1. Introduction
In times of climate change and the associated challenges for environmentally friendly energy supply, so-called microgrids (MGs) have gained more and more attention. MGs are interconnected sources of distributed energy resources (e.g., solar and wind power), energy storage, and electrical loads that can operate either independently or connected to a surrounding public electricity grid [
1]. In addition to determining optimal operating strategies for MGs (scheduling), the optimal dimensioning (sizing) of the components integrated into the MG can be crucial. However, both problems are strongly interrelated. The optimal operation of the MG strongly depends on the selected size of the system components, while the determination of the optimal component size for a given system topology is based on optimal operation. There is a vast number of articles in the relevant literature dealing with scheduling and sizing problems for MGs.
Abel et al. [
2] optimize the operation of an MG that has a fuel cell as a supply unit in addition to the storage and consumption elements. They use a mixed-integer linear mathematical model structure to minimize the costs of operation. Kotzur et al. [
3] use a fuel cell to supply energy to a residential building. In this context, the cost-optimal technology configuration is to be determined using a MILP. In the article by Jaramillo and Weidlich [
4], the authors minimize the operating costs and emissions within the framework of a MILP model for an MG. Both a PV system and a fuel-cell-electrolyzer system serve as generation units. In their work, Jochem et al. [
5] optimize the operation of an MG that uses a combined heat and power plant based on a fuel cell as the generating unit. The aim is to realize the cost-optimal charging strategy for the electric vehicles of a household. In this context, the authors use a MILP approach and a greedy algorithm and then compare the results. They come to a variation of the operating costs of 3% for the resulting operating strategies, whereby the greedy algorithm tends to be more advantageous in terms of solver performance. These studies, which however do not represent an exhaustive set, show that MILP is a prominent tool in energy system optimization. Therefore, it can be stated that for the modeling and optimization of MGs, MILP is the approach most frequently used in the scientific literature [
6]. This is due to the advantages of the approach, which are especially useful for the modeling of MGs. In particular, the possibility of simple problem formulation even for complex energy systems as well as the fast solution finding compared to other approaches are to be mentioned [
7,
8].
The term “mathematical optimization” is generally used to describe the process of finding the minimum or maximum of an objective function. The value of the objective function depends on various variables which jointly represent the degrees of freedom of the problem to be optimized. In the course of executing the optimization algorithm, these variables are assigned, which in a certain combination leads to the optimal objective function value. Thereby, all the constraints contained in the problem must be satisfied. In the context of linear problems, all functional relationships, both in the objective function and in the constraints, are linear. Mixed-integer optimization deals more precisely with optimization problems in which the variables can take on integer values in some cases and continuous values in others. Integers are mainly used in the form of binary or state variables, which are used, for example, to represent simple yes-or-no or on-or-off decisions. These are the two fundamental mathematical requirements for MILP-based models. However, mathematical functions in technical applications, such as the characteristic efficiencies of diesel generators or the c-ratios of certain battery technologies, are often nonlinear. This is why a simple integration of these properties into MILP models is not possible. Problems with these properties are called mixed-integer nonlinear problems. It is possible to solve these problems directly using solvers that can handle nonlinear formulations, such as Ipopt [
9], SCIP [
10], BARON [
11], Gurobi [
12], and many more (a state-of-the-art overview and categorization can be found on
https://www.gams.com/latest/docs/S_MAIN.html#SOLVERS_MODEL_TYPES, accessed on 15 May 2022). Nowadays, even highly non-convex MINLPs can be solved by state-of-the-art solvers [
13], which are able to determine global optima. These are, for example, ANTIGONE [
14], BARON, LINDOGlobal [
15], Octeract Engine [
16], and SCIP. Depending on the choice of the initial variable values, different local solutions result. When choosing the initial values, care should be taken that they are not initialized with the value zero, since this usually leads to numerical problems. Once a good local solution has been found, it should be saved and used for initializing further calculations [
17]. The main advantage of this direct solution approach with the mentioned solvers is that the solution is exact, as long as the problems are solvable. The solvers usually exploit specific properties of the problem such as linearity, convexity, or differentiability [
18]. In [
19,
20], for example, the authors solve a non-convex MINLP scheduling problem for an energy system. Due to the inherent nonlinearity and exhaustive search space, the formulations become computationally extensive and sometimes fail to converge to the optimal solution [
19]. In [
21], the authors size combined heat and power units within a district heating network which results in a non-convex MINLP. The solution of this problem requires different approaches since general purpose MINLP solvers cannot even solve the scheduling subproblem. Considering that, the operation’s research state-of-the-art approach consists in linearizing the initial MINLP problem to obtain a MILP which can be tackled more easily. This approach leads to two advantages [
21]:
There are convergence guarantees on the solution since the returned solution is globally optimal, without the risk of being locally trapped;
MILPs can be tackled by extremely fast and effective commercially available MILP solvers.
On the other hand, the advantage of exact solutions by direct solving is eliminated.
In [
22], Taccari et al. analyze these two different approaches (direct MINLP solving versus prior linearization). The authors compare the quality of the solution and the computing time for a set of realistic test cases in operational planning of energy systems and their components. They conclude that for the considered instances, the resulting approximate MILP models can generally be solved way more efficiently than their MINLP counterparts, and they appear to be already fairly accurate with a few linear pieces (
Section 2.2).
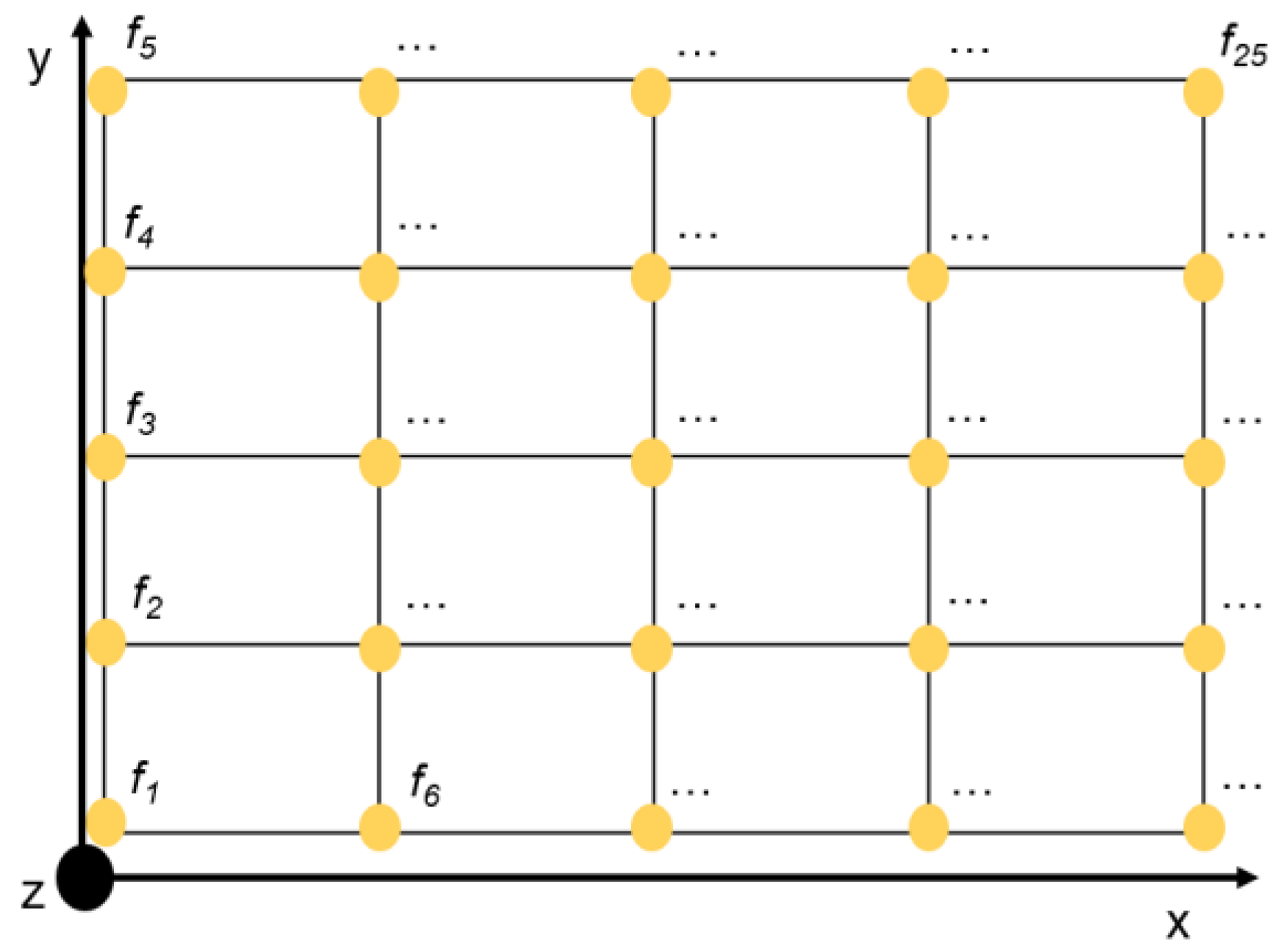
Nonlinear relationships become even more complicated if the function value depends on multiple variables (multivariate). This is why efficient and application-oriented linearization techniques for the approximation of these nonlinear relationships play a major role in mathematical optimization.
In addition to general numerical mathematics, there is already work in the literature that suggests possible ways to integrate nonlinear-bivariate functions in the MILP context. An overview is given by D’Ambrosio et al. [
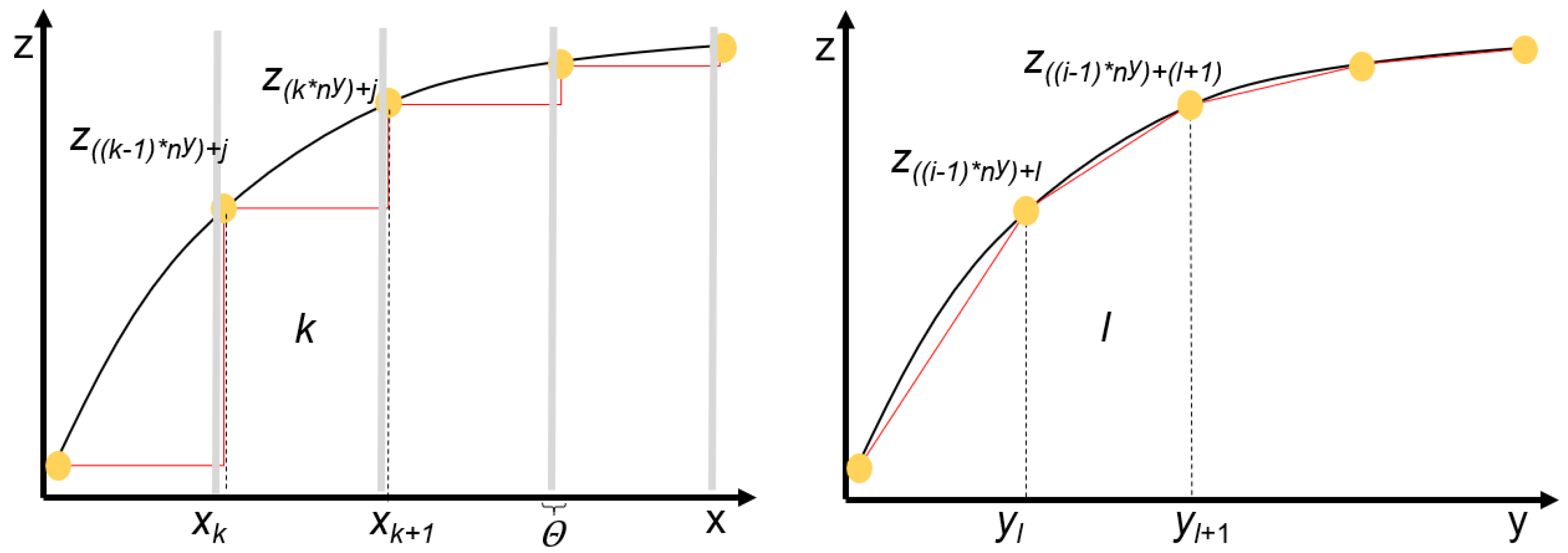
23], where three different methods are presented. The first one builds on the piecewise-linear approximation in the univariate case (1D-method), which can be found, for example, in Kelley et al. [
24]. The second is the triangular method, where discrete triangles are created in the surfaces. It is widely used in the literature [
22,
25,
26]. Finally, the authors present an alternative method, the rectangular method, where the idea is to improve the one-dimensional method through a correction term. In most cases, these existing contributions in the literature are either generic and not application-oriented [
23,
27], or they are formulated in an application-specific way [
28,
29,
30,
31].
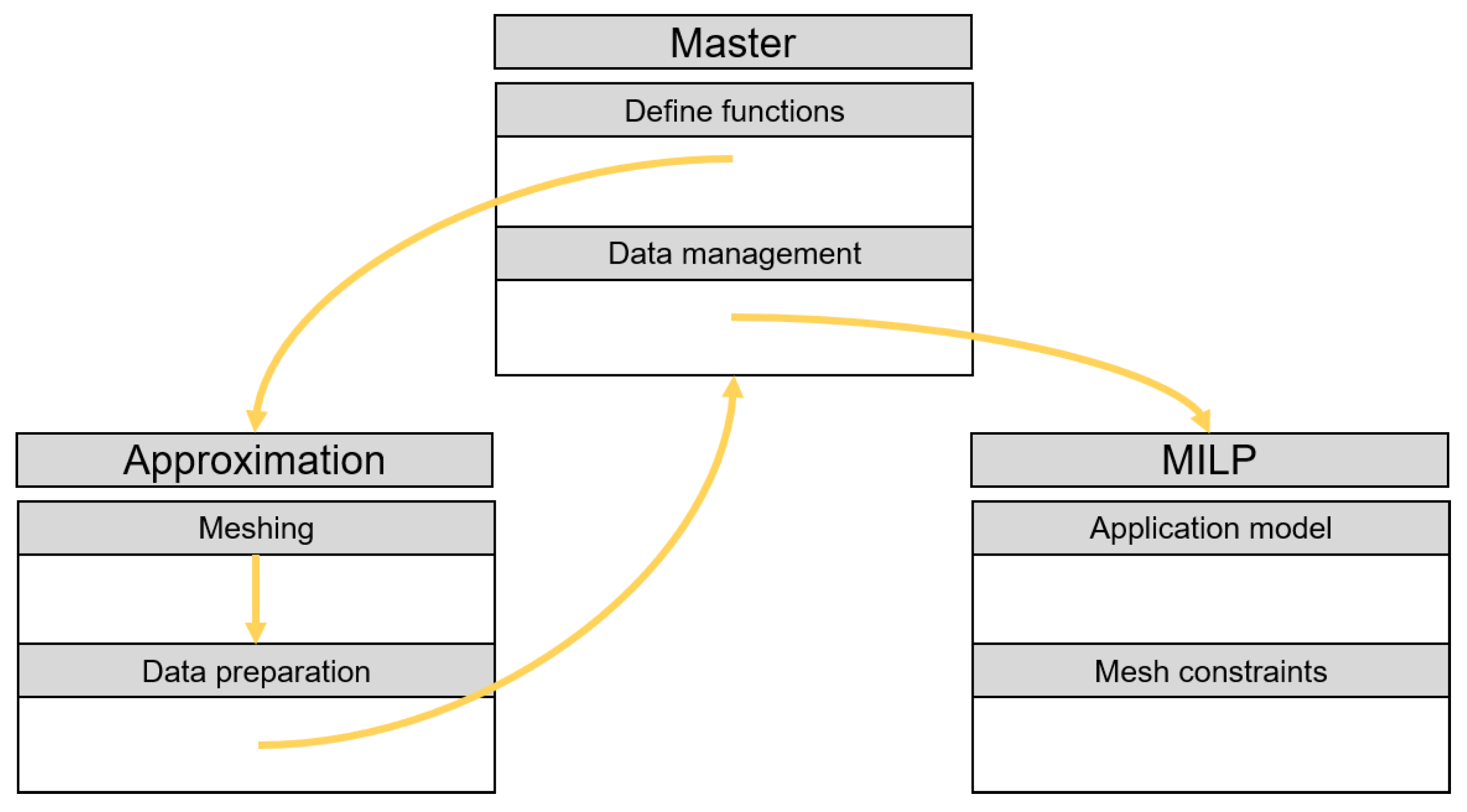
In this work, this gap shall be closed and a complete method—or algorithm—is derived, which has as the input the nonlinear-bivariate function(s) and as the output the constraints to be integrated into the MILP, regardless of the specific function or use-case. By providing the implemented code in the
Supplementary Materials for the method presented in this paper, this content can be used both as a foundation for further methodological improvement and as an easy-to-use tool for applicators. The results for a real use-case show that the objective value of the nonlinear problem deviates by only a few percentage points from the approximated value, depending on the parameterization.
The paper is structured as follows:
Section 2 presents the method both in theory and in its practical implementation. Subsequently, the method is embedded in a sizing-problem context for a defined system topology of an MG (
Section 3). The article concludes with a summary and an outlook.
3. Use-Case and Evaluation
In this section, the method presented in the previous section is evaluated for a specific task in the context of a predefined system topology for an MG. The content focuses on the solver performance and the comparison of the results, rather than on the system itself. Hence, the system is concisely introduced in
Section 3.1, and in
Section 3.2 the optimization results of the linearized problem and the nonlinear problem are compared.
3.1. Microgrid Topology
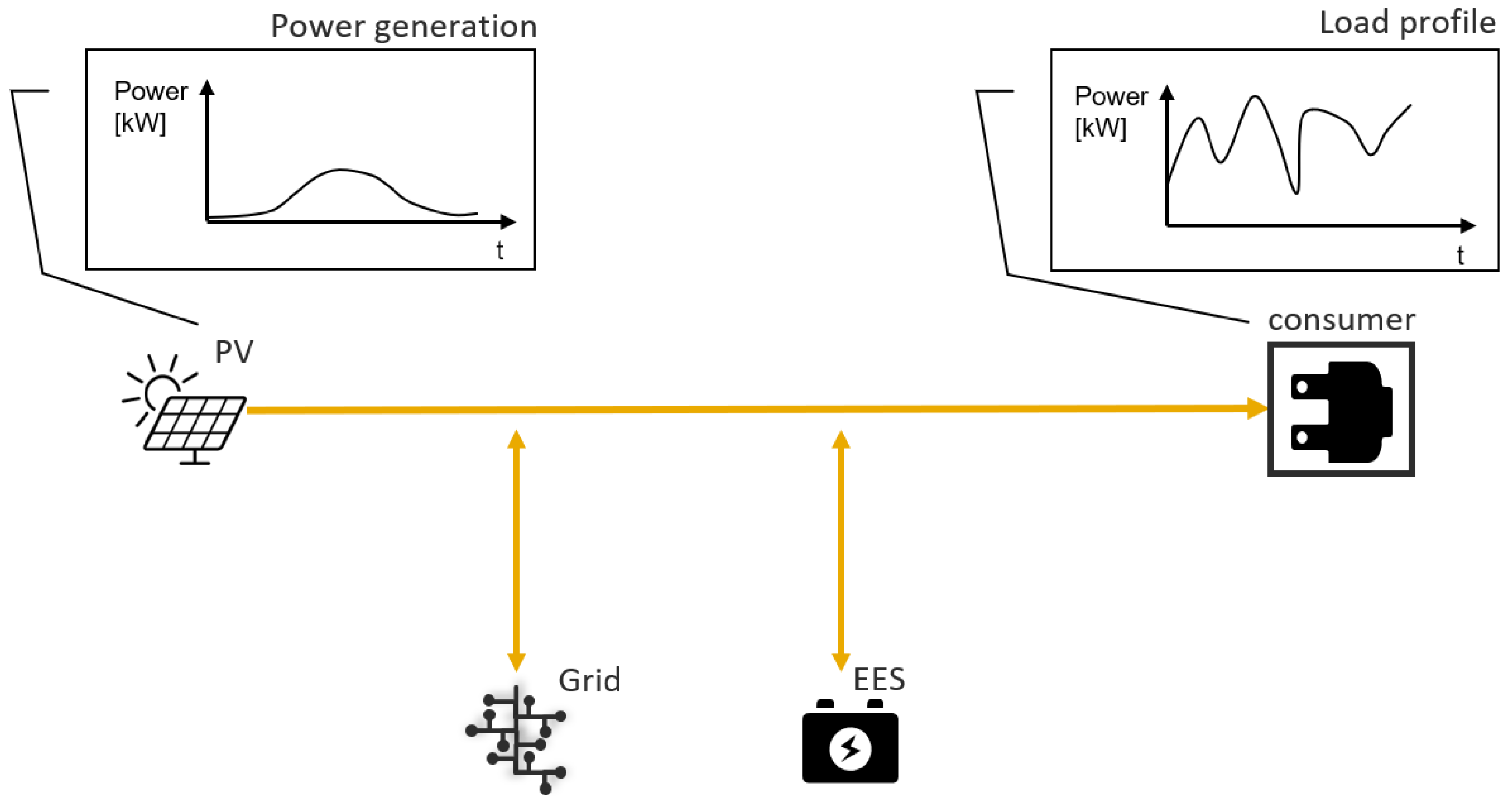
The system works as follows: consumers are supplied with electrical energy by the overall system, whereby the energy can potentially come from the photovoltaic modules (PV), the public electricity grid (PEG), or the battery (EES). Given exogenous PV production and load profiles (e.g., generated by historical or forecast data), the solver determines the cost-optimal size of the EES while deriving—and therefore also presuming—the optimal operating strategy for the overall system shown in
Figure 9.
The bidirectional arrows mean that energy can be fed into as well as out of the component block, but not at the same timestep . This is considered, for example, via exclusivity conditions in the constraints of the MILP formulations. The PV generation and demand data are historic data from a real industrial use-case for supplying electrical energy to a supermarket, which can vary over time, especially based on the season. The MG operator, in addition to selling the electrical energy to the supermarket, has certain cost and revenue blocks that must be weighed when operating the overall system and sizing the battery. Feeding PV energy into the PEG generates additional revenue, whereas demand from the PEG generates costs. These costs, in turn, consist of an energy (€/kWh) and a power price (€/kWmax); the second values the maximum demanded power in a timeframe with a cost factor. The feed-in tariff and the demand price in turn depend on the tariff structure and can fluctuate, for example, according to the region and the time of the day. These volatilities, both monetary and on the producer and consumer side, drive the advantageousness of a battery usage in such a system.
The question that arises is how big should the battery be that is chosen (
to minimize the total cost (or maximize the profits). The decision is significantly influenced by the investment costs for the battery, the useful lifetime, and which technology—and accordingly which performance—the battery is based on. In parallel with charging and discharging efficiencies (%), performance is assessed primarily by the c-rate (
in 1/h), which is defined as the ratio between maximum charging or discharging power and capacity. For lithium-ion batteries, 1C is usually used as a basis, which means that the battery can be fully charged in one hour. i.e., a linear relationship between state of charge
in %) and time. Therefore:
For other technologies, the relationship (21) is not applicable anymore. Due to chemical processes in salt-nickel batteries, for example, (21) is no longer fulfilled. Furthermore, for these batteries the functional relationship
is nonlinear and not continuously differentiable [
32]. At first glance, this seems unproblematic, since the univariate approximation methods in
Section 2.2.2 can be used to approximately integrate these functional relationships into the MILP. However, since (21) is no longer fulfilled—independent of the other properties of the function—this has immediate consequences for the optimization program, since
is no longer to be considered only as a parameter but as a variable.
The solver determines the cost-optimal values of the operational variables (e.g., optimal maximal (If (21) would be fulfilled, the maximal charging/discharge power could not vary by time) charging/discharge power
and
of the EES at each timestep) and the global variables (e.g., optimal size
of the EES over the entire optimization horizon). By general definition for storage systems:
Since (22) and (23) each represent relationships between three variables, a quadratic-bivariate relationship exists. Although some solvers can handle quadratic nonlinearities, the linearization method used in this work can be applied to this situation in accordance with the relationship
from
Section 2.3.2, where the indexed variables correspond to
. This allows a direct comparison between the solution of the nonlinear and the linearized problem and an evaluation of the presented method (
Section 3.2). The resulting MIQCP problem can be solved with Gurobi, a commercially available standard solver. The solver uses the specific type of nonlinearity—quadratic in this case—to solve the problem exactly. This makes the computation much more efficient than using a general MINLP solver, setting a computationally efficient benchmark for the method being evaluated.
Both models—MIQCP and MILP—are implemented in Python (PyCharm Community Edition 2020.3.3) in the optimization environment Pyomo (Version 6.0.1) and solved by the Gurobi (Version 9.5.0) solver for and .
3.2. Results and Evaluation
The relations (22) and (23) are integrated into the system from
Section 3.1 using the method from
Section 2. Solutions for different resolutions
are compared with the MIQCP solution to evaluate the approximation quality, where the evaluation determinants are the optimal battery size
, computation time, and the relative error with respect to the objective value. For the meshing the following applies:
in kW;
in kWh;
in kWh.
Therefore, 1000 kWh is the predefined upper limit of the battery set by the person in charge, which should not be exceeded in any case, and the lower limit is 1 kWh, to avoid division by 0. The upper limits for
and
can be derived from this, since on the one hand the storage level can never be greater than the maximum capacity, and on the other hand, the maximum charging power is limited via the relationship
(Here, it is assumed that
can have a maximum of 1/h. In this special case, the actual limit is even smaller and is considered through
in the system constraints). For different resolutions, we get different sizes for the overall model.
Table 1 shows the model sizes with different resolutions and compares them with the MIQCP model without approximation constraints.
It can be seen that as the resolution increases, the model size increases significantly, which will be accompanied by increased computation time. Most notably, the number of binary variables also increases, which is related to the fact that as the resolution increases, the number of potential decision areas increases.
To solve the problems, two solver parameters have been manually adjusted in advance: the MIP gap is set to 0% and the maximum computation time to 2000 s. Furthermore, all solver parameters remain unchanged (“untuned”), whereby the default values of Gurobi are set automatically. This also includes the absence of manually set initial values for the optimization variables.
The benchmark is set by the MIQCP’s solution, with the optimal variable value for
, the relative error, and the computation time in
Table 2. The approximation quality is measured by the relative error, which measures the deviation between the “true” optimal objective value
and the approximated optimal objective value
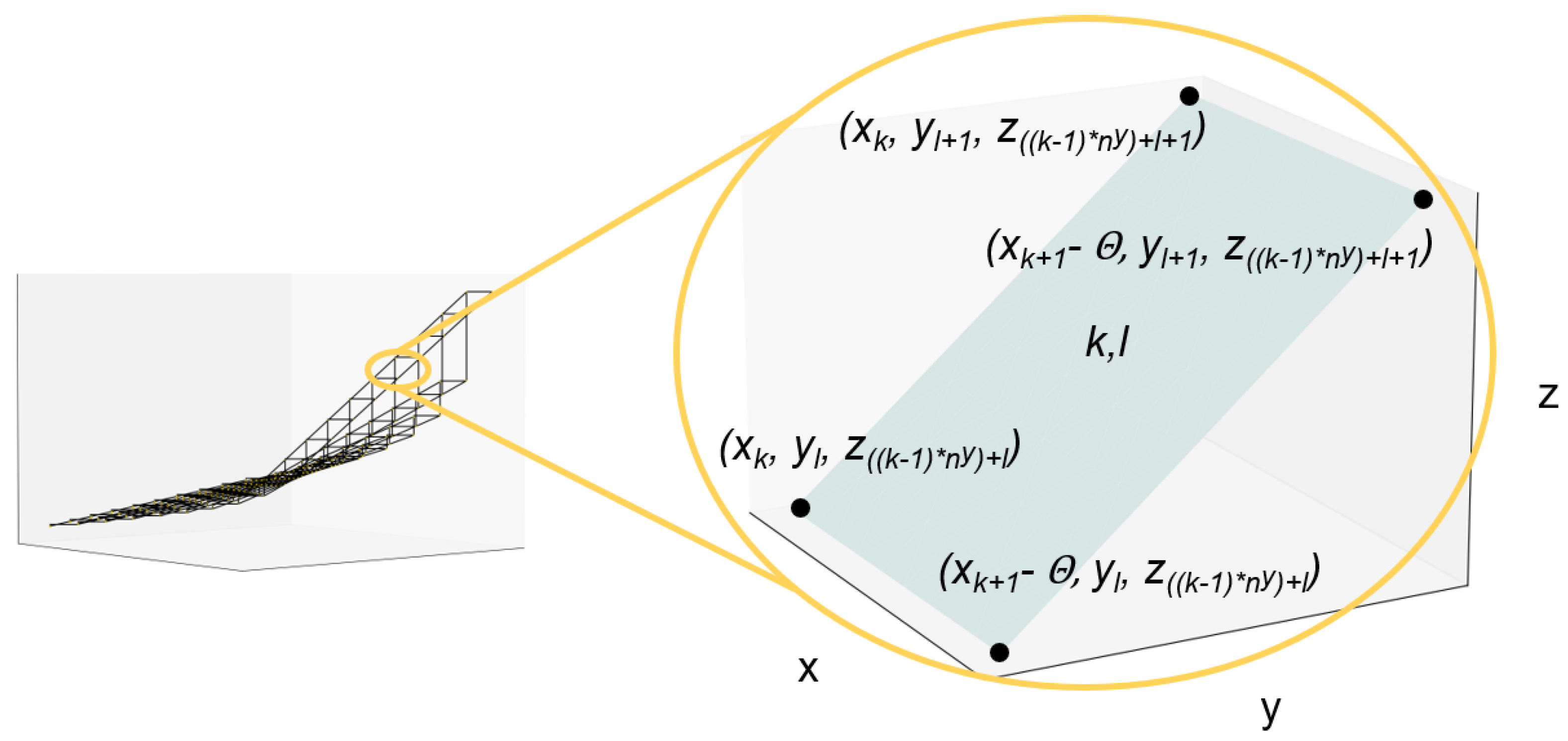
. Computation time, on the other hand, is the efficiency measure. As a trend, it can be observed that as the resolution increases, the error decreases, but at the expense of computation time. This is not surprising, and the user has to find the best compromise for the individual case. It is noticeable that the model is not solvable for a 2 × 2 resolution (geometrically a surface with only one area;
Figure 5). This is because of the too strong restriction of the solution space, since the optimizer has only one area available and is forced into it. With the 3 × 3 resolution, there are already four areas available in each timestep for the solver to choose from, making the solution space larger and the model feasible. However, the error is large compared to the higher resolution cases. With the 5 × 5 resolution, the computation time of the approximation exceeds the one of the MIQCP formulation for the first time. However, the error of 0.08% is comparatively small and does not tend to decrease at higher resolutions. With the 20 × 20 resolution, the second termination criterion—besides the MIP gap—comes into effect, and the computation is terminated after 2000 s, with a remaining MIP gap of 0.29%. Considering the results for the resolutions presented here, the 5 × 5 resolution is the best performing one based on accuracy and efficiency. It should be mentioned at this point that the results should only be interpreted in the context of the specific use-case and any numerical errors should be considered.
What also strikes us is that (the variable of interest) deviates in the order of 101 from the value assigned to the variable in the MIQCP case. This means that although the object value is approximated fairly accurately and the approximation quality can be increased with increasing resolution, the solution path, i.e., the assignment of values to the individual variables to achieve the object value, can deviate significantly. From this, one can deduce that the battery size can only be determined in the context of the underlying approximation case and is not useful for comparison. This is mainly due to the fact that the other variables—which will not be discussed further in this context—also take different values depending on the respective case. Therefore, the optimal value for the battery is only optimal in combination with the other values of the variables. This once again illustrates the dependency of sizing and scheduling as mentioned in the introduction.
In the previous section, it is mentioned what the objective function—which is a cost function—is composed of. If, hypothetically, only the battery size would be a variable in the objective function, the size would differ only by the relative error from case to case, since that would be the only variable affecting the objective function value.
The results suggest good performance also for other MINLPs—and not only MIQCPs as a special case—since the approximation itself does not depend on the type of nonlinearity.
4. Conclusions and Outlook
In this work, a detailed approach has been developed to integrate nonlinear-bivariate functions in MILP environments. On the one hand, the methodological, theoretical framework is created and formulated in detail. On the other hand, the performance is evaluated on the basis of a real use-case. This closes the research gap between generic approximation approaches and problem-specific formulations by means of a general-practical approach, whereby the concrete implementation is provided via a source code in the
Supplementary Materials. The results in
Table 2 show that the method provides satisfactory results in terms of both accuracy (error 0.08%) and efficiency (9% longer computation time), even for a conservative comparison with efficient off-the-shelf MIQCP solvers like Gurobi. However, it is important to keep in mind that these results should always be interpreted in the context of the specific use-case. In this paper, this is the MIQCP approximation for a defined MG or battery sizing problem. Accordingly, other nonlinear formulations or systems and problems may lead to different results, but this requires further research. However, the results suggest that a similar performance can be achieved for other MINLPs, since the type of nonlinearity does not matter for the approximation.
In addition to other use-cases, both in terms of system topology and problem as well as the nature of the bivariate nonlinearity, this work can also serve as a starting point for further research and methodological extensions. In
Section 2.2.1, equally distributed breakpoints are introduced. As mentioned earlier, in some cases it may make sense to distribute breakpoints unequally, whether manually or algorithmically. One algorithmic possibility is, for example, to discretize the function with a high resolution and to determine the slopes between the points. Then, one can sort the slopes by magnitude and distribute a defined number of breakpoints around the points with the largest slopes. However, for a reasonable distribution, the shape—especially the directional changes—of the function must also be considered. In addition to the position, the adequate number of breakpoints can also be determined algorithmically rather than a priori; further content can, for example, be found in Lin et al. [
33] and Asghari et al. [
34].
Another extension could be to remove the assumption of constancy (11) for each area which leads to (18) and (19) being linear. This is achieved by approximating PWL in one variable domain and PWC in the other. However, as we see, Gurobi is capable of solving MIQCPs very efficiently. It would therefore be possible to transform (18) and (19) from a linear to a quadratic expression, potentially increasing the accuracy of the approximation of general nonlinear problems (not just MIQCP). Thus, the slope depends on the position within an area and is no longer constant for the respective area. Of course, this assumes that the slope is a linear function of the variables, which can be achieved, for example, by a PWL approximation for both domains.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}