Abstract
Voice and speech are educational tools and a medium of pedagogy for teachers. Teachers tend to modify their voice and speech to support learning. This study aimed to investigate whether pre-service teachers modify their speech and voice in teaching compared to peer learning speech and whether the changes can promote learning and be beneficial for the speakers. Nine pre-service physics teachers’ voices were recorded in three learning situations and in one teaching session with similar external circumstances. Duration of speech turns, pausing, speech rate, fundamental frequency (F0) and its variation, sound pressure level (SPL) and its range, and voice quality were analyzed. Results showed that the participants had longer speech turns, decreased speech rate, and increased pausing when teaching compared to speech in peer learning situations. F0 and SPL were higher in teaching, indicating that the teaching situation was more stressful than the peer learning situation. For F0, this was confirmed by correlation analysis. From the learning point, increased pausing and slower speech rate may be beneficial, but increased F0 and SPL may, on the other hand, be harmful to future teachers as they can increase the risk of vocal overloading. Voice training for future teachers is strongly recommended.
1. Introduction
Voice and speech are needed for communication in the classroom, and they are used for e.g., instructing, clarifying, and motivating. Voice and speech, then, are an educational tool for teachers and a medium for pedagogy. According to Walsh [1], teachers tend to modify their speech in terms of language and speech. The modification of language can either support or obstruct learning, and in interactional modification, teachers use slower, louder, and more intentional speech and more pausing and emphasis. Owen [2] argues that pauses are used in educational speech for different reasons: speech is slower due to more precise articulation, and as a medium to support learners’ understanding, increased pausing can promote learners’ speech processing.
For effective communication in the classroom, appropriate vocal functioning is needed, and it contributes to students’ learning [3,4]. According to Enoc [5], student teachers’ effective teaching demonstration can be measured through several indicators, such as, for example, utilizing motivational activity, employing various teaching techniques and strategies, and developing measurable cognitive, affective, and psychomotor learning objectives. Also, effective and appropriate communication and a clear voice are considered to be assets for effective teaching demonstration [5]. In a classroom, the teacher’s voice should be intelligible, accessible, motivational, assertive, and effective [4]. The teacher’s voice can affect learning since the teacher’s vocal expression (appropriate pitch, loudness, and their variations) can help the learner identify the main points in speech [6]. Hämäläinen et al. [7] have found different voice patterns in teacher talk in classroom situations, and they suggest that pitch variation plays an important role in these patterns, as a teacher’s presentative speech has lower pitch variation compared to, for example, disputational and promotive speech.
The quality of the teacher’s voice has also been found to have an effect on learning, as the teacher’s disordered or high-pitched voice draws the learner’s attention to the reception of information, making it difficult to process the content, which causes a negative educational effect [3,8,9,10,11]. In addition, especially in early childhood education and in the lowest grades of basic education, the teacher’s voice can also affect the students’ own voice use because, through model learning, children can adopt incorrect patterns for voice use [8]. The preferred voice for teaching is considered pleasant, motivating, and able to arouse attention, and is perceived as a voice with neutral quality—that is, without any significant disturbances, with moderately low pitch and slow pace [12].
Teacher occupation includes individual and external factors that can increase risks for vocal overloading, which can lead to voice problems [9]. Vocal overloading results from a combination of individual factors, such as the rise of pitch and loudness, pressed phonation, and longer phonation time, and of external circumstances, such as, for example, the room acoustics and background noise, as well as ergonomics and long distances between teacher and students, e.g., [9,13,14,15,16]. But, apart from the external environmental factors, is the teacher’s voice affected by the speaking task itself? It should be investigated to find out whether voice and speech change even when the external circumstances are the same. This study aimed to investigate how pre-service teachers modify their voice and speech when in a teaching situation compared to a learning situation with similar external circumstances. This perspective adds to the study of how voice and speech vary in different roles, one role being a student and the other a teacher. This study aims to shed light on teacher voice and speech characteristics without the loading factors coming from the environmental influence and whether the changes can be disadvantageous for future teachers since, according to [17,18,19], voice problems can begin to occur for student teachers during their time of study.
The research question this study aims to answer is as follows: Are speech and voice characteristics of the pre-service teachers affected by the role shift from learner to teacher? Furthermore, we discuss what the changes mean in terms of vocal health and teacher-student communication.
2. Materials and Methods
2.1. Participants
The participants were university students from the course “Teaching Physics at School”. They answered the preliminary questionnaire with background information and the Voice Handicap Index (VHI) [20]. The VHI is a widely used and validated screening tool for distinguishing vocal health and vocal dysfunction between individuals [21,22,23]. A total of 23 students answered the questionnaire, and based on the VHI scores, they were divided into two groups: Group 1 (10 participants), with the healthiest voices, i.e., smallest VHI scores (in this study, less than 12), attended the voice-related part of the study, and Group 2 (13 participants), the video recorded group. Participants for this study belong to the voice-related group. None of the participants in the voice group had had any voice training.
Additionally, the participants completed the task of conceptual understanding instrument DIRECT [24], which measured their conceptual knowledge of direct current electrical circuits. The participants were third- or fourth-year students who had already studied the basics of electricity, but their conceptual understanding was somewhat still developing. The tasks are designed to bring out known misconceptions about electric current, voltage, and resistance. These misconceptions include assigning properties of energy to the concept of current or treating the battery as the source of constant current. The tasks can, therefore, be difficult even for university students [24]. The participants in the voice-related part of the study were then divided into pairs based on DIRECT instrument results, using varied pairing (pairs with high and low, high and high, and low and low scores). One pair was female-female, one was male-male, and three pairs were female-male. Since one participant was absent after the first session, nine students were investigated in the study: three pairs and one trio. They all were studying physics in order to be physics teachers; however, 2 had physics as their major subject and 7 as their minor subject (with mathematics (6) or chemistry (1) as their major subject).
2.2. Recordings
The students were recorded in three learning sessions and one teaching session. Each session was approximately 1 h and 30 min in total duration. Before each recording session, the participants answered a short questionnaire about their voice production (easier than usual—as usual—need more effort than usual) and voice quality (better than usual—usual—worse than usual) based on their notions of that day.
The external conditions and the recording setup were the same for all recording sessions: the participants sat at a table at a distance of about a meter from each other. In addition, all recordings were made in the same room, and the same tables were located identically. Nine participants were present in learning situations, compared to teaching sessions with nine to ten participants, so the amount of background noise from neighboring groups was fairly equal.
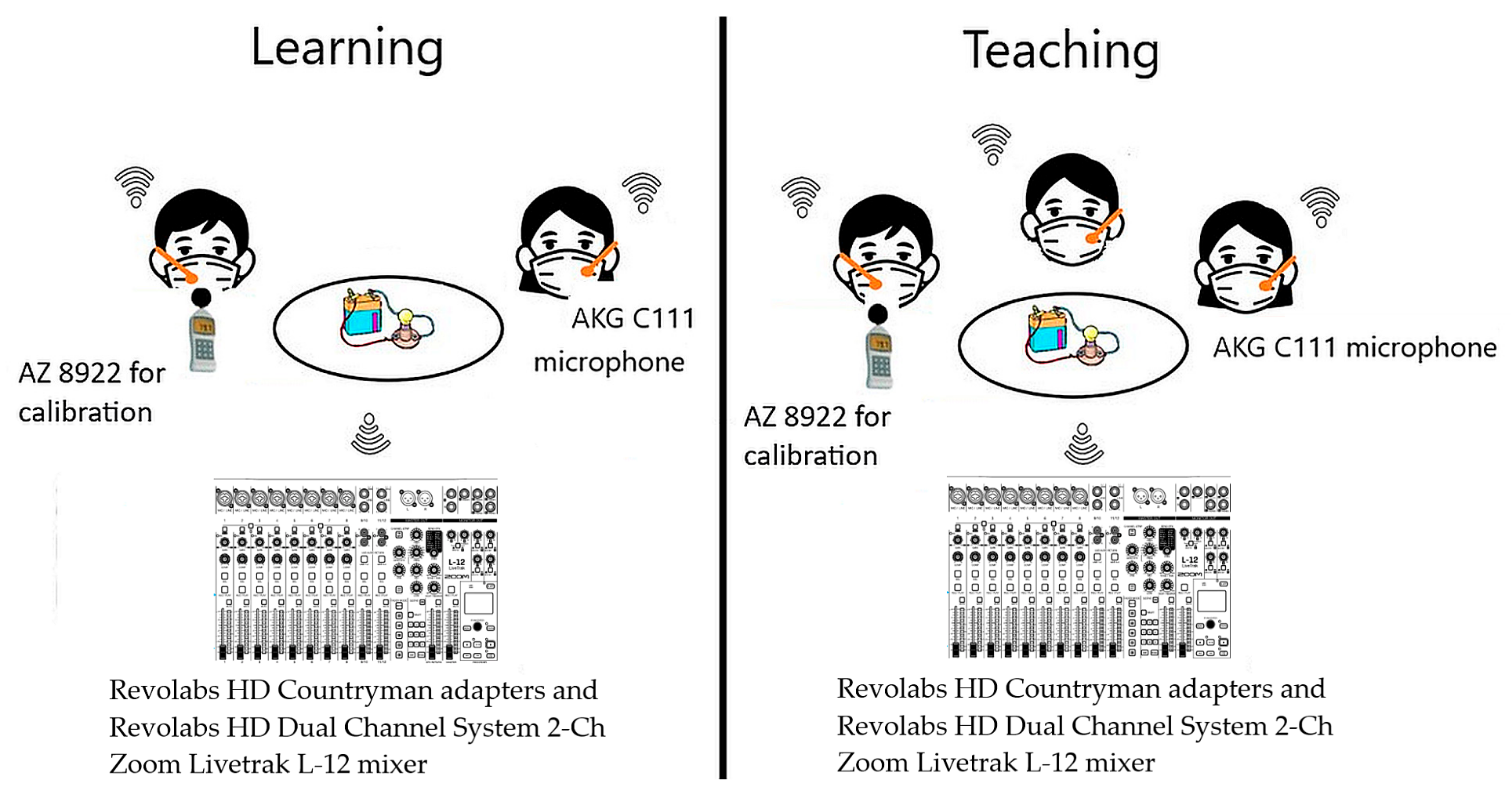
The recordings were carried out with AKG C 111 headsets (AKG Harman, Stamford, CT, USA), the microphone placed 2 cm from the mouth corner. The input frequency was 44.1 kHz, and Revolabs HD Countryman adapters (Yamaha UC, Inc., Sudbury, MA, USA) and Revolabs HD Dual Channel System 2-Ch (Yamaha UC, Inc., Sudbury, MA, USA) combined with Zoom Livetrak L-12 mixer (Zoom Corp., Tokyo, Japan) were used in the recordings. The AZ 8922 digital sound level meter (AZ Instrument Corp., Taichung City, Taiwan) was used to calibrate SPL for each speaker (Figure 1). All participants were compelled to wear surgical face masks due to the COVID-19 situation. The masks were used on every occasion; therefore, the influence of the mask [25,26] was the same in every situation throughout the recordings, and, thus, the effect of the mask on the acoustic analysis should not affect the results between recording sessions. Figure 1 shows the recording setup.

Figure 1.
The recording procedure and equipment (headset microphones, sound level meter, and the recording gear) for both studied conditions.
After the recorded sessions, the participants answered a question on a 100-point VAS line about the stressfulness of the situation (0 = not at all stressful to 100 = very stressful).
2.3. The Learning Tasks in the Sessions
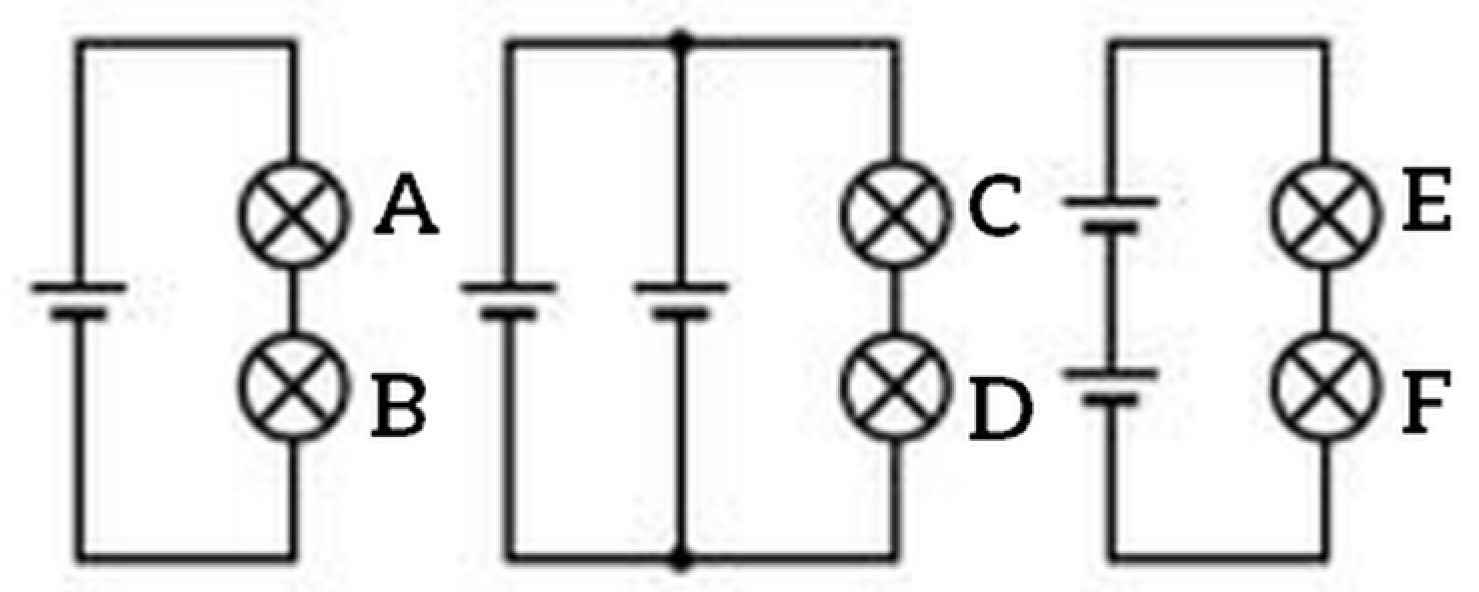
In the first three sessions, all the participants were given tasks (such as in Figure 2) to rank light bulbs in simple circuits in the order of their relative brightness.

Figure 2.
An example of a task in the sessions: rank the lightbulbs A–F per their relative brightness.
In the first two sessions, tasks became more complex per each task. Tasks in the third session were more of a repetition of the previous sessions’ ideas. In the teaching session, the participants were to teach and guide pre-service elementary school teachers as they were solving similar kinds of tasks. The tasks were adapted from McDermott and Schaffer [27]. The tasks followed the predict-observe-explain structure: First, the participants made individual predictions concerning the relative brightness of the lamps. Then, they discussed these predictions as a pair and, finally, constructed the circuits and observed whether their prediction was confirmed or if adjustments were needed. Each pair formed the final explanation based on their observations.
2.4. Acoustic Analyses of Voice and Speech
Acoustic analyses of voice provide a possibility to objectively study human speech, voice, and voice production. To answer the research question, we chose to study speaking turns where the participants explained the solutions to the tasks either (1) to a peer in a learning situation or (2) to pre-service elementary school teachers in a teaching situation. Speech samples representing such speaking turns were collected from the recordings from all sessions. In this study, a turn is considered an uninterrupted speaking turn. Samples with disturbances, such as background noise, laughter, or vocal fry (i.e., low-pitched voice with irregular vocal fold vibration and two fundamentals alternating [28]) were excluded. The total number of samples was 82 from the learning situations and 86 from the teaching situations.
Acoustic analyses were carried out with the Praat (version 6.0.49) speech analysis software [29]. For each sample, the fundamental frequency (F0), the standard deviation of fundamental frequency (F0 SD), the sound pressure level (SPL) and its range, the alpha ratio, and the speech rate and pausing were analyzed.
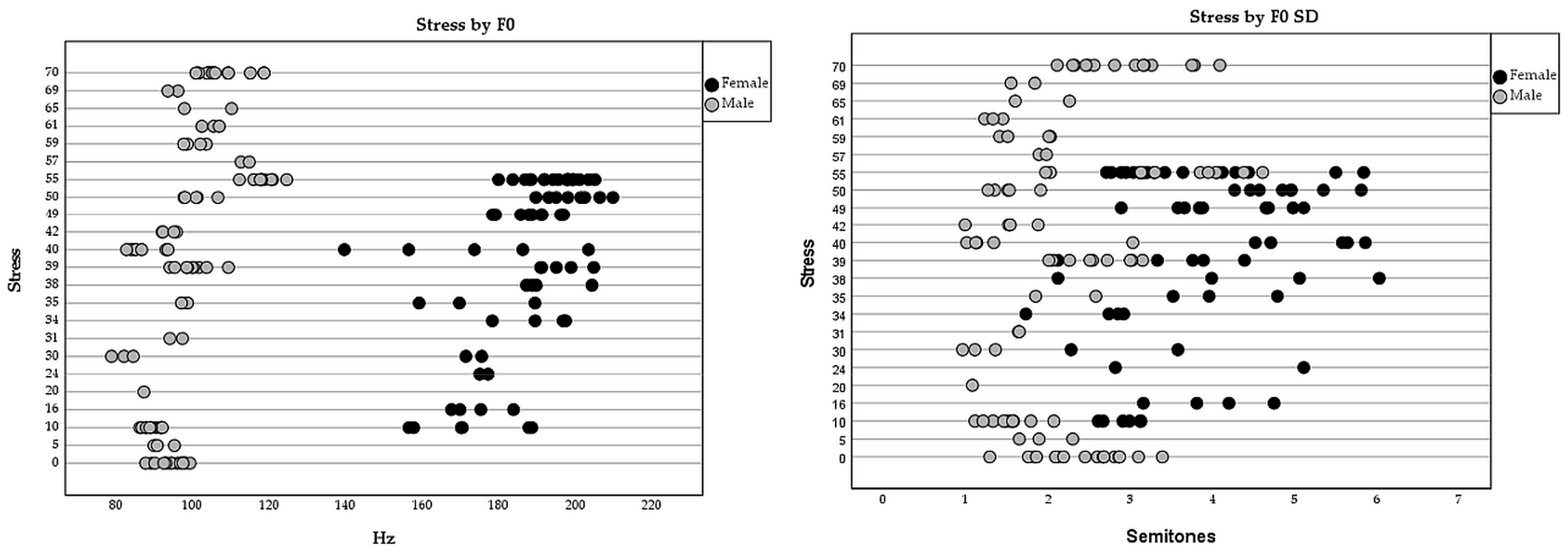
The F0 is based on the frequency of vocal fold vibration, and it is the most important counterpart to the perception of pitch. The unit for F0 is Hertz (Hz), which is one vibration per second [30]. Its variation was measured as the standard deviation of F0 within that turn in semitones. This choice was made because the logarithmic scale (as semitones re 100 Hz) is better in adapting the results to human pitch perception and making better comparisons between male and female speakers [31], see Figure 3.

Figure 3.
F0 ranges in speech in Hz and semitones for men and women. (Modified from [32]).
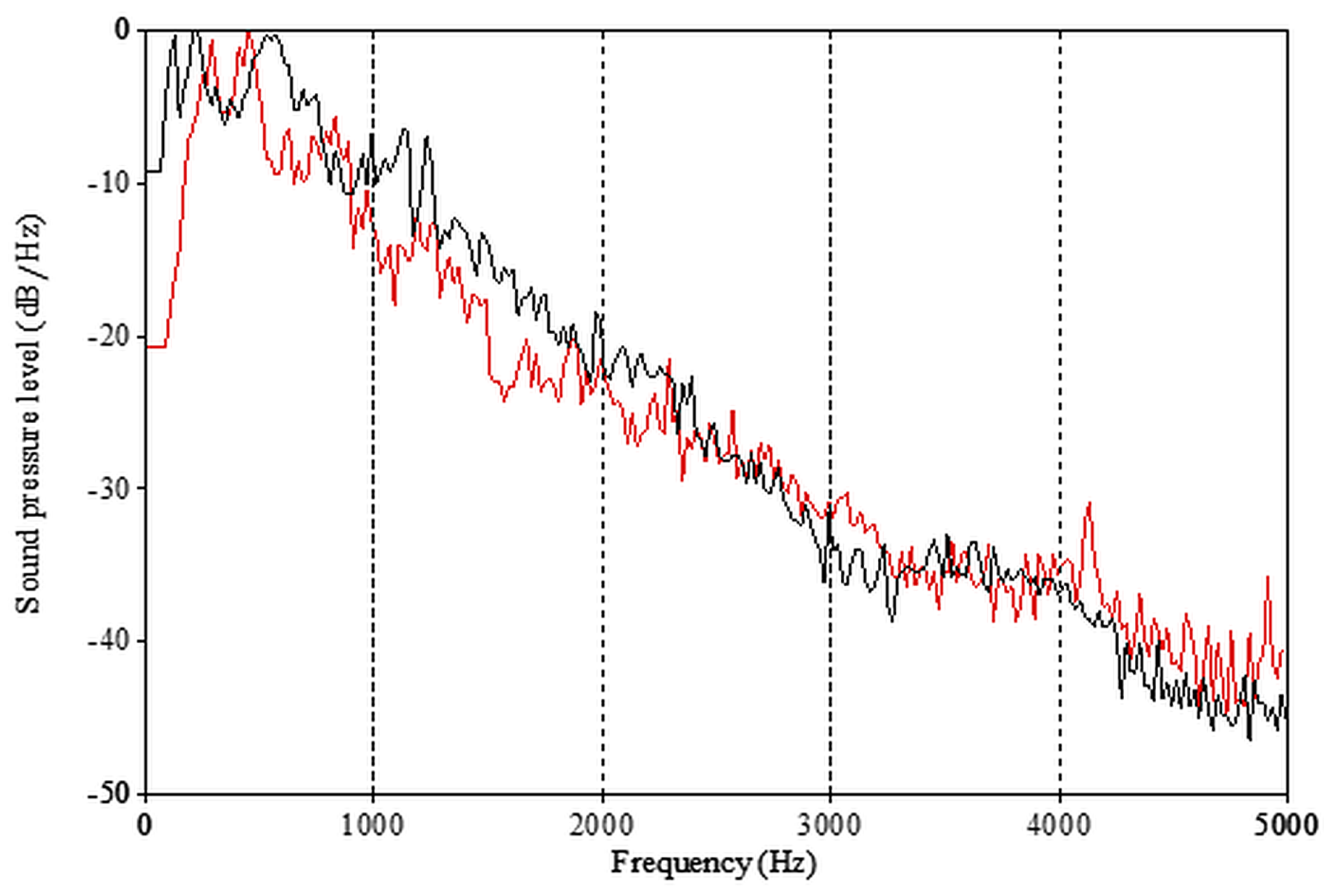
The SPL corresponds to the perception of loudness, and it is based on the amplitude of vocal fold vibration, the measuring unit being decibel (dB) [30]. Alpha ratio [33] was measured from the long-term average spectrum (LTAS) with a bandwidth of 20 Hz, as level differences between 50–1000 and 1000–5000 Hz. LTAS (Figure 4) provides information on sound energy and its distribution to different frequency areas, and it can offer information about the speaker’s voice quality, disregarding the linguistic content of speech [34,35]. Speech tempo was measured as speech rate, i.e., syllables per second, and pausing was measured automatically as the percentage of voice breaks in the signal within each turn.

Figure 4.
Example of the long-term average spectrum (LTAS) for two speakers. Black line male speaker, red line female speaker. The spectra here are based on one speaking turn for each speaker.
2.5. Statistical Analyses
IBM SPSS Statistics (version 28.0.1.0.1) was used for statistical analyses. Since the data was not normally distributed, non-parametric analyses were conducted. For pairwise comparisons between learning and teaching, the Wilcoxon signed rank test with the Monte Carlo simulation method with a 95% confidence level was used [36]. The effect size was calculated using the formula r = Z/√N, where r is the effect size, Z is the value from the Wilcoxon signed rank test, and N is the number of sample size [37]. The correlation between experienced stress and parameters was investigated by using the Pearson correlation coefficient.
3. Results
The participants’ mean age was 23.8 years (SD 1.93). The teaching situations were considered more stressful than the learning situations, as shown in Table 1.

Table 1.
The mean and standard deviation (SD) of participants’ age and experienced stress in the two situations.
Statistically significant differences in voice and speech between learning and teaching were found. Duration of the speech samples was longer in teaching situations than in learning situations; speech in teaching had more pausing and slower speech rate; and the F0, F0 SD, and SPL range were all higher in speech samples from the teaching situations than in learning situation (see Table 2).
Table 2.
Means, standard deviations (SD), and statistical significance (p) for all parameters in learning and teaching situations. Wilcoxon signed rank test with Monte Carlo simulation method for comparisons between the situations. Significance level is 0.05, ns = non-significant, N for Wilcoxon signed rank test = 82, N for F0 (Hz) for females is 35, and for males 47.
The experienced stress had a moderate correlation with F0 (r = 0.34, p < 0.001) and a small correlation with F0 SD (r = 0.18, p = 0.021), as shown in Figure 5. Other parameters showed no correlation with stress.

Figure 5.
Scatter plot with experienced stress and F0 and F0 SD.
4. Discussion
Pre-service physics teachers modify their speech and voice in the teaching situation compared to the learning situation, even when the external conditions are similar. The changes the participants made in their speech and voice were somewhat intuitive since they had no training in voice and speech.
According to the results, the pre-service physics teachers used longer uninterrupted speech turns when teaching. This suggests that they shifted to a more monologic mode [38] when teaching, i.e., they were less interactive and possibly also less dialogic [39]. While peer-to-peer discussions can be very interactive and dialogic, the teacher’s role can be non-interactive and authoritative, for example, when lecturing from a scientific perspective (monologue). On the other hand, the teacher can be non-interactive but dialogic (dialogic monologue), for example, when dealing with different perspectives presented by students. The average speech rate in spontaneous speech for Finnish speakers is 4.8–5.5 syllables per second [40], which is in line with the speech rate in this study. The speech rate was significantly slower when teaching, indicating that speech rate was affected by the situation, which is also in line with previous studies [1,2]. Longer speech turns can result from increased pausing and slower speech rate, which could indicate more authoritative speech while teaching [41].
It is presumable that the elementary school pre-service teachers had less knowledge about the tasks than the pre-service physics teachers, which might have affected the explanations the pre-service physics teachers used. This could especially affect the speech tempo and pausing since teachers tend to slow down their speech and use more pausing to give the learners more time to process the topic at hand [1,2]. This could be further studied by analyzing the elementary school pre-service teachers’ speech and its contents, how the pre-service physics teachers modify their voice and speech, and whether they use different explanations in their teaching compared to the dialogues with their peers. The length of the speech turns and temporal characteristics should be further studied together with content analysis to find whether the explanations also varied in conceptual content, structure, or terminology. Also, the prosodic cues, such as pitch contour, and other acoustic cues (e.g., jitter, shimmer, and noise-to-harmonics-ratio) in each speech turn should be investigated since it is possible that the pre-service teachers’ cues for keeping turns resulted from the acoustic cues in their voices [42].
In teaching, the participants had higher F0 and SPL, which can result from increased stress in the teaching situation, as it has been shown in previous studies, e.g., [43,44,45] that increased cognitive load and psychological stress can affect F0 and SPL. However, the increased intensity may also be a manifestation of authority [46]. To investigate this hypothesis of dominance and authority, vocal tract resonances should be studied, as they can convey information about the speakers’ expression of competence [47].
In this study, voice quality did not show significant differences resulting from the role shift from learner to teacher. As voice quality was investigated by the LTAS-based alpha-ratio, it is possible that formant frequencies of speech sounds affected the alpha-ratio [48]. Further study using inverse filtering is required, as it is a method for estimating the glottal flow signal from the corresponding acoustic speech signal and, thus, minimizing the effects of formant frequencies of different speech sounds in the sample and revealing the voice source, see, e.g., [49,50,51].
The number of pre-service physics teachers in this study was nine, which is an estimated ten percent of the students who start university studies to become a physics teacher annually in Finland. However, the number of samples in learning and teaching situations was 82 in both. Statistical analyses showed that the changes were significant with the Monte Carlo simulation method with a 95% confidence level. This suggests that the number of samples was adequate.
The researchers recognize that the use of facial masks can have an effect on acoustic voice parameters, especially the spectral components [25]. However, it is presumed that it should not affect the interpretation of these results since the facial masks were used throughout the recordings, and the effect should then be the same in all samples.
This study was designed to record speech in settings as authentic as possible to gather samples representing the actual speech of students as learners and teachers. The setting posed some challenges to the analysis, as overlapping speech, laughter, vocal fry, and other disturbances affected some samples, which were then excluded from the analyses. The availability of usable data was not a problem. The removal of data containing overlapping speech and other disturbances hits all speech sequences equally. However, because of the inability to analyze turns containing laughter, this study cannot make predictions about the teachers’ voice use in humorous situations.
The participants in this study were students with no self-reported voice problems. Their VHI index was low, indicating healthy voices [21,22,23]. However, a large amount of vocal fry was detected in the recordings. It has been found that vocal fry has increased, especially among Finnish women [52]. Vocal fry and other non-modal voice qualities have been found to have an effect on learning outcomes, as it requires more cognitive capacity from the listener than listening to modal voice quality. Non-modal voice quality and vocal fry can affect the listener’s working memory and, thereby, also the learning results. Poor voice quality can direct the learners’ attention to the voice and away from the topic [3,8,10,12].
The participants in this study had no training in speech technique during their studies and, therefore, they were possibly not aware of the quality of their voices. Although previous studies have shown that teachers and student teachers would benefit from training in speech and voice techniques for better maintaining good vocal health and also for better teaching and learning [6,53], only two universities in Finland seem to have compulsory courses on speech technique for future teachers [54,55]. Teachers’ voice problems can have vast economic effects; for example, according to Verdolini and Ramig [56], in the US, the estimated societal cost of voice problems among teachers can be about 2.5 billion dollars annually. Additionally, a poorly functioning voice can weaken a teacher’s professional identity and (professional) self-esteem and reduce work ability. Teachers’ voice problems, where possible, should be prevented or detected and corrected at a sufficiently early stage to avoid worsening of the problem [6]. An additional suggestion from this study is that pre-service teachers could gain better knowledge of their voice as an occupational tool, as well as its role in teaching and learning. This need could be met by adding voice training to the teacher education curriculum.
5. Conclusions
This study shows that the role shift from learner to teacher affects voice and speech. As teachers are invested in their students’ learning, some of the changes can be considered beneficial: slower speech rate and increased pausing give the learner more time to process the information. Also, increased variation in pitch can be beneficial as it can help the learner identify the main points in speech [6]. Considering the future teachers’ vocal health, however, some of the changes were linked with disadvantages. Examples of this are the higher F0 and SPL, which can cause vocal overloading and, thus, increase the risk of voice disorders [6,18,57].
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/educsci14020210/s1, Data S1.
Author Contributions
Conceptualization, K.J., A.-L.K., P.N. and T.M.; methodology, K.J., A.-L.K., P.N. and T.M.; formal analysis, K.J.; investigation, K.J., A.-L.K., P.N. and T.M.; data curation, K.J.; writing—original draft preparation, K.J., A.-L.K., P.N. and T.M.; writing—review and editing, K.J., A.-L.K., P.N. and T.M.; visualization, K.J. and A.-L.K.; funding acquisition, T.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Academy of Finland, grant number 341558.
Institutional Review Board Statement
The study was conducted in accordance with the Declaration of Helsinki. Ethical review and approval were waived for this study as The Ethical Committee of Research in Humanities in University of Jyväskylä follows the directives of The Finnish National board on Research Integrity (TENK) and provides pre-evaluation statements only for studies that pose a substantial risk to participants. TENK connects such risks to five conditions: deviation from informed consent, intervening in physical integrity of participants, exceptionally strong stimuli, greater than everyday probability to cause mental harm, or threat to safety of participants or close ones (Publications of TENK 3/2019, ISSN 2490-161X; https://tenk.fi/en/advice-and-materials/guidelines-ethical-review-human-sciences, accessed on 22 November 2023). Therefore, no ethical evaluation of the study could be requested from the University’s Ethical Committee as this study took place within the frame and conduct of a typical study session and applies the procedures for informed consent, triggering none of the aforementioned risk conditions.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
Data are contained within the Supplementary Materials.
Conflicts of Interest
The authors declare no conflict of interest. The funder had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Walsh, S. Classroom Interaction for Language Teachers. In English Language Development Series; Farrell, T.S.C., Ed.; TESOL International Association, TESOL Press: Alexandria, VA, USA, 2014. [Google Scholar]
- Owen, D. Do Teachers Modify Their Speech According to the Proficiency of Their Students. English Language Teacher Education and Development. Engl. Lang. Teach. Educ. Dev. 1996, 2, 31–51. Available online: http://www.elted.net/uploads/7/3/1/6/7316005/v2owen.pdf (accessed on 10 November 2023).
- Imhof, M.; Välikoski, T.-R.; Laukkanen, A.-M.; Orlob, K. Cognition and interpersonal communication: The effect of voice quality on information processing and person perception. Stud. Commun. Sci. 2014, 14, 37–44. [Google Scholar] [CrossRef]
- Servilha, E.A.M.; da Costa, A.T.F. Knowledge About Voice and the Importance of Voice as an Educational Resource in the Perspective of University Professors. Rev. CEFAC 2015, 17, 13–26. [Google Scholar] [CrossRef]
- Enoc, J.O. The Development of a Student Teachers Teaching Demonstration Performance Evaluation Tool. Eur. Sci. J. 2019, 15, 75–95. [Google Scholar] [CrossRef]
- Ilomäki, I. Opettajien ääneen liittyvä työhyvinvointi ja äänikoulutuksen vaikutukset. [Teachers’ Voice-Related Well-Being at Work and the Effects of Voice Training, in Finnish, Summary in English]. Ph.D. Dissertation, University of Tampere, Tampere, Finland, 2008. [Google Scholar]
- Hämäläinen, R.; De Wever, B.; Waaramaa, T.; Laukkanen, A.-M.; Lämsä, J. It’s Not Only What You Say, But How You Say It: Investigating the Potential of Prosodic Analysis as a Method to Study Teacher’s Talk. Frontline Learn. Res. 2018, 6, 204–227. [Google Scholar] [CrossRef]
- Valtasaari, H. Kestääkö ääni? Laulunopetuksen vaikutus opettajaksi valmistuvien äänen laatuun ja ilmaisuun. [The Impact of Voice Pedagogy Intervention on Voice Quality and Expression of Students in a Teacher Education Programme]. Ph.D. Dissertation, University of Jyväskylä, Jyväskylä, Finland, 2017. (In Finnish, Summary in English). [Google Scholar]
- Lyberg-Åhlander, V.; Haake, M.; Brännström, K.J.; Schötz, S.; Sahlén, B. Does the speaker’s voice quality influence children’s performance on a language comprehension test? Int. J. Speech Lang. Pathol. 2014, 17, 63–73. [Google Scholar] [CrossRef] [PubMed]
- Rogerson, J.; Dodd, B. Is there an effect of dysphonic teachers’voices on children’s processing of spoken language? J. Voice 2005, 19, 47–60. [Google Scholar] [CrossRef] [PubMed]
- Morton, V.; Watson, D.R. The impact of impaired vocal quality on children’s ability to process spoken language. Logoped. Phoniatr. Vocol. 2001, 26, 17–25. [Google Scholar] [CrossRef] [PubMed]
- Rodrigues, A.L.V.; de Medeiros, A.M.; Teixeira, L.C. Auditory impressions of the teacher’s voice in the perception of students, teachers and naive people. Audiol. Commun. Res. 2018, 23, e1857. [Google Scholar] [CrossRef]
- Kankare, E. Elektroglottografia (EGG) äänen laadun tutkimuksessa funktionaalisesti terveäänisillä puhujilla. Vertaileva tutkimus EGG:n sekä akustisen, perkeptuaalisen ja laryngoskopiatutkimuksen välillä lastentarhanopettajilla [Electroglottography (EGG) in Studying Voice Quality with Functionally Healthy Voices]. Ph.D. Dissertation, University of Tampere, Tampere, Finland, 2014. (In Finnish, Summary in English). [Google Scholar]
- Ilomäki, I.; Laukkanen, A.-M.; Leppänen, K.; Vilkman, E. Effects of voice training and voice hygiene education on acoustic and perceptual speech parameters and self-reported vocal well-being in female teachers. Logoped. Phoniatr. Vocol. 2008, 33, 83–92. [Google Scholar] [CrossRef]
- Fritzell, B. Voice disorders and occupations. Logoped. Phoniatr. Vocol. 1996, 21, 7–12. [Google Scholar] [CrossRef]
- Jiang, J.J.; Titze, I.R. Measurement of vocal fold intraglottal pressure and impact stress. J. Voice 1994, 8, 132–144. [Google Scholar] [CrossRef]
- Fairfield, C.; Richards, B. Reported voice difficulties in student teachers: A questionnaire survey. Br. J. Educ. Stud. 2007, 55, 409–425. [Google Scholar] [CrossRef]
- Thomas, G.; Kooijman, P.G.; Cremers, C.W.; De Jong, F.I. A comparative study of voice complaints and risk factors for voice complaints in female student teachers and practicing teachers early in their career. Eur. Arch. Oto-Rhino-Laryngol. 2006, 263, 370–380. [Google Scholar] [CrossRef] [PubMed]
- Simberg, S.; Sala, E.; Rönnemaa, A.M. A comparison of the prevalence of vocal symptoms among teacher students and other university student. J. Voice 2004, 18, 363–368. [Google Scholar] [CrossRef] [PubMed]
- Jacobson, B.H.; Johnson, A.; Grywalski, C.; Silbergleit, A.; Jacobson, G.; Benninger, M.S.; Newman, C.V. The Voice Handicap Index (VHI): Development and validation. Am. J. Speech-Lang. Pathol. 1997, 6, 66–70. [Google Scholar] [CrossRef]
- Alaluusua, S.; Johansson, M. Äänihäiriöiden aiheuttama psykososiaalinen haitta ja sen kuntoutuminen. Voice Handicap Index’n suomennoksen kokeilututkimus. [Psycho-social handicap of voice disorder and its rehabilitation: A pilot study of Finnish version of Voice Handicap Index]. Master’s Thesis, Institute of Behavioral Sciences, University of Helsinki, Helsinki, Finland, 2003. (In Finnish). [Google Scholar]
- Gräßel, E.; Hoppe, U.; Rosanowski, F. Grading of the Voice Handicap Index. HNO 2008, 56, 1221–1228. [Google Scholar] [CrossRef]
- Ohlsson, A.C.; Dotevall, H. Voice handicap index in Swedish. Logoped. Phoniatr. Vocol. 2009, 34, 60–66. [Google Scholar] [CrossRef] [PubMed]
- Engelhardt, P.V.; Beichner, R.J. Students’ understanding of direct current resistive electrical circuits. Am. J. Phys. 2004, 72, 98–115. [Google Scholar] [CrossRef]
- Nguyen, D.D.; McCabe, P.; Thomas, D.; Purcell, A.; Doble, M.; Novakovic, D.; Chacon, A.; Madill, C. Acoustic voice characteristics with and without wearing a facemask. Sci. Rep. 2021, 11, 5651. [Google Scholar] [CrossRef]
- Knowles, T.; Badh, G. The impact of face masks on spectral acoustics of speech: Effect of clear and loud speech styles. J. Acoust. Soc. Am. 2022, 151, 3359–3368. [Google Scholar] [CrossRef] [PubMed]
- McDermott, L.C.; Shaffer, P.S. Research as a guide for curriculum development: An example from introductory electricity. Part I: Investigation of student understanding. Am. J. Phys. 1992, 60, 994–1003. [Google Scholar] [CrossRef]
- Titze, I.R. Principles of Voice Production, 2nd ed.; National Center for Voice and Speech: Iowa City, IA, USA, 2000; pp. 282–287. [Google Scholar]
- Boersma, P.; Weenink, D. Praat: Doing Phonetics by Computer. Version 6.0.49. Praat: Doing Phonetics by Computer. Available online: https://uvafon.hum.uva.nl/praat/ (accessed on 5 October 2022).
- Baken, R.J.; Orlikoff, R.F. Clinical Measurement of Speech and Voice; Taylor & Francis Ltd.: London, UK, 2000. [Google Scholar]
- Hirst, D.J.; de Looze, C. Fundamental frequency and pitch. In Cambridge Handbook of Phonetics; Knight, R.-A., Setter, J., Eds.; Cambridge University Press: Cambridge, UK, 2021; pp. 336–361. [Google Scholar] [CrossRef]
- Howard, D.M. Quantifying developmental singing voice changes in children. In Proceedings of the 1st International Conference on the Physiology and Acoustics of Singing, Groningen, The Netherlands, 2–5 October 2002; Available online: https://www.researchgate.net/publication/228711083_Quantifying_developmental_singing_voice_changes_in_children/figures?lo=1 (accessed on 15 November 2023).
- Frøkjær-Jensen, B.; Prytz, S. Registration of voice quality. Annu. Rep. Inst. Phon. Univ. Cph. 1975, 9, 237–251. [Google Scholar] [CrossRef]
- Laver, J. Principles on Phonetics; Cambridge University Press: Cambridge, UK, 1994. [Google Scholar] [CrossRef]
- Laukkanen, A.-M.; Ilomäki, I.; Leppänen, K.; Vilkman, E. Acoustic measures and self-reports of vocal fatigue by female teachers. J. Voice 2008, 22, 283–289. [Google Scholar] [CrossRef]
- Mumby, P.J. Statistical power of non-parametric tests: A quick guide for designing sampling strategies. Mar. Pollut. Bull. 2002, 44, 85–87. [Google Scholar] [CrossRef]
- Tomczak, M.; Tomczak, E. The need to report effect size estimates revisited. An overview of some recommended measures of effect size. Trends Sport Sci. 2014, 1, 19–25. [Google Scholar]
- Skidmore, D. Dialogism and education. In The Routledge International Handbook of Research on Dialogic Education; Mercer, N., Wegerif, R., Major, L., Eds.; Routledge: London, UK, 2019; pp. 27–37. [Google Scholar] [CrossRef]
- Mortimer, E.; Scott, P. Meaning Making in Secondary Science Classrooms; McGraw-Hill Education: Maidenhead, UK, 2003. [Google Scholar]
- Toivola, M. Vieraan aksentin arviointi ja mittaaminen Suomessa [Evaluating and Measuring Foreign Accent in Finnish]. Ph.D. Dissertation, University of Helsinki, Helsinki, Finland, 2011. (In Finnish, Abstract in English). [Google Scholar]
- Schoerning, E.; Hand, B.; Shelley, M.; Therrien, W. Language, Access, and Power in the Elementary Science Classroom. Sci. Educ. 2015, 99, 238–259. [Google Scholar] [CrossRef]
- Gravano, A.; Hirschberg, J. Turn-taking cues in task-oriented dialogue. Comput. Speech Lang. 2011, 25, 601–634. [Google Scholar] [CrossRef]
- Huttunen, K.; Keränen, H.; Väyrynen, E.; Pääkkönen, R.; Leino, T. Effect of cognitive load on speech prosody in aviation: Evidence from military simulator flights. Appl. Ergon. 2011, 42, 348–357. [Google Scholar] [CrossRef]
- Griffin, G.R.; Williams, C.E. The effects of different levels of task complexity on three vocal measures. Aviat. Space Environ. Med. 1987, 58, 1165–1170. [Google Scholar]
- Johannes, B.; Wittels, P.; Enne, R.; Eisinger, G.; Castro, C.A.; Thomas, J.L.; Adler, A.B.; Gerzer, R. Non-linear function model of voice pitch dependency on physical and mental load. Eur. J. Appl. Physiol. 2007, 101, 267–276. [Google Scholar] [CrossRef]
- Tusing, K.J.; Dillard, J.P. The sounds of dominance: Vocal precursors of perceived dominance during interpersonal influence. Hum. Commun. Res. 2000, 26, 148–171. [Google Scholar] [CrossRef]
- Sorokowski, P.; Puts, D.; Johnson, J.; Żółkiewicz, O.; Oleszkiewicz, A.; Sorokowska, A.; Kowal, M.; Borkowska, B.; Pisanski, K. Voice of Authority: Professionals Lower Their Vocal Frequencies When Giving Expert Advice. J. Nonverbal Behav. 2019, 43, 257–269. [Google Scholar] [CrossRef]
- Nolan, F. The Phonetic Bases of Speaker Recognition; Cambridge Studies in Speech Science and Communication; Cambridge University Press: Cambridge, UK, 1983. [Google Scholar] [CrossRef]
- Airas, M. TKK Aparat: An environment for voice inverse filtering and parameterization. Logoped. Phoniatr. Vocol. 2008, 33, 49–64. [Google Scholar] [CrossRef]
- Alku, P. Glottal wave analysis with Pitch Synchronous Iterative Adaptive Inverse Filtering. Speech Commun. 1992, 11, 109–118. [Google Scholar] [CrossRef]
- Rothenberg, M. A new inverse-filtering technique for deriving the glottal air flow waveform during voicing. J. Acoust. Soc. Am. 1973, 53, 1632–1645. [Google Scholar] [CrossRef] [PubMed]
- Uusitalo, T.; Nyberg, L.; Laukkanen, A.-M.; Waaramaa, T.; Rantala, L. Has the Prevalence of Creaky Voice Increased Among Finnish University Students From the 1990s to the 2010s? J. Voice 2022, in press. [Google Scholar] [CrossRef] [PubMed]
- Sala, E.; Sihvo, S.; Laine, A. Ääniergonomia—Toimiva ääni työvälineenä. [Voice Ergonomics—Functional Voice as an Occupational Tool], 2nd ed.; Työterveyslaitos, Työturvallisuuskeskus: Helsinki, Finland, 2011. (In Finnish) [Google Scholar]
- Opinto-Opas Opettajan Pedagogiset Opinnot [Curriculum for Pedagogical Studies]. University of Lapland: Rovaniemi, Finland, 2022; Available online: https://www.ulapland.fi/loader.aspx?id=753349f7-37d7-4ffe-8008-c58e1a682bd3 (accessed on 22 November 2023). (In Finnish)
- Study Guide, Interpersonal Communication. Åbo Akademi. Available online: https://studiehandboken.abo.fi/sv/kurs/641117.0/1911?period=2022-2024 (accessed on 22 November 2023). (In Swedish).
- Verdolini, K.; Ramig, L.O. Review: Occupational risks for voice problems. Logoped. Phoniatr. Vocol. 2001, 26, 37–46. [Google Scholar] [CrossRef] [PubMed]
- Ohlsson, A.; Andersson, E.; Södersten, M.; Simberg, S.; Barregård, L. Prevalence of voice symptoms and risk factors in teacher students. J. Voice 2012, 26, 629–634. [Google Scholar] [CrossRef] [PubMed]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).