A Comprehensive Review of Adversarial Attacks and Defense Strategies in Deep Neural Networks

 ,
,  and
and
Abstract
1. Introduction
1.1. Motivation and Contribution
- We provide an extensive study of the state-of-the-art adversarial attack and defense method on all ML tasks based on DNN that leads researchers to understand the DNNs security for various tasks ML tasks, i.e., classification, regression, policy learning.
- We provide a precise formulation for both attacker and defender problems; thus, it is easy for readers with limited DNNs security knowledge to understand.
- We provide a systematic and comprehensive review of the measures used to evaluate the success of attack or defense methods. Thus, it is accessible for researchers who want to research DNN security to know the mechanisms for evaluating the success of an attack or defense of DNNs.
- We identify and discuss various open issues and potential future research directions for DNN security. This research field aims to explore new methods to secure DNN models.
1.2. Paper Organization
2. Related Work
2.1. Theoretical Researches
2.2. Specialized Domain
2.3. Topics Under Investigation
3. Background
3.1. Attacks and Defence Methods
3.1.1. Gradient Descent
3.1.2. Distance Metric
3.2. Neural Network
3.2.1. ANNs
3.2.2. DNN
3.2.3. Convolutional Neural Network (CNN)
3.2.4. RNNs
3.3. Training Algorithms Learning
3.3.1. Backpropagation
3.3.2. Self-Organization Map
3.3.3. Autoencoder
3.4. Search Optimization Methods
3.4.1. Iterative Methods
3.4.2. Heuristic Methods
3.4.3. Greedy Methods
3.4.4. Metaheuristic Methods
3.5. ML Approaches
3.5.1. Supervised
3.5.2. Unsupervised
3.5.3. RL
3.6. Adversarial ML Cycle
4. Threat Model
4.1. Adversarial Degree of Knowledge
4.1.1. White Box
4.1.2. Black Box
4.1.3. Grey Box
4.2. Adversarial Attack Scenarios
4.2.1. Attacks During Training Phase
- Data injection and modification: The attacker intentionally incorporates malicious samples into the training dataset or alters existing data points in a harmful way. These detrimental examples may be produced using the label noise method [85]. Once the training dataset is compromised, the resulting DNN model produces erroneous outputs [86].
- Logical corruption: The adversary disrupts the learning process of the DNN model, hindering its ability to learn accurately.
4.2.2. Attacks During Testing Phase
- Evasion attack: The adversary attempts to infiltrate the specific model by creating a harmful input sample that the ML model incorrectly categorizes. Most of the proposed adversarial works have incorporated this type of attack [88].
- Exploratory attack: During testing, the adversary gathers data about the learning system to gain insight into its model’s internal details or training data by creating adversarial samples, similar to side-channel attacks.
- Limited Dataset Size: the attacker needs more resources to gather public information, resulting in a relatively small dataset size.
- Out-of-Distribution DeepFake: the attacker can only gather fake images produced by certain DeepFake techniques, so not all types of DeepFakes will be in the auxiliary dataset.
5. Attack Goal and Strategies
5.1. Attack Goal
5.1.1. Classification Task
- Untargeted Misclassification: The adversary aims to raise the DNN model’s misclassification rate by feeding it adversarial examples from an untargeted adversarial attack that results in inaccurate classification. Simply put, the attacker attempts to make the model classify adversarial examples incorrectly.
- Source/Target Misclassification: Engaging in targeted adversarial attacks can achieve this objective. By adding a trigger to a specified target label, the victim DNN model system will be misled in classifying the correct label, called a target attack.
5.1.2. Confidence Reduction
5.1.3. Policy Learning Task
5.1.4. Representation Learning Task
5.1.5. Generate Synthetic Data Task
5.2. Attack Strategies
5.2.1. White-Box Attack
- Elastic-Net Attacks to DNNs (EADs): The research introduces EAD regularization, which combines the penalty functions L1 and L2, to the optimization problem of finding the minimal perturbation in an image that causes a DNN to misclassify it as a target class [91]. It shows that EAD can generalize and craft L1-oriented, more effective adversarial examples focusing on targeted attacks. It demonstrates that EAD can achieve similar or better attack performance than C&W and other breaking undefended and defensively distilled DNNs. EAD creates adversarial samples employing the iterative shrinkage-thresholding algorithm [92].
- Targeted Universal Adversarial Perturbations: This research proposed a simple iterative method to generate universal adversarial perturbations (UAPs) for image classification tasks. By integrating the straightforward iterative approach for producing non-targeted universal adversarial perturbations with the fast gradient sign method to create targeted adversarial perturbations for a given input, UAPs are imperceptible perturbations that can cause DNN to misclassify most input images into a specific target class. The results demonstrate that the technique can produce almost imperceptible UAPs that achieve high ASR for known and unknown images [93].
- Brendel and Bethge Attack: Divide the image into regions based on estimated boundaries and use for the similarity distance and the iterative algorithm to enhance the perturbation value additively; the attack calculates the best step by solving a quadratic trust-region optimization problem in each iteration. This attack improves the performance of generating adversarial examples [94].
- Shadow Attack: The attack imposes more constraints on the standard problem, which shows an effective success rate for a set of datasets. By applying a range of penalties, shadow attacks for constraints promote the imperceptibility of the resulting perturbation to the human eye by limiting the perturbation size [95].
- White-Box Bit-Flip-Based Weight Attack: The authors propose an attack paradigm that modifies the weight bits of a DNN in the deployment stage [96]. They suggested a general formula with elements to meet efficiency and covert objectives and a limitation on bit-flip quantity. They also presented two cases of the general formulation with different perturbation purposes: a single-sample attack aims to misclassify a specific sample into a target class by flipping a few bits in the memory, and a triggered samples attack aims to misclassify the samples embedded with a particular trigger by flipping a few bits and learning the trigger. They utilized the alternating-direction method of the multipliers method to solve the optimization problems and demonstrated the superiority of their methods in attacking DNNs.
- Adversarial Distribution Searching-Driven Attack (ADSAttack): Wang et al. [97] proposed the ADSAttack; this technique generates adversarial examples by exploring adversarial distributions in unsupervised hidden learning. The technique trains an autoencoder to capture the underlying features of the input data, then identifies the distribution that minimizes the classification error of the target DNN and ultimately generates adversarial instances based on this distribution using the decoder. The algorithm can produce adversarial examples that are more diverse and effective than the existing ones and can be transferred to other models and defense mechanisms. The algorithm may also have potential applications in the security, privacy, and robustness of DNNs.
- Targeted Bit-Flip Adversarial Weight Attack (T-BFA): T-BFA is a novel method for attacking DNNs by altering a small number of weight bits stored in computer memory. The paper proposed three types of T-BFA attacks: N-to-1 attack, which forces all inputs from N source classes to one target class; 1-to-1 attack, which misclassifies inputs from one source class to one target class; and 1-to-1 stealth attack, which achieves the same objective as 1-to-1 attack while preserving the accuracy of other classes. The paper also shows the practical feasibility of T-BFA attacks in a real computer system by exploiting existing memory fault injection techniques, such as the row-hammer attack, to flip the identified vulnerable weight bits in dynamic random access memory (DRAM). The paper discusses the limitations and challenges of T-BFA attacks, such as the dependency on the bit-flip profile, the trade-off between attack stealthiness and strength, and the resistance of some defense techniques, such as weight quantization, binarization, and clustering [98].
- Invisible Adversarial Attack: Wang et al. [99] introduced the invisible adversarial attack, an adaptive method that uses the human vision system (HVS) to create realistic adversarial scenarios. The technique comprises two categories of adaptive attacks: coarse-grained and fine-grained. The first attack introduces a spatial constraint on the perturbations, which only adds perturbations to the cluttered regions in an image in areas where the human visual system has reduced sensitivity. The fine-grained attack uses a novel metric called just noticeable distortion, which measures each pixel’s noticeable distortion (JND) to better simulate the HVS perceptual redundancy and set pixel-wise penalty policies for the perturbations. The algorithm can be applied to adversarial attack methods that manipulate pixel values, like FGSM [14], Basic Iterative Method (BIM) [100], and C&W [17].
- Type I Adversarial Attack: Tang et al. [101] introduced a new method to create Type I adversarial examples, where the appearance of an input image is significantly changed while maintaining the original classification predictions. Utilizing an existing understanding of the Gaussian distribution, incorporating label data into the latent space allows identifying features. In this latent space, they challenge the classifier by modifying the latent variables through a gradient descent approach. This approach utilizes a decoder to propagate forward, converting the revised latent variables into images. Additionally, a discriminator was incorporated to assess the distribution of the manifold within the latent space, facilitating the successful execution of a Type I attack. The method has successfully produced adversarial images that resemble the target images but are still classified as the original labels.
- Generative Adversarial Attack (GAA): He et al. [102] proposed the GAA, a novel Type I attack method that uses a generative adversarial network (GAN) to exploit the distribution mapping from the source domain of multiple classes to the target domain of a single class. The GAA algorithm operates under the assumption that DL models are susceptible to similar features, which means that examples with different appearances may exhibit similar features in the resulting feature space of the model. This algorithm aims to generate adversarial examples that closely resemble the target domain while evoking the original predictions of the target model. GAA updates the GAN generator and the discriminator during each iteration using a custom loss function comprising three terms: adversarial loss, feature loss, and latent loss. The adversarial loss aims to deceive the discriminator with the generated instances, the feature loss maintains the similarity between the original and created features, and the latent loss adjusts the latent vector to diversify the generated examples. GAA has generated adversarial images that resemble the target images.
- Average Gradient-Based Adversarial Attack: This attack was proposed by Zhang et al. [103], which utilizes the gradients of the loss function to create a dynamic set of adversarial examples. Unlike existing gradient-based adversarial attacks, which only use the gradient of the current example, the average gradient-based adversarial attack aims for higher success rates and better transferability.In each iteration, this algorithm generates a dynamic set of adversarial examples using the gradients of the previous iterations. Then, it calculates the average gradient of the loss function concerning the dynamic set and the current example. The average gradient determines the perturbations added to the original example.Compared to its competitors, the average gradient-based adversarial attack has produced more effective and diverse adversarial examples and has outperformed them on various datasets and models. Overall, it has proven to be a practical and robust method for evaluating the robustness of DNNs.
- Enhanced Ensemble of Identical Independent Evaluators (EIIEs) Method: The enhanced EIIE approach, introduced by Zhang et al. [104] built on the EIIE topology by incorporating details on the top bids and requests for portfolio management. The primary concept of the EIIE topology involves a neural network that assesses the potential growth of each asset in the portfolio based on the asset’s data. The enhanced EIIE method enhances the EIIE topology by introducing two additional inputs: the best bid price and the best ask price for each asset. These inputs provide precise market information to assist the network in making optimal decisions regarding portfolio allocation. The EIIE approach has shown the vulnerability of an RL agent in portfolio management. An attack could collapse the trading strategy, creating an opportunity for the attacker to profit.
- Transformed Gradient (TG) Method: A white-box approach generates adversarial perturbations by modifying the gradient of the loss function using a predefined kernel. The transfer gradient (TG) technique aims to reduce the susceptibility of adversarial instances to specific areas of the target model and improve their ability to be transferred to other models. This approach is compatible with any gradient-based attack method, such as FGSM or PGD. TG can generate adversarial instances that are more easily transferred to other models than baseline approaches, especially when targeting defense models. The TG technique is an efficient method to improve the transferability of adversarial cases [105].
5.2.2. Black-Box Attack
- Square Attack: This is a black-box adversarial attack that operates in both and norms, and it does not depend on local gradient information, making it resistant to gradient masking. This attack utilizes a random search methodology, a classic iterative optimization approach proposed by Rastrigin in 1963 [107]. In particular, the results obtained from a square attack can provide more accurate assessments of the robustness of models that exhibit gradient masking compared to traditional white-box attacks [108].
- One-Pixel Attack: Begin by selecting an image point and applying a permutation to generate a set of modifications for this point. Next, utilize a differential evolution optimization algorithm to choose solutions that meet the target. Modified pixels should have more dimensions in common with another set of dimensions [109].
- Multilabel Adversarial Examples—Differential Evolution (MLAE-DE): Jiang et al. [110] introduced the MLAE-DE approach. It is an iterative method that uses differential evolution (DE) methodology to create multilabel adversarial instances capable of deceiving DNNs is a popular population-based optimization algorithm. It involves misclassifying input from one or more source classes into a target class using a modified DNN model. This approach provided a breakthrough in DE by reducing the required fitness assessments and enhancing attack performance. MLAE-DE is a black-box approach that generates adversarial instances using only model outputs without accessing model parameters. It effectively creates adversarial images that resemble the target images while eliciting the original prediction of the targeted model. MLAE-DE has proven to be a valuable and efficient technique for generating multiple adversarial examples on large-picture datasets.
- Black-box Attack Method Based on Successor Representation: Cai et al. [111] introduced the SR-CRPA attack, a black-box strategy that manipulates rewards in the environment to train deep RL agents. The developers of the SR-CRPA method assumed that the adversary has access to the state, action, and reward information of both the agent and the environment. This approach involves using a pre-trained neural network to learn each state’s SR, which indicates the anticipated future visitation frequency of the states. At each time step, SR-CRPA uses the SR value of the current-state action combination to determine whether to initiate an attack and how to subtly perturb the reward. With just a few attacks, SR-CRPA prevents the agent from acquiring the optimal policy. In general, SR-CRPA is a discrete and effective algorithm to poison the rewards of the target agent.
- Dual-Stage Network Erosion (DSNE): Duan et al. [112] introduced the DSNE attack as a black-box approach that uses DSNE to modify the source model and create adversarial samples. The DSNE method assumes that the adversary has access to the internal components of the source model but not to the target model. This technique involves modifying the original model’s features to generate various virtual models combined by a longitudinal ensemble across iterations. DSNE biases the output of each residual block towards the skip connection in residual networks to reveal more transferable information. This results in enhanced transferability of adversarial cases with comparable computational expense. The results of the DSNE attack indicate that DNN structures are still vulnerable and network security can be improved through improved structural design.
- Serial Minigroup Ensemble Attack (SMGEA: The SMGEA attack, developed by Z et al. [113], is a transfer-based black-box technique designed to generate adversarial examples targeting a set of source models and then transferring them to various target models. The method assumes that the attacker can access multiple pre-trained white-box source models, excluding the target models. Divides the source models into multiple “minigroups” and uses three new ensemble techniques to improve transferability within each group. SMGEA employs a recursive approach to gather “long-term” gradient memories from the minigroup before and transfer them to the following minigroup. This procedure helps maintain acquired adversarial information and enhance intergroup transfer.
- CMA-ES-Based Adversarial Attack on Black-Box DNNs: Kuang et al. [114] presented a black-box method called a CMA-ES-based adversarial attack. This method creates adversarial samples for image classification using the CMA-ES. The attacker only has access to the input and output of the DNN model, the top K labels, and their confidence. The CMA-ES attack uses a Gaussian distribution to model variations in adversarial scenarios. It modifies the average and variation in the distribution according to the sample’s quality. The attack generates altered images in every iteration, picking the most successful ones to modify the distribution.
- Subspace Activation Evolution Strategy (SA-ES): Li et al. [115] introduced the SA-ES algorithm, a method to create adversarial samples for DNNs using a zeroth-order optimization method. This method assumes that the opponent can only request the model’s softmax probability value for the input through queries without being able to access the model directly. The SA-ES algorithm uses a subspace activation technique and a block-inactivation technique to detect sensitive regions in the input image that could alter the model output. In every iteration, SA-ES uses an organic evolutionary method to modify the distribution parameters of perturbations towards the optimal direction. SA-ES can efficiently find high-quality adversarial examples with a limited number of queries. This algorithm is a reliable and effective approach for focusing on the model in both digital and physical settings.
- Adversarial Attributes: In a study, Wei and colleagues [116] proposed the adversarial attributes attack. This method creates harmful examples for image classifiers by changing the semantic characteristics of the input image. The technique employs a preexisting attribute predictor to analyze the visual characteristics of each image, such as hair color. The adversarial attribute attack detects the most impactful attributes in every round and merges them with the original image to generate the perturbation.Adversarial attribute attacks can obtain a high success rate and remain undetected with only a few queries by using evolutionary computation to solve a constrained optimization problem.
- Artificial Bee Colony Attack (ABCAttack): Cao et al. [117] presented an artificial bee colony (ABC) attack, which creates adversarial examples for image classifiers using the ABC algorithm. The ABC attack assumes that the attacker can only request the softmax probability value of the model input without being able to access the model itself. ABC attack produces a set of modified images during each iteration and chooses the best ones to adjust the spread. It can accurately determine the most effective changes that cause the target model to incorrectly classify input images while staying within a set query limit. ABC attack is a method that has demonstrated effectiveness in fooling black-box image classifiers while being efficient and resistant to queries.
- Sample Based Fast Adversarial Attack Method: Wang et al. [118] introduced the sample-based fast adversarial attack method. This technique generates adversarial examples for image classifiers using data samples in a black-box approach. The technique assumes that the opponent can only obtain data samples, not the model parameters or gradients. Principal component analysis is used to identify the main differences between categories and calculate the discrepancy vector. Creating a target adversarial sample with minor adjustments involves performing a bisection line search along the vector that connects the current class to the target class.
- Attack on Attention (AoA): Chen et al. [119] developed the AoA attack, a black-box technique that generates adversarial examples for DNNs by manipulating the attention heatmaps of the input images. This attack assumes that the attacker can only request the model’s softmax probability value for the input without accessing the model itself. The approach utilizes a pre-trained attention predictor to learn attention heatmaps for each image, demonstrating the areas on which the model focuses. AoA modifies the attention heatmaps in each iteration by adding or subtracting pixels to create the perturbation.
5.2.3. Poisoning Attack
- Feature Collection Attack: Feature collision attacks occur within the framework of targeted data poisoning. The aim is to modify the training dataset so that the model incorrectly classifies a specific target, from the test set, into the base class. Techniques for feature collision in targeted data poisoning focus on adjusting training images from the base class to shift their representations in feature space closer to that of the target [124].
- Label Flipping: Label-flipping attacks involve changing the assigned labels during training, but keeping the data unchanged. Although not considered a “clean label”, these attacks do not leave easily detectable artifacts that the target could recognize [125].
- Influence Functions: Researchers can use influence functions to evaluate how a slight modification in training data impacts the model parameters learned during training. This can help to create poisoning examples and then be used to approximate solutions to the bilevel formulation of poisoning [126].
- TensorClog: In their work, Shen et al. [127] introduced the TensorClog attack, which is known as a black box attack, which involves inserting perturbations into the input data of DNNs to reduce their effectiveness and protect user privacy. The TensorClog attack assumes that the attacker can access a substantial amount of user data but not the model parameters or gradients. The approach uses a pre-trained frequency predictor to analyze the frequency domain of each input, capturing its spectral features. TensorClog modifies the frequency domain of the input by adding or subtracting pixels on each iteration to create the perturbation. The attack can effectively identify perturbations that cause the target model to converge to a higher loss and reduced accuracy using fewer queries. TensorClog is a covert and efficient technique used to corrupt the input data of DNNs.
- Text Classification: In their work, Zhang et al. [128] presented a method for identifying vulnerabilities in NLP models with limited information. They discovered the existence of universal attack triggers. Their approach consists of two stages. First, they extract harmful terms from the adversarial sample to create the knowledge base in a black-box scenario. In the second phase, universal attack triggers are created by altering the predicted outcomes for a set of samples. Incorporating the generated trigger into any clean input can significantly decrease the prediction accuracy of the NLP model, potentially bringing it down to nearly zero.
5.2.4. Extraction Attacks
6. Defense Strategies
6.1. Proactive Approach
6.1.1. Modifications to the ANN
- Gradient Regularization: Training DNNs can be challenging, as they tend to penalize even the most minor deviations in the inputs. The relative entropy between the labels and predictions may become negligible with slight input changes. That a small perturbation would probably change the output of a trained classifier [133].
- DeepCloak: DeepCloak aims to eliminate redundant features that a malicious party could exploit to create adversarial samples. Before the classification layer, the authors suggest incorporating a masking layer in the DNN model. This mask layer learns by processing pristine and altered images in a forward pass, capturing the variances in the output of earlier layers. DeepCloak filters out unnecessary features by setting them to 0, effectively removing them from adversarial examples [134].
- Deep Contractive Networks: Researchers developed denoising autoencoders (DAEs) to address adversarial noise. They train a DAE to identify and eliminate such noise. However, when they pair the DAE with the original network, the stacked network becomes more vulnerable to attacks than the original model. However, when paired with the original network, the stacked network becomes more vulnerable to attacks than the original model. Deep contractive networks (DCNs) were presented by Gu and Rigazio, which incorporate a smoothness penalty similar to that of contractive autoencoders, a type of autoencoder with an additional minimization penalty. DCNs improve the resilience of the network to adversarial attacks while maintaining performance levels [135].
6.1.2. Additions to the ANN
- Defense against UAP: UAPs reveal a significant vulnerability in the security of ML models. Akhtar et al. propose a strategy to defend against UAPs by incorporating a perturbation rectifying network (PRN) as an initial layer in the targeted model, avoiding modifying it. The PRN detects disturbed images entering the network and reconfigures them to ensure that they are classified with the same label as the original image. Researchers train the PRN using datasets that include authentic and synthetic UAPs while keeping the model parameters unchanged. They also train a perturbation detector on the cosine transform of the differences between the PRN’s inputs and outputs [136].
- MagNet: Meng and Chen proposed MagNet to defend neural network classifiers against adversarial attacks. Magnet uses distinct detector and reformer networks to identify whether incoming input images are adversarial. Researchers construct detector networks using either a reconstruction error or probability divergence. During training, they estimate the range of clean inputs and distinguish between clean and perturbed images. In testing, the system identifies and removes images that deviate from the manifold as adversarial. Reformer networks, employing random noise or an autoencoder, guide adversarial images with slight perturbations back toward the unperturbed image space, ensuring accurate classification. MagNet effectively defends against black-box and gray-box attacks, as it applies to various attacks without depending on a specific perturbation generation method [137].
6.1.3. Modifications to the Training
6.1.4. Input Transformations
6.1.5. Defense Against Poisoning Attacks
6.2. Reactive Approach
6.2.1. Adversarial Detecting
6.2.2. Detection Based on Activation Analysis
6.2.3. Input Reconstruction
6.2.4. Network Verification
6.2.5. Traceback Poison Data
6.3. Challenges of Defenses on DNNs in Real-World Systems
6.4. Discussion
7. Experimental Setup and Performance Metrics
7.1. Datasets
7.1.1. MNIS and F-MNIST
7.1.2. CIFAR-10
7.1.3. ImageNet and ILSVRC
7.1.4. CelebA
7.1.5. Street View House Numbers (SVHNs)
7.1.6. IMDB
7.1.7. SST-2 (Stanford Sentiment Treebank)
7.1.8. ASVSpoof
7.1.9. Fake or Real
7.1.10. ADD2023
7.1.11. In-The Wild (ItW)
7.1.12. Taiwan Stock Exchange (TWSE)
7.1.13. Freeway
7.1.14. Ember Malware
7.1.15. STL-10
7.2. Neural Network Architectures
7.2.1. ResNet-50
7.2.2. VGG-16
7.2.3. GoogleNet (InceptionV1)
7.2.4. MobileNet-V2
7.2.5. DenseNet121
7.2.6. LSTM (BiLSTM)
7.2.7. BERT
7.2.8. PuVAE Model
7.3. Performance Metrics
7.3.1. Rate-Based
- Success Rate: Attack success rate (ASR) or success rate refers to the proportion of adversarial examples that succeed within the specified attack budget [182].
- Average Success Rate (AvSR): The AvSR is a key metric for assessing the performance of continual learning methods. Measures the ratio of successful results across multiple experiments or trials, offering insights into how well a model adapts to changing tasks and data while preserving accuracy and stability. Let be the ASR of task after training on all N tasks [183]. The continual objective of imitation learning is to maximize the AvSR across all tasks:
- Target Fooling Rate (TFR): The equation defines the event’s occurrence rate, with a higher rate indicating that the classifier is more easily fooled [184].In targeted attacks, adversaries add perturbations to the input data to manipulate the model’s output. The objective is to ensure that the argmax function outputs the target class rather than the actual class. For example, suppose the true class is a cat, and the adversary wants the model to classify it as a dog. In that case, the adversary will adjust the input until the argmax function indicates the “dog” class as having the highest score. The TFR evaluates the effectiveness of the attack. If a significant proportion of adversarial examples successfully achieve the desired misclassification (i.e., the argmax function points to the target class), the TFR will be high, indicating a successful attack.
- Misclassification Rate (MR): The misclassification event’s occurrence rate (a higher rate indicates that the classifier is easily fooled). It measures the proportion of instances the model incorrectly classifies, providing insight into its accuracy and reliability. UPSET and ANGRI, MR is defined as the rate at which the classifier outputs a label different from the true class label of the input, according to Equation [184].It also measures the proportion of instances that the model incorrectly classifies, providing insight into its accuracy and reliability [185]. It can be expressed in terms of false positives and false negatives, respectively. True negatives (TNs), true positives (TPs), false positives (FPs), and false negatives (FNs) are calculated as follows:
7.3.2. Classification-Based Measures
- Accuracy (AC): The classification AC is determined by the number of correct predictions divided by the total number of input samples. In ML, the accuracy can be calculated from the confusion matrix, which includes the counts of TP, TN, FP, and FN. The confusion matrix summarizes the predictions made by a classification model, comparing the predicted outcomes to the actual outcomes [182].
- Accuracy Drop or Error Rate: Accuracy drop (AD) or error rate (ER) is a key metric for assessing the robustness of DNNs against adversarial and backdoor attacks. Quantifies the reduction in classification performance when a model is exposed to adversarial perturbations, backdoor triggers, or defense mechanisms and measures the proportion of incorrect predictions under these conditions.
- Precision: It is a crucial performance metric that indicates how effectively a model can identify positive instances among those it classifies as positive. This metric is particularly significant in situations with a class imbalance, where one class is significantly underrepresented; critical fields such as healthcare and fraud detection face substantial implications from false positives, which can lead to unnecessary interventions or financial losses [182].
- Recall: Also called sensitivity or the true positive rate, it quantifies the fraction of actual positive instances the model successfully recognizes [182].
7.3.3. Efficiency-Based
- Avgquery: The average amount of queries is a crucial performance measure. This measurement helps in assessing the effectiveness of adversarial attacks on ML models for black-box attacks. The average query numbers indicate how many queries an attacker must make to successfully create an adversarial example using the model. This is especially important in situations where the adversarial degree of knowledge of attackers in the black box must only use the output, commonly using this metric to measure the number of queries needed to create adversarial examples for the victim model in black-box attacks [117].
7.4. Model Stealing
- Macro-Averaged Accuracy: This metric is a widely used evaluation metric that calculates the average accuracy across all classes in a dataset. Unlike micro-averaged accuracy, which weighs classes based on their sample size, the macro-averaged approach gives equal importance to each class, regardless of the number of instances per class [129]. By averaging the accuracy of each class individually, the metric highlights how well a model performs in each category rather than favoring the majority class. Mathematically, macro-averaged accuracy is calculated by taking the sum of the accuracies for all classes and dividing it by the total number of classes. For a dataset with C classes, it can be expressed as follows:
- Performance Over Target Network (OD): This metric evaluates the accuracy of the copycat network relative to the original target network (OD). It is calculated as the ratio of the copycat network’s macro-averaged accuracy to that of the target network, expressed as a percentage. A perfect copycat network would achieve 100% of the target network’s performance, replicating its predictions exactly, including any mistakes. The formula for this metric is as follows:This metric is crucial for determining how closely the copycat network approximates the original model, particularly when the latter is inaccessible for direct evaluation due to proprietary constraints [129].
- Performance Over Smaller Problem Domain Network (PD-OL) This metric compares the accuracy of the copycat network to a baseline model trained on a smaller, limited dataset from the problem domain (PD-OL). It provides a benchmark for evaluating whether the copycat network offers a more effective solution than conventional models trained with limited resources.The formula for this metric is as follows:This comparison is particularly valuable when obtaining a large, labeled dataset from the problem domain is impractical. By demonstrating superior performance relative to the PD-OL baseline, the copycat network underscores the potential of leveraging stolen labels and data augmentation techniques [129].
7.5. Domain-Based
- Accumulated Portfolio Value (APV): This metric reflects the change in the portfolio’s value over time. It is computed as the ratio of the current portfolio value to its initial value, allowing for a clear view of the agent’s performance over a period [104].
- Maximum Drawdown (MDD): MDD captures the largest percentage drop from a peak portfolio value to a trough before a new peak is achieved. This metric highlights downside risks and is critical in assessing the resilience of the AI agent under adverse conditions [104].
- Sharpe Ratio (SR): The Sharpe Ratio measures risk-adjusted returns by evaluating the excess return per unit of risk (volatility). It is a fundamental metric for understanding how well the agent compensates for the risk taken in achieving its returns [104].
8. Future Research Directions
8.1. Digital Forensics
8.2. Identify Trigger
8.3. Deep Neural Network Architectures
8.4. Federated Learning (FL)
8.5. Transferability of Adversarial Attacks and Defense Mechanisms
8.6. Explore New Domains
8.7. Meta-Heuristic Search Strategies
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Abbreviation | Full Form |
| AI | Artificial Intelligence |
| DNNs | Deep Neural Networks |
| ML | Machine Learning |
| DL | Deep Learning |
| SVMs | Support Vector Machines |
| RNNs | Recurrent Neural Networks |
| RL | Reinforcement Learning |
| PGD | Projected Gradient Descent |
| C&W | Carlini and Wagner |
| HSJ | HopSkipJump |
| ANNs | Artificial Neural Networks |
| ADR | Average Detection Rate |
| DL App | Deep Learning Application |
| NLP | Natural Language Processing |
| PRN | Perturbation Rectifying Network |
| DCN | Deep Contractive Networks |
| HVS | Human Vision System |
| DRAM | Dynamic Random Access Memory |
| FGSM | Fast Gradient Sign Method |
| GAN | Generative Adversarial Network |
| FL | Federated Learning |
| AvSR | Average Success Rate |
| CNNs | Convolutional Neural Networks |
| MR | Misclassification Rate |
| JND | Just Noticeable Distortion |
| TN | True Negatives |
| GRU | Gated Recurrent Unit |
| SR | Sharpe Ratio |
| MDD | Maximum Drawdown |
| APV | Accumulated Portfolio Value |
| Avgquery | Average Amount of Queries |
| TP | True Positives |
| FN | False Negatives |
| TFR | Target Fooling Rate |
| TWSE | Taiwan Stock Exchange |
| ASR | Attack Success Rate |
| SST-2 | Stanford Sentiment Treebank |
| SVHN | Street View House Numbers |
| EMRC | Robust Mode Connectivity |
| AAD | Attention-based Adversarial Defense |
| FP | False Positives |
| BIM | Basic Iterative Method |
| DNR | Deep Neural Rejection |
| EBD | Entropy-based Detector |
| AoA | Attack on Attention |
| ABCAttack | Artificial Bee Colony Attack |
| SA-ES | Subspace Activation Evolution Strategy |
| SMGEA | Serial Minigroup Ensemble Attack |
| DSNE | Dual-Stage Network Erosion |
| MLAE-DE | Multilabel Adversarial Examples—Differential Evolution |
| TG | Transformed Gradient |
| GAA | Generative Adversarial Attack |
| GAN | Generative Adversarial Network |
| T-BFA | Targeted Bit-Flip Adversarial Weight Attack |
| ADSAttack | Adversarial Distribution Searching-Driven Attack |
| UAPs | Universal Adversarial Perturbations |
| EAD | Elastic-Net Attacks to DNNs |
| LSTM | Long Short-Term Memory |
| DRL | Deep Reinforcement Learning |
References
- Hinton, G. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- He, X.; Zhao, K.; Chu, X. AutoML: A survey of the state-of-the-art. Knowl.-Based Syst. 2021, 212, 106622. [Google Scholar] [CrossRef]
- Durbha, K.S.; Amuru, S. AutoML models for wireless signals classification and their effectiveness against adversarial attacks. In Proceedings of the 2022 14th International Conference on Communication Systems & NETworkS (COMSNETS), Bangalore, India, 4–8 January 2022. [Google Scholar] [CrossRef]
- He, Y.; Lin, J.; Liu, Z.; Wang, H.; Li, L.J.; Han, S. AMC: AutoML for Model Compression and Acceleration on Mobile Devices. In Proceedings of the 14th International Conference on Communication Systems & NETworkS (COMSNETS), Bangalore, India, 4–8 January 2022; pp. 1–6. [Google Scholar]
- Szegedy, C.; Wilson, A.G.; Zheng, Z.; Tsipras, D.; Dong, Y.; Rattner, J.; Sinha, A.; Bengio, S. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Yang, Z.; Li, B.; Chen, P.Y.; Song, D. Characterizing Audio Adversarial Examples Using Temporal Dependency. arXiv 2018, arXiv:1809.10875. [Google Scholar]
- Joseph, A.D. Adversarial Machine Learning; Cambridge University Press: Cambridge, UK, 2018. [Google Scholar]
- Biggio, B.; Roli, F. Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning. Pattern Recognit. 2018, 84, 317–331. [Google Scholar] [CrossRef]
- Dalvi, N.; Domingos, P.; Mausam; Sanghai, S.; Verma, D. Adversarial Classification. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 99–108. [Google Scholar]
- Lowd, D.; Meek, C. Good Word Attacks on Statistical Spam Filters. In Proceedings of the 2005 Conference on Email and Anti-Spam (CEAS), Stanford, CA, USA, 21–22 July 2005; Volume 2005. [Google Scholar]
- Biggio, B.; Nelson, B.; Laskov, P. Poisoning attacks against support vector machines. arXiv 2012, arXiv:1206.6389. [Google Scholar]
- Biggio, B.; Corona, I.; Maiorca, D.; Nelson, B.; Šrndić, N.; Laskov, P.; Roli, F. Evasion attacks against machine learning at test time. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD, Prague, Czech Republic, 23–27 September 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 387–402. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Khamaiseh, S.Y.; Bagagem, D.; Al-Alaj, A.; Mancino, M.; Alomari, H.W. Adversarial deep learning: A survey on adversarial attacks and defense mechanisms on image classification. IEEE Access 2022, 10, 102266–102291. [Google Scholar] [CrossRef]
- AlSobeh, A.; Franklin, A.; Woodward, B.; Porche, M.; Siegelman, J. Unmasking Media Illusion: Analytical Survey of Deepfake Video Detection and Emotional Insights. Issues Inf. Syst. 2024, 25, 96–112. [Google Scholar]
- Carlini, N.; Wagner, D. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar] [CrossRef]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Athalye, A.; Carlini, N.; Wagner, D. Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples. In Proceedings of the 35th International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Gu, T.; Dolan-Gavitt, B.; Garg, S. BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain. In Proceedings of the Machine Learning and Computer Security Workshop (NeurIPS), Long Beach, CA, USA, 8 December 2017. [Google Scholar]
- Li, Y.; Lyu, L.; Bai, S.; Li, B.; Liang, Y. Backdoor Learning: A Survey. arXiv 2020, arXiv:2007.08745. [Google Scholar] [CrossRef] [PubMed]
- Bagdasaryan, E.; Veit, A.; Hua, Y.; Estrin, D.; Shmatikov, V. How To Backdoor Federated Learning. In Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics (AISTATS), Online, 26–28 August 2020. [Google Scholar]
- Tramèr, F.; Zhang, F.; Juels, A.; Reiter, M.K.; Ristenpart, T. Stealing Machine Learning Models via Prediction APIs. In Proceedings of the 25th USENIX Security Symposium (USENIX Security 2016), Austin, TX, USA, 10–12 August 2016. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership Inference Attacks Against Machine Learning Models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 3–18. [Google Scholar]
- Shan, S.; Bhagoji, A.N.; Zheng, H.; Zhao, B.Y. Poison forensics: Traceback of data poisoning attacks in neural networks. In Proceedings of the 31st USENIX Security Symposium (USENIX Security 22), Boston, MA, USA, 10–12 August 2022; pp. 3575–3592. [Google Scholar]
- Abraham, A. Artificial neural networks. In Handbook of Measuring System Design; Wiley: Hoboken, NJ, USA, 2005. [Google Scholar]
- Sadeghi, K.; Banerjee, A.; Gupta, S.K. A system-driven taxonomy of attacks and defenses in adversarial machine learning. IEEE Trans. Emerg. Top. Comput. Intell. 2020, 4, 450–467. [Google Scholar] [CrossRef] [PubMed]
- Ilahi, I.; Usama, M.; Qadir, J.; Janjua, M.U.; Al-Fuqaha, A.; Hoang, D.T.; Niyato, D. Challenges and countermeasures for adversarial attacks on deep reinforcement learning. IEEE Trans. Artif. Intell. 2021, 3, 90–109. [Google Scholar] [CrossRef]
- Mohus, M.L.; Li, J. Adversarial Robustness in Unsupervised Machine Learning: A Systematic Review. arXiv 2023, arXiv:2306.00687. [Google Scholar]
- Sun, S.; Cao, Z.; Zhu, H.; Zhao, J. A survey of optimization methods from a machine learning perspective. IEEE Trans. Cybern. 2019, 50, 3668–3681. [Google Scholar] [CrossRef]
- Apostolidis, K.D.; Papakostas, G.A. A survey on adversarial deep learning robustness in medical image analysis. Electronics 2021, 10, 2132. [Google Scholar] [CrossRef]
- Ding, J.; Xu, Z. Adversarial attacks on deep learning models of computer vision: A survey. In Proceedings of the Algorithms and Architectures for Parallel Processing: 20th International Conference, ICA3PP 2020, New York, NY, USA, 2–4 October 2020; Proceedings, Part III. Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 396–408. [Google Scholar] [CrossRef]
- Zhang, W.E.; Sheng, Q.Z.; Alhazmi, A.; Li, C. Adversarial attacks on deep-learning models in natural language processing: A survey. ACM Trans. Intell. Syst. Technol. 2020, 11, 1–41. [Google Scholar] [CrossRef]
- Akhtar, N.; Mian, A. Threat of adversarial attacks on deep learning in computer vision: A survey. IEEE Access 2018, 6, 14410–14430. [Google Scholar] [CrossRef]
- Wang, J.; Wang, C.; Lin, Q.; Luo, C.; Wu, C.; Li, J. Adversarial attacks and defenses in deep learning for image recognition: A survey. Neurocomputing 2022, 514, 162–181. [Google Scholar] [CrossRef]
- Macas, M.; Wu, C.; Fuertes, W. Adversarial examples: A survey of attacks and defenses in deep learning-enabled cybersecurity systems. Expert Syst. Appl. 2023, 238, 122223. [Google Scholar] [CrossRef]
- Mengara, O.; Avila, A.; Falk, T.H. Backdoor Attacks to Deep Neural Networks: A Survey of the Literature, Challenges, and Future Research Directions. IEEE Access 2024, 12, 29004–29023. [Google Scholar] [CrossRef]
- Bhanushali, A.R.; Mun, H.; Yun, J. Adversarial Attacks on Automatic Speech Recognition (ASR): A Survey. IEEE Access 2024, 12, 88279–88302. [Google Scholar] [CrossRef]
- Costa, J.C.; Roxo, T.; Proença, H.; Inácio, P.R.M. How deep learning sees the world: A survey on adversarial attacks & defenses. IEEE Access 2024, 12, 61113–61136. [Google Scholar]
- Hoang, V.T.; Ergu, Y.A.; Nguyen, V.L.; Chang, R.G. Security risks and countermeasures of adversarial attacks on AI-driven applications in 6G networks: A survey. J. Netw. Comput. Appl. 2024, 232, 104031. [Google Scholar] [CrossRef]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A Simple and Accurate Method to Fool Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2574–2582. [Google Scholar]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef]
- Nazzal, J.M.; El-Emary, I.M.; Najim, S.A.; Ahliyya, A. Multilayer Perceptron Neural Network (MLPs) for Analyzing the Properties of Jordan Oil Shale. World Appl. Sci. J. 2008, 5, 546–552. [Google Scholar]
- Gome, L. Machine-Learning Maestro Michael Jordan on the Delusions of Big Data and Other Huge Engineering Efforts. IEEE Spectr. 2016. [Google Scholar]
- Min, S.; Lee, B.; Yoon, S. Deep learning in bioinformatics. Briefings Bioinform. 2017, 18, 851–869. [Google Scholar] [CrossRef]
- Roopak, M.; Tian, G.Y.; Chambers, J. Deep learning models for cyber security in IoT networks. In Proceedings of the 2019 IEEE 9th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 7–9 January 2019; pp. 0452–0457. [Google Scholar] [CrossRef]
- Sun, P.; Liu, P.; Li, Q.; Liu, C.; Lu, X.; Hao, R.; Chen, J. DL-IDS: Extracting Features Using CNN-LSTM Hybrid Network for Intrusion Detection System. Secur. Commun. Netw. 2020, 2020, 8890306. [Google Scholar] [CrossRef]
- Abbaspour, S.; Fotouhi, F.; Sedaghatbaf, A.; Fotouhi, H.; Vahabi, M.; Linden, M. A comparative analysis of hybrid deep learning models for human activity recognition. Sensors 2020, 20, 5707. [Google Scholar] [CrossRef]
- Fang, W.; Chen, Y.; Xue, Q. Survey on research of RNN-based spatio-temporal sequence prediction algorithms. J. Big Data 2021, 3, 97. [Google Scholar] [CrossRef]
- Xiao, J.; Zhou, Z. Research progress of RNN language model. In Proceedings of the 2020 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 27–29 June 2020; pp. 1285–1288. [Google Scholar]
- Shewalkar, A.; Nyavanandi, D.; Ludwig, S.A. Performance evaluation of deep neural networks applied to speech recognition: RNN, LSTM and GRU. J. Artif. Intell. Soft Comput. Res. 2019, 9, 235–245. [Google Scholar] [CrossRef]
- Apaydin, H.; Feizi, H.; Sattari, M.T.; Colak, M.S.; Shamshirband, S.; Chau, K.W. Comparative analysis of recurrent neural network architectures for reservoir inflow forecasting. Water 2020, 12, 1500. [Google Scholar] [CrossRef]
- Graves, A.; Graves, A. Long short-term memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–45. [Google Scholar]
- Graves, A.; Liwicki, M.; Fernández, S.; Bertolami, R.; Bunke, H.; Schmidhuber, J. A novel connectionist system for unconstrained handwriting recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 855–868. [Google Scholar] [CrossRef] [PubMed]
- Fortunato, M.; Blundell, C.; Vinyals, O. Bayesian recurrent neural networks. arXiv 2017, arXiv:1704.02798. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Chen, J.X.; Jiang, D.M.; Zhang, Y.N. A hierarchical bidirectional GRU model with attention for EEG-based emotion classification. IEEE Access 2019, 7, 118530–118540. [Google Scholar] [CrossRef]
- Svozil, D.; Kvasnicka, V.; Pospichal, J. Introduction to multi-layer feed-forward neural networks. Chemom. Intell. Lab. Syst. 1997, 39, 43–62. [Google Scholar] [CrossRef]
- Kohonen, T. Self-Organizing Maps, 3rd ed.; Springer Series in Information Sciences; Springer: Berlin/Heidelberg, Germany, 2001; Volume 30. [Google Scholar] [CrossRef]
- Pinaya, W.H.L.; Vieira, S.; Garcia-Dias, R.; Mechelli, A. Autoencoders. In Machine Learning; Academic Press: Cambridge, MA, USA, 2020; pp. 193–208. [Google Scholar]
- Stoer, J.; Bulirsch, R. Introduction to Numerical Analysis; Springer: Berlin/Heidelberg, Germany, 2002; Chapter Systems of Linear 184 Equations; pp. 190–288. [Google Scholar]
- Mart, R.; Pardalos, P.M.; Resende, M.G.C. Handbook of Heuristics; Springer Publishing Company Incorporated: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Ezugwu, A.E.; Shukla, A.K.; Nath, R.; Akinyelu, A.A.; Agushaka, J.O.; Chiroma, H.; Muhuri, P.K. Metaheuristics: A comprehensive overview and classification along with bibliometric analysis. Artif. Intell. Rev. 2021, 54, 4237–4316. [Google Scholar] [CrossRef]
- Sen, S.; Weiss, G. Learning in multiagent systems. In Multiagent Systems: A Modern Approach to Distributed Artificial Intelligence; MIT Press: Cambridge, MA, USA, 1999; pp. 259–298. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement Learning: A Survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Abu-Mostafa, Y.S.; Magdon-Ismail, M.; Lin, H.T. Learning from Data; AMLBook: New York, NY, USA, 2012; Volume 4, p. 4. [Google Scholar]
- Hinton, G.; Sejnowski, T.J. Unsupervised Learning: Foundations of Neural Computation; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Lowd, D.; Meek, C. Adversarial Learning. In Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining, Chicago, IL, USA, 21–24 August 2005; pp. 641–647. [Google Scholar] [CrossRef]
- Wang, X.; Li, J.; Kuang, X.; Tan, Y.A.; Li, J. The security of machine learning in an adversarial setting: A survey. J. Parallel Distrib. Comput. 2019, 130, 12–23. [Google Scholar] [CrossRef]
- Biggio, B.; Fumera, G.; Roli, F. Security evaluation of pattern classifiers under attack. IEEE Trans. Knowl. Data Eng. 2013, 26, 984–996. [Google Scholar] [CrossRef]
- Torr, P. Demystifying the threat modeling process. IEEE Secur. Priv. 2005, 3, 66–70. [Google Scholar] [CrossRef]
- Miller, D.J.; Xiang, Z.; Kesidis, G. Adversarial learning targeting deep neural network classification: A comprehensive review of defenses against attacks. Proc. IEEE 2020, 108, 402–433. [Google Scholar] [CrossRef]
- Santhanam, V.; Davis, L.S. A generic improvement to deep residual networks based on gradient flow. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 2490–2499. [Google Scholar] [CrossRef]
- Zhong, Y.; Deng, W. Towards transferable adversarial attack against deep face recognition. IEEE Trans. Inf. Forensics Secur. 2020, 16, 1452–1466. [Google Scholar] [CrossRef]
- Alrawashdeh, K.; Goldsmith, S. Defending deep learning based anomaly detection systems against white-box adversarial examples and backdoor attacks. In Proceedings of the 2020 IEEE International Symposium on Technology and Society (ISTAS), Tempe, AZ, USA, 12–15 November 2020; pp. 294–301. [Google Scholar]
- Carlini, N.; Wagner, D. Adversarial examples are not easily detected: Bypassing ten detection methods. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 3–14. [Google Scholar]
- Rakin, A.S.; He, Z.; Fan, D. Bit-flip attack: Crushing neural network with progressive bit search. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1211–1220. [Google Scholar]
- Yao, F.; Rakin, A.S.; Fan, D. DeepHammer: Depleting the intelligence of deep neural networks through targeted chain of bit flips. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), Boston, MA, USA, 12–14 August 2020; pp. 1463–1480. [Google Scholar]
- Rakin, A.S.; He, Z.; Fan, D. Tbt: Targeted Neural Network Attack with Bit Trojan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13198–13207. [Google Scholar]
- Yan, M.; Fletcher, C.W.; Torrellas, J. Cache Telepathy: Leveraging Shared Resource Attacks to Learn DNN Architectures. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), Boston, MA, USA, 12–14 August 2020; pp. 2003–2020. [Google Scholar]
- Xiang, Y.; Chen, Z.; Chen, Z.; Fang, Z.; Hao, H.; Chen, J.; Yang, X. Open DNN Box by Power Side-Channel Attack. IEEE Trans. Circuits Syst. II Express Briefs 2020, 67, 2717–2721. [Google Scholar] [CrossRef]
- Yu, H.; Ma, H.; Yang, K.; Zhao, Y.; Jin, Y. DeepEM: Deep Neural Networks Model Recovery through EM Side-Channel Information Leakage. In Proceedings of the 2020 IEEE International Symposium on Hardware Oriented Security and Trust (HOST), San Jose, CA, USA, 7–11 December 2020; pp. 209–218. [Google Scholar] [CrossRef]
- Das, D.; Golder, A.; Danial, J.; Ghosh, S.; Raychowdhury, A.; Sen, S. X-DeepSCA: Cross-device deep learning side channel attack. In Proceedings of the 56th Annual Design Automation Conference 2019, Las Vegas, NV, USA, 2–6 June 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Chen, J.; Jordan, M.I.; Wainwright, M.J. Hopskipjumpattack: A query-efficient decision-based attack. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), Francisco, CA, USA, 18–20 May 2020; pp. 1277–1294. [Google Scholar]
- Biggio, B.; Nelson, B.; Laskov, P. Support vector machines under adversarial label noise. In Proceedings of the Asian Conference on Machine Learning, Taoyuan, Taiwan, 13–15 November 2011; pp. 97–112. [Google Scholar]
- López-Valcarce, R.; Romero, D. Design of data-injection adversarial attacks against spatial field detectors. In Proceedings of the 2016 IEEE Statistical Signal Processing Workshop (SSP), Palma de Mallorca, Spain, 26–29 June 2016; pp. 1–5. [Google Scholar]
- Chacon, H.; Silva, S.; Rad, P. Deep learning poison data attack detection. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; pp. 971–978. [Google Scholar]
- Jiang, W.; Li, H.; Liu, S.; Luo, X.; Lu, R. Poisoning and evasion attacks against deep learning algorithms in autonomous vehicles. IEEE Trans. Veh. Technol. 2020, 69, 4439–4449. [Google Scholar] [CrossRef]
- Agrawal, G.; Kaur, A.; Myneni, S. A review of generative models in generating synthetic attack data for cybersecurity. Electronics 2024, 13, 322. [Google Scholar] [CrossRef]
- Khan, Z.; Chowdhury, M.; Khan, S.M. A Hybrid Defense Method Against Adversarial Attacks on Traffic Sign Classifiers in Autonomous Vehicles. arXiv 2022, arXiv:2205.01225. [Google Scholar]
- Chen, P.Y.; Sharma, Y.; Zhang, H.; Yi, J.; Hsieh, C.J. Ead: Elastic-net attacks to deep neural networks via adversarial examples. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Beck, A.; Teboulle, M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef]
- Hirano, H.; Takemoto, K. Simple iterative method for generating targeted universal adversarial perturbations. Algorithms 2020, 13, 268. [Google Scholar] [CrossRef]
- Brendel, W.; Rauber, J.; Kümmerer, M.; Ustyuzhaninov, I.; Bethge, M. Accurate, reliable and fast robustness evaluation. In Proceedings of the Advances in Neural Information Processing Systems. NeurIPS, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Ghiasi, A.; Shafahi, A.; Goldstein, T. Breaking certified defenses: Semantic adversarial examples with spoofed robustness certificates. arXiv 2020, arXiv:2003.08937. [Google Scholar]
- Bai, J.; Wu, B.; Li, Z.; Xia, S.T. Versatile weight attack via flipping limited bits. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 13653–13665. [Google Scholar] [CrossRef]
- Wang, H.; Zhu, C.; Cao, Y.; Zhuang, Y.; Li, J.; Chen, X. ADSAttack: An Adversarial Attack Algorithm via Searching Adversarial Distribution in Latent Space. Electronics 2023, 12, 816. [Google Scholar] [CrossRef]
- Rakin, A.S.; He, Z.; Li, J.; Yao, F.; Chakrabarti, C.; Fan, D. T-bfa: Targeted bit-flip adversarial weight attack. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7928–7939. [Google Scholar] [CrossRef]
- Wang, Z.; Song, M.; Zheng, S.; Zhang, Z.; Song, Y.; Wang, Q. Invisible adversarial attack against deep neural networks: An adaptive penalization approach. IEEE Trans. Dependable Secur. Comput. 2019, 18, 1474–1488. [Google Scholar] [CrossRef]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial examples in the physical world. In Artificial Intelligence Safety and Security; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018; pp. 99–112. [Google Scholar]
- Tang, S.; Huang, X.; Chen, M.; Sun, C.; Yang, J. Adversarial attack type I: Cheat classifiers by significant changes. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1100–1109. [Google Scholar] [CrossRef]
- He, S.; Wang, R.; Liu, T.; Yi, C.; Jin, X.; Liu, R.; Zhou, W. Type-I generative adversarial attack. IEEE Trans. Dependable Secur. Comput. 2022, 20, 2593–2606. [Google Scholar] [CrossRef]
- Wan, C.; Huang, F.; Zhao, X. Average gradient-based adversarial attack. IEEE Trans. Multimed. 2023, 25, 9572–9585. [Google Scholar] [CrossRef]
- Chen, Y.Y.; Chen, C.T.; Sang, C.Y.; Yang, Y.C.; Huang, S.H. Adversarial attacks against reinforcement learning-based portfolio management strategy. IEEE Access 2021, 9, 50667–50685. [Google Scholar] [CrossRef]
- He, Z.; Duan, Y.; Zhang, W.; Zou, J.; He, Z.; Wang, Y.; Pan, Z. Boosting adversarial attacks with transformed gradient. Comput. Secur. 2022, 118, 102720. [Google Scholar] [CrossRef]
- Wang, X.; Chen, K.; Ma, X.; Chen, Z.; Chen, J.; Jiang, Y.G. AdvQDet: Detecting Query-Based Adversarial Attacks with Adversarial Contrastive Prompt Tuning. In Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne, Australia, 28 October–1 November 2024; pp. 6212–6221. [Google Scholar]
- Rastrigin, L. The convergence of the random search method in the extremal control of a many parameter system. Autom. Remote Control 1963, 24, 1337–1342. [Google Scholar]
- Andriushchenko, M.; Croce, F.; Flammarion, N.; Hein, M. Square Attack: A Query-Efficient Black-Box Adversarial Attack via Random Search. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 484–501. [Google Scholar]
- Su, J.; Vargas, D.V.; Sakurai, K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef]
- Kong, L.; Luo, W.; Zhang, H.; Liu, Y.; Shi, Y. Evolutionary multilabel adversarial examples: An effective black-box attack. IEEE Trans. Artif. Intell. 2022, 4, 562–572. [Google Scholar] [CrossRef]
- Cai, K.; Zhu, X.; Hu, Z.L. Black-box reward attacks against deep reinforcement learning based on successor representation. IEEE Access 2022, 10, 51548–51560. [Google Scholar] [CrossRef]
- Duan, Y.; Zou, J.; Zhou, X.; Zhang, W.; He, Z.; Zhan, D.; Pan, Z. Adversarial attack via dual-stage network erosion. Comput. Secur. 2022, 122, 102888. [Google Scholar] [CrossRef]
- Che, Z.; Borji, A.; Zhai, G.; Ling, S.; Li, J.; Min, X.; Le Callet, P. SMGEA: A new ensemble adversarial attack powered by long-term gradient memories. IEEE Trans. Neural Netw. Learn. Syst. 2020, 33, 1051–1065. [Google Scholar] [CrossRef]
- Kuang, X.; Liu, H.; Wang, Y.; Zhang, Q.; Zhang, Q.; Zheng, J. A CMA-ES-Based Adversarial Attack on Black-Box Deep Neural Networks. IEEE Access 2019, 7, 172938–172947. [Google Scholar] [CrossRef]
- Li, Z.; Cheng, H.; Cai, X.; Zhao, J.; Zhang, Q. Sa-es: Subspace activation evolution strategy for black-box adversarial attacks. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 7, 780–790. [Google Scholar] [CrossRef]
- Wei, X.; Guo, Y.; Li, B. Black-box adversarial attacks by manipulating image attributes. Inf. Sci. 2021, 550, 285–296. [Google Scholar] [CrossRef]
- Cao, H.; Si, C.; Sun, Q.; Liu, Y.; Li, S.; Gope, P. Abcattack: A gradient-free optimization black-box attack for fooling deep image classifiers. Entropy 2022, 24, 412. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.M.; Gu, M.T.; Hou, J.H. Sample based fast adversarial attack method. Neural Process. Lett. 2019, 50, 2731–2744. [Google Scholar] [CrossRef]
- Chen, S.; He, Z.; Sun, C.; Yang, J.; Huang, X. Universal adversarial attack on attention and the resulting dataset Damagenet. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2188–2197. [Google Scholar] [CrossRef]
- Lu, Y.; Kamath, G.; Yu, Y. Indiscriminate data poisoning attacks on neural networks. arXiv 2022, arXiv:2204.09092. [Google Scholar]
- Chen, B.; Carvalho, W.; Baracaldo, N.; Ludwig, H.; Edwards, B.; Lee, T.; Srivastava, B. Detecting backdoor attacks on deep neural networks by activation clustering. arXiv 2018, arXiv:1811.03728. [Google Scholar]
- Havens, A.; Jiang, Z.; Sarkar, S. Online robust policy learning in the presence of unknown adversaries. In Proceedings of the 32nd International Conference on Neural Information Processing Systems (NIPS’18). Curran Associates Inc., Red Hook, NY, USA; 2018; pp. 9938–9948. [Google Scholar]
- Ding, S.; Tian, Y.; Xu, F.; Li, Q.; Zhong, S. Trojan attack on deep generative models in autonomous driving. In Proceedings of the Security and Privacy in Communication Networks: 15th EAI International Conference, SecureComm 2019, Orlando, FL, USA, 23–25 October 2019; Proceedings, Part I. Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 299–318. [Google Scholar]
- Shafahi, A.; Huang, W.R.; Najibi, M.; Suciu, O.; Studer, C.; Dumitras, T.; Goldstein, T. Poison frogs! targeted clean-label poisoning attacks on neural networks. In Proceedings of the Advances in Neural Information Processing Systems. NeurIPS, Montreal, ON, USA, 3–8 December 2018; Volume 31. [Google Scholar]
- Paudice, A.; Muñoz-González, L.; Lupu, E.C. Label sanitization against label flipping poisoning attacks. In Proceedings of the ECML PKDD 2018 Workshops: Nemesis 2018, UrbReas 2018, SoGood 2018, IWAISe 2018, and Green Data Mining 2018, Dublin, Ireland, 10–14 September 2019; pp. 5–15. [Google Scholar]
- Koh, P.W.; Steinhardt, J.; Liang, P. Stronger data poisoning attacks break data sanitization defenses. Mach. Learn. 2022, 1, 1–47. [Google Scholar] [CrossRef]
- Shen, J.; Zhu, X.; Ma, D. TensorClog: An imperceptible poisoning attack on deep neural network applications. IEEE Access 2019, 7, 41498–41506. [Google Scholar] [CrossRef]
- Shao, K.; Zhang, Y.; Yang, J.; Li, X.; Liu, H. The triggers that open the NLP model backdoors are hidden in the adversarial samples. Comput. Secur. 2022, 118, 102730. [Google Scholar] [CrossRef]
- Correia-Silva, J.R.; Berriel, R.F.; Badue, C.; De Souza, A.F.; Oliveira-Santos, T. Copycat CNN: Stealing knowledge by persuading confession with random non-labeled data. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Shen, M.; Li, C.; Yu, H.; Li, Q.; Zhu, L.; Xu, K. Decision-based query efficient adversarial attack via adaptive boundary learning. IEEE Trans. Dependable Secur. Comput. 2023, 21, 1740–1753. [Google Scholar] [CrossRef]
- Xiang, Y.; Xu, Y.; Li, Y.; Ma, W.; Xuan, Q.; Liu, Y. Side-channel gray-box attack for DNNs. IEEE Trans. Circuits Syst. II Express Briefs 2020, 68, 501–505. [Google Scholar] [CrossRef]
- Hwang, U.; Park, J.; Jang, H.; Yoon, S.; Cho, N.I. Puvae: A variational autoencoder to purify adversarial examples. IEEE Access 2019, 7, 126582–126593. [Google Scholar] [CrossRef]
- Guan, D.; Zhao, W. Adversarial Detection Based on Inner-Class Adjusted Cosine Similarity. Appl. Sci. 2022, 12, 9406. [Google Scholar] [CrossRef]
- Gao, J.; Wang, B.; Lin, Z.; Xu, W.; Qi, Y. Deepcloak: Masking deep neural network models for robustness against adversarial samples. arXiv 2017, arXiv:1702.06763. [Google Scholar]
- Gu, S.; Rigazio, L. Towards deep neural network architectures robust to adversarial examples. arXiv 2014, arXiv:1412.5068. [Google Scholar]
- Akhtar, N.; Liu, J.; Mian, A. Defense against universal adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3389–3398. [Google Scholar]
- Meng, D.; Chen, H. Magnet: A two-pronged defense against adversarial examples. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 135–147. [Google Scholar]
- Dziugaite, G.K.; Ghahramani, Z.; Roy, D.M. A study of the effect of JPG compression on adversarial images. arXiv 2016, arXiv:1608.00853. [Google Scholar]
- Tran, B.; Li, J.; Madry, A. Spectral Signatures in Backdoor Attacks. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montreal, ON, Canada, 3–8 December 2018; pp. 8011–8021. [Google Scholar]
- Metzen, J.H.; Genewein, T.; Fischer, V.; Bischoff, B. On detecting adversarial perturbations. arXiv 2017, arXiv:1702.04267. [Google Scholar]
- Katz, G.; Barrett, C.; Dill, D.L.; Julian, K.; Kochenderfer, M.J. Reluplex: A calculus for reasoning about deep neural networks. Form. Methods Syst. Des. 2022, 60, 87–116. [Google Scholar] [CrossRef]
- Aithal, M.B.; Li, X. Mitigating black-box adversarial attacks via output noise perturbation. IEEE Access 2022, 10, 12395–12411. [Google Scholar] [CrossRef]
- Wei, W.; Liu, L. Robust deep learning ensemble against deception. IEEE Trans. Dependable Secur. Comput. 2020, 18, 1513–1527. [Google Scholar] [CrossRef]
- Liu, L.; Guo, Y.; Cheng, Y.; Zhang, Y.; Yang, J. Generating robust DNN with resistance to bit-flip based adversarial weight attack. IEEE Trans. Comput. 2022, 72, 401–413. [Google Scholar] [CrossRef]
- Zoppi, T.; Ceccarelli, A. Detect adversarial attacks against deep neural networks with GPU monitoring. IEEE Access 2021, 9, 150579–150591. [Google Scholar] [CrossRef]
- Nguyen-Vu, L.; Doan, T.P.; Bui, M.; Hong, K.; Jung, S. On the defense of spoofing countermeasures against adversarial attacks. IEEE Access 2023, 11, 94563–94574. [Google Scholar] [CrossRef]
- Yang, J.T.; Jiang, H.; Li, H.; Ye, D.S.; Jiang, W. FAD: Fine-Grained Adversarial Detection by Perturbation Intensity Classification. Entropy 2023, 25, 335. [Google Scholar] [CrossRef]
- Ryu, G.; Choi, D. Detection of adversarial attacks based on differences in image entropy. Int. J. Inf. Secur. 2024, 23, 299–314. [Google Scholar] [CrossRef]
- Wu, S.; Sang, J.; Xu, K.; Zhang, J.; Yu, J. Attention, please! Adversarial defense via activation rectification and preservation. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 19, 1–18. [Google Scholar] [CrossRef]
- Sotgiu, A.; Demontis, A.; Melis, M.; Biggio, B.; Fumera, G.; Feng, X.; Roli, F. Deep neural rejection against adversarial examples. EURASIP J. Inf. Secur. 2020, 2020, 5. [Google Scholar] [CrossRef]
- Xiang, Z.; Miller, D.J.; Kesidis, G. Reverse engineering imperceptible backdoor attacks on deep neural networks for detection and training set cleansing. Comput. Secur. 2021, 106, 102280. [Google Scholar] [CrossRef]
- Shao, K.; Yang, J.; Ai, Y.; Liu, H.; Zhang, Y. BDDR: An effective defense against textual backdoor attacks. Comput. Secur. 2021, 110, 102433. [Google Scholar] [CrossRef]
- Shao, K.; Zhang, Y.; Yang, J.; Liu, H. Textual Backdoor Defense via Poisoned Sample Recognition. Appl. Sci. 2021, 11, 9938. [Google Scholar] [CrossRef]
- AlSobeh, A.M.; Gaber, K.; Hammad, M.M.; Nuser, M.; Shatnawi, A. Android malware detection using time-aware machine learning approach. Clust. Comput. 2024, 27, 12627–12648. [Google Scholar] [CrossRef]
- Wang, R.; Li, Y.; Hero, A. Deep Adversarial Defense Against Multilevel -ℓP Attacks. In Proceedings of the 2024 IEEE 34th International Workshop on Machine Learning for Signal Processing (MLSP), London, UK, 22–25 September 2024; pp. 1–6. [Google Scholar]
- Juraev, F.; Abuhamad, M.; Chan-Tin, E.; Thiruvathukal, G.K.; Abuhmed, T. Unmasking the Vulnerabilities of Deep Learning Models: A Multi-Dimensional Analysis of Adversarial Attacks and Defenses. In Proceedings of the 2024 Silicon Valley Cybersecurity Conference (SVCC), Seoul, Republic of Korea, 17–19 June 2024; pp. 1–8. [Google Scholar]
- AlSobeh, A.; Shatnawi, A.; Al-Ahmad, B.; Aljmal, A.; Khamaiseh, S. AI-Powered AOP: Enhancing Runtime Monitoring with Large Language Models and Statistical Learning. Int. J. Adv. Comput. Sci. Appl. 2024, 15, 121–133. [Google Scholar] [CrossRef]
- Alhazeem, E.; Alsobeh, A.; Al-Ahmad, B. Enhancing Software Engineering Education through AI: An Empirical Study of Tree-Based Machine Learning for Defect Prediction. In Proceedings of the 25th Annual Conference on Information Technology Education, El Paso, TX, USA, 10–12 October 2024; pp. 153–156. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Krizhevsky, A.; Hinton, G.E. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, USA, 2009. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 3730–3738. [Google Scholar]
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading Digits in Natural Images with Unsupervised Feature Learning. In Proceedings of the NIPS Workshop on Deep Learning and Unsupervised Feature Learning, Granada, Spain, 12–17 December 2011. [Google Scholar]
- Maas, A.L.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning Word Vectors for Sentiment Analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Toronto, ON, Canada, 9–14 July 2011; pp. 142–150. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Wang, X.; Yamagishi, J.; Todisco, M.; Delgado, H.; Nautsch, A.; Evans, N.; Sahidullah, M.; Vestman, V.; Kinnunen, T.; Lee, K.A.; et al. ASVspoof 2019: A Large-Scale Public Database of Synthesized, Converted and Replayed Speech. Comput. Speech Lang. 2020, 64, 101114. [Google Scholar] [CrossRef]
- Reimao, R.; Tzerpos, V. FoR: A Dataset for Synthetic Speech Detection. In Proceedings of the International Conference on Speech Technology and Human-Computer Dialogue (SpeD), Timisoara, Romania, 10–12 October 2019; pp. 1–10. [Google Scholar]
- Yi, J.; Tao, J.; Fu, R.; Yan, X.; Wang, C.; Wang, T.; Zhang, C.Y.; Zhang, X.; Zhao, Y.; Ren, Y.; et al. ADD 2023: The Second Audio Deepfake Detection Challenge. arXiv 2023, arXiv:2305.13774. [Google Scholar]
- Müller, N.; Czempin, P.; Diekmann, F.; Froghyar, A.; Böttinger, K. Does Audio Deepfake Detection Generalize? In Proceedings of the Interspeech, Incheon, Republic of Korea, 18–22 September 2022; pp. 1–5. [Google Scholar]
- Exchange, T.S. Taiwan Stock Exchange. Available online: https://www.twse.com.tw/zh/about/news/news/list.html (accessed on 5 April 2025).
- U.S. Department of Transportation. Next Generation Simulation (NGSIM) Vehicle Trajectories and Supporting Data. Available online: https://data.transportation.gov/Automobiles/Next-Generation-Simulation-NGSIM-Vehicle-Trajector/8ect-6jqj/about_data (accessed on 5 January 2025).
- Anderson, H.S.; Roth, P. Ember: An Open Dataset for Training Static PE Malware Machine Learning Models. arXiv 2018, arXiv:1804.04637. [Google Scholar]
- Coates, A.; Ng, A.; Lee, H. An Analysis of Single-Layer Networks in Unsupervised Feature Learning. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics (AISTATS), Ft. Lauderdale, FL, USA, 11–13 April 2011; pp. 215–223. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Conneau, A.; Kiela, D.; Schwenk, H.; Barrault, L.; Bordes, A. Supervised Learning of Universal Sentence Representations from Natural Language Inference Data. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (EMNLP), Copenhagen, Denmark, 9–11 September 2017; pp. 670–680. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- OECD. Catalogue of Tools & Metrics for Trustworthy AI. Available online: https://oecd.ai/en/catalogue/tools (accessed on 19 April 2025).
- Yue, W.; Liu, B.; Stone, P. T-DGR: A Trajectory-Based Deep Generative Replay Method for Continual Learning in Decision Making. In Proceedings of the 3rd Conference on Lifelong Learning Agents (CoLLAs), Pisa, Italy, 29 July–1 August 2024. [Google Scholar]
- Shafahi, A.; Huang, W.R.; Najibi, M.; Suciu, O.; Studer, C.; Dumitras, T.; Goldstein, T. UPSET and ANGRI: Breaking High Performance Image Classifiers Using Adversarial Examples. In Proceedings of the British Machine Vision Conference (BMVC), Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Nelson, B.; Barreno, M.; Chi, F.J.; Joseph, A.D.; Rubinstein, B.I.; Saini, U.; Tygar, J.D.; Ren, K.; Xia, X. Misleading Learners: Co-opting Your Spam Filter. In Machine Learning in Cyber Trust: Security, Privacy, and Reliability; Tygar, J.D., Ed.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 17–51. [Google Scholar] [CrossRef]
- Xu, G.; Xin, G.; Jiao, L.; Liu, J.; Liu, S.; Feng, M.; Zheng, X. OFEI: A Semi-Black-Box Android Adversarial Sample Attack Framework Against DLaaS. IEEE Trans. Comput. 2023, 73, 956–969. [Google Scholar] [CrossRef]
- Chang, C.W.; Liou, J.J. Enhancing Solver Robustness through Constraint Tightening for DNN Compilation. In Proceedings of the 2024 International VLSI Symposium on Technology, Systems and Applications (VLSI TSA), Hsinchu, Taiwan, 22–25 April 2024; pp. 1–4. [Google Scholar] [CrossRef]
- Insights, F.B. Machine Learning Market to Reach USD 117.19 Billion by 2027; Increasing Popularity of Self-Driving Cars to Propel Demand from Automotive Industry. GlobeNewswire. 2020. Available online: https://www.globenewswire.com/news-release/2020/07/17/2063938/0/en/Machine-Learning-Market-to-Reach-USD-117-19-Billion-by-2027-Increasing-Popularity-of-Self-Driving-Cars-to-Propel-Demand-from-Automotive-Industry-says-Fortune-Business-Insights.html (accessed on 16 October 2024).
- Michael, J.B.; Kuhn, R.; Voas, J. Cyberthreats in 2025. Computer 2020, 53, 16–27. [Google Scholar] [CrossRef]
- Chen, Z.; Li, B.; Wu, S.; Ding, S.; Zhang, W. Query-efficient decision-based black-box patch attack. IEEE Trans. Inf. Forensics Secur. 2023, 18, 5522–5536. [Google Scholar] [CrossRef]
- Li, X.C.; Zhang, X.Y.; Yin, F.; Liu, C.L. Decision-based adversarial attack with frequency mixup. IEEE Trans. Inf. Forensics Secur. 2022, 17, 1038–1052. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Wu, X.; Jha, S.; Swami, A. Distillation as a Defense to Adversarial Perturbations Against Deep Neural Networks. In Proceedings of the IEEE Symposium on Security and Privacy, San Jose, CA, USA, 22–26 May 2016; pp. 582–597. [Google Scholar]
- Hasan, F.A.; Ashqar, H.I.; AlSobeh, A.; Darwish, O. Blockchain-Based National Digital Identity Framework—Case of Palestine. In Proceedings of the 2024 International Conference on Intelligent Computing, Communication, Networking and Services (ICCNS), Dubrovnik, Croatia, 24–27 September 2024; pp. 76–83. [Google Scholar]
- Modas, A.; Moosavi-Dezfooli, S.M.; Frossard, P. Sparsefool: A few pixels make a big difference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9087–9096. [Google Scholar]
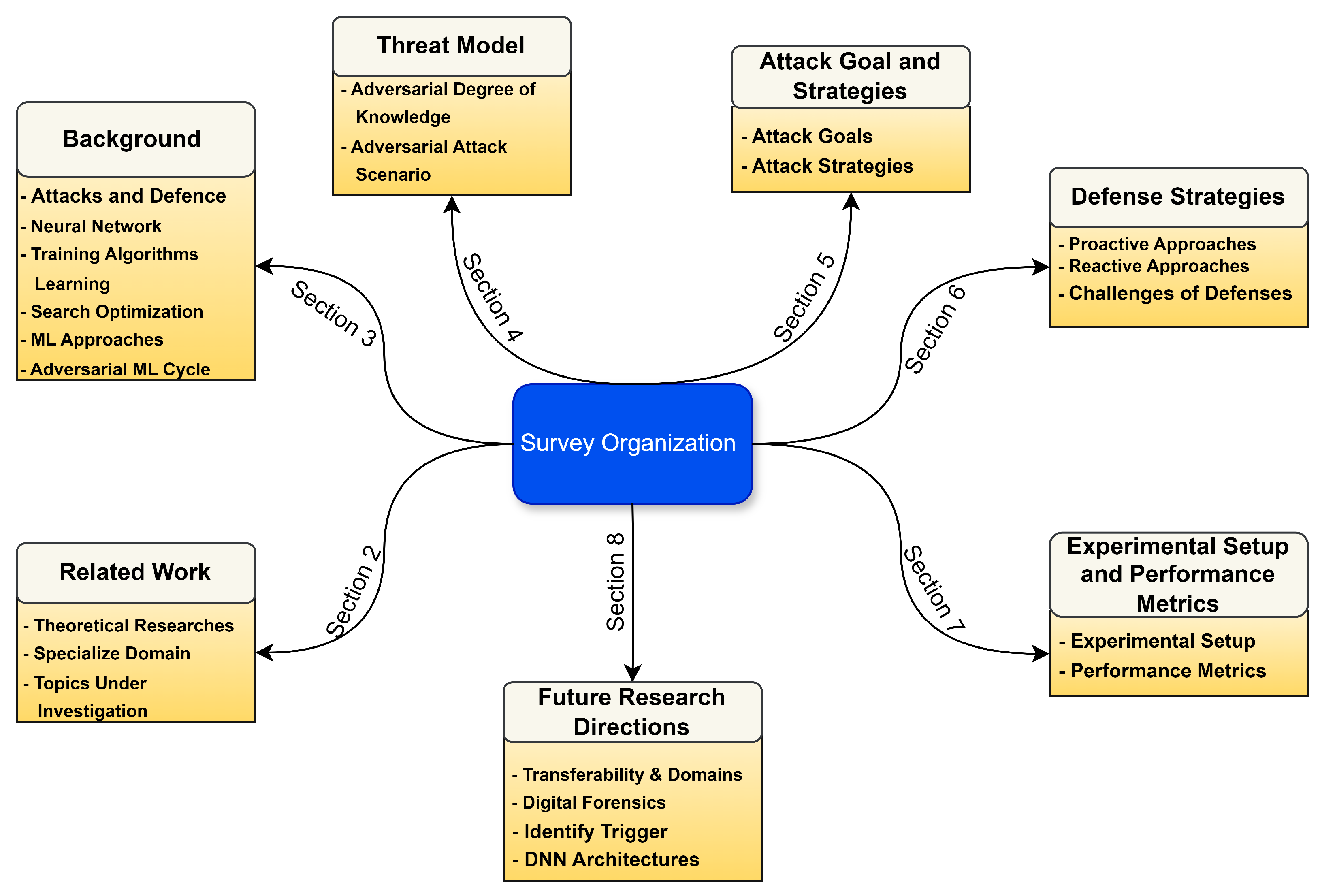
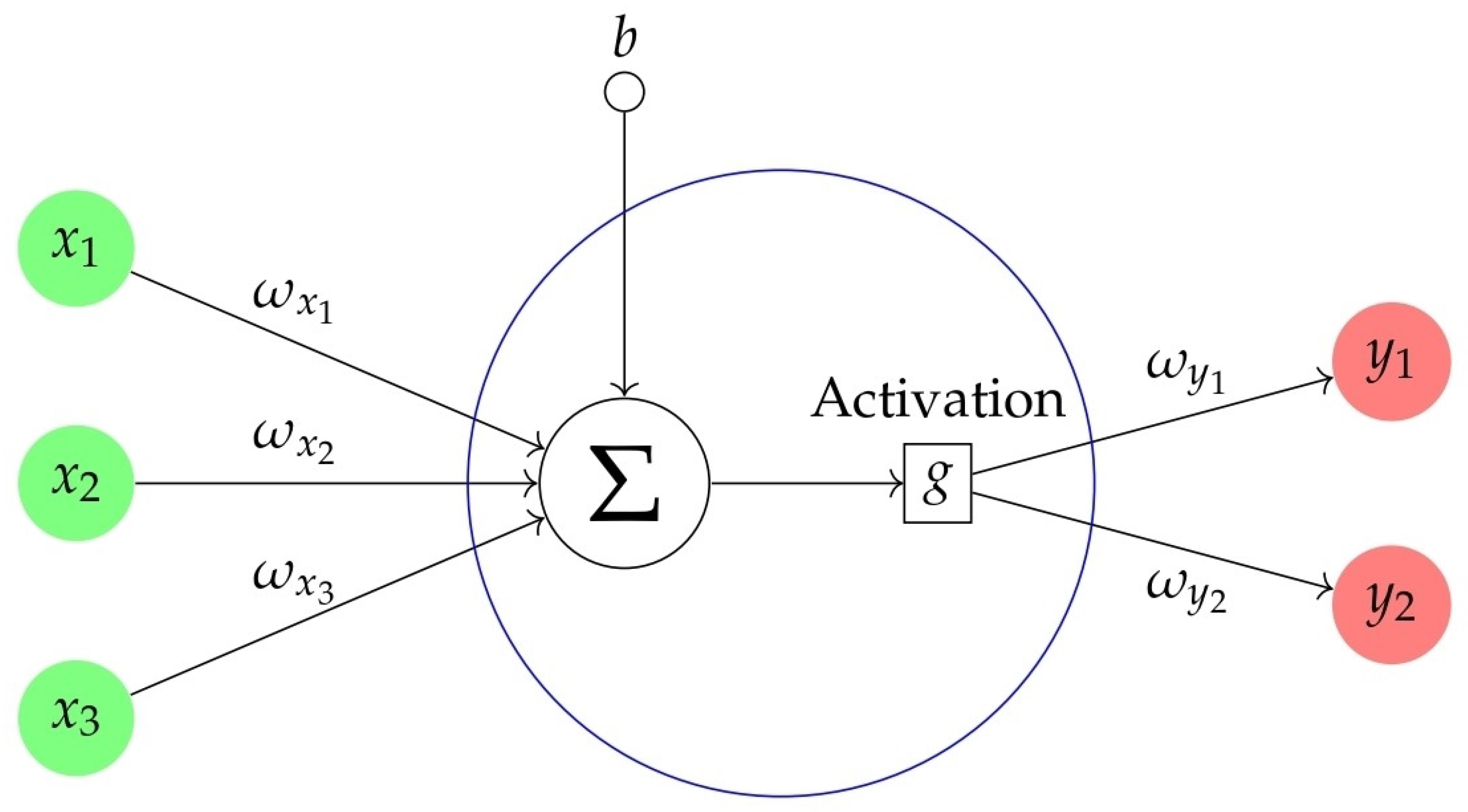
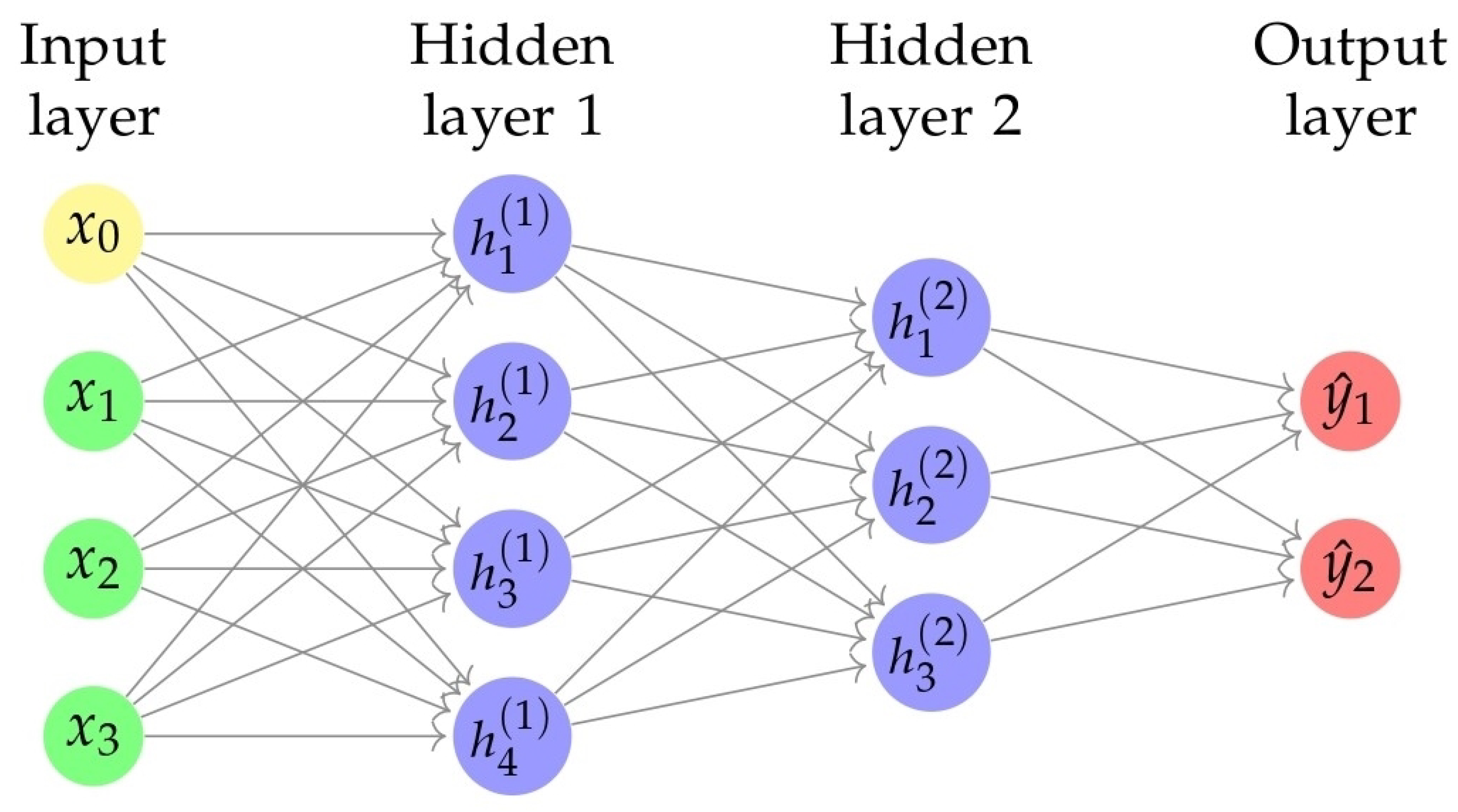


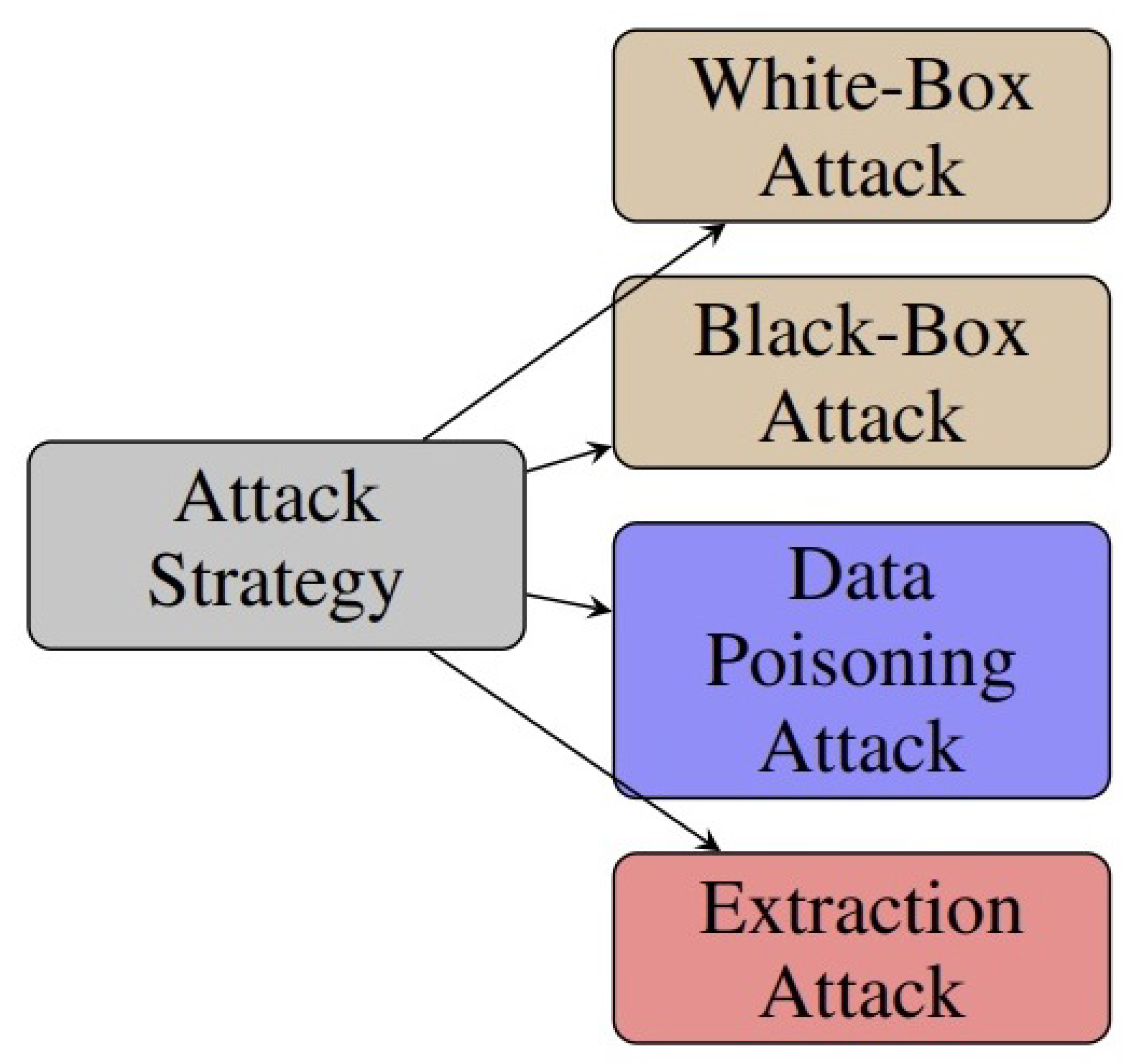


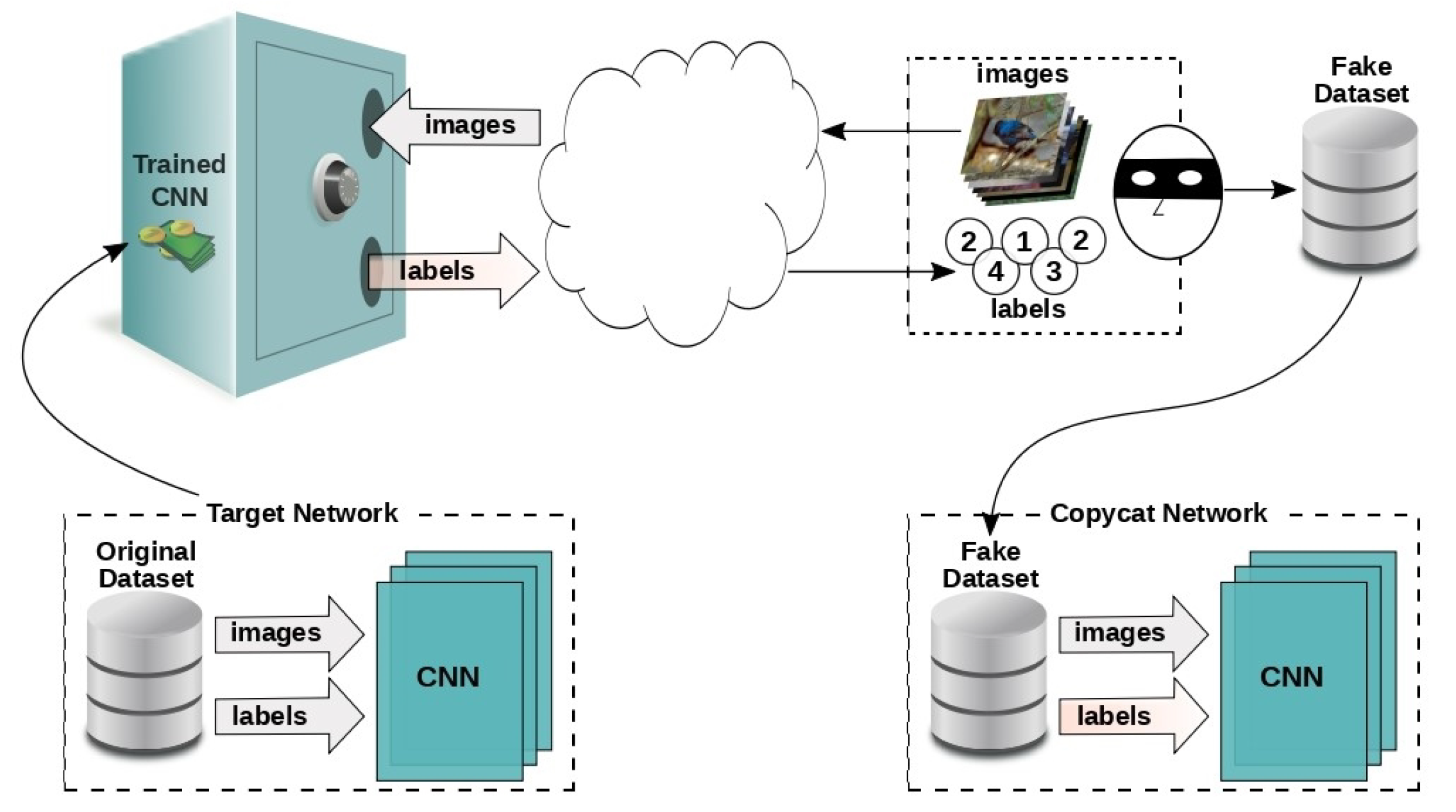


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Title | Year | Brief Description |
|---|---|---|
| Khamaiseh, et al. [15] | 2022 | This survey offered a comprehensive overview of the mathematical concepts and terminologies related to adversarial attacks and the latest defense mechanisms in image classification. |
| Sadeghi, et al. [27] | 2020 | This article introduced a system-driven taxonomy for defining ML applications and adversarial models, enabling clear replication of experiments and facilitating advancements in robust ML systems. |
| Ilahi, et al. [28] | 2020 | The review explored the increasing threats to DRL and possible strategies to protect against them. |
| Mohus, et al. [29] | 2023 | This work provided a methodical assessment of adversarial robustness in unsupervised ML, examining several attack and defense strategies in this field. |
| Apostolidis, et al. [31] | 2021 | This work summarized the latest developments in adversarial attack and defense strategies on CNN-based classification models used in medical image processing. |
| Ding, et al. [32] | 2020 | This paper provided an improved taxonomy for adversarial attacks, classic ones and the latest ones in computer vision, and also discusses some potential and some limitations. |
| Zhang, et al. [33] | 2020 | This article offered a comprehensive overview of research works that addressed the generation of textual adversarial examples on DNNs. |
| Akhtar, et al. [34] | 2018 | This article comprehensively analyzed adversarial attacks on DNN in computer vision. It focused on the challenges and methods to ensure the robustness and security of DNNs. |
| Wang, et al. [35] | 2022 | This report summarized the latest advancements and obstacles in adversarial attacks and defenses for DL models used in image recognition applications. |
| Macas, et al. [36] | 2023 | This article thoroughly analyses adversarial attacks and defenses in DNN-based cybersecurity systems. It also addresses unresolved issues and upcoming strategies to improve the robustness and reliability of DL systems against attackers. |
| Mengara, et al. [37] | 2024 | This survey examines recent advancements and challenges in backdoor attack strategies and defenses for DNN classifiers in security-sensitive applications. It highlights the most common methods for executing a backdoor attack and evaluates the most effective detection and prevention techniques. |
| Bhanushali, et al. [38] | 2024 | The survey examines adversarial attacks and defenses aimed at Automatic Speech Recognition systems that utilize DNNs. |
| Costa, et al. [39] | 2024 | This paper reviews recent adversarial attacks and defenses related to DL, specifically focusing on object recognition tasks. |
| Hoang [40] | 2024 | The survey provided the latest advances and challenges in adversarial attacks and defenses for AI-powered functionalities in 6G networks, covering classic wireless, open radio access (O-RAN), and next-generation systems. |
| This survey | 2025 | This review stands out from current surveys in multiple ways. This survey reviewed adversarial DL attacks and defense mechanisms for different ML tasks based on DNN compared with other surveys. It provides a clear formulation for both attacker and defender problems and a comprehensive overview of attack and defense strategies. |
| Title | Year | Attack | Task Type | Algorithm | Scenario | Knowledge | Target | Search |
|---|---|---|---|---|---|---|---|---|
| Bai et al. [96] | 2022 | White-Box | Classification | weight attack | Testing | White Box | Misclassify | Gradient |
| Wang et al. [97] | 2023 | Black-Box | Classification | ADSAttack | Training | Gray-Box | Misclassify | Greedy |
| Rakin et al. [98] | 2021 | White-Box | Classification | T-BFA | Testing | White-Box | Misclassify | Greedy |
| Wang et al. [99] | 2021 | White-Box | Classification | N/A | Training | White-Box | Misclassify | Gradient |
| Tang et al. [101] | 2021 | White-Box | Classification | Type I | Training | White-Box | Misclassify | Gradient |
| He et al. [102] | 2023 | black-Box | Classification | GAA | Training | black-Box | Misclassify | Iterative |
| Wan et al. [103] | 2023 | White-Box | Classification | Average gradient-based | N/A | White-Box | Misclassify | Gradient |
| Chen et al. [104] | 2021 | black-Box | Policy Learning | EIIE method | Both | black-Box | agent behavior | Greedy |
| He et al. [105] | 2022 | Black-Box | Classification | TG method | Testing | Black-Box | N/A | Gradient |
| Kong et al. [110] | 2023 | Black-Box | Classification | DE | Testing | Black-Box | Misclassify | Greedy |
| Cai et al. [111] | 2022 | Black-Box | Policy Learning | SR | Testing | Black-Box | agent behavior | Iterative |
| Duan et al. [112] | 2022 | Black-Box | Classification | DSNE | Training | Black-Box | residual networks | Gradient |
| Che et al. [113] | 2022 | Black-Box | Classification | SMGEA | Testing | White Box | N/A | Gradient |
| Kuang et al. [114] | 2019 | Black-Box | Classification | CMA-ES | Testing | Black-Box | CyberPhysical Systems | Iterative |
| Li et al. [115] | 2023 | Black-Box | Classification | SA-ES | Testing | Black-Box | Misclassify | Gradient |
| Wei et al. [116] | 2021 | Black-Box | Classification | N/A | Testing | Black-Box | Misclassify | Gradient |
| Cao et al. [117] | 2022 | Black-Box | Classification | ABCAttack | Testing | Black-Box | Misclassify | Metaheuristic |
| Wang et al. [118] | 2019 | Black-Box | Classification | N/A | Training | Black-Box | Misclassify | Iterative |
| Chen et al. [119] | 2022 | Black-Box | Classification | AoA | Training | Black-Box | Misclassify | Gradient |
| Shen et al. [127] | 2019 | Poisoning | Classification | TensorClog | Training | White-Box | Accuracy | Gradient |
| Shao et al. [128] | 2022 | Poisoning | Text Classification | N/A | Both | Black-Box | Accuracy | Greedy |
| Shen et al. [130] | 2023 | Black-Box | Representation Learning | DEAL | Testing | Black-Box | Misclassify | Iterative |
| Xiang et al. [131] | 2021 | Gray-Box | Classification | N/A | Testing | Gray-Box | Misclassify | Iterative |
| Hwang et al. [132] | 2019 | White-Box | Representation Learning | PuVAE | Training | N/A | N/A | Iterative |
| Title | Computational Cost | Approach | Type | Task Type | Mechanism | Against |
|---|---|---|---|---|---|---|
| Guan et al. [133] | Moderate | Reactive | Defense-Add-On | Classification | IACS | FGSM, PGD, JSMA, DeepFool, and CW2 |
| Aithal et al. [142] | Low | Proactive | Defense-Add-On | Classification | White Gaussian Noise Injection | black-box |
| Wei et al. [143] | High | Proactive | Defense-Add-On | Classification | XEnsemble | Evaluated by 11 popular adversarial attacks |
| Liu et al. [144] | Low | Proactive | Modifying ANN | Classification | RREC | against a targeted-BFA |
| Zoppi et al. [145] | Low | Reactive | Defense-Add-On | Classification | monitoring GPU | black-box and white-box |
| Nguyen et al. [146] | high | Proactive | Modifying ANN and Defense -Add-On | speech processing | augmentation methods | against black-box adversarial attacks, such as FGSM and PGD |
| Yang et al. [147] | Moderate | Reactive | Network Verification | Classification | AutoAttack detection | FGSM, PGD |
| Ryu et al. [148] | Low | Reactive | Defense-Add-On | Classification | entropy-based detector (EBD) | FGSM, BIM, MIM, DeepFool, and CW |
| Wu et al. [149] | High | Proactive | Modifying ANN and Defense-Add-On | Classification | Attention-based Adversarial Defense (AAD) | FGSM, PGD, and CW |
| Sotgiu et al. [150] | High | Reactive | Defense-Add-On | Classification | deep neural rejection (DNR) | multi-layer anomaly rejection approach |
| Xiang et al. [151] | moderate | Proactive | Modifying ANN | Classification | optimization-driven defense | Backdoor Attack |
| Shao et al. [152] | Moderate | Reactive | Defense-Add-On | Identifying suspicious words in input text | Backdoor Defense model based on Detection and Reconstruction | Backdoor Attack |
| Shao et al. [153] | Low | Proactive | Modifying ANN | text classification tasks | The defense method centered on recognizing poisoned samples. | against various backdoor attacks(character-level, word-level, and sentence-level backdoor attacks). |
| Hwang et al. [132] | High | Reactive | Defense-Add-On | Classification | Variational Autoencoder (VAE) | FGSM, iFGSM, and C&W |
| Representative Work | Application | Reported Performance |
|---|---|---|
| Bai et al. [96] | Image Classification | CIFAR-10 and ImageNet datasets. ASR: 100% for ResNet-20 and VGG-16. |
| Wang et al. [97] | Image Classification | CIFAR-10, ImageNet datasets. AvSR: 98.01% for ResNet-50, VGG-16, GoogleNet, MobileNet-v2. |
| Rakin et al. [98] | Image Classification | CIFAR-10 and ImageNet datasets. ASR: 100% for ResNet-20, VGG-11, ASR: for 99.99%,Accuracy 33% 59%for ResNet-18, ResNet-34, MobileNetV2. |
| Wang et al. [99] | Image Classification | MNIST, CIFAR-10, and ImageNet datasets. ASR: 100% for Custom CNN, and Inception V3 |
| Tang et al. [101] | Face Recognition | CelebA. ASR: 69.8% for gender transformation while keeping FaceNet’s person classification unchanged for the FaceNet model. |
| Cao et al. [117] | Image Classification | MNIST and CIFAR-10 datasets. ASR: 94.89% AvgQueries: 1695 for CNN model. ASR: 82.3% AvgQueries: 851 for CNN model. |
| He et al. [102] | Face Recognition | CelebA. Accuracy 71.2% for FaceNet model. |
| Kong et al. [108] | Image Classification | ImageNet. ASR: Achieved 100% ASR in most configurations. Query Efficiency: Required 73% for Inception-v3, ResNet-50, VGG-16-BN. |
| Li et al. [115] | Image Classification | MNIST and CIFAR-10 datasets. ASR: 100% within 500 queries. Query Efficiency: Achieved 74.7% for CNN ASR: 100% within 1000 queries for ResNet-50. |
| Hwang et al. [132] | Image Classification, autonomous-driving, face identification, and surveillance systems | MNIST, MNIST Fashion, and CIFAR-10 datasets. Accuracy FGSM: 96.2%, iFGSM: 94.1%, CW: 91.7% Accuracy FGSM: 84.5%, iFGSM: 81.3%, CW: 80.2% Accuracy FGSM: 68.3%, iFGSM: 65.7%, CW: 62.1%. CNN model. |
| Kuang et al. [114] | Image Classification | ImageNet datasets. ASR: 100 Average Queries: 74,948 for the InceptionV3 model. |
| Shao et al. [128] | Text Classification | SST-2 (Stanford Sentiment Treebank), IMDB datasets. ASR: 90% for SST-2 BiLSTM/BERT. |
| Xu et al. [186] | Android Malware | Detection, and virusshare malware dataset. MR: 98.25, Query Efficiency: 1176 for DNN ([200, 100], [200, 200], [10, 10])%. |
| Chang et al. [187] | Energy-Delay Product (EDP) | CIFAR-10 and ImageNet datasets. 75.9% for MobileNet v1. |
| Chen et al. [104] | Portfolio Management | TWSE dataset. ASR: Greedy and RL-based attacks reduced portfolio value to 0.92 on average. |
| Shawn et al. [25] | Malware Classification | EMBER Malware dataset Precision: 99.2%, Recall: 98.2%. |
| Shao et al. [152] | Text Classification | SST-2, IMDB dataset. SST-2: ASR 96.4% for BiLSTM model) and 100% for BERT model. IMDB: ASR 97% BiLSTM and 98.8 for BERT model%. |
| Shao et al. [153] | Recognition for Textual Backdoor Defense | SST-2, IMDB dataset. ASR(No Defense): 92.92% (SST-2, BiLSTM) and 100% (IMDB, BERT). ASR (Defense): 6.41% (SST-2, BiLSTM) and 0.20% (IMDB, BERT). |
| Correia et al. [129] | Facial Expression Recognition (FER) | Test Dataset (TD). Accuracy Target (OD): 88.7%, PD-OL: 82.5%, NPD-SL: 83.0%, PD-SL: 83.4%, NPD+PD-SL: 87.4%. CNN model. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abomakhelb, A.; Jalil, K.A.; Buja, A.G.; Alhammadi, A.; Alenezi, A.M. A Comprehensive Review of Adversarial Attacks and Defense Strategies in Deep Neural Networks. Technologies 2025, 13, 202. https://doi.org/10.3390/technologies13050202
Abomakhelb A, Jalil KA, Buja AG, Alhammadi A, Alenezi AM. A Comprehensive Review of Adversarial Attacks and Defense Strategies in Deep Neural Networks. Technologies. 2025; 13(5):202. https://doi.org/10.3390/technologies13050202
Chicago/Turabian StyleAbomakhelb, Abdulruhman, Kamarularifin Abd Jalil, Alya Geogiana Buja, Abdulraqeb Alhammadi, and Abdulmajeed M. Alenezi. 2025. "A Comprehensive Review of Adversarial Attacks and Defense Strategies in Deep Neural Networks" Technologies 13, no. 5: 202. https://doi.org/10.3390/technologies13050202
APA StyleAbomakhelb, A., Jalil, K. A., Buja, A. G., Alhammadi, A., & Alenezi, A. M. (2025). A Comprehensive Review of Adversarial Attacks and Defense Strategies in Deep Neural Networks. Technologies, 13(5), 202. https://doi.org/10.3390/technologies13050202