
Return on Advertising Spend Prediction with Task Decomposition-Based LSTM Model

 , ,
, ,  ,
,
Abstract
:1. Introduction
2. Related Work
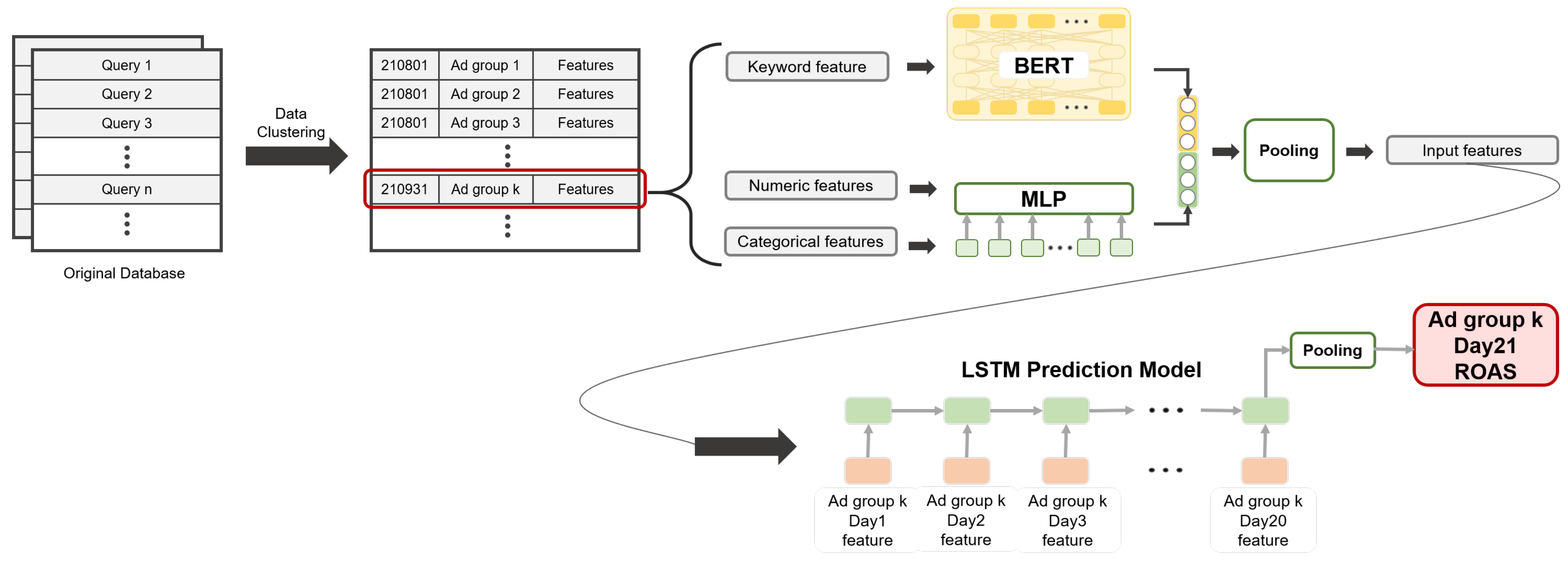
3. Proposed Method
3.1. Data Pre-Processing
3.1.1. Feature Extraction
3.1.2. Data Clustering
3.2. Prediction Model
Input Sequence Encoding
3.3. LSTM-Based Prediction Model
3.4. One-Stage Framework
3.5. Two-Stage Framework
3.5.1. Occurrence Prediction Model
3.5.2. Occurred ROAS Regression Model
3.5.3. Why Task Decomposition?
4. Experimental Results
4.1. Data Details
4.2. Training Details
4.3. Evaluation Details
4.4. Main Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Orzan, M.C.; Zara, A.I.; Căescu, Ş.C.; Constantinescu, M.E.; Orzan, O.A. Social Media Networks as a Business Environment, During COVID-19 Crisis. Rev. Manag. Comp. Int. 2021, 22, 64–73. [Google Scholar] [CrossRef]
- Krasnov, S.; Sergeev, S.; Titov, A.; Zotova, Y. Modelling of Digital Communication Surfaces for Products and Services Promotion. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2019; Volume 497, p. 012032. [Google Scholar]
- Vaver, J.; Koehler, J. Measuring Ad Effectiveness Using Geo Experiments; Technical Report; Google Inc.: Mountain View, CA, USA, 2011. [Google Scholar]
- Kerman, J.; Wang, P.; Vaver, J. Estimating Ad Effectiveness Using Geo Experiments in a Time-Based Regression Framework; Working Paper; Google Inc.: Mountain View, CA, USA, 2017. [Google Scholar]
- Blake, T.; Nosko, C.; Tadelis, S. Consumer heterogeneity and paid search effectiveness: A large-scale field experiment. Econometrica 2015, 83, 155–174. [Google Scholar] [CrossRef]
- Chen, A.; Longfils, M.; Remy, N. Trimmed Match Design for Randomized Paired Geo Experiments. arXiv 2021, arXiv:2105.07060. [Google Scholar]
- Chen, A.; Au, T.C. Robust Causal Inference for Incremental Return on Ad Spend with Randomized Paired Geo Experiments. arXiv 2019, arXiv:1908.02922. [Google Scholar] [CrossRef]
- Barajas, J.; Zidar, T.; Bay, M. Advertising Incrementality Measurement Using Controlled Geo-Experiments: The Universal App Campaign Case Study; ACM: Washington, DC, USA, 2020. [Google Scholar]
- Chan, D.; Ge, R.; Gershony, O.; Hesterberg, T.; Lambert, D. Evaluating online ad campaigns in a pipeline: Causal models at scale. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–28 July 2010; pp. 7–16. [Google Scholar]
- Ravichandran, K.; Thirunavukarasu, P.; Nallaswamy, R.; Babu, R. Estimation of return on investment in share market through ANN. J. Theor. Appl. Inf. Technol. 2005, 3, 44–54. [Google Scholar]
- Selvin, S.; Vinayakumar, R.; Gopalakrishnan, E.; Menon, V.K.; Soman, K. Stock price prediction using LSTM, RNN and CNN-sliding window model. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (Icacci), Mangalore, India, 13–16 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1643–1647. [Google Scholar]
- Sun, C.; Liu, W.; Dong, L. Reinforcement learning with task decomposition for cooperative multiagent systems. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 2054–2065. [Google Scholar] [CrossRef] [PubMed]
- Vallon, C.; Borrelli, F. Task Decomposition for Iterative Learning Model Predictive Control. In 2020 American Control Conference (ACC); IEEE: Piscataway, NJ, USA, 2020; pp. 2024–2029. [Google Scholar]
- Sen, J.; Dutta, A.; Mehtab, S. Stock portfolio optimization using a deep learning LSTM model. In 2021 IEEE Mysore Sub Section International Conference (MysuruCon); IEEE: Piscataway, NJ, USA, 2021; pp. 263–271. [Google Scholar]
- Sen, J.; Dutta, A.; Mehtab, S. Profitability analysis in stock investment using an LSTM-based deep learning model. In Proceedings of the 2021 2nd International Conference for Emerging Technology (INCET), Belgaum, India, 21–23 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–9. [Google Scholar]
- Xue, H.; Huynh, D.Q.; Reynolds, M. SS-LSTM: A hierarchical LSTM model for pedestrian trajectory prediction. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1186–1194. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Michańków, J.; Sakowski, P.; Ślepaczuk, R. LSTM in Algorithmic Investment Strategies on BTC and S&P500 Index. Sensors 2022, 22, 917. [Google Scholar] [CrossRef] [PubMed]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Ramchoun, H.; Ghanou, Y.; Ettaouil, M.; Janati Idrissi, M.A. Multilayer Perceptron: Architecture Optimization and Training. Int. J. Interact. Multimed. Artif. Intell. 2016, 4, 26–30. [Google Scholar] [CrossRef]
- Ontoum, S.; Chan, J.H. Personality Type Based on Myers-Briggs Type Indicator with Text Posting Style by using Traditional and Deep Learning. arXiv 2022, arXiv:2201.08717. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Jawahar, G.; Sagot, B.; Seddah, D. What does BERT learn about the structure of language? In Proceedings of the ACL 2019-57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Yeung, T.S.A.; Chung, E.T.; See, S. A deep learning based nonlinear upscaling method for transport equations. arXiv 2020, arXiv:2007.03432. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Gotmare, A.; Keskar, N.S.; Xiong, C.; Socher, R. A closer look at deep learning heuristics: Learning rate restarts, warmup and distillation. arXiv 2018, arXiv:1810.13243. [Google Scholar]


{kind=link}
| Feature Name | Description | Data Type | Class |
|---|---|---|---|
| stat_date | Dates of data collection | string | cluster |
| adgroup | Ad group id of the data query | string | cluster |
| ad_platform | Ad platform id of the data query | string | categorical |
| ad_program | Ad program id of the data query | string | categorical |
| device | Device that data is collected (Mobile or PC) | string | categorical |
| impr | Ad dwell time of the customer | integer | numeric |
| click | Number of clicks occurred by the customer | integer | numeric |
| rgr | Number of “Sign in” occurred by the customer | integer | numeric |
| odr | Number of orders | integer | numeric |
| cart | Number of “Add to cart” occurred by the customer | integer | numeric |
| conv | Number of conversion occurred by the customer | integer | numeric |
| cost | Cost occurred by the customer | integer | numeric |
| rvn | Revenue occurred by the customer | integer | numeric |
| keyword | Keyword used in searching ad | string | keyword |
| Train | Validate | Test | |
|---|---|---|---|
| # of data points | 334,963 | 7807 | 6980 |
| # of zero labels | 324,672 | 7483 | 6745 |
| # of non-zero labels | 10,291 | 324 | 235 |
| # of ad groups | 6764 | 141 | 141 |
| MSE | MAE | Non-Zero MSE | Non-Zero MAE | Mapped F1-Score | Mapped Precision | Mapped Recall | |
|---|---|---|---|---|---|---|---|
| One-stage | 0.68400 | 0.11545 | 21.64975 | 2.81465 | 0.00513 | 0.00271 | 0.04782 |
| One-stage + Up-scaling | 0.72601 | 0.39744 | 19.30089 | 2.32553 | 0.06116 | 0.03155 | 1.00000 |
| Two-stage | 0.68830 | 0.12501 | 19.66112 | 3.23538 | 0.27578 | 0.17062 | 0.71875 |
| Two-stage + Up-scaling | 0.81438 | 0.26652 | 11.72011 | 2.02405 | 0.40642 | 0.25850 | 0.95000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moon, H.; Lee, T.; Seo, J.; Park, C.; Eo, S.; Aiyanyo, I.D.; Park, J.; So, A.; Ok, K.; Park, K. Return on Advertising Spend Prediction with Task Decomposition-Based LSTM Model. Mathematics 2022, 10, 1637. https://doi.org/10.3390/math10101637
Moon H, Lee T, Seo J, Park C, Eo S, Aiyanyo ID, Park J, So A, Ok K, Park K. Return on Advertising Spend Prediction with Task Decomposition-Based LSTM Model. Mathematics. 2022; 10(10):1637. https://doi.org/10.3390/math10101637
Chicago/Turabian StyleMoon, Hyeonseok, Taemin Lee, Jaehyung Seo, Chanjun Park, Sugyeong Eo, Imatitikua D. Aiyanyo, Jeongbae Park, Aram So, Kyoungwha Ok, and Kinam Park. 2022. "Return on Advertising Spend Prediction with Task Decomposition-Based LSTM Model" Mathematics 10, no. 10: 1637. https://doi.org/10.3390/math10101637
APA StyleMoon, H., Lee, T., Seo, J., Park, C., Eo, S., Aiyanyo, I. D., Park, J., So, A., Ok, K., & Park, K. (2022). Return on Advertising Spend Prediction with Task Decomposition-Based LSTM Model. Mathematics, 10(10), 1637. https://doi.org/10.3390/math10101637