6.1. RQ1: How Do We Understand the Impact of Academic, Socioeconomic, and Equity Variables on the SDP Problem?
We used the correlational analysis of the variables involved to answer this question.
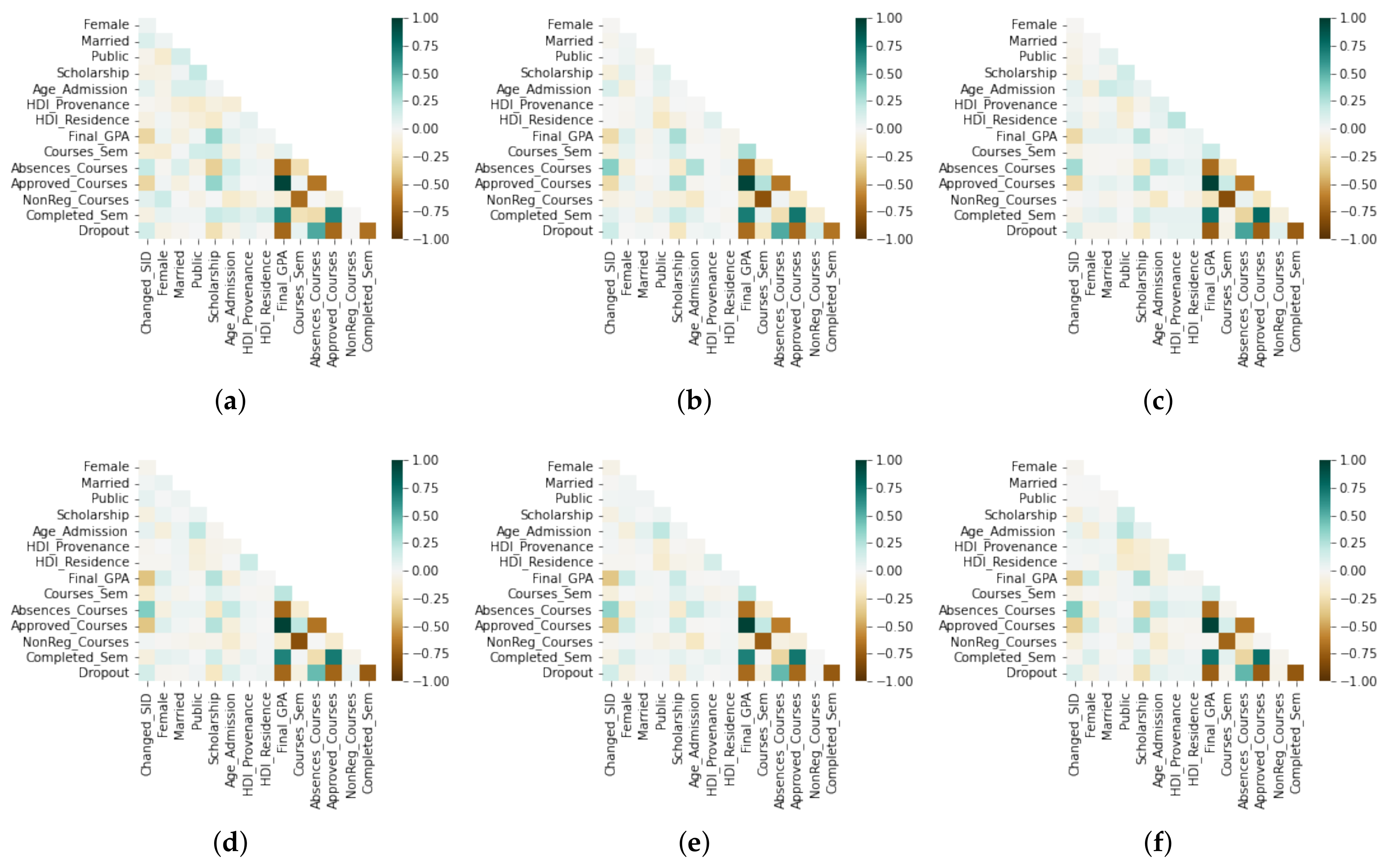
Figure 2 shows the correlation matrices for each academic department. We represent positive correlations on the green scale, and the brown scale represents negative ones. As is evident,
Completed_Sem has a strong negative correlation with
Dropout in all cases. Furthermore,
Dropout has a strong negative correlation with
Final_GPA and
Approved_Courses. However,
Dropout and
Absences_Courses have a moderate positive correlation.
In general, the correlation analysis is similar in all departments. Although a more detailed analysis, we found slight differences. In
CS, we have a weak positive correlation between
NonReg_Courses and
Dropout. However, this correlation is almost null in the rest of the departments. In summary, we concluded from
Figure 2 that the academic variables (
Final_GPA and
Approved_Courses) present a higher correlation with
Dropout. In contrast, the socioeconomic (
HDI_Provenance and
HDI_Residence) and equity (
Female) variables do not show a weak correlation in all cases. We concluded that these factors do not significantly influence predicting the dropout status.
6.2. RQ2: What Is the Most-Efficient Classification Machine Learning Method for the SDP Problem?
We utilized the Scikit-learn Python library to compute the classification probability. Now, we detail the best parameters for each classification algorithm employed in this work as follows:
Logistic Regression (LR) considers C = 0.1.
Support Vector Machine (SVM) considers C = 10 and gamma = 0.01.
Gaussian Naive Bayes (GNB) considers a variance of smoothing equal to =0.001.
K-Nearest Neighbor (KNN) considers seven neighbors.
Decision Tree (DT) considers a minimum number of samples required to be at a leaf node equal to fifty and a maximum depth of the tree equal to nine.
Random Forest (RF) considers a minimum number of samples required to be at a leaf node equal to fifty and a maximum depth of the tree equal to nine and does not use bootstrap.
Multilayer Perceptron (MP) considers three layers in the sequence (13, 8, 4, 1), an activation function defined by tanh, and = 0.001.
Convolutional Neural Network (CNN) considers two layers in the sequence (13, 6, 1) and the activation functions ReLU and sigmoid.
The predictive capacity of these models was measured using
Accuracy,
AUC, and
MSE, and these values are summarized in
Table 6. We highlight the best evaluation metrics by coloring the cell green and the worst evaluation metrics in brown.
CNN presented the best results in most cases and obtained the highest accuracy in
CS with (
Accuracy = 0.987). Even in the other cases, the accuracy values are more significant than 0.9. However,
CNN showed lower performance in some instances when we compared the
AUC. Analyzing
Psy, we found the highest accuracy value of 0.944, in contrast to what happened in
CS, whose accuracy value is 0.921 and is the lowest. Evaluating the methods based on the
AUC, we found that
RF presents the best results in five of the six data subsets. From
Table 6, we note that
GNB showed the worst evaluation metrics in most cases. Finally, based on the experimentation presented above, we concluded that
CNN is the best technique for the SDP problem employing classification algorithms.
6.3. RQ3: What Is the Most-Efficient Survival Analysis Method for the SDP Problem?
We employed survival analysis methods such as: the Cox Proportional Hazards model (CPH), Random Survival Forest (RSF), Conditional Survival Forest (CSF), and Multi-Task Logistic Regression (MTLR). In addition, variants of deep learning techniques such as Neural Multi-Task Logistic Regression model (N-MTLR), and Nonlinear Cox regression (DeepSurv) were implemented as well, and we compared them with the parametric models using the Gompertz and Weibull distributions.
We summarize in
Table 7 the values of the
C-index,
IBS,
MSE, and
MAE. Similarly, the best metrics are colored green and the opposite case in brown. The PySurvival Python library calculates the survival probability, risk score, and metrics, and the visual representation of the survival curves was obtained with the Matplotlib Python library. The parameters employed for each method were the following:
The parametric methods (Weibull and Gompertz) consider a learning rate equal to 0.01, an L2 regularization parameter equal to 0.001, the initialization method given by zeros, and the number of epochs equal to 2000.
The Cox Proportional Hazards model CPH) considers a learning rate equal to 0.5 and an L2 regularization parameter equal to 0.01. The significance level , and the initialization method is given by zeros.
Random Survival Forest (RSF) considers two-hundred trees, a maximum depth equal to twenty, the minimum number of samples required to be at a leaf node equal to ten, and the percentage of original samples used in each tree building equal to 0.85.
Conditional Survival Forest (CSF) considers two-hundred trees, a maximum depth equal to five, the minimum number of samples required to be at a leaf node equal to twenty, the percentage of original samples used in each tree building equal to 0.65, and the lower quantile of the covariate distribution for splitting equal to 0.1.
Multi-Task Logistic Regression (MTLR) considers twenty bins, a learning rate equal to 0.001, and the initialization method given by tensors with an orthogonal matrix.
Neural Multi-Task Logistic Regression (N-MTLR) considers three layers with the activation functions defined by ReLU, tanh, and sigmoid. Furthermore, MTLR uses 120 bins, a smoothing L2 equal to 0.001, and five-hundred epochs, and tensors comprise the initialization method with an orthogonal matrix.
Nonlinear Cox regression (DeepSurv) considers three layers with the activation functions defined by ReLU, tanh, and sigmoid. Furthermore, DeepSurv employs a learning rate equal to 0.001, and Xavier’s uniform initializer is the initialization method.
In almost all cases, DeepSurv presents the best results. Analyzing Psy, DeepSurv does not perform well when evaluating the IBS and MSE metrics. In most cases, the C-index value is higher than 0.90, which is a good indicator. However, this does not occur when analyzing CS (C-index = 0.891). In contrast, MSE = 0.0034, which is the best value compared to the other departments.
C-index and
IBS are the metrics of survival analysis and are not usually good predictive indicators. For this reason, in our research, we employed regression metrics such as
MSE and
MAE to evaluate the survival curves for each department.
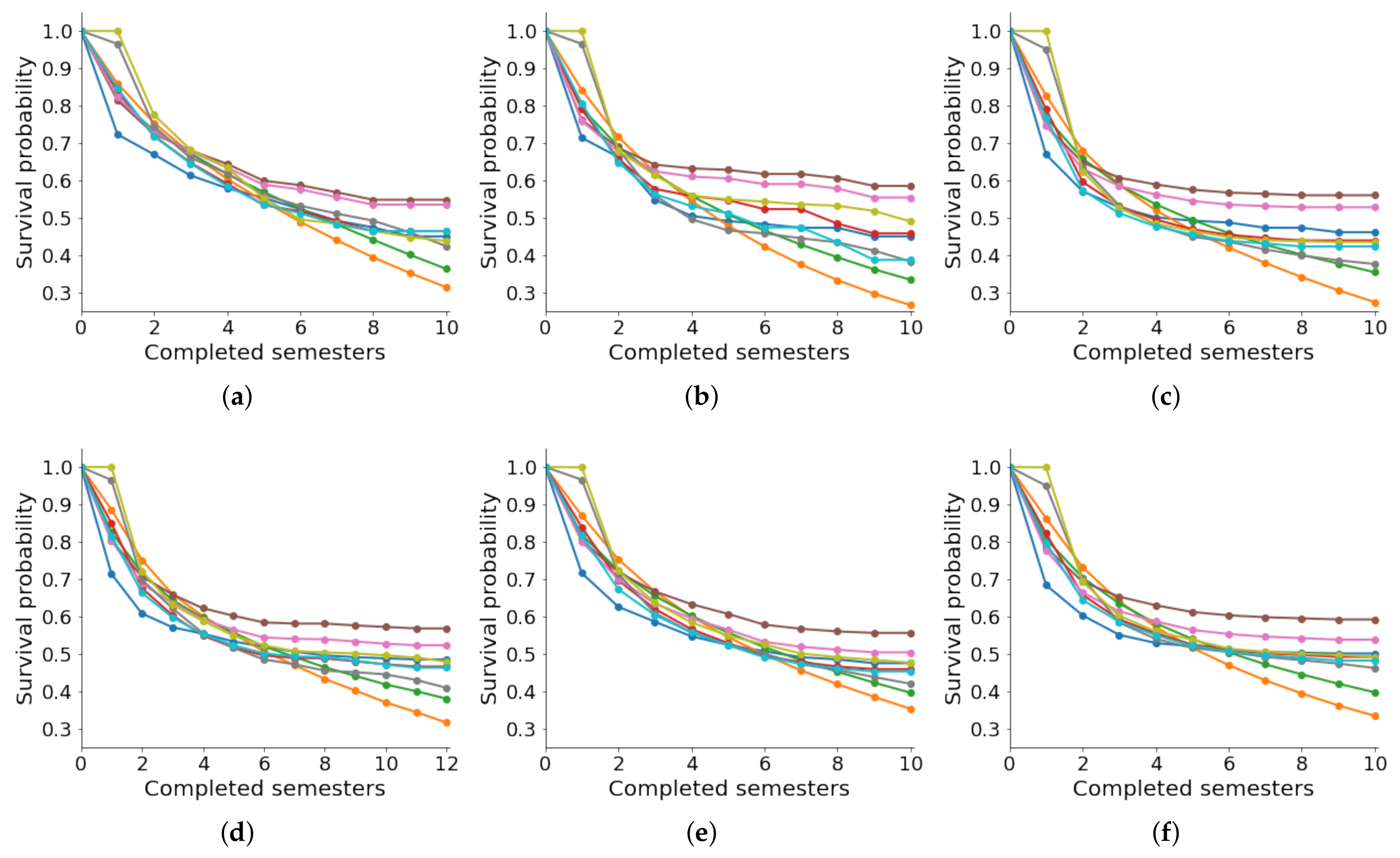
Figure 3 illustrates the actual survival curves (in blue

) by each academic department.
We employed the KM estimator to compute such curves and compared them with the predicted survival curves for the other methods. In general, parametric models such as Weibull and Gompertz do not present good results. Visually, we noticed that these methods predict lower chances of survival. In contrast, RSF and CSF have high survival probabilities; however, their approximation to the actual survival curve is very distant. MTLR and N-MTLR are very close to the actual survival curve; however, the estimation in the first two semesters is very poor. The models that present the best results when predicting the survival curve are CPH and DeepSurv. Finally, we concluded that DeepSurv is the best model in this context. However, predicting the survival probability during the first two semesters is not good for all methods.
6.4. RQ4: How Influential Is Academic Performance in Estimating Dropout Risk?
In this section, we analyze the influence of academic performance based on the level of risk of dropping out. We first calculated each predictor variable’s importance percentage and detail it in
Table 8. Some demographic attributes have very little influence, such as
Female,
Married,
Public,
Age_Admission,
HDI_Provenance, and
HDI_Residence. We found a moderate impact with the variable
Changed_SID; however, its percentage of importance depends on the department. For example, in
Edu, the importance percentage of
Changed_SID is 4.65%; in contrast, 17.87% is the importance level of
Changed_SID in
EBS.
The highest rates obtained in each department are highlighted in green, thus obtaining which variables associated with academic performance
Approved_Courses and
Final_GPA are the most influential. In most cases,
Approved_Courses has the highest percentage of importance, and it is only lower than
Final_GPA when we analyze
Edu. These results corroborate the strong negative correlation of these variables with
Dropout, as illustrated in
Figure 2. Although this confirms a strong and meaningful impact of the academic variables, we do not know to what extent they influence the different departments.
Since
DeepSurv was the best method for predicting student dropout in the survival format, we used it in the test sets to predict the risk score defined in (
7). Therefore, we implement in
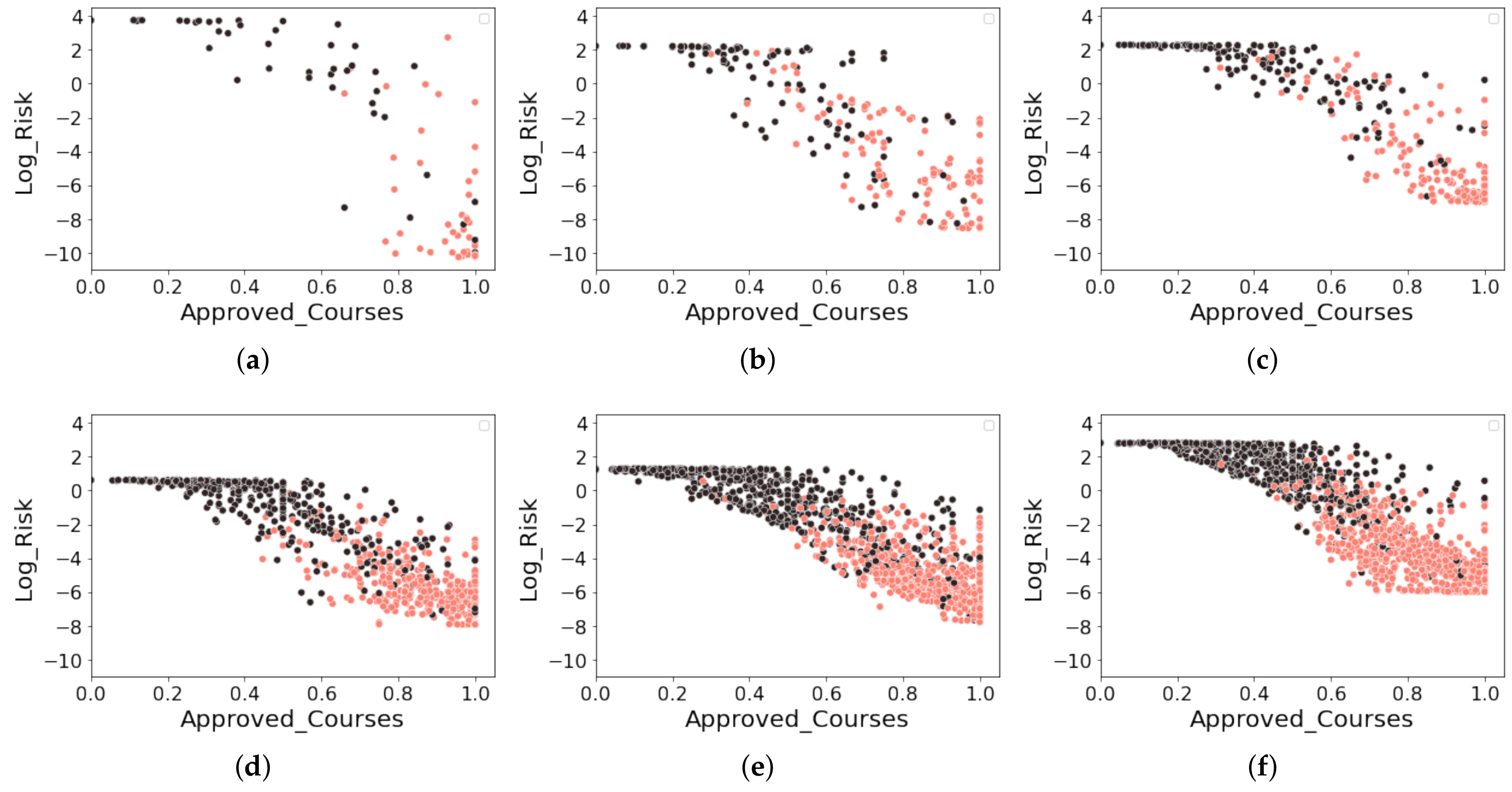
Figure 4 various scatter plots to visualize the data distribution according to the proportion of approved courses (
Approved_Courses) and the logarithm of the risk score, denoted by
Log_Risk. For each subfigure, we define the
x-axis as
Approved_Courses and the
y-axis as
Log_Risk and color the point data according to the dropout’s status (
Dropout). We highlight a student who has dropped out in black, while a student who has not dropped out is in pink.
As can be visually identified, a negative correlation exists between Approved_Courses and Log_Risk. We note a particular case in Edu in which all students with a proportion of approved courses less than 0.6 () are all dropouts. However, this situation did not occur in other departments. With this brief analysis, we found indications that the impact of Approved_Courses is more influential in Education compared to the other departments. Furthermore, each department’s predicted values of Log_Risk differ considerably. In Edu, we found on the y-axis that the range of values assumed by Log_Risk goes from −10 to 4. However, this does not happen in the other departments, which generally range between −8 and 2.
On the other hand, in STEM programs such as
CS and
Eng, we found higher numbers of students who did not drop out despite having a high failure rate in the courses (i.e.,
Approved_Courses < 0.6). Generally, these programs are challenging due to their predominant curricula based on exact sciences in the first semesters. Moreover, there is a tendency to normalize the effect of failing some courses. Complementing our analysis with the values of
NonReg_Courses from
Table 5 and
Table 8, we deduced that many students in STEM programs take courses in non-regular semesters to recover the failed courses. This is usually considered a characteristic of the persistence of these students.
More traditional programs, such as
LPS and
EBS, have a very similar behavior for the data dispersion and the range of predicted values of
Log_Risk. In this context, we can complement the persistence of these students with the variable
Changed_SID. It does not have a more prominent percentage presence as described in
Table 4; the importance of the variable in the model is one of the most relevant, as revealed in
Table 8.
Although we noticed that
Edu behaves differently from the others, we can show that
Psy is possibly the most similar to
Edu. Observing the importance percentages of
Final_GPA computed in
Table 8 in both cases, we note that these values exceed 24%, which are the highest values in our dataset. Unlike measuring the influence of economic variables from the perspective of approved courses, in
Edu and
Psi, we found that the grades are decisive, which led us to think that students in these programs generally have higher GPAs than those in other careers. Due to the wide granting of school scholarships, as reflected in Education, more than 12% of our sample has a scholarship. Generally, scholarship students seek to maintain high grades to avoid losing this study funding. On the other hand, in
Edu and
Psy, we show high importance to the hours of absence; that is, the impact of being hours absent from courses (
Absences_Courses) in these careers is a very relevant aspect if we compare it with the other departments.
Finally, we concluded from our analysis that the impact of academic variables is decisive in predicting the risk of dropping out. However, the effect that this generates is different in each department. Understanding this analysis requires a global study of the importance of the attributes and a complementary analysis based on statistical tools.


 ,
, 

 ) by each academic department.
) by each academic department.

 ), Gompertz (
), Gompertz ( ), CPH (
), CPH ( ), RSF (
), RSF ( ), CSF (
), CSF ( ), MTLR (
), MTLR ( ), N-MTLR (
), N-MTLR ( ), and DeepSurv (
), and DeepSurv ( ). (a) Education (Edu). (b) Computer Science (CS). (c) Psychology (Psy). (d) Law and Political Sciences (LPS). (e) Economic and Business Sciences (EBS). (f) Engineering (Eng).
). (a) Education (Edu). (b) Computer Science (CS). (c) Psychology (Psy). (d) Law and Political Sciences (LPS). (e) Economic and Business Sciences (EBS). (f) Engineering (Eng).



{kind=link}
{kind=link}
{kind=link}
{kind=link}