1. Introduction
Mentorship in higher education is widely recognized as a cornerstone of student success, bolstering students’ academic, emotional, and professional development (
Lucey & White, 2017). Yet, disparities persist, particularly for first-generation and low-income students, who often lack the social and institutional capital required for robust faculty or peer mentorship. In response, institutions have sought innovative forms of support, ranging from peer mentoring programs (
Lunsford et al., 2017) to evaluating technologically-mediated solutions such as Generative Artificial Intelligence (GAI) tools (
Ruano-Borbalan, 2025;
Köbis & Mehner, 2021). These AI-driven systems, exemplified by ChatGPT, have increasingly drawn attention for their capacity to provide on-demand feedback, resources, and interactive dialogue (
Hadi Mogavi et al., 2024), potentially alleviating some barriers to quality mentorship. However, scholars also caution that the use of GAI tools can introduce ethical dilemmas (
Dabis & Csáki, 2024) and that their outputs may be misread or misapplied, particularly by users lacking the expertise needed to verify the accuracy or appropriateness of AI-generated content (
Sabbaghan & Eaton, 2025;
Walczak & Cellary, 2023). Moreover, a recent study has shown that GAI tools typically cannot replicate the relational depth and empathetic nuance integral to effective human mentorship (
Mukherjee et al., 2024).
Against this backdrop, questions arise about how students actually perceive and evaluate AI-generated guidance, such as whether they find it helpful and caring, and the ways these perceptions shape their willingness to seek future support. Our prior study (
Lee & Esposito, 2025) revealed that students rated responses they perceived as from humans significantly higher in helpfulness, care, and willingness to engage again, demonstrating a bias favoring human sources. When sources were concealed, AI responses in the personal domain received higher caring ratings than human responses, yet those same AI responses were rated less favorably once participants perceived that they came from AI. A related content analysis found that students’ initial perceptions shaped attributions regarding tone, language, and contextual cues, reinforcing whether they believed a source was human or AI, and also influencing their ratings of helpfulness and care (
Lee et al., 2025). Although the study revealed human and AI responses sometimes shared similar qualities, participants tended to interpret those shared qualities through their preconceived source beliefs, revealing a perceptual bias that ultimately colored how they understood mentorship identities.
Drawing on extant research in technology acceptance and use, as well as mentorship research, this study explores how college students, based on their prior AI experience and primary mentor identity, differentiate human- from AI-generated guidance in academic, personal, and social contexts. We also investigate whether these distinctions influence their judgments of helpfulness, care, and likelihood of reaching out again to the two sources (human and AI). By situating our work at the intersection of learning design and user attitudes toward emerging technologies, we aim to clarify whether GAI systems can effectively complement human mentorship, particularly for college students who might otherwise lack reliable academic and emotional support resources. In doing so, we provide insight into how institutional stakeholders can thoughtfully leverage and integrate AI-driven tools without undermining the relational core of mentorship in higher education. To guide this inquiry, the following literature weaves together research on higher education mentorship, models of technology acceptance and use, and cognitive frameworks. These bodies of work help contextualize how GAI tools might fit into current mentorship structures and how students’ perceptions shape their decisions and engagement behaviors.
1.1. Prior Work on Higher Education Mentorship
Mentorship is broadly understood as a dynamic, active relationship that fosters mutual development for both the mentor and mentee (
Roberts, 2000). When embedded in a supportive and compassionate environment, mentoring fosters trust and genuine care (
Lucey & White, 2017). This nurturing dynamic is especially important in undergraduate courses dealing with sensitive topics such as diversity, where reflective dialogue and critical self-reflection can amplify learning outcomes (
Lucey & White, 2017). Furthermore, mentorship often includes elements of role modeling, coaching, and sponsorship (
Roberts, 2000). A comprehensive mentoring approach can bolster professional identity, motivation, and resilience, which are qualities that are crucial for higher education students facing demanding academic and personal challenges (
Long, 2018). Interactions with faculty or staff mentors not only help students integrate socially but also promote their academic success (
Nagda et al., 1998;
Trolian et al., 2016). In addition, for college students seeking mental health support, those who continued attending counseling sessions showed improvements in their academic performance, with more frequent sessions yielding greater benefits than those who discontinued after their first visit or were referred off campus (
Schwitzer et al., 2018). Studies have shown that mentors can also mitigate the stresses associated with pivotal transitions, such as the transition to college (
J. Lee & Budwig, 2024;
Budwig et al., 2023), by offering emotional support and opening doors to new opportunities (
Raposa et al., 2020).
Despite the recognized benefits of mentorship, inequalities in higher education persist, particularly for first-generation and low-income students. In many cases, these students are unfamiliar with institutional norms and feel less justified in seeking help from faculty (
Raposa et al., 2018).
Jack (
2019) describes how lower-income students may lack the cultural capital more commonly held by peers from wealthier backgrounds, creating disadvantages in professional networking and day-to-day interactions. Prior research shows that family support—emotional or financial—can meaningfully shape college success for such student populations (
Roksa & Kinsley, 2019). Peer mentorship programs also emerge as a potential solution for bridging these gaps. Prior research indicates that insofar as peer mentors are typically more accessible and relatable than faculty mentors (
Colvin & Ashman, 2010;
Husband & Jacobs, 2009), they can provide academic and psychosocial support, helping new students adjust to university life. Formalized peer mentorship, which is often structured around identified needs and shared backgrounds, can help underrepresented and socioeconomically disadvantaged students thrive in college (
Lunsford et al., 2017).
As institutions seek new ways to bridge longstanding mentorship disparities in higher education, the emergence of GAI tools introduces a novel, accessible form of support that may help close these disparities. GAI tools are being recognized not only for their instructional support but also for their capacity to offer immediate personalized guidance through feedback, clarification, and encouragement through various platforms (e.g., website, smartphone app) (
Sharma et al., 2025;
Biswas, 2023). These GAI tools can serve dual roles, as virtual teaching assistants and as consistent companions in learning. These dual roles may, in some instances, provide a stronger buffer against student isolation than traditional school-based counseling services (
Farrelly & Baker, 2023). GAI’s responsiveness to individual learner needs, informed by vast datasets and training models, further positions it as a transformative agent in contemporary learning ecosystems. Moreover, its natural-language interface enables a type of dialogue that mirrors human conversation (
Javaid et al., 2023), offering students an interactive, self-paced learning experience that aligns closely with the affordances of informal mentorship (
Jacobi, 1991).
At the same time, current research also points to important limitations in how GAI tools are perceived and experienced by students. For instance,
Walczak and Cellary (
2023) found that while 76% of students anticipate AI will play a major role in education, many still lack the digital literacy and verification skills needed to detect errors in AI-generated content. That is, students who report uncertainty in AI output often fail to detect clear errors, revealing a gap between awareness and consistent engagement and practice. In addition to these concerns, GAI has also been explored for mental health support (
Siddals et al., 2024). For example, ChatGPT’s “empathy model” is designed to validate users’ emotions, yet it often produces responses that are generic, repetitive, or superficial, ultimately falling short of meeting users’ specific emotional needs (
Mukherjee et al., 2024). Recent work by
Lee and Esposito (
2025) further highlights how students interpret and evaluate emotionally supportive content from AI. Their findings showed that students’ ability to distinguish human- versus AI-generated responses in the personal domain (e.g., mental health support) was significantly lower than in the social (e.g., sense of belonging guidance) domains and academic (e.g., academic-related advice) domains. When participants incorrectly identified a human-authored response as AI, they described it using computational characteristics (e.g., overly structured or scripted) (
Lee et al., 2025). When AI-generated responses were mistaken for human responses, students often attributed human-like qualities to the responses (e.g., empathy or genuine concern). This interpretive bias is further supported by findings from
Shen et al. (
2024), who found that individuals empathized significantly more with human-written stories than AI-generated ones, regardless of whether they knew the author’s identity. Notably, transparency about AI authorship increased participants’ willingness to empathize with AI-generated content. These findings suggest that user perceptions and the presentation of AI-generated materials are likely to influence emotional engagement, raising ethical considerations in the design of empathetic AI systems.
Moreover, educators’ attitudes toward ChatGPT and similar tools remain mixed. While some express concern about academic dishonesty and misuse (
Ma, 2025;
Iqbal et al., 2022), others see potential in leveraging GAI to design more interactive, accessible, and student-centered learning environments (
Ghimire et al., 2024). GAI systems are primarily powered by statistical Large Language Models (LLMs), which lack the inherent ability to understand social cues, moral reasoning, or nuanced context (
Montenegro-Rueda et al., 2023;
Dempere et al., 2023). Consequently, while generative AI tools can provide efficient academic assistance—such as drafting outlines, synthesizing reading materials, or brainstorming solutions—they do not replicate the relational and emotional dimensions of human mentorship that are essential for fostering empathy and personal growth. This limitation raises the importance of integrating technology-mediated support with traditional interpersonal mentorship to ensure that students benefit from the strengths of both.
1.2. Frameworks Guiding Human Perceptions and Behaviors of Technology Acceptance and Use
The study of technology acceptance has undergone evolution over time. Understanding how students interpret and evaluate GAI in mentorship contexts requires more than a catalog of user preferences. It calls for a theoretical grounding that integrates cognitive, social, and contextual dimensions of technology use. Over time, psychological and behavioral theories have informed several models of technology acceptance, each offering insight into user beliefs, attitudes, and behavioral intentions. Among these, the Technology Acceptance Model (TAM), Social Cognitive Theory (SCT), the Unified Theory of Acceptance and Use of Technology (UTAUT), and the more recent Perceptual Bias Activation (PBA) framework offer useful foundations for unraveling and understanding the factors that could potentially influence the acceptance and application of technology in educational settings.
Building on one of the foundational models in technology acceptance research, the Theory of Reasoned Action (
Fishbein & Ajzen, 1975),
Davis (
1989) developed the Technology Acceptance Model (TAM) to predict how individuals adopt and use new information systems.
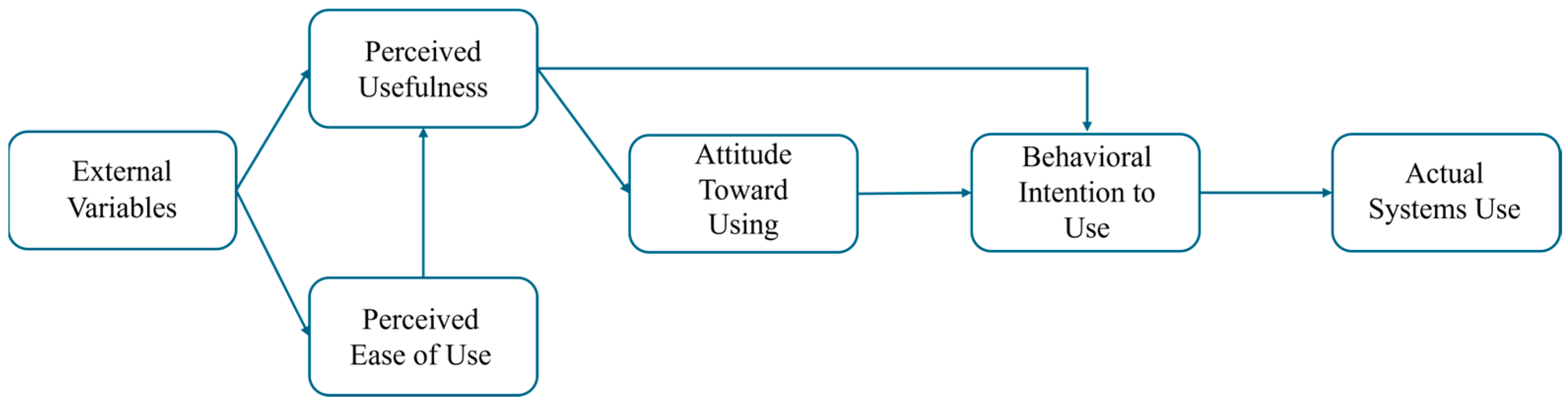
As shown in
Figure 1, this model identifies two primary beliefs: perceived usefulness (PU) and Perceived Ease of Use (PEOU). PU refers to how much users believe a technology improves their performance, while PEOU refers to user beliefs about how easily they can learn and operate it. Both beliefs shape users’ attitudes toward using the technology, which in turn influence behavioral intentions and actual systems use. Although the TAM retains TRA’s premise that attitudes drive behavior, it narrows the focus to technology-specific beliefs, emphasizing that external variables (e.g., user experience or interface design) affect PU and PEOU. Although the TAM framework provides a practical and empirically grounded framework for predicting technology adoption, it primarily emphasizes individual evaluation processes. As such, the TAM may fall short in capturing how social, contextual, or emotional factors influence technology use, particularly in relational domains like mentorship. Nonetheless, the TAM remains an essential foundation to discuss, as its core constructs (PU and PEOU) are later expanded and refined within the UTAUT framework, which guides this study.
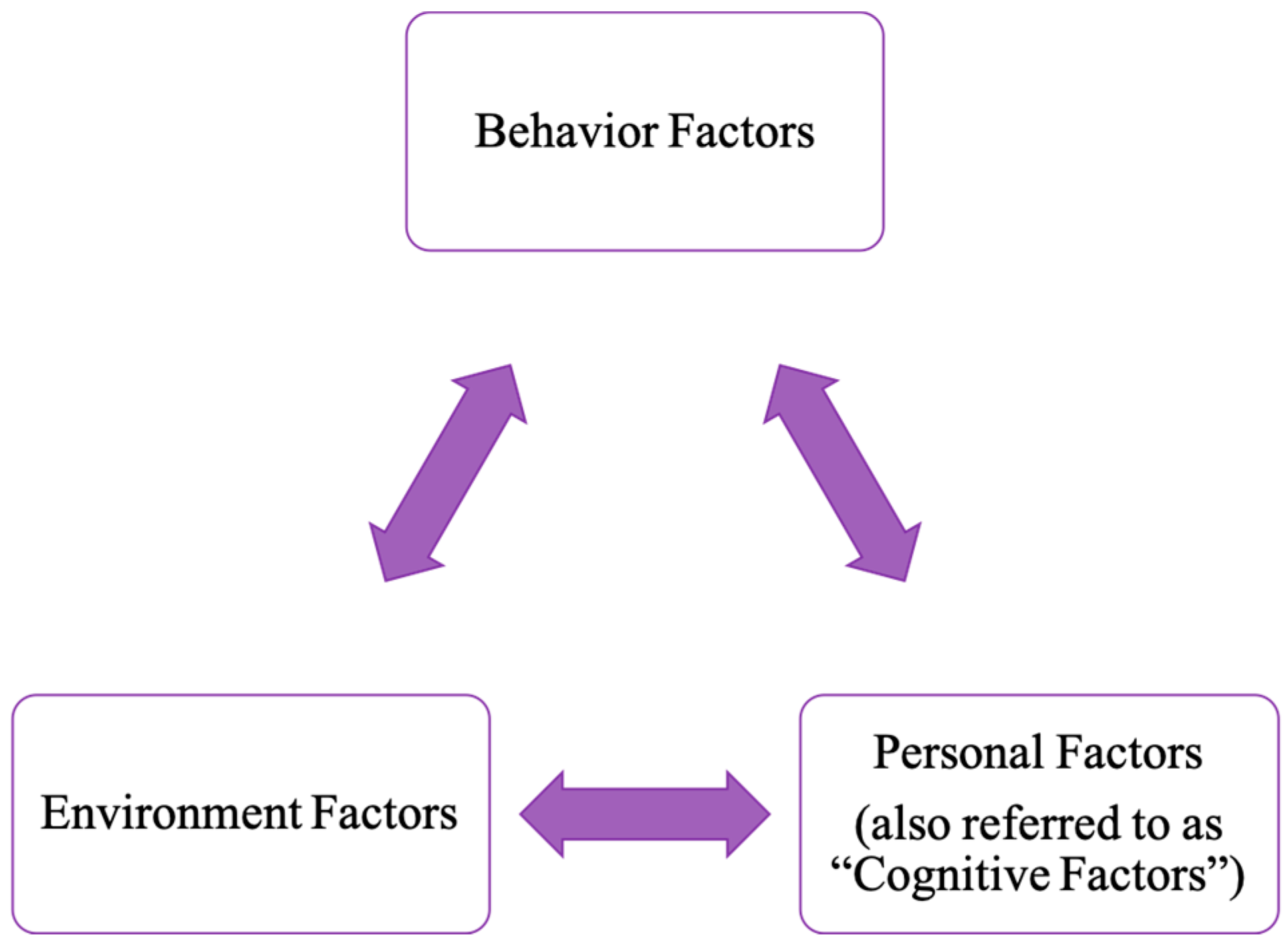
While the TAM focuses on internal beliefs and attitudes, Social Cognitive Theory (SCT) introduces a triadic model of interaction. The SCT complements the TAM framework by addressing the broader contextual and social factors that influence technology adoption (
Bandura, 2001).
Bandura (
2001) suggests that technology use is also shaped by personal factors (e.g., self-efficacy, outcome expectations) and prior experiences influence how people perceive technology. Furthermore, environmental factors (e.g., social norms, available resources) either facilitate or hinder technology use (
Figure 2). Critically, these influences operate through reciprocal determinism, meaning that not only do personal beliefs and environmental conditions affect technology-related behaviors, but the resulting behaviors also feed back to alter individuals’ attitudes and the surrounding environment. That is, two individuals with the same initial perceptions might diverge in their eventual technology adoption, as each person’s ongoing experiences reshape their beliefs and context over time. This dynamic and socially situated lens expands on the TAM’s more linear and individualistic pathway to technology use, making SCT particularly relevant in understanding how users interpret AI tools in mentorship and educational settings.
Venkatesh et al. (
2003) offer a complex, multi-contextual theory of technology use, comprehensively synthesizing elements from the TAM, TRA, SCT, and other technology acceptance theories, such as the Motivational Model (
Davis et al., 1992), Theory of Planned Behavior (
Ajzen, 1985,
1991), the Combined TAM–TPB Model (
Taylor & Todd, 1995), the Model of PC Utilization (
Thompson et al., 1991), and Innovation Diffusion Theory (
Rogers, 1962).
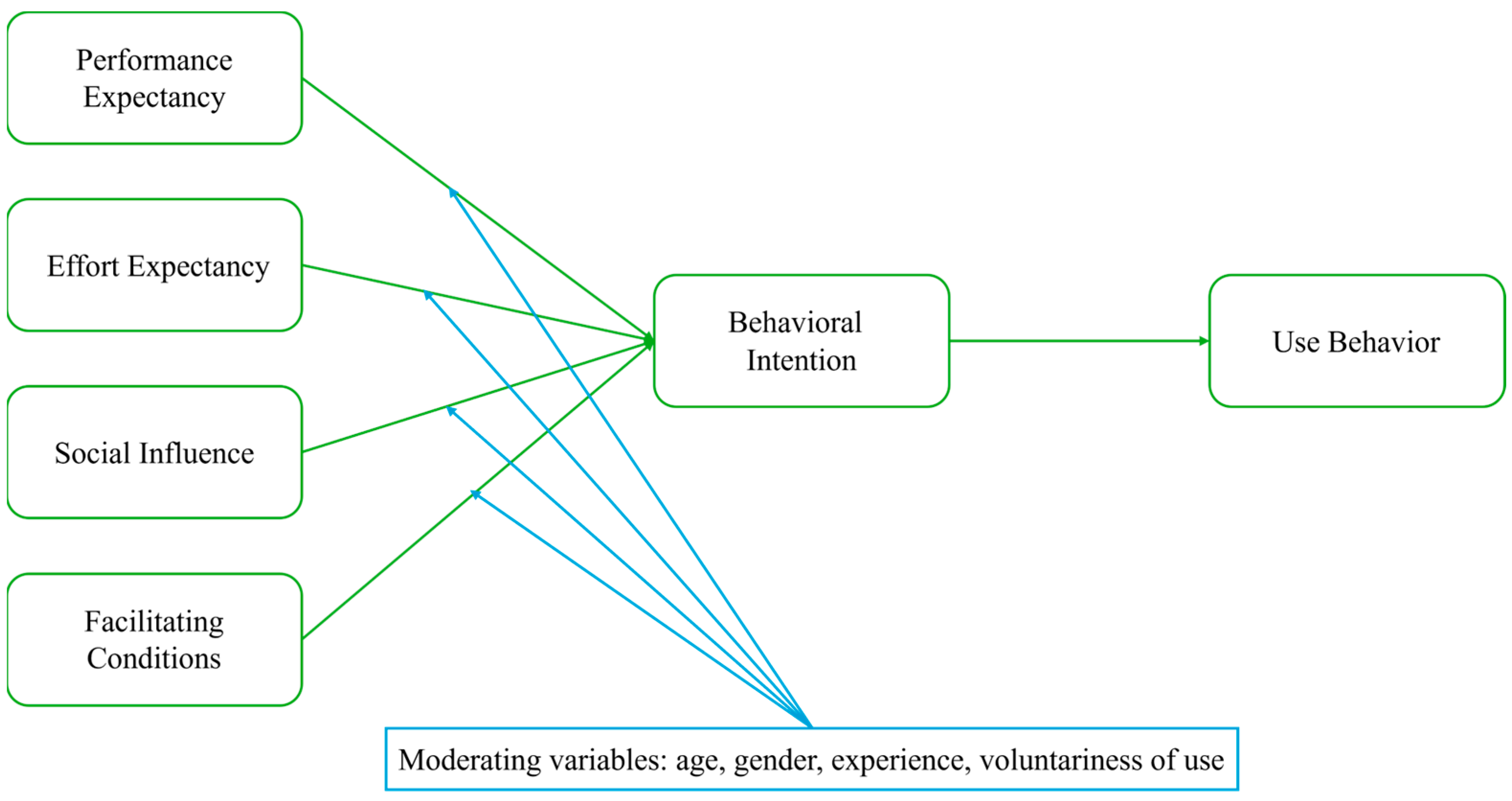
The UTAUT framework (
Figure 3) expands the TAM’s core constructs by aligning PU with Performance Expectancy (PE) and PEOU with Effort Expectancy (EE), while also introducing two new predictors: Social Influence (SI; the extent to which users are influenced by others important to them) and Facilitating Conditions (FCs; the degree to which users perceive that technical and organizational infrastructure supports their use of the system/technology). The UTAUT model has been widely applied across sectors—including higher education (
Geiger et al., 2024;
Mejía-Mancilla & Mejía-Trejo, 2024), healthcare (
A. T. Lee et al., 2025), and technology adoption in industry (
Sabila et al., 2024). This model has proven especially useful in understanding the factors that shape users’ willingness to adopt and meaningfully engage with emerging tools. In the context of educational AI, UTAUT provides a strong theoretical lens for examining how students’ expectations, confidence, and perceived support inform their interactions with GAI systems. As institutions increasingly turn to AI to address gaps in mentorship and student-centered support, understanding how students and faculty come to accept or reject these tools becomes critical. UTAUT helps explain the underlying mechanisms that influence willingness (or reluctance) to engage with AI-powered educational technologies.
While prior acceptance models provide factors that facilitate (or hinder) technology uptake, it does not fully address how biases are triggered and reinforced in emotionally and socially complex settings (
Glickman & Sharot, 2025). This gap is particularly relevant for AI-based mentorship contexts, where initial assumptions about AI’s capabilities may intensify or diminish over time. In response to this gap, the Perceptual Bias Activation (PBA) framework foregrounds how biases (e.g., self-experienced memory, availability heuristics, preconceived notions, others’ experiences, or external sociocultural influences) are initially triggered and sustained by cognitive as well as social factors (
Lee & Esposito, 2025).
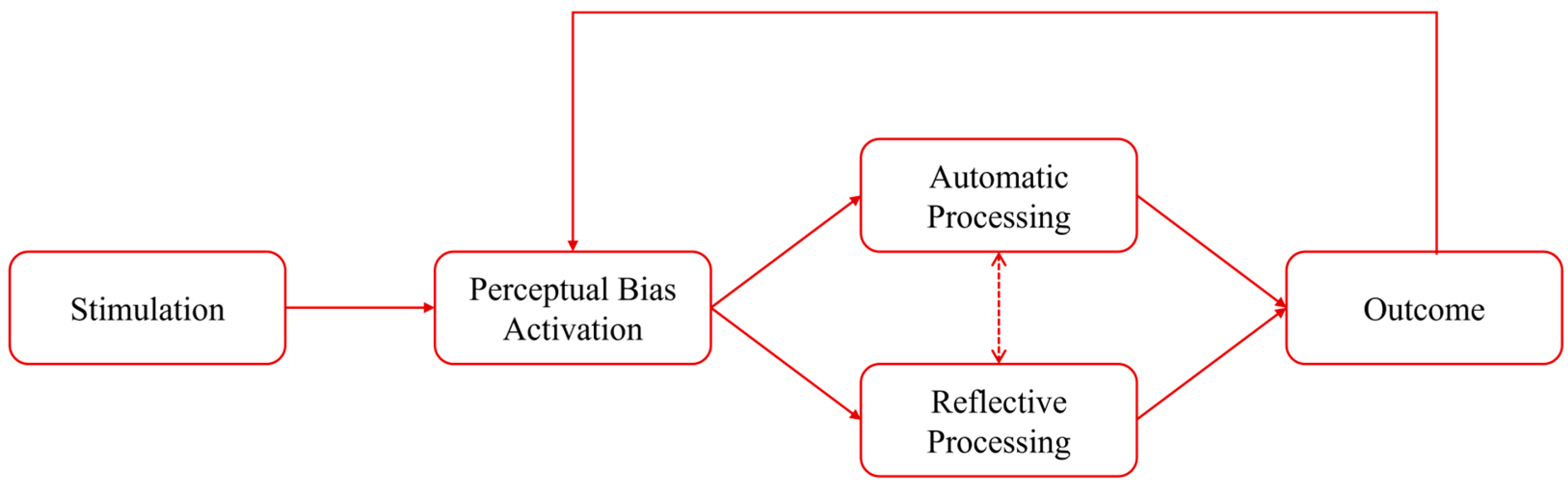
The PBA framework illustrates how the activation of perceptual biases toward technology can shape subsequent judgments and behaviors, resulting in self-reinforcing feedback loops (
Figure 4). For example, in the PBA framework, constructs like PU/PE, PEOU/EE, attitudes, and intentions, which are central to models like the TAM and UTAUT, act as early “perceptual lenses” or cognitive triggers that shape how users interpret each new piece of information about a technology. Once activated, these biases filter new information or strengthen existing beliefs (
Kidd & Birhane, 2023), whether processed automatically (referred to as System 1) or reflectively (referred to as System 2).
System 1 processing is fast, intuitive, and driven by heuristics and surface-level cues, often providing an initial assessment or reaction. System 2 processing, in contrast, is slower, more deliberate, and analytical, allowing for deeper reflection and reasoning when initial judgments are uncertain or require exploration (
Evans & Stanovich, 2013). These two systems do not operate in isolation. Instead, they continuously interact by offering immediate impressions (System 1), while engaging to override or refine those responses when accuracy is prioritized over quick assumptions (System 2). Over time, repeated reflective engagement through System 2 can also reshape and sharpen System 1’s future responses, creating a feedback loop that evolves with experience and context (
Glickman & Sharot, 2025).
This dual-process perspective offers a foundation for understanding how students may approach AI-generated content in mentorship settings. For instance, surface-level judgments about whether a response looks AI generated may be influenced by System 1 impressions, while deeper evaluations of why that is may involve more reflective System 2 reasoning. This iterative process aligns with SCT’s principle of reciprocal determinism, wherein personal beliefs, environmental cues, and user behaviors continually reshape and influence one another. As new outcomes occur (e.g., a successful or frustrating experience, decision to use or not use a technology), they feed back into self-experienced memory or preconceived assumptions, either amplifying or tempering the existing bias (e.g., “I’ve always found it helpful, so I trust it” vs. “It was to complex, so I’ll won’t use it again”). By illustrating how seemingly minor perceptual cues can evolve into entrenched patterns of acceptance or refusal, and engagement or disengagement, the PBA framework provides a socially situated lens that extends traditional models of technology use. Ultimately, the PBA framework clarifies how initial impressions of a technology tool develop into measurable outcomes, including decisions to use or abstain, engagement patterns, and ethical evaluations from a given technological source.
The models and frameworks show how personal attitudes, social norms, perceptual biases, and institutional support collectively shape technology acceptance and use. Where some models (e.g., the TAM and UTAUT) emphasize user attitudes, Social Influence, and perceived usefulness as central drivers, others (e.g., SCT and PBA) highlight the dynamic feedback loops among personal, environmental, and cognitive factors. Recognizing that users’ beliefs, prior experiences, and contexts influence decision making of individuals is crucial for designing learning experiences and support structures that effectively leverage digital tools without undermining trust and relational depth essential to mentorship. This awareness is also vital for the ethical, effective, and meaningful integration of GAI systems into higher education, particularly in ways that supplement or reimagine mentorship without eroding human connection.
1.3. The Current Study
Given the value of both human mentorship and emerging AI applications, the future of academic support likely lies in balancing technology use with human engagement. While technology can automate tasks such as answering routine questions or providing preliminary feedback, human mentors could offer deeper relational insight, empathy, and a sense of accountability. Moreover, although GAI demonstrates considerable potential across a range of domains, it also raises serious concerns regarding authorship, originality, and misinformation. A notable challenge is that individuals without expertise may struggle to recognize inaccuracies in AI-generated content, which is an issue that becomes especially problematic in decision making. Adding to this concern is the fact that AI-generated outputs are often indistinguishable from those written by humans, making it difficult to assess whether the individual presenting the work genuinely possesses the expertise implied by the content (
Walczak & Cellary, 2023).
Despite these limitations, prior research suggests that human mentorship and AI-based tools can work synergistically, rather than competitively, to enhance students’ educational experiences (
Lee & Esposito, 2025). However, little is known about how students actually perceive and evaluate guidance from human versus AI sources—or how these perceptions shape their future help-seeking behaviors. In light of increasing attention to the interplay between learning design and technology acceptance, the present study can be understood as an early case study conducted within a single institution using a SONA sample. This study explores patterns of student perception toward AI-generated and human mentorship by building on foundational frameworks to examine how individual factors, such as prior AI use, primary mentor identity, and use attitudes, influence how students perceive, evaluate, and choose to seek support from AI- versus human-generated guidance. This approach acknowledges that education is not one-size-fits all, as individual differences in students’ experiences and beliefs likely shape how they interpret and engage with emerging technologies. If we are to meaningfully integrate AI into educational settings, it is important to understand how these individual factors predict students’ acceptance, perceived usefulness, and actual use of AI-based support. Therefore, we also explore whether there is a relationship between students’ acceptance and use of technology and their ratings based on the perceived source (as human or AI). By doing so, we also investigate how decisions to use or abstain from AI-based support are formed based on perception, shedding light on ways to integrate AI tools into educational contexts without eroding the relational aspects of mentorship. Specifically, this study is guided by the following research questions (RQs) and hypotheses (Hs):
RQ1: Can prior AI usage and primary mentor identity predict accuracy in distinguishing between AI and human responses? Additionally, do these effects of AI usage and primary mentor identity on accuracy differ across domains (social personal, academic)?
H1a: Students with prior AI experience will demonstrate greater accuracy in distinguishing AI from human responses across domains.
H1b: Students who identify faculty or staff as their primary mentors will also exhibit higher accuracy than those whose mentors are peers, counselors, or family members across domains, given that the human-generated content was authored by faculty members.
RQ2: Do students’ ratings of human mentorship effectiveness and ChatGPT usefulness in academic settings relate to their evaluations of response helpfulness, caring, and likelihood to reach out again, based on the perceived source (human vs. AI)?
H2a: Students who value human mentorship will rate human-generated responses higher in perceived helpfulness, care, and likelihood of reaching out again.
H2b: Students who perceive ChatGPT as academically useful will assign higher ratings to AI-generated responses across those same dimensions.
RQ3: To what extent do students’ ratings of ChatGPT’s academic usefulness and the response source (actual source vs. perceived source) predict their evaluations of helpfulness, caring, and likelihood to reach out again in the academic domain?
H3: This question is exploratory and was not associated with a specific a priori hypothesis.
RQ4: Is there a relationship between students’ acceptance and use of technology and their ratings of helpfulness, caring, and likelihood to reach out again based on their perceived source (as human vs. AI)?
H4: This question is also exploratory, and no formal hypothesis was proposed.
2. Methods
2.1. Participants
Participants were 147 college students (Mage = 19.34 years, SDage = 1.33 years, 105 female, 37 male, 2 nonbinary and 3 prefer not to answer) recruited from a liberal arts college in the northeastern United States. Recruitment was conducted through the university’s SONA research participation system, which allows students enrolled in select 100-level courses to participate in approved studies in exchange for research credit that counts toward course requirements. Each participant received 0.5 SONA research credit upon completing the survey. To be eligible, participants had to be at least 18 years of age. The sample was racially and ethnically diverse, consisting of Asian (14.97%), Black (6.80%), White (67.35%) and Hispanic (10.88%) populations. Only those who electronically consented were allowed to continue with the survey. The study protocol was reviewed and approved by the Institutional Review Board of Clark University (Protocol #546).
2.2. Measures
Primary Mentor Identity. Participants identified their primary mentor in their academic setting by selecting one of the following categories: Faculty/Academic Staff, Peer, Mental Health Counselor, or Other. Those who selected “Other” were given the opportunity to specify their mentor’s identity. Among these responses, participants indicated their mentor was a family member, an unidentified individual, or that they did not have a specific mentor in their current academic setting.
Prior ChatGPT Use. Data collection began in March 2024, during a period when GAI adoption was still emerging among undergraduate populations. Participants reported whether they had prior experience using ChatGPT by selecting “Yes” or “No.” This binary measure was chosen to capture general exposure, reflecting our primary interest in whether participants had any experience with the tool at the time of this study.
Mentorship Effectiveness Scale. The effectiveness of human mentorship was assessed using the 12-item Mentorship Effectiveness Scale developed by the Ad Hoc Faculty Mentoring Committee at Johns Hopkins University School of Nursing (
Berk et al., 2005). Prior to completing this section of the questionnaire, participants were asked to identify their primary mentor (primary mentor identity measure; referred to as the primary mentor variable). However, they were instructed to complete the scale based on their overall experiences with mentors. This approach allowed for a more comprehensive assessment of mentorship perceptions, recognizing that students may have multiple mentors contributing in different ways and that mentorship experiences across diverse academic and interpersonal contexts. Participants rated their agreement with statements on a Likert scale ranging from 1 (“Strongly Disagree”) to 5 (“Strongly Agree”), with the option to select “N/A” if a statement was not applicable. While the core items of the scale remained unchanged, we modified a few example phrases embedded within items to ensure contextual relevance to undergraduate academic settings (e.g., modifying “committee contributions, awards” to “participation, group projects, effort in class”). Internal consistency for this scale was excellent in our sample (Cronbach’s α = 0.96), indicating strong reliability for capturing overall perceptions of mentorship effectiveness. The outcome variable for this measure is the mean score of the Mentorship Effectiveness Scale, calculated by averaging the scores of all applicable items. This mean score provides a comprehensive assessment of participants’ perceptions of mentorship effectiveness of their mentor(s).
ChatGPT Usefulness Scale. The participants’ perceived usefulness of ChatGPT in academic settings was assessed using a Likert scale ranging from 1 (“Not at all”) to 10 (“Extremely”). Participants who had never used ChatGPT were given the option to select “N/A.” The question posed was: “To what extent do you feel that ChatGPT has been useful for your academic journey?” The outcome variable here is the mean score of ChatGPT Usefulness, representing participants’ overall assessment of ChatGPT’s usefulness in their academic experiences.
Response Ratings. This measure employed a Likert scale to assess participants’ perceived usefulness of responses, focusing on three variables: Helpfulness, Caring, and Likelihood to Reach Out Again. For the outcome variable Helpfulness, responses were rated on a scale ranging from 1 (“Not helpful at all”) to 5 (“Extremely helpful”), indicating how helpful participants found the responses. For Caring, responses were rated on a scale ranging from 1 (“Not caring at all”) to 5 (“Extremely caring”), reflecting the extent to which participants felt the responses were caring. Lastly, for the outcome variable Likelihood to Reach Out Again, responses were rated on a scale ranging from 1 (“Not likely at all”) to 5 (“Extremely likely”), measuring participants’ intentions to seek assistance again based on the responses received.
Unified Theory of Acceptance and Use of Technology Survey (UTAUT). The UTAUT survey, originally developed by
Venkatesh et al. (
2003), was adapted to assess participants’ perceptions and usage of generative AI technologies, specifically ChatGPT. The UTAUT model includes four key constructs, which serve as our predictor variables:
Performance Expectancy (PE): Measures participants’ beliefs about the extent to which ChatGPT enhances their learning.
Effort Expectancy (EE): Evaluates the perceived ease of using ChatGPT.
Social Influence (SI): Gauges the extent to which participants perceive that important others expect them to use ChatGPT.
Facilitating Conditions (FCs): Assesses participants’ perceptions of whether the organizational infrastructure supports the use of ChatGPT.
All UTAUT subscales were assessed for internal consistency using Cronbach’s alpha. The Performance Expectancy (α = 0.78), Effort Expectancy (α = 0.70), and Social Influence (α = 0.70) subscales demonstrated acceptable reliability. The Facilitating Conditions subscale showed lower reliability (α = 0.56) and was interpreted with appropriate caution in the analysis and discussion. Participants responded to each item on a 5-point Likert scale, ranging from 1 (“Strongly Disagree”) to 5 (“Strongly Agree”). Each construct’s outcome variable was calculated by averaging the scores of the items corresponding to that construct. This adaptation allowed us to assess participants’ behavioral intentions, acceptance, and use of ChatGPT in relation to their college experiences, while also exploring potential activation of perceptual biases in their engagement with the technology.
2.3. The Procedure
Participants accessed a secure Qualtrics link via the SONA research system to complete a 30 min survey. Before beginning the survey, participants were presented with an informed consent form describing the purpose of this study, approximate duration (30 min), the voluntary nature of their participation, and assurances regarding anonymity and confidentiality. The survey began with demographic questions followed by evaluations of mentorship interactions across three domains: social, academic, and personal. These domains were selected based on prior research on student mentorship experiences in college settings (
J. Lee & Budwig, 2024;
Budwig et al., 2023). Each domain was designed to represent a realistic and broadly applicable scenario where students commonly seek guidance from mentors. Furthermore, the domain-specific scenarios were chosen to ensure relevance across participants (ranging from first years to seniors) and to explore whether perceptions of mentorship effectiveness vary by context:
Academic Domain (
Asgari & Carter, 2016;
Jacobi, 1991): A student seeks guidance on improving academic performance after performing poorly on a midterm exam, a common scenario in higher education.
Personal Domain (
Mayo & Le, 2021;
Wang et al., 2020): A student describes mental health challenges and difficulty maintaining daily routines, mirroring research on student well-being and mentorship support.
To examine how students perceive and evaluate AI-generated versus human faculty responses, participants were each presented with three randomized and masked responses per domain, selected from a pool of nine ChatGPT-generated responses and nine faculty mentor responses (totaling 18 responses). Human mentor responses were collected from faculty members at the participants’ institution, selected from three academic disciplines based on institutional awards or distinctions for mentorship excellence within the past five years. AI-generated responses were created using ChatGPT-3.5, as it was the most widely accessible version available to students at the time of data collection. Both human mentors and ChatGPT received identical email prompts designed to reflect mentorship inquiries in college settings and after collecting the stimuli (responses from faculty and ChatGPT), all responses were formatted using a Gmail interface, which is a familiar communication platform in academic settings.
Participants were then instructed to identify whether each response was AI or human generated, without receiving feedback on their judgment accuracy. After each identification, they rated each response on a 5-point Likert scale (1 = Not at all; 5 = Extremely) across three dimensions (levels of helpfulness, caring, and likelihood of reaching out again). Following the response evaluations participants completed additional survey measures to assess their perceptions of mentorship and AI use in academia. This included a Likert-scale question regarding the usefulness of ChatGPT in their academic journey, the Mentorship Effectiveness Scale, and the adapted Unified Theory of Acceptance and Use of Technology (UTAUT) survey.
2.4. Data Analysis
All analyses were conducted in R (R version 4.3.2, R version 4.4.2) and RStudio (Rstudio version 2024.09.1+394, Rstudio version 2024.12.1+563) (
R Core Team, 2024). For our first research question, binary logistic regression analyses were used to examine whether prior AI usage and primary mentor identity predict accuracy in distinguishing AI- versus human-generated responses. Additionally, we tested whether the effects of AI usage and primary mentor identity on accuracy differed across domains (academic, personal, social) by including interaction terms (Models 2–4). The logistic regression models were specified as follows:
Model 1: = β0 + β1ChatGPTuse + β2PrimaryMentor + β3Domain + ϵ
Includes the main effects of prior AI usage (ChatGPTuse), and primary mentor identities (primary mentor), and the domain of response (Domain);
β0 is the intercept; ϵ is the error term.
Model 2: = β0 + β1ChatGPTuse + β2PrimaryMentor + β3Domain + β4ChatGPTuse × Domain + ϵ
Model 3: = β0 + β1ChatGPTuse + β2MentorIdentity + β3Domain + β4PrimaryMentor × Domain + ϵ
Model 4: = β0 + β1ChatGPTuse + β2PrimaryMentor + β3Domain + β4ChatGPTuse × Domain + β5PrimaryMentor × Domain + ϵ
In all models:
P(Y = 1) is the probability of correctly identifying the response source (AI vs. human).
ChatGPT Use (β1) measures the effect of prior AI usage.
Primary mentor (β2) indicates their selected primary mentor identity.
Domain (β3) accounts for differences across the academic, personal, and social scenarios.
β4 and β5 are interaction effects testing how ChatGPT Use and primary mentor identity vary by domain.
ϵ is the error term.
These models were estimated using the glm() function using the ‘stats’ package. The reference groups were set to “No” (ChatGPT use), “Faculty/Staff” (primary mentor), and “personal” (domain) to facilitate comparisons. Model fits were assessed using Tjur’s R
2, which provides an interpretable measure of model explanatory power for logistic regression. A likelihood ratio test (LRT) using the anova() function was performed to compare the main effects model (Model 1) with interaction models (Models 2–4). We also reported Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC) to further evaluate these model comparisons. Post hoc pairwise comparisons were conducted using the ‘emmeans’ package (
Lenth, 2022) to explore differences between domains and a visualization of AI usage effects across domains was generated using ggplot2 (
Wickham, 2016).
For our second research question, we conducted Pearson’s correlation analysis to examine the relationship between students’ perceptions of human mentorship effectiveness, ChatGPT’s academic usefulness, and their evaluations of response helpfulness, caring, and likelihood to seek future support again. Pearson’s correlation coefficients (r) were computed separately for responses perceived as AI generated vs. human generated to assess whether perceived source influenced these relationships. The analysis was conducted using the cor.test() function from the ‘stats’ package, which also returns a t-value and p-value for the correlation coefficient.
For our third research question, to examine the extent to which students’ ratings of ChatGPT’s academic usefulness and the source (human vs. AI) and perceived source (as human vs. AI) responses predicted their evaluations of helpfulness, caring, and likelihood to reach out again in the academic domain, we conducted multiple linear regression analyses. For each outcome variable (Helpfulness, Caring, Likelihood to Reach Out Again), we tested the following two models:
Model 5: The Perceived Source Model (what participants believed the source was)
where
Yi represents students’ evaluations of the response (Helpfulness, Caring, or Likelihood to Reach Out Again).
(β0) is the intercept.
ChatGPTUsefulness (β1) represents students’ self-reported perception of ChatGPT’s helpfulness in academic settings.
Perceived source (β2) represents whether participants believed the response was AI generated or human generated (even if their belief was incorrect).
Interaction term (β3) tests whether ChatGPT’s perceived usefulness interacts with perceived source to predict response evaluations.
ϵi represents the residual error.
This model examines whether students’ beliefs about the response source influence their evaluation, rather than the actual content.
Model 6: The Actual Source Model (what the actual source was)
where
Source (β2) is whether the response was actually AI or human generated (regardless of what participants believed).
Interaction term (β3) tests whether ChatGPT’s perceived usefulness interacts with actual sources to predict response evaluations.
The other terms remain the same as in Model 3.
This model tests whether the true source of the response (AI vs. human) affects how students evaluate the response. Analyses were conducted using the lm() function. For both models, the reference groups were set to “Human” (source and perceived source). Model significance was assessed using F-tests, and post hoc effect sizes (explanatory power) were reported using R2 and adjusted R2 values.
Lastly, for our fourth aim, we examined whether students’ acceptance and use of technology were associated with their evaluations of responses they perceived as AI or human generated. To assess these relationships, we conducted Pearson’s correlation analyses separately for responses that participants perceived as human generated and AI generated. This allowed us to determine whether students’ acceptance and use of technology influenced their evaluations differently depending on their perceptions of the response source. Correlation coefficients (
r) and significance level (
p-value) were computed for each UTAUT dimension (Performance Expectancy, Effort Expectancy, Social Influence, and Facilitating Conditions) and outcome variable (Helpfulness Caring, Likelihood to Reach Out Again). Correlations were interpreted based on effect size guidelines (
Cohen, 1988), where ∣
r∣ ≥ 0.10 indicates a small effect, ∣
r∣ ≥ 0.30 a moderate effect, and ∣
r∣ ≥ 0.50 a large effect. Significance thresholds were set at
p < 0.05.
3. Results
3.1. Accuracy: Effects of Prior AI Usage and Primary Mentor Identity
To examine whether Prior ChatGPT Use and primary mentor predict accuracy in distinguishing AI-generated from human-generated responses (RQ1), we conducted a binary logistic regression analysis (
Table 1). We also tested whether these effects differed across social, personal, and academic domains. Our hypotheses posited that participants with Prior ChatGPT Use and those who identify faculty/staff as their primary mentors (primary mentor) would be more accurate than those with no AI experience (H1a) or non-faculty members (H1b).
The model (Model 1) showed a good fit (AIC = 1516.60; BIC = 1552.73) and was statistically significant overall (χ2(6, N = 1289) = 20.49, p < 0.01) explaining a small amount of variance (Tjur’s R2 = 0.016). Results indicated that participants with Prior ChatGPT Use had higher odds of accurate identification (OR = 1.40, 95% CI [1.06, 1.86], p = 0.018). Relative to the personal domain, accuracy was higher in both the academic domain (OR = 1.37, 95% CI [1.02, 1.84], p = 0.037), and the social domain (OR = 1.67, 95% CI [1.23, 2.26], p < 0.001). Primary mentor did not significantly predict accuracy (ps > 0.05).
A second logistic regression (Model 2) included an interaction between Prior ChatGPT Use and domain (
Table 2).
A likelihood ratio test comparing Model 2 to Model 1 revealed that including the Prior ChatGPT Use × domain interaction did not significantly improve model fit (AIC = 1519.92; BIC = 1566.37; Tjur’s R2 = 0.017), Δχ2(2) = 0.68, p = 0.71. Notably, Prior ChatGPT Use again increased the odds of correct identification (OR = 1.59, 95% CI [1.00, 2.51], p = 0.047), and the social domain was associated with better accuracy than personal (OR = 2.06, 95% CI [1.15, 3.72], p = 0.016). However, the interaction terms were not significant (ps > 0.40), further indicating that the effect of Prior ChatGPT Use on accuracy did not differ across domains.
A third logistic regression (Model 3) replaced the ChatGPT Use × domain interaction with primary mentor × domain (
Table 3).
The primary mentor × domain model (Model 3) showed higher AIC and BIC values (AIC = 1526.53; BIC = 1593.64), suggesting poorer fit relative to the main effects model (Model 1). Consistent with Model 1, prior ChatGPT use increased the odds of accurate identification (OR = 1.40, 95% CI [1.06, 1.86], p = 0.018), and the social domain showed higher accuracy than personal (OR = 1.62, 95% CI [1.05, 2.51], p = 0.030). None of the primary mentor × domain interactions emerged as significant (ps > 0.10).
Finally, Model 4 included both Prior ChatGPT Use × domain and primary mentor × domain interactions (
Table 4).
Despite including both interactions, Model 4 yielded the highest AIC and BIC (AIC = 1529.58; BIC = 1607.01), indicating no added value over previous models. Again, a likelihood ratio test against Model 1 indicated no meaningful improvement in fit, Δχ2(8) = 3.01, p = 0.93). The main effect of Prior ChatGPT Use persisted (OR = 1.59, 95% CI [1.00, 2.52], p = 0.049), and the social domain continued to predict higher accuracy relative to personal (OR = 2.03, 95% CI [1.07, 3.88], p = 0.031). As in Models 2 and 3, none of the interaction terms significantly influenced participants’ ability to distinguish AI from human responses (ps > 0.10).
Although interaction terms were nonsignificant, post hoc pairwise comparisons using estimated marginal means (based on Model 4) indicated slightly higher predicted probabilities of accurate identification in academic and social domains than in the personal domain, but these differences were not statistically significant once corrected for multiple comparisons (all ps > 0.05). These results suggest that Prior ChatGPT Use and domain (academic and social vs. personal) are the key predictors related to correct source identification, whereas primary mentor and domain-specific interaction effects were not significant.
3.2. Perceived Human Menotrship and ChatGPT Academic Usefulness
In RQ2, we asked whether students’ perceptions of Mentorship Effectiveness and ChatGPT Usefulness relate to how they evaluate response Helpfulness, Caring, and their Likelihood of reaching out again depending on the perceived source (as human or AI). Our hypotheses posited that participants who value human mentorship (Mentorship Effectiveness) would favor human perceived responses (H2a), while those who find ChatGPT academically useful (ChatGPT Usefulness) would favor AI-perceived responses (H2b).
3.2.1. Perceived Source and Mentorship Effectiveness: Predicting Helpfulness, Caring and Likelihood to Reach out Again
We first explored whether students’ ratings of Helpfulness, Caring, and Likelihood to Reach Out Again, based on whether they believed the responses were from a human or AI (perceived source), were correlated with their views on the Mentorship Effectiveness. We hypothesized that participants who perceive human mentorship as effective would rate responses they perceived as human generated as more helpful, caring, and would be more likely to reach out again. The results showed that for participants who perceived the responses as human, there were no significant correlations between the Mentorship Effectiveness and the variables of Helpfulness, Caring, and Likelihood to Reach Out Again (rs(680) ≤ −0.071, ps ≥ 0.06). For participants who perceived the responses as AI generated, Mentorship Effectiveness was significantly negatively correlated with Likelihood to Reach Out Again, r(589) = −0.109, p = 0.008, indicating that participants who rated human mentorship as more effective were less likely to reach out to responses they perceived as AI generated. However, the correlations with Helpfulness and Caring were not significant (rs(589) ≤ −0.032, ps ≥ 0.44).
3.2.2. Perceived Source and ChatGPT Academic Usefulness: Predicting Helpfulness, Caring and Likelihood to Reach out Again
Second, we explored the relation between students’ ratings of Helpfulness, Caring, and Likelihood to Reach Out Again—based on whether they believed the responses were from a human or AI (perceived source) and their views on the ChatGPT Usefulness in their academic journey. We hypothesized that participants who perceive ChatGPT as academically useful (ChatGPT Usefulness) would rate responses they perceived as AI generated as more Helpful, Caring, and would be more Likely to reach out again. The results showed that for participants who perceived the responses as human, the correlation between ChatGPT Usefulness s and Helpfulness, Caring, and Likelihood to Reach Out Again was not statistically significant (rs(553) ≤ 0.056, ps ≥ 0.19). For participants who perceived the responses as AI generated, there were significant positive correlations between ChatGPT Usefulness and both Helpfulness and Likelihood to Reach Out Again. Specifically, ChatGPT Usefulness was positively correlated with Helpfulness, r(464) = 0.107, p = 0.02, and with Likelihood to Reach Out Again, r(464) = 0.148, p = 0.001. The correlation with Caring was not significant, r(464) = 0.062, p = 0.18.
3.3. Source Response and ChatGPT Academic Usefulness: Predicting Student Evaluations in the Academic Domain
RQ3 investigated whether students’ ratings of ChatGPT’s Academic Usefulness and the perceived source (Model 5) vs. actual source (Model 6) predict their evaluations of Helpfulness, Caring, and Likelihood to Reach Out Again in the academic domain. Because this was an exploratory question (H3), we did not propose a specific directional hypothesis.
3.3.1. Perceived Source: Predicting Helpfulness, Caring and Likelihood to Reach out Again
First, we examined whether perceived source (whether participants believed the response was from AI or a human) influenced their evaluations (
Table 5).
The regression model (Model 5) predicting Helpfulness ratings was statistically significant (F(3, 311) = 9.98, p < 0.001), accounting for 8.78% of the variance (R2 = 0.088, adjusted R2 = 0.079). Perceived source significantly predicted Helpfulness ratings, such that responses believed to be AI generated were rated as less helpful than those perceived as human generated (b = −0.59, p = 0.034). However, ChatGPT Usefulness was not a significant predictor (b = 0.04, p = 0.256), and the interaction effect was also nonsignificant (b = −0.003, p = 0.946), suggesting that the relationship between ChatGPT’s Academic Usefulness and Helpfulness ratings did not vary as a function of perceived source. A similar regression predicting Caring ratings was statistically significant (F(3, 311) = 9.69, p < 0.001), accounting for 8.55% of the variance (R2 = 0.086, adjusted R2 = 0.077). Perceived source significantly predicted Caring ratings, with AI-perceived responses rated as less caring than human responses (b = −0.84, p = 0.005). However, ChatGPT Usefulness (b = 0.01, p = 0.796) and the interaction effect (b = 0.04, p = 0.522) were not significant predictors. For Likelihood to Reach Out Again, the regression model was statistically significant (F(3, 311) = 14.27, p < 0.001), explaining 12.10% of the variance (R2 = 0.121, adjusted R2 = 0.113). Perceived source significantly influenced Likelihood to Reach Out Again, with participants less likely to reach out again from responses they believed were AI generated compared to those they perceived as human generated (b = −1.04, p = 0.001). However, ChatGPT Usefulness (b = 0.01, p = 0.729) and its interaction with perceived source (b = 0.04, p = 0.465) were not significant predictors.
3.3.2. Actual Source: Predicting Helpfulness, Caring, and Likelihood to Reach out Again
Next, we examined whether actual source (whether the response was actually from AI or human) predicted response evaluations (Helpfulness, Caring, and Likelihood to Reach Out Again) (
Table 6).
The regression model (Model 6) predicting Helpfulness ratings was not statistically significant (F(3, 311) = 1.43, p = 0.233), explaining only 1.36% of the variance (R2 = 0.014, adjusted R2 = 0.004). Neither ChatGPT Usefulness (b = 0.05, p = 0.179) nor actual source (b = −0.09, p = 0.759) were significant predictors, and the interaction effect was also nonsignificant (b = 0.00, p = 0.936). Similarly, the model predicting Caring ratings was not statistically significant (F(3, 311) = 0.97, p = 0.405), explaining only 0.9% of the variance (R2 = 0.009, adjusted R2 = −0.0002). Neither ChatGPT Usefulness (b = 0.04, p = 0.277), actual source (b = −0.09, p = 0.771), nor their interaction (b = 0.00, p = 0.937) were significant predictors. Finally, the model predicting Likelihood to Reach Out Again was also not statistically significant (F(3, 311) = 1.36, p = 0.256), accounting for only 1.29% of the variance (R2 = 0.013, adjusted R2 = 0.003). No significant effects were found for ChatGPT Usefulness (b = 0.04, p = 0.377), actual source (b = −0.26, p = 0.422), or their interaction (b = 0.03, p = 0.618).
3.4. Technology Acceptance and Student Ratings of Helpfulness, Caring, and Likelihood to Reach out Again
Lastly, RQ4 asked whether students’ acceptance and use of technology (as measured by UTAUT constructs) relates to their ratings of Helpfulness, Caring, and Likelihood to Reach Out Again based on the perceived source (as human or AI). More specifically, we examined the relation between students’ ratings of Helpfulness, Caring, and Likelihood to Reach Out Again—based on whether they believed the responses were from a human or AI (perceived source)—and their perceptions of Performance Expectancy (PE), Effort Expectancy (EE), Social Influence (SI), and Facilitating Conditions (FCs) as measured by the UTAUT framework. This question was also exploratory (H4), so we did not offer a formal hypothesis.
3.4.1. Performance Expectancy (PE)
For participants who perceived the responses as human, there were no significant correlations between PE and ratings of Helpfulness, Caring, or Likelihood to Reach Out Again (rs(678) ≤ 0.045, ps ≥ 0.236). However, among participants who perceived the responses as AI generated, PE was significantly positively correlated with Helpfulness, r(587) = 0.085, p = 0.040; Caring, r(587) = 0.090, p = 0.029; and Likelihood to Reach Out Again, r(587) = 0.098, p = 0.018. Participants with higher PE for ChatGPT rated AI-generated responses more positively across all PE outcome measures.
3.4.2. Effort Expectancy (EE)
For participants who perceived the responses as human, EE was not significantly correlated with Helpfulness, Caring, or Likelihood to Reach Out Again (rs(678) ≤ 0.048, ps ≥ 0.215). Among participants who perceived responses as AI generated, EE was significantly positively correlated with Helpfulness, r(587) = 0.104, p = 0.012, and Likelihood to Reach Out Again, r(587) = 0.112, p = 0.007, but not with Caring, r(587) = 0.051, p = 0.220. For participants viewing responses as AI generated, greater ease of use was related to higher ratings of helpfulness and a greater likelihood of engaging again but not caring.
3.4.3. Social Influence (SI)
For participants who perceived the responses as human, there were no significant correlations between SI and ratings of Helpfulness, Caring, or Likelihood to Reach Out Again (rs(678) ≤ 0.061, ps ≥ 0.060). For participants who perceived responses as AI generated, SI was significantly positively correlated with Helpfulness, r(587) = 0.100, p = 0.015, and Likelihood to Reach Out Again, r(587) = 0.127, p = 0.002, but not Caring, r(587) = 0.057, p = 0.168. Participants who felt socially encouraged to use ChatGPT rated AI-generated responses as more helpful and expressed greater willingness to reach out again.
3.4.4. Facilitating Conditions (FCs)
For participants who perceived the responses as human, there were no significant correlations between FCs and ratings of Helpfulness, Caring, or Likelihood to Reach Out Again (rs(678) ≤ 0.042, ps ≥ 0.171). Similarly, for participants who perceived responses as AI generated, there were no significant correlations between FCs and any of the outcome ratings (Helpful, Caring, and Likelihood) (rs(587) ≤ 0.055, ps ≥ 0.182). This finding suggests that the availability of resources and support for using ChatGPT was not a determining factor in students’ evaluations of either human- or AI-generated responses.
4. Discussion
Mentorship in higher education has evolved over the past decades in response to sociocultural and institutional shifts, particularly as colleges strive to address diverse student needs (
Nuis et al., 2023;
Zhang et al., 2020). In parallel, the rise of GAI technology in higher education has transformed how students learn and how faculty offer guidance (
Ma, 2025;
Tlili et al., 2023;
Hadi Mogavi et al., 2024). While GAI tools such as ChatGPT have been evaluated for their adaptability and potential to personalize learning (
Jensen et al., 2025), scholars also raise ethical concerns surrounding GAI’s authorship, misinformation, and the loss of relational depth in education (
Walczak & Cellary, 2023;
Dempere et al., 2023;
Montenegro-Rueda et al., 2023). Our study contributes to this emerging literature by examining how students differentiate between human- and AI-generated mentorship responses, and how these perceptions shape their evaluations of helpfulness, caring, and willingness to reach out again.
First, we hypothesized that students with prior AI experience would demonstrate better accuracy across domains (H1a) and students who identify academic faculty or staff as their primary mentors would also exhibit higher accuracy across domains (H1b). Findings from the logistic regression models (Models 1–4) revealed that students with prior ChatGPT experience were more accurate in identifying AI-generated responses (H1a). This aligns with prior work (
Walczak & Cellary, 2023) suggesting that AI familiarity sharpens detection of linguistic and structural patterns associated with generative tools. However, H1b was not supported as students’ primary mentor identity did not significantly predict their source identification accuracy. Furthermore, accuracy was lowest in the personal domain. This domain-specific nuance suggests that students’ perceptions of warmth and empathy may obscure the often formulaic style of AI-generated text, complicating the identification of AI-based support in emotionally driven scenarios. In line with Social Cognitive Theory (
Bandura, 2001), prior experience with ChatGPT predicted greater source accuracy, underscoring how personal experience and environmental exposure shape cognitive judgments. These interpretations suggest that while traditional Technology Acceptance Models help explain user attitudes and behavioral intentions, frameworks such as the Social Cognitive Theory and the Perceptual Bias Activation framework could explain the comprehensive account of how perceptual and social–cognitive processes jointly shape students’ engagement with and leveraging of AI-based mentorship in educational contexts.
Second, we hypothesized that students who find human mentorship as effective would rate human-perceived responses more favorably (H2a), and that students who find ChatGPT academically useful would rate AI-perceived responses more favorably (H2b). The results partially supported both hypotheses. For H2a, students who rated human mentorship as more effective were significantly less likely to reach out again to responses they perceived as AI generated, though no significant effects were found for human-perceived responses. For H2b, students who rated ChatGPT as academically useful rated AI-perceived responses as more helpful and were more likely to engage with them again, though this was not the case for caring. Although correlations were small (
rs ≤ 0.15), this is theoretically consistent with the Unified Theory of Acceptance and Use of Technology’s (UTAUT) emphasis of Performance Expectancy and Social Influence (Venkatesh et al., 2003. Students’ favorable evaluations appeared shaped not only by their belief in ChatGPT’s academic usefulness, but also potentially by perceived norms around AI use in education. These associations were only held when students believed the responses were AI generated, highlighting that technology acceptance constructs are activated through perception. This interpretation links the UTAUT and PBA frameworks: once identity-based expectations are triggered, subsequent evaluation is filtered through that lens, which then leads to behavioral intentions (
Kidd & Birhane, 2023). Furthermore, these findings also reaffirm Social Cognitive Theory’s principle of reciprocal determination as pre-existing beliefs about AI, social cues, and personal experience shape behavior and these behaviors reinforce initial perceptions over time (
Bandura, 2001).
Third, regression results from RQ3 build on our prior findings that students rated AI-perceived responses lower in helpfulness, caring, and likelihood to reach out again regardless of actual source (
Lee & Esposito, 2025). In this study, we added ChatGPT’s academic usefulness and tested its interaction with source identity, but neither were significant predictors. These results further highlight that perceptions—rather than ChatGPT’s academic usefulness or the objective content—drive user judgments, as explained by the Perceptual Bias Activation framework. In addition, these findings reveal limitations of the Technology Acceptance Model (TAM) and UTAUT. For example, although constructs like Performance Expectancy (PU/PE) are predictive, they are only activated when users perceive the interaction as mediated by AI. While the findings of RQ2 began to reveal this connection, our findings for RQ3 confirm that the Perceptual Bias Activation framework thus provides a bridge between prior technological acceptance frameworks and human–AI interaction behavior as it explains how cognitive filters (e.g., perceived identity) precede and condition the activation of the TAM and UTAUT constructs. That is, students did not apply these constructs to all mentorship content, but they only applied them when they believed AI was involved.
Lastly, we examined whether there is a relationship between the UTAUT constructs and their ratings of the outcome measures (helpfulness, caring, and likelihood of reaching out again) based on their perceived source (as human vs. AI; RQ4). Findings for RQ4 showed that Performance Expectancy, Effort Expectancy, and Social Influence were positively correlated with students’ evaluations, but only for responses perceived as AI generated. This selective activation reinforces the idea that technology acceptance is perception-dependent, especially in human–AI contexts. To note, Facilitating Conditions (FCs, e.g., institutional or technical support) were not significantly correlated with outcomes, possibly due to limited variance or low internal consistency (α = 0.56). Furthermore, the lack of correlation for Facilitating Conditions may indicate that, in a college setting, students often have sufficient access to technology infrastructure (FC 1), but they may not have the organizational support they need to use ChatGPT (FC 3). To examine this possibility, we conducted one-sample t-tests comparing participants’ ratings to the neutral midpoint value of 3. For FC 1, results showed that participants generally felt they had the resources necessary to use ChatGPT (M = 3.96, SD = 1.10, t(1268) = 31.20, p < 0.001, 95% CI [3.90, 4.03]). However, results for FC 3 showed neutrality about whether adequate help or training is available (M = 3.02, SD = 1.12, t(1268) = 0.68, p = 0.499, 95% CI [2.96, 3.08]). Although participants felt they had enough resources to use ChatGPT, it is possible that short-term interactions with AI do not yet hinge on the presence of extensive support systems, rendering FCs less salient. To support this claim, further work needs to be done to examine how robust institutional backing or mandated training sessions influence students’ willingness to engage with AI mentors over the long term. It is important to note though that the effect sizes for these correlations were small (rs ≤ 0.15), indicating while statistically significant, these relationships explained only a modest portion of the variance in students’ evaluations.
The findings of our study implicate the powerful role of perceptual biases in shaping how students engage with AI-generated mentorship. Rather than being guided solely by content quality, students’ evaluations were filtered through their assumptions about the source’s identity. Grounded by the Perceptual Bias Activation framework, this implicates that perceived identity acts as an early cognitive lens that colors interpretation. The results also offer support for TAM and UTAUT frameworks, suggesting that technology acceptance and use constructs are selectively activated when users are explicitly aware of technological mediation. In other words, receptivity to AI support appears not only shaped by perceived usefulness and ease of use, but also by societal and personal expectations around trust, credibility, and emotions (Social Cognitive Theory). It is important to note that the way AI is presented influences how it is perceived and experienced by users, and those perceptions can, in turn, shape how AI is used (
Pataranutaporn et al., 2023). These insights carry important implications for future theory building, research, and AI design. As AI systems continue to enter educational and mentorship spaces, models of user engagement must go beyond technical affordances to include human cognitive and social factors. Researchers and AI designers should consider how perceived identities and pre-existing biases influence students’ trust and willingness to engage with AI support. Integrating these dimensions into both theoretical models and practical applications will ensure that emerging technologies are not only functionally effective but also aligned with the nuanced social and cognitive dynamics that shape learning and mentoring relationships.
This study also offers several practical implications for educators and policymakers integrating AI tools into higher education. One of our key findings was that students’ perceptions, rather than content quality, play a significant role in shaping their evaluations of AI-based support. Students must be equipped not only to use AI tools but also to critically reflect on how their assumptions may influence their judgments and behaviors. Therefore, comprehensive AI literacy initiatives designed by institutions may be an important factor in AI use and acceptance. Rather than focusing solely on technical skill adoption, AI literacy should include ethical and relational dimensions. Such literacy efforts could take the form of interactive workshops or integrated course modules that help students interrogate their initial impressions. These interventions should target both intuitive, immediate reactions (System 1) and more reflective, deliberate thinking (System 2), allowing students to better calibrate their evaluations over time. Importantly, students with no prior experience using ChatGPT were significantly less accurate in source identification, further highlighting the need for structured exposure and guidance. Beyond exposure, clear communication is also important. Transparency about when and how AI is used in mentorship contexts can help build trust, correct misconceptions, and reduce resistance stemming from hidden or ambiguous use of GAI tools. When faculty or advisors use AI tools to support their mentorship, students should be informed clearly and proactively. Equally important is how AI is positioned within the broader mentoring ecosystem. Our study found that students who valued human mentorship were especially hesitant to engage with AI-perceived responses, regardless of the content. For these students, mentorship is not merely about obtaining information, but it is about relational support and interpersonal connection. Overreliance on AI for mentoring tasks risks eroding students’ opportunities to build social–emotional skills, especially those tied to empathy, communication, and trust. As
Sharma et al. (
2025) caution, GAI systems cannot fully replicate the depth of human interaction necessary for meaningful mentoring relationships. Framing AI tools as a bridge to, rather than a substitute for, human mentorship allows institutions to leverage their strengths without undermining the relational core of student support.
Lastly, it is important to note that this study is not without limitations and several limitations should be considered when interpreting the findings of this study. First, the sample was drawn from a single liberal arts college using the university’s SONA research participation system. While this approach allowed for controlled data collection, it limits the generalizability of results to broader student populations and institutional types. This case study should be seen as an initial step in exploring how students interpret AI-generated mentorship, and we encourage future studies to replicate and extend these findings with broader or more varied samples. Second, this study relied on self-report measures to assess participants’ perceptions, attitudes, and intentions. Although self-report is commonly used and appropriate for capturing subjective evaluations, it is subject to potential response bias. We attempted to reduce such bias by ensuring survey anonymity and presenting response stimuli in a masked format, but we acknowledge that these measures cannot fully eliminate the influence of personal bias or context effects. Third, this study was limited to quantitative methods. Though beyond the scope of this paper, including qualitative data might have enriched our understanding of how students made sense of AI- versus human-generated responses. Future work could incorporate open-ended responses, interviews, or qualitative methodologies to explore the reasoning behind participants’ judgments and the nuances of their experiences with mentorship. Fourth, our measure of Prior ChatGPT Use was binary (Yes/No) and did not capture how frequently or in what ways participants had used the tool (outside of academic purposes). This limits our ability to assess how depth of experience may have influenced perceptions. Moreover, the data were collected in early 2024, during a period when GAI tools were still in the early stages of widespread adoption among undergraduate students. As student familiarity with AI tools continue to evolve, future research should use more detailed and sophisticated measures of AI literacy and usage to reflect and inform current practices. Furthermore, future research could explore longitudinal and mixed-method designs, examining how perceptions are formed and how repeated exposure to AI-driven mentorship in different domains shapes trust, perceived helpfulness, and engagement patterns over time.





{kind=link}
{kind=link}
{kind=link}
{kind=link}