We first show the lexical networks for texts A, B, and C and then extract the lexicons in the form of lexical proximity networks containing the most important terms of the lexical networks. We also inspect the community structure of the networks. In addition, we introduce the 13 property classes for the construction of the lexicon profiles. The classification of words and terms on property classes is done on the basis of how related words refer to related targets. This classification is based on interpretation; thus, it is not as unambiguous as the division into communities, which is based purely on network metrics. Here, for terms T = [SCIENCE] and T = [SCIENTIFIC KNOWLEDGE], we introduce 13 property classes, as follows:
In each lexicon, different sets of words and terms may appear in the property classes. The words that belong to each property class in the vocabulary of a given text corpora are decided by the authors; thus, the classification contains a component of interpretation. The division of words and terms into communities partially overlap with the division of words into property classes. These two divisions are complementary in the sense that the division into communities is based purely on text structure, reflecting the syntactic and context structure, while the division into property classes is based on an understanding of thematic similarities between words and terms. For each text corpus, the same set of 13 property classes is used in constructing the lexicon profiles.
3.1. Lexicon of Text Corpus A
The lexical networks corresponding to the texts A, B, and C are shown in
Figure 1,
Figure 2 and
Figure 3, respectively. The lexical network for text A shown in
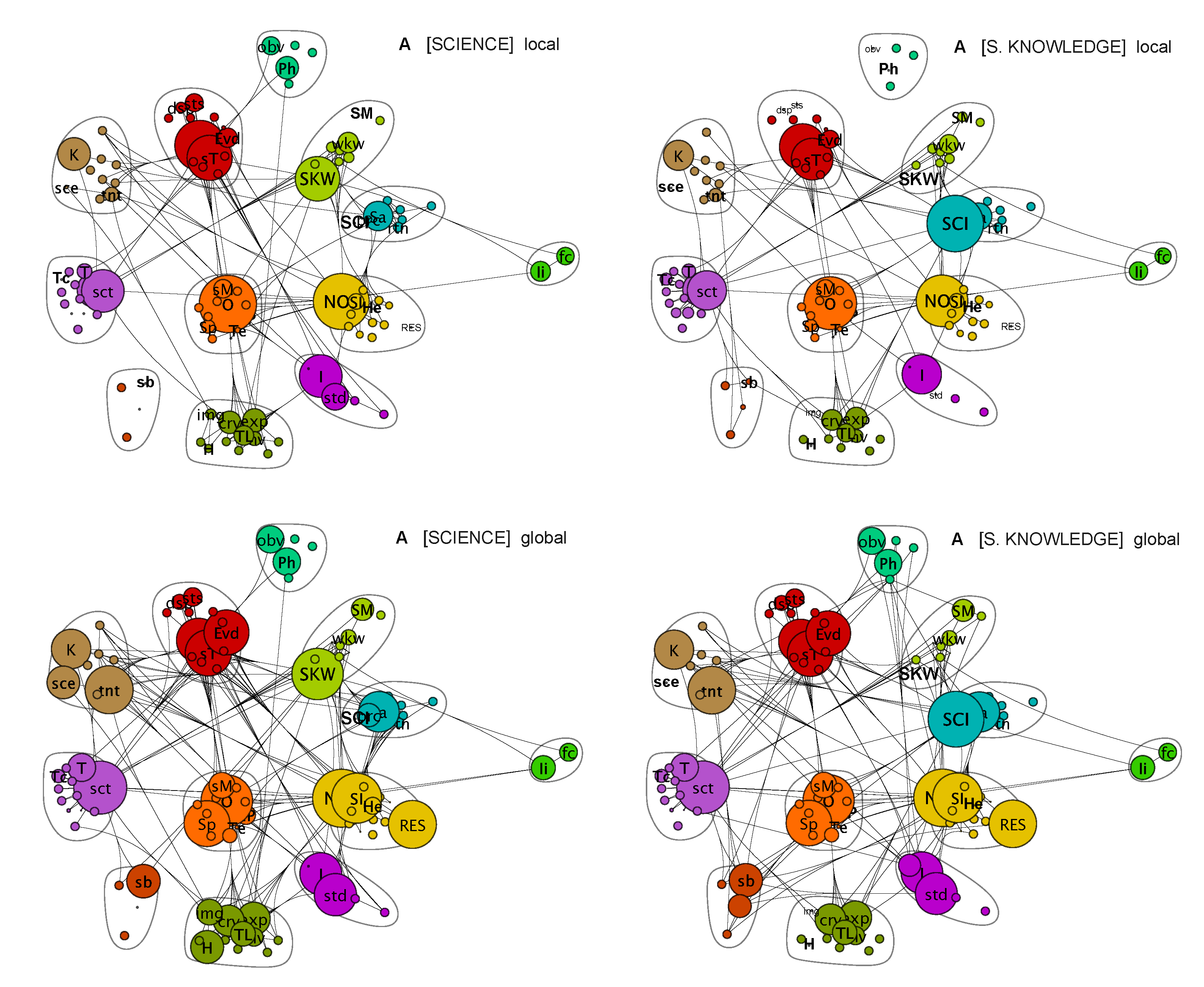
Figure 1 reveals a clear modular structure, consisting of about 11 communities in lexical networks for T = [SCIENCE] and T = [SCIENTIFIC KNOWLEDGE]. Both networks are very similar, with only small differences in the content of communities and how communities are interlinked. The lexical networks are shown for the local connectivity (local), corresponding to
, and for global connectivity, with
, which is large enough to retain the network unchanged when
is increased. The most important words and terms in the communities are denoted by abbreviations, explained in
Table 3. The size of the nodes in
Figure 1 is proportional to the communicability centrality of the node, corresponding to the role of the node in supporting the lexical meaning of other nodes in the network; the larger the node, the more important it is in the lexical network. The values of the communicability centrality
G of the most important nodes shown in
Figure 1 are given in
Table 3. In
Table 3, the communities of the words are provided.
From
Table 3, we see that words or terms that refer to closely related targets, ideas, or properties are often in different communities. This, of course, reflects the fact that related topics are discussed in different contexts and in different ways. The communities thus emerge from contextualization of discussion, not from connections between words or terms on the basis of how they refer to related targets (e.g., ideas or properties). In addition to the communities, words and terms can be classified into a property class
, with the property class given in
Table 4. From
Table 3 and
Table 4, we see that the terms and words that have the highest values of communicability provide the key terms for the communities. In the case of these most central words and terms, the division of these words into communities and property classes is to a large degree commensurate, each community roughly corresponding to one of the property classes. On the level of words and terms of intermediate and low values of communicability centrality (
), the division into communities and property classes becomes less aligned. This can be interpreted so that certain key words, like “science” and “scientific knowledge”, which thematically define the property classes, are also the words that thematically define the context of a text, but, in that context, auxiliary words that thematically belong to another context may appear. For example, in the context of scientific inquiry, “creativity” and “imagination” may appear, though these words characterize subjective human properties.
By comparing lexical networks that emphasize local connections (local,
= 0.2) to networks that place more weight on global connections (global,
), we see that the relative centralities of the words and terms change slightly; in the global picture, scientific inquiry, human aspects, subjectivity and theory-ladenness gain more weight than on the local scale. This suggests that text A discusses such topics in a contingent manner, picking up these themes in more than a few contexts. This indicates a multifaceted discussion of such topics. Of course, this conclusion has most probably been drawn also by simply reading the texts that form corpus A, but the advantage of networks analysis as shown in the figure in
Table 2 is that it is not based on human interpretation (always subjective) but only on structural analysis that is independent of the content (and thus more objective).
The comparison of lexical networks for T = [SCIENCE] to T = [SCIENTIFIC KNOWLEDGE] shows substantial similarity, although with some notable differences. For example, the words that refer to empirical aspects of science are weakly represented in [SCIENCE], while they are strongly represented in [SCIENTIFIC KNOWLEDGE]. This suggests that text A discusses the role of empirical results in relation to scientific knowledge but not so much in relation to science in general. Similarly, words referring to humans and constructions (see
Table 3) are more strongly connected as part of the network of [SCIENTIFIC KNOWLEDGE] than as part of [SCIENCE]. This, of course, does not mean that such words should be understood as characterizing [SCIENTIFIC KNOWLEDGE], but they are discussed in the context of [SCIENTIFIC KNOWLEDGE] more than in the context of [SCIENCE]. Interestingly, the community containing words referring to reality, theoretical models, and inferential aspects of science became detached in the lexical network of [SCIENTIFIC KNOWLEDGE].
The lexical network contains a wealth of information regarding the lexical and syntactic structure of the text; thus, it is difficult to gain a consolidated picture of how central the given words are and how many of them are related; in other words, the thematic dimensions of the lexicon. In addition, the community structure, while providing important information on the content of contexts, remains relatively silent about the thematic dimensions and extension of the lexicon. This information is provided by the property classes and their 13 dimensions.
Table 4 lists the words that are taken as key expressions in regard to the 13 thematic dimensions. The role and importance of each dimension as quantified in terms of lexicon profile
is based on the position of the words and terms in the lexical network, thus implicitly also containing the information of the community structure, through the values of the communicabilities of words contained in the lexicon.
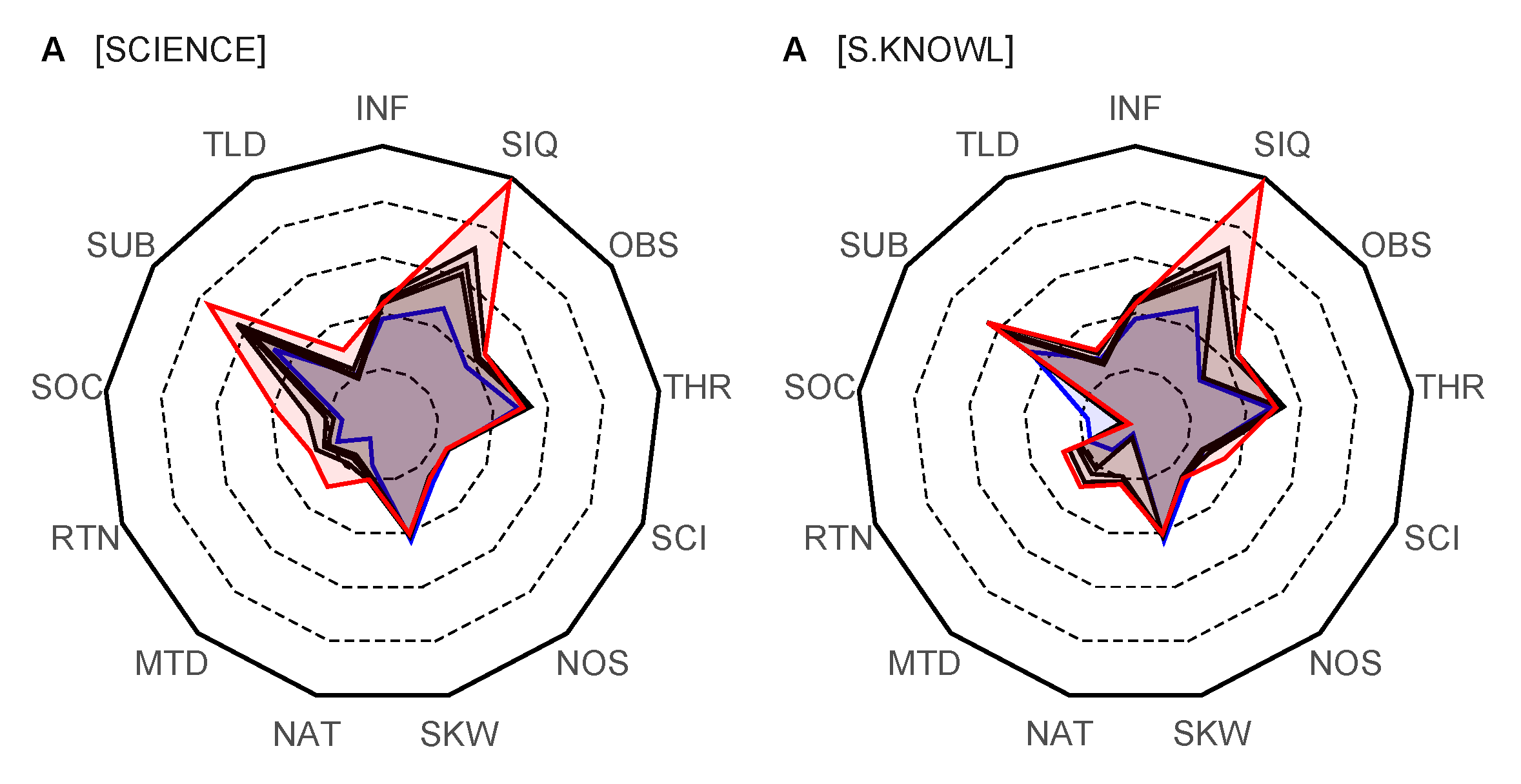
The 13-dimensional lexicon profiles for text A shown in
Figure 2 reveals how, with increasing syntactic depth, from the level of clauses to the level of connected contexts, certain dimensions become strengthened. With increasing values from
up to
the analysis gradually covers levels of L from 1 and 5 up to levels L ≤ 7, where more remote connections start to contribute. These more remote connections increasingly provide the semantic, context-related connections to the lexical terms. The more remote connections are supposedly important in providing the semantic content and also the different contextual ways to understand the meaning of terms, i.e., they reveal the context-relatedness and dependence of lexicons.
For T = [SCIENCE], the dimensions of subjectivity of knowledge (SUB), scientific inquiry (SIQ), theory (THR), and scientific knowledge (SKW) are nearly equally weighted on the local level (clauses and sentences), but, with increasing syntactic depth when the context level is taken into account, SUB and SIQ dominate the other dimensions. However, the dimensions of social embeddedness (SOC), rationality (RTN), and methodology (MTD) also gain importance but retain a relatively low significance. Obviously, the themes related to SUB and SIQ are discussed throughout the text so that their lexical support (i.e., how they attach to other words) becomes enriched; new meanings become attached through new words. For T = [SCIENTIFIC KNOWLEDGE], the thematic dimensions are very similar to T = [SCIENCE], but now the role of scientific inquiry (SIQ) is even more dominant. The role of social embeddedness is diminished to insignificance, indicating that it is not discussed much in the context of scientific knowledge. The close similarity (apart the role of SOC) is perhaps to be expected because, in text A, it is mentioned that nature of science mostly concerns aspects of nature of scientific knowledge, thus collating many aspects of science with aspects of scientific knowledge. The curious feature of the lexicon profiles, however, is the strong emphasis on vocabulary related to subjectivity (SUB) of knowledge and relatively low significance of vocabulary related to rationality (RTN) and natural phenomena, including reality (NAT). This is perhaps interpretable as a sign of the strong constructivist stance of text A, which is also reflected in the vocabulary of that text.
Finally, when the results for the thematic 13 dimensions are compared with the community structure, we can see that they correspond to each other reasonably well, although with certain clear differences. This can be taken as an indication of coherence in thematic and contextual structures, which obviously results from the fact that text A is arranged around the seven tenets, which organize the text and provide it with an overall systematic structure.
3.2. Lexicons of Text Corpus B
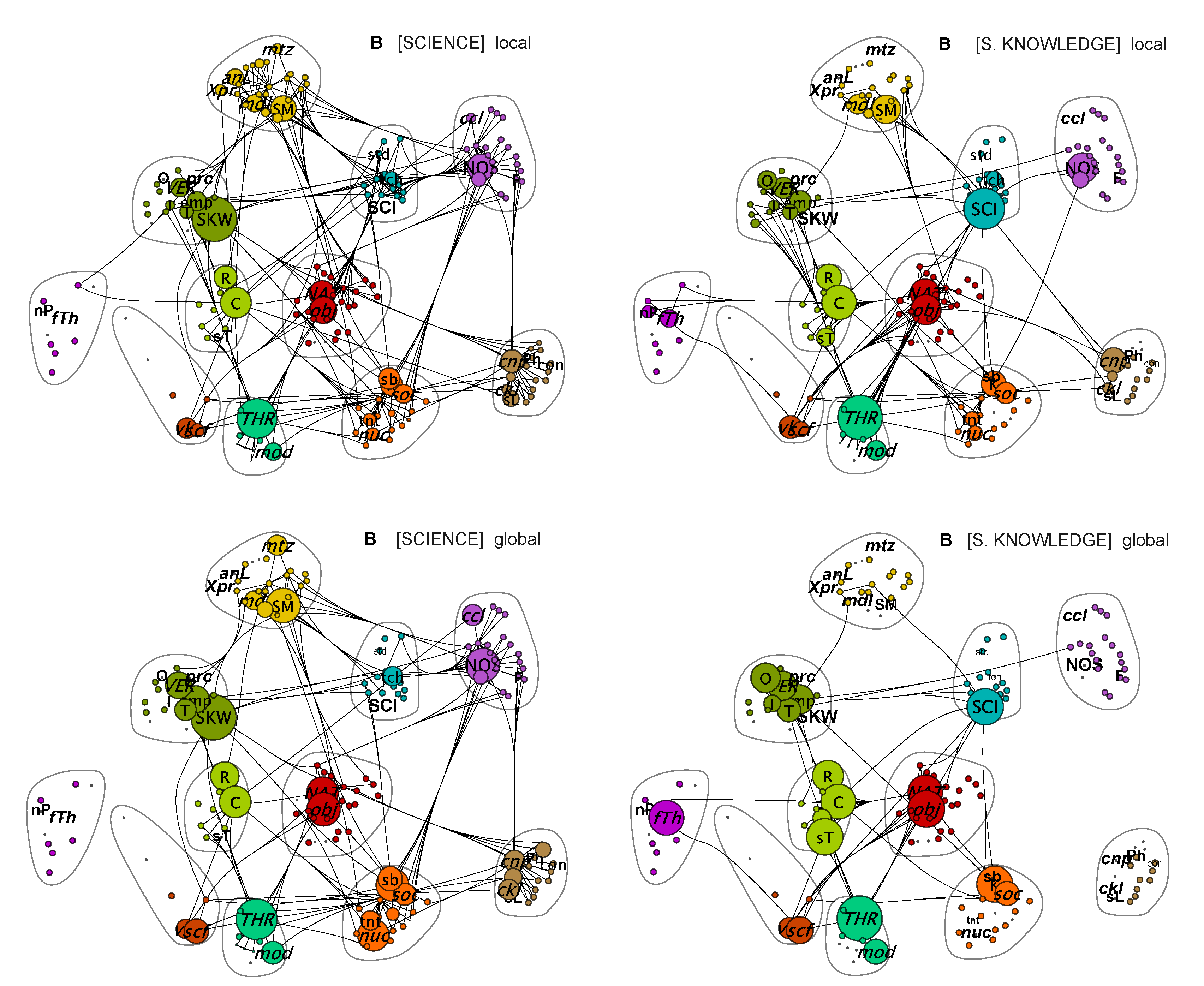
The detailed analysis of the lexical networks and lexicon of text A shows that the most interesting and important information about the lexicons can be consolidated in the form of a lexicon profile. The community structure is interesting, but dependent on context, and furthermore, the key words and terms that are central to the lexicon are essentially the same words and terms that act as key-terms in the property classes. Therefore, in what follows, we focus mostly on lexicons. The pruned lexical networks for text B are shown in
Figure 3, a summary of key terms and words with their community and property class associations in
Table 5, and the list of key terms included in the definition of lexicon profiles in
Table 6. In
Table 5, the abbreviations used in the figures are given, which allows us to read off the community structures of the networks.
The lexical networks corresponding to text B have a community structure resembling that of text A, reflecting a structure formed around the seven tenets. This is of course expected because text B is organized around the seven items in the consensus NOS list; thus, the contexts of discussions can be expected to be similarly structured in texts A and B. That the structures of the lexical networks are rather similar shows that the network captures the structural features inherent in the text corpora. When, however, we take a closer look at the words that belong to the communities, we find that a somewhat different wording is apparent in each text corpora B in comparison to A. We also see how words that belong to different property classes, formed on the basis of the mutual resemblance of the words and the targets they refer to, are distributed over different communities. This means that the same topics (related to words in similar property classes) are discussed in different contexts (related to communities).
In the case of text B, the lexical networks for [SCIENCE] are better connected than the networks for [SCIENTIFIC KNOWLEDGE]. In both cases, however, the communities including words and terms related to theory (THR), scientific knowledge (SKW), and reality and certainty (R) play central roles. Interestingly, the community corresponding to NOS becomes weakly connected in the network corresponding to [SCIENTIFIC KNOWLEDGE], revealing that, in text B, NOS is not much connected to discussions concerning scientific knowledge, although it plays an important role in discussing science. Moreover, the vocabulary related to science (recall that the term [SCIENCE] is excluded from lexical network T = [SCIENCE], but other terms and words of property class P = Science in
Table 6 are included) is weakly present in lexical network T = [SCIENCE] but central in T = [SCIENTIFIC KNOWLEDGE]. Similarly, the vocabulary related to the term [SCIENTIFIC KNOWLEDGE] is weakly present in the lexical network for T = [SCIENTIFIC KNOWLEDGE] but central to the network of T = [SCIENCE]. This kind of asymmetry was absent in the case of text A, which addressed [SCIENCE] and [SCIENTIFIC KNOWLEDGE] with more symmetric vocabularies. The asymmetry in the case of text B indicates that it approaches science and scientific knowledge as different kinds of thematic topics and does not collate them to the same degree as text A.
The lexical networks show that, for text B, the local () are better connected than the global () lexical networks, and, in the global networks, certain terms begin to dominate. This shows that, for only a few terms and words, lexical support becomes strengthened when longer connections are established at the level of cotexts and contexts are taken into account. Most of the terms and words appear only locally, on the level of sentences, but are not encountered again in sentences that belong to other contexts. This, on the other hand, means that a few important connections already introduced on the level of clauses and sentences are repeated or reiterated frequently; the text emphasizes the same aspects in many cotexts and contexts. In particular, many such terms and words emerging recurrently are related to methodology, rationality, and theory. This feature of the text is clearly visible in lexicon profiles.
The lexicon profiles corresponding to the text B are shown in
Figure 4 for T = [SCIENCE] and T = [SCIENTIFIC KNOWLEDGE]. As it has been already visible from lexical networks, text B has an extensive vocabulary related to rationality (RTN), methodology (MTD), and theory (THR), as well as theory-ladenness (TLD). In the lexicon profile for [SCIENTIFIC KNOWLEDGE], the rationality (RTN) and theory (THR) dimensions are very dominant and become more dominant over other dimensions when syntactic depth increases from the level of sentences up to the level of contexts. Consequently, rationality, theory, and methodology are apparently, on the basis of the vocabulary, topics that pertain to the whole text and are thus centrally important for the text. Such persistent emphasis on the topics of rationality, theory, and methodology is indeed evident from the general tone of text B, in that it criticizes consensus NOS on the lack of proper attention to just these topics and features of science and scientific knowledge. It is of course satisfying to find that the emphasis and general tone of the text, as apparent to a reader of the text, becomes so clearly visible in the simple (and interpretation-neutral) analysis of the vocabulary.
3.3. Lexicon of Text Corpus C
Text corpus C is aggregated from three different sources, mostly from texts related to the so-called Family Resemblance Approach (FRA) on NOS and a source explaining its philosophical underpinnings (see
Table 1). In addition, the corpus includes notions extracted from the text explaining views called features of Science on NOS (see
Table 1). The fact that the text is aggregated means that it contains a more varied and disparate set of words, is more fragmented, and the contexts are not as well aligned with the seven tenets as in corpora A and B. These features become visible in lexical networks as they are shown in
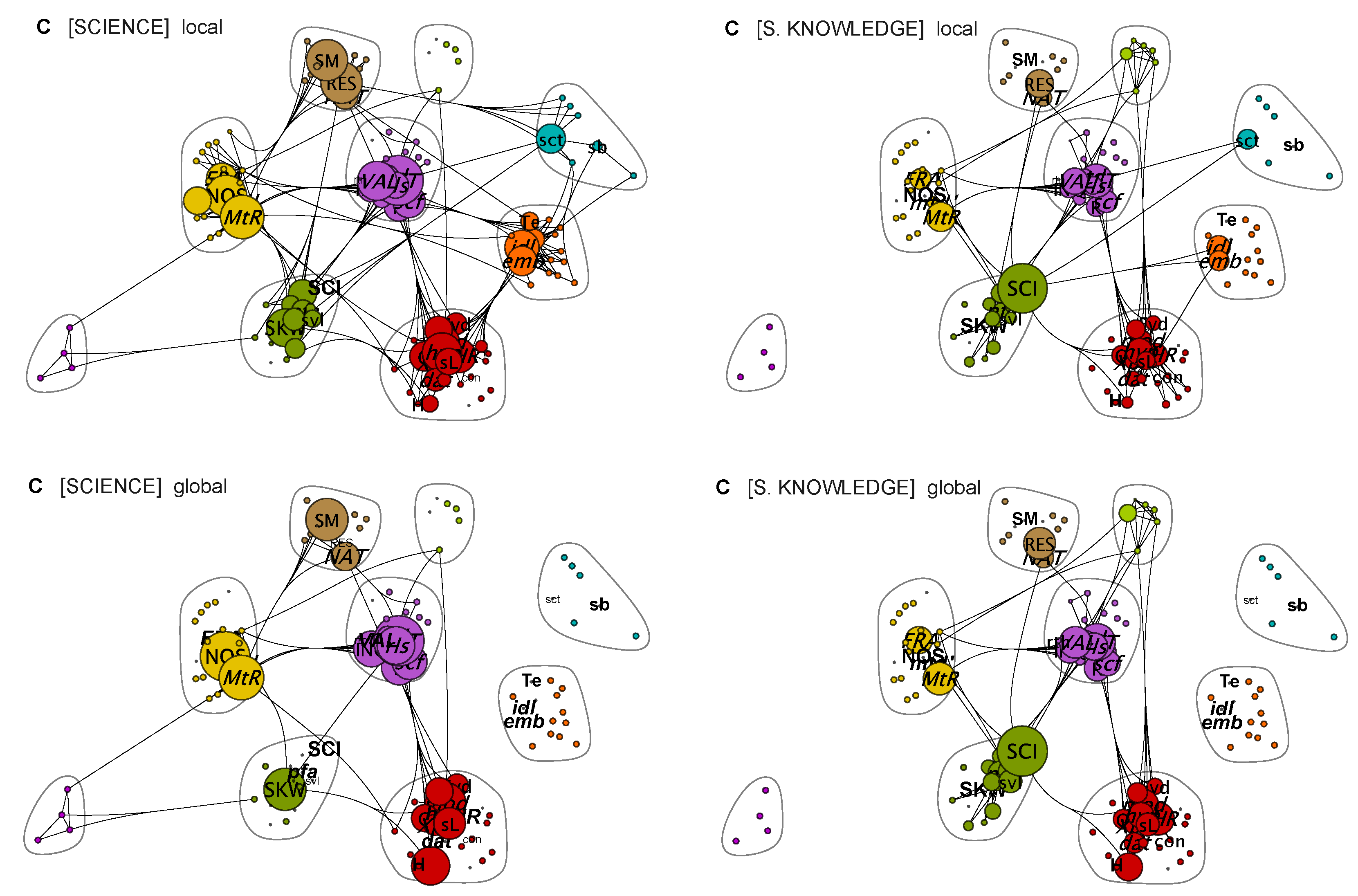
Figure 5, whereas, on the local scale, we see a few dense communities (red, yellow, green, and purple), but, on the global scale, only the red and purple communities remain dense. This behavior reflects the fact that we can find richer connections on the level of sentences than on the level of contexts because the same words most often appear only in a limited number of contexts and are not encountered recurrently in other contexts; the text does not reiterate the ideas and views in several contexts, thus the meaning of words remaining as they are formed on the level of sentences or at most at the level of cotexts. Furthermore, that behavior is strengthened because text C contains extensive lists of words and terms to exemplify the topics discussed.
The lexical networks in
Figure 5 for T = [SCIENCE] and T = [SCI. KNOWLEDGE] are somewhat different, the differences being greater than what was encountered in the networks for texts A and B. The most prominent terms listed in
Table 7 show that now much fewer terms are shared, and [SCI KNOWLEDGE] features many terms not found in [SCIENCE]. Such behavior indicates that text C discusses science and scientific knowledge in a different way. Of course, this is also evident from text C itself, since it makes the distinction between science as acognitive-epistemic system and a social-institutional system. The results in
Figure 5 and
Table 7 only quantify these differences through the metric of lexical distances of the words.
In corpus C, the richness of vocabulary is nearly twice as extensive as in A, but most words and terms appear only once or twice. The text corpus has a character of listing words, with little connection to more in-depth discussions. This, of course, results from the way the corpus is constructed, from excerpts summarizing key notions contained in the text that provide the underpinnings of notions discussed elsewhere. In particular, the property class SOC, containing words that refer to social and organizational aspects of science, is extensive. In
Table 7, only about 40% of words in that class are listed. However, the words that occur with low frequency (once or twice, mostly), and are thus not included, have a negligible effect on the lexicon profiles. In addition to the property class SOC, the property class of methods (MTD) also contains many words and terms that are mentioned only a few times and thus are omitted in
Table 7, which thus contains only about 45–50% of all possibly relevant items. The community analysis collates the words that belong to property classes SCI (science) and SKW (scientific knowledge). Similarly, communities
sL and
VAL contain many words and terms that belong to different property classes. These aspects mean that the same words may appear in very different contexts of discussion and thus have different weightings of meaning. For example, the methodological rules can be discussed from the point of view of scientific methods but equally well from the point of view of the institutional norms of doing science.
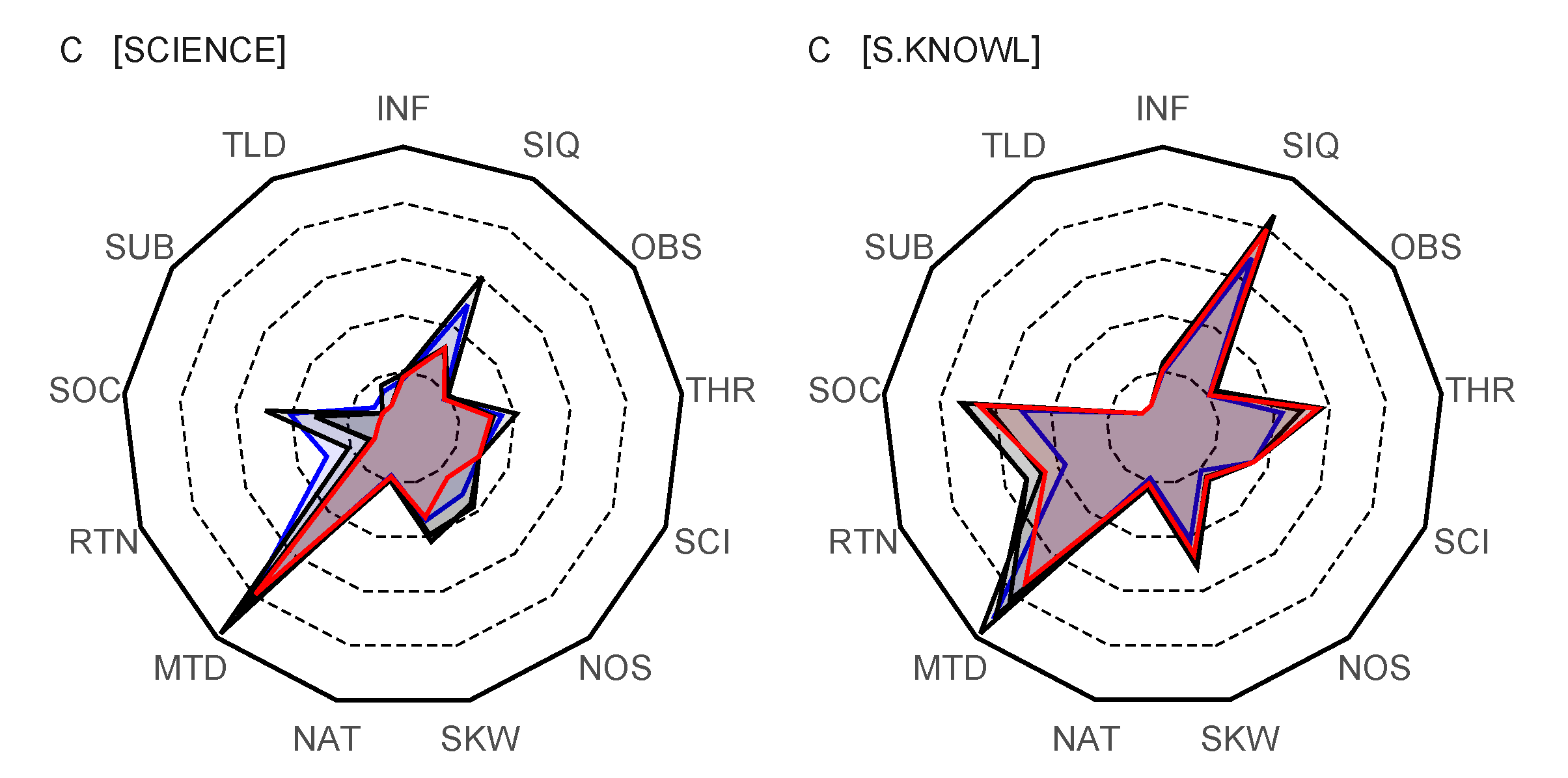
The major part of the text corpus in C is about the FRA (Family Resemblance Approach), which makes a clear distinction between the cognitive-epistemic and the social-institutional aspects of science. These focal points of discussion are also reflected in the lexicon profile shown in
Figure 6, where we see a strong focus on methodological aspects and scientific inquiry, as well as on social aspects. This division of topics into two broad categories might also explain why science and scientific knowledge overlap in the community analysis. Similarly, the overlap of models with factors related to observation, rationality, and partly also to norms may be explained by how FRA in the cognitive-epistemic part focuses on the roles of models, theories, and laws as structures of scientific knowledge. The fact that text C introduces topics contextualized in two broad thematic areas is visible from the formation of dense clusters, where words referring to different thematic areas, like methodology, knowledge structure types, and even norms, become connected. On the other hand, some words related to those thematic areas on the local scale fall out of the dense clusters on the global scale, for example, the words: empirical basis (emb), theoretical entities (Te), and idealization (idl).
A closer look at how different terms become divided into different communities reveal their closeness when they become contextualized. The community analysis, while sensitive to contextualization, may establish relationships that are difficult to understand on the basis of the thematic closeness of the words. For example, words referring to theoretical entities may appear in communities that are different from those where models and modeling appear. The way the words appear in communities is more sensitive to contextualization than thematization, whereas, for different contextualizations (depending on viewpoints taken), more contingent choices are possible than for thematical categorizations.
3.4. Comparisons of Text Corpora A, B, and C
The lexicon profiles
corresponding to text corpora A, B, and C can be used as bases for comparison that are based on thematic categorizations of words and are thus less sensitive to context than the community structure. As we have seen, in some cases (text A), the community structure parallels the thematic categorization, but these may also be essentially different (as in text C). This is one consequence of abstract words being polysemous; they do not have similarly fixed meanings as words referring to simple concrete objects. Therefore, in comparing the lexicons, we focus on lexicon profiles as based on thematic relatedness instead on community structure, which reflect context relatedness. The lexicon profiles, instead of being context dependent, attach thematically related (i.e., same kinds of referents or even synonymous) words and terms to [SCIENCE] and [SCIENTIFIC KNOWLEDGE]. This information on thematical dimensions is reduced to 13-dimensional vectors, where each dimension is denoted by one of the tags listed in
Table 4,
Table 6, and
Table 8 for property class
. The choice of key words in
Table 4,
Table 6, and
Table 8 is specific to the text, some of them identical, but generally different vocabularies are used. Therefore, the choice of key words contains an element of interpretation about the meaning of the word and to what it refers. Nevertheless, as is seen in the listings of key-words in
Table 4,
Table 6, and
Table 8, such classification contains fewer unexpected groupings of words than the grouping based on community structure.
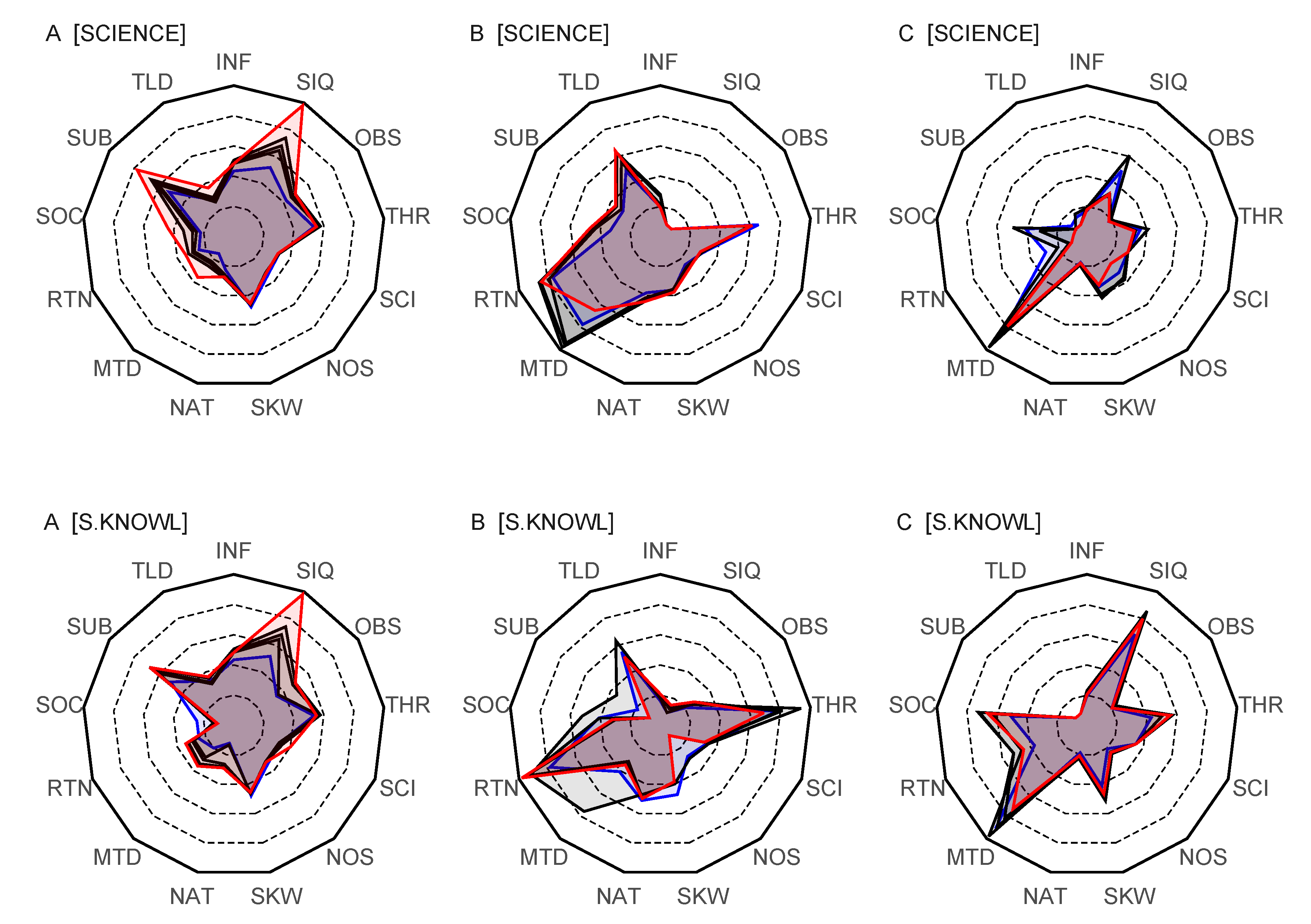
The lexicon profiles corresponding to texts A, B, and C in
Figure 2,
Figure 4, and
Figure 6 are collected for comparison in
Figure 7. It is seen that text A covers nearly all aspects contained in the 13-dimensional profile, thus having a balanced weight of vocabularies to discuss all 13 aspects. Some of the vocabularies, like methodology (MTD), rationality (RTN), and nature/reality (NAT), are under-weighted in comparison to other dimensions. In addition, the similarity of lexicon profiles for T = [SCIENCE] and T = [SCI. KNOWLEDGE) is noteworthy. The similarity is in agreement with the notion contained in the text that it sees NOS and nature of scientific knowledge (NOSK) as similar constructions. The lexicon profile puts much weight on items related to scientific inquiry (SIQ) and the subjectivity and tentativity of knowledge (SUB). These notions are also in line with the purpose stated in the text. It should be borne in mind that the results condensed in lexicon profiles are obtained purely by inspection of vocabulary and by measuring the lexical distance of words, without interpreting the content of the text (the only interpretative element is the choice of key-words, which is not guided by an interpretation of the text, but the general understanding of the authors who have backgrounds in physics and physics education).
The lexicon profile for text B is very different from that of A. Text B, as it appears, was written to extend and augment the views contained in text A and other similar texts. The dimensions MTD, RTN, and NAT, which were underrepresented in A, are now heavily overrepresented in B. In this, text B clearly serves the purpose its author mentions: to strengthen and augment the aspects omitted in consensus NOS. With regard to [SCI. KNOWLEDGE], text B has a very extensive vocabulary of items related to theory [THR], revealing a stronger emphasis on theoretical knowledge in comparison to text A. The differences between the vocabularies of A and B are so significant that it raises questions as to whether the two texts have any common ground at all. If we take at a face value the notion that lexicons and their differences indicate differences in thought and ways of framing the phenomena and posing the relevant questions, we can conclude that texts A and B indeed represent different schools of thought.
The lexicon profile for text C reveals an emphasis on methodology to the same degree as the lexicon profile for B, but now scientific inquiry and the sociological and institutional aspects also have strong vocabularies. Lexicon profile C clearly augments the aspects that are not so well represented in A, yet retains the certain richness of dimensions, although not to the same degree as A. The lexicon profile for C is not as far removed from A as B, but, in C, the dimensions related to scientific inquiry (SIQ) and methodology (MTD) are also over-emphasized in comparison to other dimensions. In general, the lexical network for C reveals a certain fragmentation and lack of coherence, but this is clearly a consequence of how the corpus of C was constructed as a collated corpus.
The lexicon profiles of A, B, and C are quite different, which can be interpreted in two ways. The first possible interpretation is that both B and C have grown from criticism towards consensus view of NOS (text A); thus, they pay attention to dimensions that their authors think text A misses or misrepresents. On reading the texts, the impression is indeed that this is clearly the goal of text B, but not so much of text C. The second interpretation is that texts B and C are meant to augment the views represented in text A, not so much to criticize and replace the consensus view. However, if this second interpretation is viable, one would expect the vocabularies of texts of B and C to overlap more with the vocabulary in A. From the perspective of overlap of vocabularies, as represented by the lexicon profiles, the common ground for easy and co-constructive discussion is shallower than might be desired. Therefore, the first interpretation, that texts B and C can be taken rather as criticism and attempts to suggest alternative views, gains credibility if one focuses only on vocabulary and how it overlaps with A. Such a visible discrepancy of vocabularies may well be one reason behind the slow convergence of views and perhaps the even formation of different schools of thought concerning NOS. However, from the viewpoint of lexicons and vocabulary, the consensus view as consolidated in seven tenets and as forming the basis of text A appears to contain a rich enough vocabulary to provide a platform for the convergence of views.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
