
Node Screening Method Based on Federated Learning with IoT in Opportunistic Social Networks



Abstract
:1. Introduction
- In order to achieve high-quality data transmission, it is necessary to evaluate nodes. Therefore, this paper establishes a community model in opportunistic social networks, divides nodes into different communities according to their evaluation results and node properties, and studies nodes within the community. Select relevant content to improve the efficiency of data transfer.
- To realize the screening of malicious nodes and the selection of heterogeneous device nodes, this paper establishes the FL distributed training system architecture based on deep reinforcement learning. Then, a node selection-oriented accuracy optimization problem model is constructed, which aims at minimizing the overall loss function of the participating equipment during each FL iteration process and satisfies the constraints including transmission and calculation delays.
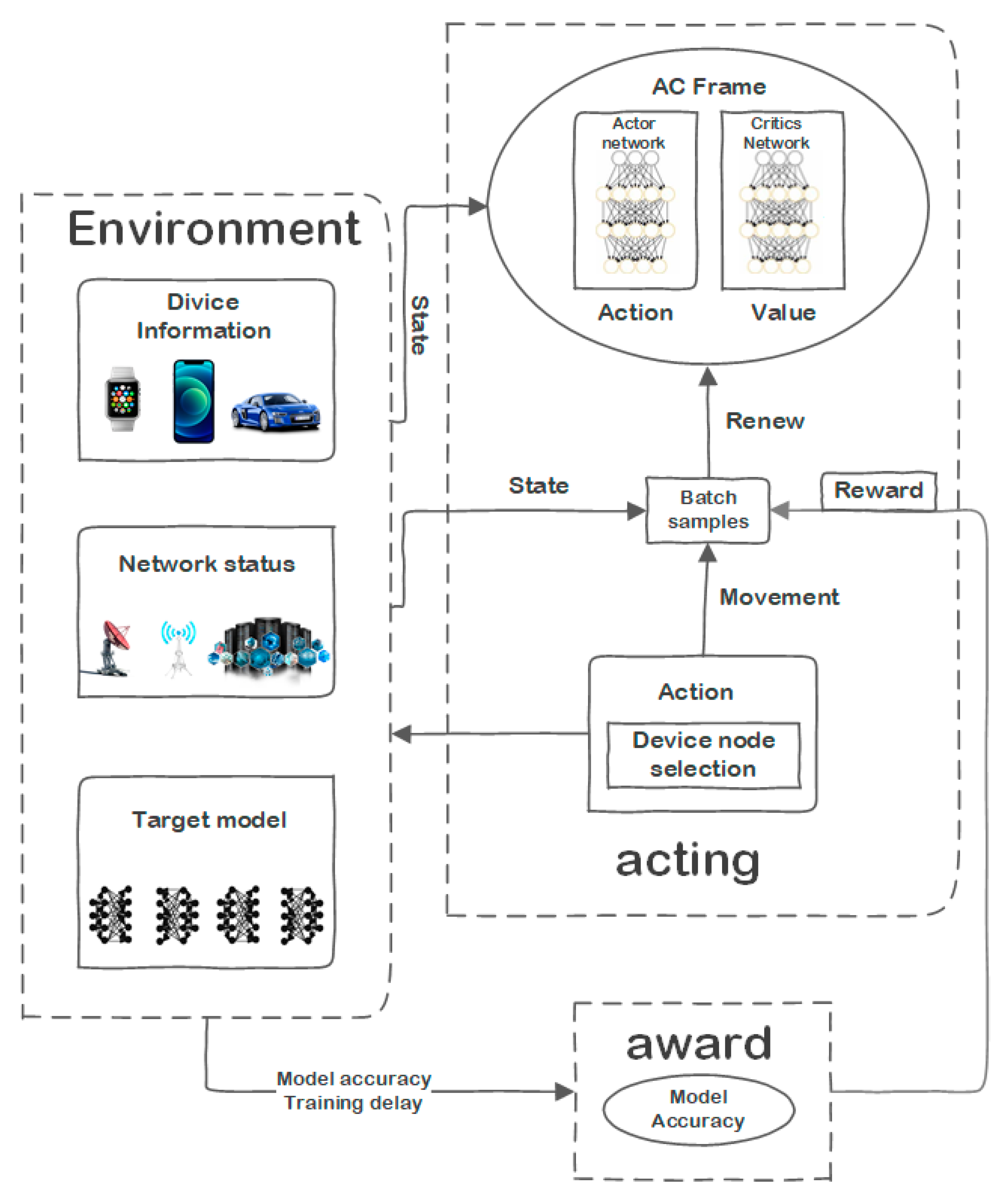
- A node selection algorithm based on distributed near-end strategy optimization is designed, and the device node selection problem in federated learning is constructed as Markov decision optimization (MDP), and actions, state spaces, and reward functions are defined. Based on the thread and PPO algorithm, a DPPO-based node selection algorithm is designed to optimize the problem and solve it.
- Based on a variety of data sets and diversified simulation training, the proposed algorithm and other routing algorithms are simulated experimentally to verify the performance. The experimental results show that the model and data transmission method proposed in this paper has a higher delivery rate, better delay performance, so it can improve data transmission reliability than other algorithms in different environments. At the same time, the algorithm has good convergence and robustness.
2. Related Work
3. Methods
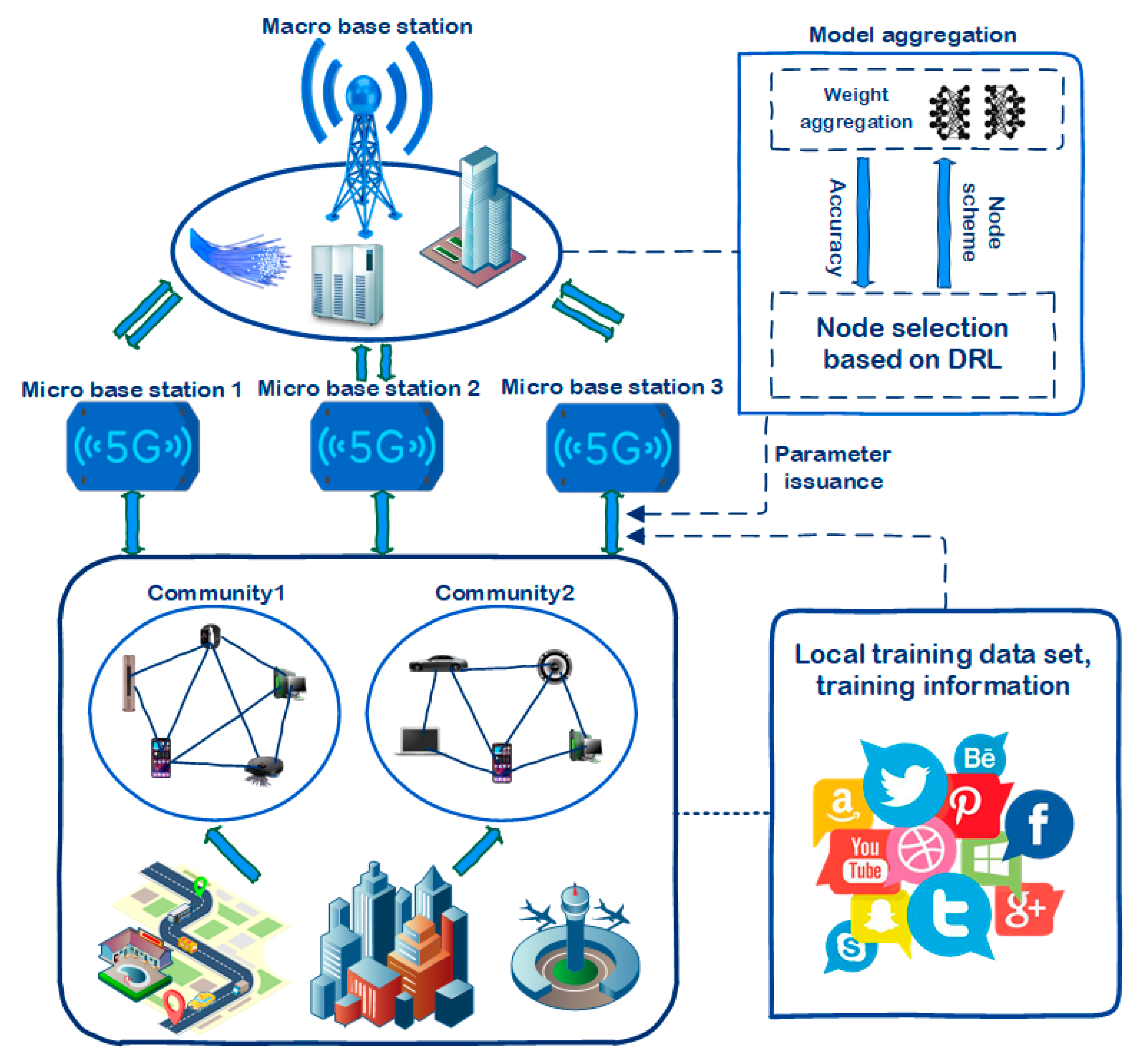
3.1. Model Description
3.2. Community Model Design
3.3. Description of the Transmission Process
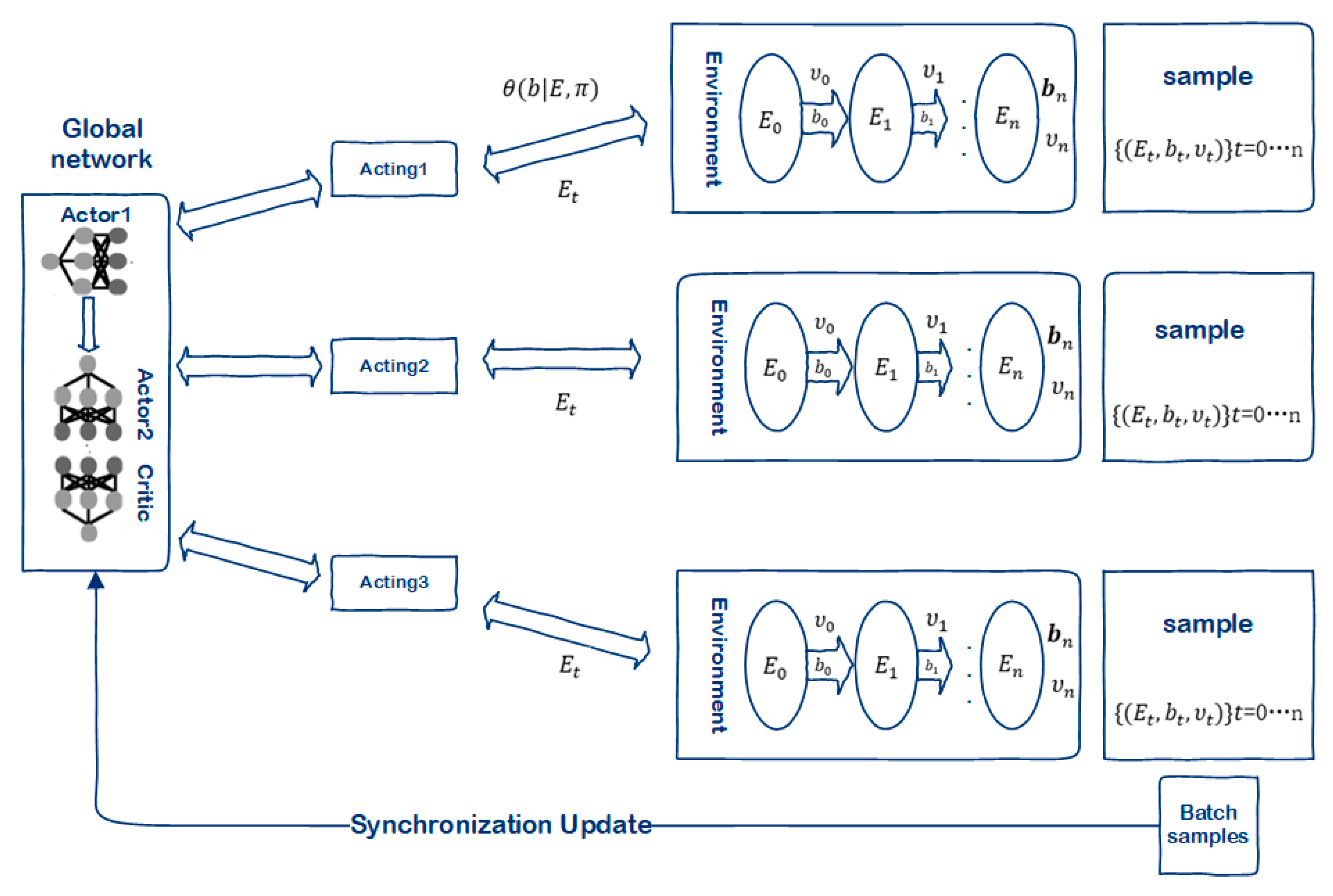
- Multithreaded Interaction.
- Global Network Update.
| Algorithm 1. FABD, FL node selection algorithm based on DPPO in IOT algorithm |
| Input: The initial state of the network, federated learning task information |
| Output: Node selection scheme |
| 1. Initialize network, equipment, and task information, randomly initialize system status and global network parameters |
| 2. FOR move ϵ {1,2,…, MO} |
| 3. FOR sub_move {1,2,…,} |
| 4. Each agent executes the node selection action according to the global PPO strategy |
| 5. Each agent obtains the reward and the next state according to Equation (16) and saves the current state, state, action, and reward as a sample |
| 6. Update current network and device status information |
| 7. END FOR |
| 8. Each agent will synchronously upload the collected data to the global network |
| 9. Update Actor1 network parameter π according to Formula (25) advantage function and Formula (24) |
| 10. Update the parameter σ of the Critic network according to backpropagation |
| 11. IF sub_move%circle==0 |
| 12. Use the function in Actor1 to update Actor2 |
| 13. END IF |
| 14. END FOR |
4. Results
4.1. Experimental Setup
- DDMPD: This algorithm is a transmission scheme based on multi-sensing domains. The available node accepts and stores some data of the source node S to itself, and then converts it into a relay node. This new relay node can transmit information widely to other nodes. When the source node moves, it can search for available nodes nearby and convert them into relay nodes according to the above method, which can effectively save overhead and ensure the security of information.
- SECM: This is an algorithm that improves the environment based on user nodes and neighbors in an opportunistic network. Such a network can identify neighbors around it, and then evaluate the probability of the nodes, so as to evaluate the neighbors to ensure that the node has a high probability of obtaining information first, this can realize cache adjustment, so that the node cache can be reasonably distributed. At the same time, the cooperation of neighboring nodes and the sharing of the node’s cache task can effectively distribute data, improve the cache use rate of the node, reduce the delay of data transmission, and improve the overall efficiency.
- ICMT: This algorithm is a method of node identification used to evaluate the probability. It adjusts the priority of the nodes that meet the high probability and rebuilds the cache space. To prevent accidental deletion of cached verses, the node’s cache task is collaboratively shared by neighboring nodes, to achieve the purpose of buffer adjustment, to ensure the effective transmission of data.
- Spray and Wait: The algorithm is an improved algorithm based on the flooding strategy. It is divided into Spray and Wait stages. Some data packets in the source node are spread first. In the second stage, if the target node is not found during the spray process, the node containing the data packet will use the Direct Delivery method to deliver the data packet to the target node. This algorithm is a kind of traditional algorithm, but the transmission delay is small, and it can maintain better algorithm performance.
- (1)
- Transmission ratio: Probability of relay node being selected (during transmission).
- (2)
- Overhead on average refers to the average cost of two nodes in the community during the information transmission process.
- (3)
- Energy consumption: The node’s energy consumption during transmission.
- (4)
- End-to-end delay: The average delay of information transmission between two nodes in the community.
4.2. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Deng, Y.; Gou, F.; Wu, J. Hybrid data transmission scheme based on source node centrality and community reconstruction in opportunistic social networks. Peer-to-Peer Netw. Appl. 2021, 14, 3460–3472. [Google Scholar] [CrossRef]
- Luo, J.; Wu, J.; Yang, W. A relationship matrix resolving model for identifying vital nodes based on community in opportunistic social networks. Trans. Emerg. Telecommun. Technol. 2021, 33, e4389. [Google Scholar] [CrossRef]
- Yang, W.; Wu, J.; Luo, J. Effective Data Transmission and Control Based on Social Communication in Social Opportunistic Complex Networks. Complexity 2020, 2020, 3721579. [Google Scholar] [CrossRef]
- Wu, J.; Gou, F.; Xiong, W.; Zhou, X. A Reputation Value-Based Task-Sharing Strategy in Opportunistic Complex Social Networks. Complexity 2021, 2021, 8554351. [Google Scholar] [CrossRef]
- Yin, S.; Xiao, Y.; Yu, G. Effective Data Selection and Management Method Based on Dynamic Regulation in Opportunistic Social Networks. Electronics 2020, 9, 1271. [Google Scholar] [CrossRef]
- Xiao, Y.; Wu, J. Data Transmission and Management Based on Node Communication in Opportunistic Social Networks. Symmetry 2020, 12, 1288. [Google Scholar] [CrossRef]
- Chen, Z.; Zhao, M. An efficient data packet iteration and transmission algorithm in opportunistic social networks. J. Ambient Intell. Humaniz. Comput. 2020, 11, 3141–3153. [Google Scholar] [CrossRef]
- Wu, J.; Gou, F.; Tan, Y. A staging auxiliary diagnosis model for non-small cell lung cancer based the on intelligent medical system. Comput. Math. Methods Med. 2021, 2021, 6654946. [Google Scholar] [CrossRef]
- Wu, J.; Gou, F.; Tian, X. Disease Control and Prevention in Rare Plants Based on the Dominant Population Selection Method in Opportunistic Social Networks. Comput. Intell. Neurosci. 2022, 2022, 1489988. [Google Scholar] [CrossRef]
- Spyropoulos, T.; Psounis, K.; Raghavendra, C.S. Spray and wait: An efficient routing scheme for intermittently connected mobile networks. In Proceedings of the 2005 ACM SIGCOMM Workshop on Delay-Tolerant Networking, ACM, New York, NY, USA, 26 August 2005; pp. 252–259. [Google Scholar] [CrossRef]
- Rahman, S.A.; Tout, H.; Ould-Slimane, H.; Mourad, A.; Talhi, C.; Guizani, M. A Survey on Federated Learning: The Journey from Centralized to Distributed On-Site Learning and Beyond. IEEE Internet Things J. 2020, 8, 5476–5497. [Google Scholar] [CrossRef]
- Wang, H.; Kaplan, Z.; Niu, D.; Li, B. Optimizing Federated Learning on Non-IID Data with Reinforcement Learning. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; pp. 1698–1707. [Google Scholar] [CrossRef]
- Yovita, L.V.; Restu, J.N. Analisis Performansi Algoritma Routing First Contact dengan Stationary Relay Node pada Delay Tolerant Network. J. Tek. Energi Elektr. Tek. Telekomun. Tek. Elektron. 2018, 4, 123. [Google Scholar] [CrossRef]
- Lin, S.; Li, Y.; Chen, P.S. Research on Improved Floyd Routing Algorithm in Opportunistic Networks. Appl. Mech. Mater. 2014, 519–520, 227–230. [Google Scholar] [CrossRef]
- Aung, C.Y.; Ho, I.W.-H.; Chong, P.H.J. Store-Carry-Cooperative Forward Routing with Information Epidemics Control for Data Delivery in Opportunistic Networks. IEEE Access 2017, 5, 6608–6625. [Google Scholar] [CrossRef]
- Khouzani, M.; Eshghi, S.; Sarkar, S.; Shroff, N.B.; Venkatesh, S.S. Optimal energy-aware epidemic routing in DTNs. EEE Trans. Autom. Control. 2012, 60, 175–182. [Google Scholar] [CrossRef] [Green Version]
- Lenando, H.; Alrfaay, M. EpSoc: Social-Based Epidemic-Based Routing Protocol in Opportunistic Mobile Social Net-work. Mob. Inf. Syst. 2018, 2018, 6462826. [Google Scholar] [CrossRef] [Green Version]
- De Rango, F.; Amelio, S.; Fazio, P. Enhancements of Epidemic Routing in Delay Tolerant Networks from an energy perspective. In Proceedings of the 9th International Wireless Communications and Mobile Computing Conference, Sardinia, Italy, 1–5 July 2013; pp. 731–735. [Google Scholar] [CrossRef]
- Karimi, S.; Darmani, Y. p-Epidemic forwarding method for heterogeneous delay-tolerant networks. J. Supercomput. 2019, 75, 7244–7264. [Google Scholar] [CrossRef]
- McGeehan, D.; Madria, S.; Lin, D. Effective social-context based message delivery using ChitChat in sparse delay tolerant networks. Distrib. Parallel Databases 2019, 38, 401–438. [Google Scholar] [CrossRef]
- Sharma, D.K.; Kukreja, D.; Chugh, S.; Kumaram, S. Supernode routing: A grid-based message passing scheme for sparse opportunistic networks. J. Ambient Intell. Humaniz. Comput. 2018, 10, 1307–1324. [Google Scholar] [CrossRef]
- Prabhavat, S.; Narongkhachavana, W.; Thongthavorn, T.; Phankaew, C. Low Overhead Localized Routing in Mobile Ad Hoc Networks. Wirel. Commun. Mob. Comput. 2019, 2019, 9652481. [Google Scholar] [CrossRef]
- Derakhshanfard, N.; Sabaei, M.; Rahmani, A.M. Sharing spray and wait routing algorithm in opportunistic net-works. Wirel. Netw. 2016, 22, 2403–2414. [Google Scholar] [CrossRef]
- Cui, J.; Cao, S.; Chang, Y.; Wu, L.; Liu, D.; Yang, Y. An Adaptive Spray and Wait Routing Algorithm Based on Quality of Node in Delay Tolerant Network. IEEE Access 2020, 7, 35274–35286. [Google Scholar] [CrossRef]
- Wu, L.; Cao, S.; Chen, Y.; Cui, J.; Chang, Y. An adaptive multiple spray-and-wait routing algorithm based on social circles in delay tolerant net-works. Comput. Netw. 1999, 189, 107901. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, Z.; Cheng, D. Efficient path routing strategy for flows with multiple priorities on scale-free networks. PLoS ONE 2017, 12, e0172035. [Google Scholar] [CrossRef] [Green Version]
- Cabaniss, R.; Vulli, S.S.; Madria, S. Social group detection based routing in Delay Tolerant Networks. Wirel. Netw. 2013, 19, 1979–1993. [Google Scholar] [CrossRef]
- Wu, J.; Xia, J.; Gou, F. Information transmission mode and IoT community reconstruction based on user influence in opportunistic s ocial networks. Peer-to-Peer Netw. Appl. 2022, 15, 1398–1416. [Google Scholar] [CrossRef]
- Li, L.; Gou, F.; Wu, J. Modified Data Delivery Strategy Based on Stochastic Block Model and Community Detection with IoT in Opportunistic Social Network. Wirel. Commun. Mob. Comput. 2022, 2022, 5067849. [Google Scholar] [CrossRef]
- Yang, W.; Luo, J.; Wu, J. Application of Information Transmission Control Strategy Based on Incremental Community Division in IoT Platform. IEEE Sens. J. 2021, 21, 21968–21978. [Google Scholar] [CrossRef]
- Gou, F.; Wu, J. Triad link prediction method based on the evolutionary analysis with IoT in opportunistic social networks. Comput. Commun. 2021, 181, 143–155. [Google Scholar] [CrossRef]
- Gou, F.; Wu, J. Message Transmission Strategy Based on Recurrent Neural Network and Attention Mechanism in Iot System. J. Circuits Syst. Comput. 2022, 31, 2250126. [Google Scholar] [CrossRef]
- Yang, Z.; Merrick, K.; Jin, L.; Abbass, H.A. Hierarchical Deep Reinforcement Learning for Continuous Action Control. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5174–5184. [Google Scholar] [CrossRef]
- Liang, X.; Du, X.; Wang, G.; Han, Z. A Deep Reinforcement Learning Network for Traffic Light Cycle Control. IEEE Trans. Veh. Technol. 2019, 68, 1243–1253. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.F.; Bennis, M.; Debbah, M.; Poor, H.V. Dynamic task offloading and resource allocation for ultra-reliable low-latency edge computing. IEEE Trans. Commun. 2019, 67, 4132–4150. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Chen, Z.; Zhao, M. SECM: Status estimation and cache management algorithm in opportunistic networks. J. Supercomput. 2018, 75, 2629–2647. [Google Scholar] [CrossRef]
- Wu, J.; Chen, Z.; Zhao, M. Information cache management and data transmission algorithm in opportunistic social networks. Wirel. Netw. 2019, 25, 2977–2988. [Google Scholar] [CrossRef]
- Sharda, S.; Singh, M.; Sharma, K. Demand side management through load shifting in IoT based HEMS: Overview, challenges and opportunities. Sustain. Cities Soc. 2020, 65, 102517. [Google Scholar] [CrossRef]
- Verma, P.; Sharma, K.; Walia, G.S. Depression Detection among Social Media Users Using Machine Learning. In Proceedings of the Inter-national Conference on Innovative Computing and Communications, New Delhi, India, 19–20 February 2021; Gupta, D., Khanna, A., Bhattacharyya, S., Hassanien, A.E., Anand, S., Jaiswal, A., Eds.; Springer: Singapore, 2021; pp. 865–874. [Google Scholar]
- Zhao, Z.; Cumino, P.; Esposito, C.; Xiao, M.; Rosário, D.; Braun, T.; Cerqueira, E.; Sargento, S. Smart Unmanned Aerial Vehicles as base stations placement to improve the mobile network operations. Comput. Commun. 2022, 181, 45–57. [Google Scholar] [CrossRef]
- Esposito, C.; Choi, C. Signaling game based strategy for secure positioning in wireless sensor networks. Pervasive Mob. Comput. 2017, 40, 611–627. [Google Scholar] [CrossRef]
- Xia, W.; Neware, R.; Kumar, S.D.; Karras, D.A.; Rizwan, A. An optimization technique for intrusion detection of industrial control network vulnerabilities based on BP neural network. Int. J. Syst. Assur. Eng. Manag. 2022, 13, 576–582. [Google Scholar] [CrossRef]
- Rizwan, A.; Serbaya, S.H.; Saleem, M.; Alsulami, H.; Karras, D.A.; Alamgir, Z. A Preliminary Analysis of the Perception Gap between Employers and Vocational Students for Career Sustainability. Sustainability 2021, 13, 11327. [Google Scholar] [CrossRef]
- Chauda, G.; Segalman, D.J. A First Violation Contact Algorithm that Correctly Captures History Dependence. Int. J. Mech. Sci. 2021, 198, 106375. [Google Scholar] [CrossRef]
- Shen, Y.; Gou, F.; Dai, Z. Osteosarcoma MRI Image-Assisted Segmentation System Base on Guided Aggregated Bilateral Network. Mathematics 2022, 10, 1090. [Google Scholar] [CrossRef]
- Yin, S.; Wu, J.; Yu, G. Low energy consumption routing algorithm based on message importance in opportunistic social networks. Peer-to-Peer Netw. Appl. 2021, 14, 948–961. [Google Scholar] [CrossRef]
- Wu, J.; Qu, J.; Yu, G. Behavior prediction based on interest characteristic and user communication in opportunistic social networks. Peer-to-Peer Netw. Appl. 2021, 14, 1006–1018. [Google Scholar] [CrossRef]
- Wu, J.; Yang, S.; Gou, F.; Zhou, Z.; Xie, P.; Xu, N.; Dai, Z. Intelligent Segmentation Medical Assistance System for MRI Images of Osteosarcoma in Developing Countries. Comput. Math. Methods Med. 2022, 2022, 6654946. [Google Scholar] [CrossRef]
- Wu, J.; Tian, X.; Tan, Y. Hospital evaluation mechanism based on mobile health for IoT system in social networks. Comput. Biol. Med. 2019, 109, 138–147. [Google Scholar] [CrossRef]
- Fang, Z.; Chang, L.; Luo, J.; Wu, J. A Data Transmission Algorithm Based on Triangle Link Structure Prediction in Opportunistic Social Networks. Electronics 2021, 10, 1128. [Google Scholar] [CrossRef]
- Desta, M.S.; Hyytiä, E.; Keränen, A.; Kärkkäinen, T.; Ott, J. Evaluating (Geo) content sharing with the ONE simulator. In Proceedings of the 11th ACM International Symposium on Mobility Management and Wireless Access MobiWac ’13, Barcelona Spain, 3–8 November 2013. [Google Scholar]
- Eagle, N.; Pentland, A. Reality mining: Sensing complex social systems. Pers. Ubiquitous Comput. 2006, 10, 255–268. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| A collection of nodes representing terminal equipment in an opportunistic network | |
| The set of edges between nodes | |
| w represents the weight between u and v | |
| Collection of servers | |
| Collection of training tasks | |
| The data set of the terminal covered by the server z | |
| The degree of community modularity at time t | |
| Indicates the total weight of the community node | |
| The total weight of all edges in the community a | |
| Represents the sum of degrees adjacent to node s in the community | |
| Represents the total data set related to the task λ | |
| The weight of the current training model represents the size of the training data set | |
| The sum of the loss function of task λ | |
| Available bandwidth between device and micro base station | |
| Available bandwidth between the device and the macro base station | |
| Channel gain between device and micro base station | |
| Channel gain between the micro base station and macro base station | |
| The transmission power of the device | |
| Transmit power of the micro base station | |
| Noise power spectral density | |
| The total transmission time for the device to upload local parameters to the model aggregation server | |
| Computational delay of terminal equipment | |
| The CPU frequency when the terminal device executes the federated learning task | |
| Total delay | |
| The state of the environment at time t in the MDP model | |
| Information about the federated learning task λ | |
| The terminal equipment can be used for the resources of the federated learning task λ at time t | |
| The data set of the terminal device at the last moment | |
| Node selection scheme at the last moment | |
| The node selection scheme of the federated learning task λ at time t is modeled as a 0–1 binary vector | |
| Reward function of task λ at time t | |
| A strategy, a mapping from state space to action space | |
| Discount factor | |
| Updated strategy parameters | |
| Strategy parameters before the update | |
| Objective gradient function | |
| The reward function under the strategy θ | |
| Dominance function | |
| Probability of taking action z in state E based on policy θ |
| Simulation Parameters | Value |
|---|---|
| Simulation time | 1–7 h |
| Network area | 4600 m 3400 m |
| Number of nodes | 400 |
| Node moving speed | 0.5–1.5 m/s |
| The maximum amount of cached information | 5 M |
| Maximum transmission domain | |
| Data packet sending interval | 25–35 s |
| Transmission speed | 251 kb/s |
| Node initial energy | 100 J |
| Sending a single data packet requires energy | 1 J |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, Y.; Gou, F.; Wu, J. Node Screening Method Based on Federated Learning with IoT in Opportunistic Social Networks. Mathematics 2022, 10, 1669. https://doi.org/10.3390/math10101669
Shen Y, Gou F, Wu J. Node Screening Method Based on Federated Learning with IoT in Opportunistic Social Networks. Mathematics. 2022; 10(10):1669. https://doi.org/10.3390/math10101669
Chicago/Turabian StyleShen, Yedong, Fangfang Gou, and Jia Wu. 2022. "Node Screening Method Based on Federated Learning with IoT in Opportunistic Social Networks" Mathematics 10, no. 10: 1669. https://doi.org/10.3390/math10101669
APA StyleShen, Y., Gou, F., & Wu, J. (2022). Node Screening Method Based on Federated Learning with IoT in Opportunistic Social Networks. Mathematics, 10(10), 1669. https://doi.org/10.3390/math10101669