1. Introduction
The next generation telecommunication network has successfully laid the backbone for the proliferation of massive IoT (Internet of Things) and its accompanying big, varying, and complex data [
1]. 5G networks will alleviate the performance tradeoffs of IoT devices under earlier wireless technologies [
2] and completely revolutionized a connected world. These IoT devices, according to Ericsson mobility report, will generate close to 163 zettabytes (ZB) of data before 2025 with 22.3 billion different applications [
3,
4]. This vast interconnection of things will challenge mobile network operator’s capacity to maintain an agile network devoid of congestion, network intrusions, and aggregated flows.
There has been a rampant surge in zombie IoT devices where attackers connect remotely to the IoT devices and install malicious bots to disrupt the normal functionality of the compromised devices. Such attacks including DDoS, spoofing, eavesdropping, and jamming [
5] have security implications on the privacy [
6] of the IoT network, benign flash event, and bandwidth consumption in the network. The vicious DDoS attack targeted at servers with false requests to consume network bandwidth is similar to genuine traffic burst, and this flooding attack speedily depletes network resources and leads to packet loss [
7].
Currently, network operators are turning to Software-Defined Networking (SDN) [
8,
9,
10] to keep pace with the emergence of IoT and enable programmability at a central and distributed level. Network robustness, adaptation, and abstraction with open APIs (Application Programming Interfaces) are core to the separation of the control plane from the forwarding devices in the SDN paradigm. With such separation, the network can be intelligently programmed to react positively to possible transient network loads and intrusions that could destabilize its functionality and operations.
With the advent of Machine Learning [
11,
12], systems automation through data analytics has seen immense applications by researchers. Machine learning algorithms have diverse features with pros and cons in producing accurate models for classification, regression, clustering, and behavioral learning. The most popular categorization of machine learning algorithms is supervised learning models [
13,
14]. Supervised learning models train agents with a labelled dataset. After enough training, the agent is fed with new data for identification and classification. Supervised learning presents an obvious disadvantage of cost in labelling the dataset properly. With variations in data from diverse applications, IoT also presents a difficulty in accurately classifying data. Unsupervised learning [
15,
16] is more about identifying relationships and patterns and less of automation. This type of learning involves a training with unlabeled data and no output. With unsupervised learning, there is no guidance on efforts to get the right groupings. Reinforcement Learning (RL) [
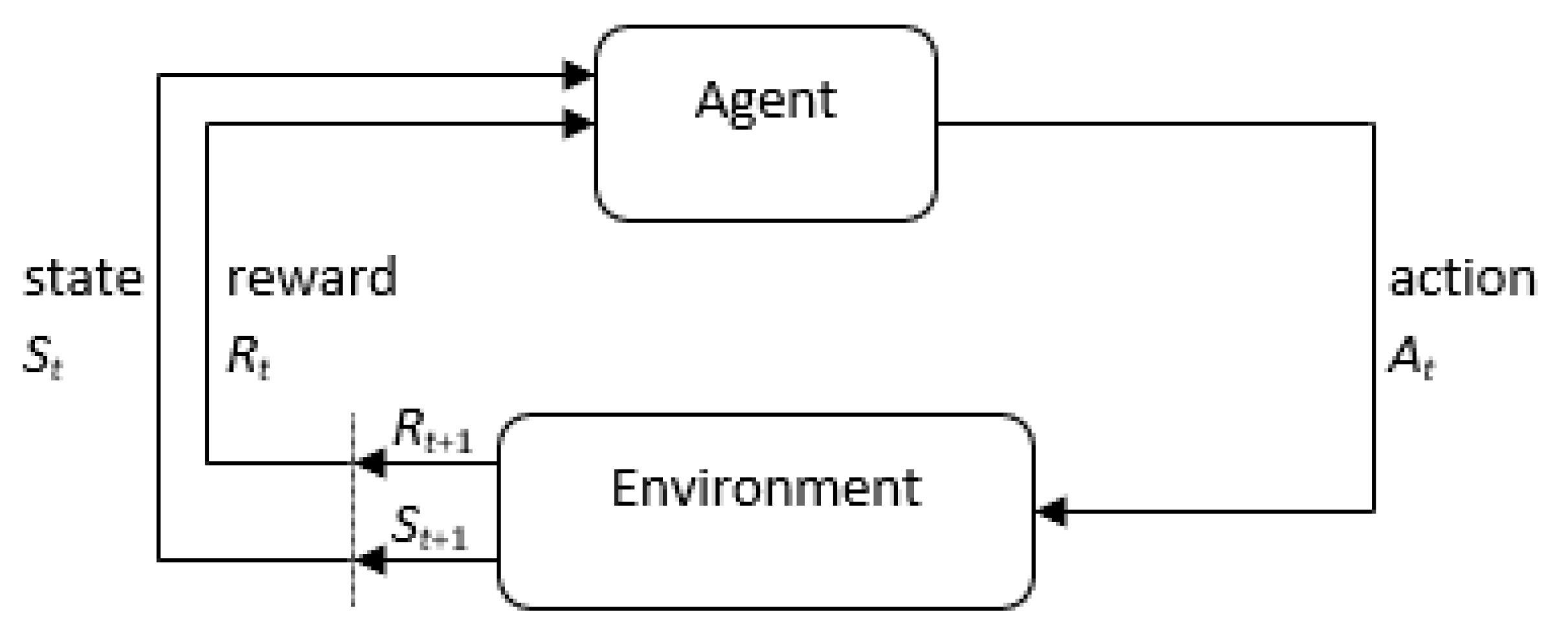
17], as shown in
Figure 1, is the real basis for automation in machines where agents take actions on the environment based on intelligent policies guided by reward systems. Agents accumulate knowledge on the environment with continuous trials and error of actions until they master the relevant actions in an exploitation–exploration tradeoff [
18].
In maintaining efficiency in networks, RL agents have seen dynamic integrations in SDN-IoT domains due to the expected network flow complexities envisaged by network operators and the possible malicious intrusion from compromised IoT devices by attackers. The network must be protected from different attack loopholes [
19] in the SDN architecture while engineering dynamic multi-path routing [
20,
21] strategies for packets from benign users. Deep Reinforcement Learning (DRL), which combines Deep Learning (DL) and Reinforcement Learning, has seen breakthroughs in complex game development, robotics, and network automation, among others, by using hidden layers to capture features and intricate details relevant to the RL agents [
2,
22]. The integration of DL in RL has also reduced the curse of dimensionality and improved the ability to solve high-dimensional problems [
22]. The security of DL models and data privacy protection has been studied in [
23,
24] and remains a concern to service providers, especially with the massive connectivity of objects. These security threats can lead to inaccurate models for training the RL agents and adversely affect performance especially for time-bound applications. Compromises to data through network attacks [
23,
24] lead to the availability of sensitive information to hackers and the occurrence of this phenomenon will compromise the confidentiality of the system.
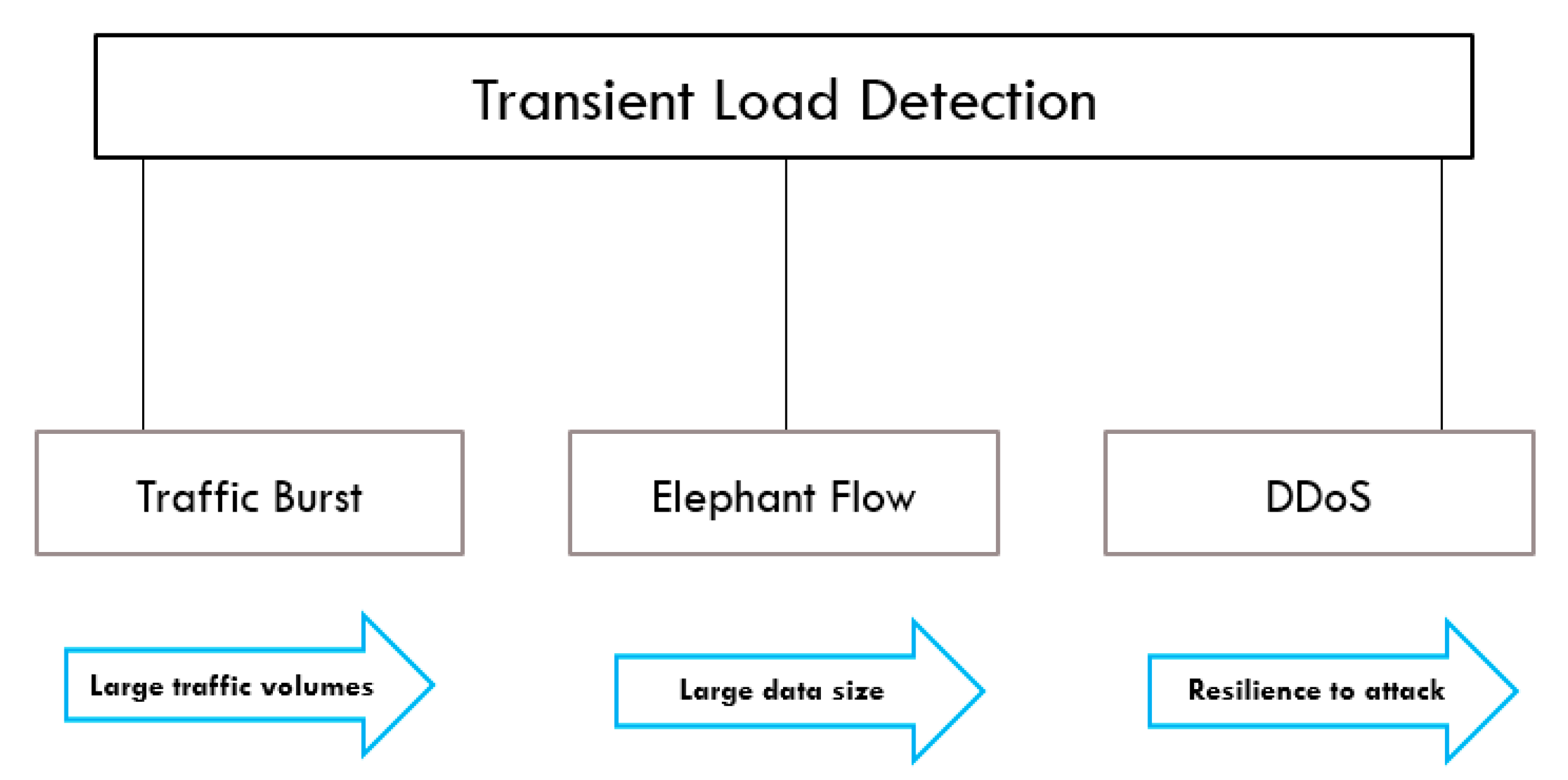
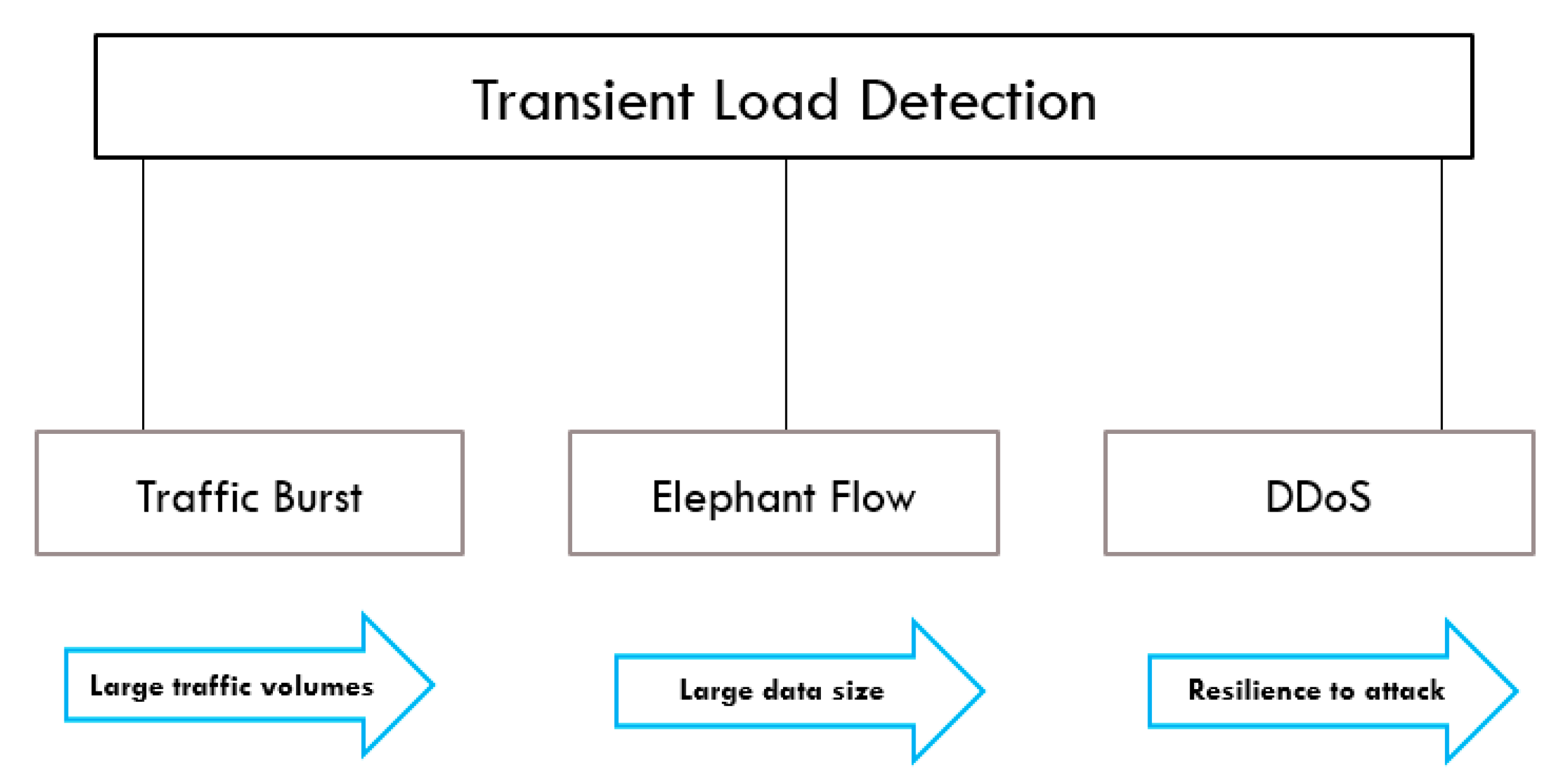
In this research, we propose a multi-agent RL framework in SDN for three use cases, as shown in
Figure 2: traffic burst detection, elephant flow, and DDoS. We extended Deep Deterministic Policy Gradient (DDPG) in multi-agent environment, Multiagent Deep Deterministic Policy Gradient (MADDPG) algorithm, and used Markov Decision Process (MDP) to mathematically model the state-action-reward representation. The rest of the article is organized as follows.
Section 2 lays the foundation for single-agent RL (SARL) and multi-agent RL (MARL) in the SDN architecture.
Section 3 reviews similar literature involving MARL.
Section 4,
Section 5 and
Section 6 describe the system into details.
Section 7 discusses the experimental results, and we conclude in
Section 8.
2. SARL and MARL
SARL and MARL are defined by the number of agents a reinforcement architecture deploys on the environment. Most research works for traffic engineering (TE) and intrusion detections (IDs) in SDN have adopted the SARL architecture. The common SARL implemented algorithms includes Q-learning [
25], SARSA algorithm [
26], the Deep Q-Network (DQN) [
25], and the Deep Deterministic Policy Gradient Algorithm (DDPG) [
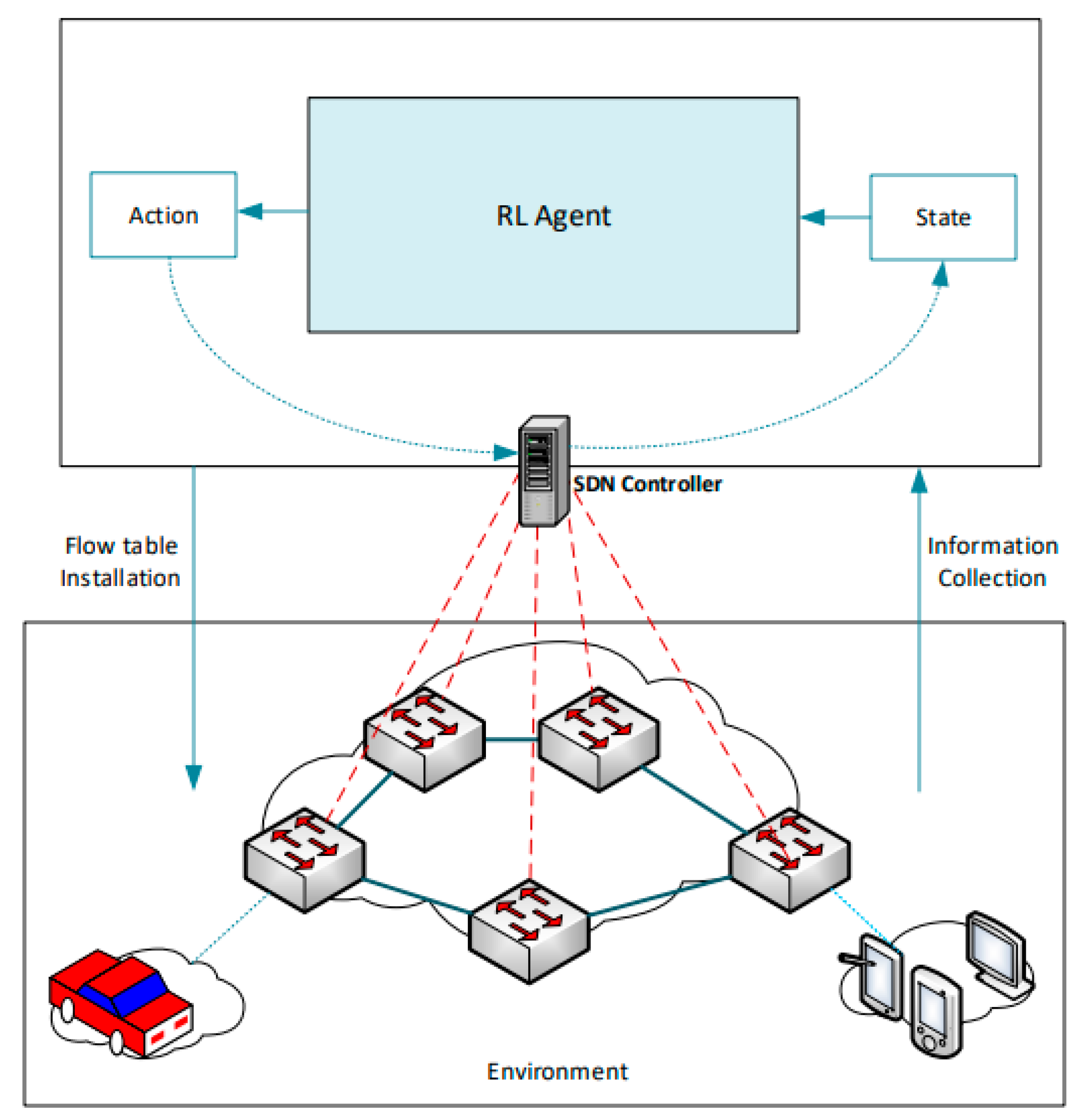
27]. DQN and DDPG algorithms have seen the integration of deep neural networks (DNNs) in optimizing the policy network of agents for higher efficiency and scalability. As shown in
Figure 3, for the SARL architecture, the SDN controller collects network metrices as state for the RL agent. The agent based on a policy enforces an action on the forwarding devices through the controller and subsequently receives a reward. The SDN controller then installs new flow rules for the OpenFlow [
28] switches in the forwarding plane.
With collaboration comes faster convergence in a cooperative and competitive environment among agents. Agents’ cooperation increases the state space representation with exhaustive dimensionality, resulting in faster executions through parallel computation in the environment. Experience sharing and cooperation in IoT-related dynamic environment have necessitated a research discussion surge from SARL to MARL, especially with the advent of 5G and newer technologies.
MARL involves interactive, autonomous systems acting on a common environment to accomplish a task within a shorter time. These lead to agents executing decentralized actions with centralized training. MARL systems have seen applications in diverse domains including game development, network management, distributed control, and decision support systems [
29,
30,
31].
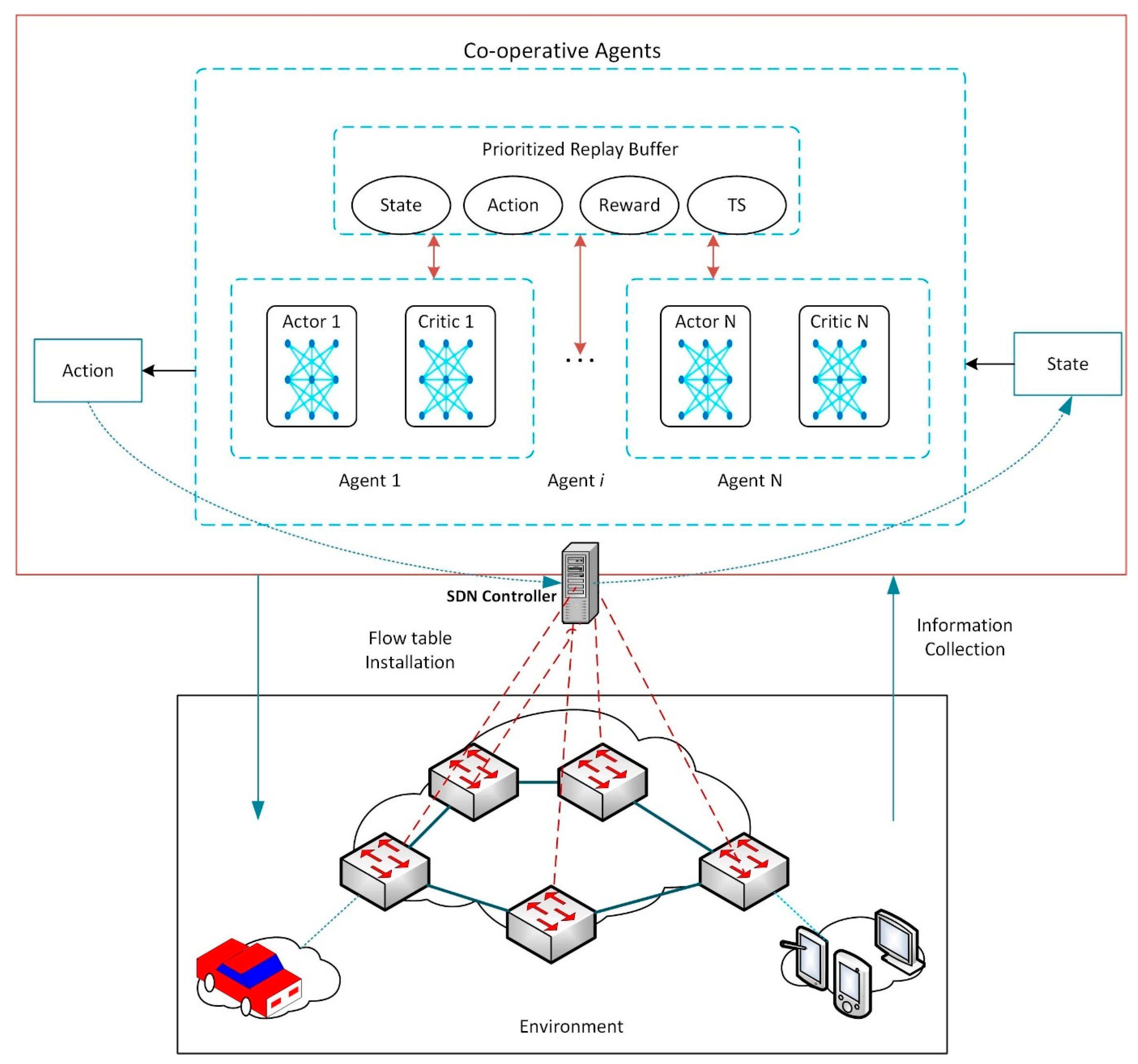
As shown in
Figure 4, multi-agents execute decentralized action on the stochastic environment using respective actor networks. A historic tuple using the replay buffer is used to store the state-action-reward of each agent after every episode. The centralized critic network is then used to evaluate the actions of the actor network of each agent through a policy gradient.
3. Review of Similar Work
For general threat mitigation in SDN environment, [
32] proposed a SARL ATMoS agent using Q-learning algorithm. The malicious host (MH) implemented in this framework is an Advanced Persistent Threats (APTs) vector, which uses dynamic attack vectors, tactics, and tools to evade detection. The RL agent operates in the controller and relies on a network observer module installed in forwarding devices for autonomous management and a reward feedback from the environment using a host behaviour profiling. Results show that the model using the SYN flood experiment converges faster after 150 iterations with 1 MH and 1 BH (Benign Host), while the APT technique converges after 1400 iterations. Adopting a proactive defence strategy in SDN, [
20] proposed a security-awareness Q-learning Route Mutation (SQ-RM) scheme with adaptive learning rate adjustment for faster convergence. The controller is implemented as the RL agent and acts as the defender against threats. Four different attack methods, node degree, critical edge, multi-target coordinated, and prior experience, were investigated and compared. Results show that SQ-RM is not effective against edge attack strategies since delay increases in the network when implemented.
In dealing with DoS attacks, [
33] proposed an RL-based Q-MIND algorithm that utilizes Q-learning in an SDN environment to mitigate stealthy attacks. The Q-MIND DoS detection scheme is implemented in the SDN application plane and communicates with the controller via the Northbound API. With 4 benign and 4 malicious hosts, the Q-MIND was compared to support vector machine (SVM) and Random Forest (RF) classifiers after 4000 normal and 4000 attack samples. Results show that Q-MIND performs better in detecting DoS after 100 iterations when compared with SVM and RF fixed classification algorithms. However, prior to the 100 iterations, SVM and RF perform better. To improve the research findings, [
33,
34] proposed a Deep Deterministic Policy Gradient (DDPG) algorithm implemented as a policy network in a RL mitigation agent to learn network flow patterns and throttle malicious TCP, SYN, UDP, and ICMP flooding attacks. The proposed framework results were compared to AIMD router throttling and CTL approaches for DDoS detection after 20,000 episodes with 10 s episode interval. Agent reward increased throughout the episode indicated by the throttling of most malicious traffic from attack nodes. The framework outperformed the AIMD router throttling approach by 3–9% and CTL approach by 18–28%.
As SDN-IoT size increases, network attack becomes prevalent. To improve network security while optimizing routing, [
35] proposed a deep reinforcement learning-based quality-of-service (QoS)-aware secure routing protocol (DQSP). Five attack nodes were used to generate gray hole and DDoS attack methods with convolutional neural network (CNN) as the training network for the RL agent. The results were compared with OSPF protocol under three performance metrics: end-to-end delay, packet delivery ratio, and routing optimization probability in attack nodes. DQSP has a 10% increase in packet delivery ratio over OSPF under gray-hole attack and a slightly lower percentage under DDoS attack. The DQSP also outperforms OSPF for end-to-end delay and guarantees network QoS with earlier identification of attack nodes compared with OSPF.
To improve flow matching in SDN-based networks, [
36] proposed a Q-learning integrated Q-DATA framework that uses support vector machine (SVM) algorithm to detect the performance status of forwarding devices. The Hping3 tool is used in 5 hosts to generate random traffic between destination servers and hosts. To enhance the use cases of the Q-DATA, Self-Organizing Map algorithm is implemented on top of the ONOS SDN controller to detect malicious traffic. Results from the simulation show that, with a high load to the OpenFlow switches, the Q-DATA framework outperforms FMS, DATA, and MMOS schemes and delivers efficient and appropriate flow policies in the network.
For energy efficient routing in SDN, [
37] proposed a deep Q-network (DQN)-based Energy Efficient routing (DQN-EER) algorithm to find energy-aware data paths between OpenFlow switches. The RL agent is implemented with deep convolutional neural network and modelled with MDP to interact with the environment. Three controllers with 16 hosts and 20 switches were used to set up the network topology. After 2300 training episodes, the DQN-EER was compared with CPLEX and CERA algorithms. Results show that DQN-EER outperforms CERA and CPLEX for energy-efficient routing when the state becomes larger.
In optimizing network routing, [
38] proposed a DRL agent targeted at optimizing network delay in SDN environment. The proposed set up involves a network topology of 14 nodes with 10 traffic intensity that ranges incrementally from 12.5% to 125% relative to the aggregated network capacity. With 1000 distinct traffic configurations, the DRL agent was trained with 100,000 step traffic matrixes. Results show that, as the training time increases, the DRL agent’s performance also increases and improves the overall network delay.
Yuan et al. [
39] proposed a MADDPG integrated algorithm in multi-agents with cooperation to solve the internet of vehicles (IoV) dynamic controller assignment problem while minimizing network delays and packet loss. The architecture is deployed in the data and the control plane of the SD Networks. The data plane is split into two sub-layers: mobile and stationary layer. The mobile layer has on-board units integrated in moving vehicles for communication with roadside units (RSUs) and base stations (BSs). The control plane has a hierarchical distribution with multiple edge controllers at the lower tier with the top tier core controllers in remote data centers.
Wu et al. [
40], in minimizing packet loss rate and increasing packet throughput in a network, proposed a MADDPG based traffic control and multi-channel reassignment (TCCA-MADDPG) algorithm in SDN-IoT. The heterogeneous IoT structure consisting of LTE network, WIFI network, and 3GPP network forms the edge layer in the architecture as layer three. The fourth layer, which consists of IoT devices, is the fog layer. The second layer is the core backbone layer that bridges the third layer to the first layer, the data center layer.
Yu et al. [
41], in optimizing routing in SDN, proposed a DDPG Routing Optimization Mechanism (DROM) framework using DRL agent integrated within the control layer. The DROM agent uses a Traffic Matrix to receive the current network load state [
10]
s from the environment and changes the weight links of the network through an action
a. The DROM agent receives a reward
r, and the state changes from
s to
s’.
4. Main Concept
We present a novel MARL system implemented with MADDPG algorithm for traffic burst, elephant flow, and DDoS detection and prevention in an SDN-IoT environment. With compromised IoT devices, it has become extremely difficult to differentiate genuine transient or crowd event packets from the compromised malicious packets emanating from zombie IoT devices. The various attack methods such as SYN, TCP, ICMP, and UDP flooding [
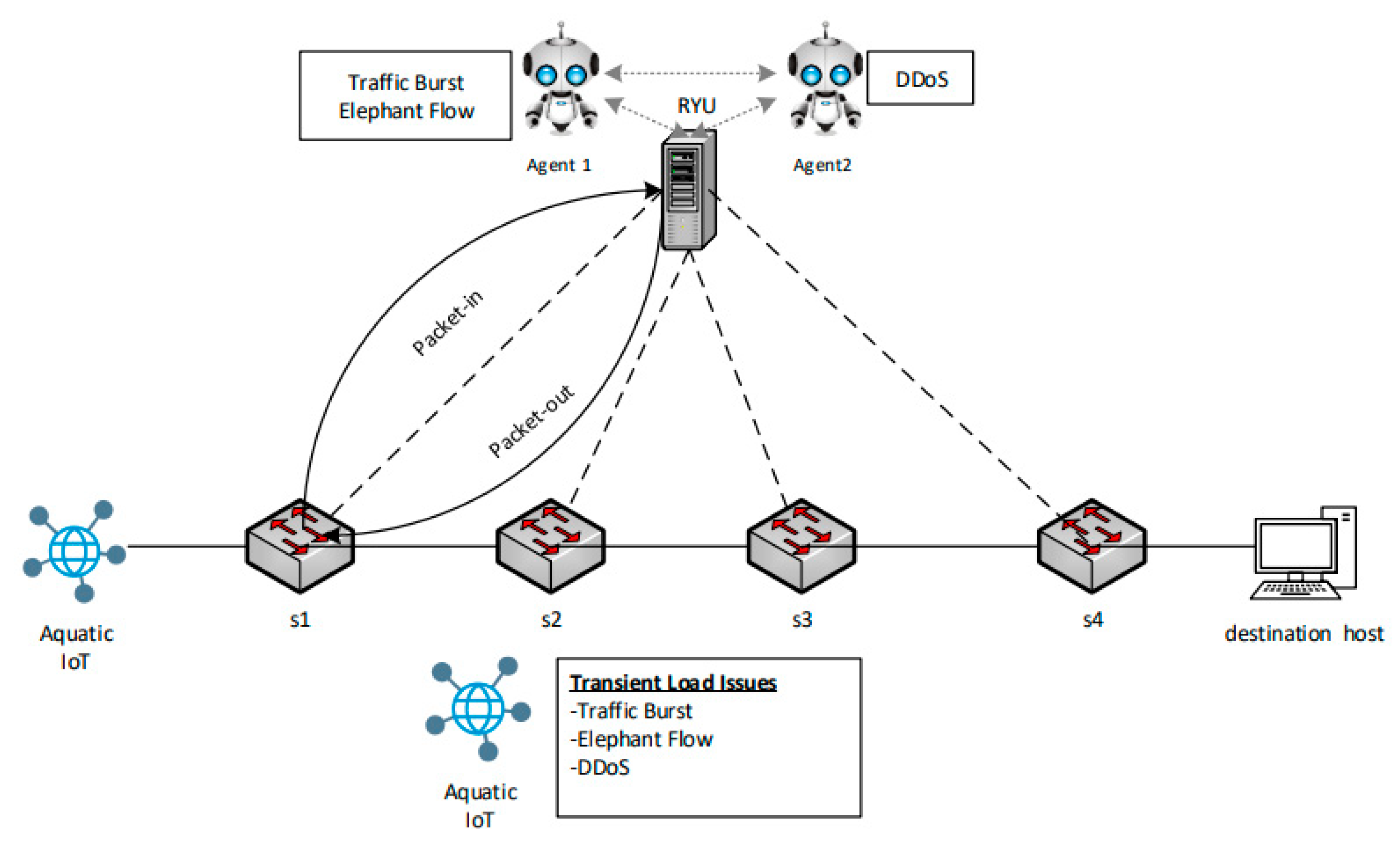
42] mimic genuine sudden spike traffic, and, if not blocked intelligently, will result in genuine packet loss to destination nodes. The primary concept of the framework, as shown in
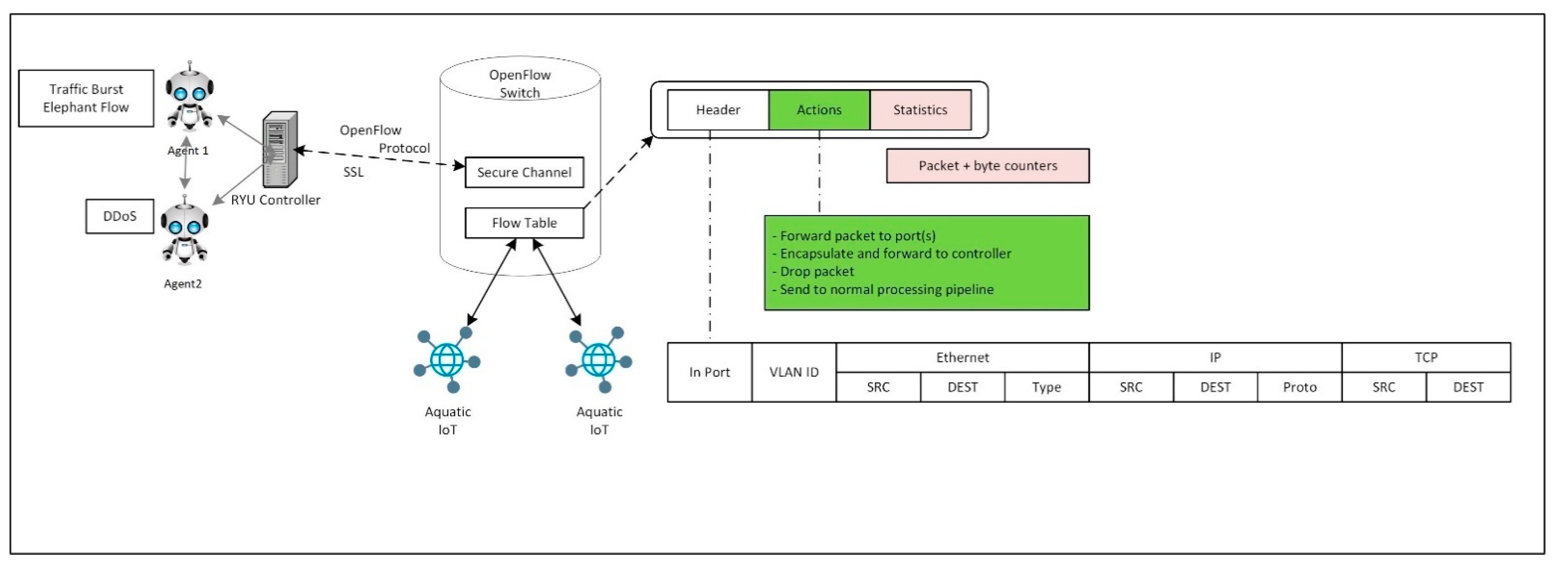
Figure 5, involves the implementation of two agents in the controller of the SDN architecture, agent 1 and agent 2. Agent 1 is responsible for genuine traffic burst and elephant flow multipath routing in the network while agent 2 is responsible for DDoS detection and blocking. During a packet miss from the OpenFlow switches, a packet-in message request is sent to the controller for new flow addresses to be installed in the flow table. The two agents instruct the SDN controller in installing new flow rules during packet-out messages to the OpenFlow switches.
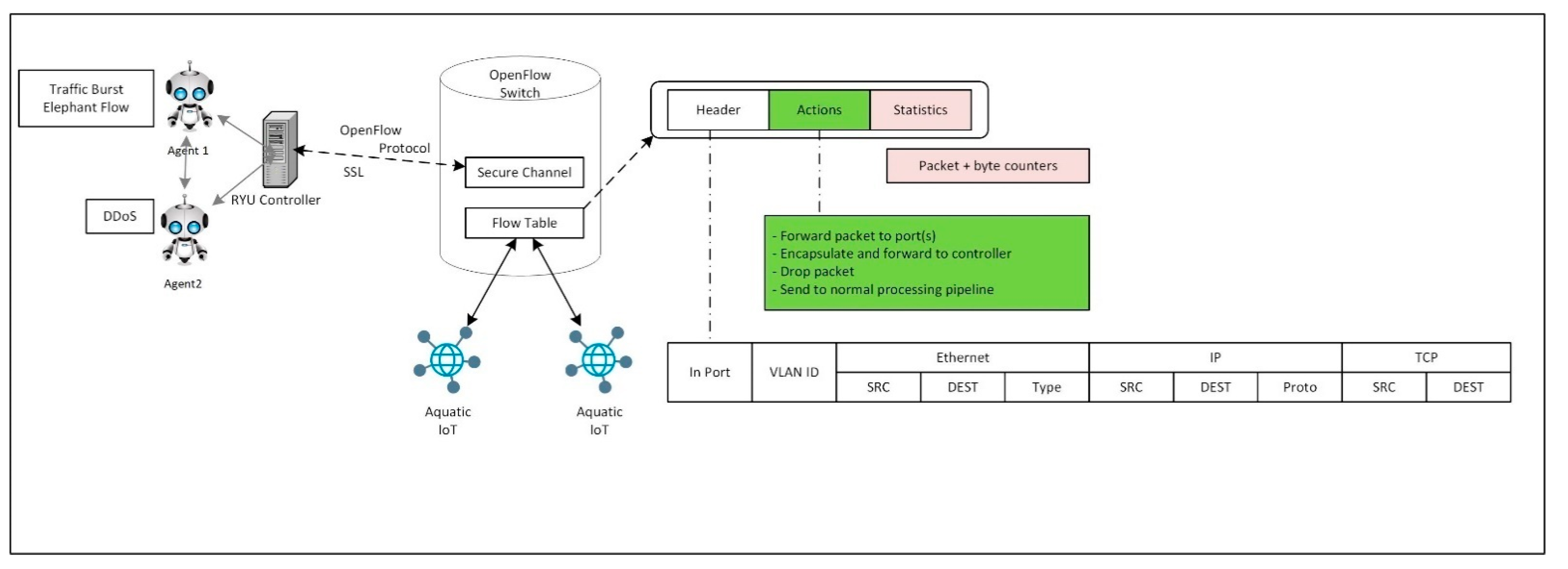
The SDN controller executes the instructions of the multi-agents through actions in the flow table of the OpenFlow switches, as depicted in
Figure 6.
With the proposed concept, each agent has a policy in updating the controller on the actions to execute on the forwarding devices based on the reward received from the environment. The reward gives an indication of the next action each agent should take. As the episode progresses, agents learn to take the best action that will result in higher rewards in an exploitation–exploration tradeoff.
5. Proposed MADDPG Framework
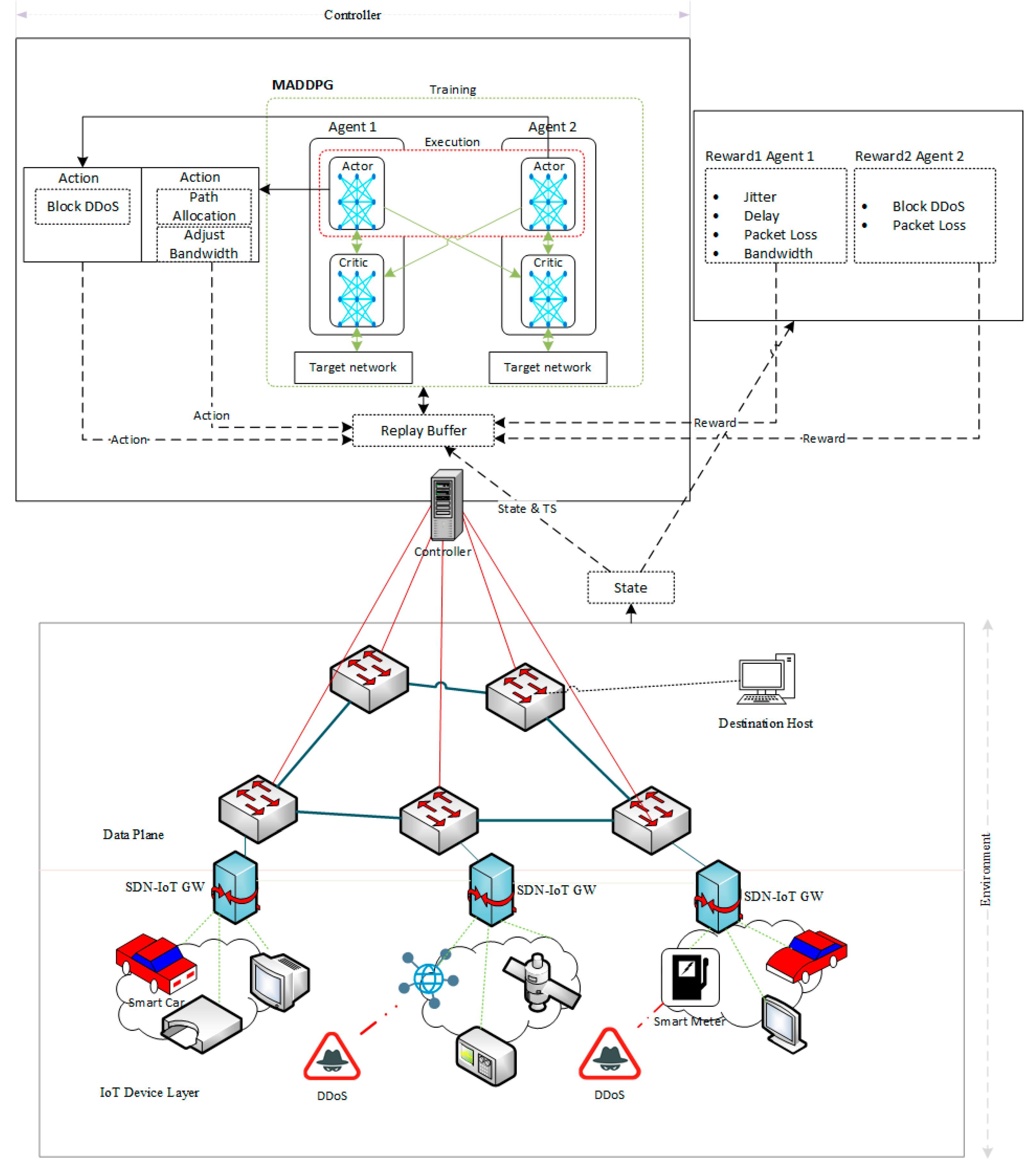
In this section, we proposed our novel MARL SDN-IoT framework with the objective to optimize the network through multipath routing while blocking DDoS traffic. The proposed architecture is the first of its kind in an SDN that utilizes two agents in a cooperative environment integrated with the MADDPG algorithm.
The MADDPG integrated MARL architecture, as shown in
Figure 7, has an RL set up consisting of two main parts: two intelligent agents in the controller and an observed environment comprising data forwarding devices and IoT devices. The design is modelled as an MDP with a state space, an action space, and a reward function. In Algorithm 1, state
in MDP is defined as essential features in the agent’s environment that are of interest. The state consists of a finite set
where
is the size of the state space. The action,
defined as a finite set
where
is applied in the environment to control the system’s state to a new state.
represents the size of the action space [
43]. With possible transitions, an action
in a state
changes the state from
to a new state
This results in a transition state of
The reward function is based on the action of the agent in a state.
represents the reward after transition from
to a new state
. A discount factor
determines the agent’s action that leads to distant future rewards relative to immediate rewards. A discount factor should range between
| Algorithm 1 Markov Decision Process (MDP) [44] |
|
An MDP is a 5-tuple , where; |
|
is a set of states |
|
is a set of actions |
|
is the probability that action in state at time |
|
will lead to state at time |
|
is the immediate reward received after a transition
|
|
from state to , due to action |
|
is the discounted factor, which is used to generate a discounted |
|
reward |
The environment, as shown in
Figure 7, has an SDN-enabled network consisting of OpenFlow switches that relate statistics and forward data flows of the network under the instructions of the SDN controller. The IoT devices, as part of the environment, generate data packets and elephant flows to destination nodes via the SDN-IoT gateway and forwarding devices. The environment also consists of zombie or compromised IoT devices that generate malicious packets to random destinations in the network.
The two agents interact with the environment using actions that alter the state of the environment and receive rewards for their respective actions. The MARL agents execute the actions via the SDN controller, which has the responsibility to make decisions, collect network statistics, and enforce agent’s actions by updating the flow table of the OpenFlow switches. Agent 1 is responsible for multipath routing of genuine transient packets and elephant flows in the network, while agent 2 is responsible for identifying and blocking DDoS flows. As depicted in
Figure 8, the MARL MADDPG flow diagram illustrates the monitoring of network metrics and the action enforcement in the network through the RYU controller, an open source SDN controller [
45].
The state space defines the environment and refers to the state of flows in the network. The state space s(t) is defined as a traffic matrix at time step t . An OpenFlow switch in time slot consists of:
A. Data link occupancy rate between the flow and the OpenFlow switches
B. Channel link occupancy between packet-in messages from the OpenFlow switches
C. Channel link occupancy between packet-out messages to the OpenFlow switches
Equation (1):
Each agent takes a decentralized action from the state using a policy. The respective action of the agents accumulates to global rewards. Agent 1 takes action based on genuine traffic burst and elephant flow and assigns the next hop to available OpenFlow switches during packet-out messages. Agent 1 also increases the bandwidth of the flow within the network demand range. Equation (2):
= switch 1 to n that are available as next hop for packet-out messages
= Bandwidth Threshold
Agent 2 takes an action involving dropping of packets transmitted beyond a rate to the controller. These lead to packet drop rule for forwarding switches Equation (3):
= switch 1 to n that send the packet-in messages
; Drop flow from node i if the frequency is beyond threshold
Based on the current state and action, each agent receives a local reward from the environment. The reward is an indication of the policy taken by the agents and subsequent refinement of policies. Each local reward aggregates to a cumulative global reward by the MARL system. Agent 1 is measured by a link utilization reward. The link utilization is a measure of delay, packet loss rate, bandwidth, and jitter metrices in the network Equation (4):
, a stepwise decrease in link utilization, gives +1 reward, and a stepwise increase gives −1 reward.
A successful packet dropping due to DDoS attracts +1 reward. Packet loss in the network attracts −1 reward Equation (5):
, when a detected DDoS packet based on the rate of flow is not installed in the packet-out switches
, when flow frequency from node results in a packet loss.
After defining the state, action and reward function of the MARL system, we modify Algorithm 2 [
46] using MDP representation and implement the new algorithm.
| Algorithm 2 Proposed MADDPG [46] |
1: for episode = 1 to do
2: Initialize a random process for action exploration
3: Receive
4: for to max-episode-length do
5: for agent , select action
6: Executive and observe
for agent , select action
Executive and observe
and new state
7: Store in replay buffer Ɗ
8:
9: for agent to do
10: Sample a random minibatch of samples ( from Ɗ
11: Set
12: Update critic by minimizing the loss 2
13: Update actor using the sampled policy gradient:
14: end for
15: Update target network parameters for each agent
16: end for
17: end for |
6. MADDPG and Deep Neural Network (DNN)
MADDPG is an extension of DDPG in multi-agents, which is an actor-critic algorithm used for continuous variables. With MADDPG, each agent has a DDPG algorithm with a centralized training network, the critic network. Each tuple transition of state-action-reward is stored in the Replay Buffer and used as the experienced buffer for the learning experiences in each batch for exploration. Each agent has two main networks, the primary and the target network, as shown in
Figure 7.
Each agent has a primary network. It comprises of the actor primary network (APN) and the critic primary network (CPN). The APN is a DNN used to explore the policy using state-action pairs. The input to the DNN is the current state and the output is an action. The CPN estimates the performance of APN and provides a critic value used to train the APN to learn the gradient of the policy. The input of the CPN is the state and the current action of the APN. Its output is a critic value. With MADDPG, the critic network of each agent has full visibility of the actions and observations of the other agent for centralized training.
Each agent has a target network used to train the CPN. In training the CPN, the loss function comprising the critic target network (CTN) value, the reward function, and the CPN value is used. Unlike the primary network, the target network comprising actor target network (ATN) and CTN uses the transformed state (TS) of the state transition rule. The input to the ATN is therefore TS and not the current state. The target network updates itself using soft update values, which slowly updates the primary network.
7. Experimental Results and Performance Evaluation
In this section, we evaluate the performance of our model with the experimental set up and discuss the results. The setup consists of the tools, parameters, and hyper-parameters used for the RL agents.
7.1. Experimental Set up
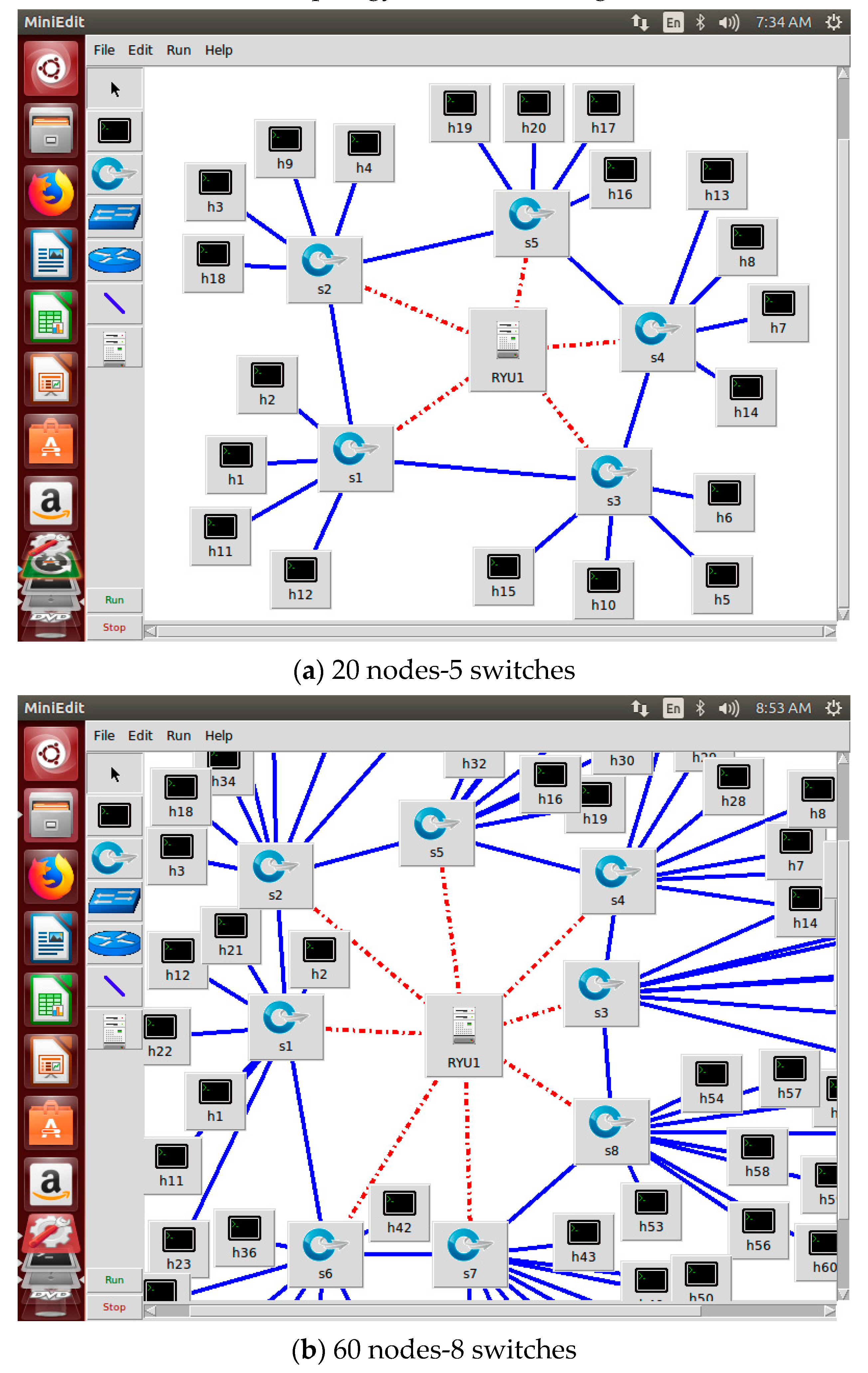
The 20 and 60 nodes network topologies were implemented using TensorFlow and Keras running on Ubuntu-18.04 LTS (64 bit) operating system with an Intel® Pentium® CPU G2030 @ 3.00 GHz and 8 GB RAM capacity. The software requirement also includes Mininet-2.0 and Python-2.7.
From
Table 1, we used RYU controller with 5 and 8 OpenFlow switches. The bandwidths for data link and channel link occupancy rates are 50 Mbps and 100 Mbps, respectively. The Transmission Control Protocol (TCP) is used to send benign traffic across the network with a sending rate of 2 Mbps. The tail drop queue management is used for dropping packets.
A fixed packet size of 56 bytes is randomly generated using Python library scapy, at an interval time of 0.1 s. The IPv6 protocol with a processing delay of 10 μs is used as the communication protocol to identify devices on the network.
DDoS packets are randomly generated from source nodes to random destinations at an interval of 0.02 s and restricted to only UDP flooding. The elephant flow is generated with a bandwidth range of 10 Mbps–1000 Mbps, at an interval of 0.1 s.
After multiple experiments, the actor learning rate for agent1 and agent 2 is set to 0.0001. The actor discount factor for agents 1 and 2 is set to 0.99. The actor target soft update is set to 0.001, while the batch size is set to 64.
The critic agent parameter has the same set-up as the actor agent parameter with an exploration of 0.1. Agent 1 and Agent 2 are set up with (300, 600) hidden units and neurons. For the actor network, the Deep Neural Network (DNN) hidden layer activation function for agent 1 and 2 is set to relu while the output layer is set to sigmoid. The critic DNN for agent 1 and 2 has a state hidden layer 1 activation function set to relu, action hidden layer 1 set to linear, state hidden layer 2 set to linear, action hidden layer 2 set to relu, and output layer activation function set to linear.
7.2. Experimental Results
In This subsection, the performance metrics considered to evaluate the MADDPG algorithm and DDPG are discussed and the results analyzed. The Mininet simulations for 20-nodes and 60-nodes network topology are shown in
Figure 9.
7.2.1. Reward
The reward is used to measure the results of the obtained action to a respective corresponding state that is perceived from the environment. In DRL, agents perform an action and obtain a reward based on the network policy. Average global reward is computed for 3000 episodes.
7.2.2. Jitter
Jitter in SDN represents the small intermittent delay in data transmission. It is caused by a number of factors including network congestion, interference, and collisions. Jitter represents the variation in the delay of packets transmitted from the source to destination nodes.
7.2.3. End to End Delay
Transmission delay refers to the time taken for data packets to move from source to destination nodes in the SDN network.
7.2.4. Packet Loss
Packet loss ratio is calculated as the difference between the number of packets received over the number of packets sent in the network. If the destination does not receive the packets, then the packet loss ratio is high; otherwise it is reduced.
7.2.5. Bandwidth Usage
It is estimated in bits per second, and a higher bandwidth helps more data to pass through it. This metric also evaluates how the network allocates the bandwidth for data transmission. When the optimum bandwidth is allocated, then the data transmission is efficient and reliable. To provide scalable and reliable services for current network traffic beyond improving network bandwidth, the system must provide a flexible mode for traffic management.
7.2.6. DDoS Detection Rate
The detection rate of DDoS detection is defined as the number of packets successfully predicted as intruder packets.
7.2.7. Global Reward
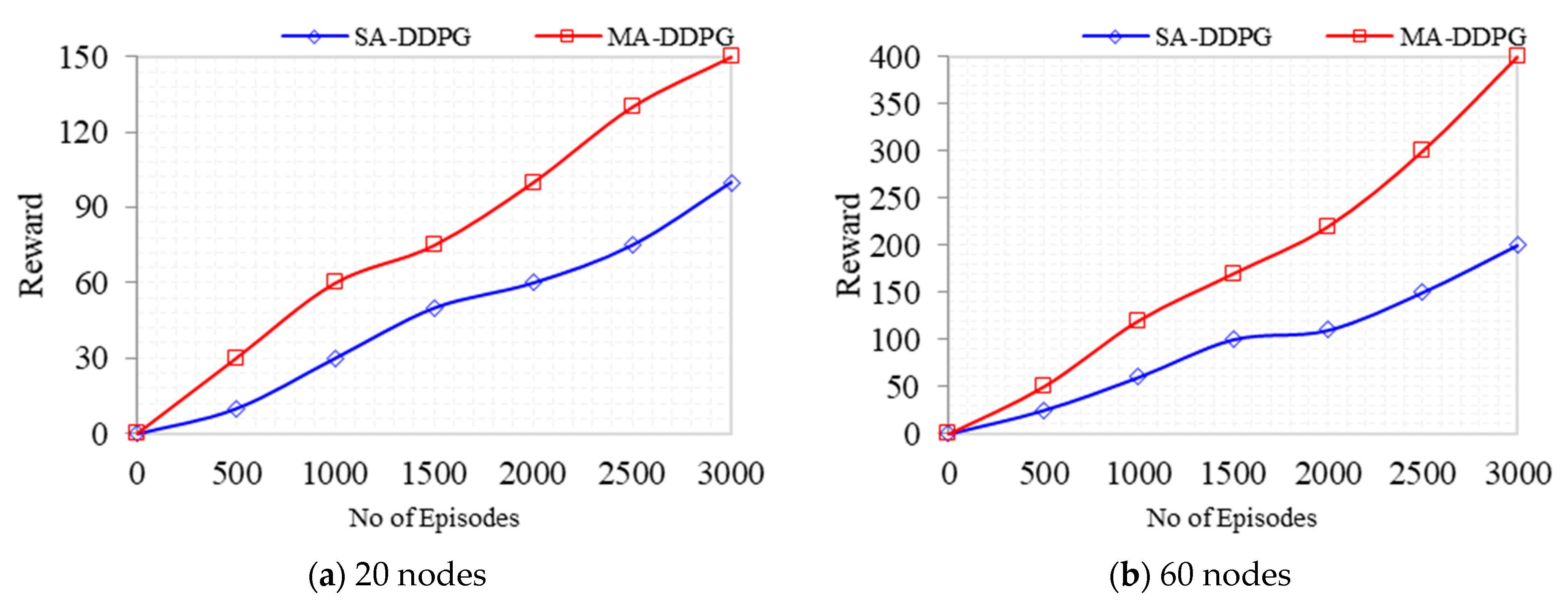
As shown in
Figure 10, after 3000 episodes, MADDPG gained a 25% cumulative global average reward over DDPG for the 20-nodes topology. The least reward gap for MADDPG was obtained from episode 1 to 1500 at 9%, while the later episodes gave a 16% reward. Due to exploration, the reward gap decreased along the episodes. For MADDPG, the average reward gap decreased from episode 1000 to 1500, while DDPG had a minimum decrease from episode 2000 to 2500. For the 60-nodes topology, the average global reward of MADDPG increased to 33% for the 3000-episode state-action transitions. MADDPG obtained the least average reward of 8% from episodes 1 to 1500, with a 24% reward for the later episodes. DDPG obtained an average least incremental reward gap from episodes 1500 to 2000, while MADDPG’s least incremental gap was obtained from episode 1000 to 1500 and episodes 1500 to 2000.
7.2.8. Jitter
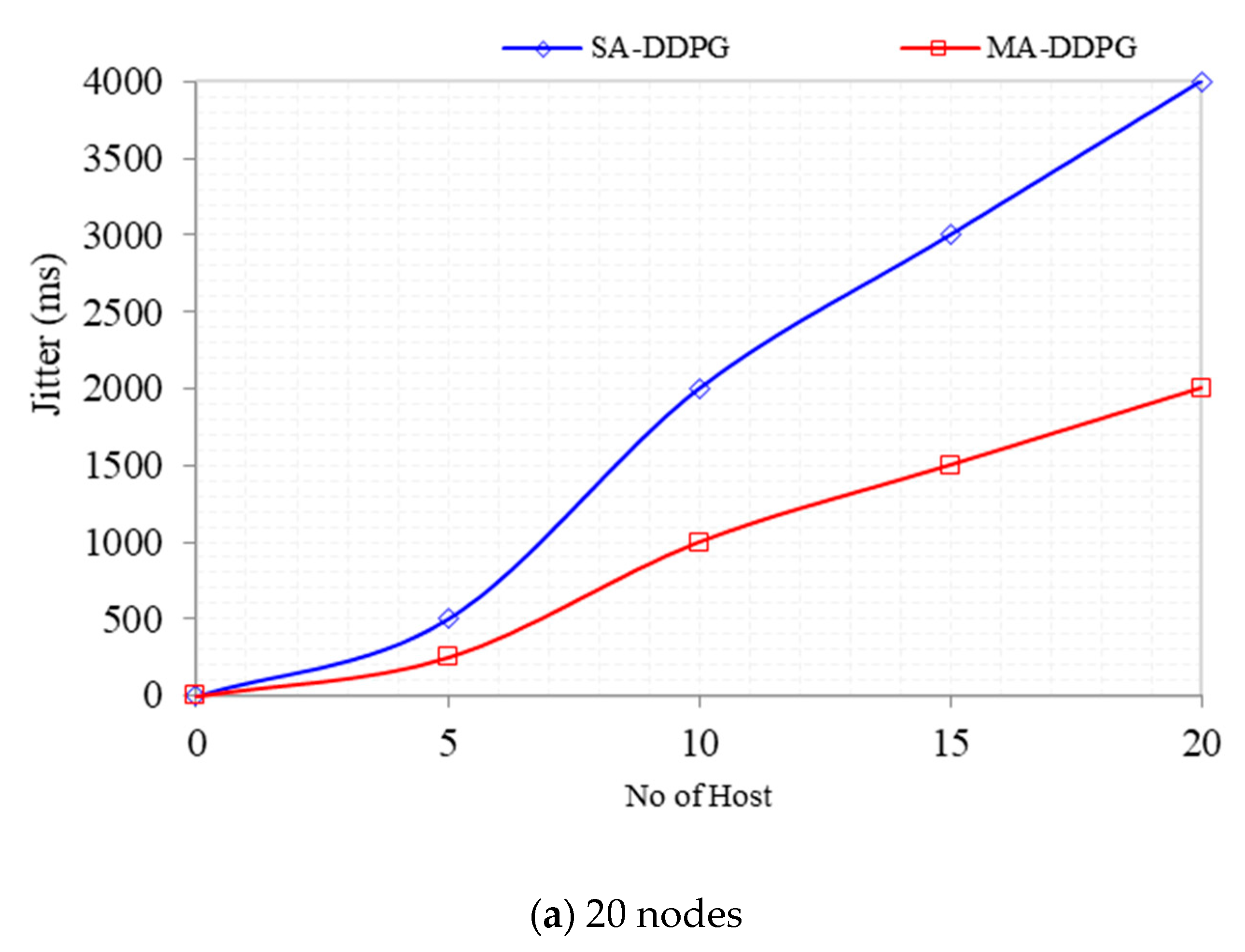
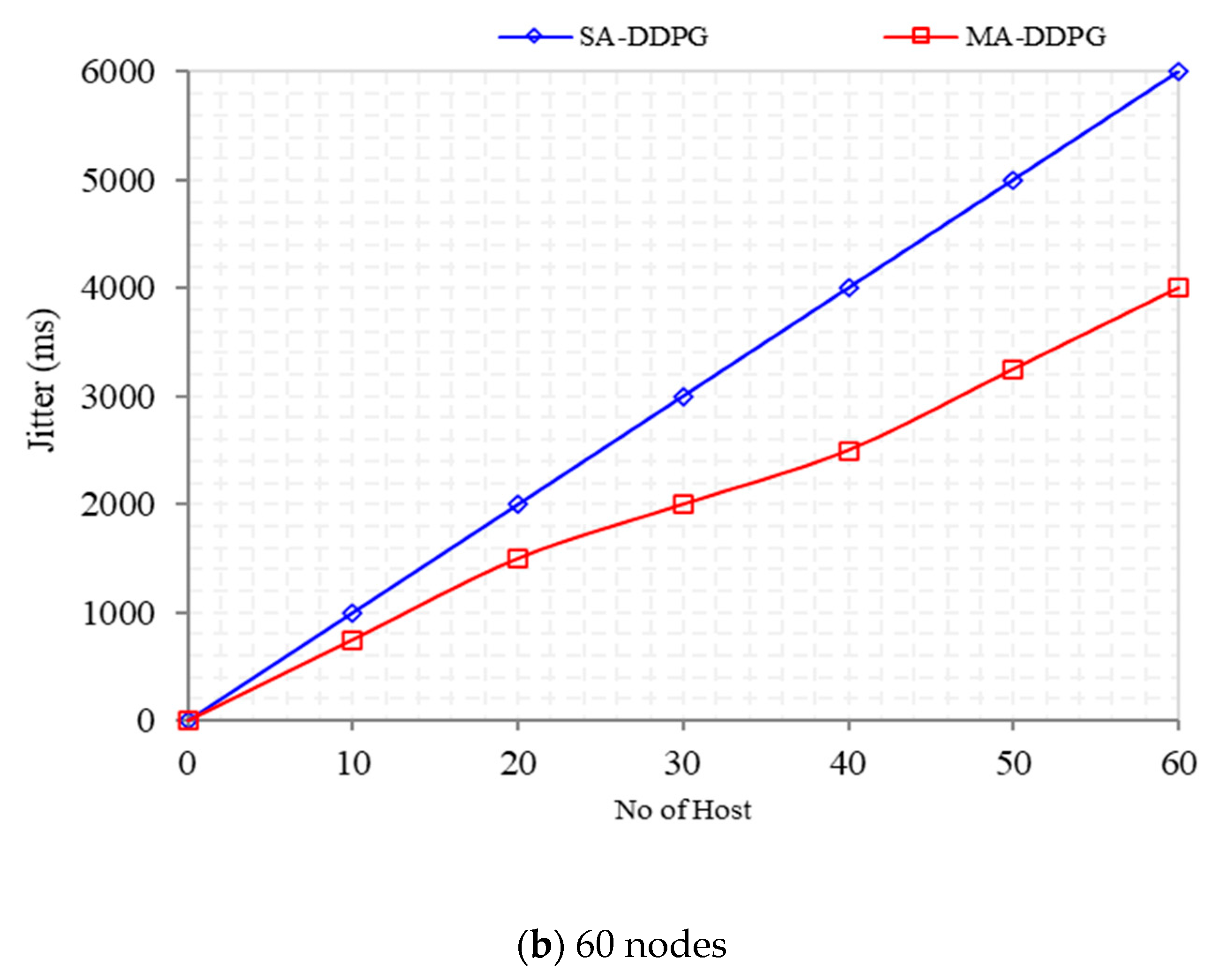
As shown in
Figure 11, as the number of nodes involved in packet transmittal increases, the average jitter increases due to link utilization and congestion. MADDPG for 20-nodes topology decreased jitter by 33% to 2000 ms compared with DDPG of 4000 ms. For the 60-nodes topology, the jitter performance for MADDPG decreased by 20% to 4000 ms compared with 6000 ms for DDPG. The initial jitter between MADDPG and DDPG until 5 nodes was close to a percentage of 2% for both 20 and 60 topologies.
7.2.9. Delay vs. No. of Switches
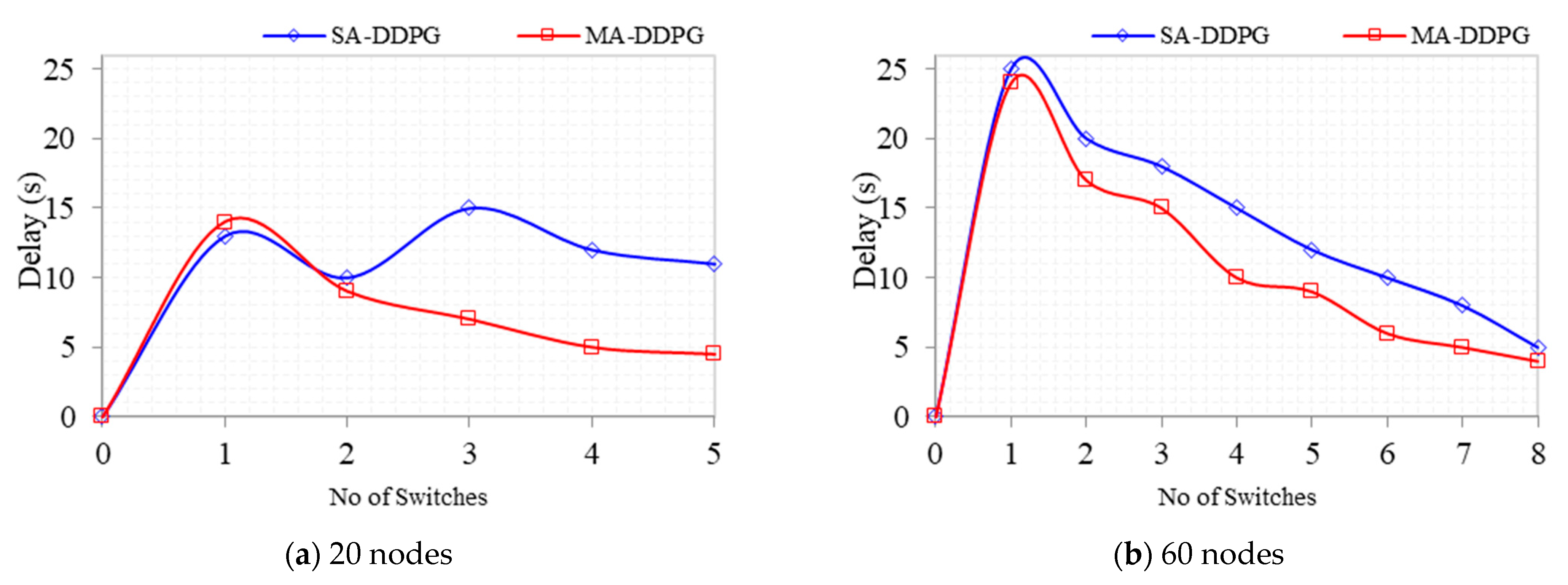
Delay is the time it takes for packets to move from source to destination nodes in the SDN network. Packets sent from source to destination nodes have a transmission delay monitored by the SDN switches using the delay in the current arrival packets from the nodes and the RYU controller. As shown in
Figure 12, as the episode progresses and the number of switches involved in packet transmission increases, the overall delay in the network decreases for both MADDPG and DDPG due to multipath routing. From the graph, MADDPG with 5 switches and 20 nodes has a 24% better delay performance from switch 1 to switch 5 compared with DDPG. This spans from a delay of 14 s from switch 1 to 4.5 s at switch 5. As the number of nodes increased to 60 with 8 switches, MADDPG’s delay performance decreased to 11% compared with DDPG. The delay performance was initially close until switch 2, giving no percentage change for the 5-switches topology and a 2% change for the 8-switches topology.
7.2.10. Packet Loss
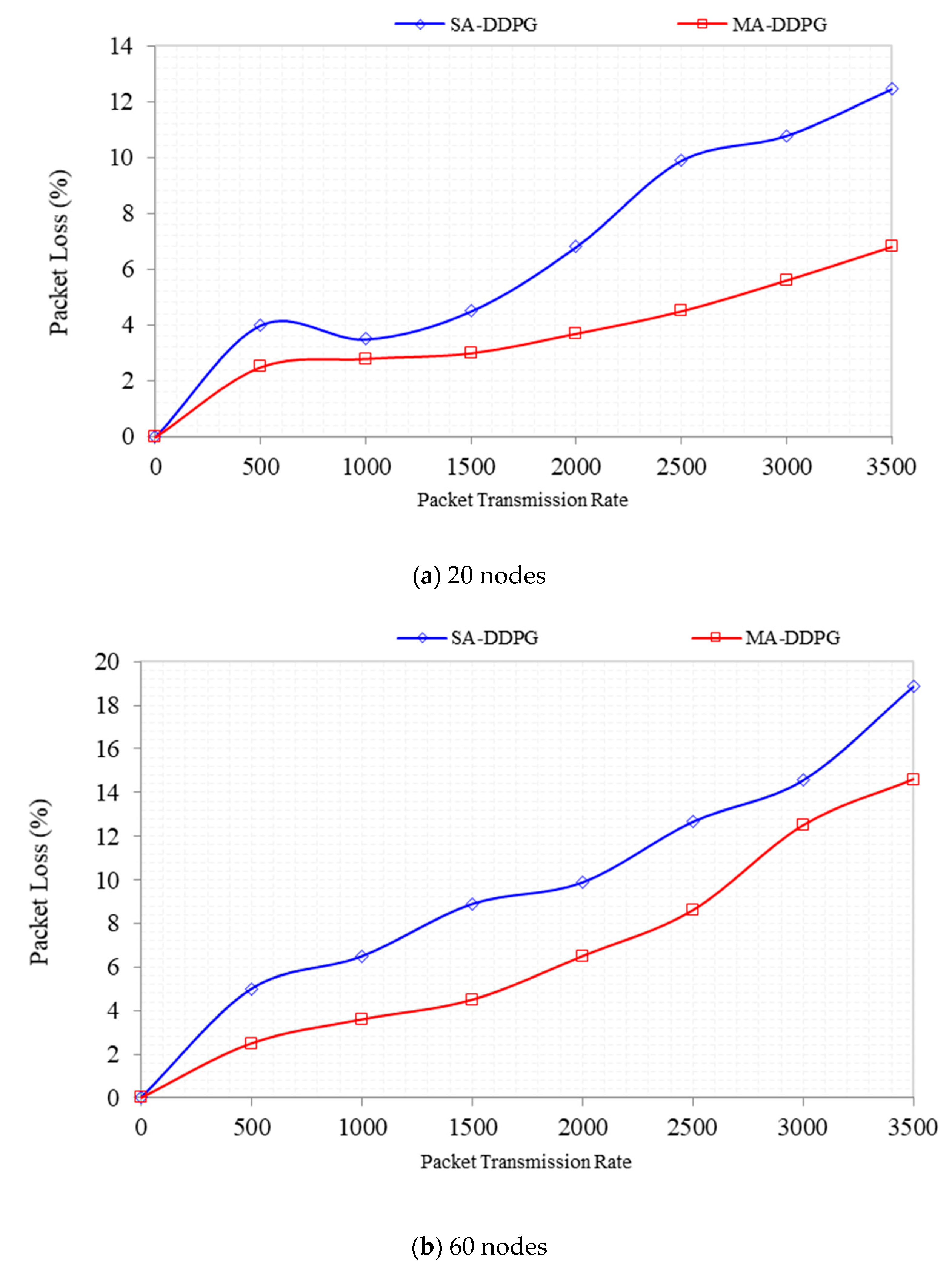
Packet loss is computed to ascertain the performance of the agents as the episode progresses. As the packet transmission rate is increased per second for flash events and DDoS, the packet loss is computed in percentage, relative to the total traffic in the network. From
Figure 13, MADDPG agent for 20 nodes had a packet loss of 6.8% when 3500 packets were transmitted per second with an initial loss of 2.5% at a transmission rate of 500 packets per second. DDPG agents for 20 nodes lost an initial packet of 4% at 500 packet rate, which increased to 12.4% at 3500 packets per second. MADDPG reduced packet loss to almost half at each stage of the packet increment at the nodes. For the 60 nodes, since more nodes in proportion to the number of switches increased the packet transmission rate, MADDP lost 14.6% packets at 3500 packets per second with an initial loss of 2.5% that increased rapidly. DDPG lost 18.86% of its packets at 3500 packets per second against an initial loss of 5% at 500 packets per second. MADDPG for 60 nodes reduced the packet loss to a quarter when compared with DDPG.
7.2.11. Bandwidth Usage
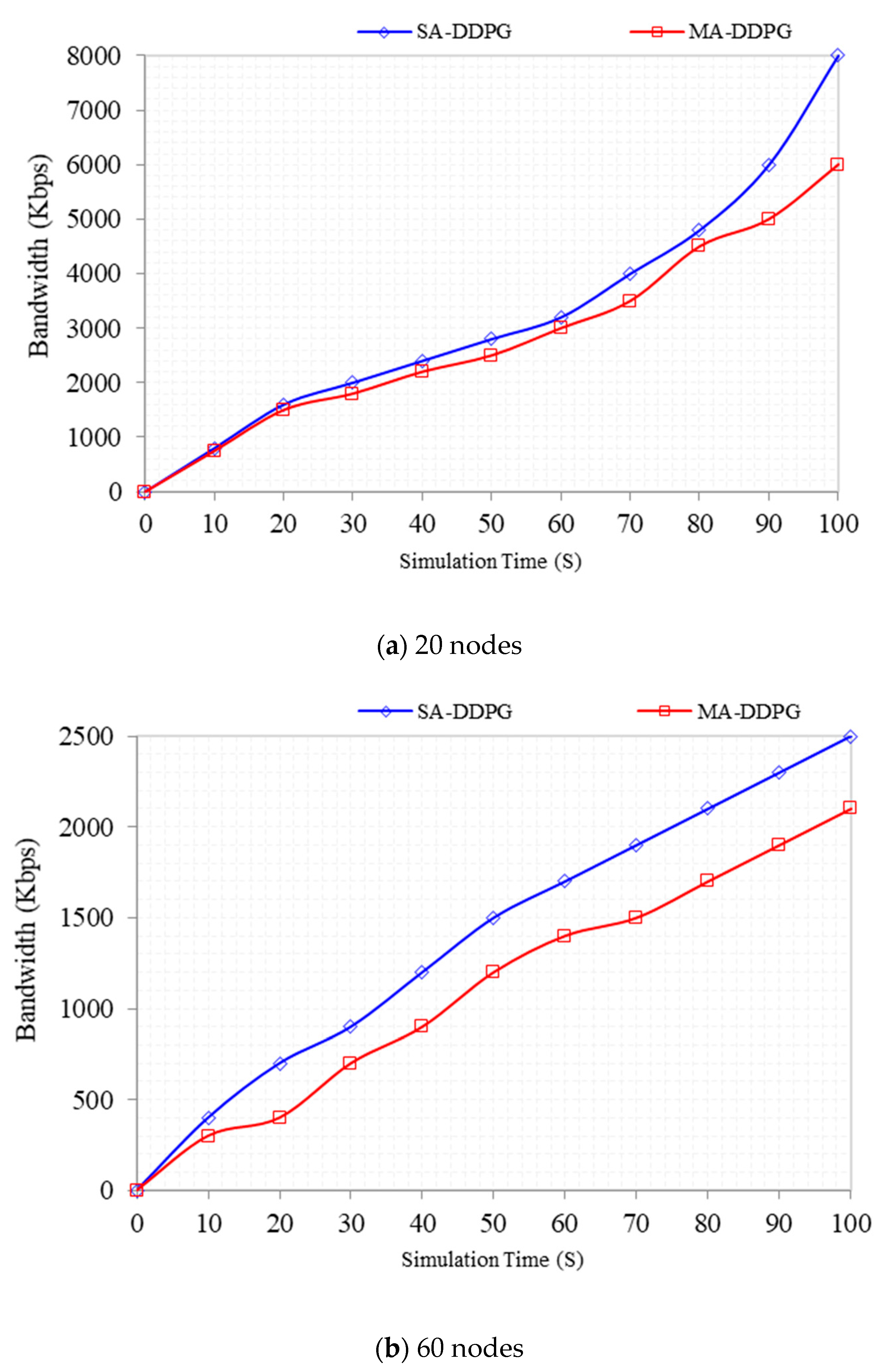
The bandwidth was captured within a 100 s simulation time frame. As shown in
Figure 14, MADDPG uses an 11%, slightly lower, bandwidth for the 20-nodes architecture than DDPG. At 100 s, MADDPG utilizes 2100 Kbps bandwidth while DDPG utilizes 2500 Kpbs bandwidth. For 60-nodes topology and the same time window, MADDPG has a 7% better bandwidth utilization compared with DDPG. The jump in bandwidth utilization for 60-nodes DDPG increased rapidly by 4.5% from the 90 s time window compared with the 3.5% before that time. The initial bandwidth utilization for the 60-nodes MADDPG at 10 s was 750 Kbps compared with 800 Kbps within the same time.
7.2.12. Intrusion Detection Rate
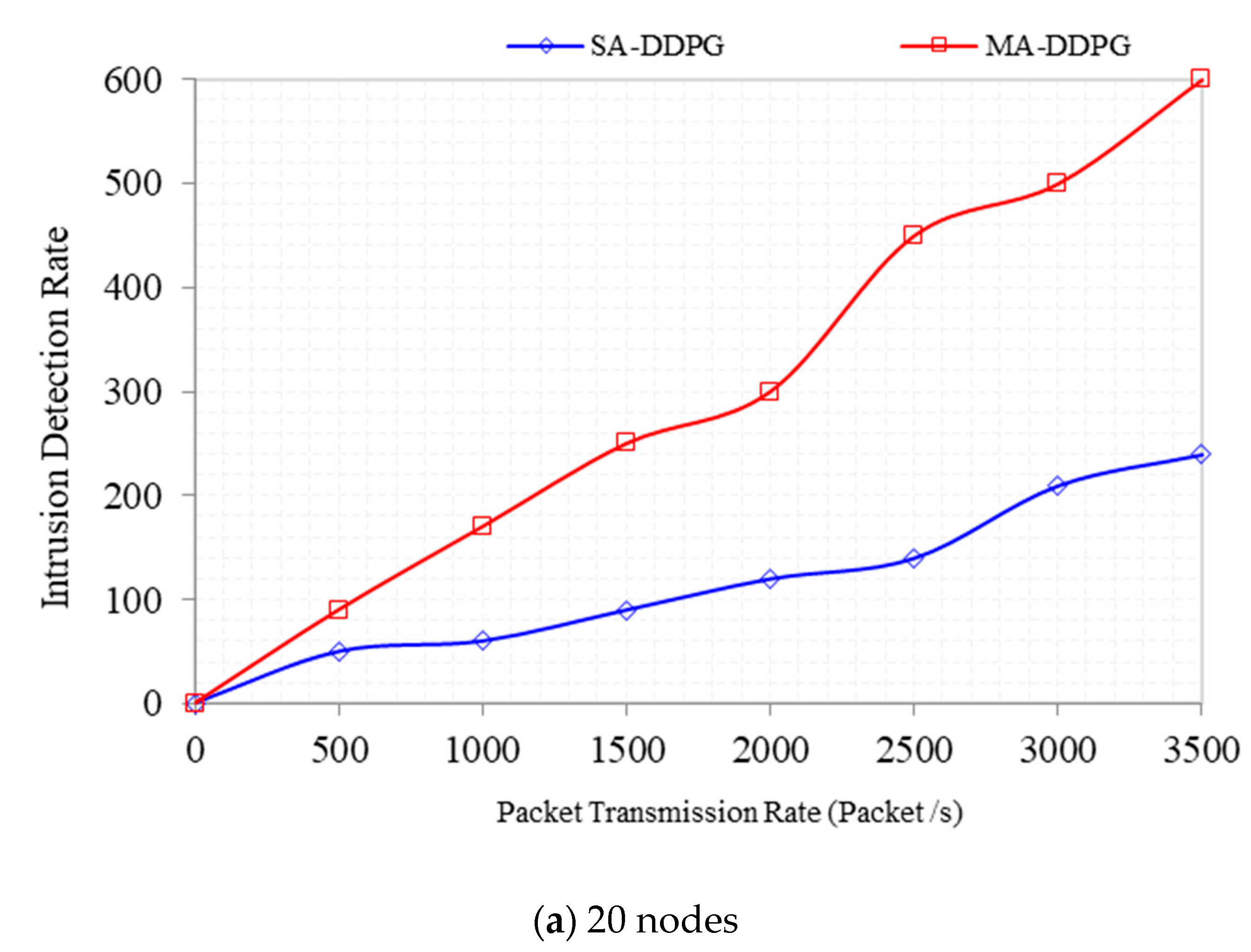
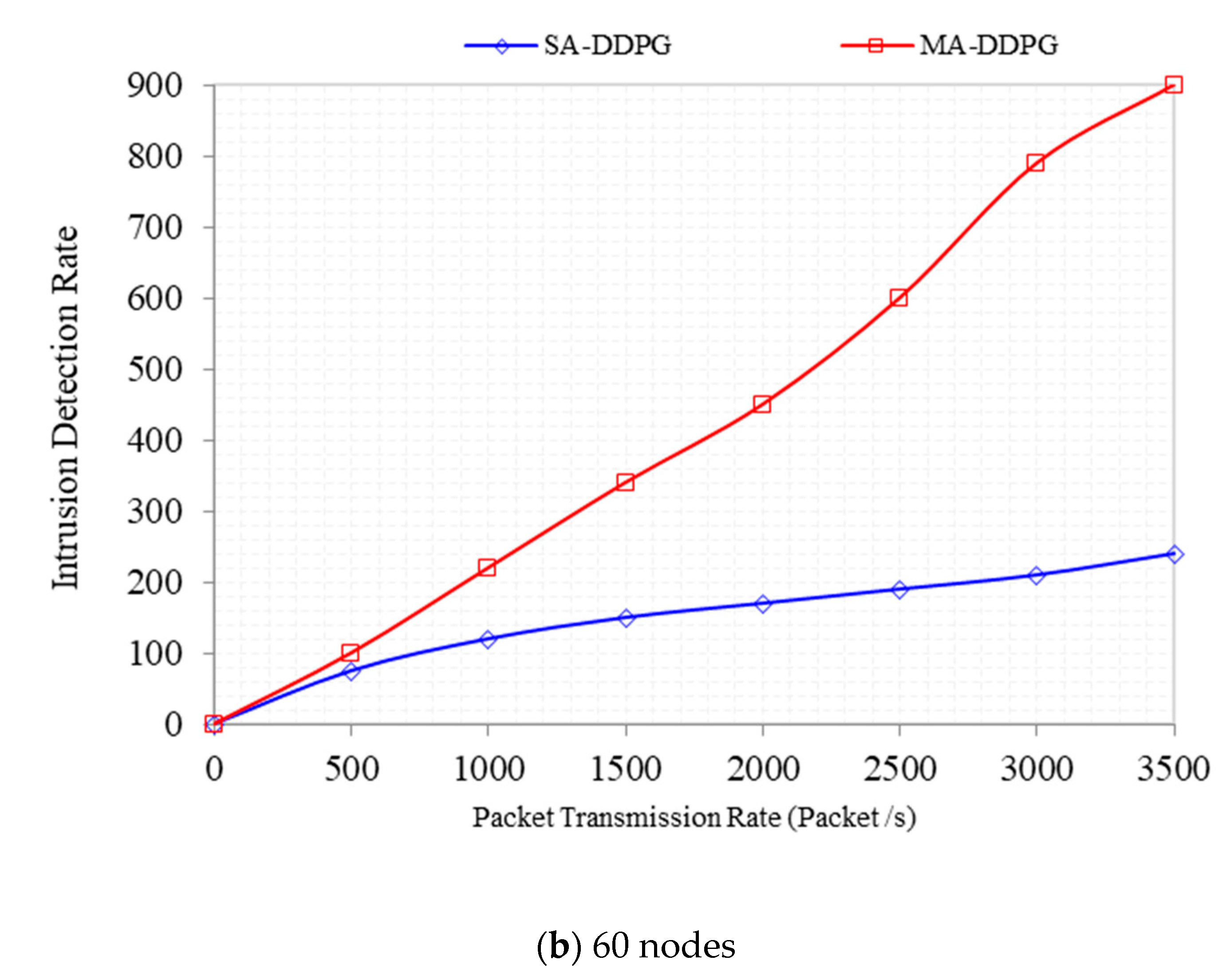
Intrusion Detection Rate captures the False Positive Rate in the network. It represents the number of compromised packets caused by DDoS as the transmission rate increases. As shown in
Figure 15, when compared with DDPG, MADDPG has a 44% improvement in DDoS detection and detected 600 packets as DDoS packets at a transmission rate of 3500 packets per second against an initial detection of 90 packets at a packet transmission rate of 500 packets per second. DDPG detected an initial DDoS packet of 50 at a transmission rate of 500 packets per second against 240 packets when the transmission rate increased to 3500 packets per second. For the 60 nodes, MADDPG has a 50% improvement in DDoS detection over DDPG. The MADDPG detected 900 DDoS packets at a transmission of 3500 packets per second with an initial detection value of 100 at a rate of 500 packets per second. DDPG detected 75 DDoS packets at an initial packet transmission rate of 500 packets per second against a high value of 240 DDoS packets against a transmission rate of 3500 packets per second.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}