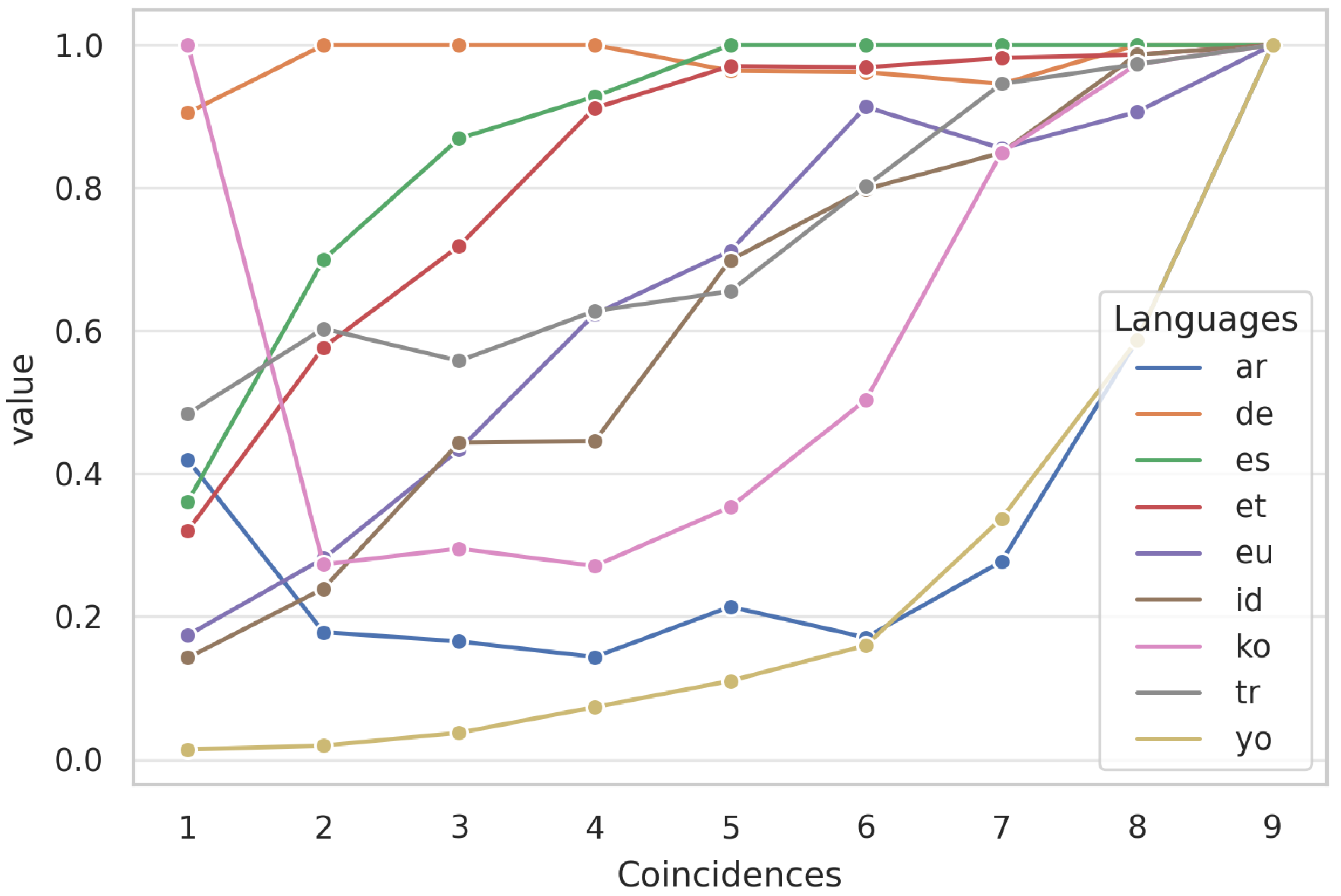
- Arabic (ar.);
- (2)
- German (de.);
- (3)
- Basque (eu.);
- (4)
- Spanish (es.);
- (5)
- Estonian (et.);
- (6)
- Indonesian (id.);
- (7)
- Korean (ko.);
- (8)
- Turkish (tr.);
- (9)
- Yoruba (yo.).
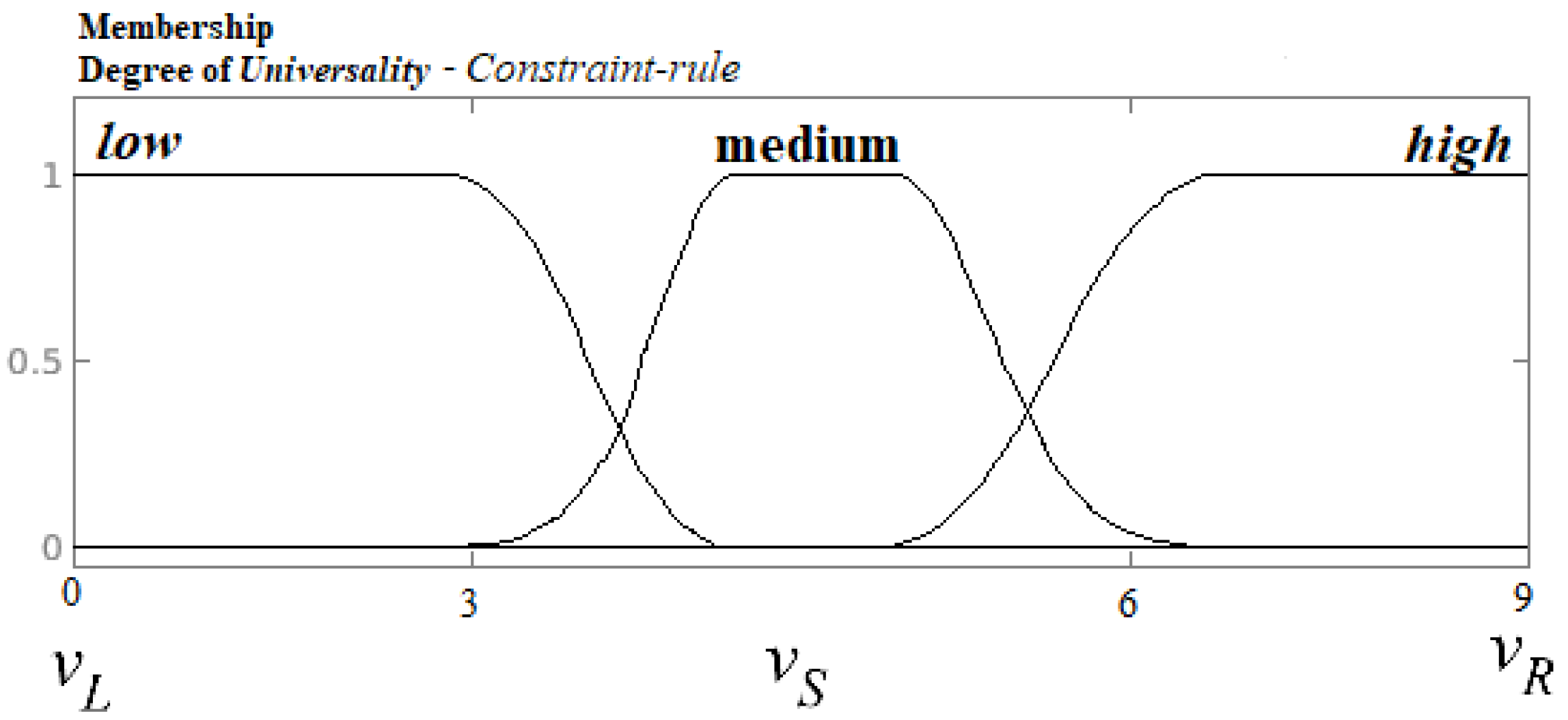
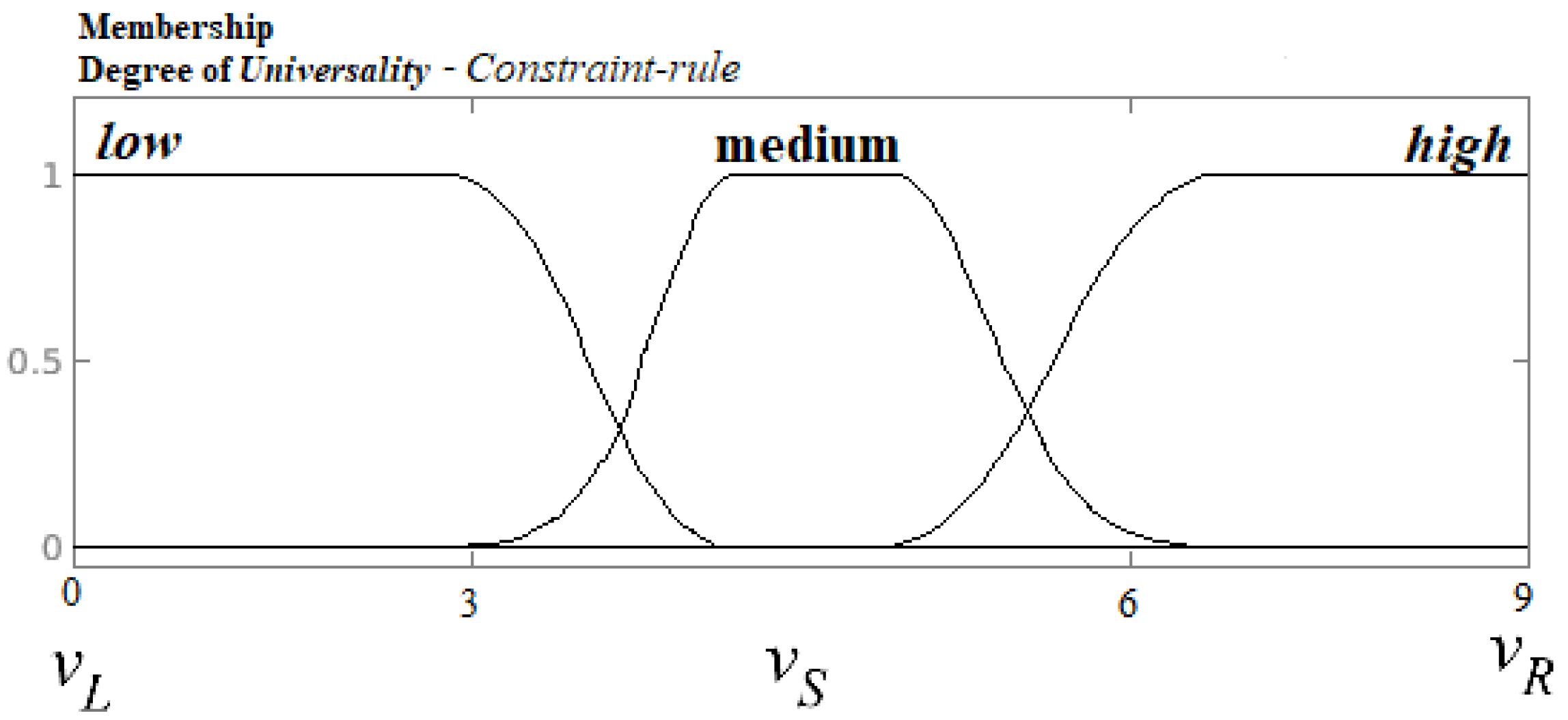
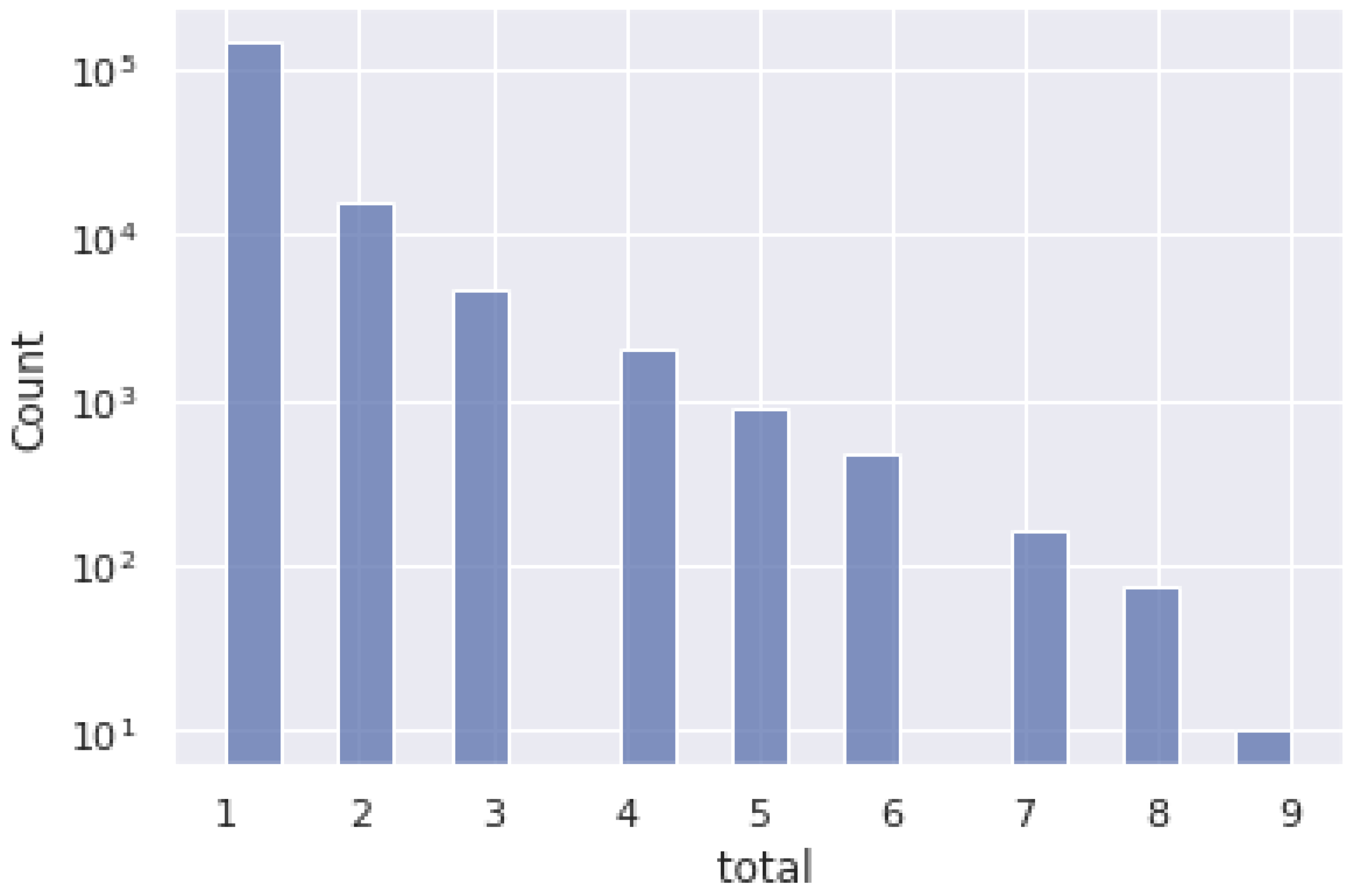
- IF a rule has between 0 and 3 coincidences, THEN the rule is a low universal and it is high in complexity.
- IF a rule has between 4 and 6 coincidences, THEN the rule is a medium universal and it is medium in complexity.
- IF a rule has between 7 and 9 coincidences, THEN the rule is a high universal and it is low in complexity.
- If a rule in a set of languages coincides with a rule in the then add +1.
- The more weight a rule has, the more universal it is in a representative set.
- The less weight a rule has, the less universal it is in a representative set.
3.2. Application of the Tasks to Computationally Build a Universal Fuzzy Property Grammar
3.2.1. Building the Universal Fuzzy Property Grammar
- (1)
- Read the excel file with all the grammar rules.
- (2)
- Make all possible combinations as strings. For example, one combination can look like: “ ”.
- (3)
- Insert all possible combinations into the MongoDB database.The MongoDB database is not necessary, but it solves many problems instead of storing universal grammars in a pure text file. The text file may be huge and have an impact on time complexity for searching for grammar rules.
3.2.2. Preparing Languages for the Universal Fuzzy Property Grammar
- (1)
- We have a set of possible grammars for n languages stored in CSV/TSV files.
- (2)
- For one language:
- (a)
- Load all possible files with language grammar rules.
- (b)
- Preprocessing (for example: remove empty spaces, replace *, …).
- -
- For evaluating universality in one rule:
- (1)
- Send query to the MongoDB database for search rule in Universal Grammar.
- (2)
- If we found a rule in Universal Grammar, we insert a new row to the Pandas Dataframe, where the Universal Grammar column will have a current rule, and the column for the current language will have 1 and other languages will have 0.
- (3)
- If we not found a rule in Universal Grammar, we insert a Universal Grammar rule and 0 for all language columns.
- (4)
- Then, we can compute the total numbers for one rule, and we can put them into the Total column.
4. Results
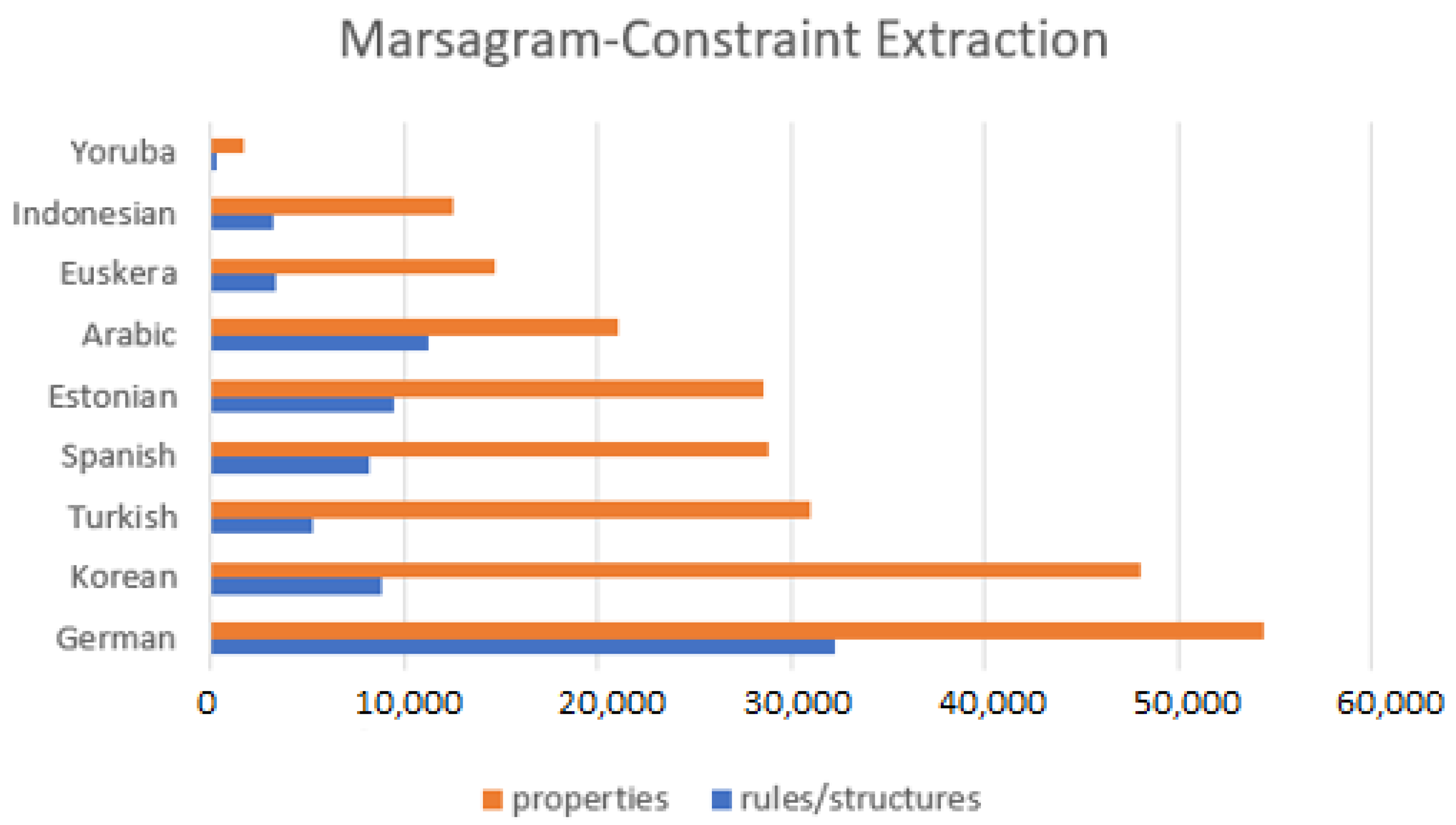
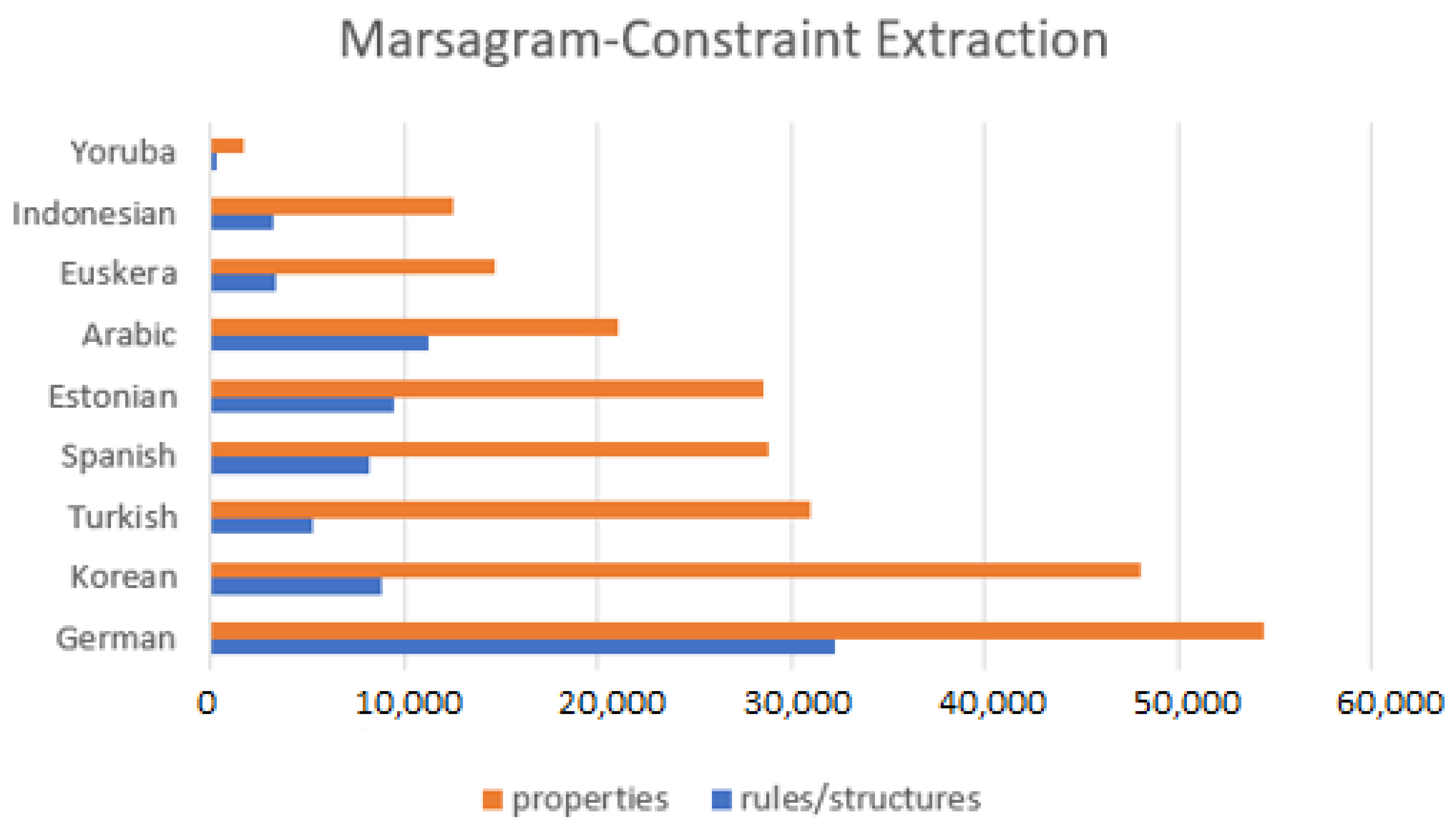
4.1. Quantitative Data of Marsagram
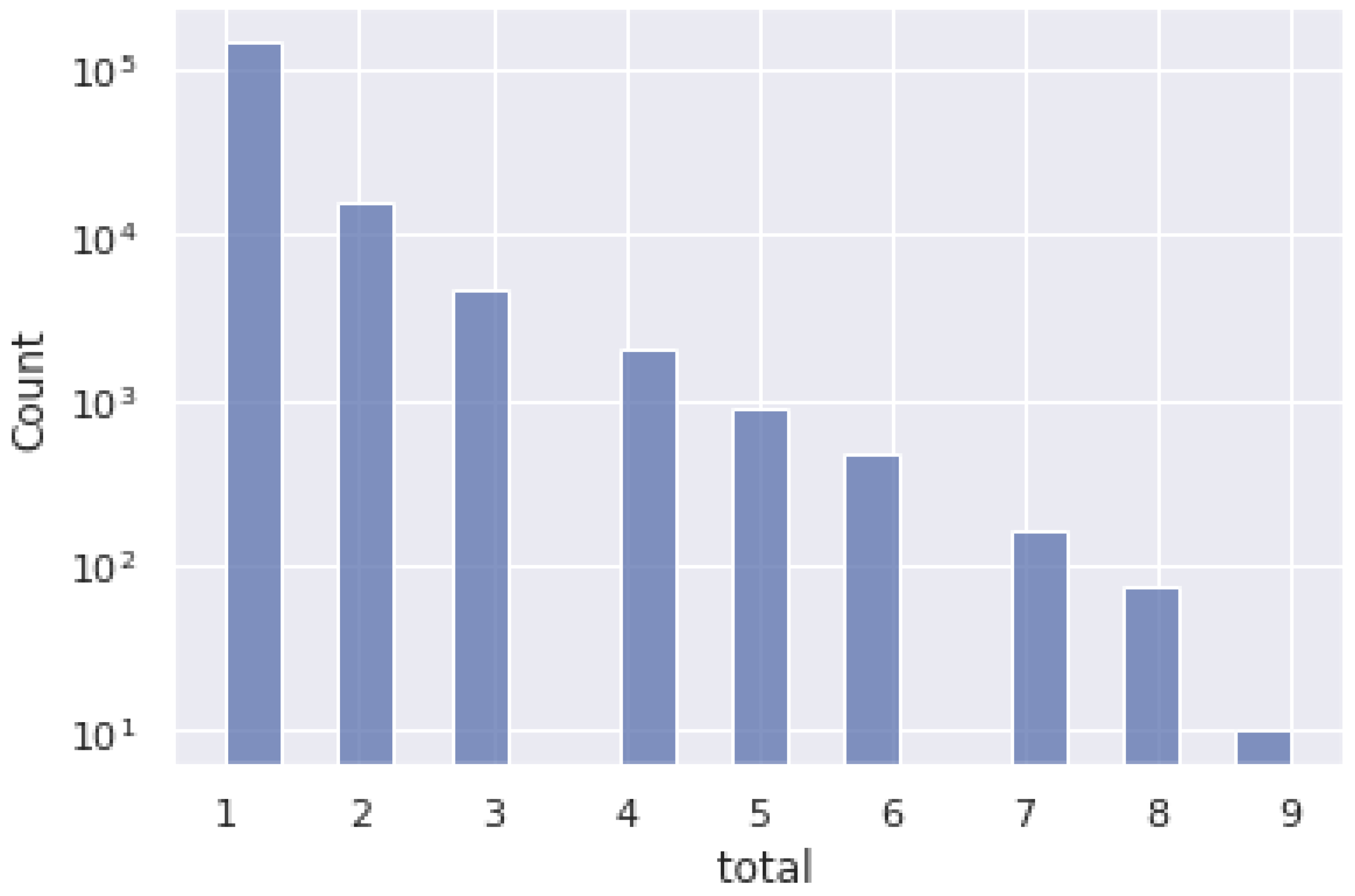
4.2. Quantitative Data Regarding Number of Rules by Weights
4.3. Distribution of the Weighted Rules per Set of Language
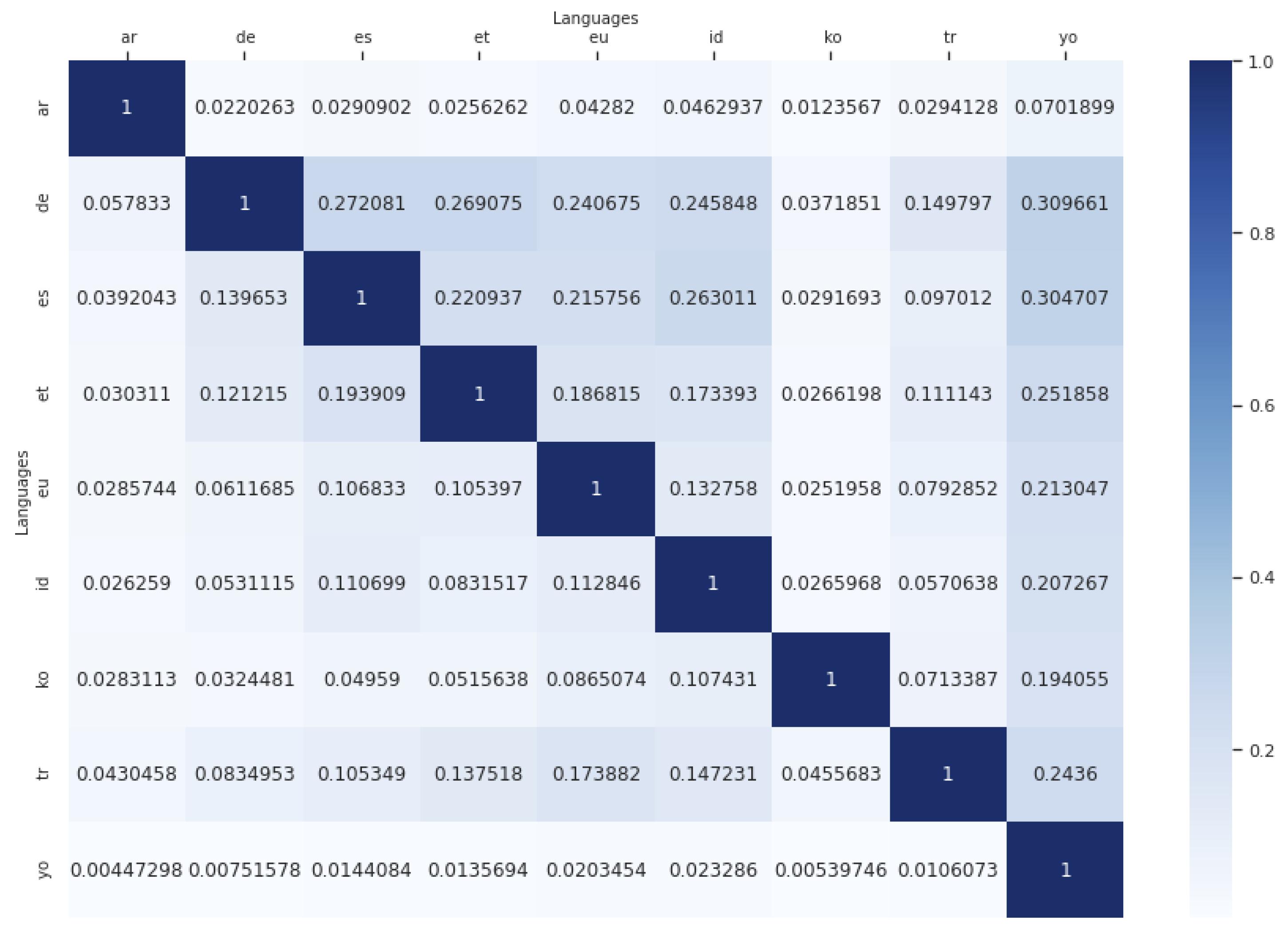
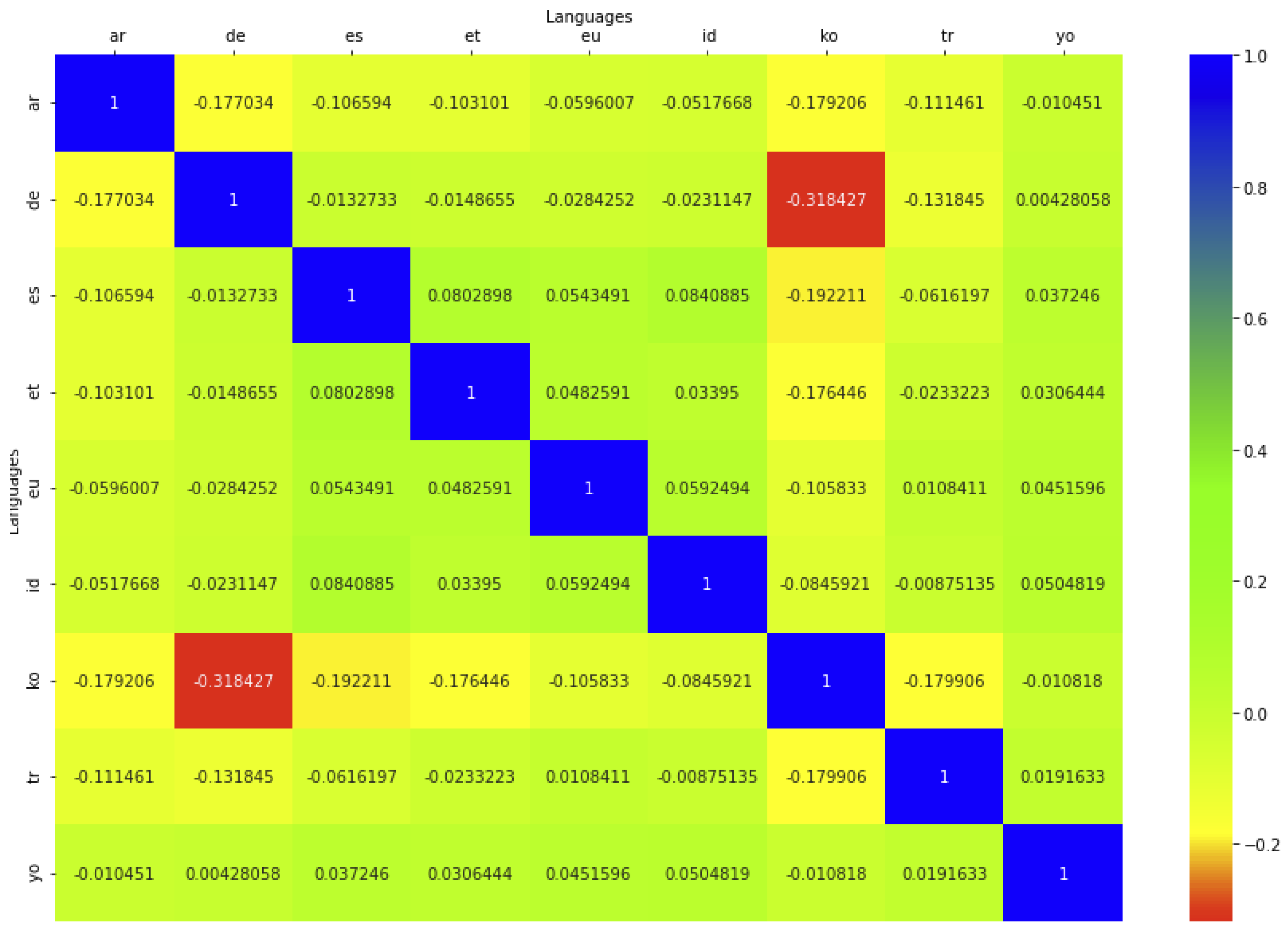
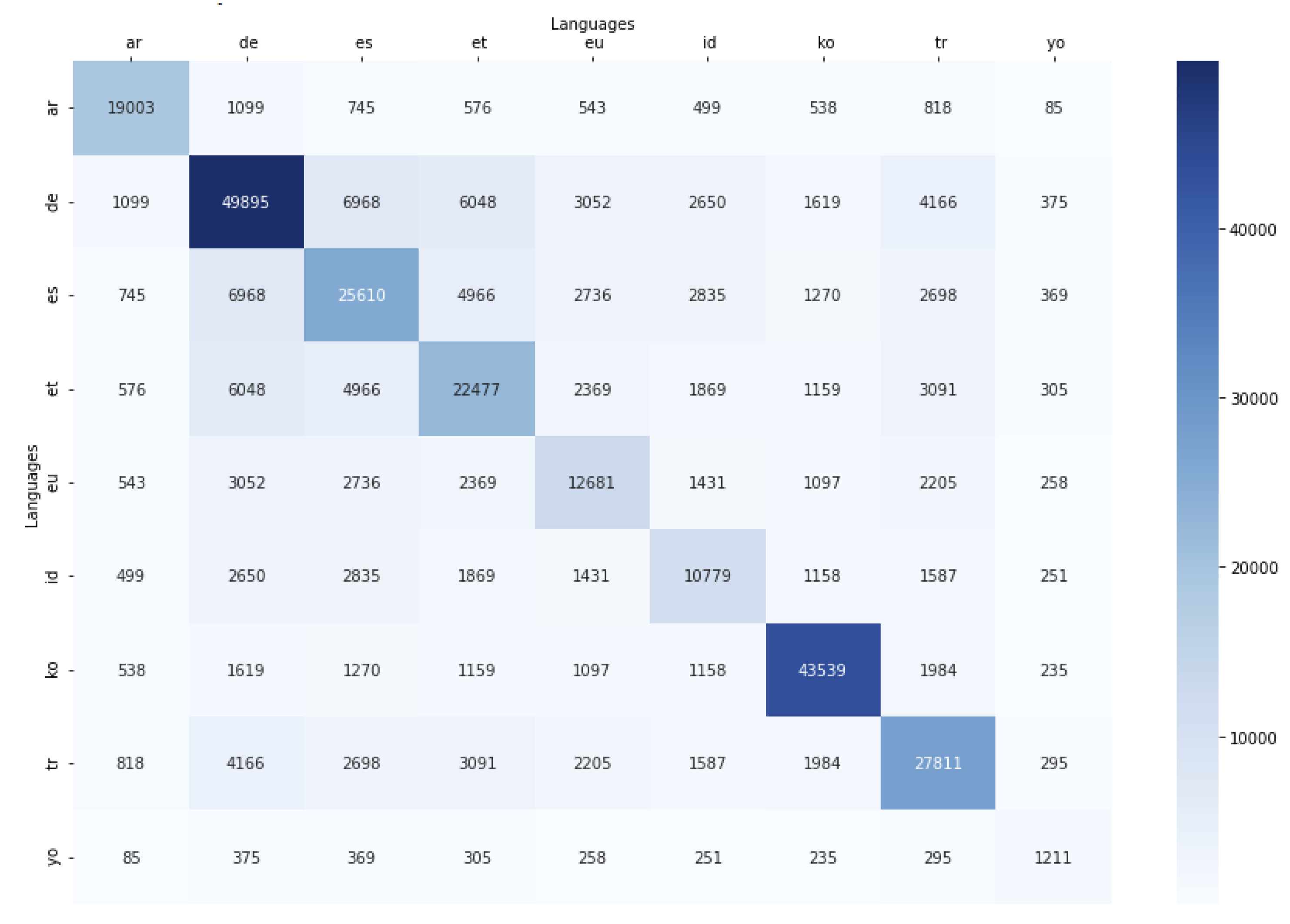
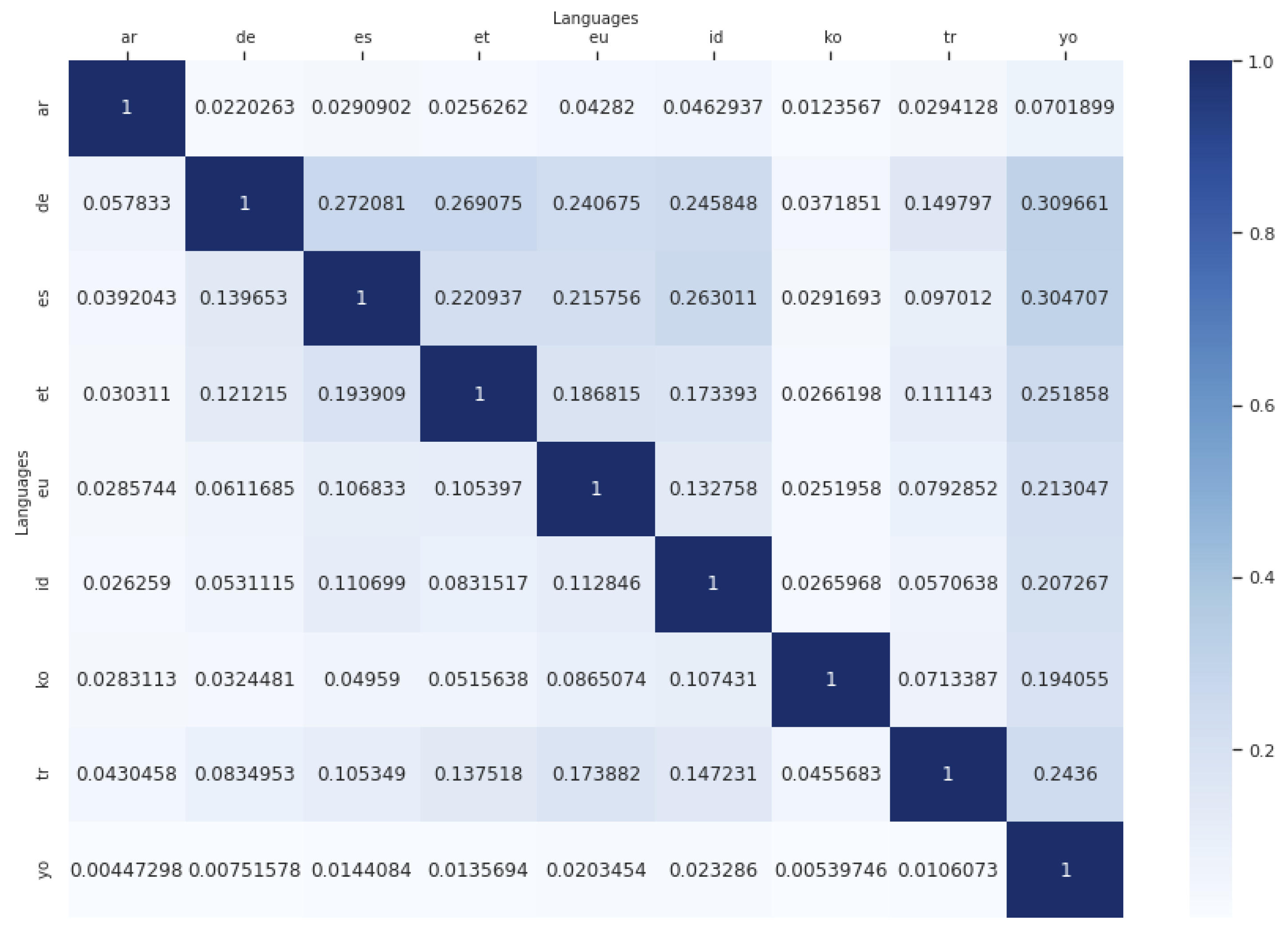
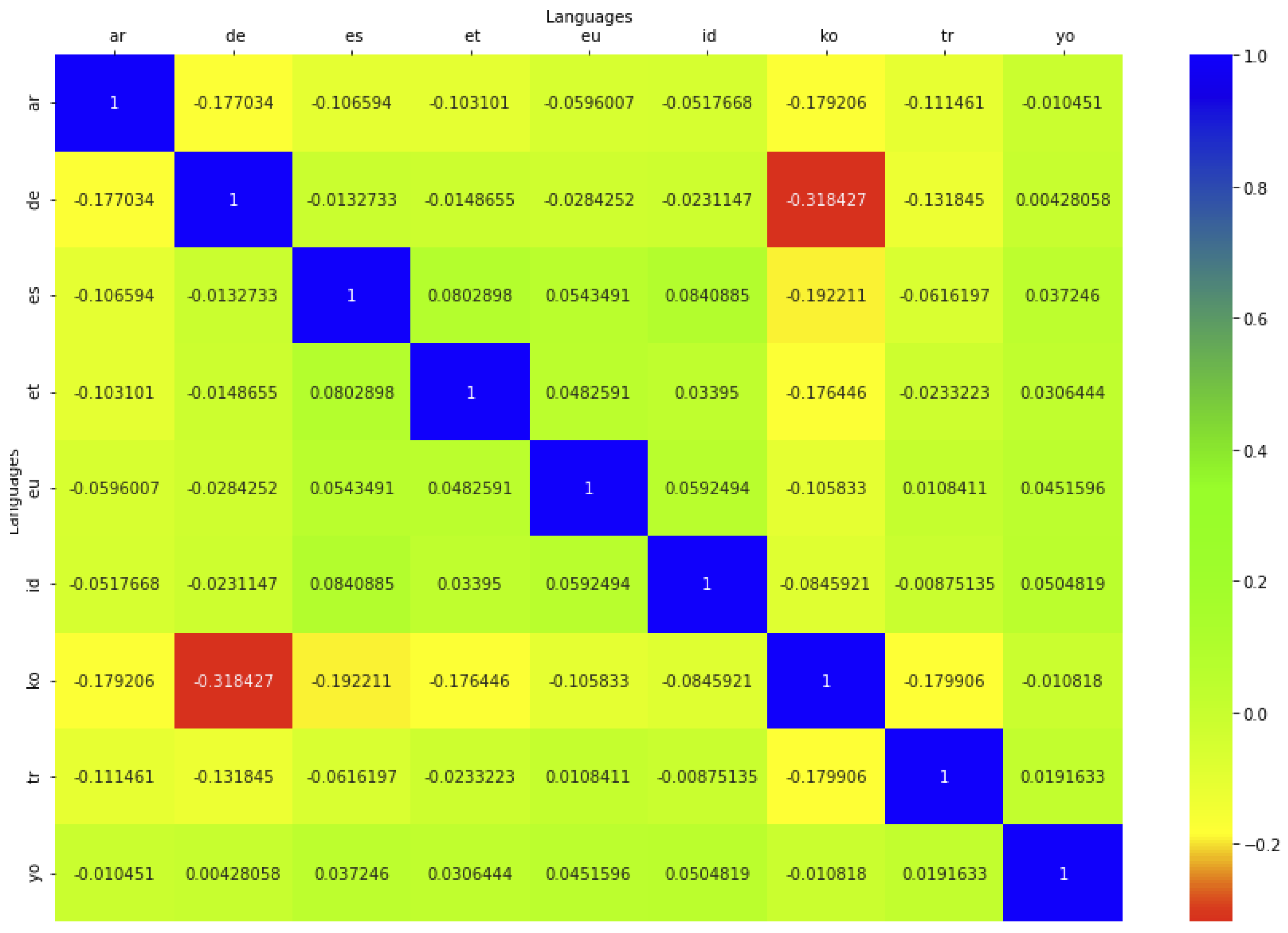
4.4. Coincidences between Languages
- Red for low quantity of shared rules;
- Yellow for quite average quantity of shared rules;
- Green for quite high quantity of shared rules;
- Blue for high quantity of shared rules.
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nefdt, R.M. The Foundations of Linguistics: Mathematics, Models, and Structures. Ph.D. Thesis, University of St Andrews, St Andrews, Scotland, 2016. [Google Scholar]
- Pullum, G.K. The central question in comparative syntactic metatheory. Mind Lang. 2013, 28, 492–521. [Google Scholar] [CrossRef]
- Kortmann, B.; Szmrecsanyi, B. Linguistic Complexity: Second Language Acquisition, Indigenization, Contact; Walter de Gruyter & Co.: Berlin, Germany, 2012. [Google Scholar]
- McWhorter, J.H. The Worlds Simplest Grammars Are Creole Grammars. Linguist. Typology 2001, 5, 125–166. [Google Scholar] [CrossRef] [Green Version]
- Baechler, R.; Seiler, G. Complexity, Isolation, and Variation; de Gruyter, Walter GmbH & Co.: Berlin, Germany, 2016; Volume 57. [Google Scholar]
- Baerman, M.; Brown, D.; Corbett, G.G. Understanding and Measuring Morphological Complexity; Oxford University Press: New York, NY, USA, 2015. [Google Scholar]
- Coloma, G. La Complejidad de Los Idiomas; Peter Lang Limited, International Academic Publishers: Bern, Switzerland, 2017. [Google Scholar]
- Conti Jiménez, C. Complejidad lingüística: Orígenes y Revisión Crítica del Concepto de Lengua Compleja; Peter Lang Limited, International Academic Publishers: Bern, Switzerland, 2018. [Google Scholar]
- Di Domenico, E. Syntactic Complexity From a Language Acquisition Perspective; Cambridge Scholars Publishing: Newcastle upon Tyne, UK, 2017. [Google Scholar]
- La Mantia, F.; Licata, I.; Perconti, P. Language in Complexity: The Emerging Meaning; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- McWhorter, J.H. Linguistic Simplicity and Complexity: Why Do Languages Undress? Walter de Gruyter: Berlin, Germany, 2011; Volume 1. [Google Scholar]
- Newmeyer, F.J.; Preston, L.B. Measuring Grammatical Complexity; Oxford University Press: New York, NY, USA, 2014. [Google Scholar]
- Ortega, L.; Han, Z. Complexity Theory and Language Development: In Celebration of Diane Larsen-Freeman; John Benjamins Publishing Company: Amsterdam, The Netherlands, 2017; Volume 48. [Google Scholar]
- Pallotti, G. A simple view of linguistic complexity. Second. Lang. Res. 2015, 31, 117–134. [Google Scholar] [CrossRef] [Green Version]
- Dahl, Ö. The Growth and Maintenance of Linguistic Complexity; John Benjamins Publishing Company: Amsterdam, The Netherlands, 2004; Volume 10. [Google Scholar]
- Miestamo, M.; Sinnemäki, K.; Karlsson, F. (Eds.) Grammatical Complexity in a Cross-Linguistic Perspective. In Language Complexity: Typology, Contact, Change; John Benjamins Publishing Company: Amsterdam, The Netherlands, 2008; pp. 22–42. [Google Scholar]
- Trudgill, P. Contact and simplification: Historical baggage and directionality in linguistic change. Linguist. Typology 2001, 5, 371–374. [Google Scholar]
- Küsters, W. Linguistic Complexity; LOT: Utrecht, The Netherlands, 2003. [Google Scholar]
- Hawkins, J.A. An efficiency theory of complexity and related phenomena. In Language Complexity as an Evolving Variable; Sampson, S., Gil, D., Trudgill, P., Eds.; Oxford University Press: New York, NY, USA, 2009; pp. 252–268. [Google Scholar]
- Andrason, A. Language complexity: An insight from complexsystem theory. Int. J. Lang. Linguist. 2014, 2, 74–89. [Google Scholar]
- Moravcsik, A. Explaining language universals. In The Oxford Handbook of Language Typology; Song, J., Ed.; Oxford University Press: Oxford, UK, 2010; pp. 69–89. [Google Scholar]
- Greenberg, J. Universals of Language; The MIT Press: Cambridge, MA, USA, 1963. [Google Scholar]
- Comrie, B. Language Universals and Linguistic Typology; The University of Chicago Press: Great Britain, UK, 1989. [Google Scholar]
- Dryer, M. Large linguistic areas and language sampling. Stud. Lang. 1989, 13, 257–292. [Google Scholar] [CrossRef]
- Dryer, M. The Greenbergian Word Order Correlations. Language 1992, 68, 81–138. [Google Scholar] [CrossRef]
- O’Horan, H.; Berzak, Y.; Vulic, I.; Reichart, R.; Korhonen, A. Survey on the Use of Typological Information in Natural Language Processing. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; Scalise, S., Magni, E., Bisetto, A., Eds.; The COLING 2016 Organizing Committee: Osaka, Japan, 2016; pp. 1297–1308. [Google Scholar]
- Ponti, E.M.; O’Horan, H.; Berzak, Y.; Vulic, I.; Reichart, R.; Poibeau, T.; Shutova, E.; Korhonen, A. Modeling Language Variation and Universals: A Survey on Typological Linguistics for Natural Language Processing. Comput. Linguist. 2019, 45, 559–601. [Google Scholar] [CrossRef]
- Lahiri, A.; Plank, F. Methods for Finding Language Universals in Syntax. In Universals of Language Today; Scalise, S., Magni, E., Bisetto, A., Eds.; Spinger: Berlin/Heidelberg, Germany, 2009; pp. 145–164. [Google Scholar]
- Bakker, D. Language Sampling. In The Oxford Handbook of Linguistic Typology; Song, J.J., Ed.; Oxford University Press: Oxford, UK, 2010; pp. 1–26. [Google Scholar]
- Chomsky, N. Aspects of the Theory of Syntax; The MIT Press: Cambridge, MA, USA, 1965. [Google Scholar]
- Wohlgemuth, J.; Cysouw, M. Rara and Rarissima; De Gruyter Mouton: Berlin, Germany, 2010. [Google Scholar]
- Wohlgemuth, J.; Cysouw, M. Rethinking Universals: How Rarities Affect Linguistic Theory; De Gruyter Mouton: Berlin, Germany, 2010. [Google Scholar]
- Lahiri, A.; Plank, F. What Linguistic Universals Can be True of. In Universals of Language Today; Scalise, S., Magni, E., Bisetto, A., Eds.; Spinger: Berlin/Heidelberg, Germany, 2009; pp. 31–58. [Google Scholar]
- Torrens Urrutia, A.; JiménezLópez, M.D.; Blache, P. Fuzziness and variability in natural language processing. In Proceedings of the 2017 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Naples, Italy, 9–12 July 2017; pp. 1–6. [Google Scholar]
- Torrens Urrutia, A. An approach to measuring complexity within the boundaries of a natural language fuzzy grammar. In Proceedings of the International Symposium on Distributed Computing and Artificial Intelligence, Toledo, Spain, 20–22 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 222–230. [Google Scholar]
- Torrens Urrutia, A. A Formal Characterization of Fuzzy Degrees of Grammaticality for Natural Language. Ph.D. Thesis, Universitat Rovira i Virgili, Tarragona, Spain, 2019. [Google Scholar]
- Novák, V. The Concept of Linguistic Variable Revisited. In Recent Developments in Fuzzy Logic and Fuzzy Sets; Sugeno, M., Kacprzyk, J., Shabazova, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; pp. 105–118. [Google Scholar]
- Novák, V. Fuzzy Logic in Natural Language Processing. In Proceedings of the 2017 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Naples, Italy, 9–12 July 2017. [Google Scholar]
- Novák, V.; Perfilieva, I.; Dvořák, A. Insight into Fuzzy Modeling; John Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]
- Novák, V. Mathematical Fuzzy Logic: From Vagueness to Commonsese Reasoning. In Retorische Wissenschaft: Rede und Argumentation in Theorie und Praxis; Kreuzbauer, G., Gratzl, N., Hielb, E., Eds.; LIT-Verlag: Wien, Austria, 2008; pp. 191–223. [Google Scholar]
- Novák, V. What is Fuzzy Natural Logic. In Integrated Uncertainty in Knowledge Modelling and Decision Making; Huynh, V., Inuiguchi, M., Denoeux, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; pp. 15–18. [Google Scholar]
- Novák, V. Fuzzy Natural Logic: Towards Mathematical Logic of Human Reasoning. In Fuzzy Logic: Towards the Future; Seising, R., Trillas, E., Kacprzyk, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; pp. 137–165. [Google Scholar]
- Novák, V. Evaluative linguistic expressions vs. fuzzy categories? Fuzzy Sets Syst. 2015, 281, 81–87. [Google Scholar] [CrossRef]
- Novák, V. Mining information from time series in the form of sentences of natural language. Int. J. Approx. Reason. 2016, 78, 192–209. [Google Scholar] [CrossRef]
- Urrutia, A.T.; López, M.D.J.; Brosa-Rodríguez, A. A Fuzzy Approach to Language Universals for NLP. In Proceedings of the 2021 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Luxembourg, 11–14 July 2021; pp. 1–6. [Google Scholar]
- Pagel, M. The History, Rate and Pattern of World Linguistic Evolution. In The Evolutionary Emergence of Language; Knight, M.S.K., Hurford, J., Eds.; Cambridge University Press: Cambridge, MA, USA, 2009; pp. 391–416. [Google Scholar]
- Newymeyer, F. Possible and Probable Languages: A Generative Perspective on Linguistic Typology; Oxford University Press: Oxford, UK, 2007. [Google Scholar]
- Dryer, M.; Haspelmath, M. The World Atlas of Language Structures Online. 2013. Available online: http://wals.info (accessed on 25 January 2022).
- Plank, F.; Filimonova, E. The Universals Archive: A Brief Introduction for Prospective Users. STUF Lang. Typol. Universals 2000, 53, 109–123. [Google Scholar] [CrossRef]
- Guzmán Naranjo, M.; Becker, L. Quantitative word order typology with UD. In Proceedings of the 17th International Workshop on Treebanks and Linguistic, Oslo, Norway, 13–14 December 2018; Linkoping University Electronic Press: Linkoping, Sweden, 2018; pp. 91–104. [Google Scholar]
- Choi, H.; Guillaume, B.; Fort, K. Corpus-based language universals analysis using Universal Dependencies. In Proceedings of the Second Workshop on Quantitative Syntax (Quasy, SyntaxFest 2021), Sofia, Bulgaria, December 2021; pp. 33–44. [Google Scholar]
- Schnell, S.; Schiborr, N.N. Crosslinguistic Corpus Studies in Linguistic Typology. Annu. Rev. Linguist. 2022, 8, 171–191. [Google Scholar] [CrossRef]
- Levshina, N. Corpus-based typology: Applications, challenges and some solutions. Linguist. Typology 2021, 26, 129–160. [Google Scholar]
- Nivre, J.; de Marneffe, M.; Ginter, F.; Goldberg, Y.; Hajic, J.; Manning, C.D.; McDonald, R.; Petrov, S.; Pyysalo, S.; Silveira, N.; et al. Universal dependencies v1: A multilingual treebank collection. In Proceedings of the Language Resources and Evaluation Conference, Portoroz, Slovenia, 23–28 May 2016; pp. 1659–1666. [Google Scholar]
- Siewierska, A. Word Order Rules; Croom Helm: New York, NY, USA, 1988. [Google Scholar]
- Gerdes, K.; Kahane, S.; Chen, X. Typometrics: From Implicational to Quantitative Universals in Word Order Typology. Glossa J. Gen. Linguist. 2021, 6, 17. [Google Scholar]
- Levshina, N.; Namboodiripad, S.; Allassonnière-Tang, M.; Kramer, M.A.; Talamo, L.; Verkerk, A.; Wilmoth, S.; Garrido Rodriguez, G.; Gupton, T.; Kidd, E.; et al. Why we need a gradient approach to word order. PsyArXiv 2021, 1–53, preprint. [Google Scholar]
- Universal Dependency Corpora. Available online: https://universaldependencies.org/ (accessed on 12 December 2021).
- Blache, P.; Rauzy, S.; Montcheuil, G. MarsaGram: An excursion in the forests of parsing trees. In Proceedings of the Language Resources and Evaluation Conference, Portoroz, Slovenia, 23–28 May 2016; p. 7. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| POS (17) | DEP (64) | Properties (4) | Pos-dep (1088) | 4,242,538,496 |
|---|---|---|---|---|
| ADJ | acl | exclude | empty (1088) | 4,734,976 |
| ADP | acl:relcl | precede | 4,247,273,472 | |
| ADV | advcl | unicity | ||
| AUX | advmod | require | ||
| CCONJ | advmod:emph | |||
| DET | advmod:lmod | |||
| INTJ | amod | |||
| NOUN | appos | |||
| NUM | aux | |||
| PART | aux:pass | |||
| PRON | case | |||
| PROPN | cc | |||
| PUNCT | cc:preconj | |||
| SCONJ | ccomp | |||
| SYM | clf | |||
| VERB | compound | |||
| X | ..+48 |
| VERB-conj exclude CCONJ-cc VERB-ccomp, 0, 1, 1, 1, 1, 1, 1, 1, 0, 7, 0.7777777777777778 |
| VERB-conj exclude CCONJ-cc PART-advmod, 0, 1, 0, 0, 1, 1, 0, 0, 0, 3, 0.3333333333333333 |
| VERB-conj exclude CCONJ-cc ADJ-amod, 0, 0, 1, 0, 0, 1, 1, 1, 0, 4, 0.4444444444444444 |
| VERB-conj exclude CCONJ-cc NOUN-nsubj, 0, 1, 0, 0, 0, 1, 0, 0, 0, 2, 0.2222222222222222 |
| VERB-conj exclude CCONJ-cc PROPN-obj, 0, 1, 1, 1, 0, 1, 1, 0, 0, 5, 0.5555555555555556 |
| VERB-conj exclude CCONJ-cc PROPN-obl, 0, 1, 1, 1, 1, 1, 0, 1, 0, 6, 0.6666666666666666 |
| VERB-conj exclude CCONJ-cc VERB-xcomp, 0, 1, 1, 1, 1, 1, 0, 0, 0, 5, 0.5555555555555556 |
| VERB-conj exclude NOUN-obj NOUN-obl, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0.1111111111111111 |
| VERB-conj exclude NOUN-obj PROPN-obj, 0, 1, 1, 1, 0, 1, 1, 0, 0, 5, 0.5555555555555556 |
| VERB-conj exclude NOUN-obj PROPN-obl, 0, 1, 1, 1, 1, 1, 0, 1, 0, 6, 0.6666666666666666 |
| VERB-conj exclude NOUN-obj VERB-xcomp, 0, 1, 1, 1, 1, 1, 0, 0, 0, 5, 0.5555555555555556 |
| VERB-conj exclude NOUN-obj ADJ-amod, 0, 0, 1, 0, 0, 1, 1, 1, 0, 4, 0.4444444444444444 |
| VERB-conj exclude NOUN-obj VERB-ccomp, 0, 1, 1, 1, 1, 1, 1, 1, 1, 8, 0.8888888888888888 |
| VERB-conj exclude NOUN-obj NOUN-nsubj:pass, 0, 1, 1, 0, 0,1, 0, 0, 0, 3, 0.3333333333333333 |
| VERB-conj exclude NOUN-obj NOUN-compound, 0, 0, 0, 0, 1, 1, 1, 1, 0, 4, 0.4444444444444444 |
| VERB-conj exclude NOUN-obj ADP-case, 0, 0, 1, 0, 0, 1, 1, 1, 0, 4, 0.4444444444444444 |
| VERB-conj exclude NOUN-obj PRON-obj, 0, 1, 1, 1, 1, 1, 1, 1, 1, 8, 0.8888888888888888 |
| VERB-conj exclude NOUN-obj VERB-acl, 0, 1, 0, 0, 0, 1, 1, 0, 0, 3, 0.3333333333333333 |
| VERB-conj exclude NOUN-obj PRON-obl, 0, 1, 1, 1, 0, 1, 0, 1, 1, 6, 0.6666666666666666 |
| VERB-conj exclude NOUN-obj VERB-fixed, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0.1111111111111111 |
| VERB-conj exclude NOUN-obj NUM-nummod, 0, 0, 0, 0, 0, 1, 1, 0, 0, 2, 0.2222222222222222 |
| VERB-conj exclude NOUN-obj PROPN-nsubj, 0, 1, 1, 1, 1, 1, 1, 0, 0, 6, 0.6666666666666666 |
| VERB-conj exclude NOUN-obj PART-advmod, 0, 1, 0, 0, 1, 1, 0, 0, 0, 3, 0.3333333333333333 |
| VERB-conj exclude NOUN-obj ADJ-xcomp, 0, 1, 1, 1, 0, 1, 0, 0, 0, 4, 0.4444444444444444 |
| VERB-conj exclude NOUN-obj PRON-nsubi, 0, 1, 1, 1, 1, 1, 1, 1, 0, 7, 0.7777777777777778 |
| VERB-conj exclude NOUN-obj VERB-advcl, 0, 1, 1, 1, 1, 1, 0, 1, 0, 6, 0.6666666666666666 |
| Language | Trees | Structures | Constraints | Order | s/Constraints |
|---|---|---|---|---|---|
| German | 150,921 | 32,242 | 54,410 | sv-ndo | 1.6875504 |
| Korean | 27,363 | 8853 | 48,097 | sv-ov | 5.43284762 |
| Turkish | 18,687 | 5275 | 30,937 | sv-ov | 5.86483412 |
| Spanish | 16,013 | 8114 | 28,808 | ndo-vo | 3.5504067 |
| Estonian | 30,972 | 9468 | 28,570 | sv-vo | 3.01753274 |
| Arabic | 19,738 | 11,226 | 21,062 | vs-vo | 1.8761803 |
| Euskera | 8993 | 3283 | 14,703 | sv-ov | 4.47852574 |
| Indonesian | 5593 | 3143 | 12,530 | sv-vo | 3.98663697 |
| Yoruba | 318 | 243 | 1647 | 6.77777778 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Torrens-Urrutia, A.; Jiménez-López, M.D.; Brosa-Rodríguez, A.; Adamczyk, D. A Fuzzy Grammar for Evaluating Universality and Complexity in Natural Language. Mathematics 2022, 10, 2602. https://doi.org/10.3390/math10152602
Torrens-Urrutia A, Jiménez-López MD, Brosa-Rodríguez A, Adamczyk D. A Fuzzy Grammar for Evaluating Universality and Complexity in Natural Language. Mathematics. 2022; 10(15):2602. https://doi.org/10.3390/math10152602
Chicago/Turabian StyleTorrens-Urrutia, Adrià, María Dolores Jiménez-López, Antoni Brosa-Rodríguez, and David Adamczyk. 2022. "A Fuzzy Grammar for Evaluating Universality and Complexity in Natural Language" Mathematics 10, no. 15: 2602. https://doi.org/10.3390/math10152602
APA StyleTorrens-Urrutia, A., Jiménez-López, M. D., Brosa-Rodríguez, A., & Adamczyk, D. (2022). A Fuzzy Grammar for Evaluating Universality and Complexity in Natural Language. Mathematics, 10(15), 2602. https://doi.org/10.3390/math10152602