
Learning Analytics with Small Datasets—State of the Art and Beyond


Abstract
1. Introduction
RQ1: How has learning analytics been applied to small datasets in the contemporary literature?
RQ2: Do the observed learning analytics provisions work in actual small-scale courses?
2. Background
2.1. LA and Small Datasets
2.2. The Learning of EALs as a Complex System
3. Methods
3.1. SLR
3.1.1. Article Search Strategy and Selection Procedure
3.1.2. Data Coding and Analysis
3.2. Empirical Study
4. Results
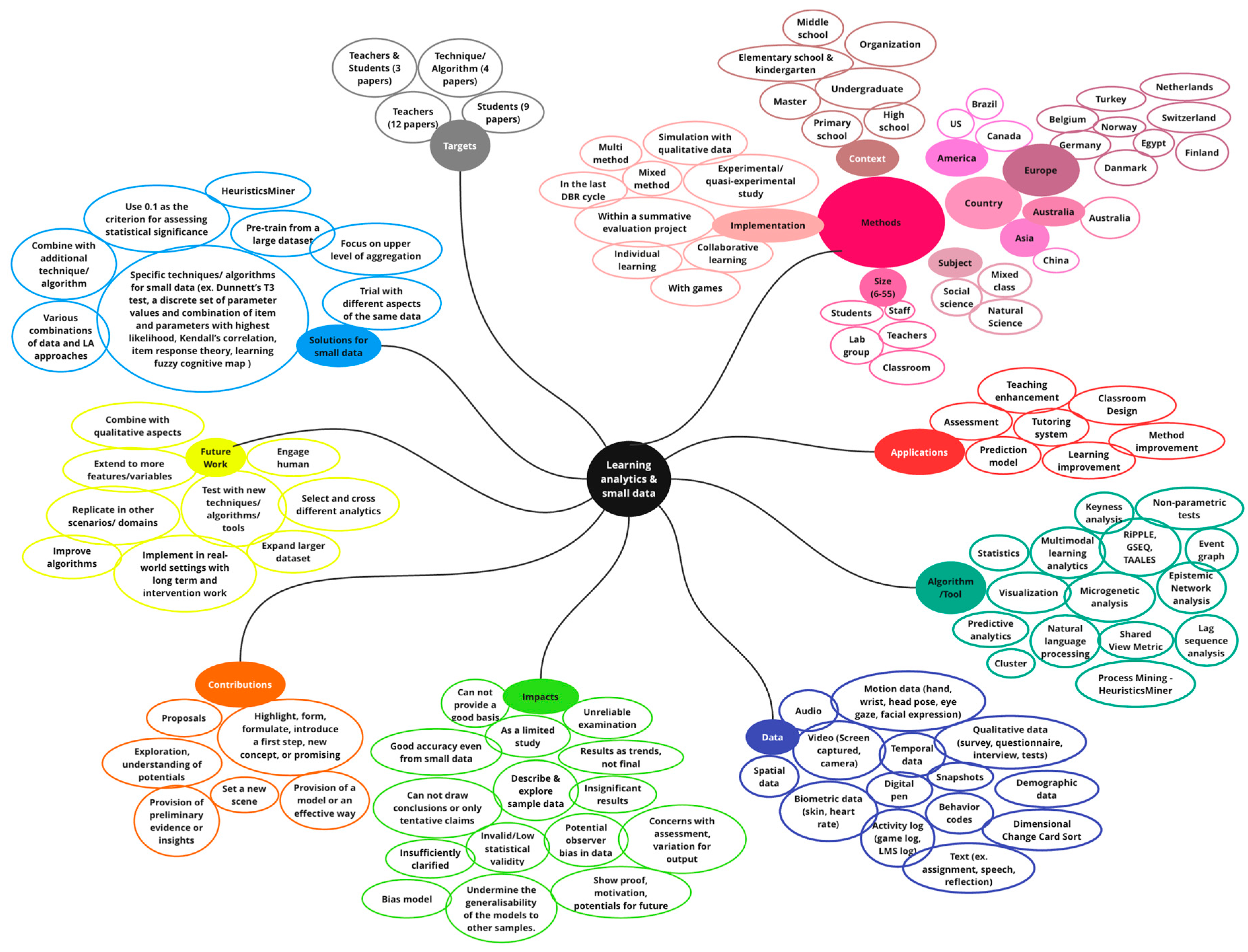
4.1. Findings of the SLR
4.2. Results from Empirical Study
4.2.1. Foundation for Data Variable Selection
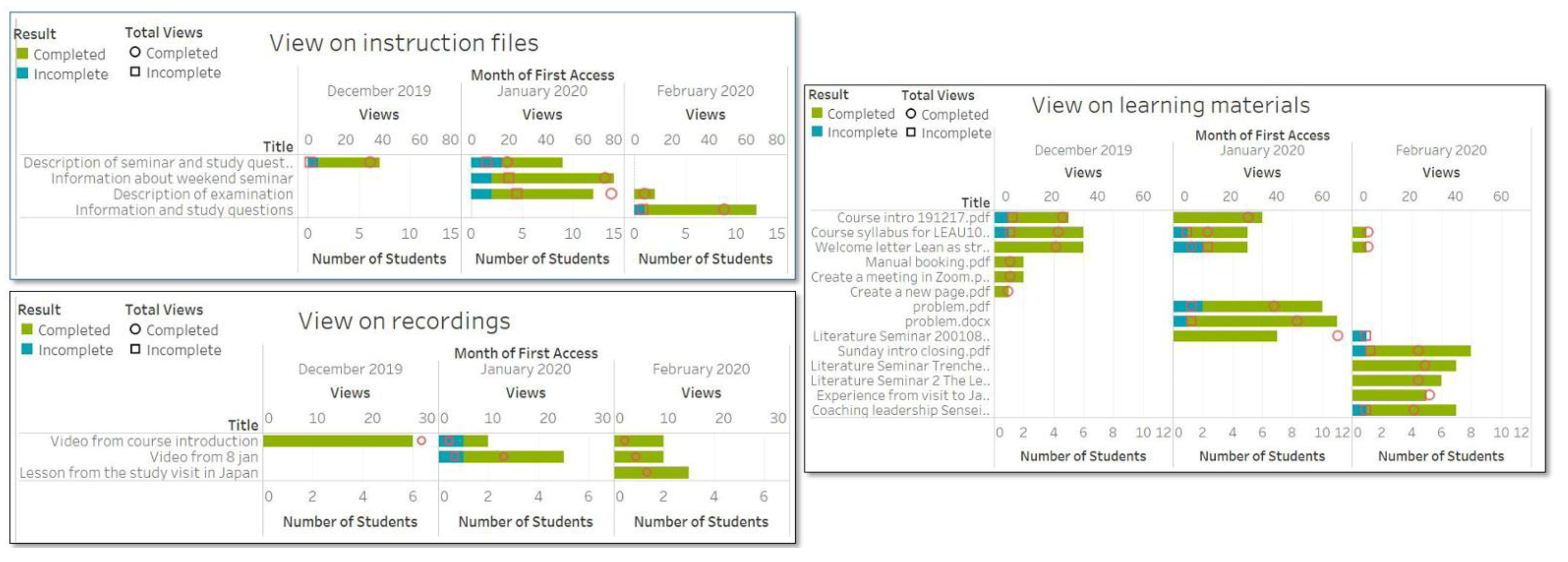
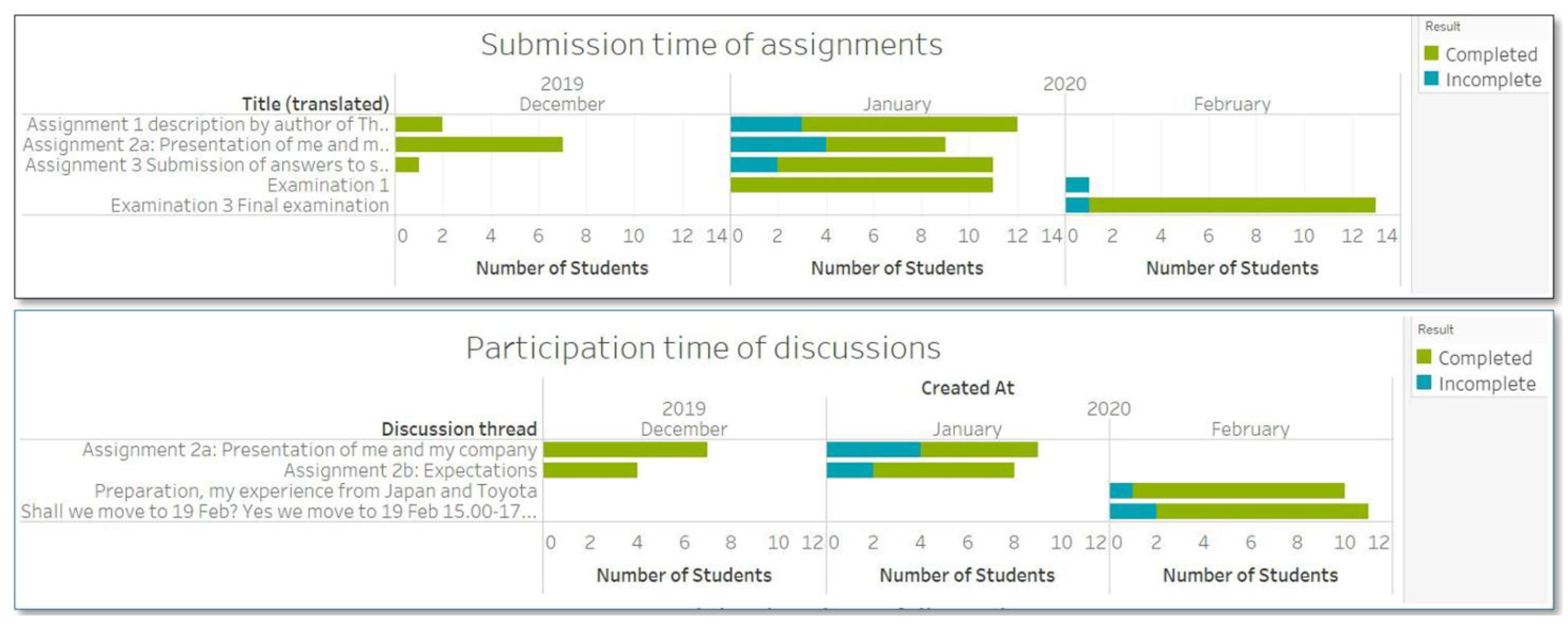
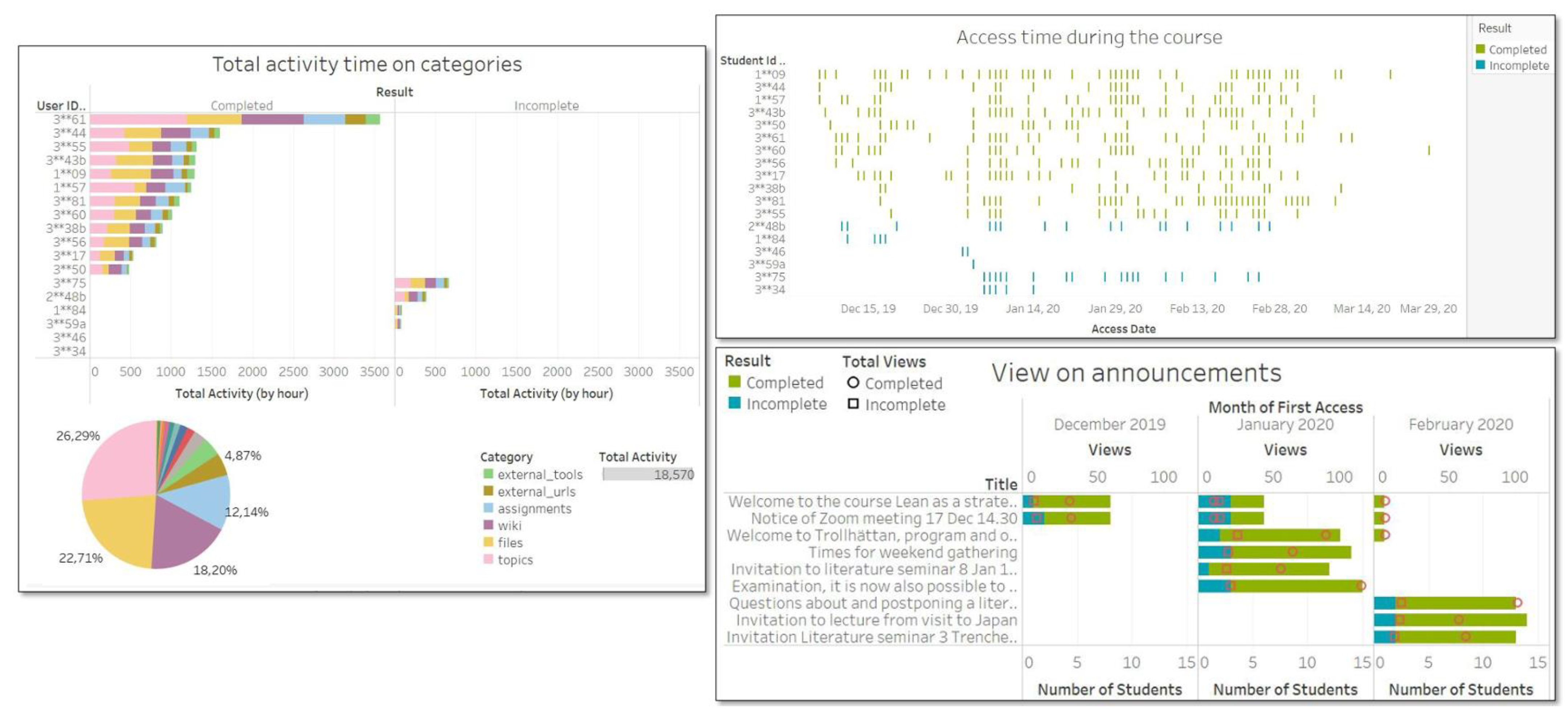
4.2.2. Analysis of Student Interactions
4.2.3. Time Investment in Different Categories of Canvas and Course Completion
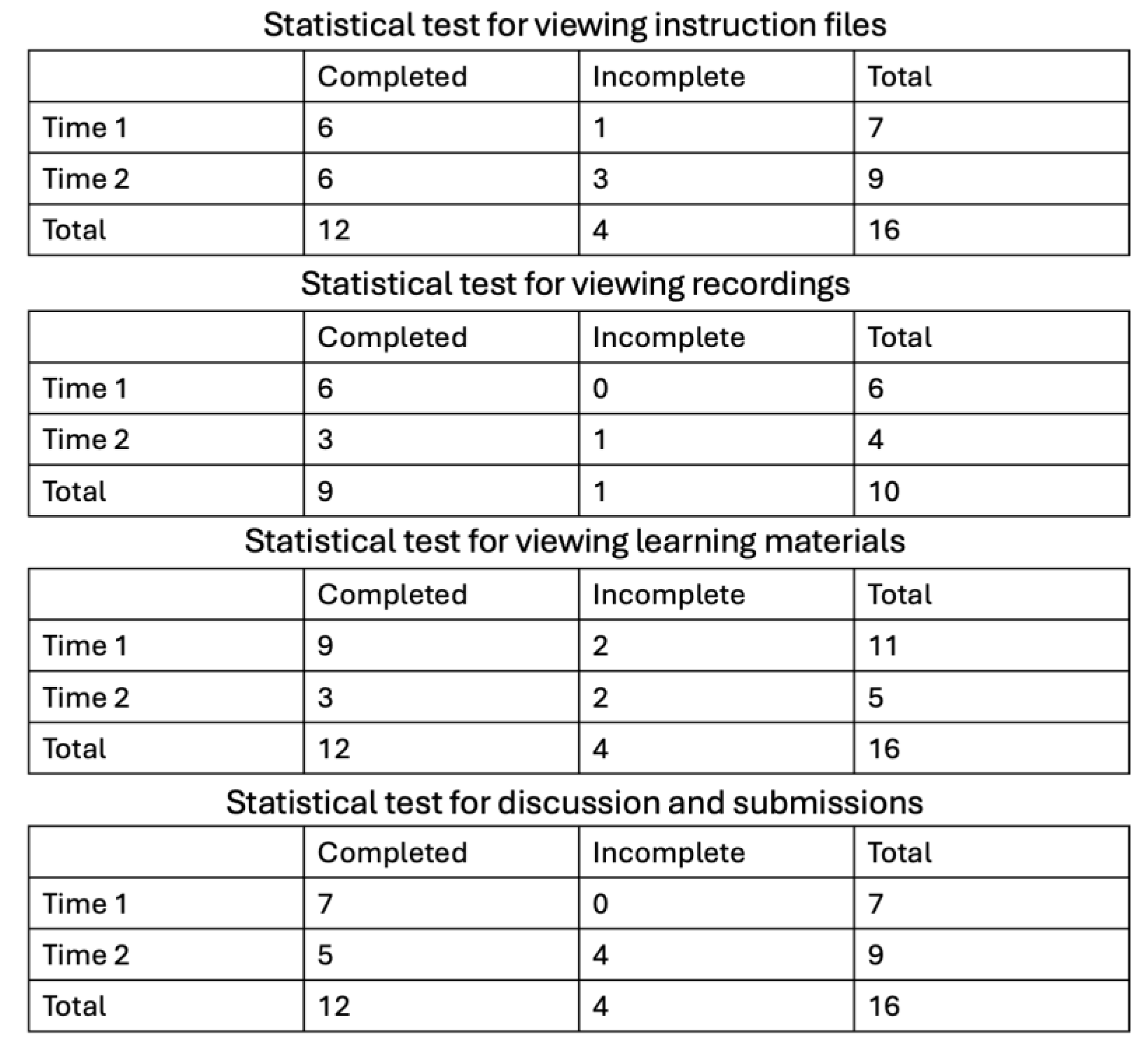
4.2.4. Access Frequency and Course Completion
4.2.5. Addressing the Empirical Findings with the LD
5. Discussions
5.1. RQ2: Do the Observed Learning Analytics Provisions Work in Actual Small-Scale Courses?
5.2. What Works and What Does Not Work
6. Conclusions
6.1. Implications for Research
6.2. Implications for Practice
Author Contributions
Funding
Conflicts of Interest
References
- Bodily, R.; Verbert, K. Trends and issues in student-facing learning analytics reporting systems research. In Proceedings of the Seventh International Learning Analytics & Knowledge Conference, Vancouver, BC, Canada, 13–17 March 2017; pp. 309–318. [Google Scholar]
- SoLAR. What is Learning Analytics? Available online: https://www.solaresearch.org/about/what-is-learning-analytics/ (accessed on 10 July 2022).
- Yan, L.; Zhao, L.; Gasevic, D.; Martinez-Maldonado, R. Scalability, sustainability, and ethicality of multimodal learning analytics. In Proceedings of the LAK22: 12th International Learning Analytics and Knowledge Conference, Online, USA, 21–25 March 2022; pp. 13–23. [Google Scholar]
- Kitto, K.; Lupton, M.; Davis, K.; Waters, Z. Incorporating student-facing learning analytics into pedagogical practice. In Proceedings of the 33rd International Conference of Innovation, Practice and Research in the Use of Educational Technologies in Tertiary Education (ASCILITE 2016), Adelaide, Australia, 28–30 November 2016; Australasian Society for Computers in Learning in Tertiary Education (ASCILITE): Tugun, Australia, 2016; pp. 338–347. [Google Scholar]
- Barab, S.A.; Hay, K.E.; Yamagata-Lynch, L.C. Constructing networks of action-relevant episodes: An in situ research methodology. J. Learn. Sci. 2001, 10, 63–112. [Google Scholar] [CrossRef]
- Hefler, G.; Markowitsch, J. Formal adult learning and working in Europe: A new typology of participation patterns. J. Workplace Learn. 2010, 22, 79–93. [Google Scholar] [CrossRef]
- Kumar, V.S.; Gress, C.L.; Hadwin, A.F.; Winne, P.H. Assessing process in CSCL: An ontological approach. Comput. Hum. Behav. 2010, 26, 825–834. [Google Scholar] [CrossRef]
- Hmelo-Silver, C.E.; Jordan, R.; Liu, L.; Chernobilsky, E. Representational tools for understanding complex computer-supported collaborative learning environments. In Analyzing Interactions in CSCL: Methods, Approaches and Issues; Springer: Berlin/Heidelberg, Germany, 2010; pp. 83–106. [Google Scholar]
- Goggins, S.P.; Xing, W.; Chen, X.; Chen, B.; Wadholm, B. Learning Analytics at” Small” Scale: Exploring a Complexity-Grounded Model for Assessment Automation. J. Univers. Comput. Sci. 2015, 21, 66–92. [Google Scholar]
- Fancsali, S.E. Variable construction for predictive and causal modeling of online education data. In Proceedings of the 1st International Conference on Learning Analytics and Knowledge, Banff, AB, Canada, 27 February–1 March 2011; pp. 54–63. [Google Scholar]
- Siemens, G.; Baker, R.S.D. Learning analytics and educational data mining: Towards communication and collaboration. In Proceedings of the 2nd International Conference on Learning Analytics and Knowledge, Vancouver, BC, Canada, 29 April–2 May 2012; pp. 252–254. [Google Scholar]
- Tair, M.M.A.; El-Halees, A.M. Mining educational data to improve students’ performance: A case study. Int. J. Inf. 2012, 2, 140–146. [Google Scholar]
- Hellas, A.; Ihantola, P.; Petersen, A.; Ajanovski, V.V.; Gutica, M.; Hynninen, T.; Knutas, A.; Leinonen, J.; Messom, C.; Liao, S.N. Predicting academic performance: A systematic literature review. In Proceedings of the Companion of the 23rd Annual ACM Conference on Innovation and Technology in Computer Science Education, Larnaca, Cyprus, 2–4 July 2018; pp. 175–199. [Google Scholar]
- Almeda, M.V.; Scupelli, P.; Baker, R.S.; Weber, M.; Fisher, A. Clustering of design decisions in classroom visual displays. In Proceedings of the Fourth International Conference on Learning Analytics and Knowledge, Indianapolis, IN, USA, 24–28 March 2014; pp. 44–48. [Google Scholar]
- Yan, L.; Martinez-Maldonado, R.; Zhao, L.; Deppeler, J.; Corrigan, D.; Gasevic, D. How do teachers use open learning spaces? Mapping from teachers’ socio-spatial data to spatial pedagogy. In Proceedings of the LAK22: 12th International Learning Analytics and Knowledge Conference, Online, 21–25 March 2022; pp. 87–97. [Google Scholar]
- MacKinnon-Slaney, F. The adult persistence in learning model: A road map to counseling services for adult learners. J. Couns. Dev. 1994, 72, 268–275. [Google Scholar] [CrossRef]
- Li, K.-C.; Wong, B.T.-M. Trends of learning analytics in STE (A) M education: A review of case studies. Interact. Technol. Smart Educ. 2020, 17, 323–335. [Google Scholar] [CrossRef]
- Andrade, A. Understanding student learning trajectories using multimodal learning analytics within an embodied-interaction learning environment. In Proceedings of the Seventh International Learning Analytics & Knowledge Conference, Vancouver, BC, Canada, 13–17 March 2017; pp. 70–79. [Google Scholar]
- Chua, Y.H.V.; Dauwels, J.; Tan, S.C. Technologies for automated analysis of co-located, real-life, physical learning spaces: Where are we now? In Proceedings of the 9th International Conference on Learning Analytics & Knowledge, Tempe, AZ, USA, 4–8 March 2019; pp. 11–20. [Google Scholar]
- Caprotti, O. Shapes of educational data in an online calculus course. J. Learn. Anal. 2017, 4, 76–90. [Google Scholar] [CrossRef]
- Van Goidsenhoven, S.; Bogdanova, D.; Deeva, G.; Broucke, S.V.; De Weerdt, J.; Snoeck, M. Predicting student success in a blended learning environment. In Proceedings of the Tenth International Conference on Learning Analytics & Knowledge, Frankfurt, Germany, 23–27 March 2020; pp. 17–25. [Google Scholar]
- Nguyen, N.B.C. Improving Online Learning Design for Employed Adult Learners. Eur. Conf. e-Learn. 2022, 21, 302–309. [Google Scholar] [CrossRef]
- Arrow, H.; McGrath, J.E.; Berdahl, J.L. Small Groups as Complex Systems: Formation, Coordination, Development, and Adaptation; Sage Publications: Thousand Oaks, CA, USA, 2000. [Google Scholar]
- Sarkis-Onofre, R.; Catalá-López, F.; Aromataris, E.; Lockwood, C. How to properly use the PRISMA Statement. Syst. Rev. 2021, 10, 117. [Google Scholar] [CrossRef]
- Glenn, J.C. The Futures Wheel. In Futures Research Methodology—Version 3; The Millennium Project: Washington, DC, USA, 2009; p. 19. [Google Scholar]
- Kim, H.-Y. Statistical notes for clinical researchers: Sample size calculation 2. Comparison of two independent proportions. Restor. Dent. Endod. 2016, 41, 154–156. [Google Scholar] [CrossRef]
- Lämsä, J.; Uribe, P.; Jiménez, A.; Caballero, D.; Hämäläinen, R.; Araya, R. Deep networks for collaboration analytics: Promoting automatic analysis of face-to-face interaction in the context of inquiry-based learning. J. Learn. Anal. 2021, 8, 113–125. [Google Scholar] [CrossRef]
- Gibson, A.; Kitto, K. Analysing reflective text for learning analytics: An approach using anomaly recontextualization. In Proceedings of the Fifth International Conference on Learning Analytics and Knowledge, Poughkeepsie, NY, USA, 16–20 March 2015; pp. 275–279. [Google Scholar]
- Scherer, S.; Weibel, N.; Morency, L.-P.; Oviatt, S. Multimodal prediction of expertise and leadership in learning groups. In Proceedings of the 1st International Workshop on Multimodal Learning Analytics, Santa Monica, CA, USA, 26 October 2012; pp. 1–8. [Google Scholar]
- Beheshitha, S.S.; Gašević, D.; Hatala, M. A process mining approach to linking the study of aptitude and event facets of self-regulated learning. In Proceedings of the Fifth International Conference on Learning Analytics and Knowledge, Poughkeepsie, NY, USA, 16–20 March 2015; pp. 265–269. [Google Scholar]
- Horn, B.; Hoover, A.K.; Barnes, J.; Folajimi, Y.; Smith, G.; Harteveld, C. Opening the black box of play: Strategy analysis of an educational game. In Proceedings of the 2016 Annual Symposium on Computer-Human Interaction in Play, Austin, TX, USA, 16–19 October 2016; pp. 142–153. [Google Scholar]
- Mangaroska, K.; Vesin, B.; Giannakos, M. Cross-platform analytics: A step towards personalization and adaptation in education. In Proceedings of the 9th International Conference on Learning Analytics & Knowledge, Tempe, AZ, USA, 4–8 March 2019; pp. 71–75. [Google Scholar]
- Barz, M.; Altmeyer, K.; Malone, S.; Lauer, L.; Sonntag, D. Digital pen features predict task difficulty and user performance of cognitive tests. In Proceedings of the 28th ACM Conference on User Modeling, Adaptation and Personalization, Online, 12–18 July 2020; pp. 23–32. [Google Scholar]
- Abdi, S.; Khosravi, H.; Sadiq, S.; Gasevic, D. Complementing educational recommender systems with open learner models. In Proceedings of the Tenth International Conference on Learning Analytics & Knowledge, Frankfurt, Germany, 23–27 March 2020; pp. 360–365. [Google Scholar]
- Lu, W.; He, H.; Urban, A.; Griffin, J. What the Eyes Can Tell: Analyzing Visual Attention with an Educational Video Game. In Proceedings of the 2021 ACM Symposium on Eye Tracking Research and Applications, Virtual Event, 25–27 March 2021; pp. 1–7. [Google Scholar]
- Roijers, D.M.; Jeuring, J.; Feelders, A. Probability estimation and a competence model for rule based e-tutoring systems. In Proceedings of the 2nd International Conference on Learning Analytics and Knowledge, Vancouver, BC, Canada, 29 April–2 May 2012; pp. 255–258. [Google Scholar]
- Raca, M.; Tormey, R.; Dillenbourg, P. Sleepers’ lag-study on motion and attention. In Proceedings of the Fourth International Conference on Learning Analytics and Knowledge, Indianapolis, IN, USA, 24–28 March 2014; pp. 36–43. [Google Scholar]
- Mansouri, T.; ZareRavasan, A.; Ashrafi, A. A learning fuzzy cognitive map (LFCM) approach to predict student performance. J. Inf. Technol. Educ. Res. 2021, 20, 221–243. [Google Scholar] [CrossRef]
- Oviatt, S. Problem solving, domain expertise and learning: Ground-truth performance results for math data corpus. In Proceedings of the 15th ACM on International Conference on Multimodal Interaction, Sydney, Australia, 9–13 December 2013; pp. 569–574. [Google Scholar]
- Peffer, M.E.; Kyle, K. Assessment of language in authentic science inquiry reveals putative differences in epistemology. In Proceedings of the Seventh International Learning Analytics & Knowledge Conference, Vancouver, BC, Canada, 13–17 March 2017; pp. 138–142. [Google Scholar]
- Diederich, M.; Kang, J.; Kim, T.; Lindgren, R. Developing an in-application shared view metric to capture collaborative learning in a multi-platform astronomy simulation. In Proceedings of the LAK21: 11th International Learning Analytics and Knowledge Conference, Irvine, CA, USA, 12–16 April 2021; pp. 173–183. [Google Scholar]
- Lazem, S.; Jad, H.A. We play we learn: Exploring the value of digital educational games in Rural Egypt. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; pp. 2782–2791. [Google Scholar]
- Martin, T.; Aghababyan, A.; Pfaffman, J.; Olsen, J.; Baker, S.; Janisiewicz, P.; Phillips, R.; Smith, C.P. Nanogenetic learning analytics: Illuminating student learning pathways in an online fraction game. In Proceedings of the Third International Conference on Learning Analytics and Knowledge, Leuven, Belgium, 8–13 April 2013; pp. 165–169. [Google Scholar]
- Hartmann, C.; Rummel, N.; Bannert, M. Using HeuristicsMiner to Analyze Problem-Solving Processes: Exemplary Use Case of a Productive-Failure Study. J. Learn. Anal. 2022, 9, 66–86. [Google Scholar] [CrossRef]
- Shen, W.; Zhan, Z.; Li, C.; Chen, H.; Shen, R. Constructing Behavioral Representation of Computational Thinking based on Event Graph: A new approach for learning analytics. In Proceedings of the 6th International Conference on Education and Multimedia Technology, Guangzhou, China, 13–15 July 2022; pp. 45–52. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Databases | Search Queries | Inclusion Criteria | Results |
|---|---|---|---|
| ACM Digital Library | (“teaching analytics” OR “learning analytics”) AND (“small data” OR “small sample”) | Between 2012 and 2022, short papers, research articles, journal papers | 92 |
| SCOPUS | Between 2012 and 2023, conference and journal papers | 18 | |
| Journal of Learning Analytics | “small data” | Entire database | 2 |
| “small sample” | 3 | ||
| Total | 115 |
| Implementations | Number of Papers |
|---|---|
| Simulation | 3 |
| Mixed-method | 3 |
| Multi-method | 1 |
| MMLA | 9 |
| Common LA | 9 |
| Game | 4 |
| Experiment/Quasi-experiment | 4 |
| Implementation Methods/Generic Algorithms | Specific Algorithms | Functions/Applicability |
|---|---|---|
| MMLA | Works in various levels of education and organizations, applied to multiple natural communication modalities | |
| Text analysis | Topic modeling | Explores underlying topics from text data |
| Word-embedding model | Automatic classification, should combine with deep networks for conversation analysis | |
| Epistemic network analysis | Assesses the quality of discourse in texts | |
| Keyness analysis | Identifies significantly frequent linguistic words | |
| Clustering | Set up hierarchical coding scheme | Identifies distinguished groups or patterns hidden in data |
| Design multifold learning activities | ||
| Use archetype clustering to support hierarchical clustering | ||
| Use agglomerative hierarchical clustering with Euclidian distance measure and Ward’s criterion | ||
| Statistical analysis | Supplement significance tests with effect size measures | Investigates relations between various measures or examines independent variables |
| Use the ϕ corr for regression and classification | ||
| Use 0.1 instead of 0.05 for statistical significance | ||
| Dunnett’s T3 test | ||
| Use a discrete set of parameter values and a combination of parameters with the highest likelihood | ||
| Nonparametric tests | ||
| Kendall’s correlation | ||
| Prediction | Learning fuzzy cognitive map | Predicts student performance |
| Two-parameter logistic ogive function of item response theory | Predicts student behaviors in rule-based e-tutoring systems | |
| Pre-training with large datasets | ||
| Process mining | HeuristicsMiner | Finds touchless learning flow or process paths |
| Microgenetic analysis | ||
| Fuzzy miner | ||
| Lag sequence analysis | ||
| Simulations |
| |
| Game-based learning |
| |
| (Quasi-)Experiments |
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, N.B.C.; Karunaratne, T. Learning Analytics with Small Datasets—State of the Art and Beyond. Educ. Sci. 2024, 14, 608. https://doi.org/10.3390/educsci14060608
Nguyen NBC, Karunaratne T. Learning Analytics with Small Datasets—State of the Art and Beyond. Education Sciences. 2024; 14(6):608. https://doi.org/10.3390/educsci14060608
Chicago/Turabian StyleNguyen, Ngoc Buu Cat, and Thashmee Karunaratne. 2024. "Learning Analytics with Small Datasets—State of the Art and Beyond" Education Sciences 14, no. 6: 608. https://doi.org/10.3390/educsci14060608
APA StyleNguyen, N. B. C., & Karunaratne, T. (2024). Learning Analytics with Small Datasets—State of the Art and Beyond. Education Sciences, 14(6), 608. https://doi.org/10.3390/educsci14060608