Abstract
In smart logistics and intelligent manufacturing scenarios, the deployment of Autonomous Guided Vehicles (AGVs) necessitates vision systems that balance stringent real-time constraints with high detection accuracy. However, contemporary lightweight models often struggle with multi-scale feature representation and precision degradation. To address these challenges, this study presents LSOD-YOLO, a tailored evolution of YOLO11n designed for embedded AGV systems. Our methodology focuses on three architectural innovations: (1) we propose a Lightweight Shared Convolution Detection (LSCD) head integrated with Group Normalization (GN) and a scale-adaptive mechanism to harmonize multi-scale feature responses; (2) we re-engineer the backbone using a Star-Net architecture enhanced by Gated MLPs and Depthwise Attention to refine local spatial modeling; and (3) we integrate multi-branch residuals and Channel Attention (CAA) into the C3k2-Star-CAA module to enhance robustness against occlusions and complex backgrounds. The experimental validation on a self-built AGV industrial dataset and COCO128 reveals a compelling performance leap: a 30 FPS increase in throughput and a 1.5% gain in precision, all achieved with 32.8% fewer parameters. These findings confirm that LSOD-YOLO achieves a superior trade-off between computational efficiency and reliability, showing great potential for seamless deployment in resource-constrained AGV visual tasks.
1. Introduction
In recent years, the deployment of Autonomous Guided Vehicles (AGVs) in intelligent warehousing and industrial automation has expanded significantly. In key tasks including precise navigation, dynamic obstacle avoidance and environmental perception, vision-based object detection technology plays a core role. However, practical AGV deployment is frequently hindered by challenges such as dense small targets, high background complexity, and limited embedded hardware resources. Consequently, these constraints impede existing models from achieving an optimal trade-off between speed and accuracy during the lightweighting process [1,2].
While an Automated Guided Vehicle (AGV) integrates multiple functional layers, including navigation, path planning, and motion control, this research specifically focuses on the visual perception system. As the ‘eyes’ of the AGV, the vision-based object detection module serves as the fundamental layer that provides critical environmental information, enabling subsequent high-level decision making and obstacle avoidance tasks. In practical applications, AGV vision systems are typically hosted on embedded edge platforms such as NVIDIA Jetson modules or dedicated NPUs. These hardware solutions provide localized computing power but are constrained by their limited cooling capacity, strict power budgets, and finite memory bandwidth. Consequently, algorithm design must prioritize not only accuracy but also hardware-friendly operations, such as minimizing FLOPs and optimizing memory access patterns to ensure seamless integration into the AGV’s control loop. Deep learning-based object detection algorithms, especially Convolutional Neural Network (CNN) methods, have substantially advanced the development of AGVs’ visual perception. Two-stage detectors (such as the R-CNN series [3,4,5]) achieve high detection accuracy, while their computational cost often limits deployment in real-time embedded systems. For example, recent studies have further optimized these frameworks for complex industrial tasks; one such approach utilized a domain-adaptive Faster R-CNN to improve non-PPE identification on construction sites by bridging feature gaps between different imaging sources [6]. Beyond the YOLO lineage, other single-stage architectures such as SSD [7] and EfficientDet [8] have significantly contributed to edge-side detection. More recently, transformer-based models like RT-DETR [9] have demonstrated competitive performance by leveraging global context modeling. Additionally, the effectiveness of data augmentation has been evaluated for rebar counting tasks using UAV imagery across both Faster R-CNN and YOLOv10-based transformer architectures [10]. However, for AGV systems with strict power and memory constraints, the challenge remains to optimize these heavy computation mechanisms for real-time inference on edge chips. In contrast, single-stage detectors (such as YOLO [6,11,12,13] and SSD [7]) directly predict target categories and locations via a single forward pass, offering a superior equilibrium between speed and accuracy. Specifically, the YOLO series has become a benchmark in industrial visual inspection, owing to its robust efficiency in balancing real-time inference with detection precision. While prior works have tackled domain adaptation or aerial count-based tasks using high-capacity or transformer-oriented models, our proposed LSOD-YOLO specifically prioritizes architectural lightweighting to fulfill the extreme resource constraints of ground-level AGV perception.
To further improve the YOLO network, many studies have modified its backbone, neck and head modules. The goal is to enhance small target detection or reduce computational cost. Historically, YOLOv3 pioneered multi-scale prediction, surpassing contemporary two-stage models in real-time tasks [14]. Subsequently, YOLOv5 leveraged the CSPDarknet structure and Mosaic augmentation to achieve a refined balance between speed and accuracy [8]. YOLOv8 adopts an anchor-free design, lightweight backbone and efficient detection head. It greatly improves real-time inference on edge devices like Jetson [15]. Its modular structure can be directly exported to formats such as ONNX/TensorRT. This modularity significantly streamlines industrial deployment by supporting direct exports to formats like ONNX and TensorRT [16]. Other works have introduced lightweight modules or customized feature fusion strategies. For example, Cao et al. [17] proposed LH-YOLO, a lightweight and high-precision model based on YOLOv8n, designed for specialized detection tasks. These methods can better handle small traffic signs or resource-constrained platforms, such as YOLO-ADual [18] and LEF-YOLO [19]. In addition, there are approaches based on depthwise separable convolution, optimized loss functions or knowledge distillation [19,20,21,22]. Despite the inherent efficiency of the YOLO lineage, a gap remains for a systematic methodology that comprehensively optimizes feature representation and multi-scale detection through synergistic module design while strictly maintaining lightweight constraints. Such a method should comprehensively improve the model’s feature expression ability and multi-scale detection performance. Additionally, it needs to realize this goal through joint design and the optimization of multiple modules, while retaining the lightweight characteristics of the model.
To ensure stable input quality, the raw visual data undergoes an initial pre-processing stage, which involves standardized resizing to 640 × 640 pixels, pixel value normalization, and noise suppression. This ensures that the LSOD-YOLO model receives consistent feature input across varying lighting and industrial environments.
Based on this, this paper takes YOLO11n as the baseline architecture. Thus, aiming at three key challenges in AGV scenarios, it proposes the following improvement strategies:
- Development of an LSCD: This component utilizes a weight-sharing mechanism to minimize parameter redundancy. By incorporating a “Decoupled BatchNorm” strategy, the model effectively adapts to feature statistics across various scales [20]. These enhancements collectively boost small target sensitivity without adding computational overhead.
- Integration of Element-wise Multiplication into the Backbone: To strengthen semantic consistency, we implement a nonlinear interaction mechanism [21] that facilitates deeper feature fusion. This approach enhances the representation of medium- and low-resolution targets through refined spatial modeling.
- Design of the C3k2-Star-CAA Module: Building upon the C3k2 block, this integrated structure synergizes multi-branch residuals with CAA. By leveraging the Star Block’s nonlinear interactions and depthwise convolutions, the module captures intricate texture details and manages occlusions more effectively, ensuring robust perception in complex environments. The CAA module dynamically aggregates feature context information via the multi-head attention mechanism. It also combines the feed-forward neural network for channel recalibration. Therefore, without significantly increasing computational cost, it effectively strengthens the model’s ability to perceive small targets and edge information in complex scenarios.
The remainder of this paper is organized as follows: Section 2 details the proposed network architecture and individual components. Section 3 describes the experimental setup and datasets. Section 4 presents a comprehensive analysis of the results, including a comparative study with state-of-the-art algorithms. Finally, Section 5 concludes the paper.
2. Materials and Methods
This study adopts YOLO11n as the baseline architecture, tailoring it for the specific requirements of lightweight AGV object detection. The overall network structure is shown in Figure 1. YOLO11n adopts an enhanced backbone network (CSPDarknet53++) and it integrates a dynamic multi-scale feature fusion mechanism. Thus, it greatly enhances the feature modeling ability of the model. Its neck structure further combines Adaptive Anchor Clustering and Weighted FPN strategies. This architecture dynamically calibrates detection weights for diverse scales, thereby enhancing the recall and localization accuracy of small targets. In the design of the detection head, YOLO11n uses a decoupled structure. It models classification and regression tasks separately. In addition, it introduces a TAA to achieve dynamic label assignment. This method improves training efficiency and prediction quality.
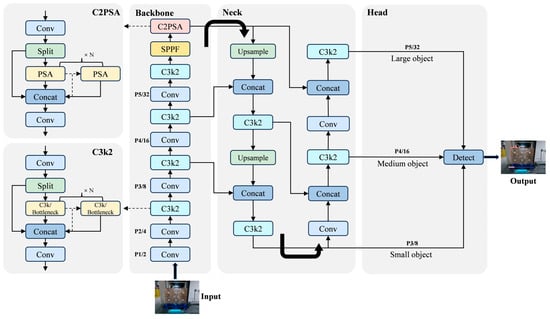
Figure 1.
Structural layout of YOLO11n.
2.1. Lightweight Backbone Network Based on StarNet
To minimize the parameter count and computational overhead while boosting feature representation, we integrate the StarNet + SPPF + C2PSA architecture as a substitute for the standard backbone. Thus, it replaces the traditional convolutional backbone network. StarNet is a lightweight feature extraction network that integrates convolution and Multilayer Perceptron (MLP) [23]. It achieves a superior equilibrium between representational capacity and inference throughput. Its network structure is shown in Figure 2, and the parameter configuration details are presented in Table 1.
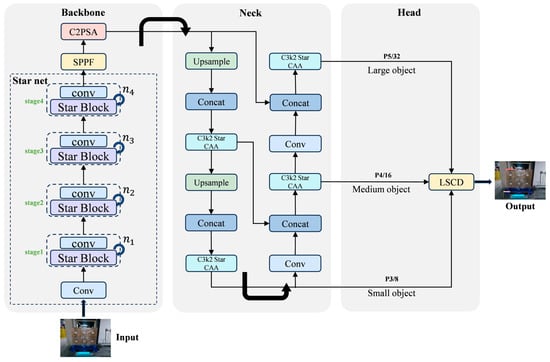
Figure 2.
Structural layout of LSOD-YOLO, in which C3k2-Star-CAA consists of Star Block and CAA modules, and LSCD denotes the lightweight detection head.

Table 1.
Depth setting list of Star Block module.
The backbone of StarNet consists of five stages: one input Stem layer and four cascaded layers from Stage 1 to Stage 4. The Stem layer is composed of a 3 × 3 convolution block and the ReLU6 activation function. It projects the three-channel RGB input into an initial feature space (base dim = 16) and performs the preliminary downsampling. Each stage first uses convolution with stride = 2 to finish the spatial downsampling and channel expansion. Then, it stacks multiple Star Block modules. The number of modules is set by the depth list (default is [1, 1, 3, 1]). Exhibiting a characteristic pyramidal hierarchy, this structure effectively captures multi-scale features, spanning from low-level spatial edges to high-level semantics.
The Star Block serves as the fundamental building unit of StarNet, incorporating ConvNext-style Depthwise Convolutions (DWConv), large-kernel receptive fields, and an MLP-based nonlinear path. Its structure is shown in Figure 3. Initially, a 7 × 7 depthwise convolution is employed for local context modeling, effectively broadening the module’s receptive field. Second, it designs a Gated Path composed of two 1 × 1 convolution branches. These branches serve as the nonlinear activation channel (f1) and linear modulation channel (f2) respectively. The two branches achieve selective feature enhancement through element-wise multiplication. An additional 1 × 1 convolution is then integrated to perform feature compression and dimensionality reduction. Finally, it introduces a residual connection mechanism based on DropPath. This mechanism further improves the training stability and generalization ability of the model.
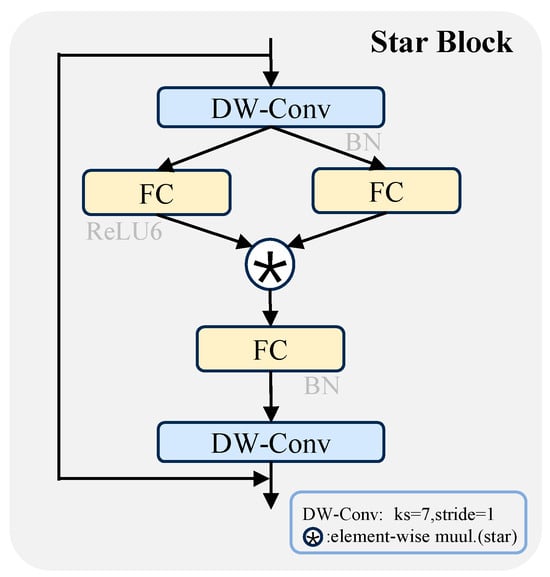
Figure 3.
Structural layout of the Star Block.
Star Block is shown in Figure 3. The element-wise multiplication mechanism employed in this module fundamentally constitutes a Star Operation, serving as a potent nonlinear alternative to conventional linear transformations. Inspired by the Kernel Trick, this mechanism projects features into a higher-dimensional nonlinear space, thereby significantly augmenting the model’s representational capacity. Specifically, the Star Operation facilitates feature interaction between a central pixel and its neighborhood along a “star-shaped path” (encompassing vertical, horizontal, and diagonal directions). By performing channel-wise multiplication, it constructs complex high-order relationships, which bolsters the model’s ability to model spatial structures and enhances the perception of small targets and fine-grained textures.
Furthermore, the Star Block offers distinct advantages in terms of computational efficiency. The primary convolutions utilize a DW structure, which effectively minimizes parameters and FLOPs, ensuring high-efficiency inference even when employing 7 × 7 large-kernel convolutions. Internally, the block integrates a dual-stage feature enhancement strategy: (i) a module-level residual connection to optimize the gradient backpropagation path and ensure training stability, and (ii) a gated fusion path to amplify the feature response within target regions. Star Operation calculation formula is as follows:
We combine weights and biases into one entity, and the result is obtained:
∗ denotes the element-wise multiplication operation. We expand the above formula, and the result is as follows:
In Equations (1)–(3), represents the augmented weight matrix formed by concatenating the weights and biases, while denotes the input feature vector augmented with a constant. Here, indicates the number of input channels, and and correspond to the -th and -th coefficients of the weights from two distinct linear branches, respectively. The symbol ∗ signifies the element-wise multiplication.
Regarding the optimization of Equation (3), the weights and are updated through standard end-to-end backpropagation. Since the Star Operation consists purely of differentiable linear transformations and element-wise multiplications, the gradients and can be efficiently computed via the chain rule. During the training phase, these parameters are iteratively optimized using the SGD optimizer to minimize the total loss function , which includes classification and bounding box regression losses.
In summary, the backbone network of StarNet achieves the robust modeling of multi-scale and complex targets, while retaining the lightweight features of the model. Furthermore, combined with the subsequent SPPF module (for multi-scale spatial fusion) and C2PSA attention mechanism, it further improves the detection performance of the model in complex industrial scenarios.
2.2. Design of C3k2-Star-CAA
In the original architecture, the neck is composed of the SPPF module and multiple C3k2 modules. Although the original C3k2 architecture facilitates flexible feature fusion, it still encounters two primary bottlenecks: first, it lacks sufficient capability to model long-range dependencies and complex geometric shapes; second, it lacks a context enhancement mechanism, making it difficult to adapt to target perception tasks in complex backgrounds.
For this reason, this paper proposes the improved module C3k2-Star-CAA. On the basis of inheriting the interface of the original C3k2 architecture, it completely replaces the bottleneck (Figure 4) with the Star Block CAA structure and introduces the CAA mechanism. The module adjusts its configuration dynamically based on the c3k parameter: when set to False, it corresponds to the lightweight version of C3k Star CAA (containing only a single Star Block CAA); when set to True, it adopts a stacked deep structure to enhance the multi-scale feature modeling capability (its structure is shown in detail in Figure 5, Figure 6 and Figure 7).
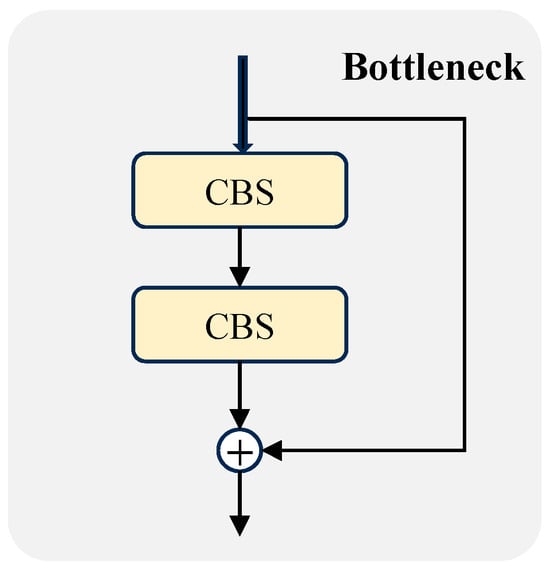
Figure 4.
Structural layout of the bottleneck, in which CBS consists of Conv, BN, and SiLU.
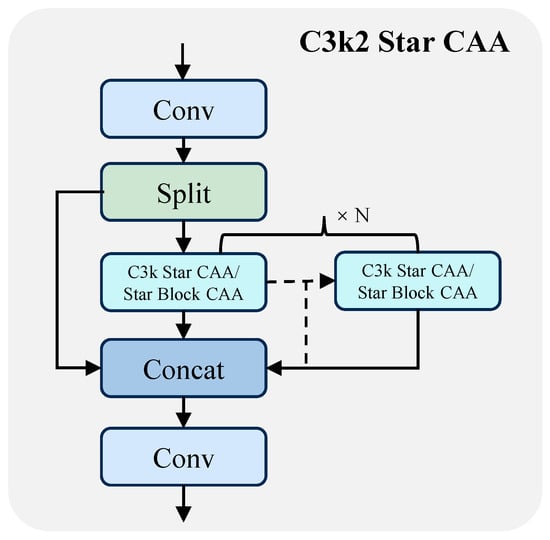
Figure 5.
Structural layout of C3k2-Star-CAA.
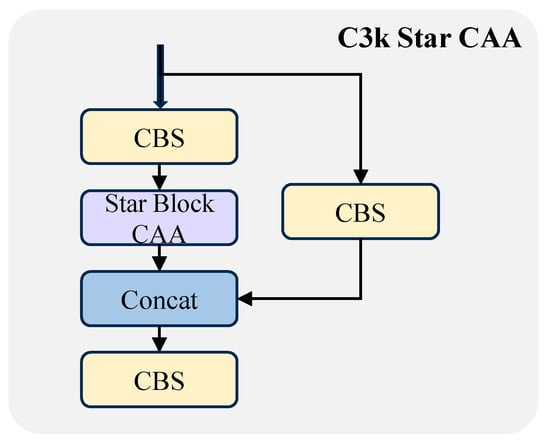
Figure 6.
Structural layout of C3k Star CAA.
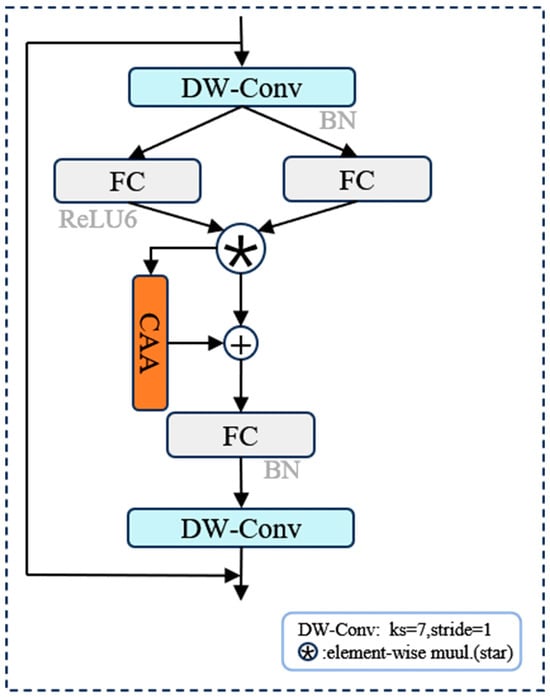
Figure 7.
Structural layout of the Star Block CAA.
The Star Block CAA is the core unit of this module, which integrates the lightweight gating structure of StarNet and the direction-aware attention mechanism. On the basis of the Star Block, it introduces the CAA module to explicitly regulate the channel and spatial dimensions. The CAA module suppresses background noise through 7 × 7 average pooling, models horizontal and vertical dependencies via Stripe Conv, generates an attention map that integrates spatial awareness and directional discriminability, and completes feature response modulation through convolution and Sigmoid activation (its structure is detailed in Figure 8).

Figure 8.
Structural layout of CAA, in which Conv GN consists of convolution and Group Normalization.
Compared with traditional attention mechanisms, CAA not only offers superior computational efficiency but also substantially augments target discriminability through directional modeling. This makes it particularly effective for industrial scenarios characterized by directional continuity and sparse spatial distribution. Furthermore, the attention module is embedded in the Star Block at the stage after gating and before convolution, allowing it to operate on unfused intermediate semantic representations, thereby facilitating more precise feature response modulation.
It is worth emphasizing that the C3k2-Star-CAA module is fully compatible with the original C3k2 interface and parameter configuration. It can directly replace the original module to be embedded into the backbone or detection head without modifying the overall network structure.
2.3. Detection Head Design
YOLO11n inherits the classic three-layer pyramid detection head structure (P3, P4, and P5) of the YOLO series. Each scale corresponds to small, medium, and large-sized objects respectively, with independent classification and regression branches tailored for each scale to ensure robust multi-scale detection.
However, directly deploying this structure on resource-constrained platforms such as AGV still faces many challenges: firstly, the independent nature of the convolution branches across the three scales leads to significant parameter redundancy; secondly, it fails to consider the representational differences across scales and lacks an effective scale-aware adjustment mechanism. Furthermore, using BatchNorm as the normalization method results in unstable training under small batch sizes, which significantly affects the reliability of model deployment.
To address the aforementioned issues, this paper designs a lightweight detection head named LSCD. By means of convolutional parameter sharing, scale-aware modeling and normalization enhancement strategies, LSCD attains a superior trade-off between accuracy, efficiency, and robustness. Its architecture is illustrated in Figure 9.
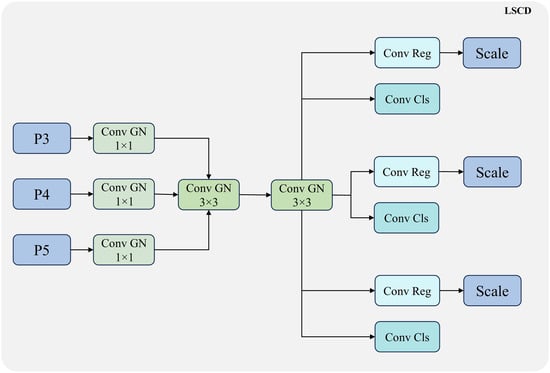
Figure 9.
Structural layout of LSCD, in which Conv Reg denotes the regression convolution module and Conv Cls denotes the classification convolution module.
2.3.1. Shared Convolutional Head Design
To address the parameter redundancy caused by the independence of the three-scale detection head, this study introduces a parameter-sharing convolutional structure, which significantly reduces model’s complexity while ensuring detection performance, and improves the consistency and generalization ability of multi-scale detection. Specifically, LSCD takes feature maps of three different scales (P3, P4, and P5) as inputs. First, the feature map of each scale undergoes channel compression and normalization through a set of independent convolution and GroupNorm layers. Then, these three groups of feature maps are concatenated together and fed into two shared 3 × 3 GroupNorm convolutional modules to extract cross-scale spatial features. This part serves as the core shared representation layer of the LSCD head, which not only reduces parameter redundancy but also enhances feature interaction across different scales, facilitating the improvement of collaborative modeling capability for both small and large objects within the same detection head [24].
After passing through the shared convolution module, the output features are fed into three scale-specific branches respectively. Each branch is composed of shared classification and regression sub-branches; that is, all scales share the same convolution weights for classification and regression, thereby further reducing the network size. The sharing mechanism not only improves the compactness of the detection head, but also enhances the capability of modeling scale-invariant features, enabling the model to achieve more stable performance in object detection tasks with a wide range of scale variations.
2.3.2. Scale-Aware Regulation
To enhance the adaptive modeling capability for objects across varying scales, this study incorporates a computationally efficient scale-aware regulation mechanism into the LSCD head. Specifically, a learnable scale layer is added at the end of each regression branch (Conv-Reg) to dynamically adjust the bounding box regression under different scales.
Based on the unified features extracted by the shared convolution module, LSCD maintains three output levels (P3, P4, and P5), tailored for small-, medium-, and large-scale targets, respectively. Each output layer is paired with an independent regression branch, and the end of each branch is equipped with a single-channel and trainable scale factor to perform scale-specific scaling adjustments on the regression coordinates.
Meanwhile, due to the significant differences in the target scale distribution processed by P3, P4, and P5, using a unified scale for prediction will lead to regression offset, error diffusion, and difficulty in training convergence. The scale layer enables each output level to autonomously modulate its response amplitude via these learned factors. This strategy alleviates regression offsets and error diffusion caused by scale distribution disparities, thereby better aligning with the position and size of the actual annotated bounding boxes and improving the accuracy and stability of bounding box regression. In summary, as an important component of the LSCD head, the scale-aware regulation module not only enables adaptive adjustment of multi-scale outputs, but also optimizes the long-standing problem of unstable regression in the anchor-free architecture, making it one of the cost-effective key improvements in lightweight object detection architectures [24].
2.3.3. Introduction of the Normalization Enhancement Strategy with GroupNorm
In most YOLO series models, Batch Normalization (BN) is widely adopted as the normalization layer [25,26], which relies on a relatively large batch size to estimate the mean and variance. However, in scenarios such as embedded deployment or edge devices, small batch sizes are often used due to computational resource constraints. This makes BN susceptible to biased statistical estimation, thereby compromising training stability and potentially impeding model convergence.
To address the aforementioned issues, this paper fully introduces the Group Normalization mechanism into the LSCD head [27] as an alternative to BN. Unlike BN, GN does not rely on batch size to calculate global statistics; instead, it performs mean and variance normalization based on channel grouping. It has good adaptability and is particularly suitable for scenarios such as small batch training, distributed training or inference. Studies have shown that GN can significantly improve the stability of small batch training and provide more consistent gradient propagation, which has also been widely validated in mainstream detectors such as FCOS, ATSS and GFL. Compared with BN, the feature normalization process of GN has a higher granularity control capability, which can better coordinate the distribution differences between features of different levels during multi-scale fusion, accelerate the convergence speed and improve the fusion effect.
Furthermore, since GN is independent of batch size, it can still maintain precise statistical consistency and feature stability in typical industrial deployments where the batch size is set to one during the inference phase, thus avoiding the prediction drift issue that may be caused by BN. For object detection systems deployed on AGV or other edge intelligent devices, GN significantly enhances the model’s generalization capability in scenarios with high concurrency and small sample inference. In conclusion, replacing the traditional BatchNorm with GroupNorm in the LSCD head not only addresses the normalization offset problem caused by small batch sizes, but also greatly improves the consistency of feature fusion and training stability, which serves as an indispensable key technical path for realizing lightweight detection architectures.
To further optimize the topological complexity, the proposed LSOD-YOLO employs a weight-sharing strategy in the LSCD head and Star Operations in the backbone. These architectural constraints streamline the network’s connectivity, effectively reducing parameter redundancy by 32.8% without sacrificing representational depth.
3. Experimental Setup
3.1. Dataset
To systematically evaluate the detection performance and practical deployment adaptability of the proposed LSOD-YOLO model in industrial scenarios, this paper conducts experimental verification on two datasets: the first is the self-constructed real-world industrial scenario dataset ZKLJ, which is used to test the actual performance of the model in AGV application scenarios; the second is COCO128, a publicly available standard dataset widely used in object detection research, which is employed for the comparative analysis of the model’s generality and transferability.
3.1.1. Self-Constructed AGV Industrial Detection Dataset
To meet the actual requirements of the Automated Guided Vehicle system in a “smart factory”, this paper constructed a target detection dataset dedicated to industrial scene perception, namely ZKLJ. This dataset covers three categories of typical dynamic obstacles: AGVs, on-site personnel, goods, and industrial forklifts. Image collection covers multiple key nodes and typical environments of the production line, including complex background occlusion, high-density multi-target scenarios, and image quality degradation conditions. To ensure data diversity and representativeness, the data collection lasted for three months, covering the entire production process. Finally, 914 original images were obtained through manual annotation, with the image size uniformly set to 640 × 640 × 3 (height × width × channels), and annotations formatted in the VOC standard. The category distribution ratio is as follows: on-site workers (33.2%), AGVs (20.1%), goods (24%), and forklifts (22.7%). To ensure the scientific validity of the dataset, we clarify the acquisition and partitioning details. Camera Setup: The images were captured using a monocular industrial camera (resolution of 1920 × 1080). Acquisition Environment: Targets were recorded at typical working distances ranging from 2 to 15 m. The lighting conditions encompassed both steady artificial fluorescent lighting within the workshop and highly variable natural light near docking bays, ensuring exposure diversity. Partitioning and Anti-Leakage Policy: The original 914 images were divided into training, validation, and testing sets according to a 7:1:2 ratio (specifically, 640 images for training, 91 for validation, and 183 for testing before augmentation). To prevent data leakage, we implemented a scene-based splitting policy: images belonging to the same continuous temporal sequence or the same physical workspace were strictly assigned to the same split. This ensures that the model is evaluated on entirely independent scene instances, rather than nearly identical adjacent frames of the training samples, thereby ensuring the reliability of the performance metrics.
To enhance the generalization capability of the model in complex environments, this paper designs a diversified data augmentation strategy, including Mosaic stitching augmentation, Cutout occlusion augmentation, geometric transformation augmentation, illumination and noise perturbation, and viewpoint spatial variation.
After data augmentation, the total size of the training dataset is expanded to 3622 images, which significantly enhances the robustness of the model in complex environments. To ensure the validity of the augmented data, we conducted a rigorous quality verification. The SSIM (Structural Similarity Index) was computed by comparing each augmented image against its corresponding original version to ensure that structural information and target silhouettes remained recognizable despite perturbations (e.g., noise or illumination changes). A mean SSIM of 0.85 indicates that the core spatial features were well-preserved. Regarding the F1-score for annotation consistency, we treated the original manual annotations as the “ground truth” and assessed whether the targets remained identifiable in the augmented samples through cross-verification. Specifically, a “positive” instance is defined as an augmented target that remains visually discriminable and correctly matched with its original label, while a “negative” instance refers to a case where extreme augmentation (e.g., excessive Cutout or noise) rendered the target unidentifiable, leading to an invalid label. An average F1-score of 0.92 confirms that the vast majority of augmented samples retained high-quality, consistent semantic information. Some sample examples are shown in Figure 10.

Figure 10.
ZKLJ dataset.
3.1.2. COCO128 Dataset
To verify the adaptability of LSOD-YOLO in general object detection tasks, this paper introduces the public standard dataset COCO128 for supplementary experiments. This dataset is selected from the MS COCO 2017 validation set (val2017), containing a total of 128 images and covering 80 common categories (such as humans, vehicles, furniture, animals, electrical appliances, etc.). It is a benchmark dataset widely used for lightweight model debugging and structure validation in the field of object detection.
Due to its moderate scale and rich categories, COCO128 is often used as a standard test set for model structure optimization, module ablation experiments, and inference efficiency evaluation [28]. In this study, COCO128 is mainly used for the comparative analysis of the transfer performance of LSOD-YOLO under different scenarios, to further verify its ability to maintain the balance between detection accuracy and inference speed under lightweight conditions, and to supplement the generality evaluation of the experimental results in industrial scenarios.
3.2. Experimental Environment
In this study, we adopt Ultralytics YOLO11n as the primary baseline and developmental framework. This implementation is selected due to its status as the current state-of-the-art in real-time lightweight object detection. While our proposed LSOD-YOLO utilizes the standardized training protocols of the Ultralytics environment, it represents a comprehensive structural evolution from standard YOLO variants (such as YOLOv8, v12, or v11). Specifically, we have re-engineered the standard architecture across three critical dimensions: (i) replacing the CSP-based backbone with a StarNet-inspired backbone for efficient high-order feature extraction; (ii) substituting standard bottlenecks with the C3k2-Star-CAA module to enhance multi-scale feature fusion and directional attention; and (iii) transforming independent decoupled heads into a shared-parameter LSCD head to minimize parameter redundancy. These systematic modifications ensure that LSOD-YOLO is uniquely optimized for the stringent constraints of AGV perception.
The proposed LSOD-YOLO model was implemented and evaluated within a software environment consisting of Python 3.9 and the PyTorch 2.0.1 deep learning framework. All experiments were conducted on a high-performance workstation running 64-bit Windows 11, equipped with an NVIDIA GeForce RTX 4070 Ti GPU (12 GB VRAM) (NVIDIA Corporation, Santa Clara, CA, USA). To ensure efficient hardware acceleration and reproducibility, we utilized CUDA 11.7 and cuDNN 8.6 for the training and inference processes. Our development involved extensive modular reconstruction and architectural customization built upon the Ultralytics YOLO11 codebase, ensuring seamless integration of the proposed StarNet backbone and LSCD head. Comprehensive specifications regarding the experimental environment are summarized in Table 2.
Table 2.
Model training environment.
To mitigate learning rate oscillation and ensure stable convergence during the training of lightweight models, we employed a linear warmup strategy for the initial three epochs, followed by a Cosine Annealing learning rate scheduler (without cyclic restarts). Importantly, to ensure a fair and rigorous benchmark across all comparative experiments, we maintained strictly identical hyperparameters and training protocols for LSOD-YOLO and all baseline models.
Specifically, all models were trained from scratch at a standardized input resolution of 640 × 640 pixels to eliminate the influence of disparate pre-training. We utilized the Stochastic Gradient Descent (SGD) optimizer with an initial learning rate of 0.01, a momentum coefficient of 0.937, and a weight decay of 0.0005. The training duration was set to 300 epochs for the ZKLJ industrial dataset and 500 epochs for the COCO128 dataset. By fixing these configurations, we ensured that the observed performance gains were purely attributable to our proposed architectural innovations rather than hyperparameter tuning.
Regarding the mathematical framework for training, the model is optimized by minimizing a composite loss function , which supervises the classification and regression tasks simultaneously. The objective function is defined as
where denotes the Binary Cross-Entropy loss, represents the Complete IoU (CIoU) loss, and is the Distribution Focal Loss. Model parameters are iteratively updated via backpropagation using the AdamW optimizer to achieve optimal convergence.
3.3. Evaluating Indicator
To comprehensively evaluate the performance of the proposed LSOD-YOLO object detection framework, this paper adopts a variety of evaluation metrics, including Precision, Recall, mAP, as well as the number of parameters, FLOPs and model size that measure model complexity. These metrics collectively assess the model’s detection performance, complexity, and deployment adaptability.
Precision refers to the proportion of true positives among the results predicted as positive by the model, which measures the model’s ability to suppress false detections. Its calculation formula is as follows:
Among these metrics, TP refers to the number of correctly detected targets, while FP refers to the number of negative samples incorrectly predicted as targets.
Recall measures the model’s ability to identify all actual targets, and its calculation formula is as follows:
Among these, FN refers to the number of positive samples that are missed in detection.
mAP is the most widely used comprehensive evaluation metric in the field of object detection. First, the AP is calculated for each category of targets—that is, the area under the Precision–Recall curve:
Then, the average value of AP across all categories is calculated to obtain the final mAP value:
mAP can not only comprehensively reflect the model’s overall detection capability across multiple categories, but also measure its stability under different confidence thresholds, thus serving as an effective indicator of the model’s overall performance.
The parameters and model’s size reflect the memory footprint and storage requirements of a model, which is particularly critical for applications deployed on edge devices such as AGVs. FLOPs represent the computational complexity of a model and are typically used to evaluate the computing resources required for model inference. The lower the FLOPs, the more lightweight the model and the more suitable it is for real-time applications.
In summary, these evaluation metrics have comprehensively evaluated the adaptability of the LSOD-YOLO detector in industrial lightweight environments from multiple dimensions, including accuracy, efficiency, and deployment friendliness.
4. Experimental Results and Discussion
4.1. Comparative Experiments
To rigorously assess the performance of LSOD-YOLO in AGV-centric detection tasks, this paper selects several mainstream detection models as comparison baselines and conducts a systematic experimental analysis. Detailed specifications for these benchmark models are provided in Table 3.
Table 3.
Information on different models.
All experiments were performed on the curated industrial dataset at a resolution of 608 × 608. Notably, all models were trained from scratch without the use of pre-trained weights to ensure an unbiased comparison of their respective architectural learning capacities. The training convergence and loss trajectories for each model are visualized in Figure 11 and Figure 12, while the comprehensive performance metrics are summarized in Table 4.
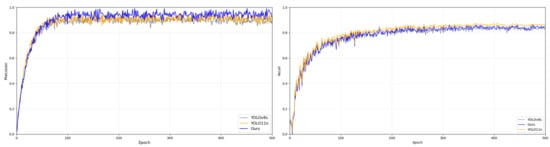
Figure 11.
Training processes of three models on the ZKLJ dataset.
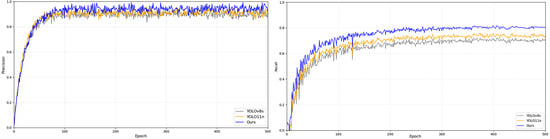
Figure 12.
Training processes of three models on the COCO dataset.
Table 4.
Performance of different models on the ZKLJ dataset.
Figure 11 and Figure 12 illustrate the validation performance (Precision and Recall) recorded at the end of each training epoch. Although the metrics for LSOD-YOLO begin to stabilize around 200 epochs on the ZKLJ dataset and 300 epochs on COCO, we opted for a full 300/500 epoch schedule to ensure that the complex attention mechanisms (C3k2-Star-CAA) and the shared convolutional weights in the LSCD head achieved absolute convergence. This extended training duration also allowed us to verify the model’s stability and confirm the absence of significant overfitting in the later stages of the lightweight architecture’s development.
As indicated in Table 4, the proposed LSOD-YOLO model consistently outperforms the baseline architecture across pivotal metrics, including Precision, Recall, and mAP, underscoring its superior capability in both target localization and classification. Meanwhile, lightweight optimization has been incorporated into the structural design of this model, leading to a 32.8% reduction in the number of parameters compared with the original model, which significantly enhances the deployment flexibility of the model. More importantly, its FLOPs have also dropped substantially, with a decrease of 31.7% relative to the original model, making it achieve the lowest computational overhead among all comparison models.
The substantial performance gains of LSOD-YOLO can be ascribed to three key architectural factors: primarily, the adoption of the lightweight StarNet as the backbone facilitates high-efficiency feature extraction; concurrently, the proposed LSCD head effectively harmonizes detection precision with inference throughput by leveraging convolutional weight sharing and scale-aware modeling, which further minimizes the model’s parameter footprint. Furthermore, the integration of the C3k2-Star-CAA module enables the seamless fusion of multi-scale features, thereby mitigating computational redundancy without compromising detection fidelity.
While conventional lightweighting strategies typically rely on established off-the-shelf backbones for feature extraction, this study evaluated the impact of three alternative architectures within the YOLO11n framework. These were used to benchmark the efficacy of our proposed LSOD-YOLO scheme. The detailed experimental comparisons are summarized in Table 5.
Table 5.
Performance of different models on the COCO128 dataset.
As shown in Table 5, the proposed LSOD-YOLO model outperforms the other three methods in the three metrics of Precision, Recall, and mAP, while maintaining the most compact parameter profile. This decisive advantage stems from the architectural synergy between the StarNet backbone, the C3k2-Star-CAA module, and the LSCD head. Together, these components facilitate robust feature extraction of AGVs while simultaneously curtailing computational overhead and improving overall detection fidelity.
Specifically, StarNet exhibits superior parameter efficiency due to its refined convolutional topology and optimized feature extraction pathways. Its core unit, the Star Block, leverages DWConv to minimize complexity while augmenting nonlinear interactions. This design not only enhances multi-scale perceptual sensitivity but also fortifies the model’s capacity to capture complex semantics and structural continuity.
In contrast, although adopting MobileNet and ShuffleNet as feature extraction networks can reduce the number of parameters and computational overhead to a certain extent, their AGV feature extraction capability is limited, leading to a significant decline in detection accuracy in complex scenarios. This is because the design of these lightweight networks sacrifices part of the feature extraction capability, making it difficult for them to capture details in complex environments. The LSOD-YOLO model maintains high detection accuracy while keeping the computational complexity low. Our model addresses the common accuracy degradation problem of lightweight models through the efficient feature extraction mechanism of StarNet and the effective integration of Star Block and DWConv.
Furthermore, qualitative evaluations were conducted in complex traffic scenarios to assess the model’s real-world robustness, with the results presented in Figure 13. As shown in Figure 13, the proposed model achieves high detection accuracy and exhibits fewer false detections and missed detections even in complex scenarios such as dense target scenes or low-light conditions. This superior performance is mainly attributed to three key aspects: the multi-scale modeling capability of the StarNet backbone, the attention enhancement mechanism of C3k2-Star-CAA, and the efficiency-optimized design of the LSCD head, which jointly and effectively boost the overall detection accuracy.

Figure 13.
Experimental results on complex engineering scenes. (a) Represents normal scenes, (b) represents dense scenes, and (c) represents low-light scenes.
4.2. Ablation Experiments
To quantify the individual contributions of each proposed component to the overall efficacy of LSOD-YOLO, we conducted a systematic ablation study. The analysis systematically disentangles the impact of three core architectural innovations: the StarNet-based lightweight backbone, the C3k2-Star-CAA feature fusion module, and the LSCD shared convolutional detection head. To ensure the integrity of the comparison, all the model variants were trained using identical hyperparameters and dataset configurations. The performance metrics, including Precision, Recall, and mAP@0.5, are detailed in Table 6 and Table 7.
Table 6.
Results of different lightweight models. YOLOv5s_MN indicates the utilization of MobileNet as the feature extraction network, while YOLOv5s_SN represents the adoption of ShuffleNet as the feature extraction network, and YOLOv5s_GH represents the adoption of GhostNet as the feature extraction network.
Table 7.
Ablation experiments on three modules of LSOD-YOLO, including backbone, C3k2-Star-CAA, and LSCD. LSOD-YOLO 1, 2, and 3 correspond to the models with the missing backbone, C3k2-Star-CAA, and LSCD, respectively.
4.2.1. StarNet Backbone Network
To validate the efficacy of the proposed lightweight backbone, the original YOLOv11 backbone was replaced with the StarNet + SPPF + C2PSA architecture in a series of comparative experiments. Quantitative results indicate that reverting to the baseline backbone leads to a decline in mAP@0.5 and Precision by approximately 1.4% and 1.1%, respectively. Simultaneously, the parameter count and computational overhead (FLOPs) increase by roughly 33% and 32%, while the inference speed decreases by 18%.These findings demonstrate that StarNet effectively captures multi-scale semantic features while maintaining minimal computational complexity, significantly bolstering the model’s representational capacity for small and occluded targets in complex industrial environments, such as AGV operating zones. Furthermore, the integration of large-kernel depthwise convolutions and the gated MLP channel mechanism within StarNet facilitates enhanced multi-scale feature expression, thereby achieving superior inference efficiency for embedded AGV applications.
4.2.2. C3k2-Star-CAA Feature Fusion Module
To assess the specific contribution of the C3k2-Star-CAA module to the model’s overall efficacy, we conducted a comparative analysis by substituting this component with the baseline C3k2 structure of the original YOLO11n.
The quantitative results indicate that the omission of the CAA mechanism precipitates a decline in Precision and Recall by approximately 2.1% and 2.2%, respectively, that its mAP@0.5 dropped by about 2.1%, and that the inference speed was reduced by 27%. These findings underscore that the C3k2-Star-CAA module, by harnessing the Star Block structure and the CAA mechanism, effectively captures horizontal and vertical directional dependencies during feature fusion. Especially in industrial scenarios with directional continuity and sparse spatial distribution (e.g., factory passages and robotic arm areas), it can significantly enhance the discriminative ability and stability of detection. The experiments demonstrate that the introduction of CAA effectively mitigates the information suppression bottleneck common in traditional attention mechanisms, enabling the model to maintain high precision and robust performance even in complex, small-target-dense scenarios.
4.2.3. Lightweight Shared Convolutional Detection Head
To verify the impact of the detection head design on model performance, a comparative experiment was conducted by replacing the improved LSCD head with the original detection head structure of YOLO11n. The experimental results show that after removing the LSCD, the model’s Precision and Recall decreased by approximately 2.7% and 2.3% respectively, its mAP@0.5 dropped by about 2.3%, and the frame rate saw an increase. The LSCD head significantly reduces redundant computations while maintaining detection accuracy through its parameter-shared convolutional structure and scale-aware regulation mechanism. In particular, the introduced Group Normalization mechanism replaces the traditional BatchNorm, which addresses the normalization shift problem under small batch training and enables the model to maintain stable inference on edge devices. In addition, the synergistic effect of Group Normalization and the shared convolutional layers improves the consistency of multi-scale features and enhances the detection head’s capability for the collaborative modeling of small and large targets. Overall, the LSCD significantly optimizes the model’s lightweight design and inference efficiency while ensuring high detection performance, making it a key module for enabling embedded deployment.
To further clarify the design logic and the specific impact of each architectural innovation, we provide a structured mapping in Table 8. The mapping results in the incremental experiments reveal an intriguing synergistic effect. While individual lightweight modifications—such as replacing the backbone with StarNet or implementing the LSCD head—initially lead to a marginal decline in mAP compared to the baseline YOLO11n due to reduced model capacity, the integration of our proposed modules progressively recovers and eventually surpasses the baseline performance. Specifically, the C3k2-Star-CAA module acts as the critical compensator, leveraging directional attention to reclaim the accuracy lost during aggressive lightweighting. This confirms that LSOD-YOLO is not merely a collection of isolated improvements, but a cohesive architecture where each component is specifically tuned to balance representational depth with extreme computational efficiency.
Table 8.
Performance evaluation of individual architectural enhancements integrated with the baseline YOLO11n.
5. Conclusions
To address the stringent requirements for both detection precision and real-time responsiveness in AGV vision systems, this study presents LSOD-YOLO, a lightweight framework derived from YOLO11n. The architecture synergistically integrates a StarNet-based backbone, the C3k2-Star-CAA feature fusion module, and the LSCD shared convolutional detection head. It greatly reduces the model’s complexity and computational load while ensuring detection accuracy, making it particularly suitable for resource-constrained industrial embedded deployment environments. The experimental results show that LSOD-YOLO achieves excellent lightweight performance and real-time performance while guaranteeing high detection accuracy. Compared to the baseline YOLO11n, the proposed model achieves a 32.8% reduction in parameters and a 31.7% decrease in computational load, while boosting inference throughput to 217 FPS and maintaining an mAP@0.5 of 93.1%. Furthermore, the model exhibits exceptional resilience and generalization in complex environments, such as those characterized by occlusions and adverse lighting. In conclusion, LSOD-YOLO provides an optimal trade-off between representational capacity and real-time efficiency, offering a scalable and robust object detection solution for intelligent manufacturing, automated warehousing, and the broader evolution of unmanned factories.
Author Contributions
S.C.: writing—review and editing, supervision, project administration, and funding acquisition. Z.W.: writing—original draft, validation, software, methodology, and conceptualization. K.L.: validation and data curation. T.Z.: visualization, validation, and data curation. W.W.: validation. X.Z.: validation. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Ningde City Major Technical Requirement Project with “Open Bidding for Selecting the Best Candidates” (Grant No. ND2024J008); the Scientific Research Start-Up Fund Project entitled “Research on Multimodal Medical Image Segmentation Technology” (Grant No. GY-Z220291); the Education and Teaching Reform Project entitled “Innovation and Practice of an Open EDA Engineering Training Teaching System Combined with the Jinhua Integrated Circuit Radiation Area” (Grant No. SJ2017008); and the Graduate Education and Teaching Reform Project entitled “Exploration of an Industry–Education Integrated Six-Dimensional Training Model for Outstanding Talents in Electrical Engineering” (Grant No. YJG23006).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data will be made available on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wei, Z.; Zou, Y.; Xu, H.; Wang, S. Small Object Detection in Traffic Scenes for Mobile Robots: Challenges, Strategies, and Future Directions. Electronics 2025, 14, 2614. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Wang, S. Domain-adaptive faster R-CNN for non-PPE identification on construction sites from body-worn and general images. Sci. Rep. 2026, 16, 4793. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Yang, Y.; Gao, X.; Wang, Y.; Song, S. VAMYOLOX: An accurate and efficient object detection algorithm based on visual attention mechanism for UAV optical sensors. IEEE Sens. J. 2022, 22, 22901–22909. [Google Scholar] [CrossRef]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs Beat YOLOs on Real-time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 16965–16974. [Google Scholar] [CrossRef]
- Wang, S. Effectiveness of traditional augmentation methods for rebar counting using UAV imagery with Faster R-CNN and YOLOv10-based transformer architectures. Sci. Rep. 2025, 15, 33702. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Tang, X.; Deng, H.; Liu, G.; Li, G.; Li, Q. FR-YOLOv7: Feature enhanced YOLOv7 for rotated small object detection in aerial images. Meas. Sci. Technol. 2024, 35, 105404. [Google Scholar] [CrossRef]
- Terven, J.; Córdova-Esparza, D.-M.; Romero-González, J.-A. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Fang, S.; Chen, C.; Li, Z.; Zhou, M.; Wei, R. YOLO-ADual: A Lightweight Traffic Sign Detection Model for a Mobile Driving System. World Electr. Veh. J. 2024, 15, 323. [Google Scholar] [CrossRef]
- Cao, Q.; Chen, H.; Wang, S.; Wang, Y.; Fu, H.; Chen, Z.; Liang, F. LH-YOLO: A Lightweight and High-Precision SAR Ship Detection Model Based on the Improved YOLOv8n. Remote Sens. 2024, 16, 4340. [Google Scholar] [CrossRef]
- Qiu, J.; Zhang, W.; Xu, S.; Zhou, H. DP-YOLO: A Lightweight Traffic Sign Detection Model for Small Object Detection. Digit. Signal Process. 2025, 165, 105311. [Google Scholar] [CrossRef]
- Li, J.; Tang, H.; Li, X.; Dou, H.; Li, R. LEF-YOLO: A Lightweight Method for Intelligent Detection of Four Extreme Wild-fires Based on the YOLO Framework. Int. J. Wildland Fire 2023, 33, WF23044. [Google Scholar] [CrossRef]
- Tang, Q.; Su, C.; Tian, Y.; Zhao, S.; Yang, K.; Hao, W.; Feng, X.; Xie, M. YOLO-SS: Optimizing YOLO for Enhanced Small Object Detection in Remote Sensing Imagery. J. Supercomput. 2025, 81, 303. [Google Scholar] [CrossRef]
- Li, R.; Chen, Y.; Wang, Y.; Sun, C. YOLO-TSF: A Small Traffic Sign Detection Algorithm for Foggy Road Scenes. Electronics 2024, 13, 3744. [Google Scholar] [CrossRef]
- Zhao, L.; Wei, Z.; Li, Y.; Jin, J.; Li, X. SEDG-YOLOv5: A Lightweight Traffic Sign Detection Model Based on Knowledge Distillation. Electronics 2023, 12, 305. [Google Scholar] [CrossRef]
- Ma, X.; Dai, X.; Bai, Y.; Wang, Y.; Fu, Y. Rewrite the Stars: The Evolution of StarNet for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 29 October–1 November 2019; pp. 9627–9636. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar] [CrossRef]
- Wu, Y.; He, K. Group Normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Lecture Notes in Computer Science; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; Volume 8693. [Google Scholar] [CrossRef]













Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.