1. Introduction
Dementia is a set of symptoms that give way to the intellectual disability (to certain degree) of individuals that have not developed a similar behavior before. The first symptom of dementia is the memory loss of things, situations, and people. Then, the loss of attention occurs, accompanied by difficulty in speaking and in solving various problems. There are many forms of dementia like Alzheimer’s, vascular dementia, dementia with Lewy bodies, frontotemporal dementia, and other neurodegenerative diseases that end up resulting in dementia, like Parkinson’s disease, epilepsy, etc.
Each year, more and more people are diagnosed with dementia. In 2015, 47 million people worldwide were affected, a number expected to increase to 75 million in 2030 and 132 million by 2050. Although it is a common belief that dementia affects only the elderly, early-onset dementia, that is before the age of 65 years, accounts for up to 9% of cases. It should also be pointed out that the progress of the syndrome does not depend on the gender, the social class, nor the geographical location of the suffering person [
1]. A well-known technique that is used in clinics to confront the effects of dementia is music therapy, which will be discussed in below.
Phylogenetically, the hippocampus is the most ancient part of the brain cortex. It is located in the medial temporal lobe, in and below the surface of the cortex, and is part of the anatomical structures that lie between the cortex and the hypothalamus of the brain (limbic system). It mediates the consolidation of mnemonic information, i.e., the transfer of information from short-term memory to long-term memory.
Human memory is mainly based on the functionality of the hippocampus in order to synthesize a vivid memory. It seems that the hippocampus connects all the different characteristics of a memory, and because of its particular function and its wiring, human beings are able to activate memories simply by the presence of some form of stimulus (e.g., sound, image, scent). Thus, the activation of a stimulus that is stored near the hippocampus has a significantly high probability to enable the correct memory, since that part of the brain is less susceptible to the dementia damage. Therefore, since the hippocampus in the human brain is closer to the primary auditory cortex, the distance that the waves have to go through inside the neurons during the production of an acoustic stimulus is shorter than the distance that they have to go through to reach any other sensory cortex. Thus, technically, it is an advantage for any memory-stimulating aid to exploit sound as the primary memory stimulus.
Taking into consideration several works found in the scientific literature, it was decided to focus on the auditory stimulus of memory using familiar sounds. The selection was made based on the fact that music and sound have a beneficial effect on people suffering from dementia, in terms of stimulation of memory for past events and activities and the sense of well-being, as presented in [
2]. This work, in combination with the work in [
3], presenting that sound stimulus helps the sufferer recall his/her identity, with better results than those produced by an optical stimulus, proves that the selection of sound stimulus is beneficial for the sufferer and has a better effect than other stimuli [
4].
As mentioned previously, a common technique with a positive effect for people with dementia is music therapy. According to studies [
4,
5], the effect of music therapy is beneficial for dementia sufferers as it helps them to identify more easily their surroundings and familiars, as well as to maintain their sense of identity. A note that has to be made at this point is that the results from the previously-mentioned works were derived during sessions at hospitals or clinics, offering music therapy services. As a conclusion, it can be said that the latter mentioned works proved that sound is an appropriate memory stimulus for people suffering from dementia, and this is the reason for the adoption of music therapy by neurologists and psychologists that take care of people suffering from dementia.
The scope of this work is to exploit the findings of the previous research results and techniques and propose an acoustic-based memory stimulus system for installation at the sufferer’s home. Thus, this will be the first home system of its kind, since the referenced research works were targeting either sufferers at clinics or required assistance from a caregiver at home. The proposed solution should be considered a novelty in the field of its application (acoustic-based memory stimulus at home), rather than in the field of its implementation. The system will be referred to hereinafter as AuDi-o-Mentia(derived from audio and dementia). The aims of the proposed home system are: (1) the memory stimulation of the sufferer when a familiar comes closer, (2) the memory stimulation of the sufferer, when a familiar enters the house, while being in a private location, and (3) in-home detection of the sufferer.
The rest of the paper is organized as follows.
Section 2 provides an overview of previous work for supportive systems at the homes of people suffering from dementia and highlights the differences from the proposed system.
Section 3 describes the desired system’s operation through use cases.
Section 4 describes the architecture of the AuDi-o-Mentia system.
Section 5 displays the implementation of the system in hardware and software.
Section 6 presents the results, and a discussion of the proposed solution is offered in
Section 7. Finally, in
Section 8, this paper concludes.
2. Previous Work
In recent years, a variety of studies for people suffering from dementia has been presented in the academic literature. A handful of them focused on various approaches to support people with dementia. Some of these works are presented below in chronological order.
2.1. Smart Homes for Dementia Sufferers
In [
6,
7], an action recognition system-based on Markov decision processes was proposed to help people with dementia complete their various day-to-day home activities. A probabilistic learning approach for behavioral patterns in smart homes for people with Alzheimer’s has been suggested by Zhang et al. [
8]. Neither of these works considers the recognition of caregivers or familiars of the sufferer. A home automated and unobtrusive monitoring system, to assist the caregivers of the sufferers, using sensing and artificial intelligence technologies, was presented in [
9]. Richter et al. [
10] developed a system to identify the deficiency and the improvement of the need of care at home of sufferers. A user-centered prototype smart home was introduced in [
11]. A framework with cameras, wearable devices, and sensors detected and predicted the aggression of people with dementia in [
12]. A computing platform was developed with the use of sensors that were placed at home to monitor the mood of people with dementia in [
13]. Another framework assessed the sufferers’ progress in daily activities at home and provided decision support systems for their doctor in [
14]. Kimino et al. [
15] developed a sensor system that collects behavioral data, to detect the early symptoms of dementia. Schinle et al. [
16] presented a support system with sensors, to model the behavior and derive the habits of people with dementia. All the latter mentioned works focused on behavior monitoring, mainly through a network of sensors installed at the sufferer’s home, and not assistance in recognizing his/her familiars, and thus increasing their social interaction.
2.2. Supporting Systems for People with Dementia
Boger et al. [
6] and Jean-Baptiste and Mihailidis [
7] developed an assisting system to guide people with dementia to perform their various day-to-day activities. This work also did not focus on social life, but rather day-to-day tasks. Zhang et al. [
8] proposed a decision support system for the assisted living of people with Alzheimer’s. A user interface able to monitor and remind the users about some information was designed by Ceccacci et al. [
17] to support daily activities for people with dementia. These works are based on the eye-brain model, which is not ideal for sufferers of neurodegenerative diseases and syndromes. Mulvenna et al. [
13] developed a platform for monitoring the mood and to affect the emotional well-being of people with dementia, but not their ability for recognizing familiars. Luckner et al. [
18] implemented prototypes to support the increase of mobility for people suffering from dementia, limiting the work to autonomy issues and easy movement.
2.3. Systems for Monitoring of People with Dementia
A wearable and low-cost sensor was implemented for the monitoring of human physical life, the daily living activities, and assisted healthy aging in [
19]. A stereo vision-based system was designed for the detection of people with dementia at their home in [
10]. A monitoring system to assist sufferers’ caregivers was presented by Osamu et al. [
9]. Another monitoring system was developed by using a user interface [
17]. Khan et al. [
12] created a framework with a multi-modal sensor network monitoring the behavior of people with dementia. Furthermore, a computing platform that uses sensors has been proposed for the monitoring of sufferers’ mood [
13]. Kasliwal and Patil [
20] proposed a tracking device for people with dementia for the monitoring of their present location, which sends their location to the caregivers’ mobile phones. Another tracking and rescue system was proposed by Wu et al. [
21] was integrated with the sufferers’ shoes and provided their real-time location to their familiars. Alam et al. [
22] suggested a wearable sensor-based system for the continuous monitoring of the physiological and behavioral parameters of people with dementia. Schinle et al. [
16] suggested a system that monitors the behavior of people with dementia not only in the daytime, but also during the night and their bedtime. Hanna et al. [
23] suggested using unmanned aerial vehicles for the locating of wandering people with dementia. All the previously-mentioned works were passive monitoring systems, without actual interaction, mainly for locating the sufferers and either detecting suspicious behavior or mood change, and caregiver automated alert systems. Again, none of these systems target the recognition of familiars by the sufferer or the enhancement of his/her social life. Furthermore, sensors and generally the proposed human-computer interface are based on visual control and monitoring and not other, more appropriate, stimulus for interaction.
2.4. Other Suggested Systems for Dementia Sufferers
Tung et al. [
24] have compiled a survey with projects that had been proposed by 2013 for the monitoring, assistance, early diagnosis, and treatment of people with Alzheimer’s disease. Quiz games based on musical and visual stimulus were created by Ferreira et al. [
25] for the assistance of the daily living activities of people with dementia. This was the first work that was found to exploit acoustic stimuli. Nishimura et al. [
26] developed a system with a 3D animated character for spoken dialogues with people with dementia to support the preservation of their memories, however using again the eye-brain model and the visual stimulus as the main means to preserve memories. Siriaraya et al. [
27] suggested systems with virtual environments for joint activities of people with dementia with their professional caregivers. Again, this work is mainly based on visual stimulus.
3. Use Cases of the Proposed System
AuDi-o-Mentia, through disappearing computing, introduces a more physical and efficient way of interaction with the sufferer. The sense of hearing is exploited as a medium to stimulate the memory of the sufferer and empower memory towards person recognition. Thus, the system is assisting this communication physically, without generating actual technological engagement. An interesting part of the work is the augmentation of a person’s identity with an acoustic tag that may be exploited explicitly by the system.
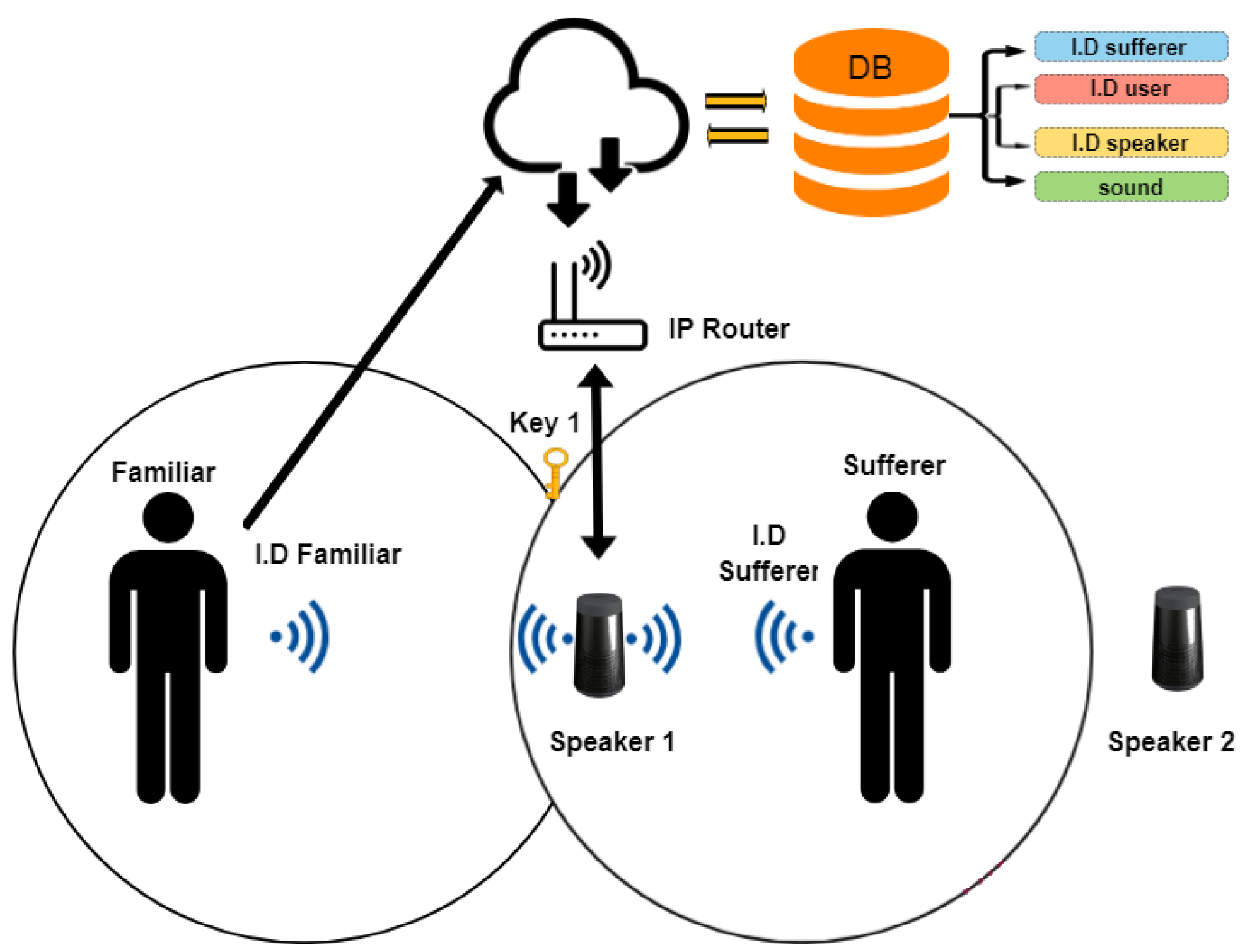
The proposed system has three types of users: (i) the Familiar, (ii) the Sufferer, and (iii) the Administrator. The user Familiar is the person whose identity is augmented by a digital Acoustic Identification (ID) signal, via a device that he/she carries (smartphone, smartwatch, etc.). This device provides a unique acoustic tag of the user for identification purposes to the system. Then, this tag is used by the system to reproduce a sound that may be recognized by the Sufferer and be associated with that Familiar person that was identified.
The user Sufferer is the one that is tracked inside the house. He/she bears a device that acts as a beacon. The signal’s power is measured by the smart speakers, and the sufferer’s proximity to each smart speaker is calculated. Then, the closest smart speaker is selected, by the system, to reproduce the associated sound to the ID of any user Familiar that requests so. The Sufferer’s identity is also augmented by a digital ID signal, via the device, which is carried on him/her (always hidden from him/her).
The user Administrator is usually a caregiver, but he/she may be also either be the sufferer or one of his/her familiar people. The main task for the Administrator is to manage the correlation list of sounds/acoustic stimulus with the associated people and the smart speakers’ list.
As mentioned in
Section 1, the aims of the proposed home system are: (1) the memory stimulus of the sufferer when a familiar gets closer to him/her, (2) the memory stimulus of the sufferer, when a familiar enters the house, while being in a private location, and (3) the detection of the sufferer in the house. The last aim is describing a geo-fencing feature of the system, since no signal from the sufferer’s device triggers an alarm of absence from the household. The operation of the proposed system can be better understood by the following figure, which is used to describe the expected typical use scenarios of the system, depending on the location of the sufferer in his/her home when a familiar enters to it.
3.1. A Typical Household
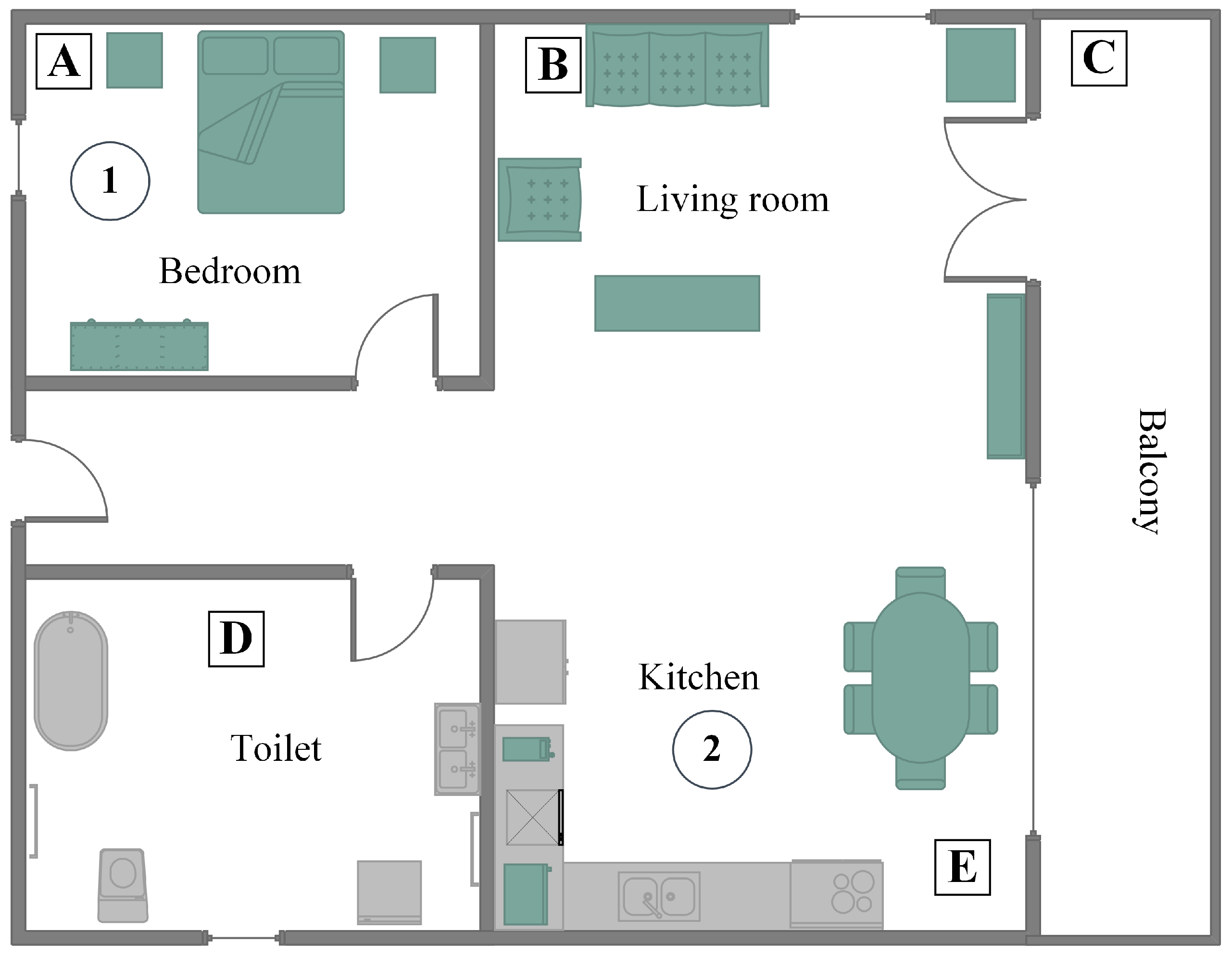
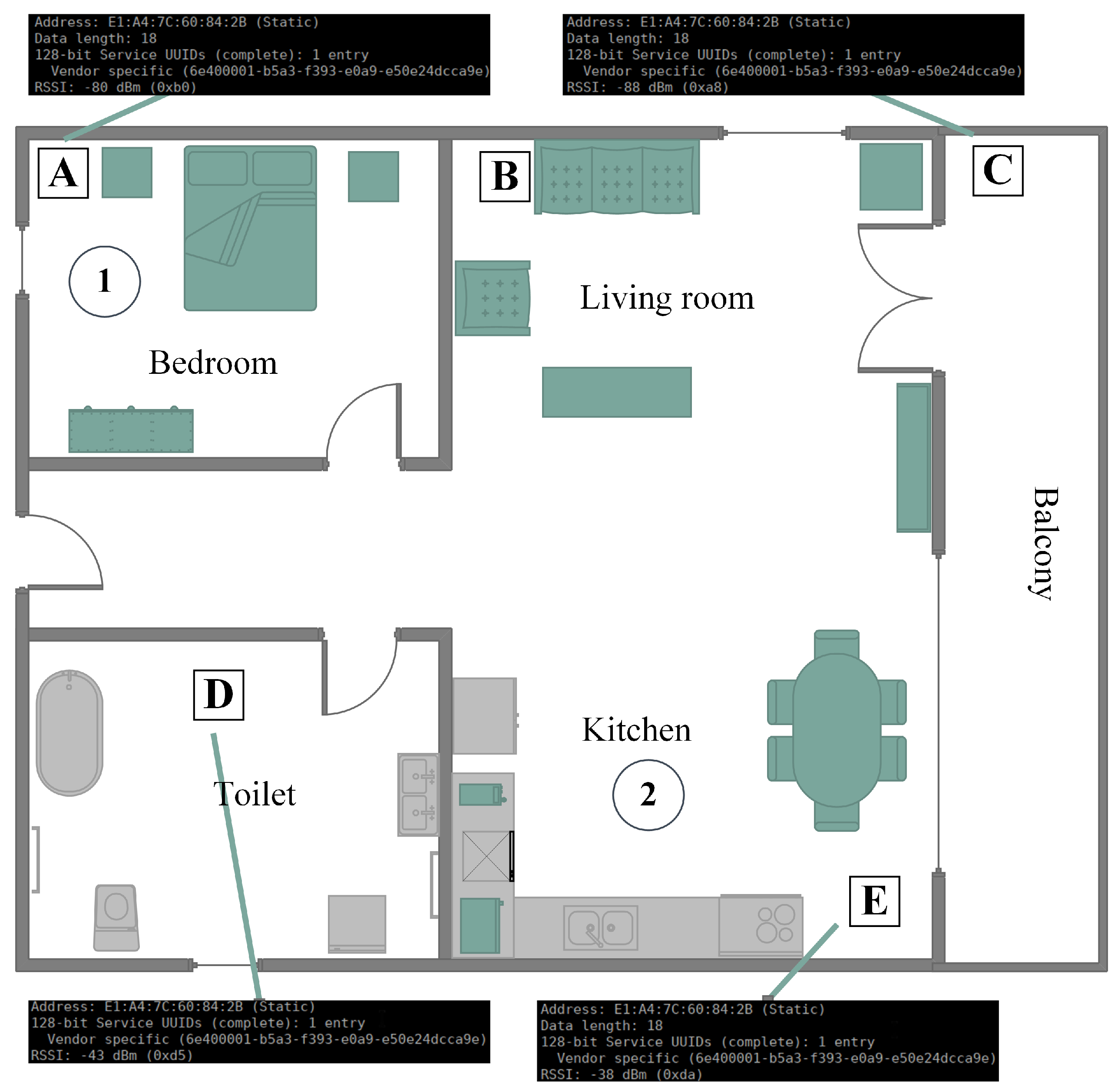
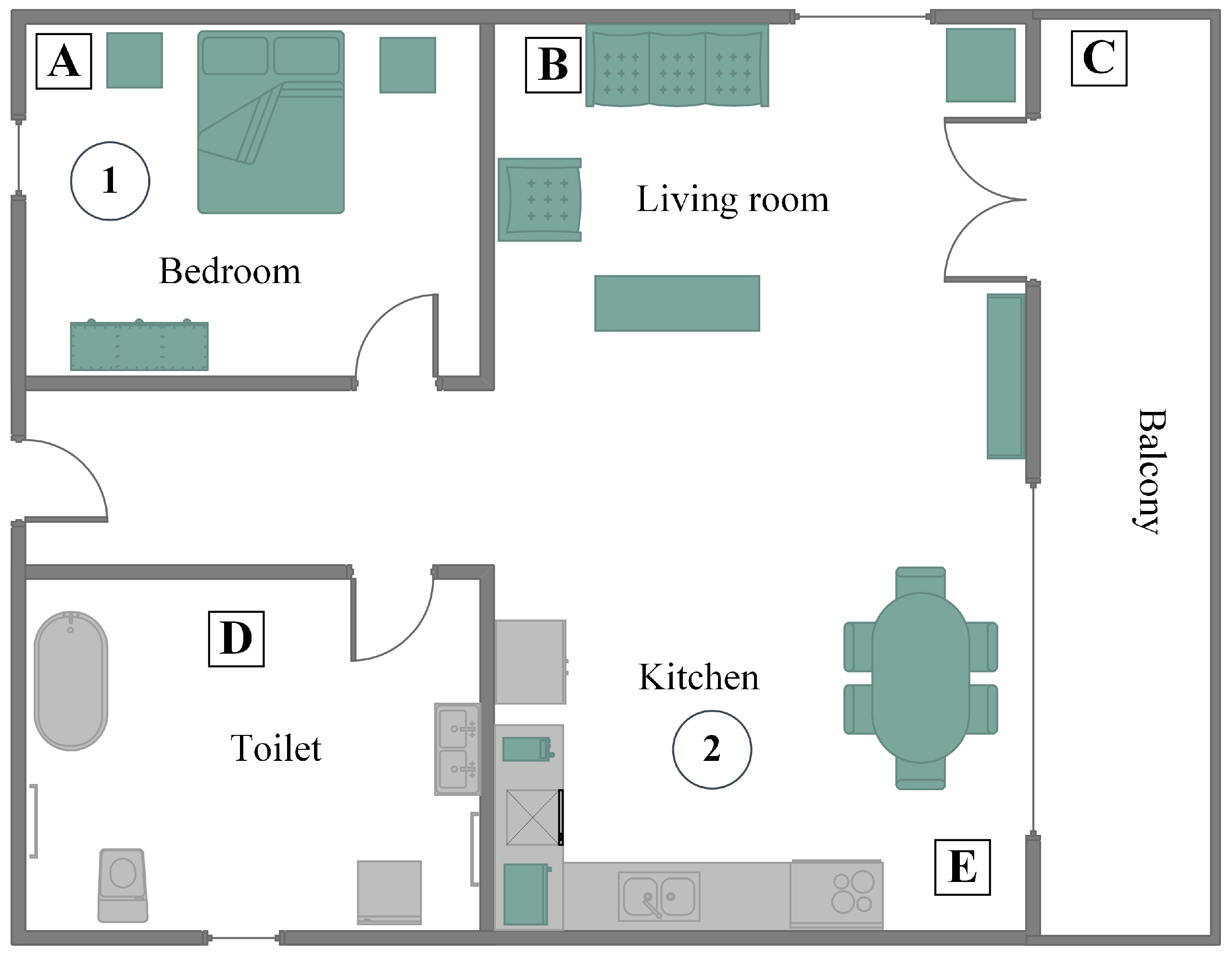
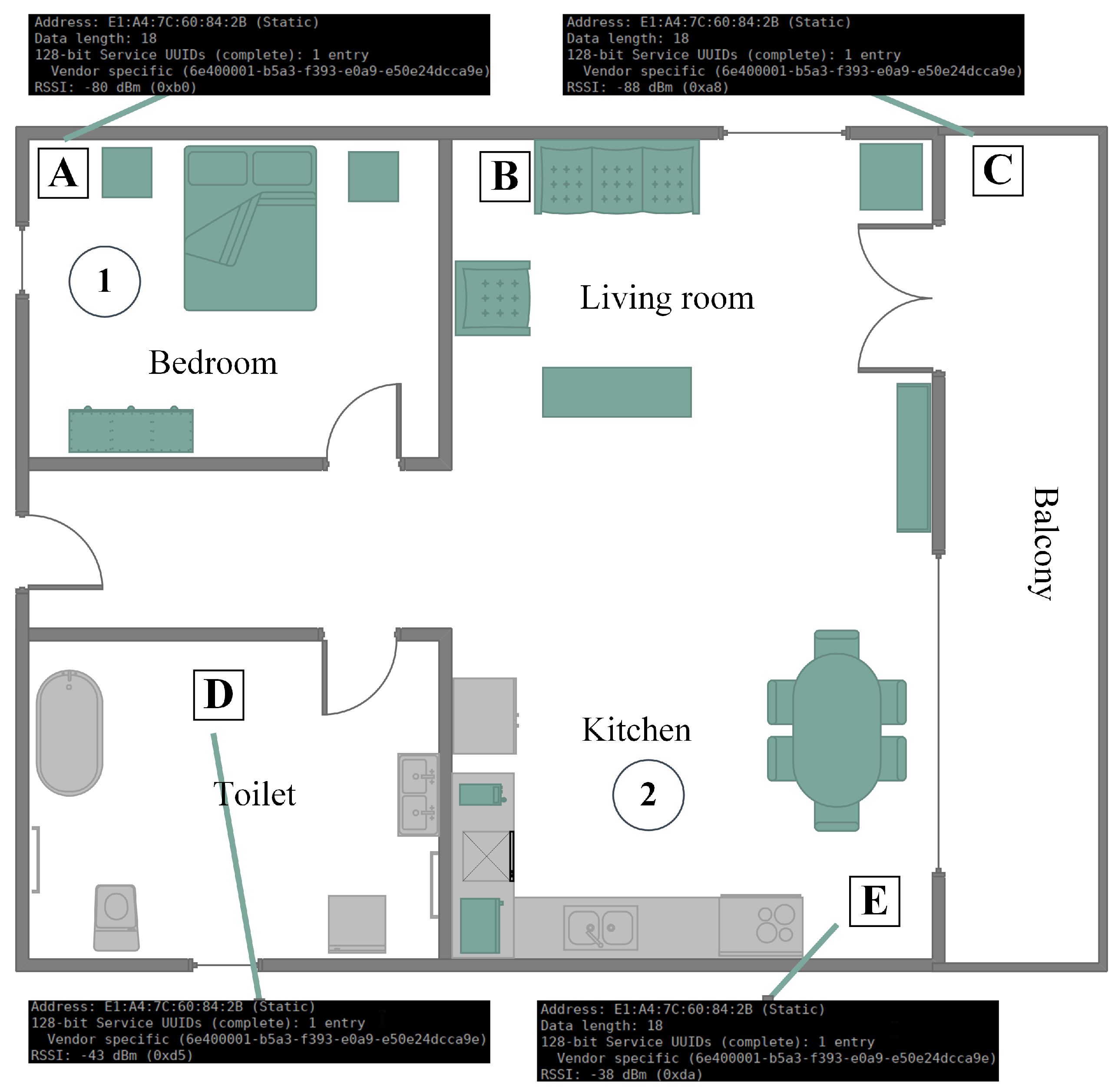
In
Figure 1, a typical household is depicted, including an entrance (door at the left of the figure), a short hall giving access to a bathroom, a bedroom, and the living room, which includes a kitchen. A balcony is also part of the household. Smart speakers are placed in the interior of the house, covering all rooms, as well as exterior locations, such as the balcony. Speakers are illustrated as squares named A–E. Furthermore, a router connecting the home network with the Internet is implied, although not illustrated for simplicity reasons. For a better description of the use cases, two locations that are circled and enumerated are provided. These are potential locations where the sufferer may be found.
3.2. Notifying the Sufferer of a Nearby Familiar
In
Figure 1, a use case of a familiar who enters in the room, where the sufferer is found, is considered. The sufferer is found at Location 2 (circled), which is part of a greater room. Although the familiar is between two smart speakers (B and E squares), only Speaker E is activated, recognizing that the sufferer is closer to it. This use case is the main function of the system, that is to stimulate the sufferer’s memory by reproducing a characteristic sound for the Familiar. In order to achieve this, a unique ID is required for each Familiar, which is matched in the cloud database with the characteristic sound. The identification (automated or semi-automated) of the Familiar’s ID is one of the two main technical goals of the system.
3.3. Sufferer in a Private Location
In
Figure 1, a use case of a familiar entering the house when the sufferer is found in a private location is considered. There are cases when a Familiar is not given access to a room; however, there is the need to notify the sufferer. That is exactly the same case as the previous one; however, it shows one requirement for the proposed system that is not included to any other similar solution, that is memory empowerment without eye contact, but rather via sound stimulation. In this case, again, the familiar is identified by the system; the closest smart speaker to the sufferer (Square D) reproduces the corresponding characteristic sound, and the sufferer is informed about the familiar’s presence in the home.
3.4. Detecting Sufferer’s Location
In
Figure 1, a use case of a familiar trying to spot the sufferer in the house is considered. In this use case, we suppose that the sufferer is found in the bedroom (Circle 1). That is the second of the two main technical goals of the system. This technical issue offers two features to the system. The first one is the discovery of the sufferer from the Familiar by activating the closest to the Sufferer smart speaker. The second feature is a form of geo-fencing, that is the digital limitation of the Sufferer in the bounds of the house. Detection of the Sufferer is achieved also either automatically or semi-automatically.
In the first case, the familiar requests from the system to activate the smart speaker that is closest to the Sufferer (Square A), in order to spot her/him in the house (localization is achieved through the digital ID that the Sufferer transmits, similarly to the Familiar). The second case is the activation of the smart speaker closest to the Sufferer in explicitly-defined time periods. If the ID of the Sufferer is not detected, that means that the Sufferer is out of range of the smart speakers’ network. This allows automatic detection of the presence (or not) of the Sufferer in the house.
4. Architecture of the Proposed System
The architecture of the proposed system is server-centric, allowing access to the users, and the devices, via the appropriate client software. The proposed system is a Software-as-a-Service (SaaS), which associates Sufferers with Familiars, and is controlled by the Administrator. The communication of the system is configured concerning two operations, namely the system administration and the sufferer’s support.
The first one is defined by the administration procedures. These procedures include the creation of a user (Sufferer or Familiar), the inclusion of Familiars on a Sufferer’s list, the association of sound files between user pairs and, finally, the management of the smart speakers (i.e., registration and removal of a speaker). Furthermore, it includes also the registration of hardware (for identifying the user’s ID, like a wristband or a smart phone of a familiar, or a digital ID device for monitoring the sufferer).
The second operation of communication concerns the support of the sufferer. That includes (1) the identification of a digital ID (a familiar that enters the house) from a smart speaker, (2) the submission of smart speakers’ requests to the cloud-based services, (3) the reproduction of the expected sound (associated with the Familiar’s sound) from the speaker nearest to the sufferer, and (4) the in-house detection of the sufferer. In brief, the process includes the initial establishment of a communication channel between the digital ID device of the familiar and the targeted smart speaker. Then, the smart speaker requires from the cloud-based service the associated sound. The cloud-based system requests from the smart speakers to report their distance from the sufferer. Then, a request to the speaker nearest to the sufferer to reproduce the associated sound is sent.
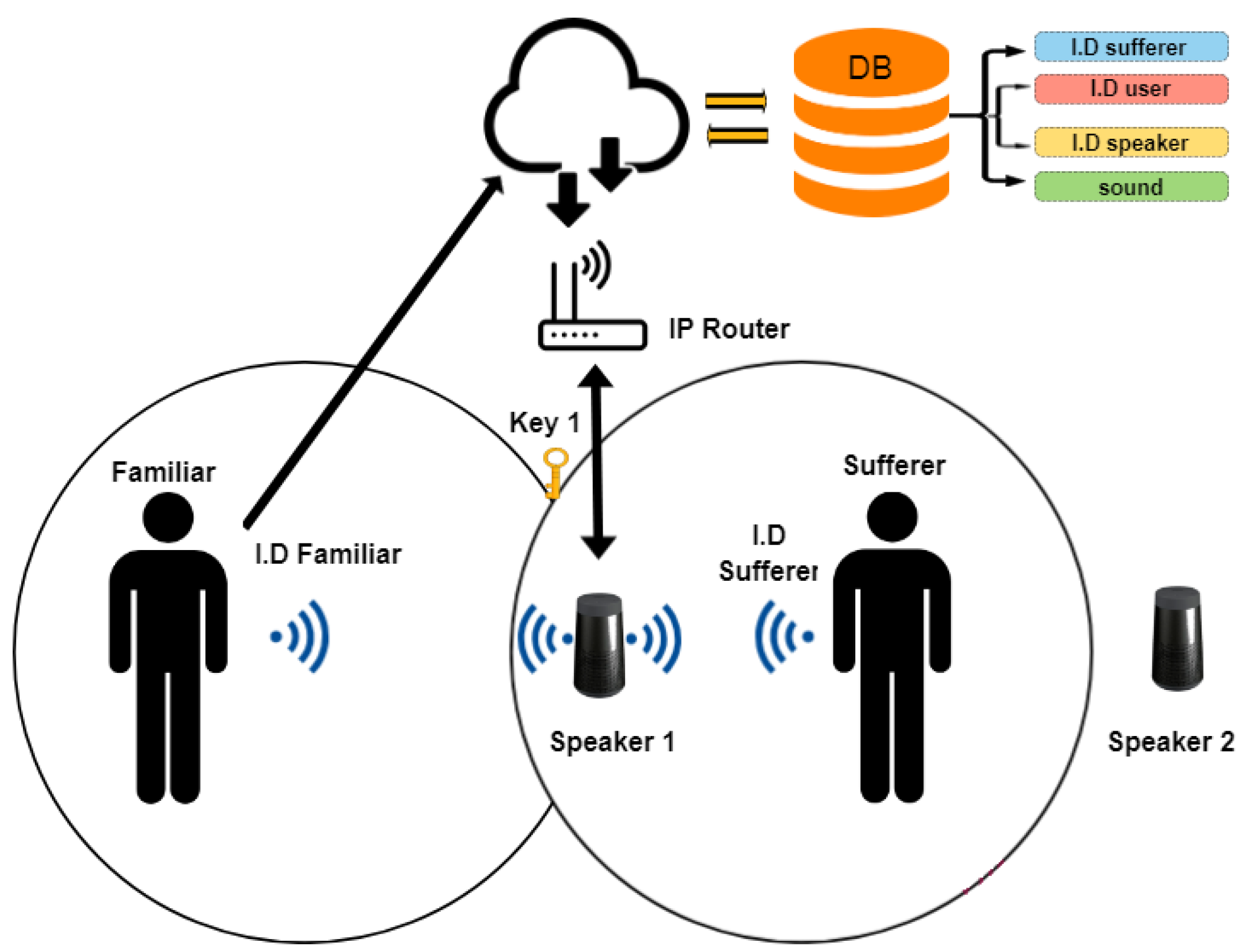
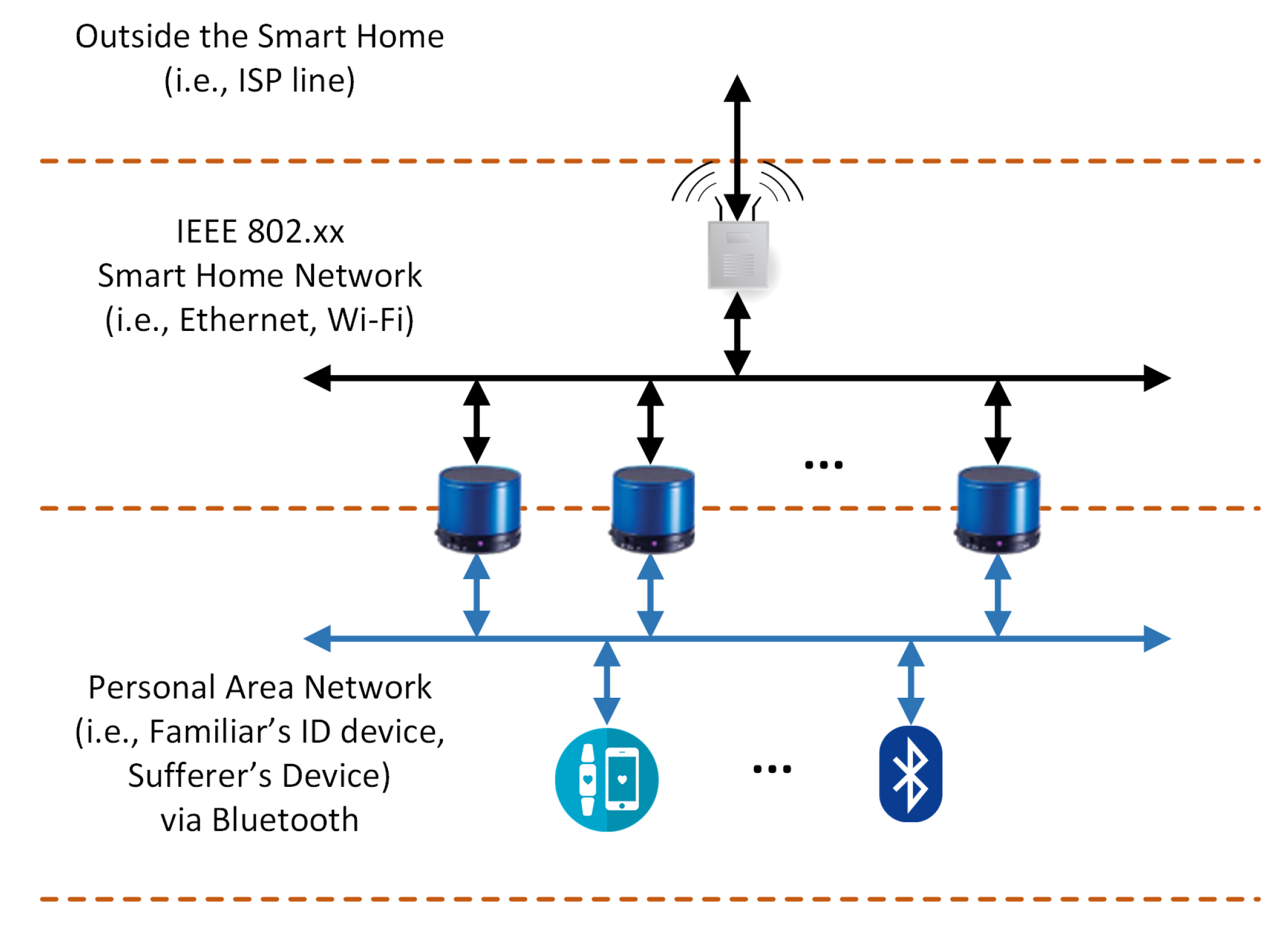
In
Figure 2, an abstract representation of the system’s architecture is depicted, exhibiting all the components of the system and their interaction. Notice that a black line denotes communication based on IEEE 802.xx (either Ethernet or Wi-Fi), and a blue line denotes a Bluetooth communication channel.
The architecture of the proposed system was selected following the paradigm of the leading enterprises in the field of smart speakers. The processing of each request was executed on a cloud-based infrastructure. Since the AuDi-o-Mentia system is not targeting a safety-critical application, the selection of the cloud-based architecture was considered efficient. Although any other architecture selection (such as fog or edge) [
28,
29] might be proven beneficial in terms of availability and performance of the system, it would however lead to additional requirements for a custom-owned platform and the design (and production) of new smart speakers. Then, this selection would make the system costly and extremely dependent on one vendor. Furthermore, it will eventually require new design effort to be spent to consider scaling up issues, as well as installation problems for the new smart speaker. Finally, it would not take advantage of any smart speaker already available on the market, which may be connected with software modifications to the proposed system. Thus, for compatibility reasons, the cloud-based architecture was selected.
In the following subsections, information regarding the architecture in terms of communication protocols, infrastructure, software, and hardware resources are detailed.
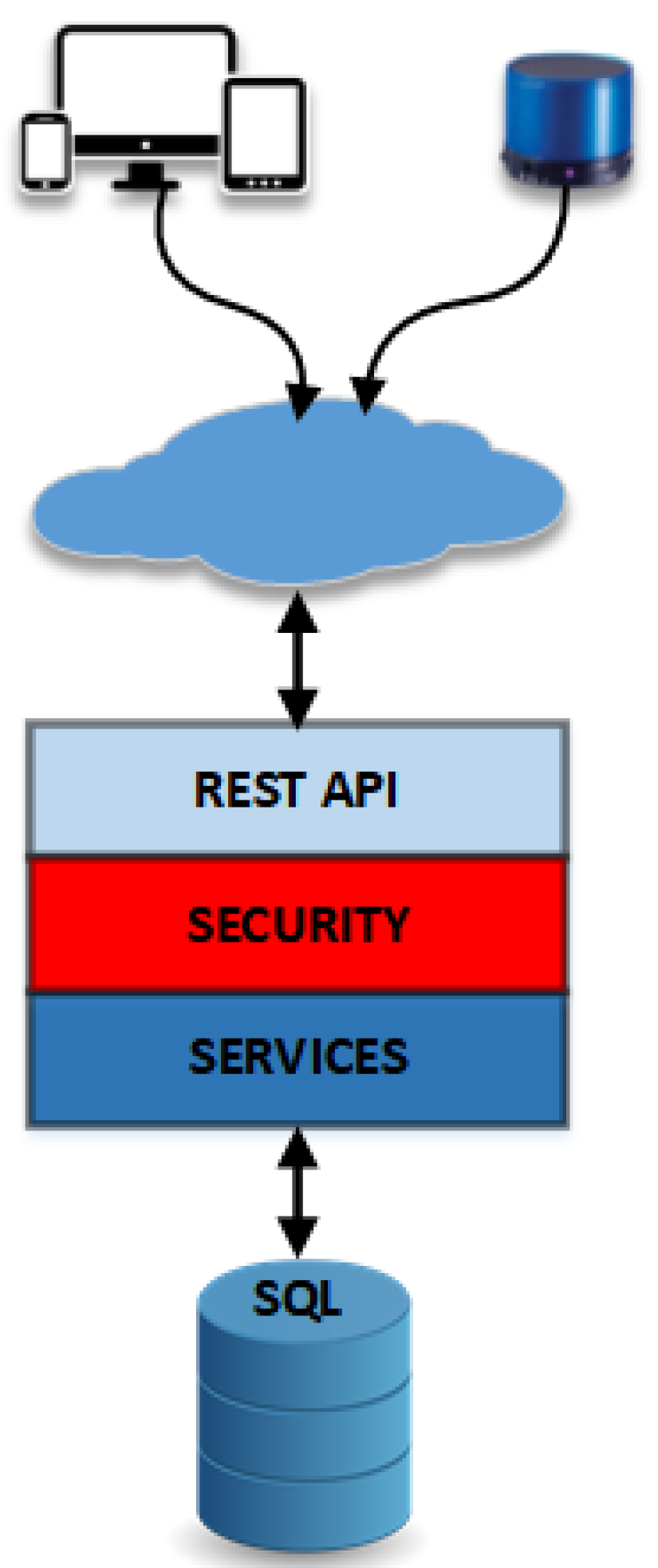
4.1. Cloud
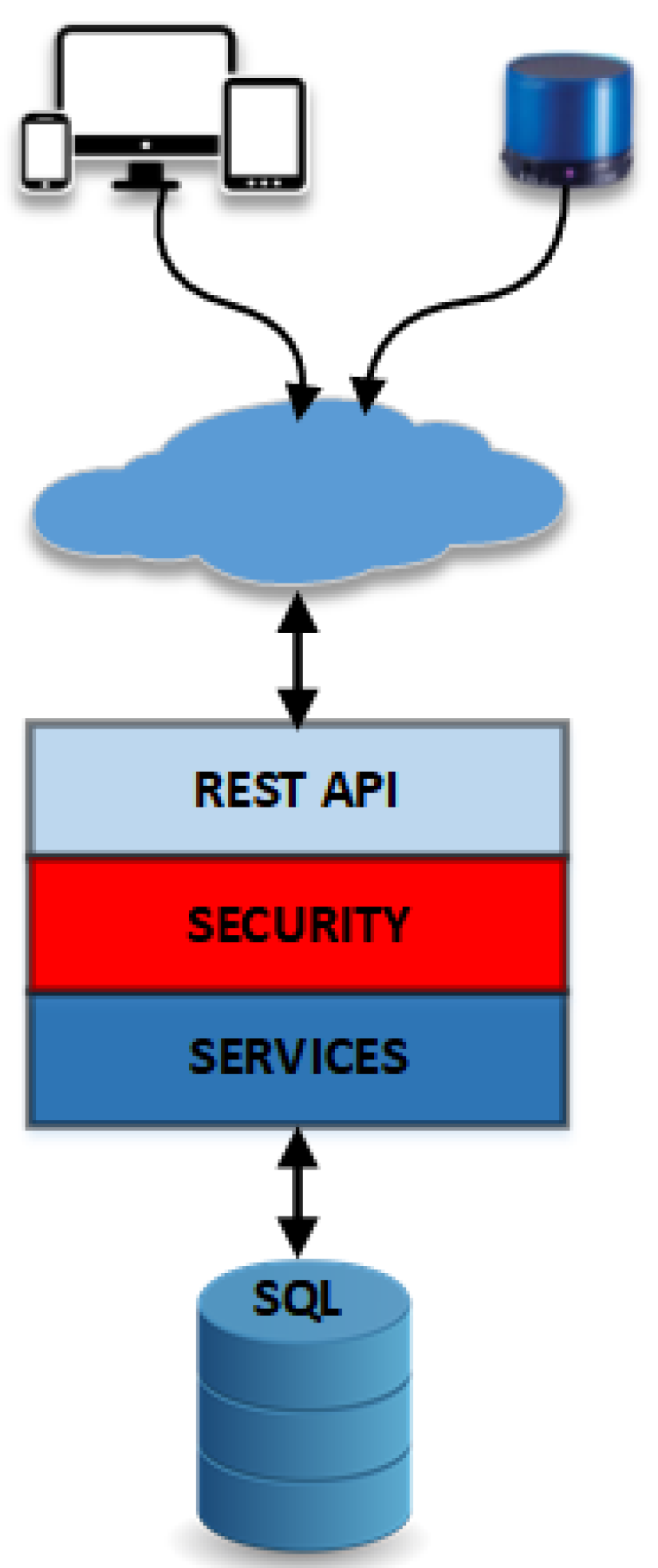
For the needs of the application, there is an available Virtual Machine (VM) on a cloud infrastructure that mainly hosts a Database (DB) schema. On the DB, data regarding the sufferer and the familiars are stored. A table that holds the correlations between the sufferer and the familiar with the characteristic sound and the duration is included in the DB schema. Furthermore, there is a table that holds the relations between the sufferer and the smart speakers. On top of that DB, there are some services in order to handle the interaction. By using services, the software can be split and take advantage of tools and technologies that best fit each time. On the next layer, there is a REST API, for other devices to interact with those services. In
Figure 3, the cloud architecture is depicted, as described before.
As seen in
Figure 3, the cloud services may be accessed either via a computer, a tablet, a smartphone, or a smart speaker. In the first case, the users Familiar and Administrator are communicating with the cloud service. The user Familiar is connecting to the system in order to register and apply to be associated with a Sufferer. The Administrator is contacting the cloud services in order to manage the database and grant/create the appropriate associations between the Sufferer and the Familiars. The second case corresponds to the communication of the system with the smart speakers, in order either to ask for information regarding the position of the Sufferer or to stream sound directly to the smart speaker that was identified as the closest to the Sufferer.
4.2. Smart Home
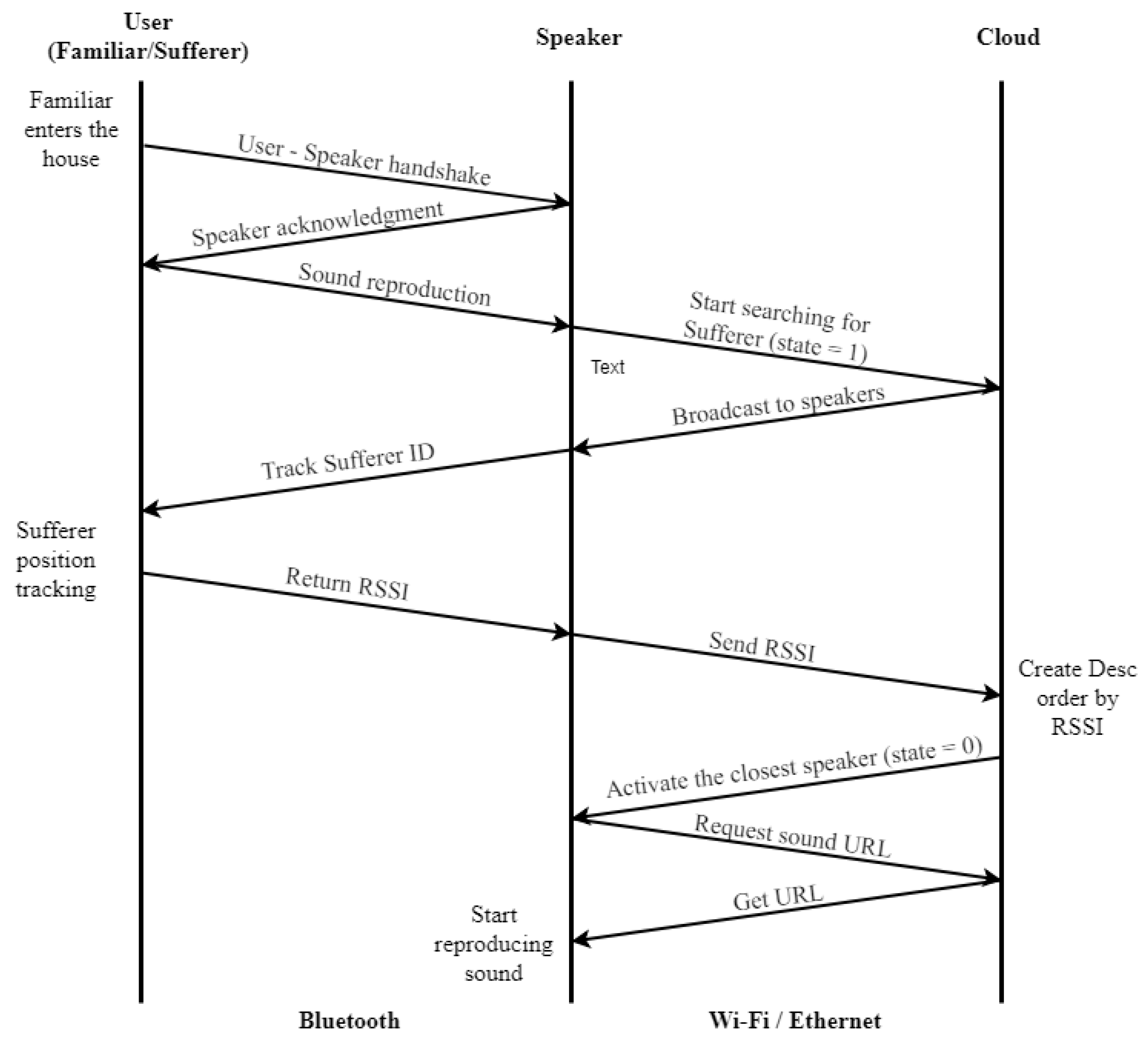
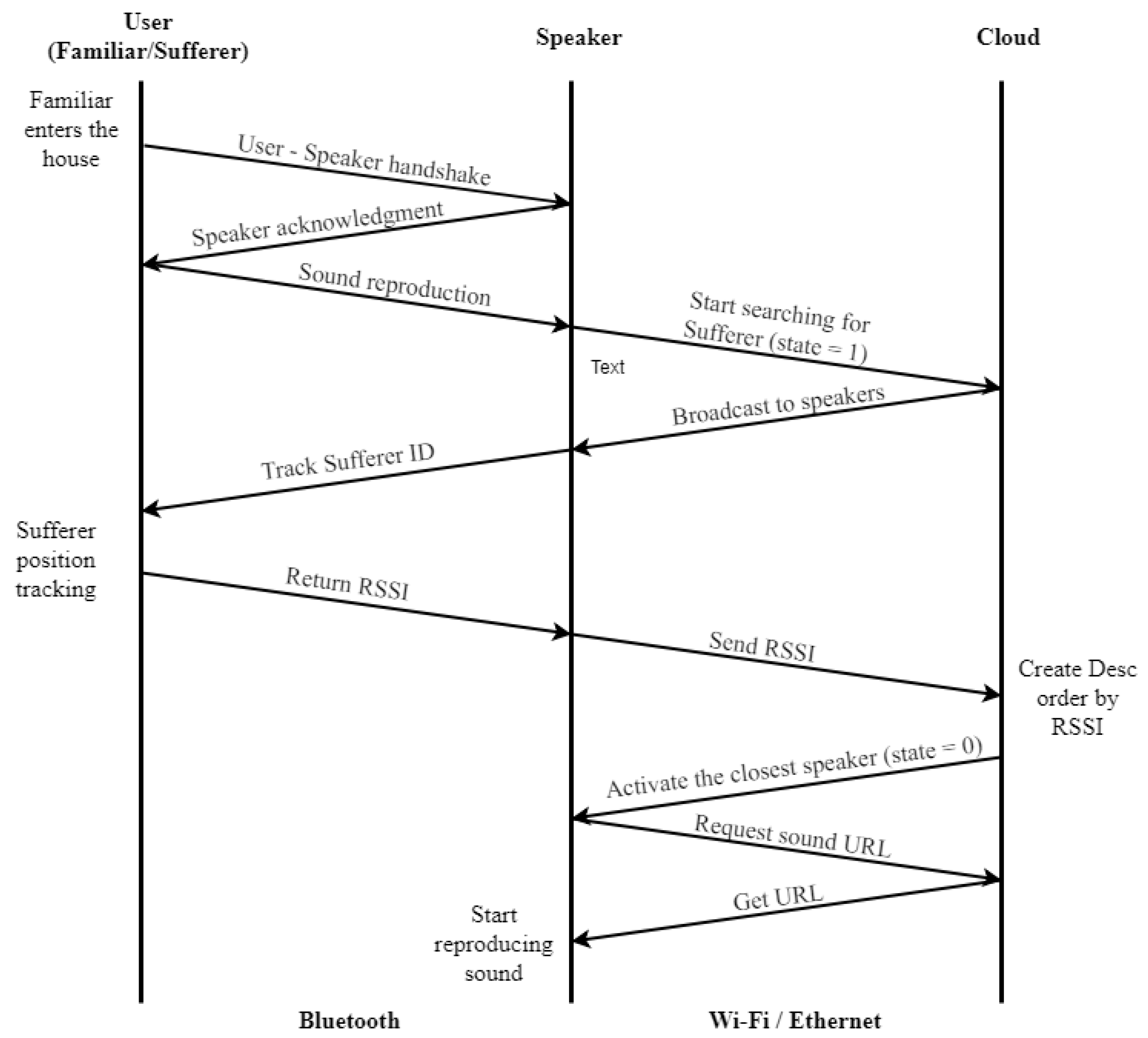
In the smart home, there are speakers with the ability to connect either via Bluetooth or Wi-Fi with the system. The use of Bluetooth allows the establishment of communication with the user Familiar in order to activate the operation of the notification of his/her presence or the in-house detection of the Sufferer. Furthermore, the Sufferer submits a beacon signal in order to make his/her presence known. The Wi-Fi communication channel is used for contacting the cloud services, in order to submit requests from the Familiar to the cloud or to submit requests from the cloud to the smart speakers. Especially for the reproduction of the associated sound with a Familiar, a detailed process chart is depicted in
Figure 4 including the communication between the user, the smart speaker, and the cloud.
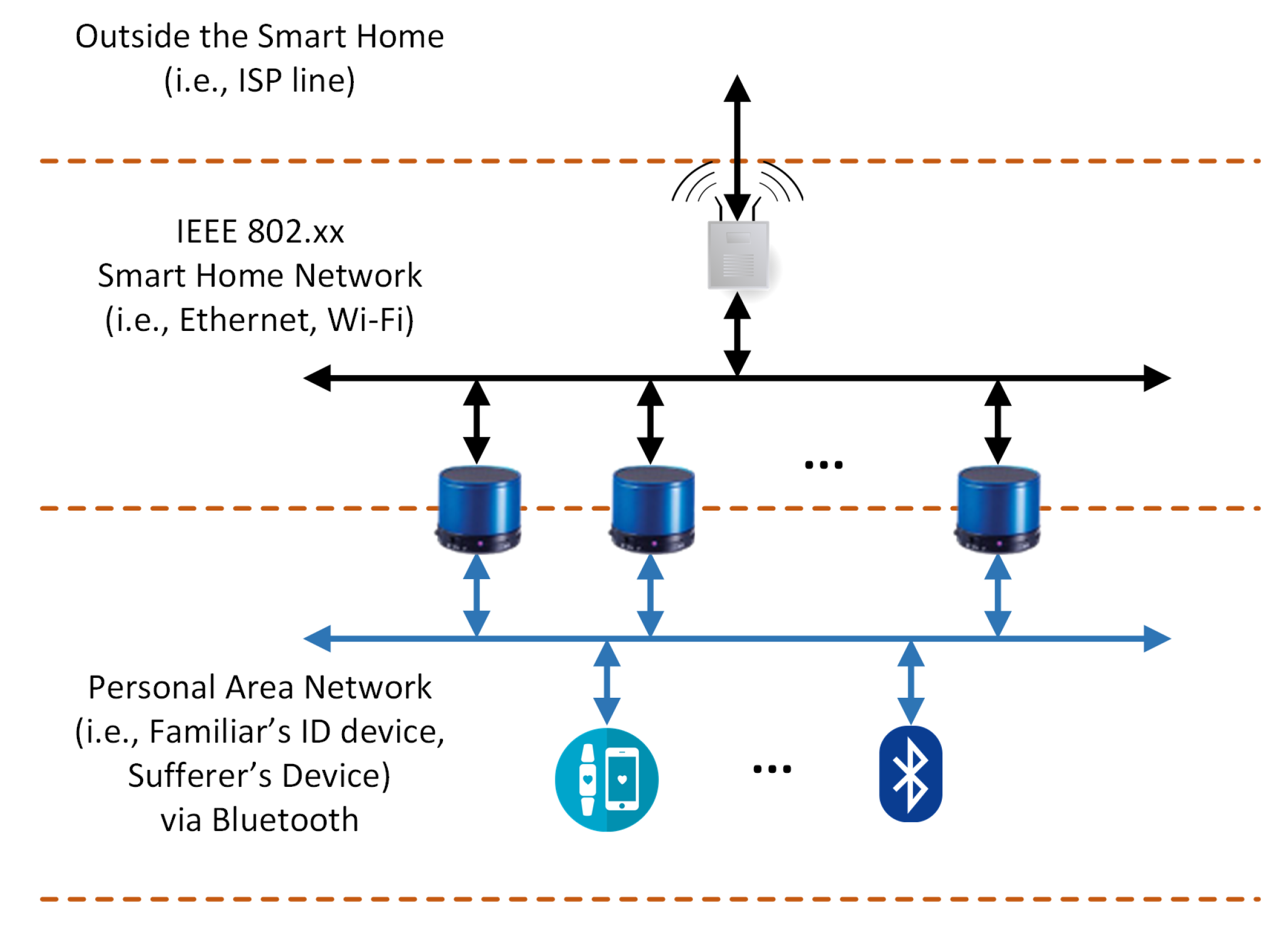
The speakers’ network at the smart home is the bridge between the user interaction and the cloud service. Each smart speaker is connected via both Ethernet/Wi-Fi and Bluetooth. The topology of the smart speakers’ network is depicted in
Figure 5. As can be seen, any device from the users (either Familiar or Sufferer) is connected to the speakers, and through them to the cloud. Access to the cloud is achieved via the in-house installed ISP router.
5. Implementation
In the implementation of the proposed system, all data transfers between the cloud/server and the devices was performed using the JavaScript Object Notation (JSON) format. Furthermore, every network packet from/to the service layer was encrypted using the AES block cipher, for security reasons. Moreover, information like passwords or the MAC address of the smart speakers (or any other device that might be needed) were encrypted using the SHA256 hash function.
5.1. Cloud/Server Side
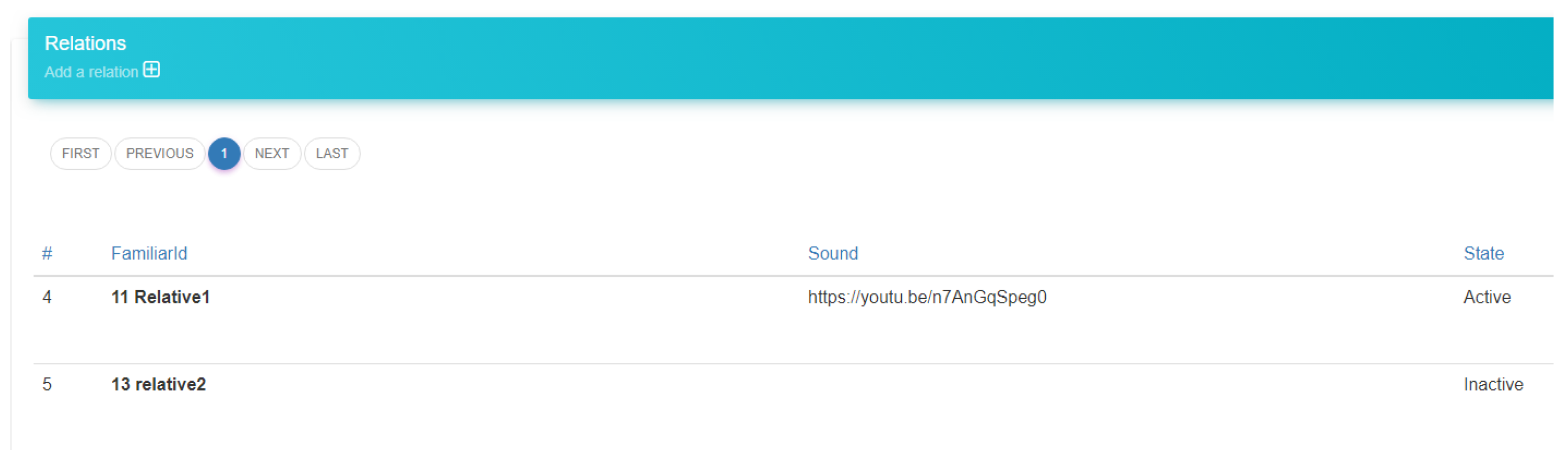
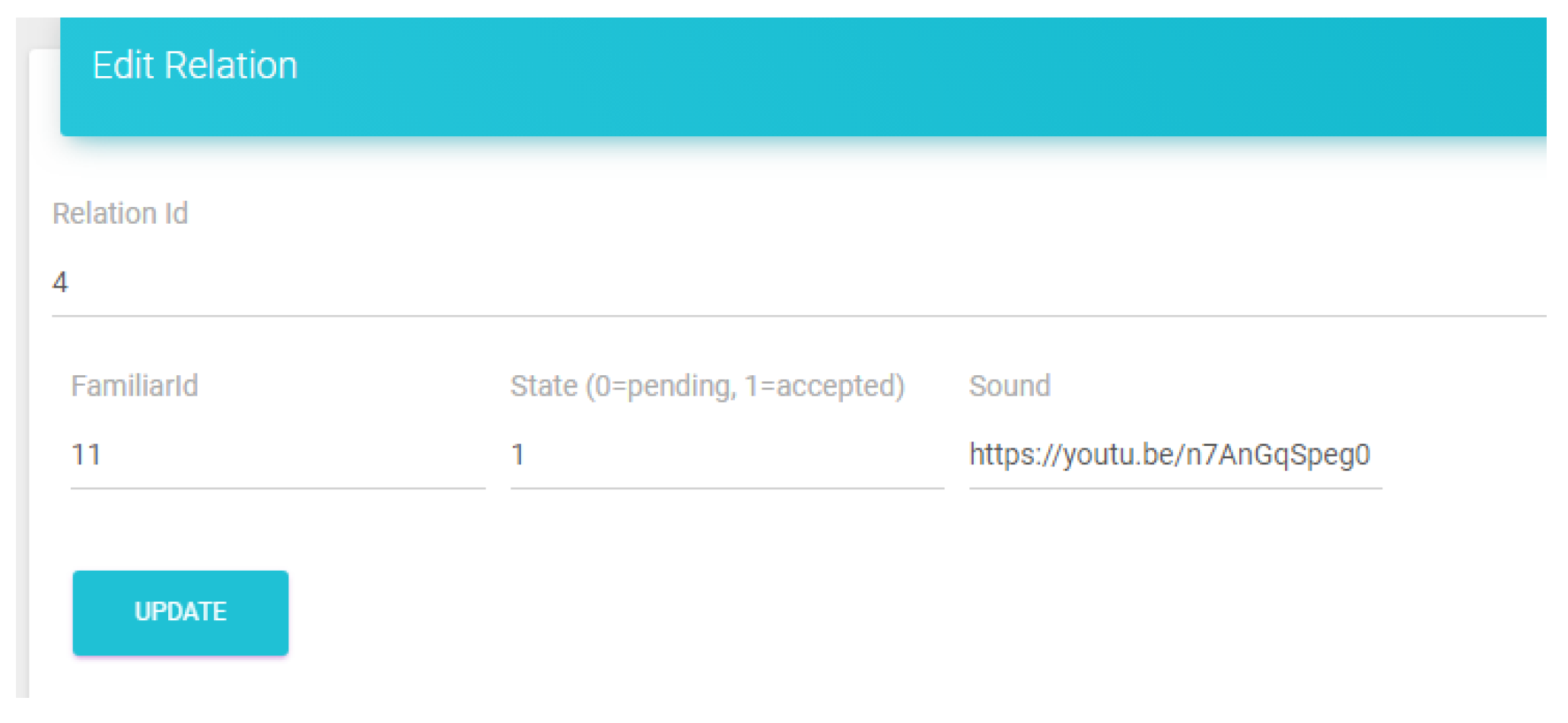
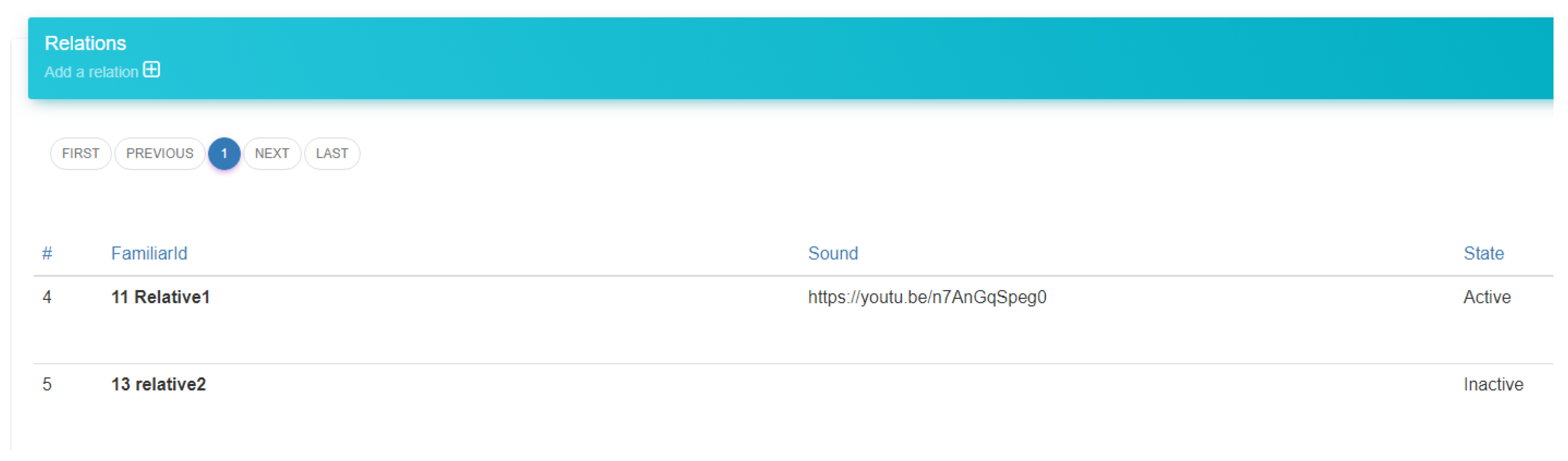
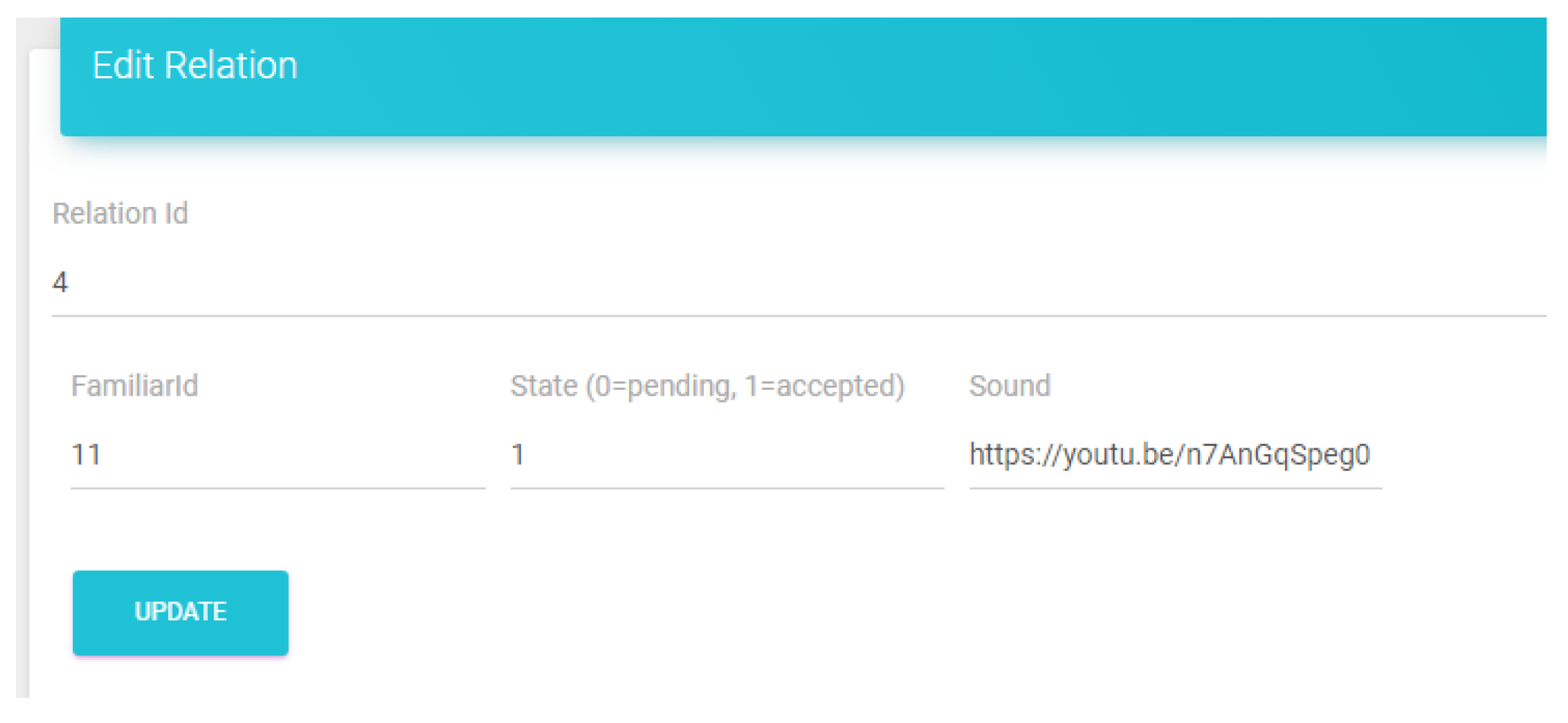
The server application was developed on Azure as a web service. The database schema was designed using MSSQL, and all the currently developed services/REST API were developed using PHP. All the users of the system (Sufferer, Familiar) had to register and get their unique ID’s. Therefore, there was a service designed to handle the administrator actions along with some views. In the following figures (
Figure 6 and
Figure 7) are the views of the administrator’s dashboard and the action to edit a correlation. Moreover, there are services to handle the actions of the speakers and the familiar. Those will be described in the following subsections.
5.2. Smart Home
In order to develop the prototype of a smart speaker, a Raspberry Pi 3 Model B+ was used, an open source hardware platform. As an Operating System (OS), Raspbian Stretch was used, and a Bluetooth server was developed using the Python programming language. Furthermore, a script was used as a Dynamic Domain Name System (DDNS), in order to keep the cloud services up to date regarding the connection. Upon the booting of the OS, the Bluetooth server is loaded, and a cron job executes a script every 24 h in order to update connection information to the cloud (the DDNS task).
The Bluetooth server accepts a connection from a familiar’s device, and it initiates the exchange of some messages as a custom handshake. After that, the familiar’s device will be recognized, and a message to the cloud REST API will be sent to retrieve the associated sound. During this process, the service on the cloud, before sending the sound URL, will notify that the smart speakers have to track the Sufferer’s position, in order to determine which speaker is the closest to him/her. In order to achieve tracking, a custom wearable device is on the sufferer (wearable device, suggested to be sewn into clothes), and by using a command at the OS level, the smart speaker can retrieve the Received-Signal-Strength-Indicator (RSSI) value (
Figure 8). After that, the speaker sends the RSSI value to the cloud, and another service is responsible for determining which speaker is the closest to the sufferer [
30]. Then, the URL of the correlated sound will be sent to that speaker only in order to start reproducing the sound.
The calculation of the RSSI is based on the general description of positioning and triangulation, as described in [
31]. The difference from the aforementioned work is that the system is interested only in the smart speaker closest to the sufferer. This means that there is no need for correlating three sources in order to position the beacon (hence the Sufferer’s ID device), but only identifying the smart speaker that detected the higher RSSI. This RSSI in turn corresponds to the shortest distance to the Sufferer. Based on research on positioning using Bluetooth 4.0, it appears that RSSI and the time-of-flight are the preferred methods to locate a Bluetooth beacon [
32,
33,
34].
When there is the need for the system to detect the sufferer, that is find the closest smart speaker, the following equation is utilized:
where
n and
A are known as Radio Frequency (RF) parameters to describe the network environment. The parameter
A is defined as the absolute energy, represented by dBm at a distance of one meter from the transmitter;
n is the signal transmission constant, and it is relevant to the signal transmission environment. Finally,
d is the distance from the transmitter node to the receiver node.
As may be observed from
Figure 8, each smart speaker returns a unique RSSI, corresponding to the power of the signal received by the Sufferer’s ID device. Then, these measures are submitted to the system, and after descending sorting, the smart speaker of the highest RSSI is selected as the closest to the Sufferer.
5.3. Mobile Application
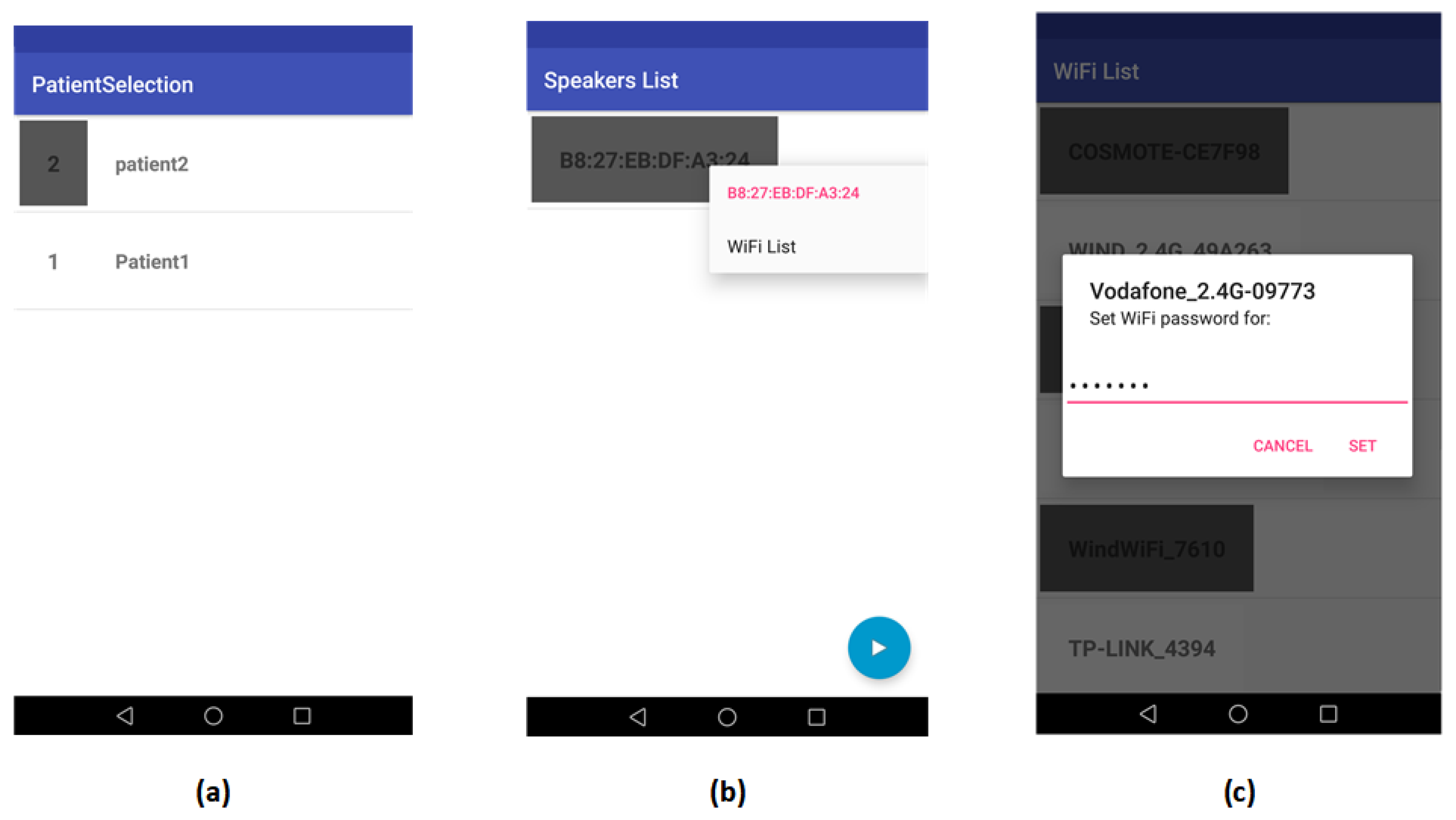
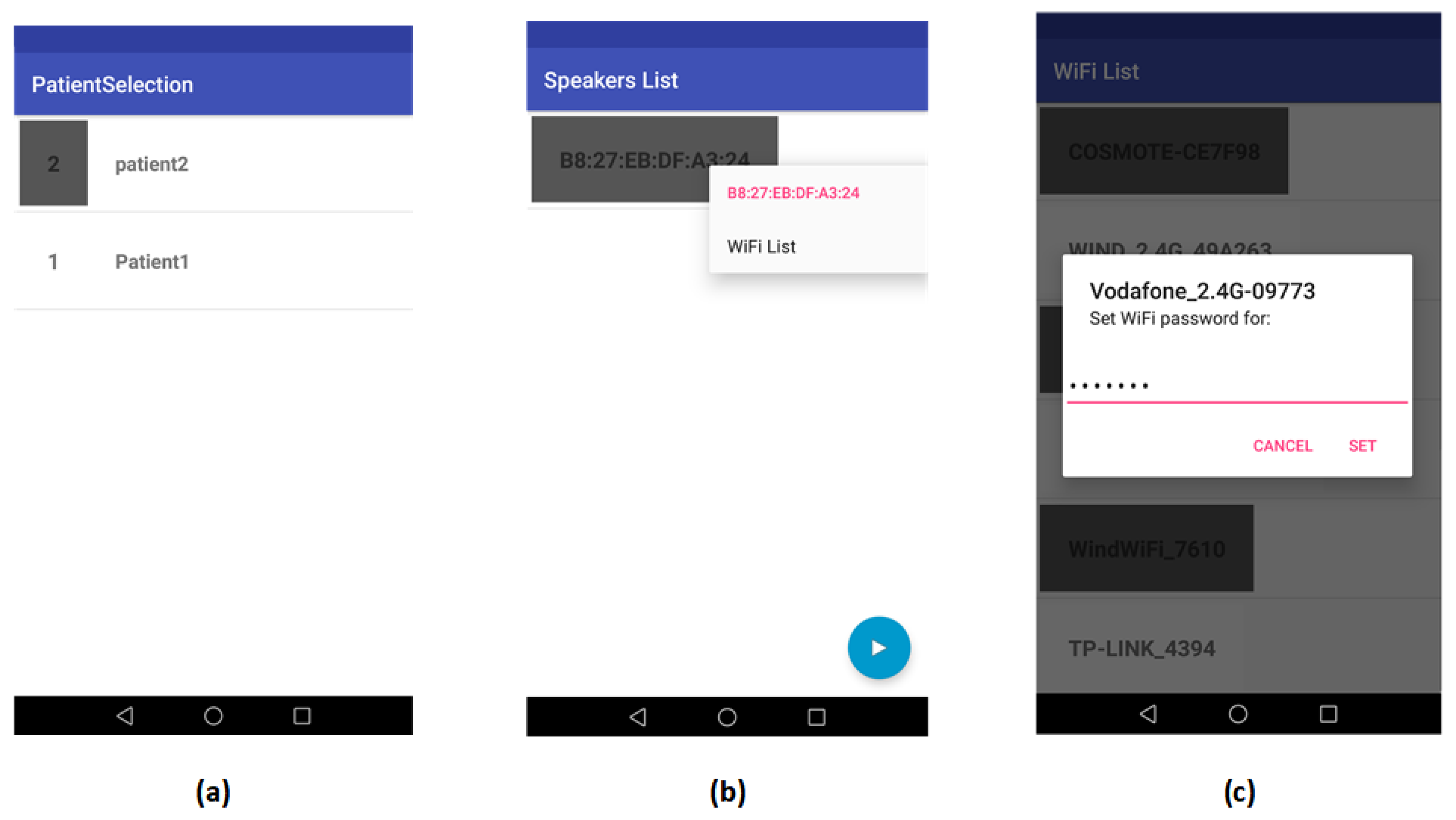
The smart phone application used by the familiar was developed using Android Studio targeting Android version Marshmallow (API Level 23) and above. The Android Studio was selected because it builds native applications for the Android platform, optimized for the targeted hardware platform. The user Familiar logs into the application, from which it is possible to select the sufferer with whom he/she will interact (it is not uncommon for relatives of sufferers to also suffer from dementia). The selection of the sufferer (
Figure 9a), fetches from the application the list of speakers (
Figure 9b) that have been registered by the Sufferer in the smart home. Management options for the smart speakers are included in the application. Finally, the Familiar may connect to the Wi-Fi home network (
Figure 9c) to access it directly with the cloud services.
When the Familiar enters the smart home, he/she taps the play button, and a request for sound reproduction is sent to the cloud service. At this point, the system requests from all speakers to report their relative position compared to the Sufferer. The RSSI of the Sufferer’s ID device is measured, and the highest value is selected. Since the higher value of all is expected to be reported by the closest speaker to the Sufferer, the Sufferer’s position is detected in relation to the closest speaker.
6. Results
The aim of this work was to exploit the findings of previous research works and propose an acoustic-based memory stimulus system for installation at the sufferer’s home. Thus, in this section, the functionality of the proposed system is tested and evaluated. The benefits of memory stimulation via sound is out of the scope of this work, since it has already been proven in other referenced works [
2,
3,
4,
5].
The proposed solution should be considered a novelty in the field of its application (acoustic-based memory stimulus at home), rather than in the field of its implementation. The aims of the proposed home system were: (1) the memory stimulus of the sufferer when a familiar gets closer, (2) the memory stimulus of the sufferer, when a familiar enters the house, while being in a private location, and (3) the in-house detection of the sufferer.
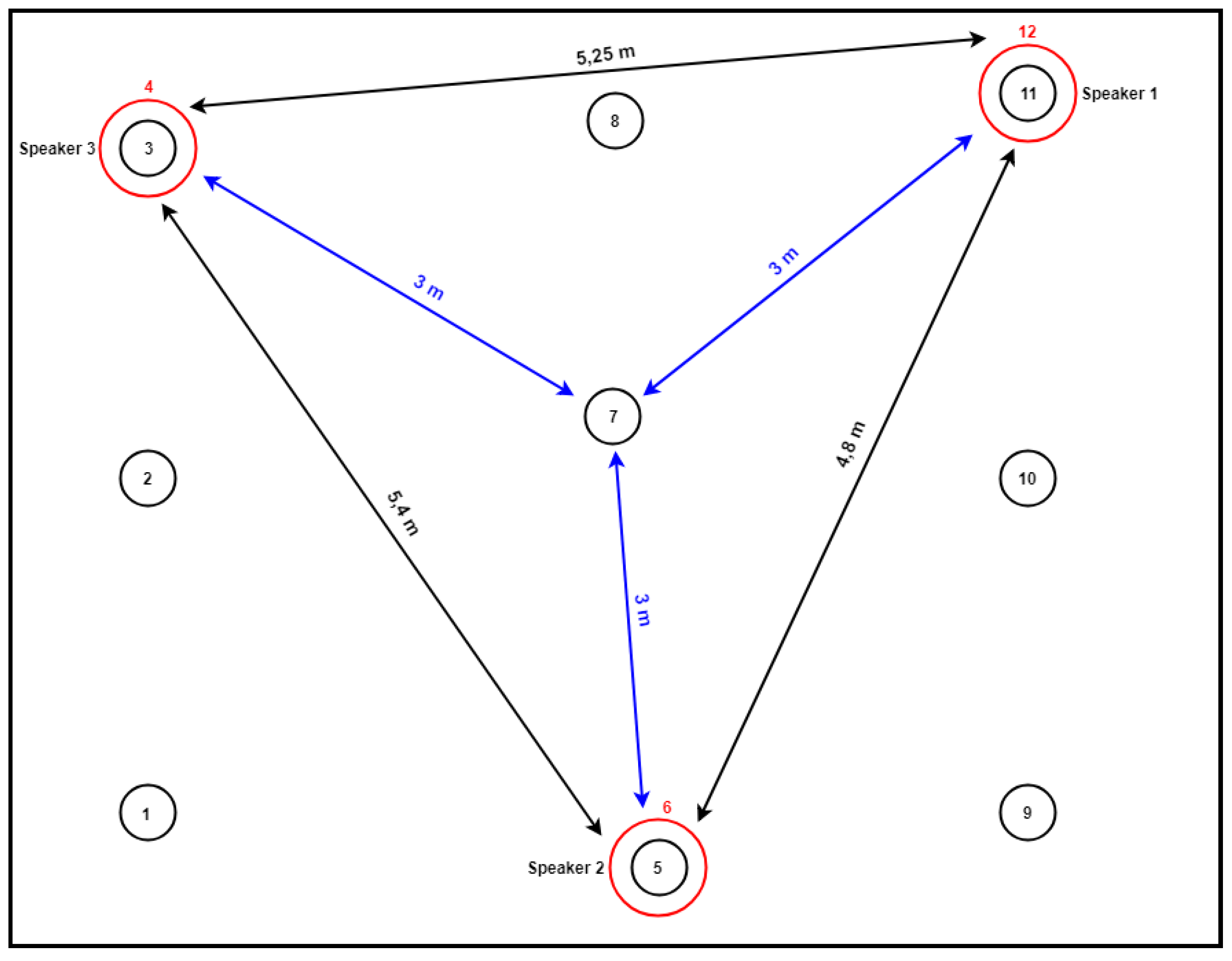
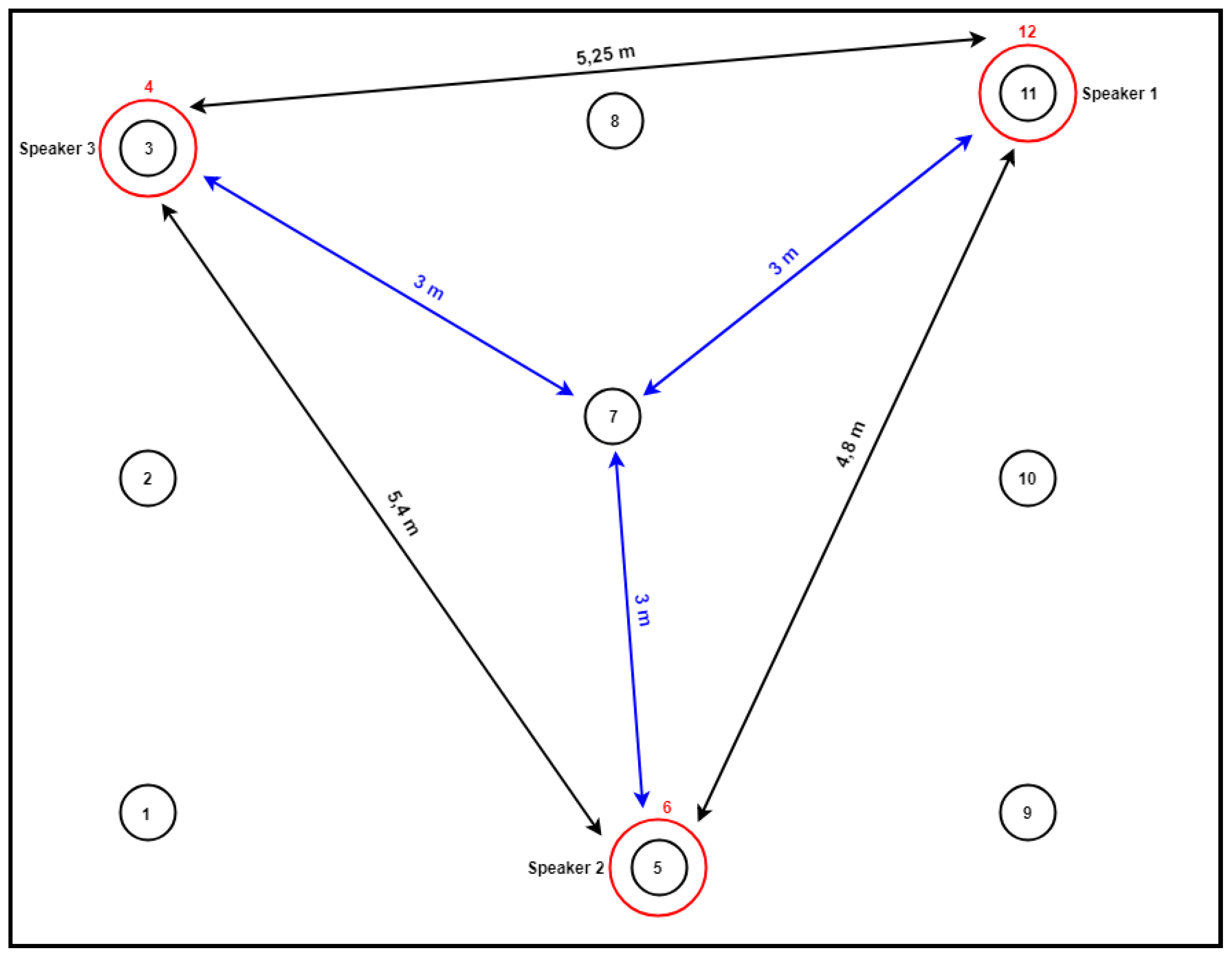
For the evaluation of the proper functionality of the system, experimental tests were carried out. The tests took place in a large, rectangular room, in which three smart speakers were placed, as seen in
Figure 10. The formation of the speakers as they were placed in the room could be linked to a scalene triangle, with the two vertices of the triangle corresponding to the two corners of one wall of the room and the third vertex in the middle of the opposite wall.
6.1. Set of Tests
For evaluation purposes, 24 different configurations were performed in total, specifically two sets of 12 configuration tests. Two Familiar users were considered, in order to evaluate the identification of the user in the room, and one Sufferer. The difference between the two sets of tests was the ID device that each Familiar carried with him/her. In both sets, and for reasons of fairness to the maturity of the technology, the ID device was a smartphone, with one device supporting Android Marshmallow (API Level 23) and the other one supporting Android Nougat (API Level 24). In both sets of configurations, the sufferer’s position in reference to the speakers’ position was almost the same. The number of configurations for test purposes was considered satisfactory. Examining the works reported in
Section 1 and
Section 2, for applications of sound as memory stimulus, it was observed that only a few works exist. In
Table 1, the previous works are reported (as referenced in [
35]). The number of participating persons was small, and in the cases that more than three people participated in the evaluation, training was required; thus, a larger sample size was necessary.
For categorization reasons, each set was associated with one and only Familiar. Furthermore, in the 12 test configurations that were performed, the position of the Sufferer was examined, regarding his/her proximity to one of the three smart speakers in the room. Additionally, the case of being between two smart speakers was considered.
6.2. Positioning of the Sufferer
When a request from the system is sent to the smart speakers to detect the position of the Sufferer, all of them try to detect the Bluetooth signal of the ID device of the Sufferer. The measure is the RSSI as reported by the Bluetooth module of the smart speaker. Based on Equation (
1), the higher the returned value from a speaker, the shorter the distance from the Sufferer.
To evaluate the monitoring process of the Sufferer in the room, 12 configuration tests were conducted (at each predefined point) in the room, as depicted in
Figure 10. As seen in
Table 2, positioning was successful for all tests. The reported values are the median value of the tests for each configuration.
In
Table 2, there is one more column at the end that corresponds to the results of the tests reported in the following subsection.
6.3. Reproduction of Sound by the Appropriate Speaker
Two sets of tests were considered for two different users. The scenario, of the evaluation, considered a Familiar entering the room and the activation of the system via his/her ID device. The evaluation’s scope was the reproduction of the correct sound, that is the one associated with the Familiar’s ID. In
Table 2 and
Table 3, the results for the two test sets are reported.
7. Discussion
The previous section had two major targets to evaluate: first, to check if identification of a Familiar is successful (that is correct reproduction of the associated sound/music per user) and, second, the successful detection of the sufferer. The latter proved to be the most difficult to achieve. In the rest of the paper, the results are discussed, and considerations are reported.
The results of the previous section show that the embedded application on the users’ devices managed to provide to the system the appropriate credentials, for identification reasons, that is the MAC address and the ID of the user. From the total number of tests, all were successful in reproducing the appropriate sound. The time interval from button press until the reproduction of the sound was measured as a few seconds, allowing the spontaneous reaction from the user in case of malfunction. Since correct functionality in 100% of the test cases was verified, no more actions were taken.
The most challenging part of the evaluation of the proposed system was the detection of the sufferer, since the sound was expected to be reproduced by the speaker closest to the sufferer. The process was relaxed and limited to the detection of the area around the Sufferer. The approach that was used was the direct exploitation of the RSSI values, as reported by the smart speakers when scanning for the Bluetooth signal of the Sufferer’s ID device. The previously-presented results of the conducted tests showed that the reported RSSI was sufficient as an indicator.
For comparison reasons, the proposed work is included in
Table 4, where other works are also reported. The works were examined for the following issues: (1) training (if there was the need for training the Sufferer or the Familiars), (2) home (system applicable for home use), (3) Familiars (the system considers the familiars and the caregivers as users), (4) developed (or just proposed), (5) evaluation (the system was evaluated in simulation), (6) test (the system was evaluated for functionality), (7) trial (system tested in real conditions), (8)–(10) stimulus (memory stimulus based on vision, audio, and haptic, respectively), (11) memory empower, (12) and ample size (Familiars and, in parenthesis, the sufferers). The comparison table shows that the proposed work is the only one that did not need training for the users; it is suitable for home use; it was developed and tested; it is based on audio; it empowers memory; and at the same time, it considers the Familiars as users. Notice that in most works that may be applied at home, the sample size was kept low mainly due to difficulty, which we also faced, in getting permission from familiars of the sufferer to install the system in their house.
Future research includes the design of a new series of smart speakers based on the developed prototype, allowing automatic and more precise communication with custom-made ID devices for the users. Especially in the case of the Sufferer, precision is an issue when he/she is found in the middle between two speakers. Thus, dynamic priority assignment should be considered in order to allow possible conflicts. Alternatively, a machine learning procedure is also considered as a solution to this problem. Furthermore, new methods to detect the Sufferer, such as the time-of-flight approach, should also be examined. Moreover, another contribution of this work, that has to be evaluated, was the development of a tool for professionals providing music therapy sessions. This tool may allow the increase of the music therapy sessions in time and its benefits.
Finally, for the future development of the proposed system, alternative configurations will be considered, such as those targeting higher performance and availability. A custom-designed gateway should be developed to meet the requirements (Wi-Fi and Bluetooth communications) of the proposed system in order to store data that are being used often and work as a cache layer between the cloud and the smart speakers. By using that gateway, we can significantly decrease the latency of the communication between the devices, reduce the processing time of data, and reduce the needs of a stable Internet connection.
8. Conclusions
In this paper, a novel solution for people suffering from Dementia was presented. The innovation of the proposed system is found in its application, to integrate a home system for assisting person recognition via auditory stimulation of the sufferer. Furthermore, the system addresses the need of people suffering from dementia to recognize their familiars and have better interaction and collaboration, without the need for training. The system offers a ubiquitous recognition system, using smart devices like smart-phones or smart-wristbands. When a familiar person is detected in the house, then a sound is reproduced on smart speakers, in order to stimulate the sufferer’s memory. The system identified all users and reproduced the appropriate sound in 100% of the cases.
The main challenge of the proposed solution was the inclusion of the system in a typical household without affecting the day-to-day living of the sufferer. This was achieved exploiting commonly-used technology in smart devices. The developed system is not visible to the sufferer, disguised as a typical speaker. The tests that were conducted prove the expected functionality. Exploring the recently-reported research works, it was observed that only a few of them considered sound as a memory stimulus. To the best of the authors’ knowledge, this is the first acoustic-based system of its kind for assisting person recognition for dementia sufferers.

 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}