Strategies for Successful Learning with Geographical Comics: An Eye-Tracking Study with Young Learners


Abstract
1. Introduction
2. Theory
2.1. Integrated Processing of Text and Picture Improves Learning
2.2. Character-Driven Narrative Supports Learning in Text–Image Combinations
2.3. Sequence of Perception Influences Cognitive Performance
3. Method
3.1. The Sample
3.2. The Research Instruments
3.3. Study Design and Procedure
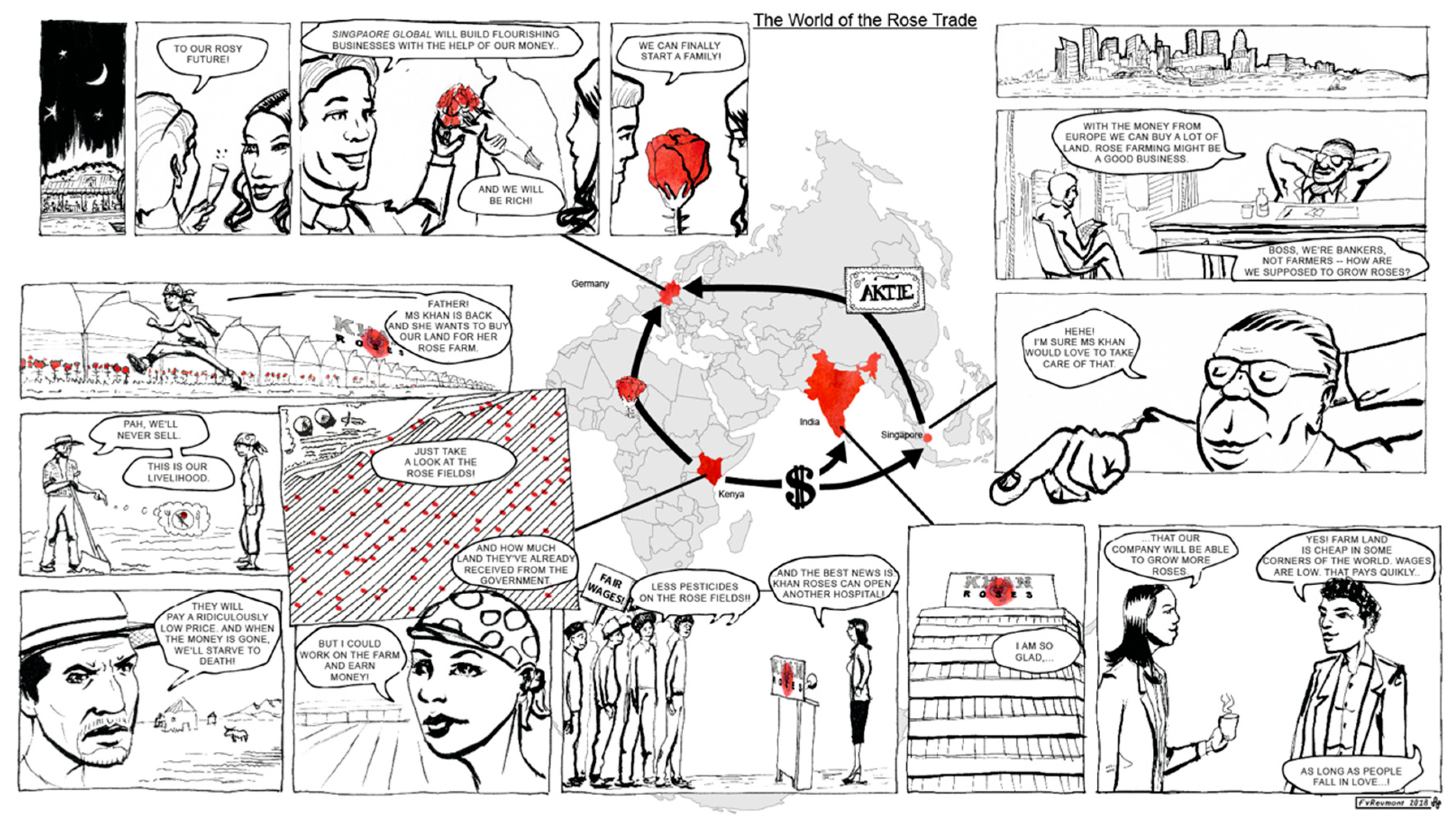
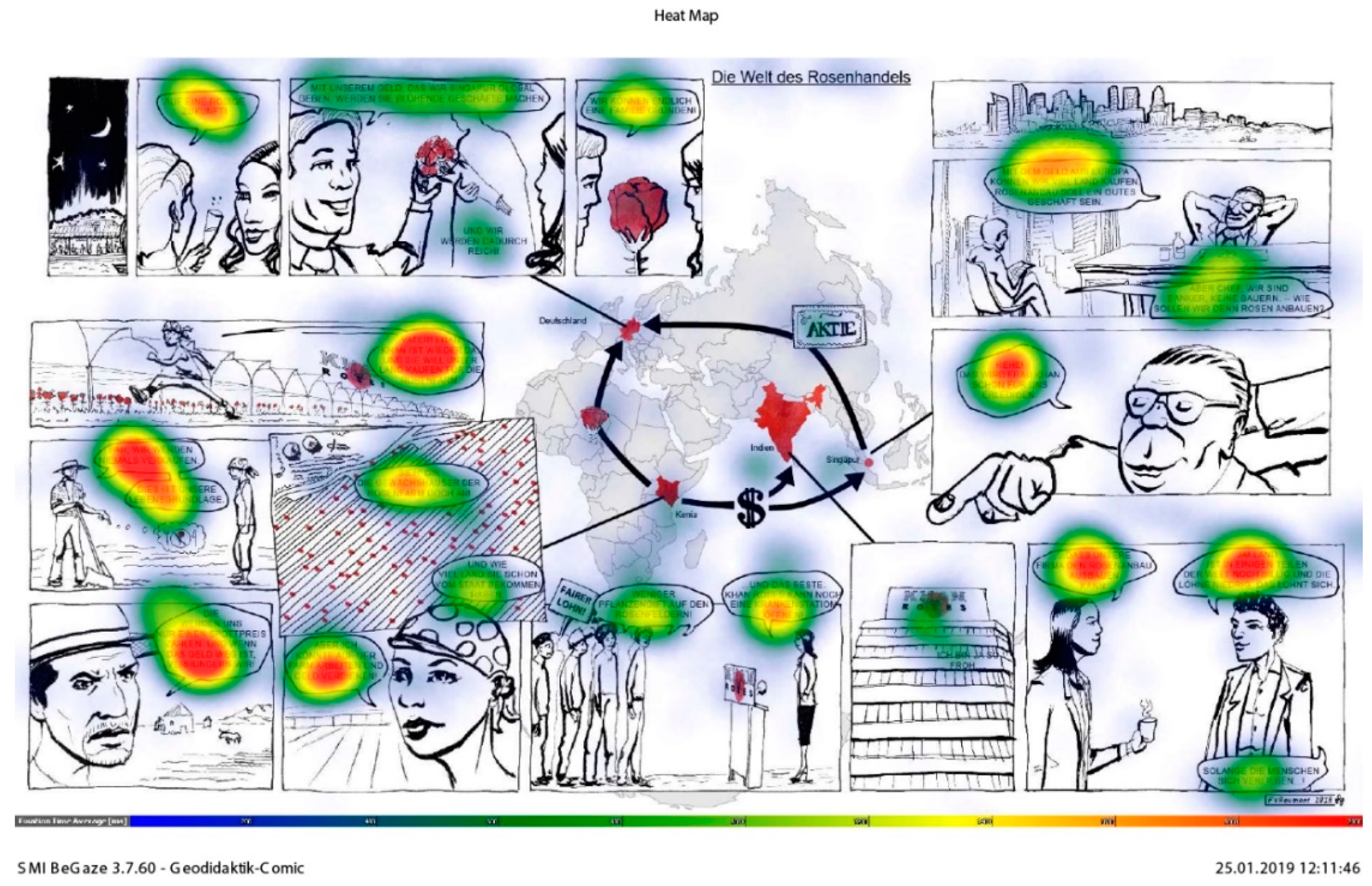
3.3.1. The Design of the Stimulus
3.3.2. Preparing the Stimulus for Eye-Tracking
3.3.3. Pre-Test
3.3.4. Experiment
3.3.5. Post-Test
3.4. Data Analysis
3.4.1. Descriptive Statistics
3.4.2. Processing the Comprehension Test Results Using Rasch Analysis
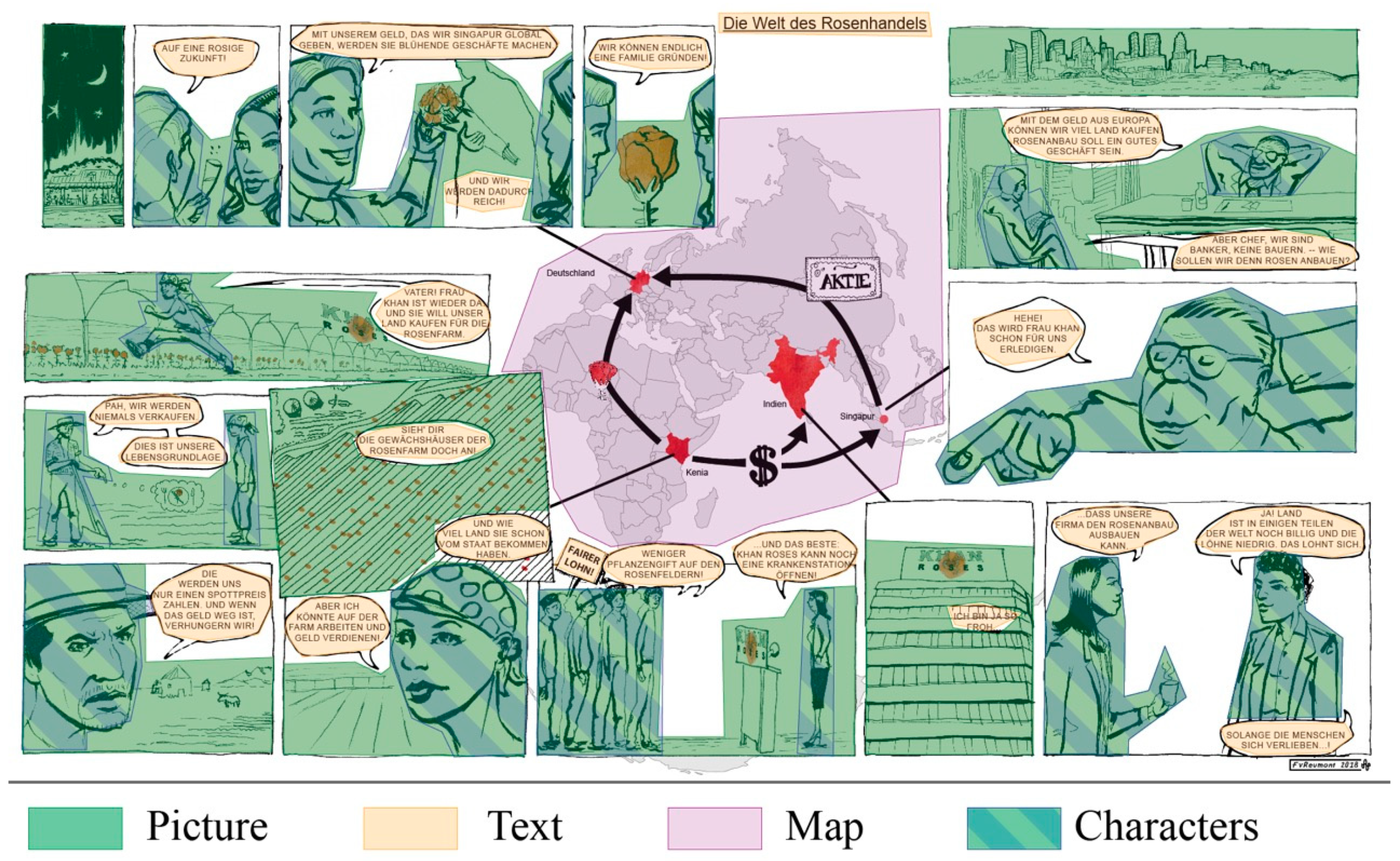
3.4.3. Analyzing the Meaning of Pictures for Comprehension
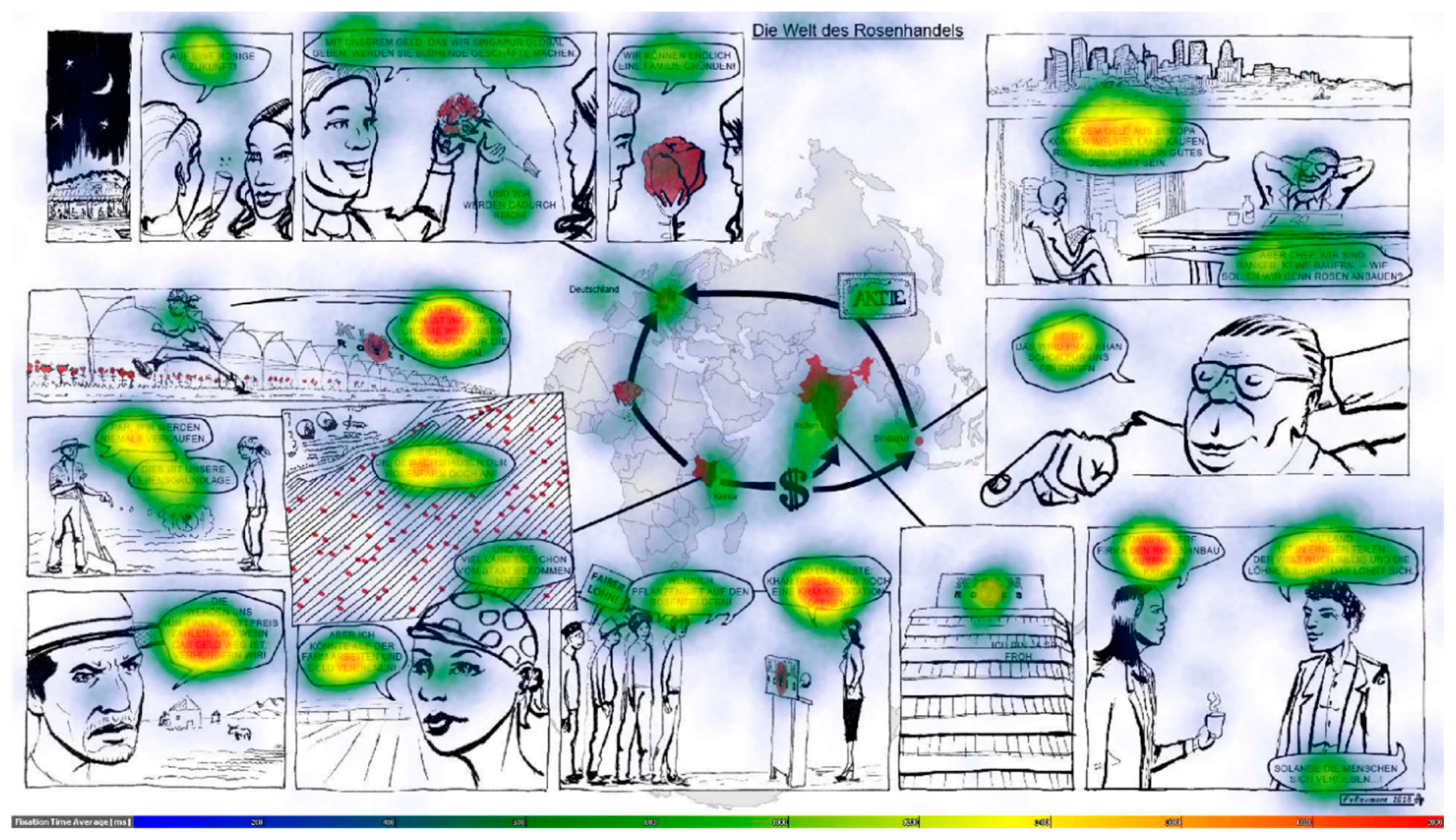
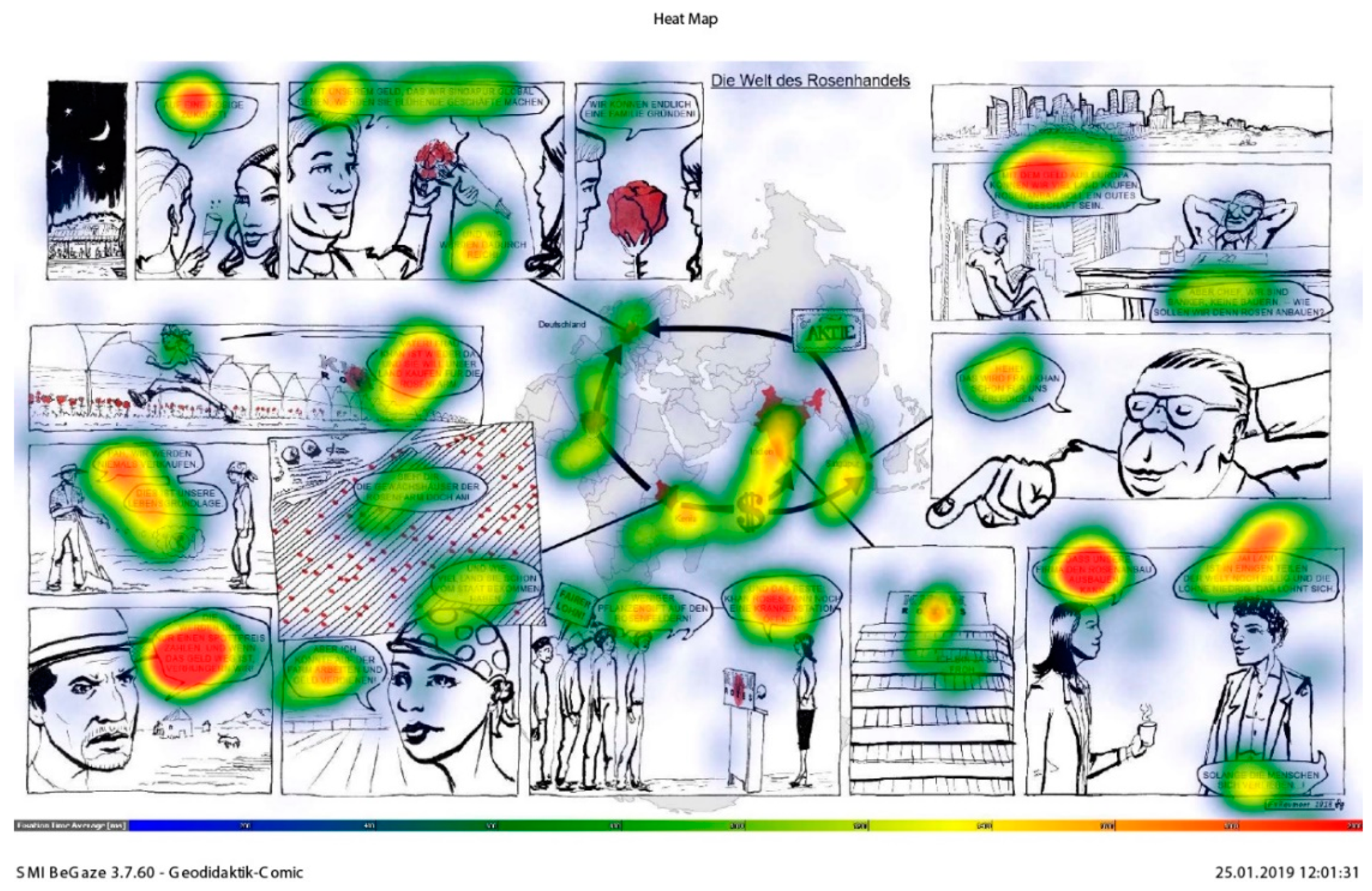
3.4.4. Processing the Eye-Tracking Data
Visual Analysis
Statistical Analysis
- (1)
- Number of transitions
- (2)
- Fixation count
- (3)
- Dwell time
- (4)
- Number of revisits
- (5)
- Sequence of AOIs
3.5. Methodological Reflection
4. Identifying Successful Strategies of Viewing a Geo-Comic: Results of the Analysis
4.1. Overview
4.2. Post-Test Results
4.3. Effects of Some of the Demographic Variables
4.3.1. Effects on Post-Test Results
4.3.2. Effects on Viewing Strategies
4.4. Integrated Media Processing
4.4.1. Effect of Pictures on Learning
4.4.2. Transitions between Map, Text, and Picture
4.5. The Role of Human Characters in Learning with a Geo-Comic
4.6. The Map
5. Discussion
5.1. Integrated Processing
5.1.1. Effects of Pictures for Learning Geographical Content
5.1.2. Switching Attention between Text, Picture, and Map
5.2. Character-Driven Narrative
5.3. The Special Role of the Map
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Farinella, M. The potential of comics in science communication. J. Sci. Commun. 2018, 17. [Google Scholar] [CrossRef]
- Sousanis, N. Unflattening; Harvard University Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Mayer, R. Multimedia Learning; Cambridge University Press: Cambridge, UK, 2001. [Google Scholar]
- Schnotz, W. Integrated Model of Text and Picture Comprehension. In The Cambridge Handbook of Multimedia Learning, 2nd ed.; Mayer, R., Ed.; Cambridge University Press: New York, NY, USA, 2014; pp. 72–103. [Google Scholar]
- Eitel, A.; Scheiter, K.; Schüler, A. How Inspecting a Picture Affects Processing of Text in Multimedia Learning. Appl. Cogn. Psychol. 2013, 27, 451–461. [Google Scholar] [CrossRef]
- Duchowski, A.T. Eye Tracking Metodology; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Mayer, R. Unique contributions of eye-tracking research to the study of learning with graphics. Learn. Instr. 2010, 20, 167–171. [Google Scholar] [CrossRef]
- Aleixo, P.; Sumner, K. Memory for biopsychology material presented in comic book format. J. Graph. Nov. Comics 2017, 8, 79–88. [Google Scholar] [CrossRef]
- Nalu, A.; Bliss, J. Comics as a cognitive training medium for expert decision making. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Las Vegas, NV, USA, 19–23 September 2011; Volume 55, pp. 2123–2127. [Google Scholar] [CrossRef]
- Göhler, J.; Narciss, S.; Niehtammer, M. Comics–Didaktisches Potenzial für Berufsbildung im Medizinisch-Pflegerischen Sektor? bwp@ Spezial 6. Proc. Hochschultage Berufl. Bild. 2013, 10, 1–16. Available online: http://www.bwpat.de/ht2013/ft10/goehler_etal_ft10-ht2013.pdf (accessed on 15 October 2020).
- Özdemir, E. The Effect of Instructional Comics on Sixth Grade Students’ Achievement in Heat Transfer.” OpenMETU, Ankara. 2010. Available online: http://etd.lib.metu.edu.tr/upload/12611749/index.pdf (accessed on 15 October 2020).
- Webb, E.; Balasubramanian, G.; ỎBroin, U.; Webb, J. Wham! Pow! Comics as user assistance. J. Usability Stud. 2012, 7, 105–117. [Google Scholar]
- Hosler, J.; Boomer, K.B. Are comic books an effective way to engage nonmajors in learning and appreciating science? CBE Life Sci. Educ. 2011, 10, 301–317. [Google Scholar]
- Brand, A.; Gao, L.; Hamann, A.; Crayen, C.; Brand, H.; Squier, S.M.; Stangl, K.; Kendel, F.; Stangl, V. Medical graphic narratives to improve patient comprehension and periprocedural anxiety before coronary angiography and percutaneous coronary intervention: A randomized trial. Annu. Intern. Med. 2019, 170, 579–581. [Google Scholar] [CrossRef] [PubMed]
- Nakazawa, J. Manga literacy and manga comprehension in Japanese children. In The Visual Narrative Reader; Cohn, N., Ed.; Bloomsbury: London, UK, 2016; pp. 157–184. [Google Scholar]
- Sui, D.Z. Visuality, aurality, and shifting metaphors of geographical thought in the late twentieth century. Ann. Assoc. Am. Geogr. 2000, 90, 322–343. [Google Scholar] [CrossRef]
- Schlottmann, A.; Miggelbrink, J. Ausgangspunkte. In Visuelle Geographien; Schlottmann, A., Miggelbrink, J., Eds.; Transcript Verlag: Bielefeld, Germany, 2015; pp. 13–25. [Google Scholar]
- Mason, L.; Pluchino, P.; Tornatora, M.C. Integrative processing of verbal and graphical information during re-reading predicts learning from illustrated text: An eye-movement study. Read. Writ. 2015, 28, 851–872. [Google Scholar] [CrossRef]
- Mason, L.; Pluchino, P.; Tornatora, M.C. Effects of picture labeling on science text processing and learning: Evidence from eye movements. Read. Res. Q. 2013, 48, 199–214. [Google Scholar] [CrossRef]
- Kirtley, C.; Murray, C.; Vaughan, P.; Tatler, B. Reading Words and Images: Factors Influencing Eye Movements in Comic Reading. In Empirical Comics Research: Digital, Multimodal, and Cognitive Methods; Dunst, A., Laubrock, J., Wildfeuer, J., Eds.; Routledge: New York, NY, USA, 2018. [Google Scholar]
- Loschky, L.; Hutson, J.; Smith, M.; Smith, T.; Magliano, J. Attention to comics: Cognitive processing during the reading of graphic literature. In Empirical Comics Research: Digital, Multimodal, and Cognitive Methods; Dunst, A., Laubrock, J., Wildfeuer, J., Eds.; Routledge: New York, NY, USA, 2018. [Google Scholar]
- Loschky, L.; Hutson, J.; Smith, M.; Smith, T.; Magliano, J. Viewing Static Visual Narratives through the Lens of the Scene Perception and Event Comprehension Theory (SPECT). In Empirical Comics Research: Digital, Multimodal, and Cognitive Methods; Dunst, A., Laubrock, J., Wildfeuer, J., Eds.; Routledge: New York, NY, USA, 2018. [Google Scholar]
- Mayer, R. Principles on Social Cues in Multimedia Learning: Personalization, Voice, Image, and Embodiment Principles. In The Cambridge Handbook of Multimedia Learning, 2nd ed.; Mayer, R., Ed.; Cambridge University Press: New York, NY, USA, 2014; pp. 72–103. [Google Scholar]
- Rothkegel, L.; Trukenbrod, H.A.; Schütt, H.H.; Wichmann, F.A.; Engbert, R. Influence of initial fixation position in scene viewing. Vis. Res. 2016, 129, 33–49. [Google Scholar] [CrossRef] [PubMed]
- Cohn, N. The Visual Language Fluency Index: A Measure of “Comic Reading Expertise”. Available online: www.visuallanguagelab.com/resources.html (accessed on 15 October 2020).
- Ministerium für Schule und Bildung des Landes Nordrhein-Westfalen. Kernlehrplan für die Sekundarstufe I Realschule in Nordrhein-Westfalen, Erdkunde (Entwurf Verbändebeteiligung: 25.02.2020). Available online: https://www.schulentwicklung.nrw.de/lehrplaene/upload/klp_SI/RS/EK/rs_ek_klp_vb_2020_02_25.pdf (accessed on 22 May 2020).
- Christensen, B.J.; Kowalczyk, C. Introduction to globalization: Strategies and effects. In Globalization; Christensen, B.J., Kowalczyk, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2017; pp. 1–16. [Google Scholar] [CrossRef]
- Karuturi Flower Farm for Sale. Available online: http://www.hortidaily.com/article/14923/Karuturi-flower-farm-for-sale (accessed on 4 February 2015).
- FIAN. Land Grabbing in Kenia. Available online: https://www.fian.de/fileadmin/user_upload/dokumente/shop/Land_Grabbing/fian_fact_sheet2010-4_kenia_final_web.pdf (accessed on 15 October 2020).
- Sunkara, K. Dubai-based Phoenix Group to invest in rose exporter Karuturi’s Kenyan biz. Available online: https://www.vccircle.com/dubai-based-phoenix-group-to-invest-in-rose-exporter-karuturis-kenyan-biz (accessed on 15 October 2020).
- Rhode-Jüchtern, T. Kreative Geographie; Wochenschau Verlag: Schwalbach/Ts, Germany, 2015. [Google Scholar]
- National Geography Standard. Available online: https://www.nationalgeographic.org/standards/national-geography-standards/6/ (accessed on 15 October 2020).
- DGfG Deutsche Gesellschaft für Geographie. Bildungsstandards im Fach Geographie für den Mittleren Schulabschluss. Available online: https://geographie.de/wp-content/uploads/2014/09/geographie_bildungsstandards.pdf (accessed on 4 June 2020).
- Hyönä, J. The use of eye movements in the study of multimedia learning. Learn. Instr. 2010, 2, 172–176. [Google Scholar] [CrossRef]
- Sabatinelli, D.; Flaisch, T.; Bradley, M.; Fitzsimmons, J.; Lang, P. Affective picture perception: Gender differences in visual cortex? Neuro Rep. 2004, 15, 1109–1112. [Google Scholar] [CrossRef] [PubMed]
- Kalyuga, S.; Sweller, J. The redundancy principle in multimedia learning. In The Cambridge Handbook of Multimedia Learning, 2nd ed.; Mayer, R., Ed.; Cambridge University Press: New York, NY, USA, 2014; pp. 247–262. [Google Scholar]
- Dittmer, J. Comic Book Visualities: A Methodological Manifesto on Geography, Montage and Narration. Trans. Inst. Br. Geogr. 2010, 35, 222–236. [Google Scholar] [CrossRef]
- Streeck, J.; Goodwin, C.; LeBaron, C. Embodied interaction in the material world: An introduction. In Embodied Interaction; Streeck, J., Goodwin, C., LeBaron, C., Eds.; Cambridge University Press: New York, NY, USA, 2011. [Google Scholar]
- Enfield, N. Elements of Formulation. In Embodied Interaction; Streeck, J., Goodwin, C., LeBaron, C., Eds.; Cambridge University Press: New York, NY, USA, 2011; pp. 59–66. [Google Scholar]
- Adams, J.; Greenwood, D.; Thomashow, M.; Russ, A. Sense of Place. In Urban Environmental Educational Review; Russ, A., Krasny, M., Eds.; Comstock Publishing Associates: Ithaca, NY, USA; London, UK, 2017. [Google Scholar]
- Koopman, E.M. Does originality evoke understanding? The relation between literary reading and empathy. Rev. Gen. Psychol. 2018, 22, 169–177. [Google Scholar] [CrossRef]
- Oatley, K.; Djikic, M. Psychology of Narrative Art. Rev. Gen. Psychol. 2018, 22, 161–168. [Google Scholar] [CrossRef]
- Budke, A. Förderung von Argumentationskompetenzen in aktuellen Geographieschulbüchern. In Aufgaben im Schulbuch; Matthes, E., Heinze, C., Eds.; Klinkhardt: Bad Heilbrunn, Germany, 2011. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Element | Fixation Count | Dwell Time in Seconds | Revisits |
|---|---|---|---|
| Text | 127.79 (77.23) | 83.72 (57.50) | 43.06 (42.58) |
| Picture | 68.79 (38.65) | 27.71 (15.14) | 34.38 (27.69) |
| Characters | 32.29 (19.03) | 11.65 (6.81) | 17.50 (13.99) |
| Map | 40.79 (53.55) | 15.63 (21.96) | 9.47 (11.40) |
| Rasch Score | Comic Comprehension Students Identify… | Learning Objectives Students Correctly… | Picture Present in the Comic? |
|---|---|---|---|
| The six most difficult items from the post-test | |||
| 3.77 | …Singapore as an industrialized country. | …apply information about globalization given in the comic to a location. | No |
| 3.77 | …India as an emerging economy. | …apply information about globalization given in the comic to a location. | No |
| 2.55 | …India as location of rose company’s headquarters | …apply information about globalization given in the comic to a location. | No |
| 2.55 | …that workers on the rose farm suffer health risks. | …evaluate the effect of the rose trade on stakeholders. | No |
| 1.77 | …Singapore as a financial market place. | …apply information from comic about globalization to location. | No |
| 1.29 | …German couple as shareholders. | …identify role of stakeholders. | No |
| The six least difficult items from the post-test | |||
| −1.14 | …globalization as part of the topic of the comic. | …identify the topic of the comic. | yes |
| −1.14 | …agent as Ms Khan. | …identify stakeholders. | yes |
| −1.14 | …agent as father. | …identify stakeholders. | yes |
| −1.62 | …[(subsistence) farmers] do not profit. | …evaluate effect of the rose trade on stakeholders. | yes |
| −1.77 | …[Ms Khan/the rose company] profit from the rose trade. | …evaluate effect of the rose trade on stakeholders. | yes |
| −2.1 | …rose trade as part of the topic of the comic. | …identify the topic of the comic. | yes |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
von Reumont, F.; Budke, A. Strategies for Successful Learning with Geographical Comics: An Eye-Tracking Study with Young Learners. Educ. Sci. 2020, 10, 293. https://doi.org/10.3390/educsci10100293
von Reumont F, Budke A. Strategies for Successful Learning with Geographical Comics: An Eye-Tracking Study with Young Learners. Education Sciences. 2020; 10(10):293. https://doi.org/10.3390/educsci10100293
Chicago/Turabian Stylevon Reumont, Frederik, and Alexandra Budke. 2020. "Strategies for Successful Learning with Geographical Comics: An Eye-Tracking Study with Young Learners" Education Sciences 10, no. 10: 293. https://doi.org/10.3390/educsci10100293
APA Stylevon Reumont, F., & Budke, A. (2020). Strategies for Successful Learning with Geographical Comics: An Eye-Tracking Study with Young Learners. Education Sciences, 10(10), 293. https://doi.org/10.3390/educsci10100293