
Opinion Mining and Analysis Using Hybrid Deep Neural Networks




Abstract
1. Introduction
- Enhanced contextual understanding: BGRU processes text bidirectionally, capturing finer-grained sentiment dependencies than plain LSTMs. LSTM retains long-term dependencies in memory, preventing the loss of vital sentiment cues in lengthy reviews.
- Addressing class imbalance: The majority of the sentiment analysis datasets suffer from skewed class distributions, leading to biased predictions. This model incorporates data balancing methods for making classification fairer and more performing on minority sentiment classes.
- Improving computational efficiency: by obtaining optimum training time without compromising on accuracy, the model lends itself to real-time sentiment analysis applications.
2. Related Work
3. Datasets and Data Preprocessing
3.1. Datasets Description
3.2. Data Preprocessing
- Dataset selection and combination for more generalization: Sentiment models tend to fall prey to the issue of domain adaptation, with models trained from one dataset being less effective in other datasets. To minimize such a problem, we combined both the IMDB movie reviews dataset and Amazon product reviews dataset so that there existed a diversified pool of sentiment expression from various domains. Through the union of datasets, we expose the model to varied writing styles, colloquial language, and sentiment trigger exposure, lessening overfitting to a particular domain.
- Overcoming class imbalance: One of the biggest downsides of DL models applied in sentiment analysis is their leaning towards majority classes as a result of data skewness. To rectify the dataset and achieve improved model performance, we combined a random sample of negative reviews from the IMDB dataset with the Amazon dataset (Table 3). Rather than relying on traditional random resampling (which can potentially introduce noise), we carefully combined a subset of negative IMDB reviews with Amazon reviews. This method gave an approximate equal balance between positive and negative sentiments while preserving the structure of the text.The numbers in Table 3 reflect a carefully adjusted subset to ensure a more balanced sentiment distribution across training and testing phases.
- Context-aware advanced text cleaning: While standard preprocessing pipelines consist of stopword elimination and stemming/lemmatization, we took the process to the limit in order to avoid context loss and valuable sentiment words elimination. We employed context-sensitive filtering in which negation terms and boosters like “very”, “extremely” were not eliminated when trying to boost sentiment classification accuracy.
- Embeddings optimization and tokenization: To convert the text data to machine data, we utilized the pre-trained word embeddings (Word2Vec) [35,36] instead of the standard Bag of Words [37]. These semantic embeddings make it possible for the model to learn the connection between words from context, and these improve model performance with synonyms and sentiment shifts. In general, an embedding layer represents the meaning of items semantically by keeping semantically similar items. It puts big entries into small places so that similar entries are close to each other. This layer identifies which words appear like other words according to geometric relations that enclose semantic relations, like the capital and country. It can be paired with any hidden layer and it is bound to one hidden layer that maps all the indexes to their embeddings. It also utilizes the entire coding lexicon. These vectors are subsequently learned as a training model.
- Smart data splitting for fair assessment: We removed unlabeled data and, unlike random dataset splits, we ensured that our 30–70% train–test split maintained sentiment proportions within both sets. We enforced stratified sampling so that negative and positive reviews were well represented within the train set and test set. The exact ratios vary slightly between models because the dataset is split. All models possess 26,688 training samples, while the test set contains 11,439 samples.
- Efficient feature vectorization and encoding: We used one-hot encoding for categorical sentiment labels so that it was simple to use with deep neural networks without sacrificing interpretability.
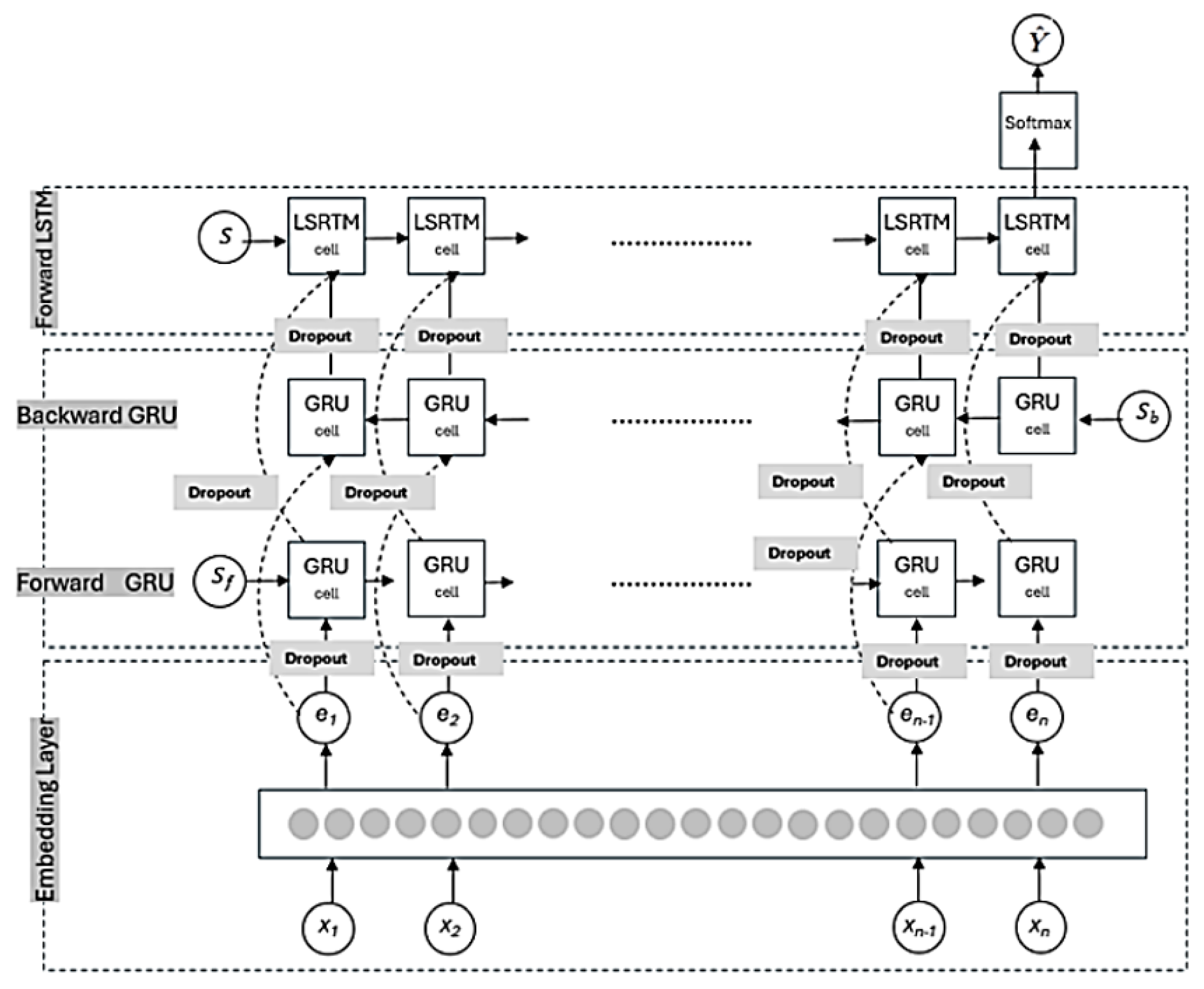
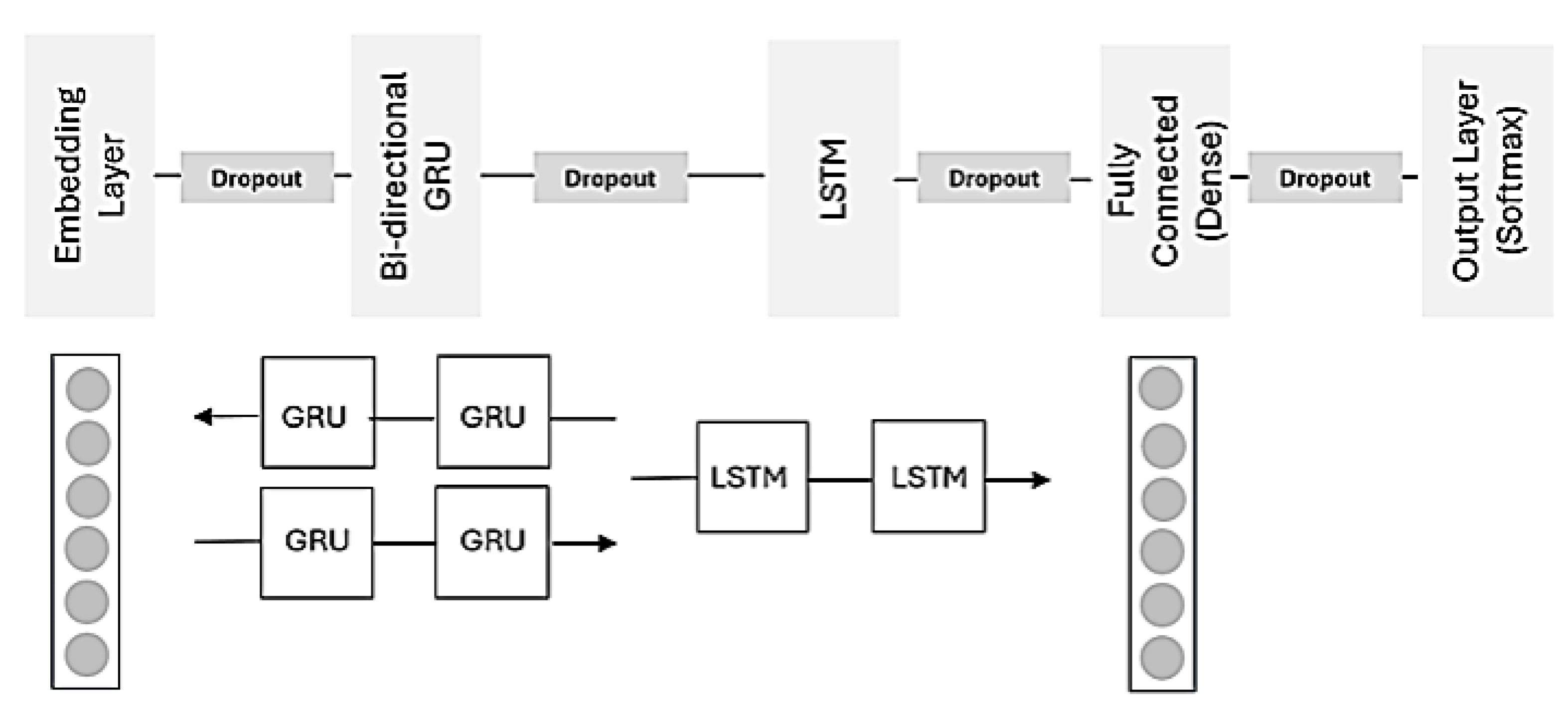
4. Hybrid Deep Neural Networks for Opinion Mining
4.1. Embedding Layer
4.2. BGRU Layer
4.3. LSTM Layer
- Forget gate: It determines the fraction of past memory to retain. It is given by Equation (11).
- Input ate: It controls how much new information is added to the memory cell. It is given by Equation (12).
- Output gate: It regulates the final hidden state based on the updated memory cell. It is given by Equation (13).Once these gates are computed, the next step is to update the memory cell and determine the hidden state. The candidate update to the memory cell is computed using Equation (14).This intermediate value represents a potential memory update before the forget and input gates determine the final contribution. The actual memory cell is then updated by selectively retaining past memory and integrating the new candidate value using Equation (15).Here, the forget gate decides how much of the previous memory is kept, while the input gate determines the impact of .Finally, the hidden state at time step t is computed based on the updated memory cell and the output gate using Equation (16).This hidden state serves as the output for the current time step and is passed to the next iteration in the sequence.By leveraging these mechanisms, LSTMs effectively manage long-range dependencies, ensuring that sentiment-related cues from earlier in the text are not lost. When combined with BGRU, this architecture strengthens the model’s ability to process complex sentiment structures, leading to more accurate classification results.
4.4. Fully Connected Dense Layer
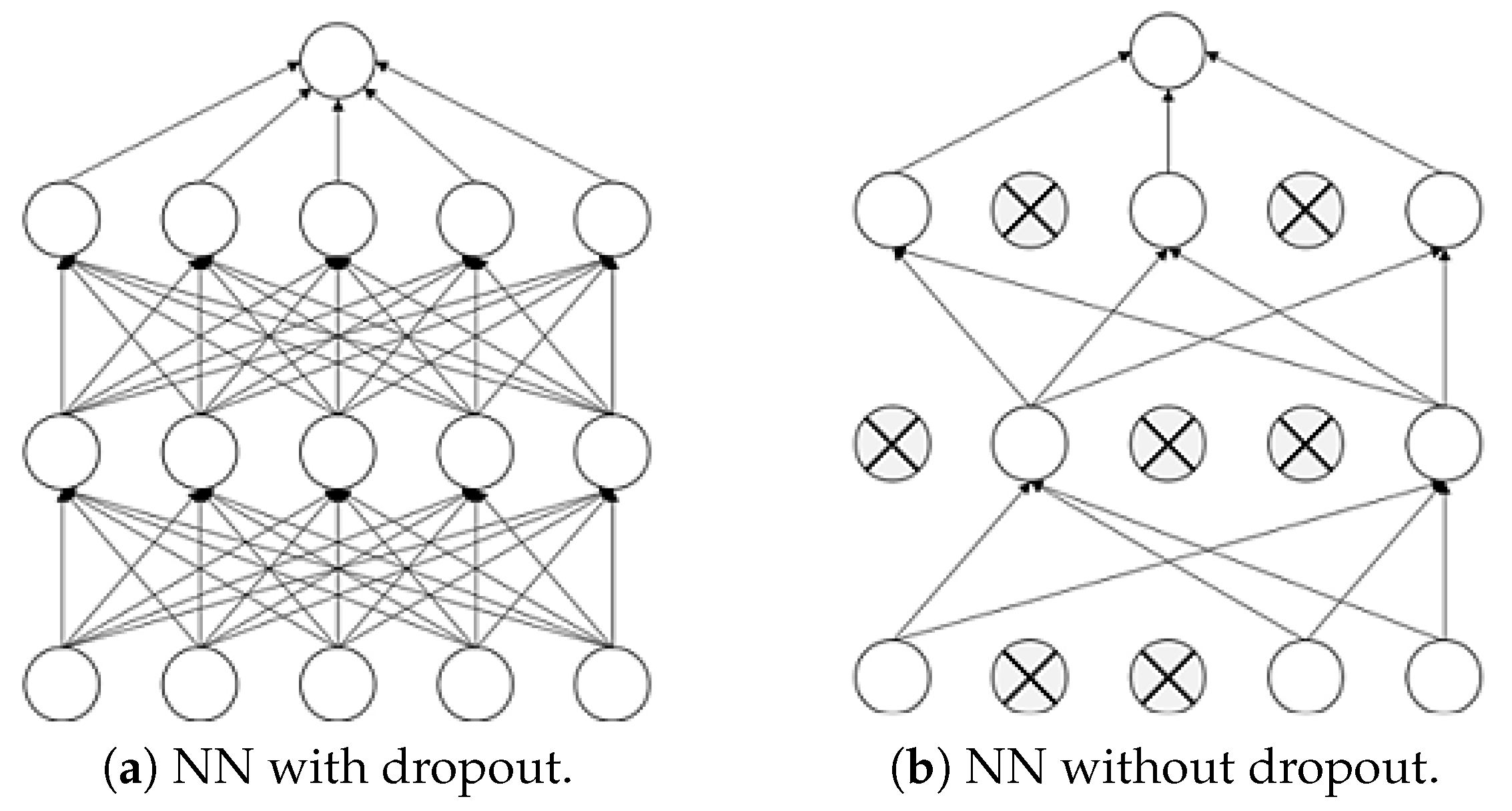
4.5. Dropout Regularization
| Algorithm 1 HBGRU-LSTM for opinion mining. |
|
5. Evaluative Experiments
5.1. Implementation and Setup
5.2. Loss Function, Performance Metrics, and Optimization
5.3. Statistical Evaluation
5.4. Results
5.5. Execution Time Performance Analysis
- Batch size: 128
- Number of epochs: 100
- Optimizer: Adam (learning rate = 0.001)
- Parallelized batch processing: It improves inference by running multiple reviews concurrently.
- Less sequence padding: It improves memory efficiency and speed for training and inference.
- Dropout regularization: It prevents redundant computation while training by randomly dropping units in the network.
- Early stopping mechanism: It prevents overtraining upon convergence, thereby saving time.
6. Discussion
- Social media monitoring: The model can be integrated with real-time social media analytics software to track and analyze customer sentiment, brand image, and public opinion trends in real time. This can be used by companies for proactive marketing and reputation management.
- E-commerce and customer review analysis: The model can enhance real-time product review analysis, allowing e-commerce sites to categorize and summarize customer opinions efficiently. This can assist businesses in product development, customer issue resolution, and recommendation optimization.
- Financial and stock market prediction: Based on real-time news articles, financial reports, and social media sentiment analysis, the model can produce forecasts of stock direction and economic trends to help investors and financial analysts make decisions.
- Patient and healthcare feedback systems: The model can be utilized to implement on patient review systems such that relevant feedback on hospitals, doctors, and treatment can be collected. This will assist healthcare professionals in enhancing the patient experience and medical treatment according to sentiment patterns.
- Customer service automation: The model can be integrated into chat-bots and virtual assistants to monitor customer sentiment in real-time, providing adequate responses and escalation of critical issues to human representatives whenever needed.
- Political and social sentiment analysis: Governments and policymakers can use the model to track public mood in real-time for policies, elections, and issues of national interest so that they can make evidence-based decisions.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BCE | Binary Cross-Entropy |
| BGRU | Bidirectional Gated Recurrent Unit |
| BoW | Bag of Words |
| CNN | Convolutional Neural Networks |
| DL | Deep Learning |
| DT | Decision Trees |
| GRUs | Gated Recurrent Units |
| HBGRU | Hybrid Bidirectional Gated Recurrent Unit |
| LSTM | Long Short Term Memory |
| ML | Machine Learning |
| NB | Naïve Bayes |
| NLP | Natural Language Processing |
| ReLU | Rectified Linear Unit |
| RNN | Recurrent Neural Networks |
| SVM | Support Vector Machine |
| TF-IDF | Term Frequency-Inverse Document Frequency |
References
- Mourtzis, D.; Vlachou, E.; Zogopoulos, V.; Gupta, R.-K.; Belkadi, F.; Debbache, A.; Bernard, A. Customer feedback gathering and management tools for product-service system design. In Proceedings of the 11th CIRP Conference on Intelligent Computation in Manufacturing Engineering (CIRP ICME), Ischia, Italy, 19–21 July 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 577–582. [Google Scholar] [CrossRef]
- Subramanian, A.; Ganesan, V.; Ramasamy, V. Analyzing Consumer Product Feedback Dynamics with Confidence Intervals. In Technology Innovation Pillars for Industry 4.0; CRC Press: Boca Raton, FL, USA, 2024; pp. 115–128. [Google Scholar] [CrossRef]
- Han, S.; Li, Y.; Jiang, Y.; Zhao, X. Exploring the persuasion effect of restaurant food product online reviews on consumers’ attitude and behavior. In Proceedings of the 1st International Conference on Internet and e-Business (ICIEB), Singapore, 25–27 April 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 57–60. [Google Scholar] [CrossRef]
- Küsgen, S.; Köcher, S. The influence of customer product ratings on purchase decisions: An abstract. In Creating Marketing Magic and Innovative Future Marketing Trends, Proceedings of the 2016 Academy of Marketing Science (AMS) Annual Conference; Springer: Berlin/Heidelberg, Germany, 2017; pp. 953–954. [Google Scholar] [CrossRef]
- Rahate, S.; Dehanka, V.; Teppalwar, T.; Surjuse, V. Review sentimental analysis. International J. Comput. Sci. Mob. Comput. 2022, 11, 37–41. [Google Scholar] [CrossRef]
- Munro, J. Online opinions changing care. Br. J. Nurs. 2017, 26, 722. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Yang, K.; Zhang, J.-Z.; Palmatier, R.-W. Uncovering synergy and dysergy in consumer reviews: A machine learning approach. Manag. Sci. 2022, 69, 2339–2360. [Google Scholar] [CrossRef]
- Dubey, G.; Rana, A.; Ranjan, J. A research study of sentiment analysis and various techniques of sentiment classification. International J. Data Anal. Tech. Strateg. 2016, 8, 122–142. [Google Scholar] [CrossRef]
- Onan, A.; Onan, A.; Korukoglu, S.; Bulut, H. A multiobjective weighted voting ensemble classifier based on differential evolution algorithm for text sentiment classification. Expert Syst. Appl. 2016, 62, 1–16. [Google Scholar] [CrossRef]
- Choudhari, P.; Veenadhari, S. Sentiment classification of online mobile reviews using combination of word2vec and bag-of-centroids. Adv. Intell. Syst. Comput. 2020, 1101, 69–80. [Google Scholar] [CrossRef]
- Wattanakitrungroj, N.; Pinpo, N.; Tongman, S. Sentiment polarity classification using minimal feature vectors and machine learning algorithms. In Proceedings of the 12th International Conference on Advanced Information Technologies (IAIT), Bangkok, Thailand, 29 June–1 July 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Krishna, M.-M.; Duraisamy, B.; Vankara, J. Independent component support vector regressive deep learning for sentiment classification. Meas. Sens. 2023, 26, 100678. [Google Scholar] [CrossRef]
- Nareshkumar, R.; Nimala, K. Interactive deep neural network for aspect-level sentiment analysis. In Proceedings of the International Conference on Artificial Intelligence and Knowledge Discovery (ICECONF), Chennai, India, 5–7 January 2023; pp. 1–8. [Google Scholar] [CrossRef]
- Poobana, S.; Rekha, K.S. Opinion mining from text reviews using machine learning algorithm. Int. J. Innov. Res. Comput. Commun. Eng. 2015, 3, 1567–1570. [Google Scholar] [CrossRef]
- Vishwakarma, S. A review paper on sentiment analysis using machine learning. Int. J. Res. Appl. Sci. Eng. Technol. 2023, 11, 528–531. [Google Scholar] [CrossRef]
- Arumugam, S.-R.; Gowr, S.; Abimala, B.; Manoj, O. Performance evaluation of machine learning and deep learning techniques. In Convergence Deep Learning Cyber-IoT System Security; Chakraborty, R., Ghosh, A., Mandal, J.K., Balamurugan, S., Eds.; Wiley: Hoboken, NJ, USA, 2022. [Google Scholar] [CrossRef]
- Bavakhani, M.; Yari, A.; Sharifi, A. A deep learning approach for extracting polarity from customers’ reviews. In Proceedings of the 5th International Conference on Web Research (ICWR), Tehran, Iran, 24–25 April 2019; pp. 276–280. [Google Scholar] [CrossRef]
- Hidri, M.S. Learning-based models for building user profiles for personalized information access. Interdiscip. J. Inf. Knowl. Manag. 2024, 19, 010. [Google Scholar] [CrossRef]
- Feng, B. Deep learning-based sentiment analysis for social media: A focus on multimodal and aspect-based approaches. Appl. Comput. Eng. 2024, 33, 1–8. [Google Scholar] [CrossRef]
- Singh, N.; Bathla, G. Evaluation of opinion mining approaches: Using deep learning for large-scale data. In Proceedings of the 2nd International Conference on Networking, Multimedia, and Information Technology (NMITCON), Bengaluru, India, 9–10 August 2024; pp. 1–8. [Google Scholar] [CrossRef]
- Anwar, K.; Garg, A.; Ahmad, S.; Wasid, M. Machine learning models for sentiment analysis: State of the art and applications. In Proceedings of the 15th International Conference on Computer Communication and Network Technology (ICCCNT), Kamand, India, 24–28 June 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Ejaz, A.; Turabee, Z.; Rahim, M.; Khoja, S.-A. Opinion mining approaches on Amazon product reviews: A comparative study. In Proceedings of the International Conference on Information and Communication Technology (ICICT), Karachi, Pakistan, 30–31 December 2017; pp. 173–179. [Google Scholar] [CrossRef]
- Baccianella, S.; Esuli, A.; Sebastiani, F. SentiWordNet 3.0: An enhanced lexical resource for sentiment analysis and opinion mining. In Proceedings of the International Conference on Language Resources and Evaluation (LREC), Valletta, Malta, 17–23 May 2010; European Language Resources Association (ELRA): Paris, France, 2010; pp. 2200–2204. Available online: https://aclanthology.org/L10-1531/ (accessed on 15 August 2024).
- Liu, P.; Joty, S.; Meng, H. Fine-grained opinion mining with recurrent neural networks and word embeddings. In Proceedings of the Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Stroudsburg, PA, USA, 2015; pp. 1433–1443. [Google Scholar] [CrossRef]
- Kurniasari, L.; Setyanto, A. Sentiment analysis using recurrent neural network. J. Phys. Conf. Ser. 2020, 1471, 012018. [Google Scholar] [CrossRef]
- Sachin, S.; Tripathi, A.; Mahajan, N.; Aggarwal, S.; Nagrath, P. Sentiment analysis using gated recurrent neural networks. SN Comput. Sci. 2020, 1, 74. [Google Scholar] [CrossRef]
- Sharma, P. Convolutional neural networks for sentiment analysis. Int. J. Sci. Technol. Eng. 2024, 12, 465–469. [Google Scholar] [CrossRef]
- Youbi, F.; Settouti, N. Convolutional neural networks for opinion mining on drug reviews. In Proceedings of the 1st International Conference on Intelligent Systems and Pattern Recognition, Virtual Event, Tunisia, 16–18 October 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 33–38. [Google Scholar] [CrossRef]
- Savla, M.; Gopani, D.; Ghuge, M.; Chaudhari, S.; Raundale, P. Sentiment Analysis of Human Speech using Deep Learning. In Proceedings of the 3rd International Conference on Intelligent Technologies (CONIT), Hubli, India, 23–25 June 2023; pp. 1–6. [Google Scholar]
- Mathews, A.; Singh, P.-N. Opinion mining from audio conversation using machine learning tools and BART transformers. In Proceedings of the 3rd International Conference on Mobile Networks and Wireless Communications (ICMNWC), Tumkur, India, 4–5 December 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Singh, S. Analysis of feature extraction techniques for sentiment analysis of tweets. Turk. J. Eng. 2024, 8, 741–753. [Google Scholar] [CrossRef]
- Alnahas, D.; Aşık, F.; Kanturvardar, A.; Ülkgün, A.M. Opinion mining using LSTM networks ensemble for multi-class sentiment analysis in e-commerce. In Proceedings of the 3rd International Informatics and Software Engineering Conference (IISEC), Ankara, Turkey, 15–16 December 2022; pp. 1–6. [Google Scholar] [CrossRef]
- ElMassry, A.-M.; Alshamsi, A.; Abdulhameed, A.-F.; Zaki, N.; Belkacem, A.-N. Machine learning approaches for sentiment analysis on balanced and unbalanced datasets. In Proceedings of the IEEE 14th International Conference on Control Systems and Computer Engineering (ICCSCE), Penang, Malaysia, 23–24 August 2024; pp. 18–23. [Google Scholar] [CrossRef]
- Suryawanshi, N. Sentiment analysis with machine learning and deep learning: A survey of techniques and applications. Int. J. Sci. Res. Arch. 2024, 12, 5–15. [Google Scholar] [CrossRef]
- Ganguly, D.; Roy, D.; Mitra, M.; Jones, G.-J. Word embedding based generalized language model for information retrieval. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 795–798. [Google Scholar] [CrossRef]
- Sivakumar, S.; Videla, L.S.; Kumar, T.R.; Nagaraj, J.; Itnal, S.; Haritha, D. Review on word2vec word embedding neural net. In Proceedings of the International Conference on Smart Electronics and Communication (ICOSEC), Trichy, India, 10–12 September 2020; pp. 282–290. [Google Scholar] [CrossRef]
- Dahouda, M.-K.; Joe, I. A deep-learned embedding technique for categorical features encoding. IEEE Access 2021, 9, 114381–114391. [Google Scholar] [CrossRef]
- Hu, M.; Jiang, L. An efficient numerical method for forward-backward stochastic differential equations driven by G-Brownian motion. Appl. Numer. Math. 2021, 165, 578–597. [Google Scholar] [CrossRef]
- Prabha, B.; Maheshwari, S.; Durgadevi, P. Sentiment Analysis using Long Short-Term Memory. In Proceedings of the 14th International Conference on Computing Communication and Networking Technologies (ICCCNT), Delhi, India, 6–8 July 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Priyadarshini, I.; Cotton, C. A novel LSTM–CNN–grid search-based deep neural network for sentiment analysis. J. Supercomput. 2021, 77, 13911–13932. [Google Scholar] [CrossRef]
- Shen, C. A transdisciplinary review of deep learning research for water resources scientists. Water Resour. Res. 2017, 54, 8558–8593. [Google Scholar] [CrossRef]
- Shim, J.W. Enhancing cross entropy with a linearly adaptive loss function for optimized classification performance. Dent. Sci. Rep. 2024, 14, 27405. [Google Scholar] [CrossRef]
- Kumar, V.; Recuper, D.R.; Riboni, D.; Helaoui, R. Ensembling Classical Machine Learning and Deep Learning Approaches for Morbidity Identification From Clinical Notes. IEEE Access 2021, 9, 7107–7126. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Methodology Used | Drawbacks | Strengths |
|---|---|---|---|
| Lexicon-based approaches [22,23] | Predefined sentiment lexicons to classify text polarity. | Fails to capture contextual meaning, requires extensive manual annotation, limited domain adaptability. | Provides a dynamic DL-based approach that learns sentiment from data rather than relying on static lexicons. |
| Traditional ML models [15,31,33,34] | Feature engineering techniques (BoW, TF-IDF, N-grams) combined with classifiers. | Requires manual feature extraction, does not generalize very well on large datasets, breaks down with class imbalance. | Evades manual feature extraction by using DL-based word embeddings. |
| DL with LSTMs [24,25] | LSTM networks for sentiment classification. | High computational cost, has difficulties with bidirectional context recognition, incapable of handling class imbalance effectively. | Enhances sequential learning through the combination of BGRU and LSTM to facilitate improved retention of information as well as bidirectional processing. |
| CNN-based models [27,28] | Convolutional filters to extract local text patterns. | Does not effectively capture long-term dependencies, limited for sequential data. | Enhances learning by combining CNN-like spatial learning with BGRU-LSTM sequential learning. |
| Transformer-based models [29,30] | Self-attention mechanisms to learn word importance dynamically. | Computationally expensive, requires extensive fine-tuning. | Provides a lightweight alternative with competitive performance. |
| Dataset | #Positive Reviews | #Negative Reviews |
|---|---|---|
| IMDB | 25,000 | 25,000 |
| AMAZON | 84,954 | 97,061 |
| Dataset | #Positive Reviews | #Negative Reviews |
|---|---|---|
| IMDB + AMAZON | 28,230 | 27,397 |
| Symbol | Description |
|---|---|
| Input sequence of words (review). | |
| Word embedding vector of dimension d. | |
| Forward and backward hidden states of BGRU at time step t. | |
| Combined BGRU hidden state at time t. | |
| LSTM cell state and hidden state at time t. | |
| Learnable weight matrices and biases. | |
| y | Sentiment label (0 = Negative, 1 = Positive). |
| Predicted sentiment label. | |
| Sigmoid activation function. | |
| Binary cross-entropy loss function. |
| Metrics | Unbalanced Dataset | Balanced Dataset |
|---|---|---|
| Positive class ratio | 74.04% | 50.75% |
| Negative class ratio | 25.96% | 49.25% |
| Accuracy in training | 93% | 94% |
| Accuracy in testing | 93.64% | 95% |
| Percent lost | 20.24% | 13.30% |
| Training loss rate | 0.17 | 0.13 |
| Classes | #Reviews | Unbalanced Dataset | Balanced Dataset | ||||
|---|---|---|---|---|---|---|---|
| Accuracy | Recall | F1-Score | Accuracy | Recall | F1-Score | ||
| Negative class | 2951 | 89% | 86% | 87% | 95% | 96% | 96% |
| Positive class | 8488 | 95% | 96% | 96% | 96% | 95% | 96% |
| Metrics | LSTM | CNN+LSTM | GRU+LSTM | HBGRU-LSTM |
|---|---|---|---|---|
| Positive class ratio | 50.7% | 52% | 50.7% | 50.75% |
| Negative class ratio | 49.3% | 48% | 49.3% | 49.25% |
| Accuracy in training | 92.0% | 93.07% | 92.24% | 94% |
| Accuracy in testing | 93.06% | 93.31% | 92.20% | 95% |
| Percent lost | 18.52% | 19.81% | 26.80% | 13.30% |
| Training loss rate | 0.19 | 0.17 | 0.19 | 0.13 |
| Model | Classification Metrics | −Class | +Class |
|---|---|---|---|
| LSTM | Accuracy | 88% | 96% |
| Recall | 91% | 94% | |
| F1-Score | 90% | 95% | |
| CNN+LSTM | Accuracy | 86% | 96% |
| Recall | 89% | 95% | |
| F1-Score | 87% | 95% | |
| GRU+LSTM | Accuracy | 93% | 92% |
| Recall | 76% | 98% | |
| F1-Score | 83% | 95% | |
| HBGRU-LSTM | Accuracy | 95% | 96% |
| Recall | 96% | 95% | |
| F1-Score | 96% | 96% |
| Model | Accuracy | F1-Score (−Class) | F1-Score (+Class) | Percent Loss |
|---|---|---|---|---|
| LSTM | 93.06% | 90% | 95% | 18.52% |
| CNN+LSTM | 93.31% | 87% | 91% | 19.81% |
| GRU+LSTM | 92.20% | 83% | 97% | 26.80% |
| HBGRU-LSTM | 95% | 96% | 97% | 13.30% |
| Model | TP | TN | FP | FN |
|---|---|---|---|---|
| LSTM | 5568 | 4962 | 677 | 232 |
| CNN+LSTM | 5710 | 4722 | 769 | 238 |
| GRU+LSTM | 5336 | 5244 | 395 | 464 |
| HBGRU-LSTM | 5573 | 5352 | 282 | 232 |
| Training Time | Inference Time | Batch Inference Time | |
|---|---|---|---|
| Notation | |||
| Runtime | 4.7 h | 1.2 ms | 1.2 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hidri, A.; Alsaif, S.A.; Alahmari, M.; AlShehri, E.; Sassi Hidri, M. Opinion Mining and Analysis Using Hybrid Deep Neural Networks. Technologies 2025, 13, 175. https://doi.org/10.3390/technologies13050175
Hidri A, Alsaif SA, Alahmari M, AlShehri E, Sassi Hidri M. Opinion Mining and Analysis Using Hybrid Deep Neural Networks. Technologies. 2025; 13(5):175. https://doi.org/10.3390/technologies13050175
Chicago/Turabian StyleHidri, Adel, Suleiman Ali Alsaif, Muteeb Alahmari, Eman AlShehri, and Minyar Sassi Hidri. 2025. "Opinion Mining and Analysis Using Hybrid Deep Neural Networks" Technologies 13, no. 5: 175. https://doi.org/10.3390/technologies13050175
APA StyleHidri, A., Alsaif, S. A., Alahmari, M., AlShehri, E., & Sassi Hidri, M. (2025). Opinion Mining and Analysis Using Hybrid Deep Neural Networks. Technologies, 13(5), 175. https://doi.org/10.3390/technologies13050175