Strategies for Successful Learning with Geographical Comics: An Eye-Tracking Study with Young Learners


Department Didactics of Mathematics and Natural Sciences, Institute of Geography Education, University of Cologne, Gronewaldstr. 2, 50931 Cologne, Germany
*
Author to whom correspondence should be addressed.
Educ. Sci. 2020, 10(10), 293; https://doi.org/10.3390/educsci10100293
Submission received: 11 September 2020
/
Revised: 7 October 2020
/
Accepted: 12 October 2020
/
Published: 21 October 2020
(This article belongs to the Section Curriculum and Instruction)
Abstract
:Many studies report that comics are useful as learning material. However, there is little known about how learning with comics works. Based on previously established theories about multimedia learning, we conducted an eye-tracking experiment to examine learning about geography with a specially designed combination of comic and map which we call geo-comic. In our experiment, we show that our geo-comic fulfills many prerequisites for promoting deep learning. Thus, we establish guidelines for an effective design of geo-comics and recommend deploying comics in combination with maps in geography classes.
1. Introduction
Comics have recently been discovered to be effective tools in science communication. However, empirical research in this field remains scarce [1], which is especially true of comics with geographical content. In theory, there are many arguments for the use of comics in the classroom. Sousanis (2015), for example, points out that comics, through their unique combination of text and imagery, can offer more perspectives than one medium alone and thus promote a deeper understanding of the content. Using visual symbols, metaphors, and realistic depictions in combination with textual modes of expression, comics create a “symphony” [2] (p. 65). With this symphony, we can learn about the world, but how exactly does learning work with such a medium? Many theories describe learning with text–picture combinations (e.g., [3,4,5]). However, we do not know whether the results of these studies apply specifically to comics; neither do we know whether they work in geographical contexts. The question remains: how can we learn about geography with comics? In this study, we wanted to find out the extent to which strategies of viewing geographical comics influence the comprehension of the comics’ content. What kinds of strategies exist? How do viewing strategies relate to the comprehension of content?
We conducted an eye-tracking experiment using a geography comic specially designed for this study. The direct observation of eye movement gives us unique insights into thought processes and cognitive information processing in learners. By moving our eyes, we can “focus our concentration (…) on the object or region of interest” [6] (p. 3). Thus, by observing someone’s eye movements, we can learn something about “what the observer found interesting” (ibid.). In other words, “eye movements provide evidence of overt visual attention” (ibid. p. 5). They enable us to measure attention and reproduce, track, and comprehend actions that are key to the intake of visual information. We can quantify otherwise inaccessible processes that have a close relationship to the forming of representative models in our mind, and we can do this on an individual level. Concerning research on instructional methods in multimedia learning, we can “go beyond asking simply ‘what works?’ or ‘when does it work?’” We can now “determine how a particular instructional method causes learning” [7] (p. 167).
In the following, we will derive hypotheses from existing theory which we want to test using a specially designed comic. The methods which we used are detailed in the next section. Subsequently, we present and discuss the relevant results of the eye-tracking experiment in the light of geography education.
2. Theory
Numerous studies have shown that learning with comics influences cognitive performance in a positive way. Aleixo and Sumner [8] report, in a study of learning about biopsychology with comics, that students learning with comics had significantly higher memory scores than those who did not learn with comics. Nalu and Bliss [9] found that learning with comics supports the speed of learning. Comparing two groups of young naval officers in training, those who learned with comics were twice as fast as those who learned with text-only material, while both groups achieved comparable test results. In medical training, several studies show that students learning with comics achieve higher degrees of knowledge accompanied with a higher motivation to learn than those learning without comics [10]. In a study of lessons teaching about burn injuries, Sinha et al. show that there were significant improvements in the test results of five to seven year olds when they learned with comics as compared to traditional classroom material. This study was conducted at the same time in India and the US. Özdemir [11], too, identifies a significant improvement in the test scores of young learners (sixth graders) who learned with comics compared to those who did not learn with comics. He also states that those students with low interest in the topic, in particular, could be better motivated to learn and were more accepting of the learning material than those who did not use comics. Even the software company Oracle recommends learning with comics, based on a study of the effectiveness of learning materials [12]. Hosler and Boomer [13] observed a significant improvement in comprehension among students using science comics as learning materials in biology classes at university level compared to those in classes where comics were not used. Brand et al. [14] also observed better comprehension in a study using comics for informing patients about the nature of their ailments. Additionally, they reported lower anxiety levels and greater satisfaction in the patients who were informed with comics. A meta-analysis of studies conducted in Japan shows two important advantages to learning with comics [15]: they seem to be easy to understand and, for many (Japanese) students, are an attractive medium for taking in information.
It seems that learning with comics can improve learning outcomes across many settings, age groups, and cultures by supporting the learning process. However, little is known about how this works, and we know even less about how this might work in geography education. We will use theories from multimedia learning or comics studies to hypothesize about learning with comics in a geographical context. To our knowledge, no investigation has been conducted on reading processes in comics in a geographical context, e.g., when a map is present in the comic in addition to the typical text–image combination. Geography is a visual discipline (e.g., [16,17]). It is common to use word–picture combinations such as diagrams, block diagrams, ground profiles, and, arguably most importantly, maps to communicate geographical content. These communication devices are essential to the geographical discourse and cannot be left out of any learning material. This means that they also should be incorporated into comics designed for learning geography. Thus, we define geo-comics as comics about geographical topics that include specifically geographical communication devices. Comics fuse text and imagery in an agent-based narration. The imagery part of the comic can very well include geographical visualizations such as maps. In our study, we test this kind of geographically enhanced science comic in order to find out the extent to which strategies of viewing geo-comics influence the reader’s comprehension of the comics’ content.
By testing our hypotheses on a comic with geographical content, our investigations shed light on how existing theories apply to geo-comics, how viewing strategies influence comprehension of geographical content, and how we can support these strategies in weaker learners as well when designing new geo-comics.
2.1. Integrated Processing of Text and Picture Improves Learning
In the following, we will discuss insights from multimedia studies and comic research that seem to be most suitable for a transfer to geography comics. We will then propose hypotheses to be tested on a geography comic to gain deeper insights into what successful learning strategies with geo-comics might be.
According to Mayer [15], the combination of text and image can help learners to better understand the content of learning material than a single medium alone. However, this is only the case if both text and image are in close proximity to each other, which clearly is the case in comics. If the distance between them gets too large, the cognitive capacities of the viewer are used for searching for the connected elements. Then, the workload for the mind becomes too large to positively affect learning [5,16]. Integrated processing of text and image is revealed by the transitions between the two media. The better the readers integrate the modalities of text and image, the better is their ability to recall the content from memory [18]. This integration is supported by placing labels on the pictures [19]. Inevitably, this is done in comics with the use of speech bubbles, which anchor information to specific elements of the image. Both Kirtley et al. [20] and Laubrock et al. [21] (p. 257) argue that during comic reading, “text and image are processed in parallel.” However, eye-tracking experiments have shown that it usually takes more time to retrieve the same amount of information from text than from image [21]. As Kirtley et al. [20] (p. 278) confirm, “more information can be taken in peripherally” while viewing images as compared to text. Loschky et al. [22] describe how viewers extract the relevant information from an image within the time span of only two fixations, moving from the gist of the picture to a salient detail. This is not possible with text, where we have to identify single characters and words. An integrated viewing process in comics concerns not only text and image but also putting different images into context with each other. Comics use panels as segmenting units that are arranged on the page, each displaying a certain slice of time. However, the interplay between the segments, as well as the arrangement of the segments on display as a whole, carry different kinds of meanings and complement each other in the learning process [2]. According to Sousanis (ibid.), comics convey a deeper understanding of content in this way, offering different perspectives and modes of expression.
Based on this theoretical context, we are able to describe potentially successful viewing strategies for comics with geographical content. First of all, if text–image combinations promote deep learning, the presence of pictures must make a difference. Following Mason et al. [18], it is a prerequisite for effective learning with text–image combinations that the viewers are able to integrate the different kinds of media in their minds. This means that they have to come back to text or picture at least once so they can reevaluate the information from one medium in light of the information found in the other medium. In order to process text–image combinations, viewers have to switch back and forth from text to image in order to connect them in their minds.
Thus, we hypothesize that:
Hypothesis 1 (H1).
Learners have a better understanding of the geographical content when a picture is present.
Hypothesis 2 (H2).
Learners show better comprehension of geographical content when more frequently switching between media (text, image, map).
2.2. Character-Driven Narrative Supports Learning in Text–Image Combinations
The embodiment principle recognizes the fact that there is deeper learning whenever human or human-like agents are present in the learning material [23]. Our innate capacity for empathy triggers emotional involvement with these presences, which in turn leads to a more involved way of processing content. Learners engage intensely in active cognitive processing when they “try to make sense of what the speaker is saying” [23] (p. 346). This heightens interest and supports willingness to learn more about the content. This effect is induced by a feeling of social presence even from fictional characters. When such a social presence is felt, “the learner works harder to select, organize, and integrate incoming information” (ibid). The result is better performance in problem solving transfer tasks. Research from different fields supports the embodiment theory. According to Nakazawa [15], for example, who has examined learning with Japanese comics, emotional storytelling and (visual) representations support the learning process. Using eye-tracking methodology, Kirtley et al. [20] found that important factors driving the reading process in comics seem to be text and the presence of images of persons: when a character was present in a panel, more time was spent on it. Laubrock et al. [21] (p. 262) also found that images of characters “receive more attention than the rest of the panel.” Panels without text and without characters were more frequently skipped by the readers. Thus, Kirtley et al. [20] (p. 279) speculate that “verbal text paired with a character may be particularly informative.”
If it is true that an engaging story featuring relatable characters helps learners to understand facts, then paying attention to the characters driving the story should be a good strategy for taking in information in geo-comics as well.
Hypothesis 3 (H3).
Paying more attention to images of the characters driving the story results in a deeper understanding of the comic’s geographical content.
2.3. Sequence of Perception Influences Cognitive Performance
In learning with text–image combinations, the order in which the learner perceives the different types of media seems to play a major role. Rothkegel et al. [24] describe the significant effect of the first fixation on the following scanpath over an image depending on its initial position. Where we look first in a given display strongly determines where we will look next. This influences the whole chain of how we move our eyes around the display. Eitel et al. [5] have discussed how students can explain spatial layouts of objects much better if they are exposed to a picture representing that layout before they read a text about it. Even when the pictures were shown only for a very short amount of time, test results were significantly better when the students were handed the text afterwards instead of before the showing of the picture. Although, in a subsequent article, Eitel et al. [5] relativize these findings somewhat, they still confirm that there is a significant effect of the sequence in which learners perceive text and picture. They suggest that the first helps to guide the student through the second. In several studies examining the process of reading comics, researchers found that text is a major factor determining how much time readers spend on a panel and influencing the order of panel viewing. Text was also found to be a predominant entry point for panel views [20]. However, Laubrock et al. [21] (p. 257) somewhat contradict this claim. They observed that the image part of a panel was visited first, but “only for a short amount of time”.
In informational material with geographical content, maps are usually used to tie together and contextualize key aspects by revealing their spatial and other relations in a common terrain. The map should thus be the guiding medium in many geographical contexts. A thorough understanding of the comic’s geographical content is expected to be more likely when the map is viewed before anything else, so that viewers are aware of the big picture before delving into more detailed contemplations.
Hypothesis 4 (H4).
Using the map as an entry point positively influences geographical understanding of the comic.
3. Method
3.1. The Sample
We presented a comic with geographical content to 36 German speaking students aged 10–14 years. We were especially interested in examining the strategies of learning with comics in young learners, because there is a great lack of knowledge about this particular age group. Most research is done with university students, for practical reasons. However, their perception and usage of media might differ considerably from that of younger learners for reasons of child development and media socialization. It was a major challenge to find participants in this age range willing to participate in the time-consuming eye-tracking experiment. The problem was even more complicated by the fact that we could not conduct several runs of the experiments in parallel, because we only had one eye-tracking device at our disposal. Our pool of participants was comprised of two different groups. One was an eighth grade of a German “Realschule”, a type of school that leads its students to vocational training after the completion of the tenth grade. The other one was a group of participants in a summer science camp for fifth to sixth graders at the end of their terms, which took place at the University of Cologne. This resulted in our group of participants attending fifth to eighth grade in various kinds of German schools, which revealed a probable influence of school type on comic viewing strategies. The age range of five years allows us to consider whether age has an effect on comic viewing strategies.
In a preceding survey, we assessed the students’ comic affinity and expertise using a visual language fluency index, namely Cohn’s VLFI [25], in order to consider the effects of comic expertise on learning outcomes. While it is generally hard to assess a person’s comic expertise, this index is widely used in comics research (e.g., [21]) and was found to produce satisfying results. We had to adapt the wording of the questionnaire in minor ways due to the young age of the participants and added “watching Youtube videos” to the list of preferred activities. This did not influence the calculation of the VLFI, however. According to this test, which is based on self-evaluation, the group (n = 33) scored rather low fluency in visual language, with an average of 8.83 points (SD = 5.26). Cohn [25] classifies a score under nine points as comparably low fluency in visual language. Of all participants, 60.6% scored in the class of low visual language fluency. Only one participant achieved a high score of 25 points, high being defined as more than 22 points. The great distance of 9 points between this score and the next lower score of 16 points made this rather exceptional. However, since the index relies on self-assessment, we cannot treat this as an outlier with certainty. It might very well be true that this one person has higher expertise than all the others. The relatively high standard deviation probably reflects the group’s heterogeneous interest in comics. While some students are fans of the medium and regularly consume manga or other comics and even draw fan art themselves, others do not show a particular interest in comics or they even dislike them.
3.2. The Research Instruments
While viewing the comic, the participants’ eye movement was captured using a SMI RED250 mobile eye-tracking device. It records the eye movement at 250 Hz with a spatial resolution (RMS) of 0.03° (human) and a gaze position accuracy of 0.4°. Prior to viewing the comic, we calibrated the eye-tracking device to each participant using five focal points. The participants had to fixate on the points in the order in which they were shown on the screen. We repeated this procedure until results were satisfactory, but not more than twice. To ensure validity, we kept all datasets showing a horizontal or vertical deviation of equal to or less than 1°. Two datasets had to be removed from the eye-tracking data analysis due to unsatisfactory calibration. In one case, the participant’s glasses were probably the reason. This resulted in an average deviation in both directions of 0.48°. Reliability of the data records in this sample was high: we registered an average tracking ratio of 96.8 percent. The eye-tracking device recorded saccade and fixation-based metrics, of which we chose fixation count, revisits, and dwell time as measures for attention (for a detailed explanation, see Section 3.3.4). We used statistical analysis mainly in the form of correlations to test for effects of viewing behavior on test results. For the application of correlational testing, the post-test results were transformed to a ratio scale using the Rasch model.
Although some researchers report gender differences, we conducted the experiment in compliance with the general ethical standards, asking parents for permission in the case of minors, which was the case for all participants. We informed the participants and their parents of potential health risks and that they were free to retreat from the eye-tracking experiment and the surveys that we conducted at any time and without suffering personal disadvantages, which two of the potential participants did. We ensured the anonymity of the participants by replacing their names with codes. The key to the codes was held exclusively by the participants, so that they could reuse them on different occasions, like the pre-test, the eye-tracking experiment, and the post-test.
3.3. Study Design and Procedure
In order to investigate young learners’ viewing strategies of comics in the context of geographical learning, we conducted an eye-tracking study with a specifically designed geography comic. This comic features a map in a prominent position at the center of the layout. The comic was designed to fit a computer screen at a full HD resolution of 1920 × 1080 px. The comic tells the stories of four stakeholder groups involved in the international rose trade, based on real events. The four stories are tied together by the map, indicating with anchors and arrows the locations of the stakeholders and the directions of flow of goods and capital. Forty-six pieces of information on the rose trade were coded in the comic using text, pictures, and map. It can be downloaded in original resolution here: https://geodidaktik.uni-koeln.de/sites/geodidaktik/website_daten/eduComic/Rosenhandel/Rosenhandel_Full-HD-1920x1080-_22in.png.
3.3.1. The Design of the Stimulus
Map-based comics that have been specially designed for young students aged 10–14 years learning geographical content are extremely rare. In order to examine viewing strategies in young learners for a comic suitable for the German schools’ curricula for geography education, we had to create our own comic. We designed the comic to accommodate the research-based hypotheses of the previous section in the context of geography training (Figure 1). If pictures support the learning process, comics should be ideal for learning with pictorial content as they are a refined combination of text and image. Text and image in comics are positioned close to each other, with mutual reference. In our specific case, the map is also an integral part of the comic, positioned in direct proximity to the text and imagery of the comic stories (Figure 1). We aimed to enable readers to switch easily between the three elements of text, image, and map in order to create a thoroughly integrated mental representation. We used connecting anchor lines, color, and shape for visually connecting comic stories and the map. We colored the representations of the rose in both the comic and the map in a distinctive red hue and chose an iconic depiction of it for both the map symbol and the roses appearing in the comic. The map is a very prominent feature of our geo-comic and ideally readers take it in first. It takes up a large portion of the central part of the display (Figure 1). The map ties the four different parts of the comic story together by linking them with the flow of capital and goods between the different locations. It functions as a guide through the stories, connecting local events to the process of globalization. We tried to avoid redundancies between text, image, and map to reduce the cognitive workload. This makes it easier to allocate the source of knowledge presented in the post-test, allowing us to identify more easily whether a particular piece of information was retrieved from image, text, or map. Place names, for instance, are only retrievable from the map. Neither image nor text contains specific information on where the story takes place. We designed map and comic stories to fit on one page so that the integrational process in the mind is not disrupted by the need to turn the page. This is also appropriate for its use in the classroom, accommodating a minimal time budget. The content makes the comic suitable for use in the context of topics like globalization, global disparities, or agriculture in different parts of the world, all of which are part of the German school curriculum for geography education [26].
In our geo-comic, we focus on the subject area of the international rose trade, discussing globalization and its aspects of “continuing expansion and intensification of economic, political, social, (and) cultural (…) relations across borders” [27] (p. 1). We further follow parts of the definition of globalization proposed by Christensen and Kowalczyk [27] by showing how globalization “changes the life styles and living conditions for people around the world, presenting new opportunities to some, but risks and threats to others.” In this context, we touch upon global interconnectedness and disparities typical of globalized industrial agriculture in different parts of the world. With our geo-comic, we show through examples how “[i]ndividuals, firms, governments […], and multinational firms all face challenges of how to respond to globalization” ([27], p. 1). According to the school curriculum of North-Rhine-Westphalia, Germany, where the study took place, these topics should be treated in grades 5–10 [26], corresponding to the 9–16 year old age group.
The comic deals with some of the geographically relevant aspects of globalized production and trade exemplified by the rose trade. Key locations of this globalized industry are shown, as well as how they are connected in the process. The story is based on true events surrounding the (formerly) biggest rose producer, the Karuturi company, as reported on, e.g., by Hortidaily [28]. The comic focuses on the owners of Khan Roses, the investors from Singapore and Germany, who also represent the consumers of the roses, and the Kenyan farmers working in the rose fields and providing the farmland to the rose growing company. Stakeholders’ possible motives, actions, and reactions are displayed. In the comic, the global player in the rose growing industry is called Khan Roses, which serves the high-class market of Europe, indicated in the comic by the arrows and rose symbols (see Figure 1). The farming company receives funding from an investment fund based in Singapore to boost their operational business in Kenya. The students can follow the flow of goods and capital in a globalized world and comprehend some of the mechanisms of the international division of labor. The Kenyan farmers whose land the company seeks to acquire as rose fields react in different ways. On the one hand, they look forward optimistically to new job opportunities, providing a regular income as an alternative to subsistence farming. This highlights to the young learners some of the advantages of (industrial) agricultural development for the poor rural population, although these advantages are qualified in the following panel, which shows a group of people campaigning for fair wages. This illustrates the often unfair characteristics of these development processes and how they are based on an unequal distribution of wealth and power. On the other hand, the farmers fear poor compensation for the loss of their titles to property and thus of their traditional livelihoods. The topic of land grabbing is problematized in this part of the story (as treated, for example, in [29]). The comic aims to offer different perspectives on this controversy to the young learners, through the example of foreign investments in the agricultural sector in less industrialized countries like Kenya. The geo-comic also looks at a Singaporean investment fund which is looking for a chance to get involved in a valuable market, namely the rose business. The fund invests in Khan Roses and will in turn receive a share of the profits. The fund raises its money from investors around the globe, including Germany, exemplified in the comic by a young couple celebrating their financial success—by buying roses. We chose Germany as a location for this part of the comic, hoping that German young learners, the target group of the comic, would be able to relate to the characters’ situation and transfer the events to their own experiences of the rose trade. We aimed at an empathic effect, allowing the readers of the geo-comic to identify their own place in the process. The couple invests in the fund with prospects of high dividends. This shows that the capital needed for rose production comes from the financially strong countries. Young learners can identify a causal relationship between the motives of stakeholders in their own country (rose purchasing and capital investment) and the situation in Kenya, affecting both local farmers and foreign company owners.
We modeled the rose company in the story on the existing company of Karuturi Global Limited, which came under financial pressure in 2015 after failing to pay salaries to its Kenyan employees on time [28]. The story of this company illustrates especially well several relevant aspects of globalization for geography education. It exemplifies both the global processes that make up globalization and the effects of it, following the definition of Christensen and Kowalczyk [27]. It illustrates the flow of goods and capital across different locations around the globe, and the globalized distribution of tasks. At the same time, this case relates the effects of these seemingly abstract processes to the livelihoods of real people, represented by the individual stakeholders. As a real case study, it provides authentic information about what globalization might mean to those affected by it. Facing the shutdown of their Kenyan operations, Karuturi found financial aid in the Phoenix Investment Fund based in Dubai [30]. We placed the headquarters of the fund in Singapore for a better display of circular flow patterns of goods and capital in a globalized world. The only fraction of the story for which we do not have any record is the German couple buying shares in the investment fund. To celebrate their financial prospects, they buy a rose and thus represent both the consumer side of the rose business and the financial profiteers. Our comic tells a story that is driven by human characters. We tell a story of globalization from the perspectives of the persons who shape it and are affected by it. Understanding a geographical phenomenon means understanding it from different perspectives. In dealing with the meaning of geographical phenomena, we can never make a positivistic statement saying something is like this; rather, we have to state that it appears like this from a certain viewpoint. Changing the viewpoint might make the same phenomenon appear completely different. Therefore, in order to engage in serious discourse about topics like climate change, tourism, or globalization in the geography classroom, students need to be aware of the pluralism of perspectives (see [31]). We designed the geo-comic to cater to this need in the hope that comics might be especially suitable for this kind of learning.
The comic conveys the geographical information purely in the narrative form. We completely avoided explanatory texts in order not to break the perspective of the stakeholders. According to the theories outlined above, immersive storytelling focusing on characters enhances the understanding of content (see Section 2.2). Consequently, our geo-comic is not an illustrative anecdote that is supposed to keep bored students interested by presenting “something new”. It is intended to establish geographical knowledge in learners by using a narrative rich in arguments and by applying the theoretical aspects of the topic to a specific case, thus following ideas expressed, e.g., by Rhode-Jüchtern [31]. Accordingly, we use narration in this context to induce a coherent understanding of the geographical phenomenon of globalization. In Rhode-Jüchtern’s sense, stories can explain spatial patterns from a subjective viewpoint, which is necessary to understand the meaning of human actions in space. In German geography education, students should be confronted with multiple perspectives. This is a central concept of teaching geography, as demanded in the national standards for geography education, (for US and Germany see [32,33]). Young learners discover the different interests of stakeholders and discuss advantages and disadvantages from these viewpoints. They practice understanding spatial conflicts by learning about differing perspectives [32,33]. Through stories, we look at a phenomenon from a distinct perspective. This subjectivity helps learners to realize that a geographical issue can be evaluated differently depending on the viewpoint of the stakeholder (examples for geography education can be found in [31]. In our story, the characters representing the stakeholders act according to certain motives and clearly display human emotions in reaction to the plot. The characters’ speech often refers to features of the landscape shown in the pictorial part of the panel. Their gestures or facial expressions point to these pictorial parts, connecting them with the text and with the characters’ emotions. Learners can reflect on the story and assume new perspectives. This is especially important in teaching geography, where we commonly deal with phenomena that appear very differently when viewed from different stances. In order for learners to assess a situation and form their own opinion of it, their views have to be open to more than one perspective (for an example, see [31]. In our example, globalization is the key to success for some people involved in the rose trade, whereas it poses a threat to others. It is very important to explicitly express these different perspectives and make them accessible to the learners, since perspectives on the individual stakeholders reveal their motivations and goals. In geographical contexts, this means that we need to understand the different perspectives on geographical conditions first, in order to understand how these conditions affect the agents in the process. The characters representing the stakeholders in our comic stories act according to certain motives and clearly display human emotions in reaction to the plot. This will enable the learners to weigh and evaluate the validity of arguments, giving meaning to geographical processes and phenomena (see, e.g., [31]).
3.3.2. Preparing the Stimulus for Eye-Tracking
For the statistical analysis of eye movement, we identified specific areas of interest (AOIs) in the geo-comic (Figure 2). An area of interest can be any element of a visual display. AOIs were established for each part of the comic containing relevant information. We marked speech bubbles, depictions of faces, persons, landscapes, and the map, including elements such as symbols, place names, and arrowheads. AOIs help to quantify aspects of eye movement. The eye-tracking software calculates its metrics for a particular area, e.g., the number of fixations in this particular area, or the time spent on the area, etc. Using different AOIs to mark areas that are occupied by text, picture, or map, we could identify viewing strategies in terms of eye-tracking metrics. We could analyze how intensely the viewers of our comic utilize the different components of the visual ensemble. This allows us to make assumptions about the distribution of attention paid to the components. In order to assess media integration (Hypothesis 2), we used the count of transitions between AOIs of differing media types, aggregating the values for all AOIs covering either text, or image, or map elements of the geo-comic. Testing the importance of depictions of human characters (Hypothesis 3), we had to analyze the metrics for all AOIs covering the faces, bodies, and body parts of the characters appearing in the geo-comic. For assessing the relevance of sequence (Hypothesis 4), we had to cover all possible entry points into the geo-comic in order to identify the first one entered by the participants. Since many of the 44 pieces of information were coded in more than one medium (text, image, map), 95 AOIs were established over the corresponding elements. At the beginning, we used different AOIs within the map, marking symbols, text, arrowheads, etc., separately, but this dissection turned out to be too detailed for meaningful analysis. Therefore, to scrutinize map viewing behavior, we effectively only used one AOI covering the whole map. All other AOIs covering parts of the map had to be ignored.
3.3.3. Pre-Test
To test for previous content knowledge on the topic dealt with in our geo-comic, the participants had to answer three questions in writing. The questions concerned the locations of sales of roses, the stakeholders in the globalized process, and possible advantages or disadvantages of the international rose trade. None of the participants displayed any knowledge of the topic prior to being exposed to the comic. Hence, any knowledge that the participants displayed in the post-test they retrieved solely from the geo-comic.
3.3.4. Experiment
After the pre-test, the instructor asked our participants to view the geo-comic. There were no further instructions, so the participants could freely explore the display. The stimulus was the sole guiding feature of the gaze. It was displayed on a full HD computer screen that exactly fitted its pixel dimensions in full screen viewing mode. The participants were given four minutes to take in the comic, but this amount of time was never completely used by any of the participants.
3.3.5. Post-Test
After the participants had looked at the comic, they were asked six questions to test their comprehension and memorization of the content. In the first question, they were asked what the comic was about. Questions two and three concerned the key locations of the rose trade, where roses were produced and where they were sold. These questions targeted the participants’ spatial orientation and understanding of spatial patterns in globalization processes. Questions four and five targeted the stakeholders, asking who profited (five) and who did not profit (four) from the rose trade. With these questions, we wanted to find out whether the learners recognized the different perspectives of the stakeholders. The students were allowed to answer orally from memory. They could not see the geo-comic while answering the questions. The oral reports were recorded and transcribed for analysis of comprehension. Only one participant preferred to write answers down. The participants’ cognitive performance was assessed by analyzing the transcribed oral reports. We compared the information in the reports with the amount of information on the rose trade that could possibly be retrieved from the comic. On a nominal scale, the participants could earn one point for each correct piece of information mentioned anywhere in their report. If a participant mentioned, for example, the location of the rose fields as described in the comic, they would earn one point. If they mentioned the role of a stakeholder in the story, they would earn another point. In this way, a total of 44 points could be scored, based on the 44 pieces of information encoded in the comic.
To retrieve all information from the comic, the participants would have to perform various tasks. They were to identify the topic of the comic as well as the locations connected with the rose trade and production. They were to use this information to describe models of globalization and disparities, e.g., by differentiating between industrialized and less industrialized countries. They were to point out the stakeholders, as displayed in the geo-comic, and indicate the role they played in the process of the rose trade and production. They were also to evaluate the effects of the globalized rose trade and production on the different stakeholders. We did not include any reflection on the comic from a meta-perspective in the performance measurement, because there is no right or wrong answer when asking about a subjective impression, e.g., whether the comic seemed realistic or not.
3.4. Data Analysis
In the following, we will describe the processing of the raw data from the post-test scores and the data produced by the eye-tracking device for further analysis.
3.4.1. Descriptive Statistics
In the first step, we analyzed the descriptive statistics of the data to describe the sample and find general patterns in the eye movements of the participants. The mean value of fixation counts, dwell time in milliseconds, and revisits were the measures used to see whether one of the modal categories of text, image, images of persons, or the map received more attention than the others. We also wanted to see whether there were phenomena that were generally similar across the participants or whether their viewing strategies and distribution of attention were rather heterogeneous and informed by individual qualities.
3.4.2. Processing the Comprehension Test Results Using Rasch Analysis
The test results were transformed to a ratio scale using the Rasch model as implemented in the Winsteps software. Each participant’s performance was thus scaled in a way that made it suitable for comparison. The resulting values (logits) were used for further analysis. The Rasch analysis was important for this study because the scores on the nominal scale did not take into consideration the difficulty of retrieving them. Some of the pieces of information were obviously much harder to understand and memorize for the participants than others and thus should be valued higher. Through Rasch analysis, these answers received a higher weight in the overall test results. Using ratio scale values allows for robust correlational testing. The Rasch model also allows us to rank the pieces of information according to the difficulty of retrieving them (within the group of participants). After Rasch analysis, each item received a ranked value on a ratio scale for better comparison.
Both item difficulty and participants’ performance ranking show a very good fitting of the Rasch model, with values for the infit MNSQ (inlier-sensitive mean square) between 0.58 and 1.4 for item difficulty and 0.77 and 1.32 for performance ranking. Generally speaking, values ranging between 0.5 and 1.5 suggest that there are no outliers. However, it might be argued that two items that were not mentioned by any participant are not on the same variable as the others. We left them in the model despite this, because we believe that they could have been found in principle.
3.4.3. Analyzing the Meaning of Pictures for Comprehension
In order to find out whether pictures support comprehension as hypothesized above, we correlated the presence of pictures with item difficulty, as indicated by the Rasch model. If any given information was partly or wholly encoded in pictorial form, a value of one was assigned to this item. Otherwise, it would be zero. This includes items that were encoded in multiple ways, such as text and pictures. Pictures were defined as recognizable images of persons, body parts, objects, or landscapes. No part of the map or the text elements fell into this category of media encoding. Then, we used this biserial variable to test for correlations with item difficulty. A strong negative correlation would mean that the presence of a picture positively influences the solvability of a test item.
3.4.4. Processing the Eye-Tracking Data
We processed the eye-tracking data for a visual and statistical evaluation.
Visual Analysis
In the first step, we conducted a brief visual analysis of the eye-tracking data through heat maps reflecting the eye movements of the participants. This gave us an overview of existing viewing strategies and the distribution of the participants’ attention. The quickest way to explore eye-tracking data is heat maps showing the number of fixations at specific locations in a color code (Figure 3). They “provide a depiction of gaze by combining fixations from multiple viewers”. A drawback is that they sacrifice “temporal order information” [6] (p. 170). Heat maps, however, do provide a “form of sanity check” [6] (p. 181): we can quickly obtain an overview of whether our collected data make sense. This allows us to draw conclusions about the importance of the elements constituting the geo-comic (text, picture, and map). Our first approach was to find out whether there were visually detectable patterns in viewing behavior. Our goal was to see whether differences in these patterns existed between the most successful and least successful participants. Heat maps were generated for the top performers, who scored in the upper third of all scores, and for the bottom performers, with scores in the lower third, to generate contrasting groups (Figure 3). Creating high contrast performance groups can reveal differences in behavior. In this way, we could isolate behaviors that were likely to have an influence on the post-test results, e.g., whether high performers looked at different parts of the geo-comic than did the weaker performers.
Statistical Analysis
The eye-tracking device records numerous metrics. However, a “serious challenge for eye-tracking researchers is to find the sometimes-missing link between eye-fixation measures and learning outcome (or cognitive performance) measures” [7] (p. 170). For this study, we selected those metrics that tell us the most about how attention was distributed over the time and space of the stimulus, our geo-comic. These metrics were the fixation count, dwell time in milliseconds, and number of revisits to each AOI. All three variables allow us to make assertions about how participants distributed their visual attention on the geo-comic, but from differing angles. Using a multitude of metrics for additional confirmation is especially important in a very complex stimulus design such as our geo-comic, where one signal can easily be lost in statistical noise. These values were then tested for normalcy and correlated to the participants’ performance in the post-test. We also used the number of transitions between AOIs to assess the extent to which viewing strategies integrated information gathered from different sources like text, picture, and map (see Section 2.1). Additionally, we used the AOIs to examine the sequence in which they were visited, in order to identify the participants who looked at the map before looking anywhere else.
- (1)
- Number of transitions
The number of transitions tells us how often the participants shifted between different AOIs and thus revealed their “attentional switching”, as Hyönä [34] (p. 174) calls it, providing an insight into “the degree of interplay” between information media. The AOIs of our stimulus were categorized into text, picture, and map so we could count the transitions in both directions between text and picture, picture and map, and map and text. Using these metrics, we wanted to find out whether a strong mental connection between text, picture, and map was crucial for successful learning with the geo-comic. The success of learning is indicated by the results of the post-tests (Section 4.2). Transitions show the degree of integration a participant uses for understanding complex displays (see Section 2.1). The more transitions there are in the viewing pattern of participants, the more likely it is that they have established a connection between the elements of text, image, and map and thus have a synthesized apprehension of the geo-comic.
- (2)
- Fixation count
Fixations are moments when the eyes of the participant rest on a small area of the visual display (see [6]). They are almost points on which the eyes of the participants focus their vision. This area of the display is brought into the focal zone of the eye, the fovea, and “naturally correspond[s] to the desire to maintain one’s gaze on an object of interest” [6] (p. 45). During this time, we can assume that the viewer is taking in information found in a particular area. Fixations are thus a measure of visual attention. They are the sort of eye movements which “best indicate the locations of viewers’ (overt) visual attention” [6] (p. 141). Accordingly, the fixation count measures how many fixations were used to explore an AOI or, in other words, how much attention a participant paid to this AOI. Using this metric, we can find out how much attention was paid, e.g., to the characters in our comic. The more the participants focus on the faces and body parts of the characters, the higher the likelihood that they have taken in graphical information about the condition of the protagonists. This is important in relation to Hypothesis 3 (Section 2.2), stating that characters appearing in the narrative promotes deep learning.
- (3)
- Dwell time
The dwell time metric is closely related to the fixation count but provides another angle from which to measure attention. According to Hyönä [34] (p. 174), it is “a useful measure, as it indicates how learners allocate their visual attention during the entire learning trial.” Fixations are usually rather short and can vary in length from around 60 milliseconds up to around 500 or 600 milliseconds, depending, for instance, on whether we look at picture or text. Generally, increased fixation duration is associated with increased cognitive function [6] and can be linked to mental activities of image search [6] (p. 289), task difficulty (ibid.), or text difficulty (ibid.). Moreover, objects which are perceived as “semantically informative […] draw longer second pass and total fixation durations” (ibid. p. 260). Dwell time is the metric summing up time spans of all fixations and the time spent during the eye movement between the fixations (saccades) within a particular AOI. Therefore, dwell time measures how much time a participant spends looking at a particular AOI in milliseconds, another indicator of attention or engagement with the information found in the area of the stimulus. Again, we used this metric to assess, from another angle, whether attention paid to characters influences comprehension of geographical phenomena as indicated by post-test results. Especially in complex displays like our geo-comic, the brain of the onlooker takes a while to process the information presented. If participants do not take their time looking at the map or picture, they are not likely to understand it. Correlating dwell time with post-test results reveals whether the more time participants spend on an element—say, the map or a character—the more likely they are to understand what they are looking at.
- (4)
- Number of revisits
The number of revisits is a count of how many times a participant came back to a particular AOI after having seen it for the first time. Usually, people come back to a piece of visual information to reconsider it in the context of something else they have seen afterwards. A random revisit is not very likely, because if a participant deems a certain AOI unimportant, they will not make the effort to come back to it. This would mean that when participants revisit images of persons in the geo-comic more often, the probability is higher that they associate some salience with the characters. Does this strategy influence the post-test results in the way stated in Hypothesis 3 (Section 2.2)?
- (5)
- Sequence of AOIs
The last metric used in this study is the order in which AOIs were visited. In particular, those participants were identified who visited the map before any other AOI. Since the map reveals the relationships between the stakeholders in our geo-comic, we wanted to see whether looking at the AOIs in a certain order influences the participants’ understanding of the geo-comic.
3.5. Methodological Reflection
However conclusive eye-tracking data may be, eye-tracking is not mind reading. It is one thing to observe how long a participant looked at a particular part of the stimulus and another to know why they did so. Hyönä [34] (p. 172) confirms this for multimedia learning and states that “eye-tracking can reveal important insights into the ongoing learning process”, especially by revealing what the learners perceived as relevant in a display. Mayer [3] (p. 169) concludes that eye-tracking is a successful tool for “testing hypotheses about perceptual processing during […] learning and thinking with graphics.” However, eye-tracking does not tell us anything about the “success or failure of comprehending the relevant piece of information” [34] (p. 173) and thus needs to be “complemented with other performance measures, such as retrospective comprehension tests”. To this end, we conducted our post-test with fairly open questions. By “tapping into the end product of learning” in this way, “the researcher is in a position to tease apart, for example, the extent to which a learning failure is a result of inadequate intake and encoding of relevant features of the learning material” [34] (p. 176). Mayer [3] (p. 170) somewhat qualifies this statement by saying “[d]etermining how to assess what someone knows remains a central challenge of instructional research.” In this study, we paid careful attention to evaluating the post-test results. Applying the Rasch method, we believe, helped immensely in getting closer to a fair judgement of the participants’ cognitive performance.
Test results are hardly ever purely objective, even when using numerical scales. Most of the time, we only retrieve grading on a nominal scale. It is impossible to compare test results without knowing the item difficulty. Apparently, high performance candidates also solved the hardest test items, whereas this was not necessarily the case for the candidates who solved only a few test items. The test scores on our nominal scale do not tell us exactly how much harder it was to find one piece of information in the geo-comic than another. Rasch analysis, however, transforms the test results from a nominal scale to a fully-fledged ratio scale, placing the participants’ cognitive performance at the correct distance from each other in terms of difficulty. We can now discern how much harder it was for our participants to determine the location or the stakeholders involved in a scene in the geo-comic. The assumption behind the Rasch model is that the more students have solved a certain task, the likelier it is that it is less difficult. Thus, we can assess not only participants’ performance using Rasch analysis but also item difficulty on a ratio scale. This allows for a much more accurate assessment of performance, and since we have values on a ratio scale, we can use them for robust statistical operations such as correlations between map viewing behavior and successful learning. See Section 4.1 for an overview of the data used in relation to our various hypotheses.
Regarding the analysis of picture comprehension, one might hope that eye-tracking data will successfully reveal viewing strategies. However, this assumption is not self-evident. Duchowski [6] (pp. 258–259) discusses the usefulness of eye-tracking analyses in scene viewing strategies. He reports that “no apparent strategies for scene viewing have been easily discerned”, in contrast, for example, to reading strategies. While, for processing details in images, many fixations are needed, viewers can develop a general understanding of the scene with only two fixations. Duchowski points out that researchers advocate the view that “the gist of a scene is abstracted on the first few fixations” (ibid.). In the specific context of our geo-comic, this means that we cannot expect to retrieve enough data for analysis of picture comprehension, especially since there is a lot of other information competing for visual attention, such as the map and the text elements. There is also yet another caveat to be considered. Observers can absorb pictorial information even outside of the eyes’ focal point, the fovea, requiring far fewer fixations to understand a scene as compared to text. Thus, if text is located close to an image that it refers to, like in the speech bubbles in our geo-comic, referring, for example, to an environment or a character, this would affect the number of fixations or time spent on the image part of a panel. Only if an object which is perceived in peripheral vision appears to be of high relevance to an observer do they usually fixate on these objects by moving them to foveal sight [6]. Duchowski (ibid. p. 259) concludes that eye movement is important in understanding how “information in the visual environment is dynamically acquired and represented.” However, concerning our geo-comic, with its highly complex and competitive display, we have to turn to additional data and methodology to achieve a more complete understanding than would be possible with eye-tracking technology alone. Rasch-modeled post-test results are an indispensable complement.
4. Identifying Successful Strategies of Viewing a Geo-Comic: Results of the Analysis
4.1. Overview
The heat map in Figure 3 represents the distributions of fixations aggregated over all participants. Not surprisingly, the text in the speech bubbles received the most fixations (indicated by the red color), whereas the rest of the comic does not seem to have raised a lot of interest in terms of visual attention. This conclusion will be qualified in our analysis. Of the imagery part of the geo-comic, the map seems to have received the most attention. Slightly blue shades indicate that of all non-textual features apart from the map, faces seem to have attracted the most visual attention. At first sight, the heat map thus seems to confirm parts of the established theory. As discussed above, text requires a lot more time and fixations in order to decipher it than pictures. Within the imagery, human characters attract the onlookers’ gaze comparably strongly. However, we can also see an interesting phenomenon that is relevant for geography education: the map apparently plays a special role in terms of viewing behavior, which clearly distinguishes it from both pictures and text.
The comparison between high and low performing learners (Figure 4 and Figure 5) reveals another striking feature. The map received much more attention in the group who achieved the best results in the post-test measuring the acquisition of knowledge. Looking at the map apparently improved post-test results, which signifies a higher degree of general comprehension of the geo-comic’s content. Although we cannot establish a causal relationship purely based on these data, paying attention to the map seems to support the understanding of geographical relationships. Section 4.4, Section 4.5 and Section 4.6 will shed more light on the relationships between successful learning and certain viewing strategies, which are not as easily discernible by visual analysis.
The first impressions given by the heat map are confirmed by the descriptive statistics. Table 1 shows the mean values for fixation count, dwell time in seconds, and revisits. It is evident that text receives the highest values by far in all metrics. This was expected (see Section 2), because more fixations and time are needed to decipher text, whereas images can be processed with less effort and even with peripheral sight. The conclusion that pictures, pictures of persons, and the map were less important in the learning process than text, however, is not valid, as will be shown below. The descriptive statistics allow yet another finding that was not visible in the heat map. It is very striking that the standard deviation is very high in all metrics. This shows that viewing behavior differed considerably among the participants. In Section 4.4, Section 4.5 and Section 4.6 we will see how this relates to the post-test results. First, however, we will take a look at the post-test results in detail and consider some demographic variables in relation to them.
The participants’ test scores on the Rasch scale (logits), visual language fluency index (VLFI), and most eye-tracking metrics were normally distributed. For correlational testing, Pearson’s r was used in all cases except where normal distribution could not be detected. In this case, we used Kendall’s tau or Spearman’s rho. These cases are indicated in this paper. An alpha level of p < 0.05 was applied to all two-tailed and one-tailed tests.
4.2. Post-Test Results
The average score in the comprehension test was 10.14 (S = 7.26), with a possible high score of 44 points. Of the 44 pieces of information available from the geo-comic, 42 were reproduced at least once by the group of participants in their oral reports. This shows that it was, in principle, possible for the students to find virtually all the pieces of information encoded in the comic. Only two items were not identified by any of the participants. They did not identify India as an emerging economy and Germany as an industrialized country, probably because of a lack of general knowledge. After the transformation of the post-test results to the Rasch model (logits), we found them to be normally distributed. The ranking of item difficulty in Table 2, produced by the Rasch model, shows that the hardest items mostly concerned locations rather than stakeholders (four out of six). The easiest items mostly concerned stakeholders (also four out of six). Out of the highest possible score of 44 in the post-test on the international rose trade, the best participant scored 28 points (63.64 percent); the lowest of any of the participants’ scores was zero points. We discuss possible reasons and explanations for these learning outcomes in detail in Section 5.
4.3. Effects of Some of the Demographic Variables
4.3.1. Effects on Post-Test Results
First, we tested for correlations between the test scores and some of the demographic variables to find out whether age, gender, grade, or comic expertise had any influence on performance in the test. No significant influences could be detected. Although some researchers report gender differences in the perception of visual stimuli in some contexts (for instance, [35]), we could not detect a significant effect of gender on the post-test results among our sample group (rpb((33) = 0.237, p = 0.176). The lack of influence of these demographic variables on the post-test results strongly supports the testing of the hypotheses described in the following sections. Most notably, comic expertise did not influence the understanding of the geo-comic presented to the participants in this study. It apparently requires no special training or strong habits to be able to decode information given in the comic form, even in a very complex display such as the comic used in this study. Even the participant with by far the highest score of 25 in comic expertise was ranked only eighth in the post-test. Although comic expertise (VLFI) decreases with age (r(32) = −0.400 p = 0.021)—which might be an indicator of less interest in comics with higher age—age as such does not influence cognitive performance in understanding or memorizing the comic among the 10 to 14 year olds. This is another indicator that comic expertise did not have an effect on learning with our geo-comic.
4.3.2. Effects on Viewing Strategies
Correlation tests using the demographic variables age, grade, VLFI, and gender did not show any effects on 47 eye-tracking metrics, including media transitions, fixation count, revisits, and most of the dwell time metrics. This means we can generally rule out any influence that these variables have on viewing strategies in the case of our geo-comic. Exceptions are correlations between age and the total dwell time over all AOIs in the geo-comic (r (33) = 0.347 p = 0.044), the overall dwell time on the stories (r (33) = 0.362 p = 0.035), and the dwell time on pictures (r (33) = 0.339 p = 0.05), using Pearson’s r in a two-tailed test with a 5% level of significance. Apparently, age has a moderately positive effect on how long something is viewed for, especially imagery. We observed a similar effect in the average fixation duration on the map (r (33) = 0.365 p = 0.034), which also increases with age. However, none of these effects make their mark on the post-test results. Post-test results are not related to age (see Section 4.3.1).
4.4. Integrated Media Processing
4.4.1. Effect of Pictures on Learning
The eye-tracking data did not reveal any viewing strategies concerning the participants’ use of pictures for content comprehension. We could not find any significant correlation between attention paid to pictures and post-test performance in terms of fixation count, dwell time, or revisits. To find out how significant pictures are for an understanding of the comic’s content, we correlated the item difficulty as ranked by the Rasch model with the presence of an image conveying the relevant information (Table 2). There was a strong negative correlation between item difficulty and the presence of a picture in a point biserial correlation: rpb (32) = −0.518 p < 0.001. In terms of effect size, this means that almost 27 percent of item difficulty is determined by the absence or presence of a picture. In contrast, explanatory text only accounted for roughly eleven percent of item difficulty, as indicated by a moderate effect between the presence of text and item difficulty: r (32) = −0.336 p = 0.026. Items which could be answered with the help of the map and item difficulty did not show any significant correlation at all: r (32) = −0.091 p = 0.555. This shows that information in pictorial form is easier to retrieve than in any other form. Pictures help with the understanding and memorizing of content in a very effective way.
This evidence supports our hypothesis:
Hypothesis 1 (H1).
Learners have a better understanding of the geographical content when a picture is present.
4.4.2. Transitions between Map, Text, and Picture
A geo-comic is an ensemble of many different kinds of modes in which information is presented, mainly map, picture, and text. We expected that switching attention more often between media types within the comic improves post-test performance. Counting the transitions between the modes of map, text, and picture, we can observe a moderate effect between test performance and the participants’ switching behavior between the map and the other modes in a one-tailed test. Students who switched more often between the map and the pictures were likely to score more highly in the post-test than those who did not: r (32) = 0.344 p = 0.023. The same is true of switching between map and text: r (32) = 0.357 p = 0.019. Our statistical analysis implies that an integrated viewing strategy of all types of media is related to content memorization and understanding. We can generally say that the more learners make use of all the different media types, the better they score in the comprehension test. However, switching between the map and other media is more effective for better scores in the post-test than switching between picture and text.
This evidence supports our hypothesis:
Hypothesis 2 (H2).
Learners show better comprehension of geographical content when more frequently switching between media (text, picture, map).
4.5. The Role of Human Characters in Learning with a Geo-Comic
For the analysis of attention paid to characters, we used the eye-tracking parameters of fixation count, revisits, and dwell time. We found moderate but highly significant effects of the number of revisits to representations of characters on overall test performance. Since revisits were not normally distributed over all the participants, we used Spearman’s ρ for the correlation: students who revisited imagery of human characters more frequently were more likely to achieve better results in the post-test, especially concerning stakeholder-related information. Making statements about the roles or motivations of stakeholders while assessing their situations in the post-test correlates clearly with revisiting imagery of characters in the geo-comic: rρ (32) = 0.379 p = 0.014. This has an effect even on overall test performance in a slightly less pronounced way: rρ (32) = 0.315 p = 0.035. Similar effects were observed for fixation count and dwell time. Here, Pearson’s r also shows moderate effects. Paying attention to human characters correlates positively with post-test performance: r (32) = 0.314, p = 0.035 (fixation count) and r (32) = 0.302, p = 0.042 (dwell time). These results imply that the more aware learners were of the characters, the higher their scores were in the post-test results.
Our evidence thus supports our hypothesis:
Hypothesis 3 (H3).
Paying more attention to images of the characters driving the story results in a deeper understanding of the comic’s geographical content.
This is emphasized by the results shown in Table 2. Four of the six easiest items were character-related, whereas four of the six hardest items were not. In the comic, character-related items were more easily understood than non-character-related items. This shows the one-tailed negative point biserial correlation between Rasch scaled item difficulty and whether these items were related to characters in the comic or not (rpb (32) = −0.316 p = 0.018). Here, characters account for roughly 10 percent of item difficulty in terms of effect size.
4.6. The Map
For this comic, heat maps visualizing the viewing behavior of the participants show that the top performers spent much more time viewing the map than the weak performers (Figure 2 and Figure 3). The map seems to play a central role in understanding the geographical content. The statistical analysis in this study confirms this first impression. Attention given to the map evidently correlates with cognitive performance in the post-test, as revealed by fixation count (r (32) = 0.37, p = 0.030) and dwell time (r (32) = 0.36, p = 0.037). Paying more attention to the map is linked with better performance in the post-test, but the map plays an important role in another context as well. For our hypothesis, the analysis reveals that there is a definite correlation between test performance and whether the map was viewed first or not: rpb (32) = 0.46, p = 0.006. Students who looked at the map before consulting any other part of the comic scored significantly higher in the post-test. The map was the most popular entry point; there were seven participants who looked at it first.
Hypothesis 4 (H4).
Using the map as an entry point positively influences geographical understanding of the comic.
5. Discussion
The geo-comic used in this study was designed to offer a lot of information and ways of retrieving it. There was no predetermined reading order, fairly complex relations, and some abstract concepts which played an important role in the geo-comic. We chose this design to enable free exploration of a complex display and to provoke different ways of viewing the comic. We wanted to produce a setting for an unbiased visual examination of the geo-comic, telling us more about how the comic works rather than finding out how students solve a task. The goal here was to find out which viewing strategies were the most successful. Identifying successful strategies allows us to draw conclusions for the design of further geo-comics and recommendations for learning with them. Our geo-comic is arguably a highly demanding learning material for the relatively young age group, due to the complexity of design and content. However, other reasons exist for the low scores of the participants in the post-test. Probably most important is the very open invitation to view the comic without further instructions, not providing any guiding criteria to the participants. For reasons of transparency, they knew that they would be asked questions afterwards, but not what the questions would be. The comic was not embedded in an educational framework or lesson sequence, and no prior knowledge could have guided their gaze. In fact, in the oral reports in the post-test, many participants remarked that a more structured design of the geo-comic would have helped them to take it in. They suggested, for instance, numbering the stories according to reading order. We purposely did not provide a reading order, however, since we wanted to test non-linearity in our geo-comic, which is essentially a map/comic combination. Non-linearity, however, seems to cause a degree of unease or even irritation. It is a fairly uncommon way of telling a story, not feasible for either text or film. It might require some habituation or even practice. Still, we can state that compared to the pre-test, the results of the post-test demonstrate that almost all participants profited from the geo-comic and extended their knowledge, although to differing degrees. Guiding the participants by giving them a task or offering focal questions beforehand would probably have helped those participants who did not perform very strongly, but it would have distorted the results. If we had done this, their intuitive strategies would have been spoiled and we would not have been able to see how the comic worked by discriminating in such a profound way between the more successful and less successful strategies. In the post-test, the participants remembered what was salient within the comic and what was needed for them to make sense of the story. From this point of view, the performance of our participants was not particularly weak but rather revealed their highly individual strategies while dealing freely in an unbiased way with complex multimedia learning material. It showed us what worked in the comic and how it worked. From this, we can conclude what kind of guidance is needed to make the most of learning with geo-comics. When using a comic in the geography classroom, we strongly recommend providing such structured guidance in order to fully exploit the comic’s advantages.
We will discuss the results of this study in detail in the following sections before drawing a final conclusion.
5.1. Integrated Processing
5.1.1. Effects of Pictures for Learning Geographical Content
The strong negative correlation of item difficulty with the presence of pictures suggests that in geography education comics should not be treated as merely funny introductions to complex topics but should be used as carriers of relevant information. Pictures embedded in a story and illustrating an integrated meaning of map and text make information very accessible. This is quite convenient for geography as a visual discipline, as described, e.g., by Sui and Schlottmann [16,17]. Our geo-comic is an example of how geographical imagery of landscapes like farms, rose plantations, or cities is naturally embedded in a story using the comic form. In comics, we can meld together geographically well-informed imagery with explanatory text and maps to create a meaningful whole, “pictures anchored by words. Relaying meaning back and forth across boundaries”, as Sousanis [2] (p. 53) puts it Our geo-comic and comics in general offer a fantastic opportunity to put into practice the spatial contingency principle of Schnotz [16] and Mayer [15], which is also discussed in the next section. This states that text and image must be situated close together in order to reduce the workload of short-term memory. We have found that visual attention to pictures, as measured by the eye-tracking device, does not correlate with cognitive performance. This probably means that, in our geo-comic, pictures were usually processed in peripheral view. In order to profit from a picture, a learner must be able to grasp the gist of it right away. Thus, pictures used in a geo-comic should be clearly discernible, so that learners can quickly take in their informational content, even if they do not take time to scrutinize them in detail. Pictures in educational comics should aim to avoid the frustration of giving a confusing first impression. This is an advantage of a well-drawn comic compared to photographs or film. Drawings tend to reduce the shapes and forms of objects to their essentials.
5.1.2. Switching Attention between Text, Picture, and Map
Our results indicate that frequent switching between the media of text, image, and map helps in the understanding and the memorizing of content, as we expected. Thus, an important viewing strategy of the participants in processing our geo-comic concerns the distribution of visual attention. This is in accordance with the findings of Schnotz [16] and Mayer [15], as well as Mason et al. [18], who argue that image and text can complement each other if the learner can create an integrated model in the mind. Consequently, switching should be made easy in any kind of multimodal learning material. Mayer [15] rightly demands a spatially tight arrangement of multimedia elements within a single display. In comics, this is a given, since speech bubbles are placed in close proximity to what they refer to and are even anchored to the picture with a pointing tip. This should make switching particularly easy. Images need to be annotated and contextualized in order to convey geographical knowledge. The contextualization of locations can take place in a map. Maps show spatial relations facilitating the comprehension of interconnectedness. However, again, a map on its own does not seem to suffice. In this study, successful learners seem to have used the map as a sort of base, switching between map and text and map and picture to get a better understanding of the content. Of course, we used each medium for what it can do best and were careful to avoid redundancies, as recommended by Kalyuga and Sweller [36], in order to reduce workload. Therefore, not all information was given in all media types, making switching essential by design. However, the strong correlation between using the map as an entry point into the comic and test performance does indeed suggest that the mental integration of the map with the other media is crucial for content comprehension (see Section 5.3). This is probably especially true in geographical contexts. Maps can effectively be used to structure further content by coherently tying together information in space. The map should be placed in an exposed position in the overall display so that it attracts the onlooker’s gaze immediately. It certainly helps if the map is aesthetically pleasing. It should also be clearly legible.
The integrated use of media which support the cognitive performance of learners also shows that the ensemble of the comic is more than its single parts. As Sousanis [2] and Dittmer [37] point out, the simultaneous yet integrated display of different modes of expression is an advantage of comics that cannot be found in any other media, not even film. Comics can enhance the perception of phenomena by offering a non-verbal description in combination with text. They represent this in a non-linear way, making use of composition, i.e., space (on the page or screen). Making switching between modes of presentation easy for learners helps them profit from this advantage for learning with multimodal material. This is especially true when maps are involved.
5.2. Character-Driven Narrative
Students who paid a lot of attention to characters in the comic were likely to better understand the comic’s content. Especially in human geographic contexts and human–environment interaction, understanding the motives and positions of stakeholders is key to grasping the bigger picture. Learning about a multitude of possible perspectives on a geographical phenomenon helps young learners to form their own opinions. In comics and thus in our geo-comic, protagonists are a natural part of the medium. The stories juxtapose differing perspectives on a central issue, i.e., the rose trade, as an example of globalization. Recognizing the existence and implications of multiple stances towards such an issue is a prerequisite for a deeper understanding of the geographical problem at hand. Representations of expressions surpassing the verbal—such as facial expressions, gesture, or posture—are easy markers of emotional states, explaining and giving reasons for the perspectives of the persons concerned. These forms of expression are an essential part of meaning making in human communication [38] and are best described in a “visual vocabulary” [39] (p. 64). They can reflect attitudes towards processes, including geographical issues on all scales, such as globalization as represented in our geo-comic, or any other process concerning the livelihoods of persons depending on their position within these processes. They reflect a person’s sense of place. The sense of place is the way in which people perceive the places they encounter and inhabit, how they relate to them, and how they value them based on experiences, imaginations, and other meaning-making processes [40]. Depictions of persons quickly help to communicate attitudes of stakeholders in a naturally accessible way, guiding us through the story. Stories told in this way are engaging, allow for empathizing with stakeholders, and are thus easy to understand [41]. Geo-comics naturally weave into their storytelling a depiction of stakeholders as they act in their environment. They can express emotional reactions to the geographical processes affecting them. With the help of stories, we can emotionally and cognitively relive other people’s experiences. Stories function like simulations [42]. This capability of stories connects the geographic data, the statistics, and the maps with the evaluating power of the individual. Thus, they can indicate clearly differing perspectives on a controversial topic. The school curriculum strongly demands this kind of approach [32,33], but learning materials such as classical text books usually fail to cater to this need (for German text books see [43]). Geo-comics can fill a wide gap here. Characters in a geo-comic should thus be designed to be relatable, displaying clear emotions. They should be placed in a meaningful scenery, interacting with their surroundings and each other. Gestures and facial expressions were important clues to the emotional state of the characters in the geo-comic and helped the viewers to empathize with them. This has an effect even on overall test performance, meaning that comics can better fulfil the curricular demand for multiple perspectives in geographical thematic content for use in the classroom than media not displaying characters and their emotions.
5.3. The Special Role of the Map
The unexpectedly strong relation between using the map as an entry point into the geo comic and cognitive performance in the post-test emphasizes the map’s role as a mental scaffold. It helps to establish relations between pieces of geographic information. This exceeds a map’s obvious function of just localizing objects or places on the earth’s surface. A map creates context by showing a common ground. In our geo-comic, switching between the map and other media has a higher effect on performance in the post-test than switching between image and text, which did not have a significant effect at all. The map alone seems to be hard to interpret for young learners. When learners use additional information to interpret the map, they can more easily understand it. Switching seems to indicate the integration of complementary information.
It is important to point out that the map may count as imagery, but it is fundamentally different from both text and pictures as far as effective viewing behavior is concerned. Our analysis shows that young learners respond to the map in a very different way than to the other two types of media. Unlike pictures, our participants apparently could not process the map with peripheral view only (as Loschky et al. [22] describe it). They had to examine the map fairly closely to put it to use effectively. However, in contrast to text, the participants did not view the map in its entirety. The heat maps show that they ignored large parts of the map and focused only on what seemed to be relevant to them. Thus, the open graphic structure of the map apparently allowed for search processes by which onlookers selected the information that they deemed important. In conclusion, understanding text (literacy), understanding pictures (sometimes referred to as graphicacy), and understanding maps are three different capabilities.
This study suggests that our geo-comic might be a useful tool for improving all three capabilities through the concerted arrangement of the three modes of text, picture, and map. The colored areas of the map, which attracted a lot of attention, also coincide with the landing points of the anchoring lines connecting each story with the map. This demonstrates that a deeper understanding of the map might be controlled by the content of the stories. The participants may have distributed their attention to selected portions of the map according to information taken from the comic stories. They created a context around the map using text and, more importantly, pictures. The success of integrated viewing strategies discussed in Section 5.1.2 further supports this assumption. The map in our geo-comic is interwoven into a network of meaning consisting of text, picture, and map. The map is explained by its relations to the stories, but it also creates meaning by relating the different stories to each other. The map can do this by using a different scale than the stories. While the map provides more of a small-scale overview, the stories perform their world-building on a scale range corresponding to immediate human perception. Using geo-comics can thus help young learners to make sense of mappings by providing them with meaning making maps. The geo-comic can improve map-reading competency when switching attention between the modes is encouraged in the learners.
The design and placement of the map within the comic plays a crucial role in promoting map competency. Placing the map in a central position, as in our geo-comic, offered the map to the viewers, making it the most popular entry point into the geo-comic. Where orientation within the map is concerned, the participants attributed saliency to color patches and outstanding symbols, which received the most attention of all the map elements, according to the heat maps. In order to encourage viewers to pay attention to the map, we suggest making it attractive and easy to look at. It should be designed to draw the eye immediately and should be placed in a central, exposed position, so it can be used as a guiding element in the context of further information.
6. Conclusions
Geo-comics, defined as a combination of text and pictures in the comic form with one or several maps, can play an important role in geography education. This study shows that they can facilitate perspectival understanding of geographical content, especially as conveyed through maps in a contextualized way. Geo-comics achieve this by bringing together facts, spatial relations, and authentic perspectives. Their non-linear nature opens up this conglomeration for free interchange in the learning process, guided by a comprehensible story. This is apparently independent of comic expertise and interest in comics within the readers (see Section 4.3). Even though there is reason to believe that a well told story which touches upon relevant issues sparks interest in the audience no matter the form it is delivered in, some students might not be motivated by using comics in the class room. However, even if students are not particularly fond of the medium, this study suggests that it still helps them understand geographical problems.
Because comics can tell stories through stakeholders’ eyes, learners can empathize with multiple perspectives. Switching between perspectives for comparison becomes possible in the personal timing of each reader. Consequently, human characters and their motivations should drive the story. Having them merely explain (geographical) facts, as is often done in science comics, means losing this opportunity. Authors of geo-comics should use recognizable character design, with characters displaying emotional states, to support comprehension and help distinguish attitudes corresponding to the characters’ perspectives.
This study shows that the comic form complies with many principles of learning with multimedia content which promote enhanced cognitive performance. However, just like any other learning material, geo-comics will never replace a teacher with a concept. In our case, this means that in the anticipatory set of a lesson plan using our geo-comic the teacher should give introductory information activating previous knowledge about global trade and developing countries to prepare students for the work with the comic. To support successful viewing strategies, the teacher should provide the learners with guided instructions, such as questions touching upon central issues. These questions serve as a scaffold to focus on, pre-structuring specific information and carving out the different perspectives represented in the comic. The students can then practice applying their knowledge to the topic of globalization in a broader sense or to different aspects and examples of the global economy. In closing, they can document the relevant information, e.g., in a mind map. Based on this, students can evaluate the situation and form an opinion. They can reflect on their own role in a globalized world inspired by the perspective closest to them, e.g., the rose consumers of an industrialized country. As yet, we will have to develop theoretically well-founded guidelines for using comics in the classroom, so that all students can benefit from the advantages of geo-comics.
In general, we can say that it is helpful to give instructions and orient the learners before exposing them to a complex display such as our geo-comic. We acknowledge that a geo-comic, just like any other complex learning material, needs to be embedded into a lesson plan in order to make an impact in its full scope. When learning with comics, students should be advised to consider carefully the agents driving the stories, to explore the geographical facts through their eyes, opening up a human perspective on geographical phenomena. This supports knowledge acquisition. Furthermore, students should be prepared to consider maps, since they often play a crucial role in understanding geographies. Hence, for the design of geo-comics, we recommend the use of one or more maps, which should be placed in key locations on the display, offering easy access and guidance. Character design should be appealing and should display comprehensible emotions. Characters should be embedded in meaningful surroundings, like landscapes or other environments, since pictures support learning.
It would be interesting to compare the processes of learning with geo-comics to learning processes with other media, such as text books or films. Another interesting comparison would be between static and interactive geo-comics, where differing degrees of guidance could be put to use.
Author Contributions
Conceptualization, F.v.R. and A.B.; methodology, F.v.R.; formal analysis, F.v.R.; investigation, F.v.R.; resources, F.v.R.; writing—original draft preparation, F.v.R.; writing—review and editing, A.B.; visualization, F.v.R.; supervision, A.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Farinella, M. The potential of comics in science communication. J. Sci. Commun. 2018, 17. [Google Scholar] [CrossRef] [Green Version]
- Sousanis, N. Unflattening; Harvard University Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Mayer, R. Multimedia Learning; Cambridge University Press: Cambridge, UK, 2001. [Google Scholar]
- Schnotz, W. Integrated Model of Text and Picture Comprehension. In The Cambridge Handbook of Multimedia Learning, 2nd ed.; Mayer, R., Ed.; Cambridge University Press: New York, NY, USA, 2014; pp. 72–103. [Google Scholar]
- Eitel, A.; Scheiter, K.; Schüler, A. How Inspecting a Picture Affects Processing of Text in Multimedia Learning. Appl. Cogn. Psychol. 2013, 27, 451–461. [Google Scholar] [CrossRef]
- Duchowski, A.T. Eye Tracking Metodology; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Mayer, R. Unique contributions of eye-tracking research to the study of learning with graphics. Learn. Instr. 2010, 20, 167–171. [Google Scholar] [CrossRef]
- Aleixo, P.; Sumner, K. Memory for biopsychology material presented in comic book format. J. Graph. Nov. Comics 2017, 8, 79–88. [Google Scholar] [CrossRef] [Green Version]
- Nalu, A.; Bliss, J. Comics as a cognitive training medium for expert decision making. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Las Vegas, NV, USA, 19–23 September 2011; Volume 55, pp. 2123–2127. [Google Scholar] [CrossRef] [Green Version]
- Göhler, J.; Narciss, S.; Niehtammer, M. Comics–Didaktisches Potenzial für Berufsbildung im Medizinisch-Pflegerischen Sektor? bwp@ Spezial 6. Proc. Hochschultage Berufl. Bild. 2013, 10, 1–16. Available online: http://www.bwpat.de/ht2013/ft10/goehler_etal_ft10-ht2013.pdf (accessed on 15 October 2020).
- Özdemir, E. The Effect of Instructional Comics on Sixth Grade Students’ Achievement in Heat Transfer.” OpenMETU, Ankara. 2010. Available online: http://etd.lib.metu.edu.tr/upload/12611749/index.pdf (accessed on 15 October 2020).
- Webb, E.; Balasubramanian, G.; ỎBroin, U.; Webb, J. Wham! Pow! Comics as user assistance. J. Usability Stud. 2012, 7, 105–117. [Google Scholar]
- Hosler, J.; Boomer, K.B. Are comic books an effective way to engage nonmajors in learning and appreciating science? CBE Life Sci. Educ. 2011, 10, 301–317. [Google Scholar]
- Brand, A.; Gao, L.; Hamann, A.; Crayen, C.; Brand, H.; Squier, S.M.; Stangl, K.; Kendel, F.; Stangl, V. Medical graphic narratives to improve patient comprehension and periprocedural anxiety before coronary angiography and percutaneous coronary intervention: A randomized trial. Annu. Intern. Med. 2019, 170, 579–581. [Google Scholar] [CrossRef] [PubMed]
- Nakazawa, J. Manga literacy and manga comprehension in Japanese children. In The Visual Narrative Reader; Cohn, N., Ed.; Bloomsbury: London, UK, 2016; pp. 157–184. [Google Scholar]
- Sui, D.Z. Visuality, aurality, and shifting metaphors of geographical thought in the late twentieth century. Ann. Assoc. Am. Geogr. 2000, 90, 322–343. [Google Scholar] [CrossRef]
- Schlottmann, A.; Miggelbrink, J. Ausgangspunkte. In Visuelle Geographien; Schlottmann, A., Miggelbrink, J., Eds.; Transcript Verlag: Bielefeld, Germany, 2015; pp. 13–25. [Google Scholar]
- Mason, L.; Pluchino, P.; Tornatora, M.C. Integrative processing of verbal and graphical information during re-reading predicts learning from illustrated text: An eye-movement study. Read. Writ. 2015, 28, 851–872. [Google Scholar] [CrossRef]
- Mason, L.; Pluchino, P.; Tornatora, M.C. Effects of picture labeling on science text processing and learning: Evidence from eye movements. Read. Res. Q. 2013, 48, 199–214. [Google Scholar] [CrossRef]
- Kirtley, C.; Murray, C.; Vaughan, P.; Tatler, B. Reading Words and Images: Factors Influencing Eye Movements in Comic Reading. In Empirical Comics Research: Digital, Multimodal, and Cognitive Methods; Dunst, A., Laubrock, J., Wildfeuer, J., Eds.; Routledge: New York, NY, USA, 2018. [Google Scholar]
- Loschky, L.; Hutson, J.; Smith, M.; Smith, T.; Magliano, J. Attention to comics: Cognitive processing during the reading of graphic literature. In Empirical Comics Research: Digital, Multimodal, and Cognitive Methods; Dunst, A., Laubrock, J., Wildfeuer, J., Eds.; Routledge: New York, NY, USA, 2018. [Google Scholar]
- Loschky, L.; Hutson, J.; Smith, M.; Smith, T.; Magliano, J. Viewing Static Visual Narratives through the Lens of the Scene Perception and Event Comprehension Theory (SPECT). In Empirical Comics Research: Digital, Multimodal, and Cognitive Methods; Dunst, A., Laubrock, J., Wildfeuer, J., Eds.; Routledge: New York, NY, USA, 2018. [Google Scholar]
- Mayer, R. Principles on Social Cues in Multimedia Learning: Personalization, Voice, Image, and Embodiment Principles. In The Cambridge Handbook of Multimedia Learning, 2nd ed.; Mayer, R., Ed.; Cambridge University Press: New York, NY, USA, 2014; pp. 72–103. [Google Scholar]
- Rothkegel, L.; Trukenbrod, H.A.; Schütt, H.H.; Wichmann, F.A.; Engbert, R. Influence of initial fixation position in scene viewing. Vis. Res. 2016, 129, 33–49. [Google Scholar] [CrossRef] [PubMed]
- Cohn, N. The Visual Language Fluency Index: A Measure of “Comic Reading Expertise”. Available online: www.visuallanguagelab.com/resources.html (accessed on 15 October 2020).
- Ministerium für Schule und Bildung des Landes Nordrhein-Westfalen. Kernlehrplan für die Sekundarstufe I Realschule in Nordrhein-Westfalen, Erdkunde (Entwurf Verbändebeteiligung: 25.02.2020). Available online: https://www.schulentwicklung.nrw.de/lehrplaene/upload/klp_SI/RS/EK/rs_ek_klp_vb_2020_02_25.pdf (accessed on 22 May 2020).
- Christensen, B.J.; Kowalczyk, C. Introduction to globalization: Strategies and effects. In Globalization; Christensen, B.J., Kowalczyk, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2017; pp. 1–16. [Google Scholar] [CrossRef]
- Karuturi Flower Farm for Sale. Available online: http://www.hortidaily.com/article/14923/Karuturi-flower-farm-for-sale (accessed on 4 February 2015).
- FIAN. Land Grabbing in Kenia. Available online: https://www.fian.de/fileadmin/user_upload/dokumente/shop/Land_Grabbing/fian_fact_sheet2010-4_kenia_final_web.pdf (accessed on 15 October 2020).
- Sunkara, K. Dubai-based Phoenix Group to invest in rose exporter Karuturi’s Kenyan biz. Available online: https://www.vccircle.com/dubai-based-phoenix-group-to-invest-in-rose-exporter-karuturis-kenyan-biz (accessed on 15 October 2020).
- Rhode-Jüchtern, T. Kreative Geographie; Wochenschau Verlag: Schwalbach/Ts, Germany, 2015. [Google Scholar]
- National Geography Standard. Available online: https://www.nationalgeographic.org/standards/national-geography-standards/6/ (accessed on 15 October 2020).
- DGfG Deutsche Gesellschaft für Geographie. Bildungsstandards im Fach Geographie für den Mittleren Schulabschluss. Available online: https://geographie.de/wp-content/uploads/2014/09/geographie_bildungsstandards.pdf (accessed on 4 June 2020).
- Hyönä, J. The use of eye movements in the study of multimedia learning. Learn. Instr. 2010, 2, 172–176. [Google Scholar] [CrossRef]
- Sabatinelli, D.; Flaisch, T.; Bradley, M.; Fitzsimmons, J.; Lang, P. Affective picture perception: Gender differences in visual cortex? Neuro Rep. 2004, 15, 1109–1112. [Google Scholar] [CrossRef] [PubMed]
- Kalyuga, S.; Sweller, J. The redundancy principle in multimedia learning. In The Cambridge Handbook of Multimedia Learning, 2nd ed.; Mayer, R., Ed.; Cambridge University Press: New York, NY, USA, 2014; pp. 247–262. [Google Scholar]
- Dittmer, J. Comic Book Visualities: A Methodological Manifesto on Geography, Montage and Narration. Trans. Inst. Br. Geogr. 2010, 35, 222–236. [Google Scholar] [CrossRef]
- Streeck, J.; Goodwin, C.; LeBaron, C. Embodied interaction in the material world: An introduction. In Embodied Interaction; Streeck, J., Goodwin, C., LeBaron, C., Eds.; Cambridge University Press: New York, NY, USA, 2011. [Google Scholar]
- Enfield, N. Elements of Formulation. In Embodied Interaction; Streeck, J., Goodwin, C., LeBaron, C., Eds.; Cambridge University Press: New York, NY, USA, 2011; pp. 59–66. [Google Scholar]
- Adams, J.; Greenwood, D.; Thomashow, M.; Russ, A. Sense of Place. In Urban Environmental Educational Review; Russ, A., Krasny, M., Eds.; Comstock Publishing Associates: Ithaca, NY, USA; London, UK, 2017. [Google Scholar]
- Koopman, E.M. Does originality evoke understanding? The relation between literary reading and empathy. Rev. Gen. Psychol. 2018, 22, 169–177. [Google Scholar] [CrossRef]
- Oatley, K.; Djikic, M. Psychology of Narrative Art. Rev. Gen. Psychol. 2018, 22, 161–168. [Google Scholar] [CrossRef]
- Budke, A. Förderung von Argumentationskompetenzen in aktuellen Geographieschulbüchern. In Aufgaben im Schulbuch; Matthes, E., Heinze, C., Eds.; Klinkhardt: Bad Heilbrunn, Germany, 2011. [Google Scholar]
Figure 1.
The comic designed for this study, translated into english.
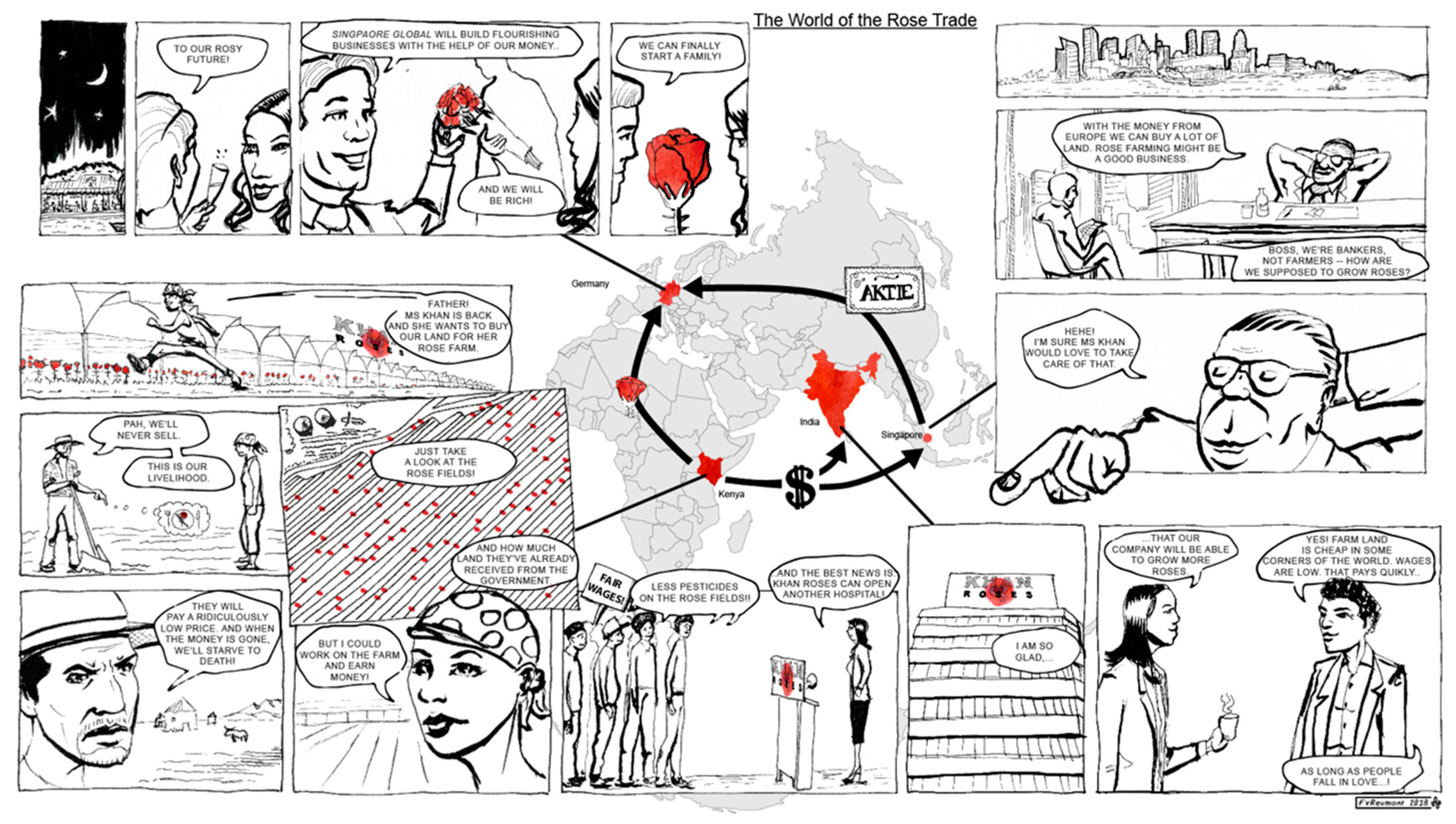
Figure 2.
The Areas of Interest (AOI) in our geo-comic. AOIs are colored according to category (text, image, map).
Figure 2.
The Areas of Interest (AOI) in our geo-comic. AOIs are colored according to category (text, image, map).
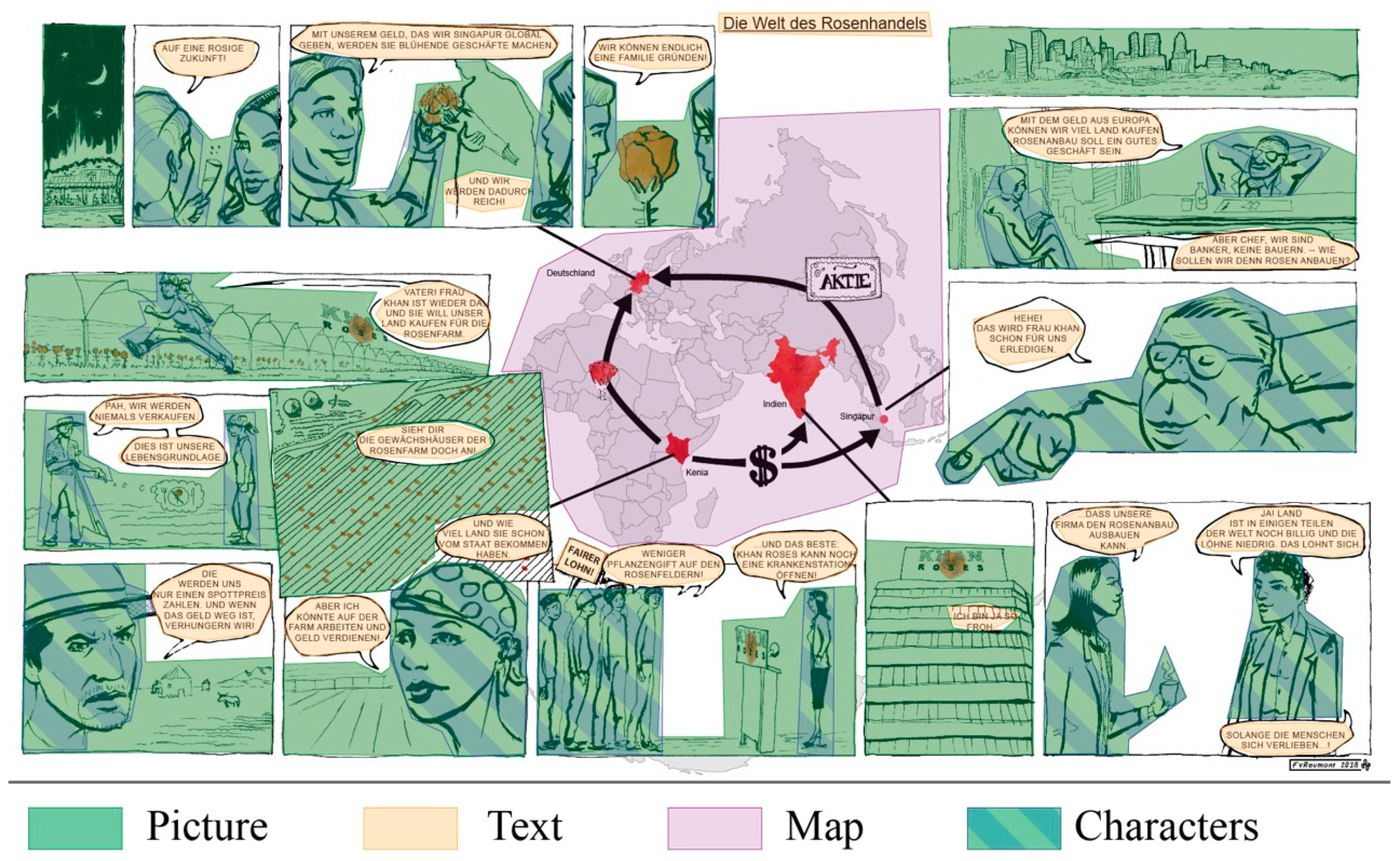
Figure 3.
Heat map showing the number of fixations aggregated over all participants. the color red signifies the highest concentration of fixations.
Figure 3.
Heat map showing the number of fixations aggregated over all participants. the color red signifies the highest concentration of fixations.
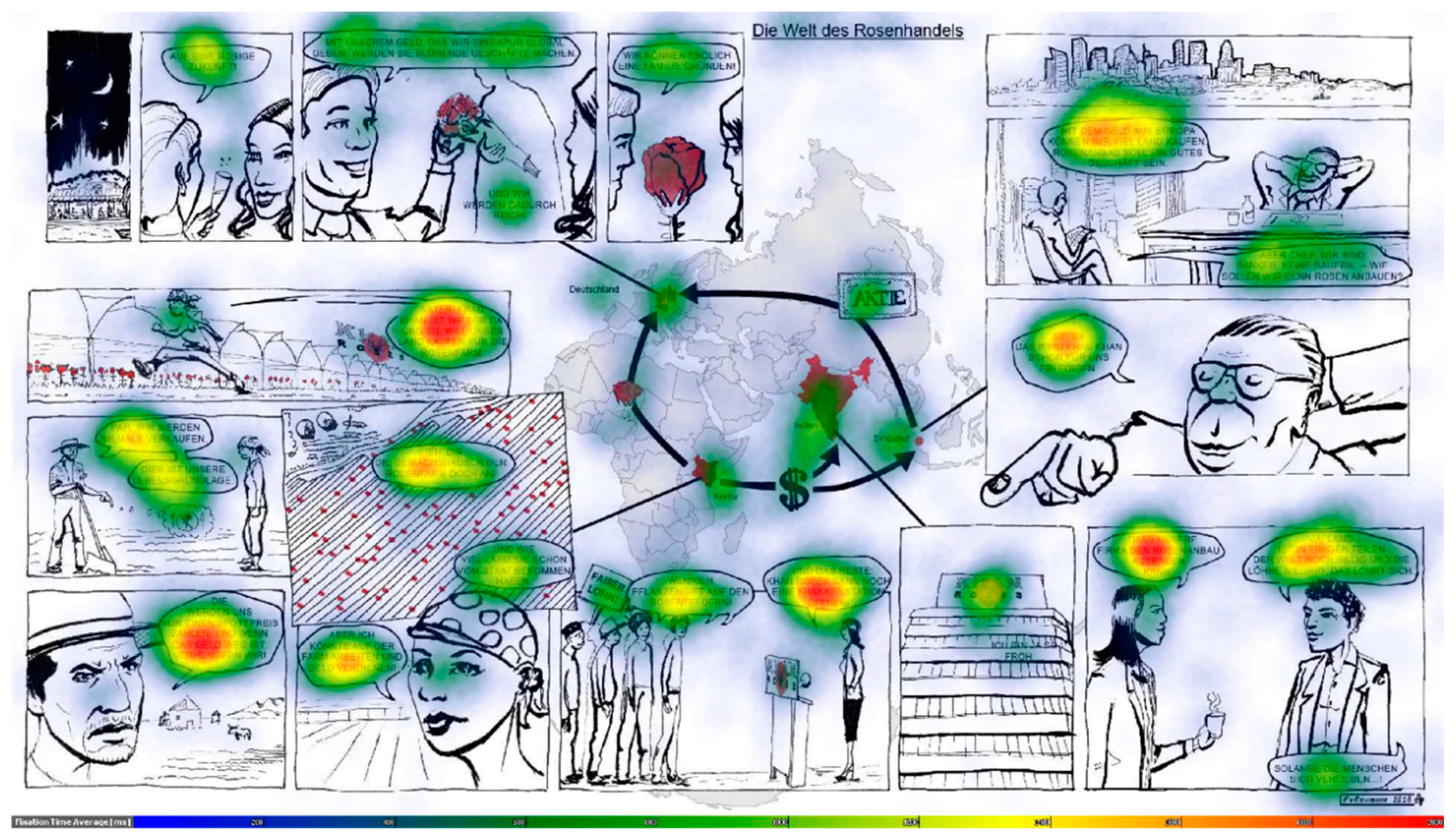
Figure 4.
Heat map showing the viewing behavior of the top performers. top performers scored more than 15 points in the post-test (n = 7).
Figure 4.
Heat map showing the viewing behavior of the top performers. top performers scored more than 15 points in the post-test (n = 7).
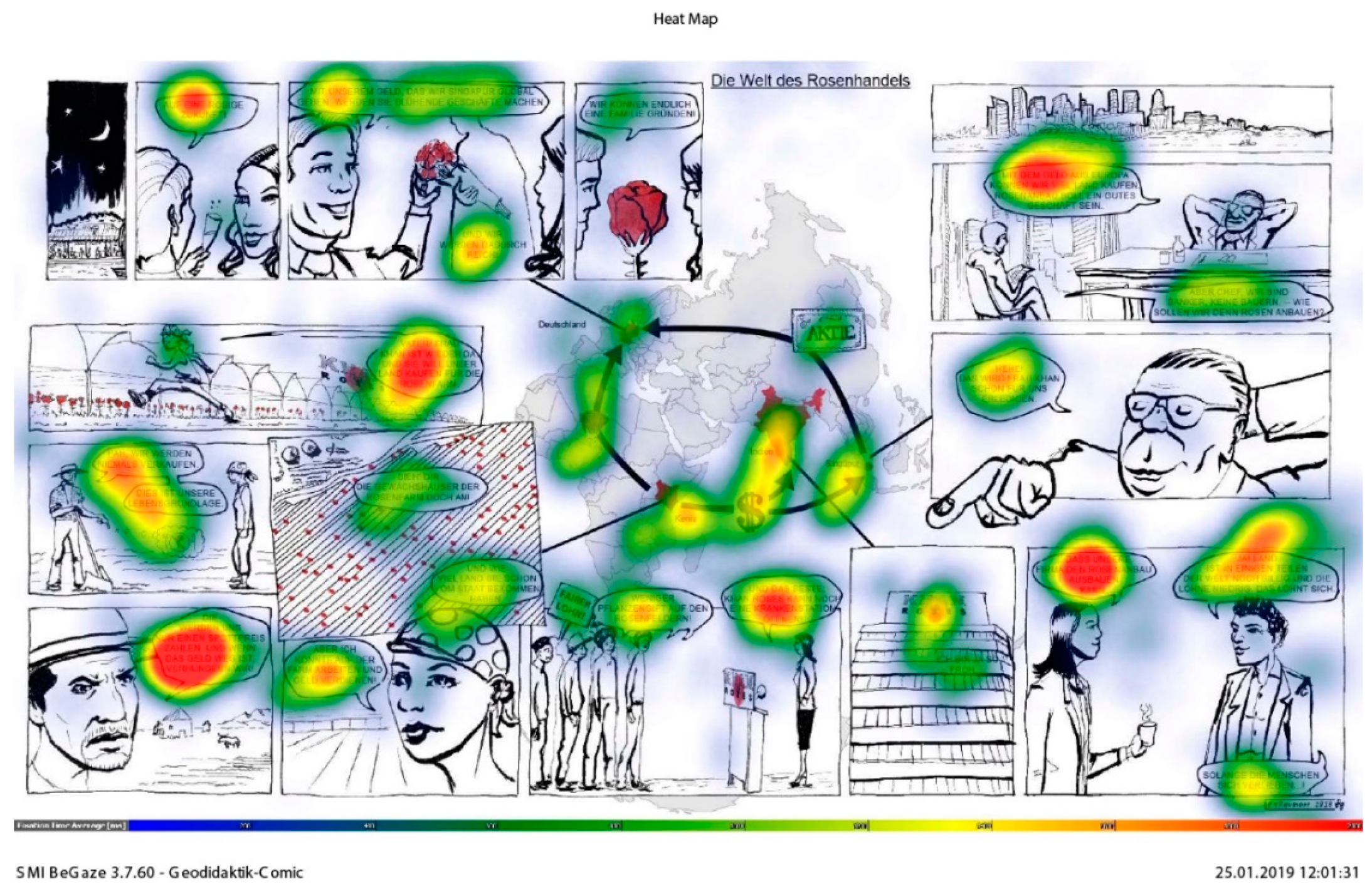
Figure 5.
Heat map showing the viewing behavior of the weakest performers. Weaker performers scored less than 5 points in the post-test (n = 10).
Figure 5.
Heat map showing the viewing behavior of the weakest performers. Weaker performers scored less than 5 points in the post-test (n = 10).


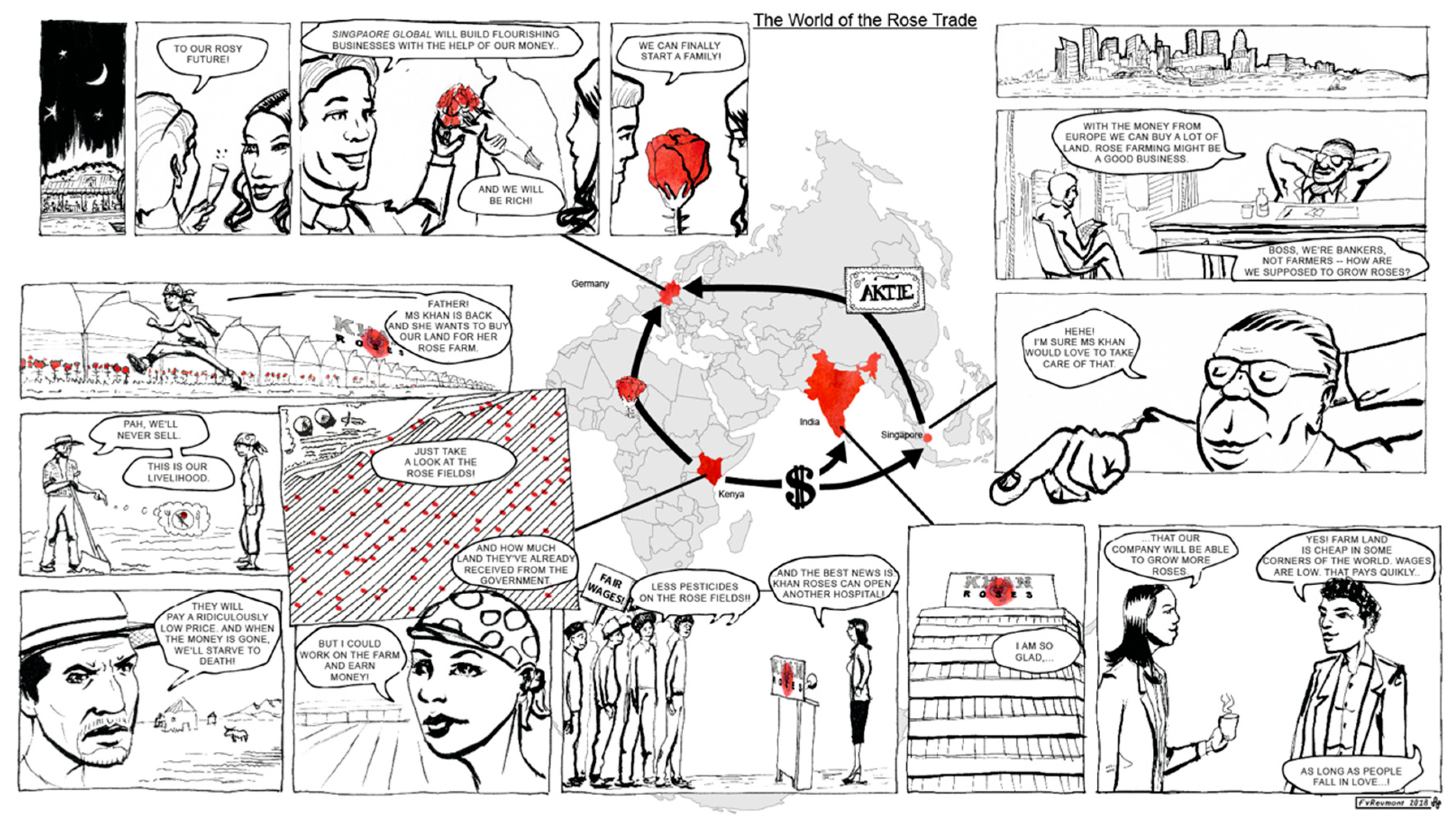{kind=link}
{kind=link}
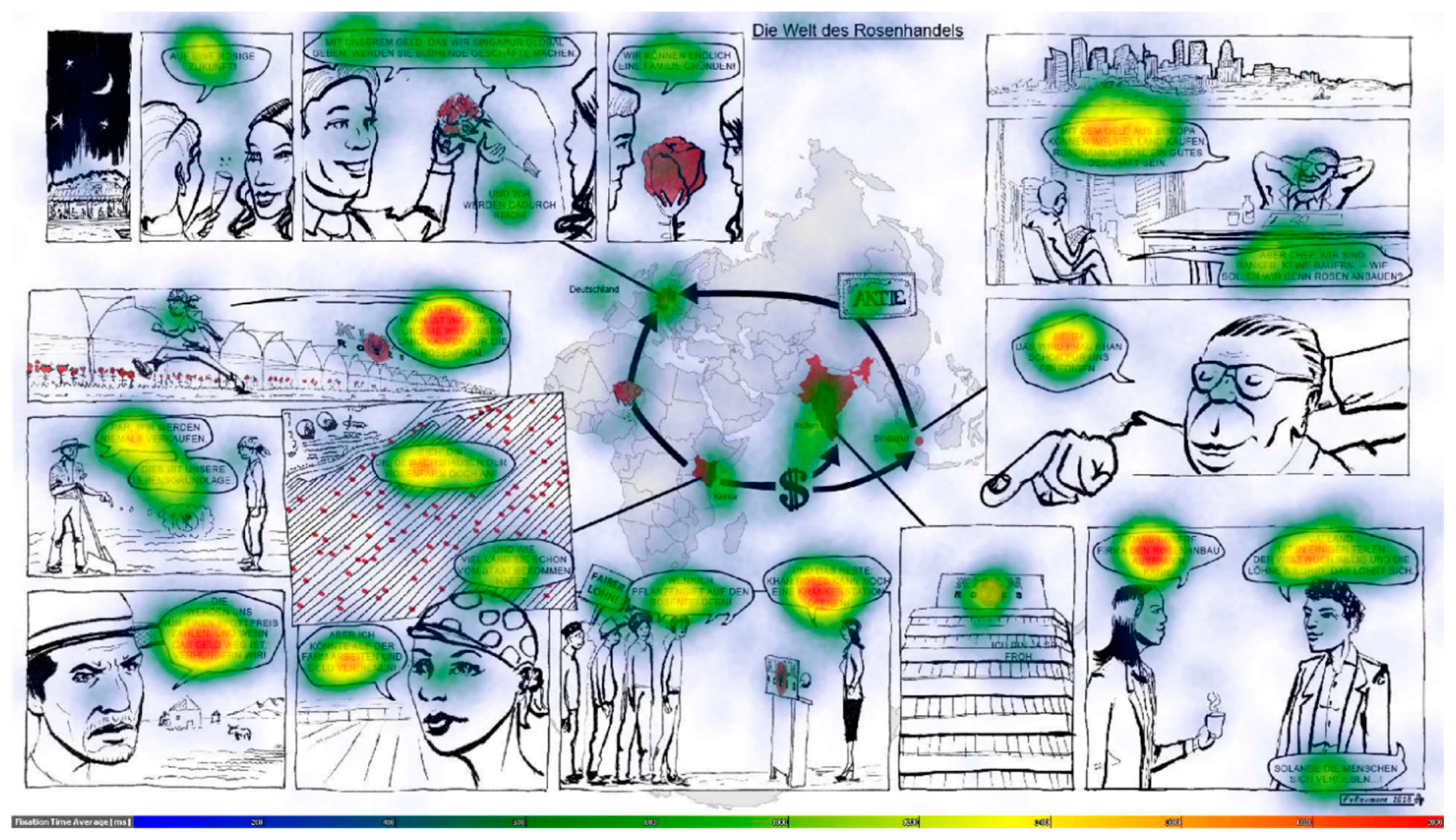{kind=link}
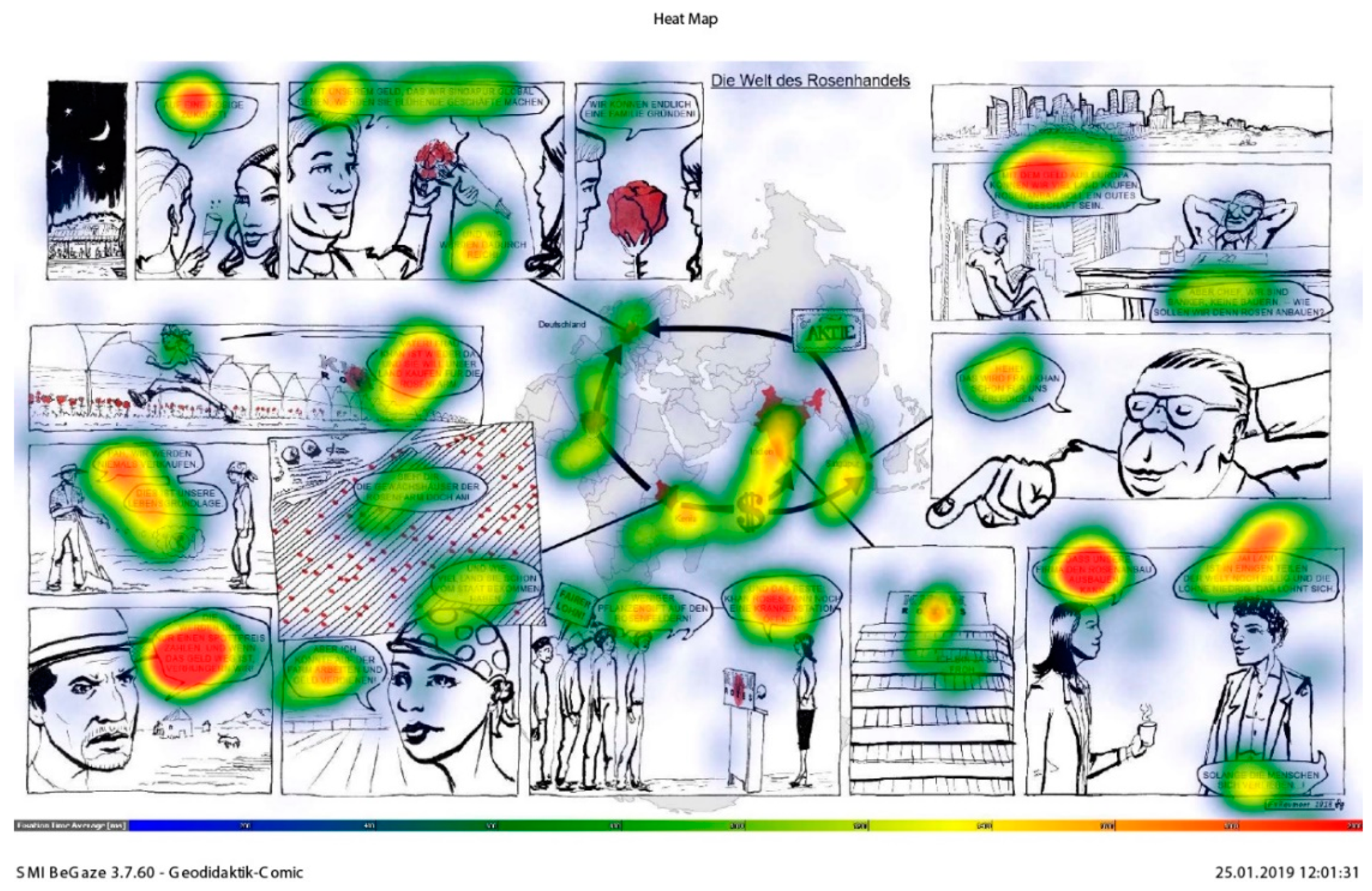{kind=link}
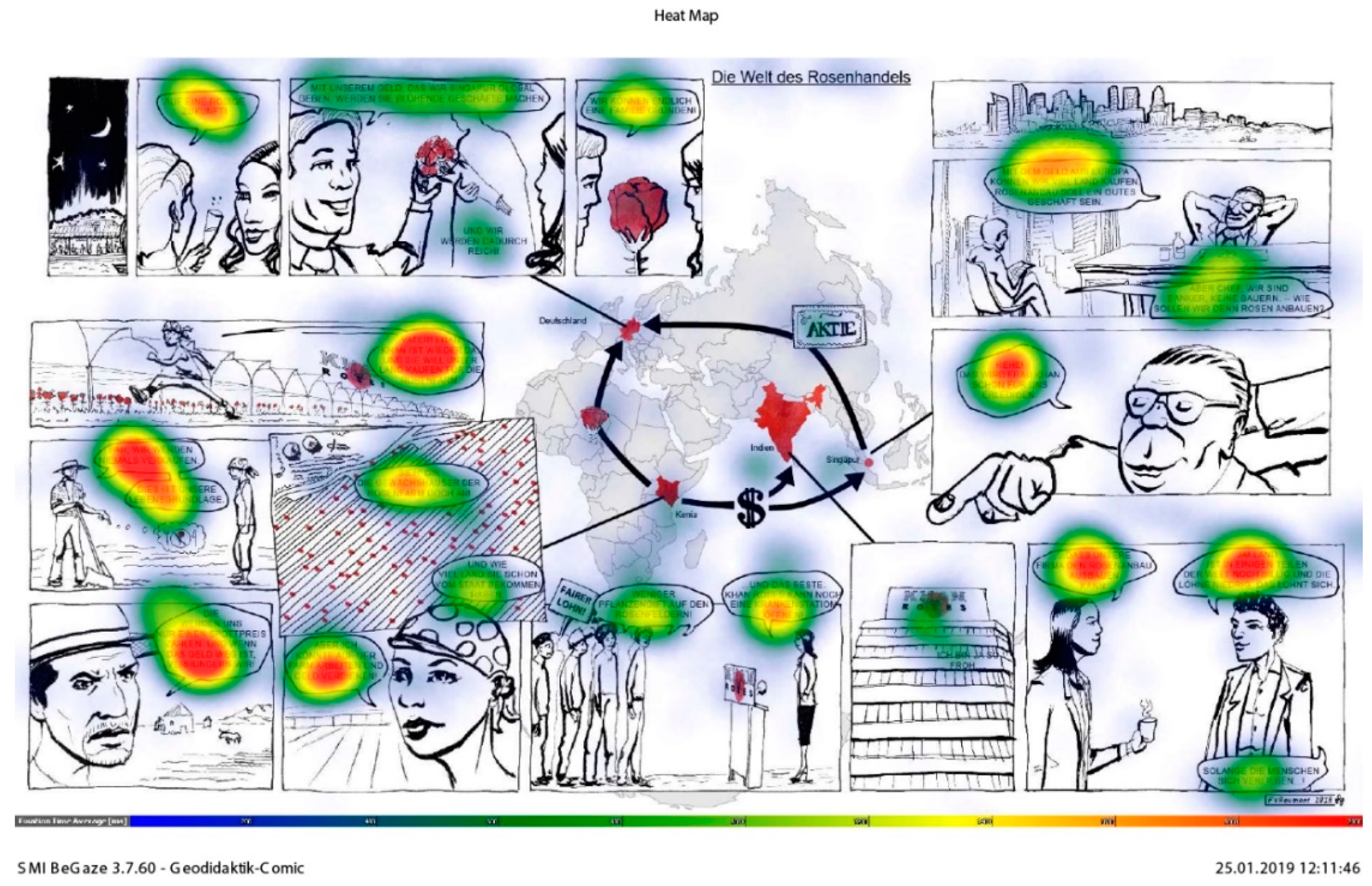{kind=link}
Table 1.
Mean values for some eye-tracking metrics over selected comic elements (standard deviation in brackets).
Table 1.
Mean values for some eye-tracking metrics over selected comic elements (standard deviation in brackets).
| Element | Fixation Count | Dwell Time in Seconds | Revisits |
|---|---|---|---|
| Text | 127.79 (77.23) | 83.72 (57.50) | 43.06 (42.58) |
| Picture | 68.79 (38.65) | 27.71 (15.14) | 34.38 (27.69) |
| Characters | 32.29 (19.03) | 11.65 (6.81) | 17.50 (13.99) |
| Map | 40.79 (53.55) | 15.63 (21.96) | 9.47 (11.40) |
Table 2.
The 6 most difficult and easiest post-test items according to rasch scaling. The easiest item is located at the bottom of the table. Items which are related to stakeholders are shaded in green; All other items are shaded in light blue.
Table 2.
The 6 most difficult and easiest post-test items according to rasch scaling. The easiest item is located at the bottom of the table. Items which are related to stakeholders are shaded in green; All other items are shaded in light blue.
| Rasch Score | Comic Comprehension Students Identify… | Learning Objectives Students Correctly… | Picture Present in the Comic? |
|---|---|---|---|
| The six most difficult items from the post-test | |||
| 3.77 | …Singapore as an industrialized country. | …apply information about globalization given in the comic to a location. | No |
| 3.77 | …India as an emerging economy. | …apply information about globalization given in the comic to a location. | No |
| 2.55 | …India as location of rose company’s headquarters | …apply information about globalization given in the comic to a location. | No |
| 2.55 | …that workers on the rose farm suffer health risks. | …evaluate the effect of the rose trade on stakeholders. | No |
| 1.77 | …Singapore as a financial market place. | …apply information from comic about globalization to location. | No |
| 1.29 | …German couple as shareholders. | …identify role of stakeholders. | No |
| The six least difficult items from the post-test | |||
| −1.14 | …globalization as part of the topic of the comic. | …identify the topic of the comic. | yes |
| −1.14 | …agent as Ms Khan. | …identify stakeholders. | yes |
| −1.14 | …agent as father. | …identify stakeholders. | yes |
| −1.62 | …[(subsistence) farmers] do not profit. | …evaluate effect of the rose trade on stakeholders. | yes |
| −1.77 | …[Ms Khan/the rose company] profit from the rose trade. | …evaluate effect of the rose trade on stakeholders. | yes |
| −2.1 | …rose trade as part of the topic of the comic. | …identify the topic of the comic. | yes |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
von Reumont, F.; Budke, A. Strategies for Successful Learning with Geographical Comics: An Eye-Tracking Study with Young Learners. Educ. Sci. 2020, 10, 293. https://doi.org/10.3390/educsci10100293
AMA Style
von Reumont F, Budke A. Strategies for Successful Learning with Geographical Comics: An Eye-Tracking Study with Young Learners. Education Sciences. 2020; 10(10):293. https://doi.org/10.3390/educsci10100293
Chicago/Turabian Stylevon Reumont, Frederik, and Alexandra Budke. 2020. "Strategies for Successful Learning with Geographical Comics: An Eye-Tracking Study with Young Learners" Education Sciences 10, no. 10: 293. https://doi.org/10.3390/educsci10100293
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.