
Pix2Next: Leveraging Vision Foundation Models for RGB to NIR Image Translation


 and
and 
Abstract

1. Introduction
- 1.
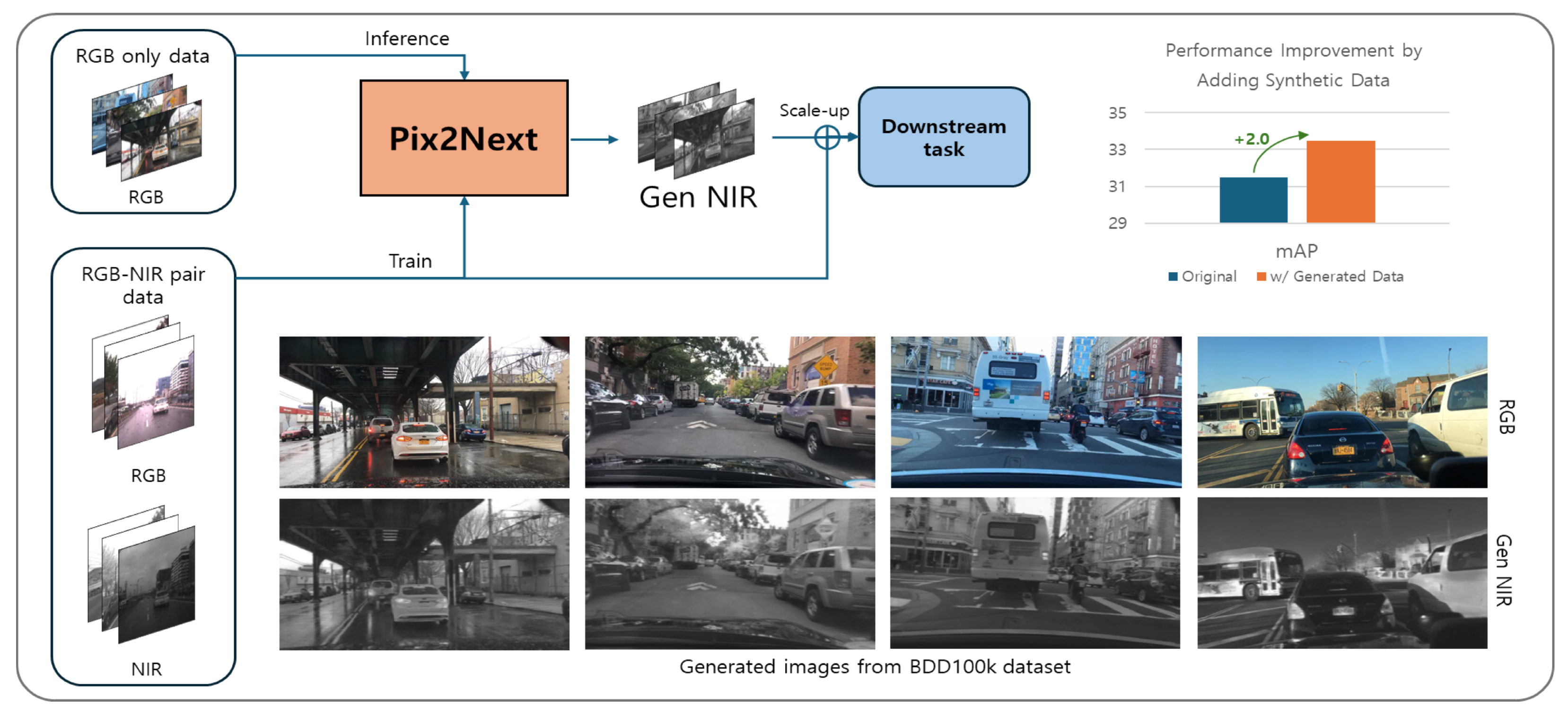
- Overcoming the challenge of limited NIR data: We address the scarcity of NIR data compared to RGB data by employing I2I translation to generate NIR images from RGB images. This allows us to expand the NIR dataset by transferring annotations from RGB images, circumventing the need for direct NIR data acquisition and annotation efforts.
- 2.
- Introducing an enhanced I2I model—Pix2Next—and demonstrating its improved performance: Existing I2I models fail to accurately capture details and spectral characteristics when translating RGB images into other wavelength domains. To overcome this limitation, we propose a novel model, Pix2Next, inspired by Pix2pixHD. Our model achieves SOTA performance in generating more accurate images in alternative wavelength domains from RGB inputs.
- 3.
- Validating the utility of generated NIR data for data augmentation: To evaluate the utility of the translated images, we scaled up the NIR dataset using our proposed model and applied it to an object detection task. The results demonstrate improved performance compared to using limited original NIR data, validating the effectiveness of our translation model for data augmentation in the NIR domain.
2. Related Work
2.1. Image-to-Image Translation
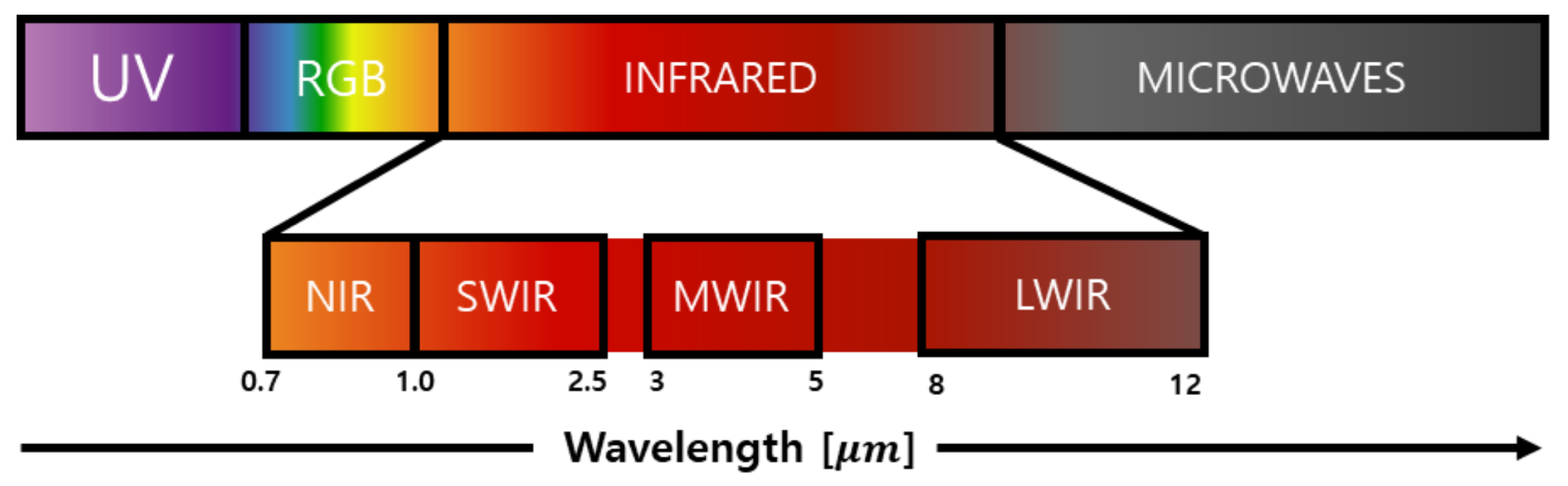
2.2. NIR/IR-Range Imaging
3. Method
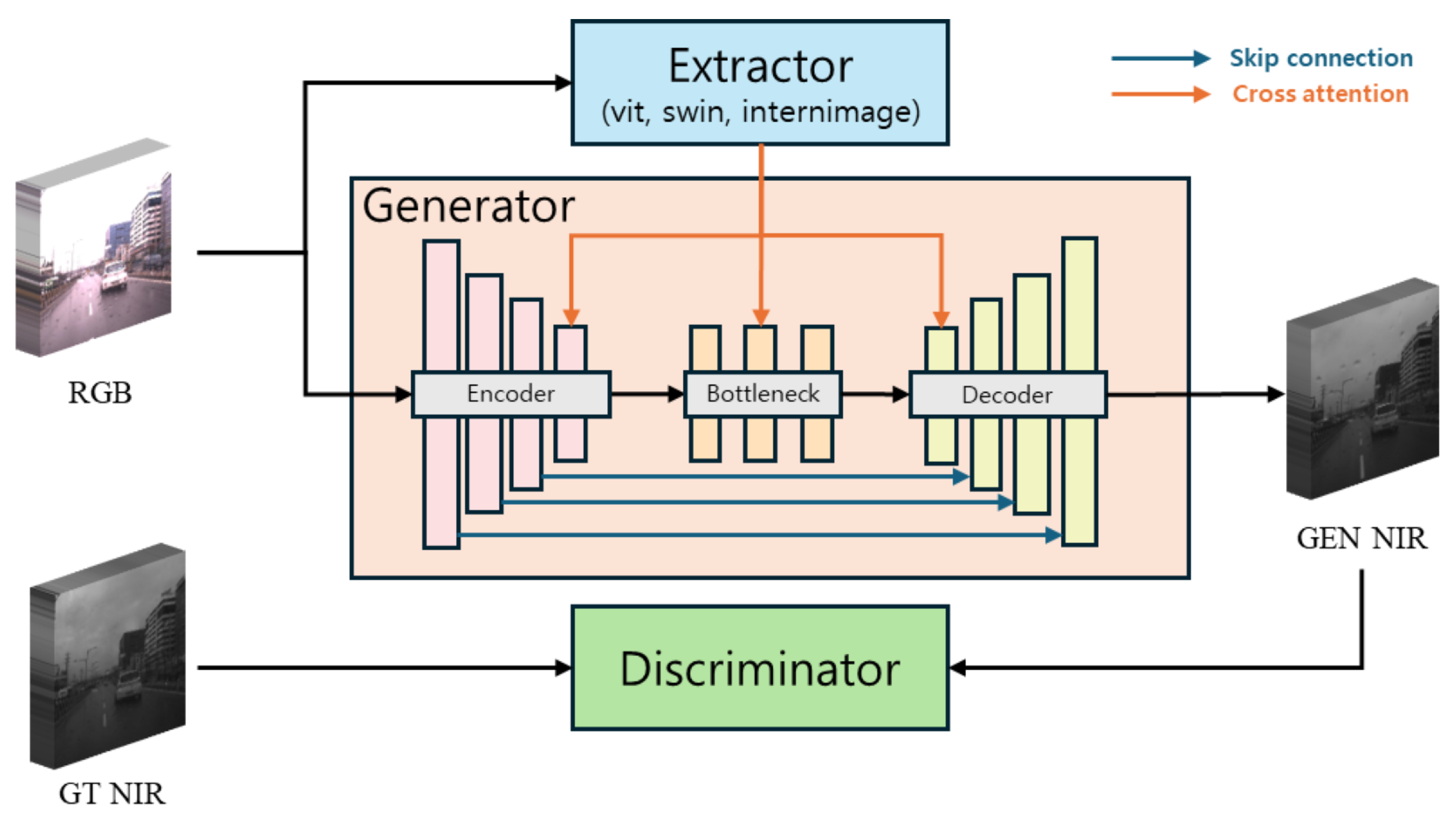
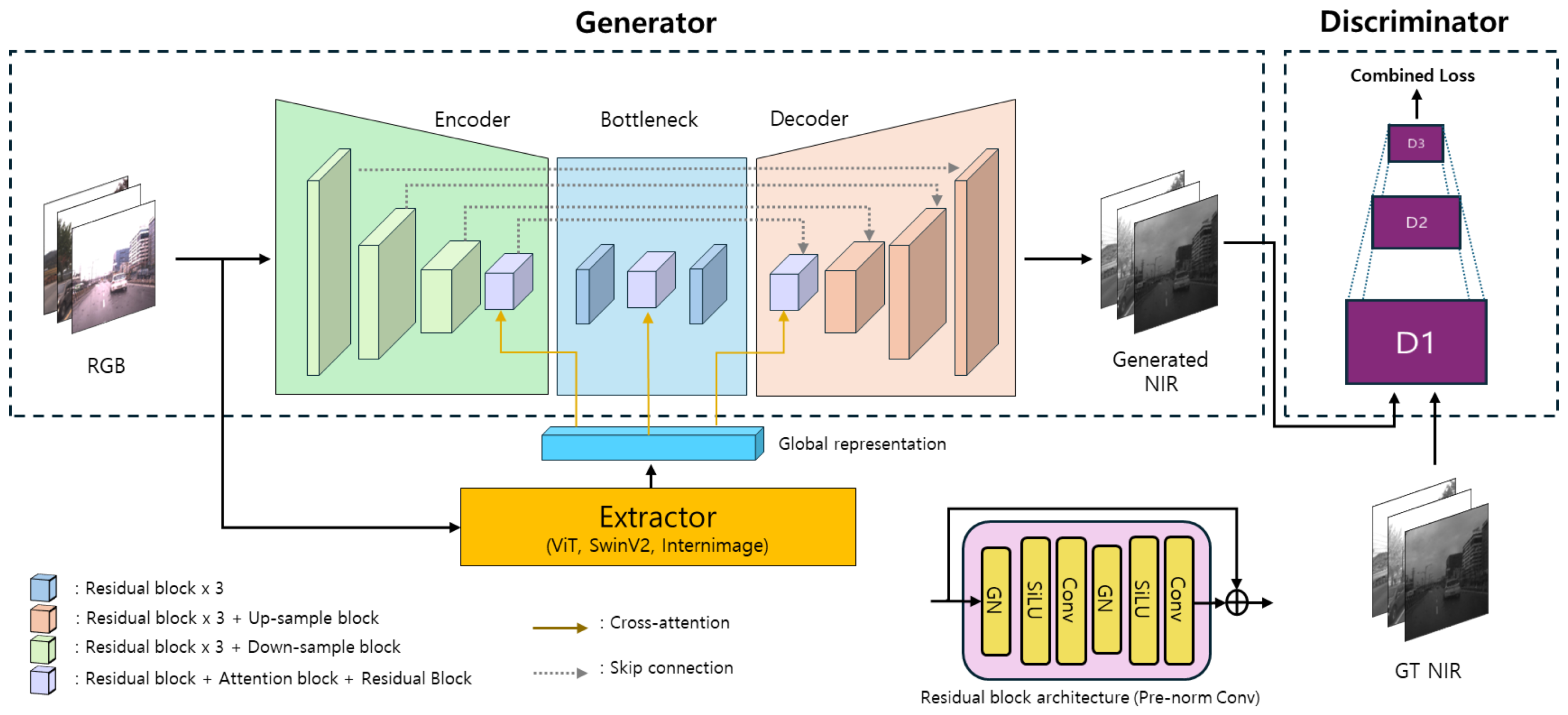
3.1. Network Architecture
| Algorithm 1 Training for RGB-to-NIR Image Translation with Multi-Scale Discriminators |
| Require: Paired dataset of RGB images X and NIR images Y Require: Initialized generator G Require: Three discriminators for multi-scale discrimination Require: Hyperparameters , Require: Learning rates , Require: Number of iterations N, batch size B
|
3.1.1. Feature Extractor
- Input Processing: The RGB input image (256 × 256 × 3) is fed into the InternImage model.
- Feature Extraction: The InternImage model processes the input through its hierarchical structure of deformable convolutions and attention mechanisms.
- Global Representation: The output of the final layer of InternImage serves as our global feature representation. This global representation is then used in the cross-attention mechanisms throughout our generator’s encoder, bottleneck, and decoder stages.
3.1.2. Generator
- Encoder: Seven blocks progressively increase the channel depth from 128 to 512, utilizing residual and downsample layers with an attention layer in the final block.
- Bottleneck: Three blocks maintain 512 channels, combining residual and attention layers for complex feature interactions.
- Decoder: Seven blocks gradually reduce channel depth from 512 to 128, using upsample layers alongside residual and attention layers.
- Normalization: Group normalization with 32 groups is applied throughout the network.
3.1.3. Discriminator
3.2. Loss Function
3.2.1. GAN Loss
3.2.2. SSIM Loss
3.2.3. Feature Matching Loss
3.2.4. Combined Loss
4. Experiments
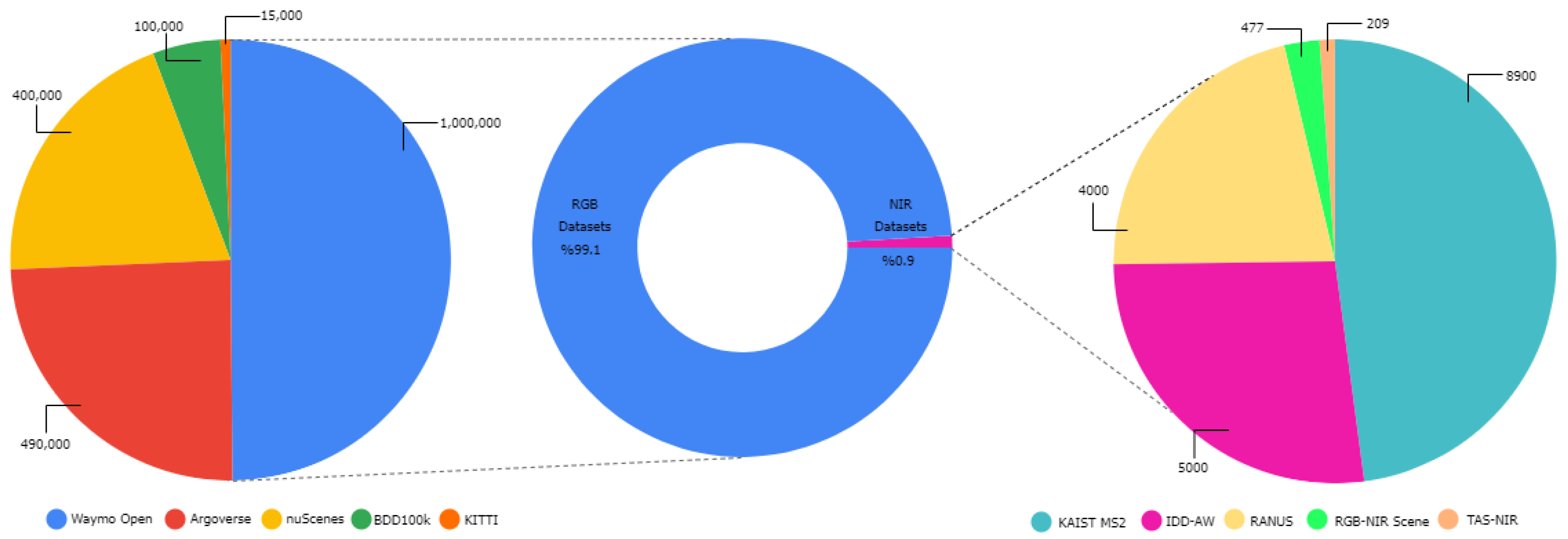
4.1. Datasets
4.2. Training Strategy
Evaluation Metrics
4.3. Quantitative and Qualitative Evaluations
4.4. Ablation Study
4.4.1. Effectiveness of Extractor
4.4.2. Effectiveness of Attention Position
4.4.3. Effectiveness of Generator
4.5. Effectiveness of Generated NIR Data
4.6. LWIR Translation
5. Discussion and Failure Cases
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bijelic, M.; Gruber, T.; Ritter, W. Benchmarking image sensors under adverse weather conditions for autonomous driving. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1773–1779. [Google Scholar]
- Wu, J.; Wei, P.; Huang, F. Color-preserving visible and near-infrared image fusion for removing fog. Infrared Phys. Technol. 2024, 138, 105252. [Google Scholar] [CrossRef]
- Infiniti Electro-Optics. NIR (Near-Infrared) Imaging (Fog/Haze Filter). 2024. Available online: https://www.infinitioptics.com/technology/nir-near-infrared (accessed on 30 August 2024).
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 3354–3361. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2446–2454. [Google Scholar]
- Chang, M.F.; Lambert, J.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; Lucey, S.; Ramanan, D.; et al. Argoverse: 3d tracking and forecasting with rich maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8748–8757. [Google Scholar]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2636–2645. [Google Scholar]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; So Kweon, I. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- Shaik, F.A.; Reddy, A.; Billa, N.R.; Chaudhary, K.; Manchanda, S.; Varma, G. Idd-aw: A benchmark for safe and robust segmentation of drive scenes in unstructured traffic and adverse weather. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 4614–4623. [Google Scholar]
- Choe, G.; Kim, S.H.; Im, S.; Lee, J.Y.; Narasimhan, S.G.; Kweon, I.S. RANUS: RGB and NIR urban scene dataset for deep scene parsing. IEEE Robot. Autom. Lett. 2018, 3, 1808–1815. [Google Scholar] [CrossRef]
- Brown, M.; Süsstrunk, S. Multi-spectral SIFT for scene category recognition. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 177–184. [Google Scholar]
- Mortimer, P.; Wuensche, H.J. TAS-NIR: A VIS+ NIR Dataset for Fine-grained Semantic Segmentation in Unstructured Outdoor Environments. arXiv 2022, arXiv:2212.09368. [Google Scholar] [CrossRef]
- An, L.; Zhao, J.; Di, H. Generating infrared image from visible image using Generative Adversarial Networks. In Proceedings of the 2019 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 17–19 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 157–161. [Google Scholar]
- Yuan, X.; Tian, J.; Reinartz, P. Generating artificial near infrared spectral band from rgb image using conditional generative adversarial network. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 3, 279–285. [Google Scholar] [CrossRef]
- Aslahishahri, M.; Stanley, K.G.; Duddu, H.; Shirtliffe, S.; Vail, S.; Bett, K.; Pozniak, C.; Stavness, I. From RGB to NIR: Predicting of near infrared reflectance from visible spectrum aerial images of crops. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 1312–1322. [Google Scholar]
- Zhao, G.; He, Y.; Wang, Z.; Wu, H.; Cheng, L. Generation of NIR Spectral Band from RGB Image with Wavelet Domain Spectral Extrapolation Generative Adversarial Network. Comput. Electron. Agric. 2024, 227, 109461. [Google Scholar] [CrossRef]
- Uddin, M.S.; Kwan, C.; Li, J. MWIRGAN: Unsupervised Visible-to-MWIR Image Translation with Generative Adversarial Network. Electronics 2023, 12, 1039. [Google Scholar] [CrossRef]
- Kniaz, V.V.; Knyaz, V.A.; Hladuvka, J.; Kropatsch, W.G.; Mizginov, V. Thermalgan: Multimodal color-to-thermal image translation for person re-identification in multispectral dataset. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018; pp. 1–20. [Google Scholar]
- Chen, Y.; Chen, P.; Zhou, X.; Lei, Y.; Zhou, Z.; Li, M. Implicit Multi-Spectral Transformer: An Lightweight and Effective Visible to Infrared Image Translation Model. arXiv 2024, arXiv:2404.07072. [Google Scholar] [CrossRef]
- Özkanoğlu, M.A.; Ozer, S. InfraGAN: A GAN architecture to transfer visible images to infrared domain. Pattern Recognit. Lett. 2022, 155, 69–76. [Google Scholar] [CrossRef]
- Luo, Y.; Pi, D.; Pan, Y.; Xie, L.; Yu, W.; Liu, Y. ClawGAN: Claw connection-based generative adversarial networks for facial image translation in thermal to RGB visible light. Expert Syst. Appl. 2022, 191, 116269. [Google Scholar] [CrossRef]
- Berg, A.; Ahlberg, J.; Felsberg, M. Generating visible spectrum images from thermal infrared. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1143–1152. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8798–8807. [Google Scholar]
- Shen, Z.; Huang, M.; Shi, J.; Xue, X.; Huang, T.S. Towards instance-level image-to-image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3683–3692. [Google Scholar]
- Huang, J.; Liao, J.; Kwong, S. Unsupervised image-to-image translation via pre-trained stylegan2 network. IEEE Trans. Multimed. 2021, 24, 1435–1448. [Google Scholar] [CrossRef]
- Liang, J.; Zeng, H.; Zhang, L. High-resolution photorealistic image translation in real-time: A laplacian pyramid translation network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9392–9400. [Google Scholar]
- Shen, Y.; Kang, J.; Li, S.; Yu, Z.; Wang, S. Style Transfer Meets Super-Resolution: Advancing Unpaired Infrared-to-Visible Image Translation with Detail Enhancement. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 4340–4348. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Li, H.; Gu, C.; Wu, D.; Cheng, G.; Guo, L.; Liu, H. Multiscale generative adversarial network based on wavelet feature learning for SAR-to-optical image translation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Ismael, S.F.; Kayabol, K.; Aptoula, E. Unsupervised domain adaptation for the semantic segmentation of remote sensing images via one-shot image-to-image translation. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Du, W.L.; Zhou, Y.; Zhu, H.; Zhao, J.; Shao, Z.; Tian, X. A semi-supervised image-to-image translation framework for SAR–optical image matching. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Roy, S.; Siarohin, A.; Sangineto, E.; Sebe, N.; Ricci, E. Trigan: Image-to-image translation for multi-source domain adaptation. Mach. Vis. Appl. 2021, 32, 1–12. [Google Scholar] [CrossRef]
- Pizzati, F.; Charette, R.D.; Zaccaria, M.; Cerri, P. Domain bridge for unpaired image-to-image translation and unsupervised domain adaptation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 2990–2998. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial net. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Li, B.; Xue, K.; Liu, B.; Lai, Y.K. Bbdm: Image-to-image translation with brownian bridge diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 1952–1961. [Google Scholar]
- Torbunov, D.; Huang, Y.; Yu, H.; Huang, J.; Yoo, S.; Lin, M.; Viren, B.; Ren, Y. Uvcgan: Unet vision transformer cycle-consistent gan for unpaired image-to-image translation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 702–712. [Google Scholar]
- Kumar, W.K.; Singh, N.J.; Singh, A.D.; Nongmeikapam, K. Enhanced machine perception by a scalable fusion of RGB–NIR image pairs in diverse exposure environments. Mach. Vis. Appl. 2021, 32, 88. [Google Scholar] [CrossRef]
- Luo, Y.; Remillard, J.; Hoetzer, D. Pedestrian detection in near-infrared night vision system. In Proceedings of the 2010 IEEE Intelligent Vehicles Symposium, San Diego, CA, USA, 21–24 June 2021; IEEE: Piscataway, NJ, USA, 2010; pp. 51–58. [Google Scholar]
- Liu, S.; Gao, M.; John, V.; Liu, Z.; Blasch, E. Deep learning thermal image translation for night vision perception. ACM Trans. Intell. Syst. Technol. (TIST) 2020, 12, 1–18. [Google Scholar] [CrossRef]
- Govardhan, P.; Pati, U.C. NIR image based pedestrian detection in night vision with cascade classification and validation. In Proceedings of the 2014 IEEE International Conference on Advanced Communications, Control and Computing Technologies, Ramanathapuram, India, 8–10 October 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1435–1438. [Google Scholar]
- Bhowmick, S.; Kuiry, S.; Das, A.; Das, N.; Nasipuri, M. Deep learning-based outdoor object detection using visible and near-infrared spectrum. Multimed. Tools Appl. 2022, 81, 9385–9402. [Google Scholar] [CrossRef]
- Ippalapally, R.; Mudumba, S.H.; Adkay, M.; HR, N.V. Object detection using thermal imaging. In Proceedings of the 2020 IEEE 17th India Council International Conference (INDICON), New Delhi, India, 10–13 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Zhu, J.Y.; Zhang, R.; Pathak, D.; Darrell, T.; Efros, A.A.; Wang, O.; Shechtman, E. Toward multimodal image-to-image translation. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Mao, K.; Yang, M.; Wang, H. Infrared and Near-Infrared Image Generation via Content Consistency and Style Adversarial Learning. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Beijing, China, 4–7 November 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 618–630. [Google Scholar]
- Wang, W.; Dai, J.; Chen, Z.; Huang, Z.; Li, Z.; Zhu, X.; Hu, X.; Lu, T.; Lu, L.; Li, H.; et al. InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 17804–17815. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Ding, K.; Ma, K.; Wang, S.; Simoncelli, E.P. Image quality assessment: Unifying structure and texture similarity. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2567–2581. [Google Scholar] [CrossRef] [PubMed]
- Zong, Z.; Song, G.; Liu, Y. Detrs with collaborative hybrid assignments training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 6748–6758. [Google Scholar]
- FLIR Dataset FREE Teledyne FLIR Thermal Dataset for Algorithm Training. 2024. Available online: https://www.flir.com/oem/adas/adas-dataset-form/?srsltid=AfmBOoqQxC-X5fpQ7xRxOq895ks2E3reFxCPv0l8aMJPX4UWz_4kiAEU (accessed on 30 August 2024).
- Liu, M.Y.; Breuel, T.; Kautz, J. Unsupervised image-to-image translation networks. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Huang, X.; Liu, M.Y.; Belongie, S.; Kautz, J. Multimodal unsupervised image-to-image translation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 172–189. [Google Scholar]
- Liu, S.; Zhu, C.; Xu, F.; Jia, X.; Shi, Z.; Jin, M. Bci: Breast cancer immunohistochemical image generation through pyramid pix2pix. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1815–1824. [Google Scholar]
- Liu, C.; Wen, J.; Xu, Y.; Zhang, B.; Nie, L.; Zhang, M. Reliable Representation Learning for Incomplete Multi-View Missing Multi-Label Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 1–17. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Configuration |
|---|---|
| Encoder | B1: res[128, 128] → res[128, 256] → res[256, 256] B2: down[256] B3: res[256, 256] → res[256, 512] → res[512, 512] B4: down[512] B5: res[512, 512] × 3 B6: down[512] B7: res[512, 512] → attn[128, 4] |
| Bottleneck | B1: res[512, 512] × 3 B2: res[512, 512] → attn[128, 4] → res[512, 512] B3: res[512, 512] × 3 |
| Decoder | B1: res[512, 512] → attn[128, 4] → res[512, 512] B2: up[512] B3: res[512, 512] → res[512, 256] → res[256, 256] B4: up[256] B5: res[256, 256] × 3 B6: up[256] B7: res[256, 128] → res[128, 128] |
| Method | Type | PSNR ↑ | SSIM ↑ | FID ↓ | RMSE ↓ | LPIPS ↓ | DISTS ↓ | STD ↓ |
|---|---|---|---|---|---|---|---|---|
| Pix2pix 1 [36] | G | 15.67 | 0.5406 | 87.69 | 9.27 | 0.2942 | 0.2141 | 34.18 |
| Pix2pixHD 1 [24] | G | 20.47 | 0.7409 | 53.38 | 8.53 | 0.1385 | 0.1742 | 23.60 |
| CycleGAN 1 [37] | G | 17.05 | 0.6679 | 42.97 | 8.98 | 0.1643 | 0.1678 | 33.02 |
| BBDM 1 [38] | D | 18.76 | 0.6614 | 49.29 | 8.74 | 0.1792 | 0.1637 | 26.84 |
| 2 [47] | G | 16.46 | 0.63 | 83.45 | - | - | - | - |
| IRFomer 1 [20] | G | 18.96 | 0.7857 | 90.89 | 8.76 | 0.2132 | 0.1964 | 26.15 |
| UVCGAN 1 [39] | G | 18.21 | 0.6711 | 46.50 | 8.91 | 0.1733 | 0.1656 | 27.30 |
| Pix2Next (Ours) | G | 20.83 (+%1.74) | 0.8031 (+%2.19) | 28.01 (+%42.96) | 8.24 (+%3.45) | 0.107 (+%22.41) | 0.1252 (+%27.13) | 20.37 (+%13.67) |
| Method | Type | PSNR ↑ | SSIM ↑ | FID ↓ | RMSE ↓ | LPIPS ↓ | DISTS ↓ | STD ↓ |
|---|---|---|---|---|---|---|---|---|
| Pix2pix [36] | G | 29.14 | 0.8735 | 42.97 | 5.66 | 0.0951 | 0.1317 | 11.32 |
| Pix2pixHD [24] | G | 28.53 | 0.8716 | 63.23 | 6.04 | 0.0935 | 0.1803 | 11.61 |
| CycleGAN [37] | G | 21.17 | 0.7665 | 60.26 | 8.36 | 0.1664 | 0.2046 | 21.16 |
| BBDM [38] | D | 19.11 | 0.6316 | 122.1 | 8.72 | 0.2932 | 0.3044 | 27.53 |
| IRFomer [20] | G | 27.07 | 0.9041 | 88.16 | 5.76 | 0.1152 | 0.1596 | 12.99 |
| UVCGAN [39] | G | 27.63 | 0.8690 | 40.09 | 6.215 | 0.1077 | 0.1289 | 13.12 |
| Pix2Next (Ours) | G | 30.41 (+%4.26) | 0.9228 (+%1.95) | 32.81 (+%20.17) | 5.06 (+%11.86) | 0.0663 (+%32.78) | 0.1040 (+%22.44) | 10.55 (+%6.8) |
| Model | FID ↓ | LPIPS ↓ | DISTS↓ |
|---|---|---|---|
| W/O Extractor | 31.26 | 0.1116 | 0.1320 |
| ResNet | 35.92 | 0.1269 | 0.1524 |
| ViT | 29.05 | 0.1185 | 0.1338 |
| SwinV2 | 30.24 | 0.1117 | 0.1299 |
| Internimage | 28.01 | 0.1070 | 0.1252 |
| Model | SSIM ↑ | FID ↓ | LPIPS ↓ | DISTS ↓ |
|---|---|---|---|---|
| B-attention | 0.7903 | 37.02 | 0.1131 | 0.1353 |
| EBD-attention | 0.8063 | 30.24 | 0.1117 | 0.1299 |
| Model | PSNR ↑ | SSIM ↑ | FID ↓ | RMSE ↓ |
|---|---|---|---|---|
| Pix2pixHD (Baseline) | 20.474 | 0.7409 | 53.38 | 8.53 |
| Pix2pixHD+Internimage | 20.87 | 0.7327 | 45.14 | 8.35 |
| Ours | 20.83 | 0.8031 | 28.01 | 8.21 |
| Method | mAP | APperson | APbicycle | APcar |
|---|---|---|---|---|
| RGB_pretrain | 0.2724 | 0.1551 | 0.1745 | 0.4874 |
| Finetune w/ranus | 0.3149 | 0.1682 | 0.2143 | 0.5622 |
| Finetune w/ranus + generated NIR | 0.3347 | 0.1704 | 0.2829 | 0.5507 |
| Method | PSNR ↑ | SSIM ↑ |
|---|---|---|
| CycleGAN [37] | 3.45 | 0.01 |
| Pix2pix [36] | 4.19 | 0.05 |
| UNIT [59] | 3.11 | 0.01 |
| MUNIT [60] | 3.65 | 0.02 |
| BCI [61] | 11.14 | 0.21 |
| IRFormer [20] | 17.74 | 0.48 |
| Ours | 23.45 | 0.66 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, Y.; Park, I.; Song, H.; Ju, H.; Nalcakan, Y.; Kim, S. Pix2Next: Leveraging Vision Foundation Models for RGB to NIR Image Translation. Technologies 2025, 13, 154. https://doi.org/10.3390/technologies13040154
Jin Y, Park I, Song H, Ju H, Nalcakan Y, Kim S. Pix2Next: Leveraging Vision Foundation Models for RGB to NIR Image Translation. Technologies. 2025; 13(4):154. https://doi.org/10.3390/technologies13040154
Chicago/Turabian StyleJin, Youngwan, Incheol Park, Hanbin Song, Hyeongjin Ju, Yagiz Nalcakan, and Shiho Kim. 2025. "Pix2Next: Leveraging Vision Foundation Models for RGB to NIR Image Translation" Technologies 13, no. 4: 154. https://doi.org/10.3390/technologies13040154
APA StyleJin, Y., Park, I., Song, H., Ju, H., Nalcakan, Y., & Kim, S. (2025). Pix2Next: Leveraging Vision Foundation Models for RGB to NIR Image Translation. Technologies, 13(4), 154. https://doi.org/10.3390/technologies13040154