

Enhancing Language Learners’ Comprehensibility through Automated Analysis of Pause Positions and Syllable Prominence


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Related Work
3. Data
4. Methodology
4.1. Methodology Relative to the Pause Position Analysis
4.2. Methodology Relative to the Stress Analysis
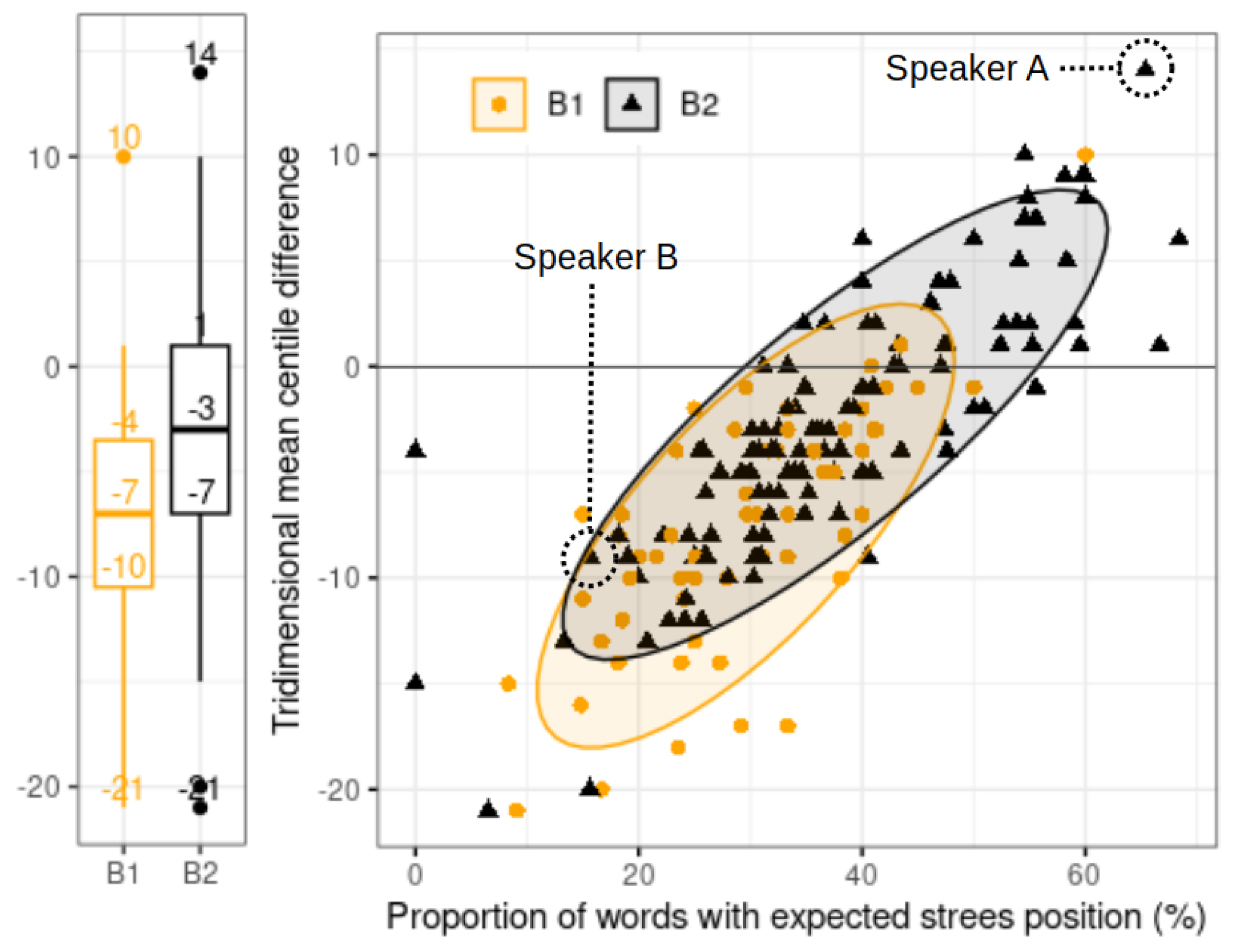
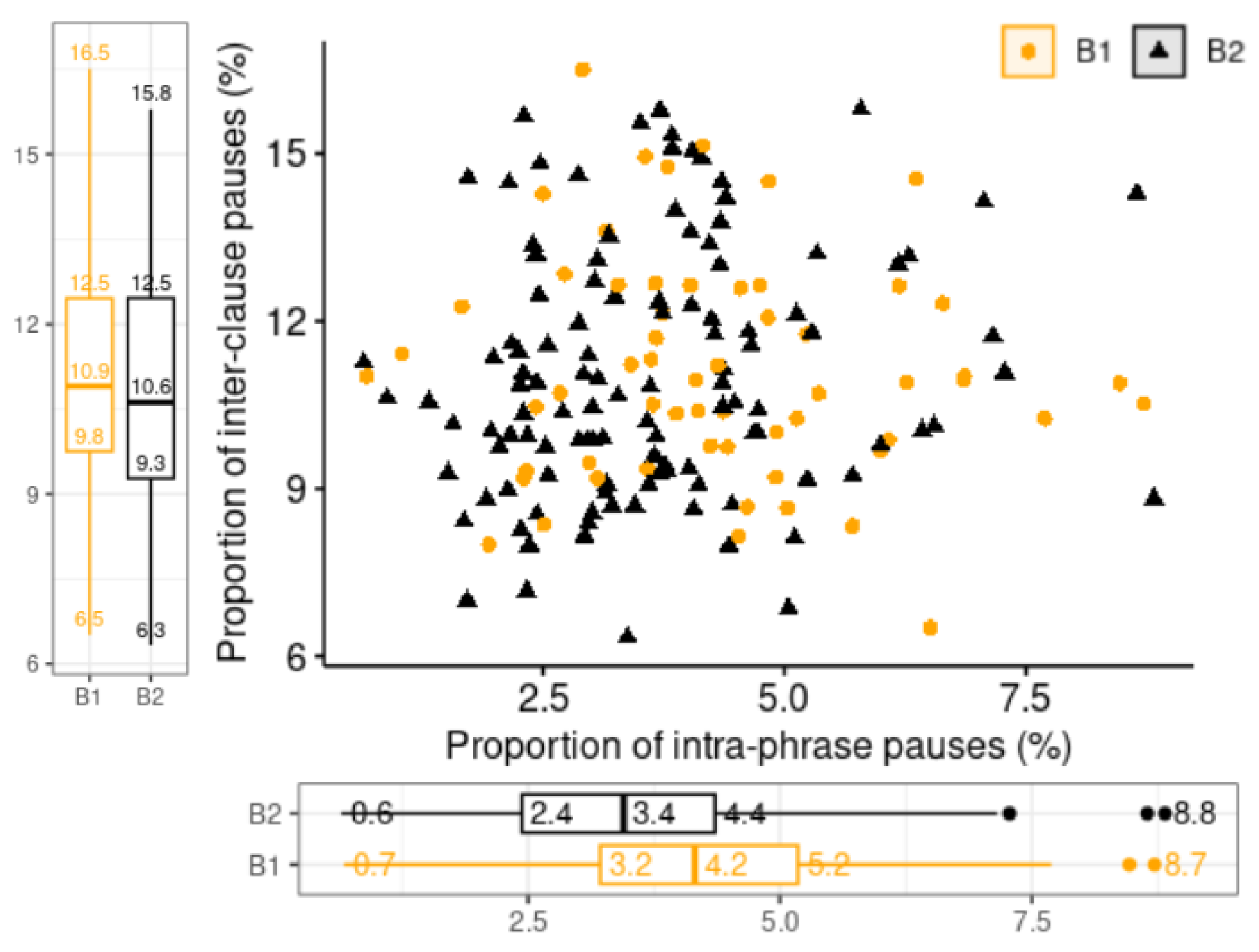
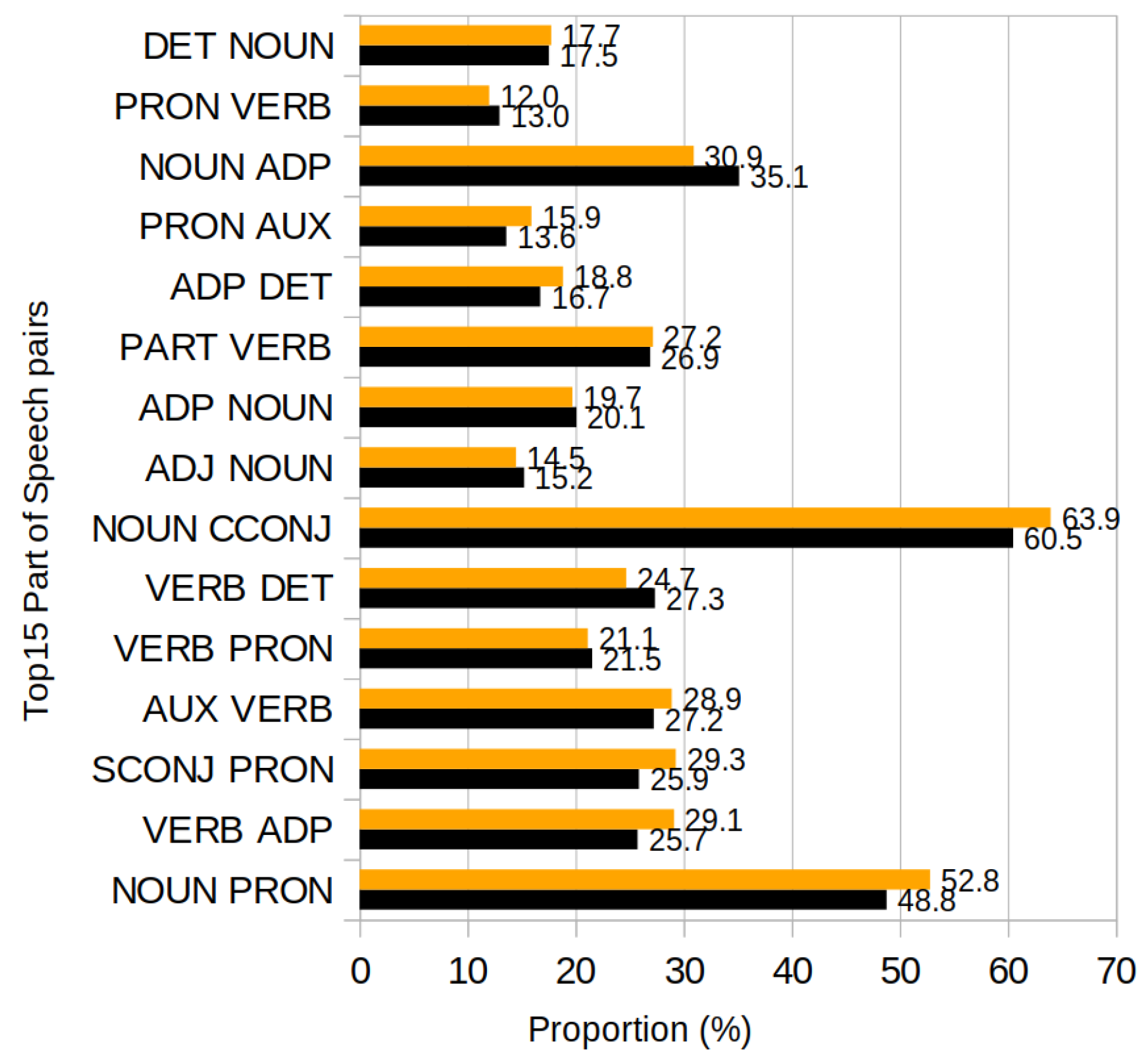
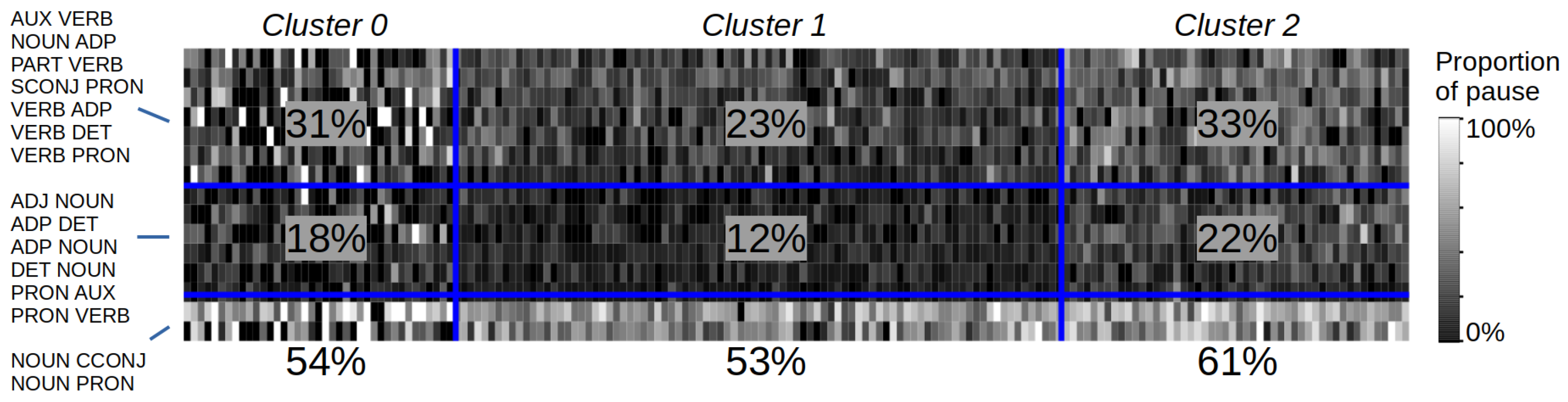
5. Results
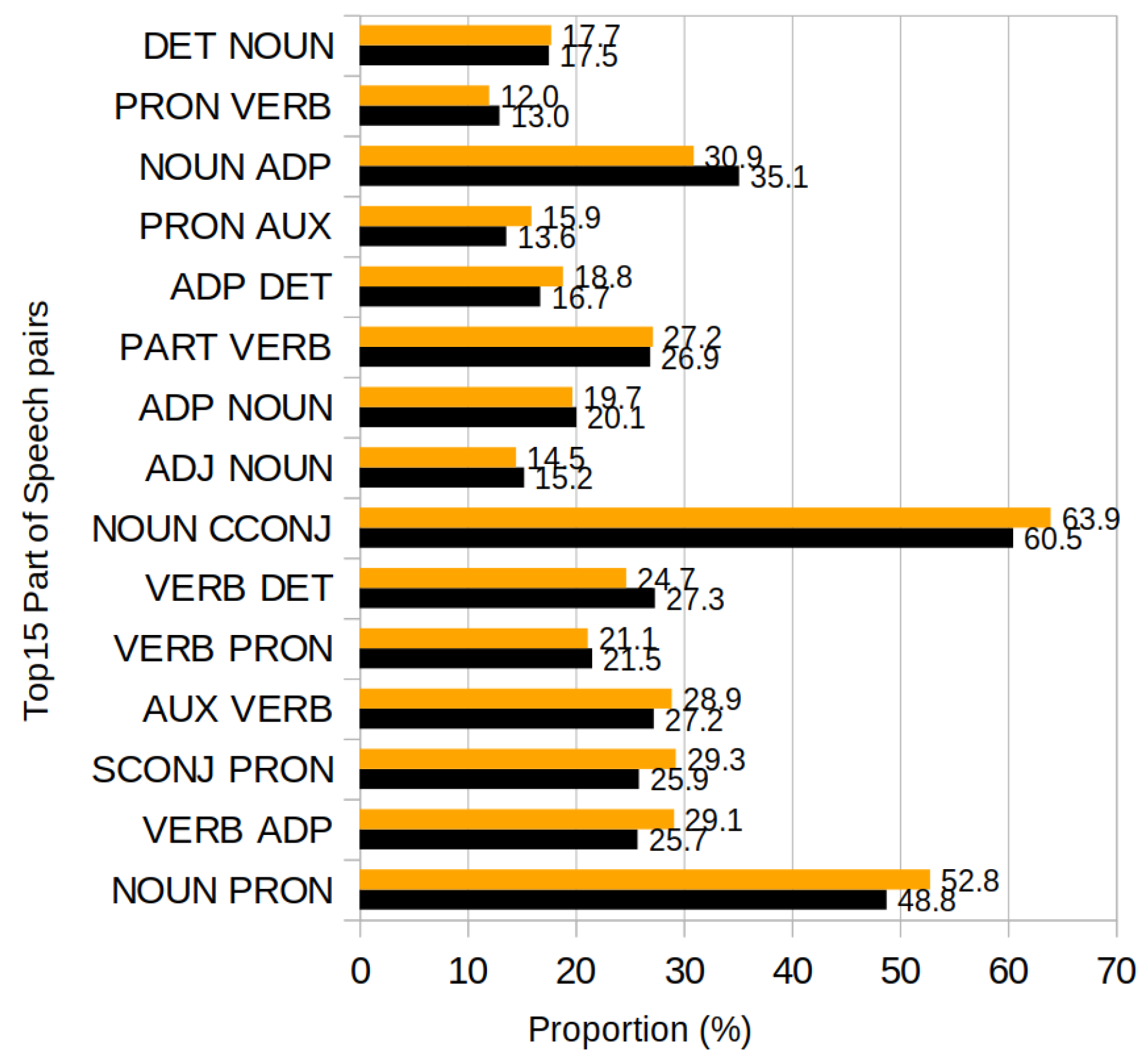
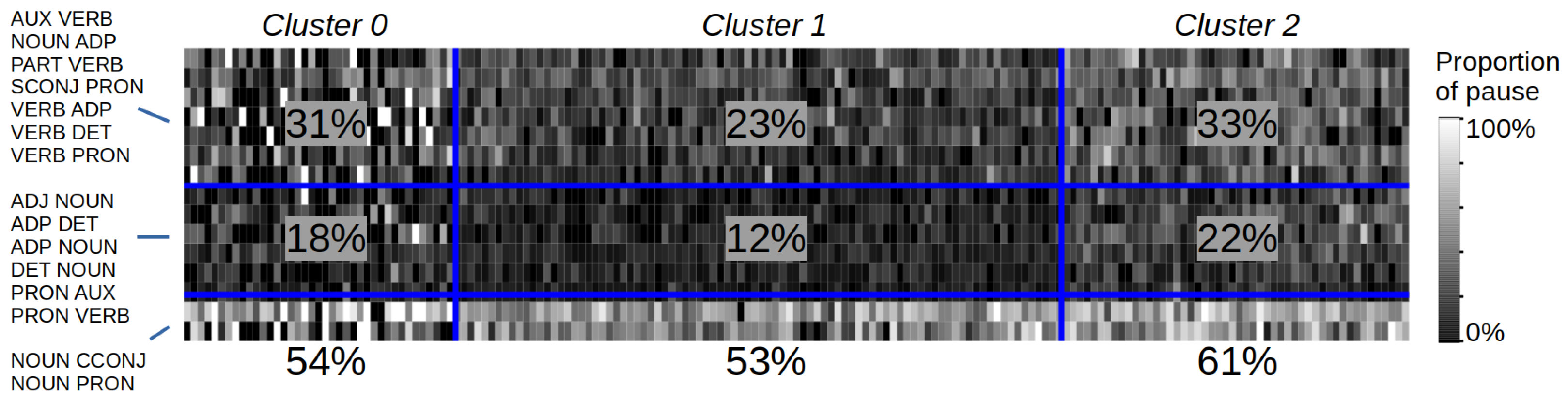
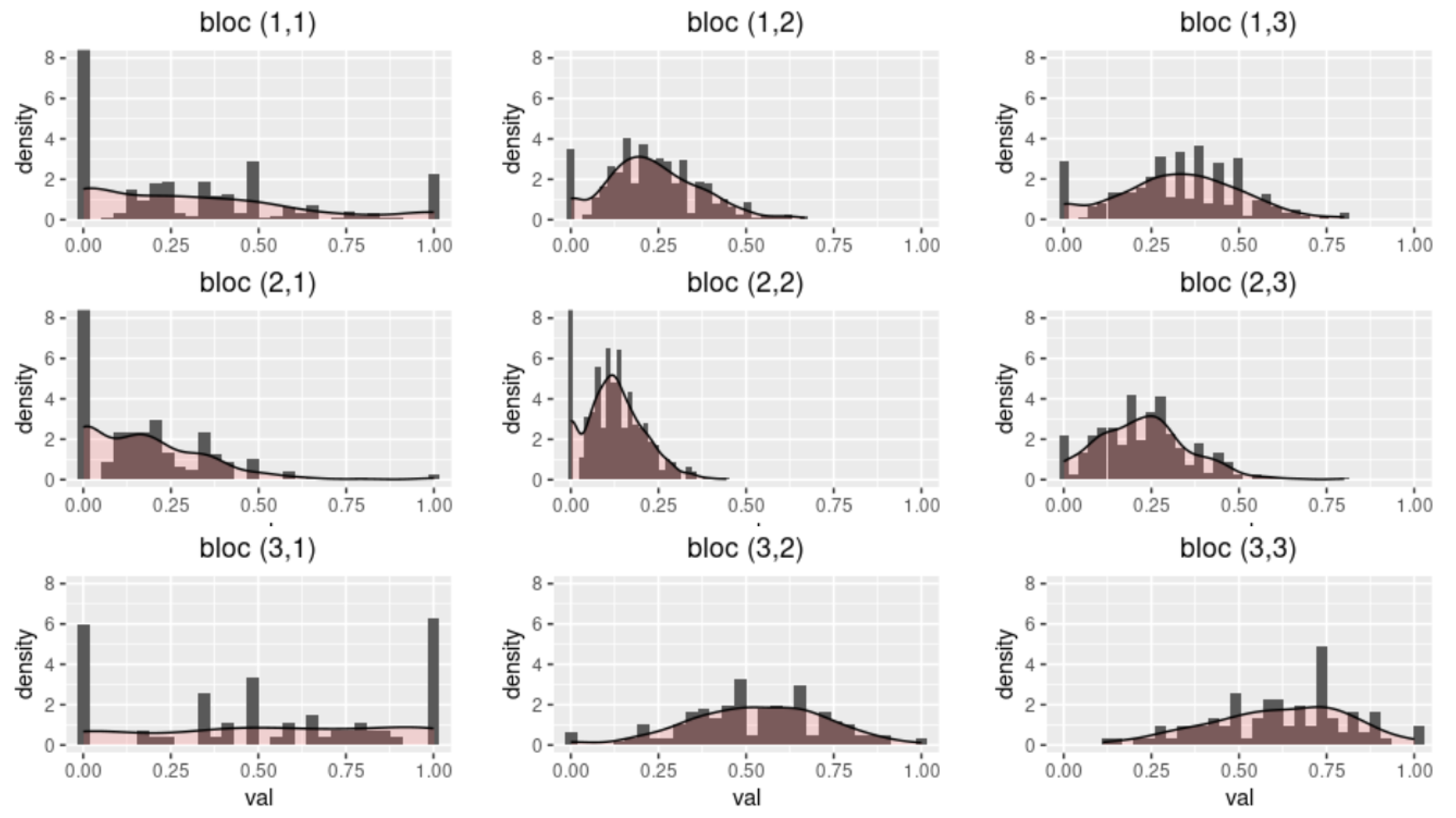
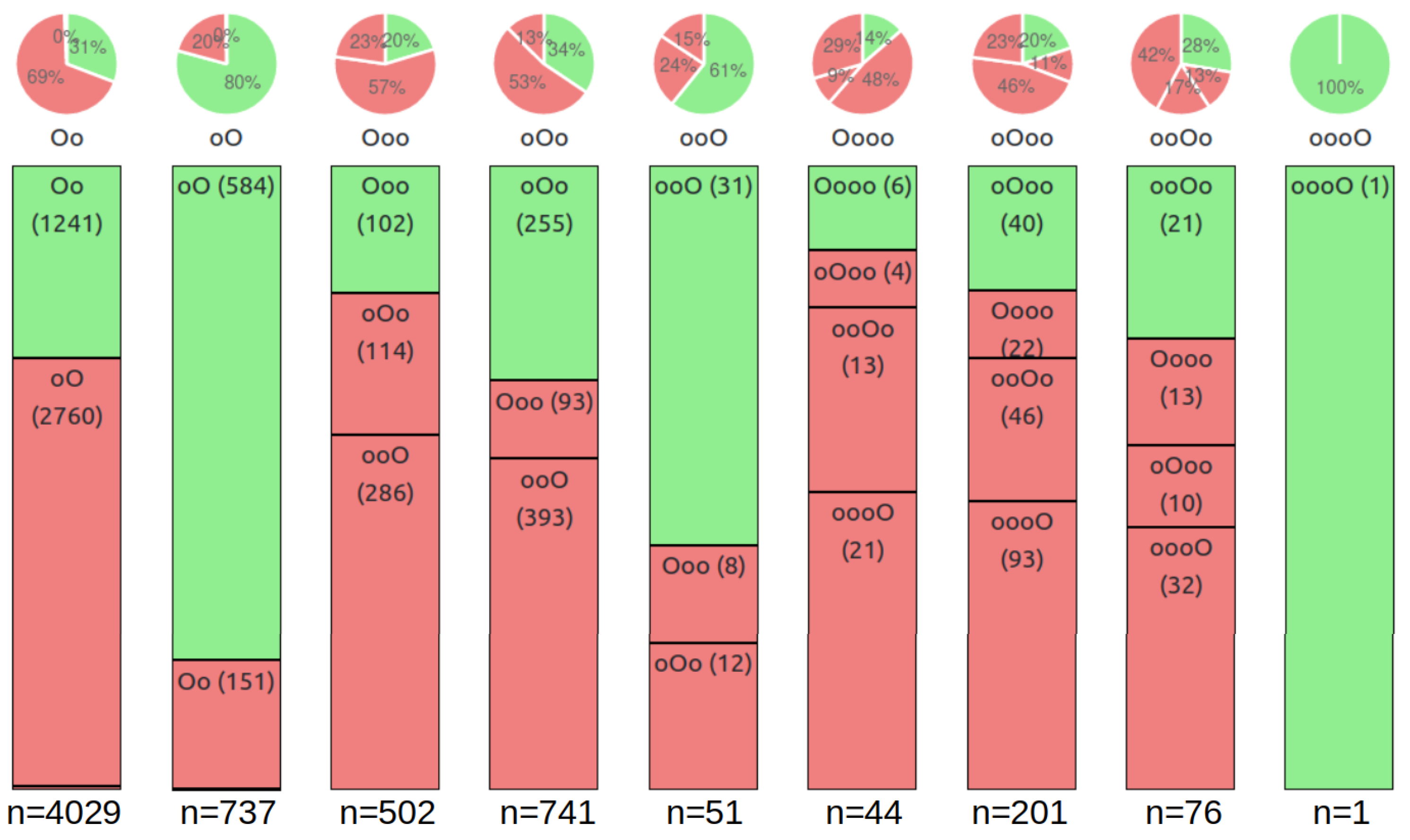
5.1. Pause Position Analysis
5.2. Lexical Stress Analysis
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | See https://www.certification-cles.fr/english/ (accessed on 1 February 2024). |
| 2 | The complete processing pipeline is open source and freely available here: https://gricad-gitlab.univ-grenoble-alpes.fr/lidilem/plspp (accessed on 1 February 2024). |
| 3 | This dictionary is available at http://www.speech.cs.cmu.edu/cgi-bin/cmudict (accessed on 1 February 2024). |
References
- Adams, Corinne. 1979. English Speech Rhythm and the Foreign Learner. Berlin and Boston: De Gruyter Mouton. [Google Scholar] [CrossRef]
- Astesano, Corine. 2001. Rythme et Accentuation en Français: Invariance et Variabilité Stylistique. Collection Langue & Parole. Paris: L’Harmattan. [Google Scholar]
- Bain, Max, Jaesung Huh, Tengda Han, and Andrew Zisserman. 2023. Whisperx: Time-accurate speech transcription of long-form audio. arXiv arXiv:2303.00747. [Google Scholar]
- Bolinger, Dwight L. 1958. A theory of pitch accent in english. WORD 14: 109–49. [Google Scholar] [CrossRef]
- Bredin, Hervé, and Antoine Laurent. 2021. End-to-end speaker segmentation for overlap-aware resegmentation. arXiv arXiv:2104.04045. [Google Scholar]
- Calbris, Geneviève, and Jacques Montredon. 1975. Approche Rythmique, Intonative et Expressive du Français Langue Étrangère: Sketches-Exercices-Illustrations-Photos-Cartes d’Expression: Les Exercices ont Éné Expérimentés au Centre de Linguistique Appliquée de Besançon. Paris: CLES International. [Google Scholar]
- Campione, Estelle, and Jean Véronis. 2002. A large-scale multilingual study of silent pause duration. Paper presented at Speech Prosody 2002, Aix-En-Provence, France, April 11–13; pp. 199–202. [Google Scholar]
- Candéa, Maria. 2000. Contribution à l’étude des pauses silencieuses et des phénomènes dits «d’hésitation» en français oral spontané: Étude sur un corpus de textes en classe de français. Ph.D. thesis, Université de la Sorbonne nouvelle-Paris III, Paris, France. [Google Scholar]
- Cao, Yating, and Hua Chen. 2019. World englishes and prosody: Evidence from the successful public speakers. Paper presented at 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, November 18–21; pp. 2048–52. [Google Scholar]
- Chen, Jin-Yu, and Lan Wang. 2010. Automatic lexical stress detection for chinese learners’ of english. Paper presented at 2010 7th International Symposium on Chinese Spoken Language Processing, Tainan, Taiwan, November 29–December 3; pp. 407–11. [Google Scholar]
- Chen, Liang-Yu, and Jyh-Shing Jang. 2012. Stress detection of english words for a capt system using word-length dependent gmm-based bayesian classifiers. Interdisciplinary Information Sciences 18: 65–70. [Google Scholar] [CrossRef]
- Cooper, Nicole, Anne Cutler, and Roger Wales. 2002. Constraints of lexical stress on lexical access in english: Evidence from native and non-native listeners. Language Speech 45: 207–28. [Google Scholar] [CrossRef]
- Coulange, Sylvain. 2023. Computer-aided pronunciation training in 2022: When pedagogy struggles to catch up. In Proceedings of the 7th International Conference on English Pronunciation: Issues and Practices. Edited by Alice Henderson and Anastazija Kirkova-Naskova. Grenoble: Université Grenoble-Alpes, pp. 11–22. [Google Scholar] [CrossRef]
- Council of Europe. 2020. Common European Framework of Reference for Languages. Strasbourg: Council of Europe. [Google Scholar]
- Cutler, Anne. 2015. Lexical stress in english pronunciation. In The Handbook of English Pronunciation. Hoboken: John Wiley & Sons, Inc., pp. 106–24. [Google Scholar]
- Cutler, Anne, and Alexandra Jesse. 2021. Word Stress in Speech Perception. Hoboken: John Wiley & Sons, Ltd., chp. 9. pp. 239–65. [Google Scholar] [CrossRef]
- de Jong, Nivja H., Jos Pacilly, and Willemijn Heeren. 2021. Praat scripts to measure speed fluency and breakdown fluency in speech automatically. Assessment in Education: Principles, Policy & Practice 28: 456–76. [Google Scholar] [CrossRef]
- de Kok, Iwan Adrianus. 2013. Listening Heads. Ph.D. thesis, University of Twente, Enschede, The Netherlands. [Google Scholar] [CrossRef]
- Derwing, Tracey M., and Murray J. Munro. 2015. Pronunciation Fundamentals: Evidence-Based Perspectives for L2 Teaching and Research. Amsterdam: John Benjamins. [Google Scholar]
- Deshmukh, Om, and Ashish Verma. 2009. Nucleus-level clustering for word-independent syllable stress classification. Speech Communication 51: 1224–33. [Google Scholar] [CrossRef]
- Duez, Danielle. 1982. Silent and non-silent pauses in three speech styles. Language and Speech 25: 11–28. [Google Scholar] [CrossRef]
- Dupoux, Emmanuel, Christophe Pallier, Nuria Sebastian, and Jacques Mehler. 1997. A destressing “deafness” in french? Journal of Memory and Language 36: 406–21. [Google Scholar] [CrossRef]
- Evanini, Keelan, and Klaus Zechner. 2019. Overview of automated speech scoring. In Automated Speaking Assessment. Innovations in Language Learning and Assessment at ETS. London: Routledge, pp. 3–20. [Google Scholar] [CrossRef]
- Ferrer, Luciana, Harry Bratt, Colleen Richey, Horacio Franco, Victor Abrash, and Kristin Precoda. 2015. Classification of lexical stress using spectral and prosodic features for computer-assisted language learning systems. Speech Communication 69: 31–45. [Google Scholar] [CrossRef]
- Field, John. 2005. Intelligibility and the listener: The role of lexical stress. TESOL Quarterly 39: 399–423. [Google Scholar] [CrossRef]
- Frost, Dan. 2023. Prosodie, Intelligibilité, Communication (PIC). ORTOLANG (Open Resources and TOols for LANGuage). Available online: www.ortolang.fr (accessed on 1 February 2024).
- Gibbon, Dafydd, and Ulrike Gut. 2001. Measuring speech rhythm. Paper presented at 7th European Conference on Speech Communication and Technology (Eurospeech 2001), Aalborg, Denmark, September 3–7; pp. 95–98. [Google Scholar] [CrossRef]
- Grabe, Esther, and Ee Ling Low. 2002. Durational variability in speech and the rhythm class hypothesis. Papers in Laboratory Phonology 7: 515–46. [Google Scholar]
- Grosman, Iulia, Anne Catherine Simon, and Liesbeth Degand. 2018. Variation de la durée des pauses silencieuses: Impact de la syntaxe, du style de parole et des disfluences. Langages 211: 13–40. [Google Scholar] [CrossRef]
- Honnibal, Matthew, Ines Montani, Sofie Van Landeghem, and Adriane Boyd. 2020. Spacy: Industrial-Strength Natural Language Processing in Python. Available online: https://zenodo.org/records/10009823 (accessed on 1 August 2023). [CrossRef]
- Isaacs, Talia, Pavel Trofimovich, and Jennifer Ann Foote. 2018. Developing a user-oriented second language comprehensibility scale for english-medium universities. Language Testing 35: 193–216. [Google Scholar] [CrossRef]
- Johnson, David O., and Okim Kang. 2015. Automatic prominent syllable detection with machine learning classifiers. International Journal of Speech Technology 18: 583–92. [Google Scholar] [CrossRef]
- Kitaev, Nikita, Steven Cao, and Dan Klein. 2019. Multilingual constituency parsing with self-attention and pre-training. In ACL. Florence: Association for Computational Linguistics, pp. 3499–505. [Google Scholar]
- Li, Chaolei, Jia Liu, and Shanhong Xia. 2007. English sentence stress detection system based on HMM framework. Applied Mathematics and Computation 185: 759–68. [Google Scholar] [CrossRef]
- Li, Kun, Shaoguang Mao, Xu Li, Zhiyong Wu, and Helen Meng. 2018. Automatic lexical stress and pitch accent detection for L2 English speech using multi-distribution deep neural networks. Speech Communication 96: 28–36. [Google Scholar] [CrossRef]
- Lickley, Robin. 2015. Fluency and Disfluency. Chichester: Wiley Online Library, pp. 445–69. [Google Scholar] [CrossRef]
- McAuliffe, Michael, Michaela Socolof, Sarah Mihuc, Michael Wagner, and Morgan Sonderegger. 2017. Montreal Forced Aligner: Trainable Text-Speech Alignment Using Kaldi. Paper presented at Interspeech 2017, Stockholm, Sweden, August 20–24; pp. 498–502. [Google Scholar] [CrossRef]
- Munro, Murray J., and Tracey M. Derwing. 2015. Intelligibility in Research and Practice. Hoboken: John Wiley & Sons, Ltd., chp. 21. pp. 375–96. [Google Scholar] [CrossRef]
- Nagle, Charles, Pavel Trofimovich, and Annie Bergeron. 2019. Toward a dynamic view of second language comprehensibility. Studies in Second Language Acquisition 41: 647–72. [Google Scholar] [CrossRef]
- Singh Bhatia, Parmeet, Serge Iovleff, and Gérard Govaert. 2017. blockcluster: An R package for model-based co-clustering. Journal of Statistical Software 76: 1–24. [Google Scholar]
- Sugahara, Mariko, Sylvain Coulange, and Tsuneo Kato. 2024. English lexical stress in awareness and production: Native and non-native speakers. Paper presented at 19th LabPhon Conference, Seoul, Republic of Korea, June 27–29. [Google Scholar]
- Tauberer, Joshua. 2008. Predicting intrasentential pauses: Is syntactic structure useful? Paper presented at Speech Prosody 2008, Campinas, Brazil, May 6–9; pp. 405–8. [Google Scholar]
- Tavakoli, Parvaneh. 2010. Pausing patterns: Differences between L2 learners and native speakers. ELT Journal 65: 71–79. [Google Scholar] [CrossRef]
- Tepperman, Joseph, and Shrikanth Narayanan. 2005. Automatic syllable stress detection using prosodic features for pronunciation evaluation of language learners. Paper presented at Proceedings. (ICASSP ’05). IEEE International Conference on Acoustics, Speech, and Signal Processing, Philadelphia, PA, USA, March 23, vol. 1, pp. 937–40. [Google Scholar]
- Tortel, Anne. 2021. Le rythme en anglais oral: Considérations théoriques et illustrations sur corpus. Recherche et Pratiques Pédagogiques en Langues 40. [Google Scholar] [CrossRef]
- Tortel, Anne, and Daniel Hirst. 2010. Rhythm metrics and the production of English L1/L2. Paper presented at Speech Prosody 2010-Fifth International Conference, Chicago, IL, USA, May 11–14. paper 959. [Google Scholar]
- Trouvain, Jürgen. 2004. Tempo Variation in Speech Production: Implications for Speech Synthesis. Ph.D. thesis, Saarland University, Saarbrücken, Germany. [Google Scholar]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Coulange, S.; Kato, T.; Rossato, S.; Masperi, M. Enhancing Language Learners’ Comprehensibility through Automated Analysis of Pause Positions and Syllable Prominence. Languages 2024, 9, 78. https://doi.org/10.3390/languages9030078
Coulange S, Kato T, Rossato S, Masperi M. Enhancing Language Learners’ Comprehensibility through Automated Analysis of Pause Positions and Syllable Prominence. Languages. 2024; 9(3):78. https://doi.org/10.3390/languages9030078
Chicago/Turabian StyleCoulange, Sylvain, Tsuneo Kato, Solange Rossato, and Monica Masperi. 2024. "Enhancing Language Learners’ Comprehensibility through Automated Analysis of Pause Positions and Syllable Prominence" Languages 9, no. 3: 78. https://doi.org/10.3390/languages9030078
APA StyleCoulange, S., Kato, T., Rossato, S., & Masperi, M. (2024). Enhancing Language Learners’ Comprehensibility through Automated Analysis of Pause Positions and Syllable Prominence. Languages, 9(3), 78. https://doi.org/10.3390/languages9030078