
Progress towards Analytically Optimal Angles in Quantum Approximate Optimisation


{kind=link}
Abstract
:1. Introduction
2. State Preparation with QAOA
3. QAOA
4. Empirical Findings Missing Analytical Theory
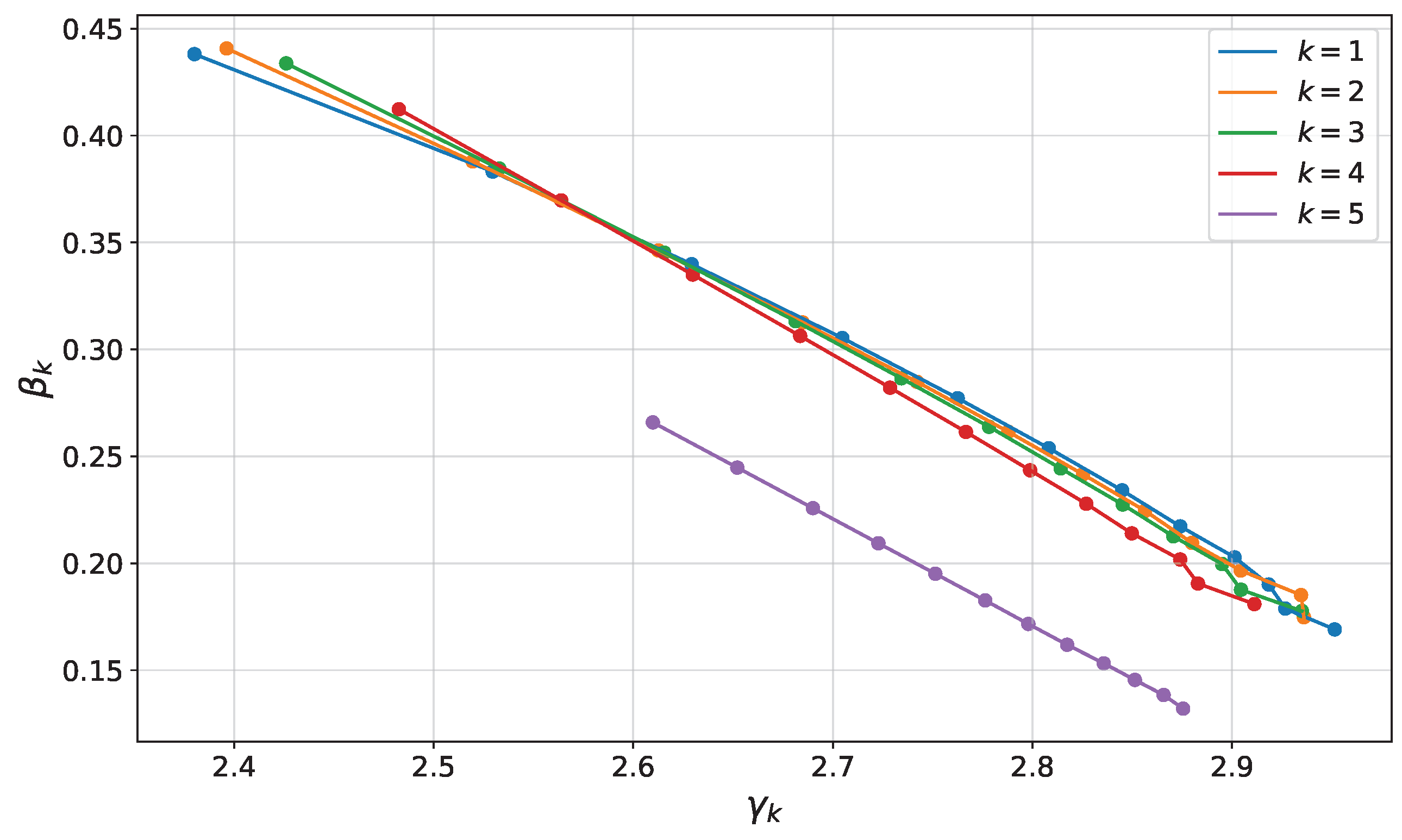
4.1. Parameter Concentration in QAOA
4.2. Last Layer Behaviour
4.3. Saturation in Layerwise Training at
4.4. Removing Saturation in Layerwise Training
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Harrigan, M.P.; Sung, K.J.; Neeley, M.; Satzinger, K.J.; Arute, F.; Arya, K.; Atalaya, J.; Bardin, J.C.; Barends, R.; Boixo, S.; et al. Quantum approximate optimization of non-planar graph problems on a planar superconducting processor. Nat. Phys. 2021, 17, 332–336. [Google Scholar] [CrossRef]
- Pagano, G.; Bapat, A.; Becker, P.; Collins, K.; De, A.; Hess, P.; Kaplan, H.; Kyprianidis, A.; Tan, W.; Baldwin, C.; et al. Quantum approximate optimization of the long-range Ising model with a trapped-ion quantum simulator. arXiv 2019, arXiv:1906.02700. [Google Scholar] [CrossRef] [PubMed]
- Guerreschi, G.G.; Matsuura, A.Y. QAOA for Max-Cut requires hundreds of qubits for quantum speed-up. Sci. Rep. 2019, 9, 6903. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Butko, A.; Michelogiannakis, G.; Williams, S.; Iancu, C.; Donofrio, D.; Shalf, J.; Carter, J.; Siddiqi, I. Understanding quantum control processor capabilities and limitations through circuit characterization. In Proceedings of the 2020 International Conference on Rebooting Computing (ICRC), Atlanta, GA, USA, 1–3 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 66–75. [Google Scholar]
- Biamonte, J. Universal variational quantum computation. Phys. Rev. A 2021, 103, L030401. [Google Scholar] [CrossRef]
- Campos, E.; Nasrallah, A.; Biamonte, J. Abrupt transitions in variational quantum circuit training. Phys. Rev. A 2021, 103, 032607. [Google Scholar] [CrossRef]
- Farhi, E.; Goldstone, J.; Gutmann, S. A Quantum Approximate Optimization Algorithm. arXiv 2014, arXiv:1411.4028. [Google Scholar]
- Niu, M.Y.; Lu, S.; Chuang, I.L. Optimizing qaoa: Success probability and runtime dependence on circuit depth. arXiv 2019, arXiv:1905.12134. [Google Scholar]
- Akshay, V.; Philathong, H.; Morales, M.E.; Biamonte, J.D. Reachability Deficits in Quantum Approximate Optimization. Phys. Rev. Lett. 2020, 124, 090504. [Google Scholar] [CrossRef] [Green Version]
- Akshay, V.; Philathong, H.; Campos, E.; Rabinovich, D.; Zacharov, I.; Zhang, X.M.; Biamonte, J. On Circuit Depth Scaling for Quantum Approximate Optimization. arXiv 2022, arXiv:2205.01698. [Google Scholar]
- Zhou, L.; Wang, S.T.; Choi, S.; Pichler, H.; Lukin, M.D. Quantum Approximate Optimization Algorithm: Performance, Mechanism, and Implementation on Near-Term Devices. Phys. Rev. X 2020, 10, 021067. [Google Scholar] [CrossRef]
- Brady, L.T.; Baldwin, C.L.; Bapat, A.; Kharkov, Y.; Gorshkov, A.V. Optimal Protocols in Quantum Annealing and Quantum Approximate Optimization Algorithm Problems. Phys. Rev. Lett. 2021, 126, 070505. [Google Scholar] [CrossRef] [PubMed]
- Farhi, E.; Harrow, A.W. Quantum Supremacy through the Quantum Approximate Optimization Algorithm. arXiv 2016, arXiv:1602.07674. [Google Scholar]
- Farhi, E.; Goldstone, J.; Gutmann, S.; Zhou, L. The quantum approximate optimization algorithm and the sherrington-kirkpatrick model at infinite size. arXiv 2019, arXiv:1910.08187. [Google Scholar] [CrossRef]
- Wauters, M.M.; Mbeng, G.B.; Santoro, G.E. Polynomial scaling of QAOA for ground-state preparation of the fully-connected p-spin ferromagnet. arXiv 2020, arXiv:2003.07419. [Google Scholar]
- Claes, J.; van Dam, W. Instance Independence of Single Layer Quantum Approximate Optimization Algorithm on Mixed-Spin Models at Infinite Size. arXiv 2021, arXiv:2102.12043. [Google Scholar] [CrossRef]
- Wang, Z.; Rubin, N.C.; Dominy, J.M.; Rieffel, E.G. X Y mixers: Analytical and numerical results for the quantum alternating operator ansatz. Phys. Rev. A 2020, 101, 012320. [Google Scholar] [CrossRef] [Green Version]
- Hodson, M.; Ruck, B.; Ong, H.; Garvin, D.; Dulman, S. Portfolio rebalancing experiments using the Quantum Alternating Operator Ansatz. arXiv 2019, arXiv:1911.05296. [Google Scholar]
- Tsoulos, I.G.; Stavrou, V.; Mastorakis, N.E.; Tsalikakis, D. GenConstraint: A programming tool for constraint optimization problems. SoftwareX 2019, 10, 100355. [Google Scholar] [CrossRef]
- Lloyd, S. Quantum approximate optimization is computationally universal. arXiv 2018, arXiv:1812.11075. [Google Scholar]
- Morales, M.E.; Biamonte, J.; Zimborás, Z. On the universality of the quantum approximate optimization algorithm. Quantum Inf. Process. 2020, 19, 1–26. [Google Scholar] [CrossRef]
- Rabinovich, D.; Adhikary, S.; Campos, E.; Akshay, V.; Anikin, E.; Sengupta, R.; Lakhmanskaya, O.; Lakhmanskiy, K.; Biamonte, J. Ion native variational ansatz for quantum approximate optimization. arXiv 2022, arXiv:2206.11908. [Google Scholar]
- Jiang, Z.; Rieffel, E.G.; Wang, Z. Near-optimal quantum circuit for Grover’s unstructured search using a transverse field. Phys. Rev. A 2017, 95, 062317. [Google Scholar] [CrossRef] [Green Version]
- Hastings, M.B. Classical and quantum bounded depth approximation algorithms. arXiv 2019, arXiv:1905.07047. [Google Scholar] [CrossRef]
- Bravyi, S.; Kliesch, A.; Koenig, R.; Tang, E. Obstacles to State Preparation and Variational Optimization from Symmetry Protection. Phys. Rev. Lett. 2019, 125, 260505. [Google Scholar] [CrossRef]
- Akshay, V.; Philathong, H.; Zacharov, I.; Biamonte, J. Reachability Deficits in Quantum Approximate Optimization of Graph Problems. Quantum 2021, 5, 532. [Google Scholar] [CrossRef]
- Akshay, V.; Rabinovich, D.; Campos, E.; Biamonte, J. Parameter concentrations in quantum approximate optimization. Phys. Rev. A 2021, 104, L010401. [Google Scholar] [CrossRef]
- Campos, E.; Rabinovich, D.; Akshay, V.; Biamonte, J. Training saturation in layerwise quantum approximate optimization. Phys. Rev. A 2021, 104, L030401. [Google Scholar] [CrossRef]
- Shaydulin, R.; Wild, S.M. Exploiting symmetry reduces the cost of training QAOA. IEEE Trans. Quantum Eng. 2021, 2, 1–9. [Google Scholar] [CrossRef]
- Streif, M.; Leib, M. Comparison of QAOA with quantum and simulated annealing. arXiv 2019, arXiv:1901.01903. [Google Scholar]
- Skolik, A.; McClean, J.R.; Mohseni, M.; van der Smagt, P.; Leib, M. Layerwise learning for quantum neural networks. Quantum Mach. Intell. 2021, 3, 1–11. [Google Scholar] [CrossRef]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rabinovich, D.; Sengupta, R.; Campos, E.; Akshay, V.; Biamonte, J. Progress towards Analytically Optimal Angles in Quantum Approximate Optimisation. Mathematics 2022, 10, 2601. https://doi.org/10.3390/math10152601
Rabinovich D, Sengupta R, Campos E, Akshay V, Biamonte J. Progress towards Analytically Optimal Angles in Quantum Approximate Optimisation. Mathematics. 2022; 10(15):2601. https://doi.org/10.3390/math10152601
Chicago/Turabian StyleRabinovich, Daniil, Richik Sengupta, Ernesto Campos, Vishwanathan Akshay, and Jacob Biamonte. 2022. "Progress towards Analytically Optimal Angles in Quantum Approximate Optimisation" Mathematics 10, no. 15: 2601. https://doi.org/10.3390/math10152601
APA StyleRabinovich, D., Sengupta, R., Campos, E., Akshay, V., & Biamonte, J. (2022). Progress towards Analytically Optimal Angles in Quantum Approximate Optimisation. Mathematics, 10(15), 2601. https://doi.org/10.3390/math10152601