1. Introduction
Consider a linear regression model
where
are
n observations of outcome and
are
p-dimensional predictors with
being i.i.d.
random vectors
, which are normally distributed with zero mean and the covariance matrix
, denoted
. We assume that the covariance matrix
has a form
if
and
if
(here and below
denotes the
identity matrix). This matrix is often called the Kac–Murdock–Szego (KMS) matrix, originally introduced in [
1]. As the autocorrelation matrix of corresponding causal AR(1) processes, the KMS matrix is positive definite and is considered due to the wide array of applications in the literature and its well known spectral properties (see, e.g., [
2] for a thorough literature review). When carefully chosen, such a structure could well-approximate a wide array of possible covariance structures (see, e.g., [
3] for a more general approach with various Toeplitz covariance structures). Furthermore,
are unobserved i.i.d. errors with
,
, and
is an unknown
p-dimensional parameter. In practice, the assumption is that
can be untenable, and it may be appropriate to add an intercept to the linear model (
1); however, for simplicity, throughout this paper we will assume that the intercept is known and the variables are centered. Similar settings are considered when dealing with certain geospatial data, longitudinal studies, microarray data, and research on approximate message passing algorithms (see, e.g., [
4,
5,
6,
7,
8,
9]).
This paper is concerned with the derivation of the exact asymptotic distribution for the suitably centered and normalized squared norm
under the assumption of the KMS type covariance structure in (
2), where
p and
n are assumed to be large. Throughout the paper, we assume that
and
. We are particularly interested in cases where
. Statistics of such form arise in various applications in the context of high-dimensional linear regression, and under normality assumptions general results can be derived using random matrix theory through Wishart distributions (see, e.g., [
7,
10,
11,
12]). Dealing with such statistics typically require strong restrictions on the model parameters
; however, in this paper, we only require that
is satisfied. Moreover, our results could be extended by using
-generating functions (e.g., parameters of FARIMA models). In comparison to the related papers, ref. [
12] assumes exact sparsity, while [
7,
10] require approximate sparsity.
We approach the problem following an observation by [
13] that the distribution of product of Gaussian random variables admits a variance-gamma distribution, which results in a set of attractive properties. We contribute to the literature on variance-gamma distribution by extending the results by [
14,
15,
16]. We demonstrate that, along with the derivation of the asymptotic distribution of
, this approach allows us to define the exact distribution of the statistic given any fixed values
, which can be expressed through a combination of gamma and normal random variables. In the related literature we were not able to find results for the exact distribution and asymptotic analysis of the statistic
based on the variance-gamma distribution. Furthermore, we deem that such a result is much easier to work with than when considering the characteristic or density functions of
straightforwardly. Therefore, in addition to the
-norm statistic, we argue that the obtained results can be easily extended towards alternative forms of the statistic, e.g., by using a different norm, which would reduce the problem to manipulating variance-gamma distribution, thus suggesting possible further research cases and useful extensions.
Additionally, we examine a specific case of parameter
by considering
,
. Similar structures of the vector
are often found in the literature when approximate sparsity of the coefficients in the linear regression model (
1) is assumed. See, e.g., [
17,
18] for a broader view towards sparsity requirements and its implications to specific high-dimensional algorithms; refs. [
19,
20] for model selection problems in autoregressive time series models; refs. [
21,
22,
23,
24,
25,
26,
27,
28] for applications on inference of high-dimensional models and high-dimensional instrumental variable (IV) regression models; or [
29,
30,
31,
32,
33] for recent applications of high-dimensional and sparse methods with financial and economic data. Performing Monte Carlo simulations, we find that the empirical distributions of the corresponding statistic approach the limiting distribution reasonably quickly even for large values of
and
c. These results suggest that the assumption of sparse structure can be included in the applications and statistical tests, thus, could be further extended following the literature on testing for sparsity or construction of signal-to-noise ratio estimators (see, e.g., [
7,
10,
11,
12]).
In this paper, , and denote the equality of distributions, convergence of distributions and convergence in probability, respectively. The notation of C represents a generic positive constant which may assume different values at various locations, and denotes the indicator function of a set A.
The structure of the paper is as follows. In
Section 2, we present the main results of the paper. In
Section 3, we present useful properties of variance-gamma distribution, which are used in
Section 4 in order to prove some auxiliary results. In
Section 5, we present the proof of the main result. Finally, in
Section 6, we provide an example of the main result under imposed approximate sparsity assumption for the parameter
of the model (
1). Technical results are presented in
Appendix A, while, for brevity, some straightforward yet tedious proofs are presented in the
Supplementary Material.
2. Main Results
In this section we formulate the main results on the normality of statistic
. Introduce the notations:
It can be observed that under
, there exist limits
Additionally, . Since is positive semi-definite, , . Indeed, , thus it suffices to take for and for .
Our first main result is the following theorem.
Theorem 1. Assume the model in (1) with covariance structure in (2). Let and let satisfyLet also the satisfyThenwhere variance has the structure Our second main result deals with the case where the centering sequence in (
8) is modified to include the limiting values of
,
.
Theorem 2. Let the assumptions of Theorem 1 hold. In addition, assume that and with . Then, The proofs of these theorems are given in
Section 5.
Remark 1. For alternative expressions of , and , see Lemma 5 below.
The following corollary deals with the case when , i.e., . The result follows from Theorem 2, noting that in this case , .
Corollary 1. Assume a model (1) with covariance structure . Let assumptions (6) and (7) be satisfied. In addition, assume that and with . Then,where 5. Proof of the Main Results
In this section we give the proofs of Theorems 1 and 2. Throughout the proofs, we express corresponding constants in terms of
and
,
, introduced in (
3)–(
5). Recall that
, and, by Remark 3,
, for
.
Proof of Theorem 1. Denote
,
. By covariance structure (
2) and
,
, we have
, where
and
.
Applying Proposition 1(iii) with
,
, and
,
,
, where
, we obtain that
where
and
with
defined as (see (
16)):
By expanding the square we can write
By further rearranging the right-hand side, we have
where
We will show that, as
,
, the term
, while the terms
and
are asymptotically normal. More precisely, we will show that
and
, where
and
are given by (
44) and (
62) below. Here, since
and
are mutually independent for each
n, it follows that
. Finally, the term
defines the mean of the statistic, i.e.,
Thus, we will conclude by establishing that
, while
, as in the statement of the theorem.
First, consider
defined in (
35). We will show that
. Denote
It is clear that
and
. Recall that, by CLT,
Therefore,
Second, consider
, defined in (
36). We will show that
with
given by
Rewrite
Applying (
40) and (
41) for the outer term of (
45), we obtain
We will show that the inner term of (
45) approaches
. Since
, by (
40) and assumption
it suffices to prove the convergence
Denote matrix
To prove (
46), we apply Lemma 2 with
,
, and
. The conditions of Lemma 2 will hold if
and
, as
. Observe, that
since
,
and
. Here we used (
40) and the observation that
Similarly, we have
since, by Lemma A4,
, while
,
. This concludes the proof of (
46).
Next, consider
, defined by (
37). We will show that
with
defined in (
62). Write
where
,
A is defined by (
47), and
Observe that
due to the Law of Large Numbers. Thus, since
and
U are independent for any
n and
, it follows that
First, we consider the inner term of (
51) and show that as
,
where
. Then, (
50) readily follows from (
51).
Recall, that
,
. Further, let
. Clearly, one has that
, where
denotes the symmetric square root of
. By the Spectral Theorem, we construct
, where
and
P is an orthogonal matrix that diagonalizes
, such that
, with
comprised of the eigenvalues of
. Then,
where
, and
Clearly,
and
. Therefore, proving the result (
52) is equivalent to showing:
where
We prove (
55) by applying Lemma 3 with
as the eigenvalues of
and
. By the conditions of Lemma 3, we need to show that the following holds
First, observe that
. Indeed, we have that
, since
by (
40) and (
49).
Next, by (
48), we find that
. Indeed, by (
48), we have
Thus, by (
58) and (
59), it follows that
and condition (
57) reduces to:
We show that (
60) holds. For the first term of (
60), we have
where the last equality follows from Lemma A5. For the second term of (
60), observe that by Hölder’s inequality and (
61),
This concludes with (
60), ensuring that the conditions of Lemma 3 hold.
Now we can establish the expression for
. By (
40), (
56), (
58) and (
59),
By (
44) and (
62), recalling that
, we have that
Finally, consider
, defined by (
38). Since
, we have that
By (
34), having established four parts by (
35)–(
38), we proved that (
39) holds due to (
42), (
43), (
50), (
62), with terms (
63) and (
64), as in the statement of the theorem, thus concluding the proof. □
Before proceeding with the proof of Theorem 2, we establish the following lemma that ensures convergence rate for and , appearing in Theorem 1, under additional restrictions for the parameters .
Lemma 4. Assume that and , , and . Then,
- (i)
- (ii)
Proof of Theorem 2. Rewrite the left-hand side of (
10) as follows:
It remains to apply Lemma 4 and Theorem 1 in order to conclude the proof of the theorem. □
We end this section by deriving two supporting results that allows us to derive convenient alternative expressions for the terms and . For this, we introduce functions and by Definition 3 below, which, under the assumptions of Theorem 1 and a given structure of ’s, requires only to evaluate the terms and . Then, due to Lemma 5 below, the expressions for , and easily follow.
Definition 3. Assume that and . Define,and define the following quantities which involve derivatives of (65)–(67): Note that, by the rules of differentiation of power series, the functions (
68)–(
71) are well defined.
Lemma 5. Let the assumptions of Theorem 1 hold. Let , and be given by (3)–(5), respectively. Then, under notation in Definition 3, the following identities hold: - (i)
- (ii)
- (iii)
Remark 3. From the assumptions of Definition 3 it follows that , for . Thus, it follows from Lemma 5 that , .
Proof of Remark 3. Cases for
and
follow straightforwardly from the assumptions. Consider
. Note that for any
p,
by (S9). In a similar manner, it can be seen that
. □
6. Approximate Sparsity: An Example
In this section, we study the case when coefficients
decay hyperbolically, i.e.,
. This assumption is analogous to the assumption of approximate sparsity, as defined by [
21]. The authors of the aforementioned paper note that for approximately sparse models, the regression function can be well approximated by a linear combination of relatively few important regressors, which is one of the reasons of popularity of variable selection approaches such as LASSO ([
36]) and its modifications (see, e.g., [
37,
38,
39]). At the same time, approximate sparsity allows all coefficients
to be nonzero, which is a more plausible assumption in many real world settings.
In order to derive the quantities in Theorem 2, we apply the results of Lemma 5. For this, we establish the expressions for the quantities in Definition 3.
Define the real dilogarithm function (see, e.g., [
40]):
(Here and below,
if
.) For
the real dilogarithm has a series representation,
Then,
Additionally, we have
Thus, by (
68) and (
74), we establish
Next, note that
where we have used identities
and (
72). Then, by (
69), (
74) and (
75),
whereas by (
71),
Furthermore, note that
where the last equality follows from Lemma A1. Next, by (
69), (
74) and (
76) we have
Thus, we can apply Lemma 5(i) and arrive at the following expression for
:
Similarly, for
, by collecting and simplifying the terms, by Lemmas 5(ii) and A1, we have
Lastly, for
, by Lemma 5(iii), through simplification of terms, we get
This allows us to apply Theorem 2 under the considered specification of the parameter and conclude with the following corollary.
Corollary 2. Assume a model (1) with (2) covariance structure and consider , . Let satisfiesThenwhereand , and are defined by (77)–(79), respectively. In order to illustrate the results of Corollary 2, we end this section with a Monte Carlo simulation study where we generate 1000 independent replications of the statistic
. The data is generated following the assumptions of Corollary 2. We consider the following parameter values:
,
,
. Due to the large number of resulting figures, we present only selected cases in
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8 and
Figure 9, which demonstrate certain disparities in greater detail. Figures show the empirical cumulative distribution function (CDF) and the empirical probability density function (PDF), together with the limiting CDF and PDF of
by (
80) for different parameter combinations. In addition, we present the corresponding Q-Q plots in order to inspect the tails of the resulting distributions in greater detail.
We find that for relatively small values of
, the observed distribution of the statistic is fairly close to the limiting distribution even for small values of
and larger
(see, e.g.,
Figure 1,
Figure 2,
Figure 3 and
Figure 4). However, slower convergence is more evident with increasing values of
. Furthermore, for moderate values of
, only with larger values of
p we observe adequate convergence towards the limiting distribution (see
Figure 5 and
Figure 6). Similar behaviour is observed when the relation between the parameters
is appropriately controlled: e.g., in
Figure 7, we see comparable results to those presented by
Figure 6, where the effect of the increase in parameter value
is countered by a smaller value of
. Alternatively, analogous effects can be achieved when reducing the values of
c, instead.
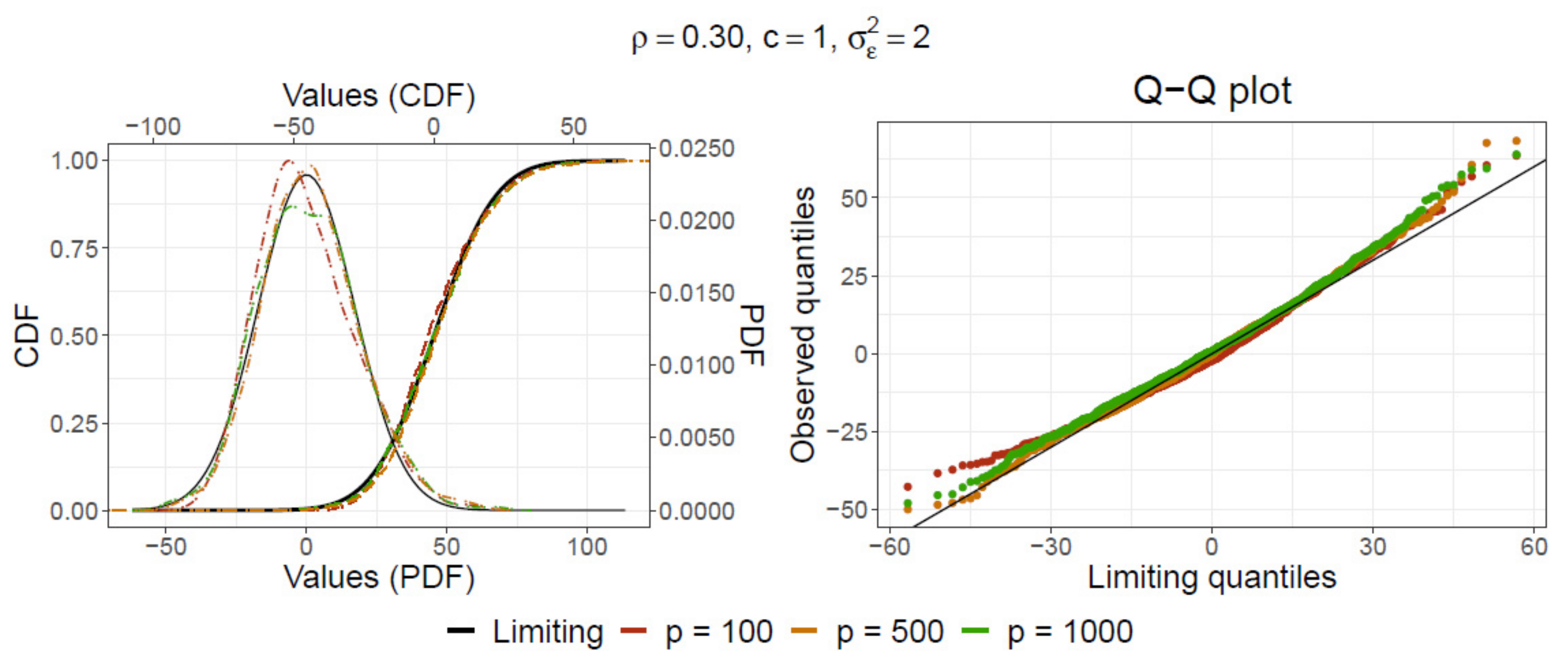
Figure 2.
Comparison of the PDF and CDF (
left) and the corresponding Q-Q plots (
right) after 1000 replications from the Monte Carlo simulation of the statistic (
80) with the limiting distribution
by the Corollary 2 (in black) for
,
,
and
.
Figure 2.
Comparison of the PDF and CDF (
left) and the corresponding Q-Q plots (
right) after 1000 replications from the Monte Carlo simulation of the statistic (
80) with the limiting distribution
by the Corollary 2 (in black) for
,
,
and
.
Figure 3.
Comparison of the PDF and CDF (
left) and the corresponding Q-Q plots (
right) after 1000 replications from the Monte Carlo simulation of the statistic (
80) with the limiting distribution
by the Corollary 2 (in black) for
,
,
and
.
Figure 3.
Comparison of the PDF and CDF (
left) and the corresponding Q-Q plots (
right) after 1000 replications from the Monte Carlo simulation of the statistic (
80) with the limiting distribution
by the Corollary 2 (in black) for
,
,
and
.
Figure 4.
Comparison of the PDF and CDF (
left) and the corresponding Q-Q plots (
right) after 1000 replications from the Monte Carlo simulation of the statistic (
80) with the limiting distribution
by the Corollary 2 (in black) for
,
,
and
.
Figure 4.
Comparison of the PDF and CDF (
left) and the corresponding Q-Q plots (
right) after 1000 replications from the Monte Carlo simulation of the statistic (
80) with the limiting distribution
by the Corollary 2 (in black) for
,
,
and
.
Figure 5.
Comparison of the PDF and CDF (
left) and the corresponding Q-Q plots (
right) after 1000 replications from the Monte Carlo simulation of the statistic (
80) with the limiting distribution
by the Corollary 2 (in black) for
,
,
and
.
Figure 5.
Comparison of the PDF and CDF (
left) and the corresponding Q-Q plots (
right) after 1000 replications from the Monte Carlo simulation of the statistic (
80) with the limiting distribution
by the Corollary 2 (in black) for
,
,
and
.
Figure 6.
Comparison of the PDF and CDF (
left) and the corresponding Q-Q plots (
right) after 1000 replications from the Monte Carlo simulation of the statistic (
80) with the limiting distribution
by the Corollary 2 (in black) for
,
,
and
.
Figure 6.
Comparison of the PDF and CDF (
left) and the corresponding Q-Q plots (
right) after 1000 replications from the Monte Carlo simulation of the statistic (
80) with the limiting distribution
by the Corollary 2 (in black) for
,
,
and
.
Figure 7.
Comparison of the PDF and CDF (
left) and the corresponding Q-Q plots (
right) after 1000 replications from the Monte Carlo simulation of the statistic (
80) with the limiting distribution
by the Corollary 2 (in black) for
,
,
and
.
Figure 7.
Comparison of the PDF and CDF (
left) and the corresponding Q-Q plots (
right) after 1000 replications from the Monte Carlo simulation of the statistic (
80) with the limiting distribution
by the Corollary 2 (in black) for
,
,
and
.
Finally, slow convergence is observed for large values of
, as expected (see
Figure 8 and
Figure 9). In such cases, the simulation results suggest that even larger values of
would be needed for more accurate results.
Figure 8.
Comparison of the PDF and CDF (
left) and the corresponding Q-Q plots (
right) after 1000 replications from the Monte Carlo simulation of the statistic (
80) with the limiting distribution
by the Corollary 2 (in black) for
,
,
and
.
Figure 8.
Comparison of the PDF and CDF (
left) and the corresponding Q-Q plots (
right) after 1000 replications from the Monte Carlo simulation of the statistic (
80) with the limiting distribution
by the Corollary 2 (in black) for
,
,
and
.
Figure 9.
Comparison of the PDF and CDF (
left) and the corresponding Q-Q plots (
right) after 1000 replications from the Monte Carlo simulation of the statistic (
80) with the limiting distribution
by the Corollary 2 (in black) for
,
,
and
.
Figure 9.
Comparison of the PDF and CDF (
left) and the corresponding Q-Q plots (
right) after 1000 replications from the Monte Carlo simulation of the statistic (
80) with the limiting distribution
by the Corollary 2 (in black) for
,
,
and
.
7. Discussion
In this paper, we consider a specific KMS covariance structure due to its attractive properties and wide application possibilities for working with real world datasets. Moreover, our results could be extended further by considering a wider family of Toeplitz covariance structures. For instance, under specific constraints, one could employ the approaches proposed in [
3] in order to extend the application of our results towards more complex covariance structures of the data.
Furthermore, for future work, it would be interesting to expand and examine the results by removing the assumption of independence between the observations , .
Finally, in this paper we have established both the exact and the asymptotic distributions of the statistic
(see (
8), (
10) and (
34)). Both distributions could be used for estimating
,
or related measures (e.g., by applying the method of moments or maximum likelihood estimation) in future research. Such research direction could open up interesting avenues when compared with popular LASSO type methods in high-dimensional linear regression. Similar approach is taken by [
10], who construct maximum likelihood estimators for the signal strength
in a high-dimensional regression context. Note that the results by [
10] are achieved under certain strong restrictions, which are consistent with the related literature (see, e.g., [
7,
41,
42]). In our case, we impose weaker assumptions; therefore, both our asymptotic or exact results could be used in order to extend the approaches in the aforementioned literature.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}