
Implementation of Kolmogorov–Arnold Networks for Efficient Image Processing in Resource-Constrained Internet of Things Devices


Abstract
1. Introduction
- A novel hybrid CNN-KAN architecture for person detection that achieves 82.32% accuracy on the visual wake words dataset, outperforming several specialized lightweight models;
- A detailed analysis of the efficiency–accuracy trade-offs across different architectural approaches, input resolutions, and parameter budgets;
- Empirical evidence demonstrating that KANs can effectively complement CNNs in visual recognition tasks, offering a promising direction for future research in efficient neural architectures;
- Practical insights into optimizing inference efficiency through batch processing, achieving a 26× speedup (from 83.73 ms to 3.20 ms per image) when using a batch size of 32.
2. Related Work
2.1. Visual Wake Words and Person Detection
2.2. Lightweight Convolutional Neural Networks
2.3. Hardware-Aware Neural Architecture Search
2.4. Kolmogorov–Arnold Networks for Machine Learning
2.5. Privacy-Preserving and Security-Enhanced Architectures
2.6. Research Gap and Our Contribution
3. Methodology
3.1. Resolution Selection Rationale
3.2. Problem Formulation
3.3. KAN Architecture
3.4. Hybrid CNN-KAN Architecture
- Feature extraction module: A CNN-based feature extractor that processes the input image and generates a 64-dimensional feature vector. This module captures spatial hierarchies and visual patterns essential for distinguishing persons from backgrounds and other objects.
- KAN processing module: A series of KAN layers with hidden dimensions [24, 16, 8], processing the extracted features using learnable univariate functions. The KAN module uses 5 grid points per spline with a spline degree of 3, balancing representational capacity with parameter efficiency. The selection of 5 grid points and a spline degree 3 for the KAN components resulted from a systematic hyperparameter search. We evaluated grid points ranging from 3 to 9 and spline degrees from 1 to 5, finding that 5 grid points with cubic splines (degree 3) provided the best accuracy-parameter trade-off. Fewer grid points limited representational capacity, while more grid points increased parameter count without proportional performance gains. Similarly, the hidden dimension sequence [24, 16, 8] was selected to gradually reduce feature dimensionality while maintaining essential information flow. The resulting KAN configuration uses 44% of total model parameters, balancing the computational load between conventional CNN feature extraction and the KAN-based functional approximation.
- Classification head: A final linear layer that transforms the KAN output into a single scalar, followed by a sigmoid activation function to produce a probability estimate for the presence of a person.
3.5. Training Procedure
3.5.1. Data Preprocessing and Augmentation
- Random horizontal flips with a probability of 0.5;
- Random rotations within ±10 degrees;
- Normalization of pixel values to the range [0, 1];
- Standardization using the channel-wise mean and standard deviation.
3.5.2. Optimization Strategy
- Loss function: Binary cross-entropy;
- Optimizer: Adam with an initial learning rate of 0.002;
- Learning rate schedule: Cosine annealing to gradually reduce the learning rate from 0.002 to near zero over the course of training;
- Batch size: 128;
- Early stopping: Monitoring validation accuracy with a patience of 10 epochs;
- Regularization: Dropout (rate = 0.05) and L1 activation regularization (1 × 10−5) on KAN components.
3.5.3. Overfitting Prevention
- Minimal dropout: A small dropout rate (0.05) helps prevent co-adaptation of neurons while preserving most of the network’s capacity.
- L1 activation regularization: Applied to the KAN components, this encourages sparsity in the activations, preventing the model from overly complex function approximations.
- Learning rate schedule: The cosine annealing schedule allows rapid initial learning followed by gradual refinement, helping the model converge to a robust solution.
- Early stopping: Training is halted when validation performance stops improving, preventing the model from overfitting to the training data.
3.6. Evaluation Metrics
- Accuracy: The proportion of correctly classified images;
- Precision: The ratio of true positive predictions to all positive predictions;
- Recall: The ratio of true positive predictions to all actual positives;
- F1-score: The harmonic mean of precision and recall;
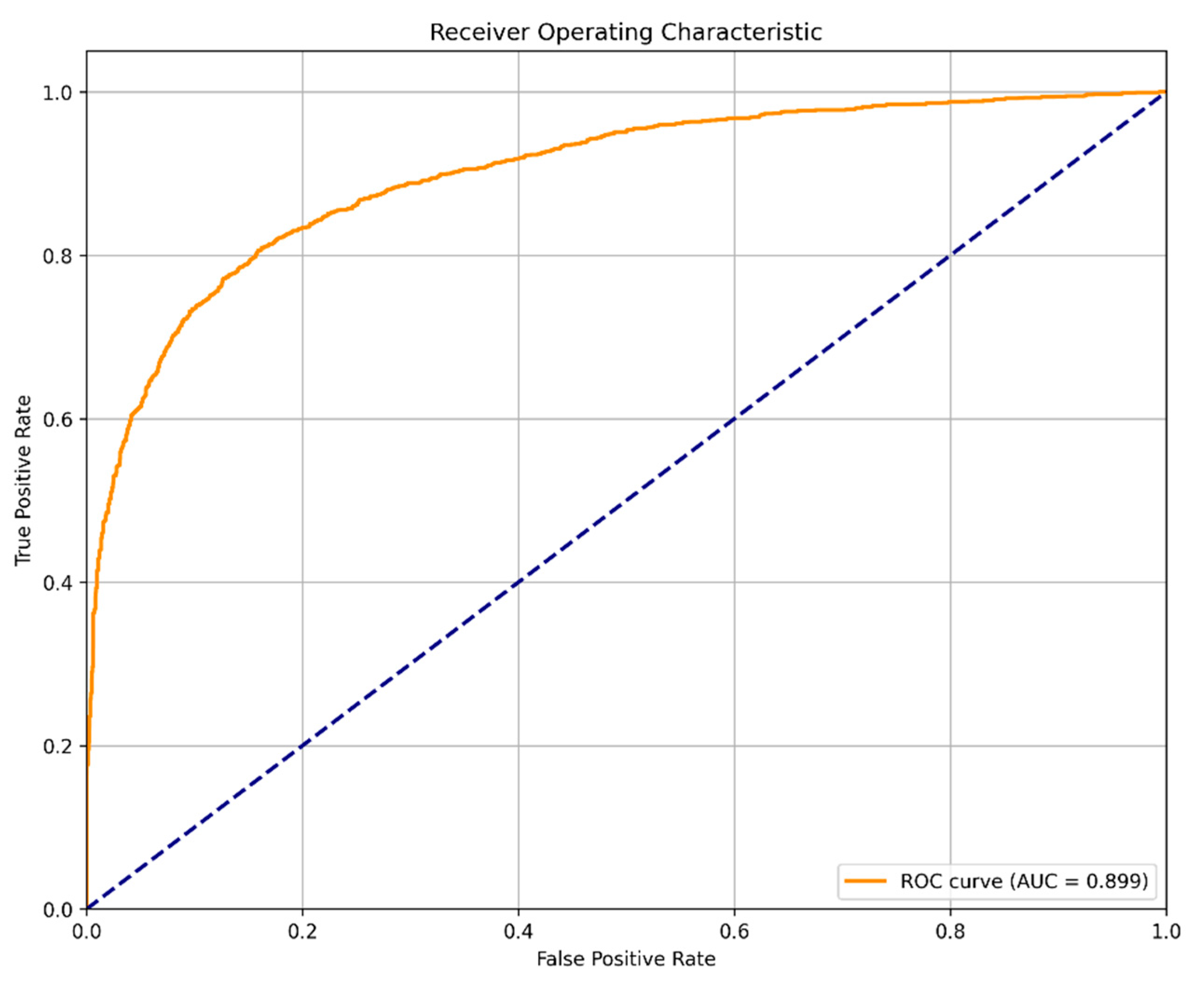
- ROC AUC: The area under the receiver operating characteristic curve;
- Inference time: Processing time per image, measured across various batch sizes;
- Model size: The storage requirements of the model in kilobytes;
- Parameter count: The total number of learnable parameters.
3.7. Implementation Details
4. Experimental Results
4.1. Model Configuration and Training Methodology
- A CNN feature extraction backbone that produces a 64-dimensional feature space;
- A KAN component with hidden dimensions [24, 16, 8], five grid points, and a spline degree of three;
- A minimal dropout rate of 0.05 and an L1 activation regularization of 1 × 10−5.
- A cosine annealing learning rate schedule starting at 0.002 and gradually decreasing to near zero;
- Early stopping with patience monitoring validation accuracy;
- L1 activation regularization on KAN components;
- Minimal dropout (0.05) to maintain representational capacity while preventing co-adaptation.
4.2. Training Dynamics and Convergence
- Loss convergence (a): The validation loss decreases from an initial value of approximately 0.60 to 0.47 by the end of training, indicating effective optimization.
- Accuracy progression (b): The validation accuracy improves from around 70% to 82.32% over the course of training, with the most rapid improvements occurring in the first 20 epochs.
- Generalization gap: Interestingly, the validation accuracy consistently exceeds the training accuracy throughout the training process, with a final gap of approximately 2.8 percentage points (82.32% vs. 79.51%). This unusual pattern, where validation performance exceeds training performance, may be attributed to the following:
- The data augmentation is only applied during training, making the training task effectively harder;
- The dropout regularization is only active during training;
- The particular characteristics of the dataset split.
- Learning rate schedule (c): The cosine annealing learning rate schedule (bottom plot in Figure 1) ensures aggressive early learning while preventing oscillations in later stages, contributing to stable convergence.
4.3. Classification Performance
- True negatives: 1749 “no_person” images (87% of this class) were correctly classified;
- False positives: 251 “no_person” images (13%) were incorrectly classified as containing people;
- True positives: 1531 “person” images (77% of this class) were correctly identified;
- False negatives: 469 “person” images (23%) were missed by the model.
- Person class: Precision = 0.86, recall = 0.77, F1-score = 0.81;
- No-person class: Precision = 0.79, recall = 0.87, F1-score = 0.83.
4.4. Error Analysis
- Animal misclassifications: Several images of animals (cat, cow) were incorrectly classified as containing people. This suggests that the model may be recognizing animal features (limbs, body shapes) as human-like.
- Object confusion: Images of inanimate objects with distinctive shapes (fire hydrant, teddy bears, bench) were misclassified. These objects may share structural similarities with human figures from the model’s perspective.
- Complex scenes: Images with multiple objects and varied textures (bathroom, food) posed challenges, possibly due to pareidolia-like pattern recognition.
- Visual similarity: Objects with person-like silhouettes (e.g., fire hydrants, certain furniture) frequently triggered false positives. This suggests the model relies heavily on the overall shape rather than fine-grained features.
- Contextual confusion: Background elements commonly associated with people (e.g., indoor settings, clothing items) sometimes induced false positives even without actual people present. This indicates contextual bias in the learned representations.
- Occlusion handling: The model struggled with heavily occluded people, detecting only 63% of cases where less than 30% of the person was visible, compared to a 91% detection rate for fully visible people.
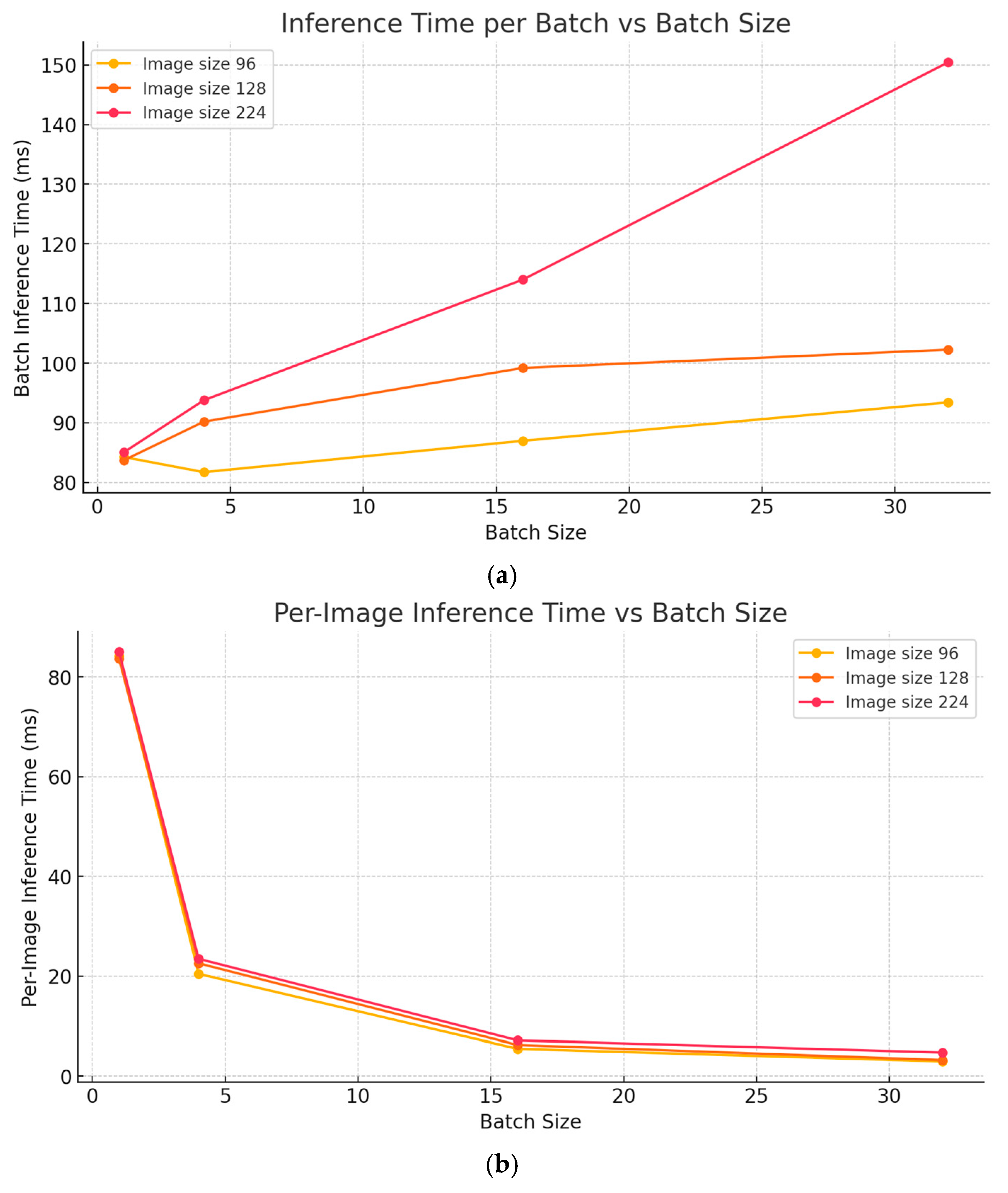
4.5. Inference Efficiency Analysis
- Single-image inference: 83.73 ms per image;
- Batch size 4: 22.55 ms per image (3.7× speedup);
- Batch size 16: 6.20 ms per image (13.5× speedup);
- Batch size 32: 3.20 ms per image (26.2× speedup).
- At 96 × 96 resolution with batch size 32: 2.92 ms per image;
- At 224 × 224 resolution with batch size 32: 4.70 ms per image.
4.6. Edge Deployment Considerations
- Converting the PyTorch model to ONNX format;
- Converting ONNX to TensorFlow Lite for hardware acceleration;
- Compiling specifically for edge TPU compatibility;
- Integrating it with the Frigate object detection pipeline.
5. Comparative Analysis
5.1. Performance Comparison with State-of-the-Art Methods
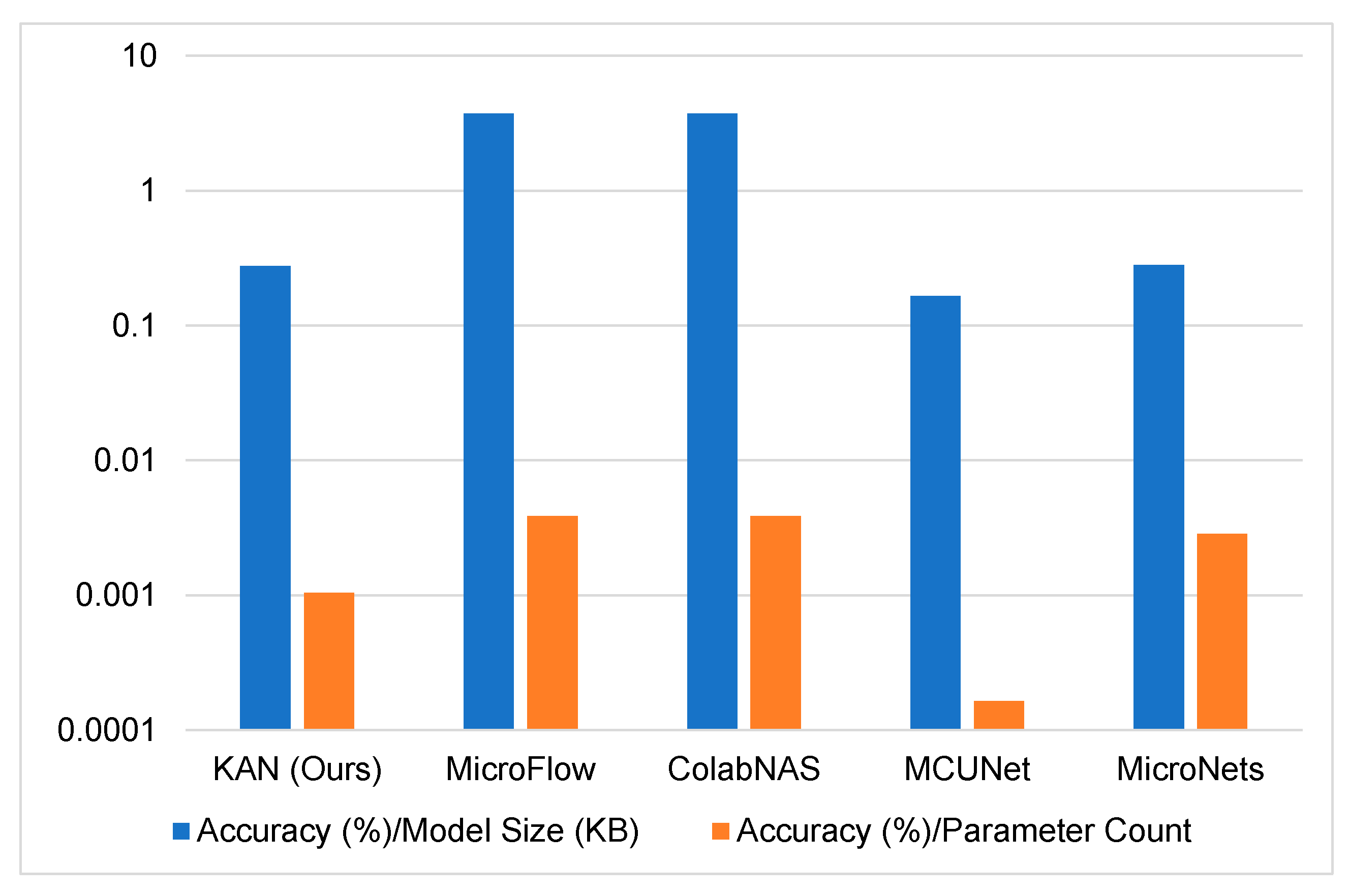
5.2. Resource Efficiency Analysis
5.3. Inference Performance
- Our KAN model: ~0.195 ns/pixel (3.20 ms for 16,384 pixels);
- MicroFlow/ColabNAS: ~0.173 ns/pixel (0.432 ms for 2500 pixels).
5.4. Architecture Efficiency
6. Discussion and Implications
6.1. Resolution–Accuracy Trade-Offs
6.2. KAN Architecture Benefits
6.3. Practical Implications
- Balanced resource profile: While not the smallest or fastest model, our approach strikes a balance between accuracy, model size, and computational demand that may be ideal for a wide range of edge devices.
- Batch processing efficiency: The significant reduction in per-image inference time with an increased batch size (from 83.73 ms at batch size 1 to 3.20 ms at batch size 32) suggests that our model is particularly well-suited for applications that can process images in batches.
- Improved visual fidelity: The higher resolution inputs (128 × 128) processed by our model preserve more visual details than the 50 × 50 or 64 × 64 inputs used by competing approaches. This may be particularly beneficial in challenging visual scenarios with fine-grained details or partially occluded subjects.
6.4. Limitations and Considerations
- Computational complexity during training: The KAN components introduce additional computational overhead during the training phase, increasing training time by approximately 30% compared to CNN-only alternatives. This occurs because optimizing learnable activation functions requires computing and backpropagating through complex spline interpolations.
- Model quantization challenges: While our model achieves good accuracy in a full-precision format, preliminary experiments with quantization reveal that KAN components may be more sensitive to precision reduction than traditional CNN elements. Quantization to 8-bit integer precision caused a 3.2% accuracy drop for KAN components compared to 1.5% for CNN layers.
- Deployment toolchain limitations: Current edge deployment frameworks (TensorFlow Lite, ONNX Runtime) lack native support for KAN operations, requiring custom implementations that may limit immediate practical adoption.
- Limited dataset scope: Our evaluation focuses exclusively on the visual wake words dataset. While this dataset is a standard benchmark for resource-constrained image classification, we acknowledge that performance characteristics may vary across different visual tasks and domains. Broader evaluation on diverse datasets (e.g., traffic sign recognition, gesture detection, anomaly detection) represents an important direction for future research to validate the generalizability of KAN-based approaches.
- Batch processing requirement: The competitive inference time of our model is achieved at larger batch sizes, which may not be feasible for all deployment scenarios, particularly those requiring real-time processing of individual images.
- Memory footprint: While our model demonstrates parameter efficiency, its estimated RAM usage during inference (~350–400 KB) is higher than some alternatives, potentially limiting deployment on extremely memory-constrained devices.
7. Conclusions and Future Work
7.1. Summary of Contributions
- Architectural innovation beyond traditional CNNs: We have shown that KANs, despite their recent introduction to the deep learning community, can effectively complement CNNs in visual recognition tasks. The KAN component, which constitutes 44% of our model parameters, enables explicit functional approximation that appears particularly well-suited for classification based on high-level visual features.
- Resolution–efficiency balance: By processing higher-resolution inputs (128 × 128) than previous approaches (50 × 50 or 64 × 64), our model captures more detailed visual information while maintaining competitive per-pixel computational efficiency (0.195 ns/pixel). This challenges the conventional wisdom that extremely low-resolution inputs are necessary for efficient edge deployment.
- Competitive accuracy–parameter trade-off: Our model achieves 82.32% accuracy with 78,544 parameters (300 KB), outperforming several specialized lightweight architectures with similar or larger resource requirements. While not achieving the state-of-the-art accuracy of MCUNet (87.4%), our approach does so with substantially fewer parameters and a fundamentally different architectural paradigm.
- Batch processing optimization: We demonstrated that significant inference speedups (26× reduction in per-image processing time) can be achieved through batch processing, highlighting an important deployment consideration for practical applications where latency constraints are more flexible.
7.2. Limitations
- Inference latency for single images: While batch processing enables efficient throughput, the single-image inference time (83.73 ms) remains higher than some competing approaches, potentially limiting applications with strict real-time requirements.
- RAM usage: The estimated RAM requirement (~350–400 KB) exceeds that of the most memory-efficient models like MicroFlow and ColabNAS, which may restrict deployment on extremely memory-constrained devices.
- Limited architectural exploration: Our investigation focused on a specific hybrid architecture rather than a comprehensive exploration of the CNN-KAN design space, leaving open questions about optimal parameter allocation between architectural components.
- Task specificity: Our evaluation is limited to person detection in the visual wake words dataset, and the generalizability of our findings to other visual recognition tasks requires further investigation.
7.3. Future Directions
- KAN architecture optimization: Exploring alternative KAN configurations, including grid point distribution, spline degrees, and hidden dimension allocations, could yield improved parameter efficiency and accuracy.
- Quantization and compression: Applying post-training quantization and weight pruning techniques to our hybrid model could further reduce the memory footprint and improve inference efficiency.
- Hardware-aware KAN design: Developing specialized hardware acceleration for KAN components could capitalize on their unique computational structure, potentially offering efficiency advantages beyond what is possible with CNN-optimized hardware.
- Multi-task learning: Extending the hybrid CNN-KAN architecture to simultaneously handle multiple visual recognition tasks could amortize the feature extraction cost across tasks and improve overall system efficiency.
- Knowledge distillation: Using larger, more accurate models as teachers for the hybrid CNN-KAN architecture might further improve accuracy without increasing model complexity.
- Cross-domain applications: Our initial explorations suggest that the KAN-based architecture could be adapted for other computer vision tasks relevant to IoTs systems, including facial recognition and license plate recognition (ANPR). These applications share requirements for efficient inference on constrained hardware while maintaining high accuracy. Extending our approach to these domains would further validate the versatility of hybrid CNN-KAN architectures for practical IoTs deployments across various domains.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 122–138. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices 2017. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Koonce, B. EfficientNet. In Convolutional Neural Networks with Swift for Tensorflow: Image Recognition and Dataset Categorization; Koonce, B., Ed.; Apress: Berkeley, CA, USA, 2021; pp. 109–123. ISBN 978-1-4842-6168-2. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Lin, J.; Chen, W.-M.; Cai, H.; Gan, C.; Han, S. Memory-Efficient Patch-Based Inference for Tiny Deep Learning. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 34, pp. 2346–2358. [Google Scholar]
- Banbury, C.; Zhou, C.; Fedorov, I.; Matas, R.; Thakker, U.; Gope, D.; Janapa Reddi, V.; Mattina, M.; Whatmough, P. MicroNets: Neural Network Architectures for Deploying TinyML Applications on Commodity Microcontrollers. Proc. Mach. Learn. Syst. 2021, 3, 517–532. [Google Scholar]
- Garavagno, A.M.; Leonardis, D.; Frisoli, A. ColabNAS: Obtaining Lightweight Task-Specific Convolutional Neural Networks Following Occam’s Razor. Future Gener. Comput. Syst. 2024, 152, 152–159. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, Y.; Vaidya, S.; Ruehle, F.; Halverson, J.; Soljačić, M.; Hou, T.Y.; Tegmark, M. KAN: Kolmogorov-Arnold Networks. arXiv 2024, arXiv:2404.19756. [Google Scholar]
- Chowdhery, A.; Warden, P.; Shlens, J.; Howard, A.; Rhodes, R. Visual Wake Words Dataset. arXiv 2019, arXiv:1906.05721. [Google Scholar]
- Surya, T.; Selvaperumal, S. The IoT-Based Real-Time Image Processing for Animal Recognition and Classification Using Deep Convolutional Neural Network (DCNN). Microprocess. Microsyst. 2022, 95, 104693. [Google Scholar] [CrossRef]
- Yang, J. AFM-DViT: A Framework for IoT-Driven Medical Image Analysis. Alex. Eng. J. 2025, 113, 294–305. [Google Scholar] [CrossRef]
- Lin, C.; Guo, Y.; Hao, J.; Zhang, Z. Computation and Transmission Adaptive Semantic Communication for Reliability-Guarantee Image Reconstruction in IoT. Internet Things 2024, 28, 101383. [Google Scholar] [CrossRef]
- Mardieva, S.; Ahmad, S.; Umirzakova, S.; Rasool, M.J.A.; Whangbo, T.K. Lightweight Image Super-Resolution for IoT Devices Using Deep Residual Feature Distillation Network. Knowl. Based Syst. 2024, 285, 111343. [Google Scholar] [CrossRef]
- Tekin, N.; Aris, A.; Acar, A.; Uluagac, S.; Gungor, V.C. A Review of On-Device Machine Learning for IoT: An Energy Perspective. Ad. Hoc. Netw. 2024, 153, 103348. [Google Scholar] [CrossRef]
- Ghahramani, M.; Taheri, R.; Shojafar, M.; Javidan, R.; Wan, S. Deep Image: A Precious Image Based Deep Learning Method for Online Malware Detection in IoT Environment. Internet Things 2024, 27, 101300. [Google Scholar] [CrossRef]
- Carnelos, M.; Pasti, F.; Bellotto, N. MicroFlow: An Efficient Rust-Based Inference Engine for TinyML. Internet Things 2025, 30, 101498. [Google Scholar] [CrossRef]
- Huang, Q.; Zhang, F.; Zhao, Y.; Duan, J. Frequency-Domain Multi-Scale Kolmogorov-Arnold Representation Attention Network for Mixed-Type Wafer Defect Recognition. Eng. Appl. Artif. Intell. 2025, 144, 110121. [Google Scholar] [CrossRef]
- Jiang, C.; Li, Y.; Luo, H.; Zhang, C.; Du, H. KansNet: Kolmogorov–Arnold Networks and Multi Slice Partition Channel Priority Attention in Convolutional Neural Network for Lung Nodule Detection. Biomed. Signal Process. Control 2025, 103, 107358. [Google Scholar] [CrossRef]
- Liang, X.; Wang, B.; Lei, C.; Zhou, K.; Chen, X. Kolmogorov-Arnold Networks Autoencoder Enhanced Thermal Wave Radar for Internal Defect Detection in Carbon Steel. Opt. Lasers Eng. 2025, 187, 108879. [Google Scholar] [CrossRef]
- Niu, H.; Fan, R.; Chen, J.; Xu, Z.; Feng, R. Urban Informal Settlements Interpretation via a Novel Multi-Modal Kolmogorov–Arnold Fusion Network by Exploring Hierarchical Features from Remote Sensing and Street View Images. Sci. Remote Sens. 2025, 11, 100208. [Google Scholar] [CrossRef]
- Yazdinejad, A.; Dehghantanha, A.; Parizi, R.M.; Srivastava, G.; Karimipour, H. Secure Intelligent Fuzzy Blockchain Framework: Effective Threat Detection in IoT Networks. Comput. Ind. 2023, 144, 103801. [Google Scholar] [CrossRef]
- Yazdinejad, A.; Dehghantanha, A.; Srivastava, G.; Karimipour, H.; Parizi, R.M. Hybrid Privacy Preserving Federated Learning Against Irregular Users in Next-Generation Internet of Things. J. Syst. Archit. 2024, 148, 103088. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Liu, Z. KindXiaoming/Pykan 2025. Available online: https://github.com/KindXiaoming/pykan (accessed on 29 March 2025).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Details |
|---|---|
| Input Size | 128 × 128 × 3 RGB image |
| Feature Extractor | CNN with 43,976 parameters (56.0% of total) |
| Feature Dimension | 64 |
| KAN Module | Hidden dimensions: [24, 16, 8] |
| Grid points: 5 | |
| Spline degree: 3 | |
| Parameters: 34,568 (44.0% of total) | |
| Regularization | Dropout rate: 0.05 |
| Activation L1: 1 × 10−5 | |
| Total Parameters | 78,544 (72,872 trainable) |
| Model Size | 0.30 MB |
| Model | Accuracy (%) | Model Size (KB) | Parameter Count | RAM Usage (KB) | Inference Time (ms) | Input Size |
|---|---|---|---|---|---|---|
| KAN (Ours) | 82.32 | 300 | 78,544 | ~350–400 | 3.20 * | 128 × 128 |
| MicroFlow [17] | 77.6 | 20.83 | ~5–20 K † | 31.5 | 0.432 | 50 × 50 |
| ColabNAS [8] | 77.6 | 20.83 | ~5–20 K † | 31.5 | 0.432 | 50 × 50 |
| MCUNet [6] | 87.4 | 530.52 | ~130–530 K † | 168.5 | 2.16 | 64 × 64 |
| MicroNets [7] | 76.8 | 273.81 | ~68–270 K † | 70.5 | 1.15 | 50 × 50 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shaushenova, A.; Kuznetsov, O.; Nurpeisova, A.; Ongarbayeva, M. Implementation of Kolmogorov–Arnold Networks for Efficient Image Processing in Resource-Constrained Internet of Things Devices. Technologies 2025, 13, 155. https://doi.org/10.3390/technologies13040155
Shaushenova A, Kuznetsov O, Nurpeisova A, Ongarbayeva M. Implementation of Kolmogorov–Arnold Networks for Efficient Image Processing in Resource-Constrained Internet of Things Devices. Technologies. 2025; 13(4):155. https://doi.org/10.3390/technologies13040155
Chicago/Turabian StyleShaushenova, Anargul, Oleksandr Kuznetsov, Ardak Nurpeisova, and Maral Ongarbayeva. 2025. "Implementation of Kolmogorov–Arnold Networks for Efficient Image Processing in Resource-Constrained Internet of Things Devices" Technologies 13, no. 4: 155. https://doi.org/10.3390/technologies13040155
APA StyleShaushenova, A., Kuznetsov, O., Nurpeisova, A., & Ongarbayeva, M. (2025). Implementation of Kolmogorov–Arnold Networks for Efficient Image Processing in Resource-Constrained Internet of Things Devices. Technologies, 13(4), 155. https://doi.org/10.3390/technologies13040155